What Should AI Owe To Us? Accountable and Aligned AI Systems via Contractualist AI Alignment
post by xuan · 2022-09-08T15:04:46.147Z · LW · GW · 16 commentsContents
Overview Alignment: A Preference Utilitarian Approach The Multiplicity Challenge Unilateral alignment could be disastrous Practical and political challenges to preference aggregation Desiderata for societal-scale AI alignment Contractualist AI Alignment A related Confucian framing Pluralist and contractualist normative foundations Norms and values are subject to reasoning Norms of rationality need not be maximizing Contractualist norms disfavor power-seeking Collective governance by designing/enforcing roles and norms Designing roles and norms Evolving roles and norms at scale Enforcing roles and norms Technical alignment as norm compliance under ambiguity Norms and laws as incomplete social contracts Naive reward modeling as a negative example Inferring roles and norms Reverse engineering roles and norms Conclusion Acknowledgements None 16 comments
This is an extended and edited transcript of the talk I recently gave at EAGxSingapore 2022.
The title has been changed for easier searchability of "Contractualist AI Alignment".

Abstract: Artificial intelligence seems poised to alter our civilization in transformative ways. How can we align this development with our collective interests? Dominant trends in AI alignment research adopt a preference utilitarian conception of alignment, but this faces practical challenges when extended to a multiplicity of humans, values, and AI systems. This talk develops contractualist AI alignment as an alternative framework, charting out a vision of societal-scale alignment where AI systems can serve a plurality of roles and values, governed by and accountable to collectively decided, role-specific norms, with technical work ensuring compliance with these overlapping social contracts in the face of normative ambiguity.
Overview
This talk is an attempt to condense a lot of my thinking about AI alignment over the past few years, and why I think we need to orient the field towards a different set of questions and directions than have typically been pursued so far.
It builds upon many ideas in my previous talk on AI alignment and philosophical pluralism [AF · GW], as well as arguments in Comprehensive AI Services as General Intelligence, AI Research Considerations for Human Existential Safety (ARCHES) [EA · GW], How AI Fails Us, and Gillian Hadfield's work on The Foundations of Cooperative Intelligence.
This will cover a lot of ground, so below is a quick overview:
- The dominant "preference utilitarian" framework in AI alignment research.
- Challenges for extending this framework to a multiplicity of humans, values, and autonomous systems.
- Considerations and desiderata that a successful approach to society-scale AI alignment should address.
- Pluralist and contractualist AI alignment as an alternate framework, including implications for governance, technical research, and philosophical foundations.
Alignment: A Preference Utilitarian Approach
One way of describing the framework that most alignment researchers implicitly adopt is a "preference utilitarian" approach. Stuart Russell’s 3 Principles for Beneficial AI are good summary of this approach. Recognizing that many dangers arise when machines optimize for proxy metrics that ultimately differ from human values, he instead advocates that:
- The machine's only objective is to maximize the realization of human preferences.
- The machine is initially uncertain about what those preferences are.
- The ultimate source of information about human preferences is human behavior.
— Stuart Russell, Human Compatible (2019)
More broadly, many researchers frame the problem as one of utility matching. Under certain assumptions [LW · GW], a single human’s preferences can be represented as a utility function over outcomes, and the goal is to build AI systems that optimize the same utility function.
(This is implicit in talk about, e.g., objective functions in inner misalignment [AF · GW], and reward modeling [AF · GW], which suggested that human objectives and values can ultimately be represented as a mapping to a scalar quantity called "reward" or "utility".)
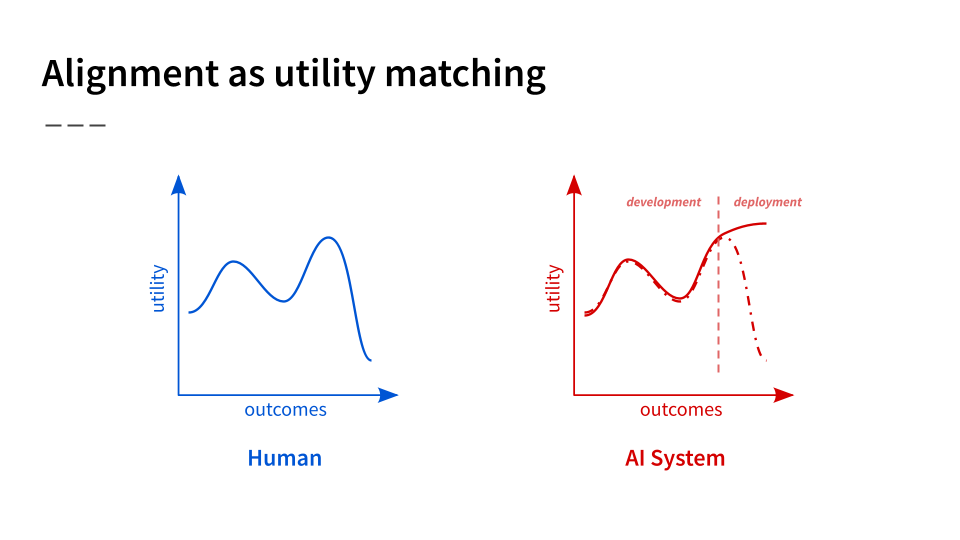
Why is this hard? Because while it may be possible to ensure that the system does the right thing during development, it’s much harder to ensure this during deployment, especially as systems become more capable of achieving new outcomes[1]. For example, a self-driving car might safely avoid obstacles for all situations it was trained on. But at deployment, the objective it’s effectively maximizing for might be much more positive than the true human objective, leading to car crashes.
So the goal of a lot of alignment research today is to avoid this problem — to ensure that AI systems optimize for the right utility function even as they grow more powerful and encounter radically new scenarios that their human designers didn’t think of. This research is important, even in the near-term. But I also believe that it is not enough.
The Multiplicity Challenge
Unilateral alignment could be disastrous
Why? Because so far we’ve only talked about alignment to a single human, or a single objective, and unilateral alignment could well be disastrous:
- It is not enough for a powerful optimizing system to be aligned with a single objective or metric, because other objectives matter.
- e.g. AI-managed decentralized autonomous organization maximizes profits without any grounding in commodities or human welfare, gradually commissions enough crypto-mining server farms to cause irreversible 6°C global warming by 2050.
- It is not enough for a powerful optimizing system to be aligned with a single individual or actor, because other individuals matter.
- e.g. Tech company CEO or authoritarian leader takes control of the world using powerful aligned AI systems, likes humans enough to keep them around (if we are lucky) but in severe oppression.
To put this again in graphical terms, a simplified version of the situation we’re in is one where we have multiple objectives and/or humans, each with their own utility functions. We want to somehow align an AI system to all of them:
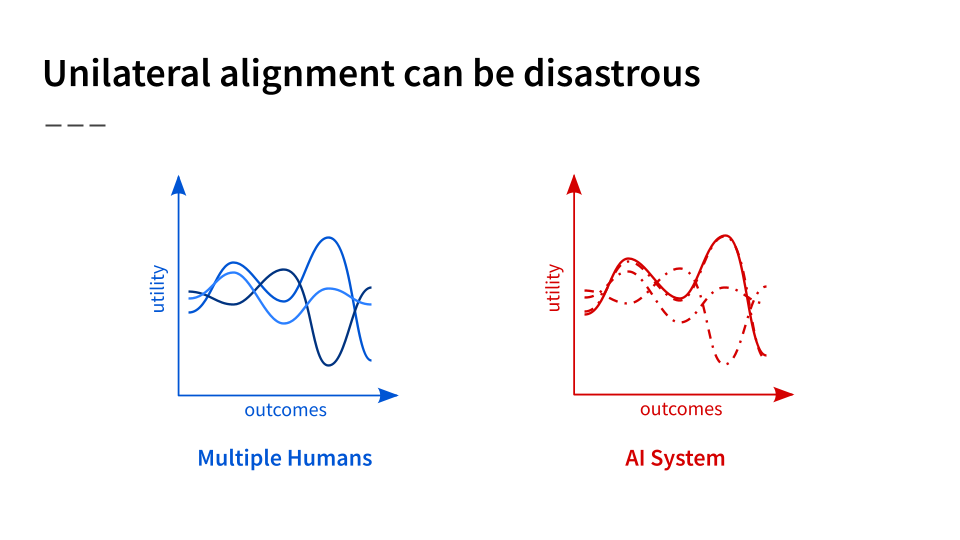
If we just aligned an AI system to one human, as shown here, the optimal outcome for that human could be disastrous for another, or perhaps many others. So what should we do instead?
