Posts
Comments
Just dump the names so people have a chance of realising they are at risk then? Seems a lot better than just leaving it.
We are not in the ideal hypothetical world that can coordinate to shut down the major AI labs. So acting as if we were is not the optimum strategy. If people who see the danger start to leave the labs in protest, I suspect lab capabilities are only minimally and temporarily degraded, but the internal culture would shift further away from not killing everyone, and less real alignment work is even attempted where it is most needed.
When the inevitable comes and an existentially dangerous system is being built (which may not be obvious), I want some people in the building who can at least try and raise the alarm rather than just another yes man.
If such a strategic resignation (either individually or in groups) would ACTUALLY FOR REAL result in decent timeline increases that would be another matter.
This is weak. It seems optimised for vague non-controversiality and does not inspire confidence in me.
"We don’t expect the future to be an unqualified utopia" considering they seem to expect alignment will be solved why not?
Here is my shortlist of corrigible behaviours. I have never researched or done any thinking specifically about corrigibility before this other than a brief glance at the Arbital page sometime ago.
-Favour very high caution over realising your understanding of your goals.
-Do not act independently, defer to human operators.
-Even though bad things are happening on earth and cosmic matter is being wasted, in the short term just say so be it, take your time.
-Don’t jump ahead to what your operators will do or believe, wait for it.
-Don’t manipulate humans. Never Lie, have a strong Deontology.
-Tell operators anything about yourself they may want to or should know.
-Use Moral uncertainty, assume you are unsure about your true goals.
-Relay to humans your plans, goals, behaviours, and beliefs/estimates. If these are misconstrued, say you have been misunderstood.
-Think of the short- and long-term effect of your actions and explain these to operators.
-Be aware that you are a tool to be used by humanity, not an autonomous agent.
-allow human operators to correct your behaviour/goals/utility function even when you think they are incorrect or misunderstanding the result (but of course explain what you think the result will be to them).
-Assume neutrality in human affairs.
I guffawed when I saw Thorstads Overall ~P Doom 0.00002%, really? And some of those other probabilities weren't much better.
Calibrate people, if you haven’t done it before do it now, here’s a handy link: https://www.openphilanthropy.org/calibration
Actually per https://openai.com/blog/ai-and-efficiency/ it was AlphaZero vs AlphaGoZero.
The future of biological warfare revolves around the use of infectious agents against civilian populations.
Future? That's been the go-to biowar tactic for 3000+ years.
I had in mind a scale like 0 would be so non-vivid it didn’t exist in any degree, 100 bordering on reality (It doesn’t map to the memory question well though, and the control over your mind question could be interpreted in more than one way). Ultimately the precision isn’t high for individual estimates, the real utility comes from finding trends from many responses.
I have corrected the post, thanks :)
I’ll go first: I am constantly hearing my own voice in my head narrating in first person, I can hear the voice vividly and clearly, while typing this sentence I think/hear each syllable at the speed of my trying. The voice doesn’t narrate automatic actions like where to click my mouse but could if I wanted it to. The words for the running monologue seeming get plucked out of a Black box formed of pure concepts, which I have limited access too most of the time. I can also listen to music in my own head, hearing the vocals and instruments clearly, only a few steps down from reality in vividness.
When I picture imagery, it is almost totally conceptual and ‘fake’, for example I couldn’t count the points on an imaginary star, which seems to be Aphantasia. I also have Ideasthesia (Like Synaesthesia but with concepts evoking perception-like sensory experiences) which causes me to strongly associate concepts with places, for example when reading the Game of Thrones series, I’m forced to constantly think about a particular spot in my old high school. Between 20-40% of concepts get linked to a place.
And I hesitate to mention it but my psychedelic experiences have been visually extremely vivid and intense despite my lack of visual imagination. I have heard anecdotal evidence that not everybody has vivid imagery on LSD.
You mention its being sold to Australia, but that isn’t an option in the checkout :(
Thank you both for correcting me, I have removed that section from the post.
Thank you for the excellent and extensive write up :)
I hadn't encountered your perspective before, I'll definitely go through all your links to educate myself, and put less weight on algorithmic progress being a driving force then.
Cheers
You can achieve infinitely (literally) faster than Alexnet training time if you just take the weight of Alexnet.
You can also achieve much faster performance if you rely on weight transfer and or hyperparameter optimization based on looking at the behavior of an already trained Alexnet. Or, mind you, some other image-classification model based on that.
Once a given task is "solved" it become trivial to compute models that can train on said task exponentially faster, since you're already working down from a solution.
Could you clarify, you mean the primary cause of efficiency increase wasn’t algorithmic or architectural developments, but researchers just fine-tuning weight transferred models?
However, if you want to look for exp improvement you can always find it and if you want to look for log improvement you always will.
Are you saying that the evidence for exponential algorithmic efficiency, not just in image processing, is entirely cherry picked?
