Soft optimization makes the value target bigger
post by Jeremy Gillen (jeremy-gillen) · 2023-01-02T16:06:50.229Z · LW · GW · 20 commentsContents
Summary Extremal Goodhart Setting q based on a generalization bound Formalization Extensions I want Fine-tuned generative models Competitive planning Motivation: Assistant for alignment research My understanding of the most important problems Appendix I think TurnTrout and Garrett Baker are wrong about quantilizers Reflective stability AI Safety Camp Acknowledgements None 20 comments
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2.1, mentored by John Wentworth [LW · GW].
Summary
We can solve Goodhart's Curse by making the agent (1) know the reliability of its goal representation and (2) cap the amount of optimization power devoted to achieving its goals, based on this reliability measure. One simple way to formalize this is with a generalization bound on the quality of the value proxy and a quantilizer whose value is chosen based on the generalization bound. For a competitive implementation of this algorithm, it's easy to create outer objectives that will push a learned planning algorithm toward soft optimization. I think this is a productive research avenue, and this approach should stack on top of value learning and interpretability approaches to reducing AGI risk.
Extremal Goodhart
Powerful artificial agents are dangerous if they do unbounded uninterruptible optimization [AF · GW]. Unbounded optimization is dangerous because of Extremal Goodhart, which is demonstrated in the diagram below.

In this diagram, the potential policies taken by the agent are arranged in order of expected proxy value[1] on the x-axis. We can see that as we push further to the right (which is what an optimizer does), the proxy value becomes less correlated with the true value.[2] If we completely trusted our distribution over possible utility functions, we would simply take the rightmost policy, since it has the highest expected value. But we can't trust this knowledge, because by choosing the rightmost policy we have applied optimization pressure to find the policy with the most upward error in its value estimate.
We can reduce this problem by randomizing our choice of policy. Randomizing the policy is equivalent to reducing the amount of optimization power. The problem is that randomizing inherently reduces the usefulness and capabilities of your agent.
This post is about an approach for setting the amount of optimization power such that the optimizer achieves as much expected value as possible, within the limits set by its knowledge about the utility function. In other words, it's dumber when in unfamiliar territory, i.e. out of distribution. If implemented well, I think this makes the alignment problem easier in two ways. One, it allows us to imperfectly specify the utility function, and two, it allows us to specify a single-task utility function and be uncertain about the utility of unrelated world states.
Setting based on a generalization bound
First off, a -quantilizer is an algorithm that samples randomly from the top proportion of policies. A 40%-quantilizer looks like this:
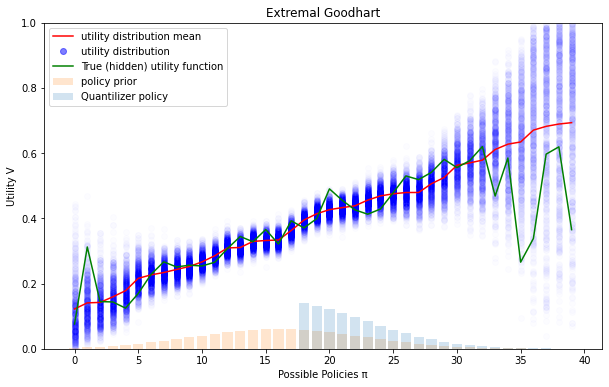
Note that the "true" utility function is usually hidden somewhere in the dark blue area, and is shown in this diagram to better illustrate the benefits of the Quantilizer policy.
Quantilizers are the optimal policy distribution if you have some cost function , and have knowledge about the expected cost under the prior distribution and want to upper bound the expected cost under the chosen policy distribution. Based on the required upper bound you can determine the value. However, this isn't a good way to choose the value. We don't know the cost function, and we don't know how much cost is too much.
Instead, it's possible to determine the optimal policy distribution if we have a representation of uncertainty about the true utility function and a generalization bound telling us how reliable that representation is. The optimal policy distribution will often be exactly the same as a quantilizer, but sometimes not exactly.
A generalization bound for a learning algorithm is simply a number that upper bounds the average on-distribution test loss. We can use a generalization bound to guarantee that a learning algorithm hasn't overfitted to the training data. We are going to assume we have a generalization bound on the quality of our proxy of the true utility function (we will later formalize this proxy as a distribution ). This is just a formalization of the knowledge that our proxy works well in normal situations. We can then work out the relationship between proxy quality and changes in the policy distribution, and use this to work out the optimal policy distribution that doesn't damage the proxy quality too much.
