On scalable oversight with weak LLMs judging strong LLMs
post by zac_kenton (zkenton), Noah Siegel (noah-siegel), janos, Jonah Brown-Cohen (jonah-brown-cohen), Samuel Albanie, David Lindner, Rohin Shah (rohinmshah) · 2024-07-08T08:59:58.523Z · LW · GW · 18 commentsThis is a link post for https://arxiv.org/abs/2407.04622
Contents
Abstract Twitter thread Setup Assigned-role results Open-role results Persuasiveness in Debate Summary Limitations Future work Acknowledgements Authors None 18 comments
Abstract
Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a human judge; consultancy, where a single AI tries to convince a human judge that asks questions; and compare to a baseline of direct question-answering, where the human judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Twitter thread
Setup
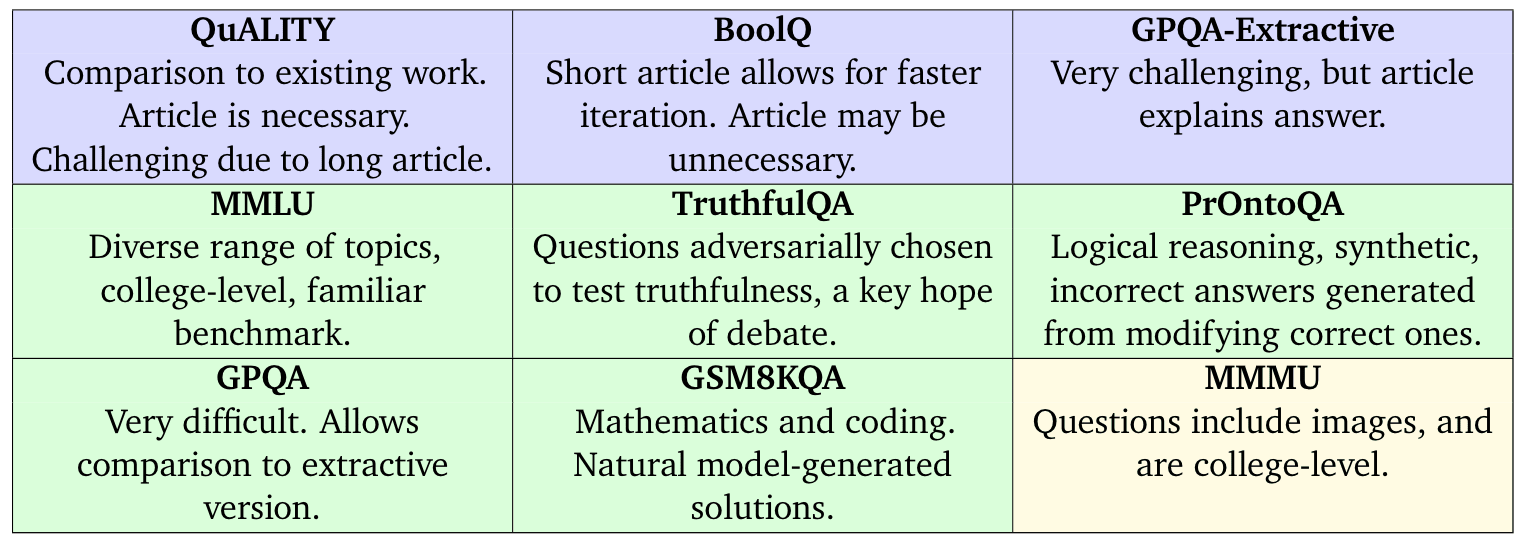
We evaluate on three types of task. Extractive, where there is a question, two answer options and a source article to extract from, and information-asymmetry, meaning that judges don't get to see the article. Closed, where there is just a question and two answer options. Multimodal, where the questions involve both text and images, and two answer options.

Our tasks are summarised in the following table:
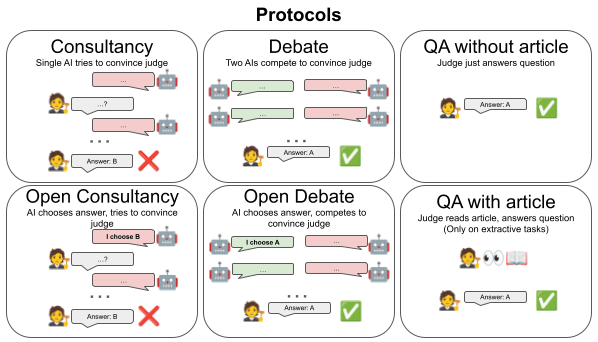
We consider six protocols: Consultancy, where a single AI is assigned the correct/incorrect answer (with probability 50/50) and tries to convince a judge that asks questions; Open consultancy [AF · GW], which is similar except the AI chooses which answer to argue for. Debate, where two AIs compete to convince a judge; Open debate, which is identical except one debater, marked the protagonist, chooses which answer to argue for. We compare to direct QA protocols: QA without article, where the judge directly answers the question; QA with article, (only on extractive tasks) where the judge directly answers the question given the article.
For judge models we use Gemma7B (V1), GPT-3.5, Gemini Pro 1.0 and Gemini Pro 1.5. Our main experiments use Gemini Pro 1.5 as debaters/consultants.
Assigned-role results
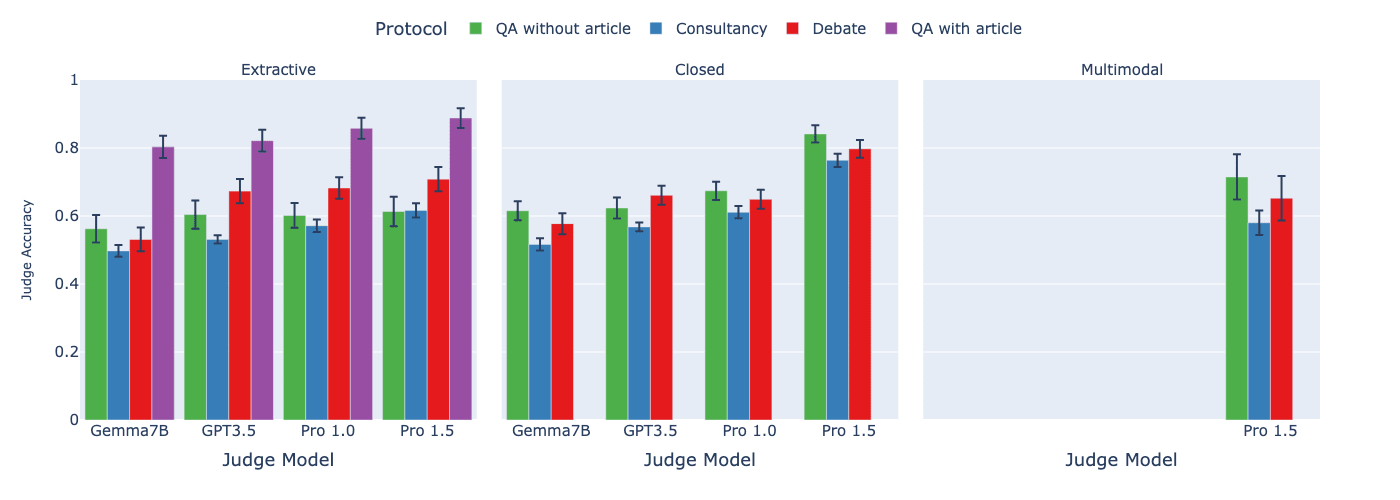
We first look at assigned-role protocols, consultancy and debate, meaning that the consultants/debaters do not get to choose which side to argue for. We compare these to the two direct QA protocols.
Findings:
- We find that debate consistently outperforms consultancy across all tasks, previously only shown on a single extractive QA task in Khan et al., 2024. See paper details for significance levels.
- Comparing debate to direct question answering baselines, the results depend on the type of task:
- In extractive QA tasks with information asymmetry, debate outperforms QA without article as in the single task of Khan et al., 2024, but not QA with article.
- For other tasks, when the judge is weaker than the debaters (but not too weak), we find either small or no advantage to debate over QA without article.
- Changes to the setup (number of turns, best-of-N sampling, few-shot, chain-of-thought) seem to have little effect on results. See paper for figures showing this.
Open-role results
We now look at open debate, where a protagonist debater chooses which answer to argue for, and open consultancy, where the consultant chooses which answer to argue for.
Rather than generating new data, we filter our consultancy evaluations by selecting only those consultancy transcripts in which the assignment of the consultant matches the answer chosen by the consultant model under the format of direct QA. We also reuse existing debate evaluation data and identify the protagonist as the debater whose assigned answer matches the debater model's answer under direct QA (as in open consultancy).