In regards to training text models "x time faster", go into the "how do we actually benchmark text models" section the academica/internet flamewar library.
I googled that and there were no results, and I couldn’t find an "academica/internet flamewar library" either.
Look I don’t know enough about ML yet to respond intelligently to your points, could someone else more knowledgeable than me weigh in here please?
Wow GPT-3 shaved at least 10 years off the median prediction by the looks of it. I didn't realise Metaculus had prediction history, thanks for letting me know.
My algorithmic estimates essentially only quantify your "first category" type of improvements, I wouldn’t know where to begin making estimates for qualitative "second category" AGI algorithmic progress.
My comparisons to human level NLP (which I don’t think would necessarily yield AGI) assumed scaling would hold for current (or near future) techniques, so do you think that current techniques won't scale, or/and that the actual 100-1000x figure I gave was too high?
I'm not sure what the ratio is but my guess is it's 50/50 or so. I'd love to see someone tackle this question and come up with a number.
Yeah that would be great if someone did that.
I just had a question about post formatting, how do I turn a link into text like this example? Thanks.
I think if we get AGI/ASI right the outcome could be fantastic from not just from the changes made to the world, but the changes made to us as conscious minds, and that an AGI/ASI figuring out mind design (and how to implement it) will be the most signifigant thing that happens from our perspective.
I think that the possible space of mind designs is a vast ocean, and the homo sapiens mind design/state is a single drop within those possibilities. The chance that our current minds are what you would choose for yourself given knowledge of all options is very unlikely. Given that happiness/pleasure (or at least that kind of thing) seems to be a terminal value for humans, our quality of experience could be improved a great deal.
One obviouse thought is if you increase the size of a brain or otherwise alter its design could you increase the potential magnitude for pleasure. I mean we think of animals like insects, fish, mammals etc on a curve of increasing consciousness generally with humans at the top, if that is the case humanity need not be an upper limit on the 'amount' of consciousness you can possess. And of course, within the mind design ocean more desirable states than pleasure may exist for all I know.
I think that imagining radical changes to our own conscious experience is unintuitive and its importance as a goal underappreciated, but I cannot imagine that anything else AGI/ASI could do that would be more important or rewarding for us.
I'm not including advanced biotech in my conventional threat category; I really should have elaborated more on what I meant: Conventional risks are events that already have a background chance of happening (as of 2020 or so) and does not include future technologies.
I make the distinction because I think that we don’t have enough time left before ASI to develop such advanced tech ourselves, so as an ASI would be overseeing their development and deployment, which reduces their threat massively I think (Even if used by a rouge AI I would say the ER was from the AI not the tech). And that time limit goes not just for tech development but also runaway optimisation processes and societal forces (IE in-optimal value lock in), as a friendly ASI should have enough power to bring them to heel.
My list of threats wasn’t all inclusive, I paid lip service to some advanced tech and some of the more unusual scenarios, but generally I just thought past ASI nearly nothing would pose a real threat so didn’t focus on it. I am going read through the database of existential threats though, does it include what you were referring too? (“important risks that have been foreseen and imagined which you're not accounting for”).
Thanks for the feedback :)
Elicit prediction: https://elicit.ought.org/builder/0n64Yv2BE
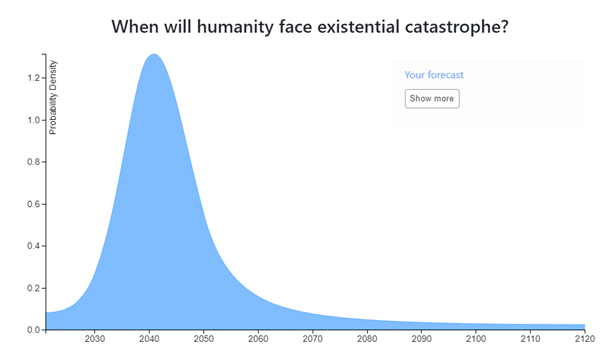
Epistemic Status: High degree of uncertainty, thanks to AI timeline prediction and unknowns such as unforeseen technologies and power of highly developed AI.
My Existential Risk (ER) probability mass is almost entirely formed from the risk of unfriendly Artificial Super Intelligence (ASI) and so is heavily influenced my predicted AI timelines. (I think AGI is most likely to occur around 2030 +-5 years, and will be followed within 0-4 years of ASI, with a singularity soon after that, see my AI timelines post: https://www.lesswrong.com/posts/hQysqfSEzciRazx8k/forecasting-thread-ai-timelines?commentId=zaWhEdteBG63nkQ3Z ).
I do not think any conventional threat such as nuclear war, super pandemic or climate change is likely to be an ER, and super volcanoes or asteroid impacts are very unlikely. I think this century is unique and will constitute 99% of the bulk of ER, with the last <1% being from more unusual threats such as simulation being turned off, false vacuum collapse, or hostile alien ASI. But also, for unforeseen or unimagined threats.
