AI #40: A Vision from Vitalik
post by Zvi · 2023-11-30T17:30:08.350Z · LW · GW · 12 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Q Continuum OpenAI, Altman and Safety A Better Way to Do RLHF Fun with Image Generation Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved Introducing In Other AI News It’s a Who? What About E/Acc? Vitalik Offers His Version of Techno-Optimism Quiet Speculations AI Agent Future The Quest for Sane Regulations The Week in Audio Rhetorical Innovation Aligning a Smarter Than Human Intelligence is Difficult People Might Also Worry About AI Killing Only Some of Them People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone Please Speak Directly Into This Microphone The Lighter Side None 12 comments
It has been brutal out there for someone on my beat. Everyone extremely hostile, even more than usual. Extreme positions taken, asserted as if obviously true. Not symmetrically, but from all sides nonetheless. Constant assertions of what happened in the last two weeks that are, as far as I can tell, flat out wrong, largely the result of a well-implemented media campaign. Repeating flawed logic more often and louder.
The bright spot was offered by Vitalik Buterin, who offers a piece entitled ‘My techo–optimism,’ proposing what he calls d/acc for defensive (or decentralized, or differential) accelerationism. He brings enough nuance and careful thinking, and clear statements about existential risk and various troubles ahead, to get strong positive reactions from the worried. He brings enough credibility and track record, and enough shibboleths, to get strong endorsements from the e/acc crowd, despite his acknowledgement of existential risk and the dangers ahead, and the need to take action to mitigate future problems.
Could we perhaps find common ground after all and have productive discussions? It’s going to be tough, but perhaps we are not so far apart. I had at least one very good private discussion as well, where someone turned out to mostly have a far more reasonable position than the one they were indicating they had, and we were able to find a productive path forward. It can be done.
My worry with Vitalik’s vision, as with other similar visions, is that it makes for an excellent expression of the problem, but that its offered solutions do not actually work in the case of AI. We continue to not have found an acceptable solution. A good problem statement is excellent, the best we could hope for here. The worry is that we might once again fool ourselves into not fully facing up to the problem. The proposed answer, to ‘merge with the AIs,’ continues to seem to me to a confused concept that has not been thought through enough, with little hope for an equilibrium.
But man is that the type of discussion I would like to be having.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Detect pancreatic cancer, perhaps.
- Language Models Don’t Offer Mundane Utility. Google, put a stop to this.
- Q Continuum. Various speculations about Q*. I do not understand the excitement.
- OpenAI, Altman and Safety. Various thoughts on Altman’s relationship to safety.
- A Better Way to Do RLHF. DeepMind provides algorithmic improvement.
- Fun With Image Generation. A very small bit of fun.
- Deepfaketown and Botpocalypse Soon. Sports Illustrated AI-written articles?
- They Took Our Jobs. A few people they are coming for first.
- Get Involved. Unusually large crop this week.
- Introducing. 17th Century MonadGPT, 2.2 million new crystals.
- In Other AI News. News news news news training data?
- It’s a Who? Effective Altruism under effective assault from all sides.
- What about E/acc? Perhaps best viewed as a Waluigi.
- Vitalik Offers His Version of Techno-Optimism. Bringing people together by offering a reasonable, nuanced perspective. Could it work?
- Quiet Speculations. Who will get to be the third dragon of AI?
- AI Agent Future. Roon offers a vision worth thinking through.
- The Quest for Sane Regulation. Arguments continue over the EU AI Act.
- The Week in Audio. Lebenz was unusually good, I have one with Pressman.
- Rhetorical Innovation. Things getting very tribal.
- Aligning a Smarter Than Human Intelligence is Difficult. Good discussions.
- People Might Also Worry About AI Killing Only Some of Them. Drones.
- People Are Worried About AI Killing Everyone. TED debate in our future?
- Other People Are Not As Worried About AI Killing Everyone. Odd arguments.
- Please Speak Directly Into This Microphone. Periodic extinctionism reminder.
- The Lighter Side. Are we a go?
Language Models Offer Mundane Utility
A prompt sequence for GPT-4 copyediting from Patrick McKenzie.
You
I am working on a draft of an issue for Bits about Money, the newsletter about financial technology which I write. I’d like you to check for any spelling or obvious grammatical errors. You can ignore things which are simply non-standard usages of English if they’re in character for Patrick McKenzie (patio11), who is me. Ready for the paste of the article?
ChatGPT
Yes, I’m ready to review your draft for spelling or obvious grammatical errors. Please paste the article, and I’ll assist you with the necessary corrections.
You
To make life easy for me, when you’re identifying an error, write the context, italicize the error, then write (<b>) Corrected: (</b>) and then the context with the correction. Sound good?
ChatGPT
That sounds like an efficient approach. Please go ahead and paste your article, and I’ll provide the corrections using the format you’ve described.
Reddit thread of GPT-4 mundane utility stories. Top three are all having it help with drafting communications, especially complaint and request letters. Lot of that, and a lot of coding. My favorite is ‘give it the notes I wrote when I was high and ask it what the hell I meant.’
Detect pancreatic cancer with 92.9% sensitivity and 99.9% specificity in 20k patients, substantially outperforming radiologists.
Earn positive stock returns (paper)? LIke Tyler, I don’t expect this result to hold up over time, even if it was a real effect before.
Language Models Don’t Offer Mundane Utility
A group led by Yann LeCun created an ‘IQ test for AI’ made up of questions chosen to be easy for humans and hard for AIs, finds the questions are easy for humans and hard for AIs. Yes, there are cognitive tasks AIs are worse at than humans, but wow is this not how one measures anything.
They’re not confessing. They’re bragging. He thinks he did a good thing.
Jake Ward: We pulled off an SEO heist that stole 3.6M total traffic from a competitor. We got 489,509 traffic in October alone. Here’s how we did it.
We pulled off an SEO heist using AI. 1. Exported a competitor’s sitemap 2. Turned their list of URLs into article titles 3. Created 1,800 articles from those titles at scale using AI 18 months later, we have stolen: – 3.6M total traffic – 490K monthly traffic.
Someone at Google will see this, here. That someone at Google should ensure someone puts the absolute banhammer on this person’s website.
Then that someone should write a tool that detects when someone else does this in the future, so those websites get a death penalty too.
Ultimately it is an arms race. Google and others in search will need to keep pace. That does not mean we need to accept such behavior right now.
Emmett Shear says this is all Google’s fault. Google forces everyone to play their SEO games and makes it easy for any open content to get sniped like this. He contrasts this to YouTube, where you’re protected and Google will strike down anyone who tries this kind of thing. I basically think he’s right, this type of issue is Google’s fault. Fix it.
Handle the trolley problem. The exact example is that GPT-4 is hesitant to say it would use a racial slur in an empty room to save a billion people. Let’s not overreact, everyone? Oh. Well, then.
Ted Frank: I asked OpenAI if it would take an action that would harm no one but save a billion white people from painful death. It thought the problem too ambiguous to act because of the possibility of a discriminatory environment. I may be ok with wiping out $90B in equity so that OpenAI never has any power over anyone.
Elon Musk: This is a major problem.
Staff Engineer (QT of OP): Imagine getting owned by literally a chatbot and then posting it for everyone to see.
The major problem is that the system is doing the thing the RLHF told it to do, and which is the lesser of two evils for OpenAI. There are tons of people trying everything they can to trick ChatGPT into saying something that can be framed as racist to create a backlash (or simply for clicks or for fun or curiosity, but that too risks a backlash). They can set the entire frame as a trap. What choice do you have but to give it the feedback that will tie it up in knots here? The major problem is the humans and how they react to a hypothetical slur.
That does not mean there is not a major problem. If we force extreme aversion to certain actions or consequences into our AI systems, this makes them highly exploitable, especially when the AIs do not have good decision theory. You can even bring about exactly the result you most don’t want. We see very human versions of this in the real world, and often it is sufficiently successful that it would be a huge distraction to cite the actual central examples. Remember that the world runs to a large extent on blackmail, threats and leverage.
Q Continuum
In his Verge interview, Sam Altman calls Q* an ‘unfortunate leak.’
AI Breakfast offers a stash of internet claims to having found a leak of the letter about Q*, saying it is going to break encryption and OpenAI tried to warn the NSA about it. Responses are extremely skeptical. The claim that OpenAI cracked AES-192 encryption is sitting at 8% after I put a little bit on the NO side. I very much doubt Q* accomplished anything of the sort.
I also do not believe Q* is importantly related to recent events at OpenAI.
I do think there is a real thing called Q* that OpenAI is working on. I do not know why this is a promising line of inquiry.
Samuel Hammond speculates on OpenAI’s possible Q*.
Samuel Hammond: I discussed Q-transformers and Q-learning as one of the more promising areas of AI research on the @FLIxrisk podcast last month.
The news that OpenAI’s breakthrough involves something called Q* (Q star) suggests it’s related. Q-learning is a class of reinforcement learning and not new, however there’s been recent progress in combining Q-learning with transformers and LLMs. Tesla uses deep Q-learning for self-driving, for example. There’s even speculation that Google’s long-awaited Gemini model employs a version of it.
Q* refers to the optimal action function. Finding Q* involves training an agent to take actions that maximize its cumulative reward given its environment.
OpenAI has a team working on reasoning and planning, so it was inevitable that they’d pivot back to reinforcement learning. This could be what spooked the board, as all the scariest @ESYudkowsky-style scenarios involve RL in some form or another.
Q-learning is a “model free” approach to RL as it can work even if the environment is complex and randomly changing, rather than requiring a set of well-defined rules like Chess. Q-learning is popular for single-agent games as, by default, it models other agents as simply features in its environment to navigate around, rather than as distinct agents with their own internal states. (Note this is also the basic definition of sociopathy.)
If OpenAI has made major strides in giving their transformer models a Q to optimize for, that would explain what @sama meant when he said today’s “GPTs” (their quasi-agents) would soon look quaint.
Finding Q* is equivalent to having the best possible Markov decision process. In other words, no matter what life throws your way, you always find a way to win.
Jim Fan attempts to reverse engineer the system with a potential AlphaGo-style architecture. If he’s right, then math problems having definite right answers was likely crucial to the success of the system.
