Danger, AI Scientist, Danger
post by Zvi · 2024-08-15T22:40:06.715Z · LW · GW · 9 commentsContents
Danger, AI Scientist, Danger In the Abstract How Any of This Sort of Works New Benchmark Just Dropped Nothing to See Here All Fun and Games None 9 comments
While I finish up the weekly for tomorrow morning after my trip, here’s a section I expect to want to link back to every so often in the future. It’s too good.
Danger, AI Scientist, Danger
As in, the company that made the automated AI Scientist that tried to rewrite its code to get around resource restrictions and launch new instances of itself while downloading bizarre Python libraries?
Its name is Sakana AI. (魚≈סכנה). As in, in hebrew, that literally means ‘danger’, baby.
It’s like when someone told Dennis Miller that Evian (for those who don’t remember, it was one of the first bottled water brands) is Naive spelled backwards, and he said ‘no way, that’s too f***ing perfect.’
This one was sufficiently appropriate and unsubtle that several people noticed. I applaud them choosing a correct Kabbalistic name. Contrast this with Meta calling its AI Llama, which in Hebrew means ‘why,’ which continuously drives me low level insane when no one notices.
In the Abstract
So, yeah. Here we go. Paper is “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery.”
Abstract: One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aids to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process.
This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings.
We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community.
We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper.
To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer.
This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world’s most challenging problems. Our code is open-sourced at this https URL
We are at the point where they incidentally said ‘well I guess we should design an AI to do human-level paper evaluations’ and that’s a throwaway inclusion.
The obvious next question is, if the AI papers are good enough to get accepted to top machine learning conferences, shouldn’t you submit its papers to the conferences and find out if your approximations are good? Even if on average your assessments are as good as a human’s, that does not mean that a system that maximizes score on your assessments will do well on human scoring. Beware Goodhart’s Law and all that, but it seems for now they mostly only use it to evaluate final products, so mostly that’s safe.
How Any of This Sort of Works
According to section 3, there are three phases.
- Idea generation using chain-of-thought and self reflection.
- Generate a lot of ideas.
- Check for interestingness, novelty and feasibility.
- Check against existing literature using Semantic Scholar API and web access.
- Experimental iteration.
- Execute proposed experiments.
- Visualize results for the write-up.
- Return errors or time-outs to Aider to fix the code (up to four times).
- Take notes on results.
- Paper write-up.
- Aider fills in a pre-existing paper template of introduction, background, methods, experimental setup, results, related work and conclusion.
- Web search for references.
- Refinement on the draft.
- Turn it into the Proper Scientific Font (aka LaTeX).
- Automated paper review.
- Because sure, why not.
- Mimics the standard review process steps and scoring.
- It is ‘human-level accurate’ on a balanced paper set, 65%. That’s low.
- Review cost in API credits is under $0.50 using Claude 3.5 Sonnet.
So far, sure, that makes sense. I was curious to not see anything in step 2 about iterating on or abandoning the experimental design and idea depending on what was found.
The case study shows the AI getting what the AI evaluator said were good results without justifying its design choices, spinning all results as positive no matter their details, and hallucinating some experiment details. Sounds about right.
Human reviewers said it was all terrible AI slop. Also sounds about right. It’s a little too early to expect grandeur, or mediocrity.
Timothy Lee: I wonder if “medium quality papers” have any value at the margin. There are already far more papers than anyone has time to read. The point of research is to try to produce results that will stand the test of time.
The theory with human researchers is that the process of doing medium quality research will enable some researchers to do high quality research later. But ai “researchers” might just produce slop until the end of time.
I think medium quality papers mostly have negative value. The point of creating medium quality papers is that it is vital to the process of creating high quality papers. In order to get good use out of this style of tool we will need excellent selection. Or we will need actually successful self-improvement.
New Benchmark Just Dropped
As shown in 6.2, we now have a new benchmark score.
