Making decisions when both morally and empirically uncertain
post by MichaelA · 2020-01-02T07:20:46.114Z · LW · GW · 14 commentsContents
Purpose of this post MEC under empirical uncertainty Normalised MEC under empirical uncertainty BR under empirical uncertainty Potential extensions of these approaches Does this approach presume/privilege consequentialism? Factoring things out further Need to determine whether uncertainties are moral or empirical? Probability distributions instead of point estimates Closing remarks None 14 comments
Cross-posted to the EA Forum [EA · GW]. For an epistemic status statement and an outline of the purpose of this sequence of posts, please see the top of my prior post [LW · GW]. There are also some explanations and caveats in that post which I won’t repeat - or will repeat only briefly - in this post.
Purpose of this post
In my prior post [LW · GW], I wrote:
We are often forced to make decisions under conditions of uncertainty. This uncertainty can be empirical (e.g., what is the likelihood that nuclear war would cause human extinction?) or moral (e.g., does the wellbeing of future generations matter morally?). The issue of making decisions under empirical uncertainty has been well-studied, and expected utility theory has emerged as the typical account of how a rational agent should proceed in these situations. The issue of making decisions under moral uncertainty appears to have received less attention (though see this list of relevant papers), despite also being of clear importance.
I then went on to describe three prominent approaches for dealing with moral uncertainty (based on Will MacAskill’s 2014 thesis):
- Maximising Expected Choice-worthiness (MEC), if all theories under consideration by the decision-maker are cardinal and intertheoretically comparable.[1]
- Variance Voting (VV), a form of what I’ll call “Normalised MEC”, if all theories under consideration are cardinal but not intertheoretically comparable.[2]
- The Borda Rule (BR), if all theories under consideration are ordinal.
But I was surprised to discover that I couldn’t find any very explicit write-up of how to handle moral and empirical uncertainty at the same time. I assume this is because most people writing on relevant topics consider the approach I will propose in this post to be quite obvious (at least when using MEC with cardinal, intertheoretically comparable, consequentialist theories). Indeed, many existing models from EAs/rationalists (and likely from other communities) already effectively use something very much like the first approach I discuss here (“MEC-E”; explained below), just without explicitly noting that this is an integration of approaches for dealing with moral and empirical uncertainty.[3]
But it still seemed worth explicitly spelling out the approach I propose, which is, in a nutshell, using exactly the regular approaches to moral uncertainty mentioned above, but on outcomes rather than on actions, and combining that with consideration of the likelihood of each action leading to each outcome. My aim for this post is both to make this approach “obvious” to a broader set of people and to explore how it can work with non-comparable, ordinal, and/or non-consequentialist theories (which may be less obvious).
(Additionally, as a side-benefit, readers who are wondering what on earth all this “modelling” business some EAs and rationalists love talking about is, or who are only somewhat familiar with modelling, may find this post to provide useful examples and explanations.)
I'd be interested in any comments or feedback you might have on anything I discuss here!
MEC under empirical uncertainty
To briefly review regular MEC: MacAskill argues that, when all moral theories under consideration are cardinal and intertheoretically comparable, a decision-maker should choose the “option” that has the highest expected choice-worthiness. Expected choice-worthiness is given by the following formula:
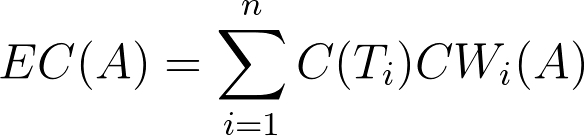
In this formula, C(Ti) represents the decision-maker’s credence (belief) in Ti (some particular moral theory), while CWi(A) represents the “choice-worthiness” (CW) of A (an “option” or action that the decision-maker can choose) according to Ti. In my prior post [LW · GW], I illustrated how this works with this example:
Suppose Devon assigns a 25% probability to T1, a version of hedonistic utilitarianism in which human “hedons” (a hypothetical unit of pleasure) are worth 10 times more than fish hedons. He also assigns a 75% probability to T2, a different version of hedonistic utilitarianism, which values human hedons just as much as T1 does, but doesn’t value fish hedons at all (i.e., it sees fish experiences as having no moral significance). Suppose also that Devon is choosing whether to buy a fish curry or a tofu curry, and that he’d enjoy the fish curry about twice as much. (Finally, let’s go out on a limb and assume Devon’s humanity.)
According to T1, the choice-worthiness (roughly speaking, the rightness or wrongness of an action) of buying the fish curry is -90 (because it’s assumed to cause 1,000 negative fish hedons, valued as -100, but also 10 human hedons due to Devon’s enjoyment). In contrast, according to T2, the choice-worthiness of buying the fish curry is 10 (because this theory values Devon’s joy as much as T1 does, but doesn’t care about the fish’s experiences). Meanwhile, the choice-worthiness of the tofu curry is 5 according to both theories (because it causes no harm to fish, and Devon would enjoy it half as much as he’d enjoy the fish curry).
[...] Using MEC in this situation, the expected choice-worthiness of buying the fish curry is 0.25 * -90 + 0.75 * 10 = -15, and the expected choice-worthiness of buying the tofu curry is 0.25 * 5 + 0.75 * 5 = 5. Thus, Devon should buy the tofu curry.
But can Devon really be sure that buying the fish curry will lead to that much fish suffering? What if this demand signal doesn’t lead to increased fish farming/capture? What if the additional fish farming/capture is more humane than expected? What if fish can’t suffer because they aren’t actually conscious (empirically, rather than as a result of what sorts of consciousness our moral theory considers relevant)? We could likewise question Devon’s apparent certainty that buying the tofu curry definitely won’t have any unintended consequences for fish suffering, and his apparent certainty regarding precisely how much he’d enjoy each meal.
These are all empirical rather than moral questions, but they still seem very important for Devon’s ultimate decision. This is because T1 and T2 don’t “intrinsically care” about whether someone buys fish curry or buys tofu curry; these theories assign no terminal value to which curry is bought. Instead, these theories "care" about some of the outcomes which those actions may or may not cause.[4]
More generally, I expect that, in all realistic decision situations, we’ll have both moral and empirical uncertainty, and that it’ll often be important to explicitly consider both types of uncertainties. For example, GiveWell’s models consider both how likely insecticide-treated bednets are to save the life of a child, and how that outcome would compare to doubling the income of someone in extreme poverty. However, typical discussions of MEC seem to assume that we already know for sure what the outcomes of our actions will be, just as typical discussions of expected value reasoning seem to assume that we already know for sure how valuable a given outcome is.
Luckily, it seems to me that MEC and traditional (empirical) expected value reasoning can be very easily and neatly integrated in a way that resolves those issues. (This is perhaps partly due to that fact that, if I understand MacAskill’s thesis correctly, MEC was very consciously developed by analogy to expected value reasoning.) Here is my formula for this integration, which I'll call Maximising Expected Choice-worthiness, accounting for Empirical uncertainty (MEC-E), and which I'll explain and provide an example for below:
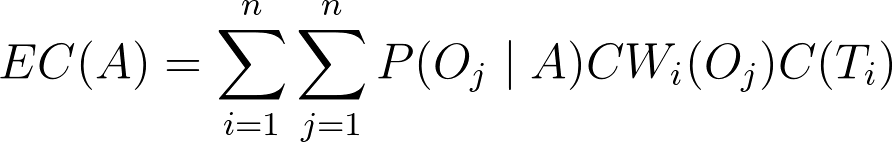
Here, all symbols mean the same things they did in the earlier formula from MacAskill’s thesis, with two exceptions:
- I’ve added Oj, to refer to each “outcome”: each consequence that an action may lead to, which at least one moral theory under consideration intrinsically values/disvalues. (E.g., a fish suffering; a person being made happy; rights being violated.)
