Inferring utility functions from locally non-transitive preferences
post by Jan (jan-2) · 2022-02-10T10:33:18.433Z · LW · GW · 15 commentsThis is a link post for https://universalprior.substack.com/p/inferring-utility-functions
Contents
Preference utilitarianism and the Von-Neumann-Morgenstern theorem. The futility of computing utility. 1. Write down all the possible elementary outcomes that we might want to know the utility of. 2. Order all the elementary outcomes from worst to best. 3. Do a sequence of psychophysics experiments where humans indicate where the exact probabilistic combination of the worst- and the best possible outcome is equivalent to an intermediate outcome. Human fallibility and reward modeling. A natural representation of utility functions. Concluding thoughts and what’s next? None 15 comments
As part of the AI Safety Camp, I've been diving a bit deeper into the foundations of expected utility theory and preference learning. In this post, I am making explicit a connection between those two things that (I assume) many people already made implicitly. But I couldn't find a nice exposition of this argument so I wrote it up. Any feedback is of course highly welcome!
Preference utilitarianism and the Von-Neumann-Morgenstern theorem.
At the risk of sounding drab, I briefly want to revisit some well-trodden territory in the realm of expected utility theory to motivate the rest of this post.
When we are thinking about the question of how to align advanced AI with human values, we are confronted with the question of whether we want to capture "How humans act" or "How humans should act" [LW · GW]. Both approaches have virtue, but if we're being ambitious[1] we probably want to aim for the latter. However, our understanding of "How humans should act" is still rather confused [AF · GW] and ready-made solutions to "plug into" an AGI are not available.
Rather than tackling the entire problem at once, we might focus on one particularly well-formalized portion of ethics first. A possible answer to the question "How should I act?" comes from preference utilitarianism where we focus on satisfying everyone's preferences (as revealed by their choices). I say that this portion of ethics is well-formalized because, it turns out, if you are being reasonable about your preferences, we can represent them succinctly in a "utility function," . This utility function has the neat property that for two possible options, and , you prefer option over option iff .
This is the famous "von-Neumann-Morgenstern theorem" which sits at the heart of an approach of "doing good better [? · GW]".
Now given that the utility function lives in the realm of mathematics, there is a seemingly natural strategy to use it to steer AI. Get everyone's utility functions, combine them into a target function, and then let the AI pick the actions that increase the target function the most. If we have to pick a single number to maximize, there is a case to be made that utility is one of the best single numbers we can hope for.
Sounds good. Where is the catch?
The futility of computing utility.
Let's start by trying to write down a utility function. The proof of the von-Neumann-Morgenstern is constructive, i.e., it doesn't only guarantee the existence of a utility function, it also shows us the way to get there. Here is a step-by-step guide:
1. Write down all the possible elementary outcomes that we might want to know the utility of.
Ah. Yeah. That's going to be a problem.
"All the things" is a lot of things. We might (and will, in this post) limit ourselves to a toy domain to make some progress, but that will be a poor substitute for the thing we want: all the possible outcomes affecting all existing humans. We might not think of some outcomes because they appear too good to be true. (Or too weird to be thinkable.) We might even want to include those outcomes in particular, as they might be the best option that nobody realized was on the table. But if we can't think of them, we can't write them down[2].
(Perhaps there is a way out. An essential nuance in the first step is writing down "all the possible elementary outcomes." We don't need to consider all the outcomes immediately. We only need to consider a set from which we can construct the more complicated outcomes. We need a basis of the space of possibilities. That's already infinitely easier, and we're always guaranteed to find a basis[3]. Hopefully, we can find a basis of a system that is rich enough to describe all relevant outcomes and simple enough to allow for linear interpolation? Of course, a semantic embedding of natural language comes to mind, but the imprecision of language is probably a deal-breaker. Perhaps the semantic embedding of a formal language/programming language is more appropriate[4]?)
Let's use a toy domain, call this an open problem, and move on.
2. Order all the elementary outcomes from worst to best.
For some inexplicable reason, my intro to computer science course at uni has prepared me for this exact task, and this task alone. We have a bunch of great algorithms for sorting the elements of a list by comparing them with each other. If we're moderately unlucky, we can hope to sort N-many outcomes with comparisons. After sorting thousands of elementary outcomes, we pick the worst (bumping your toe against a chair[5]) and the best (ice cream sandwich) and assign them utility 0 and 1. For 1000 elementary outcomes, we could do with as little as 3000 comparisons which you could knock out in an afternoon. For 100000 elementary outcomes, we're talking 500000 comparisons which will keep you busy for a while. But it's for the survival of humankind, so perhaps it's fine! This could work!
