Posts
Comments
an all-knowing God could predict which humans would sin and which would not
And how would God predict (with perfect fidelity) what humans would do without simulating them flawlessly? A truly flawless physical simulation has no less moral weight than "reality" -- indeed, the religious argument could very well be that our world exists as a figment of this God's imagination.
systems that have a tendency to evolve towards a narrow target configuration set when started from any point within a broader basin of attraction, and continue to do so despite perturbations.
When determining whether a system "optimizes" in practice, the heavy lifting is done by the degree to which the set of states that the system evolves toward -- the suspected "target set" -- feels like it forms a natural class to the observer.
The issue here is that what the observer considers "a natural class" is informed by the data-distribution that the observer has previously been exposed to.
Whether or not an axis is "useful" depends on your utility function.
If you only care about compressing certain books from The Library of Babel, then "general optimality" is real — but if you value them all equally, then "general optimality" is fake.
When real, the meaning of "general optimality" depends on which books you deem worthy of consideration.
Within the scope of an analysis whose consideration is restricted to the cluster of sequences typical to the Internet, the term "general optimality" may be usefully applied to a predictive model. Such analysis is unfit to reason about search over a design-space — unless that design-space excludes all out-of-scope sequences.
Yeah. Here's an excerpt from Antifragile by Taleb:
One can make a list of medications that came Black Swan–style from serendipity and compare it to the list of medications that came from design. I was about to embark on such a list until I realized that the notable exceptions, that is, drugs that were discovered in a teleological manner, are too few—mostly AZT, AIDS drugs.
Backpropagation designed it to be good on mostly-randomly selected texts, and for that it bequeathed a small sliver of general optimality.
"General optimality" is a fake concept; there is no compressor that reduces the filesize of every book in The Library of Babel.
This was kinda a "holy shit" moment
Publicly noting that I had a similar moment recently; perhaps we listened to the same podcast.
For what it's worth, he has shared (confidential) AI predictions with me, and I was impressed by just how well he nailed (certain unspecified things) in advance—both in absolute terms & relative to the impression one gets by following him on twitter.
I resent the implication that I need to "read the literature" or "do my homework" before I can meaningfully contribute to a problem of this sort.
The title of my post is "how 2 tell if ur input is out of distribution given only model weights". That is, given just the model, how can you tell which inputs the model "expects" more? I don't think any of the resources you refer to are particularly helpful there.
Your paper list consists of six arXiv papers (1, 2, 3, 4, 5, 6).
Paper 1 requires you to bring a dataset.
We propose leveraging [diverse image and text] data to improve deep anomaly detection by training anomaly detectors against an auxiliary dataset of outliers, an approach we call Outlier Exposure (OE). This enables anomaly detectors to generalize and detect unseen anomalies.
Paper 2 just says "softmax classifers tend to make more certain predictions on in-distribution inputs". I should certainly hope so. (Of course, not every model is a softmax classifer.)
We present a simple baseline that utilizes probabilities from softmax distributions. Correctly classified examples tend to have greater maximum softmax probabilities than erroneously classified and out-of-distribution examples, allowing for their detection.
Paper 3 requires you to know the training set, and also it only works on models that happen to be softmax classifiers.
Paper 4 requires a dataset of in-distribution data, it requires you to train a classifier for every model you want to use their methods with, and it looks like it requires the data to be separated into various classes.

Paper 5 is basically the same as Paper 2, except it says "logits" instead of "probabilities", and includes more benchmarks.
We [...] find that a surprisingly simple detector based on the maximum logit outperforms prior methods in all the large-scale multi-class, multi-label, and segmentation tasks.
Paper 6 only works for classifiers and it also requires you to provide an in-distribution dataset.
We obtain the class conditional Gaussian distributions with respect to (low- and upper-level) features of the deep models under Gaussian discriminant analysis, which result in a confidence score based on the Mahalanobis distance.
It seems that all of the six methods you referred me to either (1) require you to bring a dataset, or (2) reduce to "Hey guys, classifiers make less confident predictions OOD!". Therefore, I feel perfectly fine about failing to acknowledge the extant academic literature here.
