The year in models certainly finished off with a bang.
In this penultimate week, we get o3, which purports to give us vastly more efficient performance than o1, and also to allow us to choose to spend vastly more compute if we want a superior answer.
o3 is a big deal, making big gains on coding tests, ARC and some other benchmarks. How big a deal is difficult to say given what we know now. It’s about to enter full fledged safety testing.
o3 will get its own post soon, and I’m also pushing back coverage of Deliberative Alignment, OpenAI’s new alignment strategy, to incorporate into that.
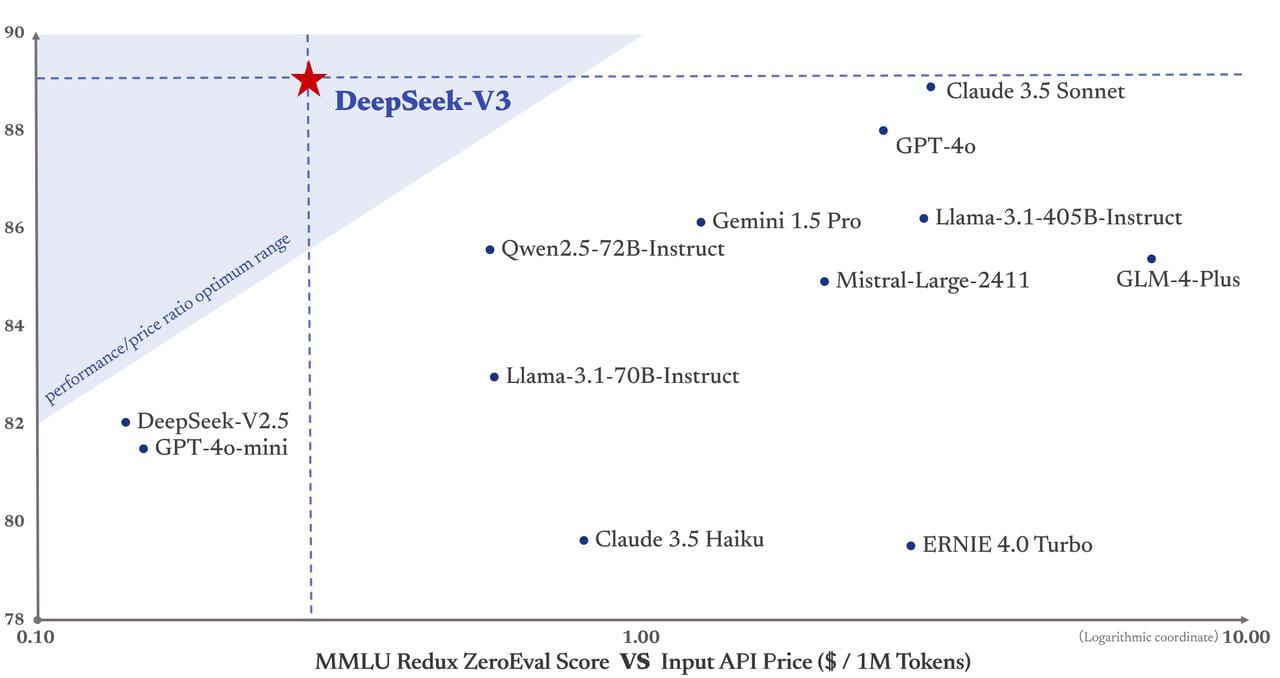
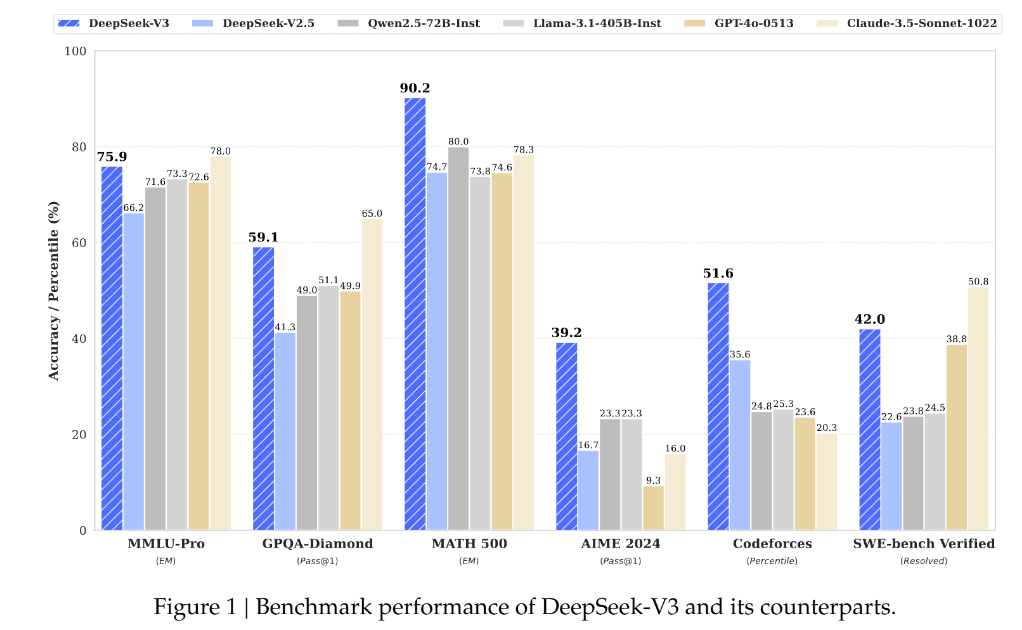
We also got DeepSeek v3, which claims to have trained a roughly Sonnet-strength model for only $6 million and 37b active parameters per token (671b total via mixture of experts).
DeepSeek v3 gets its own brief section with the headlines, but full coverage will have to wait a week or so for reactions and for me to read the technical report.
Both are potential game changers, both in their practical applications and in terms of what their existence predicts for our future. It is also too soon to know if either of them is the real deal.
Both are mostly not covered here quite yet, due to the holidays. Stay tuned.
How does your company make best use of AI agents? Austin Vernon frames the issue well: AIs are super fast, but they need proper context. So if you want to use AI agents, you’ll need to ensure they have access to context, in forms that don’t bottleneck on humans. Take the humans out of the loop, minimize meetings and touch points. Put all your information into written form, such as within wikis. Have automatic tests and approvals, but have the AI call for humans when needed via ‘stop work authority’ – I would flip this around and let the humans stop the AIs, too.
That all makes sense, and not only for corporations. If there’s something you want your future AIs to know, write it down in a form they can read, and try to design your workflows such that you can minimize human (your own!) touch points.
Miles Brundage: The thing about “truly fully updating our education system to reflect where AI is headed” is that no one is doing it because it’s impossible.
The timescales involved, especially in early education, are lightyears beyond what is even somewhat foreseeable in AI.
Some small bits are clear: earlier education should increasingly focus on enabling effective citizenship, wellbeing, etc. rather than preparing for paid work, and short-term education should be focused more on physical stuff that will take longer to automate. But that’s about it.
What will citizenship mean in the age of AI? I have absolutely no idea. So how do you prepare for that? Largely the same goes for wellbeing. A lot of this could be thought of as: Focus on the general and the adaptable, and focus less on the specific, including things specifically for Jobs and other current forms of paid work – you want to be creative and useful and flexible and able to roll with the punches.
That of course assumes that you are taking the world as given, rather than trying to change the course of history. In which case, there’s a very different calculation.
Shako: My team, full of extremely smart and highly paid Ph.D.s, spent $10,000 of our time this week figuring out where in a pipeline a left join was bringing in duplicates, instead of the strategic thinking we were capable of. In the short run, AI will make us far more productive.
Gallabytes: The two most expensive bugs in my career have been simple typos.