Unless... somebody screws up. Those 3000 comparisons have to be spot on. If you accidentally mess up one comparison, the sorting algorithm might not be able to recover[6]. And since we're working with humans, some errors are guaranteed. Can you confidently say that you prefer a mushroom risotto over a new pair of shoes? Thought so.
But now comes the real killer.
3. Do a sequence of psychophysics experiments where humans indicate where the exact probabilistic combination of the worst- and the best possible outcome is equivalent to an intermediate outcome.
After sorting all outcomes from worst to best, we offer you a sequence of lotteries for each intermediate outcome (mushroom risotto): "Would you rather accept a 10% chance of stubbing your toe and a 90% chance of an ice cream sandwich, or a guaranteed mushroom risotto?" At some point (45% stubbing your toe), your answer will change from "Yes" to "No," and then we know we are very close to finding your utility for mushroom risotto (in this case, a utility of ~0.45).

I was halfway through setting up MTurk, but let's be realistic - this will not work. Allais paradox aside, I don't have the patience to set this up, so who will have the patience to go through this? Of course, we should have seen this coming. Just because a proof is "constructive" doesn't mean that we can apply it in the messy real world. Getting a utility function out of a human will require some elbow grease.
Human fallibility and reward modeling.
Let’s shuffle some symbols. How do we account for all the human messiness and the tendency to make mistakes? A standard trick is to call it "noise"[7]. Given a true estimate of utility, , we might write the perceived utility at any given time as a random variable, , distributed around the true value,
Given two outcomes, and , the probability of assessing the utility of higher than the utility of is distributed as the difference of two Gaussians, which is again a Gaussian:
(assuming independence of and ). The error function (lovingly called ) is nasty because it doesn't have a closed-form solution. But it does have a close relative that looks almost the same and is a lot nicer mathematically, and that has a much more pleasant-sounding name than ""...
I'll replace the with a stereotypical logistic function, ,
Much nicer. Even though the logistic function has largely fallen out of favor as an activation function in machine learning, its grip on psychophysics is unbroken.
Now that we have the mathematical machinery in place, we need to calibrate it to reality. A natural choice is to take the cross-entropy between our machinery, , and the actual comparisons provided by humans, or ,
Surprise[8]! The resulting loss function is also used for the reward modeling that I discussed in a previous post[9]. The researchers who originally proposed this technique for learning human preferences say that it is similar to the Elo rating system from chess and the "Bradley & Terry model." I find the motivation of reward modeling as an approximation of the von-Neumann-Morgenstern theorem a lot more Romantic, though.
Having uncovered this connection, a natural strategy for inferring a utility function through training a neural network with comparisons of pairs of elements from the domain presents itself.
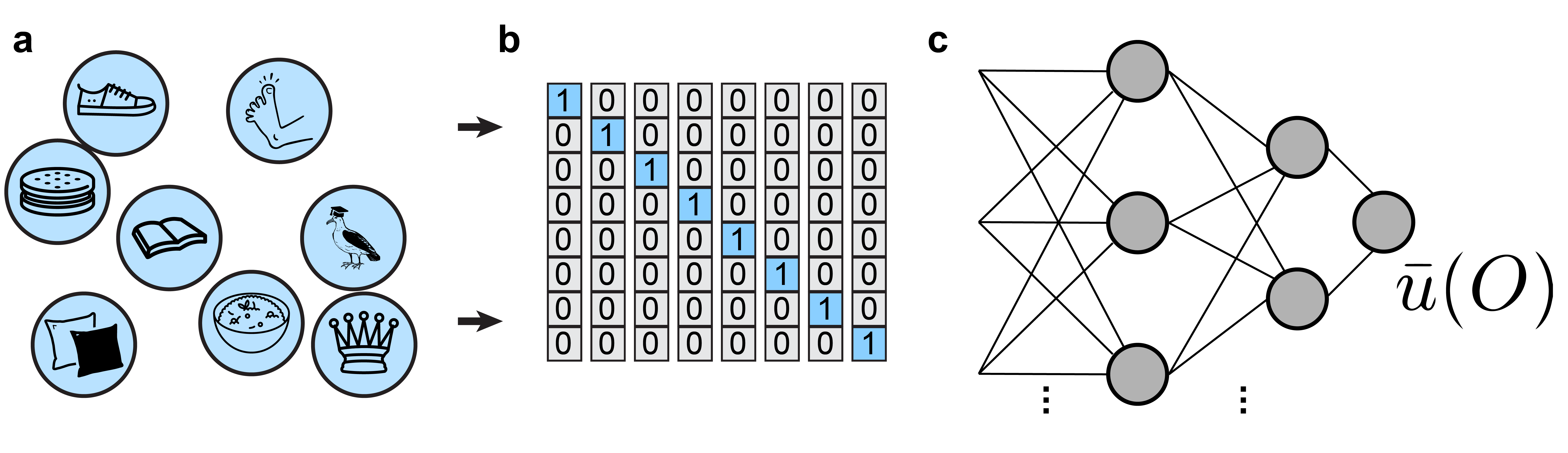
Can this work? It doesn’t involve MTurk for now, so I am happy to try!