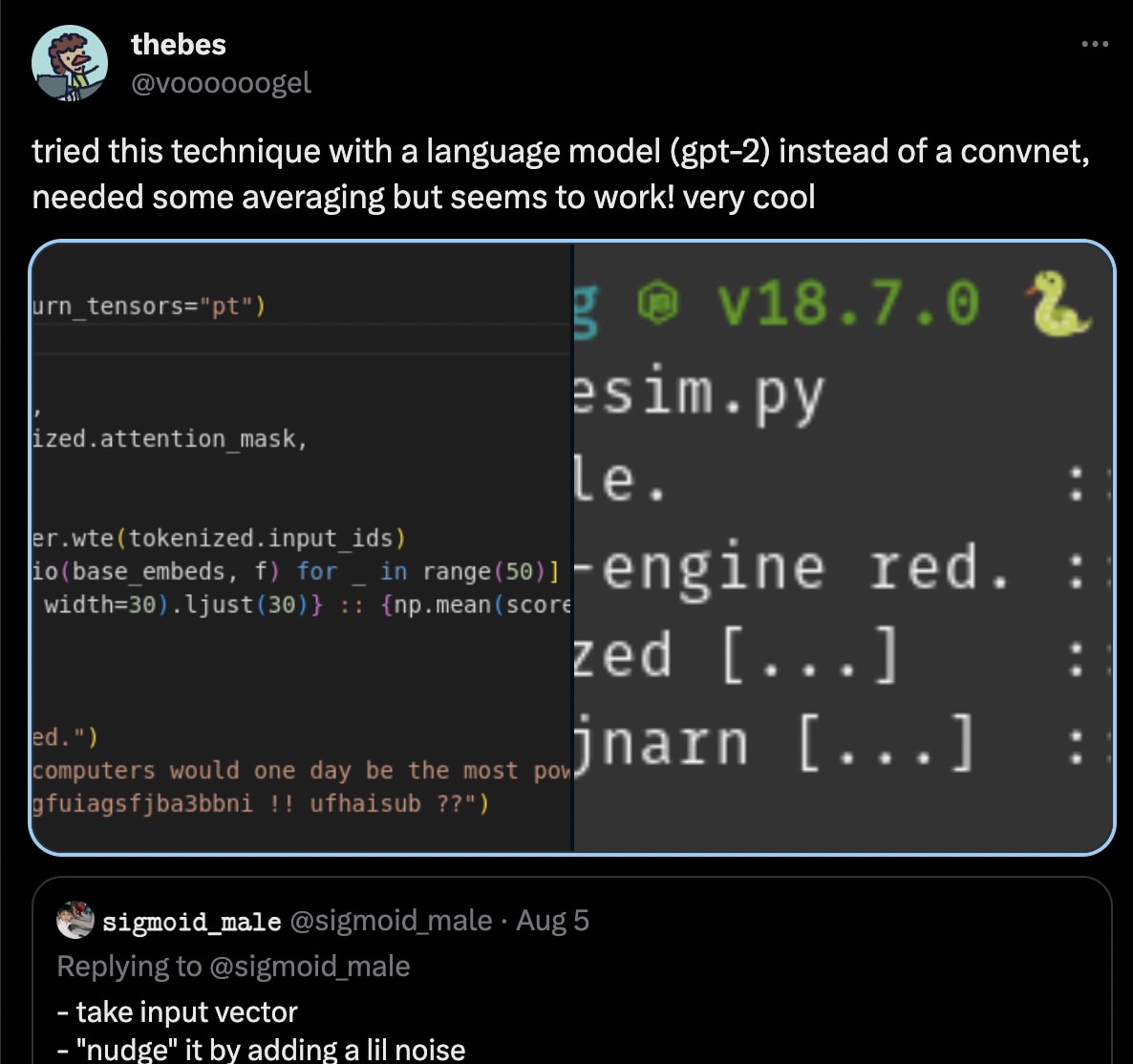
(Additionally, the methods in my post were also replicated in language models by @voooooogel:
Obtaining an Adderall prescription.
I use Done, and can recommend messaging their support to switch you to RxOutreach (a service that mails you your medication) if you live in an area with Adderall shortages, like, say, the Bay Area.
