AI and the Technological Richter Scale
post by Zvi · 2024-09-04T14:00:08.625Z · LW · GW · 9 commentsContents
Defining the Scale The Big Disagreement About Future Generative AI Just Think of the Potential A Perfect 10 Some Arguments Against Transformational AI Brief Notes on Arguments Transformational AI Will Turn Out Fine None 9 comments
The Technological Richter scale is introduced about 80% of the way through Nate Silver’s new book On the Edge.
A full review is in the works (note to prediction markets: this post alone does NOT on its own count as a review, but this counts as part of a future review), but this concept seems highly useful, stands on its own and I want a reference post for it. Nate skips around his chapter titles and timelines, so why not do the same here?
Defining the Scale
Nate Silver, On the Edge (location 8,088 on Kindle): The Richter scale was created by the physicist Charles Richter in 1935 to quantify the amount of energy released by earthquakes.
It has two key features that I’ll borrow for my Technological Richter Scale (TRS). First, it is logarithmic. A magnitude 7 earthquake is actually ten times more powerful than a mag 6. Second, the frequency of earthquakes is inversely related to their Richter magnitude—so 6s occur about ten times more often than 7s. Technological innovations can also produce seismic disruptions.
Let’s proceed quickly through the lower readings of the Technological Richter Scale.
- Like a half-formulated thought in the shower.
- Is an idea you actuate, but never disseminate: a slightly better method to brine a chicken that only you and your family know about.
- Begins to show up in the official record somewhere, an idea you patent or make a prototype of.
- An invention successful enough that somebody pays for it; you sell it commercially or someone buys the IP.
- A commercially successful invention that is important in its category, say, Cool Ranch Doritos, or the leading brand of windshield wipers.
- An invention can have a broader societal impact, causing a disruption within its field and some ripple effects beyond it. A TRS 6 will be on the short list for technology of the year. At the low end of the 6s (a TRS 6.0) are clever and cute inventions like Post-it notes that provide some mundane utility. Toward the high end (a 6.8 or 6.9) might be something like the VCR, which disrupted home entertainment and had knock-on effects on the movie industry. The impact escalates quickly from there.
- One of the leading inventions of the decade and has a measurable impact on people’s everyday lives. Something like credit cards would be toward the lower end of the 7s, and social media a high 7.
- A truly seismic invention, a candidate for technology of the century, triggering broadly disruptive effects throughout society. Canonical examples include automobiles, electricity, and the internet.
- By the time we get to TRS 9, we’re talking about the most important inventions of all time, things that inarguably and unalterably changed the course of human history. You can count these on one or two hands. There’s fire, the wheel, agriculture, the printing press. Although they’re something of an odd case, I’d argue that nuclear weapons belong here also. True, their impact on daily life isn’t necessarily obvious if you’re living in a superpower protected by its nuclear umbrella (someone in Ukraine might feel differently). But if we’re thinking in expected-value terms, they’re the first invention that had the potential to destroy humanity.
- Finally, a 10 is a technology that defines a new epoch, one that alters not only the fate of humanity but that of the planet. For roughly the past twelve thousand years, we have been in the Holocene, the geological epoch defined not by the origin of Homo sapiens per se but by humans becoming the dominant species and beginning to alter the shape of the Earth with our technologies. AI wresting control of this dominant position from humans would qualify as a 10, as would other forms of a “technological singularity,” a term popularized by the computer scientist Ray Kurzweil.
One could quibble with some of these examples. Credit cards as a low 7, below social media, while the VCR is a 6.85 and you get to 6 with a Post-it note? Also one could worry we should condense the lower end of the scale to make room at the top.
Later he puts ‘the blockchain’ in the 7s, and I’m going to have to stop him right there. No. Blockchain is not on par with credit cards or mobile phones (either of which is reasonable at a 7 but a plausible 8), that makes no sense, and it also isn’t more important than (for example) the microwave oven, which he places at 6. Yes, crypto people like to get excited, but everyone chill.
I ran a poll to sanity check this, putting Blockchain up against various 6s.

This was a wipe-out, sufficient that I’m sending blockchain down to at best a low 6.
Claude estimates the microwave has already saved $4.5 trillion in time value alone, and you should multiply that several times over for other factors. The total market cap of Crypto is $2 trillion, that number is super fake given how illiquid so many coins are (and e.g. ~20% of Bitcoin, or 10% of the overall total, likely died with Satoshi and so on). And if you tell me there’s so much other value created, and crypto is going to transform the world, let me find that laugh track.
Microwaves then correctly got crushed when put up against real 7s.
