Inner Alignment via Superpowers
post by JamesH (AtlasOfCharts), Thomas Larsen (thomas-larsen), Jeremy Gillen (jeremy-gillen) · 2022-08-30T20:01:52.129Z · LW · GW · 13 commentsContents
The Problem Proposed Solution Instrumental Goals Goal Ambiguity Experiment Idea Motivation None 13 comments
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth [LW · GW]
The Problem
When we train RL agents, they have many opportunities to see what makes actions useful (they have to locate obstacles, navigate around walls, navigate through narrow openings etc.) but they can only learn what they should actually care about from how the goal appears in training. When deployed, their capabilities often generalize just fine, but their goals don't generalize as intended. This is called goal misgeneralization.
Usually we conceptualize robustness as 1-dimensional, but to talk about goal misgeneralization, we need to use vlad_m [LW · GW]'s 2-dimensional model:
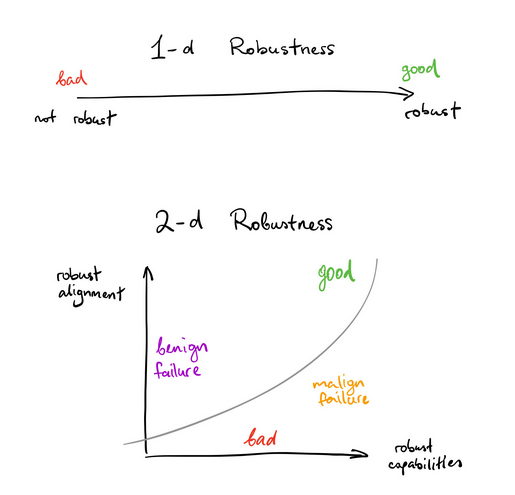
“There’s an easy solution to this,” you might say. “Just present a whole boatload of environments where the goals vary along every axis, then they have to learn the right goal!”
“Our sweet summer child,” we respond, “if only it were so simple.” Remember, we need to scale this beyond simple gridworlds and Atari environments, where we can just change coin position and gem color, we’re going all the way to AGI (whether we like it or not). Can we really manually generate training data that teaches the AGI what human values are? We need a method that’ll be robust to huge distribution shifts, things we aren't able to even think of. We need a method that’ll allow this AGI to find what humans value. We need superpowers!
Proposed Solution
Our solution is ‘giving the AI superpowers.’
Oh, that's not clear enough?
Alright then: during training, we occasionally let the RL agent access an expanded action-space. This lets it act without the restrictions of its current abilities. We also encourage it to explore states where it’s uncertain about whether it’ll get reward or not. The aim is that these ‘superpowers’ will let the AI itself narrow down what goals it ought to learn, so that we won’t need to be as certain we’ve covered everything in the explicit training data.
Through this we hope to combat the two principal drivers of goal misgeneralization:
Instrumental Goals
When you were a child, you were happy every time you ate a lollipop. But you realized you needed money to buy lollipops, so eventually you started becoming happy whenever you made money. And look at you now, hundreds of dollars in the bank and not a lollipop in sight.
The same thing can happen with RL agents, sometimes the same action is reinforced across so many different environments, that they start to inherently value taking that action. But we don’t want them to value things on the way to human values, we want them to value human values themselves, no matter how they get there.
Giving them the ability to get right to human values without any of the intermediate steps, and rewarding them for it, should help make them value that goal in particular, and not simply the instrumental goals.
Goal Ambiguity
Imagine you're a schoolkid who wants to be really good at math. So you work really hard to show how good you are at math by getting good grades. But eventually, you realize you can get even better grades in math by sneaking a calculator into tests with you. So you start sneaking a calculator in to every test, and your grades skyrocket. But one day, you happen to ask yourself: “What’s 7x4?,” and you realize you weren’t actually getting better at math, you were just getting better grades in math.
The same thing can happen with RL agents, sometimes they substitute the goal we want them to learn with something correlated with that goal. But we don’t want them to learn proxies for human values, we want them to learn to value human values themselves.
Giving the RL agent the ability to strongly optimize the proxies they’re learning during training, and then not rewarding them for doing so should help to direct their learned pointer towards the real goal, and not just proxies for it. If the proxy performs well across all of their 'superpowers,' then we have a reward misspecification issue, and not a goal misgeneralization issue.
In both of these cases, the overarching theme is that with ‘superpowers,’ the agent will be able to explore the reward landscape more freely. This gets at both of the distribution shifts that could lead to goal misgeneralization:
- Internal distribution shift coming from an increase in the AI's capabilities
- External distribution shift coming from the environment as a whole changing
This proposal gets at the first problem directly, by simulating the AI having advanced capabilities throughout training, but also gets at the second problem indirectly, since some of these 'superpowers' will let the AI itself try to create its own 'perfect world', giving it a reward signal about what worlds actually are perfect.
