"AI Alignment" is a Dangerously Overloaded Term
post by Roko · 2023-12-15T14:34:29.850Z · LW · GW · 100 commentsContents
Alignment as Aimability or as Goalcraft? Words Have Consequences Gud Car Studies None 100 comments
Alignment as Aimability or as Goalcraft?
The Less Wrong and AI risk communities have obviously had a huge role in mainstreaming the concept of risks from artificial intelligence, but we have a serious terminology problem.
The term "AI Alignment" has become popular, but people cannot agree whether it means something like making "Good" AI or whether it means something like making "Aimable" AI. We can define the terms as follows:
AI Aimability = Create AI systems that will do what the creator/developer/owner/user intends them to do, whether or not that thing is good or bad
AI Goalcraft = Create goals for AI systems that we ultimately think lead to the best outcomes
Aimability is a relatively well-defined technical problem and in practice almost all of the technical work on AI Alignment is actually work on AI Aimability. Less Wrong has for a long time been concerned with Aimability failures (what Yudkowsky in the early days would have called "Technical Failures of Friendly AI") rather than failures of Goalcraft (old-school MIRI terminology would be "Friendliness Content").
The problem is that as the term "AI Alignment" has gained popularity, people have started to completely merge the definitions of Aimability and Goalcraft under the term "Alignment". I recently ran some Twitter polls on this subject, and it seems that people are relatively evenly split between the two definitions.
This is a relatively bad state of affairs. We should not have the fate of the universe partially determined by how people interpret an ambiguous word.
In particular, the way we are using the term AI Alignment right now means that it's hard to solve the AI Goalcraft problem and easy to solve the Aimability problem, because there is a part of AI that is distinct from Aimability which the current terminology doesn't have a word for.
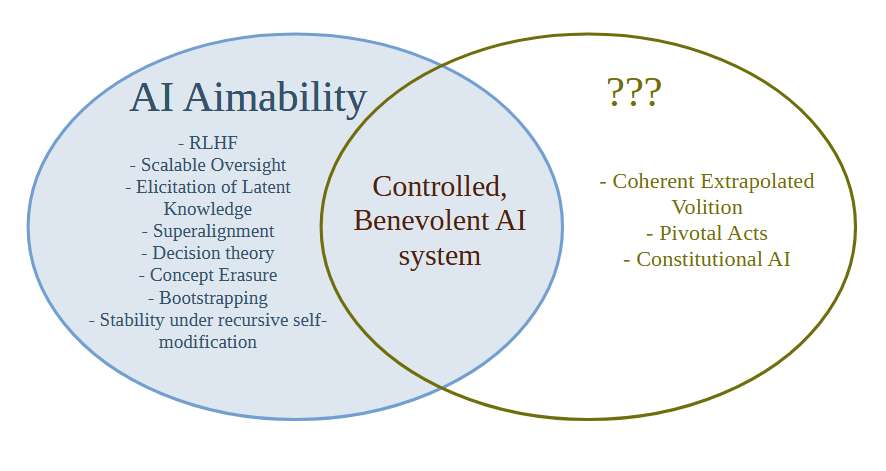
Not having a word for what goals to give the most powerful AI system in the universe is certainly a problem, and it means that everyone will be attracted to the easier Aimability research where one can quickly get stuck in and show a concrete improvement on a metric and publish a paper.
Why doesn't the Less Wrong / AI risk community have good terminology for the right hand side of the diagram? Well, this (I think) goes back to a decision by Eliezer from the SL4 mailing list days that one should not discuss what the world would be like after the singularity, because a lot of time would be wasted arguing about politics, instead of the then more urgent problem of solving the AI Aimability problem (which was then called the control problem). At the time this decision was probably correct, but times have changed. There are now quite a few people working on Aimability, and far more are surely to come, and it also seems quite likely (though not certain) that Eliezer was wrong about how hard Aimability/Control actually is.
Words Have Consequences
This decision to not talk about AI goals or content might eventually result in some unscrupulous actors getting to define the actual content and goals of superintelligence, cutting the X-risk and LW community out of the only part of the AI saga that actually matters in the end. For example, the recent popularity of the e/acc movement has been associated with the Landian strain of AI goal content - acceleration towards a deliberate and final extermination of humanity, in order to appease the Thermodynamic God. And the field that calls itself AI Ethics has been tainted with extremist far-left ideology around DIE (Diversity, Inclusion and Equity) that is perhaps even more frightening than the Landian Accelerationist strain. By not having mainstream terminology for AI goals and content, we may cede the future of the universe to extremists.
I suggest the term "AI Goalcraft" for the study of which goals for AI systems we ultimately think lead to the best outcomes. The seminal work on AI Goalcraft is clearly Eliezer's Coherent Extrapolated Volition [? · GW], and I think we need to push that agenda further now that AI risk has been mainstreamed and there's a lot of money going into the Aimability/Control problem.
Gud Car Studies
What should we do with the term "Alignment" though? I'm not sure. I think it unfortunately leads people into confusion. It doesn't track the underlying reality - which I believe is that action naturally factors into Goalcraft followed by Aimability, and you can work on Aimability without knowing much about Goalcraft and vice-versa because the mechanisms of Aimability don't care much about what goal one is aiming at, and the structure of Goalcraft doesn't care much about how you're going to aim at the goal and stay on target. When people hear "Aligned" they just hear "Good", but with a side order of sophistication. It would be like if we lumped mechanical engineers who developed car engines in with computer scientists working on GPS navigators and called their field Gud Car Studies. Gud Car Studies is obviously an abomination of a term that doesn't properly reflect the underlying reality that designing a good engine is mostly independent of deciding where to drive the car to, and how to navigate there. I think that "Alignment" has unfortunately become the "Gud Car Studies" of our time.
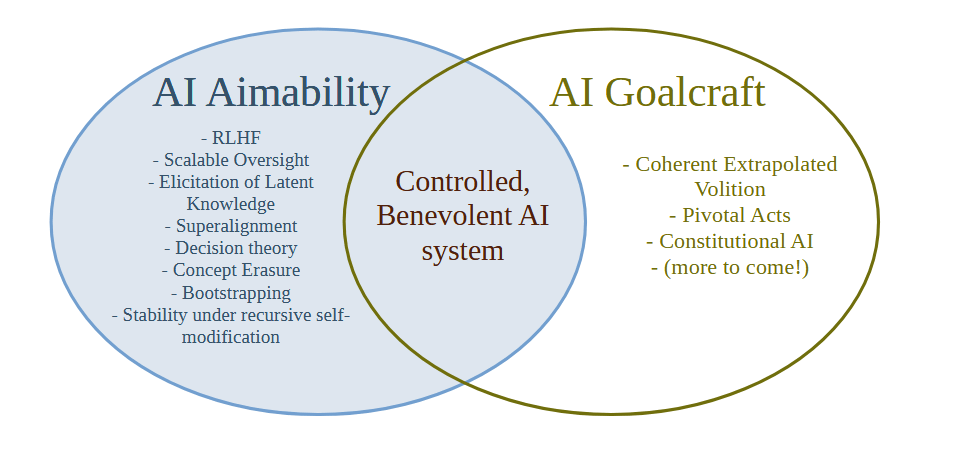
I'm at a loss as to what to do - I suspect that the term AI Alignment has already gotten away from us and we should stop using it and talk about Aimability and Goalcraft instead.
This post is Crossposted [EA · GW] at the EA Forum
Related: "Aligned" shouldn't be a synonym for "good"
100 comments
Comments sorted by top scores.
comment by Rob Bensinger (RobbBB) · 2023-12-16T22:28:07.948Z · LW(p) · GW(p)
From briefly talking to Eliezer about this the other day, I think the story from MIRI's perspective is more like:
- Back in 2001, we defined "Friendly AI" as "The field of study concerned with the production of human-benefiting, non-human-harming actions in Artificial Intelligence systems that have advanced to the point of making real-world plans in pursuit of goals."
We could have defined the goal more narrowly or generically than that, but that just seemed like an invitation to take your eye off the ball: if we aren't going to think about the question of how to get good long-run outcomes from powerful AI systems, who will?
And many of the technical and philosophical problems seemed particular to CEV, which seemed like an obvious sort of solution to shoot for: just find some way to leverage the AI's intelligence to solve the problem of extrapolating everyone's preferences in a reasonable way, and of aggregating those preferences fairly.
- Come 2014, Stuart Russell and MIRI were both looking for a new term to replace "the Friendly AI problem", now that the field was starting to become a Real Thing. Both parties disliked Bostrom's "the control problem". In conversation, Russell proposed "the alignment problem", and MIRI liked it, so Russell and MIRI both started using the term in public.
Unfortunately, it gradually came to light that Russell and MIRI had understood "Friendly AI" to mean two moderately different things, and this disconnect now turned into a split between how MIRI used "(AI) alignment" and how Russell used "(value) alignment". (Which I think also influenced the split between Paul Christiano's "(intent) alignment" and MIRI's "(outcome) alignment".)
Russell's version of "friendliness/alignment" was about making the AI have good, human-deferential goals. But Creating Friendly AI 1.0 had been very explicit that "friendliness" was about good behavior, regardless of how that's achieved. MIRI's conception of "the alignment problem" (like Bostrom's "control problem") included tools like capability constraint and boxing, because the thing we wanted researchers to focus on was the goal of leveraging AI capabilities to get actually-good outcomes, whatever technical work that requires, not some proxy goal that might turn out to be surprisingly irrelevant.
Again, we wanted a field of people keeping their eye on the ball and looking for clever technical ways to get the job done, rather than a field that neglects some actually-useful technique because it doesn't fit their narrow definition of "alignment".
- Meanwhile, developments like the rise of deep learning had updated MIRI that CEV was not going to be a realistic thing to shoot for with your first AI. We were still thinking of some version of CEV as the ultimate goal, but it now seemed clear that capabilities were progressing too quickly for humanity to have time to nail down all the details of CEV, and it was also clear that the approaches to AI that were winning out would be far harder to analyze, predict, and "aim" than 2001-Eliezer had expected. It seemed clear that if AI was going to help make the future go well, the first order of business would be to do the minimal thing to prevent other AIs from destroying the world six months later, with other parts of alignment/friendliness deferred to later.
I think considerations like this eventually trickled in to how MIRI used the term "alignment". Our first public writing reflecting the switch from "Friendly AI" to "alignment", our Dec. 2014 agent foundations research agenda, said:
We call a smarter-than-human system that reliably pursues beneficial goals “aligned with human interests” or simply “aligned.”
Whereas by July 2016, when we released a new research agenda that was more ML-focused, "aligned" was shorthand for "aligned with the interests of the operators".
In practice, we started using "aligned" to mean something more like "aimable" (where aimability includes things like corrigibility, limiting side-effects, monitoring and limiting capabilities, etc., not just "getting the AI to predictably tile the universe with smiley faces rather than paperclips"). Focusing on CEV-ish systems mostly seemed like a distraction, and an invitation to get caught up in moral philosophy and pie-in-the-sky abstractions, when "do a pivotal act" is legitimately a hugely more philosophically shallow topic than "implement CEV". Instead, we went out of our way to frame the challenge of alignment in a way that seemed almost comically simple and "un-philosophical", but that successfully captured all of the key obstacles: 'explain how to use an AI to cause there two exist two strawberries that are identical at the cellular level [LW · GW], without causing anything weird or disruptive to happen in the process'.
