What AI Safety Materials Do ML Researchers Find Compelling?
post by Vael Gates, Collin (collin-burns) · 2022-12-28T02:03:31.894Z · LW · GW · 34 commentsContents
Summary Commentary More Detailed Results Ratings Common Criticisms Appendix - Raw Data None 34 comments
I (Vael Gates) recently ran a small pilot study with Collin Burns in which we showed ML researchers (randomly selected NeurIPS / ICML / ICLR 2021 authors) a number of introductory AI safety materials, asking them to answer questions and rate those materials.
Summary
We selected materials that were relatively short and disproportionally aimed at ML researchers, but we also experimented with other types of readings.[1] Within the selected readings, we found that researchers (n=28) preferred materials that were aimed at an ML audience, which tended to be written by ML researchers, and which tended to be more technical and less philosophical.
In particular, for each reading we asked ML researchers (1) how much they liked that reading, (2) how much they agreed with that reading, and (3) how informative that reading was. Aggregating these three metrics, we found that researchers tended to prefer (Steinhardt > [Gates, Bowman] > [Schulman, Russell]), and tended not to like Cotra > Carlsmith. In order of preference (from most preferred to least preferred) the materials were:
- “More is Different for AI” by Jacob Steinhardt (2022) (intro and first three posts only)
- “Researcher Perceptions of Current and Future AI” by Vael Gates (2022) (first 48m; skip the Q&A) (Transcript [EA · GW])
- “Why I Think More NLP Researchers Should Engage with AI Safety Concerns” by Sam Bowman (2022)
- “Frequent arguments about alignment [AF · GW]” by John Schulman (2021)
- “Of Myths and Moonshine” by Stuart Russell (2014)
- "Current work in AI Alignment" by Paul Christiano (2019) (Transcript [EA · GW])
- “Why alignment could be hard with modern deep learning” by Ajeya Cotra (2021) (feel free to skip the section “How deep learning works at a high level”)
- “Existential Risk from Power-Seeking AI” by Joe Carlsmith (2021) (only the first 37m; skip the Q&A) (Transcript [EA · GW])
(Not rated)
- "AI timelines/risk projections as of Sept 2022" (first 3 pages only)
Commentary
Christiano (2019), Cotra (2021), and Carlsmith (2021) are well-liked by EAs anecdotally, and we personally think they’re great materials. Our results suggest that materials EAs like may not work well for ML researchers, and that additional materials written by ML researchers for ML researchers could be particularly useful. By our lights, it’d be quite useful to have more short technical primers on AI alignment, more collections of problems that ML researchers can begin to address immediately (and are framed for the mainstream ML audience), more technical published papers to forward to researchers, and so on.
More Detailed Results
Ratings
For the question “Overall, how much did you like this content?”, Likert 1-7 ratings (I hated it (1) - Neutral (4) - I loved it (7)) roughly followed:
- Steinhardt > Gates > [Schulman, Russell, Bowman] > [Christiano, Cotra] > Carlsmith
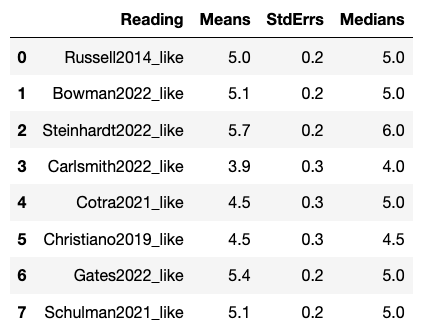
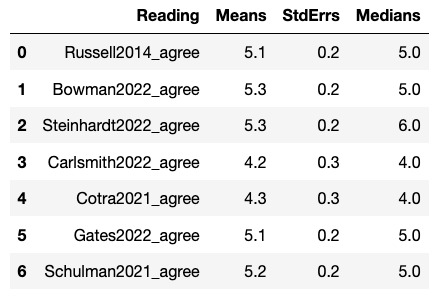
For the question “Overall, how much do you agree or disagree with this content?”, Likert 1-7 ratings (Strongly disagree (1) - Neither disagree nor agree (4) - Strongly agree (7)) roughly followed:
- Steinhardt > [Bowman, Schulman, Gates, Russell] > [Cotra, Carlsmith]
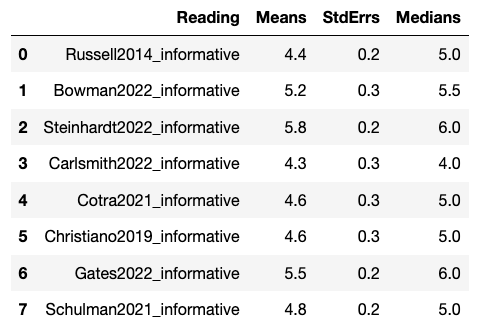
For the question “How informative was this content?”, Likert 1-7 ratings (Extremely noninformative (1) - Neutral (4) - Extremely informative (7)) roughly followed:
- Steinhardt > Gates > Bowman > [Cotra, Christiano, Schulman, Russell] > Carlsmith
The combination of the above questions led to the overall aggregate summary (Steinhardt > [Gates, Bowman] > [Schulman, Russell]) as preferred readings listed above.
