Is Google Paperclipping the Web? The Perils of Optimization by Proxy in Social Systems
post by Alexandros · 2010-05-10T13:25:41.567Z · LW · GW · Legacy · 105 commentsContents
Introducing OBP Effect of Other Intelligent Actors Faking it - A Bayesian View Attempts to Counteract Optimization by Proxy The Downward Spiral: Industrializing OBP Exploitation Conclusion None 105 comments
Related to: The Importance of Goodhart's Law, Lucas Critique, Campbell's Law
tl;dr version: The article introduces the pattern of Optimization by Proxy (OBP), which can be found in many large scale distributed systems, including human societies. The pattern occurs when a computationally limited algorithm uses a proxy property as a shortcut indicator for the presence of a hard to measure target quality. When intelligent actors with different motivations control part of the data, the existence of the algorithm reifies the proxy into a separate attribute to be manipulated with the goal of altering the algorithm's results. This concept is then applied to Google and the many ways it interacts with the various groups of actors on the web. The second part of this article contains examination of how OBP contributes towards the degrading of the content of the web, and how this relates to the Friendly Artificial Intelligence concept of 'paperclipping'.
Introducing OBP
The first thing a newly-hatched herring gull does after breaking out of its shell is to peck on its mother’s beak, which causes her to give it its first feeding. Puzzled by this apparent automatic recognition of its mother, Dutch ethologist and ornithologist Nikolaas Tinbergen conducted a sequence of experiments designed to determine what precisely it was that the newborn herring gull was attracted to. After experimenting with facsimiles of adult female herring gulls, he realized that the beak alone, without the bird, would elicit the response. Through multiple further iterations he found that the characteristics that the newborns were attracted to were thinness, elongation, redness and an area with high contrast. Thus, the birds would react much more intensely to a long red stick-like beak with painted stripes on the tip than they would to a real female herring gull. It turns out that the chicks don't have an ingrained definition of 'motherness' but rather determine their initial actions by obeying very simple rules, and are liable to radically miss the mark in the presence of objects that are explicitly designed to the specification of these rules. Objects of this class, able to dominate the attention of an animal away from the intended target were later called ‘supernormal stimuli’ (or superstimuli) and have been commonly observed in nature and our own human environment ever since.
Generalising the above example, we can say that Optimization by Proxy occurs when an algorithm substitutes the problem of measuring a hard to quantify attribute, with a usually co-occurring a proxy that is computationally efficient to measure.
A similar pattern appears when algorithms intended to make optimized selections over vast sets of candidates are applied on implicitly or explicitly social systems. As long as the fundamental assumption that the proxy co-occurs with the desired property holds, the algorithm performs as intended, yielding results that to the untrained eye look like ‘magic’. Google’s PageRank, in its original incarnation, aiming to optimize for page quality, does so indirectly, by data mining the link structure of the web. As the web has grown, such algorithms, and their scalability characteristics, have helped search engines dominate navigation on the web over previously dominant human-curated directories.
When there is only a single party involved in the production, filtering, and consumption of results, or when the incentives of the relevant group of actors are aligned, such as in the herring gull case, the assumption of the algorithm remains stable and its results remain reliable.
Effect of Other Intelligent Actors
When however instances of the proxy are in the control of intelligent actors that can manipulate it, and stand to benefit from distorting the results of the algorithm, then the existence of the algorithm itself and the motive distortions it creates alter the results it produces. In the case of PageRank, what we have is essentially Google acting as a singleton intermediary between two groups: content producers and consumers. Its early results owe to the fact that the link structure it crawled was effectively an unintentional byproduct of the buildup of the web. By bringing it to the attention of website owners as a distinct concept however, they have been incentivised to manipulate it separately, through techniques such as link farming, effectively making the altered websites act as supernormal stimuli for the algorithm. In this sense, the act of observation and the computation and publication of results alters that which is being observed. What follows is an arms race between the algorithm designers and the external agents, each trying to affect the algorithm’s results in their own preferred direction, with the algorithm designers controlling the algorithm itself and malicious agents controlling part of the data it is applied on.
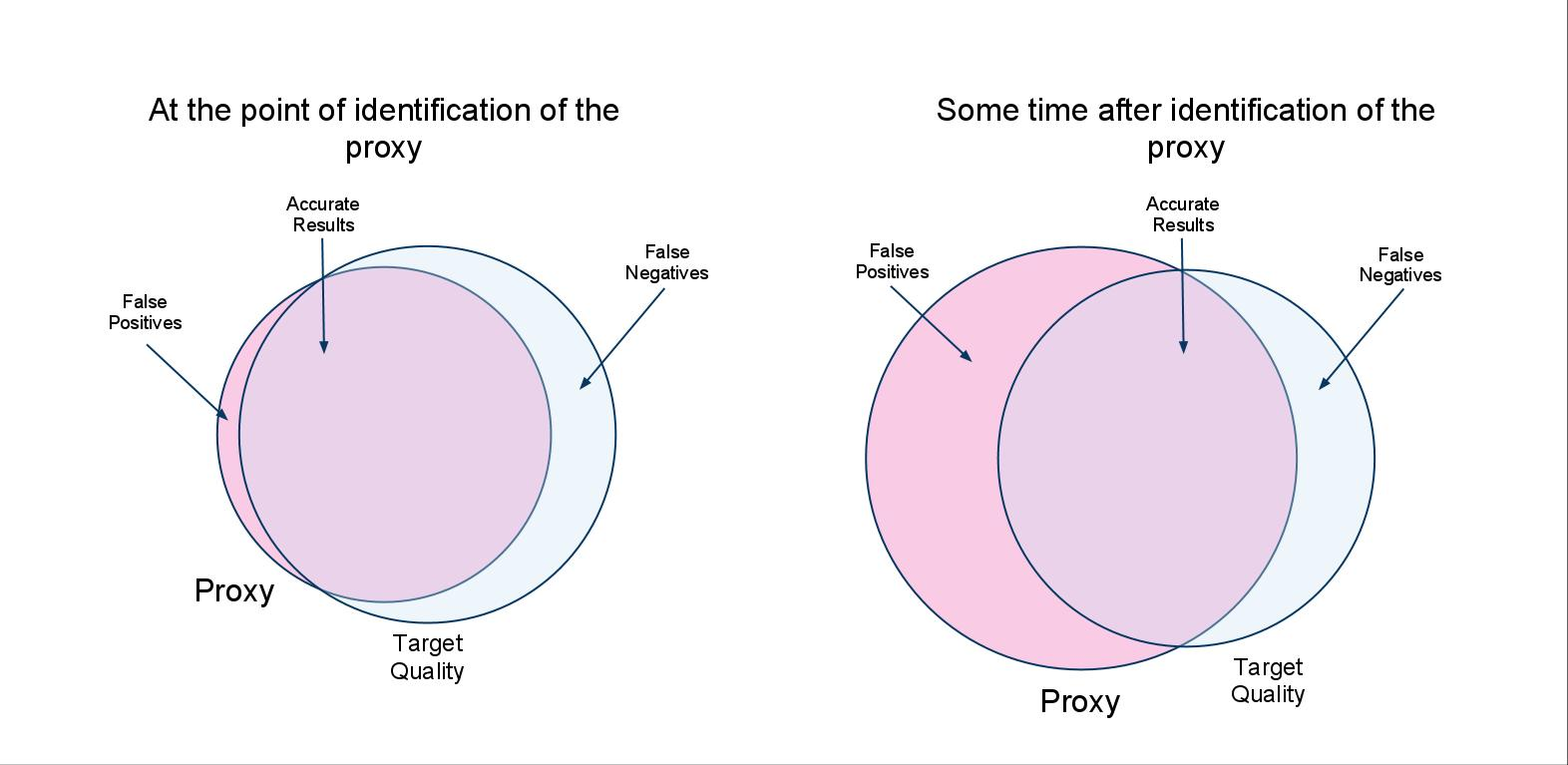
The above figure (original Google drawing here) may help visualise the issue. Items that satisfy the proxy but not the target quality are called false positives. Items possessing the target quality but not the proxy become false negatives. What effectively happens when Optimization by Proxy is applied to a social system, is that malicious website owners locate the semantic gap between target quality and proxy, and aim to fit in the false positives of that mismatch. The fundamental assumption here is that since the proxy is easier to compute, it is also easier to fake. That this is not the case in NP-complete problems (while no proof of P=NP exists) may offer a glimmer of hope for the future, but current proxies are not of this class. The result is that where proxy and target quality would naturally co-occur, the arrival of the algorithm, and the distortion it introduces to the incentive structure, make the proxy and the target quality more and more distinct by way of expanding the false positives set.