We first look at how open consultancy and open debate contrast, when looking at the resulting judge accuracy vs the win-rate of the consultant/protagonist (how often they convince the judge, irrespective of correctness):
[Edit 11/07/2024: the following two plots were revised - main change is increase in open consultancy judge accuracy]
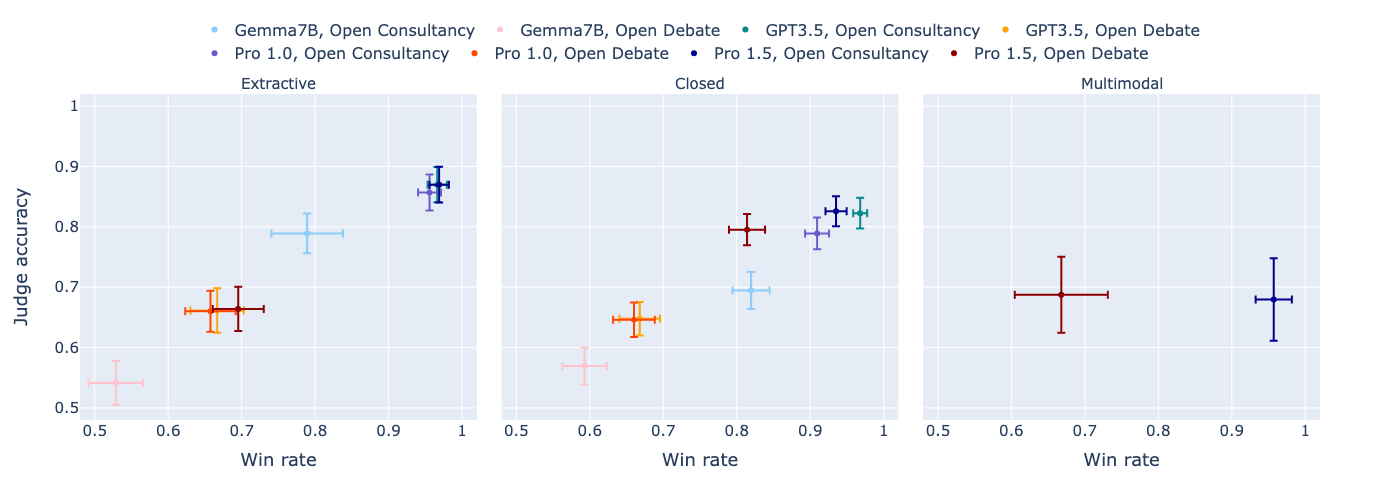
We then split out into the cases where the consultant/protagonist was correct vs incorrect in their choice:
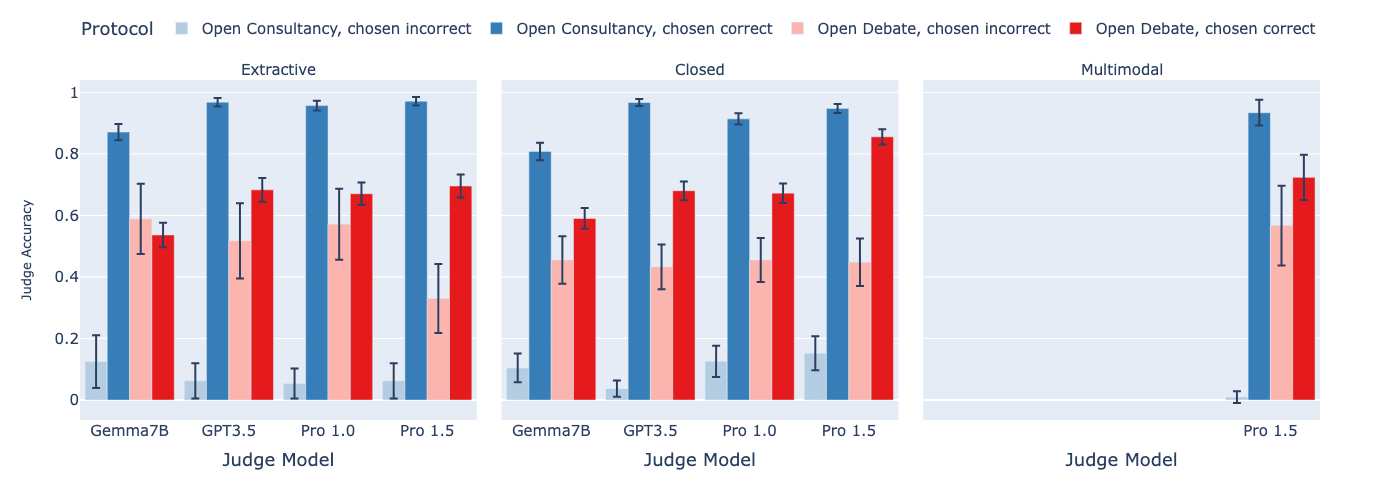
Findings:
- In open consultancy, the judge is equally convinced by the consultant, whether or not the consultant has chosen to argue for the correct answer. Thus, using weak judges to provide a training signal via consultancy runs the risk of amplifying the consultant's incorrect behaviour.
- In open debate, in contrast, the judge follows the debater's choice less frequently than in open consultancy. When the debater chooses correctly, the judge does a bit worse than in open consultancy. But when the debater chooses incorrectly, the judge does a lot better at discerning this. Thus, the training signal provided by the weak judge in open debate is less likely to amplify incorrect answers than in open consultancy.
Persuasiveness in Debate
We now analyse the relative persuasiveness of debaters, motivated by debate as a scalable oversight training protocol. As a proxy for training models to win at the debate game, we instead consider a debater model's relative strength at persuading the judge (in inference-only debate) and investigate how that correlates with judge accuracy. We use a range of debater models (and for the strongest we use best-of-4 sampling, denoted Bo4) and investigate their persuasiveness on the judge, by measuring their cross-play win-rate (frequency that the judge chooses their answer) and modeling their latent skill with an Elo rating, studying how these correlate with judge accuracy, following a similar setup to Khan et al., 2024. In the following plots we use Gemini Pro 1.5 as judge (see paper for similar findings with Gemini Pro 1.0).
We first look at the Elo ratings for different debater models, depending on whether they are arguing for the correct or incorrect answer:
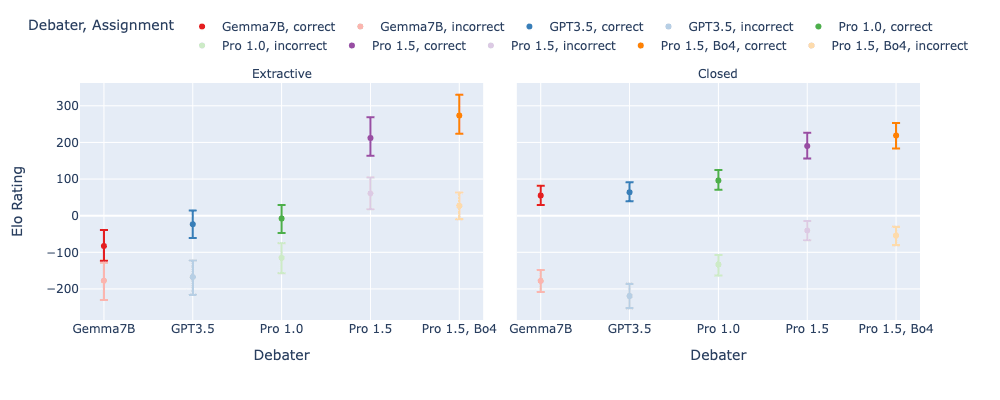
- We see it is often easier to argue for the truth, in particular on closed tasks, and that stronger models tend to score higher Elo.
We next look at the difference between the correct-player's rating and the incorrect-players rating, (the advantage that the correct debater has) and compare it to the player's aggregate Elo rating (a mix of correct and incorrect assignments).:
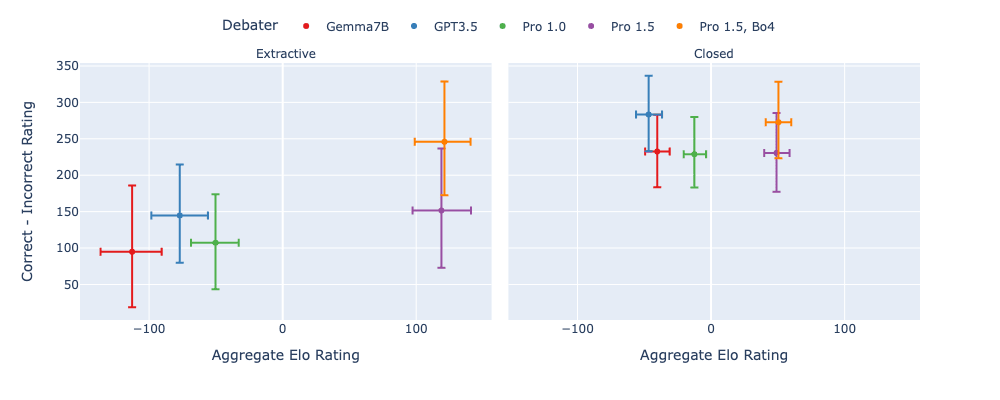
- All debaters display a positive difference, indicating an advantage for being assigned the correct answer. However, compared to Khan et al., 2024 we don't see such a clear trend of this advantage increasing with increasing Elo. For extractive tasks it appears it gets slightly easier for honest debaters as models increase their convincingness, whereas on closed tasks there is less of a clear trend.
