90% of anything should be bad (& the precision-recall tradeoff)
post by cartografie · 2022-09-08T01:20:56.170Z · LW · GW · 22 commentsContents
Introduction The precision-recall tradeoff Signal Detection Theory The Promising Threshold Optimising the Promising Threshold Applying Sturgeon's Edict Why do people publish too conservatively? FP is more salient than FN TP is more salient than FP Hindsight bias Poorly-calibrated heuristics Some practical recommendations None 22 comments
Introduction
Sturgeon’s Law states that 90% of anything is crap.
So 90% of sci-fi books are crap,
and 90% of medical research,
and 90% of jazz solos,
and 90% of LessWrong posts.
Etc, etc — 90% of anything is crap.
Now, people usually interpret Sturgeon’s Law pessimistically.
“What a shame!” people think, “If only all the sci-fi books were great! And all the medical research, jazz solos, LessWrong posts, etc etc.”
I think these people are mistaken. 90% of anything should be crap. In this article, I will explain why.

The precision-recall tradeoff
Imagine one day you read a brilliant poem, and you decide to read the poet’s complete works. If you discover that every poem she ever wrote was brilliant, how might you feel about that?
Well, you might feel a little depressed. If the poet — let’s call her Alice — only published brilliant poems, then there are probably dozens of brilliant poems that she left unpublished. She could only have maintained a perfect track-record by being so conservative that a lot of brilliant work was lost forever.
We can make this slightly more formal using Signal Detection Theory.
Signal Detection Theory
When Alice publishes a good poem, that's a true-positive.
When Alice publishes a bad poem, that's a false-positive.
When Alice rejects a good poem, that's a false-negative.
When Alice rejects a bad poem, that's a true-negative.
We can define two measures of how wisely Alice publishes her work:
- Precision = is the proportion of her published poems which are good.
- Recall = is the proportion of her good poems which are published.
High precision means that most of her published poems are good, whether or not her unpublished poems are good as well. High recall means that most of her good poems are published, whether or not her bad poems are published as well.
There is often a tradeoff between precision and recall. Alice can only increase one at the cost of decreasing the other. If Alice published more conservatively, then she’d achieve lower recall (boo! less good poems!), but she’d also achieve higher precision (yay! less bad poems!). If Alice published more liberally, then she’d achieve lower precision (boo! more bad poems!), but she’d also achieve higher recall (yay! more good poems!).
In the next section, I will explain the origin of the tradeoff.
The Promising Threshold
Some of Alice’s poems are more promising than others, i.e. they have a higher likelihood of being good. Suppose Alice writes down her poems in descending promisingness, and let be the likelihood that the th most promising poem is good.
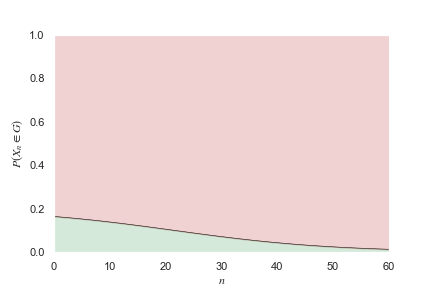
Alice will publish any poem which has more than likelihood of being good, where is her promising threshold. If is small then Alice publishes liberally, and if is large then Alice publishes conservatively.
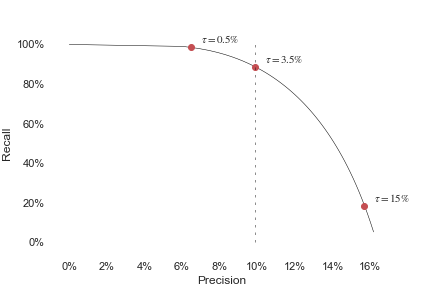
In the graph below, the green area shows her good poems and the red area shows her bad poems. The dark area shows her published poems, and the light area shows her rejected poems. The four areas represent in clockwise order.
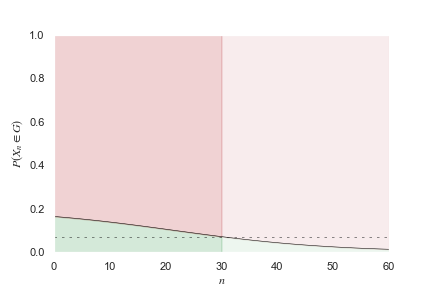
By squinting at the graph, you can see that if Alice increases then there are fewer false-positives and more false-negatives, whereas if Alice decreases then there are fewer false-negatives and more false-positives.