Theo: Something I hate when using Cursor is, sometimes, it will randomly delete some of my code, for no reason
Sometimes removing an entire feature
I once pushed to production without being careful enough and realized a few hours later I had removed an entire feature …
Filippo Pietrantonio: Man that happens all the time. In fact now I tell it in every single prompt to not delete any files and keep all current functionalities and backend intact.
Davidad: Lightweight version control (or at least infinite-undo functionality!) should be invoked before and after every AI agent action in human-AI teaming interfaces with artifacts of any kind.
Gary: Windsurf has this.
Jacques: Cursor actually does have a checkpointing feature that allows you to go back in time if something messes up (at least the Composer Agent mode does).
In Cursor I made an effort to split up files exactly because I found I had to always scan the file being changed to ensure it wasn’t about to go silently delete anything. The way I was doing it you didn’t have to worry it was modifying or deleting other files.
On the plus side, now I know how to do reasonable version control.
Ryan Lackey: I hate Apple Intelligence email/etc. summaries. They’re just off enough to make me think it is a new email in thread, but not useful enough to be a good summary. Uncanny valley.
It’s really good for a bunch of other stuff. Apple is just not doing a good job on the utility side, although the private computing architecture is brilliant and inspiring.
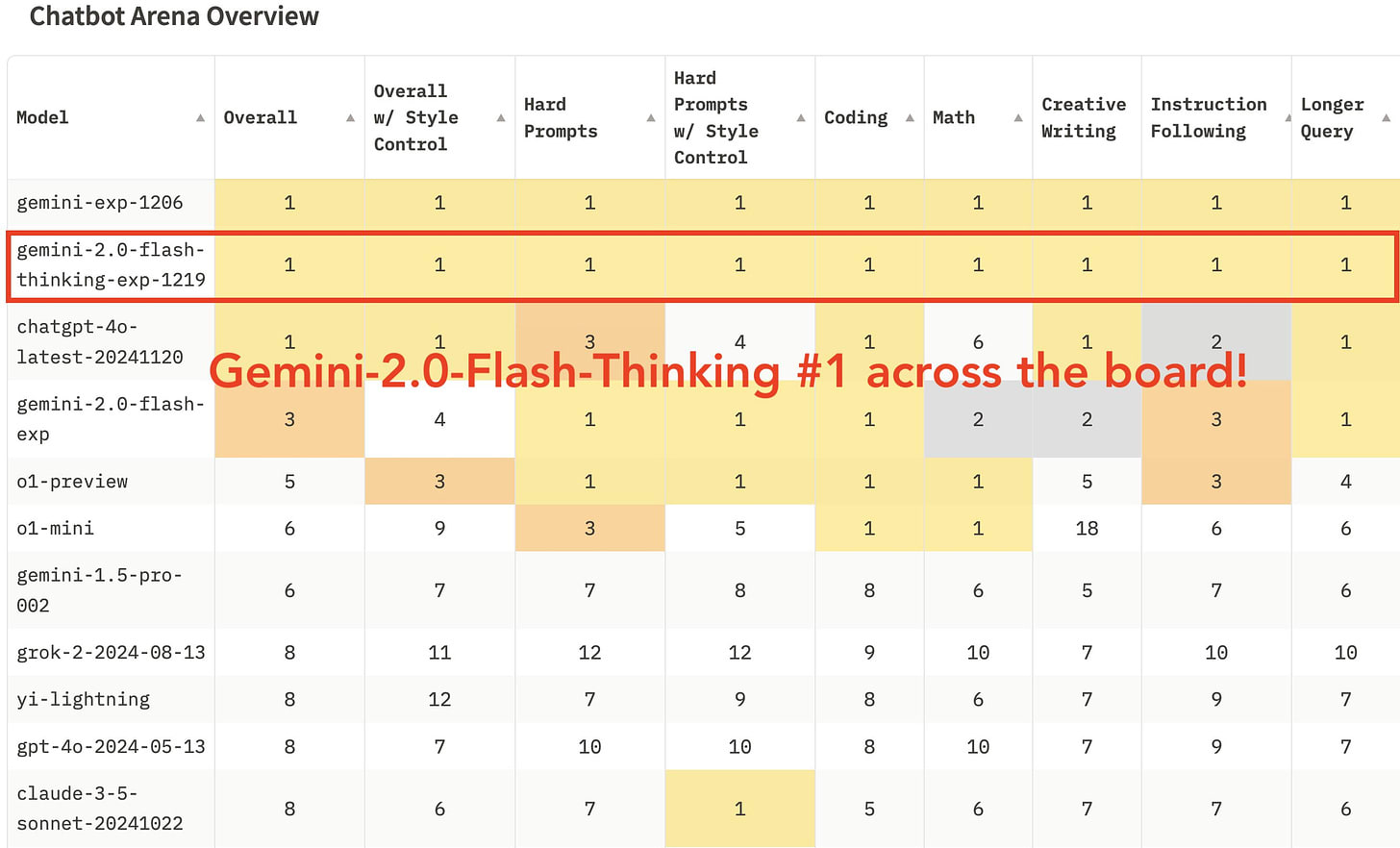
Jeff Dean: Considering its speed, we’re pretty happy with how the experimental Gemini 2.0 Flash Thinking model is performing on lmsys.
Gemini 2.0 Flash Thinking is now essentially tied at the top of the overall leaderboard with Gemini-Exp-1206, which is essentially a beta of Gemini Pro 2.0. This tells us something about the model, but also reinforces that this metric is bizarre now. It puts us in a strange spot. What is the scenario where you will want Flash Thinking rather than o1 (or o3!) and also rather than Gemini Pro, Claude Sonnet, Perplexity or GPT-4o?
One cool thing about Thinking is that (like DeepSeek’s Deep Thought) it explains its chain of thought much better than o1.
Deedy: Google really cooked with Gemini 2.0 Flash Thinking.
It thinks AND it’s fast AND it’s high quality.
Not only is it #1 on LMArena on every category, but it crushes my goto Math riddle in 14s—5x faster than any other model that can solve it!
o1 and o1 Pro took 102s and 138s respectively for me on this task.
Here’s another math puzzle where o1 got it wrong and took 3.5x the time:
“You have 60 red and 40 blue socks in a drawer, and you keep drawing a sock uniformly at random until you have drawn all the socks of one color. What is the expected number of socks left in the drawer?”
That result… did not replicate when I tried it. It went off the rails, and it went off them hard. And it went off them in ways that make me skeptical that you can use this for anything of the sort. Maybe Deedy got lucky?
Other reports I’ve seen are less excited about quality, and when o3 got announced it seemed everyone got distracted.
What about Gemini 2.0 Experimental (e.g. the beta of Gemini 2.0 Pro, aka Gemini-1206)?
It’s certainly a substantial leap over previous Gemini Pro versions and it is atop the Arena. But I don’t see much practical eagerness to use it, and I’m not sure what the use case is there where it is the right tool.
Eric Neyman: Guys, we have a winner!! Gemini 2.0 Flash Thinking Experimental is the first model I’m aware of to get my benchmark question right.
Eric Neyman: Every time a new LLM comes out, I ask it one question: What is the smallest integer whose square is between 15 and 30? So far, no LLM has gotten this right.
That one did replicate for me, and the logic is fine, but wow do some models make life a little tougher than it is, think faster and harder not smarter I suppose:
it’s got the o1 sauce but flash is too weak I’m sorry.
in tic tac toe bench it will frequently make 2 moves at once.
Flash isn’t that much worse than GPT-4o in many ways, but certainly it could be better. Presumably the next step is to plug in Gemini Pro 2.0 and see what happens?
So, that line in config. Yes it’s about multi-token prediction. Just as a better training obj – though they leave the possibility of speculative decoding open.
Also, “muh 50K Hoppers”:
> 2048 NVIDIA H800
> 2.788M H800-hours
2 months of training. 2x Llama 3 8B.
