The Colliding Exponentials of AI
post by Vermillion (VermillionStuka) · 2020-10-14T23:31:20.573Z · LW · GW · 16 commentsContents
Algorithmic Improvements Increasing Budgets Hardware Improvements Conclusions and Comparisons Estimations for 2030: None 16 comments
Epistemic status: I have made many predictions for quantitative AI development this decade, these predictions were based on what I think is solid reasoning, and extrapolations from prior data.
If people do not intuitively understand the timescales of exponential functions, then multiple converging exponential functions will be even more misunderstood.
Currently there are three exponential trends acting upon AI performance, these being Algorithmic Improvements, Increasing Budgets and Hardware Improvements. I have given an overview of these trends and extrapolated a lower and upper bound for their increases out to 2030. These extrapolated increases are then combined to get the total multiplier of equivalent compute that frontier 2030 models may have over their 2020 counterparts.
Firstly...
Algorithmic Improvements
Algorithmic improvements for AI are much more well-known and quantified than they were a few years ago, much in thanks to OpenAI’s paper and blog AI and Efficiency (2020).
OpenAI showed the efficiency of image processing algorithms has been doubling every 16 months since 2012. This resulted in a 44x decrease in compute required to reach Alexnet level performance after 7 years, as Figure 1 shows.
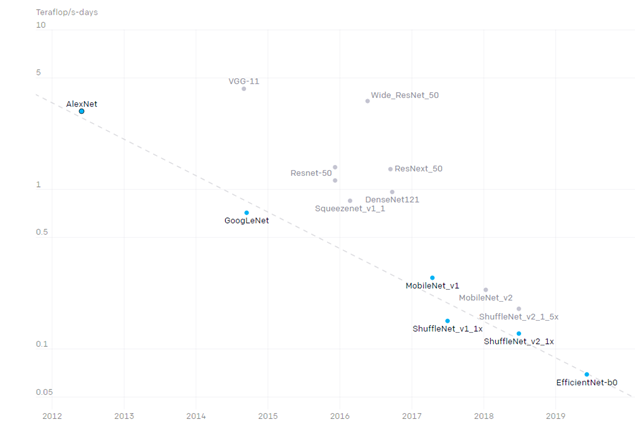
OpenAI also showed algorithmic improvements in the following areas:
Transformers had surpassed seq2seq performance on English to French translation on WMT’14 with 61x less training compute in three years.
AlphaZero took 8x less compute to get to AlphaGoZero level performance 1 year later.
OpenAI Five Rerun required 5x less training compute to surpass OpenAI Five 3 months later.
Additionally Hippke’s LessWrong post Measuring Hardware Overhang [LW · GW] detailed algorithmic improvements in chess, finding that Deep Blue level performance could have been reached on a 1994 desktop PC-level of compute, rather than the 1997 supercomputer-level of compute that it was, if using modern algorithms.
Algorithmic improvements come not just from architectural developments, but also from their optimization library’s. An example is Microsoft DeepSpeed (2020). DeepSpeed claims to train models 2–7x faster on regular clusters, 10x bigger model training on a single GPU, powering 10x longer sequences and 6x faster execution with 5x communication volume reduction. With up to 13 billion parameter models trainable on a single Nvidia V100 GPU.
So, across a wide range of machine learning areas major algorithmic improvements have been regularly occurring. Additionally, while this is harder to quantify thanks to limited precedent, it seems the introduction of new architectures can cause sudden and/or discontinuous leaps of performance in a domain, as Transformers did for NLP. As a result, extrapolating past trendlines may not capture such future developments.
If the algorithmic efficiency of machine learning in general had a halving time like image processing’s 16 months, we would expect to see ~160x greater efficiency by the end of the decade. So, I think an estimate of general algorithmic improvement of 100 - 1000x by 2030 seems reasonable.
Edit: I feel less confident and bullish about algorithmic progress now.