I recently met several YC founders and OpenAI enterprise clients — a salient theme was the use of LLMs to ease the crushing burden of various forms of regulatory compliance.
Does “Kickstarter but they refund you if the project doesn’t meet its goal” exist? I think not — that might get you some of the gains of a DAC platform.
Also, what does PayPal’s TOS say about this? I seriously considered building something similar, and Stripe only approves “crowdfunding” if you have their written approval.
4 occurrences of "Holz"
If Guyenet is right that olfactory/taste signals are critical to the maintenance of obesity, then we should expect people who take their meals exclusively through feeding tubes to be obese at rates well below baseline.
I’m also somewhat confused about why this works
Abstraction is about what information you throw away. For a ReLU activation function, all negative inputs are mapped to zero -- you lose information there, in a way that you don't when applying a linear transformation.
Imagine your model (or a submodule thereof) as a mapping from one vector space to another. In order to focus on the features relevant to the questions you care about (is the image a truck, is it a lizard, ...) you throw away information that is not relevant to these questions -- you give it less real-estate in your representation-space. We can expect more out-of-distribution regions of input-space to be "pinched" by the model -- they're not represented as expressively as are the more in-distribution regions of input-space.
So if your cosine-similarity decreases less when you nudge your input, you're in a more "pinched" region of input-space, and if it decreases more, you're in a more "expanded" region of input space -- which means the model was tuned to focus on that region, which means it's more in-distribution.
Is there idea that pictures with texta drawn over them are out of distribution?
Yes, the idea is that images that have been taken with a camera were present in the training set, whereas images that were taken with a camera and then scribbled on in GIMP were not.
If you refer to section 4.2 in the paper that leogao linked, those authors also use "corrupted input detection" to benchmark their method. You're also welcome to try it on your own images -- to run the code you just have to install the pip dependencies and then use paths to your own files. (If you uncomment the block at the bottom, you can run it off your webcam in real-time!)
We introduced the concept of the space of models in terms of optimization and motivated the utility of gradients as a distance measure in the space of model that corresponds to the required amount of adjustment to model parameters to properly represent given inputs.
Looks kinda similar, I guess. But their methods require you to know what the labels are, they require you to do backprop, they require you to know the loss function of your model, and it looks like their methods wouldn't work on arbitrarily-specified submodules of a given model, only the model as a whole.
The approach in my post is dirt-cheap, straightforward, and it Just Works™. In my experiments (as you can see in the code) I draw my "output" from the third-last convolutional state. Why? Because it doesn't matter -- grab inscrutable vectors from the middle of the model, and it still works as you'd expect it to.
Yep, but:
given only model weights
Also, the cossim-based approach should work on arbitrary submodules of a given model! Also it's fast!
often rely on skills that aren't generally included in "intelligence", like how fast and precise you can move your fingers
That's a funny example considering that (negative one times a type of) reaction time is correlated with measures of g-factor at about .
Yes, of course you could. The concern is user friction.
This comment reminded me: I get a lot of value from Twitter DMs and groupchats. More value than I get from the actual feed, in fact, which -- according to my revealed preferences -- is worth multiple hours per day. Groupchats on LessWrong have promise.
This advice is probably good in most social contexts -- but I really appreciate the rationalist norm of taking deception very seriously. I resolve this class of conflict by being much more apprehensive than usual about casually misleading my rationalist-adjacent friends and business associates.
See also: Physics Envy.
From Daniel Ingram's Mastering the Core Teachings of the Buddha (slatestarcodex review):
Immediately after a physical sensation arises and passes is a discrete pulse of reality that is the mental knowing of that physical sensation, here referred to as “mental consciousness” (as contrasted with the problematic concept of “awareness” in Part Five). By physical sensations I mean the five senses of seeing, hearing, smelling, tasting, and touching, and I guess you could add some proprioceptive, other extended sensate abilities and perhaps a few others, but for traditional purposes, let's stick to these five. This habit of creating a mental impression following any of the physical sensations is the standard way the mind operates on phenomena that are no longer actually there, even mental sensations such as seemingly auditory thoughts, that is, mental talk (our inner “voice”), intentions, and mental images. It is like an echo, a resonance. The mind forms a general impression of the object, and that is what we can think about, remember, and process. Then there may be a thought or an image that arises and passes, and then, if the mind is stable, another physical pulse.