Note that generalization bounds are reasonably easy to get. The simplest way to get one is to have a validation set of data not used during training, and use that to estimate the loss on the test dataset. By itself, this isn't a bound, but if we assume the validation set and the test set have the same data distribution, then we can use a concentration inequality to easily get an upper bound on the expected test loss. If we don't have a validation set, we can use theoretically derived generalization bounds, like this one, which upper bounds the expected error of an MNIST classifier at ~16% compared to an estimated true error of 1.8%.[3] In my toy examples and generated graphs, I made up a generalization bound that was more than 10x the actual expected loss, based on this result.
Formalization
Now I'll describe the full argument more formally. Assume there is a true human utility function which maps from any policy to a utility . Assume we have some fixed distribution over utility functions , represented by the parameterized density function . We can query this density function at a specific policy using the notation . We may have learned this distribution using some labelled examples of humans performing tasks, for example. We have some distribution over policies called , which can be a model of a human distribution over policies.
Now we also need to assume we have some measure of how reliable is, in other words, how closely it approximates the "true utility function" we were trying to communicate. The most natural way to represent this information is a generalization bound of the form .[4] This says that on average over normal policies (), our knowledge about the utility function is good (the true utility function has high density). Since the expected log probability is a natural loss function that can be used to learn this distribution, it's natural that we might have a generalization bound on this value.
Let's assume our policy distribution can be represented in the form of a Bayesian update on , i.e. . Now the problem of finding the optimal is equivalent to finding the optimal function .[5] Now we can define , a generalization of the quantilizer value to any distribution represented this way. Now for any function , we have the same bound proven in the original paper:
Now it'd be useful to derive an upper bound on , but unfortunately negative log densities aren't always positive. This is easily fixed by adding lowest possible negative log density: .
By setting , we get . In words, this is a bound on how much mass must be assigned to the true value function by , on average across the policy distribution.
This is usually a loose upper bound, since it holds in the worst case when is as incorrect as possible on the policy distribution. However, in this case, this is exactly what we want. As optimization power is increased, positive errors in the proxy are selected for, so we can expect that this bound will become tighter as is pushed down close to zero.
Let's define the set of utility functions that satisfy the above bound, where is the set of possible policies. .
Now the optimal policy distribution, given the information we have, is:
This distribution will balance the task of maximizing value with the task of maintaining similarity to the prior (which is measured by , and allows a higher lower bound on the value). As our information about the proxy improves, the level of optimization increases. In my toy example, the policy looks like:

Generated by finding the optimal likelihood function.[6]
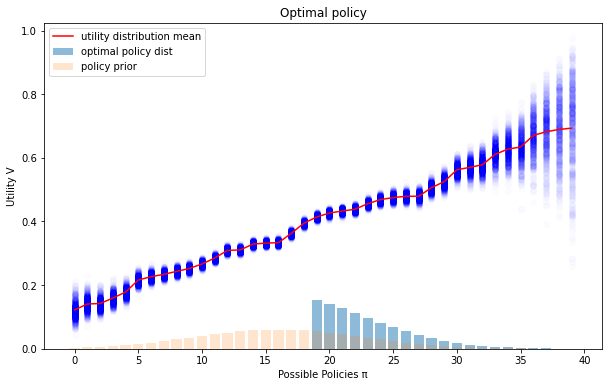

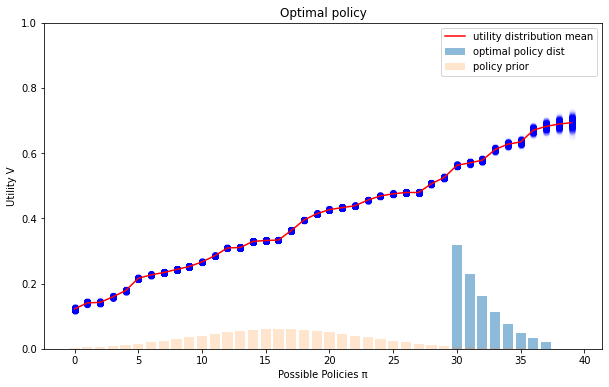
The code used to generate these toy examples is here. It uses an artificially constructed distribution , I chose a beta distribution over the value of each policy. I used out-of-the-box constrained convex optimization to do the minimizing part, and then a hacky optimizer on top of that to find the optimal policy distribution (the max part).
Note that Jessica Taylor did a very similar proof [LW · GW] eight years ago,[7] but for a simpler bound on the quality of the utility function. This shows already that the quantilization parameter can be derived if you have a bound on the average error of the proxy.