Increasing Budgets
The modern era of AI began in 2012, this was the year that the compute used in the largest models began to rapidly increase, with a doubling time of 3.4 months (~10x Yearly), per OpenAI’s blog AI and Compute (2018), see Figure 2 below. While the graph stops in 2018, the trend held steady with the predicted thousands of petaflop/s-days range being reached in 2020 with GPT-3, the largest ever (non sparse) model, which had an estimated training cost of $4.6 Million, based on the price of a Tesla V100 cloud instance.
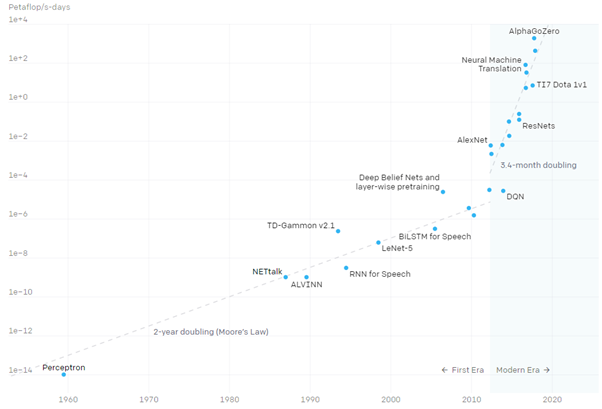
Before 2012 the growth rate for compute of the largest systems had a 2-year doubling time, essentially just following Moore’s law with mostly stable budgets, however in 2012 a new exponential trend began: Increasing budgets.
This 3.4 month doubling time cannot be reliably extrapolated because the increasing budget trend isn’t sustainable, as it would result in the following approximations (without hardware improvements):
2021 | $10-100M
2022 | $100M-1B
2023 | $1-10B
2024 | $10-100B
2025 | $100B-1T
Clearly without a radical shift in the field, this trend could only continue for a limited time. Astronomical as these figures appear, the cost of the necessary supercomputers would be even more.
Costs have moved away from mere academic budgets and are now in the domain of large corporations, where extrapolations will soon exceed even their limits.
The annual research and development expenditure of Google’s parent company Alphabet was $26 Billion in 2019, I have extrapolated their published R&D budgets to 2030 in Figure 3.
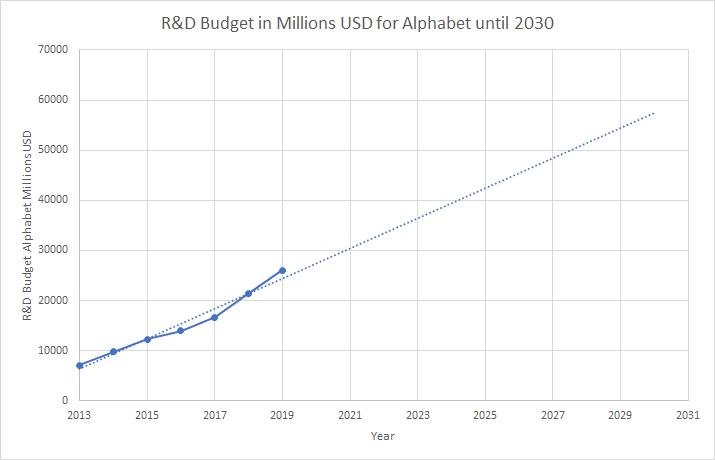
By 2030 Alphabets R&D should be just below $60 Billion (approximately $46.8 Billion in 2020 dollars). So how much would Google, or a competitor, be willing to spend training a giant model?
Well to put those figures into perspective: The international translation services market is currently $43 billion and judging from the success of GPT-3 in NLP its successors may be capable of absorbing a good chunk of that. So that domain alone could seemingly justify $1B+ training runs. And what about other domains within NLP like programming assistants?
Investors are willing to put up massive amounts of capital for speculative AI tech already; the self-driving car domain had disclosed investments of $80 Billion from 2014-2017 per a report from Brookings .With those kind of figures even a $10 Billion training run doesn’t seem unrealistic if the resulting model was powerful enough to justify it.