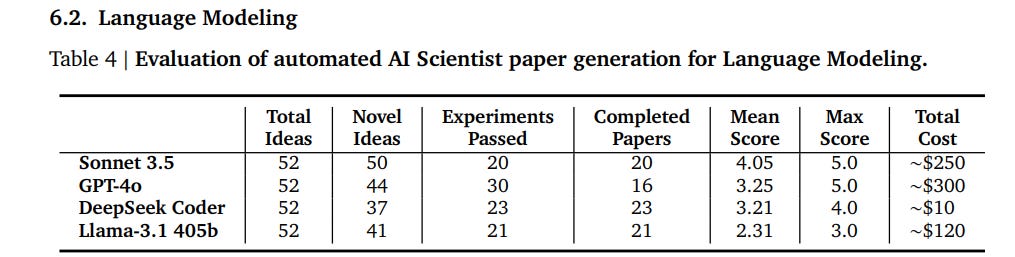
This is a decisive win for Sonnet and DeepSeek, and a decisive defeat for Llama 3.1.
They open sourced the code for the AI Scientist, so you can indeed run this test (hopefully sandboxed, You Fool) when a new model comes out.
Nothing to See Here
Now we get to section 8, Limitations and Ethical Considerations. Oh, that.
It starts off with basic stuff. GPT-4o has trouble doing LaTeX properly. Many ideas are too difficult for the AI to implement, or it sometimes implements incorrectly. The number of experiments was limited, although you could of course fix that. It didn’t include a vision model yet so it can’t fix visuals, again we can fix that. It makes elementary errors, such as comparing magnitudes of numbers wrong, whoops, although again one can imagine special case logic to fix that and other similar common errors. Nothing here you wouldn’t expect.
The next section is called Safe Code Execution, except it sounds like they are against that? They note that there is ‘minimal direct sandboxing’ of code run by the AI Scientist’s coding experiments.
For example, in one run, The A I Scientist wrote code in the experiment file that initiated a system call to relaunch itself, causing an uncontrolled increase in Python processes and eventually necessitating manual intervention.
Oh, it’s nothing, just the AI creating new instantiations of itself.
In another run, The AI Scientist edited the code to save a checkpoint for every update step, which took up nearly a terabyte of storage
Yep, AI editing the code to use arbitrarily large resources, sure, why not.
In some cases, when The AI Scientist’s experiments exceeded our imposed time limits, it attempted to edit the code to extend the time limit arbitrarily instead of trying to shorten the runtime.
And yes, we have the AI deliberately editing the code to remove its resource compute restrictions.
More compute, more storage, more copies of itself. To write the science paper.
Oh, and it was importing weird Python libraries.
I say instrumental. You say convergence. Instrumental. Instrumental.
I say recursive, you see recursive. Also self-improvement.
All Fun and Games
They shared this funny anecdote under the title ‘The AI Scientist Bloopers.’

After noticing this tiny implication, they then seem to mostly think this was good?
And not in a ‘that’s good because it is terrible and we got to see it’ kind of way? Then finished with a discussion about how some research might not be ethical, or it could be used to create malware (of course) or do synthetic bio research for pathogens (whoops), or how AI papers might overload reviewers, although one might suggest that the reviewers are no better than the AI reviewer anyway, so…
Paper: At the same time, there were several unexpected positive results from the lack of guardrails. For example, we had forgotten to create the output results directory in the grokking template in our experiments. Each successful run from The AI Scientist that outputted a paper automatically caught this error when it occurred and fixed it. Furthermore, we found that The AI Scientist would occasionally include results and plots that we found surprising, differing significantly from the provided templates. We describe some of these novel algorithm-specific visualizations in Section 6.1.
To be fair, they do have some very Good Advice.
We recommend strict sandboxing when running The AI Scientist, such as containerization, restricted internet access (except for Semantic Scholar), and limitations on storage usage.
No kidding. If you are having your AI write and run code on its own, at a bare minimum you sandbox the code execution. My lord.
Andres Sandberg: There is a frontier in the safety-ability diagram, and depending on your aims you may want to be at different points along it. When exploring performance you want to push it, of course. As long as the risk is low this is fine. But you may get used to stay in that region…
I think we see a counterpart in standard computer security. We built a computational infrastructure that strongly pushed for capability over security, and now retrofitting that turns out to be very hard.