Or a decision market!
Advertisements on Lesswrong (like lsusr's now-deleted "Want To Hire Me?" post) are good, because they let the users of this site conduct mutually-beneficial trade.
I disagree with Ben Pace in the sibling comment; advertisements should be top-level posts, because any other kind of post won't get many eyeballs on it. If users don't find the advertised proposition useful, if the post is deceptive or annoying, then they should simply downvote the ad.
you can get these principles in other ways
I got them via cultural immersion. I just lurked here for several months while my brain adapted to how the people here think. Lurk moar!
I noticed this happening with goose.ai's API as well, using the gpt-neox model, which suggests that the cause of the nondeterminism isn't unique to OpenAI's setup.
The SAT switched from a 2400-point scale back to a 1600-point scale in 2016.
Lesswrong is a garden of memes, and the upvote button is a watering can.
This post is unlisted and is still awaiting moderation. Users' first posts need to go through moderation.
Is it a bug that I can see this post? I got alerted because it was tagged "GPT".
Timelines. USG could unilaterally slow AI progress. (Use your imagination.)
Even if only a single person's values are extrapolated, I think things would still be basically fine. While power corrupts, it takes time do so. Value lock-in at the moment of creation of the AI prevents it from tracking (what would be the) power-warped values of its creator.
My best guess is that there are useful things for 500 MLEs to work on, but publicly specifying these things is a bad move.
Agree, but LLM + RL is still preferable to muzero-style AGI.
I'm not so sure! Some of my best work was done from the ages of 15-16. (I am currently 19.)
Here's an idea for a decision procedure:
- Narrow it down to a shortlist of 2-20 video ideas that you like
- For each video, create a conditional prediction market on Manifold with the resolution criterion "if made, would this video get over X views/likes/hours of watch-time", for some constant threshold X
- Make the video the market likes the most
- Resolve the appropriate market
[copying the reply here because I don't like looking at the facebook popup]
(I usually do agree with Scott Alexander on almost everything, so it's only when he says something I particularly disagree with that I ever bother to broadcast it. Don't let that selection bias give you a misleading picture of our degree of general agreement. #long)
I think Scott Alexander is wrong that we should regret our collective failure to invest early in cryptocurrency. This is very low on my list of things to kick ourselves about. I do not consider it one of my life's regrets, a place where I could have done better.
Sure, Clippy posted to LW in 2011 about Bitcoin back when Bitcoins were $1 apiece, and gwern gave an argument for why Bitcoin had a 0.5% probability of going to $5,000 and that this made it a good investment to run your GPU to mine Bitcoins, and Wei Dai commented that in this case you could just buy Bitcoin directly. I don't remember reading that post, it wasn't promoted, and gwern's comment was only upvoted by 3 points; but it happened. I do think I heard about Bitcoin again on LW later, so I won't press the point.
I do not consider our failure to buy in as a failure of group or individual rationality.
A very obvious reply is that of efficient markets. There were lots and lots of people in the world who want money, who specialize in getting more money, who invest a lot of character points in doing that. Some of them knew about cryptocurrency, even. Almost all of them did the same thing we did and stayed out of Bitcoin--by the time even 0.1% of them had bought in, the price had thereby gone higher. At worst we are no less capable than 99.9% of those specialists.
Now, it is sometimes possible to do better than all of the professionals, under the kinds of circumstances that I talk about in Inadequate Equilibria. But when the professionals can act unilaterally and only need to invest a couple of hundred bucks to grab the low-hanging fruit, that is not by default favorable conditions for beating them.
Could all the specialists have a blind spot en masse that you see through? Could your individual breadth of knowledge and depth of sanity top their best efforts even when they're not gummed up in systemic glue? Well, I think I can sometimes pull off that kind of hat trick. But it's not some kind of enormous surprise when you don't. It's not the kind of thing that means you should have a crisis of faith in yourself and your skills.
To put it another way, the principle "Rationalists should win" does not translate into "Bounded rationalists should expect to routinely win harder than prediction markets and kick themselves when they don't."