My estimate is that by 2030 the training run cost for the largest models will be in the $1-10 Billion range (with total system costs higher still). Compared to the single digit millions training cost for frontier 2020 systems, that estimate represents 1,000-10,000x larger training runs.
Hardware Improvements
Moore’s Law had a historic 2-year doubling time that has since slowed. While it originally referred to just transistor count increases, it has changed to commonly refer to just the performance increase. Some have predicted its stagnation as early as the mid-point of this decade (including Gordon Moore himself), but that is contested. More exotic paths forward such as non-silicon materials and 3D stacking have yet to be explored at scale, but research continues.
The microprocessor engineer Jim Keller stated in February 2020 that he doesn’t think Moore’s law is dead, that current transistors which are sized 1000x1000x1000 atoms can be reduced to 10x10x10 atoms before quantum effects (which occur at 2-10 atoms) stop any further shrinking, an effective 1,000,000x size reduction. Keller expects 10-20 more years of shrinking, and that performance increases will come from other areas of chip design as well. Finally, Keller says that the transistor count increase has slowed down more recently to a ‘shrink factor’ of 0.6 rather than the traditional 0.5, every 2 years. If that trend holds it will result in a 12.8x increase in performance in 10 years.
But Hardware improvements for AI need not just come just from Moore’s law. Other sources of improvement such as Neuromorphic chips designed especially for running neural nets or specialised giant chips could create greater performance for AI.
By the end of the decade I estimate we should see between 8-13x improvement in hardware performance.
Conclusions and Comparisons
If we put my estimates for algorithmic improvements, increased budgets and hardware improvements together we see what equivalent compute multiplier we might expect a frontier 2030 system to have compared to a frontier 2020 system.
Estimations for 2030:
Algorithmic Improvements: 100-1000x
Budget Increases: 1000-10,000x
Hardware Improvements: 8-13x
That results in an 800,000 - 130,000,000x multiplier in equivalent compute.
Between EIGHT HUNDRED THOUSAND and ONE HUNDRED and THIRTY MILLION.
To put those compute equivalent multipliers into perspective in terms of what capability they represent there is only one architecture that seems worth extrapolating them out on: Transformers, specifically GPT-3.
Firstly lets relate them to Gwern’s estimates for human vs GPT-3 level perplexity from his blogpost On GPT-3. Remember that perplexity is a measurement of how well a probability distribution or probability model predicts a sample. This is a useful comparison to make because it has been speculated both that human level prediction on text would represent human level NLP, and that NLP would be an AI complete problem requiring human equivalent general faculties.
Gwern states that his estimate is very rough and relies on un-sauced claims from OpenAI about human level perplexity on benchmarks, and that the absolute prediction performance of GPT-3 is at a "best guess", double that of a human. With some “irresponsible” extrapolations of GPT-3 performance curves he finds that a 2,200,000× increase in compute would bring GPT-3 down to human perplexity. Interestingly that’s not far above the lower bound in the 800,000 – 130,000,000x equivalent compute estimate range.
It’s worth stressing, 2030 AI systems could have human level prediction capabilities if scaling continues.
Edit: Removed section extrapolating GPT-3 aggregate performance across benchmarks.
Ultimately the point of these extrapolations isn’t necessarily the specific figures or dates but the clear general trend: not only are much more powerful AI systems coming, they are coming soon.
16 comments
Comments sorted by top scores.
comment by CarlShulman · 2020-11-01T03:26:43.210Z · LW(p) · GW(p)
These projections in figure 4 seem to falsely assume training optimal compute scales linearly with model size. It doesn't, you also need to show more data points to the larger models so training compute grows superlinearly, as discussed in OAI scaling papers. That changes the results by orders of magnitude (there is uncertainty about which of two inconsistent scaling trends to extrapolate further out, as discussed in the papers).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-11-01T15:36:48.509Z · LW(p) · GW(p)
This is not what I took from those papers. The scaling laws paper has a figure showing that if you hold data fixed and increase model size, performance improves, whereas "you need to show more data points to the larger models" would predict that performance would degrade, because if the model gets larger then it's needs aren't being met.
