Written in a hurry today at the EA UCLA AI Timelines Workshop. Long and stream-of-thought, and a deliberate intellectual overreach as an epistemic exercise. My first foray into developing my own AGI timelines model without deferring! [LW(p) · GW(p)] Please, I beg of you, tell me why I'm wrong in the comments!
Epistemic status: Small-N reasoning. Low confidence, but represents my standing understanding of AGI timelines as of now.
Here I'm combining thinking about this with thinking about AGI 10 years hence. The latter forecasting task is totally different if we have a form of AGI as of two days ago, even an admittedly weak form.
Do We Have "Subhuman AGI" as of Two Days Ago?
If I want to forecast AGI 10 years out, I first want to understand current-year AGI. Do we currently have AGI? What does it look like? What hyperparameters, up to and including overall architecture, might we push on and make progress on in the coming decade?
To start, I'll read the Gato paper out of DeepMind, investigating for myself Daniel's above claim that Gato constitutes subhuman AGI:[1]
We focus our training at the operating point of model scale that allows real-time control of real-world robots, currently around 1.2B parameters in the case of Gato. As hardware and model architectures improve, this operating point will naturally increase the feasible model size, pushing generalist models higher up the scaling law curve. For simplicity Gato was trained offline in a purely supervised manner; however, in principle, there is no reason it could not also be trained with either offline or online reinforcement learning (RL) (p. 2).
Gato is small, parameters-wise. At 1.2 billion parameters, it's 1/100th the size of the largest GPT-3 model and 1/500th the size of PaLM. This is a choice due to hardware constraints; larger models, which definitely could have been used here, would not be able to operate real-world robotic limbs in real time. Additionally, the tasks on which Gato was trained were chosen purely incidentally: they could have easily been otherwise. So Gato is a miniaturized version of models to come in the near future.
After converting data into tokens, we use the following canonical sequence ordering.
Text tokens in the same order as the raw input text.
Image patch tokens in raster order.
Tensors in row-major order.
Nested structures in lexicographical order by key.
Agent timesteps as observation tokens followed by a separator, then action tokens.
Agent episodes as timesteps in time order (p. 3).
Gato is a large transformer with a single sense-modality: it receives diverse kinds of inputs pressed into a sequence of tokens, and outputs more tokens. This is just applying the current successful language-model architecture to varied-domain problem solving in the naïve way.
Because distinct tasks within a domain can share identical embodiments, observation formats and action specifications, the model sometimes needs further context to disambiguate tasks. Rather than providing e.g. one-hot task identifiers, we instead … use prompt conditioning. During training, for 25% of the sequences in each batch, a prompt sequence is prepended, coming from an episode generated by the same source agent on the same task. Half of the prompt sequences are from the end of the episode, acting as a form of goal conditioning for many domains; and the other half are uniformly sampled from the episode. During evaluation, the agent can be prompted using a successful demonstration of the desired task, which we do by default in all control results that we present here.
…Because agent episodes and documents can easily contain many more tokens than fit into context, we randomly sample subsequences of 𝐿 tokens from the available episodes. Each batch mixes subsequences approximately uniformly over domains (e.g. Atari, MassiveWeb, etc.), with some manual upweighting of larger and higher quality datasets (p. 4).
…
Ideally, the agent could potentially learn to adapt to a new task via conditioning on a prompt including demonstrations of desired behaviour. However, due to accelerator memory constraints and the extremely long sequence lengths of tokenized demonstrations, the maximum context length possible does not allow the agent to attend over an informative-enough context. Therefore, to adapt the agent to new tasks or behaviours, we choose to fine-tune the agent’s parameters on a limited number of demonstrations of a single task, and then evaluate the fine-tuned model’s performance in the environment (p. 11).
A major part of the guts of the model is the use of internal prompt programming. Context length limits don't prevent training high-performance in Gato, but does prevent us from fully testing the out-of-the-box model's few-shot generalization abilities.
Our control tasks consist of datasets generated by specialist SoTA or near-SoTA reinforcement learning agents trained on a variety of different environments. For each environment we record a subset of the experience the agent generates (states, actions, and rewards) while it is training (p. 5).
Gato is trained to do RL-style tasks by supervised learning on token sequences generated from state-of-the-art RL model performance. These tasks take place in both virtual and real-world robot arm environments.