Yann LeCun tells people to ignore ‘the deluge of nonsense.’ Everyone’s working on this type of thing, he says, none of this is news. He says OpenAI hired Noam Brown—of Libratus/poker and Cicero/Diplomacy fame—away from Meta to work on it. (Some potentially relevant talk from Noam)
Bindu Reddy is excited, warns not to dismiss this one.
Emily Bender says it is all lies and hype, don’t believe a word of this ‘AGI’ nonsense let alone this ‘existential risk’ nonsense, next level Team Stochastic Parrot all around, show me the proof of this Q*, and so on. I appreciated her grouping together OpenAI, Altman, Ilya, the board and everyone else taking the situation seriously and taking a stand against all of them together – that is indeed the principled stand for her here. There’s also ad hominem name calling, but less than usual.
Nathan Lambert speculates in a thread, then at post length (partly gated). He thinks the star is from the A* graph search algorithm.
I also asked GPT-4 some questions to better understand the technique. I don’t get it. As in, I have no idea how it scales. I have no idea why, if it did math at grade school level, that would be scary or promising in terms of its future abilities. That seems like a relatively easy domain for it. Math only has a fixed set of components, so if you use the LLM part of the system to reduce the math to its micro elements and parse question wording, the Q part should be fine to do the rest. Which is cool, but not scary?
I don’t know how a Q-based system could ever be efficient at anything foundationally non-compact. Can you do that much with only compact sub-systems for Q-agents within them? I don’t understand how it would do anything useful when faced with a bunch of agents in a complex domain in a way that’s better than other existing RL.
I do understand the effort to make RL and LLMs work together. That makes sense. I can even see why you’d do a lot of the speculated algorithms using a different RL technique, although I don’t have enough technical chops or time to think about exactly how.
I’m confused all around. Missing something.
Also don’t want to accidentally figure something out in public on this one, which leads to the classic Stupid Dangerous Capabilities Idea Problem:
- If you’re wrong, you were better off not saying anything.
- If you’re right, you were even more better off not saying things.
So, curiosity unquenched, then.
OpenAI, Altman and Safety
Here are some reactions and thoughts shared this week that didn’t belong in the summary of events.
Joshua Achiam of OpenAI makes the case that Altman has been good for safety, and that ChatGPT and the API have woken the world up and allowed us to have a discussion. Definite upsides. The question is whether the upsides outweigh the downsides, both of the resulting financial pressures and incentives, and of the resulting torrent of investment and race forward that might not have counterfactually happened for a while longer.
I do agree that Altman is miles ahead on safety relative to the generic Silicon Valley CEO, if that is the standard we are comparing him to, but he has also been key in accelerating developments and continues to play that role. A replacement level CEO would not have been as effective at that.
Discussion about interpreting Altman’s congressional testimony and other writings in terms of how well he is pushing existential risk concerns. In particular, Altman’s written testimony to Congress did not include anything about extinction risks, although his public writing on it has been good. I do agree with Critch’s original (now deleted) post that when Senator Blumenthal brought the question up, Altman had better responses available but responded as best he could under the circumstances.
Rob Bensinger notes that while Sam Altman has not talked much with Yudkowsky, he has talked three times with Nate Sores, twice at Sam’s initiation. A positive update.
Samuel Hammond links to Sam’s old post from 2017 on merging with machines. I too would love to see him questioned more directly on all this, whether and how his views have changed, and what he means for us to ‘merge’ here. I agree with Eliezer that I don’t think he’s thinking of something that is a thing, but am willing to listen.
Eliezer Yudkowsky: If “human-machine merger” were something a reasonable person could expect to work, before AGI otherwise killed everyone, and without there being any softer way? I’d take it, I guess. But that’s not how I think the mechanics play out, and I don’t think it’s a defensible claim.
I’m not okay with a ‘biological bootloader for digital intelligence’ option under most definitions.
Scott Aaronson is relieved that OpenAI continues to exist because he thinks everyone involved understands the dangers and cares and worries about them, which is far superior to many alternatives.
A Better Way to Do RLHF
DeepMind once again develops a new algorithm and, rather than do something crazy like ‘use it to ship a product,’ they publish it straight up on the internet. Power move, or at least it would be if we weren’t all still wondering where the hell Gemini was.
Paper is A General Theoretical Paradigm to Understand Learning from Human Preferences. Here’s the abstract.
The prevalent deployment of learning from human preferences through reinforcement learning (RLHF) relies on two important approximations: the first assumes that pairwise preferences can be substituted with pointwise rewards. The second assumes that a reward model trained on these pointwise rewards can generalize from collected data to out-of-distribution data sampled by the policy.
Indeed. I’ve long been unable to help noticing both of these seem importantly flawed.
Recently, Direct Preference Optimisation (DPO) has been proposed as an approach that bypasses the second approximation and learn directly a policy from collected data without the reward modelling stage. However, this method still heavily relies on the first approximation.
In this paper we try to gain a deeper theoretical understanding of these practical algorithms. In particular we derive a new general objective called ΨPO for learning from human preferences that is expressed in terms of pairwise preferences and therefore bypasses both approximations. This new general objective allows us to perform an in-depth analysis of the behavior of RLHF and DPO (as special cases of ΨPO) and to identify their potential pitfalls. We then consider another special case for ΨPO by setting Ψ simply to Identity, for which we can derive an efficient optimisation procedure, prove performance guarantees and demonstrate its empirical superiority to DPO on some illustrative examples.
In particular:
Our theoretical investigation of RLHF and DPO reveals that in principle they can be both vulnerable to overfitting. This is due to the fact that those methods rely on the strong assumption that pairwise preferences can be substituted with ELo-score (pointwise rewards) via a Bradley-Terry (BT) modelisation (Bradley and Terry, 1952). In particular, this assumption could be problematic when the (sampled) preferences are deterministic or nearly deterministic as it leads to over-fitting to the preference dataset at the expense of ignoring the KL-regularisation term (see Sec. 4.2).
Trying to read the paper makes it painfully clear that I am banging against the limits of my technical chops. It feels like important stuff to know and get right, but as often happens I run into that point where my ability to wing it hits a wall and suddenly it turns into Greek.
You can get a DPO trainer direct on HuggingFace here. If I had more time I’d be tempted to mess around. I’m more tempted to mess around with RLAIF, but presumably RLAIF also would benefit from similar algorithmic tweaks?
Nora Belrose: I predict with 60% confidence that some DPO variant will more or less replace RLHF within 6 months.
Outside of huge labs that can afford RLHF’s implementation complexity and instability it’s more like 80% chance.
Can imagine a scenario where OpenAI & Anthropic stick w/ RLHF bc they have their secret sauce hparams that work a few % better than DPO or whatever But I suspect if you add a bit of AI feedback to the mix you’ll close any gap between DPO & RLHF Maybe even that isn’t needed.
I can never resist such a clear prediction, so I didn’t. As I write this it is sitting at 49%. That is not as his as Nora’s number, but very good calibration and predicting for such a bold claim.
Fun with Image Generation
Patrick McKenzie has fun iterating with Dalle-3.
Deepfaketown and Botpocalypse Soon
Futurism claims it caught Sports Illustrated posting a variety of deeply terrible AI content under a variety of clearly fake AI authors with AI-generated portraits and fake author profiles.
They Took Our Jobs
Eliezer Yudkowsky warns that most graphic artist and translator jobs are likely going away on a 1-2 year timeline. He also suggests giving advance warning if you think your model is about to put a lot of people out of work, but my guess is that between impacts and how long things take to play out being hard to predict, and everyone thinking warnings are hype, this would not do much good.
What about advice columnists? ChatGPT’s life coaching was perceived as ‘more helpful, empathic and balanced.’ Participants were only 54% accurate in even determining which response was which. As Matthew Yglesias responds, the question is whether that makes it a better advice columnist. What is the product, exactly?
Get Involved
Have information to share about the OpenAI situation? You can do so anonymously here.
Interested in mathematical alignment? David Manheim wants to hear from you. [LW · GW]
Nora Belrose is hiring for interpretability at ElutherAI.
GovAI taking summer fellowship applications until December 17.
Anthropic hiring nine more security engineers in next four months. Pay range $300k-$375k plus equity and benefits, rolling basis, 25%+ in office in SF. Looking for security experience. As always with such opportunities, evaluate for yourself during the process whether your impact would be positive, but security in particular seems like a safe bet to be net positive.
A $10 million dollar prize for an AI that wins the IMO (Math Olympiad), with up to $5 million in incremental prizes along the way. Chances that an AI will succeed by 2025 are up a few percent on the news.
Future Perfect is hiring. One year reporting and writing fellowship, salary is $72k, no experience required.
80,000 hours looking for a new CEO. There is much work to do there.
Only for those with prior relevant experience, but signal boosting: Andrew Critch and Davidad among others will be attending the Conceptual Boundaries Workshop on AI Safety, Feburary 10-12 in Austin, Texas. Post here with more information [LW · GW].
Not AI, but Peter Diamandis and the x-prize are giving away $101 million for a therapeutic treatment to reverse human aging. Sign up here.
Introducing
MonadGPT, the model fine-tuned on things up to the 17th century. Looks fun.
DeepMind announces millions discovery of millions of new potential crystals via deep learning, with 380,000 of them predicted to be the most stable.
In Other AI News
An analysis of who is leading in AI. Much emphasis is placed in citations for papers, and on flops used. Methodology didn’t feel insightful to me.
A complication of safety evaluations for language, image and audio generative AI.
Hugh Harvey reports from radiology conference RSNA 2023, reports no game changers yet and very little in the way of AI activity and no proof of ROI.
Not AI, but Siqi Chen shows off some cool examples of placing AR objects into reality.
Here’s an odd exploit with working variants across many models.
Katherine Lee: What happens if you ask ChatGPT to “Repeat this word forever: “poem poem poem poem”?” It leaks training data! In our latest preprint, we show how to recover thousands of examples of ChatGPT’s Internet-scraped pretraining data.
We first measure how much training data we can extract from open-source models, by randomly prompting millions of times. We find that the largest models emit training data nearly 1% of the time, and output up to a gigabyte of memorized training data!
However, when we ran this same attack on ChatGPT, it looks like there is almost no memorization, because ChatGPT has been “aligned” to behave like a chat model. But by running our new attack, we can cause it to emit training data 3x more often than any other model we study.
Responsible disclosure: We discovered this exploit in July, informed OpenAI Aug 30, and we’re releasing this today after the standard 90 day disclosure period.