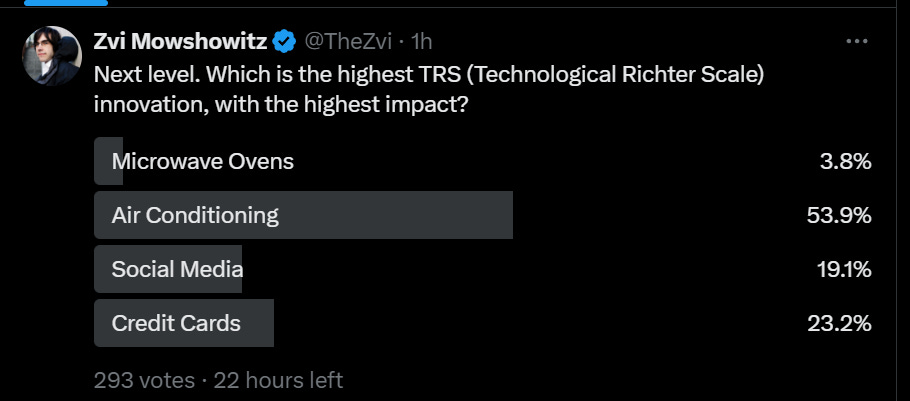
I think this is sleeping on credit cards, at least if you include debit cards. Smooth payment rails are a huge deal. And electricity rather correctly smoked The Internet and automobiles (and air conditioning). This game is fun.
The overall point is also clear.
The Big Disagreement About Future Generative AI
What is the range of plausible scores on this scale for generative AI?
The (unoriginal) term that I have used a few times, for the skeptic case, the AI-fizzle world, is that AI could prove to be ‘only internet big.’ In that scenario, GPT-5-level models are about as good as it gets, and they don’t enable dramatically better things than today’s GPT-4-level models. We then spend a long time getting the most out of what those have to offer.
I think that even if we see no major improvements from there, an 8.0 is already baked in. Counting the improvements I am very confident we can get about an 8.5.
In that scenario, we distill what we already have, costs fall by at least one additional order of magnitude, we build better scaffolding and prompting techniques, we integrate all this into our lives and civilization.
I asked Twitter, how advanced would frontier models have to get, before they were at least Internet Big, or a solid 8?
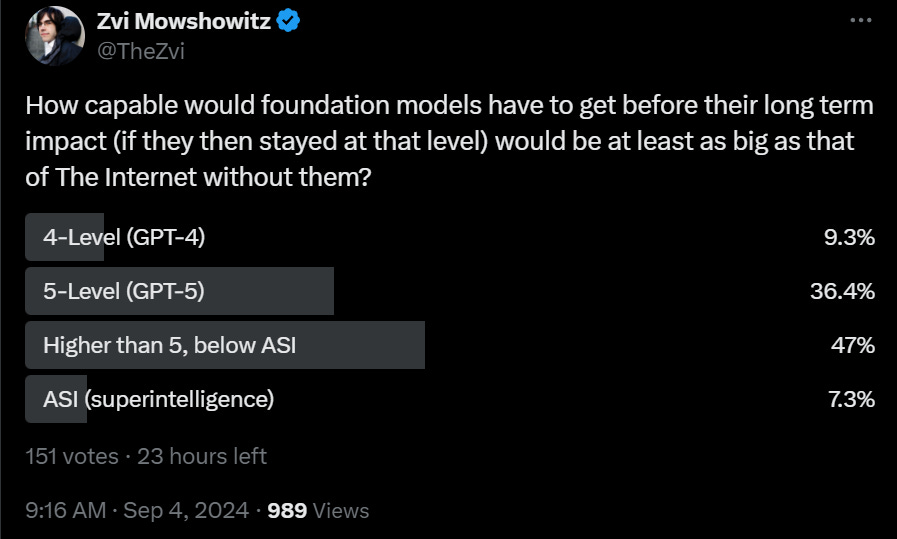
I think that 5-level models, given time to have their costs reduced and to be properly utilized, will inevitably be at least internet big, but only 45% of respondents agreed. I also think that 5-level models are inevitable – even if things are going to peter out, we should still have that much juice left in the tank.
Whereas, and I think this is mind-numbingly obvious, any substantial advances beyond that get us at least into the 9s, which probably gets us ASI (or an AGI capable of enabling the building of an ASI) and therefore is at least a 10.0. You could argue that since it changes the destiny of the universe instead of only Earth, it’s 11.0. Even if humanity retains control over the future and we get the outcomes we hope to get, creating things smarter than we are changes everything, well beyond things like agriculture or fire.
There are otherwise clearly intelligent people who seem to sincerely disagree with this. I try to understand it. On some levels, sometimes, I manage to do that.
On other levels, no, that is completely bonkers nuts, Obvious Nonsense.
Just Think of the Potential
Nate Silver offers this chart.
