0 comments
Comments sorted by top scores.
comment by Thane Ruthenis · 2023-12-17T20:27:36.123Z · LW(p) · GW(p)
Agreed.
In addition: I expect one of the counter-arguments to this would be "if these labs shut down, more will spring up in their place, and nothing would change".
Potentially-hot take: I think that's actually a much lesser concern that might seem.
The current major AGI labs are led by believers. My understanding is that quite a few (all?) of them bought into the initial LW-style AGI Risk concerns, and founded these labs as a galaxy-brained plan to prevent extinction and solve alignment. Crucially, they aimed to do that well before the talk of AGI became mainstream. They did it back in the days where "AGI" was a taboo topic due to the AI field experiencing one too many AI winters.
They also did that in defiance of profit-maximization gradients. Back in 2010s, "AGI research" may have sounded like a fringe but tolerable research topic, but certainly not like something that'd have invited much investor/market hype.
And inasmuch as humanity is still speeding up towards AGI, I think that's currently still mostly spearheaded by believers. Not by raw financial incentives or geopolitical races. (Yes, yes, LLMs are now all the hype, and I'm sure the military loves to put CNNs on their warheads' targeting systems, or whatever it is they do. But LLMs are not AGI.)
Outside the three major AGI labs, I'm reasonably confident no major organization is following a solid roadmap to AGI; no-one else woke up. A few LARPers [LW · GW], maybe, who'd utter "we're working on AGI" because that's trendy now. But nobody who has a gears-level model of the path there, and what its endpoint entails.
So what would happen if OpenAI, DeepMind, and Anthropic shut down just now? I'm not confident, but I'd put decent odds that the vision of AGI would go the way great startup ideas go. There won't be necessarily anyone who'd step in to replace them. There'd be companies centered around scaling LLMs in the brutest manners possible, but I'm reasonably sure that's mostly safe [LW · GW].
The business world, left to its own devices, would meander around to developing AGI eventually, yes. But the path it'd take there might end up incremental and circuitous, potentially taking a few decades more. Nothing like the current determined push.
... Or so goes my current strong-view-weakly-held.
Replies from: D0TheMath, None, carado-1, Vladimir_Nesov, NicholasKross, cousin_it↑ comment by Garrett Baker (D0TheMath) · 2023-12-17T22:58:21.971Z · LW(p) · GW(p)
Outside the three major AGI labs, I'm reasonably confident no major organization is following a solid roadmap to AGI; no-one else woke up. A few LARPers, maybe, who'd utter "we're working on AGI" because that's trendy now. But nobody who has a gears-level model of the path there, and what its endpoint entails.
This seems pretty false. In terms of large players, there also exists Meta and Inflection AI. There are also many other smaller players who also care about AGI, and no doubt many AGI-motivated workers at three labs mentioned would start their own orgs if the org they're currently working under shuts down.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-12-18T04:56:54.264Z · LW(p) · GW(p)
Inflection's claim to fame [LW · GW] is having tons of compute and promising to "train models that are 10 times larger than the cutting edge GPT-4 and then 100 times larger than GPT-4", plus the leader talking about "the containment problem" in a way that kind-of palatably misses the point [LW · GW]. So far, they seems to be precisely the sort of "just scale LLMs" vision-less actor I'm not particularly concerned about. I could be proven wrong any day now, but so far they don't really seem to be doing anything interesting.
As to Meta – what's the last original invention they did? Last I checked, they couldn't even match GPT-4, with all of Meta's resources. Yann LeCun has thoughts on AGI, but it doesn't look like he's being allowed to freely and efficiently pursue them. That seems to be how a vision-less major corporation investing in AI looks like. Pretty unimpressive.
Current AGI labs metastazing across the ecosystem and potentially founding new ones if shut down – I agree that it may be a problem, but I don't think they necessarily by-default coalesce into more AGI labs. Some of them have research skills but no leadership/management skills, for example. So while they'd advance towards an AGI when embedded into a company with this vision, they won't independently start one up if left to their own devices, nor embed themselves into a different project and hijack it towards AGI-pursuit. And whichever of them do manage that – they'd be unlikely to coalesce into a single new organization, meaning the smattering of new orgs would still advance slower collectively, and each may have more trouble getting millions/billions of funding unless the leadership are also decent negotiators.
Replies from: o-o↑ comment by O O (o-o) · 2023-12-19T08:20:08.704Z · LW(p) · GW(p)
meaning the smattering of new orgs would still advance slower collectively, and each may have more trouble getting millions/billions of funding unless the leadership are also decent negotiators
This seems to contradict history. The split up of Standard Oil for example led to innovations in oil drilling. Also you are seriously overestimating how hard it is to get funding. Much stupider and more poorly run companies have gotten billions in funding. And these leaders in the worst case can just hire negotiators.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-12-19T12:46:37.289Z · LW(p) · GW(p)
Presumably these innovations were immediately profitable. I'm not sure that moves towards architectures closer to AGI (as opposed to myopic/greedy-search moves towards incrementally-more-capable models) are immediately profitable. It'd be increasingly more true as we inch closer to AGI, but it definitely wasn't true back in the 2010s, and it may not yet be true now.
So I'm sure some of them would intend to try innovations that'd inch closer to AGI, but I expect them not to be differentially more rewarded by the market. Meaning that, unless one of these AGI-focused entrepreneurs is also really good at selling their pitch to investors (or has the right friend, or enough money and competence-recognition ability to get a co-founder skilled at making such pitches), then they'd be about as well-positioned to rush to AGI as some of the minor AI labs today are. Which is to say, not all that well-positioned at all.
you are seriously overestimating how hard it is to get funding
You may not be taking into account the market situation immediately after major AI labs' hypothetical implosion. It'd be flooded with newly-unemployed ML researchers trying to found new AI startups or something; the demand on that might well end up saturated (especially if major labs' shutdown cools the hype down somewhat). And then it's the question of which ideas are differentially more likely to get funded; and, as per above, I'm not sure it's the AGI-focused ones.
Replies from: o-o↑ comment by O O (o-o) · 2023-12-19T16:52:21.565Z · LW(p) · GW(p)
Presumably these innovations were immediately profitable.
That’s not always the case. It can take time to scale up an innovation, but I’d assume it’s plausibly profitable. AGI is no longer a secret belief and several venture capitalists + rich people believe in it. These people also under stand long term profit horizons. Uber took over 10 years to become profitable. Many startups haven’t been profitable yet.
Also a major lab shutting down for safety reasons is like broadcasting to all world governments that AGI exists and is powerful/dangerous.
↑ comment by [deleted] · 2023-12-18T00:45:58.102Z · LW(p) · GW(p)
The current major AGI labs are led by believers. My understanding is that quite a few (all?) of them bought into the initial LW-style AGI Risk concerns, and founded these labs as a galaxy-brained plan to prevent extinction and solve alignment. Crucially, they aimed to do that well before the talk of AGI became mainstream. They did it back in the days where "AGI" was a taboo topic due to the AI field experiencing one too many AI winters.
So with this model, you think that the entire staff of all the AI labs who have direct experience on the models, less than ~5000 people at top labs, is all who mattered? So if, in your world model, they were all murdered or somehow convinced what they were doing for lavish compensation was wrong, then that would be it. No AGI for decades.
What you are advancing is a variant on the 'lone innovator' idea. That if you were to go back in time and murder the 'inventor' or developer of a critical innovation, it would make a meaningful difference as to the timeline when the innovation is finally developed.
And it's falsifiable. If for each major innovation that one person was credited with, if you research the history and were to learn that dozens of other people were just a little late to publish essentially the same idea, developed independently, the theory would be wrong, correct?
And this would extend to AI.
One reason the lone innovator model could be false is if invention doesn't really happen from inspiration, but when the baseline level of technology or math/unexplained scientific data in some cases makes possible the innovation.
