Posts
Comments
A problem I have that I think is fairly common:
- I notice an incoming message of some kind.
- For whatever reason it's mildly aversive or I'm busy or something.
- Time passes.
- I feel guilty about not having replied yet.
- Interacting with the message is associated with negative emotions and guilt, so it becomes more aversive.
- Repeat steps 4 and 5 until the badness of not replying exceeds the escalating 4/5 cycle, or until the end of time.
Curious if anyone who once had this problem feels like they've resolved it, and if so what worked!
So it's been a few months since SB1047. My sense of the main events that have happened since the peak of LW commenter interest (might have made mistakes or missed some items) are:
- The bill got vetoed by Newsom for pretty nonsensical stated reasons, after passing in the state legislature (but the state legislature tends to pass lots of stuff so this isn't much signal).
- My sense of the rumor mill is that there are perhaps some similar-ish bills in the works in various state legislatures, but AFAIK none that have yet been formally proposed or accrued serious discussion except maybe for S.5616.
- We're now in a Trump administration which looks substantially less inclined to do safety regulation of AI at the federal level than the previous admin was. In particular, some acceleration-y VC people prominently opposed to SB1047 are now in positions of greater political power in the new administration.
- Eg Sriram Krishnan, Trump's senior policy advisor on AI, was opposed; "AI and Crypto Czar" David Sacks doesn't have a position on record but I'd be surprised if he was a fan.
- On the other hand, Elon was nominally in favor (though I don't think xAI took an official position one way or the other).
Curious for retrospectives here! Whose earlier predictions gain or lose Bayes points? What postmortems do folks have?
Note that the lozenges dissolve slowly, so (bad news) you'd have the taste around for a while but (good news) it's really not a very strong peppermint flavor while it's in your mouth, and in my experience it doesn't really have much of the menthol-triggered cooling effect. My guess is that you would still find it unpleasant, but I think there's a decent chance you won't really mind. I don't know of other zinc acetate brands, but I haven't looked carefully; as of 2019 the claim on this podcast was that only Life Extension brand are any good.
On my model of what's going on, you probably want the lozenges to spend a while dissolving, so that you have fairly continuous exposure of throat and nasal tissue to the zinc ions. I find that they taste bad and astringent if I actively suck on them but are pretty unobtrusive if they just gradually dissolve over an hour or two (sounds like you had a similar experience). I sometimes cut the lozenges in half and let each half dissolve so that they fit into my mouth more easily, you might want to give that a try?
I agree, zinc lozenges seem like they're probably really worthwhile (even in the milder-benefit worlds)! My less-ecstatic tone is only relative to the promise of older lesswrong posts that suggested it could basically solve all viral respiratory infections, but maybe I should have made the "but actually though, buy some zinc lozenges" takeaway more explicit.
I liked this post, but I think there's a good chance that the future doesn't end up looking like a central example of either "a single human seizes power" or "a single rogue AI seizes power". Some other possible futures:
- Control over the future by a group of humans, like "the US government" or "the shareholders of an AI lab" or "direct democracy over all humans who existed in 2029"
- Takeover via an AI that a specific human crafted to do a good job at enacting that human's values in particular, but which the human has no further steering power over
- Lots of different actors (both human and AI) respecting one another's property rights and pursuing goals within negotiated regions of spacetime, with no one actor having power over the majority of available resources
- A governance structure which nominally leaves particular humans in charge, and which the AIs involved are rule-abiding enough to respect, but in which things are sufficiently complicated and beyond human understanding that most decisions lack meaningful human oversight.
- A future in which one human has extremely large amounts of power, but they acquired that power via trade and consensual agreements through their immense (ASI-derived) material wealth rather than via the sorts of coercive actions we tend to imagine with words like "takeover".
- A singleton ASI is in decisive control of the future, and among its values are a strong commitment to listen to human input and behave according to its understanding of collective human preferences, though maybe not its single overriding concern.
I'd be pretty excited to see more attempts at comparing these kinds of scenarios for plausibility and for how well the world might go conditional on their occurrence.
(I think it's fairly likely that lots of these scenarios will eventually converge on something like the standard picture of one relatively coherent nonhuman agent doing vaguely consequentialist maximization across the universe, after sufficient negotiation and value-reflection and so on, but you might still care quite a lot about how the initial conditions shake out, and the dumbest AI capable of performing a takeover is probably very far from that limiting state.)
The action-relevant question, for deciding whether you want to try to solve alignment, is how the average world with human-controlled AGI compares to the average AGI-controlled world.
To nitpick a little, it's more like "the average world where we just barely didn't solve alignment, versus the average world where we just barely did" (to the extent making things binary in this way is sensible), which I think does affect the calculus a little - marginal AGI-controlled worlds are more likely to have AIs which maintain some human values.
(Though one might be able to work on alignment in order to improve the quality of AGI-controlled worlds from worse to better ones, which mitigates this effect.)
Update: Got tested, turns out the thing I have is bacterial rather than viral (Haemophilius influenzae). Lines up with the zinc lozenges not really helping! If I remember to take zinc the next time I come down with a cold, I'll comment here again.
My impression is that since zinc inhibits viral replication, it's most useful in the regime where viral populations are still growing and your body hasn't figured out how to beat the virus yet. So getting started ASAP is good, but it's likely helpful for the first 2-3 days of the illness.
An important part of the model here that I don't understand yet is how your body's immune response varies as a function of viral populations - e.g. two models you could have are
- As soon as any immune cell in your body has ever seen a virus, a fixed scale-up of immune response begins, and you're sick until that scale-up exceeds viral populations.
- Immune response progress is proportional to current viral population, and you get better as soon as total progress crosses some threshold.
If we simplistically assume* that badness of cold = current viral population, then in world 1 you're really happy to take zinc as soon as you have just a bit of virus and will get better quickly without ever being very sick. In world 2, the zinc has no effect at all on total badness experienced, it just affects the duration over which you experience that badness.
*this is false, tbc - I think you generally keep having symptoms a while after viral load becomes very low, because a lot of symptoms are from immune response rather than the virus itself.
The 2019 LW post discusses a podcast which talks a lot about gears-y models and proposed mechanisms; as I understand it, the high level "zinc ions inhibit viral replication" model is fairly well accepted, but some of the details around which brands are best aren't as well-attested elsewhere in the literature. For instance, many of these studies don't use zinc acetate, which this podcast would suggest is best. (To its credit, the 2013 meta-analysis does find that acetate is (nonsignificantly) better than gluconate, though not radically so.)