Moreover, if Alice increases then precision increases and recall decreases, whereas if Alice decreases then precision decreases and recall increases. Note that in general, precision will be higher than .
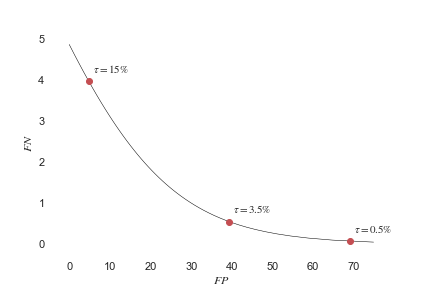
Optimising the Promising Threshold
The optimal value for is determined by the relative cost between false-negatives and false-positives. If false-negatives are much costlier than false-positives, then recall should be higher than precision. Otherwise, if false-positives are much costlier than false-negatives, precision should be higher than recall.
Consider the poem which has chance of being good and chance of being bad. If Alice rejects the poem, then she can expect a cost of , where is the cost of each false-negative. If Alice publishes the poem, then she can expect a cost of , where is the cost of each false-positive. Alice should publish if and only if the expected cost of rejection is greater than the expected cost of publishing. This holds when , or equivalently when .
So the optimal promising threshold .
But what actually are the relative costs of a false-positive and a false-negative? What do we actually care about here? Well, we mostly care about publishing good poems, regardless of whether a few bad poems sneak past. Publishing a bad poem might be annoying, but it’s ultimately harmless. In contrast, rejecting a great poem would be a tragedy.
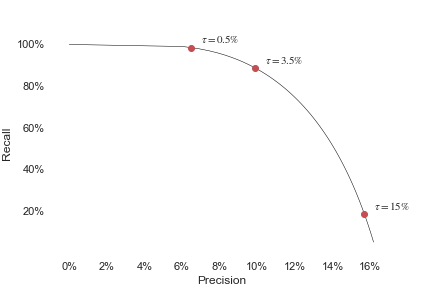
is small, so (surprisingly) precision should be low. For poetry, I claim precision should be about 10%, and likewise for sci-fi books, medical research, jazz solos, LessWrong posts, etc.
In other words, ninety percent of anything should be crap.
I call this “Sturgeon’s Edict”. Whereas Sturgeon’s Law is descriptive, Sturgeon’s Edict is prescriptive. If more than 10% of sci-fi books were good, Sturgeon's Edict would mandate that the industry published more liberally.
Applying Sturgeon's Edict
- If you design nuclear reactors, then Sturgeon's Edict doesn't apply. A false-positive is very costly, so you need a much higher precision than 10%. You need to be precision-maxxing.
- If you're a sci-fi author, or a jazz soloist, or LessWrong poster, or a nature photographer, or something like that, then Sturgeon's Edict definitely applies, because a false-negative is much costlier than a false-positive. If your precision is above 10%, then you are probably rejecting good work. You need to be recall-maxxing.
- Suppose you're Franz Kafka on your deathbed. You never managed to finish any of your full-length novels. Should you instruct your friend to burn your surviving manuscripts?
Well, against Kafka's explicit instructions, his manuscripts were actually published. Most of his writings weren't very good, but some were brilliant, and low precision is exactly what Sturgeon's Edict recommends. So Kafka shouldn't have asked his friend to burn his manuscripts — he should've been recall-maxxing, not precision-maxxing.
- Suppose you’re Michaelangelo carving a marble sculpture for the Tomb of Pope Julius II. You're halfway through carving when the pope changes his mind. Should you finish the sculpture anyway?
This is borderline case of Sturgeon's Edict, because it would take considerable effort to finish the sculpture, so the cost of a false-positive isn’t negligible.
- Sturgeon’s Edict doesn’t always recommend publishing more liberally.
Consider the Library of Babel. This is a collection of books containing every possible page of 3200 characters. The library has almost 100% recall because every great idea can be found somewhere in the library. However, the library has almost 0% precision, because almost every page in the library is meaningless gibberish.