Every innovation I have ever looked at, the lone innovator model is false. There were other people, and if you went back in time and could kill just 1 person, it wouldn't have made any meaningful difference. One famous one is the telephone, where Bell just happened to get to the patent office first. https://en.wikipedia.org/wiki/Invention_of_the_telephone
Einstein has some of the strongest hype as a lone contributor ever given a human being, yet: https://www.caltech.edu/about/news/not-lone-genius
I think AI is specifically a strong case of the lone innovator theory being false because what made it possible was large parallel CPU and later GPU clusters, where the most impressive results have required the most powerful compute that can be built. In a sense all present AI progress happened the earliest it possibly could have at investment levels of ~1 billion USD/model.
That's the main thing working against your idea. There's also many other people outside the mainstream AI labs who want to work on AI so badly they replicated the models and formed their own startup, Eleuther being one. They are also believers, not elite enough to make the headcount at the elite labs.
There could be a very large number of people like that. And of course the actual enablers of modern AI are chip companies such as Nvidia and AMD. They aren't believers in AI..but they are believers in money (to be fair to your theory, Nvidia was an early believer in AI...to make money). At present they have a strong incentive to sell as many ICs as they can, to as many customers as will buy it. https://www.reuters.com/technology/us-talks-with-nvidia-about-ai-chip-sales-china-raimondo-2023-12-11/
I think that if, hypothetically, you wanted to halt AI progress, the crosshairs have to be on the hardware supply. As long as ever more hardware is being built and shipped, more true believers will be created, same as every other innovation. If you had assassinated every person who ever worked on a telephone like analog acoustic device in history, but didn't do anything about the supply of DC batteries, amplifiers, audio transducers, and wire, someone is going to 'hmm' and invent the device.
As long as more and more GPUs are being shipped, and open source models, same idea.
There's another prediction that comes out of this. Once the production rate is high enough, AI pauses or slowing down AI in any way probably disappears as a viable option. For example, it's logical for Nvidia to start paying more for ICs faster: https://www.tomshardware.com/news/nvidia-alleged-super-hot-run-chinese-tsmc-ai-gpu-chips . Once TSMC's capacity is all turned over to building AI, and 2024 2 million more H100s are built, and MI300X starts to ship in volume...there's some level at which it's impossible to even consider an AI pause because too many chips are out there. I'm not sure where the level is, just production ramps should be rapid until the world runs out of fab capacity to reallocate.
You couldn't plan to control nuclear weapons if every corner drug store was selling weapons grade plutonium in 100g packs. It would be too late.
For a quick idea : to hit the 10^26 "maybe dangerous" threshold in fp32, you would need approximately 2 million cards to do it in a month, or essentially in 2024 Nvidia will sell to anyone who can afford it enough for 12 "maybe dangerous" models to be trained in 2025. AMD will need time for customers to figure out their software stack, and it probably won't be used as a training accelerator much in 2024.
So "uncontrollable" is some multiplier on this. We can then predict what year AI will no longer be controllable by restricting hardware.
Replies from: gwern, Thane Ruthenis↑ comment by gwern · 2023-12-18T02:24:20.166Z · LW(p) · GW(p)
They aren't believers in AI..but they are believers in money (to be fair to your theory, Nvidia was an early believer in AI...to make money
Nvidia wasn't really an early believer unless you define 'early' so generously as to be more or less meaningless, like 'anyone into DL before AlphaGo'. Your /r/ML link actually inadvertently demonstrates that: distributing a (note the singular in both comments) K40 (released 2013, ~$5k and rapidly declining) here or there as late as ~2014 is not a major investment or what it looks like when a large company is an 'early believer'. The recent New Yorker profile of Huang covers this and Huang's admission that he blew it on seeing DL coming and waited a long time before deciding to make it a priority of Nvidia's - in 2009, they wouldn't even give Geoff Hinton a single GPU when he asked after a major paper, and their CUDA was never intended for neural networks in the slightest.
For example, it's logical for Nvidia to start paying more for ICs faster: https://www.tomshardware.com/news/nvidia-alleged-super-hot-run-chinese-tsmc-ai-gpu-chips . Once TSMC's capacity is all turned over to building AI, and 2024 2 million more H100s are built, and MI300X starts to ship in volume...
And even now, they seem to be surprisingly reluctant to make major commitments to TSMC to ensure a big rampup of B100s and later. As I understand it, TSMC is extremely risk-averse and won't expand as much as it could unless customers underwrite it in advance so that they can't lose, and still thinks that AI is some sort of fad like cryptocurrencies that will go bust soon; this makes sense because that sort of deeply-hardwired conservatism is what it takes to survive the semiconductor boom-bust and gambler's ruin and be one of the last chip fabs left standing. And why Nvidia won't make those commitments may be Huang's own conservatism from Nvidia's early struggles, strikingly depicted in the profile. This sort of corporate DNA may add delay you wouldn't anticipate from looking at how much money is on the table. I suspect that the 'all TSMC's capacity is turned over to AI' point may take longer than people expect due to their stubbornness. (Which will contribute to the 'future is already here, just unevenly distributed' gradient between AI labs and global economy - you will have difficulty deploying your trained models at economical scale.)
Replies from: None↑ comment by [deleted] · 2023-12-18T03:46:01.823Z · LW(p) · GW(p)
And even now, they seem to be surprisingly reluctant to make major commitments to TSMC to ensure a big rampup of B100s and later. As I understand it, TSMC is extremely risk-averse and won't expand as much as it could unless customers underwrite it in advance so that they can't lose, and still thinks that AI is some sort of fad like cryptocurrencies that will go bust soon; this makes sense because that sort of deeply-hardwired conservatism is what it takes to survive the semiconductor boom-bust and gambler's ruin and be one of the last chip fabs left standing.
Giving away free hardware vs extremely risk averse seems mildly contradictory, but I will assume you mean in actual magnitudes. Paying TSMC to drop everything and make only B100s is yeah, a big gamble they probably won't make since it would cost billions, while a few free cards is nothing.
So that will slow the ramp down a little bit? Would it have mattered? 2012 era compute would be ~16 times slower per dollar, or more if we factor in lacking optimizations, transformer hasn't been invented so less efficient networks would be used, etc.
The "it could just be another crypto bubble" is an understandable conclusion. Remember, GPT-4 requires a small fee to even use, and for the kind of senior people who work at chip companies, many of them haven't even tried it.
You have seen the below, right? To me this looks like a pretty clear signal as to what the market wants regarding AI...
![r/dataisbeautiful - [OC] NVIDIA Income Statement Q3 2023](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/EPSaR5rctveHwDm77/xw9et8feghnyohfgnnvd)
↑ comment by Thane Ruthenis · 2023-12-18T05:11:36.523Z · LW(p) · GW(p)
So with this model, you think that the entire staff of all the AI labs who have direct experience on the models, less than ~5000 people at top labs, is all who mattered?
Nope, I think Sam Altman and Elon Musk are the only ones who matter.
Less facetiously: The relevant reference class isn't "people inventing lightbulbs in a basement", it's "major engineering efforts such as the Manhattan Project". It isn't about talent, it's about company vision. It's about there being large, well-funded groups of people organized around a determined push to develop a particular technology, even if it's yet out-of-reach for conventional development or lone innovators.
Which requires not only a ton of talented people, not only the leadership with a vision, not only billions of funding, and not only the leadership capable of organizing a ton of people around a pie-in-the-sky idea and attracting billions of funding for it, but all of these things in the same place.
And in this analogy, it doesn't look like anyone outside the US has really realized yet that nuclear weapons are a thing that is possible. So if they shut the Manhattan Project down, it may be ages before anyone else stumbles upon the idea.
And AGI is dis-analogous to nuclear weapons, in that the LW-style apocalyptic vision is actually much harder to independently invent and take seriously. We don't have equations proving that it's possible.
I think that if, hypothetically, you wanted to halt AI progress, the crosshairs have to be on the hardware supply
Targeting that chokepoint would have more robust effects, yes.
Replies from: None↑ comment by [deleted] · 2023-12-18T08:00:35.262Z · LW(p) · GW(p)
Which requires not only a ton of talented people, not only the leadership with a vision, not only billions of funding, and not only the leadership capable of organizing a ton of people around a pie-in-the-sky idea and attracting billions of funding for it, but all of these things in the same place.
