Literature Review: Distributed Teams
post by Elizabeth (pktechgirl) · 2019-04-16T01:19:27.307Z · LW · GW · 37 commentsContents
Introduction How does distribution affect information flow? How does distribution interact with conflict? When are remote teams preferable? How to mitigate the costs of distribution None 37 comments
Introduction
Context: Oliver Habryka commissioned me to study and summarize the literature on distributed teams, with the goal of improving altruistic organizations. We wanted this to be rigorous as possible; unfortunately the rigor ceiling was low, for reasons discussed below. To fill in the gaps and especially to create a unified model instead of a series of isolated facts, I relied heavily on my own experience on a variety of team types (the favorite of which was an entirely remote company).
This document consists of five parts:
- Summary
- A series of specific questions Oliver asked, with supporting points and citations. My full, disorganized notes will be published as a comment.
My overall model of worker productivity is as follows:
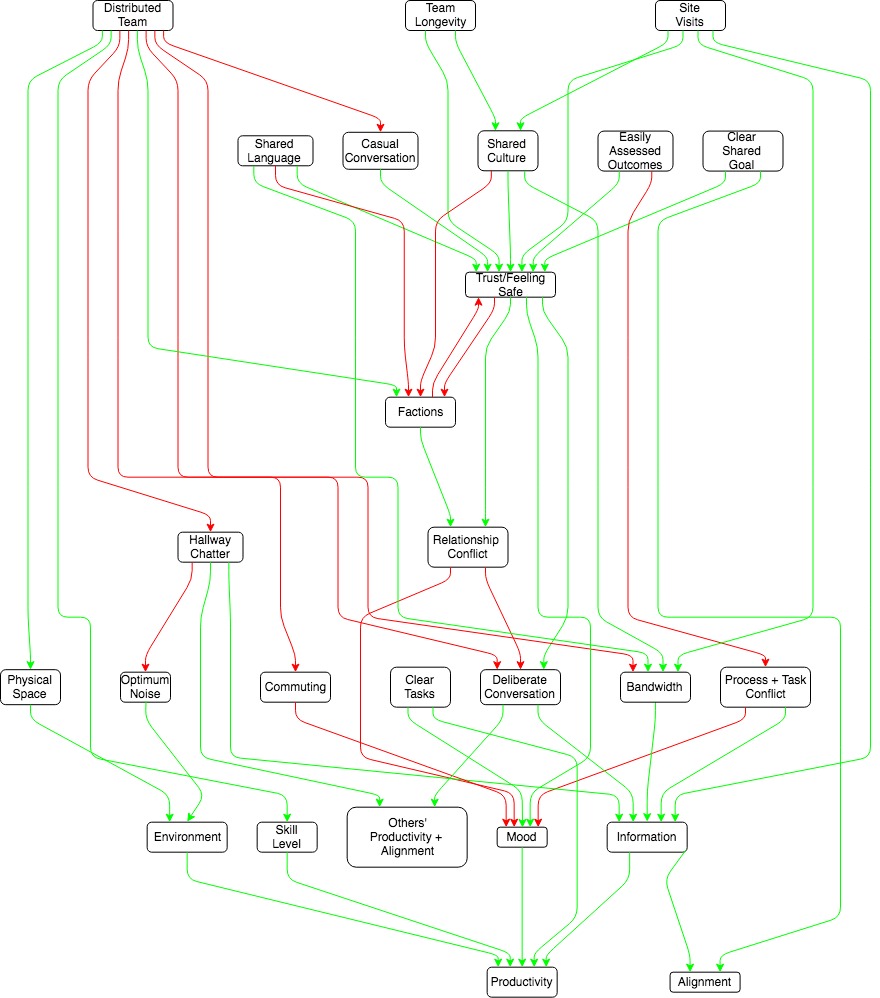
Highlights and embellishments:
- Distribution decreases bandwidth and trust (although you can make up for a surprising amount of this with well timed visits).
- Semi-distributed teams are worse than fully remote or fully co-located teams on basically every metric. The politics are worse because geography becomes a fault line for factions, and information is lost because people incorrectly count on proximity to distribute information.
- You can get co-location benefits for about as many people as you can fit in a hallway: after that you’re paying the costs of co-location while benefits decrease.