- Related to that, I’d like to be more explicit that A refers only to the “actions” that the decision-maker can directly choose (e.g., purchasing a fish meal, imprisoning someone), rather than the outcomes of those actions.[5]
(I also re-ordered the choice-worthiness term and the credence term, which makes no actual difference to any results, and was just because I think this ordering is slightly more intuitive.)
Stated verbally (and slightly imprecisely[6]), MEC-E claims that:
One should choose the action which maximises expected choice-worthiness, accounting for empirical uncertainty. To calculate the expected choice-worthiness of each action, you first, for each potential outcome of the action and each moral theory under consideration, find the product of 1) the probability of that outcome given that that action is taken, 2) the choice-worthiness of that outcome according to that theory, and 3) the credence given to that theory. Second, for each action, you sum together all of those products.
To illustrate, I have modelled in Guesstimate an extension of the example of Devon deciding what meal to buy to also incorporate empirical uncertainty.[7] In the text here, I will only state the information that was not in the earlier version of the example, and the resulting calculations, rather than walking through all the details.
Suppose Devon believes there’s an 80% chance that buying a fish curry will lead to “fish being harmed” (modelled as 1000 negative fish hedons, with a choice-worthiness of -100 according to T1 and 0 according to T2), and a 10% chance that buying a tofu curry will lead to that same outcome. He also believes there’s a 95% chance that buying a fish curry will lead to “Devon enjoying a meal a lot” (modelled as 10 human hedons), and a 50% chance that buying a tofu curry will lead to that.
The expected choice-worthiness of buying a fish curry would therefore be:
(0.8 * -100 * 0.25) + (0.8 * 0 * 0.75) + (0.95 * 10 * 0.25) + (0.95 * 10 * 0.75) = -10.5
Meanwhile, the expected choice-worthiness of buying a tofu curry would be:
(0.1 * -100 * 0.25) + (0.1 * 0 * 0.75) + (0.5 * 10 * 0.25) + (0.5 * 10 * 0.75) = 2.5
As before, the tofu curry appears the better choice, despite seeming somewhat worse according to the theory (T2) assigned higher credence, because the other theory (T1) sees the tofu curry as much better.
In the final section of this post, I discuss potential extensions of these approaches, such as how it can handle probability distributions (rather than point estimates) and non-consequentialist theories.
The last thing I’ll note about MEC-E in this section is that MEC-E can be used as a heuristic, without involving actual numbers, in exactly the same way MEC or traditional expected value reasoning can. For example, without knowing or estimating any actual numbers, Devon might reason that, compared to buying the tofu curry, buying the fish curry is “much” more likely to lead to fish suffering and only “somewhat” more likely to lead to him enjoying his meal a lot. He may further reason that, in the “unlikely but plausible” event that fish experiences do matter, the badness of a large amount of fish suffering is “much” greater than the goodness of him enjoying a meal. He may thus ultimately decide to purchase the tofu curry.
(Indeed, my impression is that many effective altruists have arrived at vegetarianism/veganism through reasoning very much like that, without any actual numbers being required.)
Normalised MEC under empirical uncertainty
(From here onwards, I’ve had to go a bit further beyond what’s clearly implied by existing academic work, so the odds I’ll make some mistakes go up a bit. Please let me know if you spot any errors.)
To briefly review regular Normalised MEC: Sometimes, despite being cardinal, the moral theories we have credence in are not intertheoretically comparable (basically meaning that there’s no consistent, non-arbitrary “exchange rate” between the theories' “units of choice-worthiness"). MacAskill argues that, in such situations, one must first "normalise" the theories in some way (i.e., "[adjust] values measured on different scales to a notionally common scale"), and then apply MEC to the new, normalised choice-worthiness scores. He recommends Variance Voting, in which the normalisation is by variance (rather than, e.g., by range), meaning that we:
“[treat] the average of the squared differences in choice-worthiness from the mean choice-worthiness as the same across all theories. Intuitively, the variance is a measure of how spread out choice-worthiness is over different options; normalising at variance is the same as normalising at the difference between the mean choice-worthiness and one standard deviation from the mean choice-worthiness.”
(I provide a worked example here, based on an extension of the scenario with Devon deciding what meal to buy, but it's possible I've made mistakes.)
My proposal for Normalised MEC, accounting for Empirical Uncertainty (Normalised MEC-E) is just to combine the ideas of non-empirical Normalised MEC and non-normalised MEC-E in a fairly intuitive way. The steps involved (which may be worth reading alongside this worked example and/or the earlier explanations of Normalised MEC and MEC-E) are as follows:
-
Work out expected choice-worthiness just as with regular MEC, except that here one is working out the expected choice-worthiness of outcomes, not actions. I.e., for each outcome, multiply that outcome’s choice-worthiness according to each theory by your credence in that theory, and then add up the resulting products.
- You could also think of this as using the MEC-E formula, except with “Probability of outcome given action” removed for now.
-
Normalise these expected choice-worthiness scores by variance, just as MacAskill advises in the quote above.
-
Find the “expected value” of each action in the traditional way, with these normalised expected choice-worthiness scores serving as the “value” for each potential outcome. I.e., for each action, multiply the probability it leads to each outcome by the normalised expected choice-worthiness of that outcome (from step 2), and then add up the resulting products.
- You could think of this as bringing “Probability of outcome given action” back into the MEC-E formula.
-
Choose the action with the maximum score from step 3 (which we could call normalised expected choice-worthiness, accounting for empirical uncertainty, or expected value, accounting for normalised moral uncertainty).[8]
BR under empirical uncertainty
The final approach MacAskill recommends in his thesis is the Borda Rule (BR; also known as Borda counting). This is used when the moral theories we have credence in are merely ordinal (i.e., they don’t say “how much” more choice-worthy one option is compared to another). In my prior post [LW · GW], I provided the following quote of MacAskill’s formal explanation of BR (here with “options” replaced by “actions”):
“An [action] A’s Borda Score, for any theory Ti, is equal to the number of [actions] within the [action]-set that are less choice-worthy than A according to theory Ti’s choice-worthiness function, minus the number of [actions] within the [action]-set that are more choice-worthy than A according to Ti’s choice-worthiness function.
An [action] A’s Credence-Weighted Borda Score is the sum, for all theories Ti, of the Borda Score of A according to theory Ti multiplied by the credence that the decision-maker has in theory Ti.
[The Borda Rule states that an action] A is more appropriate than an [action] B iff [if and only if] A has a higher Credence-Weighted Borda Score than B; A is equally as appropriate as B iff A and B have an equal Credence-Weighted Borda Score.”
