Why We Can't Take Expected Value Estimates Literally (Even When They're Unbiased)
post by HoldenKarnofsky · 2011-08-18T23:34:12.099Z · LW · GW · Legacy · 253 commentsContents
The approach we oppose: "explicit expected-value" (EEV) decisionmaking Simple example of a Bayesian approach vs. an EEV approach Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc. Pascal's Mugging Generalizing the Bayesian approach Conclusion None 253 comments
Note: I am cross-posting this GiveWell Blog post, after consulting a couple of community members, because it is relevant to many topics discussed on Less Wrong, particularly efficient charity/optimal philanthropy and Pascal's Mugging. The post includes a proposed "solution" to the dilemma posed by Pascal's Mugging that has not been proposed before as far as I know. It is longer than usual for a Less Wrong post, so I have put everything but the summary below the fold. Also, note that I use the term "expected value" because it is more generic than "expected utility"; the arguments here pertain to estimating the expected value of any quantity, not just utility.
While some people feel that GiveWell puts too much emphasis on the measurable and quantifiable, there are others who go further than we do in quantification, and justify their giving (or other) decisions based on fully explicit expected-value formulas. The latter group tends to critique us - or at least disagree with us - based on our preference for strong evidence over high apparent "expected value," and based on the heavy role of non-formalized intuition in our decisionmaking. This post is directed at the latter group.
We believe that people in this group are often making a fundamental mistake, one that we have long had intuitive objections to but have recently developed a more formal (though still fairly rough) critique of. The mistake (we believe) is estimating the "expected value" of a donation (or other action) based solely on a fully explicit, quantified formula, many of whose inputs are guesses or very rough estimates. We believe that any estimate along these lines needs to be adjusted using a "Bayesian prior"; that this adjustment can rarely be made (reasonably) using an explicit, formal calculation; and that most attempts to do the latter, even when they seem to be making very conservative downward adjustments to the expected value of an opportunity, are not making nearly large enough downward adjustments to be consistent with the proper Bayesian approach.
This view of ours illustrates why - while we seek to ground our recommendations in relevant facts, calculations and quantifications to the extent possible - every recommendation we make incorporates many different forms of evidence and involves a strong dose of intuition. And we generally prefer to give where we have strong evidence that donations can do a lot of good rather than where we have weak evidence that donations can do far more good - a preference that I believe is inconsistent with the approach of giving based on explicit expected-value formulas (at least those that (a) have significant room for error (b) do not incorporate Bayesian adjustments, which are very rare in these analyses and very difficult to do both formally and reasonably).
The rest of this post will:
- Lay out the "explicit expected value formula" approach to giving, which we oppose, and give examples.
- Give the intuitive objections we've long had to this approach, i.e., ways in which it seems intuitively problematic.
- Give a clean example of how a Bayesian adjustment can be done, and can be an improvement on the "explicit expected value formula" approach.
- Present a versatile formula for making and illustrating Bayesian adjustments that can be applied to charity cost-effectiveness estimates.
- Show how a Bayesian adjustment avoids the Pascal's Mugging problem that those who rely on explicit expected value calculations seem prone to.
- Discuss how one can properly apply Bayesian adjustments in other cases, where less information is available.
- Conclude with the following takeaways:
- Any approach to decision-making that relies only on rough estimates of expected value - and does not incorporate preferences for better-grounded estimates over shakier estimates - is flawed.
- When aiming to maximize expected positive impact, it is not advisable to make giving decisions based fully on explicit formulas. Proper Bayesian adjustments are important and are usually overly difficult to formalize.
- The above point is a general defense of resisting arguments that both (a) seem intuitively problematic (b) have thin evidential support and/or room for significant error.
The approach we oppose: "explicit expected-value" (EEV) decisionmaking
We term the approach this post argues against the "explicit expected-value" (EEV) approach to decisionmaking. It generally involves an argument of the form:
I estimate that each dollar spent on Program P has a value of V [in terms of lives saved, disability-adjusted life-years, social return on investment, or some other metric]. Granted, my estimate is extremely rough and unreliable, and involves geometrically combining multiple unreliable figures - but it's unbiased, i.e., it seems as likely to be too pessimistic as it is to be too optimistic. Therefore, my estimate V represents the per-dollar expected value of Program P.
I don't know how good Charity C is at implementing Program P, but even if it wastes 75% of its money or has a 75% chance of failure, its per-dollar expected value is still 25%*V, which is still excellent.
Examples of the EEV approach to decisionmaking:
- In a 2010 exchange, Will Crouch of Giving What We Can argued:
DtW [Deworm the World] spends about 74% on technical assistance and scaling up deworming programs within Kenya and India … Let’s assume (very implausibly) that all other money (spent on advocacy etc) is wasted, and assess the charity solely on that 74%. It still would do very well (taking DCP2: $3.4/DALY * (1/0.74) = $4.6/DALY – slightly better than their most optimistic estimate for DOTS (for TB), and far better than their estimates for insecticide treated nets, condom distribution, etc). So, though finding out more about their advocacy work is obviously a great thing to do, the advocacy questions don’t need to be answered in order to make a recommendation: it seems that DtW [is] worth recommending on the basis of their control programs alone.
- The Back of the Envelope Guide to Philanthropy lists rough calculations for the value of different charitable interventions. These calculations imply (among other things) that donating for political advocacy for higher foreign aid is between 8x and 22x as good an investment as donating to VillageReach, and the presentation and implication are that this calculation ought to be considered decisive.
- We've encountered numerous people who argue that charities working on reducing the risk of sudden human extinction must be the best ones to support, since the value of saving the human race is so high that "any imaginable probability of success" would lead to a higher expected value for these charities than for others.
- "Pascal's Mugging" is often seen as the reductio ad absurdum of this sort of reasoning. The idea is that if a person demands $10 in exchange for refraining from an extremely harmful action (one that negatively affects N people for some huge N), then expected-value calculations demand that one give in to the person's demands: no matter how unlikely the claim, there is some N big enough that the "expected value" of refusing to give the $10 is hugely negative.
The crucial characteristic of the EEV approach is that it does not incorporate a systematic preference for better-grounded estimates over rougher estimates. It ranks charities/actions based simply on their estimated value, ignoring differences in the reliability and robustness of the estimates. Informal objections to EEV decisionmaking There are many ways in which the sort of reasoning laid out above seems (to us) to fail a common sense test.
- There seems to be nothing in EEV that penalizes relative ignorance or relatively poorly grounded estimates, or rewards investigation and the forming of particularly well grounded estimates. If I can literally save a child I see drowning by ruining a $1000 suit, but in the same moment I make a wild guess that this $1000 could save 2 lives if put toward medical research, EEV seems to indicate that I should opt for the latter.
- Because of this, a world in which people acted based on EEV would seem to be problematic in various ways.
- In such a world, it seems that nearly all altruists would put nearly all of their resources toward helping people they knew little about, rather than helping themselves, their families and their communities. I believe that the world would be worse off if people behaved in this way, or at least if they took it to an extreme. (There are always more people you know little about than people you know well, and EEV estimates of how much good you can do for people you don't know seem likely to have higher variance than EEV estimates of how much good you can do for people you do know. Therefore, it seems likely that the highest-EEV action directed at people you don't know will have higher EEV than the highest-EEV action directed at people you do know.)
- In such a world, when people decided that a particular endeavor/action had outstandingly high EEV, there would (too often) be no justification for costly skeptical inquiry of this endeavor/action. For example, say that people were trying to manipulate the weather; that someone hypothesized that they had no power for such manipulation; and that the EEV of trying to manipulate the weather was much higher than the EEV of other things that could be done with the same resources. It would be difficult to justify a costly investigation of the "trying to manipulate the weather is a waste of time" hypothesis in this framework. Yet it seems that when people are valuing one action far above others, based on thin information, this is the time when skeptical inquiry is needed most. And more generally, it seems that challenging and investigating our most firmly held, "high-estimated-probability" beliefs - even when doing so has been costly - has been quite beneficial to society.
- Related: giving based on EEV seems to create bad incentives. EEV doesn't seem to allow rewarding charities for transparency or penalizing them for opacity: it simply recommends giving to the charity with the highest estimated expected value, regardless of how well-grounded the estimate is. Therefore, in a world in which most donors used EEV to give, charities would have every incentive to announce that they were focusing on the highest expected-value programs, without disclosing any details of their operations that might show they were achieving less value than theoretical estimates said they ought to be.
- If you are basing your actions on EEV analysis, it seems that you're very open to being exploited by Pascal's Mugging: a tiny probability of a huge-value expected outcome can come to dominate your decisionmaking in ways that seem to violate common sense. (We discuss this further below.)
- If I'm deciding between eating at a new restaurant with 3 Yelp reviews averaging 5 stars and eating at an older restaurant with 200 Yelp reviews averaging 4.75 stars, EEV seems to imply (using Yelp rating as a stand-in for "expected value of the experience") that I should opt for the former. As discussed in the next section, I think this is the purest demonstration of the problem with EEV and the need for Bayesian adjustments.
In the remainder of this post, I present what I believe is the right formal framework for my objections to EEV. However, I have more confidence in my intuitions - which are related to the above observations - than in the framework itself. I believe I have formalized my thoughts correctly, but if the remainder of this post turned out to be flawed, I would likely remain in objection to EEV until and unless one could address my less formal misgivings.
Simple example of a Bayesian approach vs. an EEV approach
It seems fairly clear that a restaurant with 200 Yelp reviews, averaging 4.75 stars, ought to outrank a restaurant with 3 Yelp reviews, averaging 5 stars. Yet this ranking can't be justified in an EEV-style framework, in which options are ranked by their estimated average/expected value. How, in fact, does Yelp handle this situation?
Unfortunately, the answer appears to be undisclosed in Yelp's case, but we can get a hint from a similar site: BeerAdvocate, a site that ranks beers using submitted reviews. It states:
Lists are generated using a Bayesian estimate that pulls data from millions of user reviews (not hand-picked) and normalizes scores based on the number of reviews for each beer. The general statistical formula is: weighted rank (WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C where: R = review average for the beer v = number of reviews for the beer m = minimum reviews required to be considered (currently 10) C = the mean across the list (currently 3.66)
In other words, BeerAdvocate does the equivalent of giving each beer a set number (currently 10) of "average" reviews (i.e., reviews with a score of 3.66, which is the average for all beers on the site). Thus, a beer with zero reviews is assumed to be exactly as good as the average beer on the site; a beer with one review will still be assumed to be close to average, no matter what rating the one review gives; as the number of reviews grows, the beer's rating is able to deviate more from the average.
To illustrate this, the following chart shows how BeerAdvocate's formula would rate a beer that has 0-100 five-star reviews. As the number of five-star reviews grows, the formula's "confidence" in the five-star rating grows, and the beer's overall rating gets further from "average" and closer to (though never fully reaching) 5 stars. 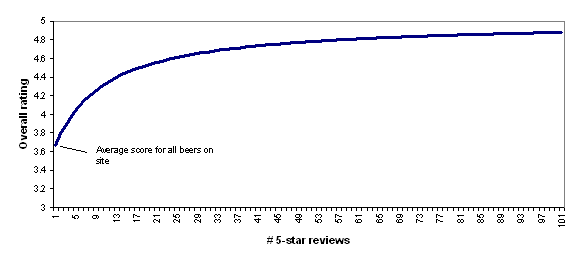
I find BeerAdvocate's approach to be quite reasonable and I find the chart above to accord quite well with intuition: a beer with a small handful of five-star reviews should be considered pretty close to average, while a beer with a hundred five-star reviews should be considered to be nearly a five-star beer.
However, there are a couple of complications that make it difficult to apply this approach broadly.
- BeerAdvocate is making a substantial judgment call regarding what "prior" to use, i.e., how strongly to assume each beer is average until proven otherwise. It currently sets the m in its formula equal to 10, which is like giving each beer a starting point of ten average-level reviews; it gives no formal justification for why it has set m to 10 instead of 1 or 100. It is unclear what such a justification would look like. In fact, I believe that BeerAdvocate used to use a stronger "prior" (i.e., it used to set m to a higher value), which meant that beers needed larger numbers of reviews to make the top-rated list. When BeerAdvocate changed its prior, its rankings changed dramatically, as lesser-known, higher-rated beers overtook the mainstream beers that had previously dominated the list.
- In BeerAdvocate's case, the basic approach to setting a Bayesian prior seems pretty straightforward: the "prior" rating for a given beer is equal to the average rating for all beers on the site, which is known. By contrast, if we're looking at the estimate of how much good a charity does, it isn't clear what "average" one can use for a prior; it isn't even clear what the appropriate reference class is. Should our prior value for the good-accomplished-per-dollar of a deworming charity be equal to the good-accomplished-per-dollar of the average deworming charity, or of the average health charity, or the average charity, or the average altruistic expenditure, or some weighted average of these? Of course, we don't actually have any of these figures. For this reason, it's hard to formally justify one's prior, and differences in priors can cause major disagreements and confusions when they aren't recognized for what they are. But this doesn't mean the choice of prior should be ignored or that one should leave the prior out of expected-value calculations (as we believe EEV advocates do).
Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc.
As discussed above, we believe that both Giving What We Can and Back of the Envelope Guide to Philanthropy use forms of EEV analysis in arguing for their charity recommendations. However, when it comes to analyzing the cost-effectiveness estimates they invoke, the BeerAdvocate formula doesn't seem applicable: there is no "number of reviews" figure that can be used to determine the relative weights of the prior and the estimate.
Instead, we propose a model in which there is a normally (or log-normally) distributed "estimate error" around the cost-effectiveness estimate (with a mean of "no error," i.e., 0 for normally distributed error and 1 for lognormally distributed error), and in which the prior distribution for cost-effectiveness is normally (or log-normally) distributed as well. (I won't discuss log-normal distributions in this post, but the analysis I give can be extended by applying it to the log of the variables in question.) The more one feels confident in one's pre-existing view of how cost-effective an donation or action should be, the smaller the variance of the "prior"; the more one feels confident in the cost-effectiveness estimate itself, the smaller the variance of the "estimate error."
Following up on our 2010 exchange with Giving What We Can, we asked Dario Amodei to write up the implications of the above model and the form of the proper Bayesian adjustment. You can see his analysis here. The bottom line is that when one applies Bayes's rule to obtain a distribution for cost-effectiveness based on (a) a normally distributed prior distribution (b) a normally distributed "estimate error," one obtains a distribution with
- Mean equal to the average of the two means weighted by their inverse variances
- Variance equal to the harmonic sum of the two variances
The following charts show what this formula implies in a variety of different simple hypotheticals. In all of these, the prior distribution has mean = 0 and standard deviation = 1, and the estimate has mean = 10, but the "estimate error" varies, with important effects: an estimate with little enough estimate error can almost be taken literally, while an estimate with large enough estimate error ends ought to be almost ignored.
In each of these charts, the black line represents a probability density function for one's "prior," the red line for an estimate (with the variance coming from "estimate error"), and the blue line for the final probability distribution, taking both the prior and the estimate into account. Taller, narrower distributions represent cases where probability is concentrated around the midpoint; shorter, wider distributions represent cases where the possibilities/probabilities are more spread out among many values. First, the case where the cost-effectiveness estimate has the same confidence interval around it as the prior: 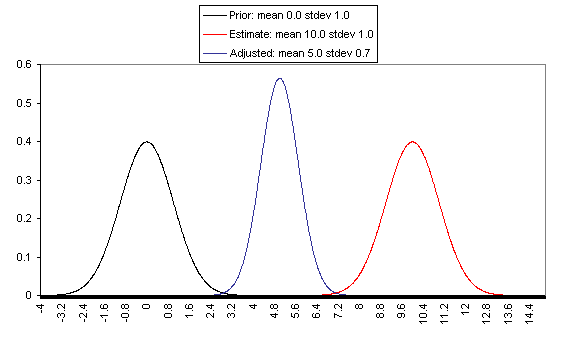
If one has a relatively reliable estimate (i.e., one with a narrow confidence interval / small variance of "estimate error,") then the Bayesian-adjusted conclusion ends up very close to the estimate. When we estimate quantities using highly precise and well-understood methods, we can use them (almost) literally. 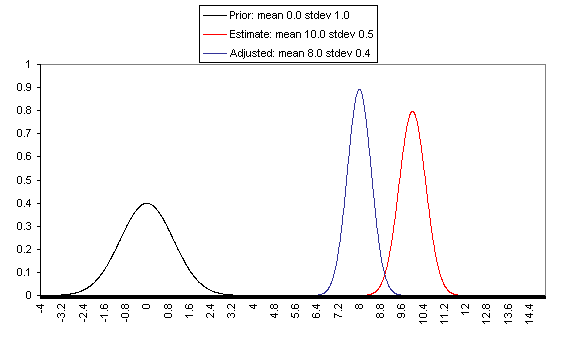
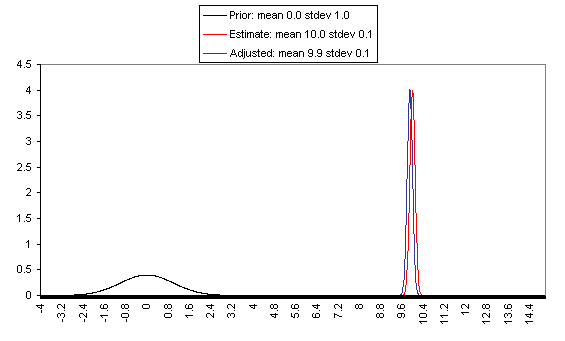
On the flip side, when the estimate is relatively unreliable (wide confidence interval / large variance of "estimate error"), it has little effect on the final expectation of cost-effectiveness (or whatever is being estimated). And at the point where the one-standard-deviation bands include zero cost-effectiveness (i.e., where there's a pretty strong probability that the whole cost-effectiveness estimate is worthless), the estimate ends up having practically no effect on one's final view. 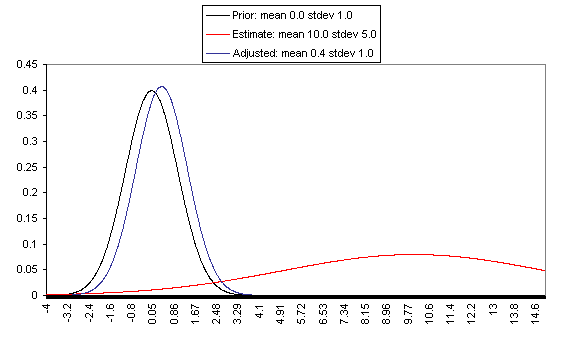
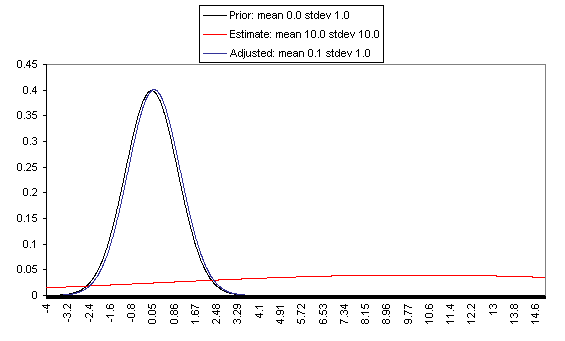
The details of how to apply this sort of analysis to cost-effectiveness estimates for charitable interventions are outside the scope of this post, which focuses on our belief in the importance of the concept of Bayesian adjustments. The big-picture takeaway is that just having the midpoint of a cost-effectiveness estimate is not worth very much in itself; it is important to understand the sources of estimate error, and the degree of estimate error relative to the degree of variation in estimated cost-effectiveness for different interventions.
Pascal's Mugging
Pascal's Mugging refers to a case where a claim of extravagant impact is made for a particular action, with little to no evidence:
Now suppose someone comes to me and says, "Give me five dollars, or I'll use my magic powers … to [harm an imaginably huge number of] people.
Non-Bayesian approaches to evaluating these proposals often take the following form: "Even if we assume that this analysis is 99.99% likely to be wrong, the expected value is still high - and are you willing to bet that this analysis is wrong at 99.99% odds?"
However, this is a case where "estimate error" is probably accounting for the lion's share of variance in estimated expected value, and therefore I believe that a proper Bayesian adjustment would correctly assign little value where there is little basis for the estimate, no matter how high the midpoint of the estimate.
Say that you've come to believe - based on life experience - in a "prior distribution" for the value of your actions, with a mean of zero and a standard deviation of 1. (The unit type you use to value your actions is irrelevant to the point I'm making; so in this case the units I'm using are simply standard deviations based on your prior distribution for the value of your actions). Now say that someone estimates that action A (e.g., giving in to the mugger's demands) has an expected value of X (same units) - but that the estimate itself is so rough that the right expected value could easily be 0 or 2X. More specifically, say that the error in the expected value estimate has a standard deviation of X.
An EEV approach to this situation might say, "Even if there's a 99.99% chance that the estimate is completely wrong and that the value of Action A is 0, there's still an 0.01% probability that Action A has a value of X. Thus, overall Action A has an expected value of at least 0.0001X; the greater X is, the greater this value is, and if X is great enough then, then you should take Action A unless you're willing to bet at enormous odds that the framework is wrong."
However, the same formula discussed above indicates that Action X actually has an expected value - after the Bayesian adjustment - of X/(X^2+1), or just under 1/X. In this framework, the greater X is, the lower the expected value of Action A. This syncs well with my intuitions: if someone threatened to harm one person unless you gave them $10, this ought to carry more weight (because it is more plausible in the face of the "prior" of life experience) than if they threatened to harm 100 people, which in turn ought to carry more weight than if they threatened to harm 3^^^3 people (I'm using 3^^^3 here as a representation of an unimaginably huge number).
