LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
I'll be there! Talk to me about boundaries and coordination/Goodness
d0themath on Richard Ngo's ShortformThere's also the problem of: what do you mean by "the human"? If you make an empowerment calculus that works for humans who are atomic & ideal agents, it probably breaks once you get a superintelligence who can likely mind-hack you into yourself valuing only power. It never forces you to abstain from giving up power, since if you're perfectly capable of making different decisions, but you just don't.
Another problem, which I like to think of as the "control panel of the universe" problem, is where the AI gives you the "control panel of the universe", but you aren't smart enough to operate it, in the sense that you have the information necessary to operate it, but not the intelligence. Such that you can technically do anything you want--you have maximal power/empowerment--but the super-majority of buttons and button combinations you are likely to push result in increasing the number of paperclips.
daniel-kokotajlo on TurnTrout's shortform feedI think this is also what I was confused about -- TurnTrout says that AIXI is not a shard-theoretic agent because it just has one utility function, but typically we imagine that the utility function itself decomposes into parts e.g. +10 utility for ice cream, +5 for cookies, etc. So the difference must not be about the decomposition into parts, but the possibility of independent activation? but what does that mean? Perhaps it means: The shards aren't always applied, but rather only in some circumstances does the circuitry fire at all, and there are circumstances in which shard A fires without B and vice versa. (Whereas the utility function always adds up cookies and ice cream, even if there are no cookies and ice cream around?) I still feel like I don't understand this.