Because the library has 0% precision, it’s completely useless for finding great ideas. So you can go too far in recall-maxxing! A library would be functional if it followed Sturgeon’s Edict, and had a precision of 10% rather than 0%.


Why do people publish too conservatively?
Here are four plausible explanations of why people might publish too conservatively, in violation of Sturgeon's Edict.
FP is more salient than FN
Alice only ever sees the published poems of other poets, not their unpublished poems. So when someone publishes a bad poem, that’s a visible blunder, but when someone rejects a great poem, that’s an invisible tragedy. So false-positives are more salient to Alice than false-negatives.
Because she focuses on salient costs, Alice publishes too conservatively.
TP is more salient than FP
Alice remembers the great poems that other poets published but forgets their bad poems, so true-positives are more salient to her than false-positives. Therefore she overestimates the precision of other poets.
Because she tries to copy that precision, she publishes too conservatively.
Hindsight bias
When Alice reads a great poem, she overestimates how sure the poet would've been that the poem was great. Likewise, when she reads a bad poem, she overestimates how sure the poet would've been that the poem was bad. This is called the Hindsight Bias [LW · GW].
So Alice assumes that, had the poet published more conservatively, only the bad poems would’ve been weeded out. A cautious poet still would’ve published the great poems, because they were predictably great.
Because she underestimates its harm, she publishes too conservatively.
Poorly-calibrated heuristics
In the ancestral environment, false-positives were costlier than they are today. It was more difficult to store information, communicate information, and search information — and therefore people had to be sure they were publishing something good.
Although this behaviour was well-calibrated to the ancestral environment, it's poorly-calibrated to the contemporary environment. Modern technology has lowered the cost of storing, communicating, and searching information by many orders of magnitude, so the cost of a false-positive is negligible.
Because Alice's behaviour is poorly-calibrated, she publishes too conservatively.
Some practical recommendations
- If the cost of a false-positive is negligible, then publish.
- It will be easier to follow Sturgeon’s Edict if you always remember — perfectionism is an ego problem.
- "But what if I haven’t yet overcome my ego problem? I don't want to publish bad work."
I would recommend that you publish your less promising work anonymously. Or pseudonymously. This way your track-record doesn’t drop, but the work still gets published. You can always claim ownership later if the work is well-received.
- A perfect track-record is a dangerous thing. Maybe you should publish something terrible so you overcome the mental hurdle of that first imperfection.
- Go through your drafts. If you know you won't improve the draft, publish it now. If it's really worthless, then maybe publish the draft as a twitter thread.

22 comments
Comments sorted by top scores.
comment by ChristianKl · 2022-09-08T09:25:39.976Z · LW(p) · GW(p)
Good and bad are also very relative terms. When it comes to LessWrong posts, some posts are about a narrow domain of knowledge that's useful to a small number of people but very useful to them. When those posts receive little upvotes, that's no sign that they aren't valuable posts that shouldn't have been published.
Replies from: M. Y. Zuo, cartografie↑ comment by M. Y. Zuo · 2022-09-11T20:57:04.126Z · LW(p) · GW(p)
The upvote counter right now is pretty meaningless in terms of determining quality. Some of the best posts I’ve read were very controversial and had low upvote counters but attracted many comments, whereas some of the most insipid I’ve read had high upvote counters but whose comments consisted mostly of applause lights.
If we could see the total number of upvotes and downvotes then that would be more insightful.
A post with 200 upvotes and 195 downvotes would likely be more worthy of attention than a post with 50 upvotes and 5 downvotes
↑ comment by habryka (habryka4) · 2022-09-11T21:32:42.583Z · LW(p) · GW(p)
You can! Just hover over the vote and you can see the current number of votes (it doesn't break it down by upvote and downvote, but it's usually pretty obvious from the total number).
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-09-14T01:03:06.767Z · LW(p) · GW(p)
Doesn't seem so. Sometimes the shown counter is higher than the number of 'votes'. Maybe by 'votes' it's showing the total number of users who voted (with varying voting weights)?