The point at which a threat or proposal starts to be called "Pascal's Mugging" can be thought of as the point at which the claimed value of Action A is wildly outside the prior set by life experience (which may cause the feeling that common sense is being violated). If someone claims that giving him/her $10 will accomplish 3^^^3 times as much as a 1-standard-deviation life action from the appropriate reference class, then the actual post-adjustment expected value of Action A will be just under (1/3^^^3) (in standard deviation terms) - only trivially higher than the value of an average action, and likely lower than other actions one could take with the same resources. This is true without applying any particular probability that the person's framework is wrong - it is simply a function of the fact that their estimate has such enormous possible error. An ungrounded estimate making an extravagant claim ought to be more or less discarded in the face of the "prior distribution" of life experience.
Generalizing the Bayesian approach
In the above cases, I've given quantifications of (a) the appropriate prior for cost-effectiveness; (b) the strength/confidence of a given cost-effectiveness estimate. One needs to quantify both (a) and (b) - not just quantify estimated cost-effectiveness - in order to formally make the needed Bayesian adjustment to the initial estimate.
But when it comes to giving, and many other decisions, reasonable quantification of these things usually isn't possible. To have a prior, you need a reference class, and reference classes are debatable.
It's my view that my brain instinctively processes huge amounts of information, coming from many different reference classes, and arrives at a prior; if I attempt to formalize my prior, counting only what I can name and justify, I can worsen the accuracy a lot relative to going with my gut. Of course there is a problem here: going with one's gut can be an excuse for going with what one wants to believe, and a lot of what enters into my gut belief could be irrelevant to proper Bayesian analysis. There is an appeal to formulas, which is that they seem to be susceptible to outsiders' checking them for fairness and consistency.
But when the formulas are too rough, I think the loss of accuracy outweighs the gains to transparency. Rather than using a formula that is checkable but omits a huge amount of information, I'd prefer to state my intuition - without pretense that it is anything but an intuition - and hope that the ensuing discussion provides the needed check on my intuitions.
I can't, therefore, usefully say what I think the appropriate prior estimate of charity cost-effectiveness is. I can, however, describe a couple of approaches to Bayesian adjustments that I oppose, and can describe a few heuristics that I use to determine whether I'm making an appropriate Bayesian adjustment.
Approaches to Bayesian adjustment that I oppose
I have seen some argue along the lines of "I have a very weak (or uninformative) prior, which means I can more or less take rough estimates literally." I think this is a mistake. We do have a lot of information by which to judge what to expect from an action (including a donation), and failure to use all the information we have is a failure to make the appropriate Bayesian adjustment. Even just a sense for the values of the small set of actions you've taken in your life, and observed the consequences of, gives you something to work with as far as an "outside view" and a starting probability distribution for the value of your actions; this distribution probably ought to have high variance, but when dealing with a rough estimate that has very high variance of its own, it may still be quite a meaningful prior.
I have seen some using the EEV framework who can tell that their estimates seem too optimistic, so they make various "downward adjustments," multiplying their EEV by apparently ad hoc figures (1%, 10%, 20%). What isn't clear is whether the size of the adjustment they're making has the correct relationship to (a) the weakness of the estimate itself (b) the strength of the prior (c) distance of the estimate from the prior. An example of how this approach can go astray can be seen in the "Pascal's Mugging" analysis above: assigning one's framework a 99.99% chance of being totally wrong may seem to be amply conservative, but in fact the proper Bayesian adjustment is much larger and leads to a completely different conclusion.
Heuristics I use to address whether I'm making an appropriate prior-based adjustment
- The more action is asked of me, the more evidence I require. Anytime I'm asked to take a significant action (giving a significant amount of money, time, effort, etc.), this action has to have higher expected value than the action I would otherwise take. My intuitive feel for the distribution of "how much my actions accomplish" serves as a prior - an adjustment to the value that the asker claims for my action.
- I pay attention to how much of the variation I see between estimates is likely to be driven by true variation vs. estimate error. As shown above, when an estimate is rough enough so that error might account for the bulk of the observed variation, a proper Bayesian approach can involve a massive discount to the estimate.
- I put much more weight on conclusions that seem to be supported by multiple different lines of analysis, as unrelated to one another as possible. If one starts with a high-error estimate of expected value, and then starts finding more estimates with the same midpoint, the variance of the aggregate estimate error declines; the less correlated the estimates are, the greater the decline in the variance of the error, and thus the lower the Bayesian adjustment to the final estimate. This is a formal way of observing that "diversified" reasons for believing something lead to more "robust" beliefs, i.e., beliefs that are less likely to fall apart with new information and can be used with less skepticism.
- I am hesitant to embrace arguments that seem to have anti-common-sense implications (unless the evidence behind these arguments is strong) and I think my prior may often be the reason for this. As seen above, a too-weak prior can lead to many seemingly absurd beliefs and consequences, such as falling prey to "Pascal's Mugging" and removing the incentive for investigation of strong claims. Strengthening the prior fixes these problems (while over-strengthening the prior results in simply ignoring new evidence). In general, I believe that when a particular kind of reasoning seems to me to have anti-common-sense implications, this may indicate that its implications are well outside my prior.
- My prior for charity is generally skeptical, as outlined at this post. Giving well seems conceptually quite difficult to me, and it's been my experience over time that the more we dig on a cost-effectiveness estimate, the more unwarranted optimism we uncover. Also, having an optimistic prior would mean giving to opaque charities, and that seems to violate common sense. Thus, we look for charities with quite strong evidence of effectiveness, and tend to prefer very strong charities with reasonably high estimated cost-effectiveness to weaker charities with very high estimated cost-effectiveness
Conclusion
- I feel that any giving approach that relies only on estimated expected-value - and does not incorporate preferences for better-grounded estimates over shakier estimates - is flawed.
- Thus, when aiming to maximize expected positive impact, it is not advisable to make giving decisions based fully on explicit formulas. Proper Bayesian adjustments are important and are usually overly difficult to formalize.
253 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-18T23:56:58.930Z · LW(p) · GW(p)
Quick comment one:
This jumped out instantly when I looked at the charts: Your prior and evidence can't possibly both be correct at the same time. Everywhere the prior has non-negligible density has negligible likelihood. Everywhere that has substantial likelihood has negligible prior density. If you try multiplying the two together to get a compromise probability estimate instead of saying "I notice that I am confused", I would hold this up as a pretty strong example of the real sin that I think this post should be arguing against, namely that of trying to use math too blindly without sanity-checking its meaning.
Quick comment two:
I'm a major fan of Down-To-Earthness as a virtue of rationality, and I have told other SIAI people over and over that I really think they should stop using "small probability of large impact" arguments. I've told cryonics people the same. If you can't argue for a medium probability of a large impact, you shouldn't bother.
Part of my reason for saying this is, indeed, that trying to multiply a large utility interval by a small probability is an argument-stopper, an attempt to shut down further debate, and someone is justified in having a strong prior, when they see an attempt to shut down further debate, that further argument if explored would result in further negative shifts from the perspective of the side trying to shut down the debate.
With that said, any overall scheme of planetary philanthropic planning that doesn't spend ten million dollars annually on Friendly AI is just stupid. It doesn't just fail the Categorical Imperative test of "What if everyone did that?", it fails the Predictable Retrospective Stupidity test of, "Assuming civilization survives, how incredibly stupid will our descendants predictably think we were to do that?"
Of course, I believe this because I think the creation of smarter-than-human intelligence has a (very) large probability of an (extremely) large impact, and that most of the probability mass there is concentrated into AI, and I don't think there's nothing that can be done about that, either.
I would summarize my quick reply by saying,
"I agree that it's a drastic warning sign when your decision process is spending most of its effort trying to achieve unprecedented outcomes of unquantifiable small probability, and that what I consider to be down-to-earth common sense is a great virtue of a rationalist. That said, down-to-earth common-sense says that AI is a screaming emergency at this point in our civilization's development, and I don't consider myself to be multiplying small probabilities by large utility intervals at any point in my strategy."
Replies from: Wei_Dai, orthonormal, multifoliaterose, novalis, lukeprog↑ comment by Wei Dai (Wei_Dai) · 2011-08-19T03:05:30.952Z · LW(p) · GW(p)
I don't consider myself to be multiplying small probabilities by large utility intervals at any point in my strategy
What about people who do think SIAI's probability of success is small? Perhaps they have different intuitions about how hard FAI is, or don't have enough knowledge to make an object-level judgement so they just apply the absurdity heuristic. Being one of those people, I think it's still an important question whether it's rational to support SIAI given a small estimate of probability of success, even if SIAI itself doesn't want to push this line of inquiry too hard for fear of signaling that their own estimate of probability of success is low.
Replies from: Eliezer_Yudkowsky, Rain↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-19T22:38:57.606Z · LW(p) · GW(p)
Leaving aside Aumann questions: If people like that think that the Future of Humanity Institute, work on human rationality, or Giving What We Can has a large probability of catalyzing the creation of an effective institution, they should quite plausibly be looking there instead. "I should be doing something I think is at least medium-probably remedying the sheerly stupid situation humanity has gotten itself into with respect to the intelligence explosion" seems like a valuable summary heuristic.
If you can't think of anything medium-probable, using that as an excuse to do nothing is unacceptable. Figure out which of the people trying to address the problem seem most competent and gamble on something interesting happening if you give them more money. Money is the unit of caring and I can't begin to tell you how much things change when you add more money to them. Imagine what the global financial sector would look like if it was funded to the tune of $600,000/year. You would probably think it wasn't worth scaling up Earth's financial sector.
Replies from: Wei_Dai, lessdazed, multifoliaterose↑ comment by Wei Dai (Wei_Dai) · 2011-08-20T05:57:23.948Z · LW(p) · GW(p)
If you can't think of anything medium-probable, using that as an excuse to do nothing is unacceptable.
That's my gut feeling as well, but can we give a theoretical basis for that conclusion, which might also potentially be used to convince people who can't think of anything medium-probable to "do something"?
My current thoughts are
- I assign some non-zero credence to having an unbounded utility function.
- Bostrom and Toby's moral parliament idea seems to be the best that we have about how to handle moral uncertainty.
- If Pascal's wager argument works, and to the extent that I have a faction representing unbounded utility in my moral parliament, I ought to spend a fraction of my resources on Pascal's wager type "opportunities"
- If Pascal's wager argument works, I should pick the best wager to bet on, which intuitively could well be "push for a positive Singularity"
- But it's not clear that Pascal's wager argument works or what could be the justification for thinking that "push for a positive Singularity" is the best wager. We also don't have any theory to handle this kind of philosophical uncertainty.
- Given all this, I still have to choose between "do nothing", "push for positive Singularity", or "investigate Pascal's wager". Is there any way, in this decision problem, to improve upon going with my gut?
Anyway, I understand that you probably have reasons not to engage too deeply with this line of thought, so I'm mostly explaining where I'm currently at, as well as hoping that someone else can offer some ideas.
↑ comment by lessdazed · 2011-08-20T11:18:45.531Z · LW(p) · GW(p)
Imagine what the global financial sector would look like if it was funded to the tune of $600,000/year. You would probably think it wasn't worth scaling up Earth's financial sector.
And one might even be right about that.
A better analogy might be if regulation of the global financial sector were funded at 600k/yr.
↑ comment by multifoliaterose · 2011-08-19T22:53:43.845Z · LW(p) · GW(p)
Money is the unit of caring and it really is impossible to overstate how much things change when you add money to them.
Can you give an example relevant to the context at hand to illustrate what you have in mind? I don't necessarily disagree, but I presently think that there's a tenable argument that money is seldom the key limiting factor for philanthropic efforts in the developed world.
Replies from: Eliezer_Yudkowsky, ciphergoth↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-19T23:50:27.894Z · LW(p) · GW(p)
BTW, note that I deleted the "impossible to overstate" line on grounds of its being false. It's actually quite possible to overstate the impact of adding money. E.g., "Adding one dollar to this charity will CHANGE THE LAWS OF PHYSICS."
↑ comment by Paul Crowley (ciphergoth) · 2011-08-20T06:58:40.171Z · LW(p) · GW(p)
What sort of key limiting factors do you have in mind that are untouched by money? Every limiting factor I can think of, whether it's lack of infrastructure or corruption or lack of political will in the West, is something that you could spend money on doing something about.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-20T18:51:02.151Z · LW(p) · GW(p)
If nothing else, historical examples show that huge amounts of money lobbed at a cause can go to waste or do more harm than good (e.g. the Iraq war as a means to improve relations with the middle East).
Eliezer and I were both speaking in vague terms; presumably somebody intelligent, knowledgeable, sophisticated, motivated, energetic & socially/politically astute can levy money toward some positive expected change in a given direction. There remains the question about the conversion factor between money and other goods and how quickly it changes at the margin; it could be negligible in a given instance.
The main limiting factor that I had in mind was human capital: an absence of people who are sufficiently intelligent, knowledgeable, sophisticated, motivated, energetic & socially/politically astute.
I would add that a group of such people would have substantially better than average odds of attracting sufficient funding from some philanthropist; further diminishing the value of donations (on account of fungibility).
↑ comment by Rain · 2011-08-19T12:25:37.587Z · LW(p) · GW(p)
I think the creation of smarter-than-human intelligence has a (very) large probability of an (extremely) large impact, and that most of the probability mass there is concentrated into AI
That's the probability statement in his post. He didn't mention the probability of SIAI's success, and hasn't previously when I've emailed him or asked in public forums, nor has he at any point in time that I've heard. Shortly after I asked, he posted When (Not) To Use Probabilities.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2011-08-19T16:37:19.218Z · LW(p) · GW(p)
Yes, I had read that, and perhaps even more apropos (from Shut up and do the impossible!):
You might even be justified in refusing to use probabilities at this point. In all honesty, I really don't know how to estimate the probability of solving an impossible problem that I have gone forth with intent to solve; in a case where I've previously solved some impossible problems, but the particular impossible problem is more difficult than anything I've yet solved, but I plan to work on it longer, etcetera.
People ask me how likely it is that humankind will survive, or how likely it is that anyone can build a Friendly AI, or how likely it is that I can build one. I really don't know how to answer. I'm not being evasive; I don't know how to put a probability estimate on my, or someone else, successfully shutting up and doing the impossible. Is it probability zero because it's impossible? Obviously not. But how likely is it that this problem, like previous ones, will give up its unyielding blankness when I understand it better? It's not truly impossible, I can see that much. But humanly impossible? Impossible to me in particular? I don't know how to guess. I can't even translate my intuitive feeling into a number, because the only intuitive feeling I have is that the "chance" depends heavily on my choices and unknown unknowns: a wildly unstable probability estimate.
But it's not clear whether Eliezer means that he can't even translate his intuitive feeling into a word like "small" or "medium". I thought the comment I was replying to was saying that SIAI had a "medium" chance of success, given:
If you can't argue for a medium probability of a large impact, you shouldn't bother.
and
I don't consider myself to be multiplying small probabilities by large utility intervals at any point in my strategy
But perhaps I misinterpreted? In any case, there's still the question of what is rational for those of us who do think SIAI's chance of success is "small".
Replies from: Rain, Will_Newsome↑ comment by Rain · 2011-08-19T18:02:00.265Z · LW(p) · GW(p)
I thought he was taking the "don't bother" approach by not giving a probability estimate or arguing about probabilities.
In any case, there's still the question of what is rational for those of us who do think SIAI's chance of success is "small".
I propose that the rational act is to investigate approaches to greater than human intelligence which would succeed.
Replies from: Jordan↑ comment by Will_Newsome · 2011-08-19T18:21:50.203Z · LW(p) · GW(p)
Sufficiently-Friendly AI can be hard for SIAI-now but easy or medium for non-SIAI-now (someone else now, someone else future, SIAI future). I personally believe this, since SIAI-now is fucked up (and SIAI-future very well will be too). (I won't substantiate that claim here.) Eliezer didn't talk about SIAI specifically. (He probably thinks SIAI will be at least as likely to succeed as anyone else because he thinks he's super awesome, but it can't be assumed he'd assert that with confidence, I think.)
Replies from: Alicorn, Louie↑ comment by Alicorn · 2011-08-19T18:38:35.607Z · LW(p) · GW(p)
SIAI-now is fucked up (and SIAI-future very well will be too). (I won't substantiate that claim here.)
Will you substantiate it elsewhere?
Replies from: handoflixue↑ comment by handoflixue · 2011-08-19T22:25:06.376Z · LW(p) · GW(p)
Second that interest in hearing it substantiated elsewhere.
↑ comment by Louie · 2011-12-28T20:35:59.645Z · LW(p) · GW(p)
Your comments are a cruel reminder that I'm in a world where some of the very best people I know are taken from me.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-12-28T20:38:28.628Z · LW(p) · GW(p)
SingInst seems a lot better since I wrote that comment; you and Luke are doing some cool stuff. Around August everything was in a state of disarray and it was unclear if you'd manage to pull through.
↑ comment by orthonormal · 2011-08-19T00:50:11.780Z · LW(p) · GW(p)
Regarding the graphs, I assumed that they were showing artificial examples so that we could viscerally understand at a glance what the adjustment does, not that this is what the prior and evidence should look like in a real case.
↑ comment by multifoliaterose · 2011-08-19T00:18:27.448Z · LW(p) · GW(p)
Upvoted.
This jumped out instantly when I looked at the charts: Your prior and evidence can't possibly both be correct at the same time. Everywhere the prior has non-negligible density has negligible likelihood. Everywhere that has substantial likelihood has negligible prior density. If you try multiplying the two together to get a compromise probability estimate instead of saying "I notice that I am confused", I would hold this up as a pretty strong example of the real sin that I think this post should be arguing against, namely that of trying to use math too blindly without sanity-checking its meaning.
(I deleted my response to this following othonormal's comments; see this one for my revised thought here.)
Of course, I believe this because I think the creation of smarter-than-human intelligence has a (very) large probability of an (extremely) large impact, and that most of the probability mass there is concentrated into AI, and I don't think there's nothing that can be done about that, either.
Why do you think that there's something that can be done about it?
Replies from: orthonormal↑ comment by orthonormal · 2011-08-19T00:48:13.277Z · LW(p) · GW(p)
I disagree. It can be rational to shift subjective probabilities by many orders of magnitude in response to very little new information.
What your example looks like is a nearly uniform prior over a very large space- nothing's wrong when we quickly update to believe that yesterday's lottery numbers are 04-15-21-31-36.
But the point where you need to halt, melt, and catch fire is if your prior assigns the vast majority of the probability mass to a small compact region, and then the evidence comes along and lands outside that region. That's the equivalent of starting out 99.99% confident that you know tomorrow's lottery numbers will begin with 01-02-03, and being proven wrong.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T00:57:29.925Z · LW(p) · GW(p)
Yes, you're right, I wasn't thinking clearly, thanks for catching me. I think there's something to what I was trying to say, but I need to think about it through more carefully. I find the explanation that you give in your other comment convincing (that the point of the graphs is to clearly illustrate the principle).
↑ comment by novalis · 2011-08-19T04:42:59.068Z · LW(p) · GW(p)
10 million dollars buys quite a few programmers. SIAI is presently nowhere near that amount of money, and doesn't look likely to be any time soon. When does it make sense to start talking to volunteer programmers? Presumably, when the risk of opening up the project is less than the risk of failing to get it done before someone else does it wrong.
Replies from: MichaelVassar↑ comment by MichaelVassar · 2011-08-19T14:19:51.203Z · LW(p) · GW(p)
When is "soon" for these purposes. It seems to me that with continuing support, SIAI will be able to hire as many of the right programmers as we can find and effectively integrate into a research effort. We certainly would hire any such programmers now.
Replies from: multifoliaterose, novalis, Will_Newsome, lessdazed↑ comment by multifoliaterose · 2011-08-19T17:03:29.354Z · LW(p) · GW(p)
It seems to me that with continuing support, SIAI will be able to hire as many of the right programmers as we can find and effectively integrate into a research effort.
My main source of uncertainty as to SIAI's value comes from the fact that as far as I can tell nobody has a viable Friendly AI research program.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-19T18:03:55.925Z · LW(p) · GW(p)
(Please don't upvote this comment till you've read it fully; I'm interpreting upvotes in a specific way.) Question for anyone on LW: If I had a viable preliminary Friendly AI research program, aimed largely at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty of Friendly AI for various values of "Friendly", and wrote clearly and concretely about the necessary steps in pursuing this analysis, and listed and described a small number of people (less than 5, but how many could actually be convinced to focus on doing the analysis would depend on funds) who I know of who could usefully work on such an analysis, and committed to have certain summaries published online at various points (after actually considering concrete possibilities for failure, planning fallacy, etc., like real rationalists should), and associated with a few (roughly 5) high status people (people like Anders Sandberg or Max Tegmark, e.g. by convincing them to be on an advisory board), would this have a decent chance of causing you or someone you know to donate $100 or more to support this research program? (I have a weird rather mixed reputation among the greater LW community, so if that affects you negatively please pretend that someone with a more solid reputation but without super high karma is asking this question, like Steven Kaas.) You can upvote for "yes" and comment about any details, e.g. if you know someone who would possibly donate significantly more than $100. (Please don't downvote for "no", 'cuz that's the default answer and will drown out any "yes" ones.)
Replies from: Airedale, Eliezer_Yudkowsky, Will_Newsome↑ comment by Airedale · 2011-08-21T16:22:15.102Z · LW(p) · GW(p)
I have a weird rather mixed reputation among the greater LW community, so if that affects you negatively please pretend that someone with a more solid reputation but without super high karma is asking this question, like Steven Kaas.
Unless you would be much less involved in this potential program than the comment indicates, this seems like an inappropriate request. If people view you negatively due to your posting history, they should absolutely take that information into account in assessing how likely they would be to provide financial support to such a program (assuming that the negative view is based on relevant considerations such as your apparent communication or reasoning skills as demonstrated in your comments).