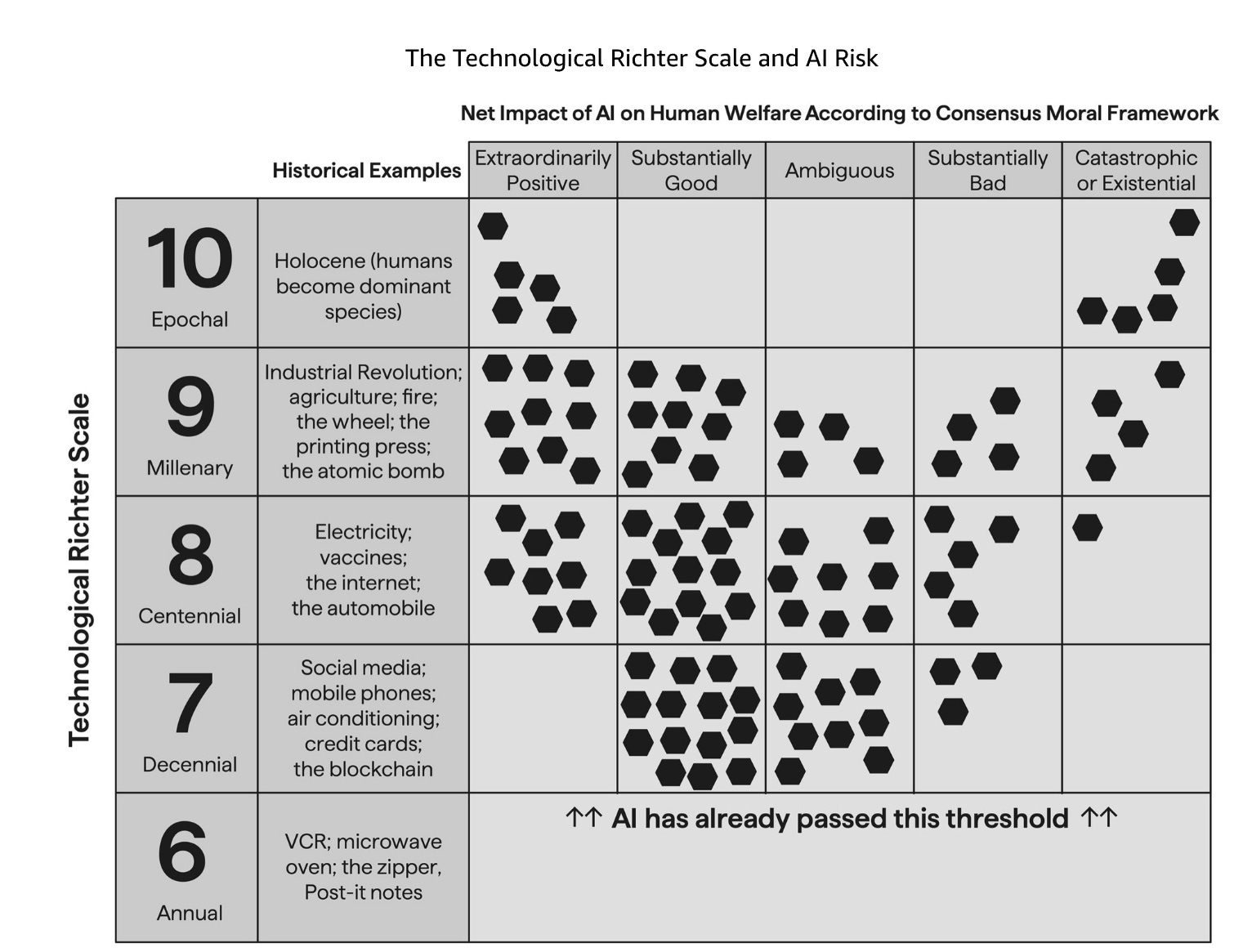
As I noted, I think you can move that ‘AI has already passed this threshold’ line up.
No, it hasn’t been as impactful as those things at 7 yet, but if civilization continues relatively normally that is inevitable.
I think this chart is actually overly pessimistic at the 8-level, and would be at the 7-level if that was still a possibility. Put me in the ‘probably extraordinary positive’ category if we stay there. The only worry is if AI at that level enables some highly disruptive technology with no available defenses, but I’d be 70%+ we’re on the extreme left in the 8-range. At the 7-range I’d be 90%+ we’re at least substantially good, and then it’s a question of how extraordinary you have to be to count.
If you tell me we got stuck at 9-level, the obvious question is how we got a 9 and then did not get a 10 soon thereafter. It’s actually tricky to imagine one without the other. But let us suppose that via some miracle of physics that is where AI stops? My guess is the distribution above is reasonable, but it’s hard because every time I try to imagine that world my brain basically shoots back ‘does not compute.’