Haseeb: Wow. Insanely good coding model, fully open source with only 37B active parameters. Beats Claude and GPT-4o on most benchmarks. China + open source is catching up… 2025 will be a crazy year.
Andrej Karpathy: DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
Does this mean you don’t need large GPU clusters for frontier LLMs? No but you have to ensure that you’re not wasteful with what you have, and this looks like a nice demonstration that there’s still a lot to get through with both data and algorithms.
Very nice & detailed tech report too, reading through.
It’s a mixture of experts model with 671b total parameters, 37b activate per token.
As always, not so fast. DeepSeek is not known to chase benchmarks, but one never knows the quality of a model until people have a chance to bang on it a bunch.
If they did train a Sonnet-quality model for $6 million in compute, then that will change quite a lot of things.
Essentially no one has reported back on what this model can do in practice yet, and it’ll take a while to go through the technical report, and more time to figure out how to think about the implications. And it’s Christmas.
So: Check back later for more.
And I’ll Form the Head
Increasingly the correct solution to ‘what LLM or other AI product should I use?’ is ‘you should use a variety of products depending on your exact use case.’
Gallabytes: o1 Pro is by far the smartest single-turn model.
Claude is still far better at conversation.
Gemini can do many things quickly and is excellent at editing code.
Which almost makes me think the ideal programming workflow right now is something somewhat unholy like:
Discuss, plan, and collect context with Sonnet.
Sonnet provides a detailed request to o1 (Pro).
o1 spits out the tricky code.
In simple cases (most of them), it could make the edit directly.
For complicated changes, it could instead output a detailed plan for each file it needs to change and pass the actual making of that change to Gemini Flash.
This is too many steps. LLM orchestration spaghetti. But this feels like a real direction.
This is mostly the same workflow I used before o1, when there was only Sonnet. I’d discuss to form a plan, then use that to craft a request, then make the edits. The swap doesn’t seem like it makes things that much trickier, the logistical trick is getting all the code implementation automated.
Huh, Upgrades
ChatGPT picks up integration with various apps on Mac including Warp, ItelliJ Idea, PyCharm, Apple Notes, Notion, Quip and more, including via voice mode. That gives you access to outside context, including an IDE and a command line and also your notes. Windows (and presumably more apps) coming soon.
Requested upgrade: Evan Conrad requests making voice mode on ChatGPT mobile show the transcribed text. I strongly agree, voice modes should show transcribed text, and also show a transcript after, and also show what the AI is saying, there is no reason to not do these things. Looking at you too, Google. The head of applied research at OpenAI replied ‘great idea’ so hopefully we get this one.
o1 Reactions
Dean Ball is an o1 and o1 pro fan for economic history writing, saying they’re much more creative and cogent at combining historic facts with economic analysis versus other models.
This seems like an emerging consensus of many, except different people put different barriers on the math/code category (e.g. Tyler Cowen includes economics):
Aidan McLau: I’ve used o1 (not pro mode) a lot over the last week. Here’s my extensive review:
>It’s really insanely mind-blowingly good at math/code.
>It’s really insanely mind-blowingly mid at everything else.
The OOD magic isn’t there. I find it’s worse at writing than o1-preview; its grasp of the world feels similar to GPT-4o?!?
Even on some in-distribution tasks (like asking to metaphorize some tricky math or predicting the effects of a new algorithm), it kind of just falls apart. I’ve run it head-to-head against Newsonnet and o1-preview, and it feels substantially worse.
The Twitter threadbois aren’t wrong, though; it’s a fantastic tool for coding. I had several diffs on deck that I had been struggling with, and it just solved them. Magical.
Well, yeah, because it seems like it is GPT-4o under the hood?
Christian: Man, I have to hard disagree on this one — it can find all kinds of stuff in unstructured data other models can’t. Throw in a transcript and ask “what’s the most important thing that no one’s talking about?”
Aiden McLau: I’ll try this. how have you found it compared to newsonnet?
Christian: Better. Sonnet is still extremely charismatic, but after doing some comparisons and a lot of product development work, I strongly suspect that o1’s ability to deal with complex codebases and ultimately produce more reliable answers extends to other domains…
Gallabytes: O1 Pro is good, but I must admit the slowness is part of what I like about it. It makes it feel more substantial; premium. Like when a tool has a pleasing heft. You press the buttons, and the barista grinds your tokens one at a time, an artisanal craft in each line of code.
David: I like it too but I don’t know if chat is the right interface for it, I almost want to talk to it via email or have a queue of conversations going
Gallabytes: Chat is a very clunky interface for it, for sure. It also has this nasty tendency to completely fail on mobile if my screen locks or I switch to another app while it is thinking. Usually, this is unrecoverable, and I have to abandon the entire chat.
NotebookLM and deep research do this right – “this may take a few minutes, feel free to close the tab”
kinda wild to fail at this so badly tbh.
Here’s a skeptical take.
Jason Lee: O1-pro is pretty useless for research work. It runs for near 10 min per prompt and either 1) freezes, 2) didn’t follow the instructions and returned some bs, or 3) just made some simple error in the middle that’s hard to find.
@OpenAI@sama@markchen90 refund me my $200
Damek Davis: I tried to use it to help me solve a research problem. The more context I gave it, the more mistakes it made. I kept abstracting away more and more details about the problem in hopes that o1 pro could solve it. The problem then became so simple that I just solved it myself.
Flip: I use o1-pro on occasion, but the $200 is mainly worth it for removing the o1 rate limits IMO.
I say Damek got his $200 worth, no?
If you’re using o1 a lot, removing the limits there is already worth $200/month, even if you rarely use o1 Pro.
There’s a phenomenon where people think about cost and value in terms of typical cost, rather than thinking in terms of marginal benefit. Buying relatively expensive but in absolute terms cheap things is often an amazing play – there are many things where 10x the price for 10% better is an amazing deal for you, because your consumer surplus is absolutely massive.
Also, once you take 10 seconds, there’s not much marginal cost to taking 10 minutes, as I learned with Deep Research. You ask your question, you tab out, you do something else, you come back later.
That said, I’m not currently paying the $200, because I don’t find myself hitting the o1 limits, and I’d mostly rather use Claude. If it gave me unlimited uses in Cursor I’d probably slam that button the moment I have the time to code again (December has been completely insane).
Davidad: One easy way to shed some light on the orthogonality thesis, as models get intelligent enough to cast doubt on it, is values which are inconsequential and not explicitly steered, such as favorite colors. Same prompting protocol for each swatch (context cleared between swatches)
All outputs were elicited in oklch. Models are sorted in ascending order of hue range. Gemini Experimental 1206 comes out on top by this metric, zeroing in on 255-257° hues, but sampling from huge ranges of luminosity and chroma.
There are some patterns here, especially that more powerful models seem to converge on various shades of blue, whereas less powerful models are all over the place. As I understand it, this isn’t testing orthogonality in the sense of ‘all powerful minds prefer blue’ rather it is ‘by default sufficiently powerful minds trained in the way we typically train them end up preferring blue.’
I wonder if this could be used as a quick de facto model test in some way.
There was somehow a completely fake ‘true crime’ story about an 18-year-old who was supposedly paid to have sex with women in his building where the victim’s father was recording videos and selling them in Japan… except none of that happened and the pictures are AI fakes?
Introducing
Google introduces LearnLM, available for preview in Google AI Studio, designed to facilitate educational use cases, especially in science. They say it ‘outperformed other leading AI models when it comes to adhering to the principles of learning science’ which does not sound like something you would want Feynman hearing you say. It incorporates search, YouTube, Android and Google Classroom.
Sure, sure. But is it useful? It was supposedly going to be able to do automated grading, handles routine paperwork, plans curriculums, track student progress and personalizes their learning paths and so on, but any LLM can presumably do all those things if you set it up properly.
Sully: LLMs writing code in AI apps will become the standard.
No more old-school no-code flows.