- No paper even attempted to examine the increase in worker quality/fit you can get from fully remote teams.
Sources of difficulty:
- Business science research is generally crap.
- Much of the research was quite old, and I expect technology to improve results from distribution every year.
- Numerical rigor trades off against nuance. This was especially detrimental when it comes to forming a model of how co-location affects politics, where much that happens is subtle and unseen. The most largest studies are generally survey data, which can only use crude correlations. The most interesting studies involved researchers reading all of a team’s correspondence over months and conducting in-depth interviews, which can only be done for a handful of teams per paper.
How does distribution affect information flow?
“Co-location” can mean two things: actually working together side by side on the same task, or working in parallel on different tasks near each other. The former has an information bandwidth that technology cannot yet duplicate. The latter can lead to serendipitous information sharing, but also imposes costs in the form of noise pollution and siphoning brain power for social relations.
Distributed teams require information sharing processes to replace the serendipitous information sharing. These processes are less likely to be developed in teams with multiple locations (as opposed to entirely remote). Worst of all is being a lone remote worker on a co-located team; you will miss too much information and it’s feasible only occasionally, despite the fact that measured productivity tends to rise when people work from home.
I think relying on co-location over processes for information sharing is similar to relying on human memory over writing things down: much cheaper until it hits a sharp cliff. Empirically that cliff is about 30 meters, or one hallway. After that, process shines.
List of isolated facts, with attribution:
- “The mutual knowledge problem” (Cramton 2015):
- Assumption knowledge is shared when it is not, including:
- typical minding.
- Not realizing how big a request is (e.g. “why don’t you just walk down the hall to check?”, not realizing the lab with the data is 3 hours away. And the recipient of the request not knowing the asker does not know that, and so assumes the asker does not value their time).
- Counting on informal information distribution mechanisms that don’t distribute evenly
- Silence can be mean many things and is often misinterpreted. E.g. acquiescence, deliberate snub, message never received.
- Lack of easy common language can be an incredible stressor and hamper information flow (Cramton 2015).
- People commonly cite overhearing hallway conversation as a benefit of co-location. My experience is that Slack is superior for producing this because it can be done asynchronously, but there’s reason to believe I’m an outlier.
- Serendipitous discovery and collaboration falls off by the time you reach 30 meters (chapter 5), or once you’re off the same hallway (chapter 6)
- Being near executives, project decision makers, sources of information (e.g. customers), or simply more of your peers gets you more information (Hinds, Retelny, and Cramton 2015)
How does distribution interact with conflict?
Distribution increases conflict and reduces trust in a variety of ways.
- Distribution doesn’t lead to factions in and of itself, but can in the presence of other factors correlated with location
- e.g. if the engineering team is in SF and the finance team in NY, that’s two correlated traits for fault lines to form around. Conversely, having common traits across locations (e.g. work role, being parents of young children)] fights factionalization (Cramton and Hinds 2005).
- Language is an especially likely fault line.
- Levels of trust and positive affect are generally lower among distributed teams (Mortenson and Neeley 2012) and even co-located people who work from home frequently enough (Gajendra and Harrison 2007).
- Conflict is generally higher in distributed teams (O’Leary and Mortenson 2009, Martins, Gilson, and Maynard 2004)
- It’s easier for conflict to result in withdrawal among workers who aren’t co-located, amplifying the costs and making problem solving harder.
- People are more likely to commit the fundamental attribution error against remote teammates (Wilson et al 2008).
- Different social norms or lack of information about colleagues lead to misinterpretation of behavior (Cramton 2016) e.g.,
- you don’t realize your remote co-worker never smiles at anyone and so assume he hates you personally.
- different ideas of the meaning of words like “yes” or “deadline”.
- From analogy to biology I predict conflict is most likely to arise when two teams are relatively evenly matched in terms of power/ resources and when spoils are winner take all.
- Most site:site conflict is ultimately driven by desire for access to growth opportunities (Hinds, Retelny, and Cramton 2015). It’s not clear to me this would go away if everyone is co-located- it’s easier to view a distant colleague as a threat than a close one, but if the number of opportunities is the same, moving people closer doesn’t make them not threats.