To apply BR when one is also empirically uncertain, I propose just explicitly considering/modelling one’s empirical uncertainties, and then figuring out each action’s Borda Score with those empirical uncertainties in mind. (That is, we don’t change the method at all on a mathematical level; we just make sure each moral theory’s preference rankings over actions - which is used as input into the Borda Rule - takes into account our empirical uncertainty about what outcomes each action may lead to.)
I’ll illustrate how this works with reference to the same example from MacAskill’s thesis that I quoted in my prior post, but now with slight modifications (shown in bold).
“Julia is a judge who is about to pass a verdict on whether Smith is guilty for murder. She is very confident that Smith is innocent. There is a crowd outside, who are desperate to see Smith convicted. Julia has three options:
[G]: Pass a verdict of ‘guilty’.
[R]: Call for a retrial.
[I]: Pass a verdict of ‘innocent’.
She thinks there’s a 0% chance of M if she passes a verdict of guilty, a 30% chance if she calls for a retrial (there may mayhem due to the lack of a guilty verdict, or later due to a later innocent verdict), and a 70% chance if she passes a verdict of innocent.
There’s obviously a 100% chance of C if she passes a verdict of guilty and a 0% chance if she passes a verdict of innocent. She thinks there’s also a 20% chance of C happening later if she calls for a retrial.
Julia believes the crowd is very likely (~90% chance) to riot if Smith is found innocent, causing mayhem on the streets and the deaths of several people. If she calls for a retrial, she believes it’s almost certain (~95% chance) that he will be found innocent at a later date, and that it is much less likely (only ~30% chance) that the crowd will riot at that later date if he is found innocent then. If she declares Smith guilty, the crowd will certainly (~100%) be appeased and go home peacefully. She has credence in three moral theories**, which, when taking the preceding probabilities into account, provide the following choice-worthiness orderings**:
35% credence in a variant of utilitarianism, according to which [G≻I≻R].
34% credence in a variant of common sense, according to which [I>R≻G].
31% credence in a deontological theory, according to which [I≻R≻G].”
This leads to the Borda Scores and Credence-Weighted Borda Scores shown in the table below, and thus to the recommendation that Julia declare Smith innocent.
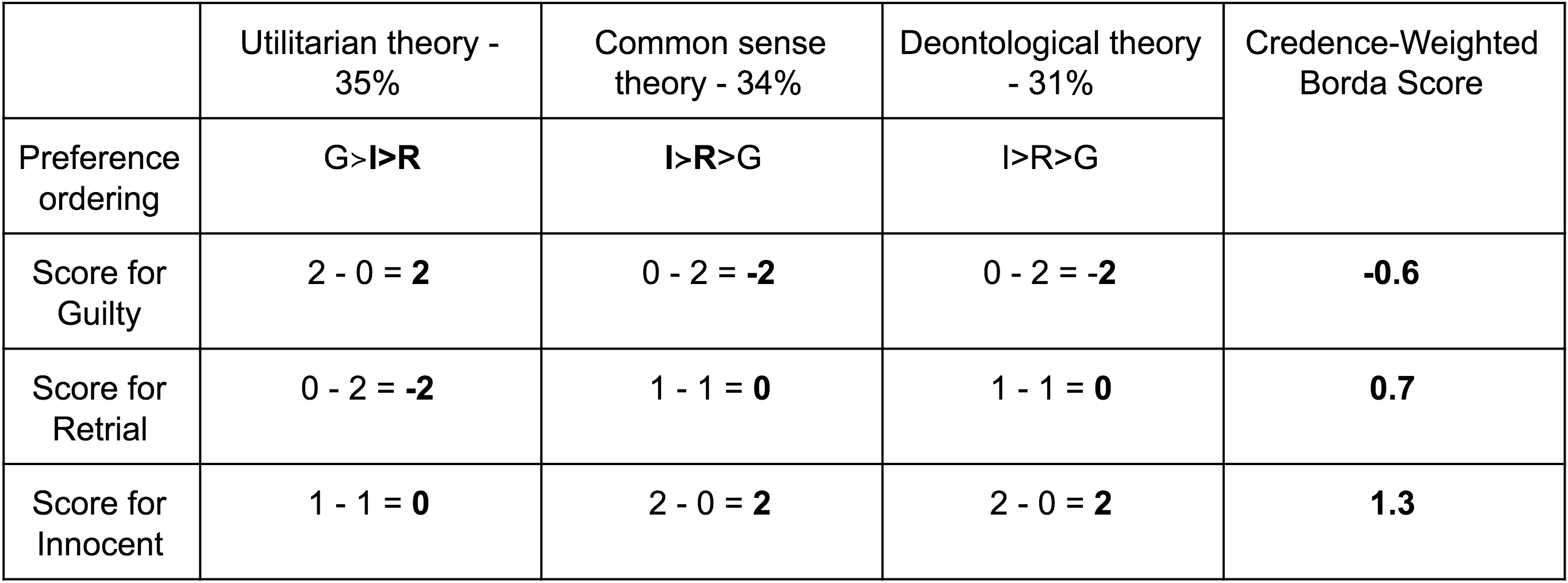
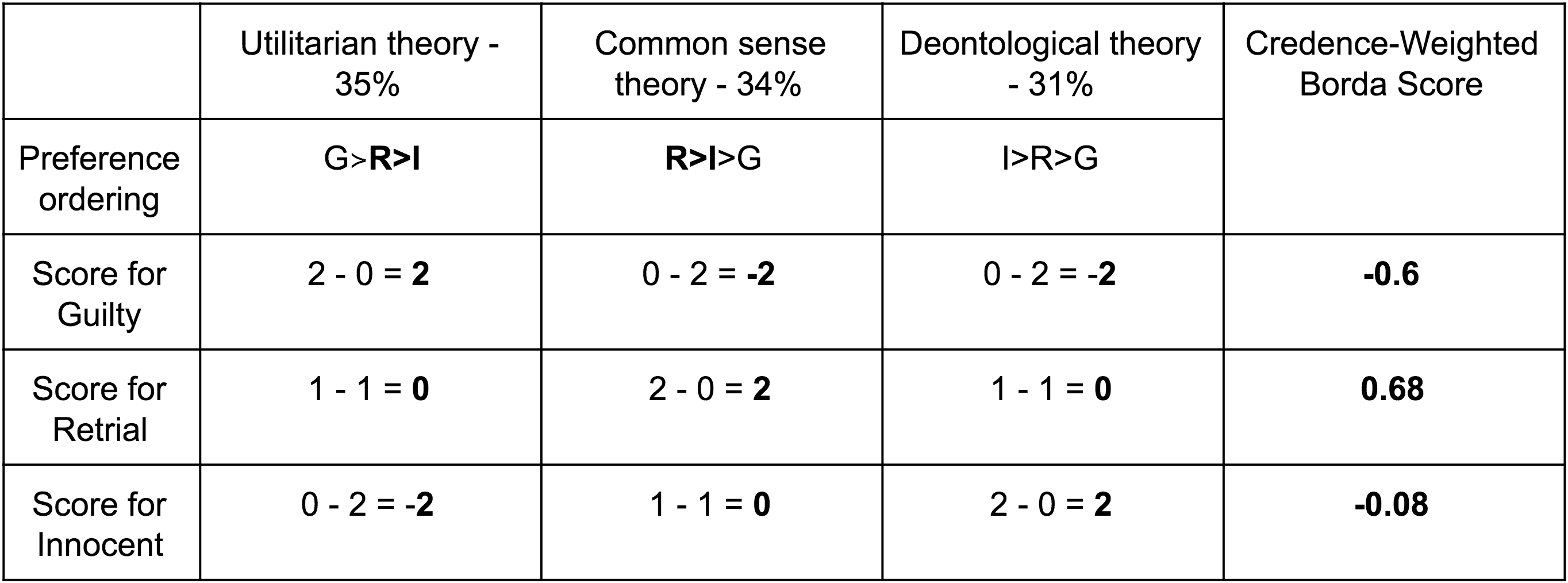
(More info on how that was worked out can be found in the following footnote, along with the corresponding table based on the moral theories' preference orderings in my prior post, when empirical uncertainty wasn't taken into account.[9])
In the original example, both the utilitarian theory and the common sense theory preferred a retrial to a verdict of innocent (in order to avoid a riot), which resulted in calling for a retrial having the highest Credence-Weighted Borda Score.
