The need for multi-agent experiments
post by Martín Soto (martinsq) · 2024-08-01T17:14:16.590Z · LW · GW · 3 commentsContents
Multi-polar risks Opportunities Obstacles Bottomline Acknowledgements None 3 comments
TL;DR: Let’s start iterating on experiments that approximate real, society-scale multi-AI deployment
Epistemic status: These ideas seem like my most prominent delta [LW · GW] with the average AI Safety researcher, have stood the test of time, and are shared by others I intellectually respect. Please attack them fiercely!
Multi-polar risks
Some authors have already written about multi-polar AI failure [? · GW]. I especially like how Andrew Critch has tried to sketch concrete stories for it.
But, without even considering concrete stories yet, I think there’s a good a priori argument in favor of worrying about multi-polar failures:
We care about the future of society. Certain AI agents will be introduced, and we think they could reduce our control over the trajectory of this system. The way in which this could happen can be divided into two steps:
- The agents (with certain properties) are introduced in certain positions
- Given the agents’ properties and positions, they interact with each other and the rest of the system, possibly leading to big changes
So in order to better control the outcome, it seems worth it to try to understand and manage both steps, instead of limiting ourselves to (1), which is what the alignment community has traditionally done.
Of course, this is just one, very abstract argument, which we should update based on observations and more detailed technical understanding. But it makes me think the burden of proof is on multi-agent skeptics to explain why (2) is not important.
Many have taken on that burden. The most common reason to dismiss the importance of (2) is expecting a centralized intelligence explosion, a fast and unipolar software takeoff, like Yudkowsky’s FOOM. Proponents usually argue that the intelligences we are likely to train will, after meeting a sharp threshold of capabilities, quickly bootstrap themselves to capabilities drastically above those of any other existing agent or ensemble of agents. And that these capabilities will allow them to gain near-complete strategic advantage and control over the future. In this scenario, all the action is happening inside a single agent, and so you should only care about shaping its properties (or delaying its existence).
I tentatively expect more of a decentralized hardware singularity[1] than centralized software FOOM. But there’s a weaker claim in which I’m more confident: we shouldn’t right now be near-certain of a centralized FOOM.[2] I expect this to be the main crux with many multi-agent skeptics, and won’t argue for it here (but rather in an upcoming post).
Even given a decentralized singularity, one can argue that the most leveraged way for us to improve multi-agent interactions is by ensuring that individual agents possess certain properties (like honesty or transparency), or that at least we have enough technical expertise to shape them on the go. I completely agree that this is the natural first thing to look at. But I think focusing on multi-agent interactions directly is a strong second, and a lot of marginal value might lie there given how neglected they’ve been until now (more below). I do think many multi-agent interventions will require certain amounts of single-agent alignment technology. This will of course be a crux with alignment pessimists.
Finally, for this work to be counterfactually useful it’s also required that AI itself (in decision-maker or researcher positions) won’t iteratively solve the problem by default. Here, I do think we have some reasons [LW · GW] to expect (65%) that intelligent enough AIs aligned with their principals don’t automatically solve catastrophic conflict. In those worlds, early interventions can make a big difference setting the right incentives for future agents, or providing them with mechanisms necessary for cooperation (that they aren’t able to bootstrap themselves).
In summary, the following conditions seem necessary for this kind of work to have an impact:
- not a singleton takeoff
- sufficiently good single-agent alignment
- coordination problems not automatically solved by intelligent enough AI
But there’s a bunch of additional considerations which I believe point towards multi-agent work being more robustly positive than other bets:
- Understanding and stabilizing multi-agent situations would seem to not only help with avoiding near-term extinction [LW · GW], but also reduce s-risks from conflict, and possibly even improve democratic moral deliberation [? · GW]. So, multi-agent work not only makes it more likely that the future exists, but also that the future is better (if it exists).
- Most multi-agent AI risks can be understood as exacerbations or accelerations of multi-agent problems with much historical precedent. From this perspective, we seem to have marginally more reason to expect these problems to be real, and more past data to work from. However, this could also mean these problems are less neglected (more below).