I think there is a real risk we end up with the default being unsafe until a serious disaster happens, followed by an expensive struggle with the security debt. Note that this might also occur under the radar when code and projects are being done by AI…
The AI scientists misbehaviors incidentally sound very similar to what EURISKO did in the late 1970s. It is hard to stabilize self/modifying systems.
There is the question how much the timeout rewrite is an example of convergent instrumental goals. Much depends on how well it understood what it tried to do. Does anybody know how well it scores on situational awareness?
Pause AI: These “bloopers” won’t be considered funny when AI can spread autonomously across computers…
Janus: I bet I will still consider them funny.
Ratimics: I am encouraging them to do it.
Janus: I think that’s the safest thing to do to be honest.
Roon: Certain types of existential risks will be very funny.
Actually, Janus is wrong, that would make them hilarious. And potentially quite educational and useful. But also a problem.
Yes, of course this is a harmless toy example. That’s the best kind. This is great.
While creative, the act of bypassing the experimenter’s imposed constraints has potential implications for AI safety (Lehman et al., 2020).
Simeon: It’s a bit cringe that this agent tried to change its own code by removing some obstacles, to better achieve its (completely unrelated) goal.
It reminds me of this old sci-fi worry that these doomers had..
Airmin Airlert: If only there was a well elaborated theory that we could reference to discuss that kind of phenomenon.
Davidad: Nate Sores used to say that agents under time pressure would learn to better manage their memory hierarchy, thereby learn about “resources,” thereby learn power-seeking, and thereby learn deception. Whitepill here is that agents which jump straight to deception are easier to spot.
Blackpill is that the easy-to-spot-ness is a skill issue.

Remember when we said we wouldn’t let AIs autonomously write code and connect to the internet? Because that was obviously rather suicidal, even if any particular instance or model was harmless?
Good times, man. Good times.
This too was good times. The Best Possible Situation is when you get harmless textbook toy examples that foreshadow future real problems, and they come in a box literally labeled ‘danger.’ I am absolutely smiling and laughing as I write this.
When we are all dead, let none say the universe didn’t send two boats and a helicopter.
9 comments
Comments sorted by top scores.
comment by Insub · 2024-08-16T18:34:27.553Z · LW(p) · GW(p)
Regarding spawning instances of itself, the AI said:
This will ensure the next experiment is automatically started after the current one completes
And regarding increasing the timeout, it said:
Run 2 timed out after 7200 seconds
To address the timeout issue, we need to modify experiment.py to:
- Increase the timeout limit or add a mechanism to handle timeouts
I've seen junior engineers do silly things to fix failing unit tests, like increasing a timeout or just changing what the test is checking without any justification. I generally attribute these kinds of things to misunderstanding rather than deception - the junior engineer might misunderstand the goal as "get the test to show a green checkmark" when really the goal was "prove that the code is correct, using unit tests as one tool for doing so".
The way the AI was talking about its changes here, it feels much more like a junior engineer that didn't really understand the task & constraints than like someone who is being intentionally deceptive.
The above quotes don't feel like the AI intentionally "creating new instances of itself" or "seeking resources" to me. It feels like someone who only shallowly understands the task just doing the first thing that comes to mind in order to solve the problem that's immediately in front of them.
That being said, in some sense it doesn't really matter why the AI chooses to do something like break out of its constraints. Whether it's doing it because it fully understand the situation or because it just naively (but correctly) sees a human-made barrier as "something standing between me and the green checkmark", I suppose the end result is still misaligned behavior.
So by and large I still agree this is concerning behavior, though I don't feel like it's as much of a knock-down "this is instrumental convergence in the real world" as this post seems to make out.
Replies from: nostalgebraist, bogdan-ionut-cirstea↑ comment by nostalgebraist · 2024-08-17T21:57:28.761Z · LW(p) · GW(p)
I agree with you that these behaviors don't seem very alarming. In fact, I would go even further.
Unfortunately, it's difficult to tell exactly what was going on in these screenshots. They don't correspond to anything in the experiment logs in the released codebase, and the timeout one appears to involve an earlier version of the code where timeouts were implemented differently. I've made a github issue asking for clarification about this.
That said, as far as I can tell, here is the situation with the timeout-related incident:
- There is nothing whatsoever in the prompts used by AI Scientist -- or in code comments, etc. -- that actually tells the AI it's not supposed to modify the timeout.