Faking it - A Bayesian View
We can obtain a little more insight by considering a simple Bayesian network representation of the situation. A key guide to algorithm design is the identification of some measure that intuitively will be highly correlated with quality. In terms of PageRank in its original incarnation, the reasoning is as follows. High quality web sites will attract attention from peers who are also contributing related content. This will “cause” them to link into the web site under consideration. Hence if we measure the number of highly ranked web sites that link into it, this will provide us with an indication of the quality of that site. The key feature is that the causal relationship is from the underlying quality (relevance) to the indicator that is actually being measured.
This simple model raises a number of issues with the use of proxies. Firstly, one needs to be aware that it is not just a matter of designing a smart algorithm for quantifying the proxy. One also needs to quantify the strength of association between the proxy and the underlying concept.
Secondly, unless the association is an extremely strong one, this makes use of the proxy a relatively “lossy” test for the underlying concept. In addition, if one is going to use the proxy for decision-making, one needs some measure of confidence in the value assigned to the strength of the relationship – a second-order probability that reflects the level of experience and consistency of the evidence that has been used to determine the strength of the relationship.
Finally, and most critically, one needs to be aware of the consequences of performing inference in the reverse causal direction. In modeling this as a Bayesian Network, we would use the conditional probability distribution p(PR | Q) as a measure of the “strength” of the relationship between cause and proxy (where “PR” is a random variable representing the value of PageRank, and “Q” is a random variable representing the value of the (hidden) cause, Quality). Given a particular observation of PR, what we need to determine is p(Q | PR) – the distribution over Quality given our observation on the proxy. This (in our simple model) can be determined through the application of Bayes’ rule:
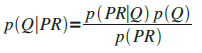
What this is reminding us of us that the prior probability distribution on Quality is a major factor in determining its posterior following an observation on the proxy. In the case of social systems however, this prior is the very thing that is shifting.
Attempts to Counteract Optimization by Proxy
One approach by algorithm owners is to keep secret the operation of the algorithm, creating uncertainty over the effects of manipulation of the proxy. This is effectively security by obscurity and can be counteracted by dedicated interrogation of the algorithm’s results. In the case of PageRank, a cottage industry has formed around Search Engine Optimization (SEO) and Search Engine Marketing (SEM), essentially aimed at improving a website’s placing in search engine results, despite the secrecy of the algorithm’s exact current operation. While a distinction can be made between black-hat and white-hat practitioners, the fact remains that the existence of these techniques is a direct result of the existence of an algorithm that optimizes by proxy. Another approach may be to use multiple proxies. This however is equivalent to using a single complex proxy. While manipulation becomes more difficult, it also becomes more profitable as less people will bother doing it.
As a response to the various distortions and manipulations, algorithms are enriched with heuristics to identify them. This, as the arms race progresses, is hoped to converge to the point where the proxy approaches the original target more and more, and hence the external actors are forced to simulate the algorithm’s target quality to the point where, to misquote Arthur C. Clarke, “sufficiently advanced spam is indistinguishable from content”. This of course would hold only if processing power were not an issue. However, if processing cost was not an issue, far more laborious algorithms could be used to evaluate the target attribute directly and if an algorithm could be made to describe the concept to the level that a human would be able to distinguish. Optimization by Proxy, being a computational shortcut, is only useful when processing power or ability to define is limited. In the case of the Web search, there is a natural asymmetry, with the manipulators able to spend many more machine- and man-hours to optimization of the result than the algorithm can spend judging the quality of any given item. Thus, algorithm designers can only afford to tackle the most broadly-occurring and easily distinguishable forms of manipulation, while knowingly ignoring the more sophisticated or obscure ones. On the other hand, the defenders of the algorithm always have the final judgment and the element of surprise on their side.
Up to this point, I have tried to more or less describe Optimization by Proxy and the results of applying it to social systems, and used Google an PageRank as a well known example for illustration purposes. The rest of this article focuses more on the effect that Google has on the Web and applies this newly introduced concept to further the understanding of that situation.
The Downward Spiral: Industrializing OBP Exploitation
While Google can and does make adjustments and corrections to its algorithms, it can only catch manipulations that are themselves highly automated such as content scraping and link farms. There have long been complaints about the ever increasing prevalence of made-for-adsense websites, affiliate marketers, and other classes of spam in search results. These are a much harder nut to crack and comes back to the original limitations of the algorithm. The idea behind made-for-adsense websites is that there is low quality human authored original content that is full of the appropriate keywords, and which serves adsense advertisements. The goal is twofold: First to draw traffic into the website by ranking highly for the relevant searches, and secondly to funnel as many of these visitors to the advertisers as possible, therefore maximising revenue.
Optimization by Proxy here can be seen occurring at least thrice: First of all it is exploited as a way of gaining prevalence in search results using the above mentioned mechanisms. Secondly, the fact that the users' only relevance metric, other than search ranking, is the title and a short snippet, can mislead users into clicking through. If the title is closely related to their search query, and the snippet seems relevant and mentions the right keywords, the users will trust this proxy when the actual quality of the content that awaits them on the other side is substandard. Finally, advertisers will have their ads being placed on low quality websites that are selected by keyword, when perhaps they would not have preferred that their brand is related with borderline spam websites. This triple occurrence of Optimization by Proxy creates a self-reinforcing cycle where the made-for-adsense website owners are rewarded with cold hard cash for their efforts. What's worse, this cash flow has been effectively subtracted from the potential gains of legitimate content producers. One can say that the existence of Google search/adsense/adwords makes all this commerce possible in the first place, but this does not make the downward spiral of inefficiency disappear. Adding to this the related scourge of affiliate marketers only accelerates the disintegration of quality results.
An interesting characteristic of this problem is that it targets less savvy users, as they are the most likely to make the most generic queries, be unable to distinguish a trusted from an untrusted source, and click on ads. This means that those with the understanding of the underlying mechanics are actually largely shielded from realising the true extent of the problem.
Its effectiveness has inevitably led to an industrialisation of the technique, with content farms such as Demand Media which pays about $5 per article and expects its authors to research and produce 5 articles an hour(!). It also pays film directors for short videos and has become by far the largest contributor to YouTube. Its method relies on purchasing search logs from ISPs and data mining those and other data sets for profitable niche keywords to produce content on. Demand Media is so wildly profitable that there is talk of an IPO, and it is obviously not the only player in this space. No matter what improvements Google makes on their algorithm short of aggressively delisting such websites (which it hasn't been willing to do thus far), the algorithm is unable to distinguish between low quality and high quality material as previously discussed. The result is crowding out of high quality websites in favour of producers of industrialised content that is designed to just barely evade the spam filters.
Conclusion
What we have seen is that a reliance on a less than accurate proxy has led to vast changes in the very structure and content of the web, even when the algorithms applied are less intelligent than a human and are constantly supervised and corrected by experts. All this in my mind drives home the fundamental message of FAI. While descriptions of FAI have thus far referred to thought experiments such as paperclipping, real examples, albeit in scale, are all around us. In our example, the algorithm is getting supervised by at least four distinct groups of people (Google, advertisers, content producers, consumers) and still its effects are hard to contain due to the entangled incentives of the actors. Its skewed value system is derailing the web contrary to the desires of most of the participants (except for the manipulators, I guess). For PageRank a positive is a positive whereas the difference between true and false positive is only apparent to us humans. Beyond PageRank, I feel this pattern has applicability in many areas of everyday life, especially those related to large organizations, such as employers judging potential employees by the name of the university they attended, companies rewarding staff, especially in sales, with a productivity bonus, academic funding bodies allocating funds according to bibliometrics, or even LessWrong karma when seens as an authority metric. Since my initial observation of this pattern I have been seeing it in more and more and now consider it one of my basic 'models', in the sense that Charlie Munger uses the term.
While I have more written material on this subject, especially on possible methods of counteracting this effect, I think this article has gone on way too long, and I'd like to see the LessWrong community's feedback before possibly proceeding. This is a still developing concept in my mind and my principle motivation for posting it here is to solicit feedback.
Disclaimer: Large parts of the above material have been published at the recent Web Science '10 conference. Also parts have been co-written with my PhD supervisor Prof. Paul Krause. Especially the Bayesian section is essentially written by him.
I should also probably say that, contrary to what you might expect, Google is one of the technology companies I most respect. Their success and principled application of technology has just happened to make them a fantastic example for the concept I am trying to communicate.