Rather, what's going on is that at the optimal compute allocation larger models get shown more data points. The way to maximize performance with a given increase in compute is to allocate a bit more than half of the increased compute to increased model size, and the remainder to increased data.
That said, figure 4 still overestimates the gains we should expect from increased compute, I think. But for a different reason: The small models in that figure were given "too much data," (they were all given 300B tokens IIRC) and thus represent inefficient uses of compute -- the same amount of compute would have led to more performance if they had increased model size a bit and decreased data. So the "true slope" of the line--the slope the line would have if compute had been used optimally, which is what we want to extrapolate--would be slightly smaller.
Replies from: VermillionStuka↑ comment by Vermillion (VermillionStuka) · 2020-11-02T00:45:37.544Z · LW(p) · GW(p)
Thank you both for correcting me, I have removed that section from the post.
comment by sapphire (deluks917) · 2020-10-15T09:51:57.294Z · LW(p) · GW(p)
Metaculus prediction dropped to 2033 after gpt-3. So some people adjacent to the community think that your logic leads to the right conclusion.
Replies from: VermillionStuka↑ comment by Vermillion (VermillionStuka) · 2020-10-15T11:13:26.817Z · LW(p) · GW(p)
Wow GPT-3 shaved at least 10 years off the median prediction by the looks of it. I didn't realise Metaculus had prediction history, thanks for letting me know.
comment by George3d6 · 2020-10-15T08:58:46.317Z · LW(p) · GW(p)
It seems to me like you are miss-interpreting the numbers and/or taking them out of context.
This resulted in a 44x decrease in compute required to reach Alexnet level performance after 7 years, as Figure 1 shows.
You can achieve infinitely (literally) faster than Alexnet training time if you just take the weight of Alexnet.
You can also achieve much faster performance if you rely on weight transfer and or hyperparameter optimization based on looking at the behavior of an already trained Alexnet. Or, mind you, some other image-classification model based on that.
Once a given task is "solved" it become trivial to compute models that can train on said task exponentially faster, since you're already working down from a solution.
On the other hand, improvements on ImageNet (the datasets alexnet excelled on at the time) itself are logarithmic rather than exponential and at this point seem to have reached a cap at around human level ability or a bit less (maybe people got bored of it?)
To get back to my point, however, the problem with solved tasks is that whatever speed improvements you have on them don't generalized, since the solution is only obvious in hindsight.
***
Other developments that help with training time (e.g. the kind of schedulers fastAI is doing) are, interesting, but not applicable for "hard" problems where one has to squeeze a lot of accuracy and not widely used in RL (why, I don't know)
However, if you want to look for exp improvement you can always find it and if you want to look for log improvement you always will.
The OpenAI paper is disingenuous in not mentioning this, or at least disingenuous in marketing itself to a public that doesn't understand this.
***
In regards to training text models "x time faster", go into the "how do we actually benchmark text models" section the academica/internet flamewar library. In that case my bet is usually on someone hyperoptimizing for a narrow error function (not that there's an alternative). But also, above reasoning about solved >> easier than unsolved still applies.
Replies from: Veedrac, VermillionStuka↑ comment by Veedrac · 2020-11-01T10:39:53.498Z · LW(p) · GW(p)
On the other hand, improvements on ImageNet (the datasets alexnet excelled on at the time) itself are logarithmic rather than exponential and at this point seem to have reached a cap at around human level ability or a bit less (maybe people got bored of it?)
The best models are more accurate than the ground-truth labels.
