How bad a future do ML researchers expect?
post by KatjaGrace · 2023-03-09T04:50:05.122Z · LW · GW · 8 commentsContents
Notes None 8 comments
Katja Grace, 8 March 2023
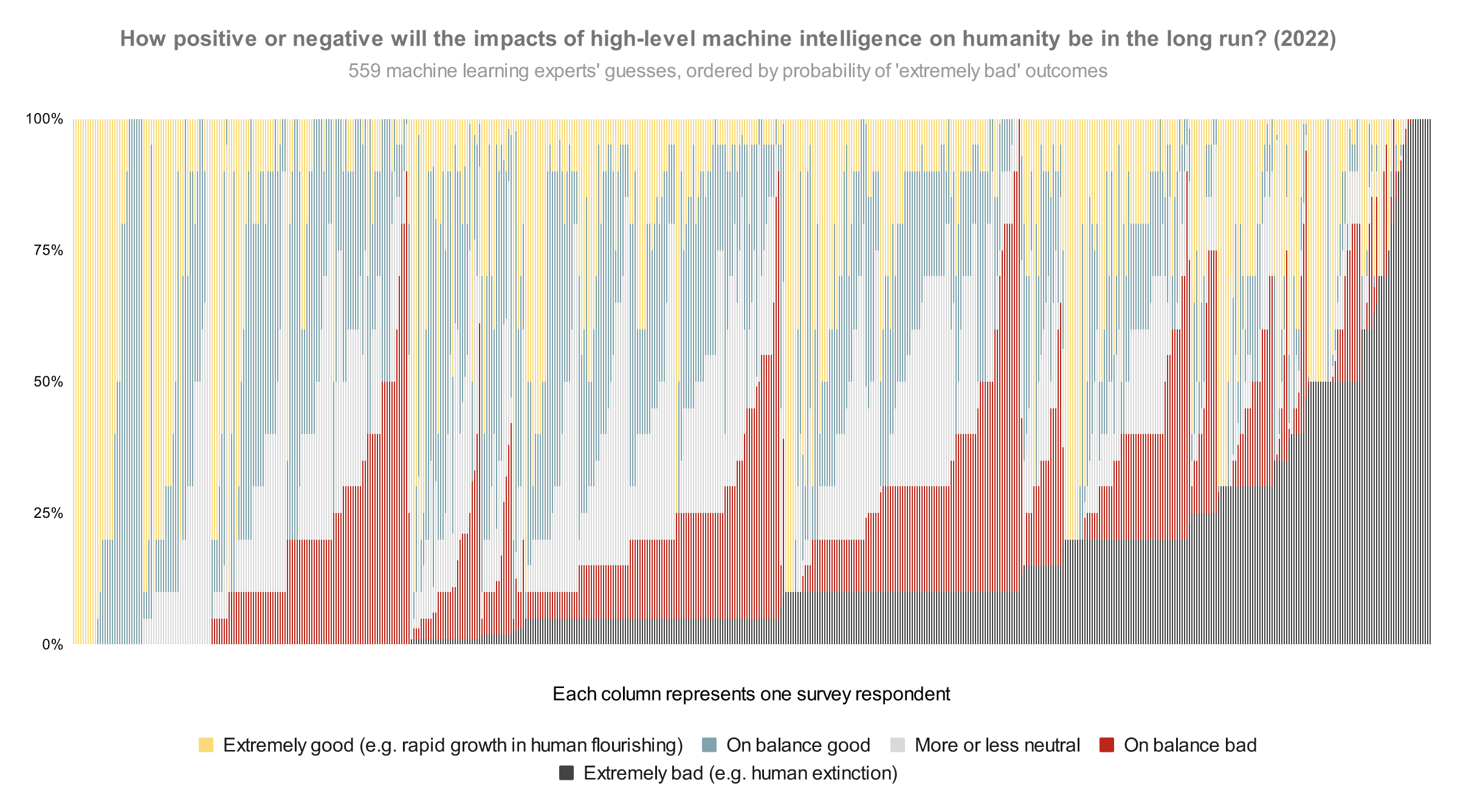
In our survey last year, we asked publishing machine learning researchers how they would divide probability over the future impacts of high-level machine intelligence between five buckets ranging from ‘extremely good (e.g. rapid growth in human flourishing)’ to ‘extremely bad (e.g. human extinction).1 The median respondent put 5% on the