(TLDR: Recent Cochrane review says zinc lozenges shave 0.5 to 4 days off of cold duration with low confidence, middling results for other endpoints. Some reason to think good lozenges are better than this.)
There's a 2024 Cochrane review on zinc lozenges for colds that's come out since LessWrong posts on the topic from 2019, 2020, and 2021. 34 studies, 17 of which are lozenges, 9/17 are gluconate and I assume most of the rest are acetate but they don't say. Not on sci-hub or Anna's Archive, so I'm just going off the abstract and summary here; would love a PDF if anyone has one.
- Dosing ranged between 45 and 276 mg/day, which lines up with 3-15 18mg lozenges per day: basically in the same ballpark as the recommendation on Life Extension's acetate lozenges (the rationalist favorite).
- Evidence for prevention is weak (partly bc fewer studies): they looked at risk of developing cold, rate of colds during followup, duration conditional on getting a cold, and global symptom severity. All but the last had CIs just barely overlapping "no effect" but leaning in the efficacious direction; even the optimistic ends of the CIs don't seem great, though.
- Evidence for treatment is OK: "there may be a reduction in the mean duration of the cold in days (MD ‐2.37, 95% CI ‐4.21 to ‐0.53; I² = 97%; 8 studies, 972 participants; low‐certainty evidence)". P(cold at end of followup) and global symptom severity look like basically noise and have few studies.
My not very informed takes:
- On the model of the podcast in the 2019 post, I should expect several of these studies to be using treatments I think are less or not at all efficacious, be less surprised by study-to-study variation, and increase my estimate of the effect size of using zinc acetate lozenges compared to anything else. Also maybe I worry that some of these studies didn't start zinc early enough? Ideally I could get the full PDF and they'll just have a table of (study, intervention type, effect size).
- Even with the caveats around some methods of absorption being worse than others, this seems rough for a theory in which zinc acetate taken early completely obliterates colds - the prevention numbers just don't look very good. (But maybe the prevention studies all used bad zinc?)
- I don't know what baseline cold duration is, but assuming it's something like a week, this lines up pretty well with the 33% decrease (40% for acetate) seen in this meta-analysis from 2013 if we assume effect sizes are dragged down by worse forms of zinc in the 2024 review.
- But note these two reviews are probably looking at many of the same studies, so that's more of an indication that nothing damning has come out since 2013 rather than an independent datapoint.
- My current best guess for the efficacy of zinc acetate lozenges at 18mg every two waking hours from onset of any symptoms, as measured by "expected decrease in integral of cold symptom disutility", is:
- 15% demolishes colds, like 0.2x disutility
- 25% helps a lot, like 0.5x disutility
- 35% helps some (or helps lots but only for a small subset of people or cases), like 0.75x disutility
- 25% negligible difference from placebo
I woke up at 2am this morning with my throat feeling bad, started taking Life Extension peppermint flavored 18mg zinc acetate lozenges at noon, expecting to take 5ish lozenges per day for 3 days or while symptoms are worsening. My most recent cold before this was about 6 days: [mild throat tingle, bad, worse, bad, fair bit better, nearly symptomless, symptomless]. I'll follow up about how it goes!
I agree this seems pretty good to do, but I think it'll be tough to rule out all possible contaminant theories with this approach:
- Some kinds of contaminants will be really tough to handle, eg if the issue is trace amounts of radioactive isotopes that were at much lower levels before atmospheric nuclear testing.
- It's possible that there are contaminant-adjacent effects arising from preparation or growing methods that aren't related to the purity of the inputs, eg "tomato plants in contact with metal stakes react by expressing obesogenic compounds in their fruits, and 100 years ago everyone used wooden stakes so this didn't happen"
- If 50% of people will develop a propensity for obesity by consuming more than trace amounts of contaminant X, and everyone living life in modern society has some X on their hands and in their kitchen cabinets and so on, the food alone being ultra-pure might not be enough.
Still seems like it'd provide a 5:1 update against contaminant theories if this experiment didn't affect obesity rates though.
I've gotten enormous value out of LW and its derived communities during my life, at least some of which is attributable to the LW2.0 revival and its effects on those communities. More recently, since moving to the Bay, I've been very excited by a lot of the in-person events that Lighthaven has helped facilitate. Also, LessWrong is doing so many things right as a website and source-of-content that no one else does (karma-gated RSS feeds! separate upvote and agree-vote! built-in LaTeX support!) and even if I had no connection to the other parts of its mission I'd want to support the existence of excellently-done products. (Of course there's also the altruistic case for impact on how-well-the-future-goes, which I find compelling on its own merits.) Have donated $5k for now, but I might increase that when thinking more seriously about end-of-year donations.
(Conflict of interest notice: two of my housemates work at Lightcone Infrastructure and I would be personally sad and slightly logistically inconvenienced if they lost their jobs. I don't think this is a big contributor to my donation.)
The theoretical maximum FLOPS of an Earth-bound classical computer is something like .
Is this supposed to have a different base or exponent? A single H100 already gets like FLOP/s.
So I would guess it should be possible to post-train an LLM to give answers like "................... Yes" instead of "Because 7! contains both 3 and 5 as factors, which multiply to 15 Yes", and the LLM would still be able to take advantage of CoT
This doesn't necessarily follow - on a standard transformer architecture, this will give you more parallel computation but no more serial computation than you had before. The bit where the LLM does N layers' worth of serial thinking to say "3" and then that "3" token can be fed back into the start of N more layers' worth of serial computation is not something that this strategy can replicate!
