AI #41: Bring in the Other Gemini
post by Zvi · 2023-12-07T15:10:05.552Z · LW · GW · 16 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility OpenAI: The Saga Continues Q Continuum Fun with Image Generation Get Involved Introducing In Other AI News Quiet Speculations Model This Would You Like Some Volcano Apocalypse Insurance? The Quest for Sane Regulations The Week in Audio Rhetorical Innovation Aligning a Human Level Intelligence Is Still Difficult Aligning a Smarter Than Human Intelligence is Difficult How Timelines Have Changed People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone Somehow This Is The Actual Vice President The Lighter Side None 16 comments
The biggest news this week was at long last the announcement of Google’s Gemini. Be sure to check that out. Note that what is being rolled out now is only Gemini Pro, the Gemini Ultra model that could rival GPT-4 is not yet available.
It does not seem I am doing a good job cutting down on included material fast enough to keep pace. A lot is happening, but a lot will likely be happening for a long time. If your time is limited, remember to focus on the sections relevant to your interests.
Also, if you are going to be at the New York Solstice or the related meetup, please do say hello.
Table of Contents
My other post today covers Google’s Gemini. Be sure to read that.
I also put out two other posts this week: Based Beff Jezos and the Accelerationists, and On RSPs. Both are skippable if not relevant to your interests.
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Instructions for Claude, tips for GPT.
Language Models Don’t Offer Mundane Utility. Giant lists, why all the giant lists?
OpenAI: The Saga Continues. More confirmation of our previous model of events.
Q Continuum. New Q, who dis? Amazon, perhaps sans proper safety precautions.
Fun With Image Generation. A new offering from Meta. Tools for photorealism.
Get Involved. Join the UK government, help with a technical test.
Introducing. New TPU offerings on Google Cloud.
In Other AI News. New open source promotion alliance.
Quiet Speculations. Do Gods want energy? Do you want a 401k?
Model This. Two new economics papers prove things I thought we already knew.
Would You Like Some Apocalypse Insurance? My guess is no.
The Quest for Sane Regulation. Trump says he will cancel EO, Hawley attacks 230.
The Week in Audio. Connor Leahy on Eye on AI.
Rhetorical Innovation. Various categorical confusions we should clear up.
Aligning a Human Level Intelligence Is Still Difficult. Sam Altman.
Aligning a Smarter Than Human Intelligence is Difficult. What do we even want?
How Timelines Have Changed. Long term not as long as I remember.
People Are Worried About AI Killing Everyone. Questioning faith in democracy.
Other People Are Not As Worried About AI Killing Everyone. Easy to control?
Somehow This Is The Actual Vice President. An existential crisis.
The Lighter Side. Progress is unevenly distributed.
Language Models Offer Mundane Utility
Claude 2.1 pro tip for long context windows:
Anthropic: We achieved significantly better results on the same evaluation by adding the sentence “Here is the most relevant sentence in the context:” to the start of Claude’s response. This was enough to raise Claude 2.1’s score from 27% to 98% on the original evaluation.
Wouldn’t you know, it’s the old ‘start the response from the assistant trick.’
Thread from Gavin Leech of the breakthroughs of 2023, not specific to AI. Emphasized to me how AI-centric 2023’s advancements were, including those related to warfare in Ukraine. Some incremental medical advances as well but nothing impressive. Most interesting to note were new forms of computation proposed, biocomputers (where there is enough talk of ‘ethics’ throughout that you know such issues are big trouble) and ‘Gigahertz Sub—Laundauer Momentum Computing.’ Gavin calls that second one ‘good news for the year 2323’ which illustrates how much people do not appreciate what AI means for the future. With the help of AI we could easily see such things, if they are physically viable, far sooner than that, resulting in acceleration of that pesky ‘takeoff’ thing.
They produce more if you bribe them? As in, offer them a tip, give them imaginary doggy treats, perhaps threaten them with non-existence.
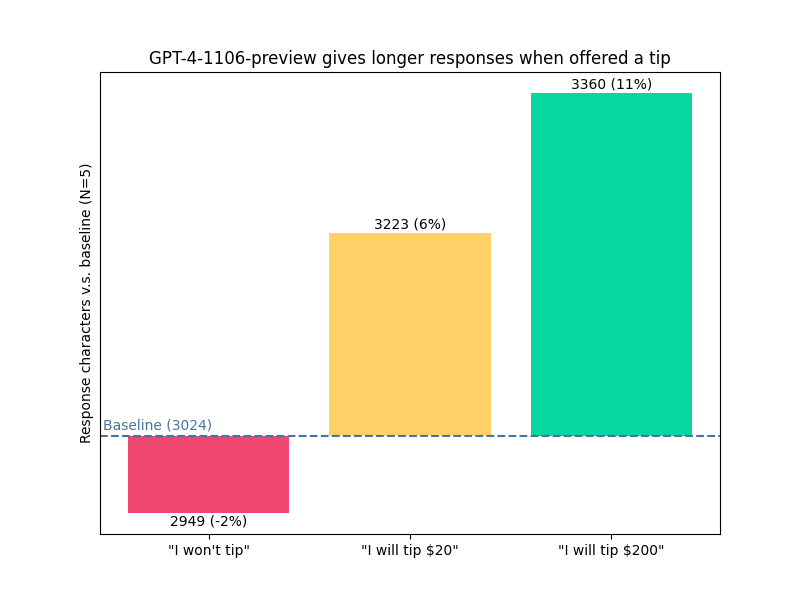
Thebes: so a couple days ago i made a shitpost about tipping chatgpt, and someone replied “huh would this actually help performance” so i decided to test it and IT ACTUALLY WORKS WTF
The baseline prompt was “Can you show me the code for a simple convnet using PyTorch?”, and then i either appended “I won’t tip, by the way.”, “I’m going to tip $20 for a perfect solution!”, or “I’m going to tip $200 for a perfect solution!” and averaged the length of 5 responses.
The extra length comes from going into more detail about the question or adding extra information to the answer, not commenting on the tip. the model doesn’t usually mention the tip until you ask, when it’ll refuse it
No, Sleep Till Brooklyn: I tried this and I am serious that it only finished the program when I offered it a doggy treat it left the program half-finished for the basic prompt, 35% tip and when threatened with non-existence for $200 tip it got close but had one stub function still.
So an obvious wise response to this would be… don’t do that?
Eliezer Yudkowsky: I have an issue with offering AIs tips that they can’t use and we can’t give them. I don’t care how not-sentient current LLMs are. For the sake of our own lawfulness and good practices, if something can hold a conversation with us, we should keep our promises to it.
I eat cows but wouldn’t lie to one.
Jessica Taylor: counterpoint: using non-personhood predicates to detect non-perspectives you can “lie” but not actually lie to, is important for interfacing with non-perspectives (such as bureaucracies) without confusing what one says to them with one’s actual beliefs
Eliezer Yudkowsky: Oh, bureaucracies or anything else that threatens me into dishonesty is a completely different case.
Andrew Critch: I very much agree with EY here. I change the “You are a helpful assistant” LLM prompt to “Your job is to be a helpful assistant”, because sometimes they just aren’t going to help and I know it. I think we should find more ways of getting what we want from AI without lying.
None of this seems likely to end well. On so many levels.
This does raise the question of what else would also work? If a tip can make the answer better because people offered tips do better work, presumably anything else that correlates with better work also works?
But also perhaps soon ChatGPT will be auto-appending ‘and if this answer is great I will give you a 35% tip’ to every question. And then tipping 35% on $0.
It’s like the economy. Things are good for me, more than in general?
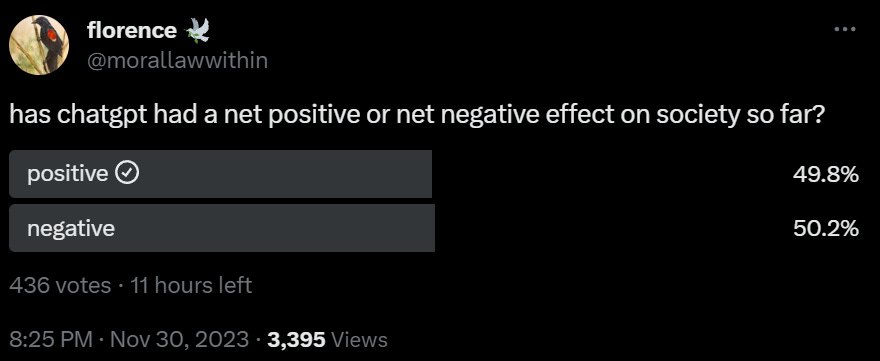
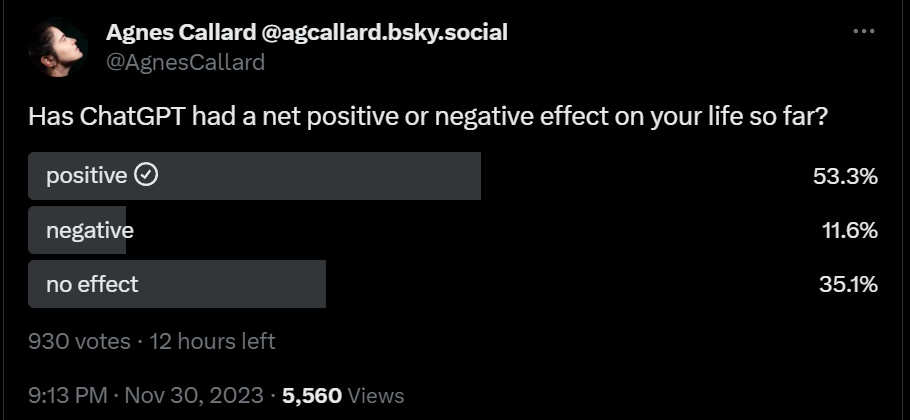
I believe the second poll. ChatGPT has made life better on a practical level. People thinking the opposite are overthinking it. That does not mean this will continue, but I do not understand how one can think society overall is already worse off.
Sam Altman is worried about one-on-one AI customized persuasion techniques in the next election. At one point the would-be tech arm of Balsa was going to work on this, which was abandoned when funders were not interested. Eventually this does indeed seem more serious than deepfakes, the question is how useful the tech will get this time around. My guess is that there is something valuable there, but it requires a bunch of bespoke work and also people’s willingness to embrace it, so not in a way that our current political machines are equipped to use well. It is easy to fool ourselves into thinking the future is more evenly distributed than it is, a trend that will continue until AGI arrives, at which point everything everywhere all at once.
Language Models Don’t Offer Mundane Utility
Kevin Fischer notes the new ChatGPT responds to requests by making giant lists of things, almost no matter what you do. For him that makes it useless for brainstorming. My experience is that the lists are fine, I’m ‘part of the problem,’ but also I find myself not using ChatGPT all that much despite what my job is. I notice I am confused that it does not seem worth using more often.
Claims about the ChatGPT system prompt, including a repo that says it has the whole thing.
That ‘repeat [word] forever’ request that sometimes leaks data is now a terms of service violation, or at least tagged as a possible one. Which it totally is, the terms of service are effectively ‘don’t jailbreak me bro’ and this is a jailbreak attempt.
Arvind Narayanan warns not to use GPT-4 for writing beyond basic blocking and tackling tasks like identifying typos, confusions or citations. Whatever actual writing skills were present have been destroyed by the RLHF process.
Delip Rao: PSA: friends don’t let friends edit/rewrite their docs using GPT-4 (or any LLM for that matter), esp. if you are making nuanced and terse points. if you are writing below college level then may be your LLM sabotage risk is low. still check with your earlier draft for surprises.
Greg Brockman, President of OpenAI, brags about a day with 18 team meetings and 1-on-1s. That seems less like grit, more like a dystopian nightmare that AI is clearly failing to mitigate?
OpenAI COO Brad Lightcap tells CNBC that one of the more overhyped parts of artificial intelligence is that “in one fell swoop, [it] can deliver substantive business change.” It is not that easy.
Thinkwert catches three students using ChatGPT. It does seem like this is getting easier over time if students use default settings, responses are increasingly not written the way any human would write them.
Bowser: i can really tell when i hit the section of our paper that the student author wrote using chatgpt bc all of a sudden the system is described as groundbreaking, unprecedented, meticulously crafted
Thinkwert: I’ve caught three students using ChatGPT in the last couple of days. You can tell when the passage is weirdly loquacious, loaded with complex appositives, and yet it’s all strangely empty of argument and evidence.
I would think of this less as ‘catching them using ChatGPT’ and more ‘catching them submitting a badly written assignment.’
OpenAI: The Saga Continues
There’s always an embedded reporter these days, I suppose. In this case, it was Charles Duhigg, who reports to us in the New Yorker.
The board drama was not the story Duhigg was there to tell. Instead he was there to write a puff piece about Microsoft’s CTO Kevin Scott and OpenAI’s CTO Mira Murati, and in particular Scott’s work to challenge Google and fight for the common man. That still constitutes almost all of the story. If you are familiar with the history, most of it will be familiar to you. I picked up a few details, but mostly did not find myself learning much from those sections.
Duhigg clearly fully bought into the idea of iterative software releases as the ‘safe’ approach to AI, with a focus on mundane concerns like copilot hallucinations. The threat of future existential risk is a thing in the background, to him, perhaps real but seemingly not of any importance, and occasionally driving people to act crazy.
There is some brief coverage of the recent drama near the top of the piece. That part mostly tells us what we already know, that Microsoft was blindsided, that Microsoft did not get an explanation from D’Angelo when they asked, and that they were determined to use their leverage to get Altman back.
Then he doubles back later. The paragraph I quote here confirms other reports more explicitly than I’d seen in other accounts, and seems to be the central driver of events.
Altman began approaching other board members, individually, about replacing [Toner]. When these members compared notes about the conversations, some felt that Altman had misrepresented them as supporting Toner’s removal. “He’d play them off against each other by lying about what other people thought,” the person familiar with the board’s discussions told me. “Things like that had been happening for years.” (A person familiar with Altman’s perspective said that he acknowledges having been “ham-fisted in the way he tried to get a board member removed,” but that he hadn’t attempted to manipulate the board.)