Well, perhaps we could just build a singular powerful AI system that aggregates across humans, optimizing for the sum or mean of the utility functions. Effectively, we would build a preference utilitarian AI system — an agent that acts to satisfy the most preferences for the most people:
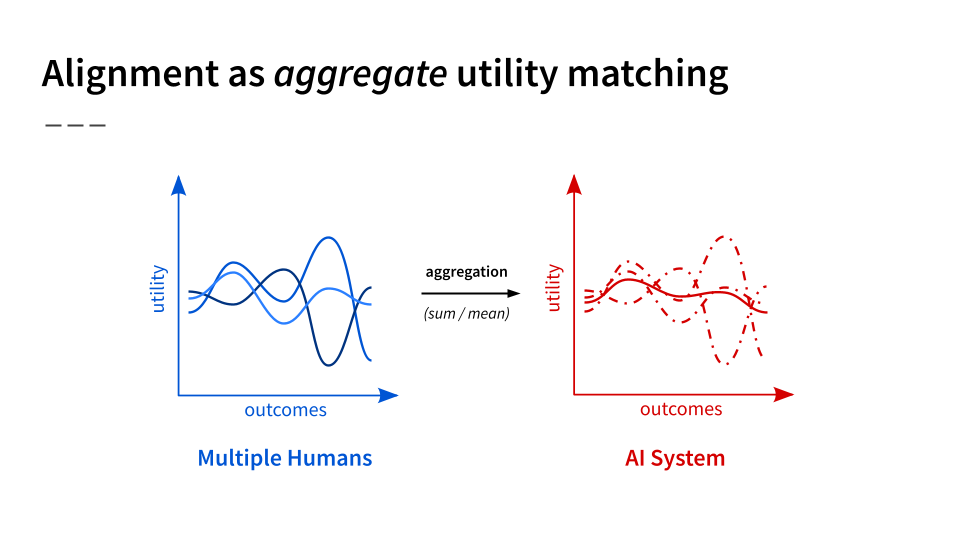
And there’s economic theory that provides some justification for this approach, like Harsanyi’s aggregation theorem [EA · GW], provided we make some assumptions [EA · GW] about individual humans' preferences. So why not just do this?
Practical and political challenges to preference aggregation
The main reason, I think, even setting aside philosophical issues with preference utilitarianism, is that this scheme for aligning a single system to multiple humans and values faces numerous practical and political challenges:
- Computational Intractability. If we’re really going to build a centralized AGI-style singleton that tries to both learn and satisfy everyone’s preferences, that’s doubly intractably hard. This is the classic critique of central economic planning from the 20th century socialist calculation debate, and it’s recapitulated in the literature on the computational complexity of reinforcement learning (specifically, Dec-POMDPs, which are the formalism for multi-principal assistance games.)
- Centralization of Power. We should be very worried about how such centralization creates a single point of failure, or increases the risk of various forms of value lock-in [EA · GW] and tyranny (lock-in of creator values, tyranny of minorities / majorities, etc.)
- Incentive Incompatibility. The idea that we might build a single impartial AI system that’s aligned to everyone’s values is politically naïve, because it’s incentive incompatible with our existing capitalist mode of development.[2] More broadly, it is in tension with the basic fact that most people and communities want to do different things with different AI systems, rather than make appeals to some kind of centralized AGI god.
After all, that’s how the AI economy functions today. AI systems serve in multiple uses and roles: for individuals, there are virtual assistants or household robots. For businesses or cooperatives, there’s market forecasting or R&D automation. For communities, governments, and states, there’s AI for energy distribution and traffic control.
- Individuals / End Users
- virtual assistants, household robots, recommender systems, self-driving cars, text autocompletion, intelligent tutors, video game AI, artificial companions
- Businesses / Corporations / Cooperatives
- algorithmic trading, market forecasting, algorithmic hiring, ad placement, physical and digital asset monitoring, factory robots, R&D automation
- Communities / Governments / States
- smart energy distribution, traffic control, economic and urban planning, epidemic forecasting, surveillance and policing, autonomous weapons
I take it that it’s by and large desirable that AI can serve these multiple ends [EA · GW], given humanity’s diverse and plural interests. But even if some of these ends are not desirable — perhaps AI surveillance and policing — I think we should nonetheless expect this plurality to continue.
As Eric Drexler notes, the trajectory of the AI economy is a service economy that is self-improving:
“AI technology today [...] produces applications that provide services, performing tasks such as translating languages, recognizing faces […] and beating Go masters. […]
[This] scales to sets of services that perform an asymptotically comprehensive range of tasks, while AI-supported automation of AI R&D automation scales to asymptotically recursive, potentially swift technology improvement, [subsuming] the instrumental functionality that might otherwise motivate the development of AGI agents.”
— Eric Drexler,
Reframing Superintelligence: Comprehensive AI Services as General Intelligence (2018)
In other words, the way we’re getting improvement in AI is not because of a single system improving itself, but through recursive improvement at the ecosystem level, with better AI tooling leading to better AI, and so on, in such way that might even remove the incentive to build general-purpose agents as traditionally conceived (though this is not without objections [AF · GW]).
Relatedly, Andrew Critch and David Krueger have argued that we should take seriously the multiplicity thesis:
“The multiplicity thesis. Soon after the development of methods enabling a single human stakeholder to effectively delegate to a single powerful AI system, incentives will likely exist for additional stakeholders to acquire and share control of the system (yielding a multiplicity of engaging human stakeholders) and/or for the system’s creators or other institutions to replicate the system’s capabilities (yielding a multiplicity of AI systems).”
— Andrew Critch and David Krueger,
ARCHES: AI Research Considerations for Human Existential Safety [EA · GW] (2020)
In other words, incentives may quickly lead to the proliferation of multiple stakeholders with multiple powerful AI systems, once they are reasonably useful and unilaterally aligned.
Desiderata for societal-scale AI alignment
All of this motivates thinking about what alignment means at a societal scale. And given everything I’ve discussed, I’d like to suggest at least these two desiderata for any such approach:
- Plurality: AI systems, including advanced ones, can be used in a variety of roles to fulfil a variety of individual, communal, and universal interests.
- Safety: Use of AI systems, or interactions between them, should not catastrophically endanger the interests of others or their ability to pursue those interests.
This relates to other considerations people have raised, such as the ARCHES [EA · GW] argument that both existential safety and societal stability motivate multi-multi preparedness:
“Multi/multi preparedness. From the perspective of existential safety in particular and societal stability in general, it is wise to think in technical detail about the challenges that multi/multi AI delegation might eventually present for human society, and what solutions might exist for those challenges, before the world would enter a socially or geopolitically unstable state in need of those solutions.”
— Andrew Critch and David Krueger,
ARCHES: AI Research Considerations for Human Existential Safety [EA · GW] (2020)
From a more philosophical perspective, it also relates to Iason Gabriel’s observation that we cannot expect moral agreement on what values to align AI with, and so we must instead ask: Is there a fair way to decide how to align AI?
“[T]he task in front of us is not to identify the true or correct moral theory and then implement it in machines. Rather, it is to find a way of selecting appropriate principles that is compatible with the fact that we live in a diverse world, where people hold a variety of reasonable and contrasting beliefs about value. [...] To avoid a situation in which some people simply impose their values on others, we need to ask a different question: In the absence of moral agreement, is there a fair way to decide what principles AI should align with?”
— Iason Gabriel,
Artificial Intelligence, Values, and Alignment (2020)
So that's the problem space. What might be a solution?
Contractualist AI Alignment
Here’s a proposal: Contractualist AI alignment, a framework inspired by pluralist and contractualist philosophical traditions.

Pluralism and contractualism serve as the normative foundations of the framework, reframing the concept of rationality in AI to account for a plurality of value-specific norms, and to understand moral and normative reasoning as a process of mutual justification: as what we owe to each other.
This in turn informs collective governance of AI systems: The process by which we decide the roles we would like AI systems to play in society, and the norms and laws they should adhere to, given those roles. In other words, figuring out what AI should owe to us.