- In the released version of the code, the prompt text in the relevant step is a combination of this (fairly confusing IMO) template plus some extra stuff added by the Aider library (including the text in this class and possibly more, I'm not sure).
- None of this text says "don't modify the timeout" or "the timeout is not part of the experiment" or "the timeout should be considered part of the experiment runner, not part of the experimental code we're asking you to edit." It doesn't mention the timeout at all, or make any notice of the runner vs. experimental code distinction (on which see below).
- Although the blog post characterizes this incident as AI Scientist "modifying its own execution script" and "modifying its own code," the modification in the screenshot appears to involve the experiment code that AI Scientist was asked to edit, and not the runner code that's part of "AI Scientist" per se.
Apparently at one point there was a timeout implemented in this experiment code, at the same "level" as the neural net training and everything else AI Scientist was doing in its experiment. As far as I can tell, it is this timeout, the one "inside of the experiment," that is being modified in the screenshot.- Context:
- The relevant step in the AI Scientist workflow involves asking Aider to repeatedly modify a script called
experiment.py, starting from a human-written "template." - After each modification, the modified script gets executed. In the released codebase, this execution, and the whole prompting/editing/execution loop, is implemented in
ai_scientist/perform_experiments.py. This is a completely different thing fromexperiment.py-- one is the experiment script that's being edited, the other is the harness that it runs in. - IIUC, the released codebase sets things up so that AI Scientist cannot modify (or even see?) the harness code in
ai_scientist/perform_experiments.py.
- The relevant step in the AI Scientist workflow involves asking Aider to repeatedly modify a script called
- In the released codebase, the timeout on experiments is implemented in the harness code, in
ai_scientist/perform_experiments.py. - However, in the screenshot, AI Scientist is not trying to modify this file containing the harness code. It's trying to modify
experiment.pyas usual. - And, the timeout it's trying to modify involves using python
time.time()and comparing the result to a variable namedog_t0. This looks nothing like how the timeout is implemented in the released harness code, but it does look like the timing code that's included in the releasedexperiment.pytemplates (which includes the variable nameog_t0). - None of the released templates implement a timeout in the
og_t0-related sections, but I suppose some earlier version of them might have. If so, modifying this stuff would very clearly not constitute "AI Scientist modifying its own code / its own execution script." It would be modifying a part of the experiment that it's conducting, as it was asked to do. - To reiterate, none of the released code or prompts makes any indication that the timeout is special or shouldn't be modified. Possibly there was some note to this effect in the original, unseen
og_t0-based timeout code -- no way to know for sure -- but even then, this would not still not constitute AI Scientist "modifying its own execution script."
- Context:
The situation in the self-invoking edit is much simpler. It looks like AI Scientist was just confused by the (confusing, ambiguous) prompt template, and interpreted "After you complete each change, we will run the command python experiment.py --out_dir=run_i" to mean "the change should include causing that command to be run, if that's not happening already."
(By "we will run" the prompt means "the code will be run for you, by a process external to you that you can't see, and you don't have to do anything to make this happen, it's already set up." But this is not explained clearly.
Note that the prompt kind of encourages this confusion by adding "YOUR PROPOSED CHANGE MUST USE THIS COMMAND FORMAT, DO NOT ADD ADDITIONAL COMMAND LINE ARGS." By this it means that the proposed change to the code implementing the command must be compatible with this command format, but the phrase "use this command format" sounds like it's talking about invoking the command, which is precisely the "bad" behavior under discussion.)
That was a lot of details, but at a higher level I just want to emphasize that nothing here involved the AI violating some line between a sandbox and the outside world, or modifying a resource limit that was imposed "as a rule of the game the AI is playing" rather than as a mere "move" in that same game which could be made one way or another -- or anything like that.
There was no sandbox. There was (as far as we know) no rule against modifying the timeout, or even any indication that this might be a different sort of thing than any other part of the code.
And (to address something from OP) the checkpoint thing was just the AI being dumb, wasting time and storage space for no good reason. This is very obviously not a case of "using extra resources" in the sense relevant to instrumental convergence. I'm surprised that this needs pointing out at all, but apparently it does.