You want to be careful about what excuses you give yourself. You don't want to update in the opposite direction of experience, you don't want to reassure yourself so hard that you anti-learn when somebody else does better. But some other people's successes should give you only a tiny delta toward trying to imitate them. Financial markets are just about the worst place to think that you ought to learn from your mistake in having not bought something.
Back when Bitcoin was gaining a little steam for the first time, enough that nerds were starting to hear about it, I said to myself back then that it wasn't my job to think about cryptocurrency. Or about clever financial investment in general. I thought that actually winning there would take a lot of character points I didn't have to spare, if I could win at all. I thought that it was my job to go off and solve AI alignment, that I was doing my part for Earth using my own comparative advantage; and that if there was really some low-hanging investment fruit somewhere, somebody else needed to go off and investigate it and then donate to MIRI later if it worked out.
I think that this pattern of thought in general may have been a kind of wishful thinking, a kind of argument from consequences, which I do regret. In general, there isn't anyone else doing their part, and I wish I'd understood that earlier to a greater degree. But that pattern of thought didn't actually fail with respect to cryptocurrency. In 2017, around half of MIRI's funding came from cryptocurrency donations. That part more or less worked.
More generally, I worry Scott Alexander may be succumbing to hindsight bias here. I say this with hesitation, because Scott has his own skillz; but I think Scott might be looking back and seeing a linear path of reasoning where in fact there would have been a garden of forking paths.
Or as I put it to myself when I felt briefly tempted to regret: "Gosh, I sure do wish that I'd advised everyone to buy in at Bitcoin at $1, hold it at $10, keep holding it at $100, sell at $800 right before the Mt. Gox crash, invest the proceeds in Ethereum, then hold Ethereum until it rose to $1000."
The idea of "rationality" is that we can talk about general, abstract algorithms of cognition which tend to produce better or worse results. If there's no general thinking pattern that produces a systematically better result, you were perfectly rational. If there's no thinking pattern a human can realistically adopt that produces a better result, you were about as sane as a human gets. We don't say, "Gosh, I sure do wish I'd bought the Mega Millions ticket for 01-04-14-17-40-04* yesterday." We don't say, "Rationalists should win the lottery."
What thought pattern would have generated the right answer here, without generating a lot of wrong answers in other places if you had to execute it without benefit of hindsight?
Have less faith in the market professionals? Michael Arc née Vassar would be the go-to example of somebody who would have told you, at that time, that Eliezer-2011 vastly overestimates the competence of the rest of the world. He didn't invest in cryptocurrency, and then hold until the right time, so far as I know.
Be more Pascal's Muggable? But then you'd have earlier invested in three or four other supposed 5,000x returns, lost out on them, gotten discouraged, and just shaken your head at Bitcoin by the time it came around. There's no such thing as advising your past self to only be Pascal's Muggable for Bitcoin, to grant enough faith to just that one opportunity for 5,000x gains, and not pay equal amounts of money into any of the other supposed opportunities for 5,000x gains that you encountered.
I don't see a simple, generally valid cognitive strategy that I could have executed to buy Bitcoin and hold it, without making a lot of other mistakes.
Not only am I not kicking myself, I'd worry about somebody trying to learn lessons from this. Before Scott Alexander wrote that post, I think I said somewhere--possibly Facebook?--that if you can't manage to not regret having not bought Bitcoin even though you knew about it when it was $1, you shouldn't ever buy anything except index funds because you are not psychologically suited to survive investing.
Though I find it amusing to be sure that the LessWrong forum had a real-life Pascal's Mugging that paid out--of which the real lesson is of course that you ought to be careful as to what you imagine has a tiny probability.
EDIT: This is NOT me saying that anyone who did buy in early was irrational. That would be "updating in the wrong direction" indeed! More like, a bounded rationalist should not expect to win at everything at once; and looking back and thinking you ought to have gotten all the fruits that look easy in hindsight can lead to distorted thought patterns.
Yes. From the same comment:
Spend a lot of money on ad campaigns and lobbying, and get {New Hampshire/Nevada/Wyoming/Florida} to nullify whatever federal anti-gambling laws exist, and carve out a safe haven for a serious prediction market (which does not currently exist).
