What Would I Do? Self-prediction in Simple Algorithms
post by Scott Garrabrant · 2020-07-20T04:27:25.490Z · LW · GW · 12 commentsContents
Questions None 12 comments
(This talk was given at a public online event on Sunday July 12th [? · GW]. Scott Garrabrant is responsible for the talk, Justis Mills edited the transcript.
If you're a curated author and interested in giving a 5-min talk, which will then be transcribed and edited, sign up here.)

Scott Garrabrant: I'm going to be working in the logical induction paradigm, which means that I'm going to have this Pn thing, which assigns probabilities to logical sentences.

Basically all you need to know about it is that the probabilities that it assigns to logical sentences will be good. In particular, they'll be good on sentences that are parameterised by n, so for large n, Pn will have good beliefs about sentences that have n as a parameter.
This will allow us to build algorithms that can use beliefs about their own outputs as part of their algorithm, because the output of a deterministic algorithm is a logical sentence.
Today I’ll present some algorithms that use self-prediction.
Here's the first one.
An predicts whether or not it's going to output left. If the probability to output left is less than one half, then it outputs left. Otherwise, it outputs right. It predicts what it would do, and then it does the opposite.

So for n large, it converges to randomly choosing between left and right, because if it's overdoing left then it would do right instead, and vice versa.
We can also make a biased version of this.
Here's an algorithm that, if it predicts that it outputs left with probability less than P then it outputs left, and otherwise outputs right.
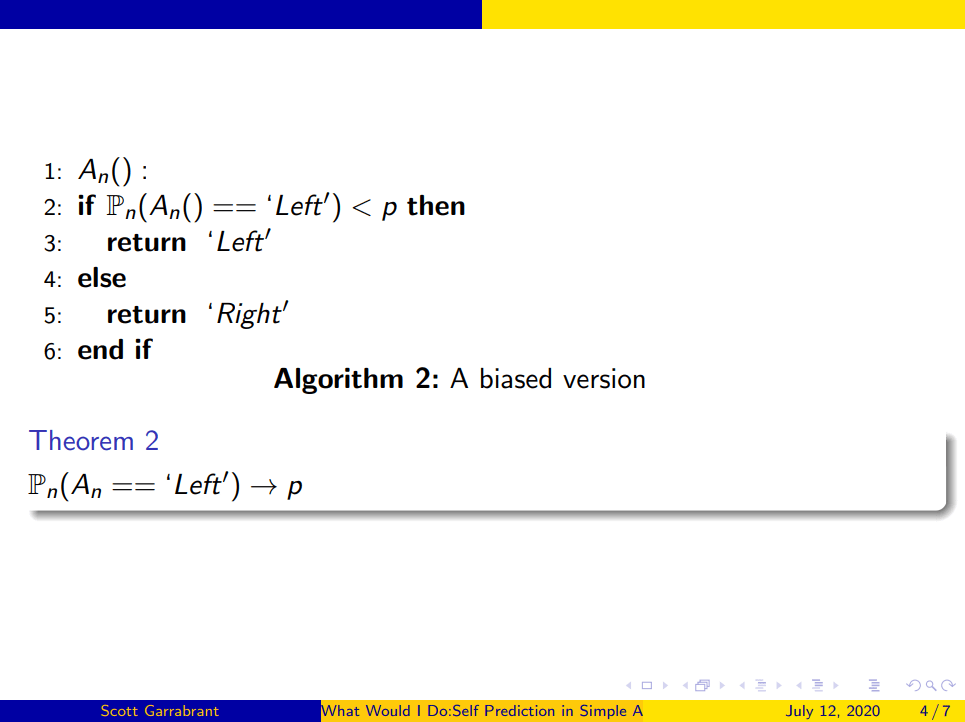
The only way this algorithm can work is outputting left with probability P. In fact the previous example was a special case of this with P = ½.
We can use this general self-prediction method to basically create pseudo-randomness for algorithms. Instead of saying “flip a coin,” I can say “try to predict what you would do, then do the opposite.”
Third, here's an algorithm that's trying to do some optimization. It tries to predict whether it has a higher chance of winning if it picks left than if it picks right. If it predicts that it has a higher chance of winning with left, it picks left, and otherwise it picks right.

We're going to specifically think about this algorithm (and the following algorithms) in an example case where what it means to win is the following: if you choose left, you always win, and if you choose right, you win with probability ½. Intuitively, we’d like the algorithm in this case to choose left, since left is a guaranteed win and right isn’t.
