Model estimating the number of infected persons in the bay area
post by Eli Tyre (elityre) · 2020-03-09T05:31:44.002Z · LW · GW · 21 commentsContents
[Edit: I already found one error in my spreadsheet, and adjusted the incubation rate, which decreased my results by an order of magnitude. My up to date spreadsheet is here, but heed it at your own risk.]
Basic argument
Use diagnosis rate and number of confirmed cases, to get the total number of symptomatic cases
Use doubling time and recent daily cases, to get the number of cases one doubling time ago
Use total number of cases and incubation period, to get the number of people who became infected one incubation period ago
Use the number of infected people (one doubling time + one incubation period) ago and the doubling time, to get the current number of infected people
Conclusion with current numbers
Noting some simplifying assumptions that I'm making:
Postscript
None
21 comments
[Edit: I already found one error in my spreadsheet, and adjusted the incubation rate, which decreased my results by an order of magnitude [LW(p) · GW(p)]. My up to date spreadsheet is here, but heed it at your own risk.]
[Epistemic status: Quite uncertain. It seems plausible that I made a major math error and this model is flat-out wrong, or that some of the inputs I used were very off. Best to think of this as a draft.]
[Thank you to Elizabeth Garrett, Luke Raskopf , jimrandomh [LW · GW], and PeterH [LW · GW].]
In my coronavirus planning, the crux between different actions is often "how many people are infected (as opposed to symptomatic) on a given day?" (For instance, when 0.5% of the Bay area population is infected, I'm going to stop going to the gym.)
This post walks through the model that I'm using to estimate current infection rates. I'd be grateful for anyone suggesting improvements, nitpicking the inputs, and especially correcting errors.
I'm computing my estimates in this messy spreadsheet, which is automatically importing data from John Hopkins CSSE's github repo. (Thanks PeterH [LW · GW]!)
Basic argument
(This model is a variation of one that Elizabeth Garrett shared with me. Please give credit where credit is due.)
My goal is to estimate the number of people who are infected (who are carriers of the disease) rather than the number of people who are currently suffering symptoms. Here I'm going to walk through a series of steps, starting from the number of confirmed cases in a location, and derive and estimate of the number of infected persons in that population.
Use diagnosis rate and number of confirmed cases, to get the total number of symptomatic cases
To estimate the number of people currently infected, I start with the number of new cases that that were diagnosed in the past doubling period.
But not all the people who developed symptoms are confirmed as having the disease. Presumably some fraction (less than one) of all people who develop symptoms are successfully diagnosed. But if you know what that fraction (the diagnosis rate or confirmation rate) is, you can get the total number of cases by multiplying the confirmed number of cases by one over the diagnosis rate.
total cases that became symptomatic in the past doubling period = cases confirmed in the most recent doubling period * 1 / confirmation rate
Use doubling time and recent daily cases, to get the number of cases one doubling time ago
If you know the doubling time of the disease, and you know how many new cases there were in the past one doubling time, you know how many cases there were at the beginning of that doubling time.
For instance, if you know that a disease has a doubling time of one week, and you know that there were 50 new cases over the past week, that means there must have been 50 cases a week ago. (Because that's what a doubling time means. After one doubling time, there are twice as many cases as you started with).
total cases that became symptomatic in the past doubling period = total cases that had already shown symptoms at the beginning of that doubling period
Use total number of cases and incubation period, to get the number of people who became infected one incubation period ago
However, the number of symptomatic cases, lags behind the number of infected people, because there's an incubation period.
If we treat the incubation period as uniform, that means that the total number of people that have shown symptoms, on any given day, is equal to the number of people who were infected one incubation period ago.
So we're now estimating the number of people that were infected two steps in the past: a doubling time and and an incubation period ago.

Use the number of infected people (one doubling time + one incubation period) ago and the doubling time, to get the current number of infected people
Once you have a number of people who were infected (though not necessarily symptomatic) a doubling time and an incubation period ago, you can multiply that number by 2 raised to "however many doubling times there have been since that day".
