Thoughts on AGI safety from the top
post by jylin04 · 2022-02-02T20:06:06.161Z · LW · GW · 3 commentsContents
1. Introduction to the alignment problem 1.1. What is the alignment problem? Comments on this presentation & comparison to earlier work 1.2. Is it necessary that we solve this problem someday? 1.3. Is it effective to work on this problem today? 1.4. My take on the cruxes Why I've become interested in AI safety 2. Epistemics of the alignment problem 2.1. Progress requires making assumptions about the properties of future AI systems. Example: An assumption inspired by the orthogonality thesis Example: Scaling deep learning 2.2. Claim: AGI will use statistical learning... 2.3. ... but the nature of the learning rule seems to differ between the ML and human anchors. Supervised learning Reinforcement learning RL with reward-learning Humans? 3. What should I work on next? 3.1. AGI safety with the ML anchor 3.2. AGI safety with the human(-inspired model) anchor 3.3. Summary and request for feedback None 3 comments
In this post, I'll summarize my views on AGI safety after thinking about it for two years while on the Research Scholars Programme at FHI -- before which I was quite skeptical about the entire subject. [1]
My goals here are twofold: (1) to introduce the problem from scratch in a way that my past self might have found helpful, and (2) to round up my current thoughts on how one might make progress on it, with an eye towards figuring out what I want to work on next. This note is currently split into 1+2 parts, aimed at addressing these two things.
More precisely,
- in Part 1 (more [LW · GW]), I will introduce the alignment problem and explain why I've become interested in it;
- in Part 2 (more [LW · GW]), I will discuss the epistemics of thinking about AGI safety at a time when AGI doesn't yet exist; and
- in Part 3 (more [LW · GW]), I will explain why the considerations of Part 2 lead me to want to work on the intersection of mechanistic interpretability and deep learning theory -- despite doubting that current algorithms will scale up to AGI.
The three parts are optimized for different audiences, with later sections being more "in the weeds" and technical. In particular, I expect that Part 1 will mostly not be new to longtime readers of this forum, and people who are already convinced that AI safety is worth thinking about may want to skip ahead to Part 2. On the other hand, Part 3 will mostly be an attempt to justify a particular research direction and not an introduction to what anyone else is doing.
Thanks to Spencer Becker-Kahn, Lukas Finnveden, Steph Lin, and Chris van Merwijk for feedback on a late-stage version of this post, and to other members of RSP for feedback on an earlier draft.
1. Introduction to the alignment problem
In this first part, I will introduce the alignment problem and explain why one might care about it from an EA point of view. This section will overlap considerably with other recent intros, especially Richard Ngo's excellent AGI safety from first principles [? · GW].
1.1. What is the alignment problem?
Suppose that in the future
- We will be able to build AI systems that are more competent than humans at performing any tasks that humans can perform, including intellectual ones such as producing corporate strategies, doing theoretical science research, etc. (let's call them "AGIs");
- We will actually build such systems;
- We will build them in such a way that they can take a wide and significant enough range of actions so that their (combined) ability to change the future will exceed that of all humans ("the AGIs will be agents"); and
- We will build them in such a way that they will actually take a wide and significant enough range of actions so that their (combined) impact on the future will exceed that of all humans.
Then after some time, the state of the world will be dominated by consequences of the AI systems' actions. So if we believe that items 1-4 will come to pass, we had better make sure that
5. These outcomes will be good by our standards ("the AGIs will be aligned with us").
This is the alignment problem in a nutshell.
Comments on this presentation & comparison to earlier work
The problem as I've just stated it is clearly not precise (e.g. I haven't defined a metric for "ability to change the future"), but I hope that I've conveyed a qualitative sense in which there may indeed be a problem, in a minimal and self-contained way. In particular,
- I haven't assumed anything about the internal cognition of the future AI systems. To this end, I've avoided using words like "(super)intelligence" or an AI system's "motivation" or "goals".
- I haven't assumed anything about the “speed of AI takeoff” or the presence or absence of “recursive self-improvement”.
- I haven't assumed anything about the extent to which the AI systems could literally pose an existential threat, although this may be built into how one chooses to define outcomes that are "good" or "bad".
- For other sometimes-ambiguous words like “agency”, “alignment” and indeed “AGI” itself, the parentheticals above define what I will take them to mean here, which may differ from the usage elsewhere. For example, my definition of alignment is focused on outcome and not on intent.
Two somewhat more technical points are that
- In the AI safety community, item 4 is often taken to be a possible class of solution to the alignment problem (sometimes called "conservatism" or "myopia"). So below, I will think of items 1-3 as setting up the problem and 4-5 as specifying it. I.e., "to solve the alignment problem" means that either we build agentic AGIs that will lead to good outcomes, or we build agentic AGIs that are conservative enough so that humans will still maintain control over the future after they have been deployed.
- Throughout this note, I will focus on the situation where we have a single AI system that satisfies assumptions 1-3. This should be contrasted with the related but broader question of how to align collections of humans + AI systems, that together may form emergent entities satisfying assumptions 1-3. The latter is both more clearly well-motivated since it applies also to the problem of "aligning" governments and corporations today, and strictly harder than the problem of aligning a single AI system, since it contains that problem as a special case.
1.2. Is it necessary that we solve this problem someday?
Perhaps we can avoid ever having to solve the alignment problem if we disagree with one of assumptions 1-3, so let's see if we agree with the assumptions. Going down the list:
Assumption #1, that we will be able to build AGI someday, seems ~inevitable to me if we believe in materialism and continued technological progress (since then we should be able to "brute-force" AGI by simulating the human brain someday, if we don't get there first by another way). At the very least, disagreement with Assumption #1 strikes me as an extraordinary claim where the burden of proof should be on the skeptic. Note though that that day may be very far in the future, and there are important disagreements around when to expect AGI that I will come back to in section 1.3. [2]
Assumption #2, that someone would actually build AGI if we can, seems fairly plausible to me in our current, poorly-coordinated world. Nonetheless, one outcome that could keep us from ever having to solve the alignment problem would be if instead we could coordinate to avoid building AGI (say if it becomes common knowledge that this technology is likely to be dangerous, and global regulations then get developed around processing power in the same way that uranium is subject to safeguards today).
Although this may be a long shot, it leads to the first of 4(+1) cruxes that I want to examine around whether there's a case to work on technical AI safety today:
- Crux #1: Not if we can coordinate to avoid ever building AGI.
