The Wizard of Oz Problem: How incentives and narratives can skew our perception of AI developments
post by Orpheus16 (akash-wasil) · 2023-03-20T20:44:29.445Z · LW · GW · 3 commentsContents
Predicting loss is not the same as predicting capabilities The Wizard of Oz Problem Why I’m worried about the Wizard of Oz problem What can we do about the Wizard of Oz problem? None 3 comments
TLDR: The Wizard of Oz Problem occurs when incentive structures cause people to seek and present information that matches a (favorable or desirable) narrative. This is not a new problem, but it may become more powerful as organizations scale, economic pressures mount, and the world reacts more strongly to AI progress. This problem is important because many AI safety proposals rely on organizations being able to seek out and interpret information impartially, iterate in response to novel and ambiguous information, think clearly in stressful situations, and resist economic & cultural incentive gradients.
The main purpose of this post is to offer a name to this collection of ideas & spark some initial discussion. In the rest of the post, I will:
- Describe how “predicting loss” is not the same as “predicting (real-world) capabilities” (here [LW · GW])
- Introduce the “Wizard of Oz Problem” which describes cases where incentive structures push people to interpret findings in ways that match a desired narrative (here [LW · GW])
- Discuss why I’m worried about the Wizard of Oz Problem in the context of AI safety plans (here [LW · GW])
- Briefly list a few things that could be done about the problem (here [LW · GW])
Predicting loss is not the same as predicting capabilities
In the GPT-4 paper, OpenAI shows that it’s able to predict the loss of GPT-4 from smaller models with 100-1000X less compute. They show a similar effect for the mean log pass rate on various coding problems.
Here’s a section from their blog post:
“As a result, our GPT-4 training run was (for us at least!) unprecedentedly stable, becoming our first large model whose training performance we were able to accurately predict ahead of time. As we continue to focus on reliable scaling, we aim to hone our methodology to help us predict and prepare for future capabilities increasingly far in advance—something we view as critical for safety.”
And here’s a tweet by OpenAI president and co-founder Greg Brockman:
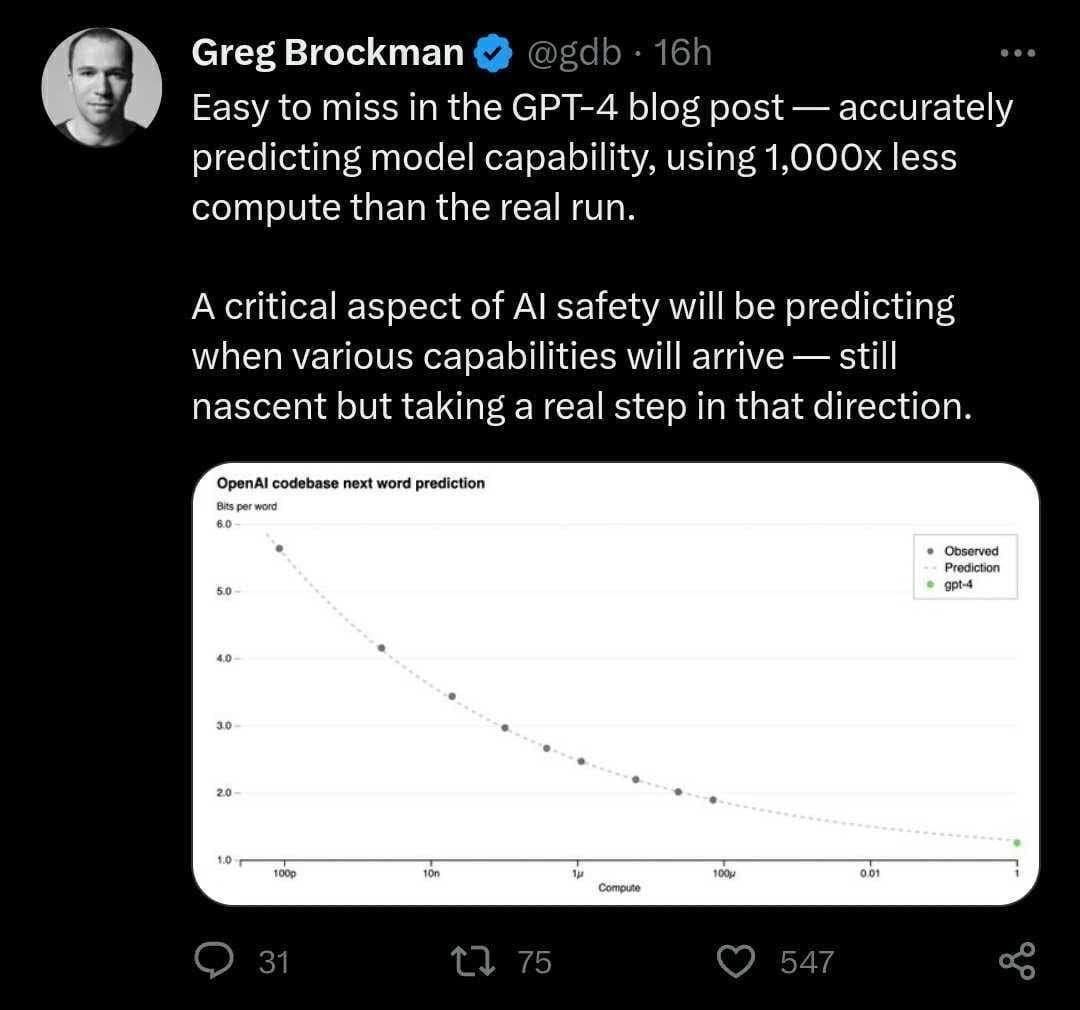
I think these findings are interesting and impressive, and I’m glad OpenAI is spending some effort trying to predict model capabilities in advance.