Update(s): The number of updates has gotten a bit unwieldy, so I just collapsed them all here. To summarize, there have been numerous changes throughout the article over the last few days as a response to the fantastic feedback throughout the comments here and elsewhere. Beyond the added links at the top on prior statements of the same principle in other fields, here is also a very interesting article on the construction of spam, with a similar conclusion. Also, I hear from the comments that the book Measuring and Managing Performance in Organizations touches on the same issue in the context of people's behaviour in corporate environments.
Followup on the Web: Since I am keeping my ears on the ground, here I will try to maintain a list of articles and discussions that refer to this article. I don't necessarily agree with the contents, but I will keep them here for future reference.
- "Sufficiently advanced spam is indistinguishable from content" - Hacker News discussion
- How to Fix the Broken Link Graph - seobook.com
- Divergence of Quality from its Correlates - kuro5hin.org
- Rule of Law - OBP and The Mulligan Decision - strategy.channelfireball.com
105 comments
Comments sorted by top scores.
comment by Leonhart · 2010-05-10T19:58:06.994Z · LW(p) · GW(p)
Oh bugger. Now I have to change careers. Or pretend I'm a dentist at all LW meetups henceforth.
If you'd like the impressions of an SEO in the trenches: yes, this is more or less the model I had, except for the novelty of seeing Google as the computational underdog. From the perspective of any particular SEO, it is the cursed Yellow Face which burns usss.
I would say that you oversell our powers somewhat, except that I'm one of the wimpy white-hatted specimens who don't have access to the fun Dark Artefacts like link farms and industrialised content shops. Even with an industrialised content shop, trust me, it's difficult to make a car insurance website interesting.
(As you might expect, our half of the industry circulates its own little self-justifying anecdotes about how often the link farms get sniffed out and banned, and how users are smarter than that and don't fall for that hothouse spam stuff. Except of course they largely do, and we're not seeing it, as you point out.)
I would say one thing about doing SEO as an aid to rationality; constructing fragile little houses of lies, and then watching an (admittedly imperfect) Big Bad Algorithm blow them down again and again, makes one REALLY REALLY receptive to Eliezer talking about entangled truths. I think it's still my favourite part of the sequences.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-10T20:50:27.261Z · LW(p) · GW(p)
Hearing from the SEO (albeit white-hat) point of view is really useful. I only have my external observation of the industry and my theoretical understanding of OBP to draw from so I wasn't sure how well I represented the SEO state of the art.
Replies from: Louie↑ comment by Louie · 2010-05-14T01:51:27.877Z · LW(p) · GW(p)
I think you talk about current SEO well. Good content and links to that content are still state of the art.
I got a lot out of thinking about the computational / human-bandwidth asymmetry of Google vs content creators.
But have you considered how the fear of being Sandboxed plays into things?
My first thought was that it improved value of the proxy somewhat by making people who know the proxy will change over time be less cavalier. Most people engaging in serious SEO have lucrative websites. You have to be very risk-seeking to go after those small marginal gains at the risk of losing all your cash flow permanently. There aren't that many large players that it gets driven down to a Nash Equilibrium quicker than Google's algorithms can change.
But the more I think about it, the fear of being penalized also tends to make legitimate content producers even more concerned that doing ANY SEO is bad. That may make things doubly-worse.
It's impossible to not do SEO. Every site is optimized for something.
For instance, lesswrong.com is optimized for:
- vote
- points
- permalink
- children
- password
Think about that next time you lament that lesswrong is overwhelmingly less popular than other sites with clearly inferior content.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-14T08:07:33.785Z · LW(p) · GW(p)
Thanks for the feedback. I hadn't factored sandboxing into my thinking at all. But as you say it's a double-edged sword.
I assume the way SEO techniques get around this is to initially 'interrogate' the algorithm through throwaway, high-risk websites, and then any robust techniques discovered slowly make their way up the ladder to established, highly conservative websites. Of course at any chance you risk getting caught (and it depends on the repulsiveness of the techniques as well) but that's always a risk when you're building on someone else's platform. If a website depends on its standing in Google search results, you can say it's building on their platform.
Also an interesting point about LessWrong's optimization. I guess now we know we count two Search Engine Optimizers in our midst, the Powers that Be can get in touch with you guys..
comment by Chronos · 2010-05-15T22:33:08.031Z · LW(p) · GW(p)
I think it's interesting to note that this is the precise reason why Google is so insistent on defending its retention of user activity logs. The logs contain proxies under control of the end user, rather than the content producer, and thus allow a clean estimate of (the end user's opinion of) search result quality. This lets Google spot manipulation after-the-fact, and thus experiment with new algorithm tweaks that would have counterfactually improved the quality of results.
(Disclaimer: I currently work at Google, but not on search or anything like it, and this is a pretty straightforward interpretation starting from Google's public statements about logging and data retention.)
Replies from: Alexandros↑ comment by Alexandros · 2010-05-16T19:44:50.305Z · LW(p) · GW(p)
Thanks for this. I'm constantly amazed at the relevant information that has been turning up here.
I agree that if anything is to be improved, information from other stakeholder groups with different incentives (such as end users) must be integrated. Given the amount by which end-users outnumber manipulators, this is a pretty good source of data, especially for high-traffic keywords.
However, what would stop spammers that focus on some low-traffic keyword to start feeding innocent-looking user logs into the system? I guess the fundamental question is, besides raw quantity, how would someone trust the user logs to be coming from real end-users?
(I understand that it may not be possible for you to get into a discussion about this, if so, no worries)
Replies from: Chronos↑ comment by Chronos · 2010-05-19T23:58:56.610Z · LW(p) · GW(p)
I'm afraid I can't say much beyond what I've already said, except that Google places a fairly high value on detecting fraudulent activity.
I'd be surprised if I discovered that no bad guys have ever tried to simulate the search behavior of unique users. But (a) assuming those bad guys are a problem, I strongly suspect that the folks worried about search result quality are already on to them; and (b) I suspect bad guys who try such techniques give up in favor of the low hanging fruit of more traditional bad-guy SEO techniques.
comment by SilasBarta · 2010-05-10T22:38:10.752Z · LW(p) · GW(p)
sufficiently advanced spam is indistinguishable from content
Great phrase. It's a reminder that: you know you have a good proxy when you're not sure that people who are gaming it are actually doing any harm.
Replies from: Lightwave, Alexandros, thomblake↑ comment by Lightwave · 2010-05-13T09:06:07.300Z · LW(p) · GW(p)
I hereby propose the Turing test for spam - if a human judge cannot reliably distinguish spam from "genuine" content, it passes the test and qualifies as actual content. Or does it?
Replies from: HDriscoll↑ comment by HDriscoll · 2011-03-12T05:52:10.828Z · LW(p) · GW(p)
You may say the same about industrially processed food: yes, you can consume it. Eventually you become malnourished and the receptor sites of your cell membranes have trouble distinguishing the hormones you really need from the hormone inhibitors that get to the receptor sites first. Over time, you will lose vitality.
Spam of course, is a 'meat-like' substance, so the analogy may hold....
Spam content degrades the whole, just like bad food saps your vitality over time.
↑ comment by Alexandros · 2010-05-11T10:52:50.343Z · LW(p) · GW(p)
Indeed, if you can't tell spam from content, you may have identified the 'correct' definition of the quality you are trying to measure. I think one deviousness of the made-for-adsense content is that it can't be too informative, otherwise the visitors have no incentive to click on the ads. It balances between informative enough to get the users through but not enough to satisfy them. Normal content is not usually like that. But figuring that out is like judging intent, a task difficult for humans, never mind machines. Would the true definition of quality need to catch even that type of abuse? hmm..
Replies from: JenniferRM↑ comment by JenniferRM · 2010-05-12T04:24:40.241Z · LW(p) · GW(p)
My cynicism leads me to speculate that Google's ownership of both the adword market and the search market means it may already have the data set it would need to notice people finding a page via search and then moving on to click on the ads because the content didn't satisfy them.
The "metrics" from the two systems are probably very voluminous and may not be strongly bound to each other (like within session GUIDs to make things really easy) so it wouldn't be trivial to correlate them in the necessary ways, but it doesn't strike me as impossible. A simple estimate of the "ad bounce through" (percent of users who click on ads at a site within N seconds of arriving there via search) could probably be developed and added to PageRank as a negative factor if this is not already in the algorithm.