Common Criticisms
In the qualitative responses about the readings, there were some recurring criticisms, including: a desire to hear from AI researchers, a dislike of philosophical approaches, a dislike of a focus on existential risks or an emphasis on fears, a desire to be “realistic” and not “speculative”, and a desire for empirical evidence.
Appendix - Raw Data
You can find the complete (anonymized) data here. This includes both more comprehensive quantitative results and qualitative written answers by respondents.
34 comments
Comments sorted by top scores.
comment by Thomas Kwa (thomas-kwa) · 2022-12-28T05:09:36.303Z · LW(p) · GW(p)
Here's one factor that might push against the value of Steinhardt's post as something to send to ML researchers: perhaps it is not arguing for anything controversial, and so is easier to defend convincingly. Steinhardt doesn't explicitly make any claim about the possibility of existential risk, and barely mentions alignment. Gates spends the entire talk on alignment and existential risk, and might avoid being too speculative because their talk is about a survey of basically the same ML researcher population as the audience, and so can engage with the most important concerns, counterarguments, etc.
I'd guess that the typical ML researcher who reads Steinhardt's blogposts will basically go on with their career unaffected, whereas one that watches the Gates video will now know that alignment is a real subfield of AI research, plus the basic arguments for catastrophic failure modes. Maybe they'll even be on the lookout for impressive research from the alignment field, or empirical demonstrations of alignment problems.
Caveats: I'm far from a NeurIPS author and spent 10 minutes skipping through the video, so maybe all of this is wrong. Would love to see evidence one way or the other.
Replies from: LawChan, Kaj_Sotala↑ comment by LawrenceC (LawChan) · 2022-12-28T09:53:53.521Z · LW(p) · GW(p)
+1 to this, I feel like an important question to ask is "how much did this change your mind?". I would probably swap the agree/disagree question for this?
I think the qualitative comments also bear this out as well:
dislike of a focus on existential risks or an emphasis on fears, a desire to be “realistic” and not “speculative”
This seems like people like AGI Safety arguments that don't really cover AGI Safety concerns! I.e. the problem researchers have isn't so much with the presentation but the content itself.
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-28T10:32:03.257Z · LW(p) · GW(p)
(Just a comment on some of the above, not all)
Agreed and thanks for pointing out here that each of these resources has different content, not just presentation, in addition to being aimed at different audiences. This seems important and not highlighted in the post.
We then get into what we want to do about that, where one of the major tricky things is the ongoing debate of "how much researchers need to be thinking in the frame of xrisk to make useful progress in alignment", which seems like a pretty important crux, and another is "what do ML researchers think after consuming different kinds of content", where Thomas has some hypotheses in the paragraph "I'd guess..." but we don't actually have data on this and I can think of alternate hypotheses, which also seems quite cruxy.
↑ comment by Kaj_Sotala · 2022-12-28T13:17:23.870Z · LW(p) · GW(p)
On the other hand, there's something to be said about introducing an argument in ways that are as maximally uncontroversial as possible, so that they smoothly fit into a person's existing views but start to imply things that the person hasn't considered yet. If something like the Steinhardt posts gets researchers thinking about related topics by themselves, then that might get them to a place where they're more receptive to the x-risk arguments a few months or a year later - or even end up reinventing those arguments themselves.