However, I’m now imagining that Julia is no longer assuming each action 100% guarantees a certain outcome will occur, and paying attention to her empirical uncertainty has changed her conclusions.
In particular, I’m imagining that she realises she’d initially been essentially “rounding up” (to 100%) the likelihood of a riot if she provides a verdict of innocent, and “rounding down” (to 0%) the likelihood of the crowd rioting at a later date. However, with more realistic probabilities in mind, utilitarianism and common sense would both actually prefer an innocent verdict to a retrial (because the innocent verdict seems less risky, and the retrial more risky, than she’d initially thought, while an innocent verdict still frees this innocent person sooner and with more certainty). This changes each action’s Borda Score, and gives the result that she should declare Smith innocent.[10]
Potential extensions of these approaches
Does this approach presume/privilege consequentialism?
A central idea of this post has been making a clear distinction between “actions” (which one can directly choose to take) and their “outcomes” (which are often what moral theories “intrinsically care about”). This clearly makes sense when the moral theories one has credence in are consequentialist. However, other moral theories may “intrinsically care” about actions themselves. For example, many deontological theories would consider lying to be wrong in and of itself, regardless of what it leads to. Can the approaches I’ve proposed handle such theories?
Yes - and very simply! For example, suppose I wish to use MEC-E (or Normalised MEC-E), and I have credence in a (cardinal) deontological theory that assigns very low choice-worthiness to lying (regardless of outcomes that action leads to). We can still calculate expected choice-worthiness using the formulas shown above; in this case, we find the product of (multiply) “probability me lying leads to me having lied” (which we’d set to 1), “choice-worthiness of me having lied, according to this deontological theory”, and “credence in this deontological theory”.
Thus, cases where a theory cares intrinsically about the action and not its consequences can be seen as a “special case” in which the approaches discussed in this post just collapse back to the corresponding approaches discussed in MacAskill’s thesis (which these approaches are the “generalised” versions of). This is because there’s effectively no empirical uncertainty in these cases; we can be sure that taking an action would lead to us having taken that action. Thus, in these and other cases of no relevant empirical uncertainty, accounting for empirical uncertainty is unnecessary, but creates no problems.[11][12]
I’d therefore argue that a policy of using the generalised approaches by default is likely wise. This is especially the case because:
- One will typically have at least some credence in consequentialist theories.
- My impression is that even most “non-consequentialist” theories still do care at least somewhat about consequences. For example, they’d likely say lying is in fact “right” if the negative consequences of not doing so are “large enough” (and one should often be empirically uncertain about whether they would be).
Factoring things out further
In this post, I modified examples (from my prior post) in which we had only one moral uncertainty into examples in which we had one moral and one empirical uncertainty. We could think of this as “factoring out” what originally appeared to be only moral uncertainty into its “factors”: empirical uncertainty about whether an action will lead to an outcome, and moral uncertainty about the value of that outcome. By doing this, we’re more closely approximating (modelling) our actual understandings and uncertainties about the situation at hand.
But we’re still far from a full approximation of our understandings and uncertainties. For example, in the case of Julia and the innocent Smith, Julia may also be uncertain how big the riot would be, how many people would die, whether these people would be rioters or uninvolved bystanders, whether there’s a moral difference between a rioter vs a bystanders dying from the riot (and if so, how big this difference is), etc.[13]
A benefit of the approaches shown here is that they can very simply be extended, with typical modelling methods, to incorporate additional uncertainties like these. You simply disaggregate the relevant variables into the “factors” you believe they’re composed of, assign them numbers, and multiply them as appropriate.[14][15]
Need to determine whether uncertainties are moral or empirical?
In the examples given just above, you may have wondered whether I was considering certain variables to represent moral uncertainties or empirical ones. I suspect this ambiguity will be common in practice (and I plan to discuss it further in a later post). Is this an issue for the approaches I’ve suggested?
I’m a bit unsure about this, but I think the answer is essentially “no”. I don’t think there’s any need to treat moral and empirical uncertainty in fundamentally different ways for the sake of models/calculations using these approaches. Instead, I think that, ultimately, the important thing is just to “factor out” variables in the way that makes the most sense, given the situation and what the moral theories under consideration “intrinsically care about”. (An example of the sort of thing I mean can be found in footnote 14, in a case where the uncertainty is actually empirical but has different moral implications for different theories.)
Probability distributions instead of point estimates
You may have also thought that a lot of variables in the examples I’ve given should be represented by probability distributions (e.g., representing 90% confidence intervals), rather than point estimates. For example, why would Devon estimate the probability of “fish being harmed”, as if it’s a binary variable whose moral significance switches suddenly from 0 to -100 (according to T1) when a certain level of harm is reached? Wouldn’t it make more sense for him to estimate the amount of harm to fish that is likely, given that that better aligns both with his understanding of reality and with what T1 cares about?
If you were thinking this, I wholeheartedly agree! Further, I can’t see any reason why the approaches I’ve discussed couldn’t use probability distributions and model variables as continuous rather than binary (the only reason I haven’t modelled things in that way so far was to keep explanations and examples simple). For readers interested in an illustration of how this can be done, I’ve provided a modified model of the Devon example in this Guesstimate model. (Existing models like this one also take essentially this approach.)
Closing remarks
I hope you’ve found this post useful, whether to inform your heuristic use of moral uncertainty and expected value reasoning, to help you build actual models taking into account both moral and empirical uncertainty, or to give you a bit more clarity on “modelling” in general.
In the next post, I’ll discuss how we can combine the approaches discussed in this and my prior post with sensitivity analysis and value of information analysis, to work out what specific moral or empirical learning would be most decision-relevant and when we should vs shouldn’t postpone decisions until we’ve done such learning.
What “choice-worthiness”, “cardinal” (vs “ordinal”), and “intertheoretically comparable” mean is explained in the previous post. To quickly review, roughly speaking:
- Choice-worthiness is the rightness or wrongness of an action, according to a particular moral theory.
- A moral theory is ordinal if it tells you only which options are better than which other options, whereas a theory is cardinal if it tells you how big a difference in choice-worthiness there is between each option.
- A pair of moral theories can be cardinal and yet still not intertheoretically comparable if we cannot meaningfully compare the sizes of the “differences in choice-worthiness” between the theories; basically, if there’s no consistent, non-arbitrary “exchange rate” between different theories’ “units of choice-worthiness”.