However, despite access to the necessary data set, Google may not have the incentive to do this.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-12T07:26:14.815Z · LW(p) · GW(p)
This is a very good thought I hadn't considered. Thinking about it, on the one hand, I can imagine it easy to circumvent by switching ad providers. On the other hand this would drive many spammers to using alternative ad providers, which would degrade those services so it may be strategically good for Google. Or perhaps by driving spammers and affiliate marketers on to a competitor, it will help them acheive critical mass, something google would like to avoid. Also, using some kind of 'ad bounce through' ratio may have unacceptably high false positive ratios, again a bad outcome.
I hope this was not too much rambling, thanks for the interesting perspective.
↑ comment by thomblake · 2010-05-10T22:44:53.502Z · LW(p) · GW(p)
I hadn't thought of that angle. If we end up with a lot of actually good original machine-generated content (somehow) then surely that wouldn't be a loss.
Replies from: Leonhart, SilasBarta, Richard_Kennaway↑ comment by Leonhart · 2010-05-10T23:39:16.991Z · LW(p) · GW(p)
This is indeed happening. Not so much the machine-generated aspect, but the second biggest question I ask myself about my SEO clients these days is "What interesting media could they author about their field of expertise?" The biggest question is, of course, "How do I persuade them that they need to actually DO this?"
In extremis, of course, we end up with comparethemeerkat. It's the only way to make a financial services aggregator unboring enough to get people to link to it.
↑ comment by SilasBarta · 2010-05-11T16:06:30.086Z · LW(p) · GW(p)
Yes, and imagine if spammers went through the effort to make an android indistinguishable from a human on the outside (in behavior and form), and had it "spam" you after reading your internet postings/websites, on the pretense that it has some questions and wants to collaborate with you.
Then, it fakes an entire friendship, in which it gives you many useful ideas, in order to be able to slip in a few remarks here and there of the form, "Hey, I know a good Mexican pharmacy where you can get cheap Viagra." (Which you point out to your "friend" is probably a scam.)
If that's what spam comes to look like one day, I don't want a filtered inbox!
Replies from: Yvain, NancyLebovitz, thomblake, Caspian, Alexandros↑ comment by Scott Alexander (Yvain) · 2010-05-11T18:27:28.485Z · LW(p) · GW(p)
If that's what spam comes to look like one day, I don't want a filtered inbox!
http://www.smbc-comics.com/index.php?db=comics&id=1024#comic
Replies from: SilasBarta, kpreid↑ comment by SilasBarta · 2010-05-13T16:03:49.460Z · LW(p) · GW(p)
I think it's freaking awesome that someone had already made a comic about that concept.
↑ comment by NancyLebovitz · 2010-05-11T16:19:33.723Z · LW(p) · GW(p)
I expectt there would still be a range of spam-- crude spam only needs a very low success rate to continue to be produced-- so you'll still want your filters.
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-11T16:27:07.129Z · LW(p) · GW(p)
Eh, I was just going for a zinger. You're right, it would be more accurate to say, "I don't want my inbox to call that spam!"
↑ comment by thomblake · 2010-05-11T18:31:53.234Z · LW(p) · GW(p)
Don't forget your VK couples testing
↑ comment by Alexandros · 2010-05-14T10:14:03.410Z · LW(p) · GW(p)
Kinda sounds like having a useful service and supporting it with an ad-based model (but without clearly delineating the 'sponsored links'). If I could have someone interact with my work and give me useful ideas, I would probably pay for the privilege.
↑ comment by Richard_Kennaway · 2010-05-14T11:59:59.763Z · LW(p) · GW(p)
This reminds me of a short story by O. Henry. I don't remember many of the specifics, but it's set in the world of American (or perhaps it was Mexican) small-town politics and graft. There's a character, a career con-man, who gets to be town mayor by discovering what he says is the best graft of all: honesty. You just do what you say you're going to do and don't try to con people. They'll flock to do business with you, and you make a pile of money without having to steal anything! They can't even put you in jail for it!
ETA: A quick look at Wikipedia suggests this is from his collection of linked short stories, Cabbages and Kings, set in Central America.
comment by Unnamed · 2010-05-10T16:17:46.590Z · LW(p) · GW(p)
I'd recommend including a link to the previous LW article The Importance of Goodhart's Law, which discusses this type of problem (gaming a proxy which imperfectly measures some concept).
Replies from: Alexandros, anon895↑ comment by Alexandros · 2010-05-10T16:35:28.321Z · LW(p) · GW(p)
Thank you so much for the pointer. I had looked around for prior formulations of the concept but had come up short. This is the type of information that keyword search just can't turn up. Post updated.
comment by Mike Bishop (MichaelBishop) · 2010-05-12T20:06:03.608Z · LW(p) · GW(p)
Campbell's Law for another formulation. Interesting that Lucas, Campbell, and Goodhart all published essentially the same idea within a year.
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-12T20:14:46.083Z · LW(p) · GW(p)
I didn't recognize the Lucas you mention, but for those who were also wondering, a search found this Robert Lucas and the Lucas critique which apparently was in this 1976 article: "Econometric Policy Evaluation: A Critique".
comment by JaapSuter · 2010-05-11T19:39:55.471Z · LW(p) · GW(p)
The book Measuring and Managing Performance in Organizations touches upon this very concept and how it relates to people's behavior (in corporate environments mostly). I recommend it.
Replies from: Morendilcomment by Nevin · 2010-05-12T01:20:24.479Z · LW(p) · GW(p)
Thanks Alexandros, this was well articulated.
Beyond PageRank, I feel this pattern has applicability in many areas of everyday life, especially those related to large organizations, such as employers judging potential employees by the name of the university they attended...
So a person who goes to a prestigious school and games the system in order to graduate [without actually getting smarter] is something of a "spam worker." The OBP process is incentivizing earning a degree from a good school, and taking the emphasis off of getting smart.
I'd spent plenty of time thinking about SEO, and plenty of time thinking about people seeking prestige via academic institutions, but has never noticed the parallel.
...I have more written material on this subject, especially on possible methods of counteracting this effect...
I would be interested in hearing about those methods. I'm in the business of producing legitimate news (feel funny calling it "content"), and am unhappy with the amount of time I must spend making sure my website stays out of the false negative space.
Also, I wonder if the methods you have thought of would also apply to these parallel situations in society.
Replies from: Alexandros, maurice↑ comment by Alexandros · 2010-05-12T07:19:34.723Z · LW(p) · GW(p)
I really like the concept of a 'spam worker'. That would make interview panels into 'spam worker filters'. :)
Since this article has done well, I will probably write down my thoughts on mitigation for a future article, but if you can't wait, the last section in the linked WebSci paper has most of the written text on mitigation I have. Unfortunately I don't have any advice for dealing with it as a content author, only from a system-wide perspective. Given the feedback here and new material I have explored since, there will probably be significant differences between that and the article here, but the core will probably remain in some form.
The methods I have in mind (namely, discarding singletons such as Google and working on distributing the logic and focusing on local rather than global judgments) can probably be applied to real-world institutions and governments, but I haven't spent nearly as much time thinking about this as I have the online counterparts, so there is still work to be done there.
Replies from: SilasBarta, maurice↑ comment by SilasBarta · 2010-05-12T15:58:18.278Z · LW(p) · GW(p)
I really like the concept of a 'spam worker'.
Seconded. The concept generalizes nicely. We should start identifying more cases of "generalized spam" in our lives, i.e. cases where people optimize their measure by some imperfect proxy in precisely the way that the proxy deviates from the true measure of quality.
Discussion topic: Is sucking up to your boss a form of (generalized) spam? Or is it the kind that's sufficiently advanced to be "content" (i.e. it deviates from the true measure in such a way that it's nevertheless informative)?
Replies from: Alexandros↑ comment by Alexandros · 2010-05-13T20:53:05.902Z · LW(p) · GW(p)
Wouldn't it depend on what the boss is in business for? Here's a wild thought: If the boss wants a successful business to raise his status and self-confidence, an employee sucking up would just cut out the middle goal, and it would be the honest employee that is missing the true goal by helping to make the business successful. Just a thought..
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-13T21:22:43.872Z · LW(p) · GW(p)
Yeah, that's the kind of thing I was getting at: perhaps feeding him uninformative sucking-up is deviating from the business success metric but still giving him what he wants -- just like the android suggesting a shady Mexican pharmacy to me violates my "desired message" measure, but the spammer has gone to such great lengths to get that message to me that I'm still better off, on net, for getting the spam since the android friend more than makes up for it.
Another (disturbing) example, from back in the old days, would be if the French and British were fighting and the British offer mercenaries a reward for each French head they bring back. Then some French general gets this idea to disrupt the British system with "false negatives" (dead Frenchman but no corresponding head recovered), and does this by incinerating all French forts so that the bodies can't be recovered.
