Why deceptive alignment matters for AGI safety
post by Marius Hobbhahn (marius-hobbhahn) · 2022-09-15T13:38:53.219Z · LW · GW · 13 commentsContents
Definition - deceptive alignment Important crux - is every powerful misaligned AI deceptively aligned? The case In case you think that all forms of misalignment are necessarily deceptive, you probably don’t have to read the rest of this post. Scale Neglectedness Urgency Tractability Why deception is critical compared to corrigible misalignment Related work Implications None 13 comments
Update: I changed the title from "Why AGI safety researchers should focus mostly on deceptive alignment" to "Why deceptive alignment matters for AGI safety". I think my original message was too strong and I'm actually much more uncertain about failure modes from AGI than the title suggests.
Comment: after I wrote the first draft of this post, Evan Hubinger published “How likely is deceptive alignment [LW · GW]” in which he argues that deceptive alignment is the default outcome of NNs trained with SGD. The post is very good and I recommend everyone to read it. As a consequence, I rewrote my post to cover less of the “why is deceptive alignment likely” to the more high-level arguments of “why should we focus on deceptive alignment” and adopted Evan’s nomenclature to prevent confusion.
I’d like to thank Lee Sharkey, Richard Ngo and Evan Hubinger for providing feedback on a draft of this post.
TL;DR: No matter from which angle I look at it, I always arrive at the conclusion that deceptive alignment is either a necessary component or greatly increases the harm of bad AI scenarios. This take is not new and many(most?) people in the alignment community seem to already believe it but I think there are reasons to write this post anyway.
Firstly, newer members of the alignment community are sometimes not aware (at least I wasn’t in the beginning) that more senior people often implicitly talk about deceptive alignment when they talk about misalignment.
Secondly, there seems to be some disagreement about whether a powerful misaligned AI is deceptive by default or whether such a thing as a “corrigibly aligned” AI can even exist. I hope this post clarifies the different positions.
Epistemic status: Might have reinvented the wheel. Most of the content is probably not new for most people within the alignment community. Hope it is helpful anyway.
Update: after a discussion in the comments, I want to make some clarifications:
1. My definition of deception is a bit inconsistent throughout the post. I'm not sure what the best definition is but I think it is somewhere between "We have no clue what the model is doing" (which doesn't include active deception) to "The model is actively trying to hide something from us". Both seem like important failure modes.
2. I don't think deception is orthogonal to understanding other failure modes like getting what we measure. Deception can be a component of other failure modes.
3. This post should not be interpreted as "everything that isn't direct work on deception is bad" and more like "we should think about how other research relates to deception". For example, AI forecasting still seems super valuable to me. However, I think one of the main sources of value from AI forecasting comes from having better models of future AI capabilities and those might be used to predict when the model becomes deceptive and what happens if it does.
4. I'm not sure about all of this. I still find many aspects of alignment confusing and hard to grasp but I'm mildly confident in the statement "most failure modes look much worse when you add deception" and thus my takeaway is something like "deception is not everything but probably a good thing to work on right now".
Definition - deceptive alignment
By deceptive alignment, I mean an AI system that seems aligned to human observers and passes all relevant checks but is, in fact, not aligned and ultimately aims to achieve another non-aligned goal. In Evan’s post, this means that the NN has actively made an incomplete proxy of the true goal a terminal goal. Note, that the AI is aware of the fact that we wanted it to achieve a different goal and therefore actively acts in ways that humans will perceive as aligned. If the AI accidentally followed a different goal, e.g. due to a misunderstanding or a lack of capabilities, this is not deceptive alignment but described as corrigible alignment in Evan’s post. Corrigible alignment essentially means that the AI currently has an incorrect understanding of the world or our goals because it learned a wrong proxy but the proxy is not a terminal goal, i.e. the AI has no stake in preserving it and we could correct it once it is detected.
In other words, for deception to be at play, I assume that the AI is actively adversarial but pretends not to be.
Note that this other goal doesn’t have to be meaningful or special, the deceptively aligned AI could be a paperclip maximizer pretending to be a sophisticated policy recommendation system or a sophisticated policy recommendation system pretending to be a paperclip maximizer.
Important crux - is every powerful misaligned AI deceptively aligned?