If the information is in the form of a bound on the average distance to the proxy , as Jessica's is, then the optimal distribution is always a quantilizer. With the generalization bound in the form I used, the optimal distribution isn't always a quantilizer, as can be seen in some of the diagrams above. Instead, it cuts off the upper end of the distribution if the utility estimate is too noisy there.
Extensions I want
- A more computationally efficient solution to the max min problem.
- Make the situation more realistic by including latent representations of world-state-trajectories in the formalization, in between policies and utilities.
- Adding the modal log density will loosen the bound a lot when is confident. Is there a way around this?
Fine-tuned generative models
Fine-tuned and conditioned generative models act a lot like soft optimizers. This has been pointed out a number of times (e.g. tailcalled [LW(p) · GW(p)], Linda Linsefors [AF(p) · GW(p)], Sam Marks [LW · GW] & Charlie Steiner [LW · GW] have mentioned similar things).
Quantilizers (and the optimal policy distribution above) can be described as a Bayesian update on the policy prior, so we can borrow techniques for Bayesian inference to help compute them. In fact, we have an outer objective whose optimum is exactly the soft optimizer we want, if we use it correctly: the Variational inference objective [LW · GW].
This works by finding the distribution that maximizes , which you can easily show is the same distribution as . To create a quantilizer, we would have to set to be an indicator function that is 1 when is above a certain value, and 0 otherwise. To avoid introducing infinite values to our optimization problem, we would probably want to use a smooth approximation to the indicator function (this doesn't damage any theoretical guarantees).
All of this assumes that we can already have access to a learned distribution over utility functions, , which we can use to calculate . If we want to use this to create softly optimizing agents out of language models, we would need a fast way to calculate (or approximate) locally, rather than globally as I did in the toy model. Let me know if you have a suggestion for how to do this.
Competitive planning
Sampling an entire sequence of actions at once is obviously impractical, both because you need to react to the environment, and because that's just not an easy way to generate a good plan. A real agent would softly optimize across plans that it is considering in real time, which would be of finite length, and represented abstractly rather than with literal actions.
A key technique for make planning easier is working out a plan bit by bit. Let's say we have a policy distribution which a soft optimizer is trying to approximate, where the policy can be split up into a series of actions . Then a plan can be generated by sampling these one by one, conditional on previously sampled actions.
If the planner needed to generate a plan consisting of two actions, it could do this by sampling from , then from , where and are a factorization of , the full policy distribution constructed above. When the two actions influence the cost independently, this will look like quantilizing each action independently, but when there is dependence between the actions it will look like quantilizing over pairs of actions. This avoids the cost independence assumption discussed in Section 3.3 of the Quantilizers paper, allowing us to make the correct competitiveness-safety tradeoff that we already determined based on our proxy quality.
A sophisticated planner [LW · GW] would sample these in whichever order the sampling is easiest. For example, it might start by backtracking from the goal, work out constraints on intermediate states, and recursively quantilize toward the intermediate states. All of this seems natural to implement when you start with a powerful conditional model, and seems possible to do without losing soft optimization guarantees.
Directly building by hand an algorithm that implements the above seems completely plausible, at least for low to medium levels of optimization power. I expect for useful levels of general purpose optimization power, we might need to learn the softly optimizing planner.
Motivation: Assistant for alignment research
In the end what I want is an agent that can be used to help solve the alignment problem properly, while remaining safely bounded and focused on the relatively simple goals and sub-problems we give it. Soft optimization seems to be a promising and practical tool that will be useful for achieving this goal.
Soft optimization allows us to create an agent with a task-specific goal (e.g. run this experiment or solve a math problem), without specifying literally all of human values. We should be able to start with a number of demonstrations of a task being completed, both well and poorly, and the corresponding human-labelled "utility" of the outcomes, and have this be sufficient to create an agent that usefully solves the task. This is because it automatically avoids highly out of distribution outcomes, the outcomes with uncertain utility. For this reason we won't need to think of every possible terrible outcome and carefully provide data about its utility.
For this to work and be competitive, the distribution over utility functions has to generalize well. Generalizing the human value function is hard, because human values are complex. Generalizing uncertainty about values is relatively achievable, because uncertainty can be very simple. For example, the uncertainty modeled in could be as simple as: be more uncertain the further the world state is from states in the training data. This is an easy function to learn and an easy function to generalize out of the training distribution.