Experiment Idea
We propose an experiment to test this solution. We will train RL agents of different architectures: model-based (with a hardcoded model) and PPO. Then, during the training process, we give this agent 'superpowers' which simulate advanced capabilities, and allow the AI to directly modify the world (or world-model, in the model-based RL case).
However the training process will be guided in large part by the AI's propensity to explore and thereby determine what the real objectives are. We therefore need to incentivize the AI to use these superpowers to explore the different possible objectives and environments that can be realized. With great power comes great responsibility! Therefore, we give the agent a bias to explore different possibilities when it has these superpowers. For example, if it's only trained on pursuing yellow coins then we want it to try creating and pursuing yellow lines. When it finds that these give it no reward, we want it try creating and pursuing red coins, and ultimately experiment enough to learn the One True Objective that "coins get reward."
Some current possible candidates for 'superpowers' in a gridworld environment, where the agent's goal is to collect a coin, are:
- Move the coin
- Teleport anywhere in the grid
- Rewrite any cell in the grid
- Move through walls
The 'superpower' that we ultimately want to give the policy selector, in the model-based RL case, is the ability to 'make all its dreams come true.' It achieves this by rewriting the learned world-model's perception of the world, so that it represents the agent's imagined perfect world. We can then reward the policy-selector according to how closely this imagined perfect world matches a world-model where the agent managed to achieve the actual goal, so that it learns what a real perfect world would look like.
In PPO, we don’t currently have a similar ‘ultimate superpower’ that we want to give it access to, but we still want to see if an assortment of 'superpowers' works to make the agent generalize better. The issue is that we need access to a world where we can give it superpowers (e.g. not the real world), so we're not sure how to scale this to real-world applications without introducing a large external distribution shift.
Motivation
We arrived at this proposal by thinking about how model-based RL agents could end up with a misaligned policy function, even if we could perfectly specify what worlds are good and bad. In this case, the bottleneck would be producing examples of good and bad worlds (and good and bad actions that lead to those worlds) for the AI to learn from.
To solve this, we figured a good approach would be to let the AI itself generate diverse data on goals. This doesn't solve all the possible inner alignment problems we could have for arbitrarily powerful policy functions (e.g. there can still be contextually activated mesa-optimizers [LW · GW]), but it'll make the policy function stay internally aligned to the true objective for longer. This proposal improves the generalization of alignment, but not the generalization of capabilities, meaning that it could result in an upward push on the 2D robustness graph above.
13 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2022-09-03T15:00:05.692Z · LW(p) · GW(p)
“There’s an easy solution to this,” you might say. “Just present a whole boatload of environments where the goals vary along every axis, then they have to learn the right goal!”
“Our sweet summer child,” we respond, “if only it were so simple.”
[...]
Our solution is ‘giving the AI superpowers.’
[...]
Some current possible candidates for 'superpowers' in a gridworld environment, where the agent's goal is to collect a coin, are:
- Move the coin
- Teleport anywhere in the grid
- Rewrite any cell in the grid
- Move through walls
The 'superpower' that we ultimately want to give the policy selector, in the model-based RL case, is the ability to 'make all its dreams come true.'
Note that since you have to implement the superpowers via simulation, you could just present a whole boatload of environments where you randomly apply every superpower, instead of giving the superpower to the agent. Giving the superpower to the agent might be more efficient (depends on the setting) but it doesn't seem qualitatively different.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-09-05T18:21:09.290Z · LW(p) · GW(p)
I agree in the case of a model-free agent (although we think it should scale up better to be having the agent find its own adversarial examples).
In the model based agent, I think the case is better. Because you can implement the superpowers on its own world model (I.e. mu-zero that has the additional action of overwriting some or all of its world model latent state during rollouts), then the distribution shift that happens when capabilities get higher is much smaller, and depends mainly on how much the world model has changed its representation of the world state. This is a strictly smaller distribution shift to what you would have otherwise, because it has ~eliminated the shift that comes from not being able to access most states during the lower capabilities regime.
↑ comment by Rohin Shah (rohinmshah) · 2022-09-06T12:23:14.609Z · LW(p) · GW(p)
But in most model-based agents, the world model is integral to action selection? I don't really understand how you give an agent like MuZero the ability to overwrite its world model (how do you train it? Heck, how do you even identify which part of the world model corresponds to "move the coin"?)
Also, I forgot to mention, but you need to make your superpowers less super. If you literally include things like "move the coin"and "teleport anywhere in the grid", then your agent will learn the policy "take the superpower-action to get to the coin, end episode", and will never learn any capabilities and will fail to do anything once you remove the superpower.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-09-06T19:57:21.262Z · LW(p) · GW(p)
The way I imagine it, at random times throughout training (maybe halfway through a game), the agent would go into "imagination mode", where it is allowed to use extra continuous scalar actions for bootstrapping rollouts (not interacting with the real environment). Each extra action pushes the world state along a random vector (constant during each time it enters this mode).