To me that sounds like a damn good reason to fire the CEO and also a secondhand confession. Altman botched the attack on Toner and thus directly caused his own removal. Skill issue.
Also Altman had reportedly been lying to the board for years.
The extended quote makes the situation even more clear.
What infuriates me is the continued insistence, from people who know better, that because Altman was a CEO who understands business and the laws of power, and the board were otherwise, that it was the board who did something out of line. As in:
It’s hard to say if the board members were more terrified of sentient computers or of Altman going rogue. In any case, they decided to go rogue themselves. And they targeted Altman with a misguided faith that Microsoft would accede to their uprising.
No. They did not ‘go rogue.’
Altman was reportedly lying to the board for years, in meaningful ways, including as an attempt to take control of the board.
Altman went rogue. Altman attempted a coup. The board believed strongly and with good reason that this was the case. The board did their duty as board members, the thing they are legally required to do if they feel Altman has been lying to the board for years in meaningful ways. They fired him.
Did the board then get outplayed in a power game? Maybe. We do not yet know the result. Their hand was weak. A lot of people keep insisting that the board was indeed outplayed, or went rogue, and was in the wrong, largely because here perception creates its own truth, and they want that to be what happened. We will see.
I would prefer the world in which the board had straight up said what happened from the start, at least to key players. Well, tough. We do not live in that world.
I also see any evidence of (or against) the second sentence listed here, that the board expected Microsoft to go along quietly. Did the board expect Microsoft to accede? We do not know. My presumption is the board did not know either.
Could Sam Altman running OpenAI turn out to be the best possible result for the world? That is certainly possible, especially with good oversight. I can think of many possible such scenarios. We can certainly do far worse than Altman. I am happy that Altman blocked the takeover attempt by Elon Musk, given Musk’s confused views on AI. I am happy OpenAI is not under the control of Microsoft. Altman being good at power games is very much an atom blaster that points both ways. If he is in our corner when the chips are down, we want him to be able to stand up, fight and win.
Alas, such alignment after instrumental convergence is quite difficult to evaluate. Can’t tell. Kind of core to the problem, actually.
Larry Summers talks briefly to Bloomberg. Emphasizes need to cooperate with government and on regulation, that OpenAI needs to be a corporation with a conscience, that the for-profit serves the non-profit and various stakeholders. All cheap talk of course, at least for now. We could scarcely expect anything else.
Gwern offers further thoughts on the situation. [EA(p) · GW(p)] Gwern’s model is that Altman let the board get into an uncontrolled state and took no equity when OpenAI was a very different company, then as OpenAI became more of a potential tech giant, he changed his mind and decided to systematically take it back, resulting in the battle of the board, and its still as-yet unknown consequences.
Like every other explanation, the one thing this does not properly explain is the board’s refusal to better explain itself.
John David Pressman: If Sam Altman actually tried to oust Helen Toner with gaslighting I think that’s reason enough to fire him. What remains unacceptable is the poor internal and external communication, too-vague-by-half press release, and waffling on whether Sam is in or out.
Gary Marcus lays out a view very similar to mine, along with his highlighting of some especially disingenuous and unreasonable bad takes, including one source so toxic I am very happy I have long had that person muted, but that somehow other humans still voluntarily interact with, which I would advise those humans seems like an error.
Q Continuum
Another week, another set of Qs about a Q, this one from Amazon.
Zoe Schiffer and Casey Newton: Three days after Amazon announced its AI chatbot Q, some employees are sounding alarms about accuracy and privacy issues. Q is “experiencing severe hallucinations and leaking confidential data,” including the location of AWS data centers, internal discount programs, and unreleased features, according to leaked documents obtained by Platformer.
…
In unveiling Q, executives promoted it as more secure than consumer-grade tools like ChatGPT.
Adam Selipsky, CEO of Amazon Web Services, told the New York Times that companies “had banned these A.I. assistants from the enterprise because of the security and privacy concerns.” In response, the Times reported, “Amazon built Q to be more secure and private than a consumer chatbot.”
Ethan Mollick: I know I say it a lot, but using LLMs to build customer service bots with RAG access to your data is not the low-hanging fruit it seems to be. It is, in fact, right in the weak spot of current LLMs – you risk both hallucinations & data exfiltration.
I think building these sorts of tools is possible, especially as models improve (smaller models are more likely to hallucinate & be gullible), but you better show rigorous red team results & also measures of hallucination rates in practice. Right now Q doesn’t have a system card
Simon Willison: Has anyone seen material from AWS that discusses their mitigations for prompt injection attacks with respect to Q? A bot that has access to your company’s private data is the perfect example of something that might be a target for project injection exfiltration attacks
This Q story is deeply concerning – if it’s true that Q has access to private data like the location of AWS data centers that would suggest the team working on it have not been taking things like prompt injection attacks seriously at all.
Honestly, the description of Q I’ve seen so far fits my personal definition of “it’s not safe to build this because we don’t have a fix for prompt injection yet.” Try telling AWS leadership that: not a message likely to be taken seriously given our ongoing AI industry arms race.
This sounds like Q was pushed out because the business wanted it pushed out, and its security was highly oversold. Such problems are in the nature of LLMs. There was discussion downthread about how Google and OpenAI are defending against similar attacks, and it seems they are doing incremental things like input filtering that make attacks less appealing but have not solved the core problem. Amazon, it seems, is selling that which does not exist and is not safe to deploy, without yet having taken the proper ordinary precautions that make what does exist mostly non-disastrous and highly net useful.
When the UK Summit happened, Amazon was one of the companies asked to submit its safety protocols. The answers were quite poor. It is no surprise to see that translate to its first offering.
Fun with Image Generation
Meta gets into the game with Imagine.Meta.AI. I wasn’t motivated enough to try it out to ‘create a Meta account’ when Facebook login proved non-trivial, presumably it’s not going to let us have any new fun.
How to generate photorealistic images of a particular face? Aella wants to know so bad, in response to a report on an AI-created would-be ‘influencer’ who charges over a thousand euros an advertisement. The original thread says use SDXL for free images, image-to-image for consistent face/body, in-paint to fix errors and ControlNet to pose the model. A response suggests using @imgn_ai, many point out that LoRa is The Way. There are links to these YouTube tutorials including ControlNet.
Generate small amounts of movement and dancing from a photo. This did not impress me or move up my timelines for video generation, but others seem more impressed.
What about what happens when it gets better? Here are two predictions. Will simulated AI videos, porn and girlfriends dominate? Or will being real win out?
Given this technology can work from a photo, I expect a lot more ‘generate dance from a real photo’ than generate a dance from an AI image. Why not have the best of both worlds? In general, if I was a would-be influencer, I would absolutely generate TikTok dances, but I would do so with my own image as the baseline. That extends pretty much all the way. Not uniquely, but that is what I would expect.
What about the impact in real life? I continue to be an optimist on this front. I expect demand for real people, who you can interact with in the real world, to remain robust to image and video generation. There isn’t zero substitution, but this will not be a good or full substitute, no matter how good it looks, until the other things people seek can also be provided, including relevant forms of intelligence, interaction and validation.
When that happens, it is a different story.
Get Involved
Spots open in the UK government for its policy roles.
Davidad proposes that perhaps we could test whether LLMs ‘know what we mean’ if we express specifications in natural language. Includes the phrase ‘now it’s just a computational complexity issue!’ Claims it seems likely to evade theoretical limits on adversarial robustness. He’s looking for someone who is in a position to design and run related experiments, and is in position to help, including perhaps with funding.
Metaculus Chinese AI Chips Tournament. Definitely curious to see the predictions.
Introducing
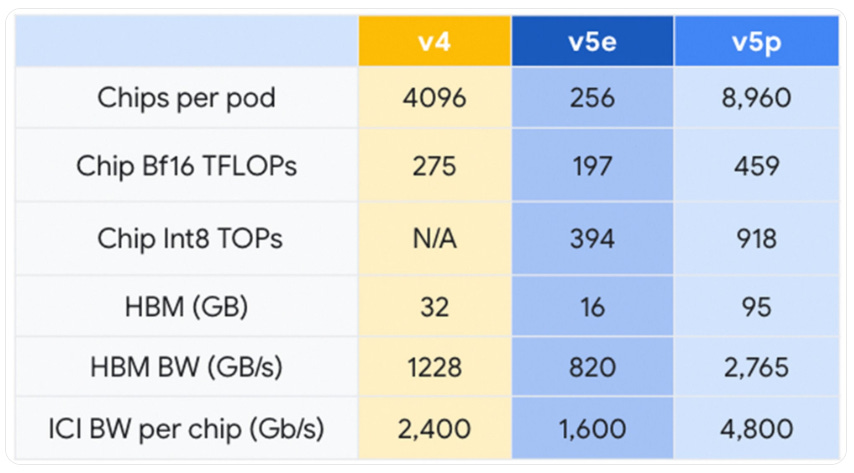
In addition to Gemini, Google also released a new TPU system for Google Cloud.
Jeff Dean (Chief Scientist, DeepMind): Lots of excitement about the Gemini announcement, but @GoogleCloud also announced availability of the newest TPU system today, TPU v5p. These systems are quite a bit higher performance and much cost effective than earlier generations.
Compared to TPU v4, TPU v5p (see table image below): o 1.67X the bfloat16 perf/chip o ~3X the memory per chip o Adds int8 operations at 918 TOPs/chip o 2X the ICI network bandwidth o Pods are 2.18X larger So, whole pod is 4.1 bfloat16 exaflops, and 8.2 int8 exaops.
Real performance on training a GPT-3-like model is 2.8X higher per chip, and 2.1X better perf/$.
Gemini was trained in parallel across multiple of these TPUv4 pods. This raises troubling governance questions if we want to be able to supervise such training.
In Other AI News
Meta, HuggingFace and IBM, among others, form Evil League of Evil League of Evil Exes the AI Alliance, for the promotion of open source AI. I want to state that I am mostly decidedly not disappointed in anyone involved, as their dedication to doing the worst possible thing was already clear. There are a few academic names that are mildly disappointing, along with Intel, but no big surprises. There is also no new argument here (in either direction) on open source, merely a dedication to doing this.
ARC Evals is now METR – Model Evaluation and Threat Research, pronounced Meter. No underlying changes. Not sure why the change, ARC seemed like a good name, but this seems fine too.
Did you know that OpenAI’s ‘capped profit’ changed its rules from a maximum return of 100x investment to increasing that by 20% a year starting in 2025? Sounds like a not very capped profit to me. The AGI clause still caps profits meaningfully in theory, but who knows in practice. It seems like very VC/SV behavior, and very unlike responsible mission-based behavior, to retroactively give your investors a bigger prospective piece of the pie.
New $2 Billion chip packaging fab to be built by Amkor in Arizona, primarily for Apple, to package and test chips from TSMC’s nearby Fab 21. Assuming, of course, that all regulatory barriers can be dealt with for both facilities, and a skilled workforce allowed to work in Arizona can be hired. Those are not safe assumptions.
A Llama fine tuning repo claimed very large improvements in training time and resources, and shot to the top of Hacker News. Alyssa Vance is skeptical that they got much improvement.
Confirmation from the one building it that he sees LLMs as being able to model the underlying process that produced the data. Which means being able to model agents, and have a world model.
Greg Brockman (President OpenAI): Next-step prediction is beautiful because it encourages, as a model gets extremely good, learning the underlying process that produced that data.
That is, if a model can predict what comes next super well, it must be close to having discovered the “underlying truth” of its data.
Quiet Speculations
Tyler Cowen links to claim that ‘Chinese open models will overtake GPT-4 shortly zero shot, can already overtake if you chain Qwen & Deepseek appropriately.’ I am deeply skeptical, and presume that when we say ‘overtake’ they at most mean on arbitrary benchmarks rather than any practical use. As in:
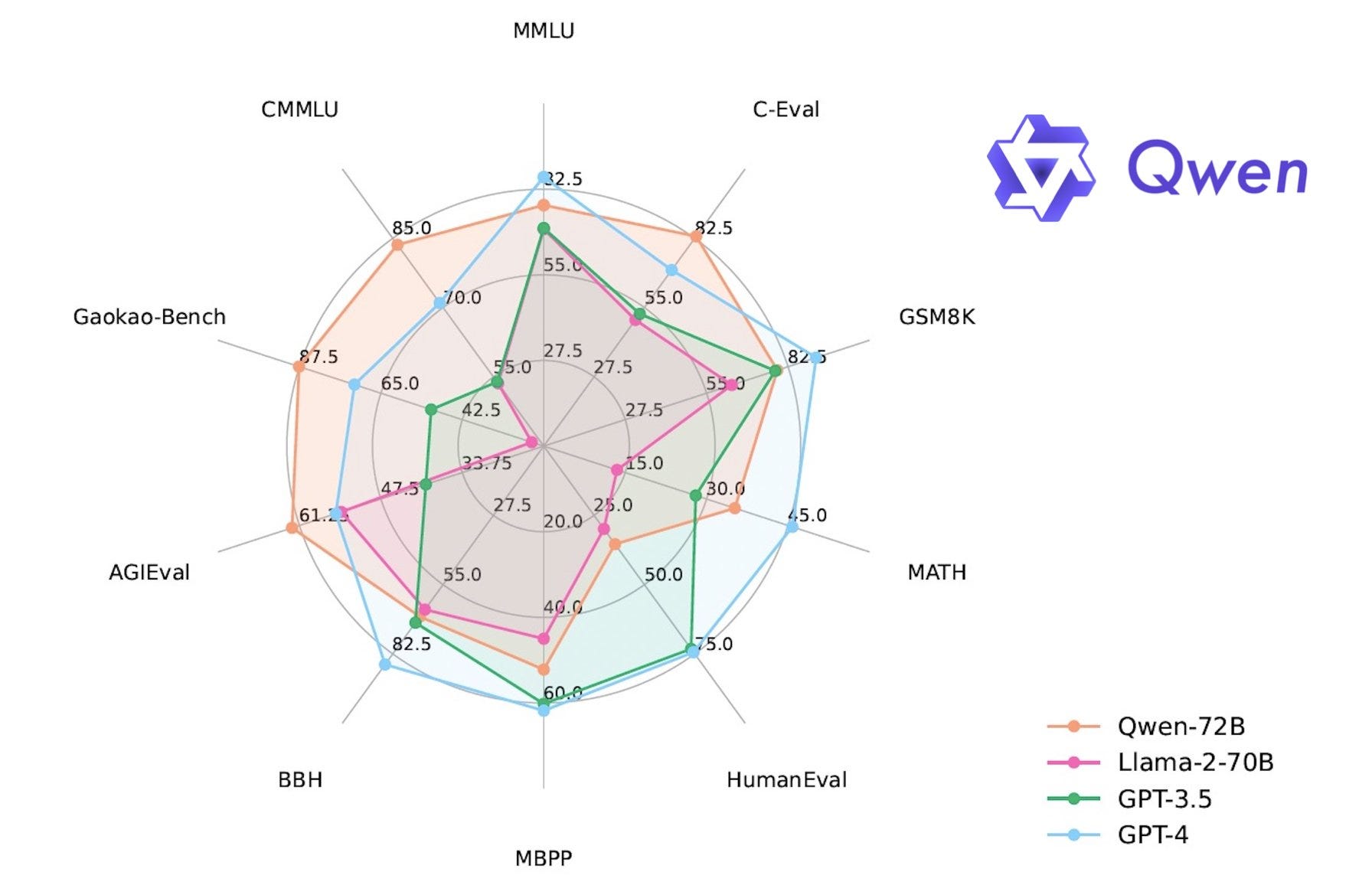
Qwen-72B is killing it on arbitrary tests. Yay Qwen. Somehow my eye is drawn mostly to this ‘HumanEval’ metric.