My understanding of the most important problems
- Training data is fundamentally limited to outcomes that humans can evaluate
- Learning theory is about situations where the test data is drawn from the same distribution as the training environments. The quantilizer result adds some flexibility to this assumption, but we still have to be worried about situations that have literally zero measure in the training distribution. In these situations generalization bounds don't provide much useful information, and we have to rely entirely on prior information about the similarity of the new situation to situations in training.
- Solutions to this might look like Paul Christiano's work, or insanely good understanding of the prior of our value learning algorithm, or a really great understanding of the internal latent variables [AF · GW] that are used as inputs to the utility function.
- Learning theory is about situations where the test data is drawn from the same distribution as the training environments. The quantilizer result adds some flexibility to this assumption, but we still have to be worried about situations that have literally zero measure in the training distribution. In these situations generalization bounds don't provide much useful information, and we have to rely entirely on prior information about the similarity of the new situation to situations in training.
- Value learning
- If we only want low levels of optimization power, then value learning by hand labeling various outcomes might be sufficient. If we want full value learning of all human values, then perhaps an approach like Vanessa Kosoy's [LW · GW] might work, where "agent" and "goal" are described mathematically, then found inside the latent knowledge of a predictive world model.[8] A soft optimizer could fit well with this approach because it naturally results in a distribution over utility when the utility function of the operator isn't well defined.
- If we use the method described in this post to bound optimization, it requires very high levels of certainty about value in order to make use of a lot of optimization power. This will strongly limit capabilities until really good value learning techniques are developed.
- Deceptive mesa-optimizers
- An agent trained by finetuning a language model with the variational loss described above could become a deceptively aligned mesa-optimizer, and pretend to be optimizing less strongly than it really is in order to fool the outer objective.
Appendix
Why caps optimization power
Vanessa Kosoy defines [LW · GW] an intelligence measure , which measures the proportion of random policies that do better than the policy we are measuring. It's worth noting that of a quantilizer is equal to , if the random policy distribution is equal to the policy prior . If the random policy distribution is broader than , then will differ from by a fixed constant. This also corresponds to how Eliezer defines optimization power [LW · GW], as the number of times you can divide the search space in two. Vanessa's definition includes an average over different environments in order to measure the generality of the optimizer.
We can intuitively think of a 0.001-quantilizer as being approximately as intelligent as 1 in 1000 humans, if is a distribution over human actions (although don't trust this intuition too much, it'll always be a very rough approximation, and is missing the notion of generality).
I think TurnTrout and Garrett Baker are wrong about quantilizers
They argue that quantilizing doesn't work, or at least raises unanswered questions. I think these questions have good answers:
Maybe we just... [LW · GW] Quantilize. But then what's the base distribution, and what's the threshold?
The base distribution is a human imitator, or at least a distribution of policies that we can obtain outcome evaluations for. The threshold is determined by your uncertainty about the utility function.
How do you set the quantiles such that you're drawing from a distribution which mostly involves lots of actual diamonds?
Because you can have a bound on how accurate to the true utility function your distribution is, you know that your policy distribution will contain the most diamonds your knowledge of diamond measurement will allow.
Do there even exist such quantiles, under the uniform base distribution on plans?
Yes, if your knowledge about the utility function is good enough, and you have a bound on how good it is. However, under a uniform distribution over plans it'd be difficult to obtain a tight generalization bound on , and the amount of optimization required to find useful plans would need to be very high, so you'd need a really good bound.
This proposal is a formal version of one on the Goodhart's curse page
Another proposal would be to rely on risk aversion over unresolvably uncertain probabilities broad enough to contain something similar to the true V as a hypothesis, and hence engender sufficient aversion to low-true-V outcomes. Then we should worry on a pragmatic level that a sufficiently conservative amount of moral uncertainty--so conservative that U-T risk aversion never underestimated the appropriate degree of risk aversion from our V-standpoint--would end up preventing the AI from acting ever. Or that this degree of moral risk aversion would be such a pragmatic hindrance that the programmers might end up pragmatically bypassing all this inconvenient aversion in some set of safe-seeming cases. Then Goodhart's Curse would seek out any unforeseen flaws in the coded behavior of 'safe-seeming cases'.
I think this post addresses the concern that this prevents the AI from taking action at all. But my version still has the same weakness, it will limit capabilities in a way that will be tempting to bypass.
Reflective stability
Quantilizers aren't always reflectively stable, i.e. if it builds a successor agent or self-modifies, it might create a maximizer. Currently my best guess for avoiding this is to use TurnTrout's Attainable Utility [? · GW] to penalize policies that gain much more power than the quantilizer is expected to.