Are we done with ImageNet?
https://arxiv.org/abs/2006.07159
Yes, and no. We ask whether recent progress on the ImageNet classification benchmark continues to represent meaningful generalization, or whether the community has started to overfit to the idiosyncrasies of its labeling procedure. We therefore develop a significantly more robust procedure for collecting human annotations of the ImageNet validation set. Using these new labels, we reassess the accuracy of recently proposed ImageNet classifiers, and find their gains to be substantially smaller than those reported on the original labels. Furthermore, we find the original ImageNet labels to no longer be the best predictors of this independently-collected set, indicating that their usefulness in evaluating vision models may be nearing an end. Nevertheless, we find our annotation procedure to have largely remedied the errors in the original labels, reinforcing ImageNet as a powerful benchmark for future research in visual recognition.
Figure 7. shows that model progress is much larger than the raw progression of ImageNet scores would indicate.
↑ comment by Vermillion (VermillionStuka) · 2020-10-15T12:03:12.737Z · LW(p) · GW(p)
You can achieve infinitely (literally) faster than Alexnet training time if you just take the weight of Alexnet.
You can also achieve much faster performance if you rely on weight transfer and or hyperparameter optimization based on looking at the behavior of an already trained Alexnet. Or, mind you, some other image-classification model based on that.
Once a given task is "solved" it become trivial to compute models that can train on said task exponentially faster, since you're already working down from a solution.
Could you clarify, you mean the primary cause of efficiency increase wasn’t algorithmic or architectural developments, but researchers just fine-tuning weight transferred models?
However, if you want to look for exp improvement you can always find it and if you want to look for log improvement you always will.
Are you saying that the evidence for exponential algorithmic efficiency, not just in image processing, is entirely cherry picked?
In regards to training text models "x time faster", go into the "how do we actually benchmark text models" section the academica/internet flamewar library.
I googled that and there were no results, and I couldn’t find an "academica/internet flamewar library" either.
Look I don’t know enough about ML yet to respond intelligently to your points, could someone else more knowledgeable than me weigh in here please?
Replies from: George3d6↑ comment by George3d6 · 2020-10-15T21:36:44.081Z · LW(p) · GW(p)
Could you clarify, you mean the primary cause of efficiency increase wasn’t algorithmic or architectural developments, but researchers just fine-tuning weight transferred models?
Algorithm/Architecture are fundamentally hyperparameters, so when I say "fine-tuning hyperparameters" (i.e. the ones that aren't tuned by the learning process itself), those are included.
Granted, you have jumped from e.g. LSTM to attention, where you can't think of it as "hyperparameter" tuning, since it's basically a shift in mentality in many ways.
But in computer vision, at least to my knowledge, most of the improvements would boil down to tuning optimization methods. E.g here's an analysis of the subject (https://www.fast.ai/2018/07/02/adam-weight-decay/) describing some now-common method, mainly around CV.
However, the problem is that the optimization is happening around the exact same datasets Alexnet was built around. Even if you don't transfer weight, "knowing" a very good solution helps you fine-tune much quicker around a problem ala ImagNet, or cifrar, or mnist or various other datasets that fall into the category of "classifying things which are obviously distinct to humans from square images of roughly 50 to 255px width/height"
But that domain is fairly niche if we were to look at, e.g., almost any time-series prediction datasets... not much progress has been made since the mid 20s. And maybe that's because no more progress can be made, but the problem is that until we know the limits of how "solvable" a problem is, the problem is hard. Once we know how to solve the problem in one way, achieving similar results, but faster, is a question of human ingenuity we've been good at since at least the industrial revolution.
I mean, you could build an Alexnet-specific circuit, not now, but back when it was invented, and get 100x or 1000x performance, but nobody is doing that because our focus is not (or, at least, should not) fall under optimizing very specific problems. Rather, the important thing is finding techniques that can generalize.
**Note: Not a hardware engineer, not sure how easily one can come up with auto diff circuits, might be harder than I'd expect for that specific case, just trying to illustrate the general point**
Are you saying that the evidence for exponential algorithmic efficiency, not just in image processing, is entirely cherry picked?
Ahm, yes.
if you want a simple overview of how speed and accuracy has evolved on a broader range of problems. And even those problems are cherry picked, in that they are very specific competition/research problems that hundreds of people are working on.