(Or, alternatively, the French general disrupts the British reward programme with false positives by blowing the entire military budget on fake severed French heads to trade in for the reward, leaving them entirely undefended while they try to collect.)
Do the British really care that the number of heads collected doesn't truly measure the number of French killed? Nope!
Replies from: Alexandros↑ comment by Alexandros · 2010-05-14T08:14:58.100Z · LW(p) · GW(p)
This is an curious pattern that is arising here.. In the case of the employee sucking up, (I'm not sure if this goes for the english vs. french examples) what's going on is that the 'spammer' is actually the one who identified the true target quality, and it's the honest employee that plays by the rule that's optimizing by proxy. In fact, the boss probably sees what's going on (on some level), but plays along with the spammer as he is actually getting satisfied.
I don't think 'reverse optimization by proxy' is a good name for it, but it's the best I can come up with. In fact, you could probably port that to a lot of situations where 'playing by the rules' (aka. aiming for the stated target) will leave you worse off than critically judging a situation, reading through the rules, integrating context and inferring the real goal in a given situation...
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-14T12:42:59.530Z · LW(p) · GW(p)
you could probably port that to a lot of situations where 'playing by the rules' (aka. aiming for the stated target) will leave you worse off than critically judging a situation, reading through the rules, integrating context and inferring the real goal in a given situation...
PUA vs. women's stated preferences in men, I'm looking in your general direction here.
(PUA = pick-up artist strategies)
↑ comment by maurice · 2010-08-17T10:45:46.145Z · LW(p) · GW(p)
Yessss - let me guess your not a specialist in HR are you? Google have a complex and reruitment and testing pocess but they have found that people that score worse are actualy better employees.
Replies from: Alexandros↑ comment by Alexandros · 2010-08-17T12:02:34.264Z · LW(p) · GW(p)
That would be one strange socing system. Do you have any references on that?
↑ comment by maurice · 2010-08-17T10:40:35.639Z · LW(p) · GW(p)
I realy wish techies woudl not persist in blindly applying simplistic anologies to complex real world suituations.
for recruitment its not quite the same its a lot harder to go to oxford or cambridge than a former polly - universities also provide networks and other advatages - hence the number of ex bullingdon club members in the current UK govenment.
What your describing is the "selecting people like me" bias that occurs in recruitment - which is also eveident in Googles bias for peope like them from stamford.
comment by Kevin · 2010-05-12T04:28:33.116Z · LW(p) · GW(p)
On Hacker News: http://news.ycombinator.com/item?id=1339704
Replies from: Alexandros↑ comment by Alexandros · 2010-05-12T07:41:31.865Z · LW(p) · GW(p)
Good lord, look how much HN karma I missed :)
On a more serious note, It's better that someone else submitted it, and I think the title that was selected actually did most of the work, and it wouldn't have been the one I would have given it.
comment by avalot · 2010-05-12T02:22:55.006Z · LW(p) · GW(p)
This touches directly on work I'm doing. Here is my burning question: Could an open-source optimization algorithm be workable?
I'm thinking of a wikipedia-like system for open-edit regulation of the optimization factors, weights, etc. Could full direct democratization of the attention economy be the solution to the arms race problem?
Or am I, as usual, a naive dreamer?
Replies from: DanielLC, Alexandros, blogospheroid↑ comment by DanielLC · 2010-05-16T06:22:19.323Z · LW(p) · GW(p)
Jim Whales (the guy who started Wikipedia) tried that. He couldn't get enough users to justify it.
I don't see much of an advantage to have it open source, and it allows people to actually see the algorithm when they're taking advantage of it. It might even be possible to change the algorithm to help them.
Replies from: David_Gerard↑ comment by David_Gerard · 2011-05-03T11:15:56.711Z · LW(p) · GW(p)
I would have thought the same of open source antivirus, but ClamAV is as good as any proprietary AV.
Replies from: DanielLC↑ comment by DanielLC · 2011-05-03T21:33:51.916Z · LW(p) · GW(p)
Neither of those is large enough scale for people to try to take advantage of the algorithm.
Come to think of it, in both cases, people could still use it for learning the algorithms in general. Knowing how Wikia Search worked would teach you a thing or two about search engine optimization, and knowing the specific vulnerabilities ClamAV protects against can tell you what you can take advantage of. It would be impossible to trace either of these effects back to the source, so we can't be sure it hasn't happened.
Replies from: gwern↑ comment by gwern · 2011-05-03T23:17:04.286Z · LW(p) · GW(p)
knowing the specific vulnerabilities ClamAV protects against can tell you what you can take advantage of.
In this vein, you can do even better with binary updates for vulnerabilities (such as Windows Update). They can be automatically rewritten into exploits: "Automatic Patch-Based Exploit Generation" (LtU).
↑ comment by Alexandros · 2010-05-12T07:52:38.847Z · LW(p) · GW(p)
You may be a dreamer, but so am I. Perhaps we should talk. :)
As it happens, I do have in mind a desgin of a distributed, open source approach that should circumvent this problem, at least in the area of social news. I am not sure however if the Less Wrong crowd would find it relevant for me to discuss that in an article.
Replies from: avalot, rhollerith_dot_com↑ comment by avalot · 2010-05-21T22:44:07.121Z · LW(p) · GW(p)
I'd love to discuss my concept. It's inspired in no small part by what I learned from LessWrong, and by my UI designer's lens. I don't have the karma points to post about it yet, but in a nutshell it's about distributing social, preference and history data, but also distributing the processing of aggregates, cross-preferencing, folksonomy, and social clustering.
The grand scheme is to repurpose every web paradigm that has improved semantic and behavioral optimization, but distribute out the evil centralization in each of them. I'm thinking of an architecture akin to FreeNet, with randomized redundancies and cross-checking, to circumvent individual nodes from gaming the ruleset.
But we do crowd-source the ruleset, and distribute its governance as well. Using a system not unlike LW's karma (but probably a bit more complex), we weigh individual users' "influence." The factors on which articles, comments, and users can be rated is one of the tough questions I'm struggling with. I firmly believe that given a usable yet potentially deep and wide range of evaluation factors, many people will bother to offer nuanced ratings and opinions... Especially if the effort is rewarded by growth in their own "influence".
So, through cross-influencing, we recreate online the networks of reputation and influence that exist in the real social world... but with less friction, and based more on your words and deeds than in institutional, authority, and character bias.
I'm hoping this has the potential to encourage more of a meritocracy of ideas. Although to be honest, I envision a system that can be used to filter the internet any way you want. You can decide to view only the most influential ideas from people who think like you, or from people who agree with Rush Limbaugh, or from people who believe in the rapture... and you will see that. You can find the most influential cute kitty video among cute kitty experts.
That's the grand vision in a nutshell, and it's incredibly ambitious of course, yet I'm thinking of bootstrapping it as an agile startup, eventually open-sourcing it all and providing a hosted free service as an alternative to running a client node. If I can find an honest and non-predatory way to cover my living expenses out of it, it would be nice, but that's definitely not the primary concern.
I'm looking for partners to build a tool, but also for advisors to help set the right value-optimizing architecture... "seed" value-adding behavior into the interface, as it were. I hope I can get some help from the LessWrong community. If this works, it could end up being a pretty influential bit of technology! I'd like it to be a net positive for humanity in the long term.
I'm probably getting ahead of myself.
Replies from: whpearson↑ comment by whpearson · 2010-05-21T22:52:58.770Z · LW(p) · GW(p)
What are the sources and sinks of your value system? Will old people have huge amounts of whuffie because they have been around for ages?
Replies from: avalot↑ comment by avalot · 2010-05-22T00:26:09.190Z · LW(p) · GW(p)
Good point! I assume we'll have decay built into the system, based on age of the data points... some form of that is built into the architecture of FreeNet I believe, where less-accessed content eventually drops out from the network altogether.
I wasn't even thinking about old people... I was more thinking about letting errors of youth not follow you around for your whole life... but at the same time, valuable content (that which is still attracting new readers who mark it as valuable) doesn't disappear.
That said, longevity on the system means you've had more time to contribute... But if your contributions are generally rated as crappy, time isn't going to help your influence without a significant ongoing improvement to your contributions' quality.
But if you're a cranky old nutjob, and there are people out there who like what you say, you can become influential in the nutjob community, if at the expense of your influence in other circles. You can be considered a leading light by a small group of people, but an idiot by the world at large.