A natural representation of utility functions.
I found that the neural network achieves near-zero loss on the comparisons after 20k steps (panel a). Runtime appears to increase linearly with the number of elements[10]. The resulting utility functions are monotonic and increase by an (approximately) equal amount from one item to another (panel b). This demonstrates that given enough time, a multilayer perceptron can sort a list.
Some might say that I used several hours of compute time on a Google Colab GPU just to sort lists, but that would be rather uncharitable. My primary motivation for this approach (human tendency to make mistakes) bears fruits in the following experiment. When I add noise to the choice procedure (resulting in 10% “random” choices), the network is still able to recover the appropriate ordering (panel c). And, even more remarkable, when I make the choice procedure loopy (i.e., nontransitive), the network can still recover a reasonable approximation of what the utility function looks like (panel d)!
This last set of experiments is exciting because introducing loops leads to nonlinear utility functions that are squashed together in the vicinity of the loop. Intuitively, if outcomes #3 and #4 are impossible to distinguish reliably, this might indicate that their utility is indeed very similar. The exciting possibility is that step 3 of the procedure above (psychometric calibration of utilities) could automatically be satisfied when options are sufficiently similar and sometimes confused[11].
Concluding thoughts and what’s next?
As mentioned at the beginning of this post, I suspect that this way of interpreting preference learning was already clear to some, but I hope that making the connection explicit is useful. I also find it great to see that we can recover a consistent utility function from inconsistent preferences (panel d of last figure). There are a lot more experiments I want to run on this toy domain to probe the limits to which preference orderings can be turned into utility functions:
- What is the largest number of elements we can sort with a given architecture? How does training time change as a function of the number of elements?
- How does the network architecture affect the resulting utility function? How do the maximum and minimum of the unnormalized utility function change?
- Which portion of possible comparisons needs to be presented (on average) to infer the utility function?
- How far can we degenerate a preference ordering until no consistent utility function can be inferred anymore?
But independent of those experiments, there are some fascinating directions that I plan to explore in a future post. Now that I have a natural way to induce utility functions, I think I can further explore the utility monster and some of the classic literature on (un-)comparability of utility functions [LW · GW]. I also really want to write a proper treatment of value handshakes [? · GW], which is a topic in dire need of exploration [LW(p) · GW(p)].
I'd be curious to hear any additional ideas for what to try, as well as comments on how feasible this approach sounds/where it's likely to break down.
- ^
- ^
I suspect that if Goodhart creeps into the argument, this is around the place where it happens.
- ^
if we're willing to embrace Zorn.
- ^
Has anybody ever looked at that? What happens when I subtract Fizzbuzz from the Fibonacci sequence?
- ^
A very close "win" over S-risk scenarios.
- ^
And the worst-case runtime shoots up to ∞ as soon as you have the probability of errors). In this situation, Bogosort might just be the most reliable solution - at least it won't terminate until it's done.
- ^
Joke aside, it’s an interesting question which factors need to come together to make something “noise.” I guess the central limit theorem can help if there are many independent factors, but that’s never really the case. The more general question is under which circumstances the residual factors are random and when they are adversarial.
- ^
Please ignore that it's already written in the section title.
- ^
The original Leike paper has an equivalent expression that does not write out the logarithm applied to the sigmoid.
- ^
My money would be on or worse, of course.