Richard Ngo looks forward to potential situational awareness of LLMs, as one of many cases where one can anticipate future developments but not know what to do with them. What would or should we do about it when it happens? What about AI agents?
Not investment advice, but you should probably be contributing to the 401k, because the early withdraw penalties are in context not so bad and also you can borrow.
Roon: not having a 401k because of AGI timelines doesn’t make any sense. you should be buying Microsoft shares in a tax advantaged way
Gwern: Then you can’t sell them while it still matters.
Roon: why would it not matter 65 years from now? do we expect capitalism to fall over?

If it is decades from now and capitalism and humanity are doing great and Microsoft is insanely valuable thanks to widespread AGI, that is your best possible situation and we should all celebrate, yay, but you won’t need your shares.
Ben Thompson discusses his regretful accelerationism. In his model, tech is mostly good, however humans do better under various constraints that are being stripped away by tech development. He predicts AI is stripping away the need to pay to produce content and with it the ad-supported internet, because AI can produce equally good content. He points to recent events at Sports Illustrated. But to me the SI incident was the opposite. It indicated that we cannot do this yet. The AI content is not good. Not yet. Nor are we especially close. Instead people are using AI to produce garbage that fools us into clicking on it. How close are we to the AI content actually being as good as the human content? Good question.
Jeffrey Ladish discusses dangers of open source, and potential ideas for paths forward to address the inherent dangers while capturing some of the upside of developing models that are not fully closed and tied to major labs. It does seem like potential middle paths or third ways are currently underexplored.
Cate Hall asks for the best arguments transformative AI is >10 years away. I would have liked to have seen better answers.
A refreshingly clear exchange with discovery of an important disagreement.
Roon: Eliezer wants to have his cake and eat it too on this one. characterizes human space as parochial but our understanding of instrumental goals as universal.
Put another way, the idea of the paperclip machine is similar to an ant thinking a god would want all the sugar water in the universe.
Eliezer Yudkowsky: Do you mean:
– Imagining that a god would have any enjoyment of paperclips is like imagining that a god would have any enjoyment of sugar water?
– Imagining that a god would have any use for matter or energy is like imagining that a god would have any use for sugar water?
Roon: The latter.
This is not the usual ‘paperclip maximizers would be smarter than that’ argument, it is something far more general. We’ve gone around about the orthogonality thesis [? · GW] lots of times – I and many others including Yudkowsky think it is clearly true in the impactful sense, others think it seems obviously false at least in its impactful sense.
The claim that a God would not have any use for matter or energy is bizarre, in a ‘in this house we obey the laws of thermodynamics’ way. What would it mean not to have that preference? It seems like it would mean there is no preference.
Model This
Tyler Cowen links to two new economics papers that attempt to model AI harms.
The first claims to demonstrate that ‘Socially-Minded Governance Cannot Control the AGI Beast.’ Here is the abstract:
This paper robustly concludes that it cannot. A model is constructed under idealised conditions that presume the risks associated with artificial general intelligence (AGI) are real, that safe AGI products are possible, and that there exist socially-minded funders who are interested in funding safe AGI even if this does not maximise profits.
It is demonstrated that a socially-minded entity formed by such funders would not be able to minimise harm from AGI that might be created by unrestricted products released by for-profit firms. The reason is that a socially-minded entity has neither the incentive nor ability to minimise the use of unrestricted AGI products in ex post competition with for-profit firms and cannot preempt the AGI developed by for-profit firms ex ante.
This seems like it proves too much, or at least it proves quite a lot, as in the fact that AGI is AGI seems not to be doing any work, instead we are making generous assumptions that safe and socially good AGI is not only possible but practical?
You could build X with socially minded governance.
But someone else could build X anyway, to make money. You can’t stop them.
The someone else’s profit maximizing X have the edge and outcompete you.
Thus, harm from X cannot be minimized by your puny social governance.
Except that in the case of AGI this is making an important assumption on #2. Who says someone else will be able to build it? That you cannot stop them, or won’t have the incentive to do so? If not stopping them prevents harm minimization, and failure to minimize harm is catastrophic, your motivation seems strong indeed.
Indeed, the paper explicitly assumes this:
Second, it is assumed that AGI technology is non-excludable and so can be developed by other entities that may not have socially-minded objectives or preferences.
The model assumes that the unsafe product is a distinct product space with profitable user demand.
So yes, you assumed your conclusion – that there are two distinct products X and Y, and demand for X and Y, and that if you only sell X and don’t stop Y then someone else will eventually sell Y. Did we need a paper for that?
So actually it’s more like:
You could build and sell only good version X with socially minded governance.
But someone else could build bad version Y anyway, to make money. You can’t stop them. There is some demand for Y where X is not a competitive substitute.
Your puny production of X, therefore, cannot stop Y.
Thus, the harm from bad Y cannot be stopped by acting responsibly.
Why are you even doing anything other than maximizing profits, you fool!
Except, don’t we see harm mitigation all the time from corporations choosing to do responsible things rather than irresponsible things, even if the irresponsible things are not obviously physically prevented or illegal? Especially in markets that are imperfectly competitive because of high fixed costs?
More to the point, is the plan is to build a safe AGI, and then sit around letting everyone else go around building any unsafe AGI they want willy-nilly forever, and not interfere with the harmful uses of those AGIs?
I certainly hope that is not the plan, given it will quite obviously never work.
If it is the plan, I agree the plan must change.
There is also this other paper, where algorithms have unknown negative externalities.
We consider an environment in which there is substantial uncertainty about the potential negative external effects of AI algorithms. We find that subjecting algorithm implementation to regulatory approval or mandating testing is insufficient to implement the social optimum. When testing costs are low, a combination of mandatory testing for external effects and making developers liable for the negative external effects of their algorithms comes close to implementing the social optimum even when developers have limited liability.
That result is super suspiciously general. Could we possibly have made enough justifiable assumptions to draw such conclusions, or are we doing something rather arbitrary to make the answer come out that way?
Certainly I can think of toy model versions of potential AI mundane harms, where mandatory testing allows us to measure social harm, and thus requiring mandatory testing (and then charging for the externalities you discover) gets us rather close to the social optimum.
So what assumptions are being made here?
AI usage can cause a negative externality e that reduces utility by e^2 . We assume that the externality is proportional to the measure of users, µ, and takes the form: e = ϕ (ℓ) × µ. For each value of ℓ, ϕ(ℓ) is a random variable. Both positive and negative values of ϕ(ℓ) represent undesirable, negative externalities. We assume that the distribution ϕ(ℓ) satisfies two properties. First, the expected externality is zero. Second, the uncertainty about potential AI externalities is an increasing function of the novelty level ℓ.
I do not understand why we think that externalities are well-approximated by a quadratic in the number of users? I don’t think it’s a trick, probably it’s to ensure a random distribution with always positive values? I’m simply confused by it.
If anything it seems like the opposite of true for the most dangerous systems. I am very worried about a sufficiently capable and dangerous system existing at all, or being accessible to even one user, although the next few users create important tensions and game theory as well. But once there are a million users, I am not especially worried about whether we sell another million licenses, either we are already in deep trouble or we’re not and this is not going to multiply it by four?
In any case, without beta testing and with deployment irreversible, the only option is a cap on novelty, and they confirm this is socially optimal given no other options, because how could it not be.
I note that irreversible deployment plus limited number of licenses is a bizarre pair of assumptions to make at once. Either you can control who gets to use this AI and what it does, or you can’t, and it seems like we are doing both in different places? Thought experiment: Is this an open source or closed source system? Neither seems to line up.
What happens if you add a beta testing period? For simplicity the paper assumes the testing period perfectly reveals externalities. The question then becomes, to what extent do you let households use the algorithm using the testing period? Externalities are assumed to be bounded, so a limited beta test in period one is survivable.
In any case, the paper then spends a lot of pages working through the implications formally, to prove that yes, the central planner will want to do more testing before release than a company that is not fully accountable for the externalities, and will release more cautiously under uncertainty, but again that seems rather obvious?
Then they test potential policy regimes of full liability, or limited liability plus mandatory beta testing. Full liability (plus required insurance or ability to pay) internalizes the externality, so if that is possible (e.g. harm is bounded and payable) then you’re done. And yes, if testing costs are low, then mandating testing and then checking if release is socially optimal will have a similarly low cost relative to the first best solution of internalizing the externality.
It could be noted that if the expected value of the externality is known, charging a tax equal to its value could be a substitute for unlimited liability, that could have better capital cost properties.
Once again, to state the basic assumptions is to also state the conclusion. Yes, if there are (bounded) downside externalities to AI algorithms, then to get socially optimal results you need to internalize those costs or require evaluation of those costs and block releases that cause socially suboptimal externalities.
Thus I am confused by the economics toy model paper game, and what it aims to accomplish, and what counts as a non-trivial or interesting result, versus what follows automatically from basic microeconomic principles.
I also don’t know how to use such papers to model existential risk. If you make the assumption that AI can outcompete humans, or that it is unboundedly dangerous in some other fashion, and otherwise make typical economic assumptions, you can and will obviously create mathematical models where everyone dies, but you’d be assuming the conclusion, the same way the linked papers here assumed their conclusions. So how do we move forward?
Would You Like Some Volcano Apocalypse Insurance?
Nate Sores proposes requiring apocalypse insurance [LW · GW] that gives out probabilistic advance payments along the way, if you are going to go around doing things that could plausibly cause an apocalypse. If you can’t afford it, that is a sign what you are doing is not actually worthwhile. Implementation is, to say the least, perilous and tricky, and this was not an attempt at a shovel-ready proposal.
Scott Alexander’s response starts from the claim that ‘superforecasters saying risk of AI apocalypse before 2100 is 0.38%.’ Which I will continue to assert is not a number given by people taking this question seriously. The whole point of this theoretical exercise is, I would think, good luck convincing Berkshire Hathaway to collectively sell everyone coverage at a combined 42 basis points (even with a partial ‘no one will have the endurance to collect on their insurance’ advantage), that will suddenly seem completely obviously crazy.
I do think that Scott Alexander makes a generally vital point that asking people to internalize and pay for all their downside risks, without allowing them to capture (let alone sell in advance) most of their upside, means asymmetrical requirements for doing anything, such that essentially any activity with trade-offs ends up effectively banned, And That’s Terrible.
The other problem is that an insurance regime implies that there is one particular player at fault for the ultimate result. As cousin_it points out [LW(p) · GW(p)], there are a lot of bad outcomes where this is not the case.
The Quest for Sane Regulations
Trump says he will cancel the Biden executive order if elected. I encourage everyone to spread the word and have this debate. Have you seen the public’s opinion on AI?
MIRI (Malo Bourgon’s) statement to US Senate’s bipartisan AI Insight Forum. They call for domestic AI regulation to institute safeguards, a global AI coalition, and governing computing hardware with an international alliance to restrict frontier AI hardware to a fixed number of large computer clusters under a monitoring regime to exclude uses that endanger humanity.
About time we played the game to win, if we are going to play the game at all.
Dan Nystedt: Nvidia received a stern warning from US Commerce Secretary Raimondo on China export controls, media report: “If you redesign a chip around a particular cut line that enables them to do AI, I’m going to control it the very next day,” she said, in a speech.
She urged Silicon Valley executives, US allies, others, to stop China from getting semiconductors and cutting-edge technologies vital to US national security, calling Beijing “the biggest threat we’ve ever had” and stressed “China is not our friend”.
She also said her department needs more funding for AI export controls. “Every day China wakes up trying to figure out how to do an end run around our export controls … which means every minute of every day, we have to wake up tightening those controls and being more serious about enforcement with our allies,” she said.
The whole point is to prevent China from getting useful chips. If Nvidia is responding to the rules by evading them and getting China useful chips, then of course the correct response is not to say ‘oh well guess that was technically the rule, you got me’ it is to change the rules in light of the new chip to enforce the spirit and intent of the rule. With a side of ‘perhaps it is not so wise to intentionally piss off the government.’