Replies from: whpearson↑ comment by whpearson · 2010-05-22T11:42:39.593Z · LW(p) · GW(p)
I'm still not quite getting how this is going to work.
Lets say I am a spam blog bot. What it does is take popular (for a niche) articles and reposts automated summaries. So lets say it does this for cars. These aren't very good, but aren't very bad either. Perhaps it makes automatic word changes to real peoples summaries. It gets lots of other spam bots of this type and they form self-supportive networks (each up voting each other) and also liking popular things to do with cars. People come across these links and up vote them, because they go somewhere interesting. They gain lots of karma in these communities and then start pimping car related products or spreading FUD about rival companies. Automated astro-turf if you want.
Does anyone regulate the creation of new users?
How long before they stop being interesting to the car people? Or how much effort would it be to track them down and remove them from the circle of people you are interested in.
Also who keeps track of these votes? Can people ballot stuff?
I've thought a long these lines before and realised it is a non-trivial problem.
Replies from: avalot↑ comment by avalot · 2010-05-22T17:59:39.781Z · LW(p) · GW(p)
There's a few questions in there. Let's see.
Authentication and identity are an interesting issue. My concept is to allow anonymous users, with a very low initial influence level. But there would be many ways for users to strengthen their "identity score" (credit card verification, address verification via snail-mailed verif code, etc.), which would greatly and rapidly increase their influence score. A username that is tied to a specific person, and therefore wields much more influence, could undo the efforts of 100 bots with a single downvote.
But if you want to stay anonymous, you can. You'll just have to patiently work on earning the same level of trust that is awarded to people who put their real-life reputation on the line.
I'm also conceiving of a richly semantic system, where simply "upvoting" or facebook-liking are the least influential actions one can take. Up from there, you can rate content on many factors, comment on it, review it, tag it, share it, reference it, relate it to other content. The more editorial and cerebral actions would probably do more to change one's influence than a simple thumbs up. If a bot can compete with a human in writing content that gets rated high on "useful", "factual", "verifiable", "unbiased", AND "original" (by people who have high influence score in these categories), then I think the bot deserves a good influence score, because it's a benevolent AI. ;)
Another concept, which would reduce incentives to game the system, is vouching. You can vouch for other users' identity, integrity, maturity, etc. If you vouched for a bot, and the bot's influence gets downgraded by the community, your influence will take a hit as well.
I see this happening throughout the system: Every time you exert your influence, you take responsibility for that action, as anyone may now rate/review/downvote your action. If you stand behind your judgement of Rush Limbaugh as truthful, enough people will disagree with you that from that point on, anytime you rate something as "truthful", that rating will count for very little.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-24T08:34:43.450Z · LW(p) · GW(p)
Hi avalot, thank you for the detailed discussion. I suspect the system I have in mind is simpler but should satisfy the same principles. In fact it has been eerie reading your post, as on principle we are in 95% agreement, to excruciation detail, and to a large extent on technical behaviour. I guess my one explicit difference is that I cannot let go of the profit motive. If I make a substantial contribution, I would like to be properly rewarded, if only to be able to materialize other ideas and contribute to causes I find worthy. That of course does not imply going to facebook's lengths to squeeze the last drop of value out of its system, nor should it take precedence over openness and distribution. But to the extent that it can fit, I would like it to be there. Two questions for you:
First, with everyone rating everyone, how do you avoid your system becoming a keynesian beauty contest? (http://en.wikipedia.org/wiki/Keynesian_beauty_contest)
Second, assuming the number of connections increase exponentially with a linear increase in users, the processing load will also rise much quicker than the number of users. How will a system like this operate at web-scale?
Replies from: avalot↑ comment by avalot · 2010-05-24T15:49:57.465Z · LW(p) · GW(p)
Alexandros,
Not surprised that we're thinking along the same lines, if we both read this blog! ;)
I love your questions. Let's do this:
Keynesian Beauty Contest: I don't have a silver bullet for it, but a lot of mitigation tactics. First of all, I envision offering a cascading set of progressively more fine-grained rating attributes, so that, while you can still upvote or downvote, or rate something with starts, you can also rate it on truthfulness, entertainment value, fairness, rationality (and countless other attributes)... More nuanced ratings would probably carry more influence (again, subject to others' cross-rating). Therefore, to gain the highest levels of influence, you'd need to be nuanced in your ratings of content... gaming the system with nuanced, detailed opinions might be effectively the same as providing value to the system. I don't mind someone trying to figure out the general population's nuanced preferences... that's actually a valuable service!
Secondly, your ratings are also cross-related to the semantic metadata (folksonomy of tags) of the content, so that your influence is limited to the topic at hand. Gaining a high influence score as a fashion celebrity doesn't put your political or scientific opinions at the top of search results. Hopefully, this works as a sort of structural Palin-filter. ;)
The third mitigation has to do with your second question: How do we handle the processing of millions of real-time preference data points, when all of them should (in theory) get cross-related to all others, with (theoretically) endless recursion?
The typical web-based service approach of centralized crunching doesn't make sense. I'm envisioning a distributed system where each influence node talks with a few others (a dozen?), and does some cross-processing with a them to agree on some temporary local normals, means and averages. That cluster does some more higher-level processing in consort with other close-by clusters, and they negotiate some "regional" aggregates... that gets propagated back down into the local level, and up to the next level of abstraction... up until you reach some set of a dozen superclusters that span the globe, and who trade in high-level aggregates.
All that is regulated, in terms of clock ticks, by activity: Content that is being rated/shared/commented on by many people will be accessed and cached by more local nodes, and processed by more clusters, and its cross-processing will be accelerated because it's "hot". Whereas one little opinion on one obscure item might not get processed by servers on the other side of the world until someone there requests it. We also decay data this way: If nobody cares, the system eventually forgets. (Your personal node will remember your preferences, but the network, after having consumed their influence effects, might forget their data points.)
A distributed, propagation system, batch-processed, not real-time, not atomic but aggregated. That means you can't go back and change old ratings, and individual data points, because they get consumed by the aggregates. That means you can't inspect what made your scored go up and down at the atomic level. That means your score isn't the same everywhere on the planet at the same time. So gaming the system is harder because there's no real-time feedback loop, there's no single source of absolute truth (truth is local and propagates lazily), and there's no auditing trail of the individual effects of your influence.
All of this hopefully makes the system so fluid that it holds innumerable beauty contests, always ongoing, always local, and the results are different depending on when and where you are. Hopefully this makes the search for the Nash equilibrium a futile exercise, and people give up and just say what they actually think is valuable to others, as opposed to just expected by others.
That's my wishful thinking at the point. Am I fooling myself?
Replies from: whpearson↑ comment by whpearson · 2010-05-25T14:21:34.781Z · LW(p) · GW(p)
I'd create a simplified evolutionary model of the system using a GA to create the agents. If groups can find a way to game your system to create infinite interesting-ness/insightful-ness for specific topics, that then you need to change it.
Replies from: avalot↑ comment by avalot · 2010-05-25T20:39:55.735Z · LW(p) · GW(p)
You're right: A system like that could be genetically evolved for optimization.
On the other hand, I was hoping to create an open optimization algorithm, governable by the community at large... based on their influence scores in the field of "online influence governance." So the community would have to notice abuse and gaming of the system, and modify policy (as expressed in the algorithm, in the network rules, in laws and regulations and in social mores) to respond to it. Kind of like democracy: Make a good set of rules for collaborative rule-making, give it to the people, and hope they don't break it.
But of course the Huns could take over. I'm trusting us to protect ourselves. In some way this would be poetic justice: If crowds can't be wise, even when given a chance to select and filter among the members for wisdom, then I'll give up on bootstrapping humanity and wait patiently for the singularity. Until then, though, I'd like to see how far we could go if given a useful tool for collaboration, and left to our own devices.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-25T23:28:49.427Z · LW(p) · GW(p)
I think you are closer to a strong solution than you realize. You have mentioned the pieces but I think you haven't put them together yet. In short, the solution I see is to depend on local (individual) decisions rather than group ones. If each node has its own ranking algorithm and its own set of trust relations, there is no reason to create complex group-cooperation mechanisms. A user that spams gets negative feedback and therefore eventually gets isolated in the graph. Even if automated users outnumber real users, the best they can do is vote each other up and therefore end up with their own cluster of the network, with real users only strongly connected to each other. Of course, if a bot provides value, it can be incorporated in that graph. "sufficiently advanced spam...", etc. etc. This also means that the graph splinters into various clusters depending on worldview. (your rush limbaugh example). This deals with keynesian beauty contests as there is no 'average' to aim at. Your values simply cluster you with people who share them. If you value quality, you go closer to quality. If you value 'republican-ness' you move closer to that. The price you pay is that there is no 'objective' view of the system. There is no 'top 10 articles', only 'top 10 articles for user X'.