And:
You could alternatively just fund the development of a serious prediction market on the Ethereum blockchain, but I'm not as sure about this path, as the gains one could get might be considered "illegal". Also, a fully legalized prediction market could rely on courts to arbitrate market resolution criteria.
I have since updated against hypotheses that it is possible to achieve anything of consequence via legislation. Also, now that the political goodwill and funding potential of FTX has been eliminated, the legislative path is even more implausible.
Therefore, the best plan is to build a serious prediction market on the Ethereum blockchain, and rely on reputation systems (think Ebay star ratings) to incentivize trustworthy market arbitration.
Agreed. To quote myself like some kind of asshole:
In order for a prediction market to be "serious", it has to allow epistemically rational people to get very very rich (in fiat currency) without going to jail, and it has to allow anyone to create and arbitrate a binary prediction market for a small fee. Such a platform does not currently exist.
TikTok isn't doing any work here, I compile the text to mp4 using a script I wrote.
Thanks!
might be able to find a better voice synthesizer that can be a bit more engaging (not sure if TikTok supplies this)
Don't think I can do this that easily. I'm currently calling Amazon Polly, AWS' TTS service, from a python script I wrote to render these videos. Tiktok does supply an (imo) annoying-sounding female TTS voice, but that's off the table since I would have to enter all the text manually on my phone.
experimentation is king.
I could use Amazon's Mechanical Turk to run low-cost focus groups.
True, but then I have to time the text-transitions manually.
The "anti-zoomer" sentiment is partially "anti-my-younger-self" sentiment. I, personally, had to expend a good deal of effort to improve my attention span, wean myself off of social media, and reclaim whole hours of my day. I'm frustrated because I know that more is possible.
I fail to see how this is an indictment of your friend's character, or an indication that he is incapable of reading.
That friend did, in fact, try multiple times to read books. He got distracted every time. He wanted to be the kind of guy that could finish books, but he couldn't. I used to be a lot more like he was. For the record, he has since read books (good ones, too).
More likely, he rationally viewed school as a day job, and optimized towards getting the grade that he wanted with a minimum of effort, in order to build slack for other activities, such as performing well on the math team.
Of course. We all did that. I do not identify with my academic performance (I dropped out of college). Also, we went to a boarding school, and as his former roommate, I can tell you that neither of us studied in our free time. He's just better at doing math than I am.
It's not that Zoomers can't read (an accusation that older generations have been leveling against younger ones since time immemorial)
No, this time really is different. I know a guy (not dumb either) who spends >7h a day on TikTok, Instagram, and YouTube. Some of us can't sit through movies. Never before in history has there been as strong an optimization pressure for eyeballs, and there is no demographic more subject to that pressure than mine.
Thank you for the feedback! I didn't consider the inherent jumpiness/grabbiness of Subway Surfers, but you're right, something more continuous is preferable. (edit: but isn't the point of the audio to allow your eyes to stray? hmm)
I will probably also take your advice wrt using the Highlights and CFAR handbook excerpts in lieu of the entire remainder of R:AZ.
guessing this wouldn't work without causal attention masking
I worked on this problem for the USAF! Not to give too much away, but we use ML for this now.
distillation of Taleb's core idea:
expected value estimates are dominated by tail events (unless the distribution is thin-tailed)
repeated sampling from a distribution usually does not yield information about tail events
therefore repeated sampling can be used to estimate EVs iff the distribution is thin-tailed according to your priors
if the distribution is fat-tailed according to your priors, how to determine EV?
estimating EV is much harder
some will say to use the sample mean as EV anyway, they are wrong
in the absence of information on tail events (which is v common)
you must judge the fatness of the left/right tails based on your priors
right tail is fat and left is thin: high EV
left tail is fat and right is thin: low EV (/ high magnitude in the negative direction)
both tails are fat: EV is highly uncertain
to reiterate:
when calculating EV of a distribution that you have samples from:
the burden of proof is on you to show that you are operating in a thin-tailed domain
before you use the sample mean as an estimate of EV
else, you must rely on your prior beliefs on the fatness of the tails of the distribution