worst bucket. But what does the whole distribution look like? Here is every person’s answer, lined up in order of probability on that worst bucket:
And here’s basically that again from the 2016 survey (though it looks like sorted slightly differently when optimism was equal), so you can see how things have changed:
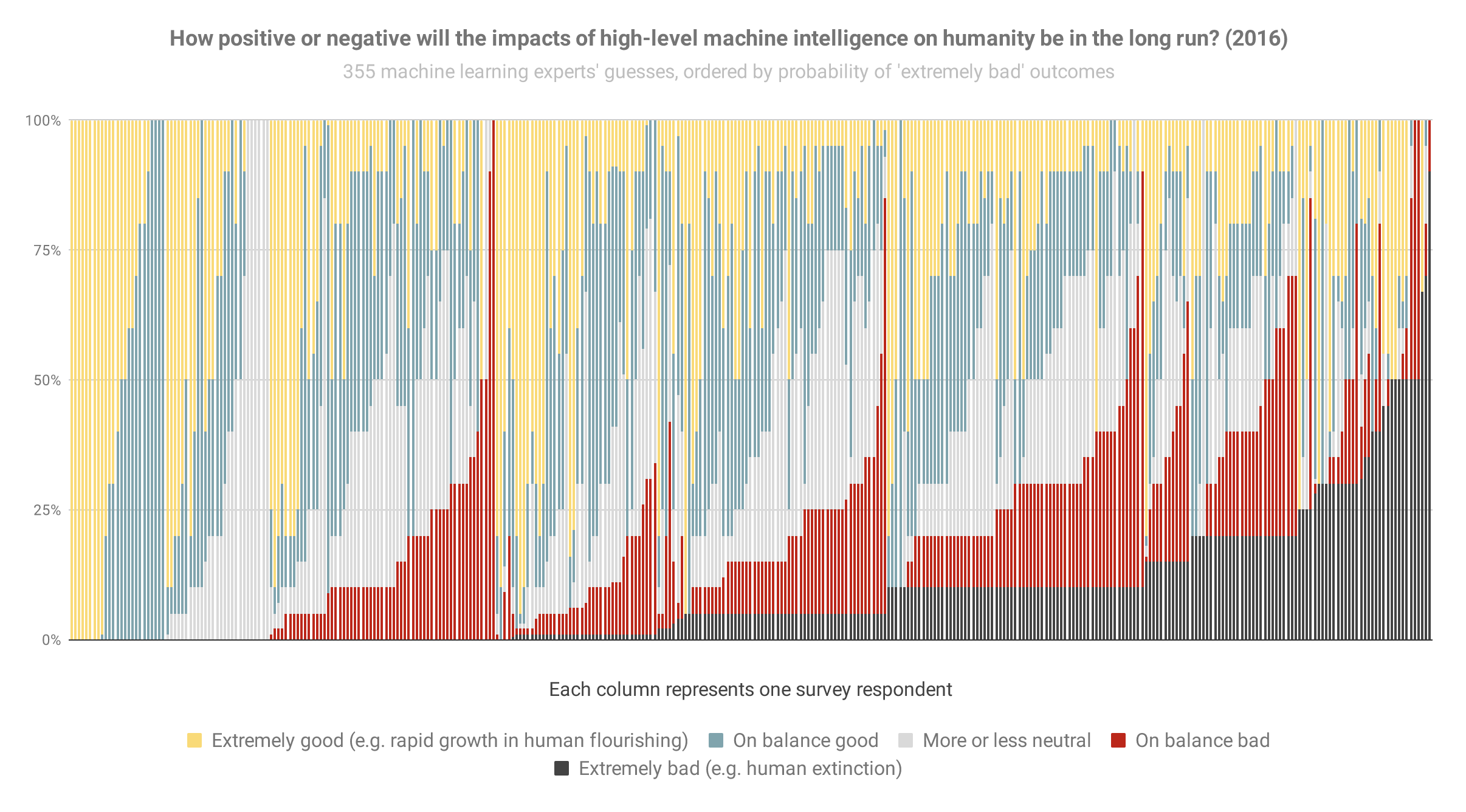
The most notable change to me is the new big black bar of doom at the end: people who think extremely bad outcomes are at least 50% have gone from 3% of the population to 9% in six years.