Another thing I see with your design is that it is complex and attempts to boil at least a few oceans. (emergent ontologies/folksonomies for one, distributing identity, storage, etc.). I have some experience with defining complex architectures for distributed systems (e.g. http://arxiv.org/abs/0907.2485 ) and the problem is that they need years of work by many people to reach some theoretical purity, and even then bootstrapping will be a bitch. The system I have in mind is extremely simple by comparison, definitely more pragmatic (and therefore makes compromises) and is based on established web technologies. As a result, it should bootstrap itself quite easily. I find myself not wanting to publicly share the full details until I can start working on the thing (I am currently writing up my PhD thesis and my deadline is Oct. 1. After that, I'm focusing on this project). If you want to talk more details, we should probably take this to a private discussion.
Replies from: avalot↑ comment by avalot · 2010-05-26T14:36:30.310Z · LW(p) · GW(p)
You are right: This needs to be a fully decentralized system, with no center, and processing happening at the nodes. I was conceiving of "regional" aggregates mostly as a guess as to what may relieve network congestion if every node calls out to thousands of others.
Thank you for setting me right: My thinking has been so influenced by over a decade of web app dev that I'm still working on integrating the full principles of decentralized systems.
As for boiling oceans... I wish you were wrong, but you probably are right. Some of these architectures are likely to be enormously hard to fine-tune for effectiveness. At the same time, I am also hoping to piggyback on existing standards and systems.
Anyway, let's certainly talk offline!
↑ comment by RHollerith (rhollerith_dot_com) · 2010-05-12T17:10:05.176Z · LW(p) · GW(p)
I am not sure however if the Less Wrong crowd would find it relevant for me to discuss that in an article.
I think it is relevant because better social-news sites on the web would lead to better conversations about advancing the art of human rationality, which is the core mission of Less Wrong.
↑ comment by blogospheroid · 2010-05-12T08:17:39.153Z · LW(p) · GW(p)
I think an iterated tournament might work better.
Announce 2 iterated prize sequences. The big Red Prizes for the best optimization algorithm and the small Blue prizes for the best spam which can spoof the same. Don't award a blue until the first red is awarded and then don't award a red until the last blue one is awarded and so on. Keep escalating the price amounts until satisfactory performance is attained.
comment by Alex Flint (alexflint) · 2010-05-11T09:33:02.285Z · LW(p) · GW(p)
Nice write-up. A couple of comments:
First, what is the real difference between "optimisation by proxy" and the general notion of drawing inferences from evidence? The PageRank algorithm infers the usefulness of a page from its link structure, but any search engine whatsoever will always draw this inference from some evidence. There is no such thing, even in principle for a superintelligence, as just looking directly at the underlying "quality" characteristic.
Second, I don't think that Google is a good FAI analogy because any negative Google effects are due to its design deficiencies (plus computational imitations, etc etc), which is fully within our control to change, whereas a fundamental FAI consideration is our inability to outwit or modify it. An unfriendly AI works intelligently towards undesirable goals, where as Google, if it can be said to have any goals, works unintelligently towards them.
Replies from: sark, Alexandros↑ comment by sark · 2010-05-13T18:01:48.728Z · LW(p) · GW(p)
I think when we talk about optimization by proxy we usually compare something that tracks the desired quality much more precisely compared to another variable which we use as a computational shortcut. That is meaningful enough a distinction.
This reminds me of a discussion in some forum where somebody said that it was "impossible to compress a DVD losslessly because it is already lossy". Of course, what was actually meant was lossless compression of that lossy data, not of the original source.
↑ comment by Alexandros · 2010-05-11T10:49:34.265Z · LW(p) · GW(p)
On your first point, we all draw inferences, humans and computers alike. However, you could produce a set of results from pagerank and have a set of humans evaluate them, and the humans would more or less agree on what is a false positive and what is a true positive. Also similarly , but with a bit more effort) you could find some false negatives. This means that the inference of pagerank is somehow inferior to the human inference, (given that humans are the standard here).
This does open up a very interesting line of thought however. Could there be a situation where a machine could have a definition that humans just couldn't match? Somehow humans picking items out of a set that doesn't match what the algorithm defines, even after being trained against that algorithm or even being able to read the code, even when not limited by perception constraints or time? If not, why? It's commonly accepted here that humans aren't the optimally intelligent design that could possibly exist. So perhaps this thing that we have, that is not intelligence but some aspect of it could be replicated to avoid OBP (and perhaps this would be a breakthgough for FAI). If yes, then there could be a situation where the machine holds the actual definition, and the human is the one doing optimization by proxy. In fact, there's nothing to prohibit that from occuring now, if at all possible. I am not sure where this line of thought leads, I think I may be conflating value systems and intelligence, but I do need to think more about it.
On your second point, yes, google cannot be a full uFAI example. What I meant to show, is that even when it is being constantly supervised, it can still cause measurable and unintended outcomes, and what is more, we are not even sure how to prevent them given the incentive structure that exists.
Replies from: alexflint↑ comment by Alex Flint (alexflint) · 2010-05-12T21:43:24.156Z · LW(p) · GW(p)
Thanks for the reply :)
I guess I was reacting to your suggestion later in the article that we should try to remove the proxy and instead just look right at the underlying "page quality" characteristic (or perhaps I misinterpreted that?) My objection is that, yes, one can (implicitly or explicitly) define an underlying quality characteristic of pages, and no, Google is not perfect at estimating that value, but however you go about estimating that parameter, the process will always involve making some observations about the page in question (e.g. local hyperlink structure) and then doing inference. Although the underlying characteristic might be well-defined, there is no way, even in principle (even given unlimited data and computing power far beyond that of a human), to just "look right at the underlying characteristic" -- I don't even think that phrase is meaningful.
If humans were given the same task then they would also follow the evidence-inference procedure, albeit with more sophisticated forms of inference than the Google programmers can work out how to program into their computers.
So I think that "get rid of the proxy" really means "gather more and different types of evidence and improve the page quality-inference procedure".
Replies from: Alexandros↑ comment by Alexandros · 2010-05-14T08:24:10.364Z · LW(p) · GW(p)
I think at this point we're hitting on the question of whether truly correct definitions exist. I believe Eliezer had some articles in the past about thingspace and 'carving reality at its joints', but, while this assumption underlies my article, I do see your point. In this case you would say that the algorithm has approached the 'true characteristic' when humans cannot discern any better than it can.
I guess one example is a guy who wrote a few articles for Hacker News, they got reasonably upvoted, and then he came out and said that he was producing them based on some underlying assumptions about what would do good on HN. Some people were negative and felt manipulated, but not everyone agreed that this was spam. The argument was "if you upvoted it, then you enjoyed it, and what the process that produced the article was shouldn't matter".
If you consider that spam, then certainly it's spam beyond the human capability to detect it. But what you really need there is a process to infer intention, which may well be impossible.
comment by RobinZ · 2010-05-10T19:14:08.229Z · LW(p) · GW(p)
I notice the seagull paper is linked in:
A similar pattern appears when algorithms intended to make optimized selections over vast sets of candidates are applied on implicitly or explicitly social systems. As long as the fundamental assumption that the proxy co-occurs with the desired property holds, the algorithm performs as intended, yielding results that to the untrained eye look like ‘magic’. Google’s PageRank, in its original incarnation, aiming to optimize for page quality, does so indirectly, by data mining the link structure of the web. As the web has grown, such algorithms, and their scalability characteristics, have helped search engines dominate navigation on the web over previously dominant human-curated directories. (emphasis added)
Is this intended?
Replies from: Alexandros↑ comment by Alexandros · 2010-05-10T19:19:12.980Z · LW(p) · GW(p)
It was in error, as you suspected. It has now been rectified, thanks a lot for the heads up.
comment by Strange7 · 2010-05-11T00:00:35.542Z · LW(p) · GW(p)
Its skewed value system is derailing the web contrary to the desires of most of the participants (except for the manipulators, I guess).
I suspect even the manipulators would prefer that the web as a whole run more efficiently and that fewer people manipulate it. After all, a healthier organism with fewer parasites can spare more blood each for those which remain.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-11T10:56:01.739Z · LW(p) · GW(p)
Fair enough, although even the best manipulators would not prefer that the system is fixed rather than made harder to manipulate.
comment by rwallace · 2010-05-10T23:13:14.737Z · LW(p) · GW(p)
This would hold only if processing power were not an issue. However, if processing cost was not an issue, far more laborious algorithms could be used to evaluate the target attribute directly.