- ^
I’d expect that the difference in utility, , will be proportional to the probability of confusing the order, .
15 comments
Comments sorted by top scores.
comment by NunoSempere (Radamantis) · 2022-02-10T15:23:44.950Z · LW(p) · GW(p)
Interesting. I have been doing this the "hard way", will link here when I post my draft.
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-10T16:27:52.458Z · LW(p) · GW(p)
Yes please, would be excited to see that!
comment by cousin_it · 2022-02-12T10:43:27.045Z · LW(p) · GW(p)
There's a bit of math directly relevant to this problem: Hodge decomposition of graph flows, for the discrete case, and vector fields, for the continuous case. Basically if you have a bunch of arrows, possibly loopy, you can always decompose it into a sum of two components: a "pure cyclic" one (no sources or sinks, stuff flowing in cycles) and a "gradient" one (arising from a utility function). No neural network needed, the decomposition is unique and can be computed explicitly. See this post [LW · GW], and also the comments by FactorialCode and me.
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-12T13:05:00.586Z · LW(p) · GW(p)
Fantastic, thank you for the pointer, learned something new today! A unique and explicit representation would be very neat indeed.
comment by Erik Jenner (ejenner) · 2022-02-10T22:55:43.094Z · LW(p) · GW(p)
I enjoyed reading this! And I hadn't seen the interpretation of a logistic preference model as approximating Gaussian errors before.
Since you seem interested in exploring this more, some comments that might be helpful (or not):
- What is the largest number of elements we can sort with a given architecture? How does training time change as a function of the number of elements?
- How does the network architecture affect the resulting utility function? How do the maximum and minimum of the unnormalized utility function change?
I'm confused why you're using a neural network; given the small size of the input space, wouldn't it be easier to just learn a tabular utility function (i.e. one value for each input, namely its utility)? It's the largest function space you can have but will presumably also be much easier to train than a NN.
Questions like the ones you raise could become more interesting in settings with much more complicated inputs. But I think in practice, the expensive part of preference/reward learning is gathering the preferences, and the most likely failure modes revolve around things related to training an RL policy in parallel to the reward model. The architecture etc. seem a bit less crucial in comparison.
Which portion of possible comparisons needs to be presented (on average) to infer the utility function?
I thought about this and very similar questions a bit for my Master's thesis before changing topics, happy to chat about that if you want to go down this route. (Though I didn't think about inconsistent preferences, just about the effect of noise. Without either, the answer should just be I guess.)
How far can we degenerate a preference ordering until no consistent utility function can be inferred anymore?
You might want to think more about how to measure this, or even what exactly it would mean if "no consistent utility function can be inferred". In principle, for any (not necessarily transitive) set of preferences, we can ask what utility function best approximates these preferences (e.g. in the sense of minimizing loss). The approximation can be exact iff the preferences are consistent. Intuitively, slightly inconsistent preferences lead to a reasonably good approximation, and very inconsistent preferences probably admit only very bad approximations. But there doesn't seem to be any point where we can't infer the best possible approximation at all.
Related to this (but a bit more vague/speculative): it's not obvious to me that approximating inconsistent preferences using a utility function is the "right" thing to do. At least in cases where human preferences are highly inconsistent, this seems kind of scary. Not sure what we want instead (maybe the AI should point out inconsistencies and ask us to please resolve them?).
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-12T13:48:52.693Z · LW(p) · GW(p)
Awesome, thanks for the feedback Eric! And glad to hear you enjoyed the post!
I'm confused why you're using a neural network
Good point, for the example post it was total overkill. The reason I went with a NN was to demonstrate the link with the usual setting in which preference learning is applied. And in general, NNs generalize better than the table-based approach ( see also my response to Charlie Steiner ).
happy to chat about that
I definitely plan to write a follow-up to this post, will come back to your offer when that follow-up reaches the front of my queue :)
But there doesn't seem to be any point where we can't infer the best possible approximation at all.
Hadn't thought about this before! Perhaps it could work to compare the inferred utility function with a random baseline? I.e. the baseline policy would be "for every comparison, flip a coin and make that your prediction about the human preference".