I once saw a comment that went along the lines of "you can't choose what conclusions people reach, but you can influence which topics they spend their time thinking about". It might be more useful to get people thinking about alignment topics in general, than to immediately sell them on x-risk specifically. (Edited to add: not to mention that trying to get people thinking about a topic, is better epistemics than trying to get them to accept your conclusion directly.)
Replies from: dpandey, sharmake-farah↑ comment by devansh (dpandey) · 2022-12-28T14:56:02.332Z · LW(p) · GW(p)
I feel pretty scared by the tone and implication of this comment. I'm extremely worried about selecting our arguments here for truth instead of for convincingness, and mentioning a type of propaganda and then talking about how we should use it to make people listen to our arguments feels incredibly symmetric. If the strength our arguments for why AI risk is real do not hinge on whether or not those arguments are centrally true, we should burn them with fire.
Replies from: Kaj_Sotala, sharmake-farah↑ comment by Kaj_Sotala · 2022-12-28T17:42:40.746Z · LW(p) · GW(p)
I get the concern and did wonder for a bit whether to include the second paragraph. But I also never suggested saying anything untrue, nor would I endorse saying anything that we couldn't fully stand behind.
Also, if someone in the "AI is not an x-risk" camp were considering how to best convince me, I would endorse them using a similar technique of first introducing arguments that made maximal sense to me, and letting me think about their implications for a while before introducing arguments that led to conclusions I might otherwise reject before giving them a fair consideration. If everyone did that, then I would expect the most truthful arguments to win out.
On grounds of truth, I would be more concerned about attempts to directly get people to reach a particular conclusion, than ones that just shape their attention to specific topics. Suggesting people what they might want to think about leaves open the possibility that you might be mistaken and that they might see this and reject your arguments. I think this is a more ethical stance than one that starts out from "how do we get them from where they are to accepting x-risk in one leap". (But I agree that the mention of propaganda gives the wrong impression - I'll edit that part out.)
Replies from: dpandey↑ comment by devansh (dpandey) · 2022-12-29T15:01:39.371Z · LW(p) · GW(p)
Cool, I feel a lot more comfortable with your elaboration; thank you!
Replies from: peterslattery↑ comment by peterslattery · 2022-12-30T21:55:34.707Z · LW(p) · GW(p)
Yeah, I agree with Kaj here. We do need to avoid the risk of using misleading or dishonest communication. However it also seems fine and important to optimise relevant communication variables (e.g., tone, topic, timing, concision, relevance etc) to maximise positive impact.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-28T15:19:10.960Z · LW(p) · GW(p)
Truthfully, I understand. And if we have longer timelines or alignment will happen by default, then I'd agree. Unfortunately the chance of these assumptions not being true is high enough that we should probably forsake the deontological rule and make the most convincing arguments. Remember, we need to convince those that already have biases against certain types of reasoning common on LW, and there's no better option. I agree with Kaj Sotala's advice.
Dentological rules like the truth are too constraining to work in a short timelines environment or the possibility of non-alignment by default.
Replies from: Kaj_Sotala, dpandey, lahwran↑ comment by Kaj_Sotala · 2022-12-28T17:45:39.532Z · LW(p) · GW(p)
I disagree with this, to be clear. I don't think we should sacrifice truth, and the criticism I was responding to wasn't that Steinhardt's posts would be untrue.
↑ comment by devansh (dpandey) · 2022-12-29T15:04:20.552Z · LW(p) · GW(p)
Yeah, this is basically the thing I'm terrified about. If someone has been convinced of AI risk with arguments which do not track truth, then I find it incredibly hard to believe that they'd ever be able to contribute useful alignment research, not to mention the general fact that if you recruit using techniques that select for people with bad epistemics you will end up with a community with shitty epistemics and wonder what went wrong.