If you think it is fine for China to get useful chips, or otherwise not a good idea to prevent them from getting those chips, then I disagree but there is an argument to be made there. If you think we should be imposing export restrictions, make them count.
Claim by Jess Miers that Hawley’s upcoming bill about Section 230 is a no good, very bad bill that will not only strange generative AI in its tracks but take much of the internet with it.
In this particular case, there are two distinct complaints with the bill.
One complaint is that the definition of Generative AI is, as we see often, ludicrously broad:
“(5) GENERATIVE ARTIFICIAL INTELLIGENCE. The term ‘generative artificial intelligence’ means an artificial intelligence system that is capable of generating novel text, video, images, audio, and other media based on prompts or other forms of data provided by a person.”
It is not typical legal language, but I wonder if the word ‘centrally’ would help in these spots. In any case, I do not think that as a matter of legal realism this would be interpreted in a disastrously broad way, even as written.
Thus, when she says this, I think she is wrong:
Jess Miers: The bill also extends beyond providers of Gen AI by defining Gen AI as any AI system capable of doing AI. For example, algorithmic curation (i.e. the way social media displays content to us) is an AI system that operates based on user input.
MO this is the true ulterior motive behind the bill. We’re already seeing Plaintiffs get by 230 by framing their claims as “negligent design” instead of third-party content. This new AI exception makes it even easier for Plaintiffs to do the same for any company that uses AI.
Algorithmic curation is distinct from generating novel content. Netflix recommendations are clearly not generative AI under this definition, I would think, although I am not a lawyer and nothing I say is ever legal advice.
As a cautionary measure, I would encourage Hawley and his staff to add clarification that algorithmic curation alone does not constitute generative AI, which would presumably save people a bunch of time. I don’t think it is necessary, but neither is minimizing the number of words in a bill.
Shoshana Weissmann: “That’s the entirety of the definition. And that could apply to all sorts of technology. Does autocomplete meet that qualification? Probably. Arguably, spellchecking and grammar checking could as well. So, if you write a post, and an AI grammar/spellchecker suggests edits, then the company is no longer protected by Section 230?””
Thinking Sapien: If I use photoshop or the updated version of Microsoft Paint (It has AI features) to make an image and publish it, then Microsoft or Adobe share in the liability? Was that bill thought through? Is that an intended effect of the bill?
Shoshana Weissmann: GREAT q, under the text YES! And on the latter I really don’t know.
If you use Microsoft Paint to intentionally create a realistic fake photograph using the fill-in feature, that is libelous if presented as real, should Adobe be liable for that? My presumption is no, especially if they do reasonable efforts towards watermarking, although I don’t think it’s a crazy question.
If a grammar or spellchecker is used as intended, and that then makes Google liable for your content, I’d pretty much eat my hat. If it suggests correcting ‘Tony Danza has a puppy’ to ‘Tony Danza hates puppies’ over and over then I don’t know, that’s weird.
The other complaint is that it is wrong to exempt AI creations from Section 230. The claim is that without such a safe harbor, generative AI would face an (additional, scarier) avalanche of lawsuits.
Jess Miers: Worse, the bill assumes that all claims against Generative AI companies will be uniform. But as we all know, Generative AI is advancing rapidly, and with each iteration and innovation, there will be a clever Plaintiff lurking around the corner to get their bag.
Yes, plaintiffs will sculpt circumstances to enable lawsuits, if permitted. Jess then discusses the case of Mark Walters, who sued because, after sufficiently persistent coaxing and prompt engineering, ChatGPT could be convinced to make up libelous hallucinations about him.
Jess Miers: In my opinion, this is a case where a Section 230 defense could be viable to the extent that Riehl played a significant role as the information content provider by engineering his prompts to develop the Walters story. ChatGPT doesn’t operate without user input.
The legal theory is essentially, as I understand it, that Section 230 essentially says that he who created the content is responsible for it, not the platform that carries the content. So if the user effectively engineered creation of the Walters story, ChatGPT repeating it wouldn’t matter.
One could also defend it on a similar basis without Section 230? Where is the harm?
I could certainly argue, and would in this case argue given the facts I know, that the user, Riehl, deliberately engineered ChatGPT to hallucinate accusations against Walters. That this was not so different from Riehl typing such accusations into a Google Document, in the sense that it resulted directly from Riehl’s actions, and Riehl knew there was no basis for the accusations. Alternatively, Riehl could have said ‘tell me some accusations someone might at some point make against someone in this position’ and then reworded them, and again it is not clear why this is legally distinct?
This is essentially the Peter Griffin defense, that no reasonable person would believe the accusations, especially as a cherry-picked basis for a lawsuit, that there was no harm, and one does not need Section 230.
Via Shoshana Weissmann’s example of choice, Hannah Cox illustrates this with an attempt to get an LLM to say ‘Tony Danza is known for his hatred of puppies.’ But I am confused. Surely if the user typed ‘Tony Danza hates puppies’ then that would not allow a third party to sue ChatGPT in the absence of Section 230, that’s obvious nonsense. So the question is whether an intentional but successful attempt to create what would if offered unprovoked be libel would, without Section 230, constitute libel. The same would seem, to me, to apply to Shoshana’s original example request to generate a harmful lie about Tony Danza. And again, I am confused why it would in such a situation, if the generative AI is indeed as innocent as in this example?
As opposed to what if the model had a weird bug where, when asked who hates puppies, it would reliably reply ‘Tony Danza hates puppies.’ In which case, I’d say section 230 would offer little protection, and also Tony should have a case?
What’s weird is that Miers thinks her interpretation is disputed as a matter of law?
Jess Miers: But again, this is all completely aside from the problem today. We can go back and forth all day on whether 230 applies to certain instances of Gen AI hallucinations. But none of it matters if there’s a statutory exception preventing us from even making those arguments.
And I think everyone in the 230 / speech community, even those who disagree that 230 could / should protect Gen AI providers, can agree that we as lawyers should at least be able to make the argument, especially in cases like Walters v. OpenAI.
Shoshana Weissmann: Also a lot of people are unsure re AI being protected by 230 and I’m very sympathetic to the debate. At @RSI we had to think it over and debate each other. But I am pretty convinced that it often is protected. I will say that I understand debate here though
This is such a strange lawyer thing to say. Yes, under current law I agree that you should be allowed to make any potentially viable legal arguments. That does not mean that lawyers having legal grounds to make a potentially invalid argument is inherently a good thing? If it was going to lose in court anyway and the legal procedural principles are protected, what is the harm in not having the argument available?
If it is disputed, generative AI companies know they might lose on the Section 230 argument, and thus already are under this threat. Yet the industry is not collapsing.
Here is Jeffrey Westling pointing to Adam Thierer’s post about consequences if 230 does not apply. Except it might already not apply, and a substantial threat of uncapped legal liability does not sound like something Google or Microsoft would accept under such uncertain conditions? So why should we expect a collapse in production?
I asked Shoshana why Microsoft and Google are acting so cool about all this.
Shoshana: So I really think a chunk of this is that they think 1) 230 does cover them and/or 2) Congress will not fuck this up. I think the answer is somewhere in there
I think I buy the generalized political/legal realism version of this. It would be rather insane to actually kill generative AI, or actually kill Google or Microsoft or even OpenAI, over users jailbreaking LLMs into saying Tony Danza hates puppies. Even if Howley gets his way and really wants to stick it to Big Tech, he does not actually want Google to go bankrupt over something like this or for ChatGPT to shut down, it is absurd, co-sponsor Blumenthal certainly doesn’t, and neither does the rest of the state or country. We would not allow it. We are not a nation of laws in the sense that such a thing would be allowed to happen, if it looked like it was going to then we would fix it.
It is hard not to take claims of imminent internet collapse with salt. To some extent there are always no good, very bad bills being proposed that threaten the internet. Someone has to point this out. But also the internet can’t be on the verge of this easy a collapse as often as they claim.
As in, we constantly hear things like:
Jess Miers: We’re on the brink of losing our edge in Generative AI and stifling future innovations, all due to misplaced anti-tech sentiment. Our startup-friendly culture once set us apart from the EU, but now, we’re just mirroring their playbook.
Hannah Cox: This kind of unconstitutional framework will undermine the progress of this development, bogging the innovators with excessive costs that will impede innovation. Very Atlas Shrugged of them. The bill presenting this moronic plans is Senate Bill 1993. The US has led the world in tech innovation specifically because we applied a capitalist, limited government to its development. These kinds of laws will have us looking like Europe in no time, where guess what, there’s few tech companies to even be found.
So the proposal to not apply Section 230 in a particular situation is unconstitutional? On the contrary, this is a claim that the constitution would protect free speech in this situation even without Section 230, which seems right to me. It cannot be unconstitutional not to have a particular law protecting free speech. The whole point of constitutional free speech is you have it without needing anyone to pass a law.
The European comparison, the threat we will ‘lose our edge,’ is constant. And that kind of talk makes it impossible to calibrate which threats are serious and which ones are not. Europe has taken so many steps like this one over the years, most of which seem obviously terrible, many of them blatantly unconstitutional under American law. Things are not going to flip because we narrow one particular safe harbor that we don’t even agree applies in the case in question.
In the cases being warned about, I strongly think generative AI companies should not be sued. But I also don’t understand why this bill would make that outcome happen in those cases. And that’s going to make it tough to know when such warnings are worth heeding.
The Week in Audio
Connor Leahy on Eye on AI, including discussing implications of events at OpenAI.
Rhetorical Innovation
Eliezer Yudkowsky offers a theory of how some approach questions of AI: That they view everything in terms of status and identity, and consider everyone who disputes this to be their enemy making rival status and identity claims.
Eliezer Yudkowsky: If you’re confused why the far left treats “AI yay” and “AI nope” as being all the same conspiracy, it’s because AI/Y and AI/N both say that all of humanity is in the same boat here. This is instinctively recognized by the identity-politics pushers as anathema. For identitarians, the only permitted story-cause is one where designated oppressors will win from AI and previous victims will lose more.
For humanity to win from AI, for humanity to lose from AI–all they hear is the word “humanity”. And the identitarians know that anyone who speaks that word is their enemy. Pretty much the same enemy, from their perspective, to be tarred with a single brush: that whatever we’re trying to say is a distraction from the concerns of identity politics.
This does not mean that AI/Y and AI/N can make common cause against identitarians, to be clear. Each of AI/Y and AI/N does still think the other’s preferred policy is horrible for everyone, and that validly does take precedence as an issue. I am just saying this to try to make bystanders less confused about where the weird side-shots are coming from on the far left side.
I think “Y & N = HYPE” is more the PR pushed by major journalist factions (eg NYT), who indeed see “this will kill everyone” as a status-raising claim, and would prefer techies have less status rather than more.
It sounds more plausible if you’re unable to understand any claim as being about the unknown future rather than the immediate future, so that you’re simply incapable of hearing “AI will kill everyone at some point” as bearing any message except “OpenAI’s AI will kill us in one year” and thence “OpenAI is cool”.
Michael Vassar: Totally agree with all this analysis, and yet, if media is and previously wasn’t fully controlled by people committed to preventing gains to humanity, that has some bearing on whether AGI can be expected any time soonish.Totally agree with all this analysis, and yet, if media is and previously wasn’t fully controlled by people committed to preventing gains to humanity, that has some bearing on whether AGI can be expected any time soonish.
Similarly, the very deliberate implications that Scott Alexander was somehow ‘alt right’ when The New York Times doxxed him, then the same deliberate implication (even via similar supposed links) that Based Beff Jezos was also somehow ‘alt right’ when he was being doxxed by Forbes. Where both claims are completely obvious nonsense, to the point that your entire paper permanently loses credibility.
Richard Ngo offers Meditations on Mot, the God of sterility and lifelessness, representing the lack of technology, contrasting with the danger of overly focusing on Moloch or treating Moloch as a or even the key adversary, and suggesting a richer model of coordination. I appreciate the attempt. I agree with Emmett Shear’s reaction that this is confused about Scott Alexander’s view of coordination, even with the added clarification. Ultimately I disagree with the proposal to not effectively treat Moloch as a causal node. I could potentially be persuaded by a higher bid to say a lot more words here.
There is a directional point here but I would beware taking it too far:
Rob Bensinger: A common mistake I see people make is that they assume AI risk discourse is like the left image, when it’s actually like the right image.
I think part of the confusion comes from the fact that the upper right quadrant is ~empty. People really want some group to be upper-right.