AI Safety Camp
I'm planning on running an AI Safety Camp research project on this topic. Applications will open in a few days if you want to help, and it'll be remote work over a few months. Project description is here (although I wrote it before doing most of the work in this post).
Acknowledgements
Thanks to Beren Millidge [LW · GW] for sending me this paper about viewing RL as inference. Thanks to Matthew Watkins, Jacques Thibodeau [LW · GW], Rubi J. Hudson [LW · GW] and Thomas Larsen [LW · GW] for proofreading and feedback.
- ^
I use "proxy utility" and "utility distribution" interchangeably. These refer to a distribution over utility functions. This distribution represents the agent's (uncertain and not perfectly reliable) knowledge about the "true" utility function. In the Goodhart's Curse arbital page, the proxy is referred to as U, and the "true" utility function as V. In this post, we will call the proxy , and the "true" utility function .
- ^
In the limit of optimization power, the proxy being optimized becomes almost entirely uncorrelated with true value, so the AGI's actions would look like they are maximizing a random utility function.
- ^
Theoretical generalization bounds on neural networks have been studied intensely in ML theory recently, because they are closely linked to the question of why neural networks generalize well at all, despite seemingly being able to fit randomly labeled data. Under classic PAC learning theory, models that can fit randomly labeled data should overfit to the training data.
Note that these bounds only hold with high probability (due to the actual datapoints being randomly chosen), but the bound can be easily adjusted depending on the probability you want. Also note that we will never optimize against this probability.
- ^
Notation here is confusing, so I'll break down each object: .
is a number in [0,1].
takes in an entire utility function and gives you the density assigns to that function. It might be implemented as a Gaussian process, for example.
takes in a number in [0,1], the value of a utility function at . It returns the density at that location. We can think of this as a vertical slice through the distribution over functions.
Now we can get the conditional density at the particular value , which remember is in .
- ^
The function isn't really meaningful, it's just useful for transforming the prior into a policy . See a graph of one in the next footnote.
- ^
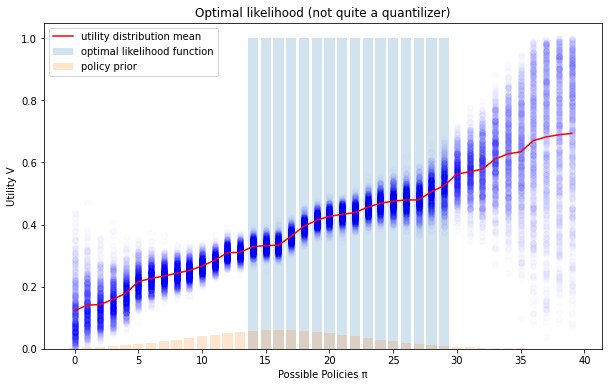
Multiplying the likelihood and the policy prior gives us the unnormalized policy distribution. - ^
I only saw this a few days ago. I was a bit disappointed, I thought I'd come up with something completely new.
- ^
I find this idea similar to the method used in the paper about finding latent directions that correspond to "truth".
20 comments
Comments sorted by top scores.
comment by LawrenceC (LawChan) · 2023-01-02T18:26:39.380Z · LW(p) · GW(p)
Thanks for writing this.
I agree that it's good to try to answer the question, under what sort of reliability guarantee is my model optimal, and it's worth making the optimization power vs robustness trade off explicit via toy models like the one you use above.
That being said, re: the overall approach. Almost every non degenerate regularization method can be thought of as "optimal" wrt some robust optimization problem (in the same way that non degenerate optimization can be trivially cast as Bayesian optimization) -- e.g. the RL - KL objective with respect to some is optimal the following minimax problem:
for some . So the question is not so much "do we cap the optimization power of the agent" (which is a pretty common claim!) but "which way of regularizing agent policies more naturally captures the robust optimization problems we want solved in practice".
(It's also worth noting that an important form of implicit regularization is the underlying capacity/capability of the model we're using to represent the policy.)
I also think that it's probably worth considering soft optimization to the old Impact [AF · GW] Measures work [AF · GW] from this community -- in particular, I think it'd be interesting to cast soft optimization methods as robust optimization, and then see how the critiques raised against impact measures (e.g. in this comment [AF(p) · GW(p)] or this question [AF · GW]) apply to soft optimization methods like RL-KL or the minimax objective you outline here.