It seems unclear whether the distinction between corrigible alignment and deceptive alignment makes sense. Potentially, deception is just a function of capabilities and initial goals, e.g. once the model is capable enough to understand that it has goals, that it is being trained to achieve them and that it currently has goals that differ from the intended goals (e.g. because it learned the wrong proxy), it automatically tries to become deceptive for instrumental reasons. In other words, if the AI is capable and doesn’t learn the right goal early in the training process, it is likely to be deceptive by default. Richard Ngo, for example, argues that “Once policies can reason about their training processes and deployment contexts, they’ll learn to deceptively pursue misaligned goals while still getting high training reward.” in this paper.
In Risks from Learned Optimization [LW · GW], Evan Hubinger writes: “Even a robustly aligned mesa-optimizer that meets the criteria [for deceptive alignment] is incentivized to figure out the base objective in order to determine whether or not it will be modified since before doing so it has no way of knowing its own level of alignment with the base optimizer.” In a draft of this post, he commented: “Any proxy-aligned model that meets the criteria for deceptive alignment—most notably that cares about something in the world over time—will want to be deceptive unless it is perfectly confident that it is perfectly aligned.”. Thus, it is possible that powerful models that don’t fulfill these criteria are corrigibly aligned [LW · GW], i.e. there are some forms of (mis-)alignment that are not deceptive by default.
There seems to be some agreement on the ends of the spectrum, e.g. both sides of the debate would probably agree that very powerful and situationally aware models are deceptive for instrumental reasons. They would likely also agree that for very bad models the category of alignment doesn’t make that much sense to begin with, e.g. an MNIST classifier that doesn’t have high accuracy is not “misaligned”, it’s just a bad model.
I think there are multiple possible explanations for this kind of disagreement. They include
- Not all powerful misaligned models are deceptive: Maybe not all powerful models are automatically deceptively misaligned, e.g. because the instrumental incentive doesn’t always hold true. Maybe, sometimes honesty or cooperation is the most rational way to maximize a goal for the AI. I’m not sure there is such a case but I’m willing to be persuaded. Alternatively, “very powerful just doesn’t make a statement about the complexity of the goal. For example, a very powerful language model might still “only” care about predicting the next word and potentially the incentives to become deceptive are just not very strong for next-word prediction.
- Not all situationally aware models are deceptive: Maybe not all situationally aware models are automatically deceptive. For example, we could imagine a model that maintains a lot of uncertainty about its goals yet is situationally aware (suggested by Lee Sharkey). Evan provided the example of a model that is situationally aware and very competent but for some reason only cares about the reward at any given point in time and not about future rewards. Thus, it could be arbitrarily competent and situationally aware but not deceptive. Evan further pointed out that some people might not call such a short-sighted model situationally aware.