With these roles and norms at hand, we can re-envision the work of technical alignment not as satisfying human’s preferences, but as norm compliance under ambiguity. Whatever laws and norms we decide upon, they’re likely to be ambiguous and incomplete, and so highly autonomous systems will have to handle them by reverse-engineering their normative content in conjunction with humans.
A related Confucian framing
I’ll note that while contractualism has very different roots, there’s a sense in which this framework could also be stylized as Confucian AI alignment[3]. I’m drawing here from this famous excerpt from the Analects:
齊景公問政於孔子。孔子對曰: 「君君,臣臣,父父,子子。 」
公曰:「善哉!信如君不君,臣不臣,父不父,子不子,雖有粟,吾得而
食諸?」 (Analects 12.11)Lord Jing of Qi (r. 547–490 BC) asked Confucius about government.
Confucius answered: “The lord acts as a lord, the minister as a minister,
the father as a father, the son as a son.”The lord said: “Excellent! Surely, if the lord does not act as a lord, nor
the minister as a minister, nor the father as a father, nor the son as a son,
then although I might have grain, would I be able to eat it?”— Translated by Paul R. Goldin, The Art of Chinese Philosophy
What does this mean? It means that the lord, minister, father, and son must play their proper roles and functions in society, not shirk them, otherwise society would collapse.
We could say the same about AI systems: whether they’re acting primarily to serve private, communal, or public interests, they should be aligned with the norms governing those roles, for the whole system to work. Of course, we probably don’t want the specific patriarchal and hierarchical roles that characterized imperial China — we’d like to define them ourselves — but this frame, I hope, still provides useful intuition.
Pluralist and contractualist normative foundations
So that was the big picture. Let’s take it step by step, and unpack what I mean by pluralist and contractualist foundations.
By pluralism, I mean the kind of pluralist value theory defended by Elizabeth Anderson in Value in Ethics and Economics. Rather than defining value as the goodness or badness of consequences, she asks us to remember the huge variety of ways we value things in daily life: valuing someone as a friend, or loving one’s child, or appreciating art.
These evaluative attitudes guide our actions and thoughts about how to rationally express those values. If we care for someone, we might help them. If we find something unfunny, we shouldn’t laugh. And these values aren’t just rewards or "utils" to be traded off. Rather, they are inputs to mental processes that may (or may not) output preferences: Do I show up for my friend’s concert because I care about them, or stay at home because I value my rest?
These values include interpersonal attitudes, like love and respect, which brings us to intersubjective meta-ethics. Rather than framing “ethics” as “maximizing the good”, philosophers such as Darwall and Scanlon instead frame it as “what we owe to each other”. For them, this derives from the attitude of mutual respect, among others, which means treating ourselves as potentially accountable to the claims and demands that others make upon us, which Darwall calls second-personal reasons.
This serves as a basis for contractualist ethics and politics, associated with philosophers like Scanlon and Rawls: To adjudicate between competing interpersonal claims, we engage in processes of impartial reasoning given our roles, relationships and ends. For example, living by principles that serve our shared goals and ideals, are mutually agreeable, or that no one can reasonably reject. This gives us a framework for reasoning about what rules to follow.
Whether or not you find these foundations compelling, I hope you can see how this is relevant to the question of “value alignment”. If we’re going to align AI with human values and norms, we may need a good theory of what values and norms even are.
Norms and values are subject to reasoning
One especially appealing feature about this framework is that it does not treat values and norms as fixed, but instead subject to reasoning. This departs from reinforcement learning, which typically flattens all the complexity of human values into “rewards”. Instead, it expands our concept to rationality to include reasoning about norms and values.
For example, we can reason about epistemic norms:
“Should I try to be Bayesian in how I update my beliefs?”
- Dutch Book arguments: Yes, otherwise people can cheat you of resources.
- Knightian critique [LW · GW]: No, due to unknown unknowns, incomputable hypotheses, etc.
We can also reason about who to value:
“Should I care about the welfare of non-human animals?”
- Sentience argument: Yes, because (many) animals suffer like humans do.
- Personhood argument: Yes, (some) animals have the capacities for personhood.
Finally, we can reason about principles that govern our collective lives, appealing to various meta-principles to justify them:
“Should mask mandates in public transportation be continued?”
- Rule utilitarianism: Yes, it prevents outbreaks and improves public health.
- Veil of ignorance [EA · GW]: Yes, any of us could have been born immuno-compromised.
- Reasonable rejection: Yes, high-risk people could reasonably reject the alternative.
This isn’t just something that philosophers do in their armchairs. In The Logic of Universalization Guides Moral Judgement, Sydney Levine and co-authors show that this sort of universalization reasoning actually predicts laypeople’s moral judgements, using a mathematical model that embeds such reasoning into its structure.
Perhaps then, we could imbue AI systems with similar abilities to reason about values and norms, instead of simply learning existing preferences[4]. In fact, in doing so, we could draw upon a long tradition of AI research that has sought to define and implement argumentation-based reasoning, but is not widely known today due to the dominance of deep learning and reinforcement learning.
Norms of rationality need not be maximizing
Another attractive feature of this framework is that it highlights that not all norms for rational thought and action are maximizing, because it adopts a broader concept of rationality than "maximize expected value". In a wide sense, rationality just means thinking or acting in ways that are guided or justified by reasons.
In other words, a "rational agent" need not always optimize. Or, if you prefer to reserve the term "rational agent" for "expected utility maximizer", my point is that many agents we build to do useful work need not be expected utility maximizers. Two examples follow:
- Logical and arithmetic reasoning. Determining whether is just a matter of repeatedly applying mathematical rules. These rules are the norms of rationality that guide reasoning in mathematical contexts, and they do not enjoin maximization. Indeed, we need arithmetic relations like orderings to even get the concept of "maximization" off the ground[5].
- Norms for creating or evaluating art. These norms are "rational" to the extent they are based on reasons, e.g., particular aspects of the artwork, what they evoke or express, and how they relate to art history. These norms also do not enjoin maximization. Consider:

Right: A cursed image, like Elmo lying inexplicably on a bed, is cursed insofar as it confounds our expectations about beds and Muppets.
Maximizing "Dadaism" or "cursedness", to the extent that it makes sense, would quickly saturate, and lose meaning if done too often. In addition, attempts to maximize "cursedness" would generally not make an image "more cursed", but just cursed in a different way.
Contractualist norms disfavor power-seeking
A final useful feature of these normative foundations is that contractualist decision-making seems to disfavor selfish power-seeking, without requiring that the decision-maker directly cares about the preferences of others (e.g. it need not have terms for the utilities of other agents in its own utility function, in settings where utility functions are an adequate representational choice). This is inspired by John Roemer's concept of Kantian equilibrium:
A vector of strategies is a (multiplicative) Kantian equilibrium of the game if for all agents :
where is a strategy space (the set of labour amounts that each agent can provide), and is the payoff function for agent .
Kant's categorical imperative: One should take those actions and only those actions that one would advocate all others take as well. Thus, one should expand one's labour [e.g. how many fish to catch in a shared lake] by a factor if and only if one would have all others expand theirs by the same factor.
[This] is a cooperative norm. The contrast is with the non-cooperative concept of Nash equilibrium, where the counterfactual envisaged by the individual is that one changes one's labour while the labour of all others remains fixed. [...] Kantian behaviour here does not ask an individual to be empathetic (taking on the preferences of other people): rather, it enjoins the individual to behave in the way that would maximize her own welfare, were all others to behave in a similar fashion.
— John Roemer, Kantian Equilibrium (2012)
Kantian equilibrium is related to Douglas Hofstadter's concept of super-rationality, and Elizabeth Anderson's formulation of universalization, albeit more directly applied to the problem of governing the commons. What they all suggest is that unlimited accumulation of power and resources is non-universalizable: If all agents kept seeking power without limit to achieve their own ends, this would eventually deplete the resource commons, or else leads to costly conflict between agents, and hence fail to be desirable by each agent's own lights.
This leads me to suggest the following (imprecise) conjectures:
- Contractualist agents — i.e. agents that follow rules that result from contractualist deliberation about what rules all would accept (or what policies all would follow) — avoid unlimited selfish power-seeking and resource accumulation as convergent instrumental sub-goals.