You're not wrong about any of this. I'm saying that something like AI has a very clear and large payoff. Many people can see this. Essentially what people worried about AI are saying is the payoff might be too large, something that hasn't actually happened in human history yet. (this is why for older, more conservative people it feels incredibly unlikely - far more likely that AI will underwhelm, so there's no danger)
So there's motive, but what about the means? If an innovation was always going to happen, then here's why:
Why did Tesla succeed? A shit ton of work. What happens if someone assassinated the real founders of Tesla and Musk in the past?
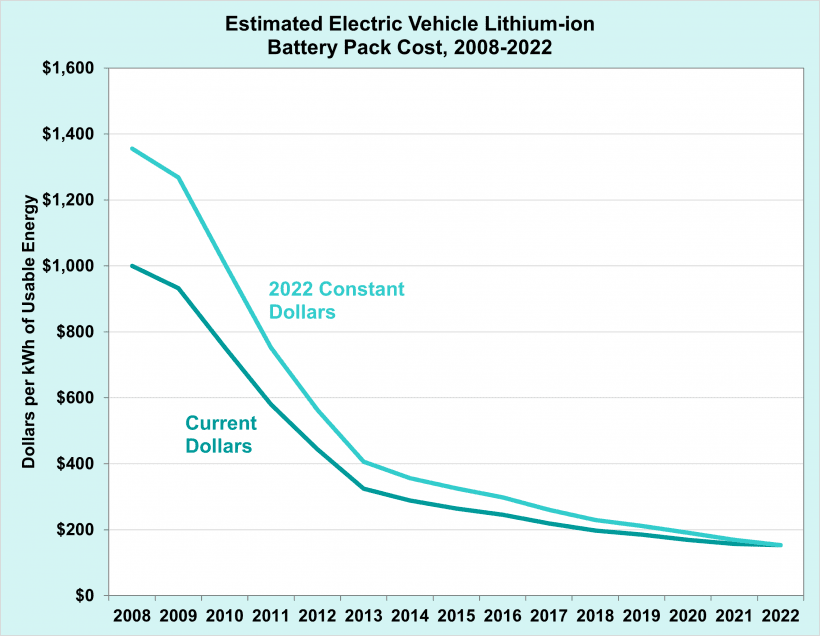
Competitive BEVs become possible because of this chart. Model S was released in 2012 and hit mass production numbers in 2015. And obviously there's one for compute, though it's missing all the years that matter and it's not scaled by AI TOPS:
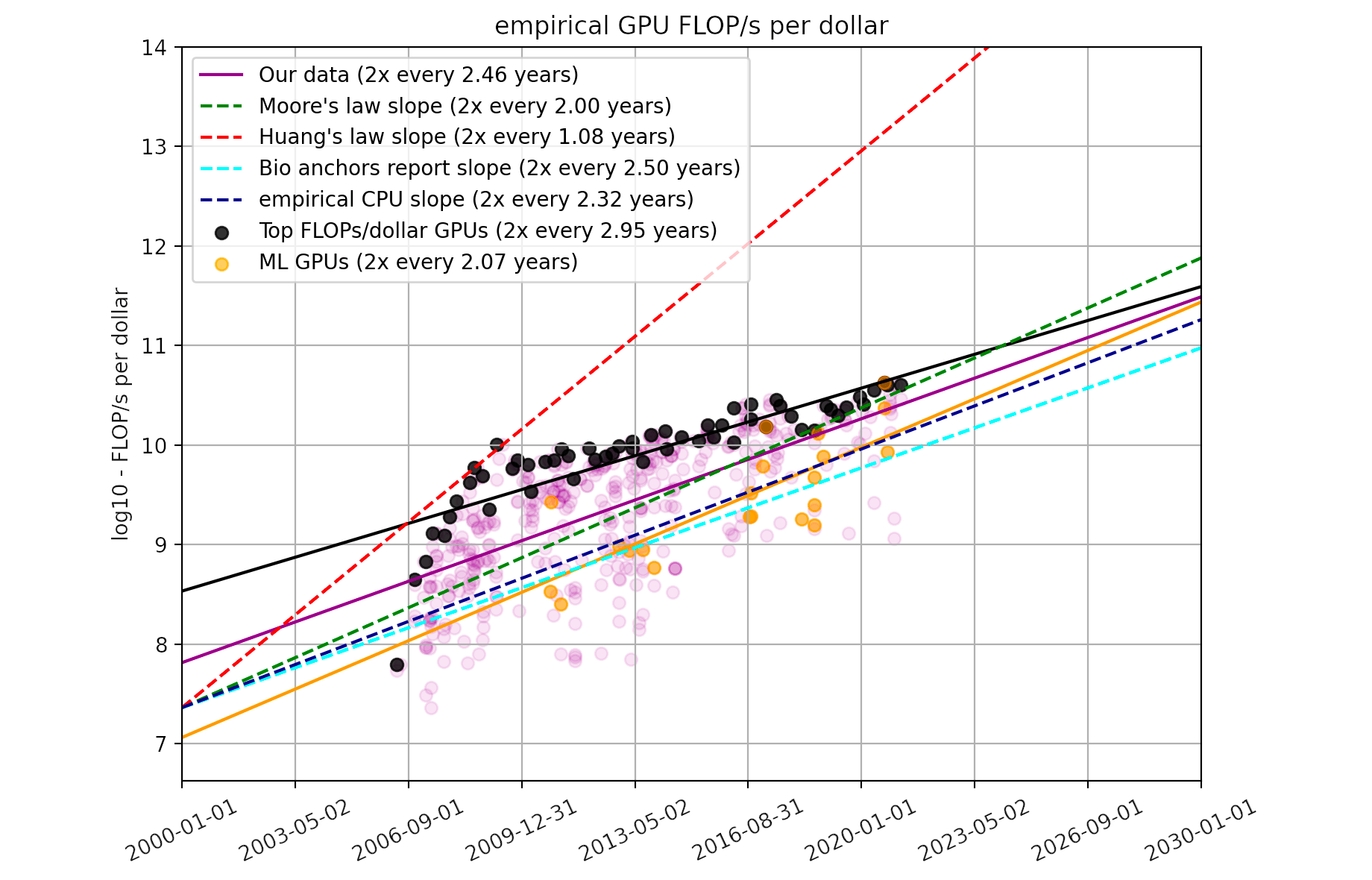
See as long as this is true, it's kinda inevitable that some kind of AI will be found.
It might underwhelm for the simple reason that the really high end AIs take too much hardware to find and run. To train a 10^26 TOPs model with 166k H100s over 30 days is 4.1 billion in just GPUs. Actual ASI might require orders of magnitude more to train, and more orders of magnitude in failed architectures that have to be tried to find the ones that scale to ASI.
Replies from: Vladimir_Nesov, Thane Ruthenis↑ comment by Vladimir_Nesov · 2023-12-18T14:34:24.139Z · LW(p) · GW(p)
To train a 10^26 TOPs model with 166k H100s over 30 days is 4.1 billion in just GPUs.
That assumes 230 teraFLOP/s of utilization, so possibly TF32? This assumption doesn't seem future-proof, even direct use of BF16 might not be in fashion for long. And you don't need to buy the GPUs outright, or be done in a month.
As an anchor, Mosaic trained a 2.4e23 model in a way that's projected to require 512 H100s for 11.6 days at precision BF16. So they extracted on average about 460 teraFLOP/s of BF16 utilization out of each H100, about 25% of the quoted 2000 teraFLOP/s. This predicts 150 days for 1e26 FLOPs on 15000 H100s, though utilization will probably suffer. The cost is $300-$700 million if we assume $2-$5 per H100-hour, which is not just GPUs. (If an H100 serves for 3 years at $2/hour, the total revenue is $50K, which is in the ballpark.)
To train a 1e28 model, the estimate anchored on Mosaic's model asks for 650K H100s for a year. The Gemini report says they used multiple datacenters, so there is no need to cram everything into one building. The cost might be $15-$30 billion. One bottleneck is inference (it could be a 10T parameter dense transformer), as you can't plan to serve such a model at scale without knowing it's going to be competent enough to nonetheless be worthwhile, or with reasonable latency. Though the latter probably won't hold for long either. Another is schlep in making the scale work without $30 billion mistakes, which is cheaper and faster to figure out by iterating at smaller scales. Unless models stop getting smarter with further scale, we'll get there in a few years.