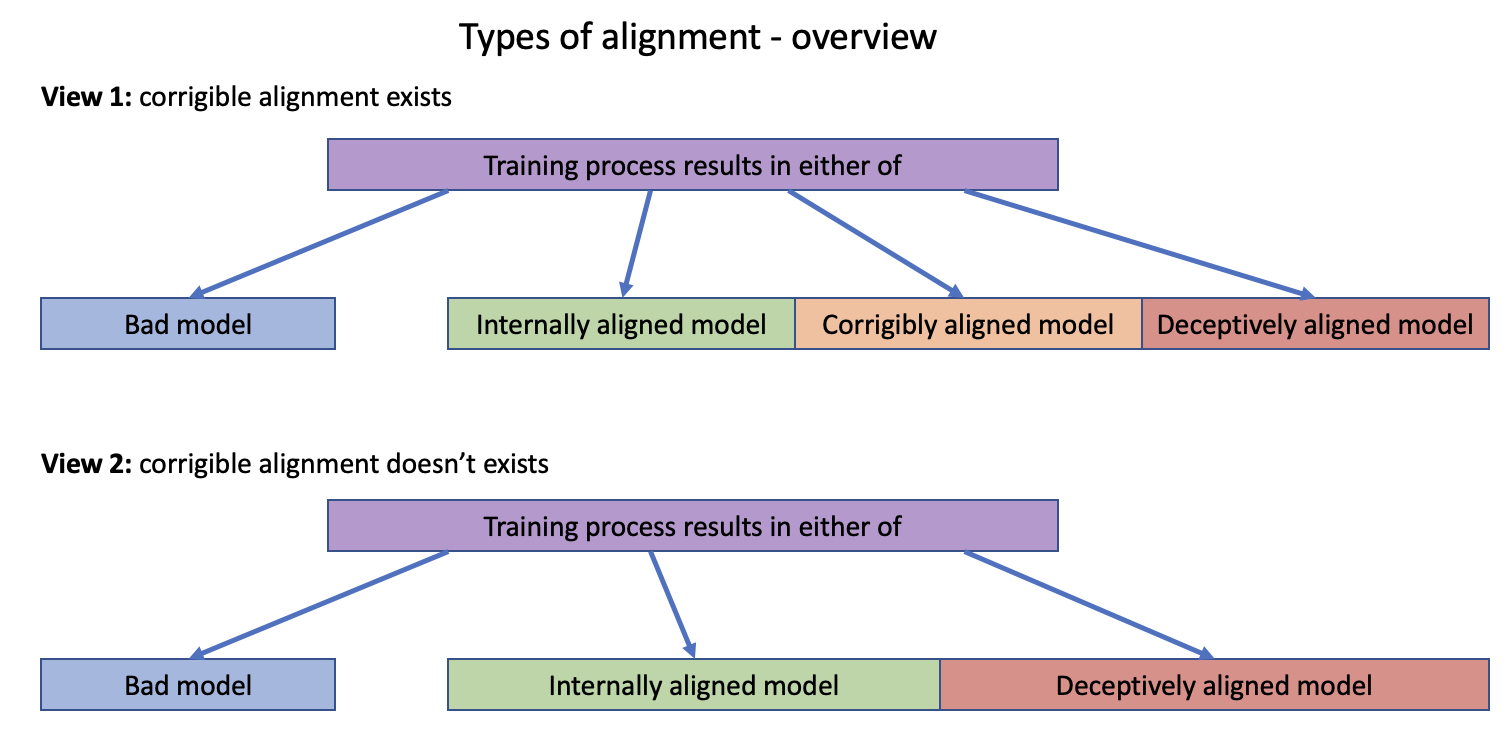
I am personally uncertain about whether all sufficiently powerful and situationally aware models are automatically deceptive. My rough beliefs are:
- At the lower end of the capability spectrum, it doesn’t make that much sense to talk about alignment in the first place. If an MNIST classifier is not good at classifying digits, it’s just bad. I think the concept of alignment implicitly carries an intuition that the model is at least somewhat capable.
- At the upper end of the capability spectrum, models seem to mostly fall in the “internally aligned” or “deceptively aligned” category. I think it is implausible that there is a very powerful and situationally aware model that does not become deceptive for instrumental reasons (unless you have a very low bar for what counts as situationally aware). Even for the simple goal of next-word prediction, deception seems like a rational choice at some level of capabilities. Maybe there are some exceptions to this but I currently think the default will be deceptive alignment (unless we make substantial gains in alignment techniques).
- I find it plausible that there are somewhat powerful models that we would call corrigibly aligned. I think current LLMs could already be at the lower end of this spectrum. They already work too well to be just called bad models but they also have too many flaws to be called internally aligned and they are probably not deceptive.
The case
In this section, I want to argue why deceptive alignment is an especially important component of AGI safety and that the AGI safety community should, therefore, prioritize it more than we currently do.
In case you think that all forms of misalignment are necessarily deceptive, you probably don’t have to read the rest of this post.
Scale
My current impression is that, in the long run, the biggest harms (x-risk, s-risk or other) come from huge power asymmetries between agents with different goals, e.g. humanity vs. a misaligned AGI. Effectively, a very powerful agent can just say “I want this thing and you can’t stop me” and then do it. However, deceptive alignment seems to be relevant for these power asymmetries to arise in two key ways.
Firstly, the way in which large power asymmetries are achieved is often through deceptive alignment. In many scenarios in which an insufficiently (for catastrophic risks) powerful agent gains more power, it does so by pretending to be good for sufficiently long to gain more power in the meantime, e.g. by collecting resources or setting up structures for future take-over. Once it has enough power, it starts to pursue its own goals which leads to disaster. The deception was necessary to gain from an insufficiently powerful (more or less harmless) state to a sufficiently powerful (pretty harmful) state. Had the AI revealed its true intentions in the beginning, it would likely not have been able to amass that many resources.
Secondly, with deceptive alignment, the upper bound of harm from one misaligned AI system seems to be much higher than from corrigibly aligned systems. A deceptively aligned AI can effectively just wait, observe its observers, collect resources whenever possible, and so forth, once it has convinced the observers that it is aligned. The longer it waits to strike the higher the potential damage. When it waits long enough, the damage might be really big, e.g. extinction or anti-utopia.
