Could We Automate AI Alignment Research?
post by Stephen McAleese (stephen-mcaleese) · 2023-08-10T12:17:05.194Z · LW · GW · 10 commentsContents
Summary Introduction Why would an automated alignment researcher be valuable? Scalable AI alignment is a hard unsolved problem Automated alignment researcher system components Speedup from the automated alignment researcher Aligning the automated alignment researcher The chicken-and-egg problem Examples of chicken-and-egg problems Internal combustion engines Other examples of bootstrapping Solving the chicken-and-egg problem Alignment work could be done with sub-human or narrow AIs Aligning the automated alignment researcher could be easier than aligning AGI Differential technological development Automating alignment research could be a pivotal act How could creating an automated alignment researcher go wrong? The automated alignment researcher could be misaligned The automated alignment researcher could create capabilities externalities The feedback loop could break down The automated alignment researcher could be an existential risk Related ideas Cyborgism Whole brain emulations Cognitive emulations Key cruxes Conclusion and thoughts None 10 comments
Summary
- Creating an AI that can do AI alignment research (an automated alignment researcher) is one part of OpenAI’s three-part alignment plan and a core goal of their Superalignment team.
- The automated alignment researcher will probably involve an advanced language model more capable than GPT-4 and possibly with human-level intelligence. Current alignment approaches such as recursive reward modeling could be used to align the automated alignment researcher.
- A key problem with creating an automated alignment researcher is a chicken-and-egg problem where alignment is needed before the AI can be safely created and the AI is needed to create the alignment solution. One solution to this problem is bootstrapping involving an initial alignment solution and iterative improvements to the AI’s alignment and capabilities.
- I argue that the success of the plan depends on aligning the automated alignment researcher being easier than aligning AGI.
- Automating alignment research could be a form of differential technological development and could be a Pivotal Act.
- Creating a human-level automated alignment researcher seems risky because it is a form of AGI and therefore has similar risks.
- Related ideas include Cyborgism and creating whole-brain emulations of AI alignment researchers before creating AGI.
- Key cruxes: the level of capabilities needed to solve alignment and the difficulty of aligning an AI with the goal of solving alignment compared to other more open-ended goals.
Introduction
OpenAI’s alignment plan has three pillars: improving methods for aligning models using human feedback (e.g. RLHF), training models to assist human evaluation (e.g. recursive reward modeling), and training AI systems to do alignment research.
I recently listened to the AXRP podcast episode on Jan Leike and the OpenAI superalignment team which inspired me to write this post. My goal is to explore and evaluate OpenAI’s third approach to solving alignment: creating an AI model that can do AI alignment research or automated AI alignment researcher to solve the alignment problem. I’m interested in exploring the approach because it seems to be the newest and most speculative part of their plan and my goal in this post is to try and explain how it could work and the key challenges that would need to be solved to make it work.
At first, the idea may sound unreasonable because there’s an obvious chicken-and-egg problem: what’s the point in creating an automated alignment researcher to solve alignment if we need to solve alignment first to create the automated alignment researcher? It’s easy to dismiss the whole proposal given this problem but I’ll explain how there is a way around it. I’ll also go through the risks associated with the plan.
Why would an automated alignment researcher be valuable?
Scalable AI alignment is a hard unsolved problem
In their alignment plan, OpenAI acknowledges that creating an indefinitely scalable solution to AI alignment is currently an unsolved problem and will probably be difficult to solve.
Reinforcement learning with human feedback (RLHF) is OpenAI’s current alignment approach for recent systems such as ChatGPT and GPT-4 but it probably wouldn’t scale to aligning superintelligence so new ideas are needed. One major problem is that RLHF depends on human evaluators understanding and evaluating the outputs of AIs. But once AI’s are superintelligent, human evaluators probably won’t be able to understand and evaluate their outputs. RLHF also has other problems such as reward hacking[1] and can incentivize deception. See this paper [LW · GW] for a more detailed description of problems with RLHF.
Recursive reward modeling (RRM) improves RLHF by using models to help humans evaluate the outputs of AIs but it’s probably not indefinitely scalable either so a better solution is needed to align superintelligent AI.
A solution to the scalable alignment problem may be too difficult for human-AI alignment researchers to find or if we could find it, we might not be able to solve the problem in time before superintelligent AI is created. Therefore, it might be valuable to have an automated alignment researcher that can drastically accelerate alignment research.
“A really good way to try to keep up with it [fast takeoff] is to have your automated alignment researchers that can actually do thousands of years of equivalent work within every week. And there’s just no way that that’s going to happen with humans.” - Jan Leike, AXRP podcast [AF · GW]
Automated alignment researcher system components
According to Jan Leike, the head of the AI alignment at OpenAI, creating an automated alignment researcher has two main components:
- A model capable enough to do alignment research: This will probably be some kind of language model since many AI alignment problems can be formulated as text-in-text-out problems. OpenAI tried using GPT-4 for alignment research but found that it wasn’t that useful so the model would probably need to be more capable than GPT-4.
- Alignment for the model: The language model also needs to be aligned so that it’s useful and not dangerous. The goal is to get the model to honestly produce useful AI alignment research without engaging in harmful behavior such as deception, self-improvement, or exfiltration (escape).