Assumption #3, that future AI systems will be able to take a wide and significant enough range of actions so as to dominate the future, seemed weak to me at first since it goes against the example set by modern ML systems. Today's AI systems (e.g. AlphaGo) are superhuman in a narrow sense, but clearly are not existential threats. This is because they are very specialized, and a system's ability to change the future depends not just on its competence at certain tasks but also on the breadth and significance of the tasks that it can perform. If future AI systems that are more capable than us at all tasks are likewise each more capable at just one or a few of them, there could still be no single AI system that would surpass our ability to change the future. (This is sometimes called the "tool AGI vs. agent AGI debate".)
However, in a world tiled by AI systems that are truly superhuman at all tasks, we can trivially get "agentic" AI systems by grouping together collections of narrow systems and calling them "AGIs". (For example, imagine a trading firm where AIs occupy every position in the firm, from making decisions about the long-term strategy to executing the individual trades.) So it's not clear to me that this leads directly to a crux.
Instead though, we can reach a crux in such worlds by contemplating the order in which the different AI capabilities get developed. In particular, perhaps we could avoid having to solve alignment by ourselves if we build AI systems that can solve it for us, sufficiently far in advance of building other systems with potentially dangerous capabilities:
- Crux #2: Not if we can build AI systems that can solve the alignment problem for us, sufficiently far in advance of building other AI systems whose capabilities would come to dominate the future.
This possibility has been discussed for some time in this community without reaching a definitive resolution. See this conversation [LW · GW] between Richard Ngo and Eliezer Yudkowsky for a recent iteration of the debate.
1.3. Is it effective to work on this problem today?
One might also agree that there is a genuine alignment problem that we will have to solve someday, but disagree that it's useful for people to think about it today. I can think of at least two reasons why someone might hold this view:
- Crux #3: Not if AGI won't be built for a really long time ("AGI timelines are long").
In particular, if we are unlikely to build AGI for long enough that we will incur more existential risk (factors) from other sources between now and then, it might make sense to defer the alignment problem to our descendants, and focus instead on solving the more pressing problems of our time.
Another crux concerns the tractability of the problem:
- Crux #4: Not if solutions are far enough from our frontier of current knowledge that we simply can't make much progress on aligning AGIs today.
Note that this could be the case even if the problem will turn out to be both important and tractable in the not-too-distant future! As an analogy, suppose that a proto-longtermist in the 1920s had worried that humans might someday try to harness the energies in stars, and that this might lead to new types of catastrophic risk. [3] They wouldn't be wrong for timeline reasons -- indeed, they would be thoroughly vindicated in a quarter-century! -- but it still seems unlikely that our longtermist could have made much progress on nuclear safety before the development of quantum mechanics. [4]
By analogy, one might especially worry about this crux if one suspects that solutions to alignment will turn out to depend strongly on the details of future algorithms. I'll say more about this in Part 2 of this note.
(Finally, a fifth crux that sometimes comes up is whether AI safety research is really distinct from "mainstream" AI research, or if the two will converge as the field of AI advances. I haven't given this crux its own bullet-point because it has a somewhat different character from the others. While the others challenge whether it's useful for anyone to work on AI safety in 2021, this one seems to intersect in a more complicated way with an individual's comparative (dis)advantages. But see John Schulman’s Frequent arguments about alignment [LW · GW] and Pushmeet Kohli's 80k hours interview for earlier thoughts along these lines.)
1.4. My take on the cruxes
What should we make of these 4(+1) cruxes? Do they leave us with a reasonable case for working on AI safety today?
Unfortunately, there's no definite way to resolve them as far as I can tell. That said, here are my current hot takes (which should be read as weakly held opinions only):
- WRT whether we might coordinate to avoid building AGI in worlds where it is imminently possible, I am pessimistic about this outcome, but unsure if it might still be easier than solving the alignment problem (insofar as the latter seems hard). One consideration that seems to point in this direction is that alignment proposals may come with safety/capability tradeoffs [LW · GW] as a rule, so we may end up having to solve either a hard coordination problem or both a hard coordination problem and a hard technical one. On the other hand, truly enforcing a ban of AGI among all future actors may require equally ambitious (and potentially dangerous!) developments, such as the establishment of a permanent regulatory body with much more power than the ones we have today. Overall, I haven't thought too much about this crux and feel ill-suited to comment on it.
- WRT whether we might build "tool AI" systems that could solve the alignment problem for us before building agentic AGIs, I used to be a fan of this idea [5] but have become more pessimistic on reflection. This is because it now feels to me that qualitative progress on theoretical problems may be one of the most "AGI-complete" tasks. (In particular, embodied cognition and its potential application to mathematics seem plausible to me / consistent with how I think I think.) But my feelings are hardly an argument, and I would love to see more rigorous takes on what this theory and others from cognitive science might imply for AI (safety).
- WRT AGI timelines, I have the impression that my timelines may be significantly longer than the median view in this community, and that this may be the point on which I most strongly disagree with others in this community. But this topic seems hard to do justice to without at least a post of its own (+ a commensurate amount of careful thinking that I haven't yet done...), so for now, here are just a few more weakly-held opinions:
- To put some numbers on my timelines if pressed, I might put an extreme lower bound on AGI at something like +10y and an upper bound at something like +500y (i.e. basically unbounded above), with a low-probability tail from ~10-30y and a ~flat distribution thereafter. Probably there should also be a low-probability tail on the upper end, but I have no idea how to reason about it. As you'll see shortly, all of these numbers are totally made up.
- My main disagreement with what seems to be a popular view in this community [6] is that I don’t think that today's algorithms will scale up to AGI. Some generators for this are that I think a language model that achieved the best possible loss on all existing text would still be far from AGI [7], and we have no idea what sorts of tasks would be "AGI-complete"; and on a mechanistic level, I doubt that the mostly-feedforward architectures of 2020 will allow for diverse enough patterns of information flow to solve all tasks at inference time (see Can you get AGI from a transformer? [AF · GW] for related thoughts). [8] Instead, I think that AGI will require new qualitative breakthroughs, the timelines for which seem basically impossible to predict. Hence my very wide error bars.