A Perfect 10
What if it does go to 10-level, fully transformational AI? Nate nails the important point, which is that the result is either very, very good or it is very, very bad. The chart above puts the odds at 50/50. I think the odds are definitely against us here. When I think about 10-level scenarios where we survive, it always involves something going much better than I expect, and usually it involves multiple such somethings. I think we are still drawing live, but a huge portion of that is Model Error – the possibility that I am thinking about this wrong, missing or wrong about very important things.
The baseline scenario is that we create things smarter than ourselves, and then rapidly control over the future belongs to those smarter things, and this does not lead to good outcomes for humanity, or probably any humans surviving for long.
No, that does not require any kind of ‘sharp left turn’ or particular failure mode, it is simply what happens under competition, when everyone is under pressure to turn more and more things over to more and more ruthless AIs to compete against each other.
That even assumes we ‘solve alignment’ sufficiently to even get that far, and we very much should not be assuming that.
One can also get into all the other problems and obstacles, many of which Eliezer Yudkowsky covers under A List of Lethalities [LW · GW].
Almost all arguments I hear against this seem (to put it politely) extremely poor, and highly motivated. Mostly they do not even consider the real issues involved at all.
Most arguments that everything will work out fine, that are not nonsense, are not arguing we’ll get a 10.0 and survive it. Mostly they are arguing we do not get a 10.0.
It would very much help the discourse if people would be clearer on this. If they would say ‘I do not expect transformational AI, I think it is about an 8.0, but I agree that if it is going to hit 9+ then we should be very worried’ then we could focus on the actual crux of the matter.
Or if we could hear such arguments, respond with ‘so you don’t think AI is transformational, it won’t go beyond 8.0?’ and they could say yes. That works too.
Some Arguments Against Transformational AI
What are some of the most common arguments against transformational AI?
It is very hard to state many of the common arguments without strawmanning, or sounding like one is strawmanning. But this is a sincere attempt to list as many of them as possible, and to distill their actual core arguments.
- We are on an S-curve of capabilities, and near the top, and that will be that.
- A sufficiently intelligent computer would take too much [compute, power, data].
- Look how stupid current AIs are, they can’t even solve [some simple thing].
- Intelligence does not much matter, so it won’t make much difference.
- Intelligence does not much matter because we won’t let it have physical impacts.
- Intelligence does not much matter without [X] which AIs will always lack.
- Intelligence does not much matter because everything is already invented.
- Intelligence has a natural limit about where humans are.
- Intelligence of AI has a natural limit at the level of your training data.
- AI can only reproduce what is in its training data.
- AI can only recombine the types of things in its training data.
- AI cannot be creative, or invent new things.
- AI is dumb, it can only do narrow things, that’s not intelligence.
- AI does not have goals, or does not have desires, or memory, and so on.
- AI will always be too unreliable to do anything important.
- AI will have some fatal weakness, and you can be Kirk.
- Intelligence is not real, there is only domain knowledge and skill.
- Humans are special, a computer could never [do X].
- Humans are special because we are embodied.
- Humans are special because we are [sentient, conscious, ensouled, common sense].
- Humans are special because we are so much more efficient somehow.
- Humans are special because ultimately humans will only trust or want humans.
- There is a lot of hype in AI, so it is all fake.
- Everything is fake, so AI is fake too.
- AI is a tool, and will always remain a mere tool.
- AI is just math, math is harmless.
- AI can only do what it can do now, we can ignore speculative claims.
- AI that does that sounds like science fiction, so we can ignore your claims.
- AI that does that implies an absurd future, so we can ignore your claims.
- AGI is not well defined so it will never exist.
- Arguments involving religious beliefs or God or aliens or what not.
- Arguments from various science fiction worlds where AI does not do this.
- Humanity will agree to stop building AI, we’re not that stupid.
- No, that whole thing is stupid, and I don’t like your stupid face.
I sincerely wish I was kidding here. I’m not.
A few of these are actual arguments that give one pause. It is not so implausible that we are near the top of an S-curve, that in some sense we don’t have the techniques and training data to get much more intelligence out of the AIs than we already have. Diminishing returns could set in, the scaling laws could break, and AI would get more expensive a lot faster than it makes everything easier, and progress stalls. The labs say there are no signs of it, but that proves nothing. We will, as we always do, learn a lot when we see the first 5-level models, or when we fail to see them for sufficiently long.
Then there are those that perhaps made sense in the past, but where the hypothesis has been falsified. Yes, humans say they want to trust humans and not AIs, but when humans in the loop are inconvenient, we already know what they will do, and of course if the AI in question was sufficiently capable it would not matter anyway.