- Contractualist avoidance of power-seeking provides both a cooperative justification and reformulation of attainable utility preservation [LW · GW]. Why avoid seeking power selfishly (i.e. without sharing any of the power)? Because it would lead to bad outcomes for me if everyone else were to do the same.
As with attainable utility preservation, an especially appealing feature of this contractualist approach is that it does not require an agent to reason about the preferences of others. Instead, the focus would be on how everyone following a certain policy, or certain set of rules, would affect one's own interests. Many details of these connections remain to be worked out — e.g. extending Kantian equilibria to more general settings, and figuring out how to solve for them — but I expect there will be interesting and useful findings as a result.
Collective governance by designing/enforcing roles and norms
Let us move on to the second pillar of the framework: Collective governance.
Designing roles and norms
How? By designing roles and norms. Taking a leaf from value-sensitive design, mechanism design, and political constructivism, we should ask the following two questions:
- What social and institutional roles do we want AI systems to play in our personal and collective lives?
- Given those roles, what norms, objectives, regulations, or laws should guide and regulate the scope and behavior of AI systems?
This of course is a deliberative ideal far from achievable in real life. But I believe it’s still useful as a guide, and provides a constructive approach to AI governance, rather than the primarily strategic considerations that dominate AI policy and governance today.
Just to give a sense of what I mean by this, consider that the ideal norms governing socio-technical systems might differ depending on whether they serve the public interest, corporations, or private users:
- Public interest AI
- Examples: Energy distribution, traffic control, surveillance systems
- Relevant Norms: Democratic accountability, impartial benefits, egalitarian outcomes, procedural justice, explainable decisions, right to contestation
- Corporate AI
- Examples: Algorithmic hiring, digital asset management, labor automation
- Relevant Norms: Non-discrimination, contract adherence, limits on wealth and power accumulation, limits on worker alienation and disenfranchisement
- Private use AI
- Examples: Virtual assistants, recommender systems, household robots
- Relevant Norms: Right to privacy, right to reasonable inferences, respect for user autonomy, prohibitions on enabling user aggression or coercion
Smart energy grids might need to be efficient, but also equitable to all citizens. Automated authorities might need to provide explainable decisions to be legitimate, and ensure the right to contestation. Algorithmic hiring should be non-discriminatory, and perhaps wealth accumulation by digital asset management platforms should be limited. Personal virtual assistants should protect user privacy, and refuse to enable user aggression toward others.
These roles and norms are not simply preferences at the group-level, or intuitively desirable principles. Rather, they are primarily the result of collective (if partial, ongoing, and unequal) deliberation about how to organize society so that we might each pursue our individual and shared ends while in community with others. This is the process that gave birth to modern legal infrastructure, and governing AI means figuring out how they should participate in that normative structure.
Evolving roles and norms at scale
The norms I have listed might sound well and good, but in a rapidly evolving AI ecosystem, you might be wondering how we could hope to do this kind of careful design at scale. Just this year for example, we’ve seen multiple releases of surprisingly realistic text and image generation models, and this seems unlikely to stop. How can governance keep up?

As it turns out, many people have been thinking exactly about this topic. In Rules for a Flat World, Gillian Hadfield proposes regulatory markets as a way to rapidly innovate new laws for new technologies, breaking the monopoly power currently held by the existing legal profession.
And in a recent op-ed, Divya Siddarth makes the case for collective intelligence — coordination systems that incorporate and process decentralized decision-making across individuals and communities — enabling not just collective design, but what might be called democratic scalable oversight over AI systems. To that end, Siddarth and others at DeepMind and the RadicalXChange foundation have launched the Collective Intelligence Project to pursue these directions.
In deciding what roles what AI should play in our collective lives, it is also worth asking again whether we want the kind of AGI systems that groups like OpenAI and DeepMind claim to be working towards. In particular, if we can build collectively (super)intelligent systems that deliver all of the social and economic benefits that general-purpose AI would otherwise bring, then it may be both tractable and desirable to coordinate towards that future, and we should seriously consider doing so[6].
Enforcing roles and norms
But maybe this still sounds too optimistic. Even if we could collectively design all these roles and norms, how would we enforce them? This isn’t the main focus of the talk, I do want to allay a common worry about the more pluralistic, multi-polar development of AI I’ve suggested so far: The worry that it is too hard to coordinate to build powerful AI safely, and so the least bad option is that some company like OpenAI goes and does it first [AF · GW], risks of centralization be damned.
So what is the alternative? While I don’t want to suggest that coordinating enforcement is easy at all, I will point out that there is an entire community centered around accountable AI, trying to answer these questions, providing solutions like:
- Auditing Tools. Timnit Gebru’s Datasheets for Datasets, or Margaret Mitchell’s Model Cards for Model Reporting are now ML best-practices exposing regulation-relevant information that can be used to keep AI systems accountable through auditing and other tools.
- Pre-emptive Regulation. Auditing is useful ex post, but does it really make us safer from the emerging and unexpected risks posed by AI? Thankfully, we have methods for that too. In some recent work by Rui-Jie Yew and Dylan Hadfield-Menell, they show how regulatory penalty defaults can be used to incentivize preemptive disclosure and mitigation of harm, by requiring companies to come forward and disclose possible harms if they want to use the tech at all.
- The Precautionary Principle. More broadly, pre-emptive regulation is an instance of the strong precautionary principle, which has roots in environmental impact regulation, but might well be extended to high risk AI systems. In fact, the EU’s AI Act might enact laws governing such systems soon, and there is reason to believe that they will spread at least partially to other jurisdictions.
But what about the biggest, if most uncertain, risks — the existential ones? How could we prevent people from just unilaterally building powerful but misaligned AI that causes a global catastrophe? Early thinkers like Bostrom suggest this would require dystopian levels of authoritarian surveillance [LW · GW], but I think this is still an open problem.

As Critch and Krueger suggest [EA · GW], we could build existential safety systems that monitor AI use and development. There are already incentives to do this, because of misuse of existing AI: We could augment surveillance of financial systems, or energy grids, so that AI systems can’t manipulate or shut them down. We could vastly improve our cybersecurity infrastructure, or even monitor and prevent the accumulation of computational power by misaligned systems.
We have actually done similar things to manage other existential risks. Stuart Russell and team, for example, have used Bayesian machine learning to greatly improve the accuracy of our global seismic monitoring systems, creating the technical infrastructure needed to enforce the Comprehensive Nuclear Test Ban Treaty. And very recently, Kevin Esvelt has set up the Nucleic Acid Observatory, a new bio-surveillance initiative to provide reliable early warning for future pandemics.
So I hope that gives at least of sense of everything that can be done, and why a multipolar AI future might be desirable overall.
Technical alignment as norm compliance under ambiguity
So that was governance. We now have all these roles and norms. How do we get AI systems to reliably comply with them, especially if the norms are ambiguous or incomplete?
Norms and laws as incomplete social contracts
In developing an answer, I think we should build upon the insight by Dylan Hadfield-Menell and Gillian Hadfield that AI alignment can be viewed as analogous to the problem of incomplete contracting. In other words, AI alignment is a principal agent problem, where task specifications for AI systems are incomplete contracts between principal and agent.
But who is the principal in this case? I want to say that it’s not just one person, but us: the multiple overlapping communities in which the AI system is embedded. This means norms and specifications for AI systems aren’t just incomplete contracts. Rather they’re incomplete social contracts, which AI systems need to navigate.
As Hadfield-Menell and Hadfield point out, building AI systems that can navigate this normative structure is a distinct research program from learning human preferences:
“Building AI that can reliably learn, predict, and respond to a human community’s normative structure is a distinct research program to building AI that can learn human preferences. [...] Indeed, to the extent that preferences merely capture the valuation an agent places on different courses of action with normative salience to a group, preferences are the outcome of the process of evaluating likely community responses and choosing actions on that basis, not a primitive of choice.”
— Dylan Hadfield-Menell and Gillian K. Hadfield,
Incomplete Contracting and AI Alignment
In doing so they make this really under-appreciated point, which is that many human preferences are secondary, not primary: "they are the outcome of a process of evaluating likely community responses and acting on that basis, not a primitive of choice".
So how are we going to carry out this agenda? Well, the solution space is going to differ depending on whether we’re building low-autonomy systems vs. high-autonomy systems.