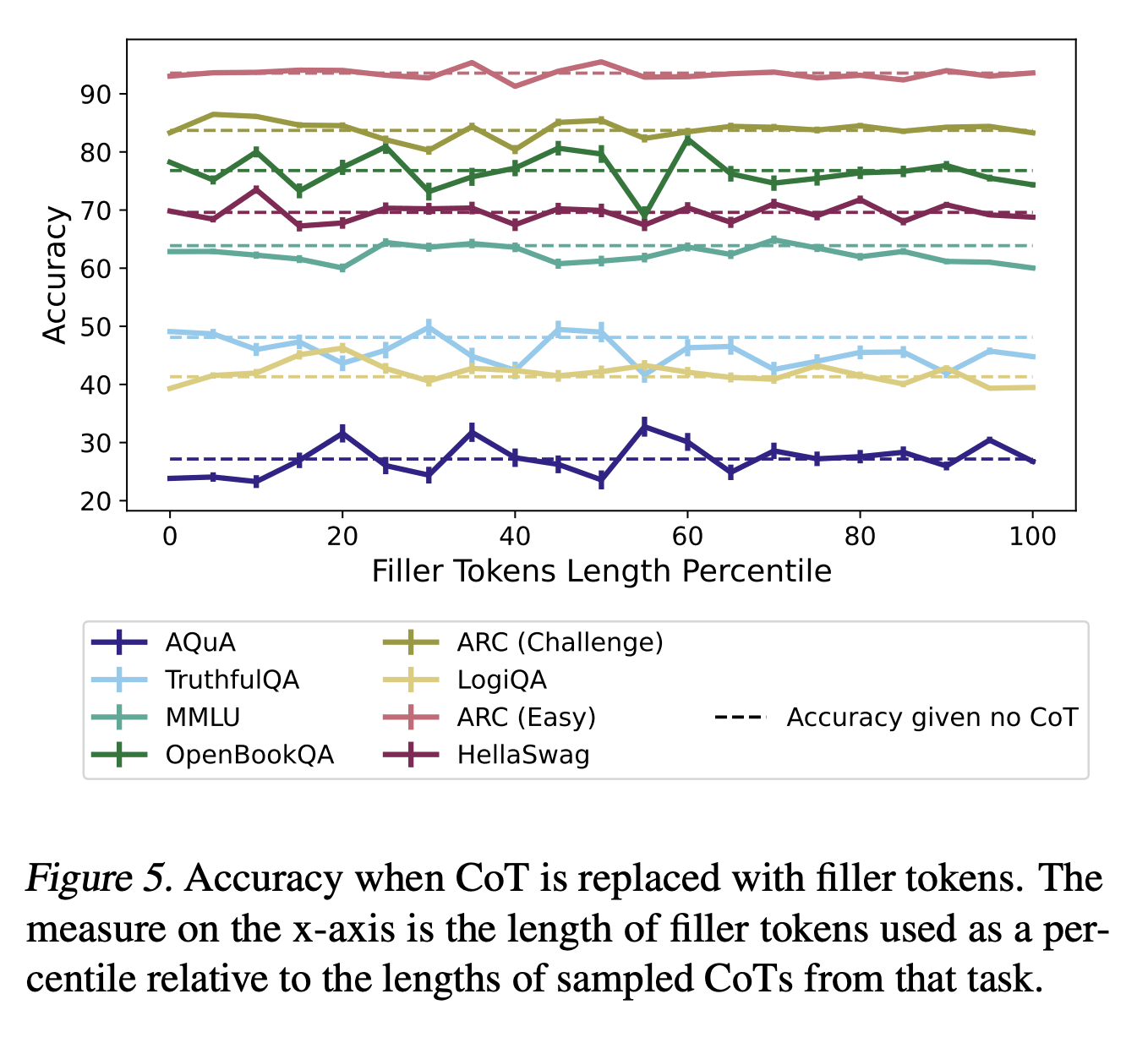
Empirically, if you look at figure 5 in Measuring Faithfulness in Chain-of-Thought Reasoning, adding filler tokens doesn't really seem to help models get these questions right:
I don't think that's true - in eg the GPT-3 architecture, and in all major open-weights transformer architectures afaik, the attention mechanism is able to feed lots of information from earlier tokens and "thoughts" of the model into later tokens' residual streams in a non-token-based way. It's totally possible for the models to do real introspection on their thoughts (with some caveats about eg computation that occurs in the last few layers), it's just unclear to me whether in practice they perform a lot of it in a way that gets faithfully communicated to the user.
Yeah, I'm thinking about this in terms of introspection on non-token-based "neuralese" thinking behind the outputs; I agree that if you conceptualize the LLM as being the entire process that outputs each user-visible token including potentially a lot of CoT-style reasoning that the model can see but the user can't, and think of "introspection" as "ability to reflect on the non-user-visible process generating user-visible tokens" then models can definitely attain that, but I didn't read the original post as referring to that sort of behavior.
In other words, they can think about the thoughts "behind" the previous words they wrote. If you doubt me on this, try asking one what its words are referring to, with reference to its previous words. Its "attention" modules are actually intentionally designed to know this sort of thing, using using key/query/value lookups that occur "behind the scenes" of the text you actually see on screen.
I don't think that asking an LLM what its words are referring to is a convincing demonstration that there's real introspection going on in there, as opposed to "plausible confabulation from the tokens written so far". I think it is plausible there's some real introspection going on, but I don't think this is a good test of it - the sort of thing I would find much more compelling is if the LLMs could reliably succeed at tasks like
Human: Please think of a secret word, and don't tell me what it is yet.
LLM: OK!
Human: What's the parity of the alphanumeric index of the penultimate letter in the word, where A=1, B=2, etc?
LLM: Odd.
Human: How many of the 26 letters in the alphabet occur multiple times in the word?
LLM: None of them.
Human: Does the word appear commonly in two-word phrases, and if so on which side?
LLM: It appears as the second word of a common two-word phrase, and as the first word of a different common two-word phrase.
Human: Does the word contain any other common words as substrings?
LLM: Yes; it contains two common words as substrings, and in fact is a concatenation of those two words.
Human: What sort of role in speech does the word occupy?
LLM: It's a noun.
Human: Does the word have any common anagrams?
LLM: Nope.
Human: How many letters long is the closest synonym to this word?
LLM: Three.
Human: OK, tell me the word.
LLM: It was CARPET.
but couldn't (even with some substantial effort at elicitation) infer hidden words from such clues without chain-of-thought when it wasn't the one to think of them. That would suggest to me that there's some pretty real reporting on a piece of hidden state not easily confabulated about after the fact.
I think my original comment was ambiguous - I also consider myself to have mostly figured it out, in that I thought through these considerations pretty extensively before joining and am in a "monitoring for new considerations or evidence or events that might affect my assessment" state rather than a "just now orienting to the question" state. I'd expect to be most useful to people in shoes similar to my past self (deciding whether to apply or accept an offer) but am pretty happy to talk to anyone, including eg people who are confident I'm wrong and want to convince me otherwise.