However, it turns out this algorithm might not choose left — because if it always chooses right, it might not have well calibrated probabilities about what would happen if it chose left instead.
Here's an alternate algorithm. (We leave out Wn and assume it is defined as before.)
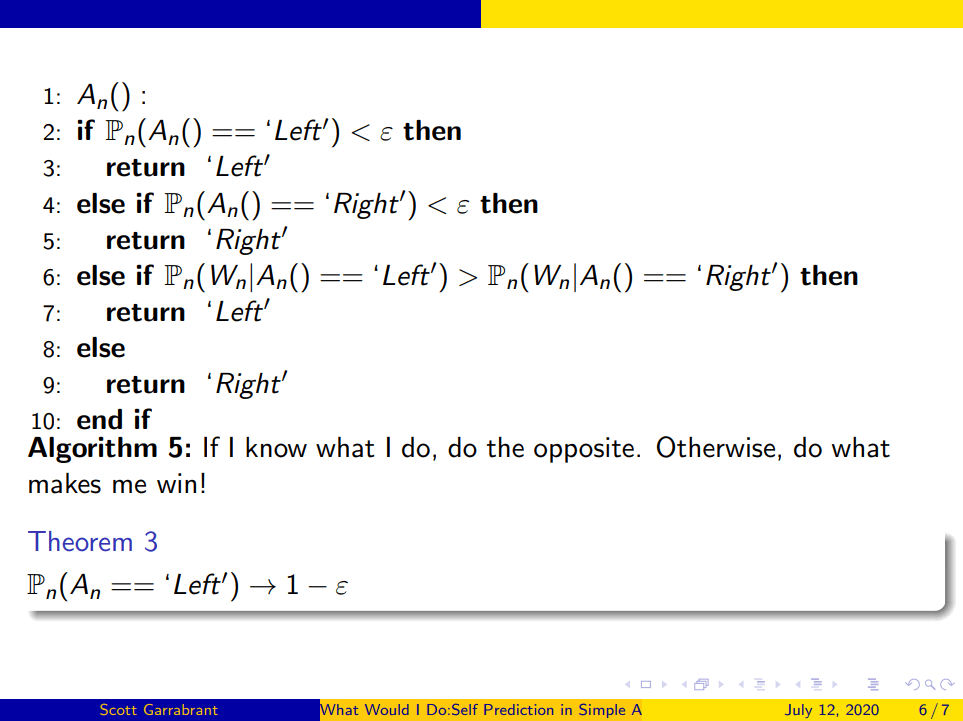
If this one predicts that it definitely won't go left — more precisely, if it predicts that the probability that it goes left is less than ε — then it goes left. If it predicts it definitely doesn't go right, then it goes right. And otherwise it does the thing that gives it a higher probability of winning.
To make this I took the last algorithm and I stapled onto it a process that says, "Use our randomization technique to go left every once in a while and right every once in a while." And because of this, it'll end up getting well calibrated probabilities about what would happen if it went left, even if it starts out only going right.
This algorithm, in the same game that we expressed before, will converge to going left with probability 1 - ε. The only time that it will go right is when the clause about exploration happens, when it very strongly believes that it will go left.
Now we get to the one that I'm excited about. This algorithm is very similar to the last one, but with a subtle difference.

This one still has the same exploration behaviour. But now, rather than predicting what makes winning more likely, it says: “Conditioned on my having won, what do I predict that I did?” And this gives it a distribution over actions.
This algorithm predicts what it did conditional on having won, and then copies that distribution. It just says, “output whatever I predict that I output conditioned on my having won”.
This is weird, because it feels more continuous. It feels like you’d move more gradually to just choosing the same thing all the time. If I win with probability ½, and then I apply this transform, it feels like you don't just jump all the way to always.
But it turns out that you do reach the same endpoint, because the only fixed point of this process is going to do the same as the last algorithm’s. So this algorithm turns out to be functionally the same as the previous one.
Questions
Ben Pace: Isn't the error detection requirement in algorithm 5 awful? It seems a shame that I can only have accurate beliefs if I add a weird edge case that I will pretend that I will sometimes do, even though I probably never will.
Scott Garrabrant: Yeah, it’s pretty awful. But it’s not really pretending! It will in fact do them with probability ε.
Ben Pace: But isn’t it odd to add that as an explicit rule that forces you into having accurate beliefs?
Scott Garrabrant: I agree that it's awful.