With that in mind, I think there’s also an issue with the way in which OpenAI is branding their results.
The ability to predict loss is not the same as the ability to make meaningful predictions about the real-world capabilities of models. To my knowledge, we currently don’t have a way of translating statements about “loss” into statements about “real-world capabilities”.
For example, I would’ve loved it if OpenAI had published Figure 4 alongside predictions from OpenAI staff. If OpenAI researchers were able to predict performance on the various standardized tests, I think that would signal real progress toward predicting real-world capabilities. I’m guessing, though, that if this had happened, it would’ve revealed that predicting performance on tests is much harder than predicting loss or predicting mean log pass rate (and test performance still seems easier to predict/measure than the messier/harder-to-define things that alignment researchers & broader society actually care about).
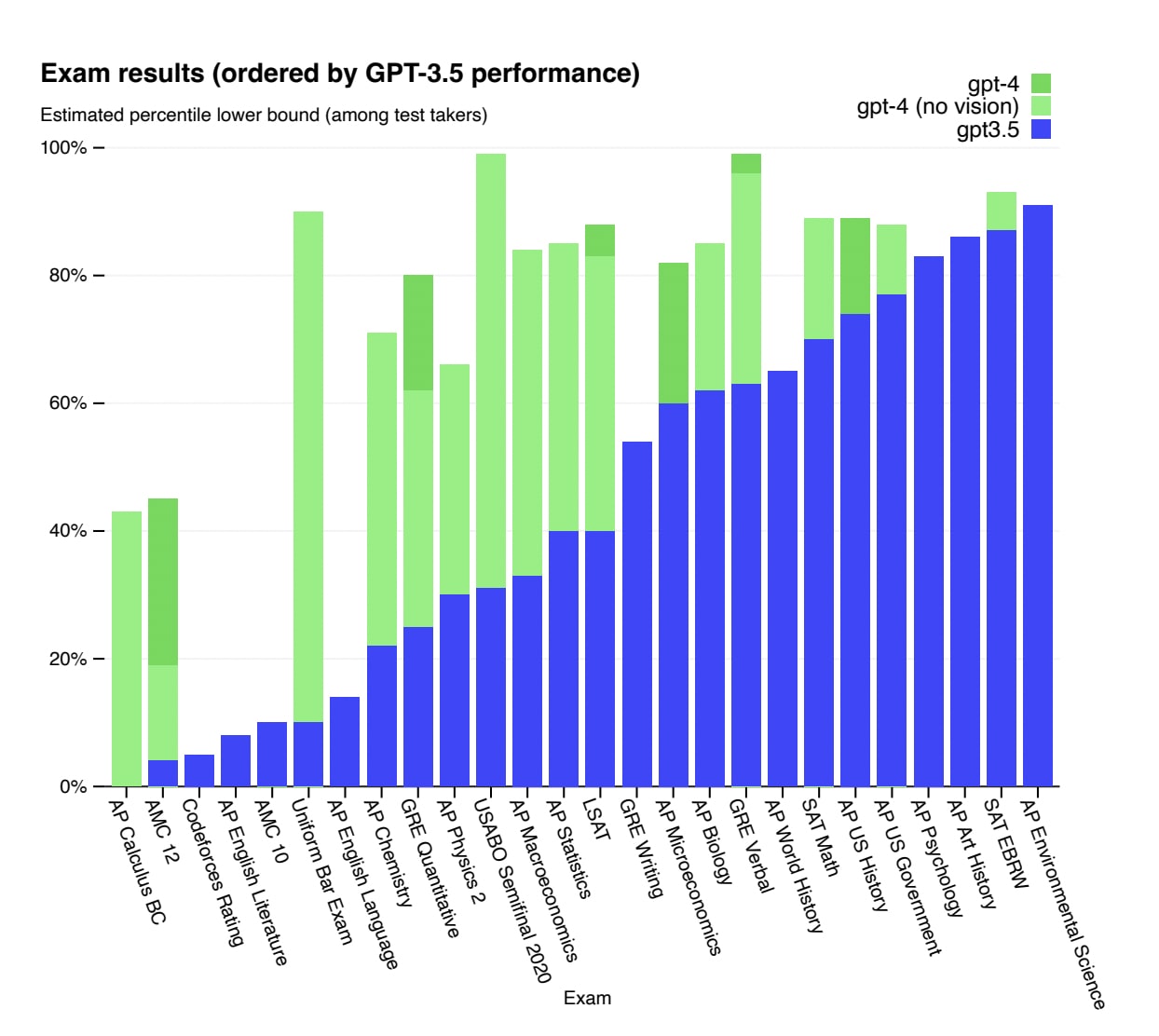
When people in the alignment community say they care about predicting capabilities or model performance, I think they usually mean things like “how dangerous will this model be?”, “will this model be able to engage in scientific reasoning?”, and “will this model be situationally aware?”