- On the low end, as a total amateur to neuroscience (!) I am willing to put some (small) weight on the hypothesis that the neocortex may be running a simple enough algorithm that we can reverse-engineer it tomorrow, though my impression is that this is not a popular view among neuroscientists. In this case, my lower bound comes from the expectation that once we do have a scalable architecture and an adequate amount of compute, there will still be a lag time to figure out how to train an instance of that architecture to get it to do interesting things. [9] One anchor for this is that it's been ten years since the deep learning revolution, but we don't yet have widespread deployment of the technology for some fairly obvious use cases like self-driving cars, despite economic incentives; see julianjm’s comments in Extrapolating GPT-N performance [AF · GW] for more along these lines. Another is that it seems to have taken 10+ years historically from when we had a concrete enough mechanism for how exactly a new technology could work to when it was actually deployed, e.g. from Szilard's insight to 1945 or from proto-airplane designs with engines to the successes of the Wright brothers.
- That said, I think it is unlikely that we will reverse-engineer AGI tomorrow given the skepticism in the nearby academic communities. Hence the low-probability tail.
- On the high end, I could also imagine that intelligence will turn out to be a really hard problem that will take us a basically unbounded amount of time to solve. There is certainly precedence for the existence of very slow problems in science, e.g. quantum gravity has been around for ~100 years and we don't seem especially close to solving it. Here it's sometimes said that whole brain emulation should provide an upper bound on the time required to get to AGI, but my (again, amateur!) impression is that this is also a hard problem with qualitatively murky timelines, since we can't simulate the roundworm yet despite having had its connectome for a long time.
- To put some numbers on my timelines if pressed, I might put an extreme lower bound on AGI at something like +10y and an upper bound at something like +500y (i.e. basically unbounded above), with a low-probability tail from ~10-30y and a ~flat distribution thereafter. Probably there should also be a low-probability tail on the upper end, but I have no idea how to reason about it. As you'll see shortly, all of these numbers are totally made up.
- Finally, WRT whether the alignment problem is tractable today, I do think that (significant) parts of the problem will depend on future AI architectures and that people in 2021 pay a penalty for trying to work on it "ahead of time". But this (+ some thoughts on what we can do nonetheless!) will be subject of the later parts of this note.
Why I've become interested in AI safety
Putting these takes together, it's not clear to me that AGI safety is the most important thing for us to work on (especially given large timeline uncertainty), or that it makes sense to encourage large numbers of people to go into it (especially given concerns about tractability) [10]. But it's also not clear to me that AGI safety is an obviously unimportant thing for humans to start to think about, as some of the louder voices on the Internet seem to believe.
So given that
- society seems well-served by having some people look at every problem with a non-negligible chance of materializing in the future;
- to the extent that one is unsure about -- or even skeptical about -- the cruxes, the best way to help to resolve them may be to go ahead and work on related things anyway; [11]
- I have a pretty strong AI-adjacent background, and
- I think that thinking about AI is fun,
I feel happy to focus on AI safety when I put on my "EA hat", while acknowledging that I'm letting personal interest do a lot of the work.
This being the case, I'll now proceed with a dive into Crux #4 (tractability), starting with a closer look at the nature of the alignment problem itself.
2. Epistemics of the alignment problem
In this next part, I'll take for granted that we care about the alignment problem and explain how I think about it. Alignment is a technical problem wrt an as-yet-nonexistent future technology. How can we best reason in this situation?
2.1. Progress requires making assumptions about the properties of future AI systems.
One fairly obvious first point is that in order to make progress on this problem, we'll have to make some assumptions about the properties of future AI systems. (In contrast, the statement of the alignment problem did not require assuming anything about the cognition of future AI systems, as I tried to emphasize back in Section 1.1.)
For example, we might choose to work on AI safety by thinking about how to align one of several different proxy models [AF · GW]. But ideas that work well for one type of model need not work well for others, and we only care about each proxy model insofar as it can shed light on how to align the actual way that AGI will be implemented in the future.
To motivate why we need to make assumptions, consider the following black-box view of what it would mean to solve the alignment problem. Suppose that we model an AI system as a box that converts inputs drawn from the current state of the world into outputs (actions) that change the future state of the world:

And we want to figure out what to put in the box (or in the surrounding dotted box, since we also get to pick our AI systems' input and output channels!), to get to futures that we like.
This model is true on a very general level. (E.g. today's image classifiers take inputs drawn from real-world pictures, and converts them to outputs that change the future state of the world by propagating through people's brains as information.) But it's way too broad of a framing to yield a tractable technical problem! If we stood a chance of figuring out how to turn current world-states into future world-states that we definitely like better with no other structure to the problem, it would remove the value proposition of the AI, and also amount to solving existential problems that our species has had since the dawn of time.
So to get to a problem that has a chance of being solvable, we had better put some structure into the box.
In the rest of this section, I will give examples of structure that one might put into the box, but a reader who is pressed for time can skip ahead to section 2.2 without losing out on the main thrust of the discussion.
Example: An assumption inspired by the orthogonality thesis
An example that was explored in the early days of AI safety was to assume that motivation could be decoupled from intelligence, and to treat intelligence as a black box of general execution ability that could be aimed at any goal.

This parametrization suggested that if we could figure out the right thing to put in the "motivation box", then perhaps we could someday outsource the problem of ranking future world-states to AI systems that are cleverer than us. Accordingly, it led some people to work on formalizing what we (humans) value, independently from engaging with the details of the "intelligence box".
This is an example of what I'll call a cognitive assumption about AGI. As the name suggests, it's an assumption that future AI systems will exhibit certain (perhaps emergent) cognitive properties when we deploy them in the world. Other assumptions of this type are that future AI systems might pursue a certain set of instrumental goals (e.g. to seek power or manipulate humans), or implement a certain type of decision theory.
However, a challenge for this type of assumption is to explain why it's one that actual future AI systems are likely to have. (Or failing that, why it's a productive approximation for people to go ahead and make anyway.) E.g. w.r.t. the example discussed here, it's indeed become popular recently to emphasize that intelligence and motivation are not really decoupled in any concrete examples that we know. [12] (But by treating the "motivation box" as its own entity, one can still find nice examples of misalignment in ML systems, see e.g. work on specification gaming. [13])
Example: Scaling deep learning
Another way to add structure to the box is to (keep intelligence and motivation coupled, but) put a particular type of algorithm into the "intelligence box":

For example, we can put a particular type of deep learning system into the box and think about how to get it to do what we want. Examples of work in this genre include Concrete problems in AI safety (+ the related subfield of aligning RL toy models) and The case for aligning narrowly superhuman models [AF · GW] (+ the new and growing subfield of aligning large language models (LLMs)).