This gives us an estimate of the number of people who are currently infected.
(If you see any errors, please leave a comment!)
Conclusion with current numbers
Given the above model, we can plug in some available numbers to get an estimate of how many people in the Bay area are currently (as of the evening of March 8, 2020) infected with COVID-19.
For number of confirmed cases, I'm using the data from John Hopkins CSSE. [See the "intermediate calculations" tab of the spreadsheet].
(Note that these numbers are including the Grand Princess Cruise Ship, which is currently in the pacific off the coast of California.)
I've heard that the doubling time for COVID-19 is between 3.5 and 7 days, so I calculated both of those, for a rough lower and upper bound. As more data comes in, I'll be able to observe the doubling time in the Bay area directly, and use that for future calculations.
(For calculating the number of new cases in the past 3.5 days, I took the difference between today and the average of 3 and 4 days ago.)
I'm very uncertain about what a reasonable confirmation rate is. Are 50% of symptomatic cases successfully being diagnosed as COVID-19? Are 30%? 10%? 1%?!
I elected to take all of them, and compute the number of people who are infected as a function of the confirmation rate. [see "Number of infected people" tab in the spreadsheet.]
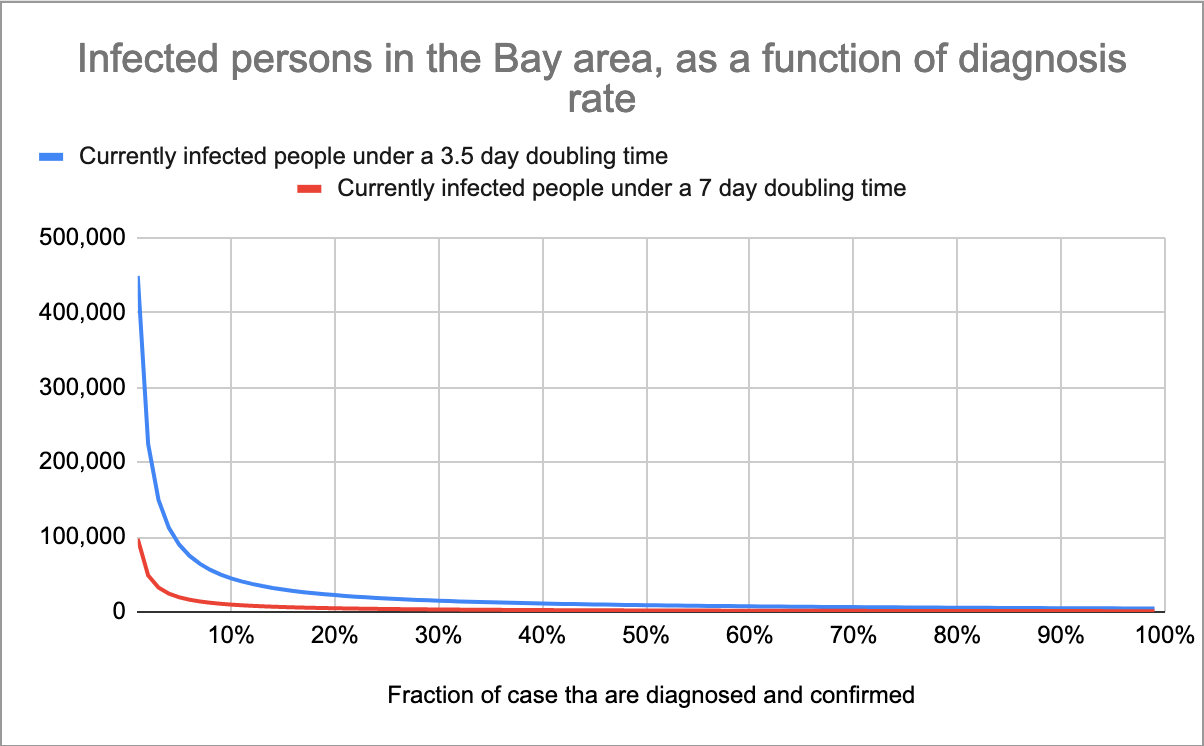
Plotted on a log scale:
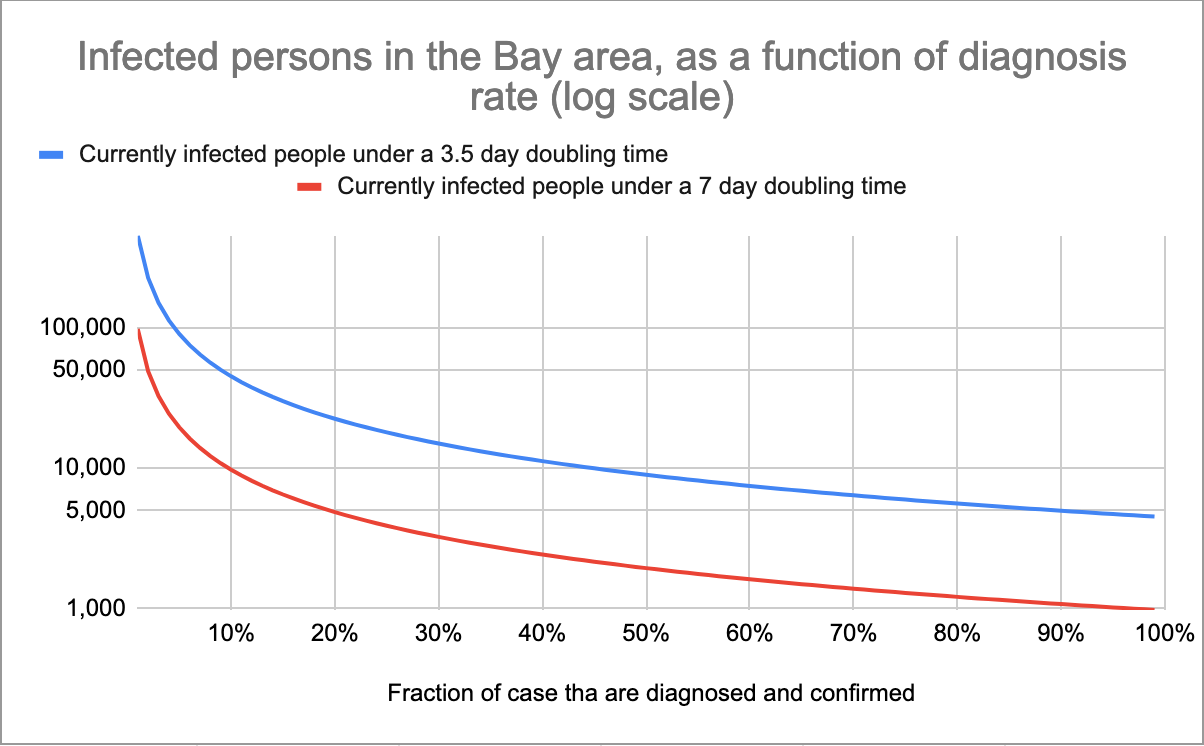
Again, I'm unsure what kind of diagnosis rate is reasonable. But, from a rough guess, I would be surprised if it was less than 5%, and surprised if it was much more than 70%.
So that gives an upper bound of 89,740 infected people (about 1.15% of the population of the Bay area) and a lower bound of 1,393 infected people (less than .01% of the population of the Bay area.
Note that that upper bound, in particular, is very sensitive to changes in the confirmation rate: if we assume that 10% of cases are successfully diagnosed, our number of infected persons drops to 44,870 (~0.5% of BA population).
Noting some simplifying assumptions that I'm making:
- I'm assuming that the spread of coronavirus is well-modeled by an exponential function [LW · GW].
- I'm assuming that everyone who is infected begins displaying symptoms exactly 2 weeks later.