dusandnesic on ACX Covid Origins Post convinced readersIs a lot of the effect not "people who read ACX trust Scott Alexander"? Like, the survey selects for most "passionate" readers, those willing to donate their free time to Scott for research with ~nothing in return. Him publicly stating on his platform "I am now much less certain of X" is likely to make that group of people be less certain of X?
johnny-lin on Transcoders enable fine-grained interpretable circuit analysis for language modelsHey Jacob + Philippe,
Hope you all don't mind but we put up layer 8 of your transcoders onto Neuronpedia, with ~22k dashboards here:
https://neuronpedia.org/gpt2-small/8-tres-dc
Each dashboard can be accessed at their own url:
https://neuronpedia.org/gpt2-small/8-tres-dc/0 goes to feature index 0.
You can also test each feature with custom text:
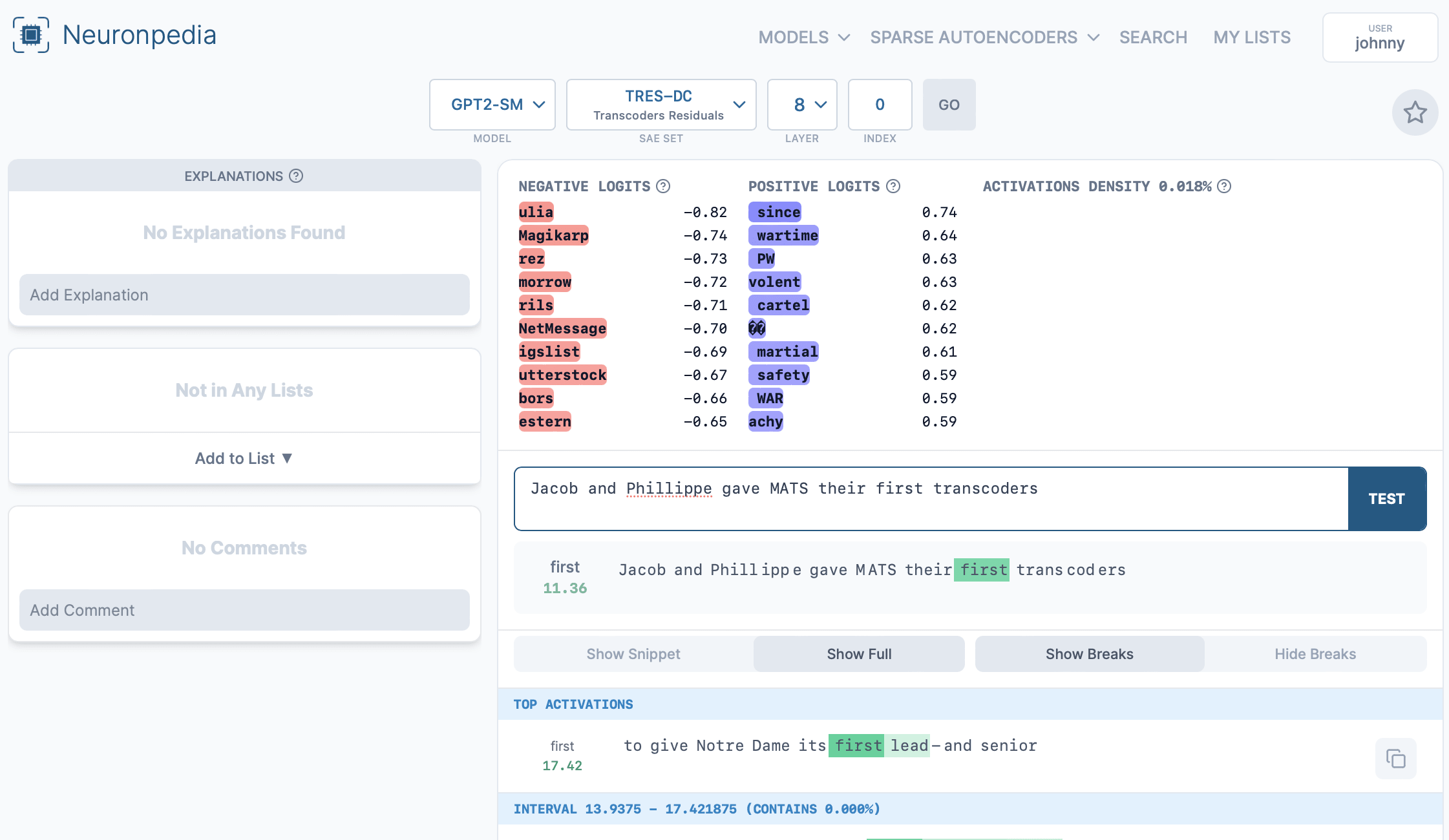
Or search all features at: https://www.neuronpedia.org/gpt2-small/tres-dc
An example search: https://www.neuronpedia.org/gpt2-small/?sourceSet=tres-dc&selectedLayers=[]&sortIndexes=[]&q=the%20cat%20sat%20on%20the%20mat%20at%20MATS
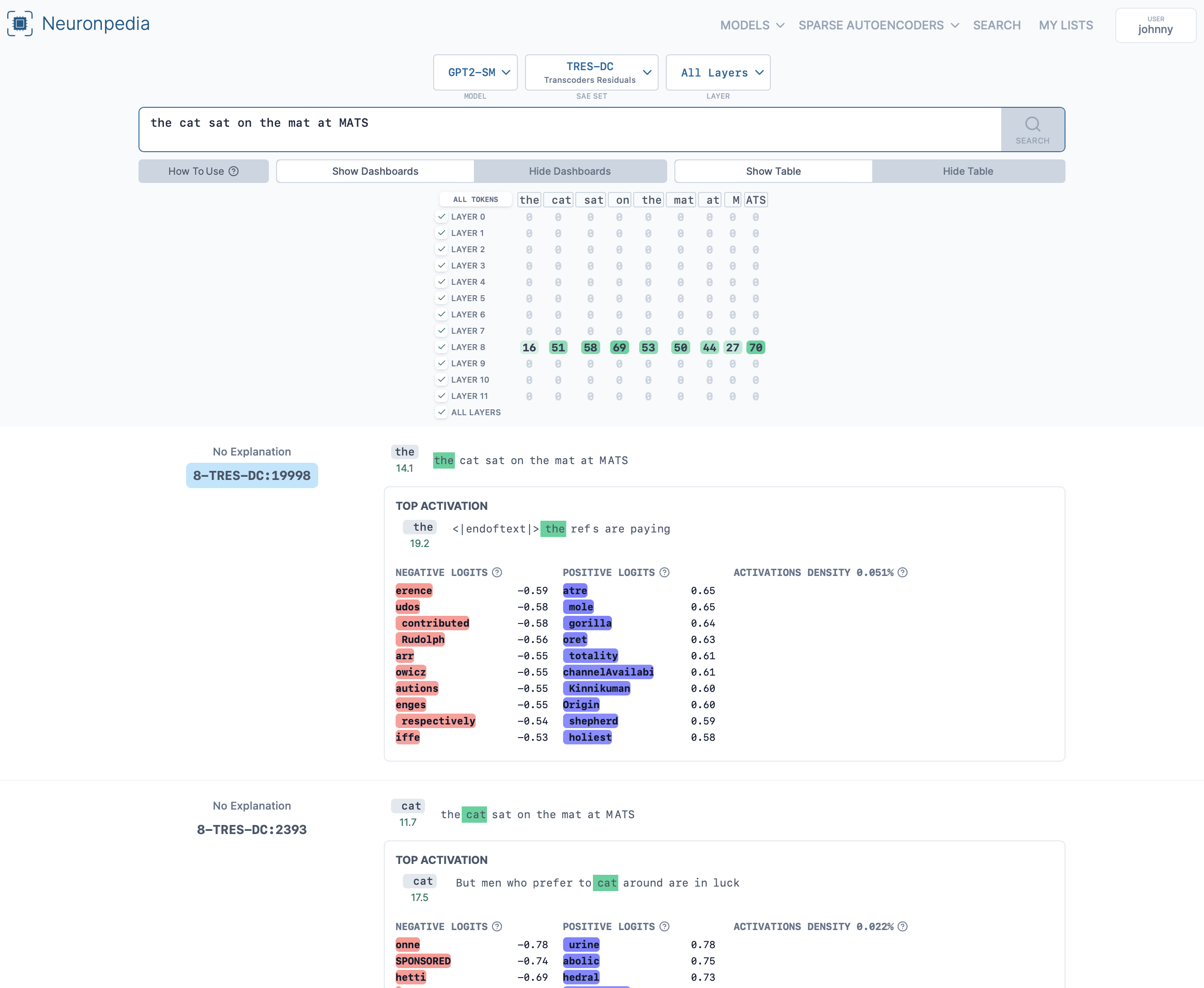
Unfortunately I wasn't able to generate histograms, autointerp, or other layers for this yet. Am working on getting more layers up first.
Verification
I did spot checks of the first few dashboards and they seem to be correct. Please let me know if anything seems wrong or off. I am also happy to delete this comment if you do not find it useful or for any other reason - no worries.
Please let me know if you have any feedback or issues with this. I will be also reaching out directly via Slack.
habryka4 on metachirality's ShortformYou can! Just go to the all-posts page, sort by year, and the highest-rated shortform posts for each year will be in the Quick Takes section:
2024:

2023:

2022:

I'm not so sure. You might be right, but I suspect that catastrophic forgetting may still be playing an important role in limiting the peak capabilities of an LLM of given size. Would it be possible to continue Llama3 8B's training much much longer and have it eventually outcompete Llama3 405B stopped at its normal training endpoint?
I think probably not? And I suspect that if not, that part (but not all) of the reason would be catastrophic forgetting. Another part would be limited expressivity of smaller models, another thing which the KANs seem to help with.
metachirality on metachirality's ShortformI think there should be a way to find the highest rated shortform posts.
ricraz on Richard Ngo's ShortformYou can think of this as a way of getting around the problem of fully updated deference, because the AI is choosing a policy based on what that policy would have done in the full range of hypothetical situations, and so it never updates away from considering any given goal. The cost, of course, is that we don't know how to actually pin down these hypotheticals.
alexander-gietelink-oldenziel on dkornai's ShortformIt also suggests that there might some sort of conservation law for pain for agents.
Conservation of Pain if you will