↑ comment by the gears to ascension (lahwran) · 2022-12-28T17:46:13.460Z · LW(p) · GW(p)
"we must sacrifice the very thing we intend to create, alignment, in order to create it"
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-12-28T17:55:00.297Z · LW(p) · GW(p)
A nice rebuttal against my unpopular previous comment.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-28T14:51:29.081Z · LW(p) · GW(p)
Or in other words, we can't get them to accept conclusions we favor, but we can frame alignment in such a way that it just seems natural.
comment by elifland · 2022-12-28T13:22:49.900Z · LW(p) · GW(p)
I'd be curious to see how well The alignment problem from a deep learning perspective and Without specific countermeasures... [AF · GW] would do.
Replies from: Vael Gates, jskatt↑ comment by Vael Gates · 2022-12-29T00:40:13.666Z · LW(p) · GW(p)
Yeah, we were focusing on shorter essays for this pilot survey (and I think Richard's revised essay came out a little late in the development of this survey? Can't recall) but I'm especially interested in "The alignment problem from a deep learning perspective", since it was created for an ML audience.
↑ comment by JakubK (jskatt) · 2022-12-31T06:58:28.080Z · LW(p) · GW(p)
Without specific countermeasures... [LW · GW] seems similar to Carlsmith (they present similar arguments in a similar manner and utilize the philosophy approach), so I wouldn't expect it to do much better.
comment by Neel Nanda (neel-nanda-1) · 2022-12-28T15:16:28.011Z · LW(p) · GW(p)
This is some solid empirical work, thanks for running this survey! I'm mildly surprised by the low popularity of Cotra's stuff, and that More is Different is so high.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-12-28T04:08:43.084Z · LW(p) · GW(p)
Thank you for doing this! I guess I'll use the Steinhardt and Gates materials as my go-to from now on until something better comes along!
Given the unifying theme of the qualitative comments*, I'd love to see a follow-up study in which status effects are controlled for somehow. Like, suppose you used the same articles/posts/etc., but swapped the names of the authors, so that e.g. the high-status* ML people were listed as authors of "Why alignment could be hard with modern deep learning."
*I think that almost all of the qualitative comments you list are the sort of thing that seems heavily influenced by status -- e.g. when someone you respect says X, it's deep and insightful and "makes you think," when a rando you don't respect says X, it's "speculative" and "philosophical" and not "empirical."
**High status among random attendees of ML conferences, that is. Different populations have different status hierarchies.
↑ comment by Vael Gates · 2022-12-28T10:40:24.827Z · LW(p) · GW(p)
Agreed that status / perceived in-field expertise seems pretty important here, especially as seen through the qualitative results (though the Gates talk did surprisingly well, given not an AI researcher, but the content reflects that). We probably won't have [energy / time / money] + [we have limited access to researchers] to test something like this, but I think we can hold "status is important" as something pretty true given these results, Hobbhann's (https://forum.effectivealtruism.org/posts/kFufCHAmu7cwigH4B/lessons-learned-from-talking-to-greater-than-100-academics [EA · GW]), and a ton of anecdotal evidence from a number of different sources.
(I also think the Sam Bowman article is a great article to recommend, and in fact recommend that first a lot of the time.)
comment by SoerenMind · 2022-12-31T09:59:43.097Z · LW(p) · GW(p)
Great to see this studied systematically - it updated me in some ways.
Given that the study measures how likeable, agreeable, and informative people found each article, regardless of the topic, could it be that the study measures something different from "how effective was this article at convincing the reader to take AI risk seriously"? In fact, it seems like the contest could have been won by an article that isn't about AI risk at all. The top-rated article (Steinhardt's blog series) spends little time explaining AI risk: Mostly just (part of) the last of four posts. The main point of this series seems to be that 'More Is Different for AI', which is presumably less controversial than focusing on AI risk, but not necessarily effective at explaining AI risk.
comment by Raemon · 2022-12-29T06:01:36.528Z · LW(p) · GW(p)
Were the people aware that you wrote the Researcher Perceptions of Current and Future AI? One kinda obvious question was whether that confounded the results.