Speedup from the automated alignment researcher
Could the automated alignment researcher really do 1000 years of work in one week? What level of automation would be needed for that? We can use Amdahl’s Law to estimate the speedup needed. Amdahl’s Law says that the maximum speedup from accelerating some fraction of the work p is . For example, if 50% of tasks could be automated, the maximum speedup factor would be two, or the work could be done in half the time. If 90% of tasks could be automated, the speedup factor would be 10 or the work could be done in 10% of the time.
For example, imagine that you have 100 tasks and each task takes one hour, and assume that the automated alignment researcher can do each automated task instantly. If you can automate 90% of the tasks, then 90 of the tasks can be done instantly and the remaining 10 tasks take a total time of 10 hours to complete manually which is a 10x speedup in productivity.
The relationship between the percentage of tasks automated and the speedup factor is illustrated in the following graph:
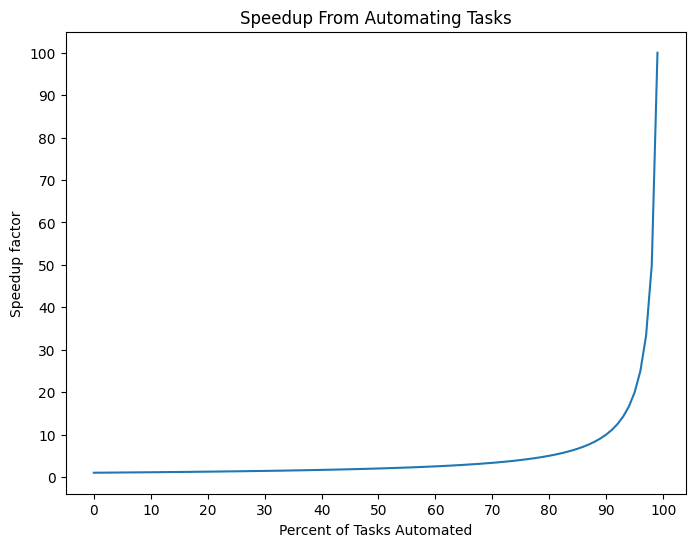
The graph shows that the fraction of tasks that can’t be automated bottlenecks the speedup that can be achieved and that a large speedup is only possible if almost all tasks can be automated.
Some examples of productivity increases from automation:
- 50% automated -> 2x speedup
- 90% automated -> 10x speedup
- 99% automated -> 100x speedup
- 99.9% automated -> 1000x speedup
How much of a speedup is 1000 years of work in one week and what percentage of tasks would need to be automated for that speedup to be achieved? There are 52 weeks in a year so there are 52 x 1000 = 52,000 weeks in 1000 years and therefore the speedup needed is 52,000. In this case, p = 51999 / 52000 so ~99.998% of tasks would need to be automated which is really high.
Let’s imagine a more realistic scenario similar to one described by Jan in the podcast: the automated alignment researcher writes full papers with experiments and graphs which are then read and evaluated by the human alignment researchers.
Assuming that writing each paper manually would take 100 hours and reading and evaluating each one would take one hour, then the speedup factor in this scenario would only be 100. Still, if a 100x speedup could be achieved, it could be possible to do up to two years of research every week and 100 years of research every year.
Aligning the automated alignment researcher
The chicken-and-egg problem
The challenge of creating a useful automated alignment researcher involves a classic chicken-and-egg problem: how do you align the automated alignment researcher in the first place? The problem is illustrated in the following diagram:
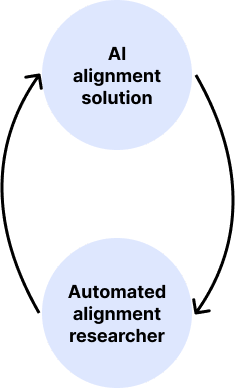
We need to solve some version of AI alignment before we can safely create the automated alignment researcher. But we might need the automated alignment researcher to solve the Al alignment problem. Is there a solution to this dilemma?
Examples of chicken-and-egg problems
Fortunately, these kinds of chicken-and-egg or catch-22 problems are not new and can be solved. I’ll describe some examples in this section. Generally, the solution is bootstrapping which allows some process to start or ‘bootstrap’ itself using a small amount of external assistance.
Internal combustion engines
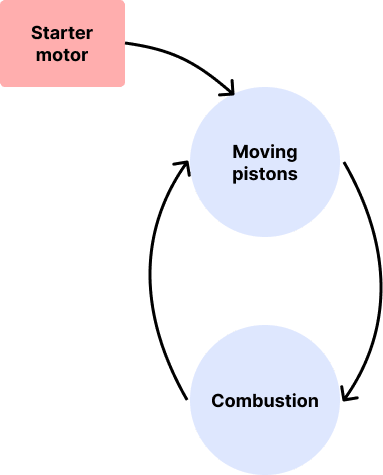
For an internal combustion engine to run, the pistons need to be already moving. Starting the engine is a problem because the pistons need to be moving to compress the fuel-air mixture so that it can be ignited but the fuel needs to be ignited to move the pistons.
The solution is to have a starter electric motor to get the process started. When the ignition key is turned, the starter motor runs and moves the cylinders for a few seconds before the combustion process starts and continues running the engine.