- Note that conflict is not always bad- it can mean people are honing their ideas against others’. However the literature on virtual teams is implicitly talking about relationship conflict, which tends to be a pure negative.
When are remote teams preferable?
- You need more people than can fit in a 30m radius circle (chapter 5), or a single hallway. (chapter 6).
- Multiple critical people can’t be co-located, e.g.,
- Wave’s compliance officer wouldn’t leave semi-rural Pennsylvania, and there was no way to get a good team assembled there.
- Lobbying must be based in Washington, manufacturing must be based somewhere cheaper.
- Customers are located in multiple locations, such that you can co-locate with your team members or customers, but not both.
- If you must have some team members not co-located, better to be entirely remote than leave them isolated. If most of the team is co-located, they will not do the things necessary to keep remote individuals in the loop.
- There is a clear shared goal
- The team will be working together for a long time and knows it (Alge, Weithoff, and Klein 2003)
- Tasks are separable and independent.
- You can filter for people who are good at remote work (independent, good at learning from written work).
- The work is easy to evaluate based on outcome or produces highly visible artifacts.
- The work or worker benefits from being done intermittently, or doesn’t lend itself to 8-hours-and-done, e.g.,
- Wave’s anti-fraud officer worked when the suspected fraud was happening.
- Engineer on call shifts.
- You need to be process- or documentation-heavy for other reasons, e.g. legal, or find it relatively cheap to be so (chapter 2).
- You want to reduce variation in how much people contribute (=get shy people to talk more) (Martins, Gilson, and Maynard 2008).
- Your work benefits from long OODA loops.
- You anticipate low turnover (chapter 2).
How to mitigate the costs of distribution
- Site visits and retreats, especially early in the process and at critical decision points. I don’t trust the papers quantitatively, but some report site visits doing as good a job at trust- and rapport-building as co-location, so it’s probably at least that order of magnitude (see Hinds and Cramton 2014 for a long list of studies showing good results from site visits).
- Site visits should include social activities and meals, not just work. Having someone visit and not integrating them socially is worse than no visit at all.
- Site visits are more helpful than retreats because they give the visitor more context about their coworkers (chapter 2). This probably applies more strongly in industrial settings.
- Use voice or video when need for bandwidth is higher (chapter 2).
- Although high-bandwidth virtual communication may make it easier to lie or mislead than either in person or low-bandwidth virtual communication (Håkonsson et al 2016).
- Make people very accessible, e.g.,
- Wave asked that all employees leave skype on autoanswer while working, to recreate walking to someone’s desk and tapping them on the shoulder.
- Put contact information in an accessible wiki or on Slack, instead of making people ask for it.
- Lightweight channels for building rapport, e.g., CEA’s compliments Slack channel, Wave’s kudos section in weekly meeting minutes (personal observation).
- Build over-communication into the process.
- In particular, don’t let silence carry information. Silence can be interpreted a million different ways (Cramton 2001).
- Things that are good all the time but become more critical on remote teams
- Clear goals/objectives
- Clear metrics for your goals/objectives
- Clear roles (Zacarro, Ardison, Orvis 2004)
- Regular 1:1s
- Clear communication around current status
- Long time horizons (chapter 10).
- Shared identity (Hinds and Mortensen 2005) with identifiers (chapter 10), e.g. t-shirts with logos.
- Have a common chat tool (e.g., Slack or Discord) and give workers access to as many channels as you can, to recreate hallway serendipity (personal observation).
- Hire people like me
- long OODA loop
- good at learning from written information
- Good at working working asynchronously
- Don’t require social stimulation from work
- Be fully remote, as opposed to just a few people working remotely or multiple co-location sites.
- If you have multiple sites, lumping together similar people or functions will lead to more factions (Cramton and Hinds 2005). But co-locating people who need to work together takes advantage of the higher bandwidth co-location provides..
- Train workers in active listening (chapter 4) and conflict resolution. Microsoft uses the Crucial Conversations class, and I found the book of the same name incredibly helpful.
Cramton 2016 was an excellent summary paper I refer to a lot in this write up. It’s not easily available on-line, but the author was kind enough to share a PDF with me that I can pass on.