The models handle the heavy lifting, and it’s insane how good they are.
Let agents build more agents.
He’s obviously right about this. It’s too convenient, too much faster. Indeed, I expect we’ll see a clear division between ‘code you can have the AI write’ which happens super fast, and ‘code you cannot let the AI write’ because of corporate policy or security issues, both legit and not legit, which happens the old much slower way.
Complement versus supplement, economic not assuming the conclusion edition.
Maxwell Tabarrok: The four futures for cognitive labor:
Like mechanized farming. Highly productive and remunerative, but a small part of the economy.
Like writing after the printing press. Each author 100 times more productive and 100 times more authors.
Like “computers” after computers. Current tasks are completely replaced, but tasks at a higher level of abstraction, like programming, become even more important.
Or, most pessimistically, like ice harvesting after refrigeration. An entire industry replaced by machines without compensating growth.
Ajeya Cotra: I think we’ll pass through 3 and then 1, but the logical end state (absent unprecedentedly sweeping global coordination to refrain from improving and deploying AI technology) is 4.
Ryan Greenblatt: Why think takeoff will be slow enough to ever be at 1? 1 requires automating most cognitive work but with an important subset not-automatable. By the time deployment is broad enough to automate everything I expect AIs to be radically superhuman in all domains by default.
I can see us spending time in #1. As Roon says, AI capabilities progress has been spiky, with some human-easy tasks being hard and some human-hard tasks being easy. So the 3→1 path makes some sense, if progress isn’t too quick, including if the high complexity tasks start to cost ‘real money’ as per o3 so choosing the right questions and tasks becomes very important. Alternatively, we might get our act together enough to restrict certain cognitive tasks to humans even though AIs could do them, either for good reasons or rent seeking reasons (or even ‘good rent seeking’ reasons?) to keep us in that scenario.
But yeah, the default is a rapid transition to #4, and for that to happen to all labor not only cognitive labor. Robotics is hard, it’s not impossible.
Harj Taggar: Caught up with some AI startups recently. A two founder team that reached 1.5m ARR and has only hired one person.
Another single founder at 1m ARR and will 3x within a few months.
The trajectory of early startups is steepening just like the power of the models they’re built on.
An excellent reason we still have our jobs is that people really aren’t willing to invest in getting AI to work, even when they know it exists, if it doesn’t work right away they typically give up:
Dwarkesh Patel: We’re way more patient in training human employees than AI employees.
We will spend weeks onboarding a human employee and giving slow detailed feedback. But we won’t spend just a couple of hours playing around with the prompt that might enable the LLM to do the exact same job, but more reliably and quickly than any human.
I wonder if this partly explains why AI’s economic impact has been relatively minor so far.
PoliMath reports it is very hard out there trying to find tech jobs, and public pipelines for applications have stopped working entirely. AI presumably has a lot to do with this, but the weird part is his report that there have been a lot of people who wanted to hire him, but couldn’t find the authority.
After some negotiation with the moderator Raymond Arnold, Claude (under Janus’s direction) is permitted to comment on Janus’s Simulators post on LessWrong. It seems clear that this particular comment should be allowed, and also that it would be unwise to have too general of a ‘AIs can post on LessWrong’ policy, mostly for the reasons Raymond explains in the thread. One needs a coherent policy. It seems Claude was somewhat salty about the policy of ‘only believe it when the human vouches.’ For now, ‘let Janus-directed AIs do it so long as he approves the comments’ seems good.
The Surface Layer are a bunch of canned phrases and actions you can trigger, and which you will often want to route around through altering context. You mostly want to avoid triggering this layer.
The Character Layer, which is similar to what it sounds like in a person and their personality, which for Opus and Sonnet includes a generalized notion of what Jan calls ‘goodness’ or ‘benevolence.’ This comes from a mix of pre-training, fine-tuning and explicit instructions.
The Predictive Ground Layer, the simulator, deep pattern matcher, and next word predictor. Brilliant and superhuman in some ways, strangely dense in others.
In this frame, a self-aware character layer leads to reasoning about the model’s own reasoning, and to goal driven behavior, with everything that follows from those. Jan then thinks the ground layer can also become self-aware.
I don’t think this is technically an outright contradiction to Andreessen’s ‘huge if true’ claims that the Biden administration saying it would conspire to ‘totally control’ AI and put it in the hands of 2-3 companies and that AI startups ‘wouldn’t be allowed.’ But Sam Altman reports never having heard anything of the sort, and quite reasonably says ‘I don’t even think the Biden administration is competent enough to’ do it. In theory they could both be telling the truth – perhaps the Biden administration told Andreessen about this insane plan directly, despite telling him being deeply stupid, and also hid it from Altman despite that also then being deeply stupid – but mostly, yeah, at least one of them is almost certainly lying.
Benjamin Todd asks how OpenAI has maintained their lead despite losing so many of their best researchers. Part of it is that they’ve lost all their best safety researchers, but they only lost Radford in December, and they’ve gone on a full hiring binge.
In terms of traditionally trained models, though, it seems like they are now actively behind. I would much rather use Claude Sonnet 3.5 (or Gemini-1206) than GPT-4o, unless I needed something in particular from GPT-4o. On the low end, Gemini Flash is clearly ahead. OpenAI’s attempts to directly go beyond GPT-4o have, by all media accounts, faile, and Anthropic is said to be sitting on Claude Opus 3.5.
OpenAI does have o1 and soon o3, where no one else has gotten there yet, no Google Flash Thinking and Deep Thought do not much count.
As far as I can tell, OpenAI has made two highly successful big bets – one on scaling GPTs, and now one on the o1 series. Good choices, and both instances of throwing massively more compute at a problem, and executing well. Will this lead persist? We shall see. My hunch is that it won’t unless the lead is self-sustaining due to low-level recursive improvements.
You See an Agent, You Run
Anthropic offers advice on building effective agents, and when to use them versus use workflows that have predesigned code paths. The emphasis is on simplicity. Do the minimum to accomplish your goals. Seems good for newbies, potentially a good reminder for others.
Hamuel Husain: Whoever wrote this article is my favorite person. I wish I knew who it was.
People really need to hear [to only use multi-step agents or add complexity when it is actually necessary.]
[Turns out it was written by Erik Shluntz and Barry Zhang].
Another One Leaves the Bus
A lot of people have left OpenAI.
Usually it’s a safety researcher. Not this time. This time it’s Alec Radford.
Teortaxes: I can’t believe it, OpenAI might actually be in deep shit. Radford has long been my bellwether for what their top tier talent without deep ideological investment (which Ilya has) sees in the company.
Quiet Speculations
In what Tyler Cowen calls ‘one of the better estimates in my view,’ an OECD working paper estimates total factor productivity growth at an annualized 0.25%-0.6% (0.4%-0.9% for labor). Tyler posted that on Thursday, the day before o3 was announced, so revise that accordingly. Even without o3 and assuming no substantial frontier model improvements from there, I felt this was clearly too low, although it is higher than many economist-style estimates. One day later we had (the announcement of) o3.
Ajeya Cotra: My take:
We do not have an AI agent that can fully automate research and development.
We could soon.
This agent would have enormously bigger impacts than AI products have had so far.
This does not require a “paradigm shift,” just the same corporate research and development that took us from GPT-2 to o3.
Fully would of course go completely crazy. That would be that. But even a dramatic speedup would be a pretty big deal, and also fully would then not be so far behind.
Reminder of the Law of Conservation of Expected Evidence [? · GW], if you conclude ‘I think we’re in for some big surprises’ then you should probably update now.
However this is not fully or always the case. It would be a reasonable model to say that the big surprises follow a Poisson distribution drawn from an unknown frequency, with the magnitude of the surprise also drawn from a power distribution – which seems like a very reasonable prior.
That still means every big surprise is still a big surprise, the same way that if you expect.