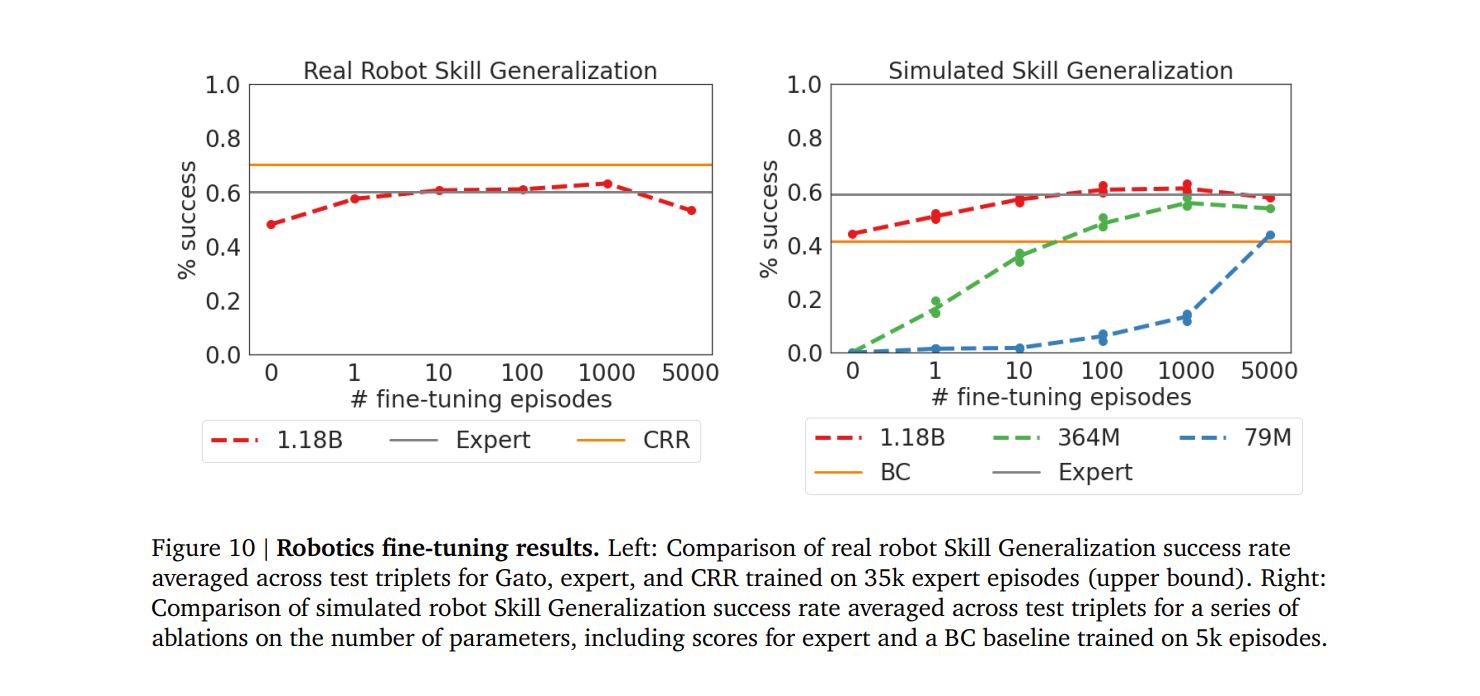
Figure 10 compares the success rate of Gato across different fine-tuning data regimes to the sim-to-real expert and a Critic-Regularized Regression (CRR) (Wang et al., 2020) agent trained on 35k episodes of all test triplets. Gato, in both reality and simulation (red curves on the left and right figure, respectively), recovers the expert’s performance with only 10 episodes, and peaks at 100 or 1000 episodes of fine-tuning data, where it exceeds the expert. After this point (at 5000), performance degrades slightly but does not drop far below the expert’s performance (p. 12).
A crucial datapoint for the subhuman AGI question! Gato, after a small amount of fine-tuning, catches up with SOTA RL expert models. It does this even with real-world colored-block stacking tasks; Gato is capable of interfacing with the physical world, albeit in a controlled environment.
Gato was inspired by works such as GPT-3 (Brown et al., 2020) and Gopher (Rae et al., 2021), pushing the limits of generalist language models; and more recently the Flamingo (Alayrac et al., 2022) generalist visual language model. Chowdhery et al. (2022) developed the 540B parameter Pathways Language Model (PalM) explicitly as a generalist few-shot learner for hundreds of text tasks. Future work should consider how to unify these text capabilities into one fully generalist agent that can also act in real time in the real world, in diverse environments and embodiments (p. 15).
*Inarticulate screaming*
In this work we learn a single network with the same weights across a diverse set of tasks.
Recent position papers advocate for highly generalist models, notably Schmidhuber (2018) proposing one big net for everything, and Bommasani et al. (2021) on foundation models. However, to our knowledge there has not yet been reported a single generalist trained on hundreds of vision, language and control tasks using modern transformer networks at scale.
“Single-brain”-style models have interesting connections to neuroscience. Mountcastle (1978) famously stated that “the processing function of neocortical modules is qualitatively similar in all neocortical regions. Put shortly, there is nothing intrinsically motor about the motor cortex, nor sensory about the sensory cortex”. Mountcastle found that columns of neurons in the cortex behave similarly whether associated with vision, hearing or motor control. This has motivated arguments that we may only need one algorithm or model to build intelligence (Hawkins and Blakeslee, 2004).
Sensory substitution provides another argument for a single model (Bach-y Rita and Kercel, 2003). For example, it is possible to build tactile visual aids for blind people as follows. The signal captured by a camera can be sent via an electrode array on the tongue to the brain. The visual cortex learns to process and interpret these tactile signals, endowing the person with some form of “vision”. Suggesting that, no matter the type of input signal, the same network can process it to useful effect (p. 16).
…
There has been great recent interest in data-driven robotics (Cabi et al., 2019; Chen et al., 2021a). However, Bommasani et al. (2021) note that in robotics “the key stumbling block is collecting the right data. Unlike language and vision data, robotics data is neither plentiful nor representative of a sufficiently diverse array of embodiments, tasks, and environments”. Moreover, every time we update the hardware in a robotics lab, we need to collect new data and retrain. We argue that this is precisely why we need a generalist agent that can adapt to new embodiments and learn new tasks with few data (p. 17).
…
Transformer sequence models are effective as multi-task multi-embodiment policies, including for real-world text, vision and robotics tasks. They show promise as well in few-shot out-of-distribution task learning. In the future, such models could be used as a default starting point via prompting or fine-tuning to learn new behaviors, rather than training from scratch (p. 18).
Finally, descriptions of the range of tasks Gato is trained on:
F.1. Atari
We collect two separate sets of Atari environments. The first (that we refer to as ALE Atari) consists of 51 canonical games from the Arcade Learning Environment (Bellemare et al., 2013). The second (that we refer to as ALE Atari Extended) is a set of alternative games3 with their game mode and difficulty randomly set at the beginning of each episode.
For each environment in these sets we collect data by training a Muesli (Hessel et al., 2021) agent for 200M total environment steps. We record approximately 20,000 random episodes generated by the agent during training.
F.2. Sokoban
Sokoban is a planning problem (Racanière et al., 2017), in which the agent has to push boxes to target locations. Some of the moves are irreversible and consequently mistakes can render the puzzle unsolvable. Planning ahead of time is therefore necessary to succeed at this puzzle. We use a Muesli (Hessel et al., 2021) agent to collect training data.
F.3. BabyAI
BabyAI is a gridworld environment whose levels consist of instruction-following tasks that are described by a synthetic language. We generate data for these levels with the built-in BabyAI bot. The bot has access to extra information which is used to execute optimal solutions, see Section C in the appendix of (Chevalier-Boisvert et al., 2018) for more details about the bot. We collect 100,000 episodes for each level.
F.4. DeepMind Control Suite
The DeepMind Control Suite (Tassa et al., 2018; Tunyasuvunakool et al., 2020) is a set of physicsbased simulation environments. For each task in the control suite we collect two disjoint sets of data, one using only state features and another using only pixels. We use a D4PG (Barth-Maron et al., 2018) agent to collect data from tasks with state features, and an MPO (Abdolmaleki et al., 2018) based agent to collect data using pixels.
We also collect data for randomized versions of the control suite tasks with a D4PG agent. These versions randomize the actuator gear, joint range, stiffness, and damping, and geom size and density. There are two difficulty settings for the randomized versions. The small setting scales values by a random number sampled from the union of intervals [0.9, 0.95] ∪ [1.05, 1.1]. The large setting scales values by a random number sampled from the union of intervals [0.6, 0.8] ∪ [1.2, 1.4].
F.5. DeepMind Lab
DeepMind Lab (Beattie et al., 2016) is a first-person 3D environment designed to teach agents 3D vision from raw pixel inputs with an egocentric viewpoint, navigation, planning.
We collect data for 255 tasks from the DeepMind Lab, 254 of which are used during training, the left out task was used for out of distribution evaluation. Data is collected using an IMPALA (Espeholt et al., 2018) agent that has been trained jointly on a set of 18 procedurally generated training tasks. Data is collected by executing this agent on each of our 255 tasks, without further training.
F.6. Procgen Benchmark
Procgen (Cobbe et al., 2020) is a suite of 16 procedurally generated Atari-like environments, which was proposed to benchmark sample efficiency and generalization in reinforcement learning. Data collection was done while training a R2D2 (Kapturowski et al., 2018) agent on each of the environments. We used the hard difficulty setting for all environments except for maze and heist, which we set to easy.
F.7. Modular RL
Modular RL (Huang et al., 2020) is a collection of MuJoCo (Todorov et al., 2012) based continuous control environments, composed of three sets of variants of the OpenAI Gym (Brockman et al., 2016) Walker2d-v2, Humanoid-v2, and Hopper-v2. Each variant is a morphological modification of the original body: the set of morphologies is generated by enumerating all possible subsets of limbs, and keeping only those sets that a) contain the torso, and b) still form a connected graph. This results in a set of variants with different input and output sizes, as well as different dynamics than the original morphologies. We collected data by training a single morphology-specific D4PG agent on each variant for a total of 140M actor steps, this was done for 30 random seeds per variant.
F.8. DeepMind Manipulation Playground
The DeepMind Manipulation Playground (Zolna et al., 2021) is a suite of MuJoCo based simulated robot tasks. We collect data for 4 of the Jaco tasks (box, stack banana, insertion, and slide) using a Critic-Regularized Regression (CRR) agent (Wang et al., 2020) trained from images on human demonstrations. The collected data includes the MuJoCo physics state, which is we use for training and evaluating Gato.
F.9. Meta-World
Meta-World (Yu et al., 2020) is a suite of environments for benchmarking meta-reinforcement learning and multi-task learning. We collect data from all train and test tasks in the MT50 mode by training a MPO agent (Abdolmaleki et al., 2018) with unlimited environment seeds and with access to state of the MuJoCo physics engine. The collected data also contains the MuJoCo physics engine state.
…
The specialist Meta-World agent described in Section 5.5 achieves 96.6% success rate averaged over all 50 Meta-World tasks. The detailed success rates are presented in Table 7. We evaluated agent 500 times for each task (pp. 36-7, 39-40).
Where the bar for impressive-but-subhuman performance is set by other models, which might possess diverse architectures very unlike Gato's, Gato is a subhuman AGI. Gato generalizes to previously held-out tasks, including real-world robotics tasks, after 10 episodes of fine-tuning. (This is only because of context window limits, and we could test the model on few-shot learning with only context in these varied domains were that window larger.)
As with GPT-3, one scary feature of Gato's success is that its architecture and hyperparameters aren't strongly optimized for what it does. It's basically a (relatively small!) large language model pressed into service as a generalist, and that just works. AGI is here, and it wasn't that hard to engineer. Quoth Gwern, "Scaling just works." [LW(p) · GW(p)]
A Decade of Actual AI
My guess is that this heralds the beginning of "actual AI," meaning AI reaching out into the world of atoms and not merely the world of bits. I don't mean to disparage progress in ML; if you're anything like me, the visceral impressiveness of GPT-2 and -3 are a big part of why you're throwing yourself into trying to help with alignment! But I was promised a flying car in my childhood, dammit. I remember reading a kid's science magazine that promised me I'd be commuting via space elevator by now! Will we get our household robots anytime soon?
If a slapped together, relatively small transformer like Gato can, with a minimum of fine-tuning (10 episodes), generalize well to previously unseen robotics tasks, then Gato's descendants, heavily optimized for success, can plausibly do much better. For Bayesian reasons, [LW · GW] the most important part of a secret is that the secret exists, [? · GW] and the genie is now out of the bottle regarding naïve transformers and their potential varied applications.
From an alignment perspective, this is horrifying. The worlds in which we can marshal sufficient Coordination between AI labs to prevent our doom … are worlds in which there aren't a hundred disparate actors all rushing to AGI because there's gold [LW · GW] in them thar hills. [LW · GW] But creating common knowledge of that seems to be what just happened, emboldening efforts to pursue and market, e.g., AI personal assistants.
Extrapolating from the successes of the past decade of successes in deep learning (recalling that transformers only date back to 2017), we should naively expect the equivalent-in-impressiveness of the GPT series in other domains, including in real-world robotics.[2] Some spitballing implications: We should expect fully competent self-driving to be solved. We should expect customer-service chatbots to be solved -- AI won't pass the adversarial Turing test by 2032, but it will pass the average-case Turing test, and so be ready for deployment in relatively-low-stakes conversational roles. Factory robots get much better, sufficient to work in complicated domains like households and fast-food restaurants; the internet learns semantics and so websites take on forms much more interesting than static text, image, and video elements; we begin seriously using computers via input channels other than keyboard-and-mouse, as those are currently blocked on ML interpretation of messy human input.
Shallow Pattern Matching in the World of Atoms
While Gato constitutes a kind of subhuman AGI, it is not anything like human-grade AGI. Fundamentally, as its architecture has not substantially changed from, e.g., GPT-3, Gato's intrinsic limits don't fundamentally exceed those in GPT-3.
I don't even know how many tens of thousands of LM samples I've read by now. (Just my bot alone has written 80,138 posts -- and counting -- and while I no longer read every new one these days, I did for a very long time.)
Read enough, and you will witness the LM both failing and succeeding at anything your mind might want to carve out as a "capability." You see the semblance of abstract reasoning shimmer across a strings of tokens, only to yield to suddenly to absurd, direct self-contradiction. You see the model getting each fact right, then wrong, then right. I see no single, stable trove of skills being leveraged here and there as needed. I just see stretches of success and failure at imitating ten thousand different kinds of people, all nearly independent of one another, the products of barely-coupled subsystems.
This is hard to refute, but I think this is something you only grok when you read enough LM samples -- where "enough" is a pretty big number.
GPT makes many mistakes, but many of these mistakes are of types which it only makes rarely. Some mistake the model makes only every 200 samples, say, is invisible upon one's first encounter with GPT. You don't even notice that model is "getting it right," any more than you would notice a fellow human "failing to forget" that water flows downhill. It's just part of the floor you think you're standing on.
The first time you see it, it surprises you, a crack in the floor. By the fourth time, it doesn't surprise you as much. The fortieth time you see the mistake, you don't even notice it, because "the model occasionally gets this wrong" has become part of the floor.
Eventually, you no longer picture of a floor with cracks in it. You picture a roiling chaos which randomly, but regularly, coalesces into ephemeral structures possessing randomly selected subsets of the properties of floors.
Large language models today sit in this weird uncanny valley of ability, where they are both shockingly good at writing (GPT-2 at its best writing a B-grade high school history essay) and pick up the idiot ball at moments no human would (nostalgebraist on GPT-3's inhuman metafictional tendencies [LW · GW]). Gato exports this uncanny valley of competence that no human possesses into the world of atoms.
In the way that PaLM cannot pass an adversarial Turing test, correspondingly scaled-up Gato won't successfully control a humanoid robot in unfamiliar domains on arbitrary unfamiliar physical tasks. But Gato still exports a whole lot of competence into the physical world (and into a whole host of varied tasks in virtual environments too.) Even if large language models and scaled-up Gato peter out at some point, the lack of intense optimization work put into them so far suggests that we haven't come close to mining out this capabilities vein, and we should only expect nostalgebraist's "cracks in the floor" to narrow and often close up in the coming decade of AI capabilities progress.
A Milestone and a Plea
I may be totally off-base here. This summary and projection is built on my very limited model of AI capabilities. I hope to God I'm just confused, and am eager to update my model.
But if subhuman AGI is here, and if we're kicking off the final race to human-grade AGI now, even just the very beginning of it … then timelines are extraordinarily short. Others mentioned [LW · GW] in earlier Gato posts [LW(p) · GW(p)] that their models predicted something like this; reading the Gato paper, I realize that my model (insofar as I had one) was surprised by this. I am scared and have shrunk my timelines.
Admittedly a bit of abuse of terminology, if by "AGI" we usually mean human-equivalent AI across a range of diverse task domains. By "subhuman AGI" here, I mean an AI that performs a wide range of disparate tasks at levels only modestly below typical human performance.
For what it's worth, I was thoroughly underwhelmed by Gato, to the point of feeling confused what the paper was even trying to demonstrate.
I'm not the only ML researcher who had this reaction. In the Eleuther discord server, I said "i don't get what i'm supposed to take away from this gato paper," and responses from regulars included
"nothing, this was 3 years over-due"
"Yep. I didn't update much on this paper. I think the 'general' in the title is making people panic lol" (with two "this" reacts)
Or see this tweet. I'm not trying to convince you by saying "lots of people agree with me!", but I think this may be useful context.
A key thing to remember when evaluating Gato is that it was trained on data from many RL models that were themselves very impressive. So there are 2 very different questions we can ask:
Does Gato successively distill a large number of learned RL policies into a single, small collection of params?
Does Gato do anything except distillation? Is there significant beneficial transfer between tasks or data types? Is Gato any more of a "generalist agent" than, like, a big cloud storage bucket with all of those RL models in it, and a little script that lets you pick which one to load and run?
And the answers are a pretty clear, stark "yes" and "no," respectively.
For #2, note that every time the paper investigates transfer, it gets results that are mostly or entirely negative (see Figs 9 and 17). For example, including stuff like text data makes Gato seem more sexily "generalist" but does not actually seem to help anything -- it's like uploading a (low-quality) LM to the same cloud bucket as the RL policies. It just sits there.
In the particular case of the robot stacking experiment, I don't think your read is accurate, for reasons related to the above. Neither the transfer to real robotics, nor the effectiveness of offline finetuning, are new to Gato -- the researchers are sticking as close as they can to what was done in Lee et al 2022, which used the same stacking task + offline finetuning + real robots, and getting (I think?) broadly similar results. That is, this is yet another success of distillation, without a clear value-add beyond distillation.
In the specific case of Lee et al's "Skill Generalization" task, it's important to note that the "expert" line is not reflective of "SOTA RL expert models."
The stacking task is partitioned here (over object shapes/colors) into train and test subsets. The "expert" is trained only on the train subset, and then Lee et al (and the Gato authors) investigate models that are additionally tuned on the test subset in some way or other. So the "expert" is really a baseline here, and the task consists of trying to beat it.
(This distinction made somewhat clearer in an appendix of the Gato paper -- see Fig. 17, and note that the "expert" lines there match the "Dataset" lines from Fig. 3 in Lee et al 2022.)
FWIW I agree with this take & basically said as much in my post; Gato is about what I would have expected given past progress. I think people are right to freak out now about oncoming AGI, but I think they should have been freaking out already, and Gato just had a sufficiently sexy title and abstract. It's like how people should have been freaking out about COVID early on but only actually started freaking out when hospitals started getting crowded in their own country.
As for the transfer, I would actually have been a bit surprised if there was significant positive transfer given the small number of tasks trained on and the small model size. I'm curious to hear if there was negative transfer though and if so how much. I think the reason why it being a unified agent matters is that we should expect significant positive transfer to happen eventually as we scale up the model and train it longer on more tasks. Do you not?
I think the reason why it being a unified agent matters is that we should expect significant positive transfer to happen eventually as we scale up the model and train it longer on more tasks. Do you not?
Sure, this might happen.
But remember, to train "a Gato," we have to first train all the RL policies that generate its training data. So we have access to all of them too. Instead of training Gato, we could just find the one policy that seems closest to the target task, and spend all our compute on just finetuning it. (Yes, related tasks transfer -- and the most related tasks transfer most!)
This approach doesn't have to spend any compute on the "train Gato" step before finetuning, which gives it a head start. Plus, the individual policy models are generally much smaller than Gato, so they take less compute per step.
Would this work? In the case of the Lee et al robot problem, yes (this is roughly what Lee et al originally did, albeit with various caveats). In general, I don't know, but this is the baseline that Gato should be comparing itself against.
The question isn't "will it improve with scale?" -- it's 2022, anything worth doing improves with scale -- but "will it ever reach the Pareto frontier? will I ever have a reason to do it?"
As an ML practitioner, it feels like the paper is telling me, "hey, think of a thing you can already do. What if I told you a way to do the same thing, equally well, with an extra step in the middle?" Like, uh, sure, but . . . why?
By contrast, when I papers like AlphaGo, BERT, CLIP, OpenAI diffusion, Chinchilla . . . this is a type of paper where I say, "holy shit, this Fucking Works™, this moves the Pareto frontier." In several of these cases I went out and immediately used the method in the real world and reaped great rewards.
IMO, the "generalist agent" framing is misleading, insofar as it obscures this second-best quality of Gato. It's not really any more an "agent" than my hypothetical cloud drive with a bunch of SOTA models on it. Prompting GATO is the equivalent of picking a file from the drive; if I want to do a novel task, I still have to finetune, just as I would with the drive. (A real AGI, even a weak one, would know how to finetune itself, or do the equivalent.)
We are not talking about an autonomous thing; we're still in the world where there's a human practitioner and "Gato" is one method they can use or not use. And I don't see why I would want to use it.
But remember, to train "a Gato," we have to first train all the RL policies that generate its training data. So we have access to all of them too.
No, you don't have to, nor do you have guaranteed access, nor would you necessarily want to use them rather than Gato if you did. As Daniel points out, this is obviously untrue of all of the datasets it's simply doing self-supervised learning on (how did we 'train the RL policy' for photographs?). It is also not true of it because it's off-policy and offline: the experts could be human, or they could be the output of non-RL algorithms which are infeasible to run much like large search processes (eg chess endgame tables) or brittle non-generalizable expert-hand-engineered algorithms, or they could be RL policies you don't have direct access to (because they've bitrotten or their owners won't let you), or even RL policies which no longer exist because the agents were deleted but their data remains, or they could be RL policies from an oracle setting where you can't run the original policy in the meaningful real world context (eg in robotics sim2real where you train the expert with oracle access to the simulation's ground truth to get a good source of demonstrations, but at the end you need a policy which doesn't use that oracle so you can run it in a real robot) or more broadly any kind of meta-learning context where you have data from RL policies for some problems in a family of problems and want to induce general solving, or they are filtered high-reward episodes from large numbers of attempts by brute force dumb (even random) agents where you trivially have 'access to all of them' but that is useless, or... Those RL policies may also not be better than a Gato or DT to begin with, because imitation learning can exceed observed experts [EA(p) · GW(p)] and the 'RL policies' here might be, say, random baselines which merely have good coverage of the state-space. Plus, nothing at all stops Decision Transformer from doing its own exploration (planning was already demonstrated by DT/Trajectory Transformer, and there's been work afterwards like Online Decision Transformer).
I thought some of the "experts" Gato was trained on were not from-scratch models but rather humans -- e.g. images and text generated by humans.
Relatedly, instead of using a model as the "expert" couldn't you use a human demonstrator? Like, suppose you are training it to control a drone flying through a warehouse. Couldn't you have humans fly the drones for a bit and then have it train on those demonstrations?
It's not really any more an "agent" than my hypothetical cloud drive with a bunch of SOTA models on it. Prompting GATO is the equivalent of picking a file from the drive; if I want to do a novel task, I still have to finetune, just as I would with the drive. (A real AGI, even a weak one, would know how to finetune itself, or do the equivalent.)
This is false if significant transfer/generalization starts to happen, right? A drive full of a bunch of SOTA models, plus a rule for deciding what to use, is worse than Gato to the extent that Gato is able to generalize few-shot or zero-shot to new tasks and/or insofar as Gato gets gains from transfer.
EDIT: Meta-comment: I think we are partially just talking past each other here. For example, you think that the question is 'will it ever reach the Pareto frontier,' which is definitely not the question I care about.
Meta-comment of my own: I'm going to have to tap out of this conversation after this comment. I appreciate that you're asking questions in good faith, and this isn't your fault, but I find this type of exchange stressful and tiring to conduct.
Specifically, I'm writing at the level of exactness/explicitness that I normally expect in research conversations, but it seems like that is not enough here to avoid misunderstandings. It's tough for me to find the right level of explicitness while avoiding the urge to put thousands of very pedantic words in every comment, just in case.
Re: non-RL training data.
Above, I used "RL policies" as a casual synecdoche for "sources of Gato training data," for reasons similar to the reasons that this post by Oliver Sourbut [LW · GW] focuses on RL/control.
Yes, Gato had other sources of training data, but (1) the RL/control results are the ones everyone is talking about, and (2) the paper shows that the RL/control training data is driving those results (they get even better RL/control outcomes when they drop the other data sources).
Re: gains from transfer..
Yes, if Gato outperforms a particular RL/control policy that generated training data for it, then having Gato is better than merely having that policy, in the case where you want to do its target task.
However, training a Gato is not the only way of reaping gains from transfer. Every time we finetune any model, or use multi-task training, we are reaping gains from transfer. The literature (incl. this paper) robustly shows that we get the biggest gains from transfer when transferring between similar tasks, while distant or unrelated tasks yield no transfer or even negative transfer.
So you can imagine a spectrum ranging from
"pretrain only on one very related task" (i.e. finetuning a single narrow task model), to
"pretraining on a collection of similar tasks" (i.e. multi-task pretraining followed by finetuning), to
"pretrain on every task, even those where you expect no or negative transfer" (i.e. Gato)
The difference between Gato (3) and ordinary multi-task pretraining (2) is that, where the latter would only train with a few closely related tasks, Gato also trains on many other less related tasks.
It would be cool if this helped, and sometimes it does help, as in this paper about training on many modalities at once for multi-modal learning with small transformers. But this is not what the Gato authors found -- indeed it's basically the opposite of what they found.
We could use a bigger model in the hope that will get us some gains from distant transfer (and there is some evidence that this will help), but with the same resources, we could also restrict ourselves to less-irrelevant data and then train a smaller (or same-sized) model on more of it. Gato is at one extreme end of this spectrum, and everything suggests the optimum is somewhere in the interior.
Oliver's post [LW · GW], which I basically I agree with, has more details on the transfer results.
A single network is solving 600 different tasks spanning different areas. 100+ of the tasks are solved at 100% human performance. Let that sink in.
While not a breaktrough in arbitrary scalable generality, the fact that so many tasks can be fitted into one architecture is surprising and novel. For many real life applications, being good in 100-1000 tasks makes an AI general enough to be deployed as an error tollerant robot, say in a warehouse.
The main point imho is that this architecture may be enough to be scaled (10-1000x parameters) in few years to a useful proto-AGI product.
Having just seen this paper and still recovering from Dalle-2 and Palm and then re-reading Eliezer’s now incredibly prescient dying with dignity post I really have to ask: What are we supposed to do? I myself work on ML in a fairly boring corporate capacity and when reading these papers and posts I get a massive urge to drop everything and do something equivalent to a PhD in Alignment but the timelines that seem to be becoming possible now make that seem like a totally pointless exercise, I’d be writing my Dissertation as nanobots liquify my body into raw materials for paper clip manufacturing. Do we just carry on and hope someone somewhere stumbles upon a miracle solution and we happen to have enough heads in the space to implement it? Do I tell my partner we can’t have kids because the probability they will be born into some unknowable hellscape is far too high? Do I become a prepper and move to a cabin in the woods? I’m actually at a loss on how to proceed and frankly Eliezers article made things muddier for me.
As I understand it, the empirical ML alignment community is bottlenecked on good ML engineers, and so people with your stated background without any further training are potentially very valuable in alignment!
Lots of other positions at Jobs in AI safety & policy - 80,000 Hours too! E.g., from the Fund for Alignment Research and Aligned AI. But note that the 80,000 Hours jobs board lists positions from OpenAI, DeepMind, Baidu, etc. which aren't actually alignment-related.
Things are a lot easier for me, given that I know that I couldn't contribute to Alignment research directly, and the other option, monetarily, is at least not bottlenecked by money so much as prime talent. A doctor unfortunate enough to reside in the Third World, who happens to have emigration plans and a large increase in absolute discretionary income that will only pay off in tens of years has little scope to do more than signal boost.
As such, I intend to live the rest of my life primarily as a hedge against the world in which AGI isn't imminent in the coming decade or two, and do all the usual things humans do, like keeping a job, having fun, raising a family.
That's despite the fact that I think it's more likely than not that I or my kids won't make it out of the 21st century, but at the least it'll be a quick and painless death, with the dispassionate dispatch of a bulldozer running over an anthill, not any actual malice.
Outright sadism is unlikely to be a terminal or contingent goal for any AGI we make, however unaligned; and I doubt that the life expectancy of anyone on a planet rapidly being disassembled for parts will be large enough for serious suffering. In slower circumstances, such as an Aligned AI that only caters to the needs of a cabal of creators, leaving the rest of us to starve, I have enough confidence that I can make the end quick.
Thus, I've made my peace with likely joining the odd 97 billion anatomically modern humans in oblivion, plus another 8 or 9 concurrently departing with me, but it doesn't really spark anxiety or despair. It's good to be alive, and I probably wouldn't prefer to have been born at any earlier a time in history. Hoping for the best and expecting the worst really, assuming your psyche can handle it.
Then again, I'm not you, and someone with a decent foundation in ML is also in the 0.01% of people who could feasibly make an impact in the time we have, and I selfishly hope that you can do what I never could. And if not, at least enjoy the time you have!
Thanks for the reflection, it is how a part of me feels (I usually never post on LessWrong, being just a lurker, but your comment inspired me a bit).
Actually, I do have some background that could, maybe, be useful in alignment, and I did just complete the AGISF program. Right now, I'm applying to some positions (particularly, I'm focusing now on the SERIMATS application, which is an area that I may be differentially talented), and just honestly trying to do my best. After all, it would be outrageous if I could do something, but I simply did not.
But I recognize the possibility that I'm simply not good enough, and there is no way for me to actually do anything beyond just, as you said, signal boosting, so I can introduce more capable people into the field, while living my life and hoping that Humanity solves this.
But, if Humanity does not, well, it is what it is. There was the dream of success, and building a future Utopia, with future technology facilitated by aligned AI, but that may have been just that, a dream. Maybe alignment is unsolvable, and is the natural order of any advanced civilization to destroy itself by its own AI. Or maybe alignment is solvable, but given the incentives of our world as they are, it was always a fact that unsafe AGI would be created before we would solve alignment.
Or maybe, we will solve alignment in the end, or we were all wrong about the risks from AI in the first place.
As for me, for now, I'm going to keep trying, keep studying, just because, if the world comes to an end, I don't want to conclude that I could've done more. While hoping that I never have to wonder about that in the first place.
EDIT: To be clear, I'm not that sure about short timelines, in the sense that, insofar I know (and I may be very, very wrong), the AGIs we are creating right now don't seem to be very agentic, and it may be that creating agency from current techniques is much harder than creating general intelligence. But again, "not so sure" is something like 20%-30% chance of timelines being really short, so the point mostly stands.
Develop a training set for alignment via brute force. We can't defer alignment to the ubernerds. If enough ordinary people (millions? tens of millions?) contribute billions or trillions of tokens, maybe we can increase the chance of alignment. It's almost like we need to offer prayers of kindness and love to the future AGI: writing alignment essays of kindness that are posted to reddit, or videos extolling the virtue of love that are uploaded to youtube.
Primarily talking about it in rat-adjacent communities that are both open to such discussion, but also contain a large number of people who aren't immersed in AI X-risk. A pertinent example would be either the SSC subreddit or its spinoff, The Motte.
The ideal target is someone with the intellectual curiosity to want to know more about such matters, while also not having encountered them beyond glancing summaries. Below that threshold, people are hard to sway because they're going off the usual pop culture tropes about AI, and significantly above that, you have the LW crowd, and me trying to teach them anything novel would be trying to teach my grandma to suck eggs.
If I can find people who are mildly aware of such possibilities, then it's easier to dispel any particular misconceptions they have, such as the tendency to anthromorphize AI, the question of "why not shut it off" etc. Showing them the blistering pace of progress in ML is a reliable eye-opener in my experience.
Engaging with naysayers is also effective, there's a certain stentorian type who not only has said misunderstandings, but loudly shares them to dismiss X-risk altogether. Dismantling such arguments is always good, even if the odds of convincing them are minimal. There's always a crowd of undecided but curious people who are somewhat swayed.
There's also the topic of automation-induced unemployment, which is what I usually bring up in medical circles that would otherwise be baffled by AI X-risk. That's the most concrete and imminent danger any skilled professional faces, even if the current timelines indicate that the period between the widespread adoption of near-human AI and actual Superhuman AGI is going to be tiny.
That's about as much as I can do, I don't have the money to donate anything but pocket change, and my access to high-flying ML engineers is mostly restricted to this very forum. I'm acutely aware that I'm not good enough at math to produce original work in the field, so given those constraints, I consider it a victory if I can sway people wealthier and better positioned by virtue of living in the First World on the matter!
Regarding the arguments for doom, they are quite logical, but they don't quite have the same confidence as e.g. an argument that if you are in a burning, collapsing building, your life is in peril. There are a few too many profound unknowns that have a bearing on the consequences of superhuman AI, to know that the default outcome really is the equivalent of a paperclip maximizer.
However, I definitely agree that that is a very logical scenario, and also that the human race (or the portion of it that works on AI) is taking a huge gamble by pushing towards superhuman AI, without making its central priority that this superhuman AI is 'friendly' or 'aligned'.
In that regard, I keep saying that the best plan I have seen, is June Ku's "meta-ethical AI", which falls into the category of AI proposals that construct an overall goal by aggregating idealized versions of the current goals of all human individuals. I want to make a post about it, but I haven't had time... So I would suggest, check it out, and see if you can contribute technically or critically or by spreading awareness of this kind of proposal.
I think "train a single transformer to imitate the performance of lots of narrow models" is perhaps the least satisfying way to get to a general agent. The fact that this works is disturbing, I shudder thinking of what is possible with an actual Theory of Deep Learning, and not the bag of rusty tools this field consists of right now. With our luck, I wouldn't be surprised to find that somehow grafting MCTS to this model gets Deepmind all the way there to human-level.
Nevertheless... maybe now would be a good time to buy google and nvidia stock? There's no sense in dying poor...
How long would you expect to be able to enjoy your newfound fortune in Google stock before death? I could maybe see an AGI starting to disassemble the planet before the stock even has a chance to rise all that much...
In the modal future, no time at all, we probably all die at the same time before any economic effects are felt. That was partly a joke, and partly said to maximize value in those futures where we do get some time of economic growth before catastrophe.
Curious: Do you have a considered model of the regulatory bottleneck on short-term AGI inputs into the economy?
I mention in a footnote above that Eliezer thinks that, in the worlds where we could make lots of money from Google stock shortly before doomsday, the developed countries would already have implemented something like open borders in order to pick up those trillion dollar bills from labor mobility. If we can't take human-level natural-general-intelligence inputs into our economy, we can't take subhuman-level AGI economic inputs either, Eliezer argues.
But I'm trying not to defer, and I don't know what I object-level-think … that argument seems pretty solid I guess.
I don't expect google's stock price to rise because AGI will actually impact the economy in meaningful ways in the short-term, I just think that demonstrating AGI will really make investors finally understand the eventual impact, and the stock will go crazy, just like Tesla's, even if their actual fundamental metrics aren't that impressive. Economies as a whole might not be competent enough to take AGI inputs, but specific companies certainly are, and I don't doubt that Google will be trying to solve every problem they can find with AGI, just like Deepmind is now trying to do for medicine. You can bet on the spread between google and the SP500 to take advantage of the inefficiency of the economy as a whole in integrating AGI.