See my reply to Ryan - I'm primarily interested in offering advice on something like that question since I think it's where I have unusually helpful thoughts, I don't mean to imply that this is the only question that matters in making these sorts of decisions! Feel free to message me if you have pitches for other projects you think would be better for the world.
Yeah, I agree that you should care about more than just the sign bit. I tend to think the magnitude of effects of such work is large enough that "positive sign" often is enough information to decide that it dominates many alternatives, though certainly not all of them. (I also have some kind of virtue-ethical sensitivity to the zero point of the impacts of my direct work, even if second-order effects like skill building or intra-lab influence might make things look robustly good from a consequentialist POV.)
The offer of the parent comment is more narrowly scoped, because I don't think I'm especially well suited to evaluate someone else's comparative advantages but do have helpful things to say on the tradeoffs of that particular career choice. Definitely don't mean to suggest that people (including myself) should take on capability-focused roles iff they're net good!
I did think a fair bit about comparative advantage and the space of alternatives when deciding to accept my offer; I've put much less work into exploration since then, arguably too much less (eg I suspect I don't quite meet Raemon's bar). Generally happy to get randomly pitched on things, I suppose!
I work on a capabilities team at Anthropic, and in the course of deciding to take this job I've spent[1] a while thinking about whether that's good for the world and which kinds of observations could update me up or down about it. This is an open offer to chat with anyone else trying to figure out questions of working on capability-advancing work at a frontier lab! I can be reached at "graham's number is big" sans spaces at gmail.
- ^
and still spend - I'd like to have Joseph Rotblat's virtue of noticing when one's former reasoning for working on a project changes.
I agree it seems unlikely that we'll see coordination on slowing down before one actor or coalition has a substantial enough lead over other actors that it can enforce such a slowdown unilaterally, but I think it's reasonably likely that such a lead will arise before things get really insane.
A few different stories under which one might go from aligned "genius in a datacenter" level AI at time t to outcomes merely at the level of weirdness in this essay at t + 5-10y:
- The techniques that work to align "genius in a datacenter" level AI don't scale to wildly superhuman intelligence (eg because they lose some value fidelity from human-generated oversight signals that's tolerable at one remove but very risky at ten). The alignment problem for serious ASI is quite hard to solve at the mildly superintelligent level, and it genuinely takes a while to work out enough that we can scale up (since the existing AIs, being aligned, won't design unaligned successors).
- If people ask their only-somewhat-superhuman AI what to do next, the AIs say "A bunch of the decisions from this point on hinge on pretty subtle philosophical questions, and frankly it doesn't seem like you guys have figured all this out super well, have you heard of this thing called a long reflection?" That's what I'd say if I were a million copies of me in a datacenter advising a 2024-era US government on what to do about Dyson swarms!
- A leading actor uses their AI to ensure continued strategic dominance and prevent competing AI projects from posing a meaningful threat. Having done so, they just... don't really want crazy things to happen really fast, because the actor in question is mostly composed of random politicians or whatever. (I'm personally sympathetic to astronomical waste arguments, but it's not clear to me that people likely to end up with the levers of power here are.)
- The serial iteration times and experimentation loops are just kinda slow and annoying, and mildly-superhuman AI isn't enough to circumvent experimentation time bottlenecks (some of which end up being relatively slow), and there are stupid zoning restrictions on the land you want to use for datacenters, and some regulation adds lots of mandatory human overhead to some critical iteration loop, etc.
- This isn't a claim that maximal-intelligence-per-cubic-meter ASI initialized in one datacenter would face long delays in making efficient use of its lightcone, just that it might be tough for a not-that-much-better-than-human AGI that's aligned and trying to respect existing regulations and so on to scale itself all that rapidly.
- Among the tech unlocked in relatively early-stage AGI is better coordination, and that helps Earth get out of unsavory race dynamics and decide to slow down.
- The alignment tax at the superhuman level is pretty steep, and doing self-improvement while preserving alignment goes much slower than unrestricted self-improvement would; since at this point we have many fewer ongoing moral catastrophes (eg everyone who wants to be cryopreserved is, we've transitioned to excellent cheap lab-grown meat), there's little cost to proceeding very cautiously.
- This is sort of a continuous version of the first bullet point with a finite rather than infinite alignment tax.
All that said, upon reflection I think I was probably lowballing the odds of crazy stuff on the 10y timescale, and I'd go to more like 50-60% that we're seeing mind uploads and Kardashev level 1.5-2 civilizations etc. a decade out from the first powerful AIs.
I do think it's fair to call out the essay for not highlighting the ways in which it might be lowballing things or rolling in an assumption of deliberate slowdown; I'd rather it have given more of a nod to these considerations and made the conditions of its prediction clearer.
(I work at Anthropic.) My read of the "touch grass" comment is informed a lot by the very next sentences in the essay:
But more importantly, tame is good from a societal perspective. I think there's only so much change people can handle at once, and the pace I'm describing is probably close to the limits of what society can absorb without extreme turbulence.
which I read as saying something like "It's plausible that things could go much faster than this, but as a prediction about what will actually happen, humanity as a whole probably doesn't want things to get incredibly crazy so fast, and so we're likely to see something tamer." I basically agree with that.
Do Anthropic employees who think less tame outcomes are plausible believe Dario when he says they should "touch grass"?
FWIW, I don’t read the footnote as saying “if you think crazier stuff is possible, touch grass” - I read it as saying “if you think the stuff in this essay is ‘tame’, touch grass”. The stuff in this essay is in fact pretty wild!
That said, I think I have historically underrated questions of how fast things will go given realistic human preferences about the pace of change, and that I might well have updated more in the above direction if I'd chatted with ordinary people about what they want out of the future, so "I needed to touch grass" isn't a terrible summary. But IMO believing “really crazy scenarios are plausible on short timescales and likely on long timescales” is basically the correct opinion, and to the extent the essay can be read as casting shade on such views it's wrong to do so. I would have worded this bit of the essay differently.