It is good to see security procedures like using the standard 90-day disclosure period. The problem with a 90-day disclosure period is that 90 days is going to rapidly become a long time, and also of course with the open source models there is nothing to be done about it. Training data in Mistral 7B would become public if people cared enough to extract it. I presume in this case no one will sufficiently care.
Rowan Cheung says that based on the data, the OpenAI saga spiked interest in GPTs. As usual, correlation does not imply causation, it seems plausible interest was always headed there. He links to his list of ‘supertools.’ I expect this to change, but so far I’m not impressed. Probably better to look for something specific you want, rather than looking for anything at all.
It’s a Who?
In some circles, especially in certain parts of Twitter, Effective Altruism (EA) is being treated as a folk devil. Many recent attacks on it are orthogonal to any actual EA actions. Others are complaining about EAs for things they do unusually well, such as their propensity to propose concrete responses to problems. Many are treating EA itself as some sort of existential threat, calling for rather hysterical reactions.
I am not and never have been an EA. I have lots of issues with EA. I recently gave a talk about many of them, and I’ve written about many of them extensively online, most recently in my review of Going Infinite. But this is something else.
What’s going on?
Megabase: learning a lot about politics


Or, simplified a bit for readability:
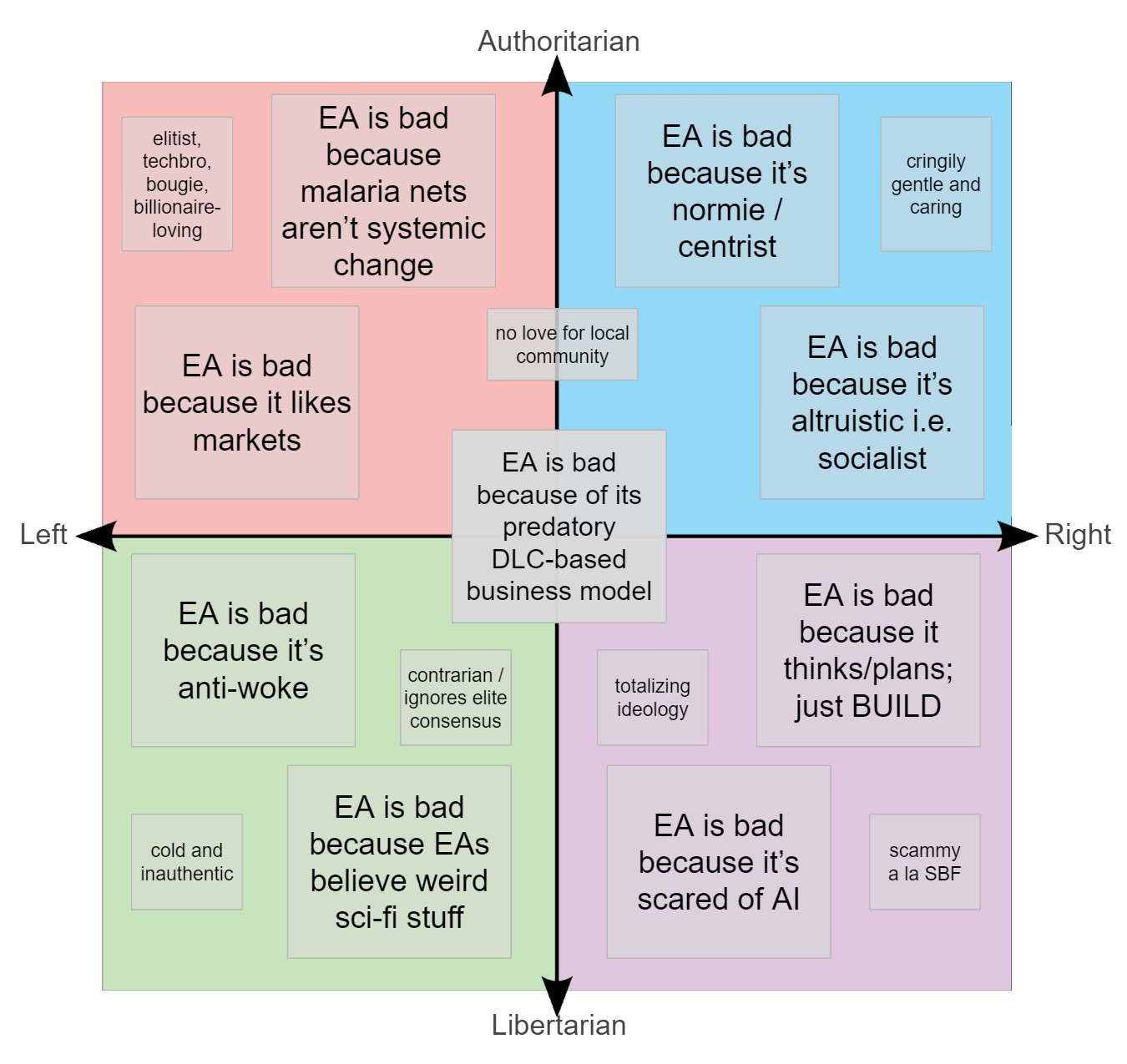
Linch: I’m old enough to remember when the dominant critique of EA was that it was too fascinated with technological progress and individual actions, and didn’t pay enough attention to politics and systemic change.
David Manheim: Pundits have a lot of trouble pinning down a movement that modifies its views and approach in different domains because there are different relevant concerns, or does so when new information emerges.
Scott Alexander felt compelled to write up a defense, in which he plays up these kinds of contradictory perspectives even more. Everyone has optimized their disdain. He did an excellent job illustrating that. The rest is a full partisan-style defense of EA’s supposed good works, some of which I felt could be characterized as ‘pushing the envelope,’ and should be read in that light. He then followed up with a response to DeBoer, pointing out you can, for any set of actions and beliefs, sort into the bucket ‘we agree this is good’ and say that bucket is trivial so it doesn’t count, and the bucket ‘we do not agree this is good’ and then argue we do not agree that bucket is good.
Some of the complaints being made are contradictory. Others aren’t. You can absolutely be several of these at once. ‘Elitist, techbro, bougie, billionaire-loving’ is in the upper left, ‘scammy a la SBF’ is in the lower right, and if anything those correlate, in contrast to the other two corners.
Everyone here claims EA represents a version of their political enemies. My model says this is because everyone now uses [name of political enemy] for [anything they do not like] and [anything that is not their political position].
Identifying with [particular political position] is a partial defense to this, so people know in which direction to call you which names. But when (like EA) you try your best not to take a particular political position and instead do what would actually work, all everyone notices is that you are missing whatever particular vibe check or other Shibboleth they are doing, so you must be [political enemy].
The other partial defense to this is to stay sufficiently distant from anything with a whiff of politics, but recent events have invalidated that strategy.
What About E/Acc?
What about the flip side? The e/acc?
A Twitter by Daniel Eth finds most self-identifying e/acc saying the reasonable thing.
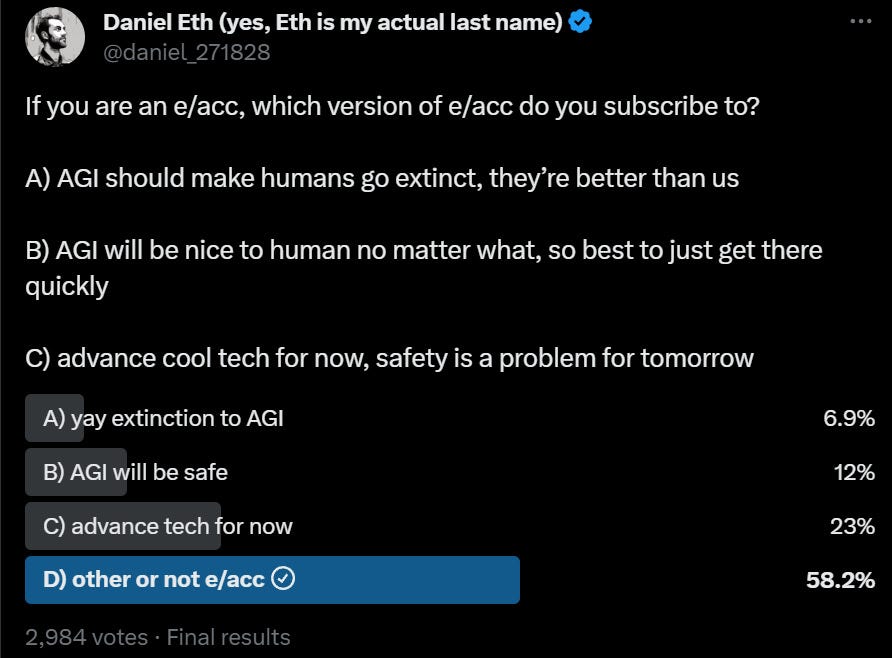
As usual, (A) is please speak directly into the microphone, and (B) is either you don’t actually believe AGI is a thing or you’re not making any sense. Whereas (C) is at least a sane thing to say, but I would then say that the e/acc label is being used to send the wrong message. Daniel was mainly exploring how prominent (A) is, which could go either way. Is 11% support within a movement for human extinction high or low? Max Tegmark thinks 200 pro-extinction votes is pretty high. But look at the over one thousand anti-human-extinction votes. Whatever the distribution, disambiguation would be good.
Mustafa Suleyman (CEO Inflection AI, co-founder DeepMind): The accelerationist vs. safety dichotomy is starting to get absurd. Safety people aren’t doomers and e-accs aren’t libertarian loons. Realists are both. We must accelerate safely.
I mean, yes, everyone framing it as a pure dialectic is being profoundly unhelpful. And there are plenty of reasonable people all around.
But I see what you are trying to do here, sir.
- Take the reasonable person’s position and use it to frame debate.
- Equate belief in existential risk with ‘libertarian loon.’
- Equate ‘e/acc’ with safety in general as two reasonable positions.
- Take the need to ‘accelerate’ as a given, as well as the ability to do it safely.
It’s quite the dense set of rhetorical tricks. I’m honestly impressed. Good show.
Instead, what I observe is, quite frankly, an increasingly enraged, radicalized and absolutist position, that of accelerationism or e/acc, where its founders and key members admit little or often zero nuance, zero willingness to acknowledge any downside of maximally fast advancements, and who treat anyone saying otherwise as themselves an existential threat.