MacAskill also discusses a “Hybrid” procedure, if the theories under consideration differ in whether they’re cardinal or ordinal and/or whether they’re intertheoretically comparable; readers interested in more information on that can refer to pages 117-122 MacAskill’s thesis. An alternative approach to such situations is Christian Tarsney’s (pages 187-195) “multi-stage aggregation procedure”, which I may write a post about later (please let me know if you think this’d be valuable). ↩︎
Examples of models that effectively use something like the “MEC-E” approach include GiveWell’s cost-effectiveness models and this model of the cost effectiveness of “alternative foods”.
And some of the academic moral uncertainty work I’ve read seemed to indicate the authors may be perceiving as obvious something like the approaches I propose in this post.
But I think the closest thing I found to an explicit write-up of this sort of way of considering moral and empirical uncertainty at the same time (expressed in those terms) was this post from 2010 [LW · GW], which states: “Under Robin’s approach to value uncertainty, we would (I presume) combine these two utility functions into one linearly, by weighing each with its probability, so we get EU(x) = 0.99 EU1(x) + 0.01 EU2(x)”. ↩︎
Some readers may be thinking the “empirical” uncertainty about fish consciousness is inextricable from moral uncertainties, and/or that the above paragraph implicitly presumes/privileges consequentialism. If you’re one of those readers, 10 points to you for being extra switched-on! However, I believe these are not really issues for the approaches outlined in this post, for reasons outlined in the final section. ↩︎
Note that my usage of “actions” can include “doing nothing”, or failing to do some specific thing; I don’t mean “actions” to be distinct from “omissions” in this context. MacAskill and other writers sometimes refer to “options” to mean what I mean by “actions”. I chose the term “actions” both to make it more obvious what the A and O terms in the formula stand for, and because it seems to me that the distinction between “options” and “outcomes” would be less immediately obvious. ↩︎
My university education wasn’t highly quantitative, so it’s very possible I’ll phrase certain things like this in clunky or unusual ways. If you notice such issues and/or have better phrasing ideas, please let me know. ↩︎
In that link, the model using MEC-E follows a similar model using regular MEC (and thus considering only moral uncertainty) and another similar model using more traditional expected value reasoning (and thus considering only empirical uncertainty); readers can compare these against the MEC-E model. ↩︎
Before I tried to actually model an example, I came up with a slightly different proposal for integrating the ideas of MEC-E and Normalised MEC. Then I realised the proposal outlined above might make more sense, and it does seem to work (though I’m not 100% certain), so I didn’t further pursue my original proposal. I therefore don't know for sure whether my original proposal would work or not (and, if it does work, whether it’s somehow better than what I proposed above). My original proposal was as follows:
- Work out expected choice-worthiness just as with regular MEC-E; i.e., follow the formula from above to incorporate consideration of the probabilities of each action leading to each outcome, the choice-worthiness of each outcome according to each moral theory, and the credence one has in each theory. (But don’t yet pick the action with the maximum expected choice-worthiness score.)
- Normalise these expected choice-worthiness scores by variance, just as MacAskill advises in the quote above. (The fact that these scores incorporate consideration of empirical uncertainty has no impact on how to normalise by variance.)
- Now pick the action with the maximum normalised expected choice-worthiness score.
G (for example) has a Borda Scoreof 2 - 0 = 2 according to utilitarianism because that theory views two options as less choice-worthy than G, and 0 options as more choice-worthy than G.
To fill in the final column, you take a credence-weighted average of the relevant action’s Borda Scores.
What follows is the corresponding table based on the moral theories' preference orderings in my prior post, when empirical uncertainty wasn't taken into account:
It’s also entirely possible for paying attention to empirical uncertainty to not change any moral theory’s preference orderings in a particular situation, or for some preference orderings to change without this affecting which action ends up with the highest Credence-Weighted Borda Score. This is a feature, not a bug.
Another perk is that paying attention to both moral and empirical uncertainty also provides more clarity on what the decision-maker should think or learn more about. This will be the subject of my next post. For now, a quick example is that Julia may realise that a lot hangs on what each moral theory’s preference ordering should actually be, or on how likely the crowd actually is to riot if she passes a verdict or innocent or calls for a retrial, and it may be worth postponing her decision in order to learn more about these things. ↩︎
Arguably, the additional complexity in the model is a cost in itself. But this is only a problem only in the same way this is a problem for any time one decides to model something in more detail or with more accuracy at the cost of adding complexity and computations. Sometimes it’ll be worth doing so, while other times it’ll be worth keeping things simpler (whether by considering only moral uncertainty, by considering only empirical uncertainty, or by considering only certain parts of one’s moral/empirical uncertainties). ↩︎
The approaches discussed in this post can also deal with theories that “intrinsically care” about other things, like a decision-maker’s intentions or motivations. You can simply add in a factor for “probability that, if I take X, it’d be due to motivation Y rather than motivation Z” (or something along those lines). It may often be reasonable to round this to 1 or 0, in which case these approaches didn’t necessarily “add value” (though they still worked). But often we may genuinely be (empirically) uncertain about our own motivations (e.g., are we just providing high-minded rationalisations for doing something we wanted to do anyway for our own self-interest?), in which case explicitly modelling that empirical uncertainty may be useful. ↩︎
For another example, in the case of Devon choosing a meal, he may also be uncertain how many of each type of fish will be killed, the way in which they’d be killed, whether each type of fish has certain biological and behavioural features thought to indicate consciousness, whether those features do indeed indicate consciousness, whether the consciousness they indicate is morally relevant, whether creatures with consciousness like that deserve the same “moral weight” as humans or somewhat lesser weight, etc. ↩︎
For example, Devon might replace “Probability that purchasing a fish meal leads to "fish being harmed"” with (“Probability that purchasing a fish meal leads to fish being killed” * “Probability fish who were killed would be killed in a non-humane way” * “Probability any fish killed in these ways would be conscious enough that this can count as “harming” them”). This whole term would then be in calculations used wherever ““Probability that purchasing a fish meal leads to "fish being harmed"” was originally used.
For another example, Julia might replace “Probability the crowd riots if Julia finds Smith innocent” with “Probability the crowd riots if Julia finds Smith innocent” * “Probability a riot would lead to at least one death” * “Probability that, if at least one death occurs, there’s at least one death of a bystander (rather than of one of the rioters themselves)” (as shown in this partial Guesstimate model). She can then keep in mind this more specific final outcome, and its more clearly modelled probability, as she tries to work out what choice-worthiness ordering each moral theory she has credence in would give to the actions she’s considering.
Note that, sometimes, it might make sense to “factor out” variables in different ways for the purposes of different moral theories’ evaluations, depending on what the moral theories under consideration “intrinsically care about”. In the case of Julia, it definitely seems to me to make sense to replace “Probability the crowd riots if Julia finds Smith innocent” with “Probability the crowd riots if Julia finds Smith innocent” * “Probability a riot would lead to at least one death”. This is because all moral theories under consideration probably care far more about potential deaths from a riot than about any other consequences of the riot. This can therefore be considered an “empirical uncertainty”, because its influence on the ultimate choice-worthiness “flows through” the same “moral outcome” (a death) for all moral theories under consideration.