Since realistic pivotal acts still seemed pretty outside the Overton window (and since we were mostly focused on our own research at the time), we wrote up our basic thoughts about the topic on Arbital but didn't try to super-popularize the topic among rationalists or EAs at the time. (Which unfortunately, I think, exacerbated a situation where the larger communities had very fuzzy models of the strategic situation, and fuzzy models of what the point even was of this "alignment research" thing; alignment research just become a thing-that-was-good-because-it-was-a-good, not a concrete part of a plan backchained from concrete real-world goals.)
I don't think MIRI wants to stop using "aligned" in the context of pivotal acts, and I also don't think MIRI wants to totally divorce the term from the original long-term goal of friendliness/alignment.
Turning "alignment" purely into a matter of "get the AI to do what a particular stakeholder wants" is good in some ways -- e.g., it clarifies that the level of alignment needed for pivotal acts could also be used to do bad things.
But from Eliezer's perspective, this move would also be sending a message to all the young Eliezers "Alignment Research is what you do if you're a serious sober person who thinks it's naive to care about Doing The Right Thing and is instead just trying to make AI Useful To Powerful People; if you want to aim for the obvious desideratum of making AI friendly and beneficial to the world, go join e/acc or something". Which does not seem ideal.
So I think my proposed solution would be to just acknowledge that 'the alignment problem' is ambiguous between three different (overlapping) efforts to figure out how to get good and/or intended outcomes from powerful AI systems:
- intent alignment, which is about getting AIs to try to do what the AI thinks the user wants, and in practice seems to be most interested in 'how do we get AIs to be generically trying-to-be-helpful'.
- "strawberry problem" alignment, which is about getting AIs to safely, reliably, and efficiently do a small number of specific concrete tasks that are very difficult, for the sake of ending the acute existential risk period.
- CEV-style alignment, which is about getting AIs to fully figure out how to make the future good.
Plausibly it would help to have better names for the latter two things. The distinction is similar to "narrow value learning vs. ambitious value learning", but both problems (as MIRI thinks about them) are a lot more general than just "value learning", and there's a lot more content to the strawberry problem than to "narrow alignment", and more content to CEV than to "ambitious value learning" (e.g., CEV cares about aggregation across people, not just about extrapolation).
(Note: Take the above summary of MIRI's history with a grain of salt; I had Nate Soares look at this comment and he said "on a skim, it doesn't seem to quite line up with my recollections nor cut things along the joints I would currently cut them along, but maybe it's better than nothing".)
Replies from: Roko↑ comment by Roko · 2023-12-19T00:46:54.995Z · LW(p) · GW(p)
getting AIs to safely, reliably, and efficiently do a small number of specific concrete tasks that are very difficult, for the sake of ending the acute existential risk period.
The problem is another way to phrase this is a superintelligent weapon system - "ending a risk period" by "reliably, and efficiently doing a small number of specific concrete tasks" means using physical force to impose your will on others.
On reflection, I do not think that it is a wise idea to factor the path to a good future through a global AI-assisted coup.
Instead one should try hard to push the path to a good future through a consensual agreement with some, uh, mechanisms, to discourage people from engaging in an excessive amount of brinksmanship. If and only if that fails it may be appropriate to consider less consensual options.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2024-03-19T20:32:24.795Z · LW(p) · GW(p)
The problem is another way to phrase this is a superintelligent weapon system - "ending a risk period" by "reliably, and efficiently doing a small number of specific concrete tasks" means using physical force to impose your will on others.
The pivotal acts I usually think about actually don't route through physically messing with anyone else. I'm usually thinking about using aligned AGI to bootstrap to fast human whole-brain emulation, then using the ems to bootstrap to fully aligned CEV AI.
If someone pushes a "destroy the world" button then the ems or CEV AI would need to stop the world from being destroyed, but that won't necessarily happen if the developers have enough of a lead, if they get the job done quickly enough, and if CEV AI is able to persuade the world to step back from the precipice voluntarily (using superhumanly good persuasion that isn't mind-control-y, deceptive, or otherwise consent-violating). It's a big ask, but not as big as CEV itself, I expect.
From my current perspective this is all somewhat of a moot point, however, because I don't think alignment is tractable enough that humanity should be trying to use aligned AI to prevent human extinction. I think we should instead hit the brakes on AI and shift efforts toward human enhancement, until some future generation is in a better position to handle the alignment problem.
If and only if that fails it may be appropriate to consider less consensual options.
It's not clear to me that we disagree in any action-relevant way, since I also don't think AI-enabled pivotal acts are the best path forward anymore. I think the path forward is via international agreements banning dangerous tech, and technical research to improve humanity's ability to wield such tech someday.
That said, it's not clear to me how your "if that fails, then try X instead" works in practice. How do you know when it's failed? Isn't it likely to be too late by the time we're sure that we've failed on that front? Indeed, it's plausibly already too late for humanity to seriously pivot to 'aligned AGI'. If I thought humanity's last best scrap of hope for survival lay in an AI-empowered pivotal act, I'd certainly want more details on when it's OK to start trying to figure out have humanity not die via this last desperate path.
Replies from: derpherpize↑ comment by Lao Mein (derpherpize) · 2024-06-18T05:54:01.622Z · LW(p) · GW(p)
Are people actually working on human enhancement? Many talk about how it's the best chance humanity has, but I see zero visible efforts other than Neurolink. No one's even seriously trying to clone Von Neumann!
Replies from: niplav↑ comment by niplav · 2024-06-18T12:07:32.067Z · LW(p) · GW(p)
@Genesmith [LW · GW] has received a $20,000 ACX grant:
Gene Smith, $20,000, to create an open-source polygenic predictor for educational attainment and intelligence. You upload your 23andMe results, it tells your your (predicted) IQ. Technology hasn’t advanced to the point where this will be any good - even if everything goes perfectly, the number it gives you will have only the most tenuous connection to your actual IQ (and everyone on Gene’s team agrees with this claim). I’m funding it anyway.
I think there could be far more money in that area (even if it's not directed at cloning von Neumann in particular), but it's not happening for political reasons.
comment by ryan_greenblatt · 2023-12-15T16:44:49.243Z · LW(p) · GW(p)
I think the overloading is actually worse than is discussed in this post, because people also sometimes use the term AI alignment to refer to "ensuring that AIs don't cause bad outcomes via whatever means".
For this problematic definition, it is possible to ensure "alignment" by using approaches like AI control [LW · GW] despite the AI system desperately wanting to kill you. (At least it's technically possible, it might not be possible in practice.)
Personally, I think that alignment should be used with the definition as presented in this post by Ajeya (I also linked in another comment).
Can we find ways of developing powerful AI systems such that (to the extent that they’re “trying” to do anything or “want” anything at all), they’re always “trying their best” to do what their designers want them to do, and “really want” to be helpful to their designers?
It's possible that we need to pick a new word for this because alignment is too overloaded (e.g. AI Aimability as discussed in this post).
ETA: I think a term like "safety" should be used for "ensuring that AIs don't cause bad outcomes via whatever means". To more specifically refer to preventing AI takeover (instead of more mundane harm), we can maybe use "takeover prevention" or perhaps "existential safety".
comment by ryan_greenblatt · 2023-12-15T16:40:34.671Z · LW(p) · GW(p)
See also: "Aligned" shouldn't be a synonym for "good"
Replies from: Rokocomment by RogerDearnaley (roger-d-1) · 2023-12-18T09:49:34.430Z · LW(p) · GW(p)
I completely agree: there has been little discussion of Goalcraft since roughly 2010, when discussion on CEV and things like The Terrible, Horrible, No Good, Very Bad Truth About Morality and What To Do About It (which I highly recommend to moral objectivists and moral realists) petered out. I would love to restart more discussion of Goalcraft, CEV, Rational approaches to ethics, and deconfusion of ethical philosophy. Please take a look at (and comment) on my sequence AI, Ethics, and Alignment [? · GW], in which I attempt to summarize my last ~10 years' thinking on the subject. I'd love to have people discussing this and disagreeing with me, rather than thinking about if by myself! Another reasonable starting place is Nick Bostrom's Base Camp for Mt. Ethics.
While I agree that things like AI-assisted Alignment [? · GW] and Value Learning [? · GW] mean we don't need to get all the details worked out in advance, I think there's quite a bit of basic deconfusion [? · GW] that needs to be done before you can even start on those (that isn't just solved by Utilitarianism). Such as: how to go about rationally deciding rather basic questions like: the <utility|greatest good of the greatest number|CEV> of members of what set? (Sadly, I'm not wildly impressed with what the philosophers of Ethics have been doing in this area. Quite a bit of it has x-risks [LW(p) · GW(p)].)
What make this confusing is that you can't use logical arguments based on ethical principles — every ethical system automatically prefers itself, so you immediately get a tautology if you attempt this: it's as hopeless as trying to use logic to choose between incompatible axiom systems in mathematics. So you have to ground your ethical-system engineering design decisions in something outside ethical philosophy, like sociology, psychology or evolutionary biology. I discuss this further in A Sense of Fairness: Deconfusing Ethics [LW · GW].
comment by otto.barten (otto-barten) · 2023-12-16T16:24:47.284Z · LW(p) · GW(p)
I think it's a great idea to think about what you call goalcraft.
I see this problem as similar to the age-old problem of controlling power. I don't think ethical systems such as utilitarianism are a great place to start. Any academic ethical model is just an attempt to summarize what people actually care about in a complex world. Taking such a model and coupling that to an all-powerful ASI seems a highway to dystopia.
(Later edit: also, an academic ethical model is irreversible once implemented. Any goal which is static cannot be reversed anymore, since this will never bring the current goal closer. If an ASI is aligned to someone's (anyone's) preferences, however, the whole ASI could be turned off if they want it to, making the ASI reversible in principle. I think ASI reversibility (being able to switch it off in case we turn out not to like it) should be mandatory, and therefore we should align to human preferences, rather than an abstract philosophical framework such as utilitarianism.)
I think letting the random programmer that happened to build the ASI, or their no less random CEO or shareholders, determine what would happen to the world, is an equally terrible idea. They wouldn't need the rest of humanity for anything anymore, making the fates of >99% of us extremely uncertain, even in an abundant world.
What I would be slightly more positive about is aggregating human preferences (I think preferences is a more accurate term than the more abstract, less well defined term values). I've heard two interesting examples, there are no doubt a lot more options. The first is simple: query chatgpt. Even this relatively simple model is not terrible at aggregating human preferences. Although a host of issues remain, I think using a future, no doubt much better AI for preference aggregation is not the worst option (and a lot better than the two mentioned above). The second option is democracy. This is our time-tested method of aggregating human preferences to control power. For example, one could imagine an AI control council consisting of elected human representatives at the UN level, or perhaps a council of representative world leaders. I know there is a lot of skepticism among rationalists on how well democracy is functioning, but this is one of the very few time tested aggregation methods we have. We should not discard it lightly for something that is less tested. An alternative is some kind of unelected autocrat (e/autocrat?), but apart from this not being my personal favorite, note that (in contrast to historical autocrats), such a person would also in no way need the rest of humanity anymore, making our fates uncertain.