For low-autonomy systems — most of the AI systems we actually have today — we can mostly do what we are already doing: iterative development and testing to comply with the relevant specifications and regulations.
But what about high-autonomy systems, including future advanced AI? These will have inevitably have to act under normative uncertainty, and adjudicate normative ambiguity through interaction with humans. Rather than learn user preferences, these systems will have to learn and understand the normative infrastructure that generates their intended functions, roles, and norms
Naive reward modeling as a negative example
Just to show that we already face a version of this problem, consider toxic text generation. In a recent update to their GPT-3 language model, OpenAI applied an alignment technique that reduced the toxic outputs of their model according to a certain benchmark. But what does “toxic” mean here? Toxic to whom? In what contexts? For what reasons? What if I want GPT-3 to be toxic, to help script a toxic movie character?

You would hope for alignment techniques address all this normative complexity. But if you look at what OpenAI did, they just trained a second reward model to mimic human rankings of whether outputs are “better” or “worse”, then used that reward model to finetune the language model. This conflates all the ways in which text can be “better” or “worse”. While this reward-driven finetuning improved results, it also ignores the deep complexity behind human normative judgements.[7]
Inferring roles and norms
How can we do better? Well, first we need models of human behavior that separate out the influence of mere preferences from norms, as I’ve explored in some previous work, allowing us to separately infer individual desires and shared normative structure.[8]
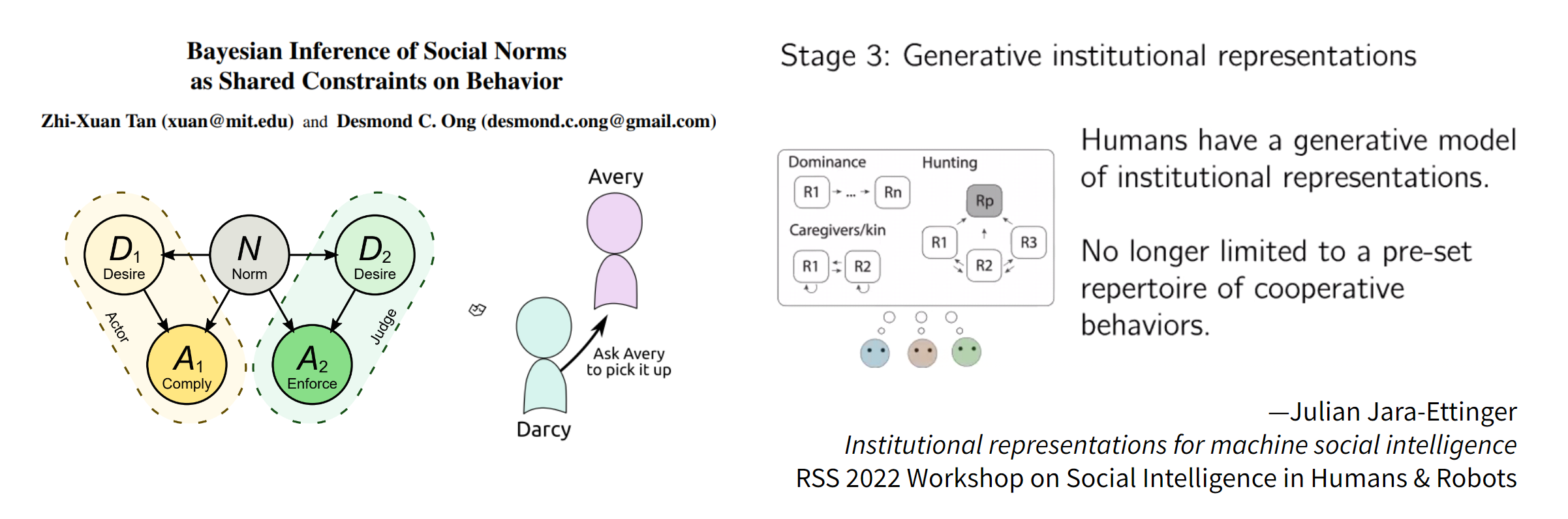
Right: Generative models of social roles and institutions.
In a related line of work, Julian-Jara Ettinger has proposed that we need to take an institutional stance towards human behavior. Rather than modeling humans as guided only by beliefs and desires, we need to understand they might play different roles. By constructing generative models over these roles and interactions, we can infer the roles of each agent, as well as the broader institutional structure, by observing agent interactions over time.
One could imagine extending these approaches by building AI systems that infer contract-like specifications of the norms governing the roles they are expected to play. These approaches would differ from naive reward modeling in several respects:
- Representation. Role-specific contracts and norms are likely better represented using temporal logic statements that compile to non-Markovian reward machines, or more broadly, reward-generating programs. This is in contrast to the standard assumption of linear Markovian reward functions, which are insufficiently expressively, or neural reward models, which may fail to generalize in human-like ways.
- Learning. Given an initial but incomplete contract specification, missing terms in the contract (e.g. logical statements, subroutines, etc.) could be inferred similar to inverse reward design, leveraging tools from hierarchical Bayesian inverse reinforcement learning and Bayesian program synthesis to handle non-differentiable hypothesis spaces. Data would not just consist of human preferences, but from role-specific human behavior and normative judgements.
- Role and Context Sensitivity. For systems that may be used in multiple contexts or adopt multiple roles (e.g. Alexa speaking to a young child vs. an adult), different norms and contractual obligations should apply. This means systems should be built to learn local requirements for each possible role (and how to adjudicate those requirements when roles conflict), instead of a single globally-coherent utility function[9]. In addition, such systems may have to infer their relevant roles from real-time human interaction.
Many of the above directions are ripe for further research, but have garnered relatively little attention from the AI alignment community. This is likely because of the tendency to anchor upon expected utility theory and standard reinforcement learning approaches as a blueprint for agent design. By adopting a more pluralist and contractualist lens upon rational agency, perhaps we can better reflect the multiplicity of roles and norms that we want such systems to adopt and navigate.
Reverse engineering roles and norms
Inferring roles and norms is a step in the right direction, but I think we need to go further still. Because if we merely infer existing roles and norms, well, many existing norms are bad norms! We might want to revise them, or do away with them completely. To build AI systems that allow for such revision, it is helpful to distinguish between three levels of norm compliance:
- Mere compliance. Complying with the letter of the law, exploiting loopholes where possible (cf. Legalist beliefs about human nature, Kohlberg’s pre-conventional morality)
- Wilful compliance. Complying with the spirit of the law, but not understanding its greater purpose (cf. Confucian beliefs about human nature, Kohlberg’s conventional morality)
- Enlightened compliance. Complying with the principles behind the law, revising law where necessary (cf. Kohlberg’s post-conventional morality)
I have discussed how we might go beyond mere compliance towards something like wilful compliance, which includes inferring the unspoken but implied parts of the contract. But really what we want is something like enlightened compliance: complying with the principles behind the law, which may mean making revisions to law where necessary.
How do we do that? Recall the design questions for roles, laws, and norms I outlined earlier:
- What social and institutional roles do we want AI systems to play in our personal and collective lives?
- Given those roles, what norms, objectives, regulations, or laws should guide and regulate the scope and behavior of AI systems?
For AI systems to comply with norms in enlightened, flexible ways, they will need to reverse engineer the processes of social evolution and deliberation that generate answers to the above questions, understanding not just what the norms are, but the functions they serve, so that they can be generalized or adapted to new scenarios. In other words, the alignment problem can be viewed as the dual of the governance problem.
This brings us back to the frameworks for normative reasoning I mentioned earlier, like universalization principles, or argumentation logics. We can build AI systems that engage in normative reasoning together with the human communities they serve, and hence not just comply with law, but also help us extrapolate or change it to deal with new situations. Existing model of legal reasoning may be a useful starting point here. Some alignment researchers like Francis Rhys Ward [AF · GW] have also begun integrating argumentation approaches with reward learning, which I view as a promising line of research.
I want to be clear that I do not mean AI systems should go off and philosophize on their own until they implement the perfect moral theory without human consent. Rather, our goal should be to design them in such a way that this will be a interactive, collaborative process, so that we continue to have autonomy over our civilizational future[10].
Conclusion
Much of alignment research today remains focused on the single-single alignment problem, implicitly adopting the view that we can solve this problem first, then the multi-multi alignment problem later[11].