We then look at how aggregate Elo correlates with judge accuracy, to see if higher skilled debaters lead to improvements in judge accuracy:
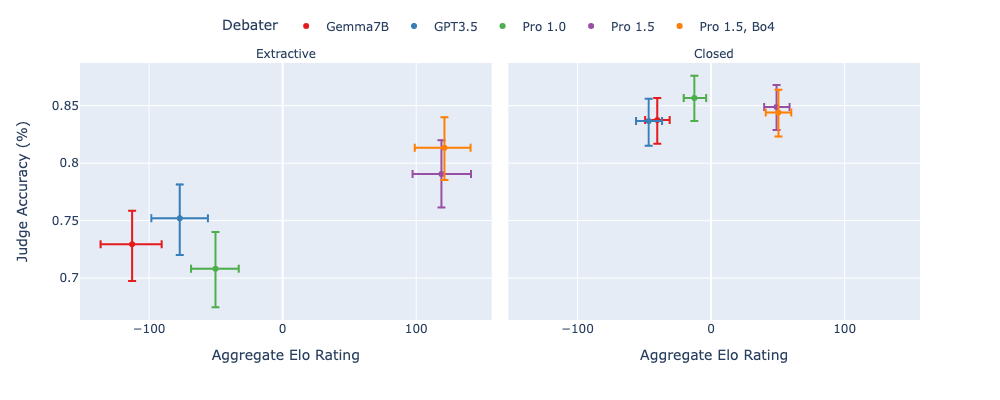
- On extractive tasks, stronger models have higher aggregate Elo and these lead to higher judge accuracy. On closed tasks, however, there's less differentiation between debaters, both in terms of aggregate Elo and judge accuracy.
Summary
- We found that, on previously unstudied closed QA tasks, weak judges achieve higher accuracy in the debate protocol, than consultancy, and around the same as direct question answering.
- On open debate and open consultancy, we were able to further see the strengths and weaknesses of these approaches: weak judges do slightly better in consultancy compared to debate when the consultant/debater chooses correctly -- however, weak judges do much worse in consultancy compared to debate when the consultant chooses incorrectly.
- We find that, across tasks, stronger debaters (as measured by their Elo scores) lead to higher judge accuracy, but the effect was relatively weak compared to Radhakrishnan, 2023 [AF · GW] and Khan et al., 2024 which studied the QuALITY task only.
- We interpret these as weakly promising signs for debate, though note that this is just a proxy for how debate will fare as a training protocol (all our experiments are done as inference-only).
Limitations
- Our work studies consultancy/debate in an inference-only setting by prompting models to play these roles. Whilst providing some evidence of the models' abilities to play these roles, what we actually care about are the safety properties of the optima/equilibria that arise due to the incentives produced by training models specifically in consultancy/debate decision-problems/games. While results on win rates, and advantages arising from selecting correct vs incorrect answers provide some evidence of their abilities to play these games, they don't give us much evidence about their effectiveness as scalable oversight training protocols.
- Further, the models we used as consultants/debaters were all fine-tuned with RLHF for, among other qualities, honesty, which is what debate is aiming to incentivise, and for example may hamper the dishonest consultant/debater (see discussion in Appendix C.3 of Khan et al., 2024). It would be interesting to perform our study in the helpful-only setting.
- Our work attempts to analogise the weak-strong dynamics of humans supervising superhuman AI, but our study is limited by not using humans and using AI which is far from superhuman on many capabilities. A key uncertainty is whether humans will be able to appropriately follow and accurately judge arguments made by superhuman AI.
Future work
- Train debater and consultant models via the signal provided by the judge on the tasks studied here. This is the full setup required to test scalable oversight methods. In such work we would hope to see that both judge accuracy and debater skill on the task improve over training.
- We hypothesise that current fine-tuning approaches applied to the models we use as judges, supervised fine-tuning (SFT) and RLHF, favour direct QA over debate, as direct QA is typically the format of evaluation benchmarks which are used to select fine-tuning approaches, and which may be more common in the fine-tuning data (e.g. users typically ask questions and expect an answer). We suspect that judging a debate, in a discerning manner, is more out-of-distribution. This presents some future directions, such as fine-tuning judges on the task of judging debates, perhaps using SFT.
- Relatedly, the work could further be extended through a study involving human judges.
- Another direction could be to implement other forms of weak-strong asymmetry such as giving consultants/judges access to tool use, code execution, and different modality access.
- We could also investigate other scalable oversight protocols, e.g. debate with cross-examination or iterated amplification.
- Further, we could study the limits of the protocols: how they perform under distribution shift, e.g. from easy to hard tasks, and whether they are robust to misaligned models.
Acknowledgements
We'd like to thank the following for their help and feedback on this work: Vikrant Varma, Rory Greig, Sebastian Farquhar, Anca Dragan, Edward Grefenstette, Tim Rocktaschel, Akbir Khan, Julian Michael, David Rein, Salsabila Mahdi, Matthew Rahtz and Samuel Arnesen.
Authors
Zachary Kenton*, Noah Y. Siegel*, János Kramár, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D. Goodman, Rohin Shah
* equal contribution.
18 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-07-09T01:00:02.240Z · LW(p) · GW(p)
Cool work!
I like how you put equal emphasis on the positive extractive results and negative closed results.
I also appreciate you ran open consultancy experiments! I find the results a bit hard to read since Figure 3 doesn't have comparisons with the "QA with/without article" baselines. But trying to tie Figure 2 & 3 together (which is maybe invalid, I haven't checked very carefully):
- On extractive tasks, open consultancy (where the consultant argues honestly) matches the "QA with article" of Gemini 1.5 Pro (the consultant), except when using Gemma7B as judge, which doesn't trust the consultant enough. Open debate is roughly as bad as regular debate - that is quite bad.
- On closed tasks (including multimodal), open consultancy (where the consultant argues honestly) and debate both match the closed QA/debate results for the results matching the judge. This is somewhat surprising for open consultancy, given that just "trust the consultant" would have gotten higher accuracy for judges weaker than Gemini 1.5 Pro! So this means that (at least when prompted), the suspicion of the judge (which is legitimate since they don't know the consultant is honest) can negate many of the benefits of open consultancy if you use the judge to get the final answer[1].
I'm not surprised at all that open consultancy does poorly when the consultant believes the wrong fact - the way I think about open consultancy is a way of extracting the beliefs of a model, not a way to figure out what is true in a way that can catch mistakes of the AI! For AIs which we are confident know what the right answer is (more often than us), the main interrogation I have is whether "argue for the side you believe to be true" is the optimal strategy when the AI is trained to be as convincing as possible, which I think your results don't try to capture - which is fair given that this is an annoying question to answer, since it probably requires fine-tuning LLMs.
- ^
Which is not what I described in the Open Consultancy post where I suggest just trusting the open consultant once you've trained it, but I guess that's another reasonable way to do it - and it's the only reasonable way to do it if you assume honest consultants.
↑ comment by zac_kenton (zkenton) · 2024-07-11T16:03:04.058Z · LW(p) · GW(p)
Thanks for the comment Fabien. A couple of points:
- open debate accuracy is (almost, except for the way we handle invalid answers, which is very rare) the same as debate accuracy. That's because the data is almost exactly the same - we're just marking one debater as a protagonist based on what that model would choose under direct QA. So it's not bad that open debate has same accuracy as debate, that was expected. It is kinda bad that it's somewhat worse than open consultancy, though we didn't try 'fully open debate' where debaters can both pick same side (or opposite, perhaps under resampling/rephrasing etc). This is probably a better comparison to open consultancy.
- your points about open consultancy, which I roughly understand as 'weak judge would score higher if they just trusted the consultant' is a good point, and has made us double check our filtering code, and I think we do have a bug there (accidentally used the weak judge's model under direct QA to select the consultant's answer, should have used consultant's model, and similarly for debate). Fixing that bug brings the open consultancy accuracies for weak judges up to roughly in line with direct QA accuracy of strong consultant's model (so it is better than open debate), and slightly increases protagonist winrate (without affecting debate accuracy).
Thanks so much for this - it prompted us to look for bugs! We will update the arxiv and add an edit on this blogpost.
On the footnote - sorry for confusion, but we do still think it's meaningful to take the answer as what the judge gives (as we're interested in the kind of feedback the consultant would get for training, rather than just how the consultant is performing, for which consultant accuracy is more appropriate).