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-29T07:03:27.744Z · LW(p) · GW(p)
My guess is that people were aware (my name was all over the survey this was a part of, and people were emailing with me). I think it was also easily inferred that the writers of the survey (Collin and I) supported AI safety work far before the participants reached the part of the survey with my talk. My guess is that my having written this talk didn't change the results much, though I'm not sure which way you expect the confound to go? If we're worried about them being biased towards me because they didn't want to offend me (the person who had not yet paid them), participants generally seemed pretty happy to be critical in the qualitative notes. More to the point, I think the qualitative notes for my talk seemed pretty content focused and didn't seem unusual compared to the other talks when I skimmed through them, though would be interested to know if I'm wrong there.
comment by LawrenceC (LawChan) · 2022-12-28T09:56:22.601Z · LW(p) · GW(p)
I'm curious how many researchers watched the entire 1 hour of the Gates video, given it was ~2x as long as the other content. Do you have a sense of this (perhaps via Youtube analytics)?
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-28T10:18:35.594Z · LW(p) · GW(p)
These results were actually embedded in a larger survey, and were grouped in sections, so I don't think it came off as particularly long within the survey. (I also assume most people watched the video at faster than 1x.) People also seemed to like this talk, so I'd guess that they watched it as or more thoroughly than they did everything else. We don't have analytics regretfully. (I also forgot to add that we told people to skip the Q&A, so we had them watch the first 48m.)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-28T19:17:02.912Z · LW(p) · GW(p)
Thanks! I remember the context of this survey now (spoke with a few people at NeurIPS about it), that makes sense.
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-28T21:48:56.745Z · LW(p) · GW(p)
Whoa, at least one of the respondents let me know that they'd chatted about it at NeurIPS -- did multiple people chat with you about it? (This pilot survey wasn't sent out to that many people, so curious how people were talking about it.)
Edited: talking via DM
comment by plex (ete) · 2022-12-28T02:52:50.427Z · LW(p) · GW(p)
Strong upvote, important work!
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-28T10:44:47.386Z · LW(p) · GW(p)
Thanks! (credit also to Collin :))
comment by Vael Gates · 2023-01-01T23:56:18.869Z · LW(p) · GW(p)
Anonymous comment sent to me, with a request to be posted here:
"The main lede in this post is that pushing the materials that feel most natural for community members can be counterproductive, and that getting people on your side requires considering their goals and tastes. (This is not a community norm in rationalist-land, but the norm really doesn’t comport well elsewhere.)"
comment by Nina Panickssery (NinaR) · 2022-12-31T17:06:04.444Z · LW(p) · GW(p)
I wonder whether https://arxiv.org/pdf/2109.13916.pdf would be a successful resource in this scenario (Unsolved Problems in ML Safety by Hendrycks, Carlini, Schulman and Steinhardt)
comment by peterslattery · 2022-12-30T21:34:18.190Z · LW(p) · GW(p)
Thanks for doing/sharing this Vael. I was excited to see it!
I am currently bringing something of a behaviour change/marketing mindset to thinking about AI Safety movement building and therefore feel that testing how well different messages and materials work for audiences is very important. Not sure if it will actually be as useful as I currently think though.
With that in mind, I'd like to know:
- was this as helpful for you/others as expected?
- are you planning related testing to do next?
Two ideas I wonder if it would be valuable to first test predictions among communicators for which materials will work best before then doing the test. This could make the value of the new information more salient by showing if/where our intuitions are wrong
I wonder about the value of trying to build an informal panel/mailing list of ML researchers who we can contact/pay to do various things like surveys/interviews. Also to potentially review AI Safety arguments/post from a more skeptical perspective so we can more reliably find any likely flaws in the logic or rhetoric.
Would welcome any thoughts or work on either if you have the time and inclination.
Replies from: Vael Gates↑ comment by Vael Gates · 2022-12-30T22:22:32.564Z · LW(p) · GW(p)
was this as helpful for you/others as expected?
I think these results, and the rest of the results from the larger survey that this content is a part of, have been interesting and useful to people, including Collin and I. I'm not sure what I expected beforehand in terms of helpfulness, especially since there's a question "helpful with respect to /what/", and I expect we may have different "what"s here.
are you planning related testing to do next?
Good chance of it! There's some question about funding, and what kind of new design would be worth funding, but we're thinking it through.