This approach to AI safety makes what I'll call a microscopic assumption, that the mechanistic details of a model being studied will be close enough to those of future AI systems that the insights drawn from aligning it today will still be relevant in the future. However, we again have no guarantee that this will be true a priori, and a challenge for this sort of work is (again) to explain why one expects it to be true.
The burden of proof increases with the specificity of the setup. While a sufficiently general technique for analyzing neural networks may work across all NN-like architectures (more on which below!), a study of prompt-engineering in GPT-3 naively seems more limited in scope, perhaps generalizing only to other autoregressive language models (or even just such models with transformer architectures).
To summarize, in order to work on the alignment problem today, we have to make assumptions about the type of system that we are trying to align. The more assumptions we make, the more progress we can make on aligning the accordingly smaller space of models that satisfy those assumptions. However, we then run a greater risk that the subspace will not contain the algorithms that will actually lead to AGI in the future. So there is a balancing act between future relevance and current tractability.
Sociologically, it may be helpful to remember that people who approach alignment with different assumptions are basically trying to solve entirely different problems, with each set of assumptions forming its own nascent "subfield" of AI safety. It could be interesting to map out and make explicit the assumptions being used by various people on the alignment forum, but I won't attempt to do it here.
2.2. Claim: AGI will use statistical learning...
My starting point for deciding which assumptions to make is to take ML systems and humans to be my favorite types of proxy models [AF · GW] [14]. This is because since humans are our only existence proof of AGI, ML systems are the closest we've come to recreating intelligence and ML + neuroscience are the best-funded areas of AI-adjacent research today, they seem likely to be closest to how AGI would actually look if we were to build it on a short time scale. (As a bonus, since both really exist, they are easy to experiment with (and we can do thought experiments of superintelligent systems by imagining simulated humans that run very quickly).)
However, since ML systems and humans are nonetheless imperfect proxies, it would be better if we could find some features at their intersection to take as our starting points.
The most obvious such feature is that both use (statistical) learning [15] [16]:
Both ML systems and humans acquire (at least some of) their capabilities from an initial state of not having them, as opposed to systems whose capabilities are hard-coded in from the start. Formally, parts of both ML systems and humans can be described as functions f: (inputs, parameters) -> outputs whose parameters get updated on seen data according to some a priori learning rule. Moreover, in both cases the number of parameters is large.
I see learning as being the main idea at the heart of ML ∩ humans, and one that unlocks new strategies and challenges for AI safety. For example, its continuous nature means that we can imagine making future AI systems safe by shaping their curricula [17], or by auditing [AF · GW] them as they are in the process of acquiring potentially dangerous capabilities. On the other hand, learning may also introduce new failure modes such as model splintering [AF · GW] and ontological crises.
So as a first pass, I'm relatively more excited about safety work that takes learning into account.
However, this framework is still rather general, and begs the question of whether there are similarities in the learning rule that's used by ML systems and humans. (Or colloquially, what "motivates" an ML system or human to learn.) Can we assume anything about the likely nature of this rule in future systems by looking at the examples set by current ones? To discuss this, I'll next try to arrange some models in a sequence that interpolates from simple supervised learning models to a "human-inspired" toy ML model and beyond.
2.3. ... but the nature of the learning rule seems to differ between the ML and human anchors.
(In this section, I will assume some familiarity with ML algorithms. But I'm no expert on ML myself, and I'd appreciate feedback if I seem to be confused!)
Supervised learning
The first type of algorithm that I'll start with is the humble supervised learning algorithm (e.g. an image classifier or language model like GPT-3). These are just function approximators that get trained on large datasets to approximate the distribution from which the data was drawn. They're like souped-up versions of linear regression algorithms, but with a lot more parameters and a more sophisticated way to fit the training set.
In these models, the rule that governs learning is set by the combination of a hard-coded loss function and a learning algorithm, often gradient descent. The loss function is often a measure of distance from the model's current state to the points in its training set. Colloquially, the model is then "motivated to" copy the training set as well as it can.
I'll draw this type of algorithm simply as

to be contrasted with the examples below.
Reinforcement learning
Next up in (conceptual) complexity are the reinforcement learning (RL) algorithms that Deepmind has famously used to solve Atari games and Go. These algorithms take as input a state of an environment (like the board position in a game of Go), and learn to output actions that optimize a hardcoded reward function over many time steps. See section one of EfficientZero: How it Works [AF · GW] for a nice review of the RL paradigm.
To do this, part of the algorithm may learn a function Q: (s,a) -> r for the reward that it thinks it will get if makes move a in state s and thereafter follows what it believes to be the best strategy. This Q-function gets learned from data in a way that's supposed to converge to the true rewards provided by the environment [18], so it has the same logical status as the outcome of the supervised learning example that we just discussed. It's just a best possible approximation of an actual function that exists in the world, that our algorithm tries to copy in some souped-up version of linear regression.
But at runtime, the algorithm doesn't just compute Q once. Rather, it first extremizes Q w.r.t. a, and then executes the actions that it thinks will lead to the greatest rewards:

In short, it contains an extra “proto-planning” step at inference time [19].
(The above was a hand-wavy retelling of a simple RL algorithm called Q-learning. There are many more complicated RL algorithms, but I think they can be viewed as having a similar qualitative structure. E.g.
- Actor-critic algorithms explicitly learn a policy function pi: s->a alongside Q, and replace "extremize Q" with "call pi" as the proto-planning step;
- Model-based RL algorithms (see here for a review) first learn to map the input data to a latent representation of the data, then run RL on the MDP that combines latent descriptions of states and actions with the ground-truth reward; and
- Model-based RL algorithms with planning may learn a local world-model to predict the immediate reward + next state at each time step, then use it to do an explicit search over sequences of actions that maximize the expected reward.)
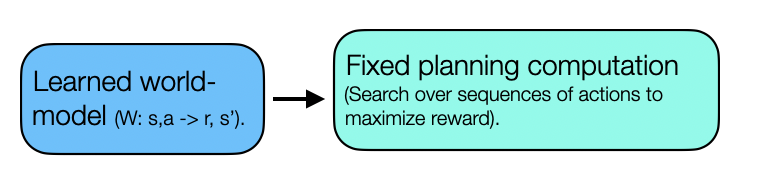
RL with reward-learning
Importantly, in both examples so far, the thing that motivated the algorithm to learn was a hard-coded signal provided by the environment -- or by the programmer! -- that the algorithm just "wanted to" extremize as best it can.
What happens if we relax this assumption and let the reward signal itself be learned?
In fact, such algorithms are in use today -- where they may improve generalization relative to pure imitation learning [20]. E.g.