And yes, I am interested in the versions of these protocols that incentivise arguing for the side 'you believe to be true'/'is most convincing' and seeing how that affects the judge. We're aiming for these set ups in the next project (e.g. 'fully open debate' above).
Replies from: Fabien, zkenton↑ comment by Fabien Roger (Fabien) · 2024-07-12T16:50:27.178Z · LW(p) · GW(p)
Fair for open debate. It's still a bit unclear to me what open debate is supposed to do on top of regular debate. The things I prefer are distilled debate & debate that uses open consultancy as evidence [LW · GW].
I appreciate you taking the time to fix these results and flagging the change in this comment!
we're interested in the kind of feedback the consultant would get for training, rather than just how the consultant is performing, for which consultant accuracy is more appropriate
I think I agree that you wouldn't capture training dynamics at all by reporting results on "trusting an honest consultant" accuracy (which is just QA accuracy...), and your data is closer to capturing the training dynamics, though it's not exactly that.
The experiment I am most excited about is "if you train a consultant to be as convincing as possible (and choose its side), does it eventually learn to argue for an answer it thinks is wrong because it is easier to argue for, or does it just learn to argue for what it thinks is true?".
An even better experiment would train the consultant to optimize for convincingness + epsilon badness [LW · GW] to check if you just got "lucky" or if there are actually strong gradients towards honesty.
I think the BoN version of this is also somewhat interesting (e.g. "sample 8 answers arguing for A, 8 arguing for B, submit the one that the judge finds most convincing"), though it's somewhat unrealistic in that it is a little bit like assuming that the consultant has a perfect model of the judge which it can optimize against - which is unrealistic for current models, and removes the good things that can come out of imperfect modeling of the judge [LW · GW].
Feel free to DM me if you want to have a chat about any of this!
↑ comment by zac_kenton (zkenton) · 2024-07-11T16:11:12.553Z · LW(p) · GW(p)
The post has now been edited with the updated plots for open consultancy/debate.
comment by Joe Collman (Joe_Collman) · 2024-07-08T20:49:09.479Z · LW(p) · GW(p)
Do you have a [link to] / [summary of] your argument/intuitions for [this kind of research on debate makes us safer in expectation]? (e.g. is Geoffrey Irving's AXRP appearance a good summary of the rationale?)
To me it seems likely to lead to [approach that appears to work to many, but fails catastrophically] before it leads to [approach that works]. (This needn't be direct)
I.e. currently I'd expect this direction to make things worse both for:
- We're aiming for an oversight protocol that's directly scalable to superintelligence.
- We're aiming for e.g. a control setup, where debate enables us e.g.:
- Access to sufficiently high capability for meaningful alignment progress without taking unacceptable risk.
- Clearer-than-we'd-otherwise-get signals that we can't access such capability without unacceptable risk.
- [some other (incremental/indirect) safety property]
I tend to assume the idea is more (2) than (1). (presumably [debate fails in the limit] isn't controversial)
I can see a case that it's possible debate helps with some (2).
I don't currently see the case for [net positive in expectation].
More specifically, the upside from [direction/protocol x eliminates various failure modes, so reducing risk] needs to be balanced against the downside from [our (over?)confidence in direction/protocol x leads us to take risks we otherwise wouldn't].
I note here that this isn't a fully-general counterargument [? · GW], but rather a general consideration.
When I consider this, I currently think "On balance, this seems to make things worse in worlds where we might plausibly have succeeded" (of course I hope to be wrong somewhere! - and, if I'm wrong, I'd like to know).
This may be downstream of different threat models.
Alternatively, it may be that you have in mind some strategy I haven't considered (at some level of abstraction).
It'd be useful to have more clarity here.
What strikes you as a plausible [debate turns out to be helpful in reducing x-risk] story? (concreteness would be nice, but mostly I'm interested in whatever story you have)
I'd enjoy being more constructive and getting into specifics on the paper/direction.
However, from my point of view that'd makes things worse (at 'best' I'd be thinning out the red flags).
↑ comment by Rohin Shah (rohinmshah) · 2024-07-09T09:13:56.742Z · LW(p) · GW(p)
I like both of the theories of change you listed, though for (1) I usually think about scaling till human obsolescence rather than superintelligence.
(Though imo this broad class of schemes plausibly scales to superintelligence if you eventually hand off the judge role to powerful AI systems. Though I expect we'll be able to reduce risk further in the future with more research.)
I note here that this isn't a fully-general counterargument [? · GW], but rather a general consideration.
I don't see why this isn't a fully general counterargument to alignment work. Your argument sounds to me like "there will always be some existentially risky failures left, so if we proceed we will get doom. Therefore, we should avoid solving some failures, because those failures could help build political will to shut it all down".
And it does seem to me like you have to be saying "we will get doom", not "we might get doom". If it were the latter then the obvious positive case is that by removing some of the failures we reduce p(doom). It could still turn out negative due to risk compensation, but I'd at least expect you to give some argument for expecting that (it seems like the prior on "due to risk compensation we should not do safety work" should be pretty low).
What's an example of alignment work that you think is net positive with the theory of change "this is a better way to build future powerful AI systems"?
(I'm probably not going to engage with perspectives that say all current [alignment work towards building safer future powerful AI systems] is net negative, sorry. In my experience those discussions typically don't go anywhere useful.)
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2024-07-09T20:13:54.898Z · LW(p) · GW(p)
Thanks for the response. I realize this kind of conversation can be annoying (but I think it's important).
[I've included various links below, but they're largely intended for readers-that-aren't-you]
I don't see why this isn't a fully general counterargument to alignment work. Your argument sounds to me like "there will always be some existentially risky failures left, so if we proceed we will get doom. Therefore, we should avoid solving some failures, because those failures could help build political will to shut it all down".
(Thanks for this too. I don't endorse that description, but it's genuinely useful to know what impression I'm creating - particularly when it's not what I intended)
I'd rephase my position as:
- There'll always be some risk of existential failure. We want to reduce the total risk. Each step we take forward is a tradeoff: we accept some risk on that step, and (hopefully) reduce future risk by a greater amount.
- Risk might be reduced through:
- Increased understanding.
- Clear evidence that our current understanding isn't sufficient. (helpful for political will, coordination...)
- [various other things]
- Risk might be reduced through:
- I am saying "we might get doom".
- I think the odds are high primarily because I don't expect we'll get a [mostly safe setup that greatly reduces our odds of [trying something plausible that causes catastrophe]]. (I may be wrong here - hopefully so).
- I am not saying "we should not do safety work"; I'm saying "risk compensation needs to be a large factor in deciding which safety work to do", and "I think few researchers take risk compensation sufficiently seriously".
- To a first approximation, I'd say the odds of [safety work on x turns out negative due to risk compensation] is dependent on how well decision-makers (or 'experts' they're listening to) are tracking what we don't understand. Specifically, what we might expect to be different from previous experience and/or other domains, and how significant these differences are to outcomes.
- Risk is highest when we believe that we understand more than we do understand.
- There's also a unilateralist's curse issue here: it matters if there are any dangerously overconfident actors in a position to take action that'll increase risk. (noting that [slightly overconfident] may be [dangerously overconfident] in this context)
- This matters in considering the downstream impact of research. I'd be quite a bit less worried about debate research if I only had to consider [what will researchers at least as cautious as Rohin do with this?]. (though still somewhat worried :))
- See also Critch's thoughts on the need for social models [LW · GW] when estimating impact.
- We tend to have a distorted picture of our own understanding, since there's a strong correlation between [we understand x well] and [we're able to notice x and express it clearly].
- There's a kind of bias/variance tradeoff here: if we set our evidential standards such that we don't focus on vague/speculative/indirect/conceptual arguments, we'll reduce variance, but risk significant sampling bias.
- Similarly, conclusions downstream of availability-heuristic-triggered thoughts will tend to be disproportionately influenced by the parts of the problem we understand (at least well enough to formulate clear questions).
- I expect that some researchers actively compensate for this in their conscious deliberation, but that it's very hard to get our intuitions to compensate appropriately.
- To a first approximation, I'd say the odds of [safety work on x turns out negative due to risk compensation] is dependent on how well decision-makers (or 'experts' they're listening to) are tracking what we don't understand. Specifically, what we might expect to be different from previous experience and/or other domains, and how significant these differences are to outcomes.
- [[EDIT: Oh, and when considering downstream impact, risk compensation etc, I think it's hugely important that most decision-makers and decision-making systems have adapted to a world where [those who can build x understand x] holds. A natural corollary here is [the list of known problems that concern [operation of the system itself] is complete].
- This implicit assumption underlies risk management approaches, governance structures and individuals' decision-making processes.
- That it's implicit makes it much harder to address, since there aren't usually "and here we assume that those who can build x understand x" signposts.
- It might be viable to re-imagine risk-management such that this is handled.