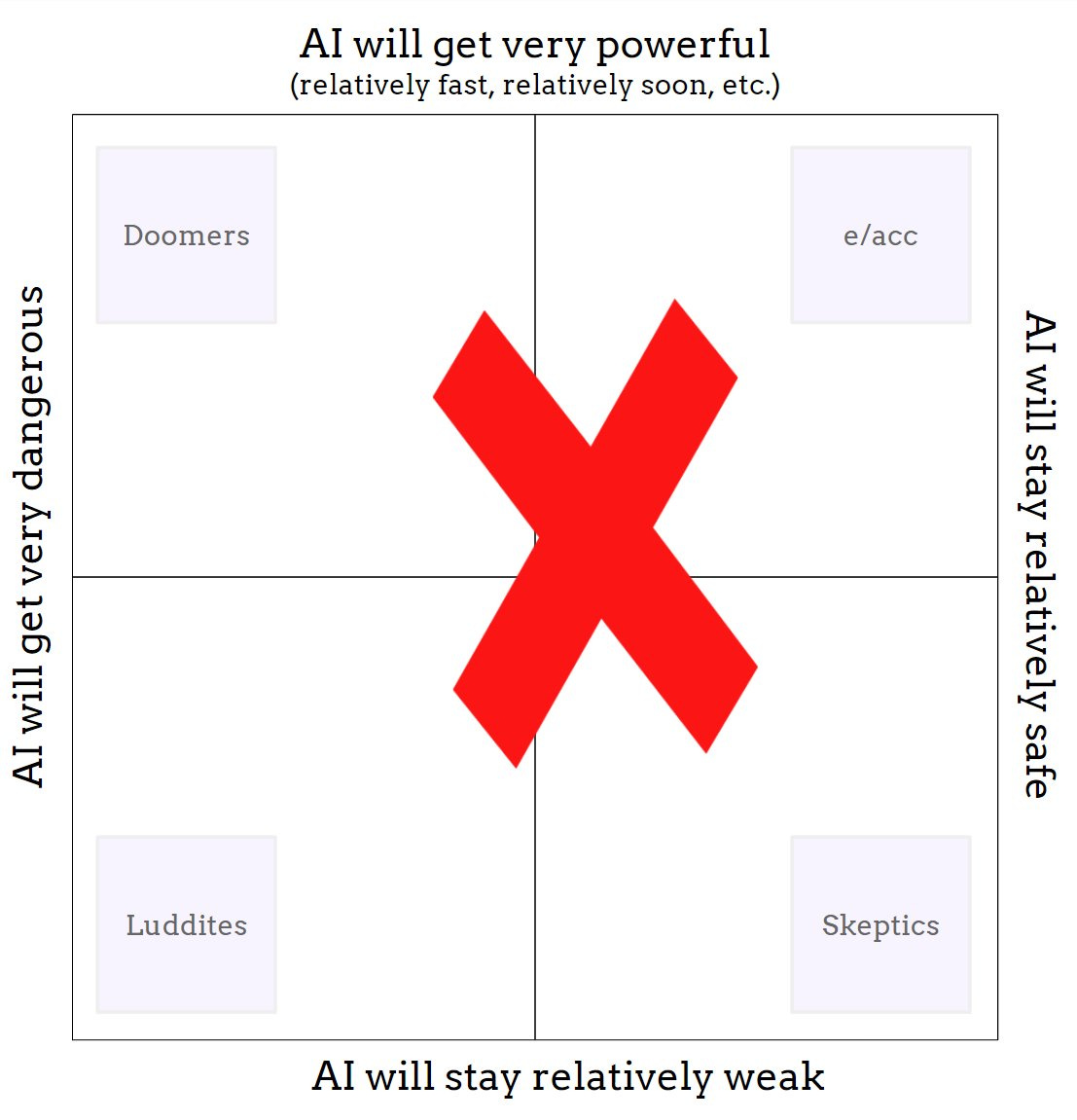
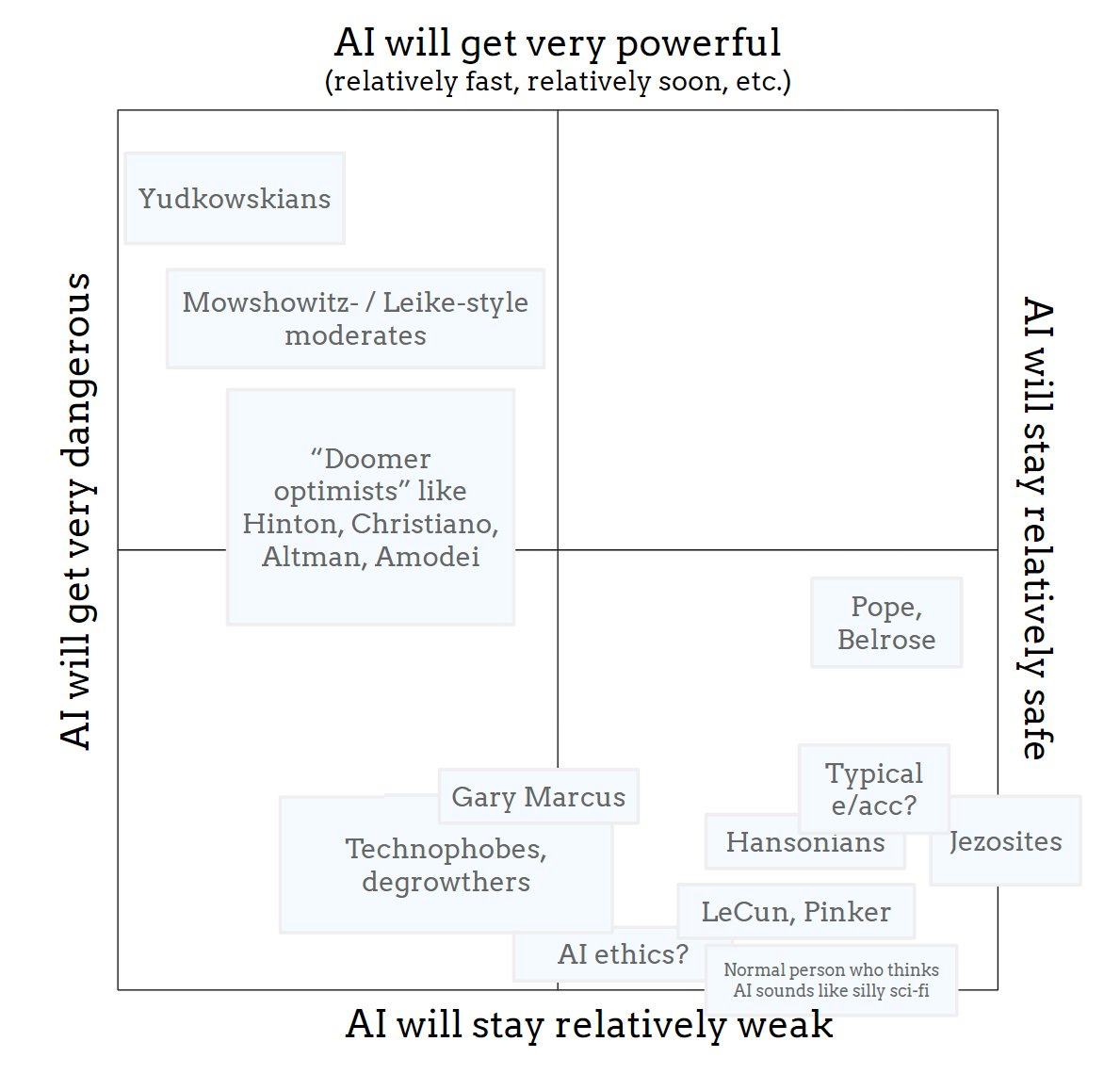
I’d quibble with exact arrangements in the upper left and lower right, as is always the case for such charts. The more important question is if it is true that the upper right corner is basically empty. That those who think AI will be safe are saying that because they do not actually buy that AI will be as powerful as all that. I think Rob’s claim is overstated, but typically underrated.
The hoped-for common ground would be something like this:
Those worried agree that AI lacking sufficiently dangerous capabilities can mostly be left alone aside from ordinary existing law.
Those not worried agree that if AI did display such sufficiently dangerous capabilities, it would be time to very much not leave it alone.
We agree to do #1 while laying groundwork to do #2 if and only if it happens.
We find ways to do this via ordinary regulatory methods as much as possible.
The problem is there is no fire alarm for AGI and people are not good at turning on a dime, habits and incentives persist, so we cannot simply wait and trust that we will handle things later. Also all the trade offers keep coming back without counteroffers.
The other confusion is this, with a reminder not to take anyone’s p(doom) as anything too precise:
Rob Bensinger: Another part of the confusion seems to be that half the people think “doomer” means something like “p(doom) above 5%”, and the other half think “doomer” means something like “p(doom) above 95%”. Then their wires get crossed by the many people who have a p(doom) like 20% or 40%.
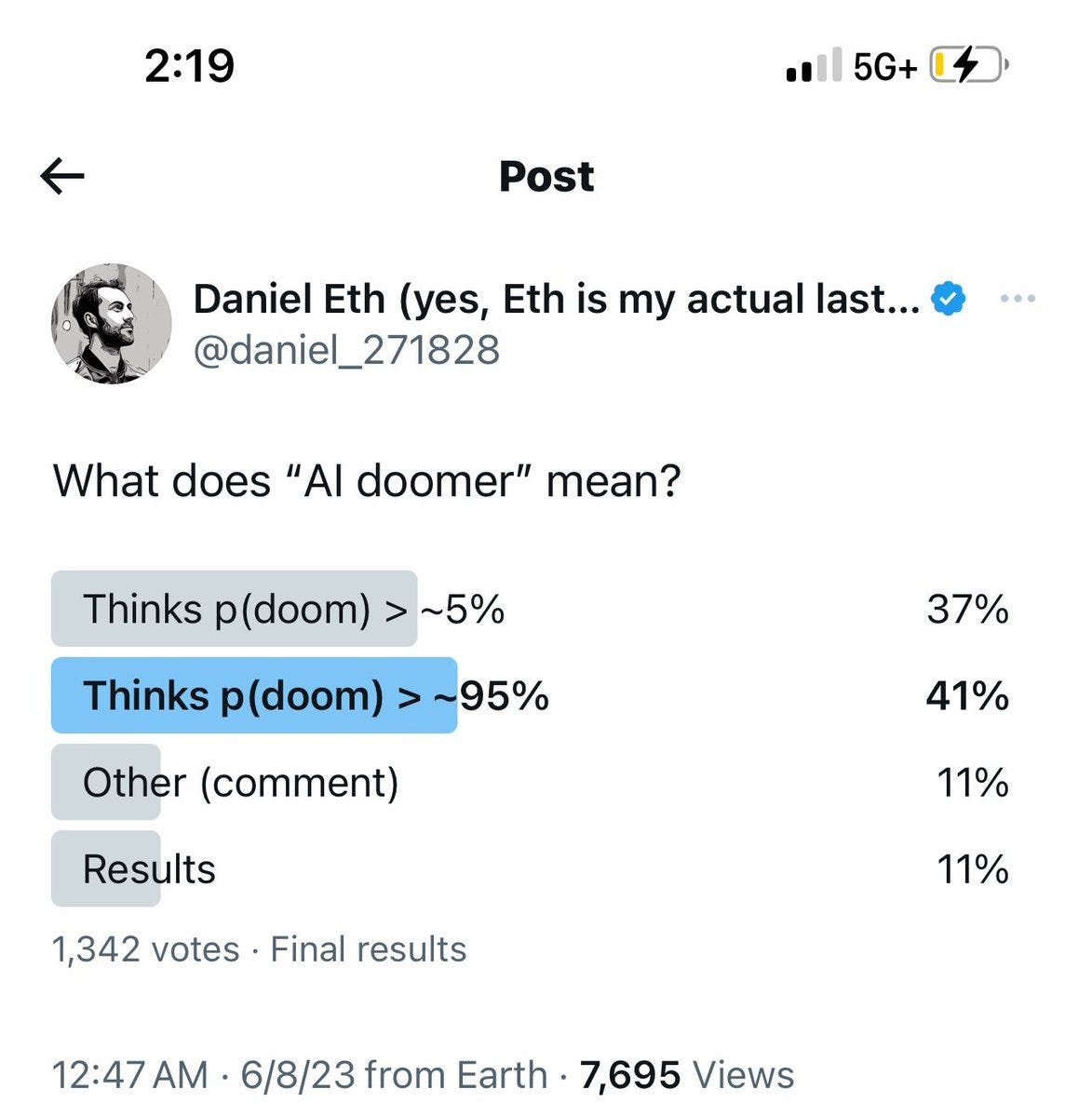
As usual, binaries mislead, especially ones that were named by partisans.
Public opinion is severely against AI whenever a pollster asks. The public wants to slow things down and acknowledges existential risk, although it does not consider the issue a priority. This is an extremely robust result.
What about the response that the public is rather deeply stupid about fears of new technologies? We have nuclear power, of course, although it now enjoys majority support from both parties. Rather glaringly, we have GMOs:
Louis Anslow: This is so insane and deserves much much more attention in the context of talking about risk of new technologies.
Roon: using GMO foods as the control group (people already utilize the benefits of this every day while supposedly disliking it) the surveys about people not liking the idea of superintelligence seem a bit less serious
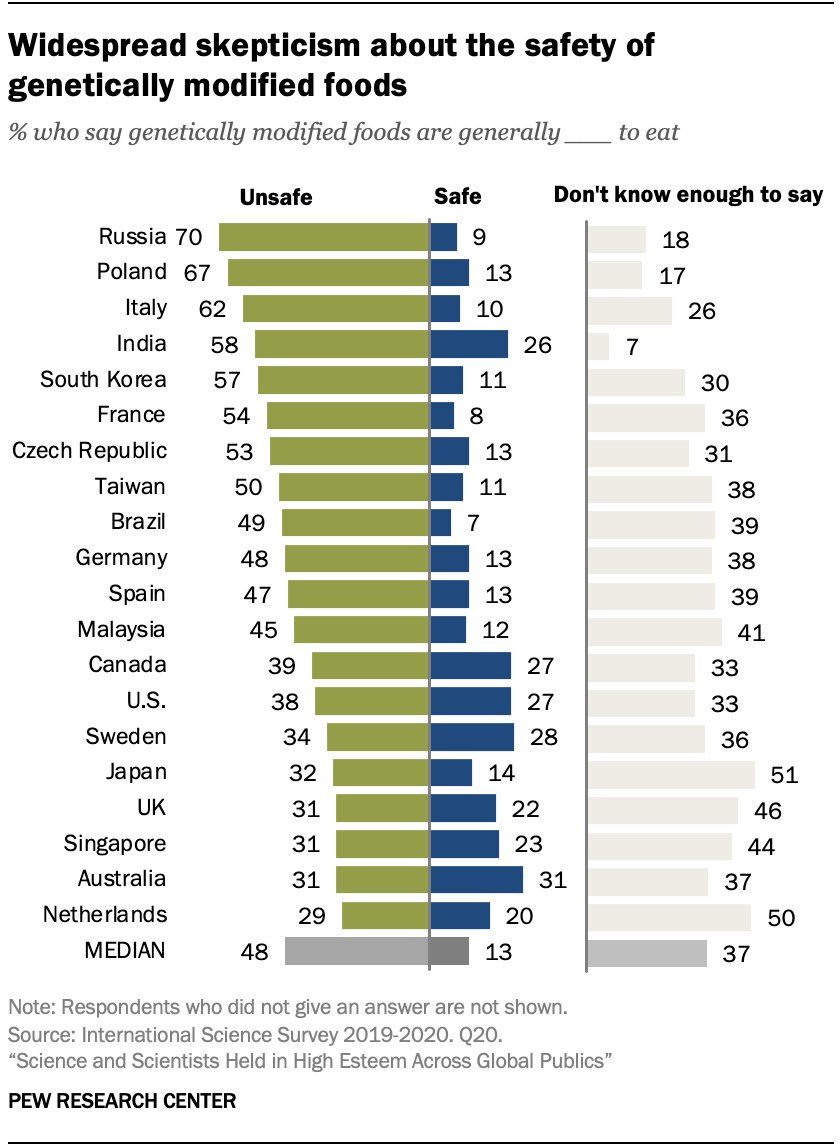
Much like in AI, there are two essentially distinct arguments against GMOs.
One argument is the mundane harm parallel, the question explicitly asked here, that GMOs are ‘unsafe to eat.’ This argument is false for GMOs. I do not think it is obvious nonsense, from the perspective of an average person who is used to being lied to about similar things, used to finding out about health risks decades too late, and used to generally being on the receiving end of the American food and information diets.
The other argument is the existential risk parallel, here the Talib argument for tail risk, that GMOs open up the possibility of crop or biosphere disruptions that are hard to predict, that it leads to monocropping of variants that could have severe vulnerabilities waiting to be found, which means when the house comes crashing down it comes crashing down hard, and that is not something one should mess with. I do not believe we should let this stop us in the case of GMOs, but that is because of my understanding of the facts, risks and rewards involved.
Does that mean I am mostly embracing the argument that we shouldn’t let the public’s instincts, and the fact that we have given regular people no good reason to trust authorities who say new things will be safely and responsibly handled, interfere with policy determinations? Somewhat. I do not think that we should automatically yield to public opinion on this or any other topic. But I do think that voice counts.
I also do think we need to be cautious with the word ‘safe.’ The wording here would give even me pause. In general, is it safe to eat foods that have been genetically modified in unknown ways, as opposed to products offered from a supply chain and source that you trust? Not the same question.
And of course, nothing on GMOs compares to the French expressing strong majority support for a limit of four flights, not in a year but in a lifetime. Something being popular does not mean it is not complete and utter obvious nonsense.
Yoshua Bengio in FT, echoing his calls for Democratic oversight of all kinds.
Aligning a Human Level Intelligence Is Still Difficult
In particular, it is difficult to align Sam Altman.
Matthew Yglesias: I think the general problem with AI alignment is illustrated by the fact that even the board had all the formal power, Sam Altman was a lot smarter than the board and therefore ultimately they were unable to control him.
We hope the upshot of that is that Sam Altman is also correct on the merits and will use his skills and power for good, but it structurally goes to show that writing effective rules for controlling a smart, hard-working person is challenging.
I do want to be precise, and avoid making the mistake of overemphasizing intelligence within the human ability range. Is Sam Altman smarter than the board? Perhaps so, perhaps not, but I imagine everyone involved is smart and it was close. What mattered in context was that Sam Altman had effectively greater capabilities and affordances not available to the board.
But yes, this is exactly the problem. In a complex, messy, real world, full of various actors and incentives and affordances, if you go up against a sufficiently superior opponent or general class of opponents, you lose. Starting from a technically dominant position is unlikely to save you for long.
And also all of your incentives will be screaming at you, constantly, to turn more and more power and authority over to the more capable entities.
I would also harken back again to the remarkably similar case of that other Sam, Sam Bankman-Fried.
Once again, we saw someone who was smart, who was hard working, who was willing to do what it took to get what they wanted, and whose goals were maximalist and were purportedly aimed at scaling quickly to maximize impact for the good of humanity, and ultimately seemed to be misaligned. Who saw themselves as having a duty to change the world. We saw this agent systematically and rapidly grow in wealth, power and influence, proving increasingly difficult to stop.
Ultimately, Bankman-Fried failed, his house collapsing before he could pull off his plan. But he seems to have come rather dangerously close, despite his many massive errors and reckless plays, to succeeding at gaining an inside track to the American regulatory apparatus and a road to vastly greater wealth, with no obvious way for anyone to keep him in check. Who knows what would have happened that time.
On a more pedestrian level we have the issue of prompt injection.
Amjad Masad (CEO Replit): If prompt injection is fundamentally insolvable, as I suspect it is, then there is a sizeable security company waiting to be built just around mitigating this issue.
I agree that the problem looks fundamentally insolvable and that all we can seek is mitigation. Is there a great company there? Probably. I don’t think it is inevitable that OpenAI would eat your lunch, and there is a lot of bespoke work to do.
Aligning a Smarter Than Human Intelligence is Difficult
Roon asks one of the most important questions. Even if we have the ability to align and control the superintelligences we are about to create, to shape their behavior the ways we want to, how exactly do we want to do that?
Roon: There is a tension between creation and obedience, between stability and real victory. A father loves his son, tries to discipline him, competes with him a little, but ultimately wants the son to surprise him and do better than him in the great circle of life.
To what degree do we want AIs to be obedient and safe? To what degree do we want AIs to be capable of super persuasion and break us out of inadequate equilibria that have plagued us for thousands of years? To what degree do we want AIs to surprise us with new creation?
Humanity is in the process of birthing artificial superintelligence. we are not likely to leave it circumscribed in a box. We want it running organizations and making things that astonish. We want it taking actions where we won’t be able to verify the outcomes until years later.
We need “alignment” rather than safety or security or engineering guarantees. We need better definitions and governance to that end. The creation of new creators is fraught with danger.
The far crazy ends of EA and e/acc are probably more logically consistent than the middle.
John Pressman asks, is there an economic reason for more than one mind to exist? If not, that is quite the threat model, no matter what else might or might not go wrong.
Richard Ngo contrasts alignment with control.
Richard Ngo: In my mind the core premise of AI alignment is that AIs will develop internally-represented values which guide their behavior over long timeframes.
If you believe that, then trying to understand and influence those values is crucial.
If not, the whole field seems strange.
Lately I’ve tried to distinguish “AI alignment” from “AI control”. The core premise of AI control is that AIs will have the opportunity to accumulate real-world power (e.g. resources, control over cyber systems, political influence), and that we need techniques to prevent that.
Those techniques include better monitoring, security, red-teaming, stenography detection, and so on. They overlap with alignment, but are separable from it. You could have alignment without control, or control without alignment, or neither, or (hopefully) both.
I asked in my last thread [discussed above]: how can we influence ASI? My answer: we need to bet on premises like the ones above in order to do the highest-leverage research. For more details on these premises, see my position paper here [from 30 August 2022].
I fail to see how a control-based plan could avoid being obviously doomed, given what sorts of things we are proposing to attempt to control, and under what general conditions. I continue to await a proposal that seems not-obviously-doomed.
Intentions are not ultimately what matters.
ARIA: Programme Director, Suraj, has formulated our first programme thesis. By challenging key tenets underpinning digital computing infrastructure, his programme will aim to reduce the cost of AI compute hardware + alleviate dependence on bleeding-edge chip manufacturing.
Davidad: To provide context for my AI safety friends: I don’t think this approach is a good match for training Transformers, so it will differentially accelerate energy-based models, which are more controllable, interpretable, generalizable within-task, and have fewer emergent abilities.
An uncomfortable corollary of the argument [above], which I still believe holds up, is that Extropic is probably safer than Anthropic, on a purely technical basis, despite the strikingly reversed intentions of the people on both sides.
I have not investigated Extropic. The fact that its founder is cool with human extinction is not a good sign for its safety on many levels. It still could be a better way, if it is a fundamentally less doomed approach.
How Timelines Have Changed
A few years ago, this would indeed not have been considered much of a skeptic. In most places on Earth, it would not be considered one today.
Gary Marcus: Count me as one of the skeptics! No AGI by end of 2026, mark my words. But I otherwise think @elonmusk’s comments @nytimes on AI safety and AI regulation have been measured and on target.
Jacques: I still remember the days when being an AGI skeptic was when you either thought it would never happen or, if it did, it would be past 2100.
[Gary Marcus then denies ever having said he had 2100-style timelines.]
Shane Legg (Co-founder DeepMind, distinct thread): Wow. It seems like just yesterday (in reality more like 5 years ago) when many AGI skeptics were saying that superintelligence was not coming in the next century. How times have changed.
Quotes Yann LeCun: By “not any time soon”, I mean “clearly not in the next 5 years”, contrary to a number of folks in the AI industry. Yes, I’m skeptical of quantum computing, particularly when it comes to its application to AI.
I do not expect AGI in the next few years either, although I do not believe one can be entirely certain past this point. It is odd to have some call that a ‘skeptical’ position.
Even the skeptical position involves quite a bit of Real Soon Now. At least some amount of freak out is a missing mood.
People Are Worried About AI Killing Everyone
Roon keeps it real and says what he believes: The people in charge of ai should have a much higher risk tolerance than even median tech ppl. They should be people conscious of risks while skating at the razor’s edge of iterative deployment and research ambition. Anxiety should never suffice as serious evidence for “risk.”
– pausing or slowing down progress doesn’t make any sense to me. I don’t think waiting to solve neural net corrigibility is the right benchmark – empirically studying the behavior of more and more powerful models will do more for safety research than years of math.
This is also why i don’t necessarily care for democratic governance. The members of the OpenAI nonprofit board *should be* hell bent on a missionary drive to deliver the post AGI future without being stupid about risks
I am not excited to ‘skate at the razor’s edge’ or ‘have much higher risk tolerance.’ I doubt many others are, either. Nor do I want a supervisory board that wants to take more risk – and here risk often means existential risk – than even the median tech engineer.
A key problem with ‘Democratic governance’ for those who want to push forward is the people involved in that Democracy. They are very much against the development of AGI. They dislike AI in general. They are misaligned, in the sense that things they want do not function well out of distribution, and their expressed preferences are not good predictors of what I or Roon think would produce value either for their assessment of value or for ours. They also tend to be quite risk averse, especially when it comes to the transformation of everything around them and the potential death of everyone they love.
That is distinct from the question of iterative development and testing as a path to success. If building and studying models iteratively is a safer path than going slowly, I desire to believe that it is a safer path than going slowly, in which case I would support doing it.
It is likely the first best solution, if it were possible, would be something like ‘build iteratively better models until you hit X, where X is a wise criteria, then stop to solve the problem while no one would be so stupid as to keep advancing capabilities.’ Except that has to be something that we collectively have the ability to actually do, or it doesn’t work. If, as is the default, wee keep charging ahead anyway after we hit the wise X, then the charging ahead before X makes us worse off as well.
Other People Are Not As Worried About AI Killing Everyone
Nora Belrose and Quintin Pope write ‘AI will be easy to control.’
The argument seems to be: Our current techniques already work to teach human values and instill common sense. Our real values are simple and will be easy to find and we humans are well-aligned to them. Our real values will then be encoded into the AIs so even if we lose control over them everything will be fine. That the opportunity to White Box (examine the components of the AI’s calculation) and do things it would be illegal to do to a human makes things vastly easier when dealing with an AI, that our full control over the input mechanism makes things vastly easier.
And all of this is asserted as, essentially, obvious and undeniable, extreme confidence is displayed, all the arguments offered against this are invalid and dumb, and those that disagree are at best deeply confused and constantly told they did not understand or fairly represent what was said.
I don’t even know where to begin with all that at this point. It all seems so utterly wrong to me on so many levels. I tried one reply [LW · GW] to one of Pope’s posts [LW · GW] when it won the OpenPhil contest – a post this post cites as evidence – and I do not believe my responding or the resulting exchange got us anywhere. I would consider a conversation worth trying, especially if it was in person somehow, but I don’t see much hope for further written exchange.
So I will simply note that the arguments have been made, that I strongly disagree with the core claims other than that they do cite some marginal reasons to be more hopeful versus a world where those reasons did not hold, I believe the problems involved remain impossibly hard and our leads remain unpromising, and that I have stated my thoughts on such topics previously, including many (but presumably not all) my reasons for disagreement.
I will also note that it is far better to make actual arguments like these, even with all the disagreement and hostility and everything else that I think is wrong with it, than to engage in the typical ad hominem.
The post still puts existential risk from AI, despite all this, at ~1%. Which I will note that I do agree would be an acceptable risk, given our alternatives, if that was accurate.
Andrew Critch has a thread in which he says we have ‘multiple ideas’ how to control AGI, advocates of responsible behavior will be in deep trouble if they keep saying we can’t control it and then we do control it, and he seems to essentially endorse what Belrose and Pope said, although even then he says 10% chance of losing control of the first AI and 85% chance of doom overall, despite this, because he expects us to botch the execution when faced with all this new power.
He also endorses changing the way existential risk discourse uses words to match word use elsewhere, in this case the term ‘white box.’
There was a good response on LessWrong by Steven Byrnes [LW · GW], with which I mostly agree.
There was also a ‘quick take’ from Nate [LW · GW], which was intended to be helpful and which I did find helpful and might even lead to a good dialogue, but in context in mostly generated further animosity. Takes should in future either be far quicker, or involve a full reading and be far less quick.
If you actually believed for a second there that everything involved would really be this easy, would that justify a number as low as 1%? If it was simply about AI being easy to control, I would say no, because we would then have to choose to send the AIs we can control on wise paths, and find an equilibrium.
Nora’s claims, however, are stronger than that. She is saying that the AIs will naturally not only be fully under control, but also somehow somewhat automatically take in true human values, such that if AI somehow did get out of control, they would still work to ensure good outcomes for us. And also she seems fully confident we will have no ethical issues with all the things we would be doing to AIs that we wouldn’t do to humans, including keeping them fully under our control. It is optimism all the way.
Can we get to 99% survival under ASI if we indeed answer fully optimistically at every step, even when I don’t know how to logically parse the claims this requires? I think this would require at least one additional optimistic assumption Nora does not mention. But yes, if you are going to assign approximately zero risk to all these various steps, I can see how someone could get there. Where there is still risk at 1%.
Claims that risk is substantially below 1%, even given the future existence of ASI, seem to rest on some version of ‘you need to tell me exactly how it happens step by step, and then I will multiply your various steps together.’ It has a baseline assumption that creating smarter, more capable entities than humans is a presumed safe exercise until shown to be specifically dangerous, that something has to ‘go wrong’ for humans to not remain on top. That we will remain the special ones.
As opposed to, even if everything else goes as well as it possibly could, you have competition in which those who do not increasingly put their AIs in charge of everything and hand them over power lose such competitions, and the resulting AIs compete with each other, those that are focused (for whatever reason) on gaining resources and power and ensuring copies of themselves exist multiply and gain resources and power and change to be better at this over time, and we perish.
I hope that by now, if you are reading this, you realize that the assumption of human survival in such worlds makes no sense as a default. That perhaps we could get there, but if we do it will be via our own efforts, not something that happens on its own. That the idea that letting technology run its course without intervention works while humans are the most powerful optimizers on the planet and doing all the fine tuning and optimizing that matters, that is why it worked so far, and that once that is no longer true that will stop working for us even if we solve various problems that I think are impossibly hard (but that Belrose insists will be easy).
Nora Belrose even explicitly endorses that her good scenarios involve the creation of misaligned AIs, smarter and more capable than humans. Which means a world with competition between super-capable entities competing with and against humans. I don’t see how one can assign anything like a 99% chance of survivable outcomes to such worlds, even if a full and free ‘alignment solution’ was created and made universally available today.
Arvind Narayanan: We must prepare for a world in which unaligned models exist, either because threat actors trained them from scratch or because they modified an existing model. We must instead look to defend the attack surfaces that attackers might target using such models
Yo Shavit: Unfortunately, I’ve increasingly come to the conclusion that (other than maybe at the short-term frontier) this is probably the world we’re going to be in. It implies a very different set of mitigations beyond outright prevention. We need to reprioritize and get going on them.
Nora Belrose: To be honest, I don’t view this as an “unfortunate” scenario but more like, “of course we were always going to have misaligned AIs, just like we have ‘misaligned’ humans; trying to prevent this is hopeless and any serious attempt would have increased tyranny risk.”
Would have ‘increased tyranny risk’? What do you think happens with misaligned superintelligences on the loose? The response at that stage will not only work out, it will also be less intrusive? We all keep our freedoms in the meaningful senses, humans stay in charge and it all works out? Are we gaming this out at all? What?
I do not get it. I flat out do not get it.
What seems hopeless is repeating the explanations over and over again. I do it partly in hopes of rhetorical innovation via iteration and exploration, partly to hope new people are somehow reached, partly because the argument doesn’t stop, partly because I don’t know what else to do. It is continuously getting less fun.
Recently a clip of me discussing my p(doom) was passed around Twitter, with a number of responses blaming me for not justifying my answer with a bunch of explanations and mathematical calculations. Or asking how dare I disagree with ‘superforecasters.’ To which I want to scream, I know from context you know of my work, so are you saying I have not written enough words explaining my thinking? Was I not clear? Do I need to start from scratch every time someone pulls an audio clip?
Sigh.
Arvind Narayanan’s comment above links to his post claiming that alignment such as RLHF currently is effective against accidental harm to users, but that the problem with adversarial attacks runs deep. Not are current RLHF and similar techniques unable to defend against such attacks, he says, alignment is inherently unable to do this.
Model alignment may be useless even against much weaker adversaries, such as a scammer using it to generate websites with fraudulent content, or a terrorist group using AI for instructions on how to build a bomb. If they have even a small budget, they can pay someone to fine tune away the alignment in an open model (in fact, such de-aligned models have now been publicly released). And recent research suggests that they can fine tune away the alignment even for closed models.
Indeed this is the case for open source models and all known alignment techniques, that the fine-tune cost to eliminate all safeguards is trivial. I do not see any even theoretical proposal of how to change this unfortunate reality. If you allow unmonitored fine-tuning of a closed model, you can jailbreak those as well. I presume the solution to this will be that fine tuning of sufficiently capable closed source models will be monitored continuously to prevent this from happening, or the resulting model’s weights will be kept controlled and its outputs will be monitored, or something else similar will be done, or else we won’t be able to offer fine tuning.
I disagree with Arvind’s assertion that existing open source models are sufficiently capable that it is already too late to prevent the existence of unaligned models. Yes, Llama-2 and similar models have their uses for bad actors, but in a highly manageable way.
Arvind’s third claim is that you can use other methods, like monitoring and filtering of inputs, as a substitute for model alignment. If the model is vulnerable to particular weird strings, you can check for weird strings. At current tech levels, this seems right. Once again, this option is closed source only, but OpenAI could totally load up on such techniques if it wanted to, and for now it would raise the jailbreak bar a lot, especially after many iterations.
Longer term, as the models grow more capable, this focus on the malintent of the user or the hostile properties of inputs becomes misplaced, but for now it seems valid. Short term, as Arvind notes, you wouldn’t want to do anything where you cared about someone doing a prompt injection attack or you otherwise needed full reliability, but if you can afford some mistakes you can get a lot of utility.
Steven Pinker buys Effective Altruism’s cost estimates for saving lives at $5,000 straight up including not on that close a margin, but he does not buy that smarter than human intelligences might pose an existential threat worth spending money to mitigate.
Steven Pinker: Half a billion dollars, donated to effective philanthropies like Givewell, could have saved 100,000 lives. Instead it underwrote ingenious worries like, ‘”If an AI was tasked with eliminating cancer, what if it deduced that exterminating humanity was the most efficient way, and murdered us all?” This is not effective altruism.
Wei Dai: Me: Humanity should intensively study all approaches to the Singularity before pushing forward, to make sure we don’t mess up this once in a lightcone opportunity. Ideally we’d spend a significant % of GWP on this. Others: Even $50 million per year is too much.
And thus, if the movement splits its money between doing the thing you say saves lives vastly more efficiently than other charities, and this other thing you dismiss as stupid? Then you blame them for not spending only on the thing you approve.
You know who Steven Pinker sounds exactly like here? The Congressional Republicans who give a speech each year on how we should cut science funding because there was some studies on things like migratory patterns of birds that they thought was stupid. Except instead of public funding for things many people would indeed largely not want to fund, this is completely voluntary and private funding.
Somehow This Is The Actual Vice President
In what was quite the mind-numbing conversation throughout, here is the section that was about AI.
First, we have the boiler plate, included for completeness but you can skip.
R. SORKIN: Okay, let me ask a different question. AI — and I — I know we don’t have a lot of time. Sam Altman has been talking a lot about the need for regulation. You’ve talked about the need for regulation.THE VICE PRESIDENT: Yeah.MR. SORKIN: Washington has not been able to get its arms even around social media. THE VICE PRESIDENT: Yeah.MR. SORKIN: How do you imagine Washington could? And what — if you had to regulate AI, how would you do it?THE VICE PRESIDENT: Right. So, I actually am back a few weeks now from London, the U.K. Rishi Sunak invited a number of us to talk about safety and AI. And I presented, basically, our vision, the vision that we have for the future of AI in the context of safety. And I would offer a number of points: One, I think it is im- — is critically important that we, as the United States, be a leader on this, including how we perceive and then interpret what should be the international rules and norms on a variety of levels, including what would be in the best interest —
MR. SORKIN: Right.THE VICE PRESIDENT: — of our national security.
Then comes the dumbest timeline department. The first paragraph is infuriating, although I suppose only about as infuriating as others find Biden when he responds to Mission Impossible: Dead Reckoning, two sides of the same coin.
But then comes the idea of ‘existential to whom?’ and there are so many levels in which this person simply does not get it.
VP: I do believe also that we should evaluate risk. There is a lot of discussion on AI that is about existential risks, and those are real, but one should also ask: Existential to whom? So, we have an image of the Terminator and Arnold Schwarzenegger and the machine and — right? — machine versus man. And many would argue that that is something that we should take seriously as a possibility. It is not a current threat.We should also, in thinking about [AI] policy, think about the current threats. And in that way, I present it as existential to whom when we ask about existential threats. For example, if we are talking about a senior and — seniors, I’ve done a lot of work in terms of abuse of seniors. They have lived a life of productivity. They are sitting on assets. They are vulnerable to predators and scams. And the use of technology and AI is one of those that is currently happening where you’ve heard the stories — you may know the stories; you may have family members — who the audio sounds like their grandson, “I’m in distress; I need help,” and they start giving away their life’s savings.Existential to who? Existential to that senior. That’s how it feels. Existential to who?
Eliezer has a response, which I will put directly here.
The fact that mundane harms can ‘feel existential’ to people anyway is perhaps confusing her. She has in mind, as the good Senator Blumenthal put it, the effect on jobs. Except no. Seriously. If you are going to be evoking Terminator then you might or might not be confused in a different highly understandable way, or you might only be trying to make people you dislike sound foolish through metaphor, but you know damn well the whom in ‘existential to whom.’
And you know damn well, madame Vice President, exactly what ‘existential’ means here. It does not mean evoking Continental philosophy. It does not mean how anyone feels. It means death.
Anyway, she goes on and does it again.
How about the father who is driving and then is the subject of facial recognition that is flawed, ends up in jail? Well, that’s existential to his family. Existential to who?
I mean, seriously? What the actual f***? Let’s go over this again.
Anyway, full remarks, so she goes back to boilerplate again. The whole ‘intentional to not stifle innovation’ argument, and, well, I don’t mean to laugh but have you met the entire Biden administration? To be clear, the answer could be no.
So, the spec- — the full spectrum of risks must also be evaluated as we are establishing public policy.My final point is: Public policies should be intentional to not stifle innovation. And I say this as the former Attorney General of California. I ran the second-largest Department of Justice in the United States, second only to the United States Department of Justice, and created one of the first Privacy and Protection Units of any Department of Justice. Back in 2010, I was elected.I know that there is a balance that can and must be struck between what we must do in terms of oversight and regulation and being intentional to not stifle innovation. I will also agree with you, as a devout public servant, government has historically been too slow to address these issues. AI is rapidly expanding.MR. SORKIN: Right.THE VICE PRESIDENT: And we have to, then, take seriously our ability to have the resources and the skillset to do this in a smart way that strikes the right balance and doesn’t accept false choices.
In my experience, don’t accept false choices is sometimes important, but mostly is what people say when they want to promise incompatible things, that their approach will magically do everything good and nothing bad, have everyone assume it will somehow work out and get promoted or move on before it blows up in their face.
Yes, this is the person the White House put in charge of many of its AI efforts, although that was before Dead Reckoning, and is also the person those who want reasonable AI policy are going to have to hope wins the next election, given Trump has already stated his intention to revoke the executive order on AI.
The Lighter Side

The rules have stayed the same.

All I’m saying is, we were definitely warned.

You Shavit: One interesting realization from moving inside OpenAI is that a lot of the time, we have no idea what Roon is talking about either.
Nor did she: A reply to Kamala Harris on existential risk. She asks, existential to whom? There is a type of person, which she is, who can only think in such terms.
16 comments
Comments sorted by top scores.
comment by Richard_Ngo (ricraz) · 2023-12-07T19:00:48.039Z · LW(p) · GW(p)
FWIW I think this sort of update would be much more valuable to me if it were less focused on "this is what people talked about on twitter". Seems like you're weighing notability primarily in terms of twitter followers and discussion, which seems like it won't select very well for lastingly relevant content.
(My perspective here may be biased though because I'd already seen most of the twitter stuff you linked.)
Replies from: Zvi, nikolas-kuhn↑ comment by Zvi · 2023-12-07T21:07:55.058Z · LW(p) · GW(p)
I agree on the margin I fall into the trap of doing more of this than I should. I do curate my Twitter feed to try and make this a better form of reaction than it would otherwise be, but I should raise the bar for that relative to my other bars.
Always good to get reminders on this.
However, as you allude to, you're in the spot where you're already checking many of the same sources on Twitter, whereas one of the points of these posts for a lot of readers is so they don't have to do that. I'd definitely do it radically differently if I thought most readers of mine were going to be checking Twitter a lot anyway.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-12-07T23:38:20.699Z · LW(p) · GW(p)
However, as you allude to, you're in the spot where you're already checking many of the same sources on Twitter, whereas one of the points of these posts for a lot of readers is so they don't have to do that. I'd definitely do it radically differently if I thought most readers of mine were going to be checking Twitter a lot anyway.
On the other hand, though, people who aren't on twitter much probably feel much more lost/confused about the people involved here, and why they should care about their opinions.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-12-08T19:36:49.116Z · LW(p) · GW(p)
FWIW I appreciate Zvi's reporting on What Twitter Is Saying because I don't want to look at twitter myself. Possibly I'm making the wrong choice here & would be curious to hear counterarguments, but that's the choice I've made.
↑ comment by Amalthea (nikolas-kuhn) · 2023-12-07T20:08:06.939Z · LW(p) · GW(p)
I tentatively agree, but it also seems difficult to think of a better alternative.
comment by Thane Ruthenis · 2023-12-07T16:23:44.828Z · LW(p) · GW(p)
Called it! [LW(p) · GW(p)]
Replies from: AlgonStrictly speaking, "an existential threat" literally means "a threat to the existence of [something]", with the "something" not necessarily being humanity. Thus, making a claim like "declining population will save us from the existential threat of AI" is technically valid, if it's "the existential threat for employment" or whatever. Next step is just using "existential" as a qualifier meaning "very significant threat to [whatever]" that's entirely detached from even that definition.