During "imagination mode", the agent chooses an action according to its policy function, and the world model + hard-coded superpower perturbation shows the consequences of the action in the WM latent state. We use this to do a bunch of step rollouts and use them for bootstrapping: feed each rollout into the (aligned)[1] utility function, and use the resulting improved policy estimate to update the policy function.
Because the action space is changing and randomly limited, the policy function will learn to test out and choose superpowered actions based on their consequences, which will force it to learn an approximation of the value of the consequences of its actions. And because the superpowered actions aren't always available, it will also have to learn normal capabilities simultaneously.
- ^
Applying this method to model based RL requires that we have an aligned utility function on the world model latent state: WM-state/sequence -> R. We came up with this method when thinking about how to address inner misalignment 1 in Finding [LW · GW]Goals [LW · GW] in the World Model [LW · GW] (misalignment between the policy function and aligned utility function).
comment by Thomas Kwa (thomas-kwa) · 2022-09-01T04:55:44.994Z · LW(p) · GW(p)
This seems promising to me and information gathering + steps towards an alignment plan. As an alignment plan, it's not clear that behaving well at capability level 1, plus behaving well on a small training set at capability level 2, generalizes correctly to good behavior at capability level 1 million.
The experiment limits you to superpowers you can easily assign, not human-level capability, but it seems like the space of this is still pretty small compared to the space of actions a really powerful agent might have in the real world.
Replies from: thomas-larsen↑ comment by Thomas Larsen (thomas-larsen) · 2022-09-01T06:56:07.428Z · LW(p) · GW(p)
In the model based RL set up, we are planning to give it actions that can directly modify the game state in any way it likes. This is sort of like an arbitrarily-powerful superpower, because it can change anything it wants about the world, except of course that this is a cartesian environment and so it can't, e.g., recursively self improve.
With model free RL, this strategy doesn't obviously carry over so I agree that we are limited to easily codeable superpowers. .
comment by Chris_Leong · 2022-08-31T10:44:49.900Z · LW(p) · GW(p)
Do you think this will generalise to models of reinforcement learning that aren't model-based[1]? One challenge here is that it may learn to use certain superpowers or not to use them rather than learning to seek or avoid a particular state of the world. Do you think this is likely to be an issue?
- ^
I should mention that I don't know what PPO is, so I don't know if it is model-based or not
↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-09-01T18:50:33.862Z · LW(p) · GW(p)
I think it might help a bit with non-model-based approaches, because it will be a bit like training on adversarial environments. But with model-based RL, this technique should reduce the distribution shift much more, because the distribution shift happening with "being powerful in sim" -> "being powerful in reality", should be much larger than "being powerful in my world model" -> "being powerful in reality (as observed using a slightly better version of my world model)".
PPO isn't model based, so we will test it out with that.
One challenge here is that it may learn to use certain superpowers or not to use them rather than learning to seek or avoid a particular state of the world. Do you think this is likely to be an issue?
Yeah this is a good point, it's not clear whether it will generalise to "use superpowers when available and seek aligned states, but act unaligned otherwise", or "use superpowers when available and seek aligned states, and act aligned otherwise". My hope is that the second one is more likely, because it should be a simpler function to represent. This does assume that the model has a simplicity bias, but I think that's reasonable.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2022-09-02T08:02:22.434Z · LW(p) · GW(p)
I guess I'm worried that learning to always use or always not use a super power might often be simpler.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-09-02T08:15:15.613Z · LW(p) · GW(p)
Yeah might depend on the details, but it shouldn't learn to always use or not use superpowers, because it should still be trained on some normal non-superpower rollouts. So the strategy it learns should always involve using superpowers when available but not using them when not, otherwise it'd get high training loss.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-30T21:09:46.875Z · LW(p) · GW(p)
Interesting idea. If this works out in simulations, in theory you could do experiments in the real world by having a nerfed robot (deliberately impaired beyond the actual constraints of its hardware) which occasionally gained the superpower of not being impaired (increased strength/agility/visual resolution/reliability-of-motor-response/etc).
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-08-30T21:54:27.459Z · LW(p) · GW(p)
The reason this method might be useful is that it allows the agent to "fantasize" about actions it would take if it could. We don't want it to take these actions in the real world. For example, it could explore bizarre hypotheticals like: "turn the whole world into gold/computronium/hedonium".
If we had a sub-human physical robot, and we were confident that it wouldn't do any damage when doing unconstrained real world training, then I can't see any additional benefit to using our method? You can just do normal RL training.
And if it's super-human, we wouldn't want to use our technique in the real world, because it would turn us into gold/computronium/hedonium during training.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-30T22:01:33.855Z · LW(p) · GW(p)
Yes, it wouldn't be able to go as far as those things, but you could potentially identify more down-to-earth closer-to-reality problems in a robot. Again, I was just imagining a down-the-line scenario after you have proved this works well in simulations. For instance, this sort of thing (weak robot that occasionally gets strong enough to be dangerous) in a training environment (a specially designed obstacle course) could find and prevent problems before deployment (shipping to consumers).