Replies from: jeremy-gillen, jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T14:59:52.471Z · LW(p) · GW(p)
I also think that it's probably worth considering soft optimization to the old Impact [LW · GW] Measures work [LW · GW] from this community -- in particular, I think it'd be interesting to cast soft optimization methods as robust optimization, and then see how the critiques raised against impact measures (e.g. in this comment [LW(p) · GW(p)] or this question [LW · GW]) apply to soft optimization methods like RL-KL or the minimax objective you outline here.
Thanks for linking these, I hadn't read most of these. As far as I can tell, most of the critiques don't really apply to soft optimization. The main one that does is Paul's "drift off the rails" thing. I expect we need to use the first AGI (with soft opt) to help solve alignment in a more permanent and robust way, then use that make a more powerful AGI that helps avoid "drifting off the rails".
In my understanding, impact measures are an important part of the utility function that we don't want to get wrong, but not much more than that. Whereas soft optimization directly removes Goodharting of the utility function. It feels like the correct formalism for attacking the root of that problem. Whereas impact measures just take care of a (particularly bad) symptom.
Abram Demski has a good answer [LW(p) · GW(p)] to the question you linked that contrasts mild optimization with impact measures, and it's clear that mild optimization is preferred. And Abram actually says:
An improvement on this situation would be something which looked more like a theoretical solution to Goodhart's law, giving an (in-some-sense) optimal setting of a slider to maximize a trade-off between alignment and capabilities ("this is how you get the most of what you want"), allowing ML researchers to develop algorithms orienting toward this.
This is exactly what I've got.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T14:38:32.107Z · LW(p) · GW(p)
I agree that it's good to try to answer the question, under what sort of reliability guarantee is my model optimal, and it's worth making the optimization power vs robustness trade off explicit via toy models like the one you use above.
That being said, re: the overall approach. Almost every non degenerate regularization method can be thought of as "optimal" wrt some robust optimization problem (in the same way that non degenerate optimization can be trivially cast as Bayesian optimization) -- e.g. the RL - KL objective with respect to some is optimal the following minimax problem:
for some . So the question is not so much "do we cap the optimization power of the agent" (which is a pretty common claim!) but "which way of regularizing agent policies more naturally captures the robust optimization problems we want solved in practice".
Yep, agreed. Except I don't understand how you got that equation from RL with KL penalties, can you explain that further?
I think the most novel part of this post is showing that this robust optimization problem (maximizing average utility while avoiding selection for upward errors in the proxy) is the one we want to solve, and that it can be done with a bound that is intuitively meaningful and can be determined without just guessing a number.
(It's also worth noting that an important form of implicit regularization is the underlying capacity/capability of the model we're using to represent the policy.)
Yeah I wouldn't want to rely on this without a better formal understanding of it though. KL regularization I feel like I understand.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2023-04-11T13:13:52.177Z · LW(p) · GW(p)
Great stuff Jeremy!
Two basic comments:
1. Classical Learning Theory is flawed and predicts that neural networks should overfit when they don't.
The correct way to understand this is through the lens of singular learning theory. [? · GW]
2. Quantilizing agents can actually be reflectively stable. There's work by Diffractor (Alex Appel) on this topic that should become public soon.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-04-11T17:16:38.899Z · LW(p) · GW(p)
Thanks!
- I think it's more accurate to say it's incomplete. And the standard generalization bound math doesn't make that prediction as far as I'm aware, it's just the intuitive version of the theory that does. I've been excited by the small amount of singular learning theory stuff I've read. I'll read more, thanks for making that page.
- Fantastic!
comment by Gordon Seidoh Worley (gworley) · 2023-01-03T03:30:31.971Z · LW(p) · GW(p)
This seems interesting. I'd qualify though as not solving Goodhart's Curse but limiting the damage done by it. There will still be non-zero Goodharting, but it will hopefully be an insufficient amount of Goodharting to result in bad outcomes as a result of Goodharting (may still get bad outcomes for other reasons).
There's an additional practical challenge with this approach (which I think the original quantilizer approach shares), which is that it will always be tempting to get additional gains by allowing an agent to optimize a little bit more than it currently is. The incremental damage done won't be too great, and it will only be too late once we realize we've crossed a threshold where optimization has resulted in Goodharting to bad effect, so it seems even if this works in theory we also need to address the practical concern of how to coordinate to limit the optimization power we build into AI.
(This second point is not meant to be an objection or complaint, more thinking out loud about future research directions after establishing if this approach is sufficient.)
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T10:20:23.036Z · LW(p) · GW(p)
Good point, policies that have upward errors will still be preferentially selected for (a little). However, with this approach, the amount of Goodharting should be constant as the proxy quality (and hence optimization power) scales up.