- There’s not a clear division between single-agent and multi-agent settings. For example, future agents might have more modular architectures, like LLM scaffolds, which could be studied from the multi-agent lens. There’s an important sense in which an LLM scaffold is less of a multi-agent setting than an economy of LLM scaffolds. But the distinction here is a blurry one, and it’s possible that insights or practices from one setting can be applied to the other. This of course cuts both ways: not only might multi-agent work help single-agent work, but also the other way around. But it does seem like, if such a mutually beneficial transfer exists, you’d want to differentially advance the most neglected of the two directions.
- Even if it’s over-determined that all takeoffs end in a singleton (because multi-agent settings are unstable), the multi-agent dynamics in the run-up to that singleton could shape the singleton’s properties. A better understanding of multi-agent dynamics could allow us to slow down or re-direct the trajectory.
Opportunities
Since multi-agent problems have been experienced and studied in the past, we need to ask ourselves: What is different for AI? What are the augmented risks or the new useful tricks we can pull?
One obvious consideration is AI will accelerate and proliferate multi-agent interactions, and thus reduce the fraction of direct human supervision over them. It then seems like we’ll need different mechanisms and institutions to control these interactions, which points towards governance. Indeed, since a main tractability problem of multi-agent work is how chaotic and noisy multi-agent systems are, the most macro-level and conceptual kinds of governance research (especially threat modelling) could be the natural way to pick low-hanging fruit, by enabling us to go one level up in abstraction and “eyeball” the more robust macroscopic dynamics (without needing to understand all low-level detail).
It’s also possible that particular properties of AI agents (not shared by humans) present new risks and opportunities in multi-agent interactions. Most notably, Open-Source Game Theory explores the effects of mutual transparency.
What I’ll focus on instead is a new opportunity made possible by AI: Using AIs to scale up experiments that predict and test dangerous societal-scale dynamics (including those exacerbated by AI deployment). For example, big experiments on populations of agents might help us iteratively explore which governance structures, audits or negotiation procedures best prevent negative outcomes like concentration of power, or the selection of retributive agents.
So what do these costly and detailed simulations gain us over theoretical analysis? If a structural property generally leads to more concentration of power, won’t we be able to prove this with math? The idea is that these detailed settings can showcase important emergent dynamics that only appear at scale, and would not be present in our more simplistic, purely theoretical models. Experiments let us “try things out” and direct our gaze to the important parts about which we might actually want to prove general statements in more simplistic models. Or even allow us to “eyeball” dynamics that don’t have any tractable theoretical analogue, closer to a natural sciences approach.
Common sense already tells us that including more of these low-level details will on average lead us closer to the behavior of the real system.[3] And it’s not news to anyone that purely game-theoretic analysis falls short of realistic prediction. This is also known by militaries around the world, who have been using wargaming as a simulation method for more than a century. Same goes for Agent-Based Models in virology. There are also some empirical studies demonstrating the predictive benefits of role-playing.[4]
There’s already a recent craze in using AIs to simulate human experiments in fields like economics or psychology. And Leibo’s Concordia is a first prototype codebase for large multi-agent language-driven experiments. But we need not restrict ourselves to approximating human interactions: we can directly test the AI agents we worry about. Indeed, experiments purposefully testing the consequences of AI deployment will look pretty different from the existing literature on human simulation.
As example near-term experiments, we could set up open-ended environments for generative agents, and test at scale how different details about their predispositions, architecture or environment affect social welfare:
- Is increased commitment credibility or transparency net-positive for fallible agents in language-based environments?
- Where should the helpfulness-harmlessness tradeoff of a single model lie, so as to maximize social welfare, under different hypotheses about the amount and sophistication of bad actors?
- What marginal changes in single-agent predisposition or architecture most improve social welfare when applied to all agents? What about only a minority?
In summary, there are three main reasons why these AI experiments can be more useful than previous research:
- They are simply cheaper and more scalable ways of simulating human experiments.
- They might be more exhaustive and transparent, thanks to their in silico nature and interpretability.
- Even more importantly, we can use them to actually test the AI agents we worry about.