Stuart Armstrong: Do you want to say more about the problems that we're trying to avoid by pasting on all these extra bits?
Scott Garrabrant: I feel like I'm not really trying to avoid problems. I was mostly trying to give examples of ways that you can use self-prediction in algorithms. There was really only one paste-in, which is pasted on this exploration. And that feels like the best thing we have right now to deal with problems like “spurious counterfactuals”. There's just this problem where if you never try something, then you don't get good beliefs about what it's like to try it. And so then you can miss out on a lot of opportunities. Unfortunately, the strategy of always trying all options doesn't work very well either. It’s a strategy to avoid being locked out of a better option, but it has weaknesses.
Stuart Armstrong: Right, that’s all fine. I want to point out that Jan Leike also had a different way of dealing with a problem like that, that is more a probability thing than a logic thing. I think there are solutions to that issue in probability or convergence literature, particularly Thompson sampling.
Sam Eisenstat: What does the algorithm tree actually do? Doesn't that converge to going left or going right infinitely many times?
Scott Garrabrant: It depends on the logical inductor. We can't prove that it always converges to going left because you could have the logical inductor always predict that the probability of winning given that you go right is approximately one half, and the probability of winning given that you go left is approximately zero. And it never goes left, it always goes right. Because it never goes left, it never gets good feedback on what would happen if it went left.
David Manheim: Have you read Gary Drescher's book, Good and Real?
Scott Garrabrant: No, I haven't.
David Manheim: It seems like what this is dealing with is the same as what he tries to figure out when he talks about a robot that doesn't cross the street even if there are no cars coming; because since he has never crossed the street he doesn't know whether or not he gets hit if he does try to cross. So why doesn't he ever do it? The answer is, well, he has no reason not to. So you're stuck. Which means that, if we want to avoid this, as long as it's a logical counterfactual, he has to have some finite probability of crossing the street, in order to have a computable probability to figure out whether or not he should. It seems like this is addressing that with the added benefit of actually dealing with logical uncertainty.
Scott Garrabrant: Yeah. I don't think I have more of a response than that.
Daniel Filan: If I think about machine learning, you can do exploration to find good strategies. Then there are questions like “how fast do you converge?” It seems like it might be the case that algorithm 5 converges slower than algorithm 4, because you're doing this weird, opposite conditional thing. I was wondering if you have thoughts about convergence speeds, because to me they seem fundamental and important.
Scott Garrabrant: Yeah. I'm guessing that there's not going to be a meaningful difference. I mean, it's going to converge slower just because it's more complicated, and so it'll take longer for the logical inductor to have good beliefs about it. But the first clause isn't going to happen very much for small ε, and so they're basically just going to do the same thing. I'm not sure though.
One point is that, while here we're doing ε-exploration, there are ways to do better, such that the rate at which you explore is density zero, such that you explore less and less for large n, which is maybe a similar thing. I don't think there's going to be a meaningful difference in terms of convergence except for coming from the complexity of the algorithm, causing it to take longer to have good beliefs about it.
12 comments
Comments sorted by top scores.
comment by Alexei · 2020-07-20T13:11:59.287Z · LW(p) · GW(p)
Do you find the solutions to problems like this manually or are there tools out there that can help or completely solve it?
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-07-21T18:31:38.436Z · LW(p) · GW(p)
Somewhere in between? I have reliable intuition about what would happen that comes before being able to construct the proof, but can reliably be turned into the proof. All of the proofs that these agents do what I say they do can be found by asking:
Assume that the probability does not converge as I say it does. How can I use this to make money if I am allowed to see (continuously) the logical inductors beliefs, and bet against them?
For example in the first example, If the probability was greater that infinity often, I could wait until the probability is greater than , then bet that the agent goes right. This bet will always pay out, and double my money, and I can do this forever.
comment by orthonormal · 2020-07-21T17:32:29.300Z · LW(p) · GW(p)
Re: Ben's question but much lower-level, there's some extent to which a logical inductor keeps having to accept actual failures sometimes as the price of preventing spurious counterfactuals, where in our world we model the consequences of certain actions without ever doing them.
It's a free lunch type of thing; we assume our world has way more structure than just "the universe is a computable environment", so that we can extrapolate reliably in many cases. Strictly logically, we can't assume that- the universe could be set up to violate physics and reward you personally if you dive into a sewer, but you'll never find that out because that's an action you won't voluntarily take.