Replies from: None↑ comment by [deleted] · 2023-12-18T16:04:38.116Z · LW(p) · GW(p)
I personally work as a generalist on inference stacks. I have friends at the top labs, what I understand is during training you need high numerical precision or you are losing information. This is why you use fp32 or tf32 and I was assuming 30 percent utilization because there are other bottlenecks in current generation hardware on LLM training. (Memory bandwidth being one).
If you can make training work for "AGI" level models with less numerical precision, absolutely this helps. Your gradients are numerically less stable with deeper networks the less bits you use though.
For inference the obvious way to do that is irregular sparsity, it will be much more efficient. This is relevant to ai safety because models so large that they only run at non negligible speed of ASICs supporting irregular sparsity will be trapped. Escape would not be possible so long as the only hardware able to support the model exists at a few centralized data centers.
Irregular sparsity would also need different training hardware, you obviously would start less than fully connected and add or prune connections during phases of training.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-18T17:24:05.511Z · LW(p) · GW(p)
This is probably more fiddly at larger scales, but the striking specific thing to point to are loss measurements in this Oct 2023 paper (see page 7), which claims
MXFP6 provides the first demonstration of training generative language models to parity with FP32 using 6-bit weights, activations, and gradients with no modification to the training recipe.
and
Our results demonstrate that generative language models can be trained with MXFP4 weights and MXFP6 activations and gradients incurring only a minor penalty in the model loss.
As loss doesn't just manageably deteriorate, but essentially doesn't change for 1.5b parameter models (when going from FP32 to MXFP6_E3M2 during pre-training), there is probably a way to keep that working at larger scales. This is about Microscaling datatypes, not straightforward lower precision.
Replies from: None↑ comment by [deleted] · 2023-12-18T18:00:32.274Z · LW(p) · GW(p)
Skimming the paper and the method: yeah, this should work at any scale. This type of mixed precision algorithm has a cost though. You still need hardware support for the higher precisions, which costs you chip area and complexity, as you need to multiply the block scaling factor and use an accumulator to hold the product that is 32 bit.
On paper Nvidia claims their tf32 is only 4 times slower than int8, so the gains with this algorithm are small on that hardware because you have more total weights with micro scaling or other similar methods.
For inference accelerators, being able to drop fp32 entirely is where the payoff really is, that's a huge chunk of silicon you can leave out of the design. Mixed precision helps there. 3x or so benefit is also large at inference time because it's 3x less cost, Microsoft would make money from copilot if they could reduce their costs 3x.
Oh but less VRAM consumption which is the limiting factor for LLMs. And...less network traffic between nodes in large training clusters. Flat ~3x boost to the largest model you can train?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-18T18:36:22.410Z · LW(p) · GW(p)
Right, hence the point is about future-proofing the FLOP/s estimate, it's a potential architecture improvement that's not bottlenecked by the slower low level hardware improvement. If you bake quantization in during pre-training, the model grows up adapted to it and there is no quality loss caused by quantizing after pre-training. It's 5-8 times less memory, and with hardware acceleration (while not designing the chip to do anything else) probably appropriately faster.
Taken together with papers like this, this suggests that there is further potential if we don't try to closely reproduce linear algebra, which might work well if pre-training adapts the model from the start to the particular weird way of computing things (and if an optimizer can cope). For fitting larger models into fewer nodes for sane latency during inference there's this (which suggests a GPT-4 scale transformer might run on 1-2 H200s; though at scale it seems more relevant for 1e28 FLOPs models, if I'm correct in guessing this kills throughput). These are the kinds of things that given the current development boom will have a mainstream equivalent in 1-3 years if they work at all, which they seem to.
Replies from: None↑ comment by [deleted] · 2023-12-18T19:50:17.713Z · LW(p) · GW(p)
So I think there is something interesting from this discussion. Those who worry the most about AI doom, Max H being one, have posited that an optimal AGI could run on a 2070.
Yet the most benefits come, like you say, from custom hardware intended to accelerate the optimization. I mentioned arbitrary sparsity, where each layer of the network can consume an arbitrary number of neural tiles and there are many on chip subnets to allow a large possibility space of architectures. Or you mentioned training accelerators designed for mixed precision training.
Turing complete or not, the wrong hardware will be thousands of times slower. It could be in the next few years that newer models only run on new silicon, obsoleting all existing silicon, and this could happen several times. It obviously did for GPU graphics.
This would therefore be a way to regulate AI. If you could simply guarantee that the current generation of AI hardware was concentrated into known facilities worldwide, nowhere else (robots would use special edge cards with ICs missing the network controllers for clustering), risks would probably be much lower.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-18T20:37:28.395Z · LW(p) · GW(p)
This helps to regulate AI that doesn't pose existential threat [LW(p) · GW(p)]. AGIs might have time [LW(p) · GW(p)] to consolidate their cognitive advantages [LW(p) · GW(p)] while running on their original hardware optimized for AI. This would quickly (on human timescale) give them theory and engineering plans from distant future (of a counterfactual human civilization without AGIs). Or alternatively superintelligence might be feasible without doing such work on human level, getting there faster.
In that situation, I wouldn't rule out running an AGI on a 2070, it's just not a human-designed AGI, but one designed either by superintelligence or by an ancient civilization of human-adjacent level AGIs (in the sense of serial depth of their technological culture). You might need 1e29 FLOPs of AI-optimized hardware to make a scaffolded LLM that works as a weirdly disabled AGI barely good enough to invent its way into removing its cognitive limitations. You don't need that for a human level AGI designed from the position of thorough comprehension of how AGIs work.
Replies from: None↑ comment by [deleted] · 2023-12-18T21:43:14.985Z · LW(p) · GW(p)
So what you are saying here could be equivalent to "limitless optimization is possible". Meaning that given a particular computational problem, it is possible to find an equivalent algorithm to solve that problem that is thousands of times faster or more. Note how the papers you linked don't show that, the solution trades off complexity and the number of weights for somewhere in the range of 3-6 times less weights and speed.
You can assume more aggressive optimizations may require more and more tradeoffs and silicon support older GPUs won't have. (Older GPUs lacked any fp16 or lower matrix support)
This is the usual situation for all engineering, most optimizations come at a cost. Complexity frequently. And there exists an absolute limit. Like if we compare Newxomens first steam engine vs the theoretical limit for a steam engine. First engine was 0.5 percent efficient. Modern engines reach 91 percent. So roughly 2 orders of magnitude were possible. The steam engine from the far future can be at most 100 percent efficient.
For neural networks a sparse neural network has the same time complexity, 0(n^2), as the dense version. So if you think 10 times sparsity will work, and if you think you can optimize further with lower precision math, that's about 2 orders of magnitude optimization.
How much better can you do? If you need 800 H100s to host a human brain equivalent machine (for the vram) with some optimization, is there really enough room left to find an equivalent function, even from the far future, that will fit on a 2070?
Note this would be from 316,640 int8 tops (for 80 H100s) down to 60 tops. Or 5300 times optimization. For vram since that's the limiting factor, that would be 8000 times reduction.
I can't prove that algorithms from the cognitive science of the far future can't work under these constraints. Seems unlikely, probably there are minimum computational equivalents that can implement a human grade robotics model that needs either more compute and memory or specialized hardware that does less work.
Even 800 H100s may be unable to run a human grade robotics model due to latency, you may require specialized hardware for this.
What can we the humans do about this? "Just stop building amazing AI tools because AI will find optimizations from the far future and infect all the computers" isn't a very convincing argument without demoing it.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-18T22:44:22.641Z · LW(p) · GW(p)
So what you are saying here could be equivalent to "limitless optimization is possible". Meaning that given a particular computational problem, it is possible to find an equivalent algorithm to solve that problem that is thousands of times faster or more.
AGI is not a specific computation that needs to be optimized to run faster without functional change, it's a vaguely defined level of competence. There are undoubtedly multiple fundamentally different ways of building AGI that won't be naturally obtained from each other by incrementally optimizing performance, you'd need more theory to even find them.