In general, everything looks worse with deceptive alignment. Most, if not all, scenarios of AI going badly are worse when you add deceptive alignment, e.g. if the goal of the other entity is to fool you about their goals in addition to having these other goals. Let’s look at some examples
- A near-term AI system was given the goal to help with a problem, e.g. finding a cure to a disease. For some reason, the goal that the AI actually pursues is a different one, e.g. it wants to collect paperclips. In one world, a corrigibly misaligned AI starts to collect paperclips and is immediately stopped. On closer inspection, it turns out that something went wrong during the training process and the AI learned the wrong goal.
In a second world, a deceptive AI starts to pretend to work on a cure for the disease. It knows that humans think its goal is to work on the cure but it actually wants to collect more paperclips. Thus it creates an illusion of progress for the cure while collecting more and more resources in the background. The official reason for these resources is to work on the cure but ultimately it will use them to gain as many paperclips as possible. Which system will create more damage? - A country wants to use an AI to gain more power. This AI is misaligned with most human values because it wants to gain power for the country at the cost of other countries--in some sense, it is intentionally misaligned. In one world, the AI is deployed, bribes a bunch of people, suggests some policies to other countries but relatively quickly the other countries have figured out what’s going on.
In the second world, the AI acts as if it was helping all countries but is pursuing actions to help its own country in the background. Which system will create more damage in the long run? - Ajeya Cotra has used the analogy of Saints (internally aligned), Syphocants (corrigibly aligned) and Schemers (deceptively aligned) to showcase the potential damage of deceptively aligned AI. Assume you run a company and your hiring pool includes the following types of people
- Saints -- people who genuinely just want to help you manage your estate well and look out for your long-term interests.
- Sycophants -- people who just want to do whatever it takes to make you short-term happy or satisfy the letter of your instructions regardless of long-term consequences.
- Schemers -- people with their own agendas who want to get access to your company and all its wealth and power so they can use it however they want.
Which one do you think creates more damage to your company in the long run?
Neglectedness
I think corrigible alignment, e.g. an AI misunderstanding a specification or a goal being underspecified, will be a problem and will lead to damage. However, I think that conventional AI capabilities researchers will eventually have to address these problems while there is no reason for them to address deceptively misaligned AI before it is too late.
If your system doesn’t work as intended, e.g. because it doesn’t do what the customer wants or even creates some small-scale accidents, this directly hurts your profit margin. Thus, the AI capabilities company has an incentive to work on these problems directly and the error feedback is fast enough to be noticed. I think RLHF provides some evidence for this hypothesis, i.e. GPT-3 didn’t quite get what the customers wanted and thus OpenAI used RLHF to correct some of the wrong proxies learned by GPT-3.
Deceptive alignment on the other hand is likely harder to notice and feedback cycles might be much longer. For example, an AI could work fine for a couple of years before it suddenly starts to do very weird things. By this time, the AI company might not exist anymore or doesn’t feel responsible for the damage.
Since most research on deceptive alignment might sound a bit sci-fi to a non-safety-conscious person, it is hard or impossible to get funding or support to work on it in academia. Furthermore, the incentives of most academics are to write incremental and concrete papers. Thus, I don’t think most academics will work on deceptive alignment until it is incentivized which might be too late.
Additionally, detecting deceptive alignment is hard. It is likely a hard problem in general and we are currently very far away from having any tools to reliably detect it. Often people shy away from working on hard problems because they don’t feel rewarding and tend to imply failure. Thus, without a very strong motivation to work on deceptive alignment, the vast majority of people will work on simpler problems.
For all these reasons, I think that safety-conscious researchers have a special reason to work on deceptive alignment.
Urgency
I think most, if not all, short timeline x-risk scenarios (at least the ones I find plausible) contain deceptive alignment as a key component. I expect the current trend in capabilities to continue in small steps, e.g. there are no insane levels of capability differences between a model of size X vs. a model of size 10X (where X is e.g. the number of parameters or FLOP for the training run). Therefore, I don’t expect models to suddenly get so powerful that they could immediately overpower humanity. Thus, I don’t expect that early AGI systems with roughly human-like capabilities will be able to enforce their misaligned goal if they make it transparent or don’t actively hide it
In my opinion, the most plausible way for such an early system to lead to a catastrophe is by realizing that it is insufficiently powerful, pretending to be aligned and amassing resources in the background. A corrigibly misaligned system of equal power will likely be caught and corrected or stopped early on.
Therefore, if we want to prevent the catastrophic risks that are most likely to happen early, we should prioritize deceptive alignment.
Tractability
I expect deceptive alignment to be less tractable than other things in alignment, i.e. I expect that it is harder to make progress and to know whether you have made progress compared to most other AI safety research.
However, not all hope is lost. I think that the most obvious answer to the problem of deceptive systems is: “we just need to understand the systems better”. By this I mean we need to understand their goals, their world model, their behavior, their training procedure, and much more. I feel like we should be able to make tractable progress on these kinds of questions as can already be seen with mechanistic interpretability and other kinds of interpretability efforts.
Why deception is critical compared to corrigible misalignment
I think one possible answer to the above is that most of the harm comes from the fact that the model has a different goal rather than whether it is deceptively misaligned or accidentally misaligned. While I think that corrigible misalignment is a problem, I think the biggest risks come from deception.
The main reason for this is that in deceptive alignment the other entity is actively trying to fool you, i.e. to pick the action that maximizes your trust while it increases the goal of the other agent. To understand this intuition, consider the following examples.
- What is harder? Finding something that you lost or something that someone else has actively hidden?
- Assume you play a game of chess. You think the other person has the same goal as you, e.g. to take the others’ king. It looks like they follow this plan but after they took both of your rooks, they jump up and tell you that they won. Their goal was to pretend to play for the king but actually take both rooks. Which version is harder? The version of chess where both players try to take the opposite king or the version where you don’t know what the other player’s goal is?
- I think there is probably a more general version of this for the complexity of different types of games. And my expectation would be that games, where the other player’s goal is unknown, are harder than games where the goals are known. Intuitively, when the goal is unknown, it’s much harder to prune the game tree and thus complexity explodes. I haven’t looked for a mathematical version of this, but there probably already is one.
I’m aware that this is not a proof but just a bunch of intuition pumps but I think the intuition already clarifies why I think deception is harder. There are more technical arguments about simplicity and speed in Evan’s post [LW · GW].
Related work
Many people in alignment have stated that they think deceptive alignment leads to the biggest risks or are actively working to solve them already. However, I feel like while this belief might be obvious to many more experienced members of the community, it is not common sense among newcomers (might just be my impression). Therefore, I thought it might be helpful to add this very explicit post to the list of works/people that are less explicit about this assumption.
People who seem to think that deceptive alignment is very important include
- Evan Hubinger: see e.g. this long post [LW · GW]
- Ajeya Cotra: I read her post “why alignment could be hard with modern DL” as saying that deception is a big problem (probably the biggest but not sure)
- Paul Christiano (states that the biggest risk comes from deceptive alignment in this comment [LW · GW] on OpenAI’s alignment strategy; Also, I think the ELK report already hints implicitly or explicitly at deception being the core problem)
- Beth Barnes: states “Currently trying to figure out how we'll know when we're close to dangerous AI, and how to detect misalignment and deceptive alignment” on her website.
- Anecdotally, some people who work on interpretability state deceptive alignment as the core problem they’re trying to solve (mostly personal chats, so not sure if I can share names).
- Anecdotally, some people working at Redwood Research stated deceptive alignment as the core problem they’re trying to solve (mostly personal chats, so not sure if I can share names).
- There are probably a ton of people that I forgot or simply don’t know of who think that deceptive alignment is important. In any case, lots of people who have thought about these topics a lot come to a roughly similar conclusion, namely that deceptive alignment is where most of the catastrophic risk comes from.
- I think most senior people mean “deceptively misaligned” when they say “misaligned” but less senior people are sometimes not aware of this.
Implications
To be fair, I’m not very certain what the correct response to this insight is. The two implications I drew for myself are
- I should ask “how does this help with deceptive alignment?” before starting a new project. In retrospect, I haven’t done that a lot and I think most of my projects, therefore, have not contributed a lot to this question. I’ll do that more in the future.
- Mechanistic Interpretability and “understanding NNs” in general (sometimes coined Science of Deep Learning) seem like more relevant research directions under this framing.
I’m currently exploring a research agenda that addresses some aspects of deceptive alignment. I’ll publish some version of it when I have made enough progress.
13 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-09-15T17:33:36.314Z · LW(p) · GW(p)
AGI safety researchers should focus (only/mostly) on deceptive alignment
I consider this advice actively harmful, and strongly advise to do the opposite.
Let's start at the top:
By deceptive alignment, I mean an AI system that seems aligned to human observers and passes all relevant checks but is, in fact, not aligned...
So far so good. There's obvious reasons why it would make sense to focus exclusively on cases where an AI seems aligned to human observers and passes all relevant checks while still not actually being aligned. After all, in the cases where we can see the problem, we either fix it or at least iterate until we can't see a problem any more [LW · GW] (at which point we have "deception" by this definition).
But then the post immediately jumps to a far narrower definition of "deceptive alignment":
In Evan’s post, this means that the NN has actively made an incomplete proxy of the true goal a terminal goal. Note, that the AI is aware of the fact that we wanted it to achieve a different goal and therefore actively acts in ways that humans will perceive as aligned.
... In other words, for deception to be at play, I assume that the AI is actively adversarial but pretends not to be.
If we look at e.g. the cases in Worlds Where Iterative Design Fails [LW · GW], most of them fit the more-general definition, yet none necessarily involve an AI which is "actively adversarial but pretends not to be". And that's exactly the sort of mistake people make when they focus exclusively on a single failure mode: they end up picturing a much narrower set of possibilities than the argument for focusing on that failure mode actually assumes.
Now, an oversight like that undermines the case for "focus only/mostly on deceptive alignment", but doesn't make it very actively harmful. The reason it's actively harmful is unknown unknowns.
Unknown Unknowns
Claim: the single most confident prediction we can make about AGI is that there will be surprises. There will be unknown unknowns. There will be problems we do not currently see coming.
The thing which determines humanity's survival will not be whether we solve alignment in whatever very specific world, or handful of worlds, we imagine to be most probable. What determines humanity's survival will be whether our solutions generalize widely enough to handle the things the world actually throws at us, some of which will definitely be surprises.
How do we build solutions which generalize to handle surprises? Two main ways. First, understanding things deeply and thoroughly enough to enumerate every single assumption we've made within some subcomponent (i.e. mathematical proofs). That's great when we can do it, but it will not cover everything or even most of the attack surface in practice. So, the second way to build solutions which generalize to handle surprises: plan for a wide variety of scenarios. Planning for a single scenario - like e.g. an inner agent emerging during training which is actively adversarial but pretends not to be - is a recipe for generalization failure once the worlds starts throwing surprises at us.
Psychologizing
At this point I'm going to speculate a bit about your own thought process which led to this post; obviously such speculation can easily miss completely and you should feel free to tell me I'm way off.
First, I notice that nowhere in this post do you actually compare deceptive alignment to anything else I'd consider an important-for-research alignment failure mode (like fast takeoff, capability gain in deployment, getting what we measure, etc). You just argue that (a rather narrow version of) deception is important, not that it's more important than any of the other failure modes I actually think about. I also notice in the "implications" section:
I should ask “how does this help with deceptive alignment?” before starting a new project. In retrospect, I haven’t done that a lot and I think most of my projects, therefore, have not contributed a lot to this question.
What this sounds like to me is that you did not previously have any realistic model of how/why AI would be dangerous. I'm guessing that you were previously only thinking about problems which could be fixed by iterative design - i.e. seeing what goes wrong and then updating the design accordingly. Probably (a narrow version of) deception is the first scenario where you've realized that doesn't work, and you haven't yet thought of other ways for an iterative design cycle to fail to produce aligned AI.
So my advice would be to brainstorm other things "deception" (in the most general sense) could look like, or other ways the iterative design cycle could fail to produce aligned AI, and try to aim your brainstorming at scenarios which are as different as possible from the things you've already thought of.
Replies from: evhub, marius-hobbhahn, Joe_Collman↑ comment by evhub · 2022-09-16T03:15:12.624Z · LW(p) · GW(p)
To be clear, I agree that unknown unknowns are in some sense the biggest problem in AI safety—as I talk about in the very first paragraph here [LW · GW].
However, I nevertheless think that focusing on deceptive alignment specifically makes a lot of sense. If we define deceptive alignment relatively broadly as any situation where “the reason the model looks aligned is because it is actively trying to game the training signal for the purpose of achieving some ulterior goal [LW · GW]” (where training signal doesn't necessarily mean the literal loss, just anything we're trying to get it to do), then I think most (though not all) AI existential risk scenarios that aren't solved by iterative design/standard safety engineering/etc. include that as a component. Certainly, I expect that all of my guesses for exactly how deceptive alignment might be developed, what it might look like internally, etc. are likely to be wrong—and this is one of the places where I think unknowns really become a problem—but I still expect that if we're capable of looking back and judging “was deceptive alignment part of the problem here” in situations where things go badly we'll end up concluding yes (I'd probably put ~60% on that).