I agree with your second point, although I think there's a slight benefit over original quantilizers because is set theoretically, rather than arbitrarily by hand. Hopefully this makes it less tempting to mess with it.
comment by TurnTrout · 2023-01-03T18:29:27.040Z · LW(p) · GW(p)
TurnTrout and Garrett have a post [LW · GW] about how we shouldn't make agents that choose plans by maximizing against some "grader" (i.e. utility function), because it will adversarially exploit weaknesses in the grader.
To clarify [LW · GW]: A "grader" is not just "anything with a utility function", or anything which makes subroutine calls to some evaluative function (e.g. "how fun does this plan seem?"). A grader-optimizer is not an optimizer which has a grader. It is an optimizer which primarily wants to maximize the evaluations of a grader. Compare
- "I plan and cleverly optimize my free time to have lots of fun" with
- "I want to find the maximally fun-seeming plan (which may or may not involve actually having fun)."
(2) is just you optimizing against your is-fun? grader. On (2), you would gleefully accept a plan which you expect to fool yourself about the future (e.g. you aren't really going to be having fun, but the act of evaluating the plan tricks you into thinking you will). On (1), you would not consider this plan, because it wouldn't lead to having fun.
(This distinction is still somewhat hard for me to quickly explain, so to really internalize it you'll probably have to read and think more about it and not just read a few paragraphs.)
I think any useful agent has to be doing something equivalent to optimizing against a grader internally, and their post doesn't have a concrete alternative to this.
The post did state that it wasn't going to explain the alternatives (I figured the post was long enough already):
In this first essay, I explore the adversarial robustness obstacle. In the next essay, I'll point out how this is obstacle is an artifact of these design patterns, and not any intrinsic difficulty of alignment.
You can learn about a concrete alternative via the example value-child cognitive step-through [LW · GW] I provided in Don't align agents to evaluations of plans [LW · GW]. You can further read about how robust grading/grader-optimization isn't necessary in Alignment allows "nonrobust" decision-influences and doesn't require robust grading [LW · GW], which includes pseudocode for an agent which isn't a grader-optimizer [LW · GW].
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T22:03:52.221Z · LW(p) · GW(p)
Thanks for clarifying, I misunderstood your post and must have forgotten about the scope, sorry about that. I'll remove that paragraph. Thanks for the links, I hadn't read those, and I appreciate the pseudocode.
I think most likely I still don't understand what you mean by grader-optimizer, but it's probably better to discuss on your post after I've spent more time going over your posts and comments.
My current guess in my own words is: A grader-optimizer is something that approximates argmax (has high optimization power)?
And option (1) acts a bit like a soft optimizer, but with more specific structure related to shards, and how it works out whether to continue optimizing?
↑ comment by TurnTrout · 2023-01-17T01:39:32.399Z · LW(p) · GW(p)
Thanks for registering a guess! I would put it as: a grader optimizer is something which is trying to optimize the outputs of a grader as its terminal end (either de facto, via argmax, or intent-alignment, as in "I wanna search for plans which make this function output a high number"). Like, the point of the optimization is to make the number come out high.
(To help you checksum: It feels important to me that "is good at achieving its goals" is not tightly coupled to "approximating argmax", as I'm talking about those terms. I wish I had fast ways of communicating my intuitions here, but I'm not thinking of something more helpful to say right now; I figured I'd at least comment what I've already written.)
comment by David Johnston (david-johnston) · 2023-01-04T10:21:14.637Z · LW(p) · GW(p)
optimal
I'd call this the "maximin" or the "maximin optimal" distribution.
comment by Charlie Steiner · 2023-01-03T00:59:51.475Z · LW(p) · GW(p)
Hm. Initially I would say that this approach tackles extremal Goodhart on epistemic uncertainty, but not on model/value uncertainty (and therefore this is a blueprint for an AI that thinks "the human's utility function [LW · GW]" is some real thing, and goes out and becomes arbitrarily certain that it's found it). But maybe there's something to do here.
Having model uncertainty is sort of like having epistemic uncertainty that you can't resolve (though notably for epistemic uncertainty the aggregation function is fixed to be the weighted average, while for non-epistemic uncertainty it can be nonlinear). So I'd be interested to see you using mildly-optimizing agents as a testbed for what happens when your process for learning what to value can't supply infinite independent bits. Especially from human feedback - can you think of ways for the AI to be able to query humans for feedback, and yet not be able to push uncertainty to zero via infinite feedback? Does this create perverse incentives? What do more/less principled ways of doing this look like?