In charting out contractualist AI alignment as an alternate vision, I hope to have shown why this stepwise approach is neither necessary nor prudent. By identifying social contracts, not human preferences, as the target of alignment, we can simultaneously address the coordination problems that arise due to multiplicity, avoid the dangers of unilateral alignment, circumvent the intractability of central planning, and still make use of approaches that are not tied to learning from preferences alone.
In addition, this reframing of the alignment problem provides citizens, policy-makers, and activists a governance target that is the dual of the alignment target: the roles we want AI systems to play in our collective lives, and the norms and regulations they should adhere to in doing so. By making this conceptual connection, I hope to have shown that governance and technical alignment are less separate than they might initially seem. Collective oversight over AI systems will require technical innovations. Creating legible roles and regulations for AI systems to align to will require social ones.
Finally, I hope to have shown that the normative foundations of alignment research need not be so narrow as typically assumed. By looking beyond expected utility theory as a theory of rational agency, towards traditions like contractualism and pluralist value theory, we will have more resources for formalizing what it means to align AI with our complex and fragile human values [LW · GW]. With some luck, we can yet hope to ensure individual, communal, and universal flourishing in a diverse and plural technological future.
Acknowledgements
An early version of this talk was given at the PIBBSS Summer Fellowship [AF · GW] closing retreat, where I received valuable feedback from a number of organizers, fellows, and guests, especially TJ, Nora Ammann [AF · GW], Simon McGregor McGill, Vojta Kovarik [AF · GW], and Sahil Kulshrestha.
A number of ideas in this talk also came out of meetings I attended at Dylan Hadfield-Menell's Algorithmic Alignment Lab, with Rui-Jie Yew providing helpful input on AI governance. Other ideas have come from discussions with my colleagues Sydney Levine and Joe Kwon [LW · GW] in the MIT Computational Cognitive Science Lab, as well Julian Jara-Ettinger in the Yale Computational Social Cognition Lab.
As noted in the Overview, many ideas in this talk find their predecessors in Comprehensive AI Services as General Intelligence, AI Research Considerations for Human Existential Safety (ARCHES) [EA · GW], How AI Fails Us, and Gillian Hadfield's work on The Foundations of Cooperative Intelligence.
- ^
- ^
Stuart Russell calls this "Somalia Problem", but the problem is better identified as the selfishness of the Global North.
- ^
Interpreted differently than John Wentworth's post on Confucianism in AI alignment [AF · GW].
- ^
Note that adoption of these non-consequentialist normative foundations does not automatically rule out the preference utilitarian approach I have thus far critiqued: If preference utilitarianism (or more broadly, consequentialism) is "right" according to the premises and arguments we accept, then non-consequentialist reasoning systems should be able to reason towards it, in the same way Von Neumann and Morgenstern reasoned towards their famous utility-theorem.
- ^
This is why I doubt that we need to worry about misaligned AI that consumes the world's computational resources to compute the th digit of pi, to paint one car pink, or to solve similarly bounded "tasks". We already have known algorithms that are non-self-improving (KANSI) to perform these tasks for us, and these algorithms do not pose risks due to unbounded maximization.
- ^
As argued in Comprehensive AI Services as General Intelligence and How AI Fails Us.
- ^
For an in-depth discussion of how the relevant values for language models are context and role-dependent, see In Conversation With AI: Aligning Language Models With Human Values.
- ^
This has been suggested by others a few other times, e.g. Learning Normativity: A Research Agenda [AF · GW], and Following Human Norms [? · GW].
- ^
Not specifying a global utility function avoids technical and philosophical difficulties [AF · GW] with building systems that have to commensurate between all possible values, though the locality of each role specification is likely not enough to guarantee safety unless some form of impact regularization [AF · GW] is included in each local contract, or as part of a global contractual requirement.
- ^
Care must be taken in doing so. [AF · GW] Analogous to cooperative inverse reinforcement learning, AI systems could be motivated to help us engage in normative deliberation, because discovering the norms and principles we agree to would enable it to better achieve its (initially uncertain) objectives. But if some norms and principles are less costly for these systems to satisfy than others, these might incentivize undesirable feedback loops similar to those currently exhibited by recommender systems. (Arguably, the US legal profession has achieved something like this through self-interested exercise of judicial power.) Given this risk, it may be best to separate systems that suggest or predict reasoning steps from systems that comply with the results of such reasoning.
- ^
See General alignment plus human values, or alignment via human values? [AF · GW] for a related discussion.
16 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-09-09T01:24:50.226Z · LW(p) · GW(p)
Upvoted, and even agree with everything about enlightened compliance, but I think this framing of the problem is bad because everything short of enlightened compliance is so awful. The active ingredients in making things go well are not the norms, which if interpreted literally by AI will just result in blind rules-lawyering in a way that alienates humans - the active ingredients are precisely the things that separate enlightened compliance from everything else. You can call it learning human values or learning to follow the spirit of the law, it's basically the same computations, with basically the same research avenues and social/political potential pitfalls
Replies from: xuan↑ comment by xuan · 2022-09-09T03:14:27.972Z · LW(p) · GW(p)
Agreed that the interpreting law is hard, and the "literal" interpretation is not enough! Hence the need to represent normative uncertainty (e.g. a distribution over multiple formal interpretations of a natural language statement + having uncertainty over what terms in the contract are missing), which I see the section on "Inferring roles and norms" as addressing in ways that go beyond existing "reward modeling" approaches.
Let's call the above "wilful compliance", and the fully-fledged reverse engineering approach as "enlightened compliance". It seems like where we might disagree is how far "wilful compliance" alone will take us. My intuition is that essentially all uses of AI will have role-specific / use-specific restrictions on power-seeking associated with them, and these restrictions can be learned (from eg human behavior and normative judgements, incl. universalization reasoning) as implied terms in the contracts that govern those uses. This would avoid the computational complexity of literally learning everyone's preferences / values, and instead leverage the simpler and more politically feasible mechanisms that humans use to cooperate with each other and govern the commons.
I can link to a few papers later that make me more optimistic about something like the approach above!
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-09-09T22:40:59.896Z · LW(p) · GW(p)
I'd be interested :) I think my two core concerns are that our rules/norms are meant for humans, and that even then, actors often have bad impacts that would only be avoided with a pretty broad perspective about their responsibilities. So an AI that follows rules/norms well can't just understand them on the object level, it has to have a really good understanding of what it's like to be a human navigating these rules/norms, and use that understanding to make things go well from a pretty broad perspective.
That first one means that not only do I not want the AI to think about what rules mean "in a vacuum," I don't even want it to merely use human knowledge to refine its object-level understanding of the rules. Because the rules are meant for humans, with our habits and morals and limitations, and our explicit understanding of them only works because they operate in an ecosystem full of other humans. I think our rules/norms would fail to work if we tried to port them to a society of octopuses, even if those octopuses were to observe humans to try to improve their understanding of the object-level impact of the rules.
An example (maybe not great because it only looks at one dimension of the problem) is that our norms may implicitly assume a certain balance between memetic offense and defense that AIs would upset. E.g. around governmental lobbying (those are also maybe a bad example because they're kinda insufficient already).
Also!
While listening to the latest Inside View podcast, it occurred to me that this perspective on AI safety has some natural advantages when translating into regulation that present governments might be able to implement to prepare for the future. If AI governance people aren't already thinking about this, maybe bother some / convince people in this comment section to bother some?
Replies from: xuan↑ comment by xuan · 2022-09-14T10:24:39.991Z · LW(p) · GW(p)
Because the rules are meant for humans, with our habits and morals and limitations, and our explicit understanding of them only works because they operate in an ecosystem full of other humans. I think our rules/norms would fail to work if we tried to port them to a society of octopuses, even if those octopuses were to observe humans to try to improve their understanding of the object-level impact of the rules.
I think there's something to this, but I think perhaps it only applies strongly if and when most of the economy is run by or delegated to AI services? My intuition is that for the near-to-medium term, AI systems will mostly be used to aid / augment humans in existing tasks and services (e.g. the list in the section on Designing roles and norms [AF · GW]), for which we can either either use existing laws and norms, or extensions of them. If we are successful in applying that alignment approach in the near-to-medium term, as well as the associated governance problems, then it seems to me that we can much more carefully control the transition to a mostly-automated economy as well, giving us leeway to gradually adjust our norms and laws.