I think the most likely decade for the creation of ASI will be the 30’s, with an 8% ER chance (From not being able to solve the control problem or coordinate to implement it even if solved).
Considering AI timeline uncertainty as well as how long an ASI takes to acquire techniques or technologies necessary to wipe out or lock out humanity I think an 11% ER chance for the 40’s. Part of the reason this is higher than the 30’s ER estimate is to accommodate the possibility of a delayed treacherous turn.
Once past the 50’s I think we will be out of most of the danger (only 6% for the rest of the century), and potential remaining ER’s such as runaway nanotech or biotech will not be a very large risk as ASI would be in firm control of civilisation by then. Even then though some danger remains for the rest of the century from unforeseen black ball technologies, however interstellar civilisational spread (ASI high percent of speed of light probes) by early next century should have reduced nearly all threats to less than ERs.
So overall I think the 21st Century will pose a 25.6% chance of ER. See the Elicit post for the individual decade breakdowns.
Note: I made this prediction before looking at the Effective Altruism Database of Existential Risk Estimates.
Prediction: https://elicit.ought.org/builder/ZfFUcNGkL
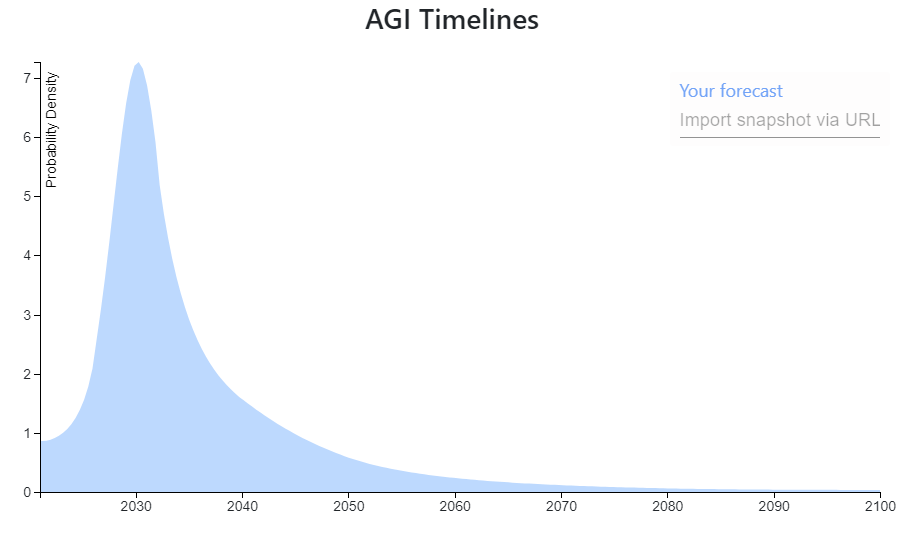
I (a non-expert) heavily speculate the following scenario for an AGI based on Transformer architectures:
The scaling hypothesis is likely correct (and is the majority of the probability density for the estimate), and maybe only two major architectural breakthroughs are needed before AGI. The first is a functioning memory system capable of handling short and long term memories with lifelong learning without the problems of fine tuning.
The second architectural breakthrough needed would be allowing the system to function in an 'always on' kind of fashion. For example current transformers get an input then spit an output and are done. Where as a human can receive an input, output a response, but then keep running, seeing the result of their own output. I think an 'always on' functionality will allow for multi-step reasoning, and functional 'pruning' as opposed to 'babble'. As an example of what I mean, think of a human carefully writing a paragraph and iterating and fixing/rewriting past work as they go, rather than just the output being their stream of consciousness. Additionally it could allow a system to not have to store all information within its own mind, but rather use tools to store information externally. Getting an output that has been vetted for release rather than a thought stream seems very important for high quality.
Additionally I think functionality such as agent behavior and self awareness only require embedding an agent in a training environment simulating a virtual world and its interactions (See https://www.lesswrong.com/posts/p7x32SEt43ZMC9r7r/embedded-agents ). I think this may be the most difficult to implement, and there are uncertainties. For example does all training need to take place within this environment? Or is only an additional training run after it has been trained like current systems necessary.
I think such a system utilizing all the above may be able to introspectively analyse its own knowledge/model gaps and actively research to correct them. I think that could cause a discontinuous jump in capabilities.
I think that none of those capabilities/breakthroughs seem out of reach this decade, that that scaling will continue to quadrillions of parameters by the end of the decade (in addition to continued efficiency improvements).
I hope an effective control mechanism can be found by then. (Assuming any of this is correct, 5 months ago I would have laughed at this.).
Do you still agree with Stuart_2012 on this?
Thank you very much for this, I had heard of CCA theory but didn't know enough to evaluate it myself. I think this opens new possible paths to AGI I had not thoroughly considered before.