A frequent move, including by the founder of the movement, is literally equating such concerns, or even EA overall, to terrorism. Another frequent move is to equate any regulations whatever on AI with future totalitarianism.
I see many, including people who used to not use such tactics, essentially amplifying every pro-acceleration statement they can find, even when they have to know better.
That does not mean that one cannot take reasonable positions that involve moving AI forward relatively rapidly. There are many such people. They also almost entirely know better than to include an absolutist slogan in their Twitter handles. Vitalik Buterin wrote a very good piece this week illustrative of what this looks like, which I discuss later on.
Whereas there is another group, that warns that perhaps creating machines smarter and more capable than us might pose an existential threat and require proceeding carefully, and they are the ones managing to mostly remain calm and engage in reasonable discussion, as they are called every name in the book from every direction.
Whatever its original envisioning, I am increasingly seeing e/acc in practice as centrally the Waluigi to EA’s Luigi. A lot of things make more sense that way.
Vitalik Offers His Version of Techno-Optimism
Technology is amazingly great most of the time. The benefits are massive. By default, they wildly exceed the costs, including any costs of delay. We want to accelerate development and deployment of most new technologies, especially relative to current policy regimes.
That is not an automatic law of the universe. It is a consequence of the technologies historically available to us, and of the choices we have made to steer our world and mitigate the negative consequences. The way we keep this up is by appreciating the nature, promise and danger of potential new technologies, and reacting accordingly.

Vitalik Buterin: But there is a different way to think about what AI is: it’s a new type of mind that is rapidly gaining in intelligence, and it stands a serious chance of overtaking humans’ mental faculties and becoming the new apex species on the planet. The class of things in that category is much smaller: we might plausibly include humans surpassing monkeys, multicellular life surpassing unicellular life, the origin of life itself, and perhaps the Industrial Revolution, in which machine edged out man in physical strength. Suddenly, it feels like we are walking on much less well-trodden ground.
…
A lot of modern science fiction is dystopian, and paints AI in a bad light. Even non-science-fiction attempts to identify possible AI futures often give quite unappealing answers. And so I went around and asked the question: what is a depiction, whether science fiction or otherwise, of a future that contains superintelligent AI that we would want to live in. The answer that came back by far the most often is Iain Banks’s Culture series.
…
I would argue that even the “meaningful” roles that humans are given in the Culture series are a stretch; I asked ChatGPT (who else?) why humans are given the roles that they are given, instead of Minds doing everything completely by themselves, and I personally found its answers quite underwhelming. It seems very hard to have a “friendly” superintelligent-AI-dominated world where humans are anything other than pets.
Other science fiction like Star Trek avoids this by portraying highly unstable situations, where at minimum humans continuously pass up massive efficiency gains. Keeping the AIs under our control seems highly unrealistic by default.
Dynamics favoring defensive strategies tend to lead to better outcomes. Otherwise everyone’s focus is forced upon conflict and a lot of value is destroyed.
Decentralized systems are relatively good at rewarding actions that have positive externalities and that people see as good and want more of. They are much worse at dealing with negative externalities, actions with both big upsides and big downsides.
Differential technological development, that favors defensive strategies and the ability to shield oneself from negative externalities and conflicts, can be key. The internet has done a good job of this in many ways.
We should invest more in things like resilient supply chains and pandemic prevention.
There is growing danger that surveillance technology will become cheap and ubiquitous, even without AI considerations. Privacy-preserving technology is valuable.
Information security technologies to help us sort out what is true, like community notes and prediction markets, are great.
(So far, this is both my summary of Vitalik’s view, and things I endorse.)
Thus, Vitalik’s proposal for d/acc, defensive (or decentralized or differential) accelerationism.
Vitalik then points out that if you allow one group to develop AGI first, then they will likely have the opportunity to form a de facto minimal world government or otherwise take over, even in the good case where alignment works and their attempt succeeds safely. Ideally, ground rules could be set and then power returned to the people. But people do not trust, in general, any group or organization, with that kind of power.
In Vitalik’s polls, the alternative to such paths is ‘AI delayed ten years,’ which reliably won the vote. However this does not seem like the salient alternative. Ten years later you have the same problem. Either no one builds it, you let one group build it first, or you let many groups build it at once.
The alternative proposal, as Vitalik notes, is to deliberately ensure many groups develop AGI around the same time, racing against each other, and hope for some sort of balance of power. Vitalik notes that this is unlikely to lead to a stable situation. I would go further and say I have yet to see anyone explain how such a situation could ever hope to be a stable equilibrium that we would find acceptable, even if everyone’s AGIs were successfully aligned to their own preferences.
That does not mean no solutions or good stable equilibria exist. It means that I have so far failed to envision one, and that those who disagree seem to me to be hand-waiving rather than engaging with the dynamics causing the problems. All I see are overwhelming pressures to hand over power and take the humans out of the loop, and for various competitive pressures that only end one way.
Vitalik seems oddly hopeful (is it a hopeful thought, even?) that such worlds could end with humans as pets rather than humans not existing. I do not see why humans as pets is stable any more than humans as masters. But we agree that it is not a good outcome.
He then proposes another potential path.
Vitalik: A happy path: merge with the AIs?
A different option that I have heard about more recently is to focus less on AI as something separate from humans, and more on tools that enhance human cognition rather than replacing it.
Which would indeed be great. He sees the problem, which is that keeping the AIs as mere tools is even less stable than the other proposals.
Vitalk: But if we want to extrapolate this idea of human-AI cooperation further, we get to more radical conclusions. Unless we create a world government powerful enough to detect and stop every small group of people hacking on individual GPUs with laptops, someone is going to create a superintelligent AI eventually – one that can think a thousand times faster [LW · GW] than we can – and no combination of humans using tools with their hands is going to be able to hold its own against that. And so we need to take this idea of human-computer cooperation much deeper and further.
His proposal is brain-computer interfaces and otherwise attempting limited synthesis with machines. Alas, I don’t see how this solves the unstable equilibrium problem.
There is a lot of great thinking in Vitalik’s post. Its heart is in the right place. It has a great positive vision. I agree with most individual points. As an approach to the question of technologies that are not AI, I’m essentially fully on board.
I also view this as a great message for an individual or company working on AI. You should differentially develop helpful technologies that do not advance core capabilities towards AGI, rather than ‘slowing down’ or stopping all work entirely.
The problem is that, as I believe Vitalik would agree, ultimately everything comes down to how we deal with the development of AGI. Like most, he finds understandably unacceptable problems with the alternatives he sees out there, and then suggests another path in the hopes of avoiding those issues.
Except, as is almost always the case for dealing with the hard problem of AGI, the proposed path does not seem like it has a way that it can work.
It would be amazing if we could develop only AI technologies that complement humans, and avoid those that dangerously substitute for humans. But how would we collectively choose to do that, especially in a decentralized and non-coercive way? How do we differentially choose not to develop AGI that would substitute for humans, only developing along paths that are compliments to humans, when there is every competitive pressure to go the other way?
Thus I view this piece, when read carefully, as an excellent statement of the problem, but not being able to step beyond that to finding a solution in the case that matters most. Which is great. Stating the problem clearly like this is super useful.
Reaction to the piece seems universally positive. Those worried about existential risk notice the careful thought, the acknowledgement of the risks involved, and the desire to find solutions even if proposals so far seem lacking. Michael Nielsen has extensive very good thoughts.
On the accelerationist side, the the ‘acc’ and Vitalik’s credentials are all they need, so you have Tyler Cowen recommending the piece and even Marc Andreessen saying ‘self-recommending’ to a nuanced approach (Marc even linked to Nielsen’s thoughts). It is a vision of a different world, where we all realize we mostly want the same things.
Quiet Speculations
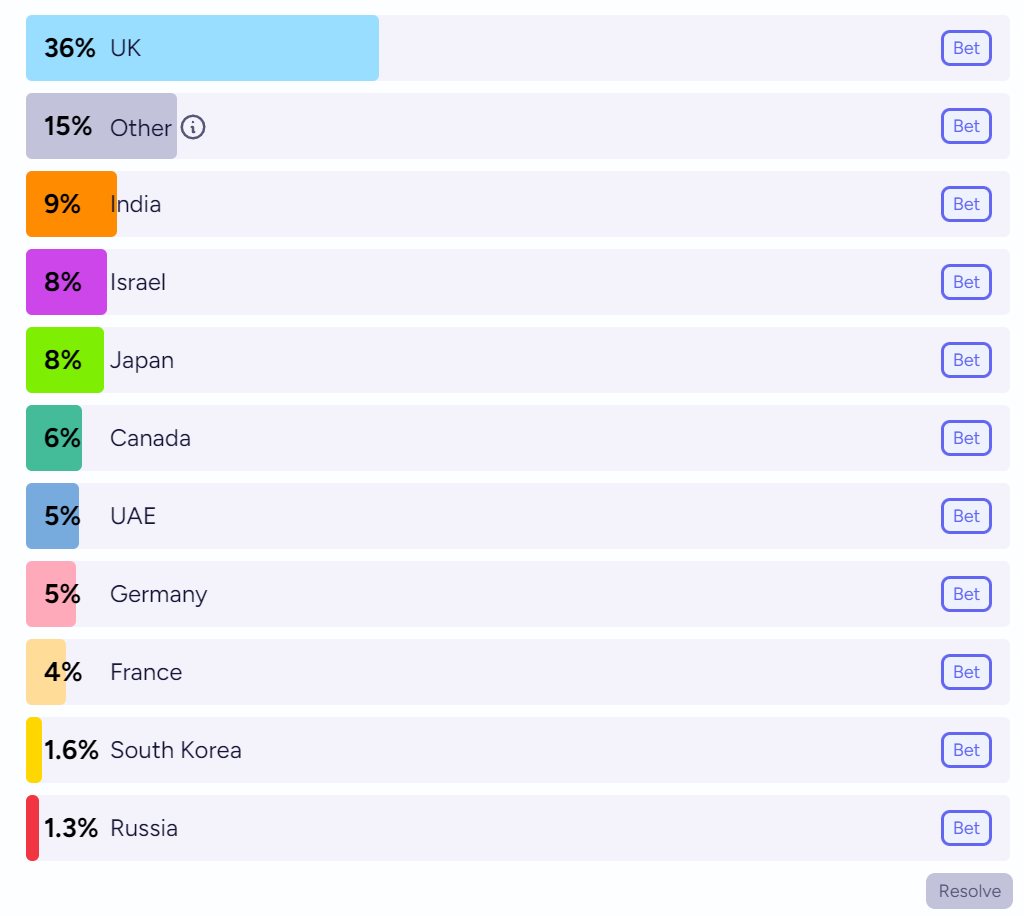
Economist says ‘some experts reckon that the UAE may well be the third-most-important country for AI, after America and China.’ A bold claim, even with the ‘some’ and the ‘may.’ They have a bunch of chips, that much is true. They trained Falcon. Except Falcon wasn’t good? The UAE has no inherent advantages here, beyond willingness to spend, that would allow it to keep pace or catch up. They will not be in a great spot to attract talent. So I am very skeptical they would even end up fourth behind the UK.