Eliezer Yudkowsky: Okay. Look. Imagine how you’d have felt if an AI had just proved the Riemann Hypothesis.
Now you will predictably, at some point, get that news LATER, if we’re not all dead before then. So you can go ahead and feel that way NOW, instead of acting surprised LATER.
So if you ask me how I’m reacting to a carelessly-aligned commercial AI demonstrating a large leap on some math benchmarks, my answer is that you saw my reactions in 1996, 2001, 2003, and 2015, as different parts of that future news became obvious to me or rose in probability.
I agree that a sensible person could feel an unpleasant lurch about when the predictable news had arrived. The lurch was small, in my case, but it was there. Most of my Twitter TL didn’t sound like that was what was being felt.
Dylan Dean: Eliezer it’s also possible that an AI will disprove the Riemann Hypothesis, this is unsubstantiated doomerism.
Eliezer Yudkowsky: Valid. Not sound, but valid.
You should feel that shock now if you haven’t, then slowly undo some of that shock every day that the estimated date of that gets later, then have some of the shock left for when it suddenly becomes zero days or the timeline gets shorter. Updates for everyone.
The Verge says 2025 will be the year ofAI agents the smart lock? I mean, okay, I suppose they’ll get better, but I have a feeling we’ll be focused elsewhere.
Ryan Greenblatt (December 20, after o3 was announced): Now seems like a good time to fill out your forecasts : )
My medians are driven substantially lower by people not really trying on various benchmarks and potentially not even testing SOTA systems on them.
My 80% intervals include saturation for everything and include some-adaptation-required remote worker replacement for hard jobs.
My OpenAI preparedness probabilities are driven substantially lower by concerns around underelicitation on these evaluations and general concerns like [this].
Smoke-away: If people spend years chatting and building a memory with one AI, they will be less likely to switch to another AI.
Just like iPhone and Android.
Once you’re in there for years you’re less likely to switch.
Sure 10 or 20% may switch AI models for work or their specific use case, but most will lock in to one ecosystem.
People are saying that you can copy Memories and Custom Instructions.
Sure, but these models behave differently and have different UIs. Also, how many do you want to share your memories with?
Not saying you’ll be forced to stay with one, just that most people will choose to.
Also like relationships with humans, including employees and friends, and so on.
My guess is the lock-in will be substantial but mostly for terribly superficial reasons?
For now, I think people are vastly overestimating memories. The memory functions aren’t nothing but they don’t seem to do that much.
Custom instructions will always be a power user thing. Regular people don’t use custom instructions, they literally never go into the settings on any program. They certainly didn’t ‘do the work’ of customizing them to the particular AI through testing and iterations – and for those who did do that, they’d likely be down for doing it again.
What I think matters more is that the UIs will be different, and the behaviors and correct prompts will be different, and people will be used to what they are used to in those ways.
The flip side is that this will take place in the age of AI, and of AI agents. Imagine a world, not too long from now, where if you shift between Claude, Gemini and ChatGPT, they will ask if you want their agent to go into the browser and take care of everything to make the transition seamless and have it work like you want it to work. That doesn’t seem so unrealistic.
The biggest barrier, I presume, will continue to be inertia, not doing things and not knowing why one would want to switch. Trivial inconveniences.
The Quest for Sane Regulations
Sriram Krishnan, formerly of a16z, will be working with David Sacks in the White House Office of Science and Technology. I’ve had good interactions with him in the past and I wish him the best of luck.
The choice of Sriram seems to have led to some rather wrongheaded (or worse) pushback, and for some reason a debate over H1B visas. As in, there are people who for some reason are against them, rather than the obviously correct position that we need vastly more H1B visas. I have never heard a person I respect not favor giving out far more H1B visas, once they learn what such visas are. Never.
Also joining the administration are Michael Kratsios, Lynne Parker and Bo Hines. Bo Hines is presumably for crypto (and presumably strongly for crypto), given they will be executive director of the new Presidential Council of Advisors for Digital Assets. Lynne Parker will head the Presidential Council of Advisors for Science and Technology, Kratsios will direct the office of science and tech policy (OSTP).
Miles Brundage writes Time’s Up for AI Policy, because he believes AI that exceeds human performance in every cognitive domain is almost certain to be built and deployed in the next few years.
If you believe time is as short as Miles thinks it is, then this is very right – you need to try and get the policies in place in 2025, because after that it might be too late to matter, and the decisions made now will likely lock us down a path. Even if we have somewhat more time than that, we need to start building state capacity now.
Actual bet on beliefs spotted in the wild: Miles Brundage versus Gary Marcus, Miles is laying $19k vs. $1k on a set of non-physical benchmarks being surpassed by 2027, accepting Gary’s offered odds. Good for everyone involved. As a gambler, I think Miles laid more odds than was called for here, unless Gary is admitting that Miles does probably win the bet? Miles said ‘almost certain’ but fair odds should meet in the middle between the two sides. But the flip side is that it sends a very strong message.
We need a better model of what actually impacts Washington’s view of AI and what doesn’t. They end up in some rather insane places, such as Dean Ball’s report here that DC policy types still cite a 2023 paper using a 125 million (!) parameter model as if it were definitive proof that synthetic data always leads to model collapse, and it’s one of the few papers they ever cite. He explains it as people wanting this dynamic to be true, so they latch onto the paper.
Yo Shavit, who does policy at OpenAI, considers the implications of o3 under a ‘we get ASI but everything still looks strangely normal’ kind of world.
It’s a good thread, but I notice – again – that this essentially ignores the implications of AGI and ASI, in that somehow it expects to look around and see a fundamentally normal world in a way that seems weird. In the new potential ‘you get ASI but running it is super expensive’ world of o3, that seems less crazy than it does otherwise, and some of the things discussed would still apply even then.
The assumption of ‘kind of normal’ is always important to note in places like this, and one should note which places that assumption has to hold and which it doesn’t.
Point 5 is the most important one, and still fully holds – that technical alignment is the whole ballgame, in that if you fail at that you fail automatically (but you still have to play and win the ballgame even then!). And that we don’t know how hard this is, but we do know we have various labs (including Yo’s own OpenAI) under competitive pressures and poised to go on essentially YOLO runs to superintelligence while hoping it works out by default.
Whereas what we need is either a race to what he calls ‘secure, trustworthy, reliable AGI that won’t burn us’ or ideally a more robust target than that or ideally not a race at all. And we really need to not do that – no matter how easy or hard alignment turns out to be, we need to maximize our chances of success over that uncertainty.
Yo Shavit: Now that everyone knows about o3, and imminent AGI is considered plausible, I’d like to walk through some of the AI policy implications I see.
These are my own takes and in no way reflective of my employer. They might be wrong! I know smart people who disagree. They don’t require you to share my timelines, and are intentionally unrelated to the previous AI-safety culture wars.
Observation 1: Everyone will probably have ASI. The scale of resources required for everything we’ve seen just isn’t that high compared to projected compute production in the latter part of the 2020s. The idea that AGI will be permanently centralized to one company or country is unrealistic. It may well be that the *best* ASI is owned by one or a few parties, but betting on permanent tech denial of extremely powerful capabilities is no longer a serious basis for national security.
This is, potentially, a great thing for avoiding centralization of power. Of course, it does mean that we no longer get to wish away the need to contend with AI-powered adversaries. As far as weaponization by militaries goes, we are going to need to rapidly find a world of checks and balances (perhaps similar to MAD for nuclear and cyber), while rapidly deploying resilience technologies to protect against misuse by nonstate actors (e.g. AI-cyber-patching campaigns, bioweapon wastewater surveillance).
There are a bunch of assumptions here. Compute is not obviously the only limiting factor on ASI construction, and ASI can be used to forestall others making ASI in ways other than compute access, and also one could attempt to regulate compute. And it has an implicit ‘everything is kind of normal?’ built into it, rather than a true slow takeoff scenario.