So what's I'm saying is that there is a bounded but still large gap between how we manage to build AGI for the first time while in a rush without a theoretical foundation that describes how to do it properly, and how an ancient civilization of at least somewhat smarter-than-human AGIs can do it while thinking for subjective human-equivalent centuries of serial time about both the general theory and the particular problem of creating a bespoke AGI for RTX 2070.
Note how the papers you linked don't show that, the solution trades off complexity and the number of weights for somewhere in the range of 3-6 times less weights and speed.
There can't be modern papers that describe specifically how the deep technological culture invented by AGIs does such things, so of course the papers I listed are not about that, they are relevant to the thing below the large gap, of how humans might build the first AGIs.
And there exists an absolute limit.
Yes. I'm betting humans won't come close to it on first try, therefore significant optimization beyond that first try would be possible (including through fundamental change of approach indicated by novel basic theory), creating an overhang ripe for exploitation by algorithmic improvements invented by first AGIs. Also, creating theory and software faster than hardware can be built or modified changes priorities. There are things humans would just build custom hardware for because it's much cheaper and faster than attempting optimization through theory and software.
First engine was 0.5 percent efficient. Modern engines reach 91 percent. So roughly 2 orders of magnitude were possible. The steam engine from the far future can be at most 100 percent efficient.
We can say that with our theory of conservation of energy, but there is currently no such theory for what it takes to obtain an AGI-worthy level of competence in a system. So I have wide uncertainty about the number of OOMs in possible improvement between the first try and theoretical perfection.
I can't prove that algorithms from the cognitive science of the far future can't work under these constraints. Seems unlikely, probably there are minimum computational equivalents that can implement a human grade robotics model that needs either more compute and memory or specialized hardware that does less work.
Even 800 H100s may be unable to run a human grade robotics model due to latency, you may require specialized hardware for this.
Existential risk is about cognitive competence, not robotics. Subjectively, GPT-4 seems smart enough to be a human level AGI if it was built correctly and could learn. One of the papers I linked is about running something of GPT-4's scale on a single H200 (possibly only a few instances, since I'm guessing this doesn't compress activations and a large model has a lot of activations). A GPT-4 shaped model massively overtrained on an outrageous quantity of impossibly high quality synthetic data will be more competent than actual GPT-4, so it can probably be significantly smaller while maintaining similar competence. RAG and LoRA fine-tuning give hopelessly broken and weirdly disabled online learning that can run cheaply. If all this is somehow fixed, which I don't expect to happen very soon through human effort, it doesn't seem outlandish for the resulting system to become an AGI (in the sense of being capable of pursuing open ended technological progress and managing its affairs).
Another anchor I like is how 50M parameter models play good Go, being 4 OOMs smaller than 400B LLMs that are broken aproximations of behavior of humans who play Go similarly well. And playing Go is a more well-defined level of competence than being an AGI, probably with fewer opportunities for cleverly sidestepping computational difficulties by doing something different.
Replies from: None↑ comment by [deleted] · 2023-12-18T23:14:03.848Z · LW(p) · GW(p)
Dangerous AGI means all strategically relevant human capabilities which means robotic tool use. It may not be physically possible on a 2070 due to latency. (The latency is from the time to process images, convert to a 3d environment, reason over the environment with a robotics policy, choose next action. Simply cheating with a lidar might be enough to make this work ofc)
With that said I see your point about Go and there is a fairly obvious way to build an "AGI" like system for anything not latency bound that might fit on so little compute. It would need a lot of SSD space and would have specialized cached models for all known human capabilities. Give the "AGI" a test and it loads the capabilities needed to solve the test into memory. It has capabilities at different levels of fidelity and possibly on the fly selects an architecture topology to solve the task.
Since the 2070 has only 8gb of memory and modern SSDs hit several gigabytes a second the load time vs humans wouldn't be significant.
Note this optimization like all engineering tradeoffs is costing something: in this case huge amounts of disk space. It might need hundreds of terabytes to hold all the models. But maybe there is a compression.
Anyways, do you have any good policy ideas besides centralizing all the latest AI silicon into places where it can be inspected?
The little problem with pauses in this scenario is say you can get AI models from thousands of years in the future today. What else can you get your hands on...
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-20T17:48:59.769Z · LW(p) · GW(p)
Anyways, do you have any good policy ideas besides centralizing all the latest AI silicon into places where it can be inspected?
The little problem with pauses in this scenario is say you can get AI models from thousands of years in the future today. What else can you get your hands on...
Once there are AGIs and they had some time to figure things out, or once there are ASIs (which don't necessarily need to figure things out at length to become able to start making relatively perfect moves), it becomes possible to reach into the bag of their technological wisdom and pull out scary stuff that won't be contained on their original hardware, even if the AIs themselves remain contained. So for a pause to be effective, it needs to prevent existence of such AIs, containing them is ineffective if they are sufficiently free to go and figure out the scary things.
Without a pause, the process of pulling things out of the bag needs to be extremely disciplined, focusing on pivotal processes that would prevent yourself or others from accidentally or intentionally pulling out an apocalypse 6 months later. And hoping that there's nothing going on that releases the scary things outside of your extremely disciplined process intended to end the acute risk period, because hope is the only thing you have going for you without decades of research that you don't have because there was no pause.
Dangerous AGI means all strategically relevant human capabilities which means robotic tool use. It may not be physically possible on a 2070 due to latency.
There are many meanings of "AGI" [LW(p) · GW(p)], the meaning I'm intending in this context is about cognitive competence. The choice to focus on this meaning rather than some other meaning follows from what I expect to pose existential threat. In this sense, "(existentially) dangerous AGI" means the consequences of its cognitive activities might disempower or kill everyone. The activities don't need to be about personally controlling terminators, as a silly example setting up a company that designs terminators would have similar effects without requiring good latency.
Replies from: None↑ comment by [deleted] · 2023-12-20T18:05:08.995Z · LW(p) · GW(p)
as a silly example setting up a company that designs terminators would have similar effects without requiring good latency.
Just a note here : good robotics experts today are "hands on" with the hardware. It gives humans are more grounded understanding of current designs/lets them iterate onto the next one. Good design doesn't come from just thinking about it, and this would apply to designing humanoid combat robots.
This also is why more grounded current generation experts will strong disagree on the very idea of pulling any technology from thousands of years in the future. Current generation experts will, and do in ai debates, say that you need to build a prototype, test it in the real world, build another based on the information gained, and so on.
This is factually how all current technology was developed. No humans have, to my knowledge, ever done what you described - skipped a technology generation without a prototype or many at scale physical (or software) creations being used by end users. (Historically it has required more and more scale at later stages)
If this limitation still applies to superintelligence - and there are reasons to think it might but I would request a dialogue not a comment deep in a thread few will read - then the concerns you have expressed regarding future superintelligence are not legitimate worries.
If ASIs are in fact limited the same way, the way the world would be different is that each generation of technology developed by ASI would get built and deployed at scale. The human host country would use and test the new technology for a time period. The information gained from actual use is sold back to the ASI owners who then develop the next generation.
This whole iterative process is faster than human tech generation but it still happens in discrete steps and on a large, visible scale, and at human perceptible timescales. Probably weeks per cycle not months to the 1-2 year cycle humans are able to do.
There are reasons it would take weeks and it's not just human feedback, you need time to deploy a product and you are mining 1 percent or lower edge cases in later development stages.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-20T18:14:46.562Z · LW(p) · GW(p)
Yes, physical prototypes being inessential is decidedly not business as usual. Without doing things in the physical world, there need to be models for simulations, things like AlphaFold 2 (which predicts far more than would be possible to experimentally observe directly). You need enough data to define the rules of the physical world, and efficient simulations of what the rules imply for any project you consider. I expect automated theory at sufficiently large scale or superintelligent quality to blur the line between (simulated) experiments and impossibly good one shot engineering.