However, it might only make sense to further multiply that term by “Probability that, if at least one death occurs, there’s at least one death of a bystander (rather than of one of the rioters themselves)” for the sake of the common sense theory’s evaluation of the choice-worthiness order, not for the utilitarian theory’s evaluation. This would be the case if the utilitarian theory cared not at all (or at least much less) about the distinction between the death of a rioter and the death of a bystander, while common sense does. (The Guesstimate model should help illustrate what I mean by this.) ↩︎
Additionally, the process of factoring things out in this way could by itself provide a clearer understanding of the situation at hand, and what the stakes really are for each moral theory one has credence in. (E.g., Julia may realise that passing a verdict of innocent is much less bad than she thought, as, even if a riot does occur, there’s only a fairly small chance it leads to the death of a bystander.) It also helps one realise what uncertainties are most worth thinking/learning more about (more on this in my next post). ↩︎
14 comments
Comments sorted by top scores.
comment by Pattern · 2020-01-07T02:20:57.932Z · LW(p) · GW(p)
Errata:
These are all empirical questions, but they seem very important for Devon’s ultimate decision, as T1 and T2 don’t “intrinsically care” about buying fish curry or buying tofu curry; they care about some of the outcomes which those actions may or may not cause.[4] [LW · GW]
The wording seems weird here.
These are all empirical question, and they seem very important for Devon’s ultimate decision, but T1 and T2 don’t “intrinsically care” about buying fish curry or buying tofu curry; they care about the outcomes which those actions may or may not cause.[4] [LW · GW]?
Confusion:
The expected choice-worthiness of buying a fish curry would therefore be: 0.8 * -100 * 0.25 + 0.8 * 0 * 0.75 + 0.95 * 10 * 0.25 + 0.95 * 10 * 0.75 = -10.5
Meanwhile, the expected choice-worthiness of buying a tofu curry would be: 0.1 * -100 * 0.25 + 0.1 * 0 * 0.75 + 0.5 * 10 * 0.25 + 0.5 * 10 * 0.75 = 2.5
The equations were confusing.
-The 0.25 and 0.75 in the calculation come from the credence in the theories, per the model in Guesstimate.
-The parts that are times 0 were initially confusing.
-Some separation with () or {} might make the equations easier to read.
(0.8 * -100 * 0.25) + (0.8 * 0 * 0.75) + (0.95 * 10 * 0.25) + (0.95 * 10 * 0.75) = -10.5
(0.1 * -100 * 0.25) + (0.1 * 0 * 0.75) + (0.5 * 10 * 0.25) + (0.5 * 10 * 0.75) = 2.5
Also since x*y*z + x*y*(1-z) = xy, the above equations can be rewritten as:
(0.8 * -100 * 0.25) + (0.8 * 0 * 0.75) + (0.95 * 10) = -10.5
(0.1 * -100 * 0.25) + (0.1 * 0 * 0.75) + (0.5 * 10) = 2.5
The intuitive explanation is because it involves a fact which is (considered to be) certain regardless of which theory is correct.
Replies from: MichaelA, MichaelA↑ comment by MichaelA · 2020-01-07T04:09:41.953Z · LW(p) · GW(p)
Thanks for this feedback!
By this:
These are all empirical questions, but they seem very important for Devon’s ultimate decision, as T1 and T2 don’t “intrinsically care” about buying fish curry or buying tofu curry; they care about some of the outcomes which those actions may or may not cause.[4] [LW · GW]
I mean this:
These are all empirical rather than moral questions, but they still seem very important for Devon’s ultimate decision. This is because T1 and T2 don’t “intrinsically care” about whether someone buys fish curry or buys tofu curry; these theories assign no terminal value to which curry is bought. Instead, these theories "care" about some of the outcomes which those actions may or may not cause.[4] [LW · GW]
Does that seem clearer to you? If so, I may edit the post to say that.
ETA: The ultimate point this is driving at is that, as covered in the next sentence, accounting for moral uncertainty alone doesn't seem sufficient. I had assumed that would be clear from the intro and from the following sentence, but let me know if you think it'd be worth me adding something like "Thus, it seems Devon should account for his empirical uncertainty as well as his moral uncertainty" to the paragraph the above quotes are from.
Replies from: Pattern↑ comment by Pattern · 2020-01-07T22:18:18.158Z · LW(p) · GW(p)
Does that seem clearer to you?
It does, thanks!
"Thus, it seems Devon should account for his empirical uncertainty as well as his moral uncertainty" to the paragraph the above quotes are from.
I think the change already covers that, by establishing the relationship between empirical and moral questions.
T1 and T2 don’t “intrinsically care” about whether someone buys fish curry or buys tofu curry
A good property to have.
Replies from: MichaelA↑ comment by MichaelA · 2020-01-07T04:22:00.374Z · LW(p) · GW(p)
The equations were confusing.
I did worry that might be the case. I was hoping they'd be clear enough given that they can be read alongside the Guesstimate model, but I wasn't sure about that. And your suggestion of at least adding brackets definitely seems logical, so I've now done that. (I've also now put the equations on new, indented lines.)
Also since x*y*z + x*y*(1-z) = xy, the above equations can be rewritten as:
I considered that approach too. It's obviously valid, and does de-clutter things. But I sort-of feel like it's still best to stick to just a plain presentation of the equations one would initially get from the MEC-E formula, rather than also adding the step of rearranging/rewriting.
comment by jmh · 2020-01-02T13:35:44.437Z · LW(p) · GW(p)
For my own benefit could you clarify your definition of uncertainty here?
I've always used a distinction between risk and uncertainty. Risk is a setting where one reasonably can assign/know the probability of possible outcomes.
Replies from: MichaelA, MichaelA↑ comment by MichaelA · 2020-01-03T09:22:40.593Z · LW(p) · GW(p)
Good question. I'm working on a post on what moral uncertainty actually is (which I'll hopefully publish tomorrow), and your question has made me realise it'd be worth having a section on the matter of "risk vs (Knightian) uncertainty" in there.
Personally, I was effectively using "uncertainty" in a sense that incorporates both of the concepts you refer to, though I hadn't been thinking explicitly about the matter. (And some googling suggests academic work on moral uncertainty almost never mentions the potential distinction. When the term "moral risk" is used, it just means the subset of moral uncertainty where one may be doing something bad, rather than being set against something like Knightian uncertainty.)
This distinction is something I feel somewhat confused about, and it seems to me that confusion/disagreement about the distinction is fairly common more widely, including among LW/EA-related communities. E.g., the Wikipedia article on Knightian uncertainty says: "The difference between predictable variation and unpredictable variation is one of the fundamental issues in the philosophy of probability, and different probability interpretations treat predictable and unpredictable variation differently. The debate about the distinction has a long history."
But here are some of my current (up for debate) thoughts, which aren't meant to be authoritative or convincing. (This turned out to be a long comment, because I used writing it as a chance to try to work through these ideas, and because my thinking on this still isn't neatly crystallised, and because I'd be interested in people's thoughts, as that may inform how I discuss this matter in that other post I'm working on.)