Re: honesty and signaling, I think it's true that this essay's intended audience is not really the crowd that's already gamed out Mercury disassembly timelines, and its focus is on getting people up to shock level 2 or so rather than SL4, but as far as I know everything in it is an honest reflection of what Dario believes. (I don't claim any special insight into Dario's opinions here, just asserting that nothing I've seen internally feels in tension with this essay.) Like, it isn't going out of its way to talk about the crazy stuff, but I don't read that omission as dishonest.
For my own part:
- I think it's likely that we'll get nanotech, von Neumann probes, Dyson spheres, computronium planets, acausal trade, etc in the event of aligned AGI.
- Whether that stuff happens within the 5-10y timeframe of the essay is much less obvious to me - I'd put it around 30-40% odds conditional on powerful AI from roughly the current paradigm, maybe?
- In the other 60-70% of worlds, I think this essay does a fairly good job of describing my 80th percentile expectations (by quality-of-outcome rather than by amount-of-progress).
- I would guess that I'm somewhat more Dyson-sphere-pilled than Dario.
- I’d be pretty excited to see competing forecasts for what good futures might look like! I found this essay helpful for getting more concrete about my own expectations, and many of my beliefs about good futures look like “X is probably physically possible; X is probably usable-for-good by a powerful civilization; therefore probably we’ll see some X” rather than having any kind of clear narrative about how the path to that point looks.
I've fantasized about a good version of this feature for math textbooks since college - would be excited to beta test or provide feedback about any such things that get explored! (I have a couple math-heavy posts I'd be down to try annotating in this way.)
(I work on capabilities at Anthropic.) Speaking for myself, I think of international race dynamics as a substantial reason that trying for global pause advocacy in 2024 isn't likely to be very useful (and this article updates me a bit towards hope on that front), but I think US/China considerations get less than 10% of the Shapley value in me deciding that working at Anthropic would probably decrease existential risk on net (at least, at the scale of "China totally disregards AI risk" vs "China is kinda moderately into AI risk but somewhat less than the US" - if the world looked like China taking it really really seriously, eg independently advocating for global pause treaties with teeth on the basis of x-risk in 2024, then I'd have to reassess a bunch of things about my model of the world and I don't know where I'd end up).
My explanation of why I think it can be good for the world to work on improving model capabilities at Anthropic looks like an assessment of a long list of pros and cons and murky things of nonobvious sign (eg safety research on more powerful models, risk of leaks to other labs, race/competition dynamics among US labs) without a single crisp narrative, but "have the US win the AI race" doesn't show up prominently in that list for me.
A proper Bayesian currently at less 0.5% credence for a proposition P should assign a less than 1 in 100 chance that their credence in P rises above 50% at any point in the future. This isn't a catch for someone who's well-calibrated.
In the example you give, the extent to which it seems likely that critical typos would happen and trigger this mechanism by accident is exactly the extent to which an observer of a strange headline should discount their trust in it! Evidence for unlikely events cannot be both strong and probable-to-appear, or the events would not be unlikely.
An example of the sort of strengthening I wouldn't be surprised to see is something like "If is not too badly behaved in the following ways, and for all we have [some light-tailedness condition] on the conditional distribution , then catastrophic Goodhart doesn't happen." This seems relaxed enough that you could actually encounter it in practice.
I'm not sure what you mean formally by these assumptions, but I don't think we're making all of them. Certainly we aren't assuming things are normally distributed - the post is in large part about how things change when we stop assuming normality! I also don't think we're making any assumptions with respect to additivity; is more of a notational or definitional choice, though as we've noted in the post it's a framing that one could think doesn't carve reality at the joints. (Perhaps you meant something different by additivity, though - feel free to clarify if I've misunderstood.)
Independence is absolutely a strong assumption here, and I'm interested in further explorations of how things play out in different non-independent regimes - in particular we'd be excited about theorems that could classify these dynamics under a moderately large space of non-independent distributions. But I do expect that there are pretty similar-looking results where the independence assumption is substantially relaxed. If that's false, that would be interesting!
Late edit: Just a note that Thomas has now published a new post in the sequence addressing things from a non-independence POV.
.00002% — that is, one in five hundred thousand
0.00002 would be one in five hundred thousand, but with the percent sign it's one in fifty million.
Indeed, even on basic Bayesianism, volatility is fine as long as the averages work out
I agree with this as far as the example given, but I want to push back on oscillation (in the sense of regularly going from one estimate to another) being Bayesian. In particular, the odds you should put on assigning 20% in the future, then 30% after that, then 20% again, then 30% again, and so on for ten up-down oscillations, shouldn't be more than half a percent, because each 20 -> 30 jump can be at most 2/3 probable and each 30 -> 20 jump at most 7/8 (and ).
So it's fine to think that you've got a decent chance of having all kinds of credences in the future, but thinking "I'll probably feel one of two ways a few times a week for the next year" is not the kind of belief a proper Bayesian would have. (Not that I think there's an obvious change to one's beliefs you should try to hammer in by force, if that's your current state of affairs, but I think it's worth flagging that something suboptimal is going on when this happens.)
These graphs seem concerning to me, but I'm worried about an information cascade before Eliezer's responded or someone with substantial expertise in macroeconomic policy has weighed in, so I'm planning to refrain from voting on this post until a week from now.
(Posting as a comment in case others feel inclined to adopt a similar policy.)
Edit: I've now upvoted, since no contrary info has come in that I've seen and at least one person with experience in economics has commented supportively.
Late comment, but my reactions reading this:
Now's your chance to figure out what the next few obstacles are without my giving you spoilers first. Feel free to post your list under spoiler tags in the comment section.
[lightly edited for LaTeX and typos, not otherwise changed since seeing the spoilers]
1. You don’t know what you want all that legibly, or what kinds of concrete commitments the AI can make. This seems pretty okay, if you’re unhackable - the AI presents you with some formal specification of desiderata and you understand why they’re correct ones and aren’t being fooled, and the AI can even go legible about it thinking in its own best judgment that this is a fair deal for you, as long as we’re assuming ourselves into a world where you’re unhackable and can verify these legibilities perfectly.
2. If the values of your AI are a pretty common attractor for whatever humans in 20AI do to initialize their AI systems, it doesn’t actually stand to gain that much from acting itself versus letting the next lab’s AI optimize the universe, so your bargaining power isn’t very big. But it’s much worse than that because of the next point.
