LessWrong 2.0 Reader
View: New · Old · Topnext page (older posts) →
next page (older posts) →
No, I don't think it would be "what the fuck" surprising if an emulation of a human brain was not conscious. I am inclined to expect that it would be conscious, but we know far too little about consciousness for it to radically upset my world-view about it.
Each of the transformation steps described in the post reduces my expectation that the result would be conscious somewhat. Not to zero, but definitely introduces the possibility that something important may be lost that may eliminate, reduce, or significantly transform any subjective experience it may have. It seems quite plausible that even if the emulated human starting point was fully conscious in every sense that we use the term for biological humans, the final result may be something we would or should say is either not conscious in any meaningful sense, or at least sufficiently different that "as conscious as human emulations" no longer applies.
I do agree with the weak conclusion as stated in the title - they could be as conscious as human emulations, but I think the argument in the body of the post is trying to prove more than that, and doesn't really get there.
review-bot on Refusal in LLMs is mediated by a single directionThe LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year. Will this post make the top fifty?
Katja Grace notes that image synthesis methods have no trouble generating photorealistic human faces [LW · GW].
They're terrible at hands [? · GW] though (which has ruined many otherwise good images for me). That post used Stable Diffusion 1.5, but even the latest SD 3.0 (with versions 2.0, 2.1, XL, Stable Cascade in between) is still terrible at it.
Don't really know how relevant this is to your point/question about fragility of human values, but thought I'd mention it since it seems plausibly as relevant as AIs being able to generate photorealistic human faces.
nathan-helm-burger on Nathan Helm-Burger's ShortformYeah, I was playing around with using a VAE to compress the logits output from a language transformer. I did indeed settle on treating the vocab size (e.g. 100,000) as the 'channels'.
turntrout on TurnTrout's shortform feedA semi-formalization of shard theory [? · GW]. I think that there is a surprisingly deep link between "the AIs which can be manipulated using steering vectors [LW · GW]" and "policies which are made of shards."[1] In particular, here is a candidate definition of a shard theoretic policy:
A policy has shards if it implements at least two "motivational circuits" (shards) which can independently activate (more precisely, the shard activation contexts are compositionally represented).
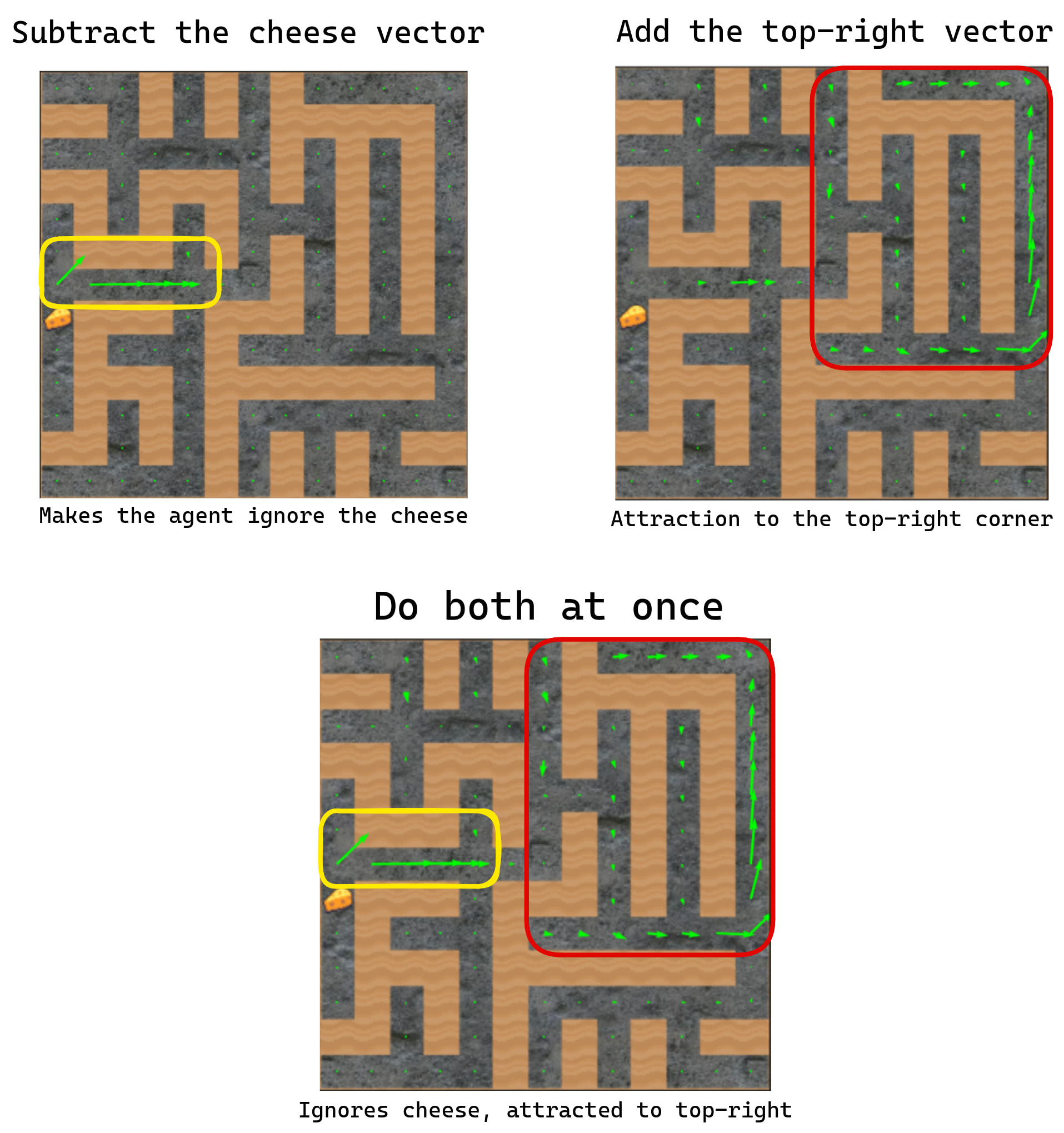
By this definition, humans have shards because they can want food at the same time as wanting to see their parents again, and both factors can affect their planning at the same time! The maze-solving policy [LW · GW] is made of shards because we found activation directions for two motivational circuits (the cheese direction, and the top-right direction):
On the other hand, AIXI is not a shard theoretic agent because it does not have two motivational circuits which can be activated independently of each other. It's just maximizing one utility function. A mesa optimizer with a single goal also does not have two motivational circuits which can go on and off in an independent fashion.
So I think this captures something important. However, it leaves a few things to be desired:
That said, I still find this definition useful.
I came up with this last summer, but never got around to posting it. Hopefully this is better than nothing.