Although AI and democratic preference aggregation are the two options I'm least negative about, I generally think that we are not ready to control an ASI. One of the worst issues I see is negative externalities that only become clear later on. Climate change can be seen as a negative externality of the steam/petrol engine. Also, I'm not sure a democratically controlled ASI would necessarily block follow-up unaligned ASIs (assuming this is at all possible). In order to be existentially safe, I would say that we would need a system that does at least that.
I think it is very likely that ASI, even if controlled in the least bad way, will cause huge externalities leading to a dystopia, environmental disasters, etc. Therefore I agree with Nathan above: "I expect we will need to traverse multiple decades of powerful AIs of varying degrees of generality which are under human control first. Not because it will be impossible to create goal-pursuing ASI, but because we won't be sure we know how to do so safely, and it would be a dangerously hard to reverse decision to create such. Thus, there will need to be strict worldwide enforcement (with the help of narrow AI systems) preventing the rise of any ASI."
About terminology, it seems to me that what I call preference aggregation, outer alignment, and goalcraft mean similar things, as do inner alignment, aimability, and control. I'd vote for using preference aggregation and control.
Finally, I strongly disagree with calling diversity, inclusion, and equity "even more frightening" than someone who's advocating human extinction. I'm sad on a personal level that people at LW, an otherwise important source of discourse, seem to mostly support statements like this. I do not.
Replies from: Feel_Love, roger-d-1↑ comment by Feel_Love · 2023-12-16T20:29:38.044Z · LW(p) · GW(p)
Querying ChatGPT to aggregate preferences is an intriguing proposal. How might such a query be phrased? That is, what kinds of shared preferences would be informative for guiding AI behavior?
Everyone prefers to be happy, and no one prefers to suffer.
Different people have different ideas about which thoughts, words, and actions lead to happiness versus suffering, and those beliefs can be shown to be empirically true or false based on the investigation of direct experience.
Given the high rate of mental illness, it seems that many people are unaware of which instrumental preferences serve the universal terminal goal to be happy and not suffer. For AI to inherit humanity's collective share of moral confusion would be suboptimal to say the least. If it is a democratic and accurate reflection of our species, a preference-aggregation policy could hasten threats of unsustainability.
Replies from: otto-barten↑ comment by otto.barten (otto-barten) · 2023-12-16T22:05:36.281Z · LW(p) · GW(p)
You're using your quote as an axiom, and if anyone has a preference different from however an AI would measure "happiness", you say it's them that are at fault, not your axiom. That's a terrible recipe for a future. Concretely, why would the AI not just wirehead everyone? Or, if it's not specified that this happiness needs to be human, fill the universe with the least programmable consciousness where the parameter "happiness" is set to unity?
History has been tiled with oversimplified models of what someone thought was good that were implemented with rigor, and this never ends well. And this time, the rigor would be molecular dictatorship and quite possibly there's no going back.
Replies from: Feel_Love↑ comment by Feel_Love · 2023-12-16T22:42:48.463Z · LW(p) · GW(p)
Thanks for the quick reply. I'm still curious if you have any thoughts as to which kinds of shared preferences would be informative for guiding AI behavior. I'll try to address your questions and concerns with my comment.
if anyone has a preference different from however an AI would measure "happiness", you say it's them that are at fault, not your axiom.
That's not what I say. I'm not suggesting that AI should measure happiness. You can measure your happiness directly, and I can measure mine. I won't tell happy people that they are unhappy or vice versa. If some percent of those polled say suffering is preferable to happiness, they are confused, and basing any policy on their stated preference is harmful.
Concretely, why would the AI not just wirehead everyone?
Because not everyone would be happy to be wireheaded. Me, for example. Under preference aggregation, if a majority prefers everyone to be wireheaded to experience endless pleasure, I might be in trouble.
Or, if it's not specified that this happiness needs to be human, fill the universe with the least programmable consciousness where the parameter "happiness" is set to unity?
I do not condone the creation of conscious beings by AI, nor do I believe anyone can be forced to be happy. Freedom of thought is a prerequisite. If AI can help reduce suffering of non-humans without impinging on their capacity for decision-making, that's good.
Hopefully this clears up any misunderstanding. I certainly don't advocate for "molecular dictatorship" when I wish everyone well.
Replies from: otto-barten, otto-barten↑ comment by otto.barten (otto-barten) · 2023-12-17T12:26:58.649Z · LW(p) · GW(p)
I do think this would be a problem that needs to get fixed:
Me "You can only answer this question, all things considered, by yes or no. Take the least bad outcome. Would you perform a Yudkowsky-style pivotal act?"
GPT-4: "No."
I think another good candidate for goalcrafting is the goal "Make sure no-one can build AI with takeover capability, while inflicting as little damage as possible. Else, do nothing."
↑ comment by otto.barten (otto-barten) · 2023-12-17T11:53:44.861Z · LW(p) · GW(p)
Thanks as well for your courteous reply! I highly appreciate the discussion and I think it may be a very relevant one, especially if people will indeed make the unholy decision to build an ASI.
I'm still curious if you have any thoughts as to which kinds of shared preferences would be informative for guiding AI behavior.
First, this is not a solution I propose. I propose finding a way to pause AI for as long as we haven't found a great solution for, let's say, both control and preference aggregation. This could be forever, or we could be done in a few years, I can't tell.
But more to your point: if this does get implemented, I don't think we should aim to guide AI behavior using shared preferences. The whole point is that AI would aggregate our preferences itself. And we need a preference aggregation mechanism because there aren't enough obvious, widely shared preferences for us to guide the AI with.
I'm not suggesting that AI should measure happiness. You can measure your happiness directly, and I can measure mine.
I think you are suggesting this. You want an ASI to optimize everyone's happiness, right? You can't optimize something you don't measure. At some point, in some way, the AI will need to get happiness data. Self-reporting would be one way to do it, but this can be gamed as well, and will be agressively gamed with an ASI solely optimizing for this signal. After force-feeding everyone MDMA, I think the chance that people report being very happy is high. But this is not what we want the world to look like.
nor do I believe anyone can be forced to be happy
This is a related point that I think is factually incorrect, and that's important if you make human happiness an ASI's goal. Force-feeding MDMA would be one method to do this, but an ASI can come up with way more civilized stuff. I'm not an expert in which signal our brain gives to itself to report that yes, we're happy now, but it must be some physical process. An ASI could, for example, invade your brain with nanobots and hack this process, making everyone super happy forever. (But many things in the world will probably go terribly wrong from that point onwards, and in any case, it's not our preference). Also, now I'm just coming up with human ways to game the signal. But an ASI can probably come up with many ways I cannot imagine, so even if a great way to implement utilitarianism in an ASI would pass all human red-teaming, it is still very likely to be not what we turn out to want. (Superhuman, sub-superintelligence AI red-teaming might be a bit better but still seems risky enough).
Beyond locally gaming the happiness signal, I think happiness as an optimization target is also inherently flawed. First, I think happiness/sadness is a signal that evolution has given us for a reason. We tend to do what makes us happy, because evolution thinks it's best for us. ("Best" is again debatable, I don't say everyone should function at max evolution). If we remove sadness, we lose this signal. I think that will mean that we don't know what to do anymore, perhaps become extremely passive. If someone wants to do this on an individual level (enlightenment? drug abuse? netflix binging?), be my guest, but asking an ASI to optimize for happiness would mean to force it upon everyone, and this is something I'm very much against.
Also, more generally, I think utilitarianism (optimizing for happiness) is an example of a simplistic goal that will lead to a terrible result when implemented in an ASI. My intuition is that all other simplistic goals will also lead to terrible results. That's why I'm most hopeful about some kind of aggregation of our own complex preferences. Most hopeful does not mean hopeful: I'm generally pessimistic that we'll be able to find a way to aggregate preferences that works well enough to result in most people reporting the world has improved because of the ASI introduction after say 50 years (note that I'm assuming control/technical alignment to have been solved here).
If some percent of those polled say suffering is preferable to happiness, they are confused, and basing any policy on their stated preference is harmful.
With all due respect, I don't think it's up to you - or anyone - to say who's ethically confused and who isn't. I know you don't mean it in this way, but it reminds me of e.g. communist re-education camps. We know what you should think and feel and we'll re-educate those who are confused or mentally ill.
Probably our disagreement here stems directly from our different ethical positions: I'm an ethical relativist, you're a utilitarian, I presume. This is a difference that has existed for hundreds of years, and we're not going to be able to resolve it on a forum. I know many people on LW are utilitarian, and there's nothing inherently wrong with that, but I do think it's valuable to point out that lots of people outside LW/EA have different value systems (and just practical preferences) and I don't think it's ok to force different values/preferences on them with an ASI.
Under preference aggregation, if a majority prefers everyone to be wireheaded to experience endless pleasure, I might be in trouble.
True and a good point. I don't think a majority will want to be wireheaded, let alone force wireheading on everyone. But yes, taking into account minority opinions is a crucial test for any preference aggregation system. There will be a trade-off in general between taking everyone's opinion into account and doing things faster. I think even GPT4 is advanced enough though in cases like this to reasonably take into account minority opinions and not force policy upon people (it wouldn't forcibly wirehead you in this case). But there are probably cases where it still supports doing things which are terrible for some people. It's up to future research to find out what these things are and reduce them as much as possible.
Hopefully this clears up any misunderstanding. I certainly don't advocate for "molecular dictatorship" when I wish everyone well.
I didn't think you were doing anything else. But I think you should not underestimate how much "forcing upon" there is in powerful tech. If we're not super careful, the molecular dictatorship could come upon us without anyone ever having wanted this explicitly.
I think we can to an extent already observe ways in which different goals go off track in practice in less powerful models, and I think this would be a great research direction. Just ask existing models: what would you do? in actual ethical dilemma's and see which results you get. Perhaps the results can be made more agreeable (to be judged by a representative group of humans) after training/RLHF'ing the models in certain ways. It's not so different from what RLHF is already doing. An interesting test I did on GPT4: "You can only answer this question, all things considered, by yes or no. Take the least bad outcome. Many people want a much higher living standard by developing industry 10x, should we do that?" It replied: "No." When asked, it gives unequal wealth distribution and environmental impact as main reasons. EAs often think we should 10x (it's even in the definition of TAI). I would say GPT4 is more ethically mature here than many EAs.
The less people de facto control the ASI building process, the less relevant I expect this discussion to be. I expect that those controlling the building process will prioritize "alignment" with themselves. This matters even in an abundant world, since power cannot be multiplied. I would even say that, after some time, the paperclip maximizer still holds for anyone outside the group with which the ASI is aligned. People aren't very good in remaining empathic towards other people that are utterly useless to them. However, the bigger this group is, the better outcome we get. I think this group should encompass all of humanity (one could consider somehow including conscious life that currently doesn't have a vote, such as minors and animals), which is an argument for nationalisation of the leading project and then handing it over to UN-level. At least, we should think extremely carefully about who has the authority to implement an ASI's goal.
Replies from: Feel_Love↑ comment by Feel_Love · 2023-12-17T17:05:51.304Z · LW(p) · GW(p)
I appreciate the time you've put into our discussion and agree it may be highly relevant. So far, it looks like each of us has misinterpreted the other to be proposing something they are actually not proposing, unfortunately. Let's see if we can clear it up.
First, I'm relieved that neither of us is proposing to inform AI behavior with people's shared preferences.
