Spend twice as much effort every time you attempt to solve a problem
post by Jsevillamol · 2020-11-15T18:37:24.372Z · LW · GW · 11 commentsContents
12 comments
In brief: in order to iteratively solve problems of unknown difficulty a good heuristic is to double your efforts every time you attempt it.
Imagine you want to solve a problem, such as getting an organization off the ground or solving a research problem. The problem in question has a difficulty rating , which you cannot know in advance.
You can try to solve the problem as many times as you want, but you need to precommit in advance how much effort you want to put into each attempt - this might be for example because you need to plan in advance how you are going to spend your time.
We are going to assume that there is little transfer of knowledge between attempts, so that each attempt succeeds iff the amount of effort you spend on the problem is greater than its difficulty rating .
The question is - how much effort should you precommit to spend on each attempt so that you solve the problem spending as little effort as possible?
Let's consider one straightforward strategy. We first spend unit of effort, then , then , and so on.
We will have to spend in total . The amount of effort spent scales quadratically with the difficulty of the problem.
Can we do better?
What if we double the effort spent each time?
We will have to spend . Much better than before! The amount of effort spent now scales linearly with the difficulty of the problem.
In complexity terms, you cannot possibly do better - even if we knew in advance the difficulty rating we would need to spend to solve it.
Is doubling the best scaling factor? Maybe if we increase the effort by each time we will spend less total effort.
In general, if we scaled our efforts by a factor then we will spend in total . This upper bound is tight at infinitely many points, and its minimum is found for - which asymptotically approaches as grows. Hence seems like a good heuristic scaling factor without additional information on the expected difficulty. But this matters less than the core principle of increasing your effort exponentially.
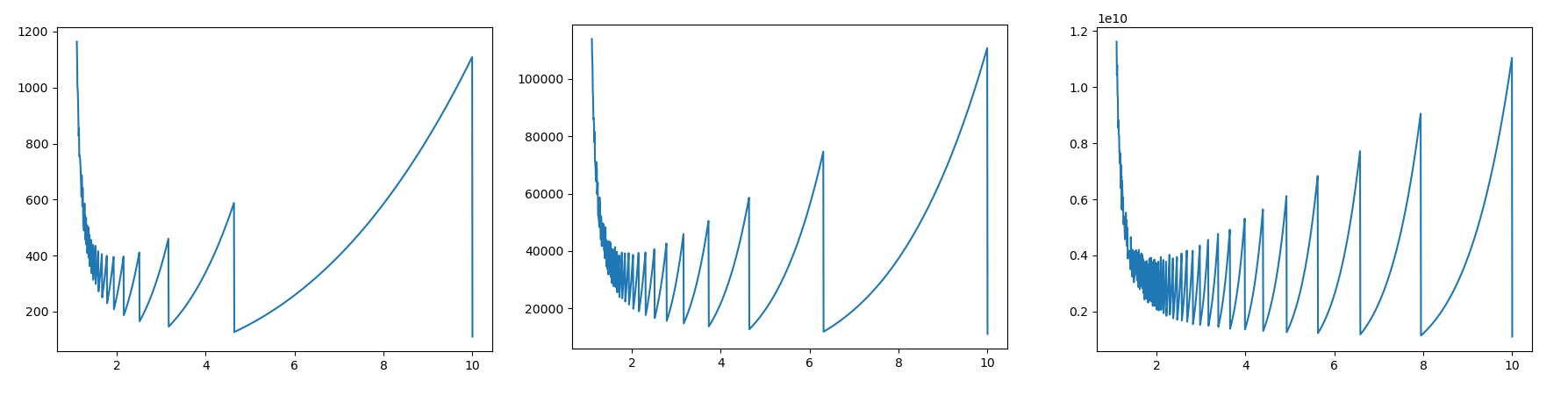
Real life is not as harsh in our assumptions - usually part of the effort spent carries over between attempts and we have information about the expected difficulty of a problem. But in general I think this is a good heuristic to live by.
Here is an (admittedly shoehorned) example. Let us suppose you are unsure about what to do with your career. You are considering research, but aren't sure yet. If you try out research, you will learn more about that. But you are unsure of how much time you should spend trying out research to gather enough information on whether this is for you.
In this situation, before committing to a three year PhD, you better make sure you spend three months trying out research in an internship. And before that, it seems a wise use of your time to allocate three days to try out research on your own. And you better spend three minutes beforehand thinking about whether you like research.
Thank you to Pablo Villalobos for double-checking the math, creating the graphs and discussing a draft of the post with me.
11 comments
Comments sorted by top scores.
comment by Mitchell_Porter · 2020-11-16T08:02:16.106Z · LW(p) · GW(p)
In gambling, the strategy of repeatedly "doubling down" is called a martingale (google to find previous discussions on LW), and the main criticism is that you may run out of money to bet, before chance finally turns in your favor. Analogously, your formal analysis here doesn't take into account the possibility of running out of time or energy before the desired goal is achieved.
I also have trouble interpreting your concrete example, as an application of the proclaimed strategy. I thought the idea was, you don't know how hard it will be to do something, but you commit to doubling your effort each time you try, however many attempts are necessary. In the example, the goal is apparently to discover whether you should pursue a career in research.