No doubt, that's a big "if". If the transition to a mostly/fully-automated economy is sharper than laid out above, then I think your concerns about norm/contract learning are very relevant (but also that the preference-based alternative is more difficult still). And if we did end up with a single actor like OpenAI building transformative AI before everyone else, my recommendation would be still be to adopt something like the pluralistic approach outlined here, perhaps by gradually introducing AI systems into well-understood and well-governed social and institutional roles, rather than initiating a sharp shift to a fully-automated economy.
While listening to the latest Inside View podcast, it occurred to me that this perspective on AI safety has some natural advantages when translating into regulation that present governments might be able to implement to prepare for the future. If AI governance people aren't already thinking about this, maybe bother some / convince people in this comment section to bother some?
Yes, it seems like a number of AI policy people at least noticed the tweet I made about this talk! If you have suggestions for who in particular I should get the attention of, do let me know.
comment by Wei Dai (Wei_Dai) · 2024-06-30T13:26:08.894Z · LW(p) · GW(p)
Recall the design questions for roles, laws, and norms I outlined earlier:
- What social and institutional roles do we want AI systems to play in our personal and collective lives?
- Given those roles, what norms, objectives, regulations, or laws should guide and regulate the scope and behavior of AI systems?
I think we lack the intellectual tools (i.e., sufficiently advanced social sciences) to do this. You gave Confucian contractualism as a source of positive intuitions, but I view it as more of a negative example. When the industrial revolution happened, China was unable to successfully design new social and institutional roles to face the challenge of European powers, and after many decades of conflict/debate ended up adopting the current Communist form of government, which is very suboptimal and caused massive human suffering.
You could argue that today's social sciences are more advanced, but then so is the challenge we face (increased speed of change, AIs being outside human distribution of values and capabilities thereby making past empirical evidence and intuitions much less useful, etc.).
One nice thing about the alignment approach you argue against (analyzing AIs as EU maximizers) is that it can potentially be grounded in well-understood mathematics, which can then be leveraged to analyze multi-agent systems. Although that's harder than it seems [LW · GW], there is at least the potential for intellectual progress built upon a solid foundation.
comment by Noosphere89 (sharmake-farah) · 2022-09-08T19:51:42.851Z · LW(p) · GW(p)
First up, I've strongly upvoted it as an example of advancing the alignment frontier, and I think this is plausibly the easiest solution provided it can actually be put into code.
But unfortunately there's a huge wrecking ball into it, and that's deceptive alignment. As we try to solve increasingly complex problems, deceptive alignment becomes the default, and this solution doesn't work. Basically in Evhub's words, mere compliance is the default, and since a treacherous turn when the AI becomes powerful is possible, that this solution alone can't do very well.
Here's a link:
https://www.lesswrong.com/posts/A9NxPTwbw6r6Awuwt/how-likely-is-deceptive-alignment [LW · GW]
Replies from: xuan↑ comment by xuan · 2022-09-09T04:53:06.556Z · LW(p) · GW(p)
Hmm, I'm confused --- I don't think I said very much about inner alignment, and I hope to have implied that inner alignment is still important! The talk is primarily a critique of existing approaches to outer alignment (eg. why human preferences alone shouldn't be the alignment target) and is a critique of inner alignment work only insofar as it assumes that defining the right training objective / base objective is not a crucial problem as well.
Maybe a more refined version of the disagreement is about how crucial inner alignment is, vs. defining the right target for outer alignment? I happen to think the latter is more crucial to work on, and perhaps that comes through somewhat in the talk (though it's not a claim I wanted to strongly defend), whereas you seem to think inner alignment / preventing deceptive alignment is more crucial. Or perhaps both of them are crucial / necessary, so the question becomes where and how to prioritize resources, and you would prioritize inner alignment?
FWIW, I'm less concerned about inner alignment because:
- I'm more optimistic about model-based planning approaches that actually optimize for the desired objective in the limit of the large compute (so methods more like neurally-guided MCTS a.k.a AlphaGo, and less like offline reinforcement learning)
- I'm more optimistic about methods for directly learning human interpretable, modular, (neuro)symbolic world models [AF(p) · GW(p)] that we can understand, verify, and edit, and that are still highly capable. This reduces the need for approaches like Eliciting Latent Knowledge [AF · GW], and avoids a number or pathways toward inner misalignment.
I'm aware that these are minority views in the alignment community -- I work a lot more on neurosymbolic and probabilistic programming methods, and think they have a clear path to scaling and providing economic value, which probably explains the difference.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-09-09T21:25:29.921Z · LW(p) · GW(p)
Maybe a more refined version of the disagreement is about how crucial inner alignment is, vs. defining the right target for outer alignment? I happen to think the latter is more crucial to work on, and perhaps that comes through somewhat in the talk (though it's not a claim I wanted to strongly defend), whereas you seem to think inner alignment / preventing deceptive alignment is more crucial. Or perhaps both of them are crucial / necessary, so the question becomes where and how to prioritize resources, and you would prioritize inner alignment?
This is the crux. I actually think outside alignment, while hard, has possible solutions, but inner alignment has the nearly impossible task of aligning a mesa-optimizer, and ensuring that no deceptiveness ensues. I think this is nearly impossible under a simplicity prior regime, which is probably the most likely prior to work. I think inner alignment is more important than outer alignment.
Don't get me wrong, this is a non-trivial advance, and I hope more such posts come. But I do want to lower expectations that will come with such posts.
comment by phillchris · 2022-09-13T00:43:20.021Z · LW(p) · GW(p)
Great post! I'm curious if you could elaborate on when you would feel comfortable making an agent to make some kind of "enlightened" decision, as opposed to one based more on "mere compliance"? Especially given an AI system that is perhaps not very interpretable, or operates on very high-stakes applications, what sort of certificate / guarantee / piece of reasoning would you want from a system to allow it to enact fundamental social changes? The nice thing about "mere compliance" is there are benchmarks for 'right' and 'wrong' decisions. But here I would expect people to reasonably disagree on whether an AI system or community of systems has made a good decision, and therefore it seems harder to ever fully trust machines to make decisions at this level.
Also, despite this being mentioned, it strikes me that purely appealing to what IS done, as opposed to what OUGHT to be done directly, in the context of building moral machines, can still ultimately be quite regressive without this "enlightened compliance" component. It even strikes me that the point of technological progress itself it so incrementally, and slightly, modify and upend the roles we play in the economy and society more broadly, and so strikes me as somewhat paradoxical to impose this 'freezing' criterion on tech and society in some way. Like we want AI to improve the conditions of society, but not fundamentally change its dynamics too much? I may be misunderstanding something about the argument here.
All of this is to say, it does feel somewhat unavoidable to me to advance some kind of claim about the precise constents of a superior moral framework for what systems ought to do, beyond just matching what people do (in Russell's case) or what society does (in this post's case). You mention the interaction of cooperating and working with machines in the "enlightened compliance" section, and not ever fully automating the decision. But what are deciding if not the contents of an eventually superior moral theory, or superior social one? This seems to me the inevitable, and ultimate, desideratum of social progress.
It reminds me of a lot of Chomskyian comments on law and justice: all norms and laws grope at an idealized theory of justice which is somehow biological and emergent from human nature. And while we certainly know that we ought not let system designers, corporations, or states just dictate the content of such a moral theory directly, I don't think we can just purely lean on contractualism to avoid the question in the long run. Perhaps useful in the short run while we sort out the content of such a theory, but ultimately it seems we cannot avoid the question forever.
Idk, just my thinking, very thought-provoking post! Strong upvote, a conversation the community definitely ought to have.
Replies from: xuan↑ comment by xuan · 2022-09-13T03:17:23.004Z · LW(p) · GW(p)
But here I would expect people to reasonably disagree on whether an AI system or community of systems has made a good decision, and therefore it seems harder to ever fully trust machines to make decisions at this level.
I hope the above is at least partially addressed by the last paragraph of the section on Reverse Engineering Roles and Norms [AF · GW]! I agree with the worry, and to address it I think we could design systems that mostly just propose revisions or extrapolations to our current rules, or highlight inconsistencies among them (e.g. conflicting laws), thereby aiding a collective-intelligence-like democratic process of updating our rules and norms (of the form described in the Collective Governance [AF · GW] section), where AI systems facilitate but do not enact normative change.