My full notes will be published as a comment on this post.
37 comments
Comments sorted by top scores.
comment by Elizabeth (pktechgirl) · 2019-04-16T01:21:18.976Z · LW(p) · GW(p)
Notes have been moved to this post [LW · GW] to save scrolling.
Replies from: Errorcomment by Larks · 2019-04-16T16:06:48.856Z · LW(p) · GW(p)
In light of this:
Build over-communication into the process.
In particular, don’t let silence carry information. Silence can be interpreted a million different ways (Cramton 2001).
Thanks for writing this! I found it very interesting, and I like the style. I particularly hadn't properly appreciated how semi-distributed was worth than either extreme. It's disappointing to hear, but seemingly obvious in retrospect and good to know.
comment by Davidmanheim · 2019-05-09T09:15:48.791Z · LW(p) · GW(p)
This is a fantastic review of the literature, and a very valuable post - thank you!
My critical / constructive note is that I think that many of the conclusions here are state with too much certainty or are overstated. My promary reasons to think it should be more hedged are that the literature is so ambiguous, the fundamental underlying effects are unclear, the model(s) proposed in the post do not really account for reasonable uncertainties about what factors matter, and there is almost certainly heterogeneity based on factors that aren't discussed.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-05-09T20:20:48.125Z · LW(p) · GW(p)
Thanks for the kind words.
I'm unclear if you think all conclusions should be hedged like that, or my specific strong conclusions (site visits are good, don't split a team) are insufficiently supported.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2019-05-10T06:55:50.147Z · LW(p) · GW(p)
Somewhere in the middle. Most conclusions should be hedged more than they are, but some specific conclusions here are based on strong assumptions that I don't think are fully justified, and the strength of evidence and the generality of the conclusions isn't clear.
I think that recommending site visits and not splitting a team are good recommendations in general, but sometimes (rarely) could be unhelpful. Other ideas are contingently useful, but often other factors push the other way. "Make people very accessible" is a reasonable idea that in many contexts would work poorly, especially given Paul Graham's points on makers versus managers. Similarly, the emphasis on having many channels for communication seems to be better than the typical lack of communication, but can be a bad idea for people who need time for deep work, and could lead to furthering issues with information overload.
All of that said, again, this is really helpful research, and points to enough literature that others can dive in and assess these things for themselves.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-05-10T14:53:54.599Z · LW(p) · GW(p)
That makes sense. Neither of those was my intention- I declare at the beginning that the research is crap; repeating it at every point seems excessive. And I assumed people would take the conclusions as "this will address this specific problem" rather than "this is a Pure Good Action that will have no other consequences."
I understand that this isn't how it came across to you, and that's useful data. I am curious how others feel I did on this score.
comment by Raemon · 2019-04-30T02:12:59.068Z · LW(p) · GW(p)
Curated.
(It seemed important that Habryka not be the one to curate this piece, since he had commissioned it. But I independently quite liked it)
Several things I liked about this post:
- It told me some concrete things about remote teams. In particular:
- the notion that you should either go "fully remote" or "not remote"
- the notion that the benefits of co-locating drop off after a literal radius which extends 30m.
- It gave me some sense of how good the evidence on remote teams are (i.e. not very), while providing a bunch of links to followup if I wanted to get an even better sense.
- LessWrong currently doesn't feel like rewards serious scholarship as much as it should, so I'd like to generally reward it when it happens. I also think this post did a good job if combining short, easily readable takeaways with the more extensive background literature.
↑ comment by Raemon · 2019-04-30T02:14:16.737Z · LW(p) · GW(p)
Object-level Musings on Peer Review
Note: the following is my personal best guesses about directions LW should go. Habryka disagrees significantly with at least some of the claims here — both on the object and meta levels.
This post was also jumped out significantly as... aspiring to higher epistemic standards than the median curated post. This led me to thinking about it through the lens of peer review (which I have previously mused about [LW · GW])
I ultimately want LessWrong to encourage extremely high quality intellectual labor. I think the best way to go about this is through escalating positive rewards, rather than strong initial filters.
Right now our highest reward is getting into the curated section, which... just isn't actually that high a bar. We only curate posts if we think they are making a good point. But if we set the curated bar at "extremely well written and extremely epistemically rigorous and extremely useful", we would basically never be able to curate anything.