- In inverse RL (IRL) (see here for a review), an algorithm first learns a reward function from among a parametric family of candidates that best explains a dataset of state-action pairs [21]. It then runs ordinary RL on the artificial MDP that uses the learned reward function in place of the ground-truth reward.

- In a subgoal discovery step of a hierarchical RL (HRL) algorithm (see McGovern-Barto (2001) and Bakker-Schmidhuber (2004) for examples), the algorithm similarly learns new goals based on an a priori unsupervised learning rule [22], then trains an RL "subagent" to achieve each discovered goal (before finally adding the learned policies to its action space as multi-step actions that it can then decide to take).

We can even iterate such steps, e.g. by having the hypothesis space of reward functions in IRL or the unsupervised learning rule in a HRL algorithm itself be learned. We can imagine iterating like this indefinitely, although the buck eventually has to stop on some a priori learning rule.
Humans?
The fact that reward function learning may lead to performance gains raises the question of whether such mechanisms could end up having a place in future AI systems. [23]
Indeed, (at least by introspection) we humans seem to do something similar, continually discovering new goals and making plans in pursuit of them. For example, I assign a high value to the idea of making an ML-inspired toy model of humans as I write this note, but six months ago a motive attached to doing this didn't exist in my head. So any attempt to mechanistically model a human has to explain how this could have come about.
(See My AGI threat model: Misaligned model-based RL agent [AF · GW] for a very interesting discussion that inspired the comments here.)
As we've just seen, ML provides a mechanism to do this in the form of iterating reward discovery with running regular RL on learned rewards. This suggests that a starting point for a "human-like ML model" may be to couple together many RL systems, e.g.
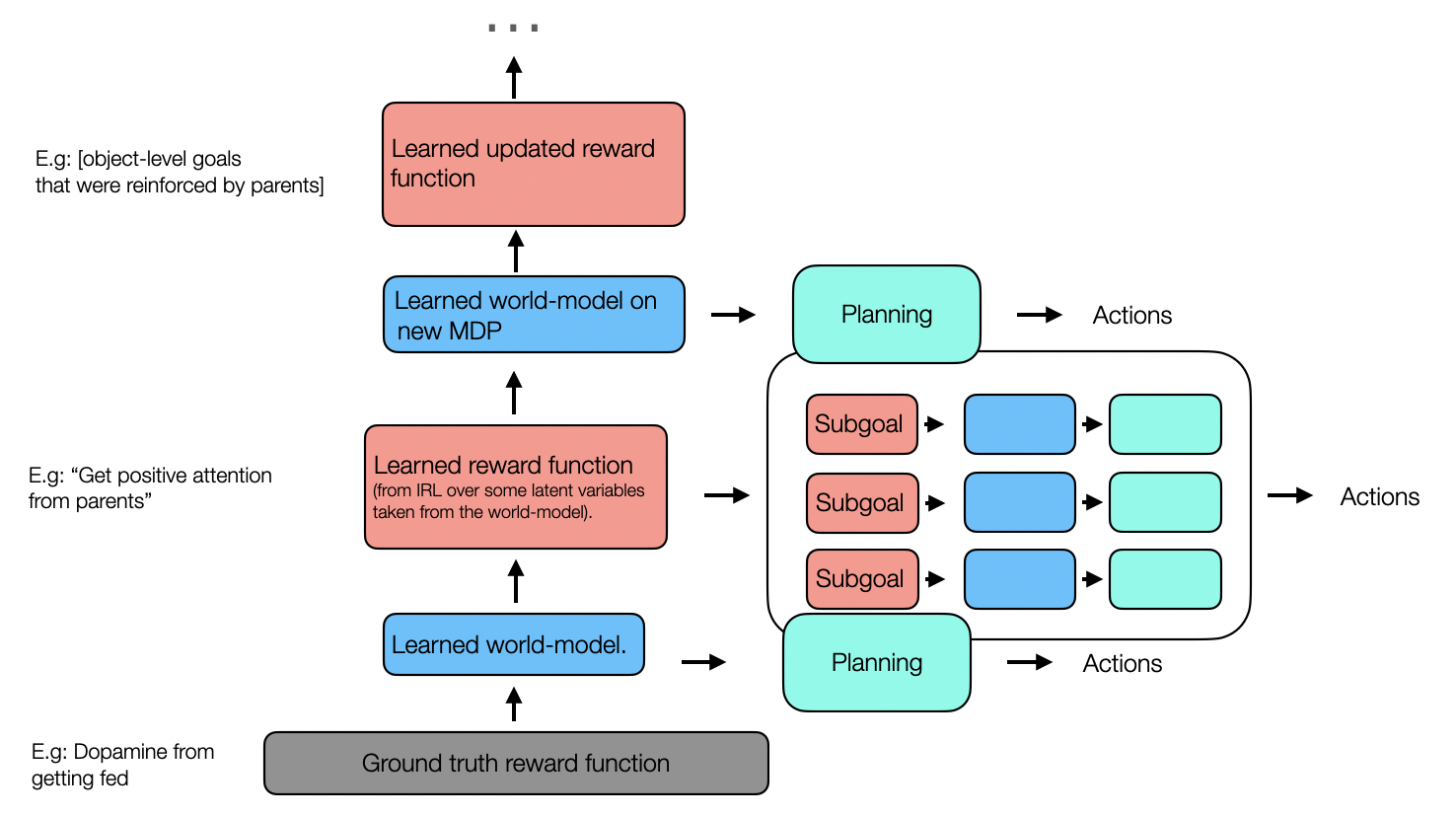
Here I've drawn IRL-inspired "subagents in series" in the vertical direction, and HRL-inspired "subagents in parallel" in the horizontal one, but this shouldn't be taken too literally. What I'm trying to point to is instead the whole class of models of coupled RL + reward-learning algorithms, with arbitrary topologies. [24] The idea of “humans as collections of subagents” has been discussed at length elsewhere on LessWrong (see e.g. the subagent [? · GW] tag on the alignment forum), and in some sense, my goal here was just to put it in an ML context so that we can start to think about in a quantitative way.