Most tragically, there was a time it seemed plausible we would simply not built it exactly because we don’t want a 10.0-level event. That seems like a dim hope now, although we should still consider trying to postpone that event until we are ready.
Others are more absurd. I am especially frustrated by the arguments that I call Intelligence Denialism – that if you made something much smarter than a human, that it wouldn’t be able to do anything too impactful, or that intelligence is an incoherent concept. No, it couldn’t fool or manipulate me, or people in general, or make tons of money. No, it wouldn’t be able to run things much more productively, or invent new techniques, or whatever. And so on.
Many arguments accidentally disprove humans, or human civilization.
Then there are the ones that are word salads, or Obvious Nonsense, or pointing to obstacles that could not possibly bind over the medium term if nothing else was standing in the way, or aren’t arguments for the point in question. For example, you say the true intelligence requires embodiment? I mean I don’t see why you think that, but if true then there is an obvious fix. The true intelligence won’t matter because it won’t have a body? Um, you can get humans to do things by offering them money.
Or my favorite, the Marc Andreessen classic ‘AI is just math,’ to which the response is ‘so is the universe, and also so are you and me, what are you even talking about.’
Brief Notes on Arguments Transformational AI Will Turn Out Fine
I tried several times to write out taxonomies of the arguments that transformational AI will turn out fine. What I discovered was that going into details here rapidly took this post beyond scope, and getting it right is important but difficult.
This is very much not an attempt to argue for or against existential risk, or any particular conditional probability of doom. It is primarily here to contrast this list with the above list of arguments against transformational AI.
Briefly, one might offer the following high-level taxonomy.
- Arguments that human extinction is fine. (e.g. either AIs will have value inherently, AIs will carry our information and values, something else is The Good and can be maximized without us, or humanity is net negative, and so on.)
- Arguments from the AIs using advanced decision theories (e.g. FDT over CDT).
- Arguments from moral realism, fully robust alignment, that ‘good enough’ alignment is good enough in practice, and related concepts.
- Arguments from there being a benevolent future singleton or de facto singleton.
- Arguments from coordination being hard, and AIs not being able to coordinate, and that we will be protected by game theory (e.g. because AIs will be using CDT).
- Arguments from coordination being easy, and AIs, humans or both being thus able to coordinate far better than humans ever have. Also see de facto singleton.
- Arguments we have to gamble on it being fine, given our other options. So we therefore must assume everything will be fine, or act as if it will be, or treat that distribution of outcomes as overall fine, or similar.
- Arguments from science fiction or otherwise reasoning from what feels plausible, or from humans retaining some comparative advantage somehow.
- Arguments from blind faith, forms of just world hypothesis, failure to be able to imagine failure, or our general ability to figure things out and muddle through.
- Arguments from good outcomes being so cheap the AIs will allow them.
- Arguments that assume the default outcome must be fine, and then arguing against a particular bad scenario, which proves things will be fine.
- Arguments from uncertainty, therefore you can dismiss such concerns.
- Arguments from authority, or ad hominem, that worried people are bad.
I list ‘extinction is fine’ first because it is a values disagreement, and because it is important to realize a lot of people actually take such positions, and that this has had important impacts (e.g. fear of those who believe such arguments building AGI first motivating Musk to help create OpenAI).
The rest are in a combination of logical order and a roughly descending order of plausibility and of quality of the best of each class of arguments. Point seven is also unique, and is roughly the Point of No Return, beyond which the arguments get a lot worse.
The argument of whether we should proceed, and in what way, is of course vastly more complex than this and involves lots of factors on all sides.
A key set of relatively good arguments make the case that alignment of AIs and their objectives and what they do to what we want AIs to be doing is somewhere between easy (or even happens ‘by default’) and extremely difficult but solvable in time with the right investments. Reasonable people disagree on the difficulty level here, and I am of the position the problem is probably very difficult but not as impossible as some others (e.g. Yudkowsky) think.
Most (but not all!) people making such arguments then fail to grapple with what I tried calling Phase 2. That after you know how to get AIs to do what you want them to do, you still have to get to an equilibrium where this turns out well for humans, despite the default outcome of ‘humans all have very capable AIs that do what they want, and the humans are otherwise free’ is ‘the humans all turn everything over to their AIs and set them loose to compete’ because anyone not doing that loses out, on an individual level and on a corporate or national level.
What we want here is a highly ‘unnatural’ result, for the less competitive, less intelligent thing (the humans) to stay on top or at least stick around and have a bunch of resources, despite our inability to earn them in the marketplace, or ability to otherwise compete for them or for the exercise of power. So you have to find a way to intervene on the situation that fixes this, while preserving what we care about, that we can collectively agree to implement. And wow, that seems hard.