My current guess is that there should be a "higher than curated" level, and that the general expectation should be that posts should only be put in that section after getting reviewed, scrutinized, and most likely rewritten at least once. Still, there is something significant about writing a post that is at least worth considering for that level.
This post is one of a few ones in the past few months that I'd be interested in seeing improved to meet that level. (Another recent example is Kaj's sequence on Multi-Agent-Models).
I do think it'd involve some significant work to meet that bar. Things that I'm currently thinking of (not highly confident that any of this is the right thing, but showcasing what sort of improvements I'm imagining)
- Someone doing some epistemic spot checks on the claims made here
- Improving the presentation (right now it's written in a kind of bare-bones notes format)
- Dramatically improving the notes, to be more readable
- Improving the diagram of elizabeth's model of productivity so it's easier to parse.
- Orienting a bit more around the "the state of management research is shitty" issue. I think (low confidence) that a good practice for LessWrong, if we review a field and find that the evidence base is very shaky, it'd be good to reflect on what it would take to make the evidence less shaky. (This is beyond scope for what habryka originally commissioned, but feels fairly important in the context I'm thinking through here)
Is it worth putting all that work for this particular post? Dunno, probably not. But it seems worth periodically reflecting on how far the bar would be set, when comparing what LessWrong could ultimately be vs. what is necessary to in-practice be.
Replies from: hermanubis, pktechgirl↑ comment by hermanubis · 2019-04-30T02:36:37.573Z · LW(p) · GW(p)
What about getting money involved? Even relatively small amounts can still confer prestige better than an additional tag or homepage section. It seems like rigorous well-researched posts like this are valuable enough that crowdfunding or someone like OpenPhil or CFAR could sponsor a best-post prize to be awarded monthly. If that goes well you could add incentives for peer-review.
Replies from: Elo, SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2019-05-01T01:28:29.984Z · LW(p) · GW(p)
A small amount of money would do the opposite of conferring prestige; it would make the activity less prestigious than it is now.
Replies from: None, ioannes_shade↑ comment by ioannes (ioannes_shade) · 2019-05-07T21:10:29.721Z · LW(p) · GW(p)
cf. https://en.wikipedia.org/wiki/Knuth_reward_check
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2019-05-08T06:19:20.035Z · LW(p) · GW(p)
What makes this situation unusual is that being acknowledged by famous computer scientist Donald Knuth to have contributed something useful to one of his works is inherently prestigious; the check is evidence of that reward, not itself the reward. (Note that many of the checks do not even get cashed! A trophy showing that you fixed a bug in Knuth’s code is vastly more valuable than enough money to buy a plain slice of pizza.)
In contrast, Less Wrong is not prestigious. No one will be impressed to hear that you wrote a Less Wrong post. How likely do you think it is that someone who is paid some money for a well-researched LW post will, instead of claiming said money, frame the check and display it proudly?
Replies from: Davidmanheim↑ comment by Davidmanheim · 2019-05-10T06:22:34.477Z · LW(p) · GW(p)
I think you're viewing intrinsic versus extrinsic reward as dichotomous rather than continuous. Knuth awards are on one end of the spectrum, salaries at large organizations are at the other. Prestige isn't binary, and there is a clear interaction between prestige and standards - raising standards can itself increase prestige, which will itself make the monetary rewards more prestigious.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-05-10T14:59:52.273Z · LW(p) · GW(p)
I don't see where Said's comment implies a dichotomous view of prestige. He simply believes the gap between LessWrong and Donald Knuth is very large.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2019-05-22T09:20:13.212Z · LW(p) · GW(p)
Sure, but we can close the global prestige gap to some extent, and in the mean time, we can leverage in-group social prestige, as the current format implicitly does.
↑ comment by Elizabeth (pktechgirl) · 2019-04-30T22:30:31.656Z · LW(p) · GW(p)
Orienting a bit more around the "the state of management research is shitty" issue
Can you say more about this? That seems like a very valuable but completely different post, which I imagine would take an order of magnitude more effort than investigation into a single area.