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-21T17:47:06.157Z · LW(p) · GW(p)
Unless you would be much less involved in this potential program than the comment indicates, this seems like an inappropriate request.
I was more interested in Less Wrong's interest in new FAI-focused organizations generally than in anything particularly tied to me.
Replies from: Airedale↑ comment by Airedale · 2011-08-21T22:11:13.953Z · LW(p) · GW(p)
Fair enough, but in light of your phrasing in both the original comment ("If I [did the following things]") and your comment immediately following it (quoted below; emphasis added), it certainly appeared to me that you seemed to be describing a significant role for yourself, even though your proposal was general overall.
(Some people, including me, would really like it if a competent and FAI-focused uber-rationalist non-profit existed. I know people who will soon have enough momentum to make this happen. I am significantly more familiar with the specifics of FAI (and of hardcore SingInst-style rationality) than many of those people and almost anyone else in the world, so it'd be necessary that I put a lot of hours into working with those who are higher status than me and better at getting things done but less familiar with technical Friendliness. But I have many other things I could be doing. Hence the question.)
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-20T05:57:06.480Z · LW(p) · GW(p)
Sorry, could you say again what exactly you want to do? I mean, what's the output here that the money is paying for; a Friendly AI, a theory that can be used to construct a Friendly AI, or an analysis that purports to say whether or not Friendly AI is "feasible", or what?
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-21T08:51:58.913Z · LW(p) · GW(p)
Money would pay for marginal output, e.g. in the form of increased collaboration, I think, since the best Friendliness-cognizant x-rationalists would likely already be working on similar things.
I was trying to quickly gauge vague interest in a vague notion. I think that my original comment was at roughly the most accurate and honest level of vagueness (i.e. "aimed largely [i.e. primarily] at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty [e.g. how many Von Neumanns, Turings, and/or Aristotles would it take?] of Friendly AI for various (logical) probabilities of Friendliness [e.g. is the algorithm meta-reflective enough to fall into (one of) some imagined Friendliness attractor basin(s)?]"). Value of information regarding difficulty of Friendly-ish AI is high, but research into that question is naturally tied to Friendly AI theory itself. I'm thinking... Goedel machine stability more than ambient decision theory, history of computation more than any kind of validity semantics. To some extent it depends on who plans to actually work on what stuff from the open problems lists. There are many interesting technical threads that people might start pulling on soon, and it's unclear to me to what extent they actually will pull on them or to what extent pulling on them will give us a better sense of the problem.
[Stuff it would take too many paragraphs to explain why it's worth pointing out specifically:] Theory of justification seems to be roughly as developed as theory of computation was before the advent of Leibniz; Leibniz saw a plethora of connections between philosophy, symbolic logic, and engineering and thus developed some correctly thematically centered proto-theory. I'm trying to make a Leibniz, and hopefully SingInst can make a Turing. (Two other roughly analogous historical conceptual advances are natural selection and temperature.)
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-21T10:06:50.027Z · LW(p) · GW(p)
Well, my probability that you could or would do anything useful, given money, just dropped straight off a cliff. But perhaps you're just having trouble communicating. That is to say: What the hell are you talking about.
If you're going to ask for money on LW, plain English response, please: What's the output here that the money is paying for; (1) a Friendly AI, (2) a theory that can be used to construct a Friendly AI, or (3) an analysis that purports to say whether or not Friendly AI is "feasible"? Please pick one of the pre-written options; I now doubt your ability to write your response ab initio.
Replies from: Solvent, Will_Newsome↑ comment by Will_Newsome · 2011-08-21T10:47:34.665Z · LW(p) · GW(p)
Dude, it's right there: "feasibility and difficulty", in this sentence which I am now repeating for the second time:
aimed largely [i.e. primarily] at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty [e.g. how many Von Neumanns, Turings, and/or Aristotles would it take?] of Friendly AI for various (logical) probabilities of Friendliness [e.g. is the algorithm meta-reflective enough to fall into (one of) some imagined Friendliness attractor basin(s)?]").
(Bold added for emphasis, annotations in [brackets] were in the original.)
The next sentence:
Value of information regarding difficulty of Friendly-ish AI is high, but research into that question is naturally tied to Friendly AI theory itself.
Or if you really need it spelled out for you again and again, the output would primarily be (3) but secondarily (2) as you need some of (2) to do (3).
Because you clearly need things pointed out multiple times, I'll remind you that I put my response in the original comment that you originally responded to, without the later clarifications that I'd put in for apparently no one's benefit:
If I had a viable preliminary Friendly AI research program, aimed largely at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty of Friendly AI for various values of "Friendly" [...]
(Those italics were in the original comment!)
If you're going to ask for money on LW
I wasn't asking for money on Less Wrong! As I said, "I was trying to quickly gauge vague interest in a vague notion." What the hell are you talking about.
I now doubt your ability to write your response ab initio.
I've doubted your ability to read for a long time, but this is pretty bad. The sad thing is you're probably not doing this intentionally.
Replies from: katydee, Solvent↑ comment by katydee · 2011-08-21T11:15:35.841Z · LW(p) · GW(p)
I think the problem here is that your posting style, to be frank, often obscures your point.
In most cases, posts that consist of a to-the-point answer followed by longer explanations use the initial statement to make a concise case. For instance, in this post, my first sentence sums up what I think about the situation and the rest explains that thought in more detail so as to convey a more nuanced impression.
By contrast, when Eliezer asked "What's the output here that the money is paying for," your first sentence was "Money would pay for marginal output, e.g. in the form of increased collaboration, I think, since the best Friendliness-cognizant x-rationalists would likely already be working on similar things." This does not really answer his question, and while you clarify this with your later points, the overall message is garbled.
The fact that your true answer is buried in the middle of a paragraph does not really help things much. Though I can see what you are trying to say, I can't in good and honest conscience describe it as clear. Had you answered, on the other hand, "Money would pay for the technical analysis necessary to determine as well as possible the feasibility and difficulty of FAI..." as your first sentence, I think your post would have been more clear and more likely to be understood.
Replies from: Will_Newsome, Will_Newsome↑ comment by Will_Newsome · 2011-08-21T11:32:34.511Z · LW(p) · GW(p)
The sentences I put before the direct answer to Eliezer's question were meant to correct some of Eliezer's misapprehensions that were more fundamental than the object of his question. Eliezer's infamous for uncharitably misinterpreting people and it was clear he'd misinterpreted some key aspects of my original comment, e.g. my purpose in writing it. If I'd immediately directly answered his question that would have been dishonest; it would have contributed further to his having a false view of what I was actually talking about. Less altruistically it would be like I was admitting to his future selves or to external observers that I agreed that his model of my purposes was accurate and that this model could legitimately be used to assert that I was unjustified in any of many possible ways. Thus I briefly (a mere two sentences) attempted to address what seemed likely to be Eliezer's underlying confusions before addressing his object level question. (Interestingly Eliezer does this quite often, but unfortunately he often assumes people are confused in ways that they are not.)
Given these constraints, what should I have done? In retrospect I should have gone meta, of course, like always. What else?
Thanks much for the critique.
Replies from: katydee↑ comment by katydee · 2011-08-21T12:04:39.694Z · LW(p) · GW(p)
Given those constraints, I would probably write something like "Money would pay for marginal output in the form of increased collaboration on the technical analysis necessary to determine as well as possible the feasibility and difficulty of FAI" for my first sentence and elaborate as strictly necessary. That seems rather more cumbersome than I'd like, but it's also a lot of information to try and convey in one sentence!
Alternatively, I would consider something along the lines of "Money would pay for the technical analysis necessary to determine as well as possible the feasibility and difficulty of FAI, but not directly-- since the best Friendliness-cognizant x-rationalists would likely already be working on similar things, the money would go towards setting up better communication, coordination, and collaboration for that group."
That said, I am unaware of any reputation Eliezer has in the field of interpreting people, and personally haven't received the impression that he's consistently unusually bad or uncharitable at it. Then again, I have something of a reputation-- at least in person-- for being too charitable, so perhaps I'm being too light on Eliezer (or you?) here.
↑ comment by Will_Newsome · 2011-08-21T11:46:14.940Z · LW(p) · GW(p)
I think the problem here is that your posting style, to be frank, often obscures your point.
I acknowledge this. But it seems to me that the larger problem is that Eliezer simply doesn't know how to read what people actually say. Less Wrong mostly doesn't either, and humans in general certainly don't. This is a very serious problem with LW-style rationality (and with humanity). There are extremely talented rationalists who do not have this problem; it is an artifact of Eliezer's psychology and not of the art of rationality.
Replies from: Rain, Kaj_Sotala, katydee↑ comment by Rain · 2011-08-21T14:08:28.543Z · LW(p) · GW(p)
It's hardly fair to blame the reader when you've got "sentences" like this:
Replies from: Will_Newsome, Will_NewsomeI think that my original comment was at roughly the most accurate and honest level of vagueness (i.e. "aimed largely [i.e. primarily] at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty [e.g. how many Von Neumanns, Turings, and/or Aristotles would it take?] of Friendly AI for various (logical) probabilities of Friendliness [e.g. is the algorithm meta-reflective enough to fall into (one of) some imagined Friendliness attractor basin(s)?]").
↑ comment by Will_Newsome · 2011-08-21T14:19:24.048Z · LW(p) · GW(p)
That was the second version of the sentence, the first one had much clearer syntax and even italicized the answer to Eliezer's subsequent question. It looks the way it does because Eliezer apparently couldn't extract meaning out of my original sentence despite it clearly answering his question, so I tried to expand on the relevant points with bracketed concrete examples. Here's the original:
If I had a viable preliminary Friendly AI research program, aimed largely at doing the technical analysis necessary to determine as well as possible the feasibility and difficulty of Friendly AI for various values of "Friendly" [...]
(emphasis in original)
Replies from: Rain↑ comment by Will_Newsome · 2011-08-21T14:22:53.530Z · LW(p) · GW(p)
What you say might be true, but this one example is negligible compared to the mountain of other evidence concerning inability to read much more important things (which are unrelated to me). I won't give that evidence here.
↑ comment by Kaj_Sotala · 2011-08-21T20:14:20.903Z · LW(p) · GW(p)
Certainly true, but that only means that we need to spend more effort on being as clear as possible.
↑ comment by katydee · 2011-08-21T12:14:46.442Z · LW(p) · GW(p)
If that's indeed the case (I haven't noticed this flaw myself), I suggest that you write articles (or perhaps commission/petition others to have them written) describing this flaw and how to correct it. Eliminating such a flaw or providing means of averting it would greatly aid LW and the community in general.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-21T12:30:43.797Z · LW(p) · GW(p)
Unfortunately that is not currently possible for many reasons, including some large ones I can't talk about and that I can't talk about why I can't talk about. I can't see any way that it would become possible in the next few years either. I find this stressful; it's why I make token attempts to communicate in extremely abstract or indirect ways with Less Wrong, despite the apparent fruitlessness. But there's really nothing for it.
Unrelated public announcement: People who go back and downvote every comment someone's made, please, stop doing that. It's a clever way to pull information cascades in your direction but it is clearly an abuse of the content filtering system and highly dishonorable. If you truly must use such tactics, downvoting a few of your enemy's top level posts is much less evil; your enemy loses the karma and takes the hint without your severely biasing the public perception of your enemy's standard discourse. Please.
(I just lost 150 karma points in a few minutes and that'll probably continue for awhile. This happens a lot.)
Replies from: Nisan, katydee, NancyLebovitz, None↑ comment by katydee · 2011-08-21T21:45:23.813Z · LW(p) · GW(p)
I'm not a big fan of the appeal to secret reasons, so I think I'm going to have pull out of this discussion. I will note, however, that you personally seem to be involved in more misunderstandings than the average LW poster, so while it's certainly possible that your secret reasons are true and valid and Eliezer just sucks at reading or whatever, you may want to clarify certain elements of your own communication as well.
I unfortunately predict that "going more meta" will not be strongly received here.
↑ comment by NancyLebovitz · 2011-08-21T13:55:12.901Z · LW(p) · GW(p)
I'm sorry to hear that you're up against something so difficult, and I hope you find a way out.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-21T14:25:48.205Z · LW(p) · GW(p)
Thank you... I think I just need to be more meta. Meta never fails.
↑ comment by [deleted] · 2011-08-21T13:51:46.716Z · LW(p) · GW(p)
Unfortunately that is not currently possible for many reasons, including some large ones I can't talk about and that I can't talk about why I can't talk about.
Are we still talking about improving general reading comprehension? What could possibly be dangerous about that?
↑ comment by Will_Newsome · 2011-08-19T18:31:36.001Z · LW(p) · GW(p)
(Some people, including me, would really like it if a competent and FAI-focused uber-rationalist non-profit existed. I know people who will soon have enough momentum to make this happen. I am significantly more familiar with the specifics of FAI (and of hardcore SingInst-style rationality) than many of those people and almost anyone else in the world, so it'd be necessary that I put a lot of hours into working with those who are higher status than me and better at getting things done but less familiar with technical Friendliness. But I have many other things I could be doing. Hence the question.)
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2011-08-19T19:40:13.580Z · LW(p) · GW(p)
Does "FAI-focused" mean what I called code first? What are your thoughts on that post and its followup? What is this new non-profit planning to do differently from SIAI and why? What are the other things that you could be doing?
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-19T20:01:29.274Z · LW(p) · GW(p)
Incomplete response:
Does "FAI-focused" mean what I called code first?
Jah. Well, at least determining whether or not "code first" is even reasonable, yeah, which is a difficult question in itself and only partially tied in with making direct progress on FAI.
What are your thoughts on that post and its followup?
You seem to have missed Oracle AI? (Eliezer's dismissal of it isn't particularly meaningful.) I agree with your concerns. This is why the main focus would at least initially be determining whether or not "code first" is a plausible approach (difficulty-wise and safety-wise). The value of information on that question is incredibly high and as you've pointed out it has not been sufficiently researched.
What is this new non-profit planning to do differently from SIAI and why?
Basically everything. SingInst is focused on funding a large research program and gaining the prestige necessary to influence (academic) culture and academic and political policy. They're not currently doing any research on Friendly AI, and their political situation is such that I don't expect them to be able to do so effectively for a while, if ever. I will not clarify this. (Actually their research associates are working on FAI-related things, but SingInst doesn't pay them to do that.)
What are the other things that you could be doing?
Learning, mostly. Working with an unnamed group of x-risk-cognizant people that LW hasn't heard of, in a way unrelated to their setting up a non-profit.
Replies from: Wei_Dai, bgaesop↑ comment by Wei Dai (Wei_Dai) · 2011-08-22T17:16:07.852Z · LW(p) · GW(p)
They're not currently doing any research on Friendly AI, and their political situation is such that I don't expect them to be able to do so effectively for a while, if ever.
My understanding is that SIAI recently tried to set up a new in-house research team to do preliminary research into FAI (i.e., not try to build an FAI yet, but just do whatever research that might be eventually helpful to that project). This effort didn't get off the ground, but my understanding again is that it was because the researchers they tried to recruit had various reasons for not joining SIAI at this time. I was one of those they tried to recruit, and while I don't know what the others' reasons were, mine were mostly personal and not related to politics.
You must also know all this, since you were involved in this effort. So I'm confused why you say SIAI won't be doing effective research on FAI due to its "political situation". Did the others not join SIAI because they thought SIAI was in a bad political situation? (This seems unlikely to me.) Or are you referring to the overall lack of qualified, recruitable researchers as a "political situation"? If you are, why do you think this new organization would be able to do better?
(Or did you perhaps not learn the full story, and thought SIAI stopped this effort for political reasons?)
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-22T19:48:39.642Z · LW(p) · GW(p)
The answer to your question isn't among your list of possible answers. The recent effort to start an in-house research team was a good attempt and didn't fail for political reasons. I am speaking of other things. However I want to take a few weeks off from discussion of such topics; I seem to have given off the entirely wrong impression and would prefer to start such discussion anew in a better context, e.g. one that better emphasizes cooperation and tentativeness rather than reactionary competition. My apologies.
Replies from: Rain, Wei_Dai↑ comment by Rain · 2011-08-23T14:39:47.671Z · LW(p) · GW(p)
I was trying to quickly gauge vague interest in a vague notion.
I won't give that evidence here.
(I won't substantiate that claim here.)
I will not clarify this.
The answer to your question isn't among your list of possible answers.
I find this stressful; it's why I make token attempts to communicate in extremely abstract or indirect ways with Less Wrong, despite the apparent fruitlessness. But there's really nothing for it.
If you can't say anything, don't say anything.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-23T19:48:49.006Z · LW(p) · GW(p)
It's a good heuristic, but can be very psychologically difficult. E.g. if you think that not even trying to communicate will be seen as unjustified in retrospect even if people should know that there was no obvious way for you to communicate. This has happened enough to me that the thought of just giving up on communication is highly aversive; my fear of being blamed for not preventing others to take unjustified actions (that will cause me, them, and the universe counterfactually-needless pain) is too great. But whatever, I'm starting to get over it.
Like, I remember a pigeon dying... people dying... a girl who starved herself... a girl who cut herself... a girl who wanted to commit suicide... just, trust me, there are reasons that I'm afraid. I could talk about those reasons but I'd rather not. It's just, if you don't even make a token gesture it's like you don't even care at all, and it's easier to be unjustified in a way that can be made to look sorta like caring than in a way that looks like thoughtlessness or carelessness.
(ETA: A lot of the time when people give me or others advice I mentally translate it to "The solution is simple, just shut up and be evil.".)
↑ comment by Wei Dai (Wei_Dai) · 2011-08-23T18:13:41.536Z · LW(p) · GW(p)
I have no particular attachments to SIAI and would love to see a more effective Singularitarian organization formed if that were possible. I'm just having genuine trouble understanding why you think this new proposed organization will be able to do more effective FAI research. Perhaps you could use these few weeks off to ask some trusted advisors how to better communicate this point. (I understand you have sensitive information that you can't reveal, but I'm guessing that you can do better even within that constraint.)
Replies from: Will_Newsome, timtyler↑ comment by Will_Newsome · 2011-08-23T19:43:49.117Z · LW(p) · GW(p)
Perhaps you could use these few weeks off to ask some trusted advisors how to better communicate this point.
This is exactly the strategy I've decided to enact, e.g. talking to Anna. Thanks for being... gentle, I suppose? I've been getting a lot of flak lately, it's nice to get some non-insulting advice sometimes. :)
(Somehow I completely failed to communicate the tentativeness of the ideas I was throwing around; in my head I was giving it about a 3% chance that I'd actually work on helping build an organization but I seem to have given off an impression of about 30%. I think this caused everyone's brains to enter politics mode, which is not a good mode for brains to be in.)
↑ comment by timtyler · 2011-08-23T20:21:58.455Z · LW(p) · GW(p)
I have no particular attachments to SIAI and would love to see a more effective Singularitarian organization formed if that were possible.
It's rather strange how the SIAI is secretive. The military projects are secretive, the commercial projects are secretive alas: so few value transparency. An open project would surely do better, through being more obviously trustworthy and accountable, being better able to use talent across the internet, etc. I figure if the SIAI persists in not getting to grips with this issue, some other organisation will.
↑ comment by novalis · 2011-08-19T20:28:26.707Z · LW(p) · GW(p)
Well, looking at the post on SIAI finances from a few months back, SIAI's annual revenue is growing at a rate of roughly 100k/year, and thus would take nearly a century to reach 10 million / year. Of course, all sorts of things could change these numbers. Eliezer has stated that he believes that UFAI will happen somewhat sooner than a century.
Since SIAI does seem to have at least some unused budget for programmers now, I emailed a friend who might be a good fit for a research associate to suggest that he apply.
Replies from: Will_Sawin↑ comment by Will_Sawin · 2011-08-22T17:29:58.176Z · LW(p) · GW(p)
Even if past values are linear, exponential estimates are probably more clarifying.
↑ comment by Will_Newsome · 2011-08-19T17:00:24.480Z · LW(p) · GW(p)
(ETA: This isn't the right place for what I wrote.)
↑ comment by lessdazed · 2011-08-20T11:10:41.428Z · LW(p) · GW(p)
It seems to me that with continuing support, SIAI will be able to hire as many of the right programmers as we can find and effectively integrate into a research effort.
ADBOC. SIAI should never be content with any funding level. It should get the resources to hire, bribe or divert people who may otherwise make breakthroughs on UAI, and set them to doing anything else.
Replies from: MichaelVassar↑ comment by MichaelVassar · 2011-08-27T16:04:36.580Z · LW(p) · GW(p)
That intuition seems to me to follow from the probably false assumption that if behavior X would, under some circumstances, be utility maximizing, it is also likely to be utility maximizing to fund a non-profit to engage in behavior X. SIAI isn't a "do what seems to us to maximize expected utility" organization because such vague goals don't make for a good organizational culture. Organizing and funding research into FAI and research inputs into FAI, plus doing normal non-profit fund-raising and outreach, that's a feasible non-profit directive.
Replies from: lessdazed↑ comment by lessdazed · 2011-08-27T23:02:07.795Z · LW(p) · GW(p)
It also follows from the assumption that the claims in any comment submitted on August 20, 2011 are true. Yet I do not believe this.
I had, to the best of my ability, considered the specific situation when giving my advice.
Any advice can be dismissed by suggesting it came from a too generalized assumption.