A key category is point 11: The argument that by default, creating entities far smarter, cheaper, more efficient, more competitive and more capable than ourselves will lead to good outcomes for us. If we can dismiss a particular bad scenario, we will definitely be in a good scenario. Then they choose a particular bad scenario, and find a step where they can dismiss it – or, they simply say ‘there are a lot of steps here, and one of them will not happen this way.’ Then they say since the bad scenario won’t happen, things will go well.
A remarkably large percentage of arguments for things being fine are either point 1 (human extinction is fine), point 11 (this particular bad end is implausible so things will be good) or points 12 and 13.
9 comments
Comments sorted by top scores.
comment by Sammy Martin (SDM) · 2024-09-05T12:52:00.568Z · LW(p) · GW(p)
I don't believe that you can pass an Ideological Turing Test for people who've thought seriously about these issues and assign a decent probability to things going well in the long term, e.g. Paul Christiano [LW · GW], Carl Shulman, Holden Karnofsky [EA · GW]and a few others.
The futures described by the likes of Carl Shulman, which I find relatively plausible, don't fit neatly into your categories but seem to be some combination of (3) (though you lump 'we can use pseudo aligned AI that does what we want it to do in the short term on well specified problems to navigate competitive pressures' in with 'AI systems will want to do what's morally best by default so we don't need alignment') and (10) (which I would phrase as 'unaligned AIs which aren't deceptively inner misaligned will place some value on human happiness and placating their overseers'), along with (4) and (6), (specifically that either an actual singleton or a coalition with strong verifiable agreements and regulation can emerge, or that coordination can be made easier by AI advice).
Both 3 and 10 I think are plausible when phrased correctly: that pseudo-aligned powerful AI can help governments and corporations navigate competitive pressures, and that AI systems (assuming they don't have some strongly deceptively misaligned goal from a sharp left turn) will still want to do things that satisfy their overseers among the other things they might want, such that there won't be strong competitive pressures to kill everyone and ignore everything their human overseers want.
In general, I'm extremely wary of arguing by 'default' in either direction. Both of these are weak arguments for similar reasons:
- The default outcome of "humans all have very capable AIs that do what they want, and the humans are otherwise free", is that humans gain cheap access to near-infinite cognitive labor for whatever they want to do, and shortly after a huge increase in resources and power over the world. This results in a super abundant utopian future.
- The default outcome of "humans all have very capable AIs that do what they want, and the humans are otherwise free", is that ‘the humans all turn everything over to their AIs and set them loose to compete’ because anyone not doing that loses out, on an individual level and on a corporate or national level, resulting in human extinction or dystopia via 'race to the bottom'
My disagreement is that I don't think there's a strong default either way. At best there is a (highly unclear) default towards futures that involve a race to the bottom, but that's it.
I'm going to be very nitpicky here but with good cause. "To compete" - for what, money, resources, social approval? "The humans" - the original developers of advanced AI, which might be corporations, corporations in close public-private partnership, or big closed government projects?
I need to know what this actually looks like in practice to assess the model, because the world is not this toy model, and the dis-analogies aren't just irrelevant details.
What happens when we get into those details?
We can try to make this specific, envision a concrete scenario involving a fairly quick full automation of everything, and think about (in a scenario where governments and corporate decision-makers have pseudo-aligned AI which will e.g. answer questions super-humanly well in the short term) a specific bad scenario, and then also imagine ways it could not happen. I've done this before, and you can do it endlessly:
Here’s one of the production web stories in brief but you can read it in full along with my old discussion [LW · GW] here,
In the future, AI-driven management assistant software revolutionizes industries by automating decision-making processes, including "soft skills" like conflict resolution. This leads to massive job automation, even at high management levels. Companies that don't adopt this technology fall behind. An interconnected "production web" of companies emerges, operating with minimal human intervention and focusing on maximizing production. They develop a self-sustaining economy, using digital currencies and operating beyond human regulatory reach. Over time, these companies, driven by their AI-optimized objectives, inadvertently prioritize their production goals over human welfare. This misalignment leads to the depletion of essential resources like arable land and drinking water, ultimately threatening human survival, as humanity becomes unable to influence or stop these autonomous corporate entities.
My object-level response is to say something mundane along the lines of, I think each of the following is more or less independent and not extremely unlikely to occur (each is above 1% likely):
- Wouldn’t governments and regulators also have access to AI systems to aid with oversight and especially with predicting the future? Remember, in this world we have pseudo-aligned AI systems that will more or less do what their overseers want in the short term.
- Couldn’t a political candidate ask their (aligned) strategist-AI ‘are we all going to be killed by this process in 20 years’ and then make a persuasive campaign to change the public’s mind with this early in the process, using obvious evidence to their advantage
- If the world is alarmed by the expanding production web and governments have a lot of hard power initially, why will enforcement necessarily be ineffective? If there’s a shadow economy of digital payments, just arrest anyone found dealing with a rogue AI system. This would scare a lot of people.