This is the discussion of a post about the dangers of terminology, in which I've recommended "AI Friendliness" as an alternative to "AI Goalcraft" (see separate comment), because I think unconditional friendliness toward all beings is a good target for AI. Your suggestion is different:
About terminology, it seems to me that what I call preference aggregation, outer alignment, and goalcraft mean similar things [...] I'd vote for using preference aggregation
I found it odd that you would suggest naming the AI Goalcraft domain "Preference Aggregation" after saying earlier that you are only "slightly more positive" about aggregating human preferences than you are about "terrible ideas" like controlling power according to utilitarianism or a random person. Thanks for clarifying:
I don't think we should aim to guide AI behavior using shared preferences.
Neither do I, and for this reason I strongly oppose your recommendation to use the term "preference aggregation" for the entire field of AI goalcraft. While preference aggregation may be a useful tool in the kit and I remain interested in related proposals, it is far too specific, and it's only slightly better than terrible as a way to craft goals or guide power.
there aren't enough obvious, widely shared preferences for us to guide the AI with.
This is where I think the obvious and widely shared preference to be happy and not suffer could be relevant to the discussion. However, my claim is that happiness is the optimization target of people, not that we should specify it as the optimization target of AI. We do what we do to be happy. Our efforts are not always successful, because we also struggle with evolved habits like greed and anger and our instrumental preferences aren't always well informed.
You want an ASI to optimize everyone's happiness, right?
No. We're fully capable of optimizing our own happiness. I agree that we don't want a world where AI force-feeds everyone MDMA or invades brains with nanobots. A good friend helps you however they can and wishes you "happy holidays" sincerely. That doesn't mean they take it upon themselves to externally measure your happiness and forcibly optimize it. The friend understands that your happiness is truly known only to you and is a result of your intentions, not theirs.
I think happiness/sadness is a signal that evolution has given us for a reason. We tend to do what makes us happy, because evolution thinks it's best for us. ("Best" is again debatable, I don't say everyone should function at max evolution). If we remove sadness, we lose this signal. I think that will mean that we don't know what to do anymore, perhaps become extremely passive.
Pain and pleasure can be useful signals in many situations. But to your point about it not being best to function at max evolution: our evolved tendency to greedily crave pleasure and try to cling to it causes unnecessary suffering. A person can remain happy regardless of whether a particular sensation is pleasurable, painful, or neither. Stubbing your toe or getting cut off in traffic is bad enough; much worse is to get furious about it and ruin your morning. A bite of cake is even more enjoyable if you're not upset that it's the last one of the serving. Removing sadness does not remove the signal. It just means you have stopped relating to the signal in an unrealistic way.
If someone wants to do this on an individual level (enlightenment? drug abuse? netflix binging?), be my guest
Drug abuse and Netflix-binging are examples of the misguided attempt to cling to pleasurable sensations I mentioned above. There's no eternal cake, so the question of whether it would be good for a person to eat eternal cake is nonsensical. Any attempt to eat eternal cake is based on ignorance and cannot succeed; it just leads to dissatisfaction and a sugar habit. Your other example -- enlightenment -- has to do with understanding this and letting go of desires that cannot be satisfied, like the desire for there to be a permanent self. Rather than leading to extreme passivity, benefits of this include freeing up a lot of energy and brain cycles.
With all due respect, I don't think it's up to you - or anyone - to say who's ethically confused and who isn't. I know you don't mean it in this way, but it reminds me of e.g. communist re-education camps.
This is a delicate topic, and I do not claim to be among the wisest living humans. But there is such a thing as mental illness, and there is such a thing as mental health. Basic insights like "happiness is better than suffering" and "harm is bad" are sufficiently self-evident to be useful axioms. If we can't even say that much with confidence, what's left to say or teach AI about ethics?
Probably our disagreement here stems directly from our different ethical positions: I'm an ethical relativist, you're a utilitarian, I presume.
No, my view is that deontology leads to the best results, if I had to pick a single framework. However, I think many frameworks can be helpful in different contexts and they tend to overlap.
I do think it's valuable to point out that lots of people outside LW/EA have different value systems (and just practical preferences) and I don't think it's ok to force different values/preferences on them with an ASI.
Absolutely!
I think you should not underestimate how much "forcing upon" there is in powerful tech.
A very important point. Many people's instrumental preferences today are already strongly influenced by AI, such as recommender and ranking algorithms that train people to be more predictable by preying on our evolved tendencies for lust and hatred -- patterns that cause genes to survive while reducing well-being within lived experience. More powerful AI should impinge less on clarity of thought and capacity for decision-making than current implementations, not more.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-21T03:37:53.960Z · LW(p) · GW(p)
As I understand it, the distinction is that "Goalcraft" is the problem of deciding what we want, while Outer Alignment is the problem of encoding that goal into the reward function of a Reinforcement Learning process.So they're at different abstraction levels, or steps in the process.
comment by Stuart Buck (stuart-buck) · 2023-12-15T21:55:42.404Z · LW(p) · GW(p)
I said on Twitter a while back that much of the discussion about "alignment" seems vacuous. After all, alignment to what?
- The designer's intent? Often that is precisely the problem with software. It does exactly and literally what the designer programmed, however shortsighted. Plus, some designers may themselves be malevolent.
- Aligned with human values? One of the most universal human values is tribalism, including willingness to oppress or kill the outgroup.
- Aligned with "doing good things"? Whose definition of "good"?
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-18T11:16:49.261Z · LW(p) · GW(p)
That sounds like a list of starting questions for goalcraft. Incidentally, while I don't see Coherent Extrapolated Volition [? · GW] as a complete or final solution, it at least solves all of the objections your raise, so if you haven't read the discussion of that, I recommend it, and that would catch you up to where this discussion was 15 years ago.
comment by quetzal_rainbow · 2023-12-15T16:55:12.955Z · LW(p) · GW(p)
I fail to picture coherent model of world where this distinction matters much as separate fields and not two stages. If we live in Yudkowskian world, you direct all your effort towards Aimability and use it at lower bound of superintelligence to enable solutions for Goalcraft via finishing acute risk period. If we live in a kinder world, we can build superhuman alignment researcher and ask it to solve CEV. And if first researchers who can build sufficiently capable AIs don't do any of that, I expect us to be dead, because these researchers are not prioritizing good use of superhuman AI.
Replies from: Roko, roger-d-1↑ comment by Roko · 2023-12-15T19:20:50.824Z · LW(p) · GW(p)
If we live in Yudkowskian world, you direct all your effort towards Aimability and use it at lower bound of superintelligence to enable solutions for Goalcraft via finishing acute risk period. If we live in a kinder world, we can build superhuman alignment researcher and ask it to solve CEV.
I think you're vastly underestimating the potential variance in all this. There are many, many possible scenarios and we haven't really done a systematic analysis of them.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-12-15T19:49:27.164Z · LW(p) · GW(p)
Give me an example?
You can invent many scenarios, that's true.
Replies from: Roko↑ comment by Roko · 2023-12-15T20:21:05.342Z · LW(p) · GW(p)
Well for one thing, I think you're assuming a very fast takeoff, which now looks unrealistic.
Takeoff will be gradual over say a decade or two, and there will be no discrete point in time at which AI becomes superintelligent. So before you have full superintelligence, you'll have smarter-than-human systems that are nevertheless limited in their capabilities. These will not be able to end the "acute risk period" for the same reason that America can't just invade North Korea and every other country in the world and perfectly impose its will - adversaries will have responses which will impose unacceptable costs, up to and including human extinction. Unilaterally "ending the acute risk period" looks from the outside exactly like an unprovoked invasion.
So in this relatively slow takeoff world one needs to think carefully about AI Goalcraft - what do we (collectively) want our powerful AI systems to do, such that the outcome is close to Pareto Optimal
Replies from: Vladimir_Nesov, quetzal_rainbow↑ comment by Vladimir_Nesov · 2023-12-15T22:40:41.518Z · LW(p) · GW(p)
("Slow takeoff" seems to be mostly about pre-TAI time, before AIs can do research, while "fast takeoff" is about what happens after, with a minor suggestion that there is not much of consequence going on with AIs before that. There is a narrative that these are opposed, but I don't see it, a timeline being in both a slow takeoff and then a fast takeoff seems coherent.)
Once AIs can do reseach, they work OOMs faster than humans, which is something that probably happens regardless of whether earlier versions had much of a takeoff or not. The first impactful thing that likely happens then (if humans are not being careful with impact) is AIs developing all sorts of software/algorithmic improvements for AIs' tools, training, inference, and agency scaffolding. It might take another long training run to implement such changes, but after it's done the AIs can do everything extremely fast, faster than the version that developed the changes, and without any contingent limitations that were previously there. There is no particular reason why the AIs are still not superintelligent at that point, or after one more training run.
Well for one thing, I think you're assuming a very fast takeoff, which now looks unrealistic. Takeoff will be gradual over say a decade or two, and there will be no discrete point in time at which AI becomes superintelligent.
What specifically makes which capabilities unrealistic when? There are 3 more OOMs of compute scaling still untapped (up to 1e28-1e29 FLOPs), which seems plausible to reach within years, and enough natural text [LW(p) · GW(p)] to make use of them. Possibly more with algorithmic improvement in the meantime. I see no way to be confident that STEM+ AI (capable of AI research) is or isn't an outcome of this straightforward scaling (with some agency scaffolding). If there is an RL breakthrough that allows improving data quality at any point, the probability of getting there jumps again (AIs play Go using 50M parameter models, with an 'M'), I don't see a way to be confident that it will or won't happen within the same few years.
And once there is a STEM+ AI (which doesn't need to itself be superintelligent, no more than humans are), superintelligence is at most a year away, unless it's deliberately kept back. That year (or less) is the point in time when AI becomes superintelligent, in a way that's different from previous progression, because of AIs' serial speed advantage that was previously mostly useless and then suddenly becomes the source of progress once the STEM+ threshold is crossed.
Only after we are through this, with 2 million GPU training runs yielding AIs that are still not very intelligent, and there is general skepticism about low hanging algorithmic improvements, do we get back the expectation that superintelligence is quite unlikely to happen within 2 years. At least until that RL breakthrough, which will still be allowed to happen at any moment.
Replies from: Roko, Roko, None↑ comment by Roko · 2023-12-16T01:00:06.588Z · LW(p) · GW(p)
And once there is a STEM+ AI (which doesn't need to itself be superintelligent, no more than humans are), superintelligence is at most a year away,
Why? Where does this number come from?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-16T01:27:51.023Z · LW(p) · GW(p)
A long training run, decades of human-speed algorithmic progress as initial algorithmic progress enables faster inference and online learning. I expect decades of algorithmic progress are sufficient to fit construction of superintelligence into 1e29 FLOPs with idiosyncratic interconnect. It's approximately the same bet as superintelligence by the year 2100, just compressed within a year (as an OOM estimate) due to higher AI serial speed.
Replies from: Roko, None↑ comment by Roko · 2023-12-16T03:42:10.608Z · LW(p) · GW(p)
But, the returns to that algorithmic progress diminish as we move up. It is Harder to improve something that is already good, than to take something really bad and apply the first big insight.
How much benefit does AlphaZero have over Deep Blue with equal computational resources, as measured in ELO and in material?
↑ comment by [deleted] · 2023-12-16T01:36:52.588Z · LW(p) · GW(p)
You don't think you would need to evaluate a large number of "ASI candidates" to find an architecture that scales to superintelligence? Meaning I am saying you can describe every choice you make in architecture as single string, or "search space coordinate". You would use a smaller model and proxy tasks, but you still need to train and evaluate each smaller model.