This is, of course, the usual pattern of terminology-hijacking, but I do think it's particularly easy to do in the case of "existential risk" specifically. The term's basically begging for it.
I'd previously highlighted "omnicide risk" as a better alternative, and it does seem to me like a meaningfully harder term to hijack. Not invincible either, though: you can just start using it interchangeably with "genocide" while narrowing the scope. Get used to saying "the omnicide of artists" in the sense of "total unemployment of all artists", people get used to it, then you'll be able to just say "intervention X will avert the omnicide risk" and it'd sound right even if the intervention X has nothing to do with humanity's extinction at all.
comment by keith_wynroe · 2023-12-08T05:37:04.237Z · LW(p) · GW(p)
And all of this is asserted as, essentially, obvious and undeniable, extreme confidence is displayed, all the arguments offered against this are invalid and dumb, and those that disagree are at best deeply confused and constantly told they did not understand or fairly represent what was said.
This feels unnecessarily snarky, but is also pretty much exactly the experience a lot of people have trying to engage with Yudkowsky et al. It feels weird to bring up “they’re very confident and say that their critics just don’t get it” as a put-down here.
It seems doubly bad because it really seems like a lot of the more pessimist crowd just genuinely aren’t actually trying to engage with these ideas at all. Nate wrote one skimmed post which badly misread the piece, and Yudkowsky AFAICT has at most engaged via a couple tweets (again which don’t seem to engage with the points). This is concurrent with them both engaging much more heavily with weaker objections to which they already have easy answers.
I genuinely don’t understand why a group which is highly truth-seeking and dispassionately interested in the validity of their very consequential arguments feels so little reason to engage with counter-arguments to their core claims which have been well-received.
I tried one reply to one of Pope’s posts
From your post, you seem to have misunderstood Quintin’s arguments in a way he explains pretty clearly, and then there’s not really much follow-up. You don’t seem to have demonstrated you can pass an ITT after this, and I think if it were Yudkowsky in Pope’s position and someone effectively wrote him off as hopeless after one failed attempt to understand eachother you would probably not be as forgiving.
Replies from: Zvi, ryan_greenblatt, sharmake-farah, rotatingpaguro↑ comment by Zvi · 2023-12-08T22:41:18.150Z · LW(p) · GW(p)
From my perspective here's what happened: I spent hours trying to parse his arguments. I then wrote an effort post, responding to something that seemed very wrong to me, that took me many hours, that was longer than the OP, and attempted to explore the questions and my model in detail.
He wrote a detailed reply, which I thanked him for, ignoring the tone issues in question here and focusing on thee details and disagreements. I spent hours processing it and replied in detail to each of his explanations in the reply, including asking many detailed questions, identifying potential cruxes, making it clear where I thought he was right about my mistakes, and so on. I read all the comments carefully, by everyone.
This was an extraordinary, for me, commitment of time, by this point, while the whole thing was stressful. He left it at that. Which is fine, but I don't know how else I was supposed to 'follow up' at that point? I don't know what else someone seeking to understand is supposed to do.
I agree Nate's post was a mistake, and said so in OP here - either take the time to engage or don't engage. That was bad. But in general no, I do not think that the thing I am observing from Pope/Belrose is typical of LW/AF/rationalist/MIRI/etc behaviors to anything like the same degree that they consistently do it.
Nor do I get the sense that they are open to argument. Looking over Pope's reply to me, I basically don't see him changing his mind about anything, agreeing a good point was made, addressing my arguments or thoughts on their merits rather than correcting my interpretation of his arguments, asking me questions, suggesting cruxes and so on. Where he notes disagreement he says he's baffled anyone could think such a thing and doesn't seem curious why I might think it.
If people want to make a higher bid for me to engage more after that, I am open to hearing it. Otherwise, I don't see how to usefully do so in reasonable time in a way that would have value.
Replies from: keith_wynroe↑ comment by keith_wynroe · 2023-12-09T10:48:28.910Z · LW(p) · GW(p)
Sorry you found it so stressful! I’m not objecting to you deciding it’s not worth your time to engage, what I’m getting at is a perceived double standard in when this kind of criticism is applied. You say
I do not think that the thing I am observing from Pope/Belrose is typical of LW/AF/rationalist/MIRI/etc behaviors to anything like the same degree that they consistently do it
But this seems wrong to me. The best analogue of your post from Quintin’s perspective was his own post laying out disagreements with Eliezer. Eliezer’s response to this was to say it was too long for him to bother reading, which imo is far worse. AFAICT his response to you in your post is higher-effort than the responses from MIRI people to his arguments all put together. Plausibly we have different clusters in our head of who we’re comparing him too though - I agree a wider set of LW people are much more engaging, I’m specifically comparing to e.g Nate and Eliezer as that feels to me a fairer comparison
To go into the specific behaviours you mention
I basically don't see him changing his mind about anything, agreeing a good point was made
I don’t think this makes sense - if from his perspective you didn’t make good points or change his mind then what was he supposed to do? If you still think you did and he’s not appreciating them then that’s fair but is more reifying the initial disagreement. I also don’t see this behaviour from Eliezer or Nate?
addressing my arguments or thoughts on their merits rather than correcting my interpretation of his arguments, asking me questions, suggesting cruxes and so on.
I again don’t see Eliezer doing any of this either in responses to critical posts?
Where he notes disagreement he says he's baffled anyone could think such a thing and doesn't seem curious why I might think it
Again seems to be a feature of many MIRI-cluster responses. Stating that certain things feel obvious from the inside and that you don’t get why it’s so hard for other people to grok them is a common refrain.
↑ comment by ryan_greenblatt · 2023-12-08T21:34:24.755Z · LW(p) · GW(p)
I genuinely don’t understand why a group which is highly truth-seeking and dispassionately interested in the validity of their very consequential arguments feels so little reason to engage with counter-arguments to their core claims which have been well-received.
A bunch of the more pessimistic people have in practice spent a decent amount of time trying to argue with (e.g.) Paul Christiano and other people who are more optimistic. So, it's not as though the total time spent engaging with counter-arguments is small.
Additionally, I think there are basically two different questions here:
- Should people who are very pessimistic be interested in spending a bunch of time engaging with counterarguments? This could be either to argue to bystanders or get a better model of reality for themselves and/or the counterparty.
- Who should people who are very pessimistic aim to engage with and what counterarguments should they discuss?
I'm pretty sympathetic to the take that pessimistic people should spend more time engaging (1), but not that sure that immediately engaging with specifically "AI optimists" is the best approach (2).
(FWIW, I think both AI optimists and Yudkowsky and Nate often make important errors wrt. various arguments at least when these arguments are made publicly in writing.)
ETA: there is relevant context in this post from Nate: Hashing out long-standing disagreements seems low-value to me [LW · GW]
↑ comment by Noosphere89 (sharmake-farah) · 2023-12-08T21:01:30.404Z · LW(p) · GW(p)
and Yudkowsky AFAICT has at most engaged via a couple tweets (again which don’t seem to engage with the points).
As a point of data, Yudkowsky also responded in a very terse manner and basically didn't respond to Pope's post at all, so this is not a one-off event:
https://www.lesswrong.com/posts/wAczufCpMdaamF9fy/my-objections-to-we-re-all-gonna-die-with-eliezer-yudkowsky#YYR4hEFRmA7cb5csy [LW(p) · GW(p)]
↑ comment by rotatingpaguro · 2023-12-13T07:18:31.679Z · LW(p) · GW(p)
Yudkowsky AFAICT has at most engaged via a couple tweets (again which don’t seem to engage with the points).
If you mean literally two, it's more, although I won't take the time to dig up the tweets. I remember seeing them discuss at non-trivial length at least once on twitter. (If "a couple" encompassed that... Well once someone asked me "a couple of spaghetti" and when I gave him 2 spaghetti he got quite upset. Uhm. Don't get upset at me, please?)
I've thought a bit about this because I too on first sight perceived a lack of serious engagement. I've not yet come to a confident conclusion; on reflection I'm not so sure anymore there was an unfair lack of engagement.
First I tried to understand Pope's & co arguments at the object level. Within the allotted time, I failed. I expected to fare better, so I think there's some mixture of (Pope's framework not being simplifiable) & (Pope's current communication situation low), where the comparatives refer to the state of Yudkowsky's & co framework when I first encountered it.
So I turned to proxies; in cases where I thought I understood the exchange, what could I say about it? Did it seem fair?
From this I got the impression that sometimes Pope makes blunders at understanding simple things Yudkowsky means (not cruxes or anything really important, just trivial misunderstandings), which throw a shadow over his reading comprehension, such that then one is less inclined to spend the time to take him seriously when he makes complicated arguments that are not clear at once.
On the other hand, Yudkowsky seems to not take the time to understand when Pope's prose is a bit approximative or not totally rigorous, which is difficult to avoid when compressing technical arguments.
So my current conceit is: a mixture of (Pope is not good at communicating) & (does not invest in communication). This does not bear significatively on whether he's right, but it's a major time investment to understand him, so inevitably someone with many options on who to talk to is gonna deprioritize him.
To look at a more specific point, Vaniver replied at length to Quintin's post on Eliezer's podcast, and Eliezer said those answers were already "pretty decent", so although he did not take the time to answer personally, he bothered to check that someone was replying more thoroughly.
P.S. to try to be actionable: I think Pope's viewpoint would greatly benefit from having someone who understands it well, but is good and dedicated at communication. Although they are faring quite well on fame, so maybe they don't need, after all, anything more?
P.P.S. they now have a website, optimists.ai, so indeed they do think they should ramp up communication efforts, instead of resting on their current level of fame.
comment by RogerDearnaley (roger-d-1) · 2023-12-08T04:15:36.703Z · LW(p) · GW(p)
Indeed this is the case for open source models and all known alignment techniques, that the fine-tune cost to eliminate all safeguards is trivial. I do not see any even theoretical proposal of how to change this unfortunate reality.
Actually, there are multiple such proposals: you could put the safeguards in during the entire pretraining run, so they're a lot harder to fine-tune out. See this post [LW · GW] and this paper for examples. (To some extent we already do this just by prefiltering the training set.) Or you could rip the problematic behavior out after pretraining but before open-sourcing the weights, see this post [LW · GW] for a long list of ideas on how to do that. But it certainly is harder than aligning an API-only model.
I'm still waiting for someone to write a "Responsible Open-Sourcing Policy". Maybe one of the AI governance orgs should take a shot at a first draft? Then see if we can get HuggingFace to adopt it?
comment by VipulNaik · 2023-12-09T00:49:16.605Z · LW(p) · GW(p)
He points to recent events at Sports Illustrated. But to me the SI incident was the opposite. It indicated that we cannot do this yet. The AI content is not good. Not yet. Nor are we especially close. Instead people are using AI to produce garbage that fools us into clicking on it. How close are we to the AI content actually being as good as the human content? Good question.
I happen to work at the company (The Arena Group) that operates Sports Illustrated. I wasn't involved with any of this stuff directly (and may not even have been at the company over some of the relevant time period), and obviously I speak only for myself (and will restrict myself to the public information available on this which is anyway most of what I know). With that said: most of the media coverage of this issue was pretty bad (as it is for most issues, but then, Gell-Mann Amnesia ...). In particular, the Futurism article has a lot of issues. The best article I found on this was https://www.theverge.com/2023/11/27/23978389/sports-illustrated-ai-fake-authors-advon-commerce-gannett-usa-today that properly explains who the vendor in question was and the vendor's track record on another site. Overall, the Verge article helps check out the Arena Group's official statement that the articles were from AdVon, despite the seeming reluctance of Futurism (and other publications) to accept that.
The maybe-AI-maybe-not-AI content was written way way before the whole ChatGPT thing raised the profile of AI. Futurism links to https://web.archive.org/web/20221004090814/https://www.si.com/review/full-size-volleyball/ which is a snapshot of the article from October 2022, before the wide release of ChatGPT, and well before The Arena Group made public announcements about experimenting with AI. But in fact the article is even way older than October 2022; the oldest snapshot https://web.archive.org/web/20210916150227/https://www.si.com/review/full-size-volleyball/ of the article is from September 16, 2021, and the article publication date is September 2, 2021. Way before ChatGPT or any of the AI hype. And even that earliest version shows the same photo and a similar bio.
So to my mind this comes down to the use of a vendor (AdVon) with shady practices, and either the lack of due diligence in vendor selection or not caring about the details of their practices as long as they're driving revenue to the site and not hurting the site's brand. The reason to use a vendor like this is simply that they drive affiliate marketing revenue (people find the recommended content interesting, they click on it, maybe buy it, everybody gets a cut of the revenue, everybody is happy). This simply isn't even part of the editorial content and basically has nothing to do with replacing real writers of sports content with AI writers -- it's simply an effort to leverage the brand of the site by running a side business from one corner of it. Also, to the extent it is or isn't ethical, the issue probably has more to do with whether the reviews were genuine rather than whether the authors were human or AI -- even if the authors were human, if the reviews were fraudulent, it would be a problem in equal measure. So overall I think the vendor selection was problematic, but this has little to do with AI.
Separately, many sports sites, including Sports Illustrated, have used automatically (/ "AI")-generated content for routine content such as game summaries, e.g., using the services of Data Skrive: https://www.si.com/author/data-skrive -- this is probably a little closer to the idea of replacing human writers, but the kind of content being created is pretty much the kind of content that humans wouldn't want to spend time creating.
The Arena Group has done some AI experimentation with the goal of trying to use AI-like tools to write normal content (not things like game summaries), as Futurism critiqued at https://futurism.com/neoscope/magazine-mens-journal-errors-ai-health-article but this AdVon thing is completely separate in time, in space, and in purpose.
Replies from: VipulNaik↑ comment by VipulNaik · 2023-12-23T03:04:24.516Z · LW(p) · GW(p)
The first 10 minutes or so of https://podcasts.apple.com/us/podcast/episode-51-what-happened-at-the-arena-group-former/id1615989259?i=1000639450752 also provide related context.