- (To the extant that infectees show symptoms earlier than two weeks, these models are overestimating the true values because there are fewer doubling times between infection and confirmation).
- I'm assuming that everyone who gets coronavirus is diagnosed and confirmed as having coronavirus on the day they develop symptoms.
- In reality, there's probably a lag (does anyone know how much of a lag?), which means these numbers will underestimate the true value, because we're actually getting data about who started showing symptoms a few days ago.
Postscript
Again, please help me correct any mistakes. Additionally, if anyone has better data for any of these inputs than I've used here, especially for the confirmation rate, please share.
And if you have a different model, please post it! I would rather be taking my estimates from an ensemble of model
21 comments
Comments sorted by top scores.
comment by Unnamed · 2020-03-09T10:11:40.978Z · LW(p) · GW(p)
I also made an estimate of the number of cases in the bay area, based on deaths and estimated death rate. My calculations are in this spreadsheet.
comment by Scott Alexander (Yvain) · 2020-03-09T05:52:36.842Z · LW(p) · GW(p)
I tried to answer the same question here and got very different numbers - somewhere between 500 and 2000 cases now.
I can't see your images or your spreadsheet, so I can't tell exactly where we diverged. One possible issue is that AFAIK most people start showing symptoms after 5 days. 14 days is the preferred quarantine period because it's almost the maximum amount of time the disease can incubate asymptomatically; the average is much lower.
Replies from: elityre, habryka4↑ comment by Eli Tyre (elityre) · 2020-03-09T06:08:40.664Z · LW(p) · GW(p)
most people start showing symptoms after 5 days.
That seems like a very likely divergence point. The difference between an incubation period of 5 days and of 14 days is an extra 1.3 to 2.5 doubling times. I might do up the same calculations with variable incubation period tomorrow.
The google sheet is shared now. It really is kind of messy though, more like scratch paper than a published document.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T20:02:04.414Z · LW(p) · GW(p)
Alright, when I change the incubation time to 5 days, and correct a formula error, I get the following:
Upper bound (assuming a 3.5 day doubling time and a 5% confirmation rate): 6,837 infected persons.
Lower bound (assuming a 7 day doubling time and a 70% confirmation rate): 384 infected persons.
...which are a lot closer to your estimates.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-10T05:50:28.437Z · LW(p) · GW(p)
Actually, I was previously assuming that people are diagnosed the day they develop symptoms, which is probably an unrealistic expectation. If I add a term for that, and assume that there's a 5 day lag, my numbers jump up again:
Upper bound: 17,100
Lower bound: 585
↑ comment by habryka (habryka4) · 2020-03-09T05:55:53.239Z · LW(p) · GW(p)
I just fixed the images for Eli.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T06:21:12.289Z · LW(p) · GW(p)
Thanks Oli.
comment by Elizabeth (pktechgirl) · 2020-03-09T18:40:47.812Z · LW(p) · GW(p)
comment by Bird Concept (jacobjacob) · 2020-03-09T08:00:03.165Z · LW(p) · GW(p)
Whereas the local steps are fairly clear, after a quick read I found it moderately confusing what this model was doing at a high-level, and think some distillation could be helpful.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T18:05:37.265Z · LW(p) · GW(p)
Makes sense. I'm not going to try and fix that today, at least.
comment by Bucky · 2020-03-09T11:08:00.852Z · LW(p) · GW(p)
I've heard that the doubling time for COVID-19 is between 3.5 and 7 days.
In the early days after COVID-19 breaks containment in a given country the doubling period is 2-3 days. I'll try to publish something showing this later today.
(This is based on a fairly arbitrary "breaking containment" criteria of 40 total cases and then seeing exponential-ish growth)
Replies from: Bucky↑ comment by Bucky · 2020-03-09T23:20:06.303Z · LW(p) · GW(p)
More details now posted [LW · GW].
comment by Rohin Shah (rohinmshah) · 2020-03-09T19:40:12.388Z · LW(p) · GW(p)
In my coronavirus planning, the crux between different actions is often "how many people are infected (as opposed to symptomatic) on a given day?"