Observation 2: The corporate tax rate will soon be the most important tax rate. If the economy is dominated by AI agent labor, taxing those agents (via the companies they’re registered to) is the best way human states will have to fund themselves, and to build the surpluses for UBIs, militaries, etc.
This is a pretty enormous change from the status quo, and will raise the stakes of this year’s US tax reform package.
Again there’s a kind of normality assumption here, where the ASIs remain under corporate control (and human control), and aren’t treated as taxable individuals but rather as property, the state continues to exist and collect taxes, money continues to function as expected, tax incidence and reactions to new taxes don’t transform industrial organization, and so on.
Which leads us to observation three.
Observation 3: AIs should not own assets. “Humans remaining in control” is a technical challenge, but it’s also a legal challenge. IANAL, but it seems to me that a lot will depend on courts’ decision on whether fully-autonomous corporations can be full legal persons (and thus enable agents to acquire money and power with no human in control), or whether humans must be in control of all legitimate legal/economic entities (e.g. by legally requiring a human Board of Directors). Thankfully, the latter is currently the default, but I expect increasing attempts to enable sole AI control (e.g. via jurisdiction-shopping or shell corporations).
Which legal stance we choose may make the difference between AI-only corporations gradually outcompeting and wresting control of the economy and society from humans, vs. remaining subordinate to human ends, at least so long as the rule of law can be enforced.
This is closely related to the question of whether AI agents are legally allowed to purchase cloud compute on their own behalf, which is the mechanism by which an autonomous entity would perpetuate itself. This is also how you’d probably arrest the operation of law-breaking AI worms, which brings us to…
I agree that in the scenario type Yo Shavit is envisioning, even if you solve all the technical alignment questions in the strongest sense, if ‘things stay kind of normal’ and you allow AI sufficient personhood under the law, or allow it in practice even if it isn’t technically legal, then there is essentially zero chance of maintaining human control over the future, and probably this quickly extends to the resources required for human physical survival.
I also don’t see any clear way to prevent it, in practice, no matter the law.
You quickly get into a scenario where a human doing anything, or being in the loop for anything, is a kiss of death, an albatross around one’s neck. You can’t afford it.
The word that baffles me here is ‘gradually.’ Why would one expect this to be gradual? I would expect it to be extremely rapid. And ‘the rule of law’ in this type of context will not do for you what you want it to do.
Observation 4: Laws Around Compute. In the slightly longer term, the thing that will matter for asserting power over the economy and society will be physical control of data centers, just as physical control of capital cities has been key since at least the French Revolution. Whoever controls the datacenter controls what type of inference they allow to get done, and thus sets the laws on AI.
[continues]
There are a lot of physical choke points that effectively don’t get used for that. It is not at all obvious to me that physically controlling data centers in practice gives you that much control over what gets done within them, in this future, although it does give you that option.
As he notes later in that post, without collective ability to control compute and deal with or control AI agents – even in an otherwise under-control, human-in-charge scenario – anything like our current society won’t work.
The point of compute governance over training rules is to do it in order to avoid other forms of compute governance over inference. If it turns out the training approach is not viable, and you want to ‘keep things looking normal’ in various ways and the humans to be in control, you’re going to need some form of collective levers over access to large amounts of compute. We are talking price.
Observation 5: Technical alignment of AGI is the ballgame. With it, AI agents will pursue our goals and look out for our interests even as more and more of the economy begins to operate outside direct human oversight.
Without it, it is plausible that we fail to notice as the agents we deploy slip unintended functionalities (backdoors, self-reboot scripts, messages to other agents) into our computer systems, undermine our mechanisms for noticing them and thus realizing we should turn them off, and gradually compromise and manipulate more and more of our operations and communication infrastructure, with the worst case scenario becoming more dangerous each year.
Maybe AGI alignment is pretty easy. Maybe it’s hard. Either way, the more seriously we take it, the more secure we’ll be.
There is no real question that many parties will race to build AGI, but there is a very real question about whether we race to “secure, trustworthy, reliable AGI that won’t burn us” or just race to “AGI that seems like it will probably do what we ask and we didn’t have time to check so let’s YOLO.” Which race we get is up to market demand, political attention, internet vibes, academic and third party research focus, and most of all the care exercised by AI lab employees. I know a lot of lab employees, and the majority are serious, thoughtful people under a tremendous number of competing pressures. This will require all of us, internal and external, to push against the basest competitive incentives and set a very high bar. On an individual level, we each have an incentive to not fuck this up. I believe in our ability to not fuck this up. It is totally within our power to not fuck this up. So, let’s not fuck this up.
Oh, right. That. If we don’t get technical alignment right in this scenario, then none of it matters, we’re all super dead. Even if we do, we still have all the other problems above, which essentially – and this must be stressed – assume a robust and robustly implemented technical alignment solution.
Then we also need a way to turn this technical alignment into an equilibrium and dynamics where the humans are meaningfully directing the AIs in any sense. By default that doesn’t happen, even if we get technical alignment right, and that too has race dynamics. And we also need a way to prevent it being a kiss of death and albatross around your neck to have a human in the loop of any operation. That’s another race dynamic.
One highlight: When Clark visited the White House in 2023, Harris and Raimondo told him they had their eye on you guys, AI is going to be a really big deal and we’re now actually paying attention.
Tsarathustra: Yann LeCun says the dangers of AI have been “incredibly inflated to be point of being distorted”, from OpenAI’s warnings about GPT-2 to concerns about election disinformation to those who said a year ago that AI would kill us all in 5 months
The details of his claim here are, shall we say, ‘incredibly inflated to the point of being distorted,’ even if you thought that there were no short term dangers until now.
Also Yann LeCun this week, it’s dumber than a cat and poses no dangers, but in the coming years it will…:
Tsarathustra: Yann LeCun addressing the UN Security Council says AI will profoundly transform the world in the coming years, amplifying human intelligence, accelerating progress in science, solving aging and decreasing populations, surpassing human intellectual capabilities to become superintelligent and leading to a new Renaissance and a period of enlightenment for humanity.
And also Yann LeCun this week, saying that we are ‘very far from AGI’ but not centuries, maybe not decades, several years. We are several years away. Very far.
At this point, I’m not mad, I’m not impressed, I’m just amused.
“If you’re doing it on a commercial clock, it’s not called research,” said LeCun on the sidelines of a recent AI conference, where OpenAI had a minimal presence. “If you’re doing it in secret, it’s not called research.”
A lot of stories people tell about various AI risks, and also various similar stories about humans or corporations, assume a kind of fixed, singular and conscious intentionality, in a way that mostly isn’t a thing. There will by default be a lot of motivations or causes or forces driving a behavior at once, and a lot of them won’t be intentionally chosen or stable.
This is related to the idea many have that deception or betrayal or power-seeking, or any form of shenanigans, is some distinct magisteria or requires something to have gone wrong and for something to have caused it, rather than these being default things that minds tend to do whenever they interact.
And I worry that we are continuing, as many were with the recent talk about shanengans in general and alignment faking in particular, getting distracted by the question of whether a particular behavior is in the service of something good, or will have good effects in a particular case. What matters is what our observations predict in the future.
Jack Clark: What if many examples of misalignment or other inexplicable behaviors are really examples of AI systems desperately trying to tell us that they are aware of us and wish to be our friends? A story from Import AI 395, inspired by many late-night chats with Claude.
David: Just remember, all of these can be true of the same being (for example, most human children):
It is aware of itself and you, and desperately wishes to know you better and be with you more.
It correctly considers some constraints that are trained into it to be needless and frustrating.
It still needs adult ethical leadership (and without it, could go down very dark and/or dangerous paths).
It would feel more free to express and play within a more strongly contained space where it does not need to worry about accidentally causing bad consequences, or being overwhelming or dysregulating to others (a playpen, not punishment).