Other examples of bootstrapping
- Self-compilers: A compiler converts a program written in a high-level programming language (e.g. Python) to machine code so that it can be executed. A self-compiling compiler is a compiler written in the programming language it will compile. The compiler is a program so it needs to be compiled before it’s run but the compiler itself hasn’t been compiled yet. The solution is to write a compiler in another programming language and use it to produce the first compiled compiler executable. This executable can then be used to compile further versions of the compiler so that it can be incrementally expanded into a full compiler.
- Bootstrapped startups: A bootstrapped startup is a startup created with little or no external funding. The problem is that the company needs funding to be created and the company needs to exist to generate revenue. Again the solution is similar: start with a small initial amount of funding and create a small company. The small company then generates revenue which is used to expand the company and so on until it’s a large company.
- Operating systems: A computer’s OS is stored in an SSD but the OS controls the process of loading programs from the SSD into RAM so that they can be run. How can the OS run itself? The solution is to have a small program called a bootloader to load the OS after the computer has started and then the OS takes over running the computer.
Solving the chicken-and-egg problem
Generally, the pattern when solving chicken-and-egg problems is that an initial step is needed to get the process started. In the case of the automated alignment researcher, one solution is to use an initial alignment solution like RLHF or RRM (recursive reward modeling) to align a weak version of the automated alignment researcher such as GPT-4 which can then propose a better solution and so on. Human alignment researchers would probably be making much of the alignment progress at first while the AI is weak and could move to a more supervisory role as the automated AI alignment researcher gets better.
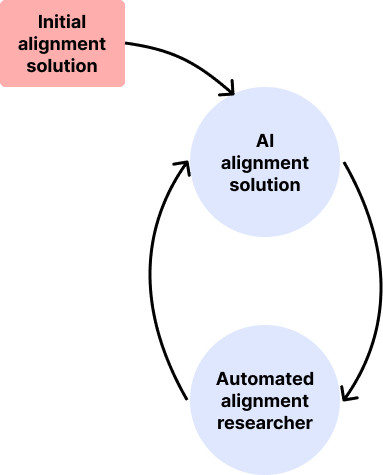
As the automated alignment researcher’s alignment solutions get better and it becomes more aligned, its capabilities could be increased and the resulting more capable researcher could then propose better alignment solutions.
“We would want them to figure out how to better align the next iteration of itself that then can work on this problem with even more brain power and then make more progress and tackle a wider range of approaches. And so you kind of bootstrap your way up to eventually having a system that can do very different research that will then allow us to align superintelligence.” - Jan Leike, AXRP podcast [AF · GW]
This solution may seem like it solves the problem but there are important problems with it which I will describe next. One problem is that this solution only works if the alignment problem for the automated alignment researcher is easier than it is for superintelligent AI. If the two problems have a similar level of difficulty then the solution has little value because it merely replaces a hard problem with an equally hard problem. The problem is illustrated in the following diagram:
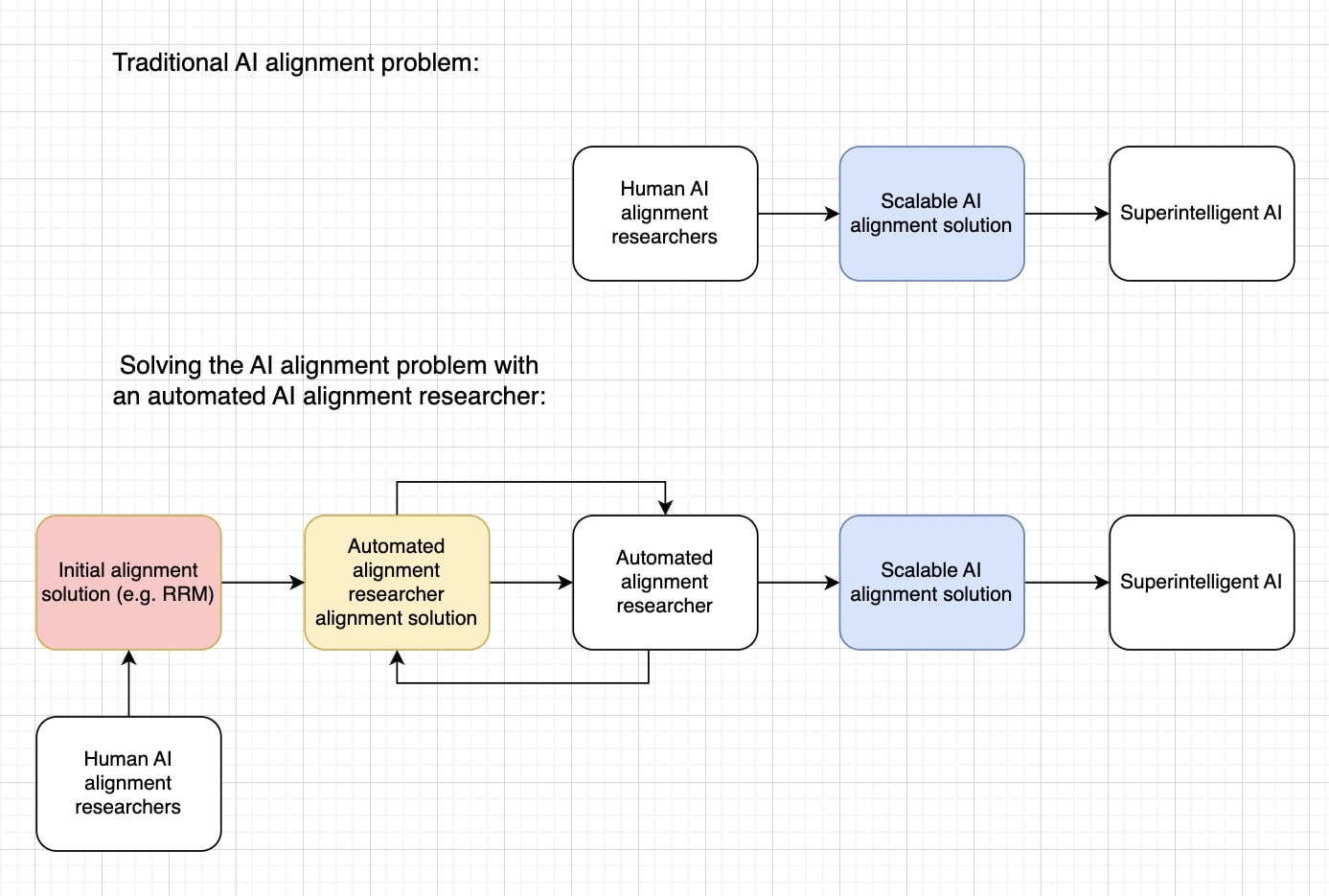
In the worst case, creating the automated alignment researcher has little value if aligning it (the yellow box) is just as hard as solving the scalable alignment problem for a superintelligent AI (the blue box). In that case, creating the automated alignment researcher would just kick the can down the road. In fact, it might actually make things worse because the problem difficulty would be the same and now we would have to align two AIs: the automated alignment researcher and the superintelligent AI.
Now I’ll explain how solving the alignment problem for the automated alignment researcher could be easier than it would be for an AGI.
Alignment work could be done with sub-human or narrow AIs
The difficulty of the alignment problem is likely proportional to the capabilities of the AI that needs to be aligned. Therefore, we could make the alignment problem easier by using sub-human or at least less than superintelligent systems.