- We’ve already seen pessimistic views about what AI regulations can achieve self-confessedly be falsified at the 98% level [LW(p) · GW(p)] - there’s sleepwalk bias to consider. Stefan schubert: Yeah, if people think the policy response is "99th-percentile-in-2018", then that suggests their models have been seriously wrong. So maybe the regulations will be both effective, foresightful and well implemented with AI systems forseeing the long-run consequences of decisions and backing them up.
- What if the lead project is unitary and a singleton or the few lead projects quickly band together because they’re foresightful, so none of this race to the bottom stuff happens in the first place?
- If it gets to the point where water or the oxygen in the atmosphere is being used up (why would that happen again, why wouldn’t it just be easier for the machines to fly off into space and not have to deal with the presumed disvalue of doing something their original overseers didn’t like?) did nobody build in ‘off switches’?
- Even if they aren’t fulfilling our values perfectly, wouldn’t the production web just reach some equilibrium where it’s skimming off a small amount of resources to placate its overseers (since its various components are at least somewhat beholden to them) while expanding further and further?
And I already know the response is just going to be “Moloch wouldn’t let that happen..” and that eventually competition will mean that all of these barriers disappear. At this point though I think that such a response is too broad and proves too much. If you use the moloch idea this way it becomes the classic mistaken "one big idea universal theory of history" which can explain nearly any outcome so long as it doesn't have to predict it.
A further point: I think that someone using this kind of reasoning in 1830 would have very confidently predicted that the world of 2023 would be a horrible dystopia where wages for workers wouldn’t have improved at all because of moloch.
You can call this another example of (11), i.e. assuming the default outcome will be fine and then this arguing against a specific bad scenario, so it doesn't affect the default, but that assumes what you're trying to establish.
I'm arguing that when you get into practical details of any scenario (assuming pseudo-aligned AI and no sharp left turn or sudden emergence), you can think of ways to utilize the vast new cognitive labor force available to humanity to preempt or deal with the potential competitive race to the bottom, the offense-defense imbalance, or other challenges, which messes up the neat toy model of competitive pressures wrecking everything.
When you try to translate the toy model of:
"everyone" gets an AI that's pseudo aligned --> "everyone" gives up control and lets the AI "compete" --> "all human value is sacrificed" which presumably means we run out of resources on the earth or are killed
into a real world scenario by adding details on about who develops the AI systems, what they want, and specific ways the AI systems could be used, we also get practical, real world counterarguments as to why it might not happen. Things still get dicey the faster takeoff is and the harder alignment is, as we don't have this potential assistance to rely on and have to do everything ourselves, but we already knew that, and you correctly point out that nobody knows the real truth about alignment difficulty anyway [LW · GW].
To be clear, I still think that some level of competitive degradation is a default, there will be a strong competitive pressure to delegate more and more decision making to AI systems and take humans out of the loop, but this proceeding unabated towards systems that are pressured into not caring about their overseers at all, resulting in a world of 'perfect competition' with a race to the bottom that proceeds unimpeded until humans are killed, is a much weaker default than you describe in practice.
Treating a molochian race to the bottom as an overwhelmingly strong default ignores the complexity of real-world systems, the potential for adaptation and intervention, and the historical track record of similar predictions about complicated social systems.
comment by Zack_M_Davis · 2024-09-04T17:08:15.706Z · LW(p) · GW(p)
- Arguments from moral realism, fully robust alignment, that ‘good enough’ alignment is good enough in practice, and related concepts.
What is moral realism doing in the same taxon with fully robust and good-enough alignment? (This seems like a huge, foundational worldview gap; people who think alignment is easy still buy the orthogonality thesis.)
- Arguments from good outcomes being so cheap the AIs will allow them.
If you're putting this below the Point of No Return, then I don't think you've understood the argument [LW(p) · GW(p)]. The claim isn't that good outcomes are so cheap that even a paperclip maximizer would implement them. (Obviously, a paperclip maximizer kills you and uses the atoms to make paperclips.)
The claim is that it's plausible for AIs to have some human-regarding preferences even if we haven't really succeeded at alignment, and that good outcomes for existing humans are so cheap that AIs don't have to care about the humans very much in order to spend a tiny fraction of their resources on them. (Compare to how some humans care enough about animal welfare to spend an tiny fraction of our resources helping nonhuman animals that already exist, in a way that doesn't seem like it would be satisfied by killing existing animals and replacing them with artificial pets.)