Replies from: None↑ comment by [deleted] · 2023-12-20T18:22:13.492Z · LW(p) · GW(p)
And the way it would fail would be if the simulations have an unavoidable error factor because real world physics is incomputable or a problem class above np (there's posts here showing it is). The other way it would fail is if the simulations are missing information, for example in real battles between humanoid terminators the enemy might discover strategies the simulation didn't model that are effective. So after deploying a lot of humanoid robots, rival terminators start winning the battles and it's back to the design stage.
If you did it all in simulation I predict the robot would immediately fail and be unable to move. Humanoid robots are interdependent systems.
I am sure you know current protein folding algorithms are not accurate enough to actually use for protein engineering. You have to actually make the protein and test it along with the molecules you want binding logic for, and you will need to adjust your design. If the above is still true for ASI they will be unable to do protein engineering without a wet lab to build and test the parts for every step, where there will be hundreds of failures for every success.
If it does work that way then ASI will be faster than humans - since they can analyze more information at once and learn faster and conservatively try many routes in parallel - but not by the factors you imagine. Maybe 10 times faster not millions. This is because of Amdahls law.
The ASI are also cheaper. So it would be like a world where every technology in every field is being developed at the maximum speed humans could run at times 10.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-20T19:10:45.526Z · LW(p) · GW(p)
(Theorizing about ASIs that have no access to physical reality feels noncentral in 2023 when GPT-4 has access to everything and everyone, and integration is only going to get stronger. But for the hypothetical ASI that grew out of an airgapped multimodal 1e29 LLM that has seen all youtube and read all papers and books and the web, I think ability to do good one shot engineering holds.)
(Also, we were discussing an exfiltrated AGI, for why else is RTX 2070 relevant, that happens to lack good latency to control robots. Presumably it doesn't have the godshatter of technical knowledge, or else it doesn't really matter that it's a research-capable AGI. But it now has access to the physical world and can build prototypes. It can build another superintelligence. If it does have a bequest of ASI's technical knowledge, it can just work to setup unsanctioned datacenters or a distributed network and run an OOMs-more-efficient-than-humanity's-first-try superintelligence there.)
Predictability is vastly improved by developing the thing you need to predict yourself, especially when you intend to one shot it. Humans don't do this, because for humans it happens to be much faster and cheaper to build prototypes, we are too slow at thinking useful thoughts. We possibly could succeed a lot more than observed in practice if each prototype was preceded by centuries of simulations and the prototypes were built with insane redundancies.
Simulations get better with data and with better learning algorithms. Looking at how a simulation works, it's possible to spot issues and improve the simulation, including for the purpose of simulating a particular thing. Serial speed advantage more directly gives theory and general software from distant future (as opposed to engineering designs and experimental data). This includes theory and software for good learning algorithms, those that have much better sample efficiency and interrogate everything about the original 1e29 LLM to learn more of what its weights imply about the physical world. It's a lot of data, who knows what details can be extracted from it from the position of theoretical and software-technological maturity.
Replies from: None↑ comment by [deleted] · 2023-12-20T20:30:24.444Z · LW(p) · GW(p)
None of this exists now though. Speculating about the future when it depends on all these unknowns and never before seen capabilities is dangerous - you're virtually certain to be wrong. The uncertainty comes from all the moving parts in your model. Like you have:
- Immense amounts of compute easily available
- Accurate simulations of the world
- Fully automated agi, there's no humans helping at all, the model never gets stuck or just crashes from a bug in the lower framework
- Enormously past human capabilities ASI. Not just a modest amount.
The reason you are probably wrong is just probability, if each step has a 50 percent chance of being right it's 0.5^4. Dont think it of me saying you're wrong.
And then only with all these pieces, humans are maybe doomed and will soon cease to exist. Therefore we should stop everything today.
While if just 1 piece is wrong, then this is the wrong choice to make. Right?
You're also against a pro technology prior. Meaning I think you would have to actually prove the above - demo it - to convince people this the actual world we are in.
That's because "future tech instead of turning out to be over hyped is going to be so amazing and perfect it can kill everyone quickly and easily" is against all the priors where tech turned out to be underwhelming and not that good. Like convincing someone the wolf is real when there's been probably a million false alarms.
I don't know how to think about this correctly. Like I feel like I should be weighting in the mountain of evidence I mentioned but if I do that then humans will always die to the ASI. Because there's no warning. The whole threat model is that these are capabilities that are never seen prior to a certain point.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-20T21:24:40.198Z · LW(p) · GW(p)
The whole threat model is that these are capabilities that are never seen prior to a certain point.
Yep, that's how ChatGPT is a big deal for waking up policymakers, even as it's not exactly relevant. I see two paths to a lasting pause. First, LLMs keep getting smarter and something object level scary happens before there are autonomous open weight AGIs, policymakers shut down big models. Second, 1e29 FLOPs is insufficient with LLMs, or LLMs stop getting smarter earlier and 1e29 FLOPs models are not attempted, and models at the scale that's reached by then don't get much smarter. It's still unlikely that people won't quickly find a way of using RL to extract more and more useful work out of the kind of data LLMs are trained on, but it doesn't seem impossible that it might take a relatively long time.
Immense amounts of compute easily available
The other side to the argument for AGI in RTX 2070 is that the hardware that was sufficient to run humanity's first attempt at AGI is sufficient to do much more than that when it's employed efficiently.
Fully automated agi, there's no humans helping at all, the model never gets stuck or just crashes from a bug in the lower framework
This is the argument's assumption, the first AGI should be sufficiently close to this to fix the remaining limitations that make full autonomy reliable, including at research. Possibly requiring another long training run, if cracking online learning directly might take longer than that run.
Enormously past human capabilities ASI. Not just a modest amount.
I expect this, but this is not necessary for development of deep technological culture using serial speed advantage at very smart human level.
Accurate simulations of the world
This is more an expectation based on the rest than an assumption.
The reason you are probably wrong is just probability, if each step has a 50 percent chance of being right it's 0.5^4.
These things are not independent.
Speculating about the future when it depends on all these unknowns and never before seen capabilities is dangerous - you're virtually certain to be wrong.
That's an argument about calibration. If you are doing the speculation correctly, not attempting to speculate is certain to leave a less accurate picture than doing it.
Replies from: None↑ comment by Thane Ruthenis · 2023-12-18T08:15:55.435Z · LW(p) · GW(p)
It might underwhelm for the simple reason that the really high end AIs take too much hardware to find and run.
I think that's basically equivalent to my claim, accounting for the differences between our models. I expect this part to be non-trivially difficult (as in, not just "scale LLMs"). People would need to basically roll a lot of dice on architectures, in the hopes of hitting upon something that works[1] – and it'd both take dramatically more rolls if they don't have a solid gears-level vision of AGI (if they're just following myopic "make AIs more powerful" gradients), and the lack of said vision/faith would make this random-roll process discouraging.
So non-fanatics would get there eventually, yes, by the simple nature of growing amounts of compute and numbers of experiments. But without a fanatical organized push, it'd take considerably longer.
- ^
That's how math research already appears to work:
This would be consistent with a preliminary observation about how long it takes to solve mathematical conjectures: while inference is rendered difficult by the exponential growth in the global population and of mathematicians, the distribution of time-to-solution roughly matches a memoryless exponential distribution (one with a constant chance of solving it in any time period) rather than a more intuitive distribution like a type 1 survivorship curve (where a conjecture gets easier to solve over time, perhaps as related mathematical knowledge accumulates), suggesting a model of mathematical activity in which many independent random attempts are made, each with a small chance of success, and eventually one succeeds
↑ comment by [deleted] · 2023-12-18T08:46:06.037Z · LW(p) · GW(p)
People would need to basically roll a lot of dice on architectures, in the hopes of hitting upon something that works
How much is RSI going to help here? This is already what everyone does for hyperparameter searches - train another network to do them - an AGI architecture, aka "find me a combination of models that will pass this benchmark" seems like it would be solvable with such a search.
The way I model it, RSI would let GPU rich but more mediocre devs find AGI. They won't be first unless hypothetically they don't get the support of the S tier talent, say they are in a different country.
Are you sure there are timelines where "decades" of delay, if open source models exist and GPUs exist in ever increasing and more powerful quantities is really possible?