Zooming out a bit, the algorithms that I discussed in this section (roughly) varied along two axes of how much search/planning was built into the algorithm and how much of its reward structure was hard-coded versus learned: [25]
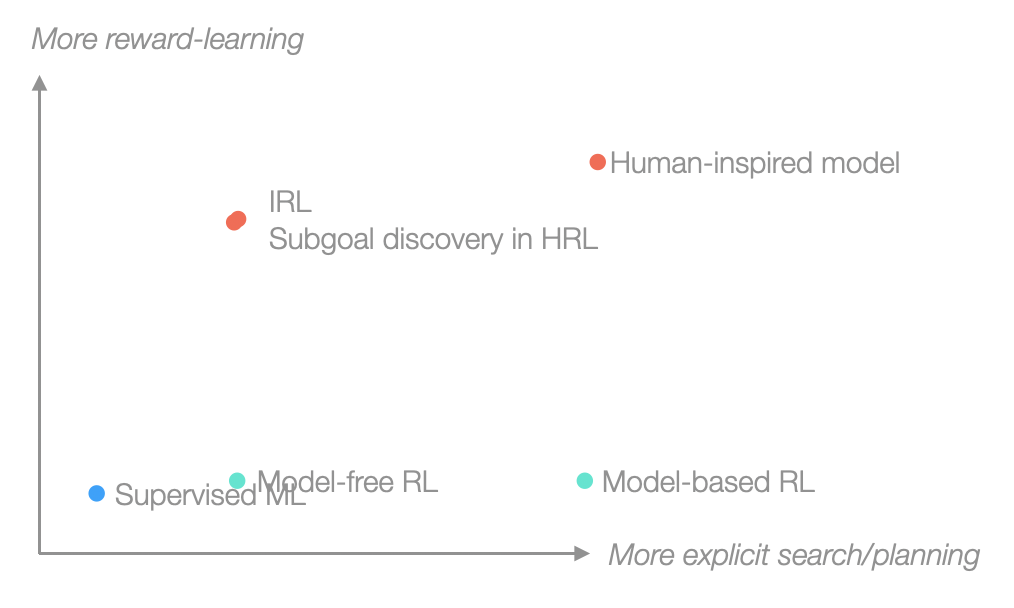
The latter especially was what we set out to study, and now we see that the supervised ML and human anchors (or at least, our human-inspired model as a stand-in for the human anchor) seem to sit at different points along this axis. Insofar as where we are along this axis affects how we should approach the alignment problem, this means that in order to proceed, we'll have to decide which proxy model we like more.
3. What should I work on next?
So if I assume that future AI systems will use statistical learning, that they will learn representations in a continuous training process, but I'm unsure about the nature of the update rule... then what should I work on next?
In this last section, I'll try to answer this question (accounting for my comparative (dis)advantages!) for AGI that's closer to either the ML or human anchor. So this part will be an attempt to motivate a particular research direction, not a review of what other people in AI safety are doing. For a birds-eye view of some of the other work in this space, see e.g. the recent Open Philanthropy RFPs or Neel Nanda's Overview of the AI Alignment Landscape [AF · GW] and links therein.
3.1. AGI safety with the ML anchor
If I think that AGI will be closer to the supervised ML anchor -- i.e. that the part of the algorithm that learns will be extremizing a hard-coded reward signal, using a simple end-to-end rule on a "big blob of compute" -- then it seems to me that trying to understand exactly how that rule works (and what sorts of cognitive processes can emerge from it) is the most well-motivated thing that I can do.
After all, if we could fully "reverse compile [AF · GW]" a model into human-understandable code, it would go most of the way towards solving the alignment problem for that model [26]. And if we could just put some constraints on a model's thinking, it could tip the alignment problem over to being solvable by the earlier logic that the more we know about how an AI system thinks, the fewer potential failure modes we'll have left to have to contend with [27]. On the other hand, I currently think that worst-case prosaic alignment is unsolvable (though others here may have different intuitions).
I think there's widespread agreement that this goal is a worthy one, but disagreement on how tractable it is in practice.
So how can we make progress on it? Specializing for the sake of argument to the case where AGI comes from scaling up deep learning, two threads seem especially relevant to me:
- Empirical work on mechanistic interpretability, e.g. the Circuits program and Anthropic's latest paper. This line of work is widely respected in this community, and has been discussed elsewhere on the forum.
- Theoretical attempts to understand deep learning, e.g. the Principles of Deep Learning Theory. This line of work seems less well-known here (though see this post [AF · GW] and pingbacks to it for some related discussions), so let me describe it briefly. The goal of this research direction is to understand why trained neural networks end up computing the (surprisingly useful) functions that they do. Subgoals include to understand which aspects of deep learning are responsible for generalization (e.g. is it in the initialization, or because SGD favors good minima...?), and how deep learning performs the representation learning by which neurons in intermediate layers of a trained network become sensitive to useful features of the world.
Concretely, a dream for this approach would be if we could write down exactly what (distribution over) learned functions we get at the end of training, given an architecture + initialization + learning algorithm + loss function + dataset. We could then see what happens as we vary each of these things to very concretely address the first set of questions above, or see exactly which parts of a setup lead to "bad" outcomes in toy problems like Redwood Research's current project [AF · GW]. Along the way, we might also hope to get insights into questions like "what are the fundamental units of representation learning", that we could then try to interpret in a Circuits-like approach. [28]
This dream may seem squarely in the realm of "things that would be nice to have but are intractable." However, I think there's been a surprising amount of recent progress on it that hasn't been discussed much on this forum. For example, following up on the solution of infinitely wide neural networks, it seems that one can perturb around them in a 1/width expansion to write down a formula for the (distribution of) function(s) learned by a realistic NN that fits on a single page [29]. I hope to write more about this, and some of the potential applications for AI safety [30], in a future post.
I see these two directions as laying the seeds for future subfields of phenomenology + theory ⊂ a "natural science" approach to understanding AI systems. If superficially similar topics like other stat mech systems [31] are any indication, there should be lots of room for growth in both directions, and I think that it would be good to differentially develop both over the more "engineering-focused" approach in the mainstream ML community (as EA has already been doing on the empirical end). [32]
3.2. AGI safety with the human(-inspired model) anchor
What if future systems will be closer to the human-inspired model, with a strong dependence on some sort of (as-yet-unknown) goal-discovery mechanism from among learned latent variables? [33]
At first glance, it then seems less clear that trying to understanding current algorithms will play (as big) a part in AI safety (since by assumption, AGI will depend strongly on the details of this future goal-discovery mechanism). On the other hand, it would be of obvious value if we could read off what goals such a system was pursuing at a given time. So I think that this anchor demands more justification from prosaic alignment work, but further motivates the need for progress on transparency of future AI architectures. [34]
So (how) can we make progress on interpreting future architectures today?