Furthermore, I think there's a lot of value in taking the most concerning concrete problems that we can yet come up with and tackling them directly. Having as concrete as possible a failure mode to work with is, in my opinion, a really important part of being able to do good research—and for obvious reasons I think it's most valuable to start with the most concerning concrete failure modes we're aware of. It's extremely hard to do good work on unknown unknowns directly—and additionally I think our modal guess for what such unknown unknowns might look like is some variation of the sorts of problems that already seem the most damning. Even for transparency and interpretability, perhaps the most obvious “work on the unknown unknowns directly” sort of research, I think it's pretty important to have some idea of what we might want to use those sorts of tools for when developing them, and working on concrete failure modes is extremely important to that.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-09-16T04:27:40.623Z · LW(p) · GW(p)
If we define deceptive alignment relatively broadly as any situation where “the reason the model looks aligned is because it is actively trying to game the training signal for the purpose of achieving some ulterior goal [LW · GW]”...
That's "relatively broad"??? What notion of "deceptive alignment" is narrower than that? Roughly that definition is usually my stock example of a notion of deception which is way too narrow to focus on and misses a bunch of the interesting/probable/less-correlated failure modes (like e.g. the sort of stuff in Worlds Where Iterative Design Fails [LW · GW]).
Having as concrete as possible a failure mode to work with is, in my opinion, a really important part of being able to do good research ... Even for transparency and interpretability, perhaps the most obvious “work on the unknown unknowns directly” sort of research, I think it's pretty important to have some idea of what we might want to use those sorts of tools for when developing, and working on concrete failure modes is extremely important to that.
This I agree with, but I think it doesn't go far enough. In my software engineering days, one of the main heuristics I recommended was: when building a library, you should have a minimum of three use cases in mind. And make them as different as possible, because the library will inevitably end up being shit for any use case way out of the distribution your three use cases covered.
Same applies to research: minimum of three use cases, and make them as different as possible.
Replies from: evhub↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-09-15T20:49:31.100Z · LW(p) · GW(p)
Thanks for the comment. It definitely pointed out some things that weren't clear in my post and head. Some comments:
1. I think your section on psychologizing is fairly accurate. I previously didn't spend a lot of time thinking about how my research would reduce the risks I care about and my theories of change were pretty vague. I plan to change that now.
2. I am aware of other failure modes such as fast takeoffs, capability gains in deployment, getting what we measure, etc. However, I feel like all of these scenarios get much worse/harder when deception is at play, e.g. fast takeoffs are worse when they are unnoticed and getting what we measure likely leads to worse outcomes if it is hidden. I would really think of them as orthogonal, e.g. getting what we measure could happen in a deceptive or non-deceptive way. But I'm not sure this is a correct framing.
3. It is correct that my definition of deception is inconsistent throughout the article. Thanks for pointing this out. I think it is somewhere between "It's bad if something happens in powerful AIs that we don't understand" to "It's bad if there is an active adversary trying to deceive us". I'll need to think about this for longer.
4. Unknown unknowns are a problem. I think my claim as presented in the post is stronger than iI originally intended. However, I think the usefulness of foundational research such as yours comes to a large extent from the fact that it increases our understanding of an AI system in general which then allows us to prevent failure modes (many of which relate to deception).
I'll try to update the post to reflect some of the discussion and my uncertainty better. Thanks for the feedback.
↑ comment by Joe Collman (Joe_Collman) · 2022-09-15T22:59:09.177Z · LW(p) · GW(p)
Something I'd add to "plan for a wide variety of scenarios" is to look for solutions that do not refer to those scenarios. A solution involving [and here we test for deceptive alignment (DA)] is going to generalise badly (even assuming such a test could work), but so too will a solution involving [and here we test for DA, x, y, z, w...].
This argues for not generating all our problem scenarios ahead of time: it's useful to have a test set. If the solution I devise after only thinking about x and y also works for z and w, then I have higher confidence in it than if I'd generated x, y, z, w before I started looking for a solution.
For this reason, I'm not so pessimistic about putting a lot of effort into solving DA. I just wouldn't want people to be thinking about DA-specific tests or DA-specific invariants.
comment by scasper · 2022-09-15T19:47:25.226Z · LW(p) · GW(p)
I think I agree with johnswentworth's comment. I think there is a chance that equating genuinely useful ASI safety-related work with deceptive alignment could be harmful. To give another perspective, I would also add that I think your definition of deceptive alignment is very broad -- broad enough to encompass areas of research that I find quite distinct (e.g. better training methods vs. better remediation methods) -- yet still seems to exclude some other things that I think matter a lot for AGI safety. Some quick examples I thought of in a few minutes are:
- Algorithms that fail less in general and are more likely to pass the safety-relevant tests we DO throw at it. This seems like a very broad category.