Your proposition is, rather than just jump into a three-year degree, test the waters in a strategy of escalating commitment that starts with as little as three minutes. Maybe you'll find out whether research is the life for you, with only minutes or weeks or months spent, rather than years. OK, that sounds reasonable.
It's as if you're applying the model of escalating commitment from a different angle than usual. Usually it's interpreted as meaning: try, try harder, try harder, try HARDER, try REALLY HARD - and eventually you'll get what you want. Whereas you're saying: instead of beginning with a big commitment, start with the smallest amount of effort possible, that could conceivably help you decide if it's worth it; and then escalate from there, until you know. Probably this already had a name, but I'll call it an "acorn martingale", where "acorn" means that you start as small as possible.
Basically, the gap between your formal argument and your concrete example, is that you never formally say, "be sure to start your martingale with as small a bet/effort as possible". And I think also implicit in your example, is that you know an upper bound on d: doing the full three-year degree should be enough to find out whether you should have done it. You don't mention the possibility that to find out whether you really like research, you might have to follow the degree with six years as a postdoc, twelve years as a professor, zillion years as a posthuman gedankenbot... which is where the classic martingale leads.
But if you do know an upper bound on the task difficulty d, then it should be possible to formally argue that an acorn martingale is optimal, and to view your concrete scenario as an example of this.
Replies from: abramdemski, gwern↑ comment by abramdemski · 2020-11-17T00:22:53.001Z · LW(p) · GW(p)
In the gambling house, we already know that gambling isn't worth it. The error of the martingale strategy is to think that you can turn lots of non-worthwhile bets into one big worthwhile bet by doubling down (which would be true if you didn't run out of money).
In the world outside the gambling house, we don't do things unless we expect that they're worth the effort. But we might not know what scale of effort is required.
The post didn't offer an analysis of cases where we give up, but I read it with the implicit assumption that we give up when something no longer looks worth the next doubling of effort. It still seemed like a reasonable heuristic. If at the beginning I think it's probable I'll want to put in the effort to actually accomplish the thing, but I want to put in minimal effort, then the doubling strategy will look like a reasonably good strategy to implement. (Adding the provision that we give up if it's not worth the next doubling makes it better.)
But let's think about how the analysis changes if we explicitly account for quitting.
Say the expected payoff of success is $P. (I'll put everything in dollars.) We know some amount of effort $S will result in success, but we don't know what it is. We're assuming we have to commit to a level of effort at the beginning of each attempt; otherwise, we could just keep adding effort and stop when we succeed (or when we don't think it's worth continuing).
We have a subjective probability distribution over the amount of effort the task might require, but the point of an analysis like the one in the post is to get a rule of thumb that's not dependent on this. So instead let's think about the break-even point $Q where, if I've made a failed attempt costing $Q, I would no longer want to make another attempt. This can be derived from my prior: it's the point where, if I knew the task was at least that difficult, my estimation of difficulty becomes too high. However, by only using this one piece of information from the prior, we can construct a strategy which is fairly robust to different probability distributions. And we need to use something from the prior, since the prior is how we decide whether to quit.
Obviously, $Q < $P.
It doesn't make sense to make any attempts with more effort than $Q. So $Q will be our max effort.
But the required amount of effort might be much lower than Q. So we don't want to just try Q straight away.
At this point, the analysis in the post can be translated to argue that we should start at some Q/() for large-ish n, and keep doubling our effort. This gives us a relatively low upper bound for our total effort (twice Q) while also giving a nice bound on our total effort in terms of the true amount of effort required, $S (specifically, our bound is four times $S) -- meaning we will never spend too much effort on an easy task.
I admit this analysis was a bit sloppy; maybe there's an improved heuristic if we think a bit more carefully about which amounts of effort are worthwhile, while still avoiding use of the full prior.
↑ comment by gwern · 2020-11-16T18:27:38.179Z · LW(p) · GW(p)
The doubling strategy also has counterparts in array allocation strategies and algorithmic analysis (it's common to double an array's size each time it gets too large, to amortize the copying). Successive Halving, a racing algorithm, is also of interest here if you think of a portfolio of tasks instead of a single task.
comment by Andrew_Critch · 2021-07-04T00:54:43.530Z · LW(p) · GW(p)
Nice post! I think something closer to would be a better multiplier than two. Reason:
Instead of minimizing the upper bound of total effort (b^2d−1)/(b-1), it makes sense to also consider the lower bound, (bd−1)/(b-1), which is achieved when d is a power of b. We can treat the "expected" effort (e.g., if you have a uniform improper prior on ) as landing in the middle of these two numbers, i.e.,
This is minimized where which approaches b=1+√2 for d large. If you squint at your seesaw graphs and imagine a line "through the middle" of the peaks and troughs, I think you can see it bottoming out at around 2.4.
Replies from: Jsevillamol↑ comment by Jsevillamol · 2021-07-05T10:03:31.068Z · LW(p) · GW(p)
Nicely done!
I think this improper prior approach makes sense.