When people in broader society are interested in capabilities or model performance, I think they usually think about things like “will this be commercially viable in X industry?”, “will this be able to replace human workers at task Y?”, and “at what point will the model be able to [write music/replace search/provide reliable research/understand context/be creative/give good medical advice]?
We don’t know how to predict this stuff. To my knowledge, no one at OpenAI has publicly claimed to know either.
If I were an outsider reading the OpenAI paper, I think the vibe I would get is something like this: “Wow, this is really impressive technology, and it’s amazing that OpenAI is already able to predict the performance of the model. With models that are 100-1000X smaller? Wow! I mean look at Figure 1-- it’s just a smooth and beautiful curve. These people really know what they’re doing, and they have things under control.”
Here’s the vibe I would want readers to come away with: “Wow, this is a really impressive technology, and it’s pretty strange that we don’t know how it works or how to predict what it will do. It’s great that companies like OpenAI are making first steps toward predicting model performance. But it’s kind of frightening that we’re so bad at doing this, and there’s no way to convert “loss” into “what the model will actually be able to do/how it will affect society”, and it doesn’t seem like the OpenAI folks-- or anyone for that matter-- knows how to make meaningful predictions about model capabilities.”
The Wizard of Oz Problem
I imagine this isn’t news to anyone at OpenAI. I’m pretty confident that Greg Brockman could explain how predicting loss is very different from predicting real-world model capabilities, how this progress is just a first step in a long journey, and how AI researchers still have very limited ability to predict the real-world capabilities of models in advance.
But when I read the OpenAI blog post and paper, I come away with this feeling that this isn’t being centered in the narrative. More broadly, I feel like the paper is trying to make me feel optimistic, hopeful, and comfortable. It’s not like anyone is flat-out lying to me, but the tone and the emphasis is on “wow, look at all this exciting progress” as opposed to “we have some pretty challenging and daunting work ahead of us, and a lot of people are very confused about a lot of things.”
I’m calling this the Wizard of Oz Problem. In the Wonderful Wizard of Oz, the wizard is an ordinary man who presents himself as more great, powerful, and competent than he actually is.
The Wizard of Oz Problem occurs when incentive structures push people to present their work in ways that match a particular narrative. This often results in interpretations that are overly positive, favorable, or biased toward a particular narrative.
Science is filled with examples of the Wizard of Oz Problem. Here’s GPT-4 explaining selective reporting:
Selective reporting can manifest in different ways, including:
- Only publishing studies with positive or statistically significant results, while suppressing or not submitting studies with negative or null findings for publication.
- Emphasizing positive outcomes in the abstract, conclusions, or press releases, while downplaying or not mentioning negative results.
- Reporting only a subset of the outcomes measured in a study, focusing on those that support the desired conclusion.
And here’s GPT-4 explaining p-hacking and other questionable data analysis techniques:
- Running multiple statistical tests and only reporting those that yield significant results.
- Selectively excluding or including data points or subgroups to influence the outcome.
- Stopping data collection once a desired result has been achieved, or continuing to collect data until a significant result is found.
- Trying various model specifications, transformations, or control variables and only reporting the model that produces the desired outcome.
These problems are pervasive. There are plenty of examples of this happening in pharmaceutical research and academic research. I’m most familiar with examples from clinical psychology and social sciences, where the problems are especially thorny, but my impression is that this stuff is problematic across a variety of fields/industries.
There are also plenty of cognitive biases that play into the Wizard of Oz problem; examples include confirmation bias, illusory superiority, self-serving bias
In the AI industry, I should be clear that I don’t think this only characterizes OpenAI (did anyone else notice that Anthropic nearly-exclusively cited its own work in its recent blog post about AI safety?). I also don’t think it's primarily the fault of any particular individuals. It’s the fault of economic systems and our own cognitive systems are working against us.