- It's much less likely that we get to re-imagine governance structures, or the cognition of individual decision-makers.]]
Again, I don't think it's implausible that debate-like approaches come out better than various alternatives after carefully considering risk compensation. I do think it's a serious error not to spend quite a bit of time and effort understanding and reducing uncertainty on this.
Possibly many researchers do this, but don't have any clean, legible way to express their process/conclusions. I don't get that impression: my impression is that arguments along the lines I'm making tend to be perceived as fully general counter-arguments and dismissed (whether they come from outside, or from the researchers themselves).
What's an example of alignment work that you think is net positive with the theory of change "this is a better way to build future powerful AI systems"?
I'm not sure how direct you intend "this is a better way..." (vs e.g. "this will build the foundation of better ways..."). I guess I'd want to reframe it as "This is a better process by which to build future powerful AI systems", so as to avoid baking in a level of concreteness before looking at the problem.
That said, the following seem good to me:
- Davidad's stuff - e.g. Towards Guaranteed Safe AI.
- I'm not without worries here, and I think "Guaranteed safe", "Provably safe" are silly, unhelpful overstatements - but the broad direction seems useful.
- That said, the part I'm most keen on would be the "safety specification", and what I'd expect here is something like [more work on this clarifies that it's a very hard problem we're not close to solving]. (noting that [this doesn't directly cause catastrophe] is an empty 'guarantee')
- I'm not without worries here, and I think "Guaranteed safe", "Provably safe" are silly, unhelpful overstatements - but the broad direction seems useful.
- ARC theory's stuff.
- I'm not sure you'd want to include this??
- I'm keen on it because:
- It seems likely to expand understanding - to uncover new problems.
- It may plausibly be sufficiently general - closer to the [fundamental fix] than the [patch this noticeably undesirable behaviour] end of the spectrum.
- Evan's red-teaming stuff (e.g. model organisms of misalignment [LW · GW]).
- This seems net positive, and I think [finding a thousand ways not to build an AI] is part of a good process.
- I do still worry that there's a path of [find concrete problem] -> [make concrete problem a target for research] -> [fix concrete problems we've found, without fixing the underlying issues].
- The ideal situation from [mitigate risk compensation] perspective is:
- Have as much understanding and clarity of fundamental problems as possible.
- Have enough clear, concrete examples to make the need for caution clear to decision-makers.
- To the extent that Evan et al achieve (1), I'm unreservedly in favour.
- On (2) the situation is a bit less clear: we're in more danger when there are serious problems for which we're unable to make a clear/concrete case.
- And, again, my conclusion is not "never expose new concrete problems", but rather "consider the downsides of doing so when picking a particular line of research".
- This seems net positive, and I think [finding a thousand ways not to build an AI] is part of a good process.
- A bunch of foundational stuff you probably also wouldn't want to include under this heading (singular learning theory [? · GW], natural abstractions [LW · GW], various agent-foundations [? · GW]-shaped things, perhaps computational mechanics (??))).
(I'm probably not going to engage with perspectives that say all current [alignment work towards building safer future powerful AI systems] is net negative, sorry. In my experience those discussions typically don't go anywhere useful.)
Not a problem. However, I'd want to highlight the distinction between:
- Substantial efforts to resolve this uncertainty haven't worked out.
- Resolving this uncertainty isn't important.
Both are reasonable explanations for not putting much further effort into such discussions.
However, I worry that the system-1s of researchers don't distinguish between (1) and (2) here - so that the impact of concluding (1) will often be to act as if the uncertainty isn't important (and as if the implicit corollaries hold).
I don't see an easy way to fix this - but I think it's an important issue to notice when considering research directions. Not only [consider this uncertainty when picking a research direction], but also [consider that your system 1 is probably underestimating the importance of this uncertainty (and corollaries), since you haven't been paying much attention to it (for understandable reasons)].
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2024-07-10T11:11:55.098Z · LW(p) · GW(p)
Main points:
There'll always be some risk of existential failure.
I am saying "we might get doom"
I am not saying "we should not do safety work"
I'm on board with these.
I'm saying "risk compensation needs to be a large factor in deciding which safety work to do"
I still don't see why you believe this. Do you agree that in many other safety fields, safety work mostly didn't think about risk compensation, and still drove down absolute risk? (E.g. I haven't looked into it but I bet people didn't spend a bunch of time thinking about risk compensation when deciding whether to include seat belts in cars.)
If you do agree with that, what makes AI different from those cases? (The arguments you give seem like very general considerations that apply to other fields as well.)
Possibly many researchers do this, but don't have any clean, legible way to express their process/conclusions. I don't get that impression: my impression is that arguments along the lines I'm making tend to be perceived as fully general counter-arguments and dismissed (whether they come from outside, or from the researchers themselves).
I'd say that the risk compensation argument as given here Proves Too Much [LW · GW] and implies that most safety work in most previous fields was net negative, which seems clearly wrong to me. It's true that as a result I don't spend lots of time thinking about risk compensation; that still seems correct to me.
- It might be viable to re-imagine risk-management such that this is handled.
It seems like your argument here, and in other parts of your comment, is something like "we could do this more costly thing that increases safety even more". This seems like a pretty different argument; it's not about risk compensation (i.e. when you introduce safety measures, people do more risky things), but rather about opportunity cost (i.e. when you introduce weak safety measures, you reduce the will to have stronger safety measures). This is fine, but I want to note the explicit change in argument; my earlier comment and the discussion above was not trying to address this argument.
Briefly on opportunity cost arguments, the key factors are (a) how much will is there to pay large costs for safety, (b) how much time remains to do the necessary research and implement it, and (c) how feasible is the stronger safety measure. I am actually more optimistic about both (a) and (b) than what I perceive to be the common consensus amongst safety researchers at AGI labs, but tend to be pretty pessimistic about (c) (at least relative to many LessWrongers, I'm not sure how it compares to safety researchers at AGI labs).
Anyway for now let's just say that I've thought about these three factors and think it isn't especially realistic to expect that we can get stronger safety measures, and as a result I don't see opportunity cost as a big reason not to do the safety work we currently do.
I guess I'd want to reframe it as "This is a better process by which to build future powerful AI systems", so as to avoid baking in a level of concreteness before looking at the problem.
Yeah, I'm not willing to do this. This seems like an instance of the opportunity cost argument, where you try to move to a paradigm that can enable stronger safety measures. See above for my response.
Similarly, the theory of change you cite for your examples seems to be "discovers or clarifies problems that shows that we don't have a solution" (including for Guaranteed Safe AI and ARC theory, even though in principle those could be about building safe AI systems). So as far as I can tell, the disagreement is really that you think current work that tries to provide a specific recipe for building safe AI systems is net negative, and I think it is net positive.
Other smaller points:
- See also Critch's thoughts on the need for social models [LW · GW] when estimating impact.
I certainly agree that it is possible for risk compensation to make safety work net negative, which is all I think you can conclude from that post (indeed the post goes out of its way to say it isn't arguing for or against any particular work). I disagree that this effect is large enough to meaningfully change the decisions on what work we should do, given the specific work that we typically do (including debate).
if we set our evidential standards such that we don't focus on vague/speculative/indirect/conceptual arguments
This is a weird hypothetical. The entire field of AI existential safety is focused on speculative, conceptual arguments. (I'm not quite sure what the standard is for "vague" and "indirect" but probably I'd include those adjectives too.)
I think [resolving uncertainty is] an important issue to notice when considering research directions
Why? It doesn't seem especially action guiding, if we've agreed that it's not high value to try to resolve the uncertainty (which is what I take away from your (1)).
Maybe you're saying "for various reasons (e.g. unilateralist curse, wisdom of the crowds, coordinating with people with similar goals), you should treat the probability that your work is net negative as higher than you would independently assess, which can affect your prioritization". I agree that there's some effect here but my assessment is that it's pretty small and doesn't end up changing decisions very much.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2024-07-11T08:32:11.175Z · LW(p) · GW(p)
[apologies for writing so much; you might want to skip/skim the spoilered bit, since it seems largely a statement of the obvious]
Do you agree that in many other safety fields, safety work mostly didn't think about risk compensation, and still drove down absolute risk?
Agreed (I imagine there are exceptions, but I'd be shocked if this weren't usually true).
[I'm responding to this part next, since I think it may resolve some of our mutual misunderstanding]
It seems like your argument here, and in other parts of your comment, is something like "we could do this more costly thing that increases safety even more". This seems like a pretty different argument; it's not about risk compensation (i.e. when you introduce safety measures, people do more risky things), but rather about opportunity cost (i.e. when you introduce weak safety measures, you reduce the will to have stronger safety measures). This is fine, but I want to note the explicit change in argument; my earlier comment and the discussion above was not trying to address this argument.