In fact, I happen to still think that working on the "science of deep learning" is the best that one can do, but the motivation is now less direct. I think the argument in this case is to treat today's AI systems as a warm-up, in hopes that by trying to solve the closest problem that we have on hand today, we will build up tooling and intuition that will make it easier for us to pivot to the real thing when it comes along.
This may seem a bit like motivated reasoning [EA · GW]. But the strategy of retreating to toy problems is a common one in science [35], and already I think that there are relevant examples of knowledge transfer in practice. E.g. Chris Olah's team was able to make progress on interpreting transformers using strategies recycled from their work on interpreting image nets, such as finding "short phrase" and "vowel" neurons by recording neurons' activations on dataset and artificial examples. And in the course of studying vanilla MLPs, the authors of PDLT found an even simpler toy family of algorithms that exhibit representation learning, letting them separate out the phenomenon of representation learning from the inductive biases introduced by network architecture.
On the other hand, I can't think of any other way to make progress on interpreting future AI systems besides working with the ones that we have today!
So the alternative would be to skip transparency altogether and try to align the human-inspired toy model as a black box, knowing only that it may emergently develop new goals in some unknown way. I think that this problem is much too underspecified to be tractable. (But let me know if you disagree!)
3.3. Summary and request for feedback
This post initially started its life as a "meta doc" for me to brainstorm what to work on next before evolving into the much longer piece that you see here. So to wrap up by going back to the original motivation:
By default I plan to continue looking into the directions in section 3.1, namely transparency of current models and its (potential) intersection with developments in deep learning theory. This actually isn't a big change from the conclusion of last year's meta post [AF · GW], but now I feel like I understand better why I'm doing it! More concretely, (having looked a bit at Circuits last year) I now plan to spend some time on theory, and will distill some of that material for this forum along the way.
Since this is what I plan to do, it'd be useful for me to know if it seems totally misguided, or if it overlaps in an interesting way with anyone else's plans. So any comments would be welcome and appreciated! Please feel free to email me if you have comments that seem better shared in private.
- ^
Throughout this note, I'll use "A(G)I safety" and "A(G)I alignment" interchangeably to mean the most specific of all of these things, namely the technical problem that people on the alignment forum are trying to solve.
- ^
Importantly, note that the questions of whether AGI could be an existential threat someday and whether it could be an existential threat in the near future seem often to be conflated in public discussions. It should be forcefully emphasized that these two problems are completely unrelated.
- ^
I'm not sure if this would have been a historically sensible worry. But Wikipedia tells me that Eddington anticipated the discovery of nuclear processes in stars around 1920!
- ^
However, this is really more of an argument against direct work. If the proto-longtermist in 1920 were otherwise thoroughly convinced that nuclear safety would become a major problem in their lifetime, they could have taken other steps towards contributing to it in the future, such as skilling up on the physics of their time.
- ^
See the section “What if AI will go well by default...” in my previous AF post [LW · GW].
- ^
See e.g. Ajeya Cotra’s Draft Report on AGI timelines.
- ^
Since for example, I can't imagine how a hypothetical system that could perfectly mimic the distribution of all human text in 1800 could have discovered quantum mechanics.
- ^
Several people in the neuroscience and cognitive science communities have also expressed skepticism that modern algorithms can scale up to AGI. See e.g. Lake et al. (2016), Marcus (2018), (chapter 2 of) Dehaene (2020), and Cremer-Whittlestone (2021) for a recent review. These views are complementary to this point; it's precisely some of these cognitive capabilities that I doubt today's algorithms can express at inference time, for reasons along the lines of Steve Byrnes's post -- but I would have to think more carefully to (try to) make crisp arguments along these lines.
It does seem at least more plausible to me that a blob of compute with a(n arbitrarily) more complicated topology might be able to scale to AGI, but this seems compatible with very long timelines, since the search space of all topologies with no further constraints seems large.
- ^
This might sound like I come down on the side of "soft takeoff [? · GW]", but I think that whether or not I do depends on how one operationalizes the takeoff. In particular, I'm agnostic about whether a hypothetical architecture that could scale to AGI would have an effect on GDP during a time when humans are tinkering with how to train it.
- ^
To add some nuance here:
- Although I've come around to being less skeptical about the alignment problem as a whole, I still think that many who are working on it are doing things that will turn out not to matter. I want to state this here not to start a fight, but to emphasize that agreement that the alignment problem is a real problem != endorsement of any given AI-safety-branded research program. I have the impression that the latter is sometimes used by critics to dismiss the former out of hand. But in reality, I think that many people who identify as "working on AI safety" would disagree that each other's work is even plausibly useful (and others may certainly disagree that my interests will be useful as well!).
- (This lack of consensus presents a complicated situation for funders. At a glance I think that a high-variance process like SFF's is reasonable in this situation, but I haven't thought too much about it.)
- It's my understanding that AI-safety-branded jobs have many more applicants than roles available, and newcomers should take this into account at a practical level.
- Although I've come around to being less skeptical about the alignment problem as a whole, I still think that many who are working on it are doing things that will turn out not to matter. I want to state this here not to start a fight, but to emphasize that agreement that the alignment problem is a real problem != endorsement of any given AI-safety-branded research program. I have the impression that the latter is sometimes used by critics to dismiss the former out of hand. But in reality, I think that many people who identify as "working on AI safety" would disagree that each other's work is even plausibly useful (and others may certainly disagree that my interests will be useful as well!).
- ^
For example, if you think that we should push for a governance-based solution to AGI safety instead of a technical one, a starting point might be to collect evidence of more speculative types of misalignment, with which to convince other people that there's a problem (h/t Chris Olah on the 80k hours podcast). And if you have a hunch that AGI timelines are really long, it would be helpful to others if you could make that hunch more precise.
- ^
This sometimes goes by the name of inner (mis)alignment.
(Though as a footnote to the footnote, that phrase was originally coined to refer to the more specific possibility that a search algorithm defined over a sufficiently expressive search space could in principle discover a different search algorithm that it implements at inference time, before sometimes getting co-opted to mean something like "poor out-of-distribution generalization".)
- ^
Although the jury is out on whether this will remain a productive assumption to make if AI moves on to other paradigms. See the comments on whether it makes sense to split things up into outer vs. inner alignment in My AGI threat model: Misaligned Model-based RL agent [AF · GW]. More on this below!
- ^
See the linked post and the recent Thought experiments provide a third anchor [LW · GW] for two other people's takes on different proxy models.