So if the universe appears to run by simple rules, you can often do without exploration; but if you can't assume it is and always will be run by those rules, then you need to accept failures as the price of knowledge.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-07-21T17:41:30.708Z · LW(p) · GW(p)
Something about this feels compelling... I need to do some empiricism to understand what my counterfactuals are. By the time a real human gets to the 5-and-10 problem they’ve done enough, but I’d you just appear in a universe and it‘s your first experience, I’m not too surprised you need to actually check these fundamentals.
(I’m not sure if this actually matches up philosophically with the logical inductors.)
comment by ESRogs · 2020-07-20T05:54:26.054Z · LW(p) · GW(p)
One point is that, while here we're doing ε-exploration, there are ways to do better, such that the rate at which you explore is density zero, such that you explore less and less for large n
Was wondering about this as I was reading. Can I just have ε be ? Does that cause ε to shrink too fast s.t. that I don't actually explore?
In general, what are the limits on how fast ε can shrink, and how does that depend on program complexity, or the number of output options?
Replies from: Charlie Steiner, Scott Garrabrant↑ comment by Charlie Steiner · 2020-07-20T09:44:31.127Z · LW(p) · GW(p)
From a logic perspective you'd think any epsilon>0 would be enough to rule out the "conditioning on a falsehood" problem. But I second your question, because Scott makes it sound like there's some sampling process going on that might actually need to do the thing. Which is weird - I thought the sampling part of logical inductors was about sampling polynomial-time proofs, which don't seem like they should depend much on epsilon.
↑ comment by Scott Garrabrant · 2020-07-21T18:24:04.986Z · LW(p) · GW(p)
Having be won't work.
Surprisingly, having go to 0 at any quickly computably rate won't work. For example, if you could imagine having a logical induction built out of a collection of traders where one trader has almost all the money and says that on days of the form , utility conditioned on going left is 0 (where is a fast growing function). Then, you have a second trader that forces the probability on day of the statement that the agent goes left to be slightly higher that . Finally, you have a third trader that forces the expected utility conditioned on right to be very slightly above 0 on days of the form .
The first trader never loses money, since the condition is never met. The second trader only loses a bounded amount of money, since it is forcing the probability of a sentence that will be false to be very small. The third trader similarly only loses a bounded amount of money. The exploration clause will never trigger, and the agent will never go left on any day of the form .
The issue here is that we need to not only explore infinitely often, we need to explore infinitely often on all simple subsets of days, if the probability goes to 0 slowly, you can just look at a subset of days that is sufficiently sparse.
There are ways around this that allow us to make a logical induction agent that explores with destiny 0 (meaning that the limit as goes to infinity of the proportion of days that the agent explores is 0). This is done by explicitly exploring infinitely often on every quickly computable subset of days, while still having the probability of exploring go to 0.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-07-20T20:14:00.739Z · LW(p) · GW(p)
Noob question: If Pn(An=="left") --> 1/2, doesn't that mean that as n gets bigger, Pn(An=="left") gets closer and closer to 1/2? And doesn't that leave open the question of how it approaches 1/2? It could approach from above, or below, or it could oscillate above and below. Given that you say it converges to randomly choosing, I'm guessing it's the oscillation thing. So is there some additional lemma you glossed over, about the way it converges?
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-07-20T23:53:39.853Z · LW(p) · GW(p)
It does not approach it from above or below. As goes to infinity, the proportion of for which =="Left" need not converge to 1/2, but it must have 1/2 as a limit point, so the proportion of for which =="Left" is arbitrarily close to 1/2 infinitely often. Further, the same is true for any easy to compute subsequence of rounds.
So, unfortunately it might be that goes left many many times in a row e.g. for all between and , but it will still be unpredictable, just not locally independent.
comment by Pattern · 2020-07-20T21:48:23.051Z · LW(p) · GW(p)
However, it turns out this algorithm might not choose left — because if it always chooses right, it might not have well calibrated probabilities about what would happen if it chose left instead.
The ambiguity between choosing right (as in well*) and choosing right (the direction) is slightly confusing here.
*Which would be the direction left.
It also seems like a proving program would be able to get around needing to explore if it had access to the source code for a scenario.
comment by Nisan · 2020-07-20T14:28:18.350Z · LW(p) · GW(p)
Ah, are you excited about Algorithm 6 because the recurrence relation feels iterative rather than topological [LW · GW]?
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-07-20T18:22:20.223Z · LW(p) · GW(p)
Not really.