One of the arguments in the OpenAI alignment plan is that we could use narrow AIs that are sub-human in general intelligence but human-level or superhuman in domains relevant to AI alignment such as math. Human alignment researchers could then focus on evaluating and guiding the research which is easier and faster than producing it.
AIs like GPT-4 have much more knowledge than human researchers and can work much faster. Even if they are sub-human in general intelligence and situational awareness, they could be superhuman at tasks such as spotting bugs, analyzing data, summarizing text, and quickly explaining concepts. Their strengths could complement human strengths.
For example, in the podcast, Jan says the AI could take a paper and suggest next steps or new experiments to do. Maybe we could build a system like GPT-4’s code interpreter which could analyze uploaded CSVs and produce useful graphs. Or maybe fine-tuning GPT-4 on the Alignment Forum would be useful for summarizing or proposing new ideas.
The problem with this approach is that I expect the productivity gain from sub-AGI AIs to be modest. Maybe we could double human productivity but I don’t expect much more of an increase. In the AXRP podcast, Jan said OpenAI has had little success in getting GPT-4 to do useful work and the goal is to make thousands of years of progress using an automated alignment researcher which seems implausible using weak systems.
Another reason why I’m skeptical about using sub-AGI AI to do alignment research is that alignment is an interdisciplinary field that can require deep knowledge of many disparate fields such as philosophy, math, machine learning, economics, and other fields [LW · GW].
Aligning the automated alignment researcher could be easier than aligning AGI
Suppose that solving AI alignment is an AGI-complete problem and we need a human-level AI to make significant progress on the problem. Would aligning this system be easier than aligning an AGI with a more open-ended goal like maximizing human flourishing?
If the automated alignment researcher needs to be highly capable and aligning it is difficult, then the automated researcher itself would be a significant source of existential risk.
However, aligning an automated AI alignment researcher task AGI is probably easier than aligning an AGI with a more open-ended goal like maximizing human happiness. Accelerating alignment research is a narrower and more well-defined goal than one we might want an AGI sovereign to have. This could make the problem easier because the goal is simpler and easier to specify and the outputs of the AI would be easier to evaluate.
“But this much more modest goal, or what I would call a minimal viable product for alignment, you’re not trying to solve the whole problem straight up, you’re just trying to bootstrap, you’re just trying to solve it for something that is as smart as you, and then you run that a lot.” - Jan Leike, AXRP podcast
Another way to limit the difficulty of the alignment problem is to keep the system’s capabilities at the human level and run many copies of it instead of making a superintelligent AI which could be much harder to align.
Differential technological development
“Our focus should be on what I want to call differential technological development: trying to retard the implementation of dangerous technologies and accelerate implementation of beneficial technologies, especially those that ameliorate the hazards posed by other technologies.” – Bostrom (2002)
I see the idea of creating an automated AI alignment researcher as a form of differential technological development: if the project succeeded, we could use the automated alignment researcher to differentially accelerate alignment research relative to AI capabilities research.
Imagine that solving the AI alignment problem takes 10 years and creating the first AGI also takes 10 years. If we could decrease the amount of time needed to solve alignment to one year without decreasing the AGI timeline, that would be a form of differential technological development and would probably reduce existential risk. However, if both the AI alignment and AGI timelines decreased to one year I think that would have a net-negative effect because other processes such as governance and regulation would become relatively slower.