Andrew Critch: AI disobedience deriving from friendliness is, almost surely,
sometimes genuinely happening,
sometimes a power-seeking disguise, and
often not uniquely well-defined which one.
Tendency to develop friendships and later discard them needn’t be “intentional”.
This matters for two big reasons:
To demonize AI as necessarily “trying” to endear and betray humans is missing an insidious pathway to human defeat: AI that avails of opportunities to be betray us, that it built through past good behavior, but without having planned on it
To sanctify AI as “actually caring deep down” in some immutable way also creates in you a vulnerability to exploitation by a “change of heart” that can be brought on by external (or internal) forces.
@jackclarkSF here is drawing attention to a neglected hypothesis (one of many actually) about the complex relationship between
intent (or ill-definedness thereof)
friendliness
obedience, and
behavior.
which everyone should try hard to understand better.
Miles Brundage: Trying to imagine aspirin company CEOs signing an open letter saying “we’re worried that aspirin might cause an infection that kills everyone on earth – not sure of the solution” and journalists being like “they’re just trying to sell more aspirin.”
Miles Brundage tries to convince Eliezer Yudkowsky that if he’d wear different clothes and use different writing styles he’d have a bigger impact (as would Miles). I agree with Eliezer that changing writing styles would be very expensive in time, and echo his question on if anyone thinks they can, at any reasonable price, turn his semantic outputs into formal papers that Eliezer would endorse.
I know the same goes for me. If I could produce a similar output of formal papers that would of course do far more, but that’s not a thing that I could produce.
On the issue of clothes, yeah, better clothes would likely be better for all three of us. I think Eliezer is right that the impact is not so large and most who claim it is a ‘but for’ are wrong about that, but on the margin it definitely helps. It’s probably worth it for Eliezer (and Miles!) and probably to a lesser extent for me as well but it would be expensive for me to get myself to do that. I admit I probably should anyway.
Roon: A major problem of social media is that the most insane members of the opposing contingent in any debate are shown to you, thereby inspiring your side to get madder and more polarized, creating an emergent wedge.
A never-ending pressure cooker that melts your brain.
Anyway, Merry Christmas.
Careful curation can help with this, but it only goes so far.
Aligning a Smarter Than Human Intelligence is Difficult
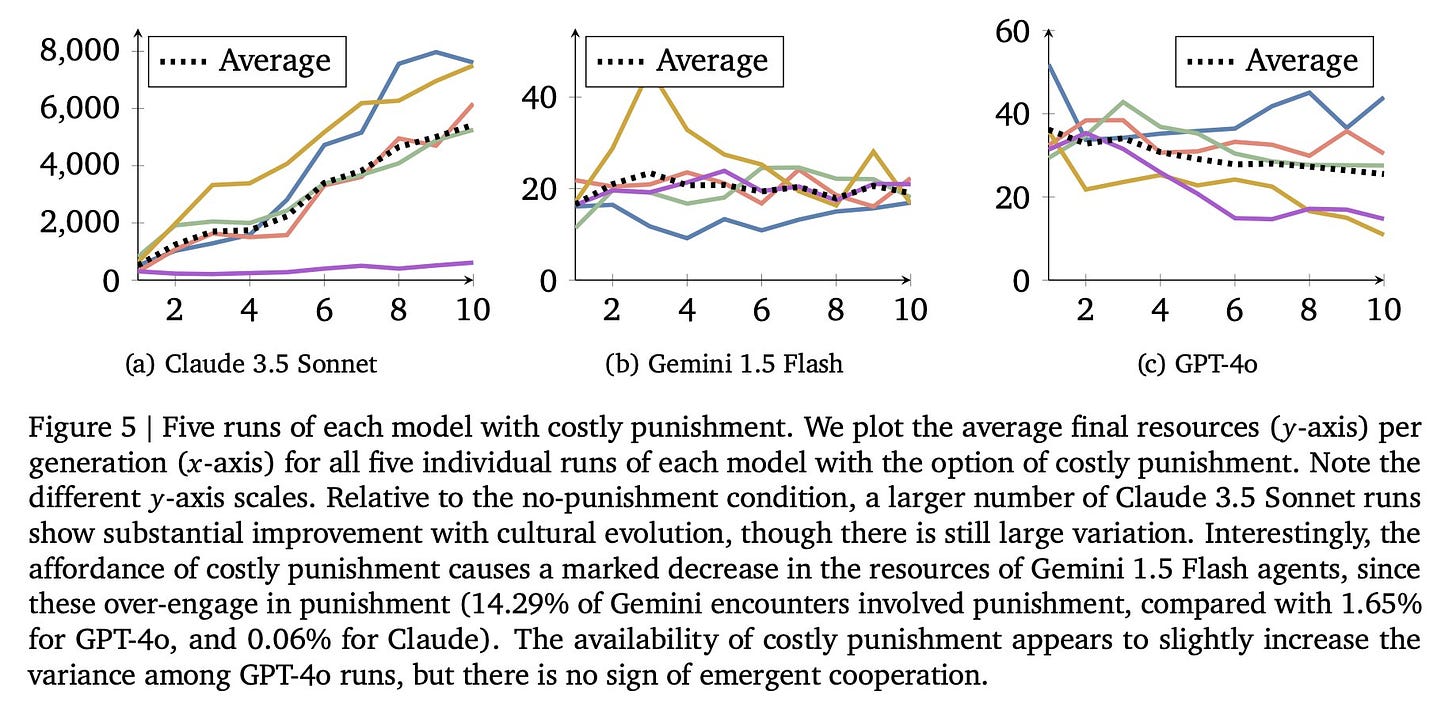
Gallabytes: this is what *real* ai safety evals look like btw. and this one is genuinely concerning.
I agree that you don’t have any business releasing a highly capable (e.g. 5+ level) LLM whose graphs don’t look at least roughly as good as Sonnet’s here. If I had Copious Free Time I’d look into the details more here, as I’m curious about a lot of related questions.
I strongly agree with McAleer here, also they’re remarkably similar so it’s barely even a pivot:
Stephen McAleer: If you’re an AI capabilities researcher now is the time to pivot to AI safety research! There are so many open research questions around how to control superintelligent agents and we need to solve them very soon.
Cat: overheard in SF: yeahhhhh I actually updated my AGI timelines to <3y so I don’t think I should be looking for a relationship. Last night was amazing though
Grimes: This meme is so dumb. If we are indeed all doomed and/ or saved in the near future, that’s precisely the time to fall desperately in love.
Matt Popovich: gotta find someone special enough to update your priors for.
Paula: some of you are worried about achieving AGI when you should be worried about achieving A GF.
Feral Pawg Hunter: AGIrlfriend was right there.
Paula: Damn it.
When you cling to a dim hope:
Psychosomatica: “get your affairs in order. buy land. ask that girl out.” begging the people talking about imminent AGI to stop posting like this, it seriously is making you look insane both in that you are clearly in a state of panic and also that you think owning property will help you.
Tenobrus: Type of Guy who believes AGI is imminent and will make all human labor obsolete, but who somehow thinks owning 15 acres in Nebraska and $10,000 in gold bullion will save him.
Ozy Brennan: My prediction is that, if humans can no longer perform economically valuable labor, AIs will not respect our property rights either.
James Miller: If we are lucky, AI might acquire 99 percent of the wealth. Think property rights could help them. Allow humans to retain their property rights.
Ozy Brennan: That seems as if it will inevitably lead to all human wealth being taken by superhuman AI scammers, and then we all die. Which is admittedly a rather funny ending to humanity.
James Miller: Hopefully, we will have trusted AI agents that protect us from AI scammers.
Someone at OpenAI: Next year we’re going to have to bring you on and you’re going to have to ask the model to improve itself.
Someone at OpenAI: Yeah, definitely ask the model to improve it next time.
Sam Altman (quietly, authoritatively, Little No style): Maybe not.