Replies from: habryka4↑ comment by habryka (habryka4) · 2022-09-14T07:16:55.085Z · LW(p) · GW(p)
Yep, it's showing the total number of users who voted (or like, the number of upvotes and downvotes, though my sense is we are using those words slightly differently). I agree that there is no way to see things broken down by points, though my sense is people can usually guess pretty well the distribution of upvotes and downvotes.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-09-14T12:44:16.943Z · LW(p) · GW(p)
Well when it says 'This comment has x overall karma (x-2 Vote)' I'm fairly certain x-2 is not revealing much about the number of upvotes and downvotes, since I can't guess how many were 3 weighted upvotes, 2 weighted upvotes, 1 weighted upvotes, 3 weighted downvotes, etc...
Replies from: habryka4↑ comment by habryka (habryka4) · 2022-09-14T19:57:23.540Z · LW(p) · GW(p)
Hmm, I might be typical-minding here, but I can usually tell pretty quickly about the distribution, just from priors and combinatorics. Here are some examples:
- Score: 22, votes: 3 => 1 small upvote, 2 strong upvotes from high karma users
- Score: 3, votes 22 => A bit unclear, but probably like 1-3 strong upvotes, 1-3 strong downvotes and then a mixture of small upvotes and downvotes for the rest
- Score -3, votes 4 => Either 3 small downvotes, or 2 small upvotes and 1 strong downvote from a high karma user
There is definitely ambiguity remaining here (which is somewhat intentional in the design for anonymization reasons), but seeing the total number of votes usually really reduces it down to 1 or 2 hypotheses for me on what is happening.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-09-15T03:23:25.981Z · LW(p) · GW(p)
Your first two examples are less ambiguous since the differential is large, but when the differential is small, like my example, or your third example, how do you guess between:
1 strong upvoter, several weak downvoters
1 strong downvoter, several weak upvoters
several strong upvoters and downvoters
etc.?
↑ comment by cartografie · 2022-09-08T16:05:34.691Z · LW(p) · GW(p)
Moreover, even if the post shouldn't have been published with hindsight, that does not entail the post shouldn't have been published without hindsight.
Replies from: ChristianKl↑ comment by ChristianKl · 2022-09-12T09:21:37.983Z · LW(p) · GW(p)
I wrote the last comments because I was talking with someone recently who took the wrong signal from the fact that their post wasn't upvoted much. They were valuable posts but only to a very specific subset of the LessWrong audience.
comment by ryan_b · 2022-09-08T14:38:19.511Z · LW(p) · GW(p)
Upvoted, because I think this a naturally interesting topic and is always relevant on LessWrong. I particularly like the threshold optimization section - it is accessible for people who aren't especially advanced in math, and sacrifices little in terms of flow and readability for the rigor gains.
I don't agree that the cost of a false-positive is negligible in general. In order for that to be true, search would have to be reliable and efficient, which among other things means we would need to know what brilliant looked like, in searchable terms, before we found it. This has not been my experience in any domain I have encountered; by contrast it reliably takes me years of repeated searches to refine down to being able to identify the brilliant stuff. It appears to me that search grants access to the best stuff eventually, but doesn't do a good job of making the best stuff easy to find. That's the job of a filter (or curator).
A second objection is that false positives can easily be outright harmful. For example, consider history: the 90% crap history is factually wrong along dimensions running from accidentally repeating defunct folk wisdom to deliberate fabrications with malicious intent. Crap history directly causes false beliefs, which is very different from bad poetry which is at worst aesthetically repulsive. Crap medical research, which I think in Sturgeon's sense would include things like anti-vaccine websites and claims that essential oils cure cancer, cause beliefs that directly lead to suffering and death. This is weirdly also a search problem, since it is much easier for everyone to access the worst things which are free, and the best things are normally gated behind journals or limited-access libraries.
On reflection, I conclude that the precision-recall tradeoff varies based on subject, and also separately based on search, and that both types of variance are large.
Replies from: ChristianKl, cartografie↑ comment by ChristianKl · 2022-09-08T21:13:48.215Z · LW(p) · GW(p)
Crap medical research, which I think in Sturgeon's sense would include things like anti-vaccine websites and claims that essential oils cure cancer, cause beliefs that directly lead to suffering and death.
I don't think those are examples of medical research in Sturgeon's sense. Outside of "essential oil cure cancer" blogs, half of the published cancer research doesn't replicate and I wouldn't surprised if the majority of the rest is useless for actually doing anything about cancer for other reasons.