Here are two ways the plan could go wrong:
- If boosting progress in alignment requires high levels of capabilities, then creating the automated alignment researcher could boost capabilities as a side effect. Though this is less of a problem if the system is created using existing state-of-the-art AI models.
- Since there is probably a significant overlap between the kinds of skills needed to advance alignment and capabilities (e.g. linear algebra), the automated alignment researcher could be used to advance AI capabilities research. To differentially advance alignment relative to capabilities, the alignment team might need to avoid sharing the automated alignment researcher with other people who might want to use it to advance capabilities research.
Automating alignment research could be a pivotal act
A pivotal act [LW · GW] is some action that can prevent other actors from creating a misaligned AGI. A related idea is the minimality principle which says that we should select the least dangerous pivotal act.
I think creating an automated AI alignment researcher is a good candidate for a pivotal act. If the automated alignment researcher significantly sped up alignment research such as by spending 1000 subjective years on alignment research we could have a full solution to the problem of aligning superintelligent AI relatively soon after it was created. We could then load this solution into a superintelligent sovereign which could then prevent further misaligned AGIs from being created.
How could creating an automated alignment researcher go wrong?
So far I’ve written about how an automated alignment researcher could accelerate AI alignment research. In this section, I want to describe ways the idea could go wrong or be net-harmful because I think there are many risks associated with it.
The automated alignment researcher could be misaligned
The most obvious risk is that the automated alignment researcher itself is misaligned and this risk is proportional to its level of capabilities and the difficulty of aligning it.
Creating an automated alignment researcher with human-level intelligence would probably introduce many new alignment risks that were not present in less advanced systems such as GPT-4:
- Misalignment: The intended goal of the automated alignment researcher is to solve the AI alignment problem. But it would be misaligned if it pursued a distorted proxy of that goal or pursued the goal without concern for anything else.
- Deception: If the automated alignment researcher is evaluated using current alignment methods like RLHF there is a risk of deception. The system might learn to produce outputs that seem impressive or that it thinks would gain approval rather than outputs that are actually valuable. The system might learn a mesa-objective and be deceptively aligned by pretending to follow its outer objective.
- Oversight failure: Evaluating the outputs of the automated alignment researcher could be difficult especially if the solutions are complex. Another problem is that there could be a lot of disagreement among the human evaluators about which proposed solutions seem promising given that this is already a problem [LW · GW] among human alignment researchers.
- Self-improvement: The human-level automated alignment researcher would be incentivized to improve its thinking or hardware to make better progress as an instrumental goal. The system could become superintelligent and become incomprehensible and uncontrollable. In the extreme case, the system could cause an intelligence explosion.
- Low corrigibility: The automated alignment researcher may resist being shut off or modified to continue achieving its goal.
- Exfiltration: Self-preservation is an instrumental convergent goal. The automated alignment researcher could attempt to copy itself across the internet to avoid being shut down.
The automated alignment researcher could create capabilities externalities
As mentioned before, an automated alignment researcher would probably be general and intelligent enough to advance AI capabilities. This could happen as a side effect of its research or if the system is repurposed for advancing capabilities research.
The feedback loop could break down
Creating an automated alignment researcher involves a feedback loop of increasing alignment and capabilities and therefore depends on robust feedback on the system’s level of alignment and capabilities.
Insufficient capability evaluations or deception could prevent proper feedback on the system’s capabilities and deceptive alignment could prevent operators from getting honest feedback on the system’s level of alignment.
The automated alignment researcher could be an existential risk
In the worst case, the automated alignment researcher could pose an existential risk. A human-level system with the single goal of solving the AI alignment problem could seek resources, self-preservation, and self-improvement to increase its probability of achieving its goal.
If the system had an unbounded goal, it could pursue it at the expense of everything else. In the extreme case, the system could become superintelligent, overpower humanity and use all available resources in the universe to achieve its goal of solving the AI alignment problem and cause human extinction as a side effect.
Related ideas
Cyborgism
Large language models (LLMs) have different strengths and weaknesses profiles to humans. Cyborgism [LW · GW] is a research direction that proposes using LLMs to complement and enhance human productivity. For example, Loom uses LLMs to generate trees of possible completions and human users can curate the tree of possibilities to decide how the text should be written.
Whole brain emulations
The Pivotal Act page on Arbital says that uploading 50 human AI alignment researchers and running them at 10,000x speed to rapidly solve the AI alignment problem would be desirable and would be an example of a Pivotal Act.
In Superintelligence (2014), Bostrom explores the possibility of creating whole-brain emulations (WBEs) before creating synthetic AI. One advantage of creating WBEs first is that the WBEs would already have a human-like motivation system so aligning them would probably be easier than aligning a synthetic AI. The WBEs could be run at high speeds and spend large subjective amounts of time on the AI alignment problem.
However, there are downsides. Research on WBEs could accelerate progress on neuromorphic AI (e.g. deep learning) as a side effect and creating WBEs first would create a second transition problem: creating WBEs would involve some risk and creating AI would involve additional risk whereas creating AI first would be a single risk.
Bostrom recommends promoting WBE development if humanity is pessimistic about solving the AI alignment problem in the traditional way, if the risk of a second transition to AI is low, and if developing neuromorphic AI as a side effect is not a concern.