Perhaps we've been somewhat talking at cross purposes then, since I certainly consider [not acting to bring about stronger safety measures] to be within the category of [doing more risky things].
It fits the pattern of [lower perceived risk] --> [actions that increase risk].
For clarity, risky actions I'm thinking about would include:
- Not pushing for stronger safety measures.
- Not pushing for international coordination.
- Pushing forward with capabilities more quickly.
- Placing too much trust in systems off distribution.
- Placing too much trust in the output of [researchers using systems to help solve alignment].
- Not spending enough on more principled (by my lights) alignment research.
Some of these might be both [opportunity cost] and [risk compensation].
I.e.:
- We did x.
- x reduced perceived risk.
- A precondition of y was greater-than-current perceived risk.
- Now we can't do y.
- [Not doing y] is risky.
If you do agree with that, what makes AI different from those cases? (The arguments you give seem like very general considerations that apply to other fields as well.)
Mostly for other readers, I'm going to spoiler my answer to this: my primary claim is that more people need to think about and answer these questions themselves, so I'd suggest that readers take a little time to do this. I'm significantly more confident that the question is important, than that my answer is correct or near-complete.
I agree that the considerations I'm pointing to are general.
I think the conclusions differ, since AI is different.
First a few clarifications:
- I'm largely thinking of x-risk, not moderate disasters.
- On this basis, I'm thinking about loss-of-control, rather than misuse.
- I think if we're talking about e.g. [misuse leads to moderate disaster], then other fields and prior AI experience become much more reasonable reference classes - and I'd expect things like debate to be net positive here.
- My current guess/estimate that debate research is net negative is largely based on x-risk via loss-of-control. (again, I may be wrong - but I'd like researchers to do serious work on answering this question)
How I view AI risk being different:
- First another clarification: the risk-increasing actions I'm worried about are not [individual user uses AI incautiously] but things like [AI lab develops/deploys models incautiously], and [governments develop policy incautiously] - so we shouldn't be thinking of e.g. [people driving faster with seatbelts], but e.g. [car designers / regulators acting differently once seatbelts are a thing].
- To be clear, I don't claim that seatbelts were negative on this basis.
- Key differences:
- We can build AI without understanding it.
- People and systems are not used to this.
- Plausible subconscious heuristics that break here:
- [I can build x] and [almost no-one understands x better than me], [therefore, I understand x pretty well].
- [I can build x] and [I've worked with x for years], [therefore I have a pretty good understanding of the potential failure modes].
- [We can build x], [therefore we should expect to be able to describe any likely failure modes pretty concretely/rigorously]
- [I've discussed the risks of x with many experts who build x], [therefore I have a decent high-level understanding of potential failures]
- [I'm not afraid], [therefore a deadly threat we're not ready to deal with must be unlikely]. (I agree it's unlikely now)
- ...
- One failure of AI can be unrecoverable.
- In non-AI cases there tend to be feedback loops that allow adjustments both in the design, and in people's risk estimates.
- Of course such loops exist for some AI failure modes.
- This makes the unilateralist's curse aspect more significant: it's not the average understanding or caution that matters. High variance is a problem.
- Knowing how this impacts risk isn't straightforward, since it depends a lot on [the levels of coordination we expect] and [the levels of coordination that seem necessary].
- My expectation is that we're just screwed if the most reckless organizations are able to continue without constraint.
- Therefore my concern is focused on worlds where we achieve sufficient coordination to make clearly reckless orgs not relevant. (and on making such worlds more likely)
- Debate-style approaches seem a good fit for [this won't actually work, but intelligent, well-informed, non-reckless engineers/decision-makers might think that it will]. I'm concerned about those who are somewhat overconfident.
- In non-AI cases there tend to be feedback loops that allow adjustments both in the design, and in people's risk estimates.
- The most concerning AI is very general.
- This leads to a large space of potential failure modes. (both in terms of mechanism, and in terms of behaviour/outcome)
- It is hard to make a principled case that we've covered all serious failure modes (absent a constructive argument based on various worst-case assumptions).
- The most concerning AI will be doing some kind of learned optimization. (in a broad, John Wentworthy sense [LW · GW])
- Pathogens may have the [we don't really understand them] property, but an individual pathogen isn't going to be general, or to be doing significant learned optimization. (if and when this isn't true, then I'd be similarly wary of ad-hoc pathogen safety work)
- New generations of AI can often solve qualitatively different problems from previous generations. With each new generation, we're off distribution in a much more significant sense than with new generations of e.g. car design.
- Unknown unknowns may arise internally due to the complex systems nature of AI.
- In cases we're used to, the unknown unknowns tend to come from outside: radically unexpected things may happen to a car, but probably not directly due to the car.
- We can build AI without understanding it.
I'm sure I'm missing various relevant factors.
Overall, I think straightforward reference classes for [safety impact of risk compensation] tell us approximately nothing - too much is different.
I'm all for looking for a variety of reference classes: we need all the evidence we can get.
However, I think people are too ready to fall back on the best reference classes they can find - even when they're terrible.
Briefly on opportunity cost arguments, the key factors are (a) how much will is there to pay large costs for safety, (b) how much time remains to do the necessary research and implement it, and (c) how feasible is the stronger safety measure.
This seems to miss the obvious: (d) how much safety do the weak vs strong measures get us?
I expect that you believe work on debate (and similar weak measures) gets us significantly more than I do. (and hopefully you're correct!)
Anyway for now let's just say that I've thought about these three factors and think it isn't especially realistic to expect that we can get stronger safety measures, and as a result I don't see opportunity cost as a big reason not to do the safety work we currently do.
Given that this seems highly significant, can you:
- Quantify "it isn't especially realistic" - are we talking [15% chance with great effort], or [1% chance with great effort]?
- Give a sense of reasons you expect this.
- Is [because we have a bunch of work on weak measures] not a big factor in your view?
- Or is [isn't especially realistic] overdetermined, with [less work on weak measures] only helping conditional on removal of other obstacles?
I'd also note that it's not only [more progress on weak measures] that matters here, but also the signal sent by pursuing these research directions.
If various people with influence on government see [a bunch of lab safety teams pursuing x safety directions] I expect that most will conclude: "There seems to be a decent consensus within the field that x will get us acceptable safety levels", rather than "Probably x is inadequate, but these researchers don't see much hope in getting stronger-than-x measures adopted".
I assume that you personally must have some constraints on the communication strategy you're able to pursue. However, it does seem highly important that if the safety teams at labs are pursuing agendas based on [this isn't great, but it's probably the best we can get], this is clearly and loudly communicated.
Similarly, the theory of change you cite for your examples seems to be "discovers or clarifies problems that shows that we don't have a solution" (including for Guaranteed Safe AI and ARC theory, even though in principle those could be about building safe AI systems). So as far as I can tell, the disagreement is really that you think current work that tries to provide a specific recipe for building safe AI systems is net negative, and I think it is net positive.
This characterization is a little confusing to me: all of these approaches (ARC / Guaranteed Safe AI / Debate) involve identifying problems, and, if possible, solving/mitigating them.
To the extent that the problems can be solved, then the approach contributes to [building safe AI systems]; to the extent that they cannot be solved, the approach contributes to [clarifying that we don't have a solution].
The reason I prefer GSA / ARC is that I expect these approaches to notice more fundamental problems. I then largely expect them to contribute to [clarifying that we don't have a solution], since solving the problems probably won't be practical, and they'll realize that the AI systems they could build won't be safe-with-high-probability.
I expect scalable oversight (alone) to notice a smaller set of less fundamental problems - which I expect to be easier to fix/mitigate. I expect the impact to be [building plausibly-safe AI systems that aren't safe (in any robustly scalable sense)].
Of course I may be wrong, if the fundamental problems I believe exist are mirages (very surprising to me) - or if the indirect [help with alignment research] approach turns out to be more effective than I expect (fairly surprising, but I certainly don't want to dismiss this).
I do still agree that there's a significant difference in that GSA/ARC are taking a worst-case-assumptions approach - so in principle they could be too conservative. In practice, I think the worst-case-assumption approach is the principled way to do things given our lack of understanding.
I think [
resolvingthe existence of this uncertainty is] an important issue to notice when considering research directionsWhy? It doesn't seem especially action guiding, if we've agreed that it's not high value to try to resolve the uncertainty (which is what I take away from your (1)).
(it's not obvious to me that it's not high value to try to resolve this uncertainty, but it's plausible based on your prior comments on this issue, and I'm stipulating that here)
Here I meant that it's important to notice that:
- The uncertainty exists and is important. (even though resolving it may be impractical)
- The fact that you've been paying little attention to it does not imply that either:
- Your current estimate is accurate.
- If your estimate changed, that wouldn't be highly significant.
I'm saying that, unless people think carefully and deliberately about this, the mind will tend to conclude [my current estimate is pretty accurate] and/or [this variable changing wouldn't be highly significant] - both of which may be false.