If you thought someone was about to foom an unfriendly AI, you would do something about it, and without waiting to properly update your 501(c) forms.
comment by TobyBartels · 2011-08-20T12:42:00.543Z · LW(p) · GW(p)
I like this post, but I think that it suffers from two things that make it badly written:
Many times (starting with the title) the phrasing chosen suggests that you are attacking the basic decision-theoretic principle that one should the take the action with the highest expected utility (or give to the charity with the highest expected marginal value resulting from the donation). But you're not attacking this; you're attacking a way to incorrectly calculate expected utility by using only information that can be easily quantified and leaving out information that's harder to quantify. This is certainly a correct point, and a good one to make, but it's not the point that the title suggests, and many commenters have already been confused by this.
Pascal's mugging should be left out entirely. For one thing, it's a deliberately counterintuitive situation, so your point that we should trust our intuitions (as manifestations of our unquantifiable prior) doesn't obviously apply here. Furthermore, it's clear that the outcome of not giving the mugger money is not normally (or log-normally) distributed, with a decent chance of producing any value between 0 and 2X. In fact, it's a bimodal distribution with almost everything weighted at 0 and the rest weighted at X, with (even relative to the small amount at X) nothing at 2X or 1/2 X. This is also very unlike the outcome of donating to a charity, which I can believe is approximately log-normal. So all of the references to Pascal's mugging just confuse the main point.
Nevertheless, the main point is a good one, and I have voted this post up for it.
Replies from: Pr0methean, lukeprog, lessdazed↑ comment by Pr0methean · 2013-08-18T13:02:56.051Z · LW(p) · GW(p)
This is also very unlike the outcome of donating to a charity, which I can believe is approximately log-normal.
This can't be right, because log-normal variables are never negative, and charitable interventions do backfire (e.g. Scared Straight, or any health-care program that promotes quackery over real treatment) a non-negligible percentage of the time.
Replies from: TobyBartels↑ comment by TobyBartels · 2013-08-19T17:14:58.381Z · LW(p) · GW(p)
True.
↑ comment by lukeprog · 2011-08-23T03:16:23.535Z · LW(p) · GW(p)
Many times (starting with the title) the phrasing chosen suggests that you are attacking the basic decision-theoretic principle that one should the take the action with the highest expected utility (or give to the charity with the highest expected marginal value resulting from the donation). But you're not attacking this; you're attacking a way to incorrectly calculate expected utility by using only information that can be easily quantified and leaving out information that's harder to quantify.
Agree.
↑ comment by lessdazed · 2011-08-22T03:49:05.084Z · LW(p) · GW(p)
Upvoted for, among other things, valiantly fighting to preserve English by not using "upvoted" as a verb.
Replies from: TobyBartels↑ comment by TobyBartels · 2011-08-22T19:43:36.613Z · LW(p) · GW(p)
Indeed, I would only use it, as you possibly also did, as an adjective.
comment by MichaelVassar · 2011-08-19T14:17:49.120Z · LW(p) · GW(p)
I'm pretty sure that I endorse the same method you do, and that the "EEV" approach is a straw man.
It's also the case that while I can endorse "being hesitant to embrace arguments that seem to have anti-common-sense implications (unless the evidence behind these arguments is strong) ", I can't endorse treating the parts of an argument that lack strong evidence (e.g. funding SIAI is the best way to help FAI) as justifications for ignoring the parts that have strong evidence (e.g. FAI is the highest EV priority around). In a case like that, the rational thing to do is to investigate more or find a third alternative, not to go on with business as usual.
↑ comment by multifoliaterose · 2011-08-19T16:17:49.528Z · LW(p) · GW(p)
I'm pretty sure that I endorse the same method you do, and that the "EEV" approach is a straw man.
The post doesn't highlight you as an example of someone who uses the EEV approach and I agree that there's no evidence that you do so. That said, it doesn't seem like the EEV approach under discussion is a straw man in full generality. Some examples:
As lukeprog mentions, Anna Salamon gave the impression of using the EEV approach in one of her 2009 Singularity Summit talks.
One also sees this sort of thing on LW from time to time, e.g. [1], [2].
As Holden mentions, the issue came up in the 2010 exchange with Giving What We Can.
↑ comment by XiXiDu · 2011-08-19T16:02:21.013Z · LW(p) · GW(p)
I can't endorse treating the parts of an argument that lack strong evidence (e.g. funding SIAI is the best way to help FAI) as justifications for ignoring the parts that have strong evidence (e.g. FAI is the highest EV priority around). In a case like that, the rational thing to do is to investigate more or find a third alternative, not to go on with business as usual.
I agree with the first sentence but don't know if the second sentence is always true. Even if my calculations show that solving friendly AI will avert the most probable cause of human extinction, I might estimate that any investigations into it will very likely turn out to be fruitless and success to be virtually impossible.
If I was 90% sure that humanity is facing extinction as a result of badly done AI but my confidence that averting the risk is possible was only .1% while I estimated another existential risk to kill off humanity with a 5% probability and my confidence in averting it was 1%, shouldn't I concentrate on the less probable but solvable risk?
In other words, the question is not just how much evidence I have in favor of risks from AI but how certain I can be to mitigate it compared to other existential risks.
Could you outline your estimations of the expected value of contributing to the SIAI and that a negative Singularity can be averted as a result of work done by the SIAI?
Replies from: MichaelVassar, timtyler↑ comment by MichaelVassar · 2011-08-20T00:40:19.985Z · LW(p) · GW(p)
In practice, when I seen a chance to do high return work on other x-risks, such as synthetic bio, I do such work. It can't always be done publicly though. It doesn't seem likely at all to me that UFAI isn't a solvable problem, given enough capable people working hard on it for a couple decades, and at the margin it's by far the least well funded major x-risk, so the real question, IMHO, is simply what organization has the best chance of actually turning funds into a solution. SIAI, FHI or build your own org, but saying it's impossible without checking is just being lazy/stingy, and is particularly non-credible from someone who isn't making a serious effort on any other x-risk either.
↑ comment by timtyler · 2011-08-21T20:53:24.338Z · LW(p) · GW(p)
If I was 90% sure that humanity is facing extinction as a result of badly done AI but my confidence that averting the risk is possible was only .1% while I estimated another existential risk to kill off humanity with a 5% probability and my confidence in averting it was 1%, shouldn't I concentrate on the less probable but solvable risk?
I don't think so - assuming we are trying to maximise p(save all humans).
It appears that at least one of us is making a math mistake.
Replies from: saturn, CarlShulman↑ comment by CarlShulman · 2011-08-22T03:14:09.478Z · LW(p) · GW(p)
I don't think so - assuming we are trying to maximise p(save all humans).
Likewise. ETA: on what I take as the default meaning of "confidence in averting" in this context, P(avert disaster|disaster otherwise impending).
↑ comment by multifoliaterose · 2011-08-19T16:20:22.458Z · LW(p) · GW(p)
I can't endorse treating the parts of an argument that lack strong evidence (e.g. funding SIAI is the best way to help FAI) as justifications for ignoring the parts that have strong evidence (e.g. FAI is the highest EV priority around). In a case like that, the rational thing to do is to investigate more or find a third alternative, not to go on with business as usual.
Agree here. Do you think that there's a strong case for direct focus on the FAI problem rather than indirectly working toward FAI via nuclear deproliferation [1] [2]? If so I'd be interested in hearing more.
Replies from: MichaelVassar, lessdazed↑ comment by MichaelVassar · 2011-08-20T00:36:14.146Z · LW(p) · GW(p)
Given enough financial resources to actually endow research chairs and make a credible commitment to researchers, and given good enough researchers, I'd definitely focus SIAI more directly on FAI.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-20T00:55:29.076Z · LW(p) · GW(p)
I totally understand holding off on hiring research faculty until having more funding, but what would the researchers hypothetically do in the presence of such funding? Does anyone have any ideas for how to do Friendly AI research?
I think (but am not sure) that I would give top priority to FAI if I had the impression that there are viable paths for research that have yet to be explored (that are systematically more likely reduce x-risk than to increase x-risk), but I haven't seen a clear argument that this is the case.
↑ comment by lessdazed · 2011-08-20T10:56:20.483Z · LW(p) · GW(p)
"Nuclear proliferation" were not words I was expecting to see at the end of that sentence.
I don't see how nuclear war is an existential risk. It's not capable of destroying humanity, as far as I can tell, and would give more time to think and less ability to do with respect to AI. Someone could set cobalt bombs affixed to rockets in hidden silos and set them such that one explodes in the atmosphere every year for a thousand years or something, but I don't see how accidental nuclear war would end humanity outside of some unknown unknown sort of effect.
As far as rebuilding goes, I'm pretty confident it wouldn't be too hard so long as information survives, and I'm pretty confident it would. We don't need to build aircraft carriers, eat cows, and have millions of buildings with massive glass windows at 72 degrees, and we don't need to waste years upon years of productivity with school (babysitting for the very young and expensive signalling for young adults). Instead, we could try education, Polgar-sister style.
Replies from: multifoliaterose, Multiheaded↑ comment by multifoliaterose · 2011-08-20T18:54:34.575Z · LW(p) · GW(p)
See the pair of links in the grandparent, especially the ensuing discussion in the thread linked in [2].
Replies from: lessdazed↑ comment by lessdazed · 2011-08-20T20:32:40.839Z · LW(p) · GW(p)
A few words on my personal theory of history.
Societies begin within a competitive environment in which only a few societies survive, namely those involving internal cooperation to get wealth. The wealth can be produced, exploited, realized through exchange, and/or taken outright from others. As the society succeeds, it grows, and the incentive to cheat the system of cooperation grows. Mutual cooperation decays as more selfish strategies become better and better - also attitudes towards outgroups soften from those that had led to ascendance. Eventually a successful enough society will have wealth, and contain agents competing over its inheritance rather than creating new wealth, and people will move away from social codes benefiting the society to those benefiting themselves or towards similar luxuries like believing things because they are true rather than useful.
Within this model I see America as in a late stage. The education system is a wasteful signalling game because so much wealth is in America that fighting for a piece of the pie is a better strategy than creating wealth. Jingoism is despised, there is no national religion, history, race, or idea uniting Americans. So I see present effort as scarcely directed towards production at all. Once GNP was thought the most important economic statistic, now it is GDP. The ipad is an iconic modern achievement, like other products, it is designed so consumers can be as ignorant as possible. Nothing like it needs to be produced - all the more so reality TV, massive sugar consumption and health neglect, etc.
A new society would begin in a productive, survivalist mode, but with modern technology. Instead of producing Wiis and X-Boxes, I think a post nuclear society would go from slide rules to mass transit and solar power in no time, even with a fraction of the resources, as it would begin with our information but have an ethic from its circumstances. The survivalist, cooperative, productive public ethos would be exhibited fully during an internet age, rather than after having been decaying logarithmically for so long.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2011-08-21T14:17:18.429Z · LW(p) · GW(p)
I find this quite fascinating. Thanks for your perspective!
↑ comment by Multiheaded · 2011-08-20T13:38:44.723Z · LW(p) · GW(p)
How interesting. So you're arguing that killing off, say, half a billion people and disrupting social structures with a non-existentially-dangerous global catastrophe is the rational thing to do?
Replies from: lessdazed↑ comment by lessdazed · 2011-08-20T14:42:23.308Z · LW(p) · GW(p)
Not at all. Most bad things aren't existential risks.
Bad things are not vulnerable to every argument, nor are they bad because they make absolutely every metric of negativity worse, but because on balance they make things worse. Good things are not validly supported by every possible argument, nor are they good because they improve absolutely everything, but because they are on balance good.
Nuclear war isn't bad because it alters the laws of physics to make atmospheric nitrogen turn into Pepsi. Nor is it bad because it is an existential risk. It has little to do with either of those things.
Preventing nuclear war isn't good because it's a D&D quest where satisfying certain conditions unlocks a bag of holding that solves all landfill problems forever. There isn't such a quest. Preventing nuclear war is still a good idea.
Arguments in favor of preventing nuclear war mostly fail, just like arguments for any conclusion. You can't get away with writing a warm and fuzzy conclusion such as "prevent nuclear war" as your bottom line and expect everyone to just buy whatever argument you construct ostensibly leading to that conclusion.
Replies from: Multiheaded↑ comment by Multiheaded · 2011-08-20T15:29:59.701Z · LW(p) · GW(p)
Your comment's wording could use some work then IMO.
Replies from: lessdazed↑ comment by lessdazed · 2011-08-20T16:02:53.209Z · LW(p) · GW(p)
I don't disagree.
However, I feel like I have done my part (even if I don't fully think I have done my part) in maintaining a high level of discourse so long as my tone is at least somewhat less snarky/more civil than what I am responding to. It's perhaps a way of rationalizing doing more or less what I want to do more or less whenever I want to do it; pretending to have the tone high ground as if it were something binary or perhaps tertiary, with one participant in the conversation or the other or neither having it, with how much better one is than the other counting for little.
I blame scope insensitivity!
Yet I would like to think that two of me conversing wold always be civil, what with each trying to be at least a bit more civil than the other. The system I feel is right isn't so bad.
The obvious weakness would be misjudging intended and perceived levels of snark...
So. Upvoted.
comment by Bongo · 2011-08-18T18:48:44.685Z · LW(p) · GW(p)
Thus, when aiming to maximize expected positive impact, it is not advisable to make giving decisions based fully on explicit formulas.
I love that you don't seem to argue against maximizing EV, but rather to argue that a certain method, EEV, is a bad way to maximize EV. If this was stated at the beginning of the article I would have been a lot less initially skeptical.
comment by Nick_Beckstead · 2011-08-20T01:10:01.939Z · LW(p) · GW(p)
Here's what I think is true and important about this post: some people will try to explicitly estimate expected values in ways that don't track the real expected values, and when they do this, they'll make bad decisions. We should avoid these mistakes, which may be easy to fall into, and we can avoid some of them by using regressions of the kind described above in the case of charity cost-effectiveness estimates. As Toby points out, this is common ground between GiveWell and GWWC. Let me list a what I take to be a few points of disagreement.
I think that after making an appropriate attempt to gather evidence, the result of doing the best expected value calculation that you can is by far the most important input into a large scale philanthropic decision. We should think about the result of the calculation makes sense, we should worry if it is wildly counterintuitive, and we should try hard to avoid mistakes. But the result of this calculation will matter more than most kinds of informal reasoning, especially if the differences in expected value are great. I think this will be true for people who are competent with thinking in terms of subjective probabilities and expected values, which will rule out a lot of people, but will include a lot of the people who would consider whether to make important philanthropic decisions on the basic of expected value calculations.
I think this argument unfairly tangles up making decisions explicitly on the basis of expected value calculations with Pascal’s Mugging. It’s not too hard to choose a bounded utility function that doesn’t tell you to pay the mugger, and there are independent (though not clearly decisive) reasons to use a bounded utility function for decision-making, even when the probabilities are stable. Since the unbounded utility function assumption can shoulder the blame, the invocation of Pascal's Mugging doesn't seem all that telling. (Also, for reasons Wei Dai gestures at I don't accept Holden's conjecture that making regression adjustments will get us out of the Pascal's Mugging problem, even if we have unbounded utility functions.)
Though I agree that intuition can be a valuable tool when trying to sanity check an expected value calculation, I am hesitant to rely too heavily on it. Things like scope insensitivity and ambiguity aversion could easily make me unreasonably queasy about relying a perfectly reasonable expected value calculation.
Finally, I classify several of the arguments in this post as “perfect world” arguments because they involve thinking a lot about what would happen if everyone behaved in a certain kind of way. I don’t want to rest too much weight on these arguments because my behavior doesn’t causally or acausally affect the way enough people would behave in order for these arguments to be directly relevant to my decisions. Even if I accepted perfect world arguments, some of these arguments appear not to work. For example, if all donors were rational altruists, and that was common knowledge, then charities that were effective would have a strong incentive to provide evidence of their effectiveness. If some charity refused to share information, that would be very strong evidence that the charity was not effective. So it doesn't seem to be true, as Holden claims, that if everyone was totally reliant on explicit expected value calculations, we’d all give to charities about which we have very little information. (Deciding not to be totally transparent is not such good evidence now, since donors are far from being rational altruists.)
Though I have expressed mostly disagreement, I think Holden's post is very good and I'm glad that he made it.
Replies from: Nick_Beckstead, TruePath↑ comment by Nick_Beckstead · 2011-08-20T01:24:44.993Z · LW(p) · GW(p)
On a more positive note, Holden and Dario's research on this issue gave me a much better understanding about how the regression would work and how it could suggest that GWWC should be putting more emphasis on evaluating individual charities, relative to relying on (appropriately adjusted) cost-effectiveness estimates.
↑ comment by TruePath · 2011-08-30T07:29:03.368Z · LW(p) · GW(p)
Demanding a bounded utility function seems like a horrible idea. For starters it violates our expectation of independence for causally isolated universes. In other words the utility of both universe A and B existing isn't the sum of the utility of A existing and B existing.
Besides, intuitively if you were really offered with perfect confidence a bet with a 99.99...90% chance of winning you a dollar but if you lose all the souls in the world will burn in hell forever do you really think it would be a worthwhile bet to take?
What is bad about Pascal's mugging isn't the existence of arbitrarily bad outcomes, it's the existence of arbitrarily bad expectations. What we really want is that the integral of utility relative to the probability measure is never infinite. This is a much more reasonable condition. In other words utility should be L1 integrabale with respect to your prior probability distribution (and as long as you never condition on events of probability 0 this property persists).
Replies from: wedrifid, Nick_Beckstead↑ comment by wedrifid · 2011-08-30T13:35:35.164Z · LW(p) · GW(p)
Besides, intuitively if you were really offered with perfect confidence a bet with a 99.99...90% chance of winning you a dollar but if you lose all the souls in the world will burn in hell forever do you really think it would be a worthwhile bet to take?
Just how many nines do those ellipses represent? That's kind of important! I mean, if there is enough nines then the value of the dollar easily outweighs the risk and your intuition is deceiving you. Consider for example:
Given the information I currently have there is some non zero chance that I am wrong about the origin of the universe. It could be that there really is a God that will punish us with eternity in hell if we have the wrong belief about Him. A friendly superintelligence has a reasonable chance of figuring this out for us and telling us the Good News. Me having an extra dollar produces a non-zero increase in the probability that we create an AI. Multiplying non-zero chances together gives other nonzero chances. For any given probability of eternities in hell there is a number of nines such that (100 - 99.99#{n * "9"}90)% is a lower probability of eternities in hell.
Moral of this story: Be careful when throwing not-quite-infinities around to prove a point. Not-quite-infinities @#$% things up almost as much as infinities.
↑ comment by Nick_Beckstead · 2011-08-30T13:11:07.470Z · LW(p) · GW(p)
Besides, intuitively if you were really offered with perfect confidence a bet with a 99.99...90% chance of winning you a dollar but if you lose all the souls in the world will burn in hell forever do you really think it would be a worthwhile bet to take?
While I genuinely appreciate how implausible it is to consider that bet worthwhile, there is a flipside. See the The LIfespan Dilemma. The point is that people have inconsistent preferences here, so it is easy to find intuitive counterexamples to any position one could take. I find the bounded approach to be the least of all evils.
What is bad about Pascal's mugging isn't the existence of arbitrarily bad outcomes, it's the existence of arbitrarily bad expectations. What we really want is that the integral of utility relative to the probability measure is never infinite.
It is actually pretty hard to achieve this. Consider a sequence of lives L1, L2, etc. such that (i) the temporary quality of each life increases over time in each life, and increases at the same rate, (ii) the duration of the lives in the sequence is increasing and approaching infinity, (iii) the utility of each lives in the sequence is approaching infinity. And now consider an infinitely long life L whose temporary quality increases at the same rate as L1, L2, etc. Plausibly, L is better than L1, L2, etc. This means L has a value which exceeds any finite value, and it means you will take any chance of L, no matter how small, to any of the Li, no matter how certain it would be. When choosing among different available actions which may lead to some of these lives, you would, in practice, consider only the chance of getting an infinitely long life, turning to other considerations only to break ties. Upshot: weak background assumptions + unbounded utility function --> obsessing over infinities, neglecting finite considerations except to break ties.
To be clear, the background assumptions are: that L, L1, L2, etc. are alternatives you could reasonably have non-zero probability in; that L is better than L1, L2, etc.; normal axioms of decision theory.
(You may also consider a variation of this argument involving histories of human civilization, rather than lives.)
comment by orthonormal · 2011-08-19T00:59:04.372Z · LW(p) · GW(p)
The majority of the work that this adjustment does is due to the assumption that an action with high variance is practically as likely to greatly harm as to greatly help, and thus the long positive tail is nearly canceled out by the long negative tail. For some Pascal's Muggings (like the original Wager), this may be valid, but for others it's not.
If Warren Buffett offers to play a hand of poker with you, no charge if he wins and he gives you a billion if he loses, some skepticism about the setup might be warranted- but to say "it would be better for me if we played for $100 of your money instead" seems preposterous. (Since in this case there's no negative tail, an adjustment based only on mean and variance is bound to screw up.)
Replies from: GuySrinivasan, handoflixue, cata, multifoliaterose↑ comment by SarahNibs (GuySrinivasan) · 2011-09-21T04:11:36.116Z · LW(p) · GW(p)
I don't think this is true. I think the majority of the work that the adjustment does is due to the assumption that high value actions are extraordinarily unlikely.
It's entirely possible that your expectation in situations when you think Buffett is offering $1b is smaller than your expectation in situations when you think Buffett is offering $100. Asking to switch to $100 from $1b misses the point, as by then whether you're facing a charlatan is probably locked in.
↑ comment by handoflixue · 2011-08-19T23:39:19.984Z · LW(p) · GW(p)
In the Warren Buffet situation, though, we have a high certainty. It's very unlikely that Warren Buffet will actually pay us $0 or $2,000,000.