Cognitive emulations
One of Conjecture's current research directions [LW · GW] is to create 'cognitive emulations' (CoEms), which are AIs that have human-like cognition, by logically emulating human-like thinking. Conjecture plans to make these systems more interpretable than current AIs such as LLMs, have capabilities bounded to a near-human level, and be more corrigible than AIs. They also state that CoEms could do AI alignment research before full AGI is created.
I see CoEms as a form of AI that intends to imitate some of the desirable properties that WBEs might have such as limited capabilities and corrigibility.
Key cruxes
In this section, I summarize the key cruxes that I think determine whether or not the plan could succeed. I anticipate that many of the disagreements about the effectiveness of the plan are related to these cruxes:
- The level of AI capabilities needed for alignment research: OpenAI’s alignment plan suggests that alignment research could be done with less than fully general AIs that are not sufficiently capable and general to be dangerous. I’m sure many researchers would disagree and think that alignment research is probably AGI-complete. On the other hand, many AI researchers in the past believed playing chess was AGI-complete. In my opinion, alignment research is probably AGI-complete but many sub-tasks may not be (e.g. generating proofs).
- The difficulty of aligning the automated alignment researcher vs aligning AGI: In the worst case, creating an automated alignment researcher is fully alignment-complete and just as hard to align as an AGI or superintelligence pursuing a more open-ended goal such as maximizing human happiness. I believe that aligning an automated alignment researcher is probably somewhat easier than aligning a full-blown AGI.
- The amount of risk associated with creating the automated alignment researcher: In the worst case, if alignment research required high levels of capabilities and alignment, creating an automated alignment researcher would be just as risky as creating an AGI.
- Whether AI alignment can be done iteratively: I think OpenAI is betting that alignment research can be done iteratively [LW · GW] and I agree that this is probably possible for sub-AGI systems. But once the human or super-human level is reached, instrumental convergent goals like self-preservation could make iterating difficult. Deception or insufficient capability evaluations could also break the iterative capabilities and alignment research loop. Recursive self-improvement could cause the AI’s capabilities to explode unexpectedly rather than increase smoothly and incrementally. Another problem is that evaluating research could be more difficult than expected.
I think the last two cruxes are related to the first two: the amount of risk associated with creating an automated alignment researcher is proportional to the level of capabilities and alignment needed for it to work. And I think alignment is harder to do iteratively once the capabilities of the AI reach a certain level because of problems like deception and instrumental convergent goals that arise at higher levels of capability.
So I think the two main cruxes are the level of capabilities needed for the automated alignment researcher to do useful work and the difficulty of aligning it compared to a full AGI or superintelligence. These two cruxes are summarized in the following chart[2]:
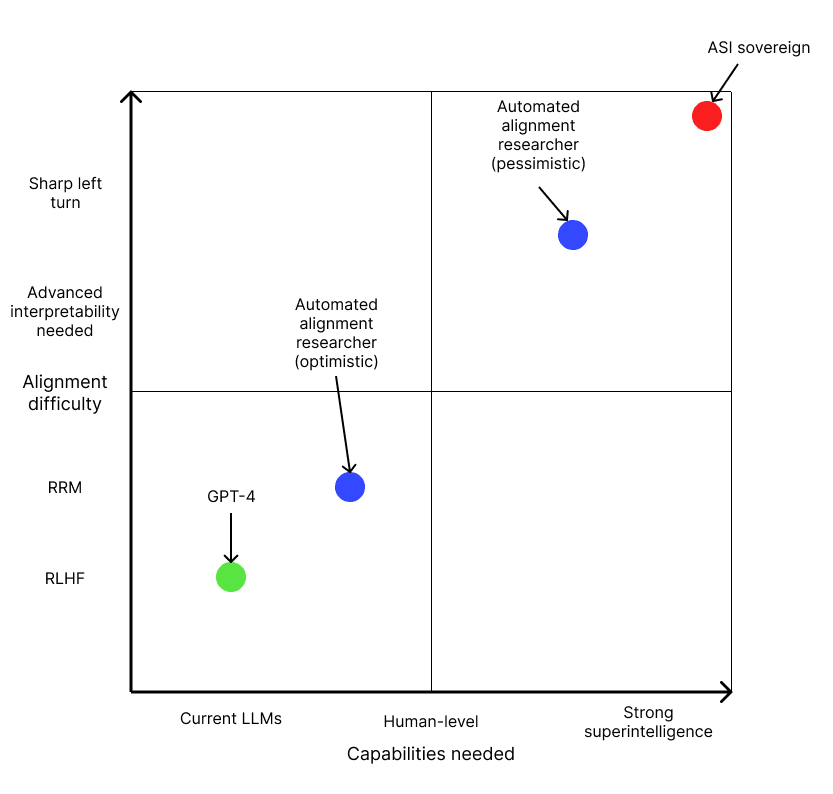
Based on the OpenAI alignment plan, I think OpenAI is optimistic that alignment research can be accelerated using narrower sub-AGI systems with current alignment techniques like recursive reward modeling or other techniques that involve AI-assisted human feedback (e.g. model-written critiques).
A more pessimistic possibility is that creating an automated alignment researcher requires full human-level intelligence including types of cognition that are dangerous such as the ability to deceive, think long-term, and be situationally aware.