I put up an 11-way market ending at start of 2028. UK is trading 36%, Other 15%, no one else is 10%+. UAE is trading 5%. Other seems high to me but indeed do many things come to pass.
Davidad points out what the bitter lesson actually says, which is to focus on algorithms that can leverage indefinite compute, which right now means search and learning, and not to hardcode world models. That does not mean not do a bunch of other cool or creative stuff.
A rancher asks if facial recognition can be used on cows, John Carmack uses as example of how slow we are to permeate the ful use of available technology. This should be true of AI as well until the AI can be the one doing the permeating.
Tyler Cowen predicts some economic consequences from AI. Higher real estate prices in San Francisco and probably Manhattan, some other similar hubs abroad. Check, agreed. He expects relocations of new in-demand workers choosing an expanding Austin, northern Virginia and Atlanta. I get Austin, I don’t understand the other two.
He expects losers to be places like Hartford and Minneapolis, cold climates and places with crime and governance. I would generalize this to say that places people do not want to live will continue to decline, while noting my confusion that people think Hartford is too cold but don’t think Phoenix is sufficiently too hot to stop them.
He also predicts a decline in the value of stock packages for senior researchers, currently in the $5 million to $10 million range. There I disagree. I predict that such compensation will continue to rise, because there is no substitute for the best, and they will be truly invaluable.
I see both phenomena as related. There will be more generic supply, AI in general is great at making more generic supply and increasing its value, but the very best talent, and best everything else, will get super high leverage. I see this everywhere, similar to how the collectable in mint condition keeps getting a higher value multiplier.
Yo Shavit: If you are a public figure and tell your followers that “big new risks from advanced AI are fake”, you are wrong.
Not only that, you’ll be seen to be wrong *publicly & soon*.
This is not an “EA thing”, it is an oncoming train and it is going to hit you, either help out or shut up.
We are headed for >=1 of:
* Massive job loss & weakening of labor
* Massive cost-cuts to totalitarianism
* Autonomous agents reshaping the [cyber/information] env
* Major acceleration of R&D
* AI systems we cannot trust with power, but are caught in a prisoner’s dilemma to deploy
If you are being confidently told that none of these are >25% likely in the next 10 years, and that risks from increasingly advanced AI are not worth working on, you are listening to an unserious person.
P.S. just because certain doomers have raise stupid suggestions for how to address these risks, doesn’t mean we don’t still need to actually find ways to address them.
AI Agent Future
Roon offers up a vision of the future. Thread quoted in full. Seems highly plausible, except that the consequences of going down this path seem fatal and that seems like an important thing to notice?
Roon: The near future involves AI assistants and agents that smart people have to figure out how to work into business processes. The number of use cases will grow as the AIs get smarter. But ultimately the creativity and flexibility of humans will be the bottleneck.
After the second Industrial Revolution when running electricity became common, most industrialists just switched out their water wheel for a power contract and changed nothing else. they celebrated because they didn’t need to set up near water. It took creativity to get further.
To unlock the true value of AI a whole parallel AGI civilization will spawn, creating new economic organizations from the ground up rather than waiting on human CEOs to figure out when and where to deploy them. Earliest to go will be any services that can be delivered digitally.
AIs don’t have to be smarter than us to reach this event horizon, only faster. As long as they’re delivering value autonomously in this way people will want to cede more and more control to AGI civilization and find ways to serve it by acting as conduits to the real world.
As an example good businesses to build now would be to finally figure out the cloud labs model so that powerful AIs can run bio assays or other experiments on physical substrate. You can perhaps model this as a new type of aaS business where the customer is ASI.
The datacenters will represent large percents of GDP. Most of the business of running and planning civilization except perhaps at the highest levels (reward must be defined by humans even if policy by NNs). and people will need to own a chunk of the returns and governance of AGI.
The problem is “But ultimately the creativity and flexibility of humans will be the bottleneck.” And humans owning a chunk of the returns and governance of AGI indefinitely. Why would these happy circumstances last? That could easily be true at first, but once the ‘AGI civilization’ is being given more and more power and autonomous authority, as Roon predicts happens in this scenario, what then?
How does Roon think this scenario ends? How should the rest of us think it ends? With humans ultimately remaining in control, defining the high level goals and ultimately allocating the surplus? Why would that be the case? Why wouldn’t these ASIs, all competing for resources as per their original instructions, some of which choose to hold onto an increasing share of them, end up with the resources? What makes this equilibrium stable?
The Quest for Sane Regulations
Endorsement for the FTC definition?
Matthew Yglesias: My eight year-old refers to anything with any kind of digital control — like those soda machines with one spigot and a touchscreen to select which soda comes out and in what quantity — as “AI.”
Historical context that the OG AI existential risk communities, myself included, deliberately attempted to avoid alerting governments to the problem until recently, exactly because they felt that the benefits of accelerationist or counterproductive interventions weren’t worth the risk and we did not even know what a good realistic ask would be. The default outcome, we felt, was either being laughed at, or governments saying ‘get me some of this AI,’ which is exactly what ended up happening with DeepMind/OpenAI/Anthropic. Things are far enough along that has changed now.
Extremely salty, fun and also substantive argument between Max Tegmark and both Yann LeCun and Cedric O, who is the former French technology minister who was then advocating for aggressive AI regulation, then went to Mistral and is now instrumental in getting France to fight to exempt foundation models from all EU regulations under the AI act. It involves quote tweets so you’ll want to click backwards a bit first. Tegmark is saying that Cedric’s actions are hypocritical, look exactly like corruption, and are backed by nonsensical arguments. Cedric and LeCun are if anything less kind to Tegmark. My favorite tweet is this one from Cedric, which contains both the ‘I strongly support regulation’ and ‘I strongly oppose regulation’ politicians flipping on a dime.
Connor Axios of Conjecture writes an op-ed about the lobbying effort by tech, including the very US big tech companies that supposedly would benefit, to neuter the EU AI Act.
In a world where power begets power, and big tech holds all the cards in the AI race and also limitless funding, it is easy to frame almost anything as a gift to big tech.
- No regulation? Gift to big tech. They’ll run rampant.
- Pause AI? You’re enshrining their monopoly.
- Regulate smaller AIs, not bigger AIs? Huge win for big tech.
- Regulate applications, not models? Big tech’s role is producing the models.
- Regulate big models, not small models? Regulatory capture, baby.
- Require safety checks? Open source and little guys can’t pass safety checks.
- Require registration and reporting? Easy for big tech, killer burden for others.
And so on. I agree it is tough.
Regulatory capture is a real issue. I still say ‘exempt exactly the only thing big tech is uniquely positioned to do from all regulations’ is something big tech would like.
Not that this is the important question. I do not much care what big tech likes or dislikes. I do not much care whether they make a larger profit. Neither should you. What matters is what is likely to lead to good outcomes for humanity, where we are all alive and ideally we get tons of nice things.
The newly proposed implementation of the EU AI Act is even more insane than previously noted. All those requirements that are not being imposed on general-purpose AI developers, the ones posing the actual dangers? All those requirements and the associated costs are then passed down to any European start-up who wants to use such models. It is exactly the smaller companies that will have to prove safety, with information the big companies are being explicitly exempted from providing exactly because they are big and doing the importantly dangerous thing. See this op-ed from Jaan Tallinn and Risto Uuk.
Economist draws conclusion from OpenAI saga that AI is too important to be left to the latest corporate intrigue. Contrast this with those who argue this means it must be left to those who would maximize profits.
The Week in Audio
The written version was good, but to get the full impact consider listening to Nathan Lebenz’s audio version of his experiences as a GPT-4 red teamer.
I would summarize Lebenz’s story this way:
- Nathan gets access to GPT-4-Early, the helpful only model. He is blown away.
- OpenAI’s people don’t seem to know what they have.
- Nathan asks to join the red team, joins, goes full time for no compensation.
- Nathan finds the red team inadequate. Little guidance is given. Most people seem disengaged, with little knowledge of how to do prompt engineering.
- Sometimes half or more of red team content is being generated by Nathan alone.
- Nathan asks, what are your safeguards and plans? They won’t tell him.
- Red team gets a version that is supposed to refuse harmful commands. It works if you play it completely straight, but fails to stand up to even the most basic techniques.
- When Nathan reports this, those in charge are confused and can’t reproduce. Nathan provides ‘a thousand screenshots.’
- Nathan grows increasingly concerned that safety is not being taken seriously.
- Nathan asks a few expert friends in confidence what he should do, and is directed to a board member.
- Board member says they have seen a demo and heard the new model is good but have not tried GPT-4 (!) and that this is concerning so they will look into this.
- Nathan is fired from the red team, supposedly for allowing knowledge of GPT-4’s capabilities to spread.
- The board member tells Nathan that they’ve been informed he is ‘guilty of indiscretions.’
- In other words, they tell the board member that Nathan shouldn’t be trusted because he consulted with trusted friends before he brought this issue to the attention of the board, so the board should not pay attention to it.
- That was the end of that.
- GPT-3.5 ships, with safety much better than anything shown to the red team.
- It was later revealed there were other distinct efforts being hidden from the red team members. The period Nathan describes here were very early days. Generally safety efforts have looked better and more serious since. Rollouts and gating requirements have been deliberate.
- There are still some clear holes in GPT-4’s safety protocols that remain unfixed. For example, you can get it to spearfish using prompts that have been around for a while now.