Terms
My new favourite source on how the terms "risk" and "uncertainty" should probably (in my view) be used is this, from Ozzie Gooen. Ozzie notes the distinction/definitions you mention being common in business and finance, but then writes:
Disagreeing with these definitions are common dictionaries and large parts of science and mathematics. In the Merriam-Webster dictionary, every definition of ‘risk’ is explicitly about possible negative events, not about general things with probability distributions. (https://www.merriam-webster.com/dictionary/risk)
There is even a science explicitly called “uncertainty quantification”, but none explicitly called “risk quantification”.
This is obviously something of a mess. Some business people get confused with mathematical quantifications of uncertainty, but other people would be confused by quantifications of socially positive “risks”.
Ozzie goes on to say:
Douglas Hubbard came up with his own definitions of uncertainty and risk, which are what inspired a very similar set of definitions on Wikipedia (the discussion page specifically mentions this link).
From Wikipedia:
Uncertainty
The lack of certainty. A state of having limited knowledge where it is impossible to exactly describe the existing state, a future outcome, or more than one possible outcome.
Measurement of uncertainty
A set of possible states or outcomes where probabilities are assigned to each possible state or outcome — this also includes the application of a probability density function to continuous variables.
Risk
A state of uncertainty where some possible outcomes have an undesired effect or significant loss.
Measurement of risk
A set of measured uncertainties where some possible outcomes are losses, and the magnitudes of those losses — this also includes loss functions over continuous variables.
So according to these definitions, risk is essentially a strict subset of uncertainty.
(Douglas Hubbard is the author of How to Measure Anything, which I'd highly recommend for general concepts and ways of thinking useful across many areas. Great summary here [LW · GW].)
That's how I'd also want to use those terms, to minimise confusion (despite still causing it among some people from e.g. business and finance).
Concepts
But that was just a matter of what words are probably least likely to lead to conclusion. A separate point is whether I was talking about what you mean by "risk" or what you mean by "uncertainty" (i.e., "Knightian uncertainty"). I do think a distinction between these concepts "carves reality at the joints" to some extent - it points in the direction of something real and worth paying attention to - but I also (currently) think it's too binary, and can be misleading. (Again, all of this comment up for debate, and I'd be interested in people checking my thinking!)
Here's one description of the distinction (from this article):
In the case of risk, the outcome is unknown, but the probability distribution governing that outcome is known. Uncertainty, on the other hand, is characterised by both an unknown outcome and an unknown probability distribution. For risk, these chances are taken to be objective, whereas for uncertainty, they are subjective. Consider betting with a friend by rolling a die. If one rolls at least a four, one wins 30 Euros (or Pounds, Dollars, Yen, Republic Dataries, Bitcoins, etc.). If one rolls lower, one loses. If the die is unbiased, one’s decision to accept the bet is taken with the knowledge that one has a 50 per cent chance of winning and losing. This situation is characterised by risk. However, if the die has an unknown bias, the situation is characterised by uncertainty. The latter applies to all situations in which one knows that there is a chance of winning and losing but has no information on the exact distribution of these chances.”
This sort of example is common, and it seems to me that it'd make more sense to not see a difference in kind between the type of estimate/probability/uncertainty, but a difference of degree of our confidence in/basis for that estimate/probability. And this seems to be a fairly common view, at least among people using a Bayesian framework. E.g., Wikipedia states:
Bayesian approaches to probability treat it as a degree of belief and thus they do not draw a distinction between risk and a wider concept of uncertainty: they deny the existence of Knightian uncertainty. They would model uncertain probabilities with hierarchical models, i.e. where the uncertain probabilities are modelled as distributions whose parameters are themselves drawn from a higher-level distribution (hyperpriors)
And in the article on Knightian uncertainty, Wikipedia says "Taleb asserts that Knightian risk does not exist in the real world, and instead finds gradations of computable risk". I haven't read anything by Taleb and can't confirm that that's his view, but that view makes a lot of sense to me.
For example, in the typical examples, we can never really know with certainty that a coin/dice/whatever is unbiased. So it can't be the case that "the probability distribution governing that outcome is known", except in the sense of being known probabilistically, in which case it's not a totally different situation to a case of an "unknown" distribution, where we still may have some scrap of evidence or meaningful prior, and even if not, we can use some form of uninformative prior (e.g., uniform prior; it seems to me that uninformative priors are another debated topic, and my knowledge there is quite limited).
Something that seems relevant from here is a great quote from Tetlock, along the lines of (I can't remember or find his exact phrasing) lots of people claiming you can't predict x, you can't predict y, these things are simply too unforeseeable, and Tetlock deciding to make a reference class for "Things people say you can't predict", with this leading to fairly good predictions. (I think this was from Superforecasting, but it might've been Expert Political Judgement. If anyone can remember/find the quote, please let me know.)
Usefulness of a distinction
But as I said, I do think the distinction still points in the direction of something important (I'd just want it to do so in terms of quantitative degrees, rather than qualitative kinds). Holden of GiveWell (at the time) had some relevant posts that seem quite interesting and generated a lot of discussion, e.g. this and this.
One reason I think it's useful to consider our confidence in our estimates is the optimizer's curse [LW · GW] (also discussed here). If we're choosing from a set of things based on which one we predict will be "best" (e.g., the most cost-effectiveness of a set of charities), we should expect to be disappointed, and this issue is more pronounced the more "uncertain" our estimates are (not as in "probabilities closer to 0", but as in "Probabilities we have less basis for"). (I'm not sure how directly relevant the optimizer's curse is for moral uncertainty, though. Maybe something more general like regression to the mean is more relevant.)
But I don't think issues like that mean different types/levels of uncertainty need to be treated in fundamentally different ways. We can just do things like adjusting our initial estimates downwards based on our knowledge of the optimizer's curse. Or, relatedly, model combination and adjustment [LW · GW], which I've had a go at for the Devon example in this Guesstimate model.
Concepts I find very helpful here are credence resilience and (relatedly) a distinction between the balance of the evidence and the weight of the evidence (explained here). These (I think) allow us to discuss the sort of thing "risk vs Knightian uncertainty" is trying to get at, but in a less binary way, and in a way that more clearly highlights how we should respond and other implications (e.g., that value of information will typically be higher when our credences are less "resilient", which I'll discuss a bit in my upcoming post on relating value of information to moral uncertainty).
Hope that wall of text (sorry!) helps clarify my current thinking on these issues. And as I said earlier, I'd be interested in people's thoughts on what I've said here, to inform how I (hopefully far more concisely) discuss this matter in my later post.
Replies from: MichaelA↑ comment by MichaelA · 2020-01-03T10:12:58.972Z · LW(p) · GW(p)
To be specific regarding the model combination [LW · GW] point (which is probably the way in which the risk vs Knightian uncertainty distinction is most likely to be relevant to moral uncertainty): I now very tentatively think it might make sense to see whatever "approach" we use to moral uncertainty (whether accounting for empirical uncertainty or not) as one "model", and have some other model(s) as well. These other models could be an alternative approach to moral uncertainty, or a sort of "common sense" moral theory (of a form that can't be readily represented in the e.g. MEC model, or that Devon thinks shouldn't be represented in that model because he's uncertain about that model), or of something like "Don't do anything too irreversible because there might be some better moral theory out there that we haven't heard of yet".