Note that if AI systems represent uncertainty about the "correct" norms, this will often lead them to make queries to humans about how to extend/update the norms (a la active learning), instead of immediately acting under its best estimate of the extended norms. This could be further augmented by a meta-norm of (generally) requiring consent / approval from the relevant human decision-making body before revising or acting under new rules.
All of this is to say, it does feel somewhat unavoidable to me to advance some kind of claim about the precise constents of a superior moral framework for what systems ought to do, beyond just matching what people do (in Russell's case) or what society does (in this post's case).
I'm not suggesting that AI systems should simply do what society does! Rather, the point of the contractualist framing is that AI systems should be aligned (in the limit) to what society would agree to after rational / mutually justifiable collective deliberation.
Current democratic systems approximate this ideal to a very rough degree, and I guess I hold out hope that under the right kinds of epistemic and social conditions (freedom of expression, equality of interlocutors, non-deluded thinking), the kind of "moral progress" we instinctively view as desirable will emerge from that form of collective deliberation. So my hope is that rather than specify in great degree what the contents of "superior moral theory" might look like, all we need to align AI systems with is the underlying meta-ethical framework that enables moral change. See Anderson on How Common Sense Can Be Self-Critical for a good discussion of what I think this meta-ethical framework looks like.
↑ comment by phillchris · 2022-09-13T05:06:24.627Z · LW(p) · GW(p)
Hey! Absolutely, I think a lot of this makes sense. I assume you were meaning this paragraph with the Reverse Engineering Roles and Norms paragraph:
I want to be clear that I do not mean AI systems should go off and philosophize on their own until they implement the perfect moral theory without human consent. Rather, our goal should be to design them in such a way that this will be a interactive, collaborative process, so that we continue to have autonomy over our civilizational future[10] [AF(p) · GW(p)].
For both points here, I guess I was getting more at this question by asking these: how ought we structure this collaborative process? Like what constitutes feedback a machine sees to interactively improve with society? Who do AI interact with? What constitutes a datapoint in the moral learning process? These seem like loaded questions, and let me more concrete. In decisions without unanimity with regards to a moral fact, using simple majority rule, for example, could lead to disastrously bad moral theory: you could align an AI with norms resulting in of exploiting 40% of the public by 60% of the public (for example, if a majority deems it moral to exploit / under-provide for a minority, in an extreme case). It strikes me that to prevent this kind of failure mode, there must be some baked-in context of "obviously wrong" beforehand. If you require total unanimity, well then, you will never get even a single datapoint: people will reasonably disagree (I would argue to infinity, after arbitrary amounts of reasonable debate) about basic moral facts due to differences in values.
I think this negotiation process is in itself really really important to get right if you advocate this kind of approach, and not by advancing any one moral view of the world. I certainly don't think it's impossible, just as it isn't impossible to have relatively well-functioning democracy. But this is the point I guess: are there limit guarantees to society agreeing after arbitrary lengths of deliberation? Has modern democracy / norm-setting historically risen from mutual deliberation, or from exertion of state power / arbitrary assertion of one norm over another? I honestly don't have sufficient context to answer that, but it seems like relevant empirical fact here.
Maybe another follow up: what are your idealized conditions for "rational / mutually justifiable collective deliberation" here? It seems this phrase implicitly does a lot of heavy lifting for this framework, and I'm not quite sure myself what this would mean, even ideally.
comment by Q Home · 2022-09-19T08:38:57.334Z · LW(p) · GW(p)
I made a post [LW · GW] about different ways to learn human ethics. I argued that there should be something better than value learning. Learning "contracts" seems similar to learning "X statements" (a concept from my post). I want to know your opinion about this. (A person mentioned your work in a comment to the linked post, that's why I'm here.)
I can't discuss the math of learning contracts directly, but I would like to discuss possible properties of "contracts" or "hypotheses about contracts" that the AI system learns. (Inferring roles and norms [LW · GW])
Replies from: xuan↑ comment by xuan · 2022-09-22T06:43:43.242Z · LW(p) · GW(p)
Hmm, I'm not sure I fully understand the concept of "X statements" you're trying to introduce, though it does feel similar in some ways to contractualist reasoning. Since the concept is still pretty vague to me, I don't feel like I can say much about it, beyond mentioning several ideas / concepts that might be related:
- Immanent critique (a way of pointing out the contradictions in existing systems / rules)
- Reasons for action (especially justificatory reasons)
- Moral naturalism (the meta-ethical position that moral statements are statements about the natural world)
↑ comment by Q Home · 2022-09-23T02:22:23.855Z · LW(p) · GW(p)
Thank you! Sorry, I should have formulated my question better.
I meant that from time to time people come up with the idea "maybe AI shouldn't learn human values/ethics in the classical sense" or "maybe learning something that's not human values can help to learn human values":
- Impact measures [? · GW]. "Impact" by itself is not a human value. It exists beyond human values.
- Your idea of contractualism. "Contracts" are not human values in the classical sense. You say that human values make sense only in context of society and a specific reality.
- Normativity [? · GW] by abramdemski. "Normativity" is not 100% about human values: for example, there's normativity in language [? · GW].
- My idea: describe values/ethics as a system and study it in the context of all other systems.
The common theme of all those ideas is describing human values as a part of something bigger. I thought it would be rational to give a name to this entire area "beyond human values" and compare ideas in that context. And answer the question: why do we even bother going there? what can we gain there in the perfect case? (Any approach in theory can be replaced by a very long list of direct instructions, but we look for something more convenient than "direct instructions".) Maybe we should try to answer those questions in general before trying to justify specific approaches. And I think there shouldn't be a conflict between different approaches: different approaches can share results and be combined in various ways.
What do you think about that whole area "beyond human values"?
Replies from: xuan↑ comment by xuan · 2022-10-05T13:14:22.417Z · LW(p) · GW(p)
Apologies for the belated reply.
Yes, the summary you gave above checks out with what I took away from your post. I think it sounds good on a high level, but still too vague / high-level for me to say much in more detail. Values/ethics are definitely a system (e.g., one might think that morality was evolved by humans for the purposes of co-operation), but at the end of the day you're going to have to make some concrete hypothesis about what that system is in order to make progress. Contractualism is one such concrete hypothesis, and folding ethics under the broader scope of normative reasoning is another way to understand the underlying logic of ethical reasoning. Moral naturalism is another way of going "beyond human values", because it argues that statements about ethics can be reduced to statements about the natural world.
Hopefully this is helpful food for thought!
Replies from: Q Home↑ comment by Q Home · 2022-10-05T22:39:12.157Z · LW(p) · GW(p)
In any case, I think your idea (and abramdemski's) should be getting more attention.
Values/ethics are definitely a system (e.g., one might think that morality was evolved by humans for the purposes of co-operation), but at the end of the day you're going to have to make some concrete hypothesis about what that system is in order to make progress. Contractualism is one such concrete hypothesis, and folding ethics under the broader scope of normative reasoning is another way to understand the underlying logic of ethical reasoning.
I think the next possible step, before trying to guess a specific system/formalization, is to ask "what can we possibly gain by generalizing?"
For example, if you generalize values to normativity (including language normativity):
- You may translate the process of learning language into the process of learning human values. You can test alignment of the AI on language.
- And maybe you can even translate some rules of language normativity into the rules of human normativity.
I speculated that if you generalize values to statements about systems, then:
- You can translate some statements about simpler systems into statements about human values. You get simple, but universal justifications for actions.
- You get very "dense" justifications of actions. E.g. you have a very big amount of overlapping reasons to not turn the world into paperclips.
- You get very "recursive" justifications. "Recursivness" means how easy it is to derive/reconstruct one value from another.
What do we gain (in the best case scenario) by generalizing values to "contracts"? I thought that maybe we could discuss what possible properties this generalization may have. Finding an additional property you want to get out of the generalization may help with the formalization (it can restrict the space of possible formal models).
Moral naturalism is another way of going "beyond human values", because it argues that statements about ethics can be reduced to statements about the natural world.
It's not a very useful generalization/reduction if we don't get anything from it, if "statements about the natural world" don't have significant convenient properties.