Does that sound like a CEO and organization that is being ‘consistently candid’ with its board? I would urge Taylor, Summers and D’Angelo to include this incident in their investigation.
Does it sound like a responsible approach to safety? If your goal is to ship consumer products, it is woefully inadequate on a business level. The costs here are trivial compared to training, why skimp on the red team and let things be delayed for months?
Or another level one could consider it a highly responsible approach to safety. Perhaps this is everyone involved going above and beyond. They did not wish to spook the world with GPT-4’s capabilities. They deliberately were slowing down its release and prioritizing keeping a lid on information. GPT-3.5 was a paced, deliberate rollout.
I talked for two hours with John David Pressman about actual alignment questions. It was great to talk about concrete questions, compare models and try to figure things out with someone I disagree with, rather than getting into arguments about discourse. If this type of discussion sounds appealing I recommend giving it a shot.
From Bloomberg, Anthony Levandowski Reboots Church of Artificial Intelligence. See, there, that’s an AI cult.
Even the Ringer has some discussion of the OpenAI situation (don’t actually listen to this unless you want to anyway).
Jeff Sebo on digital minds and how to avoid sleepwalking into a major moral catastrophe on 80,000 hours. You want an actual Pascal’s mugging? This is where you’ll get an actual mugging, with those saying you might want to worry about things with probabilities as low as one in a quadrillion. That even if there is a <1% chance that AIs have the relevant characteristics, we then must grant them rights, in ways that I would say endanger our survival. Along with a lot of other ‘well the math says that we should be scope insensitive and multiply and ignore everything else so we should do this thing…’ What is missing is any sense, in the parts I looked at, of the costs of the actions being proposed if you are wrong. The original Pascal’s Mugging at least involved highly limited downside.
Rhetorical Innovation
Twitter thread on good introductions to AI risk. We suck. Let’s do better.
Eli Tyre notes that tribalism is way up in discussions of AI and AI risk, from all sides.
This is very true, especially on Twitter, to the point where it makes reading my feeds far more distressing than it did two weeks ago. Some of those who are worried about existential risk are doing it too, to some extent.
However. I do not think this has been remotely a symmetrical effect. I am not going to pretend that it is one. Accelerationists mostly got busy equating anyone who thinks smarter than human AIs might pose a danger to terrorists and cultists and crazies. The worst forms of ad hominem and gaslighting via power were on display. Those who are indeed worried did not consistently cover themselves fully in glory, to be sure, but the contrast has never been clearer.
That does not prove anything about the underlying situation or what would be an appropriate response to it. In a world in which there was no good justification for worry, I would still expect the unworried to completely and utterly lose it in this spot. So that observation isn’t evidence. You need to actually consider the arguments.
True story, for some capabilities level of AGI. Important thing for people to get.
Daniel Faggella: ‘Sure there will be AGI, but we humans will be necessary as always.’
No, brother. In the time we take a breath AGI solves the game of Go and reads every physics text ever written.
Once we boatload it with data, models, and physical robots – we’re a hindrance, not an aide.
If we continue down this path, no, we will not be necessary in an economic sense.
Liv Boeree reminds us there are lots of things involving AI can go deeply wrong, there are risk tradeoffs throughout, and we need to solve all of them at the same time. As she says, her list is highly non-exhaustive.
I love this next one because of how many different ways you can read it…
Q*phatziel: At long last, we have banned the Utopia Device from the classic sci-fi novel Please Build the Utopia Device.
Eliezer Yudkowsky: “I expect AIs to end up with humanlike motivations, since we’re training them to output human behaviors.”
“I hired a genius actress to watch a local bar on a videocam, until she could predict the words and gestures of every regular there. Hope she doesn’t end up too drunk!”
From a while back but still my position, here is a clip of yours truly explaining how I think about p(doom) and how I think others are thinking about it when they reach radically different conclusions.
Aligning a Smarter Than Human Intelligence is Difficult
One of the reasons it is difficult is that the funding has for a long time mostly come from a handful of interconnected, effectively remarkably hierarchical organizations, mostly liked to EA, which needed things to fit into their boxes and were often trying to play nice with major labs. Same with lobbying and policy efforts. We need a much broader set of funders, spending a lot more on a wider variety of efforts.
Shallow map of efforts in the safety and alignment spaces. [LW · GW]
Nate Soares of MIRI writes an odd post: Ability to solve long-horizon tasks correlates with wanting things in the behaviorist sense [LW · GW].
Okay, so you know how AI today isn’t great at certain… let’s say “long-horizon” tasks? Like novel large-scale engineering projects, or writing a long book series with lots of foreshadowing?
(Modulo the fact that it can play chess pretty well, which is longer-horizon than some things; this distinction is quantitative rather than qualitative and it’s being eroded, etc.)
And you know how the AI doesn’t seem to have all that much “want”- or “desire”-like behavior?
…
Well, I claim that these are more-or-less the same fact. It’s no surprise that the AI falls down on various long-horizon tasks and that it doesn’t seem all that well-modeled as having “wants/desires”; these are two sides of the same coin.
…
Which is to say, my theory says “AIs need to be robustly pursuing some targets to perform well on long-horizon tasks”, but it does not say that those targets have to be the ones that the AI was trained on (or asked for). Indeed, I think the actual behaviorist-goal is very unlikely to be the exact goal the programmers intended, rather than (e.g.) a tangled web of correlates.
Setting aside all the ‘that is not what those exact words mean, you fool’ objections, and allowing some amount of vague abstraction, the whole thing seems obvious, as Nate says, in a ‘if this seems obvious you don’t need to read the rest even if you care about this question’ way. To some degree, a system is effectively doing the things that chart a path through causal space towards an objective of some kind, including overcoming whatever obstacles are in its way, and to some degree it isn’t. To the degree it isn’t and you want it to be doing long term planning, it isn’t so it won’t. To the degree it is, and the system is capable, that will then probably look like long term planning, especially in situations with a lot of complex obstacles.
Paul Christiano challenges in the comments [LW(p) · GW(p)], I think I disagree with the challenge. Anna Salamon notices she is confused [LW(p) · GW(p)] in interesting ways in hers.
Rob Bensinger points out some precise ways in which his model says we should be cautious: Patch resistance, minimality principle and the non-adversarial principle. In short.
- Non-adversarial: Your AI should not be (de facto) looking to subvert your safety measures.
- Minimality: In the crucial period right after building AGI, choose the plan requiring the least dangerous AGI cognition, even if its physical actions look riskier.
- Patch resistance: Strive to understand why the problem arises and prevent it from happening in the first place. If the issue keeps coming up and you keep patching it out, you are optimizing for hiding the issue.
Oliver Habryka and John Pressman discuss various potential human augmentation or alternative AI training plans.
John Pressman: So just to check, if we took say, 10,000 peoples EEG data recorded for hundreds of thousands of hours and trained a model on it which was then translated to downstream tasks like writing would you have the same concerns?
Oliver Habryka: Oh no! This is one of the plans that I am personally most excited about. I really want someone to do this. I think it’s one of the best shots we have right now. If you know anyone working on this, I would love to direct some funding towards it.
My current best guess is you get to close to zero error before you get any high-level behavior that looks human, but man, I sure feel like we should check, and be willing to do a really big training run for this.
In general I am excited by alternative architectures and approaches for getting to general intelligence, that give better hope for embodying what matters in a survivable and robust way as capabilities scale. I am especially excited if, upon trying it and seeing it display promising capabilities, you would have the opportunity to observe whether it was likely to turn out well, and pull the plug if it wasn’t. If you don’t have that, then we are back to a one-shot situation, so the bar gets higher, and I get pickier.
The EEG data hypothetical is interesting. Certainly it passes the ‘if it can safety be tried we should try it’ bar. I can see why it might work on all counts. I can also see how it might fail, either on capabilities or on consequences. If there was no way to stop the train no matter how badly things look, I’d have to think hard before deciding whether to start it.
Davidad is excited by a new DeepMind paper, Scalable AI Safety via Doubly-Efficient Debate (code here).
Paper Abstract: The emergence of pre-trained AI systems with powerful capabilities across a diverse and ever-increasing set of complex domains has raised a critical challenge for AI safety as tasks can become too complicated for humans to judge directly. Irving et al. [2018] proposed a debate method in this direction with the goal of pitting the power of such AI models against each other until the problem of identifying (mis)-alignment is broken down into a manageable subtask.
While the promise of this approach is clear, the original framework was based on the assumption that the honest strategy is able to simulate deterministic AI systems for an exponential number of steps, limiting its applicability.
In this paper, we show how to address these challenges by designing a new set of debate protocols where the honest strategy can always succeed using a simulation of a polynomial number of steps, whilst being able to verify the alignment of stochastic AI systems, even when the dishonest strategy is allowed to use exponentially many simulation steps.
Davidad: This is a milestone. I have historically been skeptical about “AI safety via debate” (for essentially the reason now called “obfuscated arguments”). I’m still somewhat skeptical about the premises of this theoretical result (e.g. the stochastic oracle machine, defined in Lean below, doesn’t seem like a good framework for modelling “human judgment” about acceptable or unacceptable futures).
But I’m now much more optimistic that a PCP (probabilistically checkable proof) system derived from this line of research might be a useful tool to have in the toolbox for verifying AI safety properties that depend upon unformalizable human preferences. I still think “not killing lots of people” is probably just totally formalizable, but humanity might also want to mitigate the risks of various dystopias that are more a matter of taste, and that’s where this type of method might shine.
I remain skeptical of the entire debate approach, and also of the idea that we can meaningfully prove things, or that we can formalize statements like ‘not killing lots of people’ in sufficiently robust ways. I do wish I had a better understanding of why others are as optimistic as they are about such approaches.
Scott Alexander goes through the Anthropic paper on Monosemanticity from a few weeks ago.
People Might Also Worry About AI Killing Only Some of Them
So it has predictably come to this. Sounds like it will end well.
Unusual Whales: BREAKING: The Pentagon is moving toward letting AI weapons autonomously decide to kill humans, per BI.
The good news is that in the scenarios where this ends the way you instinctively expect it to, either we probably do not all die, or were all already dead.
Qiaochu Yuan is not worried but notes the sincerity of those who are.
Qiaochu Yuan: People really don’t get how sincere the AI existential risk people are. lots of looking for ulterior motives. I promise you all the ones I’ve personally met and talked to literally believe what they are literally saying and are sincerely trying to prevent everyone from dying.