Why I’m worried about the Wizard of Oz problem
I think our odds of averting catastrophe will be higher if we can promote good, transparent, unbiased reasoning about AI progress and AI safety work.
Consider the OpenAI alignment plan, which might involve difficult decisions around when to stop scaling, how to evaluate alignment solutions proposed by AIs, when to continue scaling, and what to do with powerful AI systems. As Raemon recently noted, carefully bootstrapped alignment is organizationally hard [LW · GW]. Consider evals [LW · GW], which might involve difficult decisions around how to interpret ambiguous data about model capabilities, how to respond when models fail evals, and when to be confident that a model is truly “safe”. Consider the approach laid out in Anthropic’s blog post, which involves carefully updating one’s worldview based on empirical findings (which might often be fairly messy, inconclusive, and consistent with multiple interpretations).
The Wizard of Oz problem makes these tricky decisions much harder. By default, economic incentives and cognitive biases might push people to present overly-optimistic interpretations of their research findings, overemphasize the degree to which they “have things under control”, and make it harder to identify sources of risk.
What can we do about the Wizard of Oz problem?
The genuine answer is “I don’t know; I think this is a really hard problem, and I think the recommendations I offer below should be considered first steps. This problem is enormous, and right now, no one really knows what to do about it.” (See what I did there?)
With that in mind, here are some small things that might be help a little bit:
- Try to identify instances of the problem: Be on the lookout for cases where you or others are “painting a picture” or “telling a story”. Be especially discerning when there are incentive structures that seem to work against truth-seeking tendencies.
- Reward people for acknowledging uncertainty or mistakes: Incentives often push against people saying “I’m not sure” or “I was wrong.” When people at AI labs do this, I think it’s worth commending (see example from Ilya Sutskever here and response from Eliezer here).
- Reward people for voicing concerns: Incentives often push people toward acceleration and away from voicing concerns. When people at AI labs, I think it’s worth commending.
Finally, here are two broad areas that seem relevant. I could see research projects & applied projects in these areas being useful:
- Improving institutional decision-making & epistemics: What techniques do complex organizations use to improve institutional decision-making and promote clear thinking? What lessons can be learned from examples from other industries or historical case studies? How can these lessons be adapted or implemented for AI labs?
- Improving individual decision-making & epistemics: What techniques do individuals use to make good decisions and think clearly, especially in environments with complicated incentive gradients? What can be learned from areas like cognitive psychology, rationality [? · GW], and complex institutions [? · GW]?
I’m grateful to Alex Gray and Jeffrey Ladish for reviewing a draft of this post. I’m grateful to others on LessWrong for coming up with strange [LW · GW] but memorable [LW · GW] names [LW · GW] for a variety of concepts.
Related work I recommend: Carefully Bootstrapped Alignment is organizationally hard [LW · GW], Immoral Mazes [? · GW], Six Dimensions of Operational Adequacy in AI Projects [LW · GW]
3 comments
Comments sorted by top scores.
comment by Jsevillamol · 2023-03-21T21:47:46.233Z · LW(p) · GW(p)
To my knowledge, we currently don’t have a way of translating statements about “loss” into statements about “real-world capabilities”.
comment by Igor Ivanov (igor-ivanov) · 2023-03-29T18:16:54.678Z · LW(p) · GW(p)
I think this Wizard of Oz problem in large part is about being mindful and honest with oneself.
Wishful thinking is somewhat the default state for people. It's hard to be critical to own ideas and wishes. Especially, when things like money or career advancement are at stake.
comment by Jonathan Claybrough (lelapin) · 2023-03-21T08:31:10.287Z · LW(p) · GW(p)
I think this post would benefit from being more explicit on its target. This problem concerns AGI labs and their employees on one hand, and anyone trying to build a solution to Alignment/AI Safety on the other.
By narrowing the scope to the labs, we can better evaluate the proposed solutions (for example to improve decision making we'll need to influence decision makers therein), make them more focused (to the point of being lab specific, analyzing each's pressures), and think of new solutions (inoculating ourselves/other decision makers on AI about believing stuff that come from those labs by adding a strong dose of healthy skepticism).
By narrowing the scope to people working on AI Safety who's status or monetary support relies on giving impressions of progress, we come up with different solutions (try to explicitly reward honesty, truthfulness, clarity over hype and story making). A general recommendation I'd have is to have some kind of reviews that check against "Wizard of Oz'ing" for flagging the behavior and suggesting corrections. Currently I'd say the diversity of LW and norms for truth seeking are doing quite well at this, so posting on here publicly is a great way to control this. It highlights the importance of this place and of upkeeping these norms.