I'd recommend using "how many people are infected, and their case will eventually be severe" (where you could operationalize "severe" as "requires hospitalization", at least before hospital overcrowding is a problem).
This lets you eliminate the consideration of "what if there are lots of mild cases that we don't know about yet", which is one of the biggest uncertainties.
Of course, the chance that you catch COVID-19 is dependent on how many people are infected overall. However, if you think that the severity rate is very low (which predicts higher infection rates and more likelihood of you contracting COVID), you also think that conditional on you contracting COVID, it's not that bad. Both of these effects are roughly linear and so roughly cancel out.
The underlying thing that's going on is that you mostly don't care about contracting mild COVID, and so you mostly don't care about how many mild COVID cases exist. You can just take the severe cases, and apply the incubation period + doubling time arguments to those to get the probability of you contracting a severe case, which is what you actually care about. Note that if you do this, the "incubation period" is now the time between being infected by COVID, and being hospitalized, which is presumably longer than the incubation time for symptoms, and which we probably have worse data on.
I've been thinking of this from the self-interested case; I think the same thing applies to the prosocial case as well but I haven't thought as much about it.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T20:24:04.321Z · LW(p) · GW(p)
It seems to me that there are reasons why you would want to track the infection rate separately from severity.
Most notably, if you are in an at risk population, it is more likely that you'll come down with a severe case, if you catch it. And in that case, you just want to know how many people are infected, even is they only have mild symptoms.
As I'm currently modeling it, you just include the consideration of "what if there are lots of mild cases that we don't know about yet" in your estimate of the confirmation rate.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-03-09T21:43:43.384Z · LW(p) · GW(p)
Most notably, if you are in an at risk population, it is more likely that you'll come down with a severe case, if you catch it. And in that case, you just want to know how many people are infected, even is they only have mild symptoms.
Yeah, this is a good point. Intuitively, currently case fatality rate gives you Death given Severity (under the assumption we mostly only detect severe cases), and you need to estimate Severity given Infected. Probably when using my method you'd need to estimate the ratio of your Severity given Infected to the "average" Severity given Infected.
That said, for anyone not significantly at-risk, I'd still recommend working directly with severe cases (and I'd probably still recommend it for people who are at-risk, though the benefits are a lot lower because you have to do the very-uncertain Severity given Infected ratio estimate).
As I'm currently modeling it, you just include the consideration of "what if there are lots of mild cases that we don't know about yet" in your estimate of the confirmation rate.
Yes, but it introduces a lot of uncertainty / variance in the model's output, which ideally you could remove.
comment by Bird Concept (jacobjacob) · 2020-03-09T10:07:05.588Z · LW(p) · GW(p)
I made a new version of your spreadsheet where you can select your location (from the John Hopkins list), instead of just looking at the Bay area.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T18:03:05.826Z · LW(p) · GW(p)
This seems fine for knowing the number of cases in specific countries, but the problem is that metropolitan areas (like the Bay area), are defined by a list of counties, and not by a country.
comment by habryka (habryka4) · 2020-03-09T05:46:53.941Z · LW(p) · GW(p)
[I don't know why my images are tiny right now. Mods, help?]
Looks like you hosted your images on some external site that doesn't allow other people to access them. Looks like they are currently linking to private Google photos from what I can tell.
If you send us the images on Intercom, I can upload them for you and fix the post.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T06:10:32.666Z · LW(p) · GW(p)
Ah. I put them on google photos. What's the recommended hosting site?
Replies from: habryka4↑ comment by habryka (habryka4) · 2020-03-09T06:13:58.002Z · LW(p) · GW(p)
I often put things on imgur, though within the month we will have a new editor in beta that allows you to just upload images.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2020-03-09T06:27:07.855Z · LW(p) · GW(p)
Yay!
No more frustration when I try to use cmd-K to insert a link. I'll do a little dance when the new editor comes out.