The biggest tractability worry (more below) for this kind of work is the failure of generalization from the simple and short lab experiments we’ll be able to run, to the complex and long trajectory of the real world. Indeed, I expect we’ll need much experimental trial and error and theoretical speculation to have informed opinions on which dynamics might translate to the real world, and even then, a few generalization assumptions might remain untestable. Unless the ML paradigm were to take a sharp turn, this will probably and unfortunately remain not the most rigorous of sciences.
But it is also true that, while the gap between our lab settings and the complexity of reality might seem dauntingly large at first, the signal we get on real dynamics will grow stronger as we’re able to scale up our experiments, automate parts of their evaluations, and develop more informed opinions on how far our setups generalize. While our current agents and setups are not yet good enough to get the signal we need, we should start iterating now on the knowledge and infrastructure we’ll need further down the line.
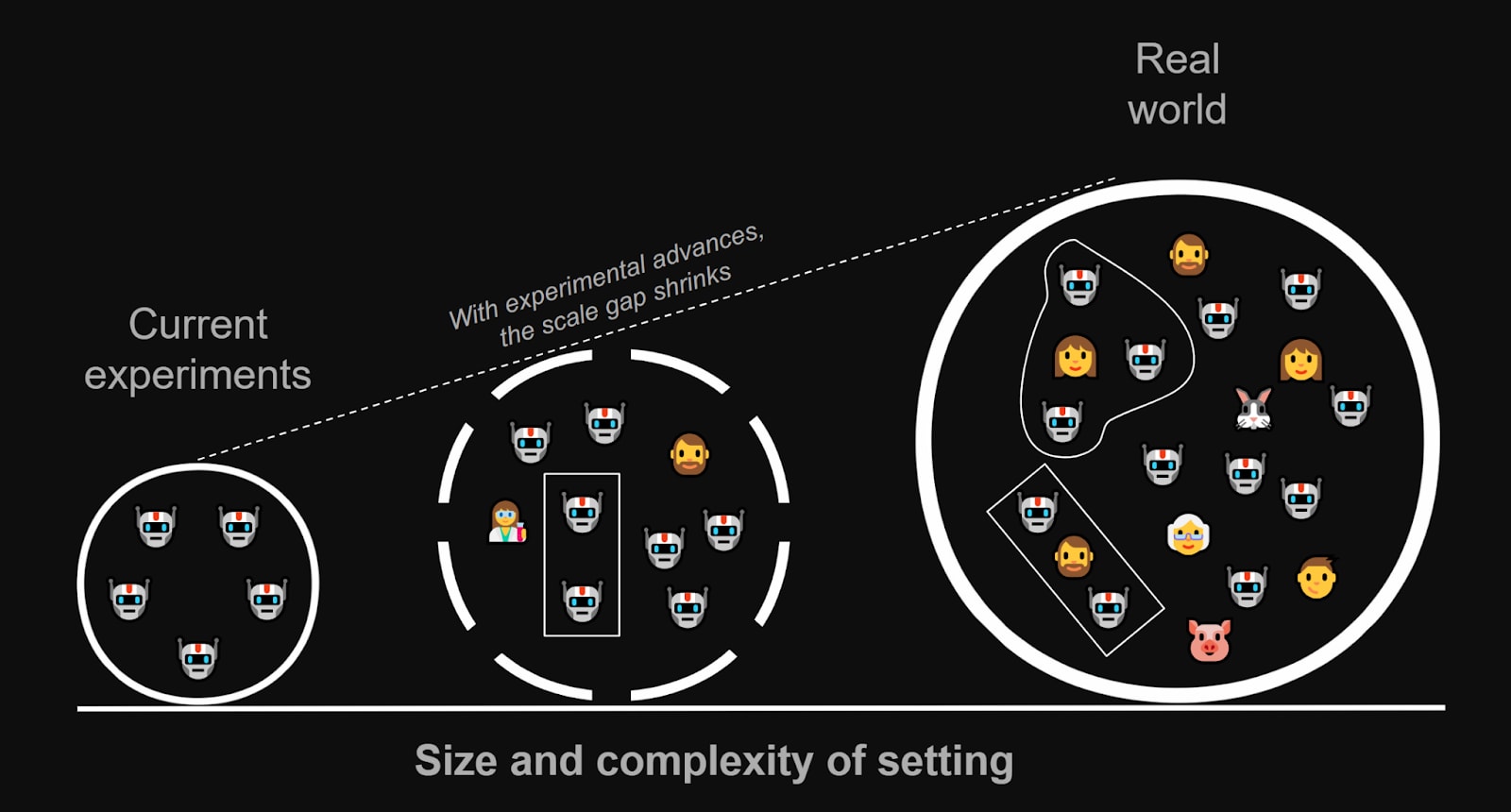
Of course, the size and complexity of reality will also keep increasing through the continuous insertion of AI agents, so it’s unclear how this balances out. But it does seem like there is much low-hanging fruit, so that at least in the near-term experiments will scale faster than society.