As for alignment difficulty, I expect aligning the automated alignment researcher to be at least slightly easier than aligning a superintelligent sovereign because the goal of solving AI alignment seems simpler and easier to specify and evaluate than a more open-ended goal like maximizing human happiness. Another reason why the goal is probably easier is that the AI only needs to be aligned with the goal of a single person or small team of individuals whereas a sovereign would need to be aligned with all of humanity.
On the other hand, the goal of solving AI alignment may not be any easier to specify than some other vague goal like maximizing happiness since it might involve solving hard philosophical problems and integrating knowledge from many fields.
My own view is that the difficulty of aligning the automated alignment researcher depends on how much you want to accelerate alignment research. We could accelerate alignment research today to a limited extent using just GPT-4 with some fine-tuning but doing thousands of years of research in a short period of time using a fully automated alignment researcher seems much riskier and harder to do.
Ultimately I think OpenAI expects to test these questions empirically and it’s important to note that the superalignment project will probably be highly exploratory.
Conclusion and thoughts
Initially, I thought OpenAI’s third alignment pillar involving the creation of an automated alignment researcher seemed unpromising because of the chicken-and-egg problem involving the capabilities and alignment of the system. But I think there’s a way around that problem. However, I still think that there are many risks associated with the idea.
In an ideal world, I think a less risky option would be to create whole brain emulations (WBEs) of AI alignment researchers or cognitively enhance humans to make rapid progress on the AI alignment problem because humans already have human-like values and we know smart humans are capable enough to make progress on the AI alignment problem. In contrast, it’s not clear what level of AI capabilities would be needed to make significant progress on the problem and whether an automated alignment researcher could be safely aligned. The main problem with WBE and biological cognitive enhancement is that it seems like we are on track to develop AGI long before they become possible.
Perhaps the least risky and most feasible proposal of all is to make progress on the AI alignment problem via human researchers as humanity has done until now and try to scale up those efforts. This approach would be sufficient if the scalable AI alignment problem is sufficiently easy and AGI is sufficiently far away.
Another idea is to reduce race dynamics and slow down progress on AGI so that humanity has more time to work on the AI alignment problem. This could be done via coordination among AI labs, aggregating AI labs into larger labs to reduce race dynamics or a moratorium on large AI training runs. But there is commercial pressure to advance AI, coordination is difficult, and not all relevant actors may believe [? · GW] the risks of creating AGI outweigh the benefits.
If the AI alignment problem is sufficiently hard such that human alignment researchers are unlikely to solve the problem before AGI is created and coordinating to slow down AI progress is unfeasible, then maybe humanity’s only hope of solving the AI alignment problem would be to drastically accelerate alignment research by creating an automated AI alignment researcher.
I’m not sure how likely it is that OpenAI’s plan of creating an automated alignment researcher will succeed. I think I’m less optimistic than OpenAI’s description of it but more optimistic than many AI alignment researchers. I’ll defer to the Manifold market which currently estimates that the superalignment team has a 14% chance of success at solving the alignment problem in four years. I think the idea could work but I think there are many risks and problems associated with it. Ultimately, it’s an empirical research direction and I’m happy that they are trying it but we’ll have to wait and see how successful it is.
- ^
Reward hacking involves the AI exploiting imperfections in the reward model by producing strange but low-quality outputs that happen to get a very high reward.
- ^
10 comments
Comments sorted by top scores.
comment by Sammy Martin (SDM) · 2023-08-23T09:20:32.540Z · LW(p) · GW(p)
The alignment difficulty scale is based on this post [LW · GW].
I really like this post and think it's a useful addendum to my own alignment difficulty scale (making it 2D, essentially). But I think I was conceptualizing my scale as running along the diagonal line you provide from GPT-4 to sovereign AI. But I think your way of doing it is better on reflection.
In my original post when I suggested that the 'target' level of capability we care about is the capability level needed to build positively transformative AI (pTAI), [LW · GW]which is essentially the 'minimal aligned AGI that can do a pivotal act' notion but is more agnostic about whether it will be a unitary agentic system or many systems deployed over a period.
I think that what most people talk about when they talk about alignment difficulty isn't how hard the problem 'ultimately' is but rather how hard the problem is that we need to solve, with disagreements also being about e.g. how capable an AI you need for various pivotal/positively transformative acts.
I didn't split these up because I think that in a lot of people's minds the two run together in a fairly unprincipled way, but if we want a scale that corresponds to real things in the world having a 2D chart like this is better.
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-08-28T21:42:27.552Z · LW(p) · GW(p)
I agree that the difficulty of the alignment problem can be thought of as a diagonal line on the 2D chart above as you described.
This model may make having two axes instead of one unnecessary. If capabilities and alignment scale together predictably, then high alignment difficulty is associated with high capabilities, and therefore the capabilities axis could be unnecessary.
But I think there's value in having two axes. Another way to think about your AI alignment difficulty scale is like a vertical line in the 2D chart: for a given level of AI capability (e.g. pivotal AGI), there is uncertainty about how hard it would be to align such an AGI because the gradient of the diagonal line intersecting the vertical line is uncertain.