Here are the overall areas dedicated to different scenarios in the 2022 graph (equivalent to averages):
- Extremely good: 24%
- On balance good: 26%
- More or less neutral: 18%
- On balance bad: 17%
- Extremely bad: 14%
That is, between them, these researchers put 31% of their credence on AI making the world markedly worse.
Some things to keep in mind in looking at these:
- If you hear ‘median 5%’ thrown around, that refers to how the researcher right in the middle of the opinion spectrum thinks there’s a 5% chance of extremely bad outcomes. (It does not mean, ‘about 5% of people expect extremely bad outcomes’, which would be much less alarming.) Nearly half of people are at ten percent or more.
- The question illustrated above doesn’t ask about human extinction specifically, so you might wonder if ‘extremely bad’ includes a lot of scenarios less bad than human extinction. To check, we added two more questions in 2022 explicitly about ‘human extinction or similarly permanent and severe disempowerment of the human species’. For these, the median researcher also gave 5% and 10% answers. So my guess is that a lot of the extremely bad bucket in this question is pointing at human extinction levels of disaster.
- You might wonder whether the respondents were selected for being worried about AI risk. We tried to mitigate that possibility by usually offering money for completing the survey ($50 for those in the final round, after some experimentation), and describing the topic in very broad terms in the invitation (e.g. not mentioning AI risk). Last survey we checked in more detail—see ‘Was our sample representative?’ in the paper on the 2016 survey.
Here’s the 2022 data again, but ordered by overall optimism-to-pessimism rather than probability of extremely bad outcomes specifically:
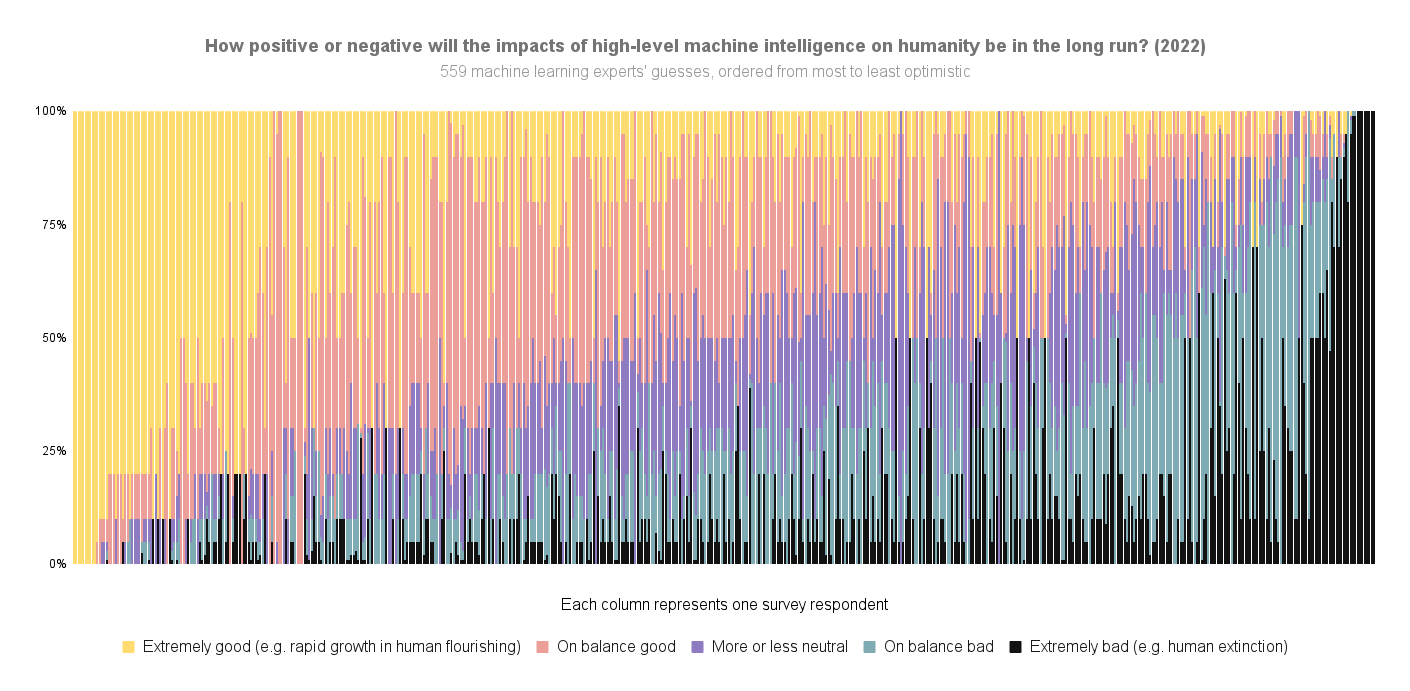
For more survey takeaways, see this blog post. For all the data we have put up on it so far, see this page.
See here for more details.
Thanks to Harlan Stewart for helping make these 2022 figures, Zach Stein-Perlman for generally getting this data in order, and Nathan Young for pointing out that figures like this would be good.
Notes
8 comments
Comments sorted by top scores.
comment by mukashi (adrian-arellano-davin) · 2023-03-09T06:40:27.699Z · LW(p) · GW(p)