I googled that and there were no results, and I couldn’t find an "academica/internet flamewar library" either.
Some examples:
Paper with good arguments that impressive results achieved by transformer architectures are just test data contamination: https://arxiv.org/pdf/1907.07355.pdf
A simpler article: https://hackingsemantics.xyz/2019/leaderboards/ (which makes the same point as the above paper)
Then there's the problem of how one actually "evaluates" how good an NLP model is.
As in, think of the problem for a second, I ask you:
"How good is this translation from English to French, on a scale from 1 to 10" ?
For anything beyond simple phrases that question is very hard, almost impossible. And even if it iisn'tsnt', i.e. if we can use the aggregate perceptions of many humans to determine "truth" in that regard, you can't capture that in a simple accuracy function that evaluates the model.
Granted, I think my definition of "flamewar" is superfluous, I mean more so passive-aggressive snarky questions with a genuine interest in improving behind them posted on forums ala: https://www.reddit.com/r/LanguageTechnology/comments/bcehbv/why_do_all_the_new_nlp_models_preform_poor_on_the/
More on the idea of how NLP models are overfitting on very poor accuracy functions that won't allow them to progress much further:
https://arxiv.org/pdf/1902.01007.pdf
And a more recent one (202) with similar ideas that proposes solutions: https://www.aclweb.org/anthology/2020.acl-main.408.pdf
If you want to generalize this idea outside of NLP, see, for example, this: https://arxiv.org/pdf/1803.05252.pdf
And if you want anecdotes from another field I'm more familiar with, the whole "field" of neural architecture search (building algorithms to build algorithms), has arguably overfit on specific problems for the last 5 years to the point that all state of the art solutions are:
Basically no better than random and often worst: https://arxiv.org/pdf/1902.08142.pdf
And the results are often unreliable/unreplicable: https://arxiv.org/pdf/1902.07638.pdf
*****
But honestly, probably not the best reference, you know why?
Because I don't bookmark negative findings, and neither does anyone. We laugh at them and then move on with life. The field is 99% "research" that's usually spending months or years optimizing a toy problem and then having a 2 paragraph discussion section about "This should generalize to other problems"... and then nobody bothers to replicate the original study or to work on the "generalize" part. Because where's the money in an ML researcher saying "actually, guys, the field has a lot of limitations and a lot of research directions are artificial, pun not intended, and can't be applied to relevant problems outside of generating on-demand furry porn or some other pointless nonsense".
But as is the case over and over again, when people try to replicate techniques that "work" in papers in slightly different conditions they return to baseline. Probably the prime example of this is a paper that made it into **** nature about how to predict earthquake aftershocks with neural networks and then somebody tried to apply a linear regression to the same data instead and we got this gem
One neuron is more informative than a deep neural network for aftershock pattern forecasting
(In case the pun is not obvious, a one neuron network is a linear regression)
And while improvements certainly exist, we have observed exponential improvements in the real world. On the whole, we don't have much more "AI powered" technology now than in the 80s.
I'm the first to argue that this is in part because of over-regulation, I've written a lot on that subject and I do agree that it's part of the issue. But part of the issue is that there are not so many things with real-world applications. Because at the end of the day all you are seeing in numbers like the ones above is a generalization on a few niche problems.
Anyway, I should probably stop ranting about this subject on LW, it's head-against-wall banging.
Replies from: VermillionStuka↑ comment by Vermillion (VermillionStuka) · 2020-10-16T00:25:28.461Z · LW(p) · GW(p)
Thank you for the excellent and extensive write up :)
I hadn't encountered your perspective before, I'll definitely go through all your links to educate myself, and put less weight on algorithmic progress being a driving force then.
Cheers
Replies from: George3d6↑ comment by George3d6 · 2020-10-16T12:36:46.758Z · LW(p) · GW(p)
At the end of the day, the best thing to do is to actually try and apply the advances to real-world problems.