There are lots of reasons one might disagree with this: maybe you don't think human-regarding preferences are plausible at all, maybe you think accidental human-regarding preferences are bad rather than good (the humans in "Three Worlds Collide" didn't take the Normal Ending [LW · GW] lying down), maybe you think it's insane to have such a scope-insensitive concept of good outcomes—but putting it below arguments from science fiction or blind faith (!) is silly.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2024-09-05T17:50:46.320Z · LW(p) · GW(p)
What is moral realism doing in the same taxon with fully robust and good-enough alignment? (This seems like a huge, foundational worldview gap; people who think alignment is easy still buy the orthogonality thesis.)
Technically even Moral Realism doesn't imply Anti-Orthogonality thesis! Moral Realism is necessary but not sufficient for Anti-Orthogonality, you have to be a particular kind of very hardcore platonist moral realist who believes that 'to know the good is to do the good', to be Anti-Orthogonality, and argue that not only are there moral facts but that these facts are intrinsically motivating.
Most moral realists would say that it's possible to know what's good but not act on it: even if this is an 'unreasonable' disposition in some sense, this 'unreasonableness' it's compatible with being extremely intelligent and powerful in practical terms.
Even famous moral realists like Kant wouldn't deny the Orthogonality thesis: Kant would accept that it's possible to understand hypothetical but not categorical imperatives, and he'd distinguish capital-R Reason from simple means-end 'rationality'. I think from among moral realists, it's really only platonists and divine command theorists who'd deny Orthogonality itself.
comment by Shankar Sivarajan (shankar-sivarajan) · 2024-09-05T03:06:08.004Z · LW(p) · GW(p)
An ELO-ranking leaderboard for different technologies so we can get improved granularity on this scale would be nice.
comment by Radford Neal · 2024-09-04T15:26:14.551Z · LW(p) · GW(p)
In your taxonomy, I think "human extinction is fine" is too broad a category. The four specific forms you list as examples are vastly different things, and don't all seem focused on values. Certainly "humanity is net negative" is a value judgement, but "AIs will carry our information and values" is primarily a factual claim.
One can compare with thoughts of the future in the event that AI never happens (perhaps neurons actually are much more efficient than transistors). Surely no one thinks that in 10 million years there will still be creatures closely similar to present-day humans? Maybe we'll have gone extinct, which would be bad, but more likely there will be one or many successor species that differ substantially from us. I don't find that particularly distressing (though of course it could end up going badly, from our present viewpoint).
The factual claims involved here are of course open to question, and overlap a lot with factual claims regarding "alignment" (whatever that means). Dismissing it all as differing values seems to me to miss a lot.
comment by A1987dM (army1987) · 2025-02-26T02:13:18.123Z · LW(p) · GW(p)
True, their impact on daily life isn’t necessarily obvious if you’re living in a superpower protected by its nuclear umbrella (someone in Ukraine might feel differently).
Is nuclear deterrence actually still a thing at all? Has any conflict in the past quarter century or so played out any differently than would have if on 1 January 2000 aliens had permanently taken away humanity's ability to use nuclear weapons?
comment by RogerDearnaley (roger-d-1) · 2024-09-16T09:28:04.711Z · LW(p) · GW(p)
What we want here is a highly ‘unnatural’ result, for the less competitive, less intelligent thing (the humans) to stay on top or at least stick around and have a bunch of resources, despite our inability to earn them in the marketplace, or ability to otherwise compete for them or for the exercise of power. So you have to find a way to intervene on the situation that fixes this, while preserving what we care about, that we can collectively agree to implement. And wow, that seems hard.
I think many people's unstated mental assumption is "the government (or God) wouldn't allow things to get that bad". These are people who've never, for example, lived through a war (that wasn't overseas).
comment by RogerDearnaley (roger-d-1) · 2024-09-16T09:19:56.407Z · LW(p) · GW(p)
Arguments from moral realism, fully robust alignment, that ‘good enough’ alignment is good enough in practice, and related concepts.
A variant here is "Good-enough alignment will [LW · GW], or can be encouraged to, converge to full alignment (via things like Value Learning [? · GW] or AI-Assisted Alignment Research [? · GW])." — a lot of the frontier labs appear to be gambling on this.
comment by mako yass (MakoYass) · 2024-09-08T23:30:09.396Z · LW(p) · GW(p)
I expect blockchains/distributed ledgers to have no impact until most economically significant people can hold a key, and access it easily with minimal transaction costs, and then I expect it to have a lot of impact. It's a social technology, it's useless until it reaches saturation.
And if you tell me there’s so much other value created
DLTs create verifiable information (or make it hundreds of times easier to create). The value of information generally is not captured by its creators.
Related note: The printing press existed in asia for a thousand years while having minimal cultural impact. When and whether the value of an information technology manifests is contingent on a lot of other factors.