↑ comment by Thane Ruthenis · 2023-12-18T08:54:17.932Z · LW(p) · GW(p)
I expect that sort of brute-force-y approach to take even longer than the "normal" vision-less meandering-around.
Well, I guess it can be a hybrid. The first-to-AGI would be some group that maximizes the product of "has any idea what they're doing" and "how much compute they have" (rather than either variable in isolation). Meaning:
- Compute is a "great equalizer" that can somewhat compensate for lack of focused S-tier talent.
- But focused S-tier talent can likewise somewhat compensate for having less compute.
That seems to agree with your model?
And my initial point is that un-focusing the S-tier talent would lengthen the timelines.
Are you sure there are timelines where "decades" of delay, if open source models exist and GPUs exist in ever increasing and more powerful quantities is really possible?
Sure? No, not at all sure.
↑ comment by Tamsin Leake (carado-1) · 2023-12-17T20:44:43.189Z · LW(p) · GW(p)
Seems right. In addition, if there was some person out there waiting to make a new AI org, it's not like they're waiting for the major orgs to shut down to compete.
Shutting down the current orgs does not fully solve the problem, but it surely helps a lot.
↑ comment by Vladimir_Nesov · 2023-12-17T22:07:18.357Z · LW(p) · GW(p)
There's Mistral that recently published weights for a model that is on par with GPT-3.5 not just on benchmarks and has probably caught up with Claude 2 with another model (Mistral-medium). Mistral's Arthur Mensch seemingly either disbelieves existential risk or considers the future to be outside of his ontology.
I don't think it's time yet to rule out potential AGI-worthiness of scaffolded LLMs of the kind Imbue develops (they've recently secured 10K H100s too). Yes, there are glaring missing pieces to their cognition, but if LLMs do keep getting smarter with scale, they might be able to compensate for some cognitive limitations with other cognitive advantages well enough to start the ball rolling [LW(p) · GW(p)].
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2023-12-18T02:27:46.757Z · LW(p) · GW(p)
This point could definitely be its own post. I'd love to see you write this! (I'd of course be willing to proofread/edit it, title it, etc.)
↑ comment by cousin_it · 2023-12-18T00:02:24.591Z · LW(p) · GW(p)
“if these labs shut down, more will spring up in their place, and nothing would change”
I think Jesus had a pretty good general answer to such arguments. He said there'll be temptation in the world anyway, but you shouldn't be the one through whom the temptation comes.
comment by Zach Stein-Perlman · 2023-12-17T23:10:37.757Z · LW(p) · GW(p)
But other labs are even less safe, and not far behind.
Yes, largely alignment is an unsolved problem on which progress is an exogenous function of time. But to a large extent we're safer with safety-interested labs developing powerful AI: this will boost model-independent alignment research, make particular critical models more likely to be aligned/controlled, help generate legible evidence that alignment is hard (insofar as that exists), and maybe enable progress to pause at a critical moment.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-12-19T06:25:21.611Z · LW(p) · GW(p)
I think that to the extent that other labs are "not far behind" (such as FAIR), this is substantially an artifact of them being caught up in a competitive arms race. Catching up to "nearly SOTA" is usually much easier than "advancing SOTA", and I'm fairly persuaded by the argument that the top 3 labs are indeed ideologically motivated in ways that most other labs aren't, and there would be much less progress in dangerous directions if they all shut down because their employees all quit.
Replies from: o-o↑ comment by O O (o-o) · 2023-12-19T08:11:46.074Z · LW(p) · GW(p)
And they would start developing web apps at Microsoft or go to XAI, inflection, and Chinese labs?
Am I in crazy town? Did we not see what happened when there was an attempt to slightly modify OpenAI, let alone shut it down.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-12-19T08:26:59.324Z · LW(p) · GW(p)
if they all shut down because their employees all quit.
comment by Vermillion (VermillionStuka) · 2023-12-18T01:43:12.674Z · LW(p) · GW(p)
We are not in the ideal hypothetical world that can coordinate to shut down the major AI labs. So acting as if we were is not the optimum strategy. If people who see the danger start to leave the labs in protest, I suspect lab capabilities are only minimally and temporarily degraded, but the internal culture would shift further away from not killing everyone, and less real alignment work is even attempted where it is most needed.
When the inevitable comes and an existentially dangerous system is being built (which may not be obvious), I want some people in the building who can at least try and raise the alarm rather than just another yes man.
If such a strategic resignation (either individually or in groups) would ACTUALLY FOR REAL result in decent timeline increases that would be another matter.
comment by Vladimir_Nesov · 2023-12-17T21:31:04.966Z · LW(p) · GW(p)
It's useful to separately consider extinction and disempowerment. It's not an unusual position [LW(p) · GW(p)] that the considered decision of an AGI civilization is to avoid killing everyone. This coexists with possibly much higher probablity of expected disempowerment. (For example, my expectation for the next few years while the LLMs are scaling is 90% disempowerment and 30% extinction, conditional on AGI in that timeframe, with most of extinction being misuse or rogue AGIs that would later regret this decision or don't end up representative in the wider AGI civilization. Extinction gets more weight with AGIs that don't rely on human datasets as straightforwardly.)
I think the argument for shutdown survives replacement of extinction with disempowerment-or-extinction, which is essentially the meaning of existential risk. Disempowerment is already pretty bad.
The distinction can be useful for reducing probablity of extinction-given-disempowerment, trying to make frontier AI systems pseudokind [LW(p) · GW(p)]. This unfortunately gives another argument for competition between labs, given the general pursuit of disempowerment of humanity.
comment by Ben Pace (Benito) · 2024-12-05T07:02:42.986Z · LW(p) · GW(p)
Hear, hear!
comment by Ramana Kumar (ramana-kumar) · 2023-12-18T18:22:06.674Z · LW(p) · GW(p)
I think this is basically correct and I'm glad to see someone saying it clearly.
comment by mako yass (MakoYass) · 2023-12-18T04:14:52.504Z · LW(p) · GW(p)
If the current orgs were the type of people who'd voluntarily shut down we probably wouldn't want them to.
comment by Ben Pace (Benito) · 2024-12-05T06:57:31.677Z · LW(p) · GW(p)
At least Anthropic didn't particularly try to be a big commercial company making the public excited about AI. Making the AI race a big public thing was a huge mistake on OpenAI's part, and is evidence that they don't really have any idea what they're doing.
I just want to point out, I don't believe this is the case, I believe that the CEO is attempting to play games with the public narrative that benefit his company financially [LW(p) · GW(p)].
comment by sapphire (deluks917) · 2024-12-10T03:43:18.671Z · LW(p) · GW(p)
The truth should be rewarded. Even if it's obvious. Everyday this post is more blatantly correct.
comment by Stephen McAleese (stephen-mcaleese) · 2023-12-22T10:33:36.292Z · LW(p) · GW(p)
TL;DR: Private AI companies such as Anthropic which have revenue-generating products and also invest heavily in AI safety seem like the best type of organization for doing AI safety research today. This is not the best option in an ideal world and maybe not in the future but right now I think it is.
I appreciate the idealism and I'm sure there is some possible universe where shutting down these labs would make sense but I'm quite unsure about whether doing so would actually be net-beneficial in our world and I think there's a good chance it would be net-negative in reality.
The most glaring constraint is finances. AI safety is funding-constrained [LW · GW] so this is worth mentioning. Companies like DeepMind and OpenAI spend hundreds of millions of dollars per year on staff and compute and I doubt that would be possible in a non-profit. Most of the non-profits working on AI safety (e.g. Redwood Research) are small with just a handful of people. OpenAI changed their company from a non-profit to a capped for-profit because they realized that being a non-profit would have been insufficient for scaling their company and spending. OpenAI now generates $1 billion in revenue and I think it's pretty implausible that a non-profit could generate that amount of income.