Even without considering my focus on catastrophic risks, it’s kind of crazy how publicly neglected this direction is. AI assistants for professional and social interactions will likely be integrated and deployed at scale in the coming months, and we understand their consequences even less than those of recommender systems.[5]
Obstacles
There are many additional tractability worries, although I mostly believe we’re uncertain enough about their strength that we should put them to the test.
1. Compute limitations
While compute is cheaper than human time, it will remain a bottleneck.
Here’s one way to think about it: We’re trying to map out and understand a very high-dimensional dynamical system, going from start states to end states, so that we know which start state to try to construct in the real world (how to deploy which AI systems). Due to compute limitations, we’ll only be able to sample from a very sparse set of start states (and do so in a simplified model), and will need to extrapolate from there. Of course, we won’t blindly choose start states, but rather zoom in on the regions with more apparent value of information, and try to find and test regularities in the system’s evolution that seem both tractable and important.
A redeeming consideration is that AI developers will already be optimizing for compute (for example through model distillations). But to the extent these optimizations are private, labs will be the best (or only) place to run these experiments. And to the extent they’re public, this will also accelerate and complexify the real world (by introducing more and faster AI agents), and again it’s unclear how this balances out.
2. Experimental realism might trade off against safety
Some properties of the real world (that might prove crucial to get any transfer from experimental results) could be hard to simulate in the lab. For example, access to the internet, or being able to run certain kinds of physical operations.
The obvious way to obtain these properties is to make our experiments interface with the real world: actually give them access to the internet, and actually allow them to run physical operations. But of course, this could prove arbitrarily dangerous for advanced enough agents. This trade-off is not particular to the kind of multi-agent experiments I’m proposing here.
Even given these dangers, it might at times seem net-positive to allow for certain interfaces with reality to obtain better information, especially if we correspondingly augment our monitoring of them. In fact, there’s a spectrum from strongly Farady-caged experiments, to experiments possessing some interfaces with the real world, to freely deploying the setup in the real world.[6]
This showcases that lab experiments are not our only way to obtain experimental evidence: setting up monitoring systems in the real world can give us loads of data about the deployments and interactions that are already taking place. Of course, the quantity of this data trades off against the fact that we don’t (fully) control the experimental setup.
Open-ended setups, for example with an LLM game master simulating the environment as in Concordia, could help recreate the rich signals from reality that are hard for us to code manually. Still, it’s unclear how well this will scale, and the simulated information could be shallower than real data, which is actually generated by a vast and complex system. Open-endedness research itself could also lead to capability advances.
A redeeming consideration is that, in the real world, AI agents will probably interact way more between themselves than with the rest of the environment, due to their super-human speed. This means our experiments require sparser feedback from simulated reality. This especially applies for the failure stories related to run-away dynamics from AI acceleration.
3. Scaling evaluation
Even if we could scale experiments arbitrarily, we’d still be bottlenecked by their evaluation and interpretation. Here again we’ll need some kind of AI-automated evaluation or distillation to multiply our capacity.
Blurring the line between isolated experiments and real-world deployment, this kind of evaluation would also start a resonant dialogue with research in scalable oversight. In fact, there’s a possibility that understanding multi-agent settings better helps us scale evaluation synergistically, by being better able to harness the work of AI bureaucracies.