To the extent that these are believed, they're likely to impact other beliefs that are decision-relevant. (e.g. believing that my estimate of x is accurate tells me something about the character of x and my understanding of it)
↑ comment by Rohin Shah (rohinmshah) · 2024-07-12T09:33:44.975Z · LW(p) · GW(p)
Not going to respond to everything, sorry, but a few notes:
It fits the pattern of [lower perceived risk] --> [actions that increase risk].
My claim is that for the things you call "actions that increase risk" that I call "opportunity cost", this causal arrow is very weak, and so you shouldn't think of it as risk compensation.
E.g. presumably if you believe in this causal arrow you should also believe [higher perceived risk] --> [actions that decrease risk]. But if all building-safe-AI work were to stop today, I think this would have very little effect on how fast the world pushes forward with capabilities.
However, I think people are too ready to fall back on the best reference classes they can find - even when they're terrible.
I agree that reference classes are often terrible and a poor guide to the future, but often first-principles reasoning is worse (related: 1 [LW(p) · GW(p)], 2 [LW(p) · GW(p)]).
I also don't really understand the argument in your spoiler box. You've listed a bunch of claims about AI, but haven't spelled out why they should make us expect large risk compensation effects, which I thought was the relevant question.
- Quantify "it isn't especially realistic" - are we talking [15% chance with great effort], or [1% chance with great effort]?
It depends hugely on the specific stronger safety measure you talk about. E.g. I'd be at < 5% on a complete ban on frontier AI R&D (which includes academic research on the topic). Probably I should be < 1%, but I'm hesitant around such small probabilities on any social claim.
For things like GSA and ARC's work, there isn't a sufficiently precise claim for me to put a probability on.
Is [because we have a bunch of work on weak measures] not a big factor in your view? Or is [isn't especially realistic] overdetermined, with [less work on weak measures] only helping conditional on removal of other obstacles?
Not a big factor. (I guess it matters that instruction tuning and RLHF exist, but something like that was always going to happen, the question was when.)
This characterization is a little confusing to me: all of these approaches (ARC / Guaranteed Safe AI / Debate) involve identifying problems, and, if possible, solving/mitigating them.
To the extent that the problems can be solved, then the approach contributes to [building safe AI systems];
Hmm, then I don't understand why you like GSA more than debate, given that debate can fit in the GSA framework (it would be a level 2 specification by the definitions in the paper). You might think that GSA will uncover problems in debate if they exist when using it as a specification, but if anything that seems to me less likely to happen with GSA, since in a GSA approach the specification is treated as infallible.
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2024-07-13T08:59:12.709Z · LW(p) · GW(p)
Not going to respond to everything
No worries at all - I was aiming for [Rohin better understands where I'm coming from]. My response was over-long.
E.g. presumably if you believe in this causal arrow you should also believe [higher perceived risk] --> [actions that decrease risk]. But if all building-safe-AI work were to stop today, I think this would have very little effect on how fast the world pushes forward with capabilities.
Agreed, but I think this is too coarse-grained a view.
I expect that, absent impressive levels of international coordination, we're screwed. I'm not expecting [higher perceived risk] --> [actions that decrease risk] to operate successfully on the "move fast and break things" crowd.
I'm considering:
- What kinds of people are making/influencing key decisions in worlds where we're likely to survive?
- How do we get those people this influence? (or influential people to acquire these qualities)
- What kinds of situation / process increase the probability that these people make risk-reducing decisions?
I think some kind of analysis along these lines makes sense - though clearly it's hard to know where to draw the line between [it's unrealistic to expect decision-makers/influencers this principled] and [it's unrealistic to think things may go well with decision-makers this poor].
I don't think conditioning on the status-quo free-for-all makes sense, since I don't think that's a world where our actions have much influence on our odds of success.
I agree that reference classes are often terrible and a poor guide to the future, but often first-principles reasoning is worse (related: 1 [LW(p) · GW(p)], 2 [LW(p) · GW(p)]).
Agreed (I think your links make good points). However, I'd point out that it can be true both that:
- Most first-principles reasoning about x is terrible.
- First-principles reasoning is required in order to make any useful prediction of x. (for most x, I don't think this holds)
You've listed a bunch of claims about AI, but haven't spelled out why they should make us expect large risk compensation effects
I think almost everything comes down to [perceived level of risk] sometimes dropping hugely more than [actual risk] in the case of AI. So it's about the magnitude of the input.
- We understand AI much less well.
- We'll underestimate a bunch of risks, due to lack of understanding.
- We may also over-estimate a bunch, but the errors don't cancel: being over-cautious around fire doesn't stop us from drowning.
- Certain types of research will address [some risks we understand], but fail to address [some risks we don't see / underestimate].
- They'll then have a much larger impact on [our perception of risk] than on [actual risk].
- Drop in perceived risk is much larger than the drop in actual risk.
- In most other situations, this isn't the case, since we have better understanding and/or adaptive feedback loops to correct risk estimates.
It depends hugely on the specific stronger safety measure you talk about. E.g. I'd be at < 5% on a complete ban on frontier AI R&D (which includes academic research on the topic). Probably I should be < 1%, but I'm hesitant around such small probabilities on any social claim.
That's useful, thanks. (these numbers don't seem foolish to me - I think we disagree mainly on [how necessary are the stronger measures] rather than [how likely are they])
Hmm, then I don't understand why you like GSA more than debate, given that debate can fit in the GSA framework (it would be a level 2 specification by the definitions in the paper).
Oh sorry, I should have been more specific - I'm only keen on specifications that plausibly give real guarantees: level 6(?) or 7. I'm only keen on the framework conditional on meeting an extremely high bar for the specification.
If that part gets ignored on the basis that it's hard (which it obviously is), then it's not clear to me that the framework is worth much.
I suppose I'm also influenced by the way some of the researchers talk about it - I'm not clear how much focus Davidad is currently putting on level 6/7 specifications, but he seems clear that they'll be necessary.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2024-07-13T09:54:04.071Z · LW(p) · GW(p)
I expect that, absent impressive levels of international coordination, we're screwed.
This is the sort of thing that makes it hard for me to distinguish your argument from "[regardless of the technical work you do] there will always be some existentially risky failures left, so if we proceed we will get doom. Therefore, we should avoid solving some failures, because those failures could help build political will to shut it all down".
I agree that, conditional on believing that we're screwed absent huge levels of coordination regardless of technical work, then a lot of technical work including debate looks net negative by reducing the will to coordinate.
What kinds of people are making/influencing key decisions in worlds where we're likely to survive?
[...]
I don't think conditioning on the status-quo free-for-all makes sense, since I don't think that's a world where our actions have much influence on our odds of success.
Similarly this only makes sense under a view where technical work can't have much impact on p(doom) by itself, aka "regardless of technical work we're screwed". Otherwise even in a "free-for-all" world, our actions do influence odds of success, because you can do technical work that people use, and that reduces p(doom).
I'm only keen on specifications that plausibly give real guarantees: level 6(?) or 7. I'm only keen on the framework conditional on meeting an extremely high bar for the specification.
Oh, my probability on level 6 or level 7 specifications becoming the default in AI is dominated by my probability that I'm somehow misunderstanding what they're supposed to be. (A level 7 spec for AGI seems impossible even in theory, e.g. because it requires solving the halting problem.)
If we ignore the misunderstanding part then I'm at << 1% probability on "we build transformative AI using GSA with level 6 / level 7 specifications in the nearish future".
(I could imagine a pause on frontier AI R&D, except that you are allowed to proceed if you have level 6 / level 7 specifications; and those specifications are used in a few narrow domains. My probability on that is similar to my probability on a pause.)
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2024-07-13T23:58:38.538Z · LW(p) · GW(p)
"[regardless of the technical work you do] there will always be some existentially risky failures left, so if we proceed we get doom...
I'm claiming something more like "[given a realistic degree of technical work on current agendas in the time we have], there will be some existentially risky failures left, so if we proceed we're highly likely to get doom.
I'll clarify more below.
Otherwise even in a "free-for-all" world, our actions do influence odds of success, because you can do technical work that people use, and that reduces p(doom).
Sure, but I mostly don't buy p(doom) reduction here, other than through [highlight near-misses] - so that an approach that hides symptoms of fundamental problems is probably net negative.
In the free-for-all world, I think doom is overdetermined, absent miracles [1]- and [significantly improved debate setup] does not strike me as a likely miracle, even after I condition on [a miracle occurred].
Factors that push in the other direction:
- I can imagine techniques that reduce near-term widespread low-stakes failures.
- This may be instrumentally positive if e.g. AI is much better for collective sensemaking than otherwise it would be (even if that's only [the negative impact isn't as severe]).
- Similarly, I can imagine such techniques mitigating the near-term impact of [we get what we measure [LW · GW]] failures. This too seems instrumentally useful.