I am a bit confused on the step when you go from an improper prior to saying that the "expected" effort would land in the middle of these numbers. This is because the continuous part of the total effort spent vs doubling factor is concave, so I would expect the "expected" effort to be weighted more in favor of the lower bound.
I tried coding up a simple setup where I average the graphs across a space of difficulties to approximate the "improper prior" but it is very hard to draw a conclusion from it. I think the graph suggests that the asymptotic minimum is somewhere above 2.5 but I am not sure at all.
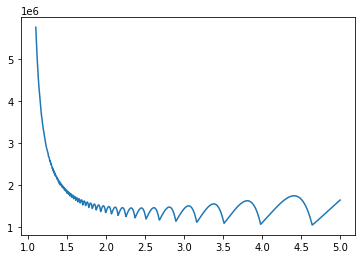
Also I guess it is unclear to me whether a flat uninformative prior is best, vs an uninformative prior over logspace of difficulties.
What do you think about both of these things?
Code for the graph:
import numpy as np
import matplotlib.pyplot as plt
import math
effort_spent = lambda d,b : (b**(np.ceil(math.log(d, b))+1)-1) / (b-1)
ds = np.linspace(2, 1000000, 100000)
hist = np.zeros(shape=(1000,))
for d in ds:
bs = np.linspace(1.1, 5, 1000)
hist += np.vectorize(lambda b : effort_spent(d,b))(bs) / len(ds)
plt.plot(bs, hist);comment by Jsevillamol · 2022-01-09T22:17:09.456Z · LW(p) · GW(p)
This is a nice little post, that explores a neat idea using a simple math model. I do stand by the idea, even if I remain confused about the limits about its applicability.
The post has received a mixed response. Some people loved it, and I have received some private messages from people thanking me for writing it. Others thought it was confused or confusing.
In hindisight, I think the choice of examples is not the best. I think a cleaner example of this problem would be from the perspective of a funder, who is trying to finance researchers to solve a concrete research problem. How many FTEs should it fund each year? This model gives a good answer.
Andrew Critch chimed in with an extension [LW(p) · GW(p)] considering minizing effort spent on the average case instead of in the worst case, which I thought was very cool. I replied to it afterwards [LW(p) · GW(p)], taking his idea further.
One thing I love of this community is collaborative improvement. Receiving constructive feedback in posts is very useful, and I feel that happened here.
comment by adamShimi · 2020-11-16T21:04:30.063Z · LW(p) · GW(p)
We are going to assume that there is little transfer of knowledge between attempts, so that each attempt succeeds iff the amount of effort you spend on the problem is greater than its difficulty rating .
This hypothesis is plain false for research. Like, most of the time, you find the solution between attempts, not while investing the maximum amount of effort that you ever did. What I find true is that there is usually a minimal amount of total effort to invest before your intuition can kick in when you're doing something else, but you can do it in multiple times. It might even be more productive to do so.
You do mention my issue at the end of your post:
Real life is not as harsh in our assumptions - usually part of the effort spent carries over between attempts and we have information about the expected difficulty of a problem. But in general I think this is a good heuristic to live by.
But having an assumption that is so blatantly false makes me very dubious that this model has any use, at least in the context of research.
comment by Dagon · 2020-11-15T19:25:29.506Z · LW(p) · GW(p)
Each attempt succeeds iff the amount of effort you spend on the problem is greater than its difficulty rating .
Do you have any reasons to believe that this models real-world problems well? I think factors other than effort matter a great deal, and to some extent, effort can be conserved or expended based on learning DURING the effort. You don't have to pre-commit, you can re-allocate as your knowledge and success criteria change. Importantly, the vast majority of worthwhile problems are not binary in success - there's lots of different ways to get/contribute value.
In this situation, before committing to a three year PhD, you better make sure you spend three months trying out research in an internship to try out research. And before that, it seems a wise use of your time to allocate three days to try out research on your own. And you better spend three minutes beforehand thinking about whether you like research.
That's ridiculous, or at least misleading. You should be researching and considering that DURING your previous training, and it's nowhere near exactly logarithmic.
comment by Donald Hobson (donald-hobson) · 2020-11-16T18:34:31.103Z · LW(p) · GW(p)
In computer science, this is a standard strategy for allocating blocks of memory.
Suppose you have some stream of data that will end at some point. This could come from a user input or a computation that you don't want to repeat. You want to store all the results in a contiguous block of memory. You can ask for a block of memory of any size you want. The strategy here is that whenever you run out of space, you ask for a block that's twice as big and move all your data to it.
comment by ChristianKl · 2020-11-16T14:03:08.585Z · LW(p) · GW(p)
Can your advice be rephrased as "tackle half as many problems while keeping the effort you take constant"? If not, how does your advice differ?
Replies from: Jsevillamol↑ comment by Jsevillamol · 2020-11-16T16:00:30.733Z · LW(p) · GW(p)
I don't think so.
What I am describing is an strategy to manage your efforts in order to spend as little as possible while still meeting your goals (when you do not know in advance how much effort will be needed to solve a given problem).
So presumably if this heuristic applies to the problems you want to solve, you spend less on each problem and thus you'll tackle more problems in total.