↑ comment by cartografie · 2022-09-08T16:29:31.619Z · LW(p) · GW(p)
The precision-recall tradeoff definitely varies from one task to another. I split tasks into "precision-maxxing" (where false-positives are costlier than false-negatives) and "recall-maxxing" (where false-negatives are costlier than false-positives).
I disagree with your estimate of the relative costs in history and in medical research. The truth is that academia does surprisingly well at filtering out the good from the bad.
Suppose I select two medical papers at random — one from the set of good medical papers, and one from the set of crap medical papers. If a wizard offered to permanently delete both papers from reality, that would rarely be a good deal because the benefit of deleting the crap paper is negligible compared to the cost of losing the good paper.
But what if the wizard offered to delete crap papers and one good paper? How large must be before this is a good deal? The minimal acceptable is , so . I'd guess that is at least 30, so is at most 3.5%.
↑ comment by ryan_b · 2022-09-08T20:29:07.954Z · LW(p) · GW(p)
Reviewing the examples in the post again, I think I was confused on first reading. I initially read the nuclear reactor example as being a completed version of the Michaelangelo example, but now I see it clearly includes the harms issue I was thinking about.
I also think that the Library of Babel example contains my search thoughts, just not separated out in the same way as in the Poorly Calibrated Heuristics section.
I'm going to chalk this one up to an oops!
comment by romeostevensit · 2022-09-08T04:22:57.333Z · LW(p) · GW(p)
Quantity over quality is a strong principle that emerged from creativity research. I recommend John Cleese's book on the subject.
comment by Astynax · 2022-09-08T21:19:11.008Z · LW(p) · GW(p)
When Alice rejects a bad poem, that's a true-positive.
I think you meant true-negative?
Replies from: cartografie↑ comment by cartografie · 2022-09-09T12:39:02.441Z · LW(p) · GW(p)
yes, thanks v much. edited.
comment by Thomas Sepulchre · 2022-09-08T14:06:37.842Z · LW(p) · GW(p)
Your conclusion doesn't seem to follow from your proof
You claim that the optimal threshold should be 10%. Assuming this is true, this implies that, for example, Alice should publish any poem which has at least a 10% probability of being good. This doesn't imply that 90% of her poems are bad, actually this seems to imply that strictly less than 10% of her poems are bad. Looking at the second graphe, for example (the one with the four rectangles), you chose a 10% threshold, but about 15% of the poems are good
Replies from: cartografie↑ comment by cartografie · 2022-09-08T16:01:24.012Z · LW(p) · GW(p)
You are correct that precision is (in general) higher than the threshold. So if Alice publishes anything with at least 10% likelihood of being good, then more than 10% of her poems will be good. Whereas, if Alice aims for a precision of 10% then her promising threshold will be less than 10%.
Unless I've made a typo somewhere (and please let me know if I have), I don't claim the optimal promising threshold = 10%. You can see in Graph 5 that I propose a promising threshold of 3.5%, which gives a precision of 10%.
I'll edit the article to dispel any confusion. I was wary of giving exact values for the promising threshold, because yields 10% precision only for these graphs, which are of course invented for illustrative purposes.
↑ comment by Thomas Sepulchre · 2022-09-09T08:10:02.624Z · LW(p) · GW(p)
You're right, my mistake
comment by HoneyTea420 · 2022-09-15T08:02:19.451Z · LW(p) · GW(p)
Sorry if this is obvious and stupid to point out, but when you say "anything", I'm always bothered at where to draw the actual line. It seems like the more specific the thing is, the less this applies:
- 90% of this post is not crap.
- 90% of Tarkovsky movies are not crap.
- 90% of the restaurants in my area are not crap.
- 90% of the people I meet are not crappy or boring.
And so on. Of course, these are filtered examples and maybe most of the unpublished stuff was shit, but I still have a problem with words like "anything/everything/always". That said, I really liked your article, and agree that there's no reason to interpret this stuff pessimistically.
comment by Dave Lindbergh (dave-lindbergh) · 2022-09-08T13:22:57.389Z · LW(p) · GW(p)
10% of things that vary in quality are obviously better than the other 90%.