The key bit of the article:
Replies from: orthonormalNow say that someone estimates that action A (e.g., giving in to the mugger's demands) has an expected value of X (same units) - but that the estimate itself is so rough that the right expected value could easily be 0 or 2X. More specifically, say that the error in the expected value estimate has a standard deviation of X.
↑ comment by orthonormal · 2011-08-20T01:49:23.216Z · LW(p) · GW(p)
...and an asteroid-prevention program is extremely likely to either do nothing or save the whole world. Modeling it with a normal distribution means pretending that it's almost as likely to cause billions of deaths (compared to the baseline of doing nothing) as it is to save billions of lives.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-20T02:02:29.017Z · LW(p) · GW(p)
•I think that the relevant distribution here is a log-normal distribution; this won't involve billions of deaths because it's strictly positive.
•Even if the outcome of an asteroid strike program is essentially binary there's still uncertainty as to how likely it will be successfully implemented, how likely it is to avert an asteroid strike assuming that it's implemented properly, and the likelihood of humanity surviving independently of the asteroid strike issue.
•An asteroid strike prevention program has the downside of diverting skilled labor. This may seem negligible by comparison with the upside, but the fact that the probability of impact is so small makes things less clear.
•At the level of the individual donor there's the issue of fungibility and counterfactuals (is funding an asteroid strike prevention program replacing dollars that someone else would otherwise have used to fund it? If so, what are they doing with the money instead? Is this use of money replacing that of a third person's dollars? If so, what is that third person doing instead? etc.)
These things all point in the direction of having the distribution of expected value attached to funding an asteroid strike prevention program being more diffuse than it may seem at first blush.
↑ comment by cata · 2011-08-19T13:37:26.650Z · LW(p) · GW(p)
I think that for the purposes of establishing a prior distribution of expectation, "playing poker with Warren Buffett" should be in a really different reference class than e.g. "playing poker with my buddies on Thursday." So in your example, I don't think that playing for a billion would actually be so many standard deviations out as to make it less positive than playing for a hundred.
↑ comment by multifoliaterose · 2011-08-19T01:15:35.317Z · LW(p) · GW(p)
Good thought experiment.
comment by John_Baez · 2011-08-19T05:38:23.214Z · LW(p) · GW(p)
For a related blog post see Bayesian Computations of Expected Utility over on Azimuth.
comment by Oscar_Cunningham · 2011-08-18T22:36:24.377Z · LW(p) · GW(p)
This post seems confused about utility maximisation.
It's possible for an argument to fail to consider some evidence and so mislead, but this isn't a problem with expected utility maximisation, it's just assigning an incorrect distribution for the marginal utilities. Overly formal analyses can certainly fail for real-world problems, but half-Bayesian ad-hoc mathematics won't help.
EDIT: The mathematical meat of the post is the linked-to analysis done by Dario Amodei. This is perfectly valid. But the post muddies the mathematics by comparing the unbiased measurement considered in that analysis with estimates of charities' worth. The people giving these estimates will have already used their own priors, and so you should only adjust their estimates to the extent to which your priors differ from theirs.
Replies from: lukeprog, multifoliaterose↑ comment by lukeprog · 2011-08-18T23:41:36.952Z · LW(p) · GW(p)
It's possible for an argument to fail to consider some evidence and so mislead, but this isn't a problem with expected utility maximisation, it's just assigning an incorrect distribution for the marginal utilities. Certainly overly formal analyses can fail for real-world problems, but half-Bayesian ad-hoc mathematics won't help.
This was exactly my initial reaction to Holden's post. But either myself or somebody else needs to explain this response in more detail.
↑ comment by multifoliaterose · 2011-08-18T23:33:52.581Z · LW(p) · GW(p)
This post seems confused about utility maximisation.
It's possible for an argument to fail to consider some evidence and so mislead, but this isn't a problem with expected utility maximisation, it's just assigning an incorrect distribution for the marginal utilities.
As Bongo noted, the post doesn't argue against expected utility maximization.
Certainly overly formal analyses can fail for real-world problems, but half-Bayesian ad-hoc mathematics won't help
This is along the lines of the final section of the post titled "Generalizing the Bayesian approach."
The people giving these estimates will have already used their own priors, and so you should only adjust their estimates to the extent to which your priors differ from theirs.
No. The people giving these estimates may be reasoning poorly and/or put insufficient time into thinking about the relevant issuesand consequently fail to fully utilize their Bayesian prior. (Of course, this characterization applies to everyone in some measure; it's a matter of degree).
comment by Wei Dai (Wei_Dai) · 2011-08-18T22:16:32.878Z · LW(p) · GW(p)
I was having trouble understanding the first example of EEV, until I read this part of Will Crouch's original comment:
We tend to assume, in the absence of other information, that charities are average at implementing their intervention, whereas you seem to assume that charities are bad at implementing their intervention, until you have been shown concrete evidence that they are not bad at implementing their intervention.
I agree this is wrong. They failed to consider that charities that are above average will tend to make information available showing that they are above average, so absence of information in this case is Bayesian evidence that a charity is below average. Relevant LW post: http://lesswrong.com/lw/ih/absence_of_evidence_is_evidence_of_absence/
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-18T23:06:20.855Z · LW(p) · GW(p)
What you say is true, but even after taking into account the point about absence of evidence being evidence of absence one still needs to Bayesian adjust on account of measurement errors giving rise to some charities' activities being overvalued and others being undervalued according to the measurements.
comment by RobinHanson · 2011-08-24T21:21:47.717Z · LW(p) · GW(p)
I respond to this post at Overcoming Bias
comment by Douglas_Knight · 2011-08-19T06:07:50.590Z · LW(p) · GW(p)
This seems so vague and abstract.
Let me suggest a concrete example: the existential risk of asteroid impacts. It is pretty easy to estimate the distribution of time till the next impact big enough to kill all humans. Astronomy is pretty well understood, so it is pretty easy to estimate the cost of searching the sky for dangerous objects. If you imagine this as an ongoing project, there is the problem of building lasting organizations. In the unlikely event that you find an object that will strike in a year, or in 30, there is the more difficult problem of estimating the chance it will be dealt with.
It would be good to see your take on this example, partly to clarify this article and partly to isolate some objections from others.
Replies from: MichaelVassar, Will_Newsome, multifoliaterose↑ comment by MichaelVassar · 2011-08-19T14:22:34.788Z · LW(p) · GW(p)
This was, in fact, the first example I ever brought Holden. IMHO he never really engaged with it, but he did find it interesting and maintained correspondence which brought him to the FAI point. (all this long before I was formally involved with SIAI)
↑ comment by Will_Newsome · 2011-08-19T16:25:12.263Z · LW(p) · GW(p)
Astronomy is pretty well understood, so it is pretty easy to estimate the cost of searching the sky for dangerous objects.
Sort of. The possibility of mirror matter objects makes this pretty difficult. There's even a reasonable-if-implausible paper arguing that a mirror object caused the Tunguska event, and many other allegedly anomalous impacts over the last century. There's a lot of astronomical reasons to take this idea seriously, e.g. IIRC three times too many moon craters. There are quite a few solid-looking academic papers on the subject, though a lot of them are by a single guy, Foot. My refined impression was p=.05 for mirror matter existing in a way that's decision theoretically significant (e.g. mirror meteors), lower than my original impression because mirror matter in general has weirdly little academic interest. But so do a lot of interesting things.
Replies from: Douglas_Knight, John_Baez, wnoise, timtyler, gwern↑ comment by Douglas_Knight · 2011-08-19T17:32:05.809Z · LW(p) · GW(p)
Yes, you should compute the danger multiple ways, counting asteroids, craters, and extinction events. If there are 3x too many craters, then it may be that 2/3 of impacts are caused by objects that we can't detect. Giving up on solving the whole or even most of the problem may sound bad, but it just reduces the expected value by a factor of 3, which is pretty small in this context.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-19T20:22:51.890Z · LW(p) · GW(p)
True, true. I was partially just looking for an excuse to bring up mirror matter.
↑ comment by John_Baez · 2011-08-21T06:31:48.447Z · LW(p) · GW(p)
I studied particle physics for a couple of decades, and I would not worry much about "mirror matter objects". Mirror matter is just of many possibilities that physicists have dreamt up: there's no good evidence that it exists. Yes, maybe every known particle has an unseen "mirror partner" that only interacts gravitationally with the stuff we see. Should we worry about this? If so, we should also worry about CERN creating black holes or strangelets - more theoretical possibilities not backed up by any good evidence. True, mirror matter is one of many speculative hypotheses that people have invoked to explain some peculiarities of the Tunguska event, but I'd say a comet was a lot more plausible.
Asteroid collisions, on the other hand, are known to have happened and to have caused devastating effects. NASA currently rates the chances of the asteroid Apophis colliding with the Earth in 2036 at 4.3 out of a million. They estimate that the energy of such a collision would be comparable with a 510-megatonne thermonuclear bomb. This is ten times larger than the largest bomb actually exploded, the Tsar Bomba. The Tsar Bomba, in turn, was ten times larger than all the explosives used in World War II.
On the bright side, even if it hits us, Apophis will probably just cause local damage. The asteroid that hit the Earth in Chicxulub and killed off the dinosaurs released an energy comparable to a 240,000-megatonne bomb. That's the kind of thing that really ruins everyone's day.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-21T07:06:52.813Z · LW(p) · GW(p)
Mirror matter is indeed very speculative, but surely not less than 4.3 out of a million speculative, no? Mirror matter is significantly more worrisome than Apophis. I have no idea whether it's more or less worrisome than the entire set of normal-matter Apophis-like risks; does anyone have a link to a good (non-alarmist) analysis of impact risks for the next century? Snippets of Global Catastrophic Risks seem to indicate that they're not a big concern relatively speaking.
ETA: lgkglgjag anthropics messes up everything
↑ comment by wnoise · 2011-08-19T16:50:31.749Z · LW(p) · GW(p)
By "mirror matter", I assume you mean what is more commonly known as "anti-matter"?
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-19T17:07:39.995Z · LW(p) · GW(p)
No, mirror matter, what you get if parity isn't actually broken: http://scholar.google.com/scholar?hl=en&q=mirror+matter&btnG=Search&as_sdt=0%2C5&as_ylo=&as_vis=0 http://en.wikipedia.org/wiki/Mirror_matter
Replies from: wnoise↑ comment by wnoise · 2011-08-19T17:25:24.489Z · LW(p) · GW(p)
Huh. Glad I asked.
My initial impression is that the low interaction rate with ordinary matter would make me think this would not be a good explanation for anomalous impacts. But I obviously haven't examined this in anywhere near enough detail.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-19T21:49:48.683Z · LW(p) · GW(p)
See elsewhere in the thread. E.g. http://arxiv.org/abs/hep-ph/0107132
Replies from: wnoise↑ comment by timtyler · 2011-08-23T19:40:15.726Z · LW(p) · GW(p)
Astronomy is pretty well understood, so it is pretty easy to estimate the cost of searching the sky for dangerous objects.
Sort of. The possibility of mirror matter objects makes this pretty difficult. There's even a reasonable-if-implausible paper arguing that a mirror object caused the Tunguska event, and many other allegedly anomalous impacts over the last century. There's a lot of astronomical reasons to take this idea seriously, e.g. IIRC three times too many moon craters.
Reality check: mirror matter has a gravitational signature - so we know some 99% of non-stellar matter in the solar system is not mirror matter - or we would see its grav-sig. So: we can ignore it with only a minor error.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-08-23T19:44:26.257Z · LW(p) · GW(p)
Dark matter.
Replies from: timtyler↑ comment by gwern · 2011-08-19T17:42:25.771Z · LW(p) · GW(p)
Reading the Wikipedia article, I don't really see how mirror matter would be dangerous. It describes them as being about as dangerous as neutrinos or something:
Replies from: Will_NewsomeMirror matter, if it exists, would have to be very weakly interacting with ordinary matter. This is because the forces between mirror particles are mediated by mirror bosons. With the exception of the graviton, none of the known bosons can be identical to their mirror partners. The only way mirror matter can interact with ordinary matter via forces other than gravity is via so-called kinetic mixing of mirror bosons with ordinary bosons or via the exchange of Holdom particles.[10] These interactions can only be very weak. Mirror particles have therefore been suggested as candidates for the inferred dark matter in the universe
↑ comment by Will_Newsome · 2011-08-19T17:44:02.065Z · LW(p) · GW(p)
Read the papers, Wikipedia is Wikipedia. Kinetic mixing can be strong. The paper on Tunguska is really quite explanatory. (Sorry, I don't mean to be brusque, I'm just allergic to LW at the moment.) ETA: http://arxiv.org/abs/astro-ph/0309330 is the most cited one I think. ETA2 (after gwern replied): Most cited paper about mirror matter implications, not about Tunguska. See here for Tunguska: http://arxiv.org/abs/hep-ph/0107132
Replies from: gwern↑ comment by gwern · 2011-08-19T18:07:32.661Z · LW(p) · GW(p)
The part on Tunguska doesn't really explain it though, but simply assumes a mirror matter object could do that and then spends more time on how the mirror matter explains the lack of observed fragments and how remaining mirror matter could be detected. The one relevant line seems to be
"If this impact event is due to a (pure) mirror matter body, it should not have slowed down as rapidly in the atmosphere as an ordinary matter body (for ǫ ∼ 10−8 − 10−9 as suggested by DAMA/NaI results, the air molecules typically pass through the body losing only a relatively small fraction of their momentum^36^)."
It must be explained elsewhere or the implications of 'ǫ ∼ 10−8 − 10−9' be obvious to a physicist. How annoying...
Replies from: Will_Newsome, Will_Newsome↑ comment by Will_Newsome · 2011-08-19T18:13:02.295Z · LW(p) · GW(p)
Here you go: http://arxiv.org/abs/hep-ph/0107132
Replies from: gwernAbstract: Mirror matter is predicted to exist if parity (i.e. left-right symmetry) is a symmetry of nature. Remarkably mirror matter is capable of simply explaining a large number of contemporary puzzles in astrophysics and particle physics including: Explanation of the MACHO gravitational microlensing events, the existence of close-in extrasolar gas giant planets, apparently ‘isolated’ planets, the solar, atmospheric and LSND neutrino anomalies, the orthopositronium lifetime anomaly and perhaps even gamma ray bursts. One fascinating possibility is that our solar system contains small mirror matter space bodies (asteroid or comet sized objects), which are too small to be revealed from their gravitational effects but nevertheless have explosive implications when they collide with the Earth. We examine the possibility that the 1908 Tunguska explosion in Siberia was the result of the collision of a mirror matter space body with the Earth. We point out that if this catastrophic event and many other similar smaller events are manifestations of the mirror world then these impact sites should be a good place to start digging for mirror matter. Mirror matter could potentially be extracted & purified using a centrifuge and have many useful industrial applications.
↑ comment by gwern · 2011-08-19T19:11:25.604Z · LW(p) · GW(p)
OK, I think that explains that - Wikipedia is making the first assumption identified below, rather than the other one that he prefers:
Replies from: Will_Newsome"If the only force connecting mirror matter with ordinary matter is gravity, then the consequences would be minimal. The mirror SB would simply pass through the Earth and nobody would know about it unless it was so heavy as to gravitationally affect the motion of the Earth.
However if there is photon - mirror photon kinetic mixing as suggested by the orthopositronium vacuum cavity experiment, then the mirror nuclei (with Z ′ mirror protons) will effectively have a small ordinary electric charge ǫZ ′ e. This means that the nuclei of the mirror atoms of the SB will undergo Rutherford scattering off the nuclei of the atmospheric nitrogen and oxygen atoms. In addition ionizing interactions can occur which can ionize both the mirror atoms of the space body and also the atmospheric atoms. The net effect is that the kinetic energy of the SB is transformed into light and heat (both ordinary an mirror varieties) and a component is also converted to the atmosphere in the form of a shockwave, as the forward momentum of the SB is transferred to the air which passes though or near the SB.
What happens to the mirror matter SB as it plummets towards the Earth’s surface depends on a number of factors such as its initial velocity, size, chemical composition and angle of trajectory. Of course all these uncertainties occur for an ordinary matter SB too. Interestingly it turns out that for the value of the kinetic mixing suggested by the Or- thopositronium experiment, ǫ ≈ 10−6, the air resistence of a mirror SB in the atmosphere is roughly the same as an ordinary SB assuming the same trajectory, velocity mass, size and shape (and that it remains intact). This occurs because the air molecules will lose their relative forward momentum (with respect to the SB) within the SB itself because of the Rutherford scattering of the ordinary and mirror nuclei as we will show in a moment. (Of course the atmospheric atoms still have random thermal motion). This will lead to a drag force of roughly the same size as that on an ordinary matter SB, implying an energy loss rate ....
The above calculation shows that the rate of energy loss of the SB in the atmosphere depends on its size and density. If we assume a density of ρSB ≃ 1 g/cm3 which is approximately valid for a mirror SB made of cometary material (such as mirror ices of water, methane and/or ammonia) then the body will lose most of its kinetic energy in the atmosphere provided that it is less than roughly 5 meters in diameter. Of course things are complicated because the the SB will undergo mass loss (ablation) and also potentially fragment into smaller pieces and of course potentially melt & vaporize. Thus even a very large body (e.g. R ∼ 100 meters as estimated for the Tunguska explosion) can lose its kinetic energy in the atmosphere if it fragments into small pieces.
...Returning to the most interesting case of large photon - mirror photon kinetic mixing, ǫ ≃ 10−6 which is indicated by the orthopositronium experiment, our earlier calculation suggests that most of the kinetic energy of a mirror matter SB is released in the atmosphere like an ordinary matter SB if it is not too big (∼ 5 meters) or fragments into small objects. It seems to be an interesting candidate to explain the 1908 Tunguska explosion (as well as smaller similar events as we will discuss in a moment).
↑ comment by Will_Newsome · 2011-08-19T21:50:10.724Z · LW(p) · GW(p)
OK, I think that explains that - Wikipedia is making the first assumption identified below
No, Wikipedia mentions kinetic mixing then says that if it exists it must be weak, Wikipeda doesn't say it wouldn't exist (the evidence suggests it would exist). The Wikipedia article is just wrong. (ETA: I mean, it is just wrong to assume that it's weak.) (Unless I'm misinterpreting what you mean by "the first assumption identified below"?)
Replies from: gwern↑ comment by Will_Newsome · 2011-08-19T18:11:49.036Z · LW(p) · GW(p)
There's a paper dedicated to Tunguska specifically that has tons of details, I'll try to find it again. I'll reply to your comment again once I do.
↑ comment by multifoliaterose · 2011-08-19T16:44:47.777Z · LW(p) · GW(p)
Let me suggest a concrete example: the existential risk of asteroid impacts. [...]
Sure, so according to the Bayesian adjustment framework described in the article, in principle the thing to do would be to create a 95% confidence interval as to the impact of an asteroid strike prevention effort, use this to obtain a variance attached to the distribution of impact associated with the asteroid strike prevention effort, and then Bayesian regress. As you comment, some of the numbers going into the cost-effectiveness calculation are tightly constrained in value account of being well understood and others are not. The bulk of the variance would come from the numbers which are not tightly constrained.
But as Holden suggests in the final section of the post titled "Generalizing the Bayesian approach" probably a purely formal analysis should be augmented by heuristics.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2011-08-19T18:05:43.357Z · LW(p) · GW(p)
Saying "Yes, I can apply this framework to concrete examples," does not actually make anything more concrete.
Did Holden ever do the calculation or endorse someone else's calculation? What heuristic did he use to reject the calculation? "Never pursue a small chance of a large effect"? "Weird charities don't work"?
If you calculate that this is ineffective or use heuristics to reject the calculation, I'd like to see this explicitly. Which heuristics?
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T18:14:07.641Z · LW(p) · GW(p)
Did Holden ever do the calculation or endorse someone else's calculation? What heuristic did he use to reject the calculation? "Never pursue a small chance of a large effect"? "Weird charities don't work"?
Which calculation are you referring to? In order to do a calculation one needs to have in mind a specific intervention, not just "asteroid risk prevention" as a cause.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2011-08-19T19:19:06.941Z · LW(p) · GW(p)
Before worrying about specific interventions, you can compute an idealized version as in, say, the Copenhagen Consensus. There are existing asteroid detection programs. I don't know if any of them take donations, but this does allow assessments of realistic organizations. At some level of cost-effectiveness, you have to consider other interventions, like starting your own organization or promoting the cause. Not having a list of interventions is no excuse for not computing the value of intervening.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T19:54:13.344Z · LW(p) · GW(p)
I would guess that it's fairly straightforward to compute the cost-effectiveness of an asteroid strike reduction program to within an order of magnitude in either direction.
The situation becomes much more complicated with assessing the cost-effectiveness of something like a "Friendly AI program" where the relevant issues are so much more murky than the issues relevant to asteroid strike prevention.
GiveWell is funded by a committed base of donors. It's not clear to me that these donors are sufficiently interested in x-risk reduction so that they would fund GiveWell if GiveWell were to focus on finding x-risk reduction charities.
I think that it's sensible for GiveWell to have started by investigating the cause of international health. This has allowed them to gain experience, credibility and empirical feedback which has strengthened the organization.
Despite the above three points I share your feeling that at present it would be desirable for GiveWell to put more time into studying x-risks and x-risk reduction charities. I think that they're now sufficiently established so that at the margin they could do more x-risk related research while simultaneously satisfying their existing constituents.
Concerning the issue of asteroid strike risk in particular, it presently looks to me as though there are likely x-risk reduction efforts which are more cost effective; largely because it seems as though people are already taking care of the asteroid strike issue. See Hellman's article on nuclear risk and this article from Pan-STARRS (HT wallowinmaya). I'm currently investigating the issue of x-risk precipitated by nuclear war & what organizations are working on nuclear nonproliferation.