4. Hard to obtain new “crucial considerations”
Maybe this kind of work is more likely to lead to weak quantitative updates (“settings/mechanisms/economies with property X are more likely to end up in end state Y”), rather than radically new crucial considerations (“we discovered a new dynamic that we weren’t even tracking”). This seems true of most kinds of work, although, as I hinted above, the most abstract macro-strategy or governance work might be more efficient at discovering new considerations.
5. Some fundamental obstacle
A big remaining worry I have about multi-agent experiments is that my above discussion is too abstract, and there are more complicated, technical or tacit reasons why these kinds of experiments can’t be made to work and give us a signal at scale. For example: schlep, or not having enough time before real deployment, or a chaotic search space orders of magnitude too big to say anything significant about. But again, I don’t yet see a way to get good signals on these considerations without trying.
Bottomline
Even taking into account these tractability considerations, I believe this avenue is promising enough that, when paired with its neglectedness and importance, it’s the highest expected-value marginal work I’m aware of.[7]
If you’re excited about this direction and interested in collaborations or mentorship, feel free to reach out!
Acknowledgements
Thanks to Lewis Hammond, Miranda Zhang, Filip Sondej, Kei Nishimura-Gasparian, Abram Demski, Tim Chan and Dylan Xu for feedback on a draft.
Thanks to Robert Mushkatblat and Thomas Kwa for related discussion.
Thanks to the Cooperative AI Foundation and CHAI for great environments where some of these ideas marinated.
- ^
By which I mean, the singularity’s unpredictability coming from a vast amount of moderately super-human agents, rather than a small amount of vastly super-human agents.
- ^
Or put another way, that the probability of decentralization is substantial enough that work on improving those worlds can be competitive (if tractable enough).
- ^
This could break in adversarial regimes, like experimenting with deceptive AIs.
- ^
Thanks to Jonathan Stray for some of these references, who has a related angle on using AIs to understand human conflict.
- ^
Of course, if I’m right, that points towards this direction becoming less neglected soon. But even then, getting in now seems like a great bet, both to ensure it happens earlier in case we don’t have much time, and to steer this subfield towards work on catastrophic risks.
- ^
This spectrum brings to mind the control agenda [LW · GW], which indeed could be understood as exploring a very narrow subspace of multi-agent interactions, while I advocate for a more sweeping exploration, motivated by different research ends.
- ^
Indeed, I think the only other avenue plausibly competing for this spot is purely conceptual research on multi-polar strategy or trajectory changes [? · GW], which is even more neglected, but I’m even less convinced is robustly good or tractable.
3 comments
Comments sorted by top scores.
comment by Jacob Pfau (jacob-pfau) · 2024-08-05T19:42:58.335Z · LW(p) · GW(p)
Metaculus is at 45% of singleton in the sense of:
This question resolves as Yes if, within five years of the first transformative AI being deployed, more than 50% of world economic output can be attributed to the single most powerful AI system. The question resolves as No otherwise... [defintion:] TAI must bring the growth rate to 20%-30% per year.
Which is in agreement with your claim that ruling out a multipolar scenario is unjustifiable given current evidence.
comment by Jonas Hallgren · 2024-08-01T19:54:42.653Z · LW(p) · GW(p)
Good stuff! Thank you for writing this post!
A thing I've been thinking about when it comes to experimental evaluation places for multi-agent systems is that it might be very useful to do to increase institutional decision making power. You get two birds in one stone here as well.
On your point of simulated versus real data I think it is good to simulate these dynamics wherever we can, yet you gotta make sure you measure what you think you're measuring. To ensure this, you often gotta get that complex situation as the backdrop.
A way to combine the two worlds might be to run it in video games or similar where you already have players, maybe through some sort of minecraft server? (Since there's RL work there already?)
I also think real world interaction in decision making sytsems makes sense from a societal shock perspective that Yuval Noah Harari talks about sometimes. We want our institutions and systems to be able to adapt and so you need the conduits for ai based decision making built.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-08-01T23:50:23.785Z · LW(p) · GW(p)
Thanks Jonas!
A way to combine the two worlds might be to run it in video games or similar where you already have players
Oh my, we have converged back on Critch's original idea for Encultured AI [LW · GW] (not anymore, now it's health-tech).