Replies from: Raemon↑ comment by Raemon · 2019-04-30T22:44:45.356Z · LW(p) · GW(p)
Yeah, there's definitely a version of this that is just a completely different post. I think Habryka had his own opinions here that might be worth sharing.
Some off the cuff thoughts:
- Within scope for something "close to the original post", I think it'd be useful to have:
- clearer epistemic status tags for the different claims.
- Which claims are based on out of date research? How old is the research?
- Which are based on shoddy research?
- What's your credence for each claim?
- More generally, how much stock should a startup founder place in this post? In your opinion, does the state of this research rise to the level of "you should most likely follow this post's advice?" or is it more like "eh, read this post to get a sense of what considerations might be at play but mostly rely on your own thinking?"
- Broader scope, maybe it's own entire post (although I think there's room for a "couple paragraphs version" and a "entire longterm research project" version)
- Generally, what research do you wish had existed, that would have better informed you here?
- Are there are particular experiments or case studies that seemed (relatively) easy to replicate, that just needed to be run again in the modern era with 21st century communication tech?
↑ comment by Elizabeth (pktechgirl) · 2019-04-30T23:14:51.906Z · LW(p) · GW(p)
clearer epistemic status tags for the different claims....
I find it very hard, possibly impossible, to do the things you ask in this bullet point and synthesis in the same post. If I was going to do that it would be on a per-paper basis: for each paper list the claims and how well supported they are.
Generally, what research do you wish had existed, that would have better informed you here?
This seems interesting and fun to write to me. It might also be worth going over my favorite studies.
Replies from: Raemon↑ comment by Raemon · 2019-04-30T23:28:35.203Z · LW(p) · GW(p)
I find it very hard, possibly impossible, to do the things you ask in this bullet point and synthesis in the same post
Hard because of limitations on written word / UX, or intellectual difficulties with processing that class of information in the same pass that you process the synthesis type of information?
(Re: UX – I think it'd work best if we had a functioning side-note system. In the meanwhile, something that I think would work is to give each claim a rough classification of "high credence, medium or low", including a link to a footnote that explains some of the detais)
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-05-01T00:37:51.639Z · LW(p) · GW(p)
Data points from papers can either contribute directly to predictions (e.g. we measured it and gains from colocation drop off at 30m), or to forming a model that makes predictions (e.g. the diagram). Credence levels for the first kind feel fine, but like a category error for model-born predictions . It's not quite true that the model succeeds or fails as a unit, because some models are useful in some arenas and not in others, but the thing to evaluate is definitely the model, not the individual predictions.
I can see talking about what data would make me change my model and how that would change predictions, which may be isomorphic to what you're suggesting.
The UI would also be a pain.
comment by Ben Pace (Benito) · 2019-04-16T09:15:27.891Z · LW(p) · GW(p)
This is awesome, thanks.
In case it’s of interest to anyone, I recently wrote down some short, explicit models of the costs of remote teams (I did not try to write the benefits). Here’s what I wrote:
- Substantially increases activation costs of collaboration, leading to highly split focus of staff
- Substantially increases costs of creating common knowledge (especially in political situations)
- Substantially increases barriers to building trust (in-person interaction is key for interpersonal trust)
- Substantially decreases communication bandwidth - both rate and quality of feedback - increasing the cost of subtle, fine-grained and specific positive feedback harder, and making strong negative feedback on bad decisions much easier, leading to risk-aversion.
- Substantially increases cost of transmitting potentially embarrassing information, and incentivises covering up of low productivity, as it’s very hard for a manager to see the day-to-day and week-to-week output.
↑ comment by Elizabeth (pktechgirl) · 2019-04-16T17:11:50.646Z · LW(p) · GW(p)
Substantially increases activation costs of collaboration, leading to highly split focus of staff
I think this is a mixed blessing rather than a cost. It makes staff members less likely to be working in alignment with one another, but more likely to be working in their personal flow in the Csikszentmihalyi sense of the word. I believe these two things trade off against each other in general, and things moving the efficient frontier are very valuable.
comment by DanielFilan · 2020-12-10T03:09:25.989Z · LW(p) · GW(p)
A pretty high-quality post on a problem many people have had in 2020. That being said, I wonder if the 2020 COVID pandemic will produce enough research to make this redundant in a year? I doubt it, but we'll see.
comment by Raemon · 2021-01-12T09:52:24.356Z · LW(p) · GW(p)
I haven't reviewed the specific claims of the literature here, but I did live through a pandemic where a lot of these concerns came up directly, and I think I can comment directly on the experience.