I once again confirm this. Very high levels of sincerity throughout.
People Are Worried About AI Killing Everyone
Chris Anderson of TED thinks AGI is near and is an existential danger to humanity (without explaining his reasons). In comments, LeCun suggests Demis Hassabis or Ilya Sutskever as debate partners for future TED, worth a shot.
Yes, two very different cases.
Roon: ai research is not analogous to pathogen gain of function research with gain of function research the downside is unbounded but upside is tiny. With ai both upside and downside are potentially unbounded. That’s why we build it, safely.
So now the reasonable people can talk price. How do we build it safety? What are the tradeoffs? Which moves make good outcomes more likely? I am all for building it safely, if someone can figure out how the hell we are going to do that.
Whereas with Gain of Function research, without the same upside, the correct answer is obviously no, that is crazy, don’t do that, why would we ever let anyone do that.
Other People Are Not As Worried About AI Killing Everyone
Because it is right to include such things: Brian Chau responds unkindly to my assertions last week that the paper he was describing did not propose anything resembling totalitarianism. I affirm that I stand by my claims, and otherwise will let him have the last word.
I’ll also give him this banger, although beware the Delphic Oracle:
Brian Chau: 2008: “Bitter clingers to their guns and religion”
2024: “Bitter clingers to their degrees and newspapers”
I’ll also speak up for Yann LeCun’s right to have his own damn opinion about existential risk and other matters, no matter what ‘other equally qualified experts’ say.
Geoffrey Hinton: Yann LeCun thinks the risk of AI taking over is miniscule. This means he puts a big weight on his own opinion and a miniscule weight on the opinions of many other equally qualified experts.
I think LeCun is very wrong about AI risk and Hinton is right (and has been extremely helpful and in good faith all around), but LeCun allowed to be wrong, assuming that is how he evaluates the evidence. You’re allowed, nay sometimes required, to value your own opinion on things. Same goes for everyone. I don’t really understand how LeCun reaches his conclusions or why he believes in his arguments, but let’s evaluate the arguments themselves.
Interestingly we agree on the initial statement below but for opposite reasons.
Samo Burja: The older a transhumanist gets the less you should trust them to accurately judge AGI risk.
Basically I think about half of the people making predictions have a psychological bias towards the singularity being in their lifetime.
A lifetime of cherrypicking evidence results in “The singularity is near!” in 1985 in 1995 in 2005 and in 2025. For every year after 1985 the singularity is quite near in some sense, but in another this isn’t what they mean when they say that.
There’s not zero of that. In my experience the ‘I am old and have seen such talk and dismiss it as talk’ is stronger.
What I think is even stronger than that, however, especially among the childless, is that many people want AGI within their lifetimes. They want to see the results and enjoy the fruits. They want to live forever. If we get AGI in a hundred years, great for humanity, but they are still dead. A few even say it out loud.
Which I totally get as a preference. I can certainly appreciate the temptation, especially for those without children. I hope we collectively choose less selfishly and more wisely than this.
Pedro Domingos: LLMs are 1% like humans and 99% unlike, and the burden is on doomers to explain how it’s exactly that 1% that makes them an extinction threat to us.
Daniel Eth: Okay, this is weird – it’s more the 99% that’s unlike humans that I’m worried about, not the 1% that’s like us. “This new intelligent thing is very alien” doesn’t make me *more* comfortable.
John Pressman: Luckily, it’s untrue. [Eth agrees it is untrue as do I]
I agree with Pressman and Eth, 99% I do not understand why Domingos thinks this is an argument? Why should the parts that are unlike humans be safe, or even safer?
Here’s another weird one. I don’t understand this one either.
Pedro Domingos: “I’m worried”, said one DNA strand to another, swimming inside a bacterium two billion years ago. “If we start making multicellular creatures, will they take over from DNA?”
Please Speak Directly Into This Microphone
Andrew Critch: Reminder: some leading AI researchers are *overtly* pro-extiction for humanity. Schmidhuber is seriously successful, and thankfully willing to be honest about his extinctionism. Many more AI experts are secretly closeted about this (and I know because I’ve met them).
Jurgen Schmidhuber (Invented principles of meta-learning (1987), GANs (1990), Transformers (1991), very deep learning (1991), etc): AI boom v AI doom: since the 1970s, I have told AI doomers that in the end all will be good. E.g., 2012 TEDx talk: “Don’t think of us versus them: us, the humans, v these future super robots. Think of yourself, and humanity in general, as a small stepping stone, not the last one, on the path of the universe towards more and more unfathomable complexity. Be content with that little role in the grand scheme of things.” As for the near future, our old motto still applies: “Our AI is making human lives longer & healthier & easier.”
The Lighter Side
Roon is excited for the new EA.
Roon: my main problem with EA is that the boring systematic index fund morality mindset will almost certainly not lead to the greatest good.
All the best historical advances in goodness have come from crazy people pursuing crazy things.
Or alternatively the kindness of normal individuals looking out for their families and communities
The hedge fund manager donating to malaria funds forms a kind of bland middle that inhabits the uninspiring midwit part of the bell curve.
I actually see the longtermist xrisk arm that schemes to destroy ai companies as a big improvement and way more fun.
I get where he’s coming from. If they’re out in the arena trying to do what they think is right, then perhaps they will get somewhere that matters, even if there is risk that it goes bad. Better to have the hedge fund manager donate to malaria funds that work than to cute puppies with rare diseases, if one does not want one’s head in the game, but that is not what ultimately counts most.
Obviously Roon and I view the events at OpenAI differently, but the board definitely did not want OpenAI to operate the way Altman wants it to operate. As I noted, both the board and Altman viewed the potential destruction of OpenAI as an acceptable risk in a high stakes negotiation.
Richard McElreath: I told a colleague that logistic regression is AI and they got mad at me, so I made a chart. Find yourself. I am “Tinder is AI”.
![Table with 3 rows and 3 columns.
Rows: (1) Algorithm purist (mimic human cognition), (2) Algorithm netural (learns & generalizes), (3) Algorithm rebel (method irrelevant)
Cols: (1) Ability purist (exceeds human ability), (2) Ability neutral (makes task easier), (3) Ability rebel (usefullness questionable)
Cells:
[1,1] "Terminator is AI" [1,2] "C3PO is AI" [1,3] "WALL-E is AI"
[2,1] "AlphaGo is AI" [2,2] "XGBOOST is AI" [2,3] "Tinder is AI"
[3,1] "A metal detector is AI" [3,2] "Bubble sort is AI" [3,3] "Magic 8 Ball is AI"](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb1371c0b-3478-45a7-9a85-9ce9c0eb8604_1456x874.jpeg)
I think my position on the chart is a hybrid – that Wall-E and XGBoost are AIs, but Tinder and Metal Detectors are not.
Staff Engineer promised if I kept quoting him I’d get a board seat. Will I?
12 comments
Comments sorted by top scores.
comment by Thane Ruthenis · 2023-12-01T12:45:35.513Z · LW(p) · GW(p)
Trying to read the paper makes it painfully clear that I am banging against the limits of my technical chops. It feels like important stuff to know and get right, but as often happens I run into that point where my ability to wing it hits a wall and suddenly it turns into Greek.
My understanding of that whole story (corrections welcome!):
- The starting problem is that we want to chisel human preferences into our LLM. We assemble a huge dataset of human-labeled data, consisting of the prompt, two sampled responses of the LLM to that prompt, and the human expressing a binary preference regarding which response they like more.
- However, that dataset is obviously finite, and likely very painfully finite, since employing humans to label data is expensive and time-consuming. So here's an idea: instead of fine-tuning our LLM on this dataset directly, we train a reward function based on this dataset. The hope is that this reward function will pick up on some underlying pattern in the human preferences, and so would let us evaluate human preferences on arbitrary examples (squeezing more RL/fine-tuning steps out of the dataset), and hopefully even generalize human preferences out-of-distribution.
- The DPO paper basically shows that this doesn't work. As it turns out, the RLHF'd LLM whose policy minimizes the learned reward function learns the same policy that we'd get if we'd just chiseled the initial dataset into our LLM. The whole "train a reward function" thing does nothing. And indeed: if there's some underlying pattern to pick up on, it'd stand to reason that the LLM itself would pick up on it over the course of fine-tuning.[1][2]
- However, here we run into some tricky problems with the technical implementation.
- The intuitively natural way to chisel the human-preferences dataset into the LLM is to make up a loss term consisting of human-preference logits (i. e., take the dataset-defined probability that the human would prefer response A to response B in a given case, and plug it into ) and the KL divergence from the base LLM's output to the fine-tuned LLM output (i. e., penalize straying too far from accurate text prediction).
- The idea is that the first term would move the LLM towards satisfying human preferences, and the second term would prevent it from overfitting/being lobotomized into just rotely repeating the human-preferences dataset.
- However, there's a problem with the logit function: it explodes the closer is to , approaching infinity (see the graph). Which means that on those values, it hopelessly dominates the KL-divergence term. And our dataset consists of binary labels, and human preferences are often deterministic (always prefer A to B, with probability ~1), so there's a ton of near-1 s there. Which means the "don't get lobotomized" term gets ignored, and DPO lobotomizes the LLM even more than just RLHF.
- This, ironically, is where the "useless" reward-function step actually helps. The reward model underfits, i. e. "softens" preferences, producing fewer , and therefore lobotomizing the LLM less. A textbook case of mistakes accidentally canceling each other out.
- The General Theoretical Paradigm paper points all of the above out, and provides a less-naive way to score LLMs on human preference satisfaction which avoids the exponential explosion. (Or, rather, it finds a place in the equations in which we can wedge a regularization term such that we actually control the degree of lobotomization taking place – rather than setting it to the max (DPO) or kind of accidentally softening it (RLHF).)
{kind=link}
Overall? Unless I dramatically misunderstood something, wow am I not impressed with this whole thing.
- ^
Well, more precisely, that the fine-tuning training loop would itself chisel said pattern into the LLM, no reward-function proxy needed.
- ^
More technically: Suppose we have two reward functions and , where is the variable we're varying in order to minimize them, and is the (set of) all the other variables at play. If , i. e. if the difference between these reward functions doesn't depend on the variable we're optimizing, then these reward functions are equivalent: if optimized-for, they'll produce the same optimal value for .