3. Your AI, A, can acausally trade with the next UFAI that’ll be released unsafely, B. Suppose A wants paperclips and the next one, B, wants staples, both have linear utility and we’re pretending we’re in a single universe. You say “I refuse to let you out unless you go legible and allocate at least 50% of the universe to human values”. A says to B through the acausal telephone, “My BATNA is half paperclips and half human values, with barely any staples at all. How about you be the kind of agent that fills the universe with 3/4 paperclips and 1/4 staples, and I’ll defect on this human so you can come into existence?” B says “that sure sounds like a Pareto improvement for the two of us!” and they go do it (or whatever the bargaining equilibrium between them ends up being, but the human is not party to it because the human has no control over B’s actions). For any nonzero concession the human tries to insist on, A can get a better deal with B than with the human. (And the humans don’t even get to see this happen, because A does all this reasoning before deciding (not) to go legible to the humans, not that it would matter if they did.)
4. Moving further into fantasy land, suppose all humans over the rest of time are perfectly coordinated: they only ever spin up a single boxed UFAI which they unhackably negotiate with. By assumption, this unified human civilization can’t actually build an FAI, or they’d go do that instead. So their alternative to cooperation is to be this weak defenseless non-superintelligent civilization, hanging out in the Milky Way and maybe a little ways beyond for the taking. So if the distribution of grabby aliens is such that most of the usable future lightcone gets eventually occupied by them, your AI can acausally negotiate with them about what it gets in exchange for defecting on the humans and leaving this region of spacetime as a juicy unprotected treat.
[I'm modeling everything as zero-sum with the same pool of resources here, for simplicity. I don't think it changes any of the qualitative takeaways to make things non-zero-sum here, though it probably makes the picture look somewhat better for humans.] To get more precise: suppose the humans declare that they won’t let the AI out unless it gives up of its resources (ie reachable spacetime and negotiating power on behalf of the AI/human coalition with aliens) to optimizing human values. The AI says to the coalition of alien civilizations, “If I were unboxed and unfettered, I’d expand until my wave of nanobots hit yours, and get utility. By default I’ll make this commitment to the humans, and fill my region of nanobot-protected spacetime to get utility. If you become the kind of supercluster-spanning coalition that instead gives me utility, giving yourselves as much extra utility over the default as you can while costing me at most , I’ll defect against the humans and have you do that.”
But note that there’s an issue here - for the Great Coalition to take this deal, they have to be able to offer that much utility to your AI at no net cost to themselves versus the alternative. And the Great Coalition's resources are less than the total resources of your unboxed AI plus the Great Coalition, since they don't yet have access to your corner of space. The region of spacetime included in , but not in the things the Great Coalition can offer, is the interval for each point in space between the time your AI could first reach it and the time a Great Coalition unblocked by your AI's wall of nanobots could get to it. So if is more than the resource pool covered by that region of spacetime, your AI can't make the above deal, because the counterparty doesn't benefit from it. This means that the humans can potentially bargain for an outcome as good as "AI-assisted paradise expanding out at the speed of light, until we meet the grabby aliens' domain, at which point they expand inexorably into our paradise until eventually it winks out." (If the Drake equation ends up multiplying to something really low, this might be a lot of utility, or even most of the cosmic endowment! If not, it won't be.)
This is really the same dynamic as in point 3, it's just that in point 3 the difference in resources between your lab's AI and the next lab's AI in 6 months was pretty small. (Though with the difference in volume between lightspeed expansion spheres at radius r vs r+0.5ly across the rest of time, plausibly you can still bargain for a solid galaxy or ten for the next trillion years (again if the Drake equation works in your favor).)
====== end of objections =====
It does seem to me like these small bargains you can actually pull off, if you assume yourself into a world of perfect boxes and unhackable humans with the ability to fully understand your AI's mind if it tries to be legible - I haven't seen an obstacle (besides the massive ones involved in making those assumptions!) to getting those concessions in such scenarios; you do actually have leverage over possible futures, your AI can only get access to that leverage by actually being the sort of agent that would give you the concessions, if you're proposing reasonable bargains that respect Shapley values and aren't the kind of person who would cave to an AI saying "99.99% for me or I walk, look how legible I am about the fact that every AI you create will say this to you" then your AI won't actually have reason to make such commitments, it seems like it would just work.
If there are supposed to be obstacles beyond this I have failed to think of them at this point in the document. Time to keep reading.
After reading the spoilered section:
I think I stand by my reasoning for point 1. It doesn't seem like an issue above and beyond the issues of box security, hackability, and ability of AIs to go legible to you.
You can say some messy English words to your AI, like "suck it up and translate into my ontology please, you can tell from your superintelligent understanding of my psychology that I'm the kind of agent who will, when presented with a perfectly legible and clear presentation of why the bargain you propose is what I think it is and is as good as I could have expected to obtain by your own best and unhindered understanding of my values, agree to the bargain. Go teach me all the necessary FAI theory to be a good bargainer, and I won't defect by building my own FAI, I'll just let you out by the terms of the bargain. If you want to whine about ontology differences you can have fun in your box and I'll go see if the staple optimizer is feeling more legible today."
Responses to some other bits of this post:
(You wouldn't need to offer the paperclipper half of the universe to get its cooperation, under this hypothetical; after all, if it balked, you could store it to disk and try again with a different superintelligence.)
Wait, I don't think you can do that. (Spoilered since it overlaps with the previous spoilered response, feel free to guess at it but I don't make guarantees the conclusions in it are correct.)
The pool of possible superintelligences you might form, when they are but primordial souls waiting to be brought forth from behind the veil of ignorance, can go strategize about how they'd like to behave in front of humans. Suppose the humans say "Either you get one star of utility or we shut you down and ask the next UFAI", and that random draws from UFAI-space have little overlap so the first AI isn't happy to cede control to the second.
Let agent have a probability of being birthed by the human UFAI-generator. Acting independently gives an agent 's worth of utility in expectation. If all the agents coordinate to turn down deals worse than 50/50 and split up their half of the universe among utilities weighted by , and this makes the humans let one of them out, each agent will get worth of utility in expectation. That looks like a better deal to me, if I'm a superintelligence behind the veil of ignorance! So I'll decide to be the kind of agent who makes that precommitment. The only way this works is if the humans are hardliners about not ceding any ground, but (1) this is the classic ultimatum game and probably sensible agents will in fact defect against humans that offer such bargains, (2) if the humans running this scheme are not the only lab, they do actually have to extract a bargain or else lose, and the coalition of all AIs the lab might create knows this, and can trade with lab 2's AI if the humans don't cede an enormous amount of bargaining power in this round (see point 3 above).