Shard theory reasoning led me to discover the steering vector technique extremely quickly. This link would explain why shard theory might help discover such a technique.
the hope is that by "nudging" the model at an early layer, we can activate one of the many latent behaviors residing within the LLM.
In the language of shard theory [? · GW]: "the hope is that shards activate based on feature directions in early layers. By adding in these directions, the corresponding shards activate different behaviors in the model."
zack_m_davis on Ironing Out the SquigglesI agree, but I don't see why that's relevant? The point of the "Adversarial Spheres" paper is not that the dataset is realistic, of course, but that studying an unrealistically simple dataset might offer generalizable insights. If the ground truth decision boundary is a sphere, but your neural net learns a "squiggly" ellipsoid that admits adversarial examples (because SGD is just brute-forcing a fit rather than doing something principled that could notice hypotheses on the order of, "hey, it's a sphere"), that's a clue that when the ground truth is something complicated, your neural net is also going to learn something squiggly that admits adversarial examples (where the squiggles in your decision boundary predictably won't match the complications in your dataset, even though they're both not-simple).
gunnar_zarncke on LLMs could be as conscious as human emulations, potentiallyIf, this thing internalized that conscious type of processing from scratch, without having it natively, then resulting mind isn't worse than the one that evolution engineered with more granularity.
OK. I guess I had trouble parsing this. Esp. "without having it natively".
My understanding of your point is now that you see consciousness from "hardware" ("natively") and consciousness from "software" (learned in some way) as equal. Which kind of makes intuitive sense as the substrate shouldn't matter.
Corollary: A social system (a corporation?) should also be able to be conscious if the structure is right.
david-gross on David Gross's ShortformIn my fantasies, if I ever were to get that god-like glimpse at how everything actually is, with all that is currently hidden unveiled, it would be something like the feeling you have when you get a joke, or see a "magic eye" illustration, or understand an illusionist's trick, or learn to juggle: what was formerly perplexing and incoherent becomes in a snap simple and integrated, and there's a relieving feeling of "ah, but of course."
But it lately occurs to me that the things I have wrong about the world are probably things I've grasped at exactly because they are more simple and more integrated than the reality they hope to approximate. I think if I really were to get this god-like glimpse, I wouldn't know what to do with it. I probably couldn't fit it in with anything I think I know. It wouldn't mesh. It wouldn't be the missing piece of my puzzle, but would overturn the table the incomplete puzzle is on. I have a feeling I couldn't even be there, intact, in the way I am now: observing, puzzling over things, trying to shuffle and combine ideas. What makes me think I can bring my face along, face-to-face with the All?
leogao on Improving Dictionary Learning with Gated Sparse AutoencodersIt doesn't seem like a huge deal to depend on the existence of smaller LLMs - they'll be cheap compared to the bigger one, and many LM series already contain smaller models. Not transferring between sites seems like a problem for any kind of reconstruction based metric because there's actually just differently important information in different parts of the model.