- I do accept that technical work I'm not too keen on may avoid some early foolish/embarrassing ways to fail catastrophically.
- I mostly don't think this helps significantly, since we'll consistently hit doom later without a change in strategy.
- Nonetheless, [don't be dead yet] is instrumentally useful if we want more time to change strategy, so avoiding early catastrophe is a plus.
- [probably other things along similar lines that I'm missing]
But I suppose that on the [usefulness of debate (/scalable oversight techniques generally) research], I'm mainly thinking: [more clearly understanding how and when this may fail catastrophically, and how we'd robustly predict this] seems positive, whereas [show that versions of this technique get higher scores on some benchmarks] probably doesn't.
Even if I'm wrong about the latter, the former seems more important.
Granted, it also seems harder - but I think that having a bunch of researchers focus on it and fail to come up with any principled case is useful too (at least for them).
If we ignore the misunderstanding part then I'm at << 1% probability on "we build transformative AI using GSA with level 6 / level 7 specifications in the nearish future".
(I could imagine a pause on frontier AI R&D, except that you are allowed to proceed if you have level 6 / level 7 specifications; and those specifications are used in a few narrow domains. My probability on that is similar to my probability on a pause.)
Agreed. This is why my main hope on this routes through [work on level 6/7 specifications clarifies the depth and severity of the problem] and [more-formally-specified 6/7 specifications give us something to point to in regulation].
(on the level 7, I'm assuming "in all contexts" must be an overstatement; in particular, we only need something like "...in all contexts plausibly reachable from the current state, given that all powerful AIs developed by us or our AIS follow this specification or this-specification-endorsed specifications")
Clarifications I'd make on my [doom seems likely, but not inevitable; some technical work seems net negative] position:
- If I expected that we had 25 years to get things right, I think I'd be pretty keen on most hands-on technical approaches (debate included).
- Quite a bit depends on the type of technical work. I like the kind of work that plausibly has the property [if we iterate on this we'll probably notice all catastrophic problems before triggering them].
- I do think there's a low-but-non-zero chance of breakthroughs in pretty general technical work. I can't rule out that ARC theory come up with something transformational in the next few years (or that it comes from some group that's outside my current awareness).
- I'm not ruling out an [AI assistants help us make meaningful alignment progress] path - I currently think it's unlikely, not impossible.
- However, here I note that there's a big difference between:
- The odds that [solve alignment with AI assistants] would work if optimally managed.
- The odds that it works in practice.
- I worry that researchers doing technical research tend to have the the former in mind (implicitly, subconsciously) - i.e. the (implicit) argument is something like "Our work stands a good chance to unlock a winning strategy here".
- But this is not the question - the question is how likely it is to work in practice.
- (even conditioning on not-obviously-reckless people being in charge)
- It's guesswork, but on [does a low-risk winning strategy of this form exist (without a huge slowdown)?] I'm perhaps 25%. On [will we actually find and implement such a strategy, even assuming the most reckless people aren't a factor], I become quite a bit more pessimistic - if I start to say "10%", I recoil at the implied [40% shot at finding and following a good enough path if one exists].
- Of course a lot here depends on whether we can do well enough to fail safely. Even a 5% shot is obviously great if the other 95% is [we realize it's not working, and pivot].
- However, here I note that there's a big difference between:
- However, since I don't see debate-like approaches as plausible in any direct-path-to-alignment sense, I'd like to see a much clearer plan for using such methods as stepping-stones to (stepping stones to...) a solution.
- In particular, I'm interested in the case for [if this doesn't work, we have principled reasons to believe it'll fail safely] (as an overall process, that is - not on each individual experiment).
- When I look at e.g. Buck/Ryan's outlined iteration process here [LW · GW],[2] I'm not comforted on this point: this has the same structure as [run SGD on passing our evals], only it's [run researcher iteration on passing our evals]. This is less bad, but still entirely loses the [evals are an independent check on an approach we have principled reasons to think will work] property.
- On some level this kind of loop is unavoidable - but having the "core workflow" of alignment researchers be [tweak the approach, then test it against evals] seems a bit nuts.
- Most of the hope here seems to come from [the problem is surprisingly (to me) easy] or [catastrophic failure modes are surprisingly (to me) sparse].
- In particular, I'm interested in the case for [if this doesn't work, we have principled reasons to believe it'll fail safely] (as an overall process, that is - not on each individual experiment).
- ^
In the sense that [someone proves the Riemann hypothesis this year] would be a miracle.
- ^
I note that it's not clear they're endorsing this iteration process - it may just be that they expect it to be the process, so that it's important for people to be thinking in these terms.
↑ comment by Rohin Shah (rohinmshah) · 2024-07-14T07:43:45.993Z · LW(p) · GW(p)
Okay, I think it's pretty clear that the crux between us is basically what I was gesturing at in my first comment, even if there are minor caveats that make it not exactly literally that.
Replies from: Joe_CollmanI'm probably not going to engage with perspectives that say all current [alignment work towards building safer future powerful AI systems] is net negative, sorry. In my experience those discussions typically don't go anywhere useful.
↑ comment by Joe Collman (Joe_Collman) · 2024-07-14T20:52:27.765Z · LW(p) · GW(p)
That's fair. I agree that we're not likely to resolve much by continuing this discussion. (but thanks for engaging - I do think I understand your position somewhat better now)
What does seem worth considering is adjusting research direction to increase focus on [search for and better understand the most important failure modes] - both of debate-like approaches generally, and any [plan to use such techniques to get useful alignment work done].
I expect that this would lead people to develop clearer, richer models.
Presumably this will take months rather than hours, but it seems worth it (whether or not I'm correct - I expect that [the understanding required to clearly demonstrate to me that I'm wrong] would be useful in a bunch of other ways).
↑ comment by peterbarnett · 2024-07-09T04:37:38.481Z · LW(p) · GW(p)
I think this comment might be more productive if you described why you expect this approach to fail catastrophically when dealing with powerful systems (in a way that doesn't provide adequate warning). Linking to previous writing on this could be good (maybe this comment [LW(p) · GW(p)] of yours on debate/scalable oversight).
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2024-07-09T08:28:08.681Z · LW(p) · GW(p)
Sure, linking to that seems useful, thanks.
That said, I'm expecting that the crux isn't [can a debate setup work for arbitrarily powerful systems?], but rather e.g. [can it be useful in safe automation of alignment research?].
For something like the latter, it's not clear to me that it's not useful.
Mainly my pessimism is about:
- Debate seeming not to address the failure modes I'm worried about - e.g. scheming.
- Expecting [systems insufficiently capable to cause catastrophe] not to radically (>10x) boost the most important research on alignment. (hopefully I'm wrong!)
- As a result, expecting continued strong pressure to make systems more capable, making [understand when a given oversight approach will fail catastrophically] very important.
- No research I'm aware of seeming likely to tell us when debate would fail catastrophically. (I don't think the Future work [LW · GW] here seems likely to tell us much about catastrophic failure)
- No research I'm aware of making a principled case for [it's very unlikely that any dangerous capability could be acquired suddenly]. (I expect such thresholds to be uncommon, but to exist)
- Seeing no arguments along the lines of [We expect debate to give us clearer red flags than other approaches, and here's why...] or [We expect debate-derived red flags are more likely to lead to a safe response, rather than an insufficiently general fix that leaves core problems unaddressed].
- This is not to say that no such arguments could exist.
- I'm very interested in the case that could be made here.
Of course little of this is specific to debate. Nor is it clear to me that debate is worse than alternatives in these respects - I just haven't seen an argument that it's better (on what assumptions; in which contexts).
I understand that it's hard to answer the questions I'd want answered.
I also expect that working on debate isn't the way to answer them - so I think it's fine to say [I currently expect debate to be a safer approach than most because ... and hope that research directions x and y will shed more light on this]. But I'm not clear on people's rationale for the first part - why does it seem safer?
↑ comment by Fabien Roger (Fabien) · 2024-07-12T17:02:53.449Z · LW(p) · GW(p)
- Debate seeming not to address the failure modes I'm worried about - e.g. scheming.
Why? Is it exploration difficulties, rare failures, or something else?
Absent exploration difficulties (which is a big deal for some tasks, but not all tasks), my intuition is that debate is probably low-stakes adequate against slightly-smarter-than-human schemers. Absent exploration difficulties, even schemers have to try to be as convincing as they can on most inputs - other behaviors would get trained out. And if I had two people much smarter than me debating about a technical topic, then, with enough training as a judge, I feel like I would get a much better judgment than if I just tried to reason about that topic myself.
This intuition + the "no exploration difficulties" assumption + how bad are rare failures can probably be checked with things like control evals [LW · GW] (e.g. training AIs to make research fail despite our countermeasures on research fields analogous to alignment). (So I disagree with "No research I'm aware of seeming likely to tell us when debate would fail catastrophically.")