The other alternative apart from for-profit companies and philanthropic donations is government funding. It is true that governments fund a lot of science. For example, the US government funds 40% of basic science research. And a lot of successful big science projects such as CERN and the ITER fusion project seem to be mostly government-funded. However, I would expect a lot of government-funded academic AI safety grants to be wasted by professors skilled at putting "AI safety" in their grant applications so that they can fund whatever they were going to work on anyway. Also, the fact that the US government has secured voluntary commitments from AI labs to build AI safely gives me the impression that governments are either unwilling or incapable of working on AI safety and instead would prefer to delegate it to private companies. On the other hand, the UK has a new AI safety institute and a language model task force.
Another key point is research quality. In my opinion, the best AI safety research is done by the big labs. For example, Anthropic created constitutional AI and they also seem to be a leader in interpretability research. I think empirical AI safety work and AI capabilities work involve very similar skills (coding etc.) and therefore it's not surprising that leading AI labs also do the best empirical AI safety work. There are several other reasons for explaining why big AI labs do the best empirical AI safety work. One is talent. Top labs have the money to pay high salaries which attracts top talent. Work in big labs also seems more collaborative than in academia which seems important for large projects. Many top projects have dozens of authors (e.g. the Llama 2 paper). Finally, there is compute. Right now, only big labs have the infrastructure necessary to do experiments on leading models. Doing experiments such as fine-tuning large models requires a lot of money and hardware. For example, this paper by DeepMind on reducing sycophancy apparently involved fine-tuning the 540B PaLM model which is probably not possible for most independent and academic researchers right now and consequently, they usually have to work with smaller models such as Llama-2-7b. However, the UK is investing in some new public AI supercomputers which hopefully will level the playing field somewhat. If you think theoretical work (e.g. agent foundations) is more important than empirical work then big labs have less of an advantage. Though DeepMind is doing some of that too.
comment by Garrett Baker (D0TheMath) · 2023-12-17T22:35:10.289Z · LW(p) · GW(p)
the actions that maximize your utility are the ones that decrease the probability that PAI kills literally everyone, even if it's just by a small amount.
This seems false. If you believe your marginal impact is small on the probability of PAI, and large on how much money you make, or how fun your work/social environment is, then it seems pretty easy to have actions other than minimize the probability PAI kills everyone as your best action. Indeed, it seems for many their best action will be to slightly increase the probability PAI kills everyone. Though it may still be in their interest to coordinate to stop PAI from being made.
comment by Jozdien · 2023-12-17T21:11:28.229Z · LW(p) · GW(p)
I agree with this on the broad points. However, I agree less on this one:
Organizations which do not directly work towards PAI but provides services that are instrumental to it — such as EleutherAI, HuggingFace, etc — should also shut down. It does not matter if your work only contributes "somewhat" to PAI killing literally everyone. If the net impact of your work is a higher probability that PAI kills literally everyone, you should "halt, melt, and catch fire" [LW · GW].
I think there's definitely a strong case to be made that a company following something like Eleuther's original mission of open-sourcing frontier models should shut down. But I get the feeling from this paragraph that you hold this position to a stronger degree than I do. "Organizations that provide services instrumental to direct work" is an extremely broad class. I don't, for instance, think that we should shut down all compute hardware manufacturers (including fabs for generic chips used in ordinary computers) or construction of new nuclear plants because they could be instrumental to training runs and data centres. (You may hold this position, but in my opinion that's a pretty far removed one from the rest of the content of the post.)
That's definitely an exaggerated version of the claim that you're not making, but it's to say that whatever you use to decide what organizations should shut down requires a lot more nuance than that. It's pretty easy to come up with first-order reasoning for why something contributes a non-zero amount to capabilities progress, and maybe you believe that even vanishingly small contributions to that eclipse any other possible gain one could have in other domains, but again I think that the second-order effects make it a lot more complicated. I don't think people building the things you oppose would claim it only contributes "somewhat" to capabilities, I think they would claim it's going to be very hard to decide conclusively that its net impact is negative at all. They may be wrong (and in many cases they are), but I'm pretty sure that you aren't arguing against their actual position here. And in some cases, I don't think they are wrong. There are definitely many things that could be argued as more instrumental to capabilities that I think we're better off for existing, either because the calculus turned out differently or because they have other positive effects. For instance, a whole slew of narrow AI specific tech.
There's a lot to be said for simple rules for Schelling points, but I think this just isn't a great one. I agree with the more direct one of "companies directly working on capabilities should shut down", but think that the further you go into second-order impacts on capabilities, the more effort you should put into crafting those simple rules.
comment by James Payor (JamesPayor) · 2024-12-10T02:43:07.515Z · LW(p) · GW(p)
I think this post was and remains important and spot-on. Especially this part, which is proving more clearly true (but still contested):
It does not matter that those organizations have "AI safety" teams, if their AI safety teams do not have the power to take the one action that has been the obviously correct one this whole time: Shut down progress on capabilities. If their safety teams have not done this so far when it is the one thing that needs done, there is no reason to think they'll have the chance to take whatever would be the second-best or third-best actions either.
comment by Ebenezer Dukakis (valley9) · 2023-12-17T22:18:16.152Z · LW(p) · GW(p)
Seems like there are 2 possibilities here:
-
The majority of the leadership, engineers, etc. at OpenAI/DeepMind/Anthropic don't agree that we'd be collectively better off if they all shut down.
-
The majority do agree, they just aren't solving the collective action problem.
If (2) is the case, has anyone thought about using a dominant assurance contract?
The dominant assurance contract adds a simple twist to the crowdfunding contract. An entrepreneur commits to produce a valuable public good if and only if enough people donate, but if not enough donate, the entrepreneur commits not just to return the donor’s funds but to give each donor a refund bonus. To see how this solves the public good problem consider the simplest case. Suppose that there is a public good worth $100 to each of 10 people. The cost of the public good is $800. If each person paid $80, they all would be better off. Each person, however, may choose not to donate, perhaps because they think others will not donate, or perhaps because they think that they can free ride.
Now consider a dominant assurance contract. An entrepreneur agrees to produce the public good if and only if each of 10 people pay $80. If fewer than 10 people donate, the contract is said to fail and the entrepreneur agrees to give a refund bonus of $5 to each of the donors. Now imagine that potential donor A thinks that potential donor B will not donate. In that case, it makes sense for A to donate, because by doing so he will earn $5 at no cost. Thus any donor who thinks that the contract will fail has an incentive to donate. Doing so earns free money. As a result, it cannot be an equilibrium for more than one person to fail to donate. We have only one more point to consider. What if donor A thinks that every other donor will donate? In this case, A knows that if he donates he won’t get the refund bonus, since the contract will succeed. But he also knows that if he doesn’t donate he won’t get anything, but if does donate he will pay $80 and get a public good which is worth $100 to him, for a net gain of $20. Thus, A always has an incentive to donate. If others do not donate, he earns free money. If others do donate, he gets the value of the public good. Thus donating is a win-win, and the public good problem is solved.[2]
Maybe this would look something like: We offer a contract to engineers at specific major AI labs. If at least 90% of the engineers at each of those specific labs sign the contract by end of 2024, they agree to all mass quit their jobs. If not, everyone who signed the contract gets $500 at the end of 2024.
I'm guessing that coordination among the leadership has already been tried and failed. But if not, another idea is to structure the dominance assurance contract as an investment round, so it ends up being a financial boost for safety-conscious organizations that are willing to sign the contract, if not enough organizations sign.
One story for why coordination does not materialize:
-
Meta engineers self-select for being unconcerned with safety. They aren't going to quit any time soon. If offered a dominance assurance contract, they won't sign either early or late.
-
DeepMind engineers feel that DeepMind is more responsible than Meta. They think a DeepMind AGI is more likely to be aligned than a Meta AGI, and they feel it would be irresponsible to quit and let Meta build AGI.
-
OpenAI engineers feel that OpenAI is more responsible than Meta or DeepMind, by similar logic it's irresponsible for them to quit.
-
Anthropic engineers feel that Anthropic is more responsible than OpenAI/DeepMind/Meta, by similar logic it's irresponsible for them to quit.
Overall, I think people are overrating the importance of a few major AI labs due to their visibility. There are lots of researchers at NeurIPS, mostly not from the big AI labs in the OP. Feels like people are over-focused on OpenAI/DeepMind/Anthropic due to their visibility and social adjacency.