If this happens to accurately describe how the human makes the decision, then the utility function should not be able to perform better than the baseline (and perhaps even worse). How much more structure can we add to the human choice before the utility function performs better than the random baseline?
it's not obvious to me that approximating inconsistent preferences using a utility function is the "right" thing to do
True! I guess one proposal to resolve these inconsistencies is CEV, although that is not very computable.
comment by Kaarel (kh) · 2022-02-11T16:23:43.163Z · LW(p) · GW(p)
I liked the post; here are some thoughts, mostly on the "The futility of computing utility" section:
1 )
If we're not incredibly unlucky, we can hope to sort N-many outcomes with comparisons.
I don't understand why you need to not be incredibly unlucky here. There are plenty of deterministic algorithms with this runtime, no?
2) I think that in step 2, once you know the worst and the best outcome, you can skip to step 3 (i.e. the full ordering does not seem to be needed to enter step 3. So instead of sorting in n log n time, you could find min and max in linear time, and then skip to the psychophysics.
3) Could you elaborate on what you mean by a basis of possibility-space? It is not obvious to me that possibility-space has a linear structure (i.e. that it is a vector space), or that utility respects this linear structure (e.g. the utility I get from having chocolate ice cream and having vanilla ice cream is not in general approximated well by the sum of the utilities I get from having only one of these, and similarly for multiplication by scalars). Perhaps you were using these terms metaphorically, but then I currently have doubts about this being a great metaphor / would appreciate having the metaphor spelled out more explicitly. I could imagine doing something like picking some random subset of the possibilities, doing something to figure out the utilities of this subset, and then doing some linear regression (or something more complicated) on various parameters to predict the utilities of all possibilities. It seems like a more symmetric way to think about this might be to consider the subset of outcomes (with each pair, or some of the pairs, being labeled according to which one is preferred) to be the training data, and then training a neural network (or whatever) that predict utilities of outcomes so as to minimize loss on this training data. And then to go from training data to any possibility, just unleash the same neural network on that possibility. (Under this interpretation, I guess "elementary outcomes" <-> training data, and there does not seem to be a need to assume linear structure of possibility-space.)
4) I think I have something cool to say about a specific and very related problem. Input: a set of outcomes and some pairwise preferences between them. Desired output: a total order on these outcomes such that the number of pairs which are ordered incorrectly is minimal. It turns out that this is NP-hard: https://epubs.siam.org/doi/pdf/10.1137/050623905. (The problem considered in this paper is the special case of the problem I stated where all the pairwise preferences are given, but well, if a special case is NP-hard, then the problem itself is also NP-hard.)
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-12T13:35:57.028Z · LW(p) · GW(p)
Thanks for the comment! (:
- True, fixed it! I was confused there for a bit.
- This is also true. I wrote it like this because the proof sketch on Wikipedia included that step. And I guess if step 3 can't be executed (complicated), then it's nice to have the sorted list as a next-best-thing.
- Those are interesting points and I'm not sure I have a good answer (because the underlying problems are quite deep, I think). My statement about linearity in semantic embeddings is motivated by something like the famous "King – Man + Woman = Queen" from word2vec. Regarding linearity of the utility function - I think this should be given by definition, or? (Hand-wavy: Using this we can write and so on).
But your point is well-taken, the semantic embedding is not actually always linear. This requires some more thought. - Ahhh very interesting, I'd not have expected that intuitively, in particular after reading the comment from @cousing_it above. I wonder how an explicit solution with the Hodge decomposition can be reconciled with the NP-hardness of the problem :thinkies:
↑ comment by Kaarel (kh) · 2022-02-12T14:27:31.451Z · LW(p) · GW(p)
3. Ahh okay thanks, I have a better picture of what you mean by a basis of possibility space now. I still doubt that utility interacts nicely with this linear structure though. The utility function is linear in lotteries, but this is distinct from being linear in possibilities. Like, if I understand your idea on that step correctly, you want to find a basis of possibility-space, not lottery space. (A basis on lottery space is easy to find -- just take all the trivial lotteries, i.e. those where some outcome has probability 1.) To give an example of the contrast: if the utility I get from a life with vanilla ice cream is u_1 and the utility I get from a life with chocolate ice cream is u_2, then the utility of a lottery with 50% chance of each is indeed 0.5 u_1 + 0.5 u_2. But what I think you need on that step is something different. You want to say something like "the utility of the life where I get both vanilla ice cream and chocolate ice cream is u_1+u_2". But this still seems just morally false to me. I think the mistake you are making in the derivation you give in your comment is interpreting the numerical coefficients in front of events as both probabilities of events or lotteries and as multiplication in the linear space you propose. The former is fine and correct, but I think the latter is not fine. So in particular, when you write u(2A), in the notation of the source you link, this can only mean "the utility you get from a lottery where the probability of A is 2", which does not make sense assuming you don't allow your probabilities to be >1. Or even if you do allow probabilities >1, it still won't give you what you want. In particular, if A is a life with vanilla ice cream, then in their notation, 2A does not refer to a life with twice the quantity of vanilla ice cream, or whatever.