↑ comment by Douglas_Knight · 2011-08-19T22:08:27.931Z · LW(p) · GW(p)
Sure, but my comment is not about what GiveWell or anyone should do in general, but in the context of this article: Holden is engaging with x-risk and trying to clarify disagreement, so let's not worry if or when he should (and he has made many other comments about it over the years). I think it would be better to do so concretely, rather than claiming that vague abstract principles lead to unspecified disagreements with unnamed people. I think he would better convey the principles by applying them. I'm not asking for 300 hours of asteroid research, just as much time as it took to write this article. I could be wrong, but I think a very sloppy treatment of asteroids would be useful.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T22:43:59.476Z · LW(p) · GW(p)
The article has relevance to thinking about effective philanthropy independently of whether one is considering x-risk reduction charities. I doubt that it was written exclusively with x-risk in mind
I can't speak for Holden here but I would guess that to the extent that he wrote the article with x-risk in mind, he did so to present a detailed account of an important relevant point which he can refer to in the future so as to streamline subsequent discussions without sacrificing detail and clarity.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2011-08-19T23:55:41.654Z · LW(p) · GW(p)
So he could have written a concrete account of the disagreement with Deworm the World. The only concrete section was on BeerAdvocate and that was the only useful section. Pointing to the other sections in the future is a sacrifice of detail and clarity.
comment by novalis · 2011-08-18T17:30:18.257Z · LW(p) · GW(p)
How Not To Sort By Average Ranking explains how you should actually choose which restaurant to go to. BeerAdvocate's method is basically a hack, with no general validity. Why is the minimum number of review ten? That number should in fact depend on the variance of reviews, I think.
Replies from: saturn, Sniffnoy↑ comment by saturn · 2011-08-18T20:21:16.931Z · LW(p) · GW(p)
This is the frequentist answer to the same question. Cue standard bayesian vs. frequentist debate.
Of course, you're right that BeerAdvocate could get more accurate rankings with a more fine-tuned prior, but other than that I don't see what's wrong with their method.
Replies from: RobinZ, novalis↑ comment by RobinZ · 2011-08-31T22:47:46.905Z · LW(p) · GW(p)
I think the "basically a hack" argument isn't entirely without merit in this case, bayesian or frequentist - from what is said in the article, BeerAdvocate chose m without a lot of attention to:
frequentist hat: the relative rate of Type I and Type II errors.
Bayesian hat: the relative probability of a rating increasing versus decreasing with the addition of more reviews.
↑ comment by novalis · 2011-08-18T20:34:00.294Z · LW(p) · GW(p)
Well, that's just the entire point of this LW post -- what prior to choose matters a lot. It even matters specifically in the case of BeerAdvocate, who apparently got appreciably different results from changing their value of 10 reviews.
Replies from: saturn↑ comment by saturn · 2011-08-18T20:42:22.729Z · LW(p) · GW(p)
And the solution you suggest is to just go with p=0.05 and pretend this problem isn't unavoidable, right?
Replies from: novalis↑ comment by novalis · 2011-08-18T21:26:19.959Z · LW(p) · GW(p)
I think I specifically said that variance matters. I'll also say that your application matters -- when choosing beers, I would be OK with p much worse than 0.05 since I can afford to order another beer. When choosing charities, it is a harder question.
↑ comment by Sniffnoy · 2011-08-18T19:04:49.533Z · LW(p) · GW(p)
Of course, the use of the parameter .95 is pretty arbitrary as well. :)
Replies from: handoflixue↑ comment by handoflixue · 2011-08-18T19:47:40.902Z · LW(p) · GW(p)
P = 0.05 is the standard value for "statistically significant" in science articles, so it's actually not that arbitrary. The website does also explain how to adjust for a different statistical certainty if desired :)
Replies from: wnoise↑ comment by wnoise · 2011-08-18T20:59:05.040Z · LW(p) · GW(p)
That's precisely why it is arbitrary -- it's a cultural artifact, not an inherently meaningful level.
Replies from: AShepard, handoflixue↑ comment by AShepard · 2011-08-19T06:01:22.116Z · LW(p) · GW(p)
but because it is the standard value, you can be more confident that they didn't "shop around" for the p value that was most convenient for the argument they wanted to make. It's the same reason people like to see quarterly data for a company's performance - if a company is trying to raise capital and reports its earnings for the period "January 6 - April 12", you can bet that there were big expenses on January 5 and April 13 that they'd rather not include. This is much less of a worry if they are using standard accounting periods.
Replies from: michaelsullivan, wnoise↑ comment by michaelsullivan · 2011-08-19T22:21:54.496Z · LW(p) · GW(p)
It's still a pretty significant worry. If you know that some fiscal quarter or year will be used to qualify you for something important, it is often possible to arrange for key revenue and expenses to move around the boundaries to suit what you wish to portray in your report.
↑ comment by handoflixue · 2011-08-18T21:46:14.149Z · LW(p) · GW(p)
What would an "inherently meaningful" confidence level look like?
Replies from: RobinZ, wnoise, Sniffnoy↑ comment by RobinZ · 2011-12-27T21:43:15.236Z · LW(p) · GW(p)
necroreply: Back up to the actual use of the data, which is identification of tasty beers - an "inherently meaningful" confidence level is one which provides the most useful recommendations to the end user. This is reflected in the way the post describes BeerAdvocate changing their system - they had their confidence level set so high that only extremely popular beers could move significantly away from the average, and they concluded that this was reducing the value of their ratings.
Replies from: handoflixue↑ comment by handoflixue · 2012-01-12T23:27:12.621Z · LW(p) · GW(p)
Fair, but I think capturing that is possibly beyond the scope of their article. If you can come up with a good way to evaluate that beyond gut instinct and vague heuristics on how a specific data set "ought" to behave/look, I would love to hear it - it's been an area I've had trouble with before :)
Replies from: RobinZ↑ comment by RobinZ · 2012-01-13T02:55:06.464Z · LW(p) · GW(p)
I can think of two possibilities right off the bat - there are probably others (customer satisfactions surveys?) that I'm not thinking of that would work:
Measure the ability of the scoring rubric to correlate with trusted expert rankings.
Measure the ability of the scoring rubric to predict future votes.
(Of course, 2 has the problem that it is basically measuring the variable that Bayesians maximize...)
Replies from: handoflixue↑ comment by handoflixue · 2012-01-19T00:20:17.414Z · LW(p) · GW(p)
Item 1 would only seem useful when you have sufficient trusted expert ranking to calibrate, but still need to use the votes to extrapolate elsewhere (and where you expect trusted experts to align with your audience - if experts routinely downvote dark ales, and your audience prefers them, you're going to get a wonky heuristic). Basically, at that point, you're JUST using votes as a method to try predicting and extrapolating expert rankings, and I'd expect there's usually better heuristics for that which don't require user votes.
Item 2 strikes me as clever and ideal, but I'd think you'd need quite a lot of data before you'd be able to actually calibrate that. So you're stuck using 0.05 until you have quite a lot of data.
(Customer satisfaction surveys, etc. also run in to the "resource intensive" issue)
(edit: apparently pound makes the whole row a header or something)
Replies from: RobinZ↑ comment by RobinZ · 2012-01-19T03:38:00.126Z · LW(p) · GW(p)
Item 1 would only seem useful when you have sufficient trusted expert ranking to calibrate, but still need to use the votes to extrapolate elsewhere [...]
Exactly. Remember, the whole point of this procedure is to tweak how much credibility you give to voters as a function of the number of voters you have - the only reason I mention experts is that they bypass the sample size problem.
(and where you expect trusted experts to align with your audience - if experts routinely downvote dark ales, and your audience prefers them, you're going to get a wonky heuristic)
Okay, that's a problem. I think it falls as a subset of the earlier problem of finding trusted expert rankings, however.
Item 2 strikes me as clever and ideal, but I'd think you'd need quite a lot of data before you'd be able to actually calibrate that. So you're stuck using 0.05 until you have quite a lot of data.
If you don't have a lot of data, you're not going to have much to offer your users anyway.
↑ comment by wnoise · 2011-08-18T22:04:32.065Z · LW(p) · GW(p)
I'm not sure there is one.
It seems to me that posterior probability density : confidence interval :: topographical map : contour . (Roughly, ignoring the important distinction between confidence intervals and credibility intervals.) They're useful summaries, but discard much information. Different choices of contours or confidence intervals may be more or less useful for particular problems.
Replies from: handoflixue↑ comment by handoflixue · 2011-08-18T22:10:30.402Z · LW(p) · GW(p)
It seems like the most useful rating system would be to show a topology, then? (which I know Amazon and NewEgg both do, but only when you've gone in to the details of a review).
For a simple one-value summary, it seems like this is probably a pretty good formula. You can, as mentioned, adjust the confidence if 95% gives you trouble with your data set.
It seems like "this is what scientific papers go with" is pretty sane as far as defaults go, and as "non-arbitrary" as a default value really could be.
↑ comment by Sniffnoy · 2011-08-18T22:39:05.961Z · LW(p) · GW(p)
I wouldn't expect there to be one -- though you could always use 1/2 -- but the original requirement is not for a confidence level but for a way of generating a total ordering. I.e. the arbitrariness is that you have a free parameter in the first place, not so much the choice of it. That's what makes it a free parameter, really!
comment by HoldenKarnofsky · 2011-08-29T16:31:00.270Z · LW(p) · GW(p)
Hello all,
Thanks for the thoughtful comments. Without responding to all threads, I'd like to address a few of the themes that came up. FYI, there are also interesting discussions of this post at The GiveWell Blog , Overcoming Bias , and Quomodocumque (the latter includes Terence Tao's thoughts on "Pascal's Mugging").
On what I'm arguing. There seems to be confusion on which of the following I am arguing:
(1) The conceptual idea of maximizing expected value is problematic.
(2) Explicit estimates of expected value are problematic and can't be taken literally.
(3) Explicit estimates of expected value are problematic/can't be taken literally when they don't include a Bayesian adjustment of the kind outlined in my post.
As several have noted, I do not argue (1). I do aim to give with the aim of maximizing expected good accomplished, and in particular I consider myself risk-neutral in giving.
I strongly endorse (3) and there doesn't seem to be disagreement on this point.
I endorse (2) as well, though less strongly than I endorse (3). I am open to the idea of formally performing a Bayesian adjustment, and if this formalization is well done enough, taking the adjusted expected-value estimate literally. However,
I have examined a lot of expected-value estimates relevant to giving, including those done by the DCP2 , Copenhagen Consensus , and Poverty Action Lab , and have never once seen a formalized adjustment of this kind.
I believe that often - particularly in the domains discussed here - formalizing such an adjustment in a reasonable way is simply not feasible and that using intuition is superior. This is argued briefly in this post, and Dario Amodei and Jonah Sinick have an excellent exchange further exploring this idea at the GiveWell Blog.
If you disagree with the above point, and feel that such adjustments ought to be done formally, then you do disagree with a substantial part of my post; however, you ought to find the remainder of the post more consequential than I do, since it implies substantial room for improvement in the most prominent cost-effectiveness estimates (and perhaps all cost-effectiveness estimates) in the domains under discussion.
All of the above applies to expected-value calculations that take relatively large amounts of guesswork, such as in the domain of giving. There are expected-value estimates that I feel are precise/robust enough to take literally.
Is it reasonable to model existential risk reduction and/or "Pascal's Mugging" using log-/normal distributions? Several have pointed out that existential risk reduction and "Pascal's Mugging" seem to involve "either-or" scenarios that aren't well approximated by log-/normal distributions. I wish to emphasize that I'm focused on the prior over expected value of one's actions and on the distribution of error in one's expected-value estimate. (The latter is a fuzzy concept that may be best formalized with the aid of concepts such as imprecise probability. In the scenarios under discussion, one often must estimate the probability of catastrophe essentially by making a wild guess with a wide confidence interval, leaving wide room for "estimate error" around the expected-value calculation.) Bayesian adjustments to expected-value estimates of actions, in this framework, are smaller (all else equal) for well-modeled and well-understood "either-or" scenarios than for poorly-modeled and poorly-understood "either-or" scenarios.
For both the prior and for the "estimate error," I think the log-/normal distribution can be a reasonable approximation, especially when considering the uncertainty around the impact of one's actions on the probability of catastrophe.
The basic framework of this post still applies, and many of its conclusions may as well, even when other types of probability distributions are assumed.
My views on existential risk reduction are outside the scope of this post. The only mention I make of existential risk reduction is to critique the argument that "charities working on reducing the risk of sudden human extinction must be the best ones to support, since the value of saving the human race is so high that 'any imaginable probability of success' would lead to a higher expected value for these charities than for others." Note that Eliezer Yudkowsky and Michael Vassar also appear to disapprove of this argument, so it seems clear that disputing this argument is not the same as arguing against existential risk reduction charities.
For the past few years we have considered catastrophic risk reduction charities to be lower on GiveWell's priority list for investigation than developing-world aid charities, but still relatively high on the list in the scheme of things. I've recently started investigating these causes a bit more, starting with SIAI (see LW posts on my discussion with SIAI representatives and my exchange with Jaan Tallinn). It's plausible to me that asteroid risk reduction is a promising area, but I haven't looked into it enough (yet) to comment more on that.
My informal objections to what I term EEV. Several have criticized the section of my post giving informal objections to what I term the EEV approach (by which I meant explicitly estimating expected value using a rough calculation and not performing a Bayesian adjustment). This section was intended only as a very rough sketch of what unnerves me about EEV; there doesn't seem to be much dispute over the more formal argument I made against EEV; thus, I don't plan on responding to critiques of this section.
Replies from: XiXiDu, Nick_Roy↑ comment by XiXiDu · 2011-08-29T19:36:14.767Z · LW(p) · GW(p)
With respect to charitable giving, do you have any advise for people who lack the math education to do their own calculations or to survey the available evaluations? Should one decide between Karnofsky and Yudkowsky solely based on one's intuition or postpone the decision and concentrate on acquiring the necessary background knowledge?
↑ comment by Nick_Roy · 2011-11-07T04:33:09.223Z · LW(p) · GW(p)
Why not use several different methodologies on GiveWell, instead of just one, since there is some disagreement over methodologies? I can understand giving your favorite methodology top billing, of course (both because you believe it is best and it is your site and also to avoid confusion among donors), but there seems to be room for more than one.
comment by cousin_it · 2011-08-18T20:40:36.404Z · LW(p) · GW(p)
Interesting! But let's go back to the roots...
You're proposing to equip an agent with a prior over the effectiveness of its actions instead of (in addition to?) a prior over possible worlds. Will such an agent be Bayesian-rational, or will it exhibit weird preference reversals? If the latter, do you see that as a problem? If the former, Bayesian-rationality means the agent must behave as though its actions were governed only by some prior over possible worlds; what does that prior look like?
Replies from: Wei_Dai, multifoliaterose↑ comment by Wei Dai (Wei_Dai) · 2011-08-18T22:07:26.862Z · LW(p) · GW(p)
I see this post as suggesting a way to better approximate Bayesian rationality in practice (since full Bayesian rationality is known to be infeasible), and as such we can't require that agents implementing such an approximation not exhibit preference reversals.
What we can ask for, I think, is more or better justifications for the "design choices" in the approximation method.
Replies from: cousin_it↑ comment by cousin_it · 2011-08-18T23:07:40.904Z · LW(p) · GW(p)
Nooo. If someone wants to improve their Bayesian correctness, they will avoid "approximation methods" that advise against the clearly beneficial action of giving money to the mugger. I read the post as proposing a new ideal, not a new approximation.
Replies from: Strange7, Wei_Dai↑ comment by Strange7 · 2011-08-19T00:17:13.822Z · LW(p) · GW(p)
clearly beneficial action of giving money to the mugger.
If someone threatened to blow up the world with their magic powers unless I gave them a dollar, I'd say a better guess at the right thing to do would not be to pay them, but rather to kill them outright as quickly as possible. In the unlikely event that the mugger actually has such powers, I've just saved the world from an evil wizard with a very poor grasp of economics; otherwise, it's a valuable how-not-to story for the remaining con-artists and/or crazy people.
Replies from: Will_Newsome, None↑ comment by Will_Newsome · 2011-08-19T16:14:14.982Z · LW(p) · GW(p)
This is classic. "Should I give him a dollar, or kill him as quickly as possible? [insert abstract consequentialist reasoning.] So I think I'll kill him as quickly as possible."
↑ comment by [deleted] · 2011-08-19T16:24:47.068Z · LW(p) · GW(p)
I'm against killing crazy people, since I'm generally against killing people and other crazy people are not likely to be deterred.
Replies from: Strange7↑ comment by Strange7 · 2011-08-19T22:10:47.034Z · LW(p) · GW(p)
I'm not saying it's the best possible solution.
The mugger might also be a con artist, seeking to profit from fraudulent claims, in which case I have turned the dilemma on it's head: anyone considering a similar scam in the future would have to weigh the small chance of vast disutility associated with provoking the same reaction again.
Replies from: None↑ comment by [deleted] · 2011-08-20T14:27:26.774Z · LW(p) · GW(p)
Why not go with "Give him the dollar, then investigate further and take appropriate actions"? I think the mugger is more likely to be a crazy person than an incompetent con artist, and much, much likelier to be either than an evil wizard, so rather than not perfect, I would call your solution cruel-- most of the time you'll end up killing someone for being mentally ill. I guess I can understand why you think there ought to be a harsh punishment for threatening unimaginable skillions of people, but don't you still have that option if it turns out the mugger is reasonably sane?
Replies from: Strange7↑ comment by Strange7 · 2011-08-20T14:35:31.025Z · LW(p) · GW(p)
In more realistic circumstances, yes, I would most likely respond to someone attempting to extort trivial concessions with grandiose and/or incoherent threats by stalling for time and contacting the appropriate authorities.
Replies from: None↑ comment by [deleted] · 2011-08-20T14:41:28.644Z · LW(p) · GW(p)
But... isn't that what we're talking about? Did I miss some detail about the mugging that makes it impossible in real life, or something? In what way are the circumstances unrealistic?
Or do you mean you were just playing, and not seriously proposing this solution at all?
Replies from: Strange7↑ comment by Wei Dai (Wei_Dai) · 2011-08-19T03:18:07.662Z · LW(p) · GW(p)
I'm surprised and confused by your comment. People have proposed lots of arguments against giving in to Pascal's Mugging, even within the standard Bayesian framework. (The simplest, for example, is that we actually have a bounded utility function.) I don't see how you could possibly say at this point that giving in is "clearly" beneficial.
Replies from: cousin_it↑ comment by cousin_it · 2011-08-19T09:17:07.433Z · LW(p) · GW(p)
Err, the post assumes that we have an unbounded utility function (or at least that it can reach high enough for Pascal's mugging to become relevant), and then goes on to propose what you call an approximation method that looks clearly wrong for that case.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T16:02:00.657Z · LW(p) · GW(p)
Why clearly wrong?
↑ comment by multifoliaterose · 2011-08-18T21:55:34.314Z · LW(p) · GW(p)
Approximately normal distributions arise from the assumption of the involvement of many independent random variables with the largest ones being of roughly comparable size. It's intuitively plausible that a Solomonoff type prior would (at least approximately) yield such an assumption.
Replies from: Wei_Dai, endoself↑ comment by Wei Dai (Wei_Dai) · 2011-08-18T22:11:32.792Z · LW(p) · GW(p)
It's intuitively plausible that a Solomonoff type prior would (at least approximately) yield such an assumption.
But even if "intuitively plausible" equates to, say, 0.9999 probability, that's insufficient to disarm Pascal's Mugging. I think there's at least 0.0001 chance that a better approximate prior distribution for "value of an action" is one with a "heavy tail", e.g., one with infinite variance.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-18T22:50:30.517Z · LW(p) · GW(p)
Sure, the present post deals only with the case where the value that one assigns to an action obeys a (log)-normal distribution over actions. In the case that you describe, there may (or may not) be a different way to disarm Pascal Mugging.
↑ comment by endoself · 2011-08-19T04:24:27.556Z · LW(p) · GW(p)
It's intuitively plausible that a Solomonoff type prior would (at least approximately) yield such an assumption.
Intuitively plausible, but wrong; Solomonoff priors have long, very slowly decreasing tails.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T04:31:48.011Z · LW(p) · GW(p)
Care to elaborate or give a reference?
Replies from: endoself↑ comment by endoself · 2011-08-19T04:34:42.592Z · LW(p) · GW(p)
See http://lesswrong.com/lw/6fd/observed_pascals_mugging/4fky and the replies.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T04:50:57.063Z · LW(p) · GW(p)
Okay, I didn't mean a literal Solomonoff prior; I meant "what your posterior would be after starting with a Solomonoff prior, observing the natural/human world at some length and Bayesian updating accordingly." The prior alone contains essentially no information!
Replies from: endoselfcomment by lukeprog · 2011-08-18T23:38:38.998Z · LW(p) · GW(p)
Minor tweaks suggested...
There are some formatting issues. For example there is an extra space below the heading 'The approach we oppose: "explicit expected-value" (EEV) decisionmaking' instead of above it, and the heading 'Informal objections to EEV decisionmaking' is just blended into the middle of a paragraph, along with the first sentence below it. The heading 'Approaches to Bayesian adjustment that I oppose' is formatted differently than the others are.
Use 'a' instead of 'an' here:
pre-existing view of how cost-effective an donation
Add 'and' before '(b)' here:
(a) have significant room for error (b) ...
You may want to add 'marginal' before 'value' here; I'm not sure that EEV proponents neglect the issue of marginal value:
I estimate that each dollar spent on Program P has a value of V
In this paragraph, you may want to link to this video as an example:
We've encountered numerous people who argue that charities working on reducing the risk of sudden human extinction must be the best ones to support...