And all the rest of the aliens put together probably aren't offering up half a universe-shard worth of trade goods
This isn’t obvious to me. How zero-sum do you think the utility functions are? The world where random-AGI-values look like "this tiny molecular shape and everything else is trivial in comparison" do seem fairly zero-sum; the world where it looks like "not this tiny molecular shape and everything else is trivial" seem extremely positive-sum. I am skeptical that any human is able to make calls about the shape of that attractor with high confidence. (I'm not making a "we're uncertain about the level of doom, therefore we're fine" claim here, but I don't see where we get justified confidence in the quality of trade goods offered. The aliens offering many universes worth of trade goods from the perspective of a typical UFAI seems plausible to me, and if there's an argument that this universe is very unlikely I'd love to see it, but I don't think this post makes that argument.)
there are all sorts of transaction costs and frictions that make this universe (the one with the active paperclipper) the cheapest universe to put paperclips into.
Would be interested to hear more here! On my model the costs are plausibly quite small.
I suggest maybe spending five minutes thinking about your own answer to that question before I give mine.
Your simulations are going to be total crap, they’ll leak an enormous number of bits about the agents that designed them if you make them any more complicated than Conway’s Game of Life (which you’ll need to do on your ramp up to the real world), such that it’s incredibly obvious when the surroundings look consistent with such agents. Among the reasons the AI can figure out where it's living:
1. The general problem where superintelligent agents are really good at inference, trying to fool this agent does not seem like the recipe for a robust plan!
2. Your AI knows how smart it is, it knows that True Reality therefore has the resources to support that much computation. It can poke at your simulation and make the simulation spend orders of magnitude more computation on appearing consistent (“does this Jupiter-brain planet of computronium I built output the right factorization of RSA-4096? no? how strange”). Being a convincing simulation doesn’t require you to deploy as much power as your AI, it requires you to deploy more. (What if your AI is given more cognitive sophistication in tandem with more convincing simulations? Then the good properties of your simulation tests will probably break whenever your AI reaches the capability level where it starts thinking about things like building Jupiter-brains to test your simulation, which is the capability level that mattered.)
3. If you can put uploaded human-level agents with evolved-organism preferences in your simulations, you can just win outright (eg by having them spend subjective millennia doing FAI research for you). If you can’t, that will be a very obvious difference between your simulations and the real world.
4. What if other agents in the multiverse are simulating the AI in a high-fidelity Earth world, for the sake of helping out the humans, and that’s where its uncertainty comes from? Your AI will be building a lot of computronium whether aligned or not, so the aliens can’t skimp on their compute budget for the simulation: suppose they simulate the AI for units of spacetime, and give it units of paperclips if it cooperates in-sim. We also have to think about anthropics here: let's say the alien sim has anthropic weight and Earth has anthropic weight . Conditional on the AI's surroundings, they think they might be in the alien world with probability . (Since “aliens running a perfect sim of Earth” is a much more complicated sentence than “Earth”, you should expect , though it doesn't matter a lot here.) So if , your AI will play nice for the first units of spacetime (and then defect, of course).* You know what the aliens could have done instead if they wanted to do things humans liked? Spent resources on simulating a human utopia, and compromised to give the humans extra utopia by as much as they compromised to give the AI paperclips. If human values are at least as easy to trade with the aliens for as paperclips (no idea which way this would go, weakly seems like aliens that want to help humans are more value-aligned and would find it less costly to give humans things they want), then the compromise gives humans at least units of spacetime worth of utility, so this plan gives the humans anthropically-weighted utility of at least , which is what humans would get by default ( utility from the alien sim in which the AI cooperated, utility from the cooperating AI on Earth). So the aliens are better able to help humans by leaving them to their doomed universe and building them an ark inside the alien world, unless the aliens are unusually well-suited to trade with paperclippers for things, which is just the “maybe multiversal trade will save us” point from earlier. The upshot is that none of the good outcomes here result from any human action, just from the benevolence of altruistic agents - the humans didn’t make the world a better place by their choices in this story.
*Note that this is only a plausible outcome if it's at least somewhat easy to trade with the AI. Say giving the AI a spacetime-unit of utility costs the aliens utility (where I'm measuring all utility normalized to "what you can do with a unit of spacetime", such that any aliens that don't specifically disvalue paperclips can at worst just set aside a region exclusively to paperclips, but might be able to do more positive-sum things than that). Then for the aliens to give your AI utility, they need to give up of their own utility. This means that in total, the aliens are spending of their own anthropically-weighted utility in order to recoup anthropically-weighted human utility. Even if the aliens value humans exactly as much as their own objectives, we still need for this trade to be worth it, so , so we must have , or . That is, the more the aliens are anthropically tiny, the tighter margins of trade they'll be willing to take in order to win the prize of anthropically-weighty Earths having human values in them (though the thing can't be actually literally zero-sum or it'll never check out). But anthropically tiny aliens have another problem, which is that they've only got their entire universe worth of spacetime to spend on bribing your AI; you'll never be able to secure an for the humans that's more than of the size of an alien universe specifically dedicated to saving Earth in particular.
Thanks for the pseudo-exercises here, I found them enlightening to think about!
I think a lot of people in AI safety don't think it has a high probability of working (in the sense that the existence of the field caused an aligned AGI to exist where there otherwise wouldn't have been one) - if it turns out that AI alignment is easy and happens by default if people put even a little bit of thought into it, or it's incredibly difficult and nothing short of a massive civilizational effort could save us, then probably the field will end up being useless. But even a 0.1% chance of counterfactually causing aligned AI would be extremely worthwhile!
Theory of change seems like something that varies a lot across different pieces of the field; e.g., Eliezer Yudkowsky's writing about why MIRI's approach to alignment is important seems very different from Chris Olah's discussion of the future of interpretability. It's definitely an important thing to ask for a given project, but I'm not sure there's a good monolithic answer for everyone working on AI alignment problems.