4. I think the gradient part of the Hodge decomposition is not (in general) the same as the ranking with the minimal number of incorrect pairs. Fun stuff
Replies from: kh, jan-2↑ comment by Kaarel (kh) · 2022-02-12T15:42:56.756Z · LW(p) · GW(p)
more on 4: Suppose you have horribly cyclic preferences and you go to a rationality coach to fix this. In particular, your ice cream preferences are vanilla>chocolate>mint>vanilla. Roughly speaking, Hodge is the rationality coach that will tell you to consider the three types of ice cream equally good from now on, whereas Mr. Max Correct Pairs will tell you to switch one of the three preferences. Which coach is better? If you dislike breaking cycles arbitrarily, you should go with Hodge. If you think losing your preferences is worse than that, go with Max. Also, Hodge has the huge advantage of actually being done in a reasonable amount of time :)
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-15T10:11:58.891Z · LW(p) · GW(p)
Great explanation, I feel substantially less confused now. And thank you for adding two new shoulder advisors [LW · GW] to my repertorie :D
↑ comment by Jan (jan-2) · 2022-02-15T10:07:36.575Z · LW(p) · GW(p)
Thank you for the thoughtful reply!
3. I agree with your point, especially that should be true.
But I think I can salvage my point by making a further distinction. When I write I actually mean where is a semantic embedding that takes sentences to vectors. Already at the level of the embedding we probably have
and that's (potentially) a good thing! Because if we structure our embedding in such a way that points to something that is actually comparable to the conjunction of the two, then our utility function can just be naively linear in the way I constructed it above, I belieeeeeve that this is what I wanted to gesture at when I said that we need to identify an appropriate basis in an appropriate space (i.e. where and whatever else we might want out of the embedding). But I have a large amount of uncertainty around all of this.
Replies from: kh↑ comment by Kaarel (kh) · 2022-10-07T11:13:07.906Z · LW(p) · GW(p)
I still disagree / am confused. If it's indeed the case that , then why would we expect ? (Also, in the second-to-last sentence of your comment, it looks like you say the former is an equality.) Furthermore, if the latter equality is true, wouldn't it imply that the utility we get from [chocolate ice cream and vanilla ice cream] is the sum of the utility from chocolate ice cream and the utility from vanilla ice cream? Isn't supposed to be equal to the utility of ?
My current best attempt to understand/steelman this is to accept , to reject , and to try to think of the embedding as something slightly strange. I don't see a reason to think utility would be linear in current semantic embeddings of natural language or of a programming language, nor do I see an appealing other approach to construct such an embedding. Maybe we could figure out a correct embedding if we had access to lots of data about the agent's preferences (possibly in addition to some semantic/physical data), but it feels like that might defeat the idea of this embedding in the context of this post as constituting a step that does not yet depend on preference data. Or alternatively, if we are fine with using preference data on this step, maybe we could find a cool embedding, but in that case, it seems very likely that it would also just give us a one-step solution to the entire problem of computing a set of rational preferences for the agent.
A separate attempt to steelman this would be to assume that we have access to a semantic embedding pretrained on preference data from a bunch of other agents, and then to tune the utilities of the basis to best fit the preferences of the agent we are currently dealing with. That seems like it a cool idea, although I'm not sure if it has strayed too far from the spirit of the original problem.
comment by Charlie Steiner · 2022-02-10T21:19:17.084Z · LW(p) · GW(p)
Wait, I feel like I missed something. What's the advantage of a NN over a simple Elo-like algorithm here?
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-12T13:09:13.963Z · LW(p) · GW(p)
Hey Charlie!
Good comment, gave me a feeling "oh, ups, why didn't I?" for a while. I think having the Elo-like algorithm as a baseline to compare to would have been a good thing to have in any case. But there is something that the NN can do that the Elo-like algorithm can't; generalization. Every "new" element (or even an interpolation of older elements) will get the "initial score" (like 1500 in chess) in Elo, while the NN can exploit similarities between the new element and older elements.