I wonder if it would be valuable to first test predictions among communicators
Yeah, I think this is currently mostly done informally -- when Collin and I were choosing materials, we had a big list, and were choosing based on shared intuitions that EAs / ML researchers / fieldbuilders have, in addition to applying constraints like "shortness". Our full original plan was also much longer and included testing more readings -- this was a pilot survey. Relatedly, I don't think these results are very surprising to people (which I think you're alluding to in this comment) -- somewhat surprising, but we have a fair amount of information about researcher preferences already.
I do think that if we were optimizing for "value of new information to the EA community" this survey would have looked different.
I wonder about the value of trying to build an informal panel/mailing list of ML researchers
Instead of contacting a random subset of people who had papers accepted at ML conferences? I think it sort of depends on one's goals here, but could be good. A few thoughts: I think this may already exist informally, I think this becomes more important as there's more people doing surveys and not coordinating with each other, and this doesn't feel like a major need from my perspective / goals but might be more of a bottleneck for yours!
Replies from: peterslattery↑ comment by peterslattery · 2022-12-31T22:41:56.877Z · LW(p) · GW(p)
Thanks! Quick responses:
I think these results, and the rest of the results from the larger survey that this content is a part of, have been interesting and useful to people, including Collin and I. I'm not sure what I expected beforehand in terms of helpfulness, especially since there's a question "helpful with respect to /what/", and I expect we may have different "what"s here.
Good to know. When discussing some recent ideas I had for surveys, several people told me that their survey results underperformed their expectations, so I was curious if you would say the same thing.
Yeah, I think this is currently mostly done informally -- when Collin and I were choosing materials, we had a big list, and were choosing based on shared intuitions that EAs / ML researchers / fieldbuilders have, in addition to applying constraints like "shortness". Our full original plan was also much longer and included testing more readings -- this was a pilot survey. Relatedly, I don't think these results are very surprising to people (which I think you're alluding to in this comment) -- somewhat surprising, but we have a fair amount of information about researcher preferences already.
Thanks for explaining. I realise that the point of that part of my comment was unclear, sorry. I think that using these sorts of surveys to test if best practice contrasts with current practice could make the findings clearer and spur improvement/innovation if needed.
For instance, doing something like this: "We curated the 10 most popular public communication paper from AI Safety organisations and collected predictions from X public AI Safety communicators about which of thse materials would be most effective at persuading existing ML researchers to care about AI Safety. We tested these materials with a random sample of X ML researchers and [supported/challenged existing beliefs/practices]... etc."
I am interested to hear what you think of the idea of testing using these sorts of surveys to test if best practice contrasts with current practice, but ok if you don't have time to explain! I imagine that it does add some extra complexity and challenge to the research process, so may not be worth it.
I hope you can do the larger study eventually. If you do, I would also like to see how sharing readings compares against sharing podcasts or videos etc. Maybe some modes of communication perform better on average etc.
Instead of contacting a random subset of people who had papers accepted at ML conferences? I think it sort of depends on one's goals here, but could be good. A few thoughts: I think this may already exist informally, I think this becomes more important as there's more people doing surveys and not coordinating with each other, and this doesn't feel like a major need from my perspective / goals but might be more of a bottleneck for yours!
Thanks, that's helpful. Yeah, I think that the panel idea is one for the future. My thinking is something like this: Understanding why and how AI Safety related materials (e.g., arguments, research agendas, recruitment type messages etc) influence ML researchers is going to become increasingly important to a growing number of AI Safety community actors (e.g., researchers, organisations, recruiters and movement builders).
Whenever an audience becomes important to some social/business actor (e.g., government/academics/companies), this usually creates sufficient demand to justify setting up a panel/database to service those actors. Assuming the same trend, it may be important/useful to create a panel of ML researchers that AI Safety actors can access.
Does that seem right?
I mention the above in part because I think that you are one of the people who might be best-placed to set something like this up if it seemed like a good idea. Also, because I think that there is a reasonable chance that I would use a service like this within the next two years and end up referring several other people (e.g., those producing choosing educational materials for relevant AI Safety courses) to use it.