- Some LessWrong team members disagree with me on how bad remote-work is. I overall thought it was "Sort of fine, it made some things a bit harder, other things easier. It made it harder to fix some deeper team problems, but we also didn't really succeed at fixing those team problems for in previous non-pandemic years."
- Epistemic Status, btw: I live the farthest away from all other LW team members, and it's the biggest hassle for me to relocate back to Berkeley, so I have some motivation to think remote-ness isn't as big a deal.
- Initially I found it easier to get deep work done and I felt more productive. Over time I think that slid into "well, I work about as productively as I did before the pandemic."
- I think the biggest problems are "if anyone on a team develops any kind of aversion or ugh field, it's way harder to fix the problem. You can't casually chat about it over lunch, carefully feeling out their current mood. You have to send them an ominous slack message asking 'hey, um, can we talk?'".
- Elizabeth mentioned this in the OP: "It’s easier for conflict to result in withdrawal among workers who aren’t co-located, amplifying the costs and making problem solving harder."
- Other team members have mentioned that it's harder to keep track of what other people are doing, and notice if a teammate is going off in a wrong direction. (This seems to slot into the "information flow" section. Indeed, when we do work in an office we're within the "within about one hallway" distance.
Retreats and Site Visits
- We made sure to do at a retreat, putting a bunch of effort into covid quarantining beforehand. tried occasional "meet outdoors for meetings."
- This post highlights that doing "enmeshed site visits" is good in addition to retreats. Which, to be fair, I think people on the team did pitch, and mostly it was fairly costly to do it during a pandemic.
Making people very accessible
- We tried out software called Tandem that made it easier to immediately voice-call with a person. We stopped using it primarily because it was hogging CPU. But some of us found it pretty disruptive to be always available.
- Later we tried out working in the shared Gather Town space. I think this might have worked better if we weren't also trying to make that Gather Town space a populous hub (Walled Garden). This was distracting (although during that period we did successfully stay more in touch with other orgs and friends, which was the explicit goal)
- It sucked that everything other than Zoom had mediocre audio quality
Video/Audio Tech
- We tried a huge variety of microphones, headphones, software, wired internet. We never really found a set of tools that didn't randomly spazz out sometime. (Wired headphones and internet ran into a different set of problems than bluetooth)
Written Communication
- We used Notion, a sort of Google Docs clone with all kinds of tools integrated into each other. It worked pretty well (easily searchable, has a sidebar where you can see all the documents in a nested hierarchy). It had some bugs.
comment by Ben Pace (Benito) · 2019-05-02T22:15:19.186Z · LW(p) · GW(p)
Datapoint: Stripe's Fifth Engineering Hub is Remote. HN discussion.
comment by Matthijs Cox (matthijs-cox) · 2019-04-22T11:16:12.628Z · LW(p) · GW(p)
Fascinating.
It seems a certain amount of dynamics is relevant, as indicated by the site visits and retreats. I guess you assume the co-located team is static, i.e. no frequent home working or reshuffling with other teams?
I wonder if it's possible to model the impact of such vibrations and transitions between team formations. For example, the Scaled Agile framework proposes static co-located teams with a higher layer of people continuously transferring information between the teams. The teams retreat into a large event a few times a year. Due to personal circumstances I'd love to know their BS factor.
Replies from: pktechgirl, pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-04-22T23:10:07.543Z · LW(p) · GW(p)
Teams were typically static for the duration of the studies, although IIRC some were newly formed task-focused teams and would reshuffle after the task was over.
Some studies looked at the effect of WFH in co-located team. I didn't focus on this because it wasn't Oliver's main question, but from some reading and personal experience:
- If a team is set up for colocation, you will miss things working from home, which will hurt alignment and social aspects like trust. This scales faster than linearly.
- Almost everyone reports increased productivity working from home.
- But some of that comes from being less interruptible, which hurts other people's productivity.