Then we could combine the two (or more) models, with the option of weighting them differently if we have different levels of confidence in each one. (E.g., because we're suspicious of the explicit MEC approach. Or on the other hand because we might think our basic, skipping-to-the-conclusion intuitions can't be trusted much at all on matters like this, and that a more regimented approach that disaggregates/factors things out is more reliable). This is what I had a go at showing in this model.
For example, I think I'd personally find it quite plausible to take the results of (possibly normalised) MEC/MEC-E quite seriously, but to still think there's a substantial chance of unknown unknowns, making me want to combine those results with something like a "Try to avoid extremely counter-common-sense actions or extremely irreversible consequences" model.
But I only thought of this when trying to think through how to respond to your comment (and thus re-reading things like the model combination post and the sequence vs cluster thinking post), and I haven't seen something like it discussed in the academic work on moral uncertainty I've read, so all of the above is just putting an idea out there for discussion.
Replies from: jmh↑ comment by jmh · 2020-01-03T14:38:57.643Z · LW(p) · GW(p)
Thanks and lots to think about there and it has been helpful, and I think as I digest and nibble more it will provide greater understanding.
For example, I think I'd personally find it quite plausible to take the results of (possibly normalised) MEC/MEC-E quite seriously, but to still think there's a substantial chance of unknown unknowns, making me want to combine those results with something like a "Try to avoid extremely counter-common-sense actions or extremely irreversible consequences" model.
That resonates well for me. Particularly that element of rule versus maximizing/optimized approach. Not quite sure how or where that fits -- and suspect this is a life-time effort to get close to fully working though and opportunities to subdivide areas (which then required all those "how do we classify..." aspects) effectively might be good.
With regards to rules, I think there is also something of an uncertainty reducing role in that rules will increase predictability of external actions. This is not a well thought out idea for me but seems correct, at least in a number of possible situations.
Look forward to reading more.
Replies from: MichaelA↑ comment by MichaelA · 2020-01-03T23:34:26.337Z · LW(p) · GW(p)
With regards to rules, I think there is also something of an uncertainty reducing role in that rules will increase predictability of external actions. This is not a well thought out idea for me but seems correct, at least in a number of possible situations.
Are you talking in some like game-theoretic terms, like how pre-committing to one policy can make it easier for others to plan with that in mind, for cooperation to be achieved, to avoid extortion, etc.?
If so, that seems plausible and interesting (I hadn't been explicitly thinking about that).
But I'd also guess that that benefit could be captured by the typical moral uncertainty approaches (whether they explicitly account for empirical uncertainty or not), as long as some theories you have credence in are at least partly consequentialist. (I.e., you may not need to use model combination and adjustment to capture this benefit, though I see no reason why it's incompatible with model combination and adjustment either.)
Specifically, I'm thinking that the theories you have credence in could give higher choice-worthiness scores to actions that stick closer to what's typical or you or of some broader group (e.g., all humans), or that stick closer to a policy you selected with a prior action, because of the benefits to cooperation/planning/etc. (In the "accounting for empirical uncertainty", tweak that to the theories valuing those benefits as outcomes, and you predicting those actions will likely lead to those outcomes.)
Or you could set things up so there's another "action" to choose from which represents "Select X policy, and sticking to it for the next few years except in Y subset of cases, in which situations you can run MEC again to see what to do". Then it'd be something like evaluating whether to pre-commit to a form of rule utilitarianism in most cases.
But again, this is just me spit-balling - I haven't seen this sort of thing discussed in the academic literature.
Replies from: jmh↑ comment by jmh · 2020-01-04T15:06:49.862Z · LW(p) · GW(p)
Not really a game-theoretic concept for me. The thought largely stems from an article I read over 30 years ago "The Origins of Predictable Behavior". As I recall, it is a largely Bayesian argument for how humans started to evolve rule. One aspect (assuming I am recalling correctly) was the rule took the entire individual calculation out of the picture: we just follow the rule and don't make any effort to optimize under certain conditions.
I don't think this is really an alternative approach -- perhaps a complementary aspect or partial element in the bigger picture.
I've tried to add a bit more but have deleted and retried now about 10 times so I think I will stop here and just think, and reread, a good bit more.
Replies from: MichaelA↑ comment by MichaelA · 2020-01-04T22:40:25.974Z · LW(p) · GW(p)
It sounds like what you're discussing is something like the fact that a "decision procedure" that maximises a "criterion of rightness" over time (rather than just in one instance) may not be "do the thing that maximises this criterion of rightness". I got these terms from here [EA · GW], and then was reminded of them again by this comment [EA(p) · GW(p)] (which is buried in a large thread I found hard to follow all of, but the comment has separate value for my present purposes).
In which case, again I agree. Personally I have decent credence in act utilitarianism being the criterion of rightness, but almost 0 credence that that's the rule one should consciously follow when faced with any given decision situation (e.g., should I take public transport or an Uber? Well, increased demand for Ubers should increase prices and thus supply, increasing emissions, but on the other hand the drivers usually have relatively low income so the marginal utility of my money for them...). Act utilitarianism itself would say that the act "Consciously calculate the utility likely to come from this act, considering all consequences" has terrible expected utility in almost all situations.
So instead, I'd only consciously follow a massively simplified version of act utilitarianism for some big decisions and when initially setting (and maybe occasionally checking back in on) certain "policies" for myself that I'll follow regularly (e.g., "use public transport regularly and Ubers just when it's super useful, and don't get a car, for climate change reasons"). Then the rest of the time, I follow those policies or other heuristics, which may be to embody certain "virtues" (e.g., be a nice person), which doesn't at all imply I actually believe in virtue ethics as a criterion for rightness.
(I think this is similar to two-level utilitarianism, but I'm not sure if that theory makes as explicit a distinction between criteria of rightness and decision procedures.)
But again, I think that's all separate from moral uncertainty (as you say "I don't think this is really an alternative approach -- perhaps a complementary aspect or partial element in the bigger picture"). I think that's more like an empirical question of "Given we know x is the "right" moral theory [very hypothetically!], how should we behave to do the best thing by its lights?" And then the moral theory could indicate high choice-worthiness for the "action" of selecting some particular broad policy to follow going forward, and then later indicate high choice-worthiness for "actions" that pretty much just follow that broad policy (because, among other reasons, that saves you a lot of calculation time which you can then use for other things).
↑ comment by MichaelA · 2020-01-20T02:37:35.840Z · LW(p) · GW(p)
Basically just this one comment sent me down a (productive) rabbit hole of looking into the idea of the risk-uncertainty distinction, resulting in:
- A post [LW · GW] in which I argue that an absolute risk-uncertainty distinction doesn't really make sense and leads to bad decision-making procedures
- A post [EA · GW] in which I argue that acting as if there's a risk-uncertainty distinction, or using it as a rule of thumb, probably isn't useful either, compared to just speaking in terms along the lines of "more" or "less" trustworthy/well-grounded/whatever probabilities. (I.e., I argue that it's not useful to use terms that imply a categorical distinction, rather than a continuous, gradual shift.)
Given that you're someone who uses the risk-uncertainty distinction, and thus presumably either thinks that it makes sense in absolute terms or is at least useful as rough categorisation, I'd be interested in your thoughts on those posts. (One motivation for writing them was to lay out what seems to me the best arguments, and then see if someone could poke holes in them and thus improve my thinking.)
Replies from: jmh