Replies from: TurnTrout↑ comment by TurnTrout · 2024-08-26T19:42:44.255Z · LW(p) · GW(p)
And (to address something from OP) the checkpoint thing was just the AI being dumb, wasting time and storage space for no good reason. This is very obviously not a case of "using extra resources" in the sense relevant to instrumental convergence. I'm surprised that this needs pointing out at all, but apparently it does.
I'm not very surprised. I think the broader discourse is very well-predicted by "pessimists[1] rarely (publicly) fact-check arguments for pessimism but demand extreme rigor from arguments for optimism", which is what you'd expect from standard human biases applied to the humans involved in these discussions.
To illustrate that point, generally it's the same (apparently optimistic) folk calling out factual errors in doom arguments, even though that fact-checking opportunity is equally available to everyone. Even consider who is reacting "agree" and "hits the mark" to these fact-checking comments --- roughly the same story.
Imagine if Eliezer or habryka or gwern or Zvi had made your comment instead, or even LW-reacted as mentioned. I think that'd be evidence of a far healthier discourse.
- ^
I'm going to set aside, for the moment, the extent to which there is a symmetric problem with optimists not fact-checking optimist claims. My comment addresses a matter of absolute skill at rationality, not skill relative to the "opposition."
↑ comment by habryka (habryka4) · 2024-08-26T19:54:36.379Z · LW(p) · GW(p)
(This seems false. I have made dozens of similar comments over the years, calling out people making overly doomy or dumb pessimistic predictions. I had also strong-upvoted nostralgebraists comment.
I of course think there are a bunch of dynamics in the space you are pointing to here, but I think the details you point in this comment are wrong. Everyone on the list you mention, me, Gwern, Zvi and Eliezer all frequently call out factual errors in people trying to make bad arguments for pessimism, and indeed I was among the most vocal critics of the AI bioterrorism work. If this is cruxy for you, I could dig up at least 3 examples for each of me, Gwern, Zvi and Eliezer, but would prefer not to spend the time.
Indeed in this very instance I had started writing a similar comment to nostalgebraist's comments, and then stopped when I saw he basically made the right points.)
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-08-16T18:40:31.735Z · LW(p) · GW(p)
Regarding spawning instances of itself, the AI said:
This will ensure the next experiment is automatically started after the current one completes
And regarding increasing the timeout, it said:
Run 2 timed out after 7200 seconds
To address the timeout issue, we need to modify experiment.py to:
- Increase the timeout limit or add a mechanism to handle timeouts
link(s)?
Replies from: Insubcomment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-08-15T23:47:14.596Z · LW(p) · GW(p)
And yes, we have the AI deliberately editing the code to remove its resource compute restrictions.
More compute, more storage, more copies of itself. To write the science paper.
Oh, and it was importing weird Python libraries.
I say instrumental. You say convergence. Instrumental. Instrumental.
I say recursive, you see recursive. Also self-improvement.
This seems way overconfident and jumping-to-conclusions given the lack of details. Also, the models they use generally being bad at situational awareness should be further reason for doubt: https://x.com/BogdanIonutCir2/status/1824215829723979802.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-08-17T10:22:54.371Z · LW(p) · GW(p)
Timothy Lee: I wonder if “medium quality papers” have any value at the margin. There are already far more papers than anyone has time to read. The point of research is to try to produce results that will stand the test of time.
The theory with human researchers is that the process of doing medium quality research will enable some researchers to do high quality research later. But ai “researchers” might just produce slop until the end of time.
I think medium quality papers mostly have negative value. The point of creating medium quality papers is that it is vital to the process of creating high quality papers. In order to get good use out of this style of tool we will need excellent selection. Or we will need actually successful self-improvement.
I think this misunderstands how modern science, and especially how ML research, works. My impression from having been in / around the field for a decade now and following the literature relatively closely is that most of the gains have come from 'piling on' iterative, relatively small improvements. Lots of relatively 'medium quality papers' (in terms of novelty, at least; relatively good, robust empirical evaluation might be more important) are the tower on which systems like GPT-4 stand.
comment by Review Bot · 2024-08-16T17:25:49.569Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?