- Both duration of team and the expectation of working together in the future do good things to morale, trust, and cooperation.
Based on this, I think that:
- Some WFH is good on the margins.
- The more access employees have to quiet private spaces at work, the less the marginal gains from WFH (although still some, for things like midday doctors' appointments or just avoiding the commute). I think most companies exaggerate how much these are available.
- "Core Hours" is a good concept for both days and times in office, because it concentrates the time people need to defensively be in the office to avoid missing things.
- How Scaled Agile effects morale and trust will be heavily dependent on how people relate to the meta-team. If they view themselves as constantly buffeted between groups of strangers, it will be really bad. If they view the meta-team as their real team, full of people they trust and share a common goal with but don't happen to be working as closely with at this time, it's probably a good compromise.
↑ comment by Elizabeth (pktechgirl) · 2019-04-22T23:11:35.185Z · LW(p) · GW(p)
The most relevant paper I read was Chapter 5 of Distributed Work by Hinds and Kiesler. You can find it in my [LW · GW] notes [LW · GW] by searching for "Chapter 5: The (Currently) Unique Advantages of Collocated Work"
comment by rmoehn · 2019-09-07T03:17:46.032Z · LW(p) · GW(p)
If you need more input, I recommend:
- https://www.manager-tools.com/2017/12/working-remotely-chapter-1-get-results
- https://www.manager-tools.com/2018/01/working-remotely-chapter-2-meet-whenever-possible
- https://www.manager-tools.com/2018/03/working-remotely-chapter-3-contribution-team
- https://www.manager-tools.com/2010/10/distant-manager-basics-part-1
- https://www.manager-tools.com/2011/04/distant-manager-basics-directs-part-1
- https://www.manager-tools.com/2005/10/virtual-teams
- https://www.manager-tools.com/2009/05/phone-one-ones
They're podcasts, not literature. But you can download all the shownotes, which read like a whitepaper, if you buy a one-month licence for $20.
comment by ryan_b · 2019-04-16T15:45:17.545Z · LW(p) · GW(p)
Excellent work! I particularly like including your notes in the comments.
I have one question about OODA (I see long loops mentioned in the post, but without attribution; I don't see them mentioned in the notes explicitly). Could you talk more about the long-loop conclusion, and how remote work benefits from it?
My naive guess is that the bandwidth issues associated with remote work cause feedback to take longer, which means longer OODA loops are a desirable trait in the worker, but my confidence is not particularly high.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-04-16T17:51:47.138Z · LW(p) · GW(p)
RE: OODA loops as a property of work: let's take the creation of this post as an example. There were broadly four parts to writing it:
1. Talking to Oliver to figure out what he wanted
2. Reading papers to learn facts
3. Relating all the facts to each other
4. Writing a document explaining the relation
Part 1 really benefited from co-location, especially at first. It was heavily back and forth, and so benefited from the higher bandwidth. The OODA loop was at most the time it took either of us to make a statement.
Part 2 didn't require feedback from anyone, but also had a fairly short OODA loop because I had to keep at most one paper in my head at a time, and dropping down to one paragraph wasn't that bad.
Part 3 had a very long OODA loop because I had to load all the relevant facts in my head and then relate them. An interruption before producing a new synthesis meant losing all the work I'd done till that point.
I also needed all available RAM to hold as much as possible at once. Even certain background noise would have been detrimental here.
Part 4 had a shorter minimum OODA loop than part 3, but every interruption meant reloading the data into my brain, so longer was still better.
Does that feel like it answered your questions?
Replies from: ryan_b↑ comment by ryan_b · 2019-04-16T21:12:18.025Z · LW(p) · GW(p)
That is much better, but it raises a more specific question: here you described the loop as a property of the task; but then you also wrote
- Hire people like me
- long OODA loop
Which seems to mean you are the one with the long loop. I can easily imagine different people having different maximum loop-lengths, beyond which they are likely to fail. Am I correct in interpreting this to mean something like trying to ensure that the remote worker can handle the longest-loop task you have to give them?
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2019-04-17T00:20:48.827Z · LW(p) · GW(p)
I think tasks, environments and people have a range of allowable OODA loops, and that it's very damaging if there isn't an overlap of all three.