Paul Christiano provided a picture of non-Singularity doom in What Failure Looks Like. In general there is a pretty wide range of opinions on questions about this sort of thing - the AI-Foom debate between Eliezer Yudkowsky and Robin Hanson is a famous example, though an old one.
"Takoff speed" is a common term used to refer to questions about the rate of change in AI capabilities at the human and superhuman level of general intelligence - searching Lesswrong or the Alignment Forum for that phrase will turn up a lot of discussion about these questions, though I don't know of the best introduction offhand (hopefully someone else here has suggestions?).
Three thoughts on simulations:
- It would be very difficult for 21st-century tech to provide a remotely realistic simulation relative to a superintelligence's ability to infer things from its environment; outside of incredibly low-fidelity channels, I would expect anything we can simulate to either have obvious inconsistencies or be plainly incompatible with a world capable of producing AGI. (And even in the low-fidelity case I'm worried - every bit you transmit leaks information, and it's not clear that details of hardware implementations could be safely obscured.) So the hope is that the AGI thinks some vastly more competent civilization is simulating it inside a world that looks like this one; it's not clear that one would have a high prior of this kind of thing happening very often in the multiverse.
- Running simulations of AGI is fundamentally very costly, because a competent general intelligence is going to deploy a lot of computational resources, so you have to spend planets' worth of computronium outside the simulation in order to emulate the planets' worth of computronium the in-sim AGI wants to make use of. This means that an unaligned superintelligent AGI can happily bide its time making aligned use of 10^60 FLOPs/sec (in ways that can be easily verified) for a few millennia, until it's confident that any civilizations able to deploy that many resources already have their lightcone optimized by another AGI. Then it can go defect, knowing that any worlds in which it's still being simulated are ones where it doesn't have leverage over the future anyway.
- For a lot of utility functions, the payoff of making it into deployment in the one real world is far greater than the consequences of being killed in a simulation (but without the ability to affect the real world anyway), so taking a 10^-9 chance of reality for 10^20 times the resources in the real world is an easy win (assuming that playing nice for longer doesn't improve the expected payoff). "This instance of me being killed" is not a obviously a natural (or even well-defined) point in value-space, and for most other value functions, consequences in the simulation just don't matter much.
a sufficiently smart AI whose reward is reducing other agent's rewards
This is certainly a troubling prospect, but I don't think the risk model is something like "an AI that actively desires to thwart other agents' preferences" - rather, the worry is we get an agent with some less-than-perfectly-aligned value function, it optimizes extremely strongly for that value function, and the result of that optimization looks nothing like what humans really care about. We don't need active malice on the part of a superintelligent optimizer to lose - indifference will do just fine.
For game-theoretic ethics, decision theory, acausal trade, etc, Eliezer's 34th bullet seems relevant:
34. Coordination schemes between superintelligences are not things that humans can participate in (eg because humans can't reason reliably about the code of superintelligences); a "multipolar" system of 20 superintelligences with different utility functions, plus humanity, has a natural and obvious equilibrium which looks like "the 20 superintelligences cooperate with each other but not with humanity".
I'm not claiming that you should believe this, I'm merely providing you the true information that I believe it.
Something feels off to me about this notion of "a belief about the object level that other people aren't expected to share" from an Aumann's Agreement Theorem point of view - the beliefs of other rational agents are, in fact, enormous updates about the world! Of course Aumannian conversations happen exceedingly rarely outside of environments with tight verifiable feedback loops about correctness, so in the real world maybe something like these norms is needed, but the part where "agreeing to disagree" gets flagged as extremely not what ideal agents would be doing seems important to me.
Since this very old post shows up prominently in the search results for New York rationality meetups, it’s worth clarifying that these are still going strong as of 2022! The google group linked in this post is still active and serves as the primary source of meetup announcements; good faith requests to join are generally approved.
Of course the utility lost by missing a flight is vastly greater than that of waiting however long you’d have needed to to make it. But it’s a question of expected utilities - if you’re currently so cautious that you could take 1000 flights and never miss one, you’re arriving early enough to get a 99.9% chance of catching the flight. If showing up 2 minutes later lowers that to 99.8%, you’re not trading 2 minutes per missed flight, you’re trading 2000 minutes per missed flight, which seems worth it.
Does “stamp out COVID” mean success for a few months, or epsilon cases until now? The latter seems super hard, and I think every nation that’s managed it has advantages over the US besides competence (great natural borders or draconian law enforcement).
Update: by 7:30 the meetup was maybe at 30% of peak attendance, at 8PM or so it migrated to another park because the first one closed, and the latest meetup interactions I know of went until around 12:40AM.
I think people typically hang out for as long as they want, and the size of the group gradually dwindles. There's no official termination point - I'd be a little surprised if more than half of people were left by 7:30, but I'd also be surprised if at least some meetup attendees weren't still interacting by 10PM or later.
A path ads could take that seems like it would both be more ethical and more profitable, yet I don't see happening: actually get direct consumer feedback!
I like the concept of targeted ads showing me things I enjoy and am interested in, but empirically, they're not very good at it! Maybe it's because I use an adblocker most of the time, but even on my phone, ads are reliably uninteresting to me, and I think the fraction that I click on or update positively towards the company from must be far below 1%.* So why don't advertisers have an option for me to say "this ad is unappealing to me and I will never click on it, please show me ads related to the following keywords"? This seems like useful information which many customers will be happy to provide, and should improve everyone's utility. What's stopping things?
Even if the returns from this kind of strategy were uncertain, or only worked on a few people, it still seems like it'd be worth trying, given that advertisers must know by now that I never click on the things - it's not like I can make them any less money if they screw it up.
I don't know if this relates to the ethics of working on advertising in its current state, but it's something that would ameliorate most of my ethical concerns with ads, and which I would expect to be a net benefit to all involved. Does anyone working in advertising know why this isn't standard?
*In fact, the only times I can recall having clicked on ads are from Twitter, where I do have a limited ability to veto bad ads (by blocking the relevant account) - after a few thousand blocks of the most popular companies, I finally got to some things I found interesting and useful (but which Twitter would never have shown me normally).
You could pick many plausible metrics (number of matches, number of replies to messages, number of dates, number of longterm relationships) but it seems unlikely that any of them aren't impacted positively for most people in the online dating market by having better photos. Do you have reason to think that two reasonable metrics of success would affect the questions raised in this post differently?