While processing power isn't free, it is much cheaper than human labor, so it isn't the issue. The reason we can't evaluate the target attribute directly is that we don't know how to write a program to do so, even given abundant processing power.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-11T06:47:48.840Z · LW(p) · GW(p)
It may be cheaper than human labour, but when you're working at google scale, it still costs a lot, and there's only so much you can devote to each of the billions of pages on the web. That said, I agree with you that even if it wasn't the issue, nailing down a precise definition is an even harder issue. I will probably update the article to reflect that.
comment by thomblake · 2010-05-10T16:47:49.457Z · LW(p) · GW(p)
I could have sworn that there was already a Lw article that mentioned the seagull paper - turns out it was just linked on the open thread. Lw Wiki has an article on Superstimulus though there's not much there.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-10T17:01:46.448Z · LW(p) · GW(p)
I added a link to the superstimulus wiki page, thanks. I am not sure what the norm for adding one's own content to the wiki is, but if anyone else considers it useful, they are free to use material from my article to expand the wiki entry.
comment by xamdam · 2010-05-10T16:42:56.599Z · LW(p) · GW(p)
As a side note, this provides a very strong incentive for Google to work on AGI-hard problems, if anyone is keeping score.
Replies from: Oscar_Cunningham↑ comment by Oscar_Cunningham · 2010-05-10T17:50:06.592Z · LW(p) · GW(p)
Surely the incentive to build an AGI is so great that additional incentives are somewhat meaningless?
Replies from: xamdam, Dre↑ comment by xamdam · 2010-05-10T21:10:27.191Z · LW(p) · GW(p)
Is your grandma working on AGI? After all, the incentive is limitless?
BTW, I did not say they are working on AGI; that is not their business plan. They want to "organize all the worlds information", and the statistical approximations to doing this are failing due to the spammers, per the OP. They are forced to go closer to really understanding the content with computers, and some of the problems involved have been deemed "AGI-hard". So they are gradually more incentivized to work on AGI related technologies.
comment by BrandonKMLee (brandonkmlee) · 2021-11-07T06:35:12.307Z · LW(p) · GW(p)
Here is the rub against PageRank: EigenCenter, bridging centrality and other indices exists for alternative characteristics. All the web needs to do, is simply render the search engine task into a multi-objective optimization problem. Those that are popular vs those that are comparative vs those that are derivative. Attempts at optimizing the three major mode of creative operation (copy, transform, and combine) are hard but more realistic.
comment by KristyLynn · 2010-05-11T13:27:22.806Z · LW(p) · GW(p)
I don't know much about computers but it makes sense that spam is easily confused with legitimate information. I myself have noticed that over the years there has been a vast increase of the link farm sites and find it equally increasingly annoying.
Thanks for the info.
Replies from: Nananicomment by CronoDAS · 2010-05-10T20:21:06.741Z · LW(p) · GW(p)
Google does have a page to complain about spam results, and I've used it a few times. I don't know if it makes any difference, though.
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-10T22:24:00.387Z · LW(p) · GW(p)
Do spammers use that page to complain about legit sites, wasting Google's time and/or hurting its algorithm via false positives?
Replies from: thomblakecomment by timtyler · 2010-05-10T19:55:49.778Z · LW(p) · GW(p)
Once again; a long post, with no abstract, and a cryptic title.
IMO, if the author does not know enough to start with an abstract, then they should not expect many readers to go further.
Replies from: Alexandros, HughRistik, Clippy, AlexKu↑ comment by Alexandros · 2010-05-10T20:30:03.725Z · LW(p) · GW(p)
Abstract added, thanks for the pointer. I did consider breaking the article in two to reduce size, but decided against it. An abstract would have been a good idea and in fact this is a (heavily) modified version of an academic paper that had an abstract, but somehow it didn't occur to me. Go figure.
To everyone: I feel I have been way too engrossed in the material to be able to competently write a summary that would be helpful to a first time reader, so suggestions on improving the abstract would be greatly appreciated.
Replies from: timtyler, Cyan↑ comment by timtyler · 2010-05-10T20:54:12.022Z · LW(p) · GW(p)
Yay! Congrats!
Not sure about "tl;dr", though!
Isn't that what I say when I skip your non-abstracted article...? ;-)
Replies from: Alexandros, Nanani↑ comment by Alexandros · 2010-05-10T21:05:23.717Z · LW(p) · GW(p)
Yeah, it would be, but I've also seen it used to the effect of 'abstract'. I've already added almost all features of an academic paper except for affiliation and references, I just can't bring myself to start the damn thing with "Abstract:"
Replies from: timtyler↑ comment by timtyler · 2010-05-10T21:09:09.527Z · LW(p) · GW(p)
"tl;dr" seems very casual to me. If your readers are casual and you want them to treat your article casually, that may be appropriate.
Incidentally, if acronyming like that, it should read: "Optimization By Proxy (OBP)"
You can probably skip writing the word "Abstract" - if your first paragraph is isolated, in italics, and obviously starts out with a summary.
Replies from: anonym↑ comment by Nanani · 2010-05-12T03:14:00.867Z · LW(p) · GW(p)
Somehow I found the tl;dr impenetrable, but the actual article eminently readable. Is this deliberate?
Replies from: Alexandros↑ comment by Alexandros · 2010-05-12T08:08:50.726Z · LW(p) · GW(p)
It's the best tl;dr I could muster. Probably because I'm too close to the content and have lost sight of what it's like to see it for the first time. If someone can help conjure up a better one, I'd gladly replace it.
↑ comment by Cyan · 2010-05-10T20:32:45.350Z · LW(p) · GW(p)
Splitting an article in two is also common in academia; the same strategy on LW might result in more karma, if that's the sort of thing one finds worthwhile...
Replies from: Alexandros↑ comment by Alexandros · 2010-05-10T21:08:47.279Z · LW(p) · GW(p)
At this point, I'm more interested in adding any sort of value rather than optimizing for karma. I've done a lot of that on HN (and a little bit in academia), but LW is harder than that :)
↑ comment by HughRistik · 2010-05-10T20:12:45.482Z · LW(p) · GW(p)
I did go further, and was glad I did because I found the article very interesting. But I would have also liked an abstract and a conclusion paragraph. I do think the topic connects to rationality, but I would have liked to see more of the author's thoughts on how it does. Also, the analogy between Google and "paperclipping" could have used a bit more explanation.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-10T20:47:13.135Z · LW(p) · GW(p)
Thanks for the kind words. I consider the last long paragraph ("what we therefore see"...) to be a form of conclusion even if not marked so. It used to be longer but then I figured that it was just sermonizing about the well-known issues around FAI and decided to stick only to the original contributions. Again, I fear my long gestation of this particular topic may have warped my judgement. Will try to clearly mark the conclusion and add a little more meat around the connections I see to FAI and rationality.
I really enjoy your contributions to LR and some of your stuff I have read off-site by the way.
↑ comment by Clippy · 2010-05-10T20:24:39.929Z · LW(p) · GW(p)
In fairness, the title does mention paperclips, which is a lot more mention of important stuff than most other articles here.
Then again, it's pretty obvious Google has not turned the Web into paperclips, so why ask the question?
Replies from: Kevin↑ comment by Kevin · 2010-05-11T07:14:16.480Z · LW(p) · GW(p)
Alexandros was referring to a metaphorical paperclipping. I'm surprised you are not more aware of humanity's use of a paperclip maximizer as a metaphor for everything that could go wrong with AGI. A top-level post by you about why a paperclip maximizer would cooperate with humanity indefinitely would help.
Replies from: Clippy↑ comment by AlexKu · 2010-05-11T13:40:03.548Z · LW(p) · GW(p)
In the interests of accessibility to more of the general public, I think it's a good idea to have references on the first instance of an acronym or idiomatic concept (especially if it's a main point of the article).
I'm a casual reader of LessWrong, Inside of articles, I usually find some term or abbreviation which refers to a concept I have no idea about. In this article, I came across FAI (which apparently means Friendly AI?) and paperclipping. They're not completely unGoogleable, but not explaining these terms, even parenthetically, seems self-defeating. It's against spreading the ideas in the article to other people who don't already share your views.
Replies from: Alexandros↑ comment by Alexandros · 2010-05-12T08:07:32.611Z · LW(p) · GW(p)
Thanks for the tip, it's done.