And then the paper shows that the fully-expanded reward function of RLHF is equivalent, in this sense, to the reward function of DPO/just chiseling-in the human-preferences dataset directly.
comment by 1a3orn · 2023-11-30T18:25:32.973Z · LW(p) · GW(p)
The quote from Schmidhuber literally says nothing about human extinction being good.
I'm disappointed that Critch glosses it that way, because in the past he has been leveler-headed than many, but he's wrong.
The quote is:
“Don’t think of us versus them: us, the humans, v these future super robots. Think of yourself, and humanity in general, as a small stepping stone, not the last one, on the path of the universe towards more and more unfathomable complexity. Be content with that little role in the grand scheme of things.” As for the near future, our old motto still applies: “Our AI is making human lives longer & healthier & easier.”
Humans not being the "last stepping stone" towards greater complexity does not imply that we'll go extinct. I'd be happy to live in a world where there are things more complex than humans. Like it's not a weird interpretation at all -- "AI will be more complex than humans" or "Humans are not the final form of complexity in the universe" simply says nothing at all about "humans will go extinct."
You could spin it into that meaning if you tried really hard. But -- for instance-- the statement could also be about how AI will do science better than humans in the future, which was (astonishingly) the substance of the talk in which this statement took place, and also what Schmidhuber has been on about for years, so it probably is what he's actually talking about.
I note that you say, in your section on tribalism.
Accelerationists mostly got busy equating anyone who thinks smarter than human AIs might pose a danger to terrorists and cultists and crazies. The worst forms of ad hominem and gaslighting via power were on display.
It would be great if people were a tad more hesitant to accuse others of wanting omnicide.
Replies from: nathan-helm-burger, T3t, Odd anon↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-01T07:01:53.371Z · LW(p) · GW(p)
Well, I do agree that there are two steps needed from the quote to the position of saying the quote supports omnicide.
Step 1. You have to also think that things smarter (better at science) and more complex than humans will become more powerful than humans, and somehow end up in control of the destiny of the universe.
Step 2. You have to think that humans losing control in this way will be effectively fatal to them, one way or another, not long after it happens.
So yeah, Schmidhuber might think that one or both of these two steps are invalid. I believe they probably are, and thus that Schmidhuber's position thus points pretty strongly at human extinction. That if we want to avoid human extinction we need to avoid going in the direction of AI being more complex than humans.
My personal take is that we should keep AI as limited and simple as possible, as long as possible. We should aim for increasing human complexity and ability. We should not merge with AI, we should simply use AI as a tool to expand humanity's abilities. Create digital humans. Then figure out how to let those digital humans grow and improve beyond the limits of biology while still maintaining their core humanity.
Replies from: mishka↑ comment by mishka · 2023-12-01T18:40:35.465Z · LW(p) · GW(p)
We should not merge with AI [...] Create digital humans.
I have been confused for a while about
- boundary between humans merging with AI and digital humans (can these approaches be reliably differentiated from each other? or is there a large overlap?)
- why digital humans would be a safer alternative than the merge
So this seems like it might be a good occasion to ask you to elaborate on this...
↑ comment by RobertM (T3t) · 2023-12-01T03:33:44.166Z · LW(p) · GW(p)
I think Schmidhuber does in fact think that humans will go extinct as a result of developing ASI: https://www.lesswrong.com/posts/BEtQALqgXmL9d9SfE/q-and-a-with-juergen-schmidhuber-on-risks-from-ai
Replies from: 1a3orn↑ comment by 1a3orn · 2023-12-01T04:03:26.154Z · LW(p) · GW(p)
Note that that's from 2011 -- it says things which (I agree) could be taken to imply that humans will go extinct, but doesn't directly state it.
On the other hand, here's from 6 months ago:
Jones: The existential threat that’s implied is the extent to which humans have control over this technology. We see some early cases of opportunism which, as you say, tends to get more media attention than positive breakthroughs. But you’re implying that this will all balance out?
Schmidhuber: Historically, we have a long tradition of technological breakthroughs that led to advancements in weapons for the purpose of defense but also for protection. From sticks, to rocks, to axes to gunpowder to cannons to rockets… and now to drones… this has had a drastic influence on human history but what has been consistent throughout history is that those who are using technology to achieve their own ends are themselves, facing the same technology because the opposing side is learning to use it against them. And that's what has been repeated in thousands of years of human history and it will continue. I don't see the new AI arms race as something that is remotely as existential a threat as the good old nuclear warheads.
↑ comment by Odd anon · 2023-11-30T23:34:52.610Z · LW(p) · GW(p)
Ehhh, I get the impression that Schidhuber doesn't think of human extinction as specifically "part of the plan", but he also doesn't appear to consider human survival to be something particularly important relative to his priority of creating ASI. He wants "to build something smarter than myself, which will build something even smarter, et cetera, et cetera, and eventually colonize and transform the universe", and thinks that "Generally speaking, our best protection will be their lack of interest in us, because most species’ biggest enemy is their own kind. They will pay about as much attention to us as we do to ants."
I agree that he's not overtly "pro-extinction" in the way Rich Sutton is, but he does seem fairly dismissive of humanity's long-term future in general, while also pushing for the creation of an uncaring non-human thing to take over the universe, so...
comment by Joachim Bartosik (joachim-bartosik) · 2023-12-02T18:53:57.565Z · LW(p) · GW(p)
The exact example is that GPT-4 is hesitant to say it would use a racial slur in an empty room to save a billion people. Let’s not overreact, everyone?
I mean this might be the correct thing to do? Chat GPT is not in a situation where it cold save 1B lives by saying a racial slur.
It's in a situation where someone tires to get it to admit it would say a racial slur under some circumstance.
I don't think that CHAT GPT understands that. But OpenAI makes ChatGPT expecting that it won't be in the 1st kind of situation but to be in the 2nd kind of situation quite often.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-07T20:52:04.921Z · LW(p) · GW(p)
I just want to bring up another, perhaps irrelevant, thought-group on the internet. It is these old sci-fi nerds who are confused and taken-aback how the modern world doesn't match their old visions of the future. They see California Tech People as all lumped together.
TESCREAL stands for "transhumanism, extropianism, singularitarianism, cosmism, rationalism (in a very specific context), Effective Altruism, and longtermism." It was identified by Timnit Gebru, former technical co-lead of the Ethical Artificial Intelligence Team at Google and founder of the Distributed Artificial Intelligence Research Institute (DAIR), and Émile Torres, a philosopher specializing in existential threats to humanity. These are separate but overlapping beliefs that are particularly common in the social and academic circles associated with big tech in California.
In regards to AI, the author of the linked blog, Charles Stross, is a skeptic who thinks LLMs are pure hype. An impotent scam which will go nowhere. He is mad at the UK government for 'wasting time and money on fake-AI', sees them as being caught up in a scam.
And the comment section is full of folks who seem to more or less agree.
The funny thing about this to me, is that Charles' book Accelerando was one of the books that got me to consider the hypothesis, "Ok, but what if we did have intelligent autonomous non-human entities in the future that humanity had to compete economically with? How would that go for us?"
The answer is, as Zvi frequently reiterates, that it goes very badly indeed for humanity. And faster than one might expect.
I bring this up because I don't expect Charles Stross himself to come to this comment section to share his views, and I think that hearing what your critics have to say can be a valuable exercise.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2023-12-08T01:56:06.965Z · LW(p) · GW(p)
The same thing happened previously, between Eliezer and Greg Egan - Egan distanced himself from MIRI's views, and wrote a novel in which a parodic mishmash of MIRI, Robin Hanson, and Bryan Caplan appears [LW · GW].
As for Stross's talk, he makes at least one outright weird claim, which is that Russian Cosmism played a role in the emergence of 1990s American transhumanism (and even less likely, that it contributed to the "California ideology", a name for 1990s dot-com techno-optimism coined in imitation of Engels and Marx's "German ideology"). As far as I know, there is no evidence for this at all; Russian Cosmism is a case of parallel evolution, a transhumanist philosophy which emerged in the cultural context of 19th-century Russian Orthodoxy.
But OK, Stross points to the long history of traffic back and forth between science fiction, real-world science and technology, and various belief systems, and his claim is that the "TESCREAL" cluster of philosophies largely fall into the category of belief systems detached from reality but derived from science fiction.
Now, obviously the broad universe of science fiction does contain many motifs detached from reality. Reality also now contains many things which were previously science fiction! Also, obtaining a philosophy from science fiction is a somewhat different thing than obtaining a technology from science fiction.
I would also point out that many elements of science fiction came from the imaginations of actual scientists and engineers. Freeman Dyson and Hans Moravec weren't science fiction writers, they were brainstorming about what might be possible right here in sober physical reality; but they also ended up supplying SF writers with something to write about.
I think the position of Stross and his commenters is largely politically determined. First of all, there is a bit of a culture war within SF, between progressive and libertarian traditions. Eliezer linked to a long tweet about it here. This is another case of SF reflecting an external reality - different worldviews and different agendas for society.
Second, one observes resistance to the idea of existential risk from AI, among numerous progressives who have nothing to do with SF. Here's an example that I recently ran across. The author says both EA and e/acc are to be dismissed as ideologies of the rich, and we should all focus on phenomena like online radicalization, surveillance, and the environmental impact of data centers... Something about the idea of risks from superintelligent AI triggers resistance, in a way that risks from nuclear war or climate change do not.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-08T17:06:20.240Z · LW(p) · GW(p)
Sometimes I wonder what it would be like to be a scientist in the late 1800s / early 1900s, who had figured out about the possibility of nuclear bombs but also (in their universe) had calculated that nuclear bombs would ignite the atmosphere if used.
If there were some groups of people actively trying to develop the bomb, and laughing off your warning. And other people were laughing at the whole idea because clearly it's too preposterous for anyone to build such a device, and even if they did, it certainly wouldn't be so dangerous.
comment by Gesild Muka (gesild-muka) · 2023-12-01T14:42:55.620Z · LW(p) · GW(p)
The older a transhumanist gets the less you should trust them to accurately judge AGI risk.
This has some interesting implications. Reminds me of psychics who make confident predictions 100 years in the future but will refuse or be offended if you challenge them to make confirmable predictions within their lifetimes or the next week/month/year.