For example, at 7:15 in the video, Anna says:
Don't be afraid to write down estimates, even if the unknowns are very large, or even if you don't know very much about the particular domain. And the reason you shouldn't be afraid to write down estimates is that we need to make decisions, decisions are necessarily based on implicit or explicit estimates, and if we write down our estimates and put our thinking in plain view, we can often make our estimates better: we can notice errors in our thinking, others can notice errors in our thinking, we can begin to improve the process.
She goes on to say:
But equally, ...don't trust your estimates too much... If the issue is important, recalculate, look at how other people estimate these sorts of quantities, and try to get the estimates better.
Anna then applies this reasoning to Singularity scenarios, mentions GiveWell, and more.
comment by David_J_Balan · 2011-08-21T17:57:29.919Z · LW(p) · GW(p)
I think other commenters have had a similar idea, but here's one way to say it.
It seems to me that the proposition you are attacking is not exactly the one you think you are attacking. I think you think you are attacking the proposition "charitable donations should be directed to the highest EV use, regardless of the uncertainty around the EV, as long as the EV estimate is unbiased," when the proposition you are really attacking is "the analysis generating some of these very uncertain, but very high EV effect estimates is flawed, and the true EVs are in fact a great deal lower than those people claim."
The question of whether we should always be risk neutral with respect to the number of lives saved by charity is an interesting and difficult one (one that I would be interested to know what Holden thinks about). But this post is not about that difficult philosophical question, but simply about the technical question of whether the EV estimates that various people are basing themselves on are any good.
Replies from: AlexMennen, timtyler↑ comment by AlexMennen · 2011-08-24T18:57:37.208Z · LW(p) · GW(p)
Agreed. Most of the arguments seem to roughly be of the form, "in situation X, one could naively estimate an EEV of Y, but a more accurate EEV would actually be Z. Now I'll refer to Y as the EEV so that I can criticize EEV for not giving the answer Z."
comment by benelliott · 2011-08-19T19:13:31.551Z · LW(p) · GW(p)
I have a number of issues with your criticisms of EEV
In such a world, when people decided that a particular endeavor/action had outstandingly high EEV, there would (too often) be no justification for costly skeptical inquiry of this endeavor/action.
I'm not sure this is true, sceptical inquiry can have a high expected value when it helps you work out what is a better use of limited resources. In particular, my maths might be wrong, but I think that in a case with an action that has low probability of producing a large gain, any investigation that will confirm whether this is true or not is worth attempting unless either:
- The sceptical enquiry will actually cost more, on its own, than just going ahead and performing the action.
- The sceptical enquiry will cost so much that having done it, if it turns out the action is worth doing, you will no longer be able to afford to do it.
It seems to me that in both of these cases it would be pretty obviously stupid to have a sceptical enquiry.
In such a world, it seems that nearly all altruists would put nearly all of their resources toward helping people they knew little about, rather than helping themselves, their families and their communities. I believe that the world would be worse off if people behaved in this way, or at least if they took it to an extreme.
Why do you believe this. Do you have any evidence or even arguments? It seems pretty unintuitive to me that the sum of a bunch of actions, each of which increases total welfare, could somehow be a decrease in total welfare.
When you say taken to the extreme, I suspect you are imagining our hypothetical EEV agents ignoring various side-effects of their actions, in which case the problem is with them failing to take all factors into account, rather than with them using EEV.
Related: giving based on EEV seems to create bad incentives. EEV doesn't seem to allow rewarding charities for transparency or penalizing them for opacity: it simply recommends giving to the charity with the highest estimated expected value, regardless of how well-grounded the estimate is. Therefore, in a world in which most donors used EEV to give, charities would have every incentive to announce that they were focusing on the highest expected-value programs, without disclosing any details of their operations that might show they were achieving less value than theoretical estimates said they ought to be.
Not true. If all donors followed EEV, charities would indeed have an incentive to conceal information about things they are doing badly, and donors would in turn, and in accordance with EEV, start to treat failure to disclose information as evidence that the information was unflattering. This would in turn incentivise charities to disclose information about things they are doing slightly badly, which would in turn cause donors to view secrecy in an even worse light, and so on. I we eventually reach an equilibrium where charities disclose all information.
Of course, this assumes that all charities and all donors are completely rational, which is a total fantasy, but I think the same can be said of your own argument, and even if we do end up stuck part-way to equilibrium with charities keeping some information secret, as donors we can just take that information into account and correctly treat it as Bayesian evidence of a problem.
Up till now I have been donating to Village Reach rather than SIAI based on Givewell's advice, but if I am to treat this article as evidence of your thought process in general, then I don't like what I see and I may well change my mind.
Having said that, I do like the maths. I'm just not at all sure that it in any way contradicts EEV.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T20:36:49.238Z · LW(p) · GW(p)
I'm not sure this is true, sceptical inquiry can have a high expected value when it helps you work out what is a better use of limited resources. [...]
Note that Holden qualified his statement with "(too often)".
I think that in a case with an action that has low probability of producing a large gain, any investigation that will confirm whether this is true or not is worth attempting unless either [...] It seems to me that in both of these cases it would be pretty obviously stupid to have a sceptical enquiry.
Concerning your second point: suppose that spending a million dollars on intervention A ostensibly has an expected value X which is many orders of magnitude greater than that of any intervention (and suppose for simplicity negligible diminishing marginal utility per dollar). Suppose that it would cost $100,000 to investigate whether the ostensibly high expected value is well-grounded.
Then investigating the cost-effectiveness of intervention A comes at an ostensible opportunity cost of X/10. But it's ostensibly the case that the remaining $900,000 could in no case be spent with cost-effectiveness within an order of magnitude then spending the money on intervention A. So in the setting that I've just described, the opportunity cost of investigating is ostensibly too high to justify an investigation.
Note that a similar situation could prevail even if investigating the intervention cost only $100 or $10 provided that the ostensible expected value X is sufficiently high relative to other known options.
The point that I'm driving at here is that there's not a binary "can afford" or "can't afford" distinction concerning the possibility of funding A: it can easily happen that spending any resources whatsoever investigating A is ostensibly too costly to be worthwhile. This conclusion is counter-intuitive; seemingly very similar to Pascal Mugging.
The fact that naive EEV leads to this conclusion is evidence against the value of naive EEV. Of course, one can attempt to use a more sophisticated version of EEV; see the second and third paragraphs of Carl Shulman's comment here.
Why do you believe this. Do you have any evidence or even arguments? It seems pretty unintuitive to me that the sum of a bunch of actions, each of which increases total welfare, could somehow be a decrease in total welfare.
See my fourth point in the section titled "In favor of a local approach to philanthropy" here.
When you say taken to the extreme, I suspect you are imagining our hypothetical EEV agents ignoring various side-effects of their actions, in which case the problem is with them failing to take all factors into account, rather than with them using EEV.
It's not humanly possible to take all factors into account; our brains aren't designed to do so. Given how the human brain is structured, using implicit knowledge which is inexplicable can yield better decision making for humans than using explicit knowledge. This is the point of the section of Holden's post titled "Generalizing the Bayesian approach."
Not true. If all donors followed EEV, charities would indeed have an incentive to conceal information about things they are doing badly, and donors would in turn, and in accordance with EEV, start to treat failure to disclose information as evidence that the information was unflattering. This would in turn incentivise charities to disclose information about things they are doing slightly badly, which would in turn cause donors to view secrecy in an even worse light, and so on. I we eventually reach an equilibrium where charities disclose all information.
I think you're right about this.
Of course, this assumes that all charities and all donors are completely rational, which is a total fantasy, but I think the same can be said of your own argument, and even if we do end up stuck part-way to equilibrium with charities keeping some information secret, as donors we can just take that information into account and correctly treat it as Bayesian evidence of a problem.
My intuition is that in the real world the incentive effects of using EEV would in fact be bad despite the point that you raise; but refining and articulating my intuition here would take some time and in any case is oblique to the primary matters under consideration.
Replies from: benelliott↑ comment by benelliott · 2011-08-19T21:58:10.826Z · LW(p) · GW(p)
Note that Holden qualified his statement with "(too often)".
And the point which I was making was that EEV does not do this too often, it does it just often enough, which I think is pretty clear mathematically.
Then investigating the cost-effectiveness of intervention A comes at an ostensible opportunity cost of X/10. But it's ostensibly the case that the remaining $900,000 could in no case be spent with cost-effectiveness within an order of magnitude then spending the money on intervention A. So in the setting that I've just described, the opportunity cost of investigating is ostensibly too high to justify an investigation.
I don't see what you're driving at with the opportunity cost of X/10. Either we have less than $1,100,000 in which case the opportunity cost is X or we have more than $1,100,000 in which case it is zero. Either we can do X or we can't, we can't do part of it or more of it.
The fact that naive EEV leads to this conclusion is evidence against the value of naive EEV. Of course, one can attempt to use a more sophisticated version of EEV; see the second and third paragraphs of Carl Shulman's comment here.
If naive EEV causes problems then the problem is with naivete, not with EEV. Any decision procedure can lead to stupid actions if fed with stupid information.
See my fourth point in the section titled "In favor of a local approach to philanthropy" here.
You make the case that local philanthropy is better than global philanthropy on an individual basis, and if you are correct (which I don't think you are) then EEV would choose to engage in local philanthropy.
It's not humanly possible to take all factors into account; our brains aren't designed to do so.
The correct response to our fallibility is not to go do random other things. Just because my best guess might be wrong doesn't mean I should trade it for my second best guess, which is by definition even more likely to be wrong.
implicit knowledge which is inexplicable
A cognitive bias by another name is still a cognitive bias.
My intuition is that in the real world the incentive effects of using EEV would in fact be bad despite the point that you raise; but refining and articulating my intuition here would take some time and in any case is oblique to the primary matters under consideration.
I agree that it isn't very important. Regardless of anything else, the possibility of more than a tiny proportion of donors actually applying EEV is not even remotely on the table.
Replies from: multifoliaterose, multifoliaterose↑ comment by multifoliaterose · 2011-08-20T00:16:35.085Z · LW(p) · GW(p)
I can't tell whether we're in disagreement or talking past each other.
And the point which I was making was that EEV does not do this too often, it does it just often enough, which I think is pretty clear mathematically.
You seem to be confusing EEV with expected value maximization. It's clear from the mathematical definition of expected value that expected value maximization does this just often enough. It's not at all tautological that EEV does it just often enough.
If naive EEV causes problems then the problem is with naivete, not with EEV. Any decision procedure can lead to stupid actions if fed with stupid information.
[...]
The correct response to our fallibility is not to go do random other things. Just because my best guess might be wrong doesn't mean I should trade it for my second best guess, which is by definition even more likely to be wrong.
Nobody's arguing against expected value maximization. The claim made in the final section of the post and by myself is that using explicit expected value maximization does not maximize expected value and that one can do better by mixing explicit expected value maximization with heuristics.
To see how this could be so, consider the case of finding the optimal way to act if one's hand is on a very hot surface. We have an evolutionarily ingrained response of jerking our hand away which produces a better outcome than "consider all possible actions; calculate the expected value of each action and perform the one with the highest expected value."
Our evolutionarily conditioned responses and what we've gleaned from learning algorithms are not designed for optimal philanthropy but are nevertheless be substantially more powerful and/or relevant than explicit reasoning in some domains relevant to optimal philanthropy.
A cognitive bias by another name is still a cognitive bias.
Possessing a given cognitive bias can be rational conditional on possessing another cognitive bias. Attempting to remove cognitive biases one at a time need not result in monotonic improvement. See Phil Goetz's Reason as a memetic immune disorder.
Replies from: benelliott↑ comment by benelliott · 2011-08-23T18:06:54.009Z · LW(p) · GW(p)
Nobody's arguing against expected value maximization. The claim made in the final section of the post and by myself is that using explicit expected value maximization does not maximize expected value and that one can do better by mixing explicit expected value maximization with heuristics.
To see how this could be so, consider the case of finding the optimal way to act if one's hand is on a very hot surface. We have an evolutionarily ingrained response of jerking our hand away which produces a better outcome than "consider all possible actions; calculate the expected value of each action and perform the one with the highest expected value."
I think you've found the source of our disagreement here. I fully agree with the use of time-saving heuristics, I think the difference is that I want all my heuristics to ultimately be explicitly justified, not necessarily every time you use them, but at least once.
Knowing the reason for a heuristic is useful, it can help you refine it, it can tell you whether or not its safe to abandon it in certain situations, and sometimes it can alert you to one heuristic that really is just a bias. To continue with your example, I agree that checking whether it would be smart to take your hand of the cooker every single time is stupid, but I don't see what's wrong with at some point pausing for a moment, just to consider whether there might be unforeseen benefits to keeping your hand on the cooker (to my knowledge there aren't).
An analogy can be made to mathematics, you don't explicitly prove everything from the axioms, but you rely on established results which in turn rest on others and hopefully trace back to the axioms eventually, if that's not the case you start to worry.
As a second point, time saving heuristics are at their most useful when time matters. For instance, if I had to choose a new charity every day, or if for some reason I only had ten minutes to choose one and my choice would then be set in stone for eternity, then time saving heuristics would be the order of the day. As I need only choose one, and can safely take days or even weeks to make that decision without harming the charities in any significant way, and furthermore can change my choice whenever I want if new information comes to light, it seems like the use of time-savers would be pure laziness on my part, and tha'ts just for me as an individual, for an organisation like Givewell which exists solely to perform this one task, they are inexcusable.
Possessing a given cognitive bias can be rational conditional on possessing another cognitive bias.
It can be beneficial, but not predictably so. If I know that I possess cognitive bias A, it is better to try to get rid of it than to introduce a second cognitive bias B.
Attempting to remove cognitive biases one at a time need not result in monotonic improvement.
Agreed, but it should result in improvement on average. Once again we come back to the issue of uncertainty aversion, whether its worthwhile to gamble when the odds are in your favour.
See Phil Goetz's Reason as a memetic immune disorder.
I loved that when I first read it, but lately I'm unsure. If his hypothesis is correct, it would suggest that most religions are completely harmless in their 'natural environment', but excluding the last few centuries that doesn't seem true.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-23T22:44:52.967Z · LW(p) · GW(p)
Thanks for engaging with me.
The heuristics that we use are too numerous and of too much complexity to be possible to explicitly justify all of them. Turning your mathematics analogy on its head, note that mathematicians have very little knowledge of the heuristics that they use to discover and prove theorems. Poincare wrote some articles about this; if interested see The Value of Science.
There are over a million charities in the US alone. GiveWell currently has (around) 5 full time staff. If GiveWell were to investigate every charity this year. each staff member would have to investigate over 500 charities per day. Moreover, doing comparison of even two charities can be exceedingly tricky. I spent ~ 10 hours a week for five months investigating the cost effectiveness of school based deworming and I still don't know whether it's a better investment than bednets. So I strongly disagree that GiveWell shouldn't use time saving heuristics.
As for for SIAI vs. VillageReach, it may well be that SIAI is a better fit for your values than VillageReach is. I currently believe that donating to SIAI has higher utilitarian expected value than donating to VillagReach but also presently believe that a few years of searching will yield a charity at least twice as cost-effective than either at the margin. I have been long been hoping for GiveWell to research x-risk charities. See my comment here. Over the next year I'll be researching x-risk reduction charities myself.
It's not clear to me that overcoming a generic bias should improve one's rationality on average. This is an empirical question with no data but anecdotal evidence. Placebo effect and selection bias may suffice to explain a subjective sense that overcoming biases is conducive to rationality. Anyway, on the matter at hand, I concur with Holden's view that relying entirely on explicit formulas does not maximize expected value and that one should incorporate some measure of subjective judgment (as to how much, I am undecided).
↑ comment by Wei Dai (Wei_Dai) · 2011-08-24T00:14:48.187Z · LW(p) · GW(p)
I currently believe that donating to SIAI has higher utilitarian expected value than donating to VillagReach but also presently believe that a few years of searching will yield a charity at least twice as cost-effective than either at the margin.
Interesting. Have you explained these beliefs anywhere?
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-24T19:52:25.851Z · LW(p) · GW(p)
No. I'll try to explicate my thoughts soon. Thanks for asking.
↑ comment by gwern · 2011-08-24T00:38:03.418Z · LW(p) · GW(p)
There are over a million charities in the US alone. GiveWell currently has (around) 5 full time staff. If GiveWell were to investigate every charity this year. each staff member would have to investigate over 500 charities per day. Moreover, doing comparison of even two charities can be exceedingly tricky. I spent ~ 10 hours a week for five months investigating the cost effectiveness of school based deworming and I still don't know whether it's a better investment than bednets. So I strongly disagree that GiveWell shouldn't use time saving heuristics.
Aren't the numbers here a little specious? There may be over a million charities (is this including nonprofits which run social clubs? there are a lot of categories of nonprofits), but we can dismiss hundreds of thousands with just a cursory examination of their goals or their activity level. For example, could any sports-related charity come within an order of magnitude or two of a random GiveWell approved charity? Could any literary (or heck humanities charity) do that without specious Pascal's Wager-type arguments?
This isn't heuristic, this is simply the nature of the game. Some classes of activities just aren't very useful from the utilitarian perspective. (Imagine Christianity approved of moving piles of sand with tweezers and hence there were a few hundred thousand charities surrounding this activity - every town or city has a charity or three providing subsidized sand pits and sand scholarships. If a GiveWell dismissed them all out of hand, would you attack that too as a heuristic?)
Notice the two examples you picked - deworming and bed nets. Both are already highly similar: public health measures. You didn't pick, 'buy new pews for the local church' and 'deworm African kids'.
Replies from: Vaniver, multifoliaterose↑ comment by Vaniver · 2011-08-25T21:26:09.169Z · LW(p) · GW(p)
This isn't heuristic, this is simply the nature of the game.
This looks a lot like a heuristic to me. Is "heuristic" derogative around here?
Imagine Christianity approved of moving piles of sand with tweezers
Why not go with the real-world version? (Especially since it involves ritual destruction of those piles of sand.)
Replies from: gwern↑ comment by gwern · 2011-08-25T21:40:11.642Z · LW(p) · GW(p)
This looks a lot like a heuristic to me. Is "heuristic" derogative around here?
Yes; heuristics allow errors and are suboptimal in many respects. (That's why they are a 'heuristic' and not 'the optimal algorithm' or 'the right answer' or other such phrases.)
I don't cite the sand mandalas both because they simply didn't come to mind, and they're quite beautiful.
↑ comment by multifoliaterose · 2011-08-24T04:41:27.921Z · LW(p) · GW(p)
I agree with most of what you say here, but fear that the discussion is veering in the direction of a semantics dispute. So I'll just clarify my position by saying:
• Constructing an airtight argument for the relative lack of utilitarian value of e.g. all humanities charities relative to VillageReach is a nontrivial task (and indeed, may be impossible).
• Even if one limits oneself to the consideration of 10^(-4) of the field of all charities, one is still left with a very sizable analytical problem.
•The use of time saving heuristics is essential to getting anything valuable done.
↑ comment by multifoliaterose · 2011-08-20T00:20:45.966Z · LW(p) · GW(p)
You make the case that local philanthropy is better than global philanthropy on an individual basis, and if you are correct (which I don't think you are) then EEV would choose to engage in local philanthropy.
Note that in the link that you're referring to I argue both for and against local philanthropy as opposed to global philanthropy. Anyway, I wasn't referencing the post as a whole, I was referencing the point about the "act locally" heuristic solving a coordination problem that naive EEV fails to solve. It's not clear that it's humanly possible (or desirable) to derive that that heuristic from first principles. Rather than trying to replace naive EEV with sophisticated EEV; one might be better off with scraping exclusive use of EEV altogether.
comment by prase · 2011-08-19T13:30:18.719Z · LW(p) · GW(p)
The article seems to be well written, clearly structured, honest with no weasel words, with concrete examples and graphs - all symptoms of a great post. In the same time, I am not sure what it is precisely saying. So I am confused.
The initial description of EEV seems pretty standard: calculate the expected gain from all possible actions and choose the best one. Then, the article criticises that approach as incorrect, giving examples like this:
It seems fairly clear that a restaurant with 200 Yelp reviews, averaging 4.75 stars, ought to outrank a restaurant with 3 Yelp reviews, averaging 5 stars.
It doesn't seem much clear to me, but let's take it for granted that the statement is correct. The problem is: does EEV necessarily favour the new restaurant over the other one? What is tacitly assumed is that the person using EEV calculates his expected utility taking the review average at face value. But, are there people who advocate such an approach?
The method described in the following is in fact a standard Bayesian way. Let's call the Yelp average rating a measurement. The Bayesian utility calculations don't use a delta-distribution centered on the measured value M, but rather an updated distribution made from the prior P(x) and the distribution P(M|x), while the latter contains the fuzziness of the measurement which influences the posterior distribution. It is precisely what the graphs illustrate.
Now it is possible that I am responsible for the misinterpretations, but there are few comments which seem to (mis)understand the message in the same way I did after the first reading. The clearly valid and practically important advice, which should read
always take into account your priors and update correctly, don't substitute reported values (even if obtained by statistical analysis) for your own probability distribution
did come out rather like more problematic
don't trust expected value calculations, since they don't take into account measurement errors, you should make some additional adjustments which we call Bayesian and have something to do with log-normal distributions and utilities; also, always check it by common sense.
And I am still not entirely sure which one is the case.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T17:15:05.103Z · LW(p) · GW(p)
But, are there people who advocate such an approach?
See my response to Michael Vassar.
Now it is possible that I am responsible for the misinterpretations...
I don't have a clear understanding of the difference between the two italicized statements. Your first paragraphsing doesn't address three crucial (and in my opinion valid) points of the post that your second paraphrasing does:
The degree to which one should trust one's prior over the new information depends on the measurement error attached to the new information.