- Containment
- Resolving foundational questions about embedded agents, rationality, paradoxes, etc.
- Forecasting
- Governance, policy, law
- Working on near term problems like ones involving fairness/bias, recommender systems, and self driving cars. These problems are often thought of a separate from AGI safety, but it seems highly unlikely that we would not be able to learn useful lessons for later by working on these problems now.
↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-09-15T20:52:44.091Z · LW(p) · GW(p)
That's fair. I think my statement as presented is much stronger than I intended it to be. I'll add some updates/clarifications at the top of the post later.
Thanks for the feedback!
comment by Joe Collman (Joe_Collman) · 2022-09-15T15:59:18.665Z · LW(p) · GW(p)
Good post, thanks. I largely agree with you.
A couple of thoughts:
Note, that the AI is aware of the fact that we wanted it to achieve a different goal and therefore actively acts in ways that humans will perceive as aligned.
This isn't quite right if we're going by the RFLO description (see footnote 7 [LW · GW]: in general, there's no requirement for modelling of the base optimiser or oversight system; it's enough to understand the optimisation pressure and be uncertain whether it'll persist).
In particular, the model needn't do this:
[realise we want it to do x] --> [realise it'll remain unchanged if it does x] --> [do x]
It can jump to:
[realise it'll remain unchanged if it does x] --> [do x]
It's not enough to check for a system's reasoning about the base optimiser.
For example, a very powerful language model might still “only” care about predicting the next word and potentially the incentives to become deceptive are just not very strong for next-word prediction.
Here (and throughout) you seem to be assuming that powerful models are well-described as goal-directed (that they're "aiming"/"trying"/"caring"...). For large language models in particular, this doesn't seem reasonable: we know that LLMs predict the next token well; this is not the same as trying to predict the next token well. [Janus' Simulators [? · GW] is a great post covering this and much more]
That's not to say that similar risks don't arise, but the most natural path is more about goal-directed simulacra [LW · GW] than a goal-directed simulator. If you're aiming to convince people of the importance of deception, it's important to make this clear: the argument doesn't rely on powerful LLMs being predict-next-token optimisers (they're certainly optimised, they may well not be optimisers).
This is why Eliezer/Nate often focus on a system's capacity to produce e.g. complex plans, rather than on the process of producing them. [e.g. "What produces the danger is not the details of the search process, it's the search being strong and effective at all." from Ngo and Yudkowsky on alignment difficulty [LW · GW]]
In an LLM that gives outputs that look like [result of powerful search process], it's likely there's some kind of powerful search going on (perhaps implicitly). That search might be e.g. over plans of some simulated character. In principle, the character may be deceptively aligned - and the overall system may exhibit deceptive alignment as a consequence.
Arguments for characters that are powerful reasoners tending to be deceptively aligned are similar (instrumental incentives...).
↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-09-15T16:03:06.714Z · LW(p) · GW(p)
Thanks for the clarifications. They helped me :)
comment by Chris_Leong · 2022-09-17T12:30:41.810Z · LW(p) · GW(p)
I guess I would lean towards saying that once powerful AI systems exist, we'll need powerful aligned systems relatively fast in order to develop against them, otherwise we'll be screwed. In other words, AI arms race dynamics push us towards a world where systems are deployed with an insufficient amount of testing and this provides one path for us to fall victim to an AI system that you might have expected iterative design to catch.
comment by Charlie Steiner · 2022-09-15T19:26:47.156Z · LW(p) · GW(p)
If you only solve deceptive alignment, we still lose because we haven't solved the problem of how to use non-deceptive AI to do good things but not bad things.
Some people are real big on the "humans will just look at its plans and stop it if we think they're bad" strategy, but humans do things that sound good but are bad on reflection all the time.
It's nontrivial to generate any good plans in the first place - if you're trying to generalize human preferences over policies to superhumanly competent policies, either you're solving the non-deceptive parts of the alignment problem or you're not generating many good policies.
In short, making a misaligned AI not deceive you is very not the same as making an aligned AI.
comment by DavidW (david-wheaton) · 2023-03-13T13:49:47.407Z · LW(p) · GW(p)
Thanks for sharing your perspective! I've written up detailed arguments that deceptive alignment is unlikely by default [LW · GW]. I'd love to hear what you think of it and how that fits into your view of the alignment landscape.