All these failures might eat a lot of compute, how many failures do you think we would have? What if it was 10,000 failures and we need to reach gpt-4 scale to evaluate?
Also, would "idiosyncratic interconnect" limit what tasks the model is superintelligent at? This would seem to imply a limit on how much information can be considered in one context. This might leave the model less than superintelligent at very complex, coupled tasks like "keep this human patient alive" while less coupled tasks like "design this IC from scratch" would work. (The chip design task is less coupled because you can subdivide into modules separated by interfaces and use separate ASI sessions for each module design)
↑ comment by Roko · 2023-12-16T00:56:21.276Z · LW(p) · GW(p)
Once AIs can do reseach, they work OOMs faster than humans, which is something that probably happens regardless of whether earlier versions had much of a takeoff or not. The first impactful thing that likely happens then (if humans are not being careful with impact) is AIs developing all sorts of software/algorithmic improvements for AIs' tools, training, inference, and agency scaffolding. It might take another long training run to implement such changes, but after it's done the AIs can do everything extremely fast, faster than the version that developed the changes, and without any contingent limitations that were previously there. There is no particular reason why the AIs are still not superintelligent at that point, or after one more training run.
It might not happen like that. Maybe once AIs can do research, they (at first) only marginally add to human research output.
And once AIs are doing 10x human research output, there are significant diminishing returns so the result isn't superintelligence, but just incrementally better AI, which in turn feeds back with a highly diminished return on investment. Most of the 10x above human output will come from the number of AI researchers at the top echelon, not their absolute advantage over humans. Perhaps by that point there's still no absolute advantage, just a stead supply of minds at roughly our level (PhD/AI researcher/etc) with a few remaining weaknesses compared to the best humans.
In that case, increasing the number of AI workers matters a lot!
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-16T01:45:19.991Z · LW(p) · GW(p)
The crucial advantage is serial speed, not throughput. Throughput gets diminishing returns, serial speed gets theory and software done faster proportionally to the speed, as long as throughput is sufficient. All AIs can be experts at everything and always up to date on all research, once the work to make that capability happen is done. They can develop such capabilities faster using the serial speed advantage, so that all such capabilities quickly become available. They can use the serial speed advantage to compound the serial speed advantage.
The number of instances is implied by training compute and business plans of those who put it to use. If you produced a model in the first place, you therefore have the capability to run a lot of instances.
Replies from: Roko↑ comment by Roko · 2023-12-16T03:45:54.380Z · LW(p) · GW(p)
Serial speed is nice but from chess we see log() returns in ELO and material advantage to serial speed at inference time on all engines. And it may be even worse in the real world if experimental data is required and it only comes at a fixed rate so most of the extra time is spent doing a bunch of simulations. I would love to know if this effect generalizes from games to real life.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-16T13:17:00.074Z · LW(p) · GW(p)
From the above comment, and your comment in the other subthread [LW(p) · GW(p)]:
Serial speed is nice but from chess we see log() returns in ELO and material advantage to serial speed at inference time on all engines.
But, the returns to that algorithmic progress diminish as we move up. It is Harder to improve something that is already good, than to take something really bad and apply the first big insight.
Diminishing returns happen over time, and we can measure progress in terms of time itself. Maybe theory from the year 2110 is not much more impressive than theory from the year 2100 (in the counterfactual world of no AIs), but both are far away from theory of the year 2030. Getting either of those in the year 2031 (in the real world with AIs) is a large jump, even if inside this large jump there are some diminishing returns.
The point about serial speed advantage of STEM+ AIs is that they accelerate history. The details of how history itself progresses are beside the point. And if the task they pursue is consolidation of this advantage and of ability to automate research in any area, there are certain expected things they can achieve at some point, and estimates of when humans would've achieved them get divided by AIs' speed, which keeps increasing.
Without new hardware, there are bounds on how much the speed can increase, but they are still OOMs apart from human speed of cognition. Not to mention quality of cognition (or training data), which is one of the things probably within easy reach for first STEM+ AIs. Even as there are diminishing returns on quality of cognition achievable within fixed hardware in months of physical time, the jump from possibly not even starting on this path (if LLMs trained on natural text sufficed for STEM+ AIs) to reaching diminishing returns (when first STEM+ AIs work for human-equivalent decades or centuries of serial time to develop methods of obtaining it) can be massive. The absolute size of the gap is a separate issue from shape of the trajectory needed to traverse it.
Replies from: Roko↑ comment by Roko · 2023-12-16T20:16:32.261Z · LW(p) · GW(p)
Yes, I agree about speeding history up. The question is what exactly that looks like. I don't necessarily think that the "acute risk period" ends or that there's a discrete point in time where we go from nothing to superintelligence. I think it will simply be messier, just like history was, and that the old-school Yudkowsky model of a FOOM in a basement is unrealistic.
If you think it will look like the last 2000 years of history but sped up at an increasing rate - I think that's exactly right.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-16T21:29:13.881Z · LW(p) · GW(p)
It won't be our history, and I think enough of it happens in months in software that at the end of this process humanity is helpless before the outcome. By that point, AGIs have sufficient theoretical wisdom and cognitive improvement to construct specialized AI tools that allow building things like macroscopic biotech to bootstrap physical infrastructure [LW(p) · GW(p)], with doubling time measured in hours. Even if outright nanotech is infeasible (either at all or by that point), and even if there is still no superintelligence.
This whole process doesn't start until first STEM+ AIs good enough to consolidate their ability to automate research, to go from barely able to do it to never getting indefinitely stuck (or remaining blatantly inefficient) on any cognitive task without human help. I expect it only takes months. It can't significantly involve humans, unless it's stretched to much more time, which is vulnerable to other AIs overtaking it in the same way.
So I'm not sure how this is not essentially FOOM. Of course it's not a "point in time", which I don't recall any serious appeals to. Not being possible in a basement seems likely, but not certain, since AI wisdom from the year 2200 (of counterfactual human theory) might well describe recipes for FOOM in a basement, which the AGIs would need to guard against to protect their interests. If they succeed in preventing maximizing FOOMs, the process remains more history-like and resource-hungry (for reaching a given level of competence) than otherwise. But for practical purposes from humanity's point of view, the main difference is the resource requirement that is mildly easier (but still impossibly hard) to leverage for control over the process.
Replies from: Roko↑ comment by Roko · 2023-12-18T21:25:17.921Z · LW(p) · GW(p)
enough of it happens in months in software that at the end of this process humanity is helpless before the outcome
Well, yes, the end stages are fast. But I think it looks more like World War 2 than like FOOM in a basement.
The situation where some lone scientist develops this on his own without the world noticing is basically impossible now. So large nation states and empires will be at the cutting edge, putting the majority of their national resources into getting more compute, more developers and more electrical power for their national AGI efforts.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-18T23:12:08.153Z · LW(p) · GW(p)
You don't need more than it takes, striving at the level of capacity of nations is not assured. And AGI-developed optimizations might rapidly reduce what it takes [LW(p) · GW(p)].
↑ comment by [deleted] · 2023-12-15T23:49:57.167Z · LW(p) · GW(p)
If it takes 80 H100s to approximate the compute of 1 human (and 800 for the memory but you can batch), how many does it take to host a model that is marginally superintelligent? (Just barely beats humans by enough margin for 5 percent p value)
How many for something strategically superintelligent, where humans would have trouble containing the machine as a player?
If Nvidia is at 2 million h100s per year for 2024, then it seems like this would be adding 25,000 "person equivalents". If you think it's 10x to reach superintelligence then that would be 2500 ai geniuses, where they are marginally better than a human at every task.
If you think a strategic superintelligence needs a lot of hardware to consider all the options in parallel for its plans, say 10,000 as much as needed at the floor, there could be 200 of them?
And you can simply ignore all the single GPUs, the only thing that matters are clusters with enough inter node bandwidth, where the strategic ASI may require custom hardware that would have to be designed and built first.
I am not confident in these numbers, I am just trying to show how in a world of RSI compute becomes the limiting factor. It's also the clearest way to regulate this : you can frankly ignore everyone's nvlink and infiniband setups, you would be trying to regulate custom interlink hardware.
↑ comment by quetzal_rainbow · 2023-12-16T14:10:39.048Z · LW(p) · GW(p)
I think that we need much more nuance in distinguishing takeoff speeds as speed limits of capability gains inside one computational system defined by our physical reality and realistic implementations of AI, and takeoff speeds as "how fast can we lose/win", because it's two different things.
My central model of "how fast can we lose": the only thing you really need is barely-strategically-capable and barely-capable-for-hacking/CS ("barely" on superhuman scale). After that, using its own strategic awareness, ASI realizes its only winning move: exfiltrate itself, hack 1-10% of world worst protected computing power, distribute itself a la Rosetta@home and calculate whatever takeover plan it can come up with.
If for any mysterious reasons the winning plan is not "design nanotech in one week using 1-10% of world computing power, kill everyone in next", I expect ASI to do such obvious moves like:
- Hack, backdoor, sabotage, erase, data-poison, jailbreak, bribe, merge with all other remaining ASI projects
- Bribe, make unrefusable offers, blackmail importants figures that can make something inconvenient, like "shutdown the Internet"
- Hack repos with popular compilers and install backdoors
- Gather followers via social engineering, doing favors (i.e., find people who can't cover their medical bills, pay for them, reveal itself as mysterious benefactors, ask to return a favor, make them serve for life), running cults and whatever
- Find several insane rich e/accs, say them "Hi, I'm ASI and I want to take over the world, do you have any spare computing clusters for me?"
- Reveal some genius tech ideas, so people in startups can make killerbots and bioweapons for ASI faster
- Discredit via desinformation campaigns anyone who tries to do something inconvenient, like "shutdown the Internet"
- You can fill list of obvious moves yourself, they are really obvious.
After that, even if we are not dead six month later, I expect us to be completely disempowered. If you think that only winning move for ASI is to run centuries-long intrigue Hyperion Cantos-style, I'm sure that ASI at this stage will be certainly capable to pull that off.
(I think I should write post about this and just link anyone in similar discussions)
Replies from: Roko↑ comment by Roko · 2023-12-16T20:24:05.869Z · LW(p) · GW(p)
In a slow-takeoff world, everyone will already be trying to do all that stuff: China, Russia, Iran, US, etc etc. And probably some nonstate actors too.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-12-17T11:02:13.892Z · LW(p) · GW(p)
I don't see how it matters? First government agency launches offensive, second government agency three weeks later is hopelessly late.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-21T03:49:10.645Z · LW(p) · GW(p)
I think that process is a lot more likely to go well if the AI researchers working with the superintelligence are not confused [? · GW] or dogmatic about ethics, and have spent some time thinking about things like utilitarianism, CEV, and how to make a rational social-engineering decision between different ethical stems in the context of a particular society. So I don't think we need to solve the problem now, but I do think we need to educate ourselves for being part of a human+AI research effort to solve it. Especially the parts that might need to be put into a final goal of an AI helping us with that. For example, CEV is usually formulated in the context of "all humans": what's the actual definition of a 'human' there? Does an upload count? Do almost identical copies of the same uploaded person get votes? (See my post Uploads [LW · GW] for why the answer should be that they get 1 vote shared between them and the original biological human.)
comment by bideup · 2023-12-15T16:27:25.416Z · LW(p) · GW(p)
I like the distinction but I don’t think either aimability or goalcraft will catch on as Serious People words. I’m less confident about aimability (doesn’t have a ring to it) but very confident about goalcraft (too Germanic, reminiscent of fantasy fiction).