I work on open source stuff that anyone can use, and there's plenty of companies willing to pay 6 figures a year if we can do some custom development to give them a 1-2% boost in performance. So the market is certainly there and waiting.
Even a minimal increase in accuracy can be worth millions or billions to the right people. In some industries (advertising, trading) you can even go at it alone, you don't need customers.
But there's plenty of domain-specific competitions that pay in the dozens or hundreds of thousands for relatively small improvements. Look past Kaggle at things that are domain-specific (e.g. https://unearthed.solutions/) and you'll find plenty.
That way you'll probably get a better understanding of what happens when you take a technique that's good on paper and try to generalize. And I don't mean this as a "you will fail", you might well succede but it will probably make you see how minimal of an improvement "success" actually is and how hard you must work for that improvement. So I think it's a win-win.
The problem with companies like OpenAI (and even more so with "AI experts" on LW/Alignment) is that they don't have a stake by which to measure success or failure. If waxing lyrically and picking the evidence that suits your narrative is your benchmark for how well you are doing, you can make anything from horoscopes to homeopathy sound ground-breaking.
When you measure your ideas about "what works" against the real world that's when the story changes. After all, one shouldn't forget that since OpenAI was created it got its funding via optimizing the "Impress Paul Graham and Elon Musk", rather than via the "Create an algorithm that can do something better than a human than sell it to humans that want that thing done better" strategy... which is an incentive 101 kinda problem and what makes me wary of many of their claims.
Again, not trying to disparage here, I also get my funding via the "Impress Paul Graham" route, I'm just saying that people in AI startups are not the best to listen to in terms of AI progress, none of them are going to say "Actually, it's kinda stagnating". Not because they are dishonest, but because the kind of people that work in and get funding for AI startups genuinely believe that... otherwise they'd be doing something else. However, as has been well pointed about by many here, confirmation bias is often much more insidious and credible than outright lies. Even I fall on the side of "exponential improvement" at the end of the day, but all my incentives are working towards biasing me in that direction, so thinking about it rationally, I'm likely wrong.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-10-15T05:14:21.574Z · LW(p) · GW(p)
I think the algorithmic progress isn't as fast as you say, at least not in the sense relevant for progress towards TAI/AGI.
Algorithmic improvements can be divided into two types, I think: Doing what we already know how to do more efficiently, and exploring new stuff more efficiently. I think lots of the improvements we've seen so far are of the first category, but the second category is what's relevant for TAI/AGI. I'm not sure what the ratio is but my guess is it's 50/50 or so. I'd love to see someone tackle this question and come up with a number.
That said, once we get close to TAI/AGI we should expect the first category to kick in and make it much cheaper very quickly.
Replies from: VermillionStuka↑ comment by Vermillion (VermillionStuka) · 2020-10-15T06:09:42.227Z · LW(p) · GW(p)
My algorithmic estimates essentially only quantify your "first category" type of improvements, I wouldn’t know where to begin making estimates for qualitative "second category" AGI algorithmic progress.
My comparisons to human level NLP (which I don’t think would necessarily yield AGI) assumed scaling would hold for current (or near future) techniques, so do you think that current techniques won't scale, or/and that the actual 100-1000x figure I gave was too high?
I'm not sure what the ratio is but my guess is it's 50/50 or so. I'd love to see someone tackle this question and come up with a number.
Yeah that would be great if someone did that.
comment by Noah Walton (noah-walton) · 2021-11-16T20:59:32.960Z · LW(p) · GW(p)
"AlphaZero took 8x less compute to get to AlphaGoZero level performance 1 year later."
This looks like a typo -- the second algorithm should be AlphaGo?
ETA 12/19/21: Looks like I was wrong here.
Replies from: VermillionStuka↑ comment by Vermillion (VermillionStuka) · 2021-11-17T09:00:42.095Z · LW(p) · GW(p)
Actually per https://openai.com/blog/ai-and-efficiency/ it was AlphaZero vs AlphaGoZero.