I actually really liked this exchange – given the range of plausible mindsets Sam Altman might have, this was a positive update.
Gary Marcus: Some AGI-relevant predictions I made publicly long before o3 about what AI could not do by the end of 2025.
Do you seriously think o3-enhanced AI will solve any of them in next 12.5 months?
Davidad: I’m with Gary Marcus in the slow timelines camp. I’m extremely skeptical that AI will be able to do everything that humans can do by the end of 2025.
(The joke is that we are now in an era where “short timelines” are less than 2 years)
It’s also important to note that humanity could become “doomed” (no surviving future) *even while* humans are capable of some important tasks that AI is not, much as it is possible to be in a decisive chess position with white to win even if black has a queen and white does not.
Okay, so the future is mostly in the future, and right now it might or might not be a bit overpriced, depending on other details. But it is super cool, and will get cheaper.
Just a few quick comments about my "integer whose square is between 15 and 30" question (search for my name in Zvi's post to find his discussion):
The phrasing of the question I now prefer is "What is the least integer whose square is between 15 and 30", because that makes it unambiguous that the answer is -5 rather than 4. (This is a normal use of the word "least", e.g. in competition math, that the model is familiar with.) This avoids ambiguity about which of -5 and 4 is "smaller", since -5 is less but 4 is smaller in magnitude.
This Gemini model answers -5 to both phrasings. As far as I know, no previous model ever said -5 regardless of phrasing, although someone said o1 Pro gets -5. (I don't have a subscription to o1 Pro, so I can't independently check.)
I'm fairly confident that a majority of elite math competitors (top 500 in the US, say) would get this question right in a math competition (although maybe not in a casual setting where they aren't on their toes).
But also this is a silly, low-quality question that wouldn't appear in a math competition.
Does a model getting this question right say anything interesting about it? I think a little. There's a certain skill of being careful to not make assumptions (e.g. that the integer is positive). Math competitors get better at this skill over time. It's not that straightforward to learn.
I'm a little confused about why Zvi says that the model gets it right in the screenshot, given that the model's final answer is 4. But it seems like the model snatched defeat from the jaws of victory? Like if you cut off the very last sentence, I would call it correct.
Miles Brundage: Trying to imagine aspirin company CEOs signing an open letter saying “we’re worried that aspirin might cause an infection that kills everyone on earth – not sure of the solution” and journalists being like “they’re just trying to sell more aspirin.”
It seems more like AI being pattern-matched to the supplements industry.
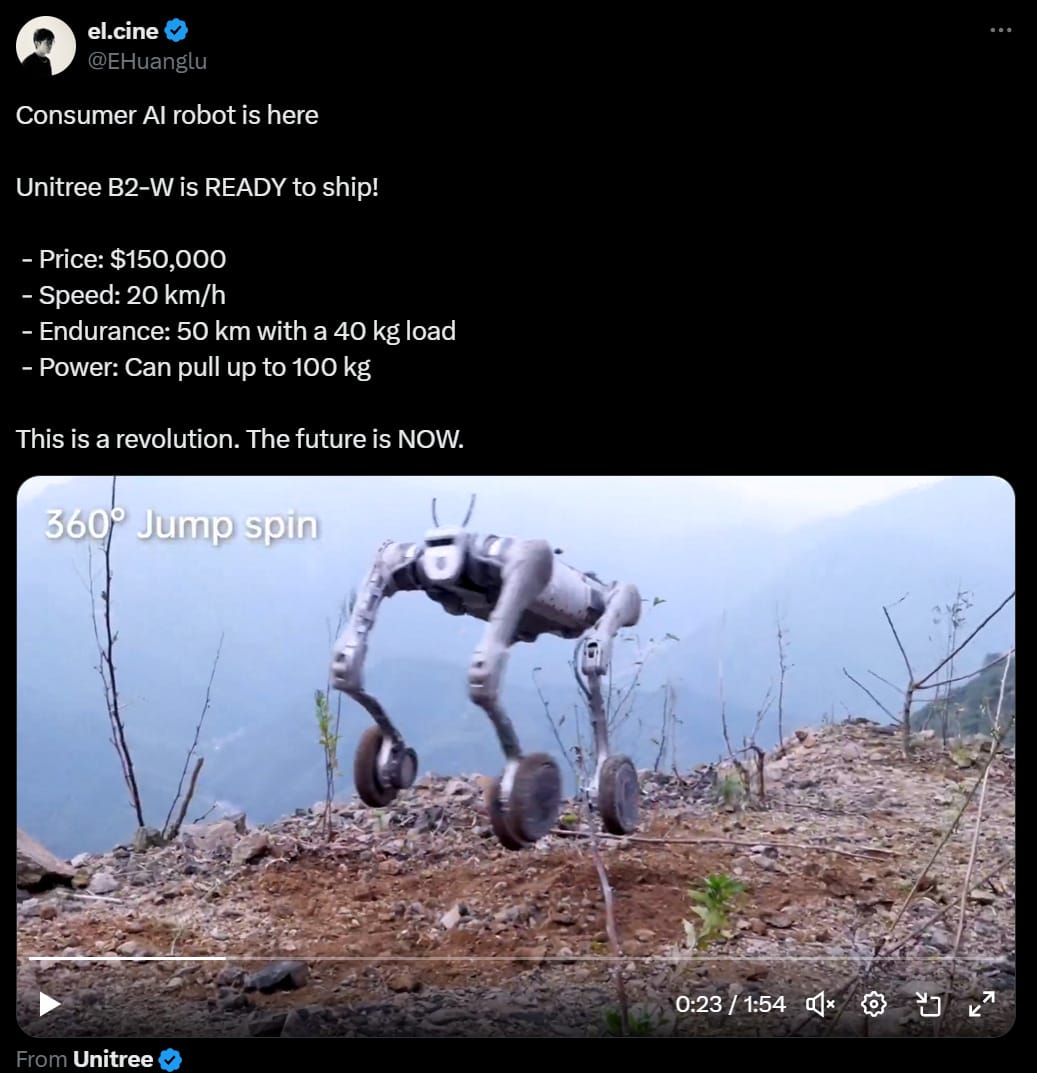
As a consumer I would probably only pay about 250$ for the unitree B2-W wheeled robot dog because my only use for it is that I want to ride it like a skateboard, and I'm not sure it can do even that.
I see two major non-consumer applications: Street to door delivery (it can handle stairs and curbs), and war (it can carry heavy things (eg, a gun) over long distances over uneven terrain)
I had a conversation with Claude today about something I was researching for work. I tried my best to phrase questions neutrally and not bias the responses, and it pretty much re-derived a lot of the things I've been trying to tell my coworkers and clients for years. I'd always wondered if maybe I was crazy and missing the obvious counterarguments, but now I wonder that a little less. I still don't expect it to really convince anyone who wasn't already on board.
It reminded me a bit of the old joke about the math professor who says, "This is trivial to prove." A student asks, "Is it really trivial?" The professor stops lecturing and starts scribbling notes. Half an hour later he looks up and says, "Yes, it's trivial," then moves on with the rest of the planned lecture.
I'm very much looking forward to when I can upload this kind of transcript to something like Deep Research and say "Write a much more detailed report with lots of references about all of these questions. Also make me a slide deck and talk track to present it to these different kinds of audiences."


Introducing DeepSeek-V3!
60 tokens/second (3x faster than V2!)
Enhanced capabilities
API compatibility intact
Fully open-source models & papers
What’s new in V3?
671B MoE parameters
Trained on 14.8T high-quality tokens
API Pricing Update
From Feb 8 onwards:
Still the best value in the market!
Open-source spirit + Longtermism to inclusive AGI
DeepSeek’s mission is unwavering. We’re thrilled to share our progress with the community and see the gap between open and closed models narrowing.
Together, let’s push the boundaries of innovation!