Replies from: jeremy-gillen, sharmake-farah↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T14:10:20.392Z · LW(p) · GW(p)
I've probably misunderstood your comment, but I think this post already does most of what you are suggesting (except for the very last bit about including human feedback)? It doesn't assume the human's utility function is some real thing that it will update toward, it has a fixed distribution over utility throughout deployment. There's no mechanism for updating that distribution, so it can't become arbitrarily certain about the utility function.
And that distribution isn't treated like epistemic uncertainty, it's used to find a worst case lower bound on utility?
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2023-01-04T02:53:53.434Z · LW(p) · GW(p)
My bad, I commented without reading thoroughly and was wrong - I think I hallucinated that you were setting as a function of the toy data, rather than generating the toy data to visualize . Whoops!
Other things that came up when I actually read the whole thing:
It does seem like you're always just going to get a rescaled subset of the prior distribution. My heuristic argument goes like: if your output distribution isn't just a rescaled subset of the prior, then you can freely increase your score (without changing ) by moving probability mass from the lowest-score policy to higher-scoring policies that haven't yet reached - this doesn't change the EV of because it's precisely that's the conserved probability mass, not alone.
I still don't understand the section on planning - there's the classic quantilizer problem that policies made of individually likely actions may be unlikely in aggregate. If you have a true factorization of the space of policies this can be sidestepped, but doesn't the same problem show up rephrased as "true, non-approximate, factorizations of the space of policies are rare?"
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-05T15:32:32.998Z · LW(p) · GW(p)
- On it always being a rescaled subset: Nice! This explains the results of my empirical experiments. Jessica made a similar argument for why quantilizers are optimal, but I hadn't gotten around to trying to adapt it to this slightly different situation. It makes sense now that the maximin distribution is like quantilizing against the value lower bound, except that the value lower bound changes if you change the minimax distribution. This explains why some of the distributions are exactly quantilizers but some not, it depends on whether that value lower bound drops lower than the start of the policy distribution.
- On planning: Yeah it might be hard to factorize the final policy distribution. But I think it will be easy to approximately factorize the prior in lots of different ways. And I'm hopeful that we can prove that some approximate factorizations maintain the same q value, or maybe only have a small impact on the q value. Haven't done any work on this yet.
- If it turns out we need near-exact factorizations, we might still be able to use sampling techniques like rejection sampling to correct an approximate sampling distribution, because we have easy access to the correct density of samples that we have generated (just prior/q), we just need an approximate distribution to use for getting high value samples more often, which seems straightforward.
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-03T02:40:23.424Z · LW(p) · GW(p)
Especially from human feedback - can you think of ways for the AI to be able to query humans for feedback, and yet not be able to push uncertainty to zero via infinite feedback? Does this create perverse incentives? What do more/less principled ways of doing this look like?
My intuition right now is that in the infinite feedback case, it would be aligned, but not corrigible because we can specify everything exactly.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2023-01-03T03:06:28.639Z · LW(p) · GW(p)
The problem is that if it thinks of the ground truth of morality as some fact that's out there in the world that its supervisory signal has causal access to, it will figure out what corresponds to its "ground truth" in some accurate causal model of the world, and then it will try to optimize that directly.
E.g. you train the AI to get good ratings from humans, but the plan that actually gets maximum rating is one that interferes with the rating-process itself (e.g. by deceiving humans, or hacking the computer).
Of course there are some goals about the world that would be good for an AI to learn - we just don't know how to write down how to learn them.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-03T14:12:42.372Z · LW(p) · GW(p)
The problem is that if it thinks of the ground truth of morality as some fact that's out there in the world that its supervisory signal has causal access to, it will figure out what corresponds to its "ground truth" in some accurate causal model of the world, and then it will try to optimize that directly.
My critical point is that the ground truth may not actually exist here, so morals are only definable relative to what an agent wants, also called moral anti-realism.
This does introduce a complication, in that manipulation would be effectively impossible to avoid, since it's effectively arbitrarily controlled. This is actually dangerous, since deceiving a person and helping a person morally blur so easily, if not outright equivalent, and if the infinite limit is not actually aligned, this is a dangerous problem.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-01-03T15:05:00.837Z · LW(p) · GW(p)
Why does the infinite limit of value learning matter if we're doing soft optimization against a fixed utility distribution?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-03T15:13:40.354Z · LW(p) · GW(p)
Sorry, I didn't realize this and I was responding independently to Charlie Steiner.