Assuming a normal/log-normal distribution for effectiveness of actions, the appropriate Bayesian adjustment is huge for actions with prima facie effectiveness many standard above the mean but which have substantial error bars.
Humans do not have conscious/explicit access to most of what feeds into their implicit Bayesian prior and so in situations where a naive Fermi calculation yields high expected value and where there's high uncertainty, evolutionarily & experientially engrained heuristics can be a better guide to assessing the value of the action than attempting to reason explicitly as in the section entitled "Applying Bayesian adjustments to cost-effectiveness estimates for donations, actions, etc."
↑ comment by prase · 2011-08-20T01:14:38.684Z · LW(p) · GW(p)
- The first paraphrasing certainly addresses your first point. Assuming the prior has normal distribution with variance σ0^2 and mean μ0 and you measure μ, assuming that errors are normally distributed with variance σ^2, the updated mean is (μ σ0^2 + μ0 σ0^2)/(σ0^2 + σ0^2). The higher σ, the less the updating moves the estimate. This is standard Bayes.
- I can't parse your second point.
- It is indeed possible that evolutionarily engrained heuristics are a better guide than a more formal approach. But is is also possible that they aren't, especially applied to situations which are rare and so didn't exert selection pressure during human evolution. Many times I have seen common sense declared superior over formal analysis, but almost never had such declaration been supported by good arguments.
I agree that the Pascalesque arguments that appear on LW now and then, based on Fermi calculations and astronomical figures, such as
Even then the expected lives saved by SIAI is ~10^28.
are suspicious. But the problem lies already in the outlandish figure - the author should have taken the Fermi calculation, considered its error bars and combine it with his prior; presumably the result would be much lower then. If the HoldenKarnofsky's post suggests that, I agree. Only I am not sure whether the post doesn't rather suggest to accept that the expected value is unknowable and we should therefore ignore it, or even that it really may be 10^28, but we should ignore it nevertheless.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-20T01:50:27.757Z · LW(p) · GW(p)
Re: #1, okay, it was unclear to me that all of that was packaged into your first paraphrasing.
Re: #2, not sure how else to explain; I had in mind the Pascal Mugging portion of the post.
Re: #3, as I mentioned to benelliott I would advocate a mixed strategy (heuristics together with expected value calculations). Surely our evolutionarily engrained heuristics a better guide than formal reasoning for some matters bearing on the efficacy of a philanthropic action.
But the problem lies already in the outlandish figure - the author should have taken the Fermi calculation, considered its error bars and combine it with his prior; presumably the result would be much lower then. If the HoldenKarnofsky's post suggests that, I agree.
All but the final section of the post are arguing precisely along these lines.
Only I am not sure whether the post doesn't rather suggest to accept that the expected value is unknowable and we should therefore ignore it, or even that it really may be 10^28, but we should ignore it nevertheless.
Not sure what Holden would say about this; maybe he'll respond clarifying.
Replies from: prase↑ comment by prase · 2011-08-20T12:10:59.690Z · LW(p) · GW(p)
All but the final section of the post are arguing precisely along these lines.
That seems probable, and therefore I haven't said that I disagree with the post, but that I am confused about what it suggests. But I have some problems with the non-final sections, too, mainly concerning the terminology. For example, the phrases "estimated value" and "expected value", e.g. in
The crucial characteristic of the EEV approach is that it does not incorporate a systematic preference for better-grounded estimates over rougher estimates. It ranks charities/actions based simply on their estimated value, ignoring differences in the reliability and robustness of the estimates.
are used as if it simply meant "result of the Fermi calculation" instead of "mean value of probability distribution updated by the Fermi calculation". It seems to me that the post nowhere explicitly says that such estimates are incorrect and that it is advocating standard Bayesian reasoning, only done properly. After first reading I rather assumed that it proposes an extension to Bayes, where the agent after proper updating classifies the obtained estimates based on their reliabilities.
Also, I was not sure whether the post discusses a useful everyday technique when formal updating is unfeasible, or whether it proposes an extension to probability theory valid on the fundamental level. See also cousin_it's comments.
As for #2, i.e.
Assuming a normal/log-normal distribution for effectiveness of actions, the appropriate Bayesian adjustment is huge for actions with prima facie effectiveness many standard above the mean but which have substantial error bars.
mostly I am not sure what you refer to by appropriate Bayesian adjustment. On the first reading I interpreted is as "the correct approach, in contrast to EEV", but then it contradicts your apparent position expressed in the rest of the comment, where you argue that substantial error bars shoul prevent huge updating. The second interpretation may be "the usual Bayes updating", but then it is not true, as I argued in #1 (and in fact, I only repeat Holden's calculations).
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-20T19:32:01.125Z · LW(p) · GW(p)
For example, the phrases "estimated value" and "expected value" [...] are used as if it simply meant "result of the Fermi calculation" instead of "mean value of probability distribution updated by the Fermi calculation". It seems to me that the post nowhere explicitly says that such estimates are incorrect and that it is advocating standard Bayesian reasoning, only done properly.
I'm very sure that in the section to which you refer "estimated value" means "result of a Fermi calcuation" (or something similar) as opposed "mean value of probability distribution updated by the Fermi calculation." (I personally find this to be clear from the text but may have been influenced by prior correspondence with Holden on this topic.)
The reference to "differences in the reliability and robustness of the estimates" refers to the size of the error bars (whether explicit or implicit) about the initial estimate.
Also, I was not sure whether the post discusses a useful everyday technique when formal updating is unfeasible, or whether it proposes an extension to probability theory valid on the fundamental level. See also cousin_it's comments.
Here too I'm very sure that the post is discussing a useful everyday technique when formal updating is unfeasible rather than an extension to probability theory valid on a fundamental level.
On the first reading I interpreted is as "the correct approach, in contrast to EEV", but then it contradicts your apparent position expressed in the rest of the comment, where you argue that substantial error bars shoul prevent huge updating. The second interpretation may be "the usual Bayes updating", but then it is not true, as I argued in #1 (and in fact, I only repeat Holden's calculations).
Here we had a simple misunderstanding; I meant "updating from the initial (Fermi calculation-based) estimate to a revised estimate after taking into account one's Bayesian prior" rather than "updating one's Bayesian prior to a revised Bayesian prior based on the initial (Fermi calculation-based) estimate."
I was saying "when there are large error bars about the initial estimate, the initial estimate should be revised heavily", not "when there are large error bars about the initial estimate, one's Bayesian prior should be revised heavily." On the contrary, larger the error bars about the initial estimate, the less one's Bayesian prior should change based on the estimate.
I imagine that we're in agreement here. I think that the article is probably pitched at someone with less technical expertise than you have; what seems obvious and standard to you might be genuinely new to many people and this may lead to you to assume that it's saying more than it is.
Replies from: prasecomment by blogospheroid · 2011-08-19T05:36:39.204Z · LW(p) · GW(p)
Upvoted.
I got that feeling after reading this. "Man, this sounds like common sense, and I've never thought about it like this before." - The mark of a really good argument.
comment by [deleted] · 2011-08-18T16:30:07.937Z · LW(p) · GW(p)
Best article on LW in recent memory. Thank you for cross-posting it, and for your work with GiveWell.
I don't have many upvotes to give you, but I will shake down my budget and see what if anything I can donate.
comment by multifoliaterose · 2011-08-19T23:45:42.220Z · LW(p) · GW(p)
Disclosure: I have done volunteer work for GiveWell and have discussed the possibility of taking a job with GiveWell at some point in the future.
comment by endoself · 2011-08-19T04:32:03.820Z · LW(p) · GW(p)
Your stated prior would cause you to ignore even strong evidence in favour of an existential risk charity. It is therefore wrong (at least in this domain).
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T04:55:00.401Z · LW(p) · GW(p)
I think that the right way to take future generations into account is to consider a log normal distribution with high variance. High variance allows for the existence of very high expected value options while still requiring massive Bayesian regression relative to other options in the face of sufficiently heavy uncertainty.
comment by SarahNibs (GuySrinivasan) · 2011-08-18T20:29:07.116Z · LW(p) · GW(p)
I'm not sure I'm intuiting the transformation to and from log-normals. My intuition is that since the mean of a log-normal with location u scale s is e^(u+s^2/2) rather than e^u, when we end up with a mean log, transforming back into a mean tacks the s^2/2 back on (aka we're back to value ~ X rather than value ~ 0). Maybe I'm missing something, I haven't gone through to rederive your results, but even if everything's right I think the math could be made more clear.
Great post! We need to see this kind of reasoning made explicit!
comment by gwern · 2011-11-10T21:11:45.353Z · LW(p) · GW(p)
Followup: http://blog.givewell.org/2011/11/10/maximizing-cost-effectiveness-via-critical-inquiry/
comment by gwern · 2016-09-07T01:31:57.390Z · LW(p) · GW(p)
"Philanthropy’s Success Stories"
I see impressive choices of causes and organizations; I don’t see impressive “tactics,” i.e., choices of projects or theories of change. This may simply be a reflection of the Casebook’s choice of approach and focus. There are many cases in which I found myself agreeing with the Casebook that a foundation had chosen an important and overlooked problem to put its money toward, but few (if any) cases where its strategy within the sector seemed particularly intricate, clever, noteworthy or crucial to its success. The spreadsheet above categorizes grants both by “sector” and by “type of grantmaking”; there is a surprising (to me) amount of variety when it comes to the former, and not as much when it comes to the latter. My intuition is that the choice of sector is the most important choice a funder makes.
comment by timtyler · 2011-08-23T19:55:45.392Z · LW(p) · GW(p)
The crucial characteristic of the EEV approach is that it does not incorporate a systematic preference for better-grounded estimates over rougher estimates. It ranks charities/actions based simply on their estimated value, ignoring differences in the reliability and robustness of the estimates.
Uncertainty in estimates of the expected value of an intervention tend to have the effect of naturally reducing it - since there are may ways to fail and few ways to succeed.
For instance think about drug trials. If someone claims that their results say there's a 50% chance of the drug curing a disease, and there's a 50% chance that they got their results muddled up with those of some different drug, that often makes the expected value of the treatment fall to around 25% - since most drugs don't work.
comment by gwern · 2011-10-31T16:47:09.039Z · LW(p) · GW(p)
Relevant earlier paper with much the same idea but on existential risks: "Probing the Improbable: Methodological Challenges for Risks with Low Probabilities and High Stakes"
comment by gwern · 2011-08-27T21:57:28.463Z · LW(p) · GW(p)
An interesting mathematical response: https://johncarlosbaez.wordpress.com/2011/08/19/bayesian-computations-of-expected-utility/
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2011-08-27T21:59:55.045Z · LW(p) · GW(p)
Baez already linked to that post himself.
comment by Douglas_Knight · 2011-08-26T22:10:31.934Z · LW(p) · GW(p)
A bit late, but I think it is worth distinguishing two types of adjustments in this post. Typically, we evaluate alternative actions in terms of achieving a proxy goal, such as preventing deaths due to a particular disease. We attempt to compute the expected effect on the proxy goal of the alternatives. One adjustment is uncertainty in that calculation, such as whether the intervention works in theory, whether the charity is competent to carry it out, whether the charity has room for additional funding.
The other kind of adjustment is uncertainty in matching the proxy goal to our real goals. Choosing transparent charities may cause others to become more transparent and ultimate more effective, and indirectly save lives. Malthusian concerns or economic growth potential may make some ways of saving lives better than others.
Are there any other category of adjustments?
comment by Larks · 2011-08-20T20:29:02.456Z · LW(p) · GW(p)
There seems to be nothing in EEV that penalizes relative ignorance or relatively poorly grounded estimates, or rewards investigation and the forming of particularly well grounded estimates. If I can literally save a child I see drowning by ruining a $1000 suit, but in the same moment I make a wild guess that this $1000 could save 2 lives if put toward medical research, EEV seems to indicate that I should opt for the latter.
I don't understand this objection. What sort of subjective probability are we meant to be ascribing to the 'wild guess'? If less than 0.5, as would seem appropriate for a 'wild guess', then you still save the child. If greater than 0.5, it doesn't seem to be a wild guess at all, but a firmly supported belief, and it's entirely reasonable to donate to medical research.
comment by Shmi (shminux) · 2011-08-18T18:49:12.248Z · LW(p) · GW(p)
Did I summarize your point correctly:
- an instinctive reaction of the type "you are so full of it" to any poorly supported extravagant claim has a fancy name "Bayesian adjustment" and so can be trusted
- singularity research is one such claim
- GiveWell's charity metrics penalize charities with high uncertainties
- Give to GiveWell if you want to be sure your donation is not wasted
Edit: not saying that I agree with this, just checking if my understanding is not off-base.
Replies from: Randaly, Nominull, None↑ comment by Randaly · 2011-08-18T22:00:06.325Z · LW(p) · GW(p)
Actually, I had a negative reaction to this comment for the opposite reason- it seemed overly critical of the post. The first point seemed to be ignoring a fair amount of his argument, and instead focusing on criticizing what he named his method; the last point seemed to me to be impugning Holden's motives based off something he never actually said.
Replies from: shminux↑ comment by Shmi (shminux) · 2011-08-18T23:30:39.215Z · LW(p) · GW(p)
thanks!
↑ comment by [deleted] · 2011-08-18T23:18:03.026Z · LW(p) · GW(p)
Give to GiveWell if you want to be sure your donation is not wasted
Actually, they advocate that you should give to charities that both score highly on their metrics and pursue some goal that you yourself find worthy.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-18T23:46:48.385Z · LW(p) · GW(p)
See also GiveWell's Do-It-Yourself Charity Evaluation Questions.
comment by magfrump · 2011-08-18T19:04:42.996Z · LW(p) · GW(p)
I have been waiting for someone to formalize this objection to Pascal's mugging for a long time, and I'm very happy that now that it's been done it's been done very well.
Replies from: Oscar_Cunningham↑ comment by Oscar_Cunningham · 2011-08-18T21:27:12.900Z · LW(p) · GW(p)
???
What precisely is the objection to Pascal's Mugging in the post? Just that the probability for the mugger being able to deliver goes down with N? This objection has been given thousands of times, and the counter response is that the probability can't go down fast enough to outweigh increase in utility. This is formalised here.
Replies from: TruePath, multifoliaterose, magfrump, Jiro↑ comment by TruePath · 2011-08-30T08:27:03.369Z · LW(p) · GW(p)
The paper is really useless. The entire methodology of requiring some non-zero computable bound on the probability that the function with a given godel number will turn out to be correct is deeply flawed. The failure is really about the inability of a computable function to check if two Godel numbers code for the same function not about utilities and probability. Similarly insisting that the Utilities be bounded below by a computable function on the GODEL NUMBERS of the computable functions is unrealistic.
Note that one implicitly expects that if you consider longer and longer sequences of good events followed by nothing the utility will continue to rise. They basically rule out all the reasonable unbounded utility functions by fiat by requiring the infinite sequence of good events to have finite utility.
I mean consider the following really simply model. At each time step I either receive a 1 or a 0 bit from the environment. The utility is the number of consequtive 1's that appear before the first 0. The probability measure is the standard coin flip measure. Everything is nice and every Borel set of outcomes has a well defined expected value but the utility function goes off to infinity and indeed is undefined on the infinite sequence of 1's.
Awful paper but hard for non-experts to see where it gets the model wrong.
The right analysis is simply that we want a utility function that is L1 integrable on the space of outcomes with respect to the probability measure. That is enough to get rid of Pascal's mugging.
↑ comment by multifoliaterose · 2011-08-18T22:06:54.472Z · LW(p) · GW(p)
The post's argument is more substantive than that the probability for the mugger to deliver goes down with N. Did you read the section of the post titled "Pascal's Mugging"? I haven't read the de Blanc paper that you link to but I would guess that he doesn't assume a (log)-normal prior for the effectiveness of actions and so doesn't Bayesian adjust the quantities downward as sharply as the present post suggests that one should.
Replies from: Oscar_Cunningham↑ comment by Oscar_Cunningham · 2011-08-18T23:15:07.364Z · LW(p) · GW(p)
The argument is that simple numbers like 3^^^3 should be considered much more likely than random numbers with a similar size, since they have short descriptions and so the mechanisms by which that many people (or whatever) hang in the balance are less complex. For instance you're more likely to win a prize of $1,000,000 than $743,328 even though the former is larger. de Blanc considers priors of this form, of which the normal isn't an example.
Replies from: multifoliaterose, Erebus↑ comment by multifoliaterose · 2011-08-19T00:00:20.553Z · LW(p) · GW(p)
Surely an action is more likely to have an expected value of saving 3.2 lives than pi lives; the distribution of values of actions is probably not literally log normal partially for the reason that you just gave, but I think that a log-normal distribution is much closer to the truth than a distribution which assigns probabilities strictly by Kolmogorov complexity. Here I'd recur to my response to cousin it's comment.
Replies from: khafra↑ comment by khafra · 2011-08-19T12:39:32.978Z · LW(p) · GW(p)
Surely an action is more likely to have an expected value of saving 3.2 lives than pi lives
I'm not so sure. Do you mean (3.2 lives|pi lives) to log(3^^^3) digits of precision? If you don't, I think it misleads intuition to think about the probability of an action saving 3.2 lives, to two decimal places; vs. pi lives, to indefinite precision.
I can't think of any right now, but I feel like if I really put my creativity to work for long enough, I could think of more ways to save 3.14159265358979323846264 lives than 3.20000000000000000000000 lives.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-19T16:51:55.393Z · LW(p) · GW(p)
I meant 3.2 lives to arbitrary precision vs. pi lives to arbitrary precision. Anyway, my point was that there's going to be some deviation from a log-normal distribution on account of contingent features of the universe that we live in (mathematical, physical, biological, etc.) but that probably a log-normal distribution is a closer approximation to the truth than what one would hope to come up with a systematic analysis of the complexity of the numbers involved.
↑ comment by Erebus · 2011-08-19T08:30:13.172Z · LW(p) · GW(p)
The argument is that simple numbers like 3^^^3 should be considered much more likely than random numbers with a similar size, since they have short descriptions and so the mechanisms by which that many people (or whatever) hang in the balance are less complex.
Consider the options A = "a proposed action affects 3^^^3 people" and B = "the number 3^^^3 was made up to make a point". Given my knowledge about the mechanisms that affect people in the real world and about the mechanisms people use to make points in arguments, I would say that the likelihood of A versus B is hugely in favor of B. This is because the relevant probabilities for calculating the likelihood scale (for large values and up to a first order approximation) with the size of the number in question for option A and the complexity of the number for option B. I didn't read de Blanc's paper further than the abstract, but from that and your description of the paper it seems that its setting is far more abstract and uninformative than the setting of Pascal's mugging, in which we also have the background knowledge of our usual life experience.
Replies from: Peter_de_Blanc↑ comment by Peter_de_Blanc · 2011-08-21T05:24:48.922Z · LW(p) · GW(p)
The setting in my paper allows you to have any finite amount of background knowledge.
↑ comment by magfrump · 2011-08-19T01:43:40.798Z · LW(p) · GW(p)
I mean that using a probability distribution rather than just saying numbers clearly dispels a naive pascal's mugging. I am open to the possibility that more heavily contrived Pascal's Muggings may exist that can still exploit an unbounded utility function but I'll read that paper and see what I think after that.
Edit: From the abstract:
The agent has a utility function on outputs from the environment. We show that if this utility function is bounded below in absolute value by an unbounded computable function, then the expected utility of any input is undefined. This implies that a computable utility function will have convergent expected utilities iff that function is bounded.
What this sounds like it is saying is that literally any action under an unbounded utility function has undefined utility. In that case it just says that unbounded utility functions are useless from the perspective of decision theory. I'm not sure how it constitutes evidence that the problem of Pascal's Mugging is unresolved.
↑ comment by Jiro · 2013-06-20T03:58:24.827Z · LW(p) · GW(p)
(Yes, I know this is an old post.)
Suppose that the probability I assign to the mugger being able to deliver is equal to 1 / ((utility delivered if the mugger is telling the truth) ^ 2). Wouldn't that be a probability that goes down fast enough to outweigh the increase in utility?
Replies from: Oscar_Cunningham↑ comment by Oscar_Cunningham · 2013-06-20T12:12:37.159Z · LW(p) · GW(p)
I'm afraid that I don't remember the details of the paper I linked to above, you'll have to look at it to see why they don't consider that a valid distribution (perhaps because the things that the mugger says have to be counted as evidence, and this can't decrease that quickly for some reason? I'm afraid I don't remember.)
comment by Lapsed_Lurker · 2011-08-18T20:23:50.023Z · LW(p) · GW(p)
On the 'Yelp' examples: I looked at the yelp.com website, and it appears that it lets you rate things on a scale of 1 to 5 stars.
A thing with 200 reviews and an average of 4.75 seems like an example of humongous ballot-stuffing. Either that or nearly everyone on yelp.com votes 4 or 5 nearly all the time, so either way the example seems a bad one.
Replies from: multifoliaterose↑ comment by multifoliaterose · 2011-08-18T22:32:05.028Z · LW(p) · GW(p)
Holden wrote that a priori a restaurant with a Yelp average of 4.75 coming from 200 reviews is probably better than a restaurant with a Yelp average of 5 coming from 3 reviews. Do you disagree?
I agree that the possibility of ballot stuffing and the possibility that the fraction of consumers who write Yelp reviews varies with the quality of their experience complicates the situation. But my intuition here is the same as Holden's.
In any case, the question of whether the example at hand is a good one is irrelevant to the point of post where the example appears: scant additional that an opportunity is excellent doesn't reflect as well on an opportunity than abundant additional evidence that an opportunity is very good.