- ^
See also Rich Sutton's Bitter Lesson, where he argued that learning is one of only two methods to scale with compute -- the other being search, which past experience suggests is not enough to get us to AGI by itself.
- ^
Other features that may belong to ML ∩ humans are that both seem to learn (at least superficially) similar internal representations when trained on real-world data, and that both sometimes take inputs /outputs in natural language, the former by design.
- ^
With today's experiments on fine-tuning LLMs being an early example.
- ^
At least provably so for small state spaces.
- ^
Though this isn't so different from a shell around a supervised learning classifier that turns the softmax output of the classifier into an actual prediction, so there’s a continuity between these two examples.
One other way in which RL algorithms differ from SL is that in RL, the magnitude of the reward available depends on where one is in the state space of the MDP. But this is a difference in the reward structure of the environment, not in the algorithm itself.
- ^
Where one directly learns a policy \pi: s->a as a supervised learning problem starting from expert (s,a) data.
- ^
This can basically be done as a supervised learning problem where, starting from a reward ansatz R(s) = \alpha_i \phi_i(s) with random \alpha’s and fixed features \phi, we iteratively compare data generated from an MDP with that ansatz to the expert data, then update the \alpha’s in the direction of getting a better match.
- ^
E.g. by looking for “bottleneck” regions of the state space that appear often or uniquely in good trajectories, or clusters in the state space that could point to the presence of an interesting coarse-grained idea.
- ^
Note that the direction of the logic is different here from how reward-learning algorithms are often discussed in the AI safety community.
I'm not interested in reward-learning with an eye towards making AI systems safer (by having them learn human preferences/values and so on). Rather, I'm wondering if we suppose that some more general use of reward-learning will turn out to be a key part of how our capabilities friends implement AGI in the future, how then can we try to align such algorithms?
- ^
I'm also agnostic about the rule by which the reward-learning steps pick out new goals. In particular, I don't mean to imply from the vertical axis that the model should literally do IRL with its own past actions as the expert data.
- ^
As a digression, it’s interesting to compare this drawing to the ontology in the Late 2021 MIRI conversations [? · GW] on LW. It seems like the supervised ML end of the drawing matches Eliezer Yudkowsky’s “shallow pattern recognizer” in the first debate with Richard Ngo [LW · GW] (by definition), while the human end may be a closer match to the “deep problem solver”, assuming that the “subagents” in the latter case cohere with some higher-level preference (which need not follow from an assumption about the presence of subagents alone.)
In other words, I think it’s plausible that some structure of subagents taking ownership of instrumental goals may be necessary but not sufficient for “deep problem solving”. But once we allow an explicit mechanism for the generation and pursuit of instrumental goals, this is where much of the risk comes from from the earliest days of AI safety discussions. - ^
Modulo making sure that we can audit what the model is "thinking" quickly enough to be competitive with not auditing it.
- ^
For example, I could imagine that a solution to the ELK problem [LW · GW] in practice might involve showing that "human simulators" (with varying amounts of fidelity) are unlikely to arise in certain situations, making some of the strategies in the report viable. (This sort of approach is related to the branch of solution called "science" in the report.)
- ^
Since there's no a priori reason that they have to be single neurons. Perhaps there's some other basis in the neuron space, or combination of neurons and weights, that would lead to less polysemantic activations?
- ^
To leading order in the 1/width expansion -- but realistic NNs are in the perturbative regime.
Cf. p. 375 of the above-linked PDLT.
- ^
- ^
See here for a review explaining how deep learning is sort of like a statistical physics system.
- ^
I plan to write more in the future about whether it might make sense to do so on the theoretical end as well, after taking neglectedness in academia into account.
- ^
Here I'm assuming that there's a difference between this case and the previous one -- i.e. that such mechanisms would not spontaneously emerge from training a big enough blob of compute on an end-to-end-reward.
- ^
A more abstract way in which this anchor differs from the previous one is that it's less clear to me that the paradigm of splitting the alignment problem into an "outer" and "inner" part would be (as) useful if AGI turns out to make significant use of a reward-learning mechanism.
This is because with the supervised ML anchor, we have a fixed loss landscape where we can mathematically talk about the global minimum and the difference between it and generic local minima. But in the human-inspired toy model, we do not. Rather, we would have a tower of many loss landscapes where each possible outcome of a reward-learning step changes the loss landscape of subsequent RL problems.
- ^
Note that I'm looking for a warm-up problem for interpreting future AI systems only, not a warm-up problem for the entire alignment problem. The latter is so big that I think it's harder to argue that any toy model will end up being relevant in the end. This was basically the point of section 2.
Nonetheless, the latter has been used to justify work on other systems like LLMs [AF · GW] and abstract models [AF(p) · GW(p)].
3 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-02-03T06:33:09.552Z · LW(p) · GW(p)
I think interpretability/transparency are great things to work on. Basically all plausible stories for how to get good things involve attempts to use interpretability tools in some capacity.
If I were to play devil's advocate, I would say that precisely because interpretability is so obviously useful, if you have less-obvious ideas for things to do you should consider working on those instead, because lots of other people can be directed at obvious good things like interpretability. This way of phrasing things is maybe not great, and it shouldn't totally dominate your cost-benefit.
comment by Koen.Holtman · 2022-02-11T13:49:00.945Z · LW(p) · GW(p)
I like your section 2. As you are asking for feedback on your plans in section 3:
By default I plan to continue looking into the directions in section 3.1, namely transparency of current models and its (potential) intersection with developments in deep learning theory. [...] Since this is what I plan to do, it'd be useful for me to know if it seems totally misguided
I see two ways to improve AI transparency in the face of opaque learned models:
-
try to make the learned models less opaque -- this is your direction
-
try to find ways to build more transparent systems that use potentially opaque learned models as building blocks. This is a research direction that your picture of a "human-like ML model" points to. Creating this type of transparency is also one of the main thoughts behind Drexler's CAIS [LW · GW]. You can also find this approach of 'more aligned architectures built out of opaque learned models' in my work, e.g. here [LW · GW].
Now, I am doing alignment research in part because of plain intellectual curiosity.
But an argument could be made that, if you want to be maximally effective in AI alignment and minimising x-risk, you need to do either technical work to improve systems of type 2, or policy work on banning systems which are completely opaque inside, banning their use in any type of high-impact application. Part of that argument would also be that mainstream ML research is already plenty interested in improving the transparency of current generation neural nets, but without really getting there yet.