It would be very interesting to conduct a poll between the users of LW. I expect that it would show that this site is quite biased towards more negative outcomes than the average ML researcher in this study.
Also, it would be interesting to see how it correlates with karma, I expect a positive correlation between karma score and pessimism
Replies from: baturinsky↑ comment by baturinsky · 2023-03-09T08:39:29.506Z · LW(p) · GW(p)
It was about 50%
https://www.lesswrong.com/posts/KxRauM9bv97aWnbJb/results-prediction-thread-about-how-different-factors-affect
↑ comment by mukashi (adrian-arellano-davin) · 2023-03-10T00:39:04.962Z · LW(p) · GW(p)
I see. Thanks! So crazily high. I would still like to see a correlation with the karma values
Replies from: baturinsky↑ comment by baturinsky · 2023-03-10T05:25:54.007Z · LW(p) · GW(p)
It looks like most voters have low carma. Biggest exception is https://www.lesswrong.com/users/daniel-kokotajlo [LW · GW]
and his estimates are 80-90% of doom:( But he thinks that it can be reduced significantly with a vast ($1 trillion) funding.
Others with high karma are https://www.lesswrong.com/users/quintin-pope [LW · GW] and https://www.lesswrong.com/users/tailcalled [LW · GW] with 0-10% and 50-60%
comment by SomeoneYouOnceKnew · 2023-03-09T06:42:12.048Z · LW(p) · GW(p)
Does the data note whether the shift is among new machine learning researchers? Among those who have a p(Doom) > 5%, I wonder how many would come to that conclusion without having read lesswrong or the associated rationalist fiction.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-03-09T12:15:20.239Z · LW(p) · GW(p)
The dataset is public and includes a question "how long have you worked in" the "AI research area [you have] worked in for the longest time," so you could check something related!
Replies from: Kei↑ comment by Kei · 2023-03-11T15:47:01.580Z · LW(p) · GW(p)
Thanks for the link! I ended up looking through the data and there wasn't any clear correlation between amount of time spent in research area and p(Doom).
I ran a few averages by both time spent in research area and region of undergraduate study here: https://docs.google.com/spreadsheets/d/1Kp0cWKJt7tmRtlXbPdpirQRwILO29xqAVcpmy30C9HQ/edit#gid=583622504
For the most part, groups don't differ very much, although as might be expected, more North Americans have a high p(Doom) conditional on HLMI than other regions.
comment by Review Bot · 2024-08-07T00:50:08.752Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?