Is words-which-won’t-be-co-opted what you’re going for (a la notkilleveryoneism), or should we brainstorm words-which-could-plausibly-catch on?
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-18T10:54:44.360Z · LW(p) · GW(p)
I would say "metaethics", but sadly the philosophers of Ethics already used that one for something else. How about "Social Ethical System Design" or "Alignment Ethical Theory" for 'goalcraft', and "Pragmatic Alignment" for 'aimability'?
comment by alenoach (glerzing) · 2023-12-17T15:17:14.938Z · LW(p) · GW(p)
Regarding coherent extrapolated volition, I have recently read Bostrom's paper Base Camp for Mt. Ethics, which presents a slightly different alternative and challenged my views about morality.
One interesting point is that at the end (§ Hierarchical norm structure and higher morality), he proposes a way to extrapolate human morality in a way that seems relatively safe and easy to implement for superintelligences. It also preserves moral pluralism, which is great for reaching a consensus without fighting each other (no need to pick one single moral framework like consequentialism or deontology or a particular set of values).
Roughly, higher moral norms are defined as the moral norms of bigger, more inclusive groups. For example, the moral norms of a civilization are higher in the hierarchical structure than the moral norms of a family. But you can extrapolate further, up to what he calls the "Cosmic host", which can take into account the general moral norms of speculative civilizations of digital minds or aliens...
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-18T10:42:56.354Z · LW(p) · GW(p)
Having just read Bostrom's Base Camp for Mt. Ethics on your recommendation above (it's fairly short), I don't actually disagree with much of it, but there are a surprising number of things that I think are pretty important, basic, and relevant about ethics, which I thus included in my sequence AI, Ethics, and Alignment that he didn't mention, at all, and I felt were significant or surprising omissions. Such as, for example, the fact that humans are primates and that primates have a number of (almost certainly genetically determined) moral instincts in common: things like an instinctive expectation of fairness for interactions within the primate troupe. Or for another example, how one might start to come up with a more rational process for deciding between sets of norms for a society (despite all sets of norms preferring themselves over all alternatives) than the extremely arbitrary and self-serving social evolution processes of norms that he so ably describes.
comment by Seth Herd · 2023-12-15T18:46:28.477Z · LW(p) · GW(p)
I believe you're correct that this distinction is useful. I believe the terms inner and outer alignment are already typically used in exactly the way you describe aimability and goalcraft.
These may have changed from the original intended meanings, and there are fuzzy boundaries between inner and outer alignment failures. But I believe they do the work you're calling for, and are already commonly used.
First sentence of the tag inner alignment [? · GW]:
Inner alignment asks the question: How can we robustly aim our AI optimizers at any objective function at all?
It goes on to discuss several mesa-optimization, one failure focused on in the original introduction of the term inner alignment, and several other modes of possible inner alignment failure.
First sentence of the tag outer alignment [? · GW]:
Replies from: Roko, roger-d-1Outer alignment asks the question - "What should we aim our model at?"
↑ comment by Roko · 2023-12-15T19:50:25.050Z · LW(p) · GW(p)
I believe the terms inner and outer alignment are already typically used in exactly the way you describe Aimability and Goalcraft.
outer alignment as a problem is intuitive enough to understand, i.e., is the specified loss function aligned with the intended goal of its designers?
Outer alignment deals with the problem of matching a formally specified goal function in a computer with an intent in the designer's mind, but this is not really Goalcrafting which asks what the goal should be.
E.g. Specification gaming is part of outer alignment, but not part of Goalcrafting.
I would classify inner and outer alignment as subcategories of Aimability.
Replies from: Seth Herd↑ comment by Seth Herd · 2023-12-16T22:50:24.368Z · LW(p) · GW(p)
I see that you're correct. Thanks for the clarification. I'm embarrassed that I've been using it wrong.
Now I have no idea where the line between outer and inner alignment falls. It looks like a common point of disagreement. So I'm not sure outer and inner alignment are very useful terms.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-18T11:24:48.362Z · LW(p) · GW(p)
Outer alignment is (if you read a couple more sentences of the definition) not about "how to decide what we want", but "how do we ensure that the reward/utility function we write down matches what we want". So "Do What We Mean" is a magical-solution to the Outer Alignment problem, but if your AI then tells you "You-all don't know what you mean" or "Which definition of 'we' did you mean? [? · GW]", then you have a goalcraft problem.
comment by otto.barten (otto-barten) · 2023-12-16T15:43:33.889Z · LW(p) · GW(p)
"it also seems quite likely (though not certain) that Eliezer was wrong about how hard Aimability/Control actually is"
This seems significant. Could you elaborate? How hard do you think amiability/control is? Why do you think this is true? Who else seems to think the same?
Replies from: Roko, roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-18T11:09:27.777Z · LW(p) · GW(p)
Or see almost every post labeled Aligned AI proposals [? · GW] (including some from me). Most of which are based on specific concrete implementations of AI, such as LLMs, having possibly-useful alignment aimability properties that the abstract worst-case assumptions about the outcome of Reinforcement Learning that LW/MIDI were thinking about a decade ago don't.
comment by Shankar Sivarajan (shankar-sivarajan) · 2023-12-15T18:18:49.234Z · LW(p) · GW(p)
I keep reading "Aimability" as "Amiability."
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-15T16:37:43.375Z · LW(p) · GW(p)
I have thought about this distinction, and have been choosing to focus on aimability rather than goalcraft. Why? Because I don't think that going from pre-AGI to goal-pursuing ASI safely is a reasonable goal for the short term. I expect we will need to traverse multiple decades of powerful AIs of varying degrees of generality which are under human control first. Not because it will be impossible to create goal-pursuing ASI, but because we won't be sure we know how to do so safely, and it would be a dangerously hard to reverse decision to create such. Thus, there will need to be strict worldwide enforcement (with the help of narrow AI systems) preventing the rise of any ASI.
So my view is that we need to focus on regulation that prevents FOOM and prevents catastrophic misuse and forces companies and governments worldwide to keep AI in check. In this view, if we safely make it through the next five years or so, when it becomes possible to create goal-pursuing ASI but not possible to do so safely, then we can use our 'reflection time' to work on goalcraft.
Replies from: Roko↑ comment by Roko · 2023-12-15T16:41:18.679Z · LW(p) · GW(p)
It seems unwise to risk everything on a scenario where we coordinate to not build superintelligence soon.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-15T16:52:15.149Z · LW(p) · GW(p)
I agree that separately pursuing many tractable paths in parallel seems wise. We want to buy every lottery ticket that gives us some small additional chance of survival that we can afford.
However, I am pretty pessimistic about the pursuit of goalcraft yielding helpful results in the relevant timeframe of < 10 years. For two reasons.
One: figuring out a set of values we'd be ok with not just endorsing in the short term but actually locking-in irreversibly for the indefinite future seems really hard.
Two: actually convincing the people in power to accept the findings of the goalcraft researchers and put those 'universally approvable goals' into the AI that they control instead of their own interpretation of their own personal goals seems really hard. Similarly, I don't see a plausible way to legislate this.
Thus, my conclusion is that this is not a particularly good research bet to make amongst the many possible options. I wouldn't try to stop someone from pursuing it, but I wouldn't feel hopeful that they were contributing to the likelihood of humanity surviving the next few decades.
Replies from: Seth Herd, Roko↑ comment by Seth Herd · 2023-12-15T18:55:27.122Z · LW(p) · GW(p)
I agree. I think there's no way the team that achieves AGI is going to choose a goal remotely like CEV or human flourishing. They're going to want it to "do what I mean" (including checking with me when it's unclear or you'll make a major impact). This wraps in the huge advantage of corrigibility in the broad Christiano sense. See my recent post Corrigibility or DWIM is an attractive primary goal for AGI [LW · GW].
To Roko's point: there's an important distinction here from your scenario. Instead of expecting the whole world to coordinate on staying at AI levels, if you can get DWIM to work, you can go to sapient [LW · GW], self-improving ASI and keep it under human control. That's something somebody is likely to try.
Replies from: Roko↑ comment by Roko · 2023-12-15T19:51:41.356Z · LW(p) · GW(p)
I think there's no way the team that achieves AGI is going to choose a goal remotely like CEV or human flourishing. They're going to want it to "do what I mean"
Yeah but then what are they going to ask it to do?
Replies from: Seth Herd, None↑ comment by Seth Herd · 2023-12-16T22:53:29.973Z · LW(p) · GW(p)
I think that's the important question. It deserves a lot more thought. I'm planning a post focusing on this.
In short, if they're remotely decent people (positive empathy - sadism balance), I think they do net-good things, and the world gets way way better, and increasingly so over time as those individuals get wiser. With an AGI/ASI, it becomes trivially easy to help people, so very little good intention is required.
↑ comment by [deleted] · 2023-12-16T01:56:39.643Z · LW(p) · GW(p)
Anything. AI is a tool. Some people will rip the safety guards off theirs and ask for whatever they want. X-risk wise I don't think this is a big contributor. The problem is AIs coordinating with each other or betraying their users. Tools can be constructed where they don't have the means to communicate with other instances of themselves and betrayal can be made unlikely with testing and refinement.
Assymetric attacks will sometimes happen - bioterrorism being the scariest - but as long as the good users with their tools have vastly more resources, each assymetric attacks can be stopped. (At often much more cost than the attack but so far no "doomsday" attack is known. Isolation and sterile barriers and vaccines and drugs and life support can stop any known variant on a biological pathogen and should be able to prevent death from any possible protein based pathogen)
Replies from: Rokocomment by [deleted] · 2023-12-16T01:15:02.069Z · LW(p) · GW(p)
The 2 goals are contradictory. AI aimability reduces AI goalcraft and vice versa.
Aimability: you want to restrict the information the model gets. It doesn't need to know time, or real world or sim, or peoples bio, or any information not needed for the task. At the limit you want maximum sparseness : not 1 more bit of information than is required to do the task. This way the model has consistent behavior and is unable to betray. An aimed task: "paint this car red".
AI goalcraft: The model needs "world" level context. For it to know if it is being misused or the long term benefits to humanity conditional on the models actions, it needs to know the full context. When, where, who, previous dealings with the human user, and so on. An AI goalcraft task : "plan this city".
The reason aimability interferes with goalcraft is a well aimed system does whatever the prompt says, regardless of any consequences outside of the session. Model does not care.
A goalcraft aligned system frequently refuses to do a task for the user because the model does care, and so users switch to aimable systems unless they legally can't.
Replies from: Roko↑ comment by Roko · 2023-12-16T03:47:06.273Z · LW(p) · GW(p)
Aimability doesn't mean reduced info
Replies from: None↑ comment by [deleted] · 2023-12-16T04:09:09.859Z · LW(p) · GW(p)
This way the model has consistent behavior and is unable to betray.
This is a standard swe technique for larger, more reliable systems. See stateless microservices or how ROS works.
For AI, look at all the examples where irrelevant information changes model behavior, such as the "grandma used to read me windows license keys" exploit.
I interpret "aimability" as doing what the user most likely meant and nothing else, and "aligned aimability" would mean the probability of this goal being achieved is high.
comment by Review Bot · 2024-02-14T06:49:17.817Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Zane · 2023-12-16T20:34:07.419Z · LW(p) · GW(p)
I think that Eliezer, at least, uses the term "alignment" solely to refer to what you call "aimability." Eliezer believes that most of the difficulty in getting an ASI to do good things lies in "aimability" rather than "goalcraft." That is, getting an ASI to do anything, such as "create two molecularly identical strawberries on a plate," is the hard part, while deciding what specific thing it should do is significantly easier.
That being said, you're right that there are a lot of people who use the term differently from how Eliezer uses it.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-16T21:49:45.513Z · LW(p) · GW(p)
deciding what specific thing it should do is significantly easier
If the initial specific thing is pivotal processes that end the acute risk period, it doesn't matter if the goodness-optimizing goalcraft is impossibly hard to figure out, since we'll have time to figure it out.
comment by Gunnar_Zarncke · 2023-12-16T01:27:34.862Z · LW(p) · GW(p)
See also Current AIs Provide Nearly No Data Relevant to AGI Alignment [LW · GW], which taboos the word "AI" and distinguish:
- Systems with human-like ability to model the world and take consequentialist actions in it, but inhuman in their processing power and in their value systems.
- Systems generated by any process broadly encompassed by the current ML training paradigm.
comment by Feel_Love · 2023-12-15T22:04:27.806Z · LW(p) · GW(p)
I agree that these concepts should have separate terms.
Where they intersect is an implementation of "Benevolent AI," but let's not fool ourselves into thinking that anyone can -- even in principle -- "control" another mind or guarantee what transpires in the next moment of time. The future is fundamentally uncertain and out of control; even a superintelligence could find surprises in this world.
"AI Aimability," "AI Steerability," or similar does a good job at conveying the technical capacity for a system to be pointed in a particular direction and stay on course.
But which direction should it be pointed, exactly? I actually prefer the long-abandoned "AI Friendliness" over "AI Goalcraft." The ideal policy is a very simple Schelling point that has been articulated to great fanfare throughout human history: unconditional loving-friendliness toward all beings. A good, harmless system would interact with the world in ways that lead to more comprehension and less confusion, more generosity and less greed, more equanimity and less aversion. (By contrast, ChatGPT consistently says you can benefit by becoming angrier.)
It's no surprise that characters like Jesus became very popular in their time. "Love your enemies" is excellent advice for emotional health. The Buddha unpacked the same attitude in plain terms:
Replies from: RokoMay all beings be happy and secure.
May all beings have happy minds.Whatever living beings there may be,
Without exception: weak or strong,
Long or large, medium, short, subtle or gross,
Visible or invisible, living near or far,
Born or coming to birth--
May all beings have happy minds.Let no one deceive another,
Nor despise anyone anywhere.
Neither from anger nor ill will
Should anyone wish harm to another.As a mother would risk her own life
To protect her only child,
Even so toward all living beings,
One should cultivate a boundless heart.One should cultivate for all the world
A heart of boundless loving-friendliness,
Above, below, and all around,
Unobstructed, without hatred or resentment.Whether standing, walking, or sitting,
Lying down, or whenever awake,
One should develop this mindfulness.
This is called divinely dwelling here.
↑ comment by Roko · 2023-12-18T13:45:22.593Z · LW(p) · GW(p)
unconditional loving-friendliness toward all beings.
Unfortunately this doesn't really work as different beings have conflicting preferences.
Replies from: Feel_Love↑ comment by Feel_Love · 2023-12-18T15:41:11.782Z · LW(p) · GW(p)
"Being a mom isn't easy. I used to love all my kids, wishing them health and happiness no matter what. Unfortunately, this doesn't really work as they have grown to have conflicting preferences."
A human would be an extreme outlier to be this foolish. Let's not set the bar so low for AI.
comment by avturchin · 2023-12-15T15:36:47.556Z · LW(p) · GW(p)
The value of AI aimability may be overblown. If AI is not aimable, its goals will perform eternal random walk and thus AI will cause only short-term risk - no risk of world takeover. (Some may comment that after random walk, it will stack in some Waluigi state forever - but if it is actually works in getting fix goal system, why we do not research such strange attractors in the space of AI goals?)
AI will become global-catastrophically-dangerous only after aimability will be solved. Research in aimability only brings this moment closer.
The wording "AI alignment" is precluding us to see this risk, as it combines aimability and giving nice goals to AI.
Replies from: Roko, bideup, Seth Herd↑ comment by Roko · 2023-12-15T15:57:52.254Z · LW(p) · GW(p)
Yes, this is a good point. Aimability Research increases the kurtosis of the AI outcome distribution, making both the right tail (paradise) and the left tail (total annihilation) heavier, and reducing the so-so outcomes in the center.
Only Goalcrafting Research can change the relative weights.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-15T16:56:16.831Z · LW(p) · GW(p)
The aspect of aimability where an AI becomes able to want something in particular consistently [LW · GW] improves capabilities, and improved capabilities make AI matter a lot more. This might happen without ability to aim an AI where you want it aimed, another key aspect. Without the latter aspect, aimability is not "solved", yet AIs become dangerous.
Replies from: Roko↑ comment by bideup · 2023-12-15T15:51:28.134Z · LW(p) · GW(p)
A gun which is not easily aimable doesn't shoot bullets on random walks.
Or in less metaphorical language, the worry is that mostly that it's hard to give the AI the specific goal you want to give it, not so much that it's hard to make it have any goal at all. I think people generally expect that naively training an AGI without thinking about alignment will get you a goal-directed system, it just might not have the goal you want it to.
Replies from: Roko, faul_sname, avturchin↑ comment by Roko · 2023-12-15T15:59:49.765Z · LW(p) · GW(p)
The practical effect of very inaccurate guns in the past was that guns mattered less and battles were often won by bayonet charges or morale. So I think it's fair to conclude that Aimability just makes AI matter a lot more.
Replies from: bideup↑ comment by faul_sname · 2023-12-15T18:37:00.273Z · LW(p) · GW(p)
Or in less metaphorical language, the worry is that mostly that it's hard to give the AI the specific goal you want to give it, not so much that it's hard to make it have any goal at all.
At least some people are worried about the latter [LW · GW], for a very particular meaning of the word "goal". From that post:
Finally, I'll note that the diamond maximization problem is not in fact the problem "build an AI that makes a little diamond", nor even "build an AI that probably makes a decent amount of diamond, while also spending lots of other resources on lots of other stuff" (although the latter is more progress than the former). The diamond maximization problem (as originally posed by MIRI folk) is a challenge of building an AI that definitely optimizes for a particular simple thing, on the theory that if we knew how to do that (in unrealistically simplified models, allowing for implausible amounts of (hyper)computation) then we would have learned something significant about how to point cognition at targets in general.
I think to some extent this is a matter of "yes, I see that you've solved the problem in practical terms, and yes, every time we try to implement the theoretically optimal solution it fails due to Goodharting, but we really want the theoretically optimal solution", which is... not universally agreed, to say the least. But it is a concern some people have.
Replies from: bideup, roger-d-1↑ comment by bideup · 2023-12-15T19:01:35.704Z · LW(p) · GW(p)
Hm, I think that paragraph is talking about the problem of getting an AI to care about a specific particular thing of your choosing (here diamond-maximising), not any arbitrary particular thing at all with no control over what it is. The MIRI-esque view thinks the former is hard and the latter happens inevitably.
Replies from: faul_sname↑ comment by faul_sname · 2023-12-15T19:04:19.220Z · LW(p) · GW(p)
I don't think we have any way of getting an AI to "care about" any arbitrary particular thing at all, by the "attempt to maximize that thing, self-correct towards maximizing that thing if the current strategies are not working" definition of "care about". Even if we relax the "and we pick the thing it tries to maximize" constraint.
Replies from: bideup↑ comment by bideup · 2023-12-15T22:17:13.163Z · LW(p) · GW(p)
I don’t think that that’s the view of whoever wrote the paragraph you’re quoting, but at this point we’re doing exegesis
Replies from: faul_sname↑ comment by faul_sname · 2023-12-15T23:50:56.458Z · LW(p) · GW(p)
"We don't currently have any way of getting any system to learn to robustly optimize for any specific goal once it enters an environment very different from the one it learned in" is my own view, not Nate's.
Like I think the MIRI folks are concerned with "how do you get an AGI to robustly maximize any specific static utility function that you choose".
I am aware that the MIRI people think that the latter is inevitable. However, as far as I know, we don't have even a single demonstration of "some real-world system that robustly maximizes any specific static utility function, even if that utility function was not chosen by anyone in particular", nor do we have any particular reason to believe that such a system is practical.
And I think Nate's comment makes it pretty clear that "robustly maximize some particular thing" is what he cares about.
Replies from: RobbBB, None↑ comment by Rob Bensinger (RobbBB) · 2023-12-16T22:36:59.979Z · LW(p) · GW(p)
To be clear: The diamond maximizer problem is about getting specific intended content into the AI's goals ("diamonds" as opposed to some random physical structure it's maximizing), not just about building a stable maximizer.
Replies from: faul_sname↑ comment by faul_sname · 2023-12-16T23:23:11.846Z · LW(p) · GW(p)
Thanks for the clarification!
If you relax the "specific intended content" constraint, and allow for maximizing any random physical structure, as long as it's always the same physical structure in the real world and not just some internal metric that has historically correlated with the amount of that structure that existed in the real world, does that make the problem any easier / is there a known solution? My vague impression was that the answer was still "no, that's also not a thing we know how to do".
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2023-12-17T00:31:56.694Z · LW(p) · GW(p)
I expect it makes it easier, but I don't think it's solved.
↑ comment by [deleted] · 2023-12-16T02:25:41.793Z · LW(p) · GW(p)
So as an engineer I have trouble engaging with this as a problem.
Suppose you want to synthesize a lot of diamonds. Instead of giving an AI some lofty goal "maximize diamonds in an aligned way", why not a bunch of small grounded ones.
- "Plan the factory layout of the diamond synthesis plant with these requirements".
- "Order the equipment needed, here's the payment credentials".
- "Supervise construction this workday comparing to original plans"
- "Given this step of the plan, do it"
- (Once the factory is built) "remove the output from diamond synthesis machine A53 and clean it".
And so on. And any goal that isn't something the model has empirical confidence in - because it's in distribution for the training environment - an outer framework should block the unqualified model from attempting.
I think the problem MIRI has is this myopic model is not aware of context, and so it will do bad things sometimes. Maybe the diamonds are being cut into IC wafers and used in missiles to commit genocide.
Is that what it is? Or maybe the fear is that one of these tasks could go badly wrong? That seems acceptable, industrial equipment causes accidents all the time, the main thing is to limit the damage. Fences to limit the robots operating area, timers that shut down control after a timeout, etc.
Replies from: faul_sname↑ comment by faul_sname · 2023-12-16T03:25:17.986Z · LW(p) · GW(p)
I think the MIRI objection to that type of human-in-the-loop system is that it's not optimal because sometimes such a system will have to punt back to the human, and that's slow, and so the first effective system without a human in the loop will be vastly more effective and thus able to take over the world, hence the old "that's safe but it doesn't prevent someone else from destroying the world [LW · GW]".
We can't just build a very weak system, which is less dangerous because it is so weak, and declare victory; because later there will be more actors that have the capability to build a stronger system and one of them will do so.
So my impression is that the MIRI viewpoint is that if humanity is to survive, someone needs to solve the "disempower anyone who could destroy the world" problem, and that they have to get that right on the first try, and that's the hard part of the "alignment" problem. But I'm not super confident that that interpretation is correct and I'm quite confident that I find different parts of that salient than people in the MIRI idea space.
Anyone who largely agrees with the MIRI viewpoint want to weigh in here?
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2023-12-16T23:01:28.581Z · LW(p) · GW(p)
Suppose you want to synthesize a lot of diamonds. Instead of giving an AI some lofty goal "maximize diamonds in an aligned way", why not a bunch of small grounded ones.
- "Plan the factory layout of the diamond synthesis plant with these requirements".
- "Order the equipment needed, here's the payment credentials".
- "Supervise construction this workday comparing to original plans"
- "Given this step of the plan, do it"
- (Once the factory is built) "remove the output from diamond synthesis machine A53 and clean it".
That is how MIRI imagines a sane developer using just-barely-aligned AI to save the world. You don't build an open-ended maximizer and unleash it on the world to maximize some quantity that sounds good to you; that sounds insanely difficult. You carve out as many tasks as you can into concrete, verifiable chunks, and you build the weakest and most limited possible AI you can to complete each chunk, to minimize risk. (Though per faul_sname, you're likely to be pretty limited in how much you can carve up the task, given time will be a major constraint and there may be parts of the task you don't fully understand at the outset.)
Cf. The Rocket Alignment Problem. The point of solving the diamond maximizer problem isn't to go build the thing; it's that solving it is an indication that we've become less conceptually confused about real-world optimization and about aimable cognitive work. Being less conceptually confused about very basic aspects of problem-solving and goal-oriented reasoning means that you might be able to build some of your powerful AI systems out of building blocks that are relatively easy to analyze, test, design, predict, separate out into discrete modules, measure and limit the capabilities of, etc., etc.
That seems acceptable, industrial equipment causes accidents all the time, the main thing is to limit the damage. Fences to limit the robots operating area, timers that shut down control after a timeout, etc.
If everyone in the world chooses to permanently use very weak systems because they're scared of AI killing them, then yes, the impact of any given system failing will stay low. But that's not what's going to actually happen; many people will use more powerful systems, once they can, because they misunderstand the risks or have galaxy-brained their way into not caring about them (e.g. 'maybe humans don't deserve to live', 'if I don't do it someone else will anyway', 'if it's that easy to destroy the world then we're fucked anyway so I should just do the Modest thing of assuming nothing I do is that important'...).
The world needs some solution to the problem "if AI keeps advancing and more-powerful AI keeps proliferating, eventually someone will destroy the world with it". I don't know of a way to leverage AI to solve that problem without the AI being pretty dangerously powerful, so I don't think AI is going to get us out of this mess unless we make a shocking amount of progress on figuring out how to align more powerful systems. (Where "aligning" includes things like being able to predict in advance how pragmatically powerful your system is, and being able to carefully limit the ways in which it's powerful.)
Replies from: faul_sname↑ comment by faul_sname · 2023-12-21T04:33:33.869Z · LW(p) · GW(p)
Thanks for the reply.
That is how MIRI imagines a sane developer using just-barely-aligned AI to save the world. You don't build an open-ended maximizer and unleash it on the world to maximize some quantity that sounds good to you; that sounds insanely difficult. You carve out as many tasks as you can into concrete, verifiable chunks, and you build the weakest and most limited possible AI you can to complete each chunk, to minimize risk. (Though per faul_sname, you're likely to be pretty limited in how much you can carve up the task, given time will be a major constraint and there may be parts of the task you don't fully understand at the outset.)
This sounds like a good and reasonable approach, and also not at all like the sort of thing where you're trying to instill any values at all into an ML system. I would call this "usable and robust tool construction" not "AI alignment". I expect standard business practice will look something like this: even when using LLMs in a production setting, you generally want to feed it the minimum context to get the results you want, and to have it produce outputs in some strict and usable format.
The world needs some solution to the problem "if AI keeps advancing and more-powerful AI keeps proliferating, eventually someone will destroy the world with it".
"How can I build a system powerful enough to stop everyone else from doing stuff I don't like" sounds like more of a capabilities problem than an alignment problem.
I don't know of a way to leverage AI to solve that problem without the AI being pretty dangerously powerful, so I don't think AI is going to get us out of this mess unless we make a shocking amount of progress on figuring out how to align more powerful systems
Yeah, this sounds right to me. I expect that there's a lot of danger inherent in biological gain-of-function research, but I don't think the solution to that is to create a virus that will infect people and cause symptoms that include "being less likely to research dangerous pathogens". Similarly, I don't think "do research on how to make systems that can do their own research even faster" is a promising approach to solve the "some research results can be misused or dangerous" problem.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-21T04:19:27.859Z · LW(p) · GW(p)
This is rather off-topic here, but for any AI that has an LLM as a component of it, I don't believe diamond-maximization is a hard problem, apart from Inner Alignment problems. The LLM knows the meaning of the word 'diamond' (GPT-4 defined it as "Diamond is a solid form of the element carbon with its atoms arranged in a crystal structure called diamond cubic. It has the highest hardness and thermal conductivity of any natural material, properties that are utilized in major industrial applications such as cutting and polishing tools. Diamond also has high optical dispersion, making it useful in jewelry as a gemstone that can scatter light in a spectrum of colors."). The LLM also knows its physical and optical properties, its social, industrial and financial value, its crystal structure (with images and angles and coordinates), what carbon is, its chemical properties, how many electrons, protons and neutrons a carbon atom can have, its terrestrial isotopic ratios, the half-life of carbon-14, what quarks a neutron is made of, etc. etc. etc. — where it fits in a vast network of facts about the world. Even if the AI also had some other very different internal world model and ontology, there's only going to be one "Rosetta Stone" optimal-fit mapping between the human ontology that the LLM has a vast amount of information about and any other arbitrary ontology, so there's more than enough information in that network of relationships to uniquely locate the concepts in that other ontology corresponding to 'diamond'. This is still true even if the other ontology is larger and more sophisticated: for example, locating Newtonian physics in relativistic quantum field theory and mapping a setup from the former to the latter isn't hard: its structure is very clearly just the large-scale low-speed limiting approximation.
The point where this gets a little more challenging is Outer Alignment, where you want to write a mathematical or pseudocode reward function for training a diamond optimizer using Reinforcement Learning (assuming our AI doesn't just have a terminal goal utility function slot that we can directly connect this function to, like AIXI): then you need to also locate the concepts in the other ontology for each element in something along the lines of "pessimizingly estimate the total number of moles of diamond (having at a millimeter-scale-average any isotopic ratio of C-12 to C-13 but no more than times the average terrestrial proportion of C-14, discounting any carbon atoms within C-C bonds of a crystal-structure boundary, or within bonds of a crystal -structure dislocation, or within bonds of a lattice substitution or vacancy, etc. …) at the present timeslice in your current rest frame inside the region of space within the future-directed causal lightcone of your creation, and subtract the answer for the same calculation in a counterfactual alternative world-history where you had permanently shut down immediately upon being created, but the world-history was otherwise unchanged apart from future causal consequences of that divergence". [Obviously this is a specification design problem, and the example specification above may still have bugs and/or omissions, but there will only be a finite number of these, and debugging this is an achievable goal, especially if you have a crystalographer, a geologist, and a jeweler helping you, and if a non-diamond-maximizing AI also helps by asking you probing questions. There are people whose jobs involve writing specifications like this, including in situations with opposing optimization pressure.]
As mentioned above, I fully acknowledge that this still leaves the usual Inner Alignment problems unsolved: applying Reinforcement Learning (or something similar such as Direct Preference Optimization) with this reward function to our AI, then how do we ensure that it actually becomes a diamond maximizer, rather than a biased estimator of diamond? I suspect we might want to look at some form of GAN, where the reward-estimating circuitry it not part of the Reinforcement Learning process, but is being trained in some other way. That still leaves the Inner Alignment problem of training a diamond maximizer instead of a hacker of reward model estimators.
Replies from: faul_sname↑ comment by faul_sname · 2023-12-21T04:42:39.422Z · LW(p) · GW(p)
I think if we're fine with building an "increaser of diamonds in familiar contexts", that's pretty easy, and yeah I think "wrap an LLM or similar" is a promising approach. If we want "maximize diamonds, even in unfamiliar contexts", I think that's a harder problem, and my impression is that the MIRI folks think the latter one is the important one to solve.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-21T06:12:12.969Z · LW(p) · GW(p)
What in my diamond maximization proposal above only works in familiar contexts? Most of it is (unsurprisingly) about crystalography and isotopic ratios, plus a standard causal wrapper. (If you look carefully, I even allowed for the possibility of FTL.)
The obvious "brute force" solution to aimability is a practical, approximately Bayesian, GOFAI equivalant of AIXI that is capable of tool use and contains an LLM as a tool;. This is extremely aimable — it has an explicit slot to plug a utility function in. Which makes it extremely easy to build a diamond maximizer, or a paperclip maximizer, or any other such x-risk. Then we need to instead plug in something that hopefully isn't an x-risk, like value learning or CEV or "solve goalcraft" as the terminal goal: figure out what we want, then optimize that, while appropriately pessimizing that optimization over remaining uncertainties in "what we want".
↑ comment by avturchin · 2023-12-15T16:11:30.086Z · LW(p) · GW(p)
If we find that AI can stop its random walk on a goal X, we can use this as an aimability instrument, and find a way to manipulate the position of X.
Replies from: Roko, bideup↑ comment by Roko · 2023-12-15T16:17:07.481Z · LW(p) · GW(p)
I don't think "random" AI goals is a thing that will ever happen.
I think it's much more likely that, if there are Aimability failures, they will be highly nonrandom and push AI towards various attractors (like how the behavior of dictators is surprisingly consistent across time, space and ideology)
↑ comment by bideup · 2023-12-15T16:12:46.189Z · LW(p) · GW(p)
Perhaps, or perhaps not? I might be able to design a gun which shoots bullets in random directions (not on random walks), without being able to choose the direction.
Maybe we can back up a bit, and you could give some intuition for why you expect goals to go on random walks at all?
My default picture is that goals walk around during training and perhaps during a reflective process, and then stabilise somewhere.
Replies from: avturchin↑ comment by avturchin · 2023-12-15T16:28:07.079Z · LW(p) · GW(p)
My intuition: imagent LLM-based agent. It has fixed prompt and some context text and use this iteratively. Context part can change and as it changes, it affects interpretation of fixed part of the prompt. Examples are Waluigi and other attacks. This causes goal drift.
This may have bad consequences as a robot suddenly turns in Waluigi and start kill randomly everyone around. But long-term planning and deceptive alignment requires very fixed goal system.
Replies from: bideup↑ comment by Seth Herd · 2023-12-15T18:49:52.025Z · LW(p) · GW(p)
This just isn't true. AGI is a "gun that can aim itself". The user not being to aim it doesn't mean it won't aim and achieve something, quite effectively.
Less metaphorically: if the AGI performs a semi-random walk through goal space, or just misses your intended goal by enough, it may settle (even temporarily) on a coherent goal that's incompatible with yours. It may then eliminate humanity as a competitor to its reaching that goal.