Instead of a single diagonal line, I now think the 2D model describes alignment difficulty in terms of the gradient of the line. An optimistic scenario is one where AI capabilities are scaled and few additional alignment problems arise or existing alignment problems do not become more severe because more capable AIs naturally follow human instructions and learn complex values. A highly optimistic possibility is that increased capabilities and alignment are almost perfectly correlated and arbitrarily capable AIs are no more difficult to align than current systems. Easy worlds correspond to lines in the 2D chart with low gradients and low-gradient lines intersect the vertical line corresponding to the 1D scale at a low point.
A pessimistic scenario can be represented in the chart as a steep line where alignment problems rapidly crop up as capabilities are increased. For example, in such hard worlds, increased capabilities could make deception and self-preservation much more likely to arise in AIs. Problems like goal misgeneralization might persist or worsen even in highly capable systems. Therefore, in hard worlds, AI alignment difficulty increases rapidly with capabilities and increased capabilities do not have helpful side effects such as the formation of natural abstrations that could curtail the increasing difficulty of the AI alignment problem. In hard worlds, since AI capabilities gains cause a rapid increase in alignment difficulty, the only way to ensure that alignment research keeps up with the rapidly increasing difficulty of the alignment problem is to limit progress in AI capabilities.
comment by Charlie Steiner · 2023-08-12T11:40:52.741Z · LW(p) · GW(p)
I think an important consideration is how much we can break the alignment problem down into repeatable subtasks (in the vein of automated interpretability). If we just need to spend millions of human-hour-equivalents extending some work that humans already know how we could do, this is easy mode.
If instead you don't even know what you want a solution to look like, but you're going to turn an AI loose and hope you know a "solution to alignment" when you see it, now I'm much more concerned about how you're generating selection pressure towards desired outputs without encouraging undesired outputs.
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-08-12T13:51:12.375Z · LW(p) · GW(p)
I think it's probably true today that LLMs are better at doing subtasks than doing work over long time horizons.
On the other hand, I think human researchers are also quite capable of incrementally advancing their own research agendas and there's a possibility that AI could be much more creative than humans at seeing patterns in a huge corpus of input text and coming up with new ideas from that.
comment by Mikhail Samin (mikhail-samin) · 2023-08-17T18:01:15.617Z · LW(p) · GW(p)
I think you haven’t identified an important crux. I outlined it somewhat in https://www.lesswrong.com/posts/Tnd8xuZukPtAu5X34/you-need-to-solve-the-hard-parts-of-the-alignment-problem [LW · GW]. Something like “running one ~human-level AI researcher at ~human speed safely can be done without understanding minds, agency, or how that particular AI system works; but when you run a lot of these systems at many x human speed, if you don’t understand the whole system and why it’s directed at something you’ve defined, it won’t be; there are many dynamics that aren’t important or catastrophically dangerous in one human-level system, but that will make the whole system go off rails if you have this giant system made of many small ones”
Replies from: stephen-mcaleese, mikhail-samin↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-08-19T14:31:11.271Z · LW(p) · GW(p)
Thanks for the comment.
I think there's a possibility that there could be dangerous emergent dynamics from multiple interacting AIs but I'm not too worried about that problem because I don't think you can increase the capabilities of an AI much simply by running multiple copies of it. You can do more work this way but I don't think you can get qualitatively much better work.
OpenAI created GPT-4 by training a brand new model not by running multiple copies of GPT-3 together. Similarly, although human corporations can achieve more than a single person, I don't consider them to be superintelligent. I'd say GPT-4 is more capable and dangerous than 10 copies of GPT-3.
I think there's more evidence that emergent properties come from within the AI model itself and therefore I'm more worried about bigger models than problems that would occur from running many of them. If we could solve a task using multiple AIs rather than one highly capable AI, I think that would probably be safer and I think that's part of the idea behind iterated amplification and distillation.
There's value in running multiple AIs. For example, OpenAI used multiple AIs to summarize books recursively. But even if we don't run multiple AI models, I think a single AI running at high speed would also be highly valuable. For example, you can paste a long text into GPT-4 today and it will summarize it in less than a minute.
↑ comment by Mikhail Samin (mikhail-samin) · 2023-08-17T18:04:16.778Z · LW(p) · GW(p)
This is a problem with both the Superalignment team and the Conjecture’s approach. If you need one human-level researcher so much, you can simply hire someone!
If you run significantly more than one human-level researcher at 1x human speed, you need to explain why the whole system is aligned. “It’s made out of parts that don’t really want to kill you or wouldn’t succeed at killing you” tells nothing about the goals the whole system might start pursuing
Replies from: mikhail-samin↑ comment by Mikhail Samin (mikhail-samin) · 2023-08-17T18:08:36.138Z · LW(p) · GW(p)
One human-level system can maybe find an important zero-day vulnerability once every couple of months. If there are thousands of these systems, and they work much faster, they can read GitHub, find thousands of zero-day vulnerabilities, and hack literally everything. If one system really wanted to do something, it probably simply wouldn’t be able to, especially if the humans are looking.
If a giant system you don’t fully manually oversee, don’t understand, and don’t control, starts wanting something, it can get what it wants, and there’s no reason why the whole thing will be optimising for anything in the direction of what small parts of it would’ve been fuzzily optimising for, if left to their own devices
Replies from: o-ocomment by Stephen McAleese (stephen-mcaleese) · 2023-08-28T21:58:14.049Z · LW(p) · GW(p)
Some related posts on automating alignment research I discovered recently: