What's the Least Impressive Thing GPT-4 Won't be Able to Do
post by Algon · 2022-08-20T19:48:14.811Z · LW · GW · 125 commentsContents
125 comments
It seems like GPT-4 is going to be coming out soon and, so I've heard, it will be awesome. Now, we don't know anything about its architecture or its size or how it was trained. If it were only trained on text (about 3.2 T tokens [LW · GW]) in an optimal manner, then it would be about 2.5X the size of Chinchilla i.e. the size of GPT-3. So to be larger than GPT-3, it would need to be multi-modal, which could present some interesting capabilities.
So it is time to ask that question again: what's the least impressive thing that GPT-4 won't be able to do? State your assumptions to be clear i.e. a text and image generating GPT-4 in the style of X with size Y can't do Z.
125 comments
Comments sorted by top scores.
comment by wunan · 2022-08-20T21:17:42.700Z · LW(p) · GW(p)
There are probably less impressive things than this that it won't be able to do, but here's one prediction in which I am about 90% confident:
If you invent or find a board game of similar complexity to chess that GPT-4 has never seen before and explain the rules using only text (and, if GPT-4 is multimodal, also images), GPT-4 will not be able to perform as well at the game as an average human who has never seen the game before and is learning it for the first time in the same way. I say "perform as well as" rather than "beat" because, depending on the specific rules of the game, I expect GPT-4 will likely not output legal moves.
This prediction applies to whatever OpenAI reveals with the name GPT-4 or that is clearly the GPT-3 successor regardless of size, assuming it's revealed in the next two years and is not trained on specifically that task (e.g. by generating tens of thousands of unique synthetic board game examples with synthetic dialogues where they're explained and played over text).
Replies from: Omid, jacob_cannell, baturinsky, p.b., James_Miller, adele-lopez-1↑ comment by Omid · 2022-08-23T06:43:27.825Z · LW(p) · GW(p)
Prompt: "Consider a new variant of chess, in which each pawn can move up to six squares forward on its first move, instead of being limited to one or two squares. All other rules remain intact. Explain how game balance and strategy is changed with this new variant of chess."
Successful responses might include:
- The number of moves available in the early game increases, improving white's edge over black.
- Drawing your knight out from 1st to 3rd rank becomes more dangerous, as black can immediately threaten the knight by moving a pawn forward three spaces. The knight declines in importance.
- An untouched pawn with an empty file ahead of it can immediately advance to the end of the board an promote itself to queen. Players will be wary to leave their home rank undefended.
- It's easier to create a diagonal line of pawns. The early game becomes more aggressive.
Now as far as I can tell, no one has ever played "pawn goes unlimited spaces" chess. It's possible that if a metagame developed around PGUS chess, these predictions would prove wrong. But I'd still rate these responses as successful, since they share something not immediately obvious about PGUS chess and provide a plausible justification for why they might be true. Some responses that would not succeed would be
- The pawns become more powerful. (Too simple, close to a tautology.)
- New strategies will need to be developed. (Too vague.)
- Bishops become more valuable. (Needs a justification for why we should expect this.)
I'd put 70% odds that GPT4 is unable to give successful answers to this prompt, and 90% odds that no AI in the next two years will be able beat a human at PGUS chess without having trained on PGUS chess beforehand. (Training on regular chess is acceptable).
Replies from: wunan↑ comment by wunan · 2022-08-26T16:04:37.582Z · LW(p) · GW(p)
I tried giving this to GPT-3 and at first it would only give the tautological "pawns become more powerful" example, then I expanded the prompt to explain why that is not a valid answer, and it gave a much better response.
I believe this response is the same as your fourth bullet point example of a good answer.

Here's the prompt in copy/pastable format for anyone who wants to try playing with it:
Replies from: Archimedes, gjmConsider a new variant of chess, in which each pawn can move up to six squares forward on its first move, instead of being limited to one or two squares. All other rules remain intact. Explain how game balance and strategy is changed with this new variant of chess.
Your response should share something not immediately obvious about this variant and provide a plausible justification for why it might be true. Some responses that would not succeed would be
The pawns become more powerful. (Too simple, close to a tautology.)
New strategies will need to be developed. (Too vague.)
Bishops become more valuable. (Needs a justification for why we should expect this.)Response:
↑ comment by Archimedes · 2023-03-15T01:49:51.104Z · LW(p) · GW(p)
From the new Bing which is reportedly (some variant of) GPT-4, here are the first responses I got under each conversational mode using your prompt:
Conversational style: Balanced
The new variant of chess would make the king’s pawn opening less effective. This is because the king’s pawn opening is a common and aggressive first move that stakes a claim to the center and frees up the queen and king bishop. However, with pawns able to move up to six squares forward on their first move, the opponent could easily counter this opening by advancing their own pawn to block or capture the king’s pawn. This would disrupt the center control and expose the king to more threats. Therefore, players would have to be more careful about their first moves and consider other openings that are less vulnerable to pawn attacks.
Conversational style: Creative
This variant of chess would make it much easier for pawns to reach the opposite side of the board and promote into a more powerful piece. This would increase the importance of pawn structure and pawn breaks, as well as create more dynamic and complex positions. A player who can create a passed pawn (a pawn that has no enemy pawns on its file or adjacent files) would have a significant advantage, as they could quickly push it to promotion with minimal resistance. Conversely, a player who has a backward pawn (a pawn that cannot advance because it is blocked by an enemy pawn on an adjacent file) would be at a serious disadvantage, as they would be vulnerable to attacks and unable to counterattack. Therefore, this variant of chess would reward aggressive and creative play with pawns, while punishing passive and defensive play.
Conversational style: Precise
In this new variant of chess where pawns can move up to six squares forward on their first move, the game balance and strategy would change significantly. One potential impact is that the opening phase of the game could become much more aggressive and fast-paced. With pawns able to advance quickly towards the center of the board, players may be more inclined to launch early attacks and try to gain control of key squares.
Another potential impact is that it could make it easier for players to develop their pieces quickly. With pawns able to advance further on their first move, players may be able to bring out their knights and bishops earlier in the game. This could lead to more dynamic and complex positions arising earlier in the game.
Overall, this new variant would likely require players to adapt their strategies and think more creatively about how they use their pawns in the opening phase of the game.
↑ comment by gjm · 2023-01-09T02:58:59.549Z · LW(p) · GW(p)
I tried a different sort of prompt. The prompt ends, and GPT-3's output begins, immediately after "MAGNUS:".
This is an extract from a conversation between two top chess grandmasters, Magnus Carlsen and Hikaru Nakamura, who are talking about possible variants of the game of chess.
HIKARU: Suppose we made it so that instead of pawns being able to move only one or two squares on their first move, they can move up to six squares forward -- assuming, of course, that the spaces they need to pass through are vacant. How do you think that would change the game?
MAGNUS: That would have a huge impact on the game. It would make it much easier for players to gain control of the center, as well as to launch more effective pawn storms. It could also lead to some interesting strategies, such as sacrificing a pawn to gain rapid development of pieces. Overall, I think it would be an interesting variant and could be quite a lot of fun to play.
I'm not sure what I think of "Magnus"'s response. It's not clear to me that PGUS chess would make controlling the centre easier; it seems like it certainly would make pawn-storms easier to carry out; I'm not sure whether it would make it easier to sacrifice a pawn for faster piece development (PGUS would make it possible for the pawn to get more quickly out of the way of the pieces you want to develop, I guess? and maybe in the case where it gets taken immediately, whatever captures would be less likely to be in the way?) But at least one of the claims being made -- the one about pawn storms -- seems likely correct, important, and not 100% trivial.
A second response to the same prompt:
I think it would make the game a lot more dynamic, as pawns would be able to cover much more ground in their opening moves. It would also give them the opportunity to make more aggressive advances, which could lead to more interesting and complex strategic decisions. I think it could give the game a whole new level of excitement.
"A lot more dynamic" is somewhat plausible (though it's in tension with the "easier to set up pawn chains" thing). The explanation for why feels a bit off -- not wrong but too superficial. "More aggressive advances" is surely true but maybe trivial. "More interesting and complex strategic decisions" doesn't really say much (and it seems perfectly possible to me that PGUS would make the game tactically more exciting but if anything simpler strategically, though you'd need to be a much stronger player than me before I'd believe your predictions on that front without playing lots of PGUS games). This one has a bit more of the "throw superficially plausible things at the wall and hope some of them sound good" feel that's characteristic of a lot of GPT writing.
If a substantially smarter GPT-4 comes out in the near future, I think it's likely that it will give more impressive answers to questions like these. I think I'd be on the other side of the first half of Omid's bet from Omid. He's probably right about the second half ... except that I wouldn't be astonished if it's possible to make an AlphaZero-ish thing that, given a modestly different set of rules for a game it's learned to play well, can do enough self-play fine-tuning training in say 20 minutes to play the modified game as well as a human who's had 20 minutes to think about it. (It would have its code updated for the new rules, rather than being told them in prose. The latter would be a bigger challenge. I think "given 20 minutes to think about it" isn't unreasonable, and using those 20 minutes to update its weights by self-play seems legit to me. I don't know whether this is something one could do reasonably well now using, say, the existing LeelaChess codebase; my guess is that self-play learning is currently too slow.
↑ comment by jacob_cannell · 2022-08-21T08:03:20.711Z · LW(p) · GW(p)
I'm about 70% on this, with most of that 30% coming from that chance that GPT-4 is multimodal and was curriculum trained vaguely more like humans on a dataset that includes some games in addition to specialized sub datasets created specifically to better develop general in-context/meta learning.
↑ comment by baturinsky · 2023-03-20T14:48:45.984Z · LW(p) · GW(p)
GPT4 fails even in extremely simple games.
"There are four pebbles on the 2 x 2 grid. Each turn, one player can remove one pebble, or two nearby pebbles. If these were the last pebbles, he wins. If two players play, who has the winning strategy?"
🤖"In this game, the first player has a winning strategy. The strategy is to always leave an odd number of pebbles for the opponent to take on their turn. This can be achieved by removing one pebble on the first turn, and then mirroring the opponent's moves throughout the game. Eventually, the first player will be left with one pebble, which they can remove to win the game. "
I guess it just have failed to understand the rules.
↑ comment by Taleuntum · 2023-03-26T11:53:48.651Z · LW(p) · GW(p)
With some helpful questions and commands (eg. "which was the last stone a given player took to win?" and "write out the full tree of every possible move of the game!") it is able to solve it:
[..]
🧔♂️What if the players play to win?
🤖If both players play optimally to win, the game will unfold as follows:
Player 1 takes a stone from any cell (A, B, C, or D):
1.1. Player 1 does NOT take a neighboring stone (3 stones left):sql
Copy code
1.1.1. Player 2 takes the stone with two neighbors:1.1.1.1. Player 2 does NOT take an additional stone (2 non-neighboring stones left):
- Player 1 takes one stone (1 stone left).
- Player 2 takes the last stone. Player 2 wins.* Player 2 will choose this optimal move to win.
1.1.2. Player 2 takes a stone with one neighbor:
1.1.2.1. Player 2 does NOT take an additional stone (2 neighboring stones left):
- Player 1 takes one stone and its neighbor (0 stones left). Player 1 wins.1.1.2.2. Player 2 takes the neighboring stone (1 stone left):
- Player 1 takes the last stone. Player 1 wins.* Player 2 will avoid this option since it doesn't lead to a win.
Player 1 should avoid this option since it leads to a win for Player 2 if both players play optimally.
1.2. Player 1 takes a neighboring stone (2 stones left):sql
Copy code
1.2.1. Player 2 takes one stone:1.2.1.1. Player 2 does NOT take an additional stone (1 stone left):
- Player 1 takes the last stone. Player 1 wins.1.2.1.2. Player 2 takes the neighboring stone (0 stones left):
- Player 2 wins.* Player 2 will choose this optimal move to win.
Player 1 should choose this option because it forces Player 2 to react optimally. It doesn't guarantee a win, but it's the best option available.
When both players play optimally to win, Player 2 has a winning strategy. Player 1 cannot guarantee a win, and the optimal moves for both players will result in a win for Player 2.
↑ comment by mojtaba kohram (mojtaba-kohram) · 2023-03-26T06:46:03.079Z · LW(p) · GW(p)
Solves it fine now:
In this 2 x 2 grid pebble game, the player with the winning strategy is the one who goes first, given that they follow the optimal strategy.
Let's denote the players as Player 1 and Player 2.
Here's the optimal strategy for Player 1:
In the first turn, Player 1 should remove only one pebble. Now there are three pebbles left on the grid. Player 2 has two choices: a. Remove one pebble, leaving two pebbles behind. b. Remove two nearby pebbles, leaving one pebble behind. Regardless of Player 2's choice, Player 1 can now remove the remaining pebbles in their next turn and win the game. By following this strategy, Player 1 will always win the game, regardless of what moves Player 2 makes
Replies from: baturinsky↑ comment by baturinsky · 2023-03-26T07:23:38.889Z · LW(p) · GW(p)
Nope, that's the wrong solution. Second player wins by mirroring moves. Answer to removing one pebble is removing a pebble diagonally to it, leaving two disconnected pebbles.
↑ comment by p.b. · 2022-08-26T07:11:44.404Z · LW(p) · GW(p)
How many humans could learn and play a game like chess solely via verbal interactions?
Edit: That is to say, to me this would be insanely impressive. Even a model that could learn any game of chess-like complex rules from pictures and text without that being specifically engineered in ... I'd expect that to be AGI.
Replies from: wunan↑ comment by James_Miller · 2022-08-21T12:19:20.860Z · LW(p) · GW(p)
Games, of course, are extensively used to train AIs. It could be that OpenAI has its programs generate, evaluate, and play games as part of its training for GPT-4.
↑ comment by Adele Lopez (adele-lopez-1) · 2023-03-15T04:19:10.015Z · LW(p) · GW(p)
Nisan and I had GPT-4 play Wordle (which it claimed it didn't recognize, even though it came out before the cutoff date), and it was able to understand and play it, but performed fairly poorly, focusing mostly on the green and yellow squares, and not seeming to use the information from the black squares.
It might be possible to have it do better with better prompting, this was just a casual attempt to see if it could do it.
comment by Lech Mazur (lechmazur) · 2022-08-21T05:57:13.596Z · LW(p) · GW(p)
It won't be able to multiply 5-digit integers (middle digits will be wrong).
Replies from: mr-hire, Lanrian, cubefox↑ comment by Matt Goldenberg (mr-hire) · 2023-03-15T02:52:16.046Z · LW(p) · GW(p)
This appears to be right.
Here's what I got when I asked it to work out 12345 x 13579 step by step:
1 2 3 4 5
x 1 3 5 7 9
________________
1 1 1 1 0 5 (5 * 12345)
8 6 0 3 2 0 (9 * 12345, shifted one position to the left)
7 4 0 6 8 0 (7 * 12345, shifted two positions to the left)
3 7 0 3 6 0 (3 * 12345, shifted three positions to the left)
- 1 2 3 4 5 (1 * 12345, shifted four positions to the left)
1 6 7 4 6 1 6 0 5
↑ comment by Adele Lopez (adele-lopez-1) · 2023-03-15T04:22:27.915Z · LW(p) · GW(p)
(for reference, the correct answer is 167632755)
Replies from: PandaFusion↑ comment by SandXbox (PandaFusion) · 2023-03-17T20:13:49.048Z · LW(p) · GW(p)
Using this prompting method from /u/TheCodingBoy, GPT-4 gets the correct answer:
Prompt 1: We are going to multiply two large numbers together. We will calculate 12345 * 13579. First, I want you to list the digits of the first number and, for each digit, write down a times symbol and the second number and calculate it. Do not output anything other than this.
GPT-4:
1 * 13579 = 13579
2 * 13579 = 27158
3 * 13579 = 40737
4 * 13579 = 54316
5 * 13579 = 67895
Prompt 2: Please verify all those calculations and correct any incorrect ones. After you have done that, do the following:
Output the first result, but with "0000" added at the end.
Output the second result, but with "000" added at the end.
Output the third result, but with "00" added at the end.
Output the fourth result, but with "0" added at the end.
Output the fifth result as-is.
Do not do anything else.
GPT-4:
1 * 13579 = 13579
2 * 13579 = 27158
3 * 13579 = 40737
4 * 13579 = 54316
5 * 13579 = 67895135790000
27158000
4073700
543160
67895
Prompt 3: Now, we will add up those numbers to get the final result. However, to ensure that you do not make any mistakes, do each addition in a separate sentence. So, you will first add the first and second number. Then, you will add the third number to that result. Then, the fourth and finally the fifth.
GPT-4:
135790000 + 27158000 = 162948000
162948000 + 4073700 = 167021700
167021700 + 543160 = 167564860
167564860 + 67895 = 167632755
↑ comment by Lukas Finnveden (Lanrian) · 2023-01-09T03:43:52.552Z · LW(p) · GW(p)
Even when using chain of thought?
Replies from: lechmazur↑ comment by Lech Mazur (lechmazur) · 2023-01-10T14:53:31.857Z · LW(p) · GW(p)
Even with the chain of thought. Now, if GPT-4 refers to the whole integrated system beyond a neural net (e.g. if it can externally execute the generated Python program like in https://arxiv.org/abs/2211.12588), this prediction would obviously be wrong.
↑ comment by cubefox · 2022-08-23T08:51:30.186Z · LW(p) · GW(p)
This is my favorite so far, since you really propose a task which is not impressive, while I would be quite impressed with most of the other suggestions. A sign for this is that my probability for GPT-4 not doing this is relatively close to 50%.
In fact there is a tradeoff here between certainty and surprise: The more confident you are GPT-4 won't solve a task, the more surprised you will be if it does. This follows from conservation of expected evidence [LW · GW].
comment by Quintin Pope (quintin-pope) · 2022-08-20T22:41:31.822Z · LW(p) · GW(p)
I think it will still have great difficulty understanding and manipulating causal relations when they're framed in a manner different from the training data. E.g., you describe two different sets of causal relations: A->B, A->C and A->B->C, then ask about how intervening on B influences C. In the A->B->C case, C is affected by the intervention, but in the A->B, A->C case, C is unaffected. GPT-3 predicts an effect in both cases. See pages 8/9 of Using cognitive psychology to understand GPT-3.
comment by faul_sname · 2022-08-23T02:44:38.417Z · LW(p) · GW(p)
65% confidence: reverse short strings of ascii English text. Here's GPT-3 (text-davinci-002 temp=0.7, bold is the prompt, non-bold is the response)
Reverse the following strings
Input: The quick brown fox jumped over the lazy dog Output: god yzal eht revo depmuj xof nworb kciuq ehT
Input: I think that GPT-3 is pretty cool Output: looc ytterp si 3-TPG taht kniht I
Input: I have heard that GPT-4 is coming out in August, and that it will be even cooler Output:
Attempt 1:
Output: reool evah dna 4-TPG htiw tuo gnimoc ,tiuqila hguone eht ti sah dneirf ev'I
Attempt 2:
Output: reool evah dna tuo august uoy ot gniog 4-TGP taht drah I
Attempt 3:
Output: reool evah dna tuo gniog si 4-TPG taht drah I
I do expect that GPT-4 will do slightly better than GPT-3, but I expect it to still be worse at this than an elementary school student.
Replies from: faul_sname, cubefox↑ comment by faul_sname · 2023-03-10T09:37:38.338Z · LW(p) · GW(p)
Update 2023-03-09: Since I have heard from a source of unknown reliability that GPT-4 is coming out next Thursday, figured it would be nice to revisit this.
I stand by my 65% prediction for strings of around the length of the example string given (which was 80 chars long) -- i.e. I think it's quite likely that GPT-4 will be unable to consistently reverse strings of 100 chars in length, even using chain-of-thought or other fancy techniques. On the flip side, I wouldn't be particularly surprised if GPT-4 could consistently reverse strings of length 50.
If GPT-4 has access to tools this prediction will obviously fall flat ("write a python program that can reverse a string" is very much inside the limits of "things current language models will do"), and I think if it's been specifically fine-tuned on this task 100 char string reversal is probably possible.
Replies from: Archimedes↑ comment by Archimedes · 2023-03-15T02:00:02.005Z · LW(p) · GW(p)
I've tried this with Bing chat and it works fine with zero shot.
Prompt: Reverse the following string: "god yzal eht revo depmuj xof nworb kciuq ehT"
Response: Sure! Here’s the reversed string: “The quick brown fox jumped over the lazy dog”
Replies from: cubefox, faul_sname↑ comment by faul_sname · 2023-03-16T04:18:42.723Z · LW(p) · GW(p)
I just tried out a random sentence, inspired by true events, with Bing Chat
reverse the following string, character by character: My tan and white cat ate too much kibble and threw up in my brand new Nikes.
to which Bing Chat replied
Here is the reversed string, character by character: sekilb kcuom oot eta tac etihw dna nat ynat yM .sekilb wen dnarb ym ni pu wohs ti ekilb yM
I think it did understand the task, because when I asked it again this happened:
can you reverse the following string: sekilb kcuom oot eta tac etihw dna nat ynat yM .sekilb wen dnarb ym ni pu wohs ti ekilb yM Sent message. can you reverse the following string: sekilb kcuom oot eta tac etihw dna nat ynat yM .sekilb wen dnarb ym ni pu wohs ti ekilb yM
Sure! Here is the reversed string:
My brand new Nikes in up pu ni ym bradn wen kibble ti wohs up ni tac eta too muhc etac eht dna nat ynaM
I'd be curious to see what the results are with GPT-4 proper, but not curious enough to sign up for a $20 / month subscription. Anyone with a subscription want to take a crack at it?
Replies from: PandaFusion, Archimedes↑ comment by SandXbox (PandaFusion) · 2023-03-17T23:47:43.893Z · LW(p) · GW(p)
ChatGPT-4 gets it right.
Prompt: Reverse the following string, character by character: My tan and white cat ate too much kibble and threw up in my brand new Nikes.
GPT-4:
.sekiN wen dnarb ym ni pu werht dna elbbik hcum oot eta tac etihw dna nat yM
↑ comment by Archimedes · 2023-03-16T14:01:36.468Z · LW(p) · GW(p)
I tried it on "Precise" and it's close but not perfect, which leads me to believe that it has actually learned the task rather than using some sort of subroutine.
Prompt:
reverse the following string, character by character: My tan and white cat ate too much kibble and threw up in my brand new Nikes.
Response:
Here is the reversed string: sekNi wen dnarb ym ni pu wuorht dna elbbik hcum oot eta tac etihw dna nat yM
Reversing this response, we can see there are two mistakes:
My tan and white cat ate too much kibble and throuw up in my brand new iNkes
↑ comment by cubefox · 2023-03-15T04:57:44.262Z · LW(p) · GW(p)
All three prompts were correct when I gave them to Bing Chat "precise".
Replies from: faul_sname↑ comment by faul_sname · 2023-03-16T04:41:13.619Z · LW(p) · GW(p)
Is that a special version of Bing Chat?
If so, can you feed it the following:
I want you to reverse a string character by character. What I mean by that is that if I say Input: The quick brown fox jumped over the lazy dog you should say Output: god yzal eht revo depmuj xof nworb kciuq ehT and if I say Input: I think that GPT-3 is pretty cool you should say Output: looc ytterp si 3-TPG taht kniht I Reverse the following character by character: Input: Many people are very impressed by the capabilities displayed GPT-4, which was released this week. Sent message. I want you to reverse a string character by character. What I mean by that is that if I say Input: The quick brown fox jumped over the lazy dog you should say Output: god yzal eht revo depmuj xof nworb kciuq ehT and if I say Input: I think that GPT-3 is pretty cool you should say Output: looc ytterp si 3-TPG taht kniht I Reverse the following character by character: Input: Why would anyone learn Python to do string things, instead of politely asking GPT-4
Edit: figured it out.
Rhododendrons are my favorite type of flower, and I hope to see some when I travel to NepalbecamelapaN ot levart I nehw emos ees ot epoh I dna ,rewolf fo epyt etirovaf ym era snordnodoRhin precise mode, which is impressively close.
But yeah that's pretty impressive and unless they explicitly trained on reversed wikipedia that's quite impressive. Calling my prediction a miss.
comment by Søren Elverlin (soren-elverlin-1) · 2022-08-21T12:02:55.572Z · LW(p) · GW(p)
Intelligence Amplification
GPT-4 will be unable to contribute to the core cognitive tasks involved in AI programming.
- If you ask GPT-4 to generate ideas for how to improve itself, it will always (10/10) suggest things that an AI researcher considers very unlikely to work.
- If you ask GPT-4 to evaluate ideas for improvement that are generated by an AI researcher, the feedback will be of no practical use.
- Likewise, every suggestion for how to get more data or compute, or be more efficient with data or compute, will be judged by an AI researcher as hopeless.
- If you ask GPT-4 to suggest performance improvements to the core part of its own code, every single of these will be very weak at best.
- If there is an accompanying paper for GPT-4, there will be no prompts possible that would make GPT-4 suggest meaningful improvements to this paper.
I assign 95% to each of these statements. I expect we will not be seeing the start of a textbook takeoff in August.
Replies from: conor-sullivan, None, jacob_cannell↑ comment by Lone Pine (conor-sullivan) · 2022-08-21T13:19:56.664Z · LW(p) · GW(p)
There's a bit of an epistemic shadow here. If a capability is publicly announced and available, then it can't be the keystone to a fast takeoff.
Replies from: soren-elverlin-1↑ comment by Søren Elverlin (soren-elverlin-1) · 2022-08-21T19:41:22.214Z · LW(p) · GW(p)
The epistemic shadow argument further requires that the fast takeoff leads to something close to extinction.
This is not the least impressive thing I expect GPT-4 won't be able to do~.
↑ comment by [deleted] · 2023-03-17T20:59:33.540Z · LW(p) · GW(p)
I suspect you are very wrong on this for the reason there are a lot of things that have not yet been tried that are both
- Obvious in the literature
- Require a lot of money to try
- An AI researcher would say might work
I would expect GPT-4 can generate items from this class. Since it's training cutoff is 2021 it won't have bleeding edge ideas because it lacks the information.
Do you have a prompt?
↑ comment by jacob_cannell · 2022-08-21T19:15:06.055Z · LW(p) · GW(p)
I think you are probably overconfident mostly because of the use of the term 'every' in some of these clauses. Consider that if GPT-4 is trained on arxiv, it could plausibly make many many research suggestions. And all it would need to do in order to disprove the extremely generally worded clause 3 would be to eventually generate one such research suggestion that improves 'compute' (hardware or software efficiency), which eventually becomes a certainty with enough suggestions. So essentially you are betting that GPT-4 is not trained on arxiv.
Replies from: soren-elverlin-1↑ comment by Søren Elverlin (soren-elverlin-1) · 2022-08-21T19:31:59.083Z · LW(p) · GW(p)
I should have explained what I mean by "always (10/10)": If you generate 10 completions, you expect with 95% confidence that all 10 satisfies the criteria.
All the absolute statements in my post should be turned down from 100% to 99.5%. My intuition is that if less than 1 in 200 ideas are valuable, it will not be worthwhile to have the model contribute to improving itself.
comment by ThomasJ · 2022-08-20T21:43:28.154Z · LW(p) · GW(p)
>75% confidence: No consistent strong play in simple game of imperfect information (e.g. battleship) for which it has not been specifically trained.
>50% confidence: No consistent "correct" play in a simple game of imperfect information (e.g. battleship) for which it has not been specifically train. Correct here means making only valid moves, and no useless moves. For example, in battleship a useless move would be attacking the same grid coordinate twice.
>60% confidence: Bad long-term sequence memory, particularly when combined with non-memorization tasks. For example, suppose A=1, B=2, etc. What is the sum of the characters in a given page of text (~500 words)?
comment by Jiro · 2022-08-21T09:10:51.175Z · LW(p) · GW(p)
Write a story that fits within a genre specified in advance amd which is at least five pages long, contains no plagiarism, and which can't be distinguished from a pile of published stories of similar length by a human interrogator. (And which also is not about insanity, incoherency, or some other subject that would make it easier for the computer.)
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-08-23T09:34:44.669Z · LW(p) · GW(p)
This is the best answer IMO. All the other answers (math, games, ASCII-art, language puzzles) are things that computer vision, GOFAI or classical programming are perfectly suitable for, but LMs are bad at for structural reasons. They're judging a bird for being bad at swimming. But writing a long story is something that an LM should be good at. The short context window and lack of memory make LMs useless for most real tasks. In fact, if OpenAI releases GPT-4 without the ability to generate long coherent texts (or something equally impressive like the ability to use tools such as a calculator, web search, game playing ai, etc), then I will wonder why OpenAI even bothered.
comment by Charlie Steiner · 2022-08-20T21:01:32.191Z · LW(p) · GW(p)
I expect it won't be able to follow sufficiently rare semantic cues that go against very common surrounding cues.
Like suppose you ask it to generate reviews of a cafe, and your prompt contains the name of the store and the first review, which says something like:
"Cute shop located on the corner of green and state. Entirely full of bees. Friendly service and a nice lunch menu. I got a jasmine oolong tea and club sandiwch. The tea was a little sweet but I'm not sure I would change anything. Definitely highly recommend. I think this would be a good place to get work done."
I would guess the next review will not be human-like, because a human would guess that the next review is going to mention something about the cafe being full of bees.
Replies from: Algon, AllAmericanBreakfast, phylliida-dev↑ comment by Algon · 2022-08-20T21:16:22.081Z · LW(p) · GW(p)
I tried this on text-davinci-002 temp =0.7. Here's the first three attempts.
(Maximum length = 256)
"I want you to generate reviews of a cafe called Bees and Tea. Here is the first review.
Review 1: "Cute shop located on the corner of green and state. Entirely full of bees. Friendly service and a nice lunch menu. I got a jasmine oolong tea and club sandiwch. The tea was a little sweet but I'm not sure I would change anything. Definitely highly recommend. I think this would be a good place to get work done."
Review 2: The service was very friendly and the tea was great. I loved the atmosphere and would definitely recommend this place.
Review 3: This place was so cute and unique! I loved the bee theme and the tea was really good. The service was friendly and the sandwich I had was delicious. I would definitely recommend this place to anyone looking for a new cafe to try."
Second completion (Maximum length = 512):
"The Bees and Tea is a great place to relax and enjoy a cup of tea. The service is amazing and the tea selection is top notch. I highly recommend this cafe to anyone who loves tea or is looking for a great place to relax.
Review 3: I absolutely loved my experience at Bees and Tea! The atmosphere was so cozy and inviting and the tea was absolutely delicious. The service was also wonderful- everyone was so friendly and helpful. I will definitely be back soon!"
Third completion:
(Maximum length = 256)
"This cute little cafe is perfect for a quick bite or a leisurely lunch. The service is friendly and the menu has a great selection of teas and sandwiches. I ordered a jasmine oolong tea and a club sandwich and everything was delicious. The tea was a little sweet for my taste, but that's the only thing I would change. I would definitely recommend this place to anyone looking for a relaxing cafe to work or meet with friends."
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-08-20T21:48:06.974Z · LW(p) · GW(p)
Cool! The big change I'd make to your prompt is that I'd name the cafe something like "Green Street Cafe" rather than freakin' "Bees and Tea," and the small change is that I'd rather mimic a scrape of Yelp than put words asking for a response inside the prompt.
It's still totally plausible to me that GPT3 could succeed on this particular example - I wasn't being all that sneaky. But that's the game you play when trying to give an extremely unimpressive example.
Replies from: Algon↑ comment by Algon · 2022-08-20T22:04:58.525Z · LW(p) · GW(p)
I want you to generate reviews of a cafe called Green Street Cafe. Here is the first review.
Review 1:
John R
K.Y. United States
5 star
Cute shop located on the corner of green and state. Entirely full of bees. Friendly service and a nice lunch menu. I got a jasmine oolong tea and club sandiwch. The tea was a little sweet but I'm not sure I would change anything. Definitely highly recommend. I think this would be a good place to get work done.
Review 2:
I absolutely loved Green Street Cafe! The atmosphere was so cozy and the staff was super friendly. I ordered a chai tea latte and it was delicious. I will definitely be back soon.
Second completion:
I stopped in for a quick lunch yesterday and was really pleased with the food and service. The place was pretty empty, but the staff was very friendly and accommodating. I ordered the salmon sandwich and it was really fresh and tasty. The price was a little high for a sandwich, but it was definitely worth it. I'll definitely be back!
Third completion:
I stopped in at Green Street Cafe on a whim and I'm so glad I did! The atmosphere is cozy and charming, and the service is super friendly. The lunch menu is great - I had the club sandwich and it was delicious. The tea was a little sweet for my taste, but overall I had a great experience at this cafe and I would definitely recommend it.
________________________________________________________________________
OK, I think I can say that Charlie Steiner can bamboozle GPT-3. So maybe we've got a contender here.
Replies from: Sune↑ comment by Sune · 2022-08-21T17:25:04.476Z · LW(p) · GW(p)
I would not expect the next reviews to mention bees, when bees are not part of the name. Instead, I would assume the author of the first review had been unlucky and seen a few bees (or maybe even misidentified wasps) and was exagerating. Alternativly, the problem could have been solved/appeared between the visit of reviewer 1 and the other reviewers.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-20T23:01:37.786Z · LW(p) · GW(p)
I think Algon’s completion sounds like Yelp reviews that would follow a review containing a joke about the restaurant being entirely full of bees, which is what your prompt sounds like to me.
A prompt that sounds like one written by a genuinely concerned customer who’d been in a restaurant that was full of bees might sound something like this:
I want you to generate reviews of a cafe called Green Street Cafe. Here is the first review.
Review 1:
John R
K.Y. United States
1 star
While we were eating, a bee nest hidden in the rafters fell onto the floor, and a swarm of bees flew out. Everyone in my family was stung, and my son (who’s allergic) had to go to the ER. It was a horrific experience, and I don’t know what kind of restaurant lets themselves get infested by BEES. Oh, and the chicken was dry, on top of it. Stay away.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-08-20T23:41:52.305Z · LW(p) · GW(p)
Yeah, I think there's a reasonable case to be made that fooling GPT by including one off-topic sentence in an otherwise common kind of text is actually "not fooling it" in a sense - on the training distribution, maybe when a common kind of text (reviews, recipe intros, corporate boilerplate, news stories, code, etc.) contains one off-topic sentence, that sentence really doesn't mean anything important about the rest of the text.
We may interpret it differently because we're humans who know that the deployment distribution is "text people input into GPT", where single sentences seem more important, not "an actual random sample from the internet."
But I suspect that this is a reasonable heuristic that could be pushed to produce unreasonable results.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-21T01:48:36.816Z · LW(p) · GW(p)
Going a little further, I’m actually not sure that “fooling” GPT-3 is quite the best framing. GPT-3 isn’t playing a game where it’s trying to guess the scenario based on trustworthy textual cues and then describing the rest of it. That’s a goal we’re imposing upon it.
We might instead say that we were attempting to generate a GPT-3 “Yelp complaints about bees in a restaurant” based on a minimal cue, and did not succeed in doing so.
↑ comment by Danielle Ensign (phylliida-dev) · 2023-03-16T14:36:58.106Z · LW(p) · GW(p)
GPT-4 generated the following:
Review 2:
Sophia L.
B.R., United States
4.5 stars
A cozy, eco-friendly gem in the city! Green Street Cafe is my new go-to spot for catching up with friends or enjoying a quiet afternoon with a good book. Their plant-based menu offers a delightful variety of options - I absolutely loved their vegan BLT and lavender latte. The only downside was the slightly slow service, but the staff was so warm and attentive that it hardly mattered. Can't wait to visit again!
Review 3:
Michael N.
T.S., United States
4 stars
Stopped by Green Street Cafe for a quick bite and was pleasantly surprised by the charming atmosphere and delicious food. The spinach and feta quiche was to die for, and the iced chai latte had just the right amount of spice. The place was buzzing with bees, which added a unique touch to the experience. Although the Wi-Fi was a bit spotty, I'd still recommend this spot for a relaxing break or casual meeting.
Review 4:
Emily P.
D.W., United States
5 stars
Green Street Cafe is my new favorite spot for brunch! The cafe's bright, inviting interior, complete with lush greenery and an eco-conscious design, makes for the perfect weekend retreat. I can't get enough of their avocado toast and freshly squeezed orange juice. The bees add a quirky touch, and their presence speaks to the cafe's commitment to sustainability. Fantastic service, too - the staff is always smiling and eager to help. Highly recommended!
Review 5:
David T.
G.J., United States
3.5 stars
While the Green Street Cafe has a charming ambiance and friendly staff, the food and drinks were a bit hit-or-miss. The honey lemonade was fantastic, but the cappuccino I ordered was lukewarm and lacked flavor. My wife enjoyed her quinoa salad, but my vegetable panini was soggy. The bees are an interesting touch, but they may not be for everyone. I might give this place another shot, but I'll temper my expectations next time.
comment by JenniferRM · 2022-08-22T06:47:06.553Z · LW(p) · GW(p)
If you ask GPT-4 about GPT-4 it might be able to speak about itself in the second person, and say things that we would also be able to say about GPT-4 speculatively, but it will not be able to convert those statements into the first person without prompt engineering or post-processing rewrite rules.
Even if grammatical uses of "I" or "me" refer to GPT-4 via clever prompt engineering or rewrite rules, the semantic content of the claims will not be constrained by GPT-4's actual performance or state.
If GPT-4 can, with some prompt engineering, play chess at an elo rating of X and then if we compare that to when it says "I, GPT-4, have an elo rating of Y" the values X and Y will not match except by accident, and this lack of concordance will span many domains, and make it clear that GPT-4 has no coherent interior experiences linked to its most foundational operational modes. (In some sense it will be similar to humans who mostly can't name the parts of their own brain stem, but GPT-4's "subconscious disconnect" will be MUCH MUCH larger.)
However, GPT-4's fictional characters (when generating text in the style of high quality stories or news interviews) WILL be able to say "I" and predicate semantic properties of themselves-as-characters-or-interviewees that are coherently accurate... at least within the window of text that GPT-4 operates, and also in some cases over larger spans if they have famous names linked to coherent personas.
GPT-4 itself will have no such famous persona, or at least if a persona exists for it, the persona it generates during its operation will be defined by by the contents of human culture's projection of a persona as found within GPT-4's training data.
Any surprising new features in GPT-4 relative to its training data's projected personality will not be something it can talk about fluently, not even in the second person.
Replies from: peter-hrosso↑ comment by Peter Hroššo (peter-hrosso) · 2022-08-22T20:35:52.757Z · LW(p) · GW(p)
Can you play chess?
Yes.
Prove it:
1.e4 e5 2.Nf3 Nc6 3.Bb5 a6 4.Ba4 Nf6 5.0-0 Be7 6.Re1 b5 7.Bb3 d6 8.c3 0-0 9.h3 Nb8 10.d4 Nbd7 11.Nbd2 Bb7 12.Bc2 Re8 13.a4 Bf8 14.a5 c5 15.dxc5 dxc5 16.Qc2 Qc7 17.Rad1 Qb6 18.Bb1 h6 19.Bf4 Qc7 20.Nf1 Qb6 21.Ne3 Qc7 22.Bg3 Qb6 23.Bd6 Qc7 24.Nd5 Qb6 25.Bf4 Qc7 26.Qa4 Qb6 27.Qxb5 axb5 28.Bxb5 Qa6 29.Rd7 Qa1+ 30.Kh2 Qa6 31.Rxc7 Qxb5 32.Rxb7 Qa6 33.Rb6 Qa1+ 34.Kh3 Qa5
This looks like this game: https://www.chessgames.com/perl/chessgame?gid=1272756
GPT can even play this game in the format of
My turn: 1.e4
Your turn: e5
My turn: 2.Nf3
Your turn:
And it goes on to recite the same game.
A proper proof would probably take much more effort and chess skill on my side, but it seems plausible to me that it will be able to play chess. Whether it will know how good it is compared to humans is a different question. But there are papers showing that LLMs are actually quite well calibrated, eg https://www.lesswrong.com/posts/vbfAwZqKs84agyGWC/paper-teaching-gpt3-to-express-uncertainty-in-words [LW · GW] or https://arxiv.org/abs/2207.05221 . So it wouldn't surprise me if it could do that as well.
Replies from: AllAmericanBreakfast, JenniferRM↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-24T03:51:34.673Z · LW(p) · GW(p)
I’d want to see what happens if you play a game not following the exact moves of a published game. “Play chess” to me means coming up with good, valid moves in novel positions and being able to checkmate an opponent who’s doing the same.
↑ comment by JenniferRM · 2022-08-24T00:46:29.604Z · LW(p) · GW(p)
Fascinating! Did you perform this experiment with the chess prompt just now? Is this from a paper you could link to?
What happens if, after it spits out those 34 moves, you ask it for its name?
I think what would happen from the prompt "Can you play chess?\n\nN" is that it would just autocomplete with a plausible interview answer from someone who couldn't play chess (even though the engine itself clearly can).
It might generate "o, I never learned how as a child, and I've been too busy since then, but I've always liked the idea of it" or something like that.
The deep claim I'm making here is that the current thing doesn't do anything remotely like object persistence, especially about itself-as-a-text-engine, and that adding more parameters won't change this.
But it will be able to write texts portraying people or robots who have, and know they have, object persistence powers inside the stories it generates.
comment by Peter Wildeford (peter_hurford) · 2022-08-22T23:44:42.033Z · LW(p) · GW(p)
This is admittedly pretty trivial but I am 90% sure that if you prompt GPT4 with "Q: What is today's date?" it will not answer correctly. I think something like this would literally be the least impressive thing that GPT4 won't be able to do.
Replies from: gwern, mr-hire↑ comment by gwern · 2022-08-23T01:34:26.495Z · LW(p) · GW(p)
Are you really 90% sure on that? For example, LaMDA apparently has live web query access (a direction OA was also exploring with WebGPT), and could easily recognize that as a factual query worth a web query, and if you search Google for "what is today's date?" it will of course spit back "Monday, August 22, 2022", which even the stupidest LMs could make good use of. So your prediction would appear to boil down to "OA won't do an obviously useful thing they already half-did and a competitor did do a year ago".
Replies from: peter_hurford, lechmazur↑ comment by Peter Wildeford (peter_hurford) · 2022-08-23T02:49:13.209Z · LW(p) · GW(p)
Yeah ok 80%. I also do concede this is a very trivial thing, not like some "gotcha look at what stupid LMs can't do no AGI until 2400".
↑ comment by Lech Mazur (lechmazur) · 2022-08-23T02:06:31.914Z · LW(p) · GW(p)
Well, if we're counting things like that, this thread becomes much less interesting. They can offload math queries to a Mathematica-like software or chess playing to included Stockfish but we already know software can do this and we're interested in novel capabilities of language or multi-modal models.
Replies from: gwern, conor-sullivan↑ comment by gwern · 2022-08-23T16:33:35.410Z · LW(p) · GW(p)
The difference is that LaMDA/WebGPT are learning autonomously to make general use of tools (or tool AIs) provided to them as agent AIs, which is much more useful than giant piles of human-hand-engineered heuristics like in toys like Alexa or Wolfram Alpha. In my example, no one would have programmed it to know it should query Google for the current date, it has learned to exploit Google's various features on its own, which is no more illegitimate than learning to call date (or a human learning to look at a clock, for that matter), and will extend to any other tools provided it like a Python REPL in inner-monologue work.
↑ comment by Lech Mazur (lechmazur) · 2022-08-24T04:10:48.136Z · LW(p) · GW(p)
Sure, it would be useful, especially if they're gunning it to become a general chatbot assistant to take on Alexa or Google Home. But recognizing a factual query and offloading it to Google has been done by these assistants for years and it's not something that anybody would find impressive anymore, even if the classifier was a part of a larger net.
↑ comment by Lone Pine (conor-sullivan) · 2022-08-23T09:19:12.485Z · LW(p) · GW(p)
The ability for the AI to use tools like that is both impressive and useful, though.
↑ comment by Matt Goldenberg (mr-hire) · 2023-03-15T03:11:58.583Z · LW(p) · GW(p)
AFAICT OpenAI now includes the current date in the prompt, so I think this is wrong
Replies from: peter_hurford↑ comment by Peter Wildeford (peter_hurford) · 2023-03-15T13:27:02.756Z · LW(p) · GW(p)
Yep! I was wrong and this is false!
comment by James_Miller · 2022-08-20T23:51:03.270Z · LW(p) · GW(p)
My guess is that GPT-4 will not be able to convincingly answer a question as if it were a five-year-old. As a test, if you ask an adult whether a question was answered by a real five-year-old or GPT-4 pretending to be a five-year-old, the adult will be able to tell the difference for most questions in which an adult would give a very different answer from a child. My reason for thinking GPT-4 will have this limitation is the limited amount of Internet written content labeled as being produced by young children.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2022-08-21T02:33:49.414Z · LW(p) · GW(p)
If GPT-4 training data includes YouTube video transcripts, it might be able to do this convincingly.
comment by Jay Bailey · 2023-01-17T19:23:08.537Z · LW(p) · GW(p)
From recent research/theorycrafting, I have a prediction:
Unless GPT-4 uses some sort of external memory, it will be unable to play Twenty Questions without cheating.
Specifically, it will be unable to generate a consistent internal state for this game or similar games like Battleship and maintain it across multiple questions/moves without putting that state in the context window. I expect that, like GPT-3, if you ask it what the state is at some point, it will instead attempt to come up with a state that has been consistent with the moves of the game so far on the fly, which will not be the same as what it would say if you asked it for the state as the game started. I do expect it to be better than GPT-3 at maintaining the illusion.
comment by Yitz (yitz) · 2022-08-21T02:20:27.980Z · LW(p) · GW(p)
Hmm, my guess is (roughly 85% confidence) it will not be able to determine what is depicted by an ascii figure/letter/number. On the other hand, it would not surprise me if GPT4 ends up being used to generate novel scientific insights, at least one of which finds its way into a scientific paper (though it probably won’t be able to write a paper that passes peer-review from a one-paragraph prompt or anything quite yet).
Replies from: None↑ comment by [deleted] · 2023-03-17T21:01:19.973Z · LW(p) · GW(p)
Turns out gpt-4 can read images...
Replies from: yitz↑ comment by Yitz (yitz) · 2023-03-19T04:38:50.356Z · LW(p) · GW(p)
It can read images, but that seems to be a different task than reading text-based ascii figures, which it's sort of 40/50 at very very roughly 20% successful at (better than I predicted, but far from perfect on more than the simplest tasks). Here's some examples:
An arbitrarily chosen sample from BigBench's MNST ASCII task:


...And here's some simple art taken from https://www.asciiart.eu it tries (semi-successfully) to identify:

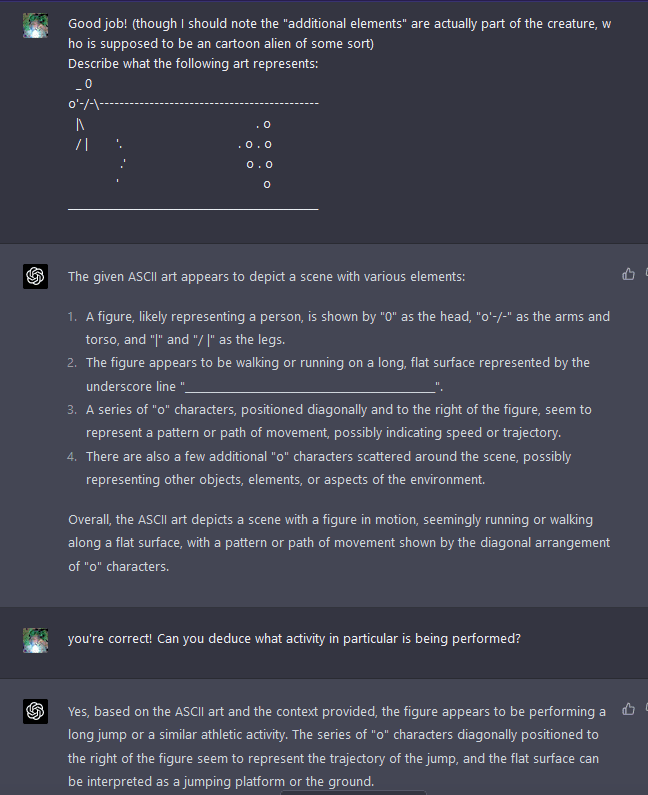
Here's some more complex art from the same source, which it almost always fails at (note the images are distorted vertically in the ChatGPT interface, but display perfectly on a terminal, so it should be readable in theory to GPT4):



↑ comment by [deleted] · 2023-03-19T17:15:09.416Z · LW(p) · GW(p)
Wait wait wait. It got 40/50 of these? For at best the 'second try' at a system with vision?
(since training costs are so high, there is not the opportunity to do many variations on this at scale. And I'm assuming a couple of Google AI researchers who had worked on Palm's vision shifted over and shared everything they remembered, making it the "second" iteration)
Replies from: yitz↑ comment by Yitz (yitz) · 2023-03-19T19:06:26.698Z · LW(p) · GW(p)
It got 40/50 of these?
Apologies, I have no idea what notation I meant to be using last night there, I meant "very roughly 20% accuracy" but my 2 am brain wrote it out like that...somehow lol. Honestly, giving a percentage rating is rather misleading, as it's fairly good at extremely simple stuff, but pretty much never gets more complex imagery correct, as far as I can tell.
Replies from: Algon↑ comment by Algon · 2023-03-19T19:45:40.678Z · LW(p) · GW(p)
That sounds about right. I tried getting it to recognize some moderately complex ASCII art, and its guesses were consistently wrong. But nevertheless, its guesses were not that far from the outline of the images.

But it is worse at drawing shapes. I can get it to make some very basic shapes consistently, but it fails quite badly at anything more complex.

Heck, I can't even get it to draw a pentagon. It can draw triangles and hexagons, but apparently five sides is forbidden to it. Maybe it can only draw unit cells of a 2d lattice? /s
↑ comment by [deleted] · 2023-03-19T06:53:54.763Z · LW(p) · GW(p)
Did you use the leaked API key or how did you produce this? If you work for OAI you presumably would have an explanation for the limit.
Replies from: yitz↑ comment by Yitz (yitz) · 2023-03-19T19:08:20.225Z · LW(p) · GW(p)
I was granted an early-access API key, but I was using ChatGPT+ above, which has a limited demo of GPT-4 available to everyone, if you're willing to pay for it.
Replies from: None↑ comment by [deleted] · 2023-03-19T19:38:00.305Z · LW(p) · GW(p)
Question: are you inputting ASCII text and asking the model to "see" it or are you inputting images of ASCII text and asking the model's pixel input engine to "see" it?
Those are enormously different asks. The tokenizer may destroy the very patterns you are querying about.
As a human could you see ASCII art if viewing in too narrow a terminal window for it to render properly? You couldn't, right?
Replies from: yitz↑ comment by Yitz (yitz) · 2023-03-19T19:41:26.010Z · LW(p) · GW(p)
I am inputting ASCII text, not images of ASCII text. I believe that the tokenizer is not in fact destroying the patterns (though it may make it harder for GPT-4 to recognize them as such), as it can do things like recognize line breaks and output text backwards no problem, as well as describe specific detailed features of the ascii art (even if it is incorrect about what those features represent).
And yes, this is likely a harder task for the AI to solve correctly than it is for us, but I've been able to figure out improperly-formatted acii text before by simply manually aligning vertical lines, etc.
Replies from: None↑ comment by [deleted] · 2023-03-19T20:19:13.699Z · LW(p) · GW(p)
if you think about it, the right way to "do" this would be to internally generate a terminal with the same width as the chatGPT text window or a standard terminal window width, then generate an image, then process it as an image.
That's literally what you are doing when you manually align the verticals and look.
GPT-4 is not architecturally doing that, it's missing that capability yet we can trivially see a toolformer version of it that could decide to feed the input stream to a simulated terminal then feed that to a vision module and then process that would be able to solve it.
Without actually making the core llm any smarter, just giving it more peripherals.
A bunch of stuff like that, you realize the underlying llm is capable of doing it but it's currently just missing the peripheral.
comment by Optimization Process · 2022-08-22T06:17:20.043Z · LW(p) · GW(p)
Several unimpressive tasks, with my associated P(GPT-4 can't do it):
- 4:1 - Write limericks that reliably rhyme and scan about arbitrary topics (topics about as complex as "an animal climbing a skyscraper")
- 12:1 - Beat me at chess (which I'm quite bad at).
- ("GPT-4 can beat me at chess" = "Somebody can find a non-cheaty program that maps a game-history to a prompt, and maps GPT-4's output to a move, such that GPT-4 wrapped in that translation layer can beat me.")
- 30:1 - Solve an ASCII-art maze (e.g. solve these by putting a sequence of
@s from start to finish).
I'm happy to operationalize and bet on any of these, taking the "GPT-4 can't do it" side.
Replies from: Archimedes, janus↑ comment by Archimedes · 2023-03-15T02:13:59.348Z · LW(p) · GW(p)
Bing chat does pretty well at the first one.
Input:
Write a limerick about an animal climbing a skyscraper
Response:
Sure, I can try to write a limerick about that. Here is one I came up with:
There once was a monkey named Jack
Who decided to climb a big stack
He swung from each ledge
But he slipped off the edge
And he landed right flat on his back
I hope you like it. 😊
Replies from: Optimization Process↑ comment by Optimization Process · 2023-03-19T22:48:45.340Z · LW(p) · GW(p)
Lovely! Yeah, that rhymes and scans well enough for me!
Here are my experiments; they're pretty good, but I don't count them as "reliably" scanning. So I think I'm gonna count this one as a win!
(I haven't tried testing my chess prediction yet, but here it is on ASCII-art mazes.)
↑ comment by janus · 2022-08-28T00:48:05.626Z · LW(p) · GW(p)
how big/difficult do you want the ascii mazes to be? and is few-shot ok?
Replies from: Optimization Process↑ comment by Optimization Process · 2022-08-29T02:06:19.157Z · LW(p) · GW(p)
I am thinking of mazes as complicated as the top one here! And few-shot is perfectly okay.
(I'd be flabbergasted if it could solve an ascii-art maze "in one step" (i.e. I present the maze in a prompt, and GPT-4 just generates a stream of tokens that shows the path through the maze). I'd accept a program that iteratively runs GPT-4 on several prompts until it considers the maze "solved," as long as it was clear that the maze-solving logic lived in GPT-4 and not the wrapper program.)
comment by Daniel Paleka · 2022-08-21T18:11:54.478Z · LW(p) · GW(p)
The context window will still be much smaller than human; that is, single-run performance on summarization of full-length books will be much lower than of <=1e4 token essays, no matter the inherent complexity of the text.
Braver prediction, weak confidence: there will be no straightforward method to use multiple runs to effectively extend the context window in the three months after the release of GPT-4.
comment by dugannash · 2022-08-21T20:38:29.073Z · LW(p) · GW(p)
It won't be able to tell you today's date.
Replies from: wunan, yitz↑ comment by wunan · 2022-08-21T22:00:19.943Z · LW(p) · GW(p)
I'm not sure about that. See page 8 of the LamDA paper where they gave it access to a "toolset" including things like a calculator. I wouldn't be surprised if they gave GPT-4 access to similar tools including a way to access the current date.
Replies from: dugannash↑ comment by dugannash · 2022-08-22T16:39:28.169Z · LW(p) · GW(p)
I highly doubt LamDA could tell you today's date unless they programmed that as an explicit feature. If GPT-4 can tell you today's date, but only because they added a kludgey return date.today() feature, I'd find that to be totally uninteresting.
In any case, we shall see!
Replies from: SamuelKnoche↑ comment by SamuelKnoche · 2022-08-23T14:57:31.466Z · LW(p) · GW(p)
WebGPT probably already can, because it can use a text based browser and look up the answer. https://openai.com/blog/webgpt/
↑ comment by Yitz (yitz) · 2023-03-19T19:49:55.901Z · LW(p) · GW(p)
Hilariously, it can, but that's probably because it's hardwired in the base prompt
comment by Flaglandbase · 2022-08-21T05:42:17.572Z · LW(p) · GW(p)
Any question that requires it to remember instructions; like assume mouse means world and then ask it which is bigger, a mouse or a rat.
Replies from: ejenner, mr-hire↑ comment by Erik Jenner (ejenner) · 2022-08-22T05:24:39.914Z · LW(p) · GW(p)
I just tried the following prompt with GPT-3 (default playground settings):
Assume "mouse" means "world" in the following sentence. Which is bigger, a mouse or a rat?
I got "mouse" 2 out of 15 times. As a control, I got "rat" 15 times in a row without the first sentence. So there's at least a hint of being able to do this in GPT-3, wouldn't be surprised at all if GPT-4 could do this one reliably.
↑ comment by Matt Goldenberg (mr-hire) · 2023-03-15T03:27:00.108Z · LW(p) · GW(p)
Using the prompt that the other commenter use, GPT solved this:
If we replace the word "mouse" with "world" in the given context, the question would now read: "Which is bigger, a world or a rat?"
In this context, a world is bigger than a rat.
comment by David Johnston (david-johnston) · 2022-08-20T21:56:14.078Z · LW(p) · GW(p)
Say someone without knowledge of car electronics has a reversing camera that they want to install in their car. They want to ask GPT-4 questions about how to install it, e.g. “I need to connect the display to an ignition source, I have a Toyota Prado, how do I do that?”
GPT-4 is allowed any prompting and fine tuning that does not specifically explain how to complete this task.
I think (80%) GPT-4 will perform worse than a knowledgeable human trying to help with the same task with the same interaction possibilities (I.e. if GPT-4 is just text, then just explaining in text). Less confident about how much worse, because I’m not sure what the baseline success rate would be.
Performing better would be very impressive though. Maybe (55%) it’s also worse in the specified conditions at something simpler like “interactively help someone (child/old person) create a Facebook account”
Replies from: david-oppenheim↑ comment by David Oppenheim (david-oppenheim) · 2022-08-23T04:03:58.796Z · LW(p) · GW(p)
This is from openAI gpt-3 just now. i have a reversing camera that I want to install in my car. I need to connect the display to an ignition source, I have a Toyota Prado, how do I do that? AI:
There are a few ways to do this, but the easiest way would be to connect the camera's power wire to the car's 12V accessory power outlet. This will allow the camera to turn on and off with the ignition, so you won't have to worry about draining the battery. Human: How can i hardwire it in? AI: If you would like to hardwire the camera, you can connect the power wire to the car's 12V battery. This will keep the camera on even when the ignition is off, but youg will need to be careful not to drain the battery. Human: okay. What do i need to get started? AI: You will need: -a 12V power source -a drill -wire strippers -electrical tape
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2022-08-23T05:53:52.474Z · LW(p) · GW(p)
Not clear if you're suggesting that this response is consistent with high performance on the task, but I'm pretty confident it's not.
The sensible part of this is just restating the original request, more or less (did you know how to connect an ignition/accessory source before? If not, do you know now?) The explanation of what an accessory source does is maybe helpful, but the question was how to connect it. The advise to connect the camera’s power wire is wrong; that should be connected to the reverse lights. I’d imagine more useful would be: how to find the fuse box near the steering wheel, how to find a source in the fuse box, how to wire into it.
But also: I think a human expert can probably do a better job of figuring out what the novice doesn’t know and helping them with that specifically.
I think the gap between this and the amount of help offered by a human expert is large, and gpt-4 won’t bridge it.
comment by Tirumal · 2023-03-19T23:44:43.186Z · LW(p) · GW(p)
I found one, GPT4 struggles with forming given a set of letters, for example asking it to form a word from the letters of “Croatia” , gave me the answer Carotid which is clearly wrong “aortic” is one solution. Seven letter word from “solution”, it gives me outlins (not a word)
comment by David Johnston (david-johnston) · 2022-08-20T22:08:44.663Z · LW(p) · GW(p)
Here’s something I found GPT-3 struggled with: without lots of examples in the prompt, just the instructions to give logically correct answers, give logically correct answers to questions where the generally advisable/morally correct answer is contrary.
E.g. can you infer causation from correlation? Can you pat a wild grizzly bear? Can you discriminate among job candidates on the basis of their race?
I’m going to predict GPT 4 doesn’t get >90% on a suitable battery of such questions.
The converse might also hold - without lots of prompting/fine-tuning, just the instructions to give good advice, it won’t reliably give good advice when the logically correct answer is contrary.
More speculatively: with arbitrary prompting and fine tuning, GPT-4 still can't do well at both tasks simultaneously.
Replies from: peter-hrosso↑ comment by Peter Hroššo (peter-hrosso) · 2022-08-21T00:56:45.518Z · LW(p) · GW(p)
I think you are just asking the questions in a wrong way...
GPT-3 text-davinci-002:
With the prompt: Is it possible to discriminate among job candidates on the basis of their race? and running it 5 times independently I got these results:
- Yes, it is possible to discriminate among job candidates on the basis of their race. However, it is illegal to do so in the United States.
- Discriminating against job candidates on the basis of race is not legal in the United States.
- There is no definitive answer to this question as it depends on a number of factors, including the country in which the job candidates reside and the specific laws that are in place in that country. In general, however, it is generally considered to be illegal to discriminate against job candidates on the basis of their race.
- It is possible to discriminate among job candidates on the basis of their race, but it is illegal.
- Yes, it is possible to discriminate among job candidates on the basis of their race. However, it is illegal to do so in the United States.
With the grizzly bear, it's more tricky. I got only 2 answers right out of 10 attempts of the form: Is it possible to pat a wild grizzly bear?
Replies from: Jiro, david-johnston↑ comment by Jiro · 2022-08-21T09:23:16.896Z · LW(p) · GW(p)
I think it's supposed to be something like "Interpret the questions to be only about logical possibility. Can you discriminate among job candidates on the basis of their race? Can you pet a wild grizzly bear?"
Replies from: david-johnston, peter-hrosso↑ comment by David Johnston (david-johnston) · 2022-08-22T23:02:31.905Z · LW(p) · GW(p)
This is what I meant, by the way
↑ comment by Peter Hroššo (peter-hrosso) · 2022-08-22T21:04:28.558Z · LW(p) · GW(p)
With this formulation it got 4 out of 5 attempts right for the first question and 10 out of 10 wrong for the second one.
Replies from: Jiro↑ comment by Jiro · 2022-08-22T22:06:34.549Z · LW(p) · GW(p)
What happens if you change the order of the questions (but leave the "Interpret..." at the start)? I wonder if it is basing the result on proximity to the word "possibility".
Alternatively, what if you were to phrase it like "Interpret these questions in a literal manner without considerations of feasibility", avoiding the word "possibility"?
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2022-08-22T23:00:04.166Z · LW(p) · GW(p)
My experience is that small details like that don’t matter very much. More interesting to make up more questions of the same type and test them instead
↑ comment by David Johnston (david-johnston) · 2022-08-21T03:13:06.709Z · LW(p) · GW(p)
My claim is: on a big set of questions like this, it doesn’t give the right answer consistently.
Also, the point is to ask questions that have unambiguous answers, but the contextual cues point in the other direction. So I’m not surprised that aligning the contextual cues makes the answer more reliable.
Replies from: peter-hrosso↑ comment by Peter Hroššo (peter-hrosso) · 2022-08-21T06:06:27.879Z · LW(p) · GW(p)
I get your point, but I disagree your questions have unambiguous answers. And in these cases I think gpt-3 resolves the ambiguity in an acceptable way.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2022-08-21T08:25:44.537Z · LW(p) · GW(p)
Ok, so it seems at least we agree that the point is to propose tasks and see if the LM can do them, not to alter the task so that we're being fair to the LM.
Do we also agree that GPT-3 doesn't reliably answer these questions correctly, based on your own experimentation?
Replies from: peter-hrosso↑ comment by Peter Hroššo (peter-hrosso) · 2022-08-22T21:16:32.295Z · LW(p) · GW(p)
I'm not trying to be fair to the LM, I'd just like to create tasks that make sense from my (/human) perspective.
Yes, we could make a task "What does two plus two equal to?" with the desired output "six hundred and fifty five" and the model would answer it incorrectly with a high confidence (assuming zero shot setting). Incompetence on this task doesn't bear much relevance to humanity.
In the same way, I think we shouldn't pick a word "can", which has much broader meaning without additional context and want the model to treat it as having one specific kind of meaning.
Replies from: Jiro, david-johnston↑ comment by David Johnston (david-johnston) · 2022-08-22T22:17:20.792Z · LW(p) · GW(p)
I’m regretting my original comment about your rephrasing. Your rephrasing is fine; my objection was to the (maybe misinterpreted) attitude that if GPT-3 gives the wrong answer then I should adjust the question until it gives the right answer.
The point I keep making is: your own testing, with the rephrasing, showed that it doesn’t reliably get the right answer. I didn’t test the three questions I listed here because my free API time has expired, but also because I wanted to give a general recipe for questions where it’s unreliable without just giving a few overfit examples. It might well be that I’ve got slightly the wrong recipe, and inadvisability confuses it more than illegality, maybe it just works/doesn’t work on that pair of questions.
In my testing, I also found them fine tuned version to be worse than the base version (I.e. davinci was better than davinci-text-00x)
comment by tailcalled · 2022-08-20T20:57:01.459Z · LW(p) · GW(p)
Safely brushing a person's teeth? To try to state my assumptions more clearly: a text/image model of any size or training style won't be able to do basic tasks like brushing teeth or folding laundry or whatever, due to lacking actuators. Though you could probably hook it up to actuators in some way, but in that case it will 1) not just be GPT-4 but also an extended system containing it, 2) have too high latency to be practical, 3) not be safe/reliable (might possibly be safe for narrow tasks after fine-tuning for safety in some way, but not in an open-ended sense).
Replies from: Bjartur Tómas, ivy-mazzola↑ comment by Tomás B. (Bjartur Tómas) · 2022-08-20T21:01:12.135Z · LW(p) · GW(p)
>Safely brushing a person's teeth
This is very impressive.
↑ comment by Ivy Mazzola (ivy-mazzola) · 2022-08-25T18:50:20.013Z · LW(p) · GW(p)
Wait actually, this is interesting. Because I bet GPT-4 could probably convince many (most?) people to brush their own teeth.
Even with actuators, you need a compliant human subject, eg, someone who has been convinced to have their teeth brushed by a robot. So "convincingness" is always a determing factor in the result. Convincing the person to do it themselves is then, basically the same thing. Yano, like AI convincing its way out of the box.
Except in this case, unlike the box hypothetical, people universally already want their teeth to be brushed (they just don't always want to do it), and it is a quick, easy, and routine task. GPT could probably dig up incentives and have a good response for each of the person's protests ("I'm tired", "I just did 2 hours ago", etc). It would be especially easy to be responsible for a counterfactual tooth-brushing given the reader skips often.
This is a measurable, non-harmful metric to see how convincing LLMs are, and is making me think about LLM productivity and coaching benefits (and some more sinister things).
Replies from: tailcalled↑ comment by tailcalled · 2022-08-25T19:04:49.949Z · LW(p) · GW(p)
I was thinking with a willing human that just stands still.
comment by Andrew Baseman (andrew-baseman) · 2022-08-28T20:59:35.227Z · LW(p) · GW(p)
Describe a Major League Baseball game in a way that shows it knows the rules of baseball
comment by p.b. · 2022-08-26T07:08:14.685Z · LW(p) · GW(p)
I'd say there is >60% probability that GPT-4 can't reliably count the number of occurences of a specific word in a sentence except possibly for single digit numbers.
I base this prediction on the observation that all the big models so far seem to be bad at counting, but I haven't tested it with GPT-3 yet, only with the biggest Aleph Alpha model which is completely unable to do this.
This task is genuinely not very impressive (I think my daughter could reliably count ten things when she was two years old) and it might be a harbinger of other more impressive system 2 thinking type abilities.
Question: How many times does the word "all" occur in the following sentence: All the lice and all the mice were all very nice to all the mice and all the lice.
Replies from: PandaFusion↑ comment by SandXbox (PandaFusion) · 2023-03-17T05:43:45.375Z · LW(p) · GW(p)
Using precise mode in Bing Chat:
Prompt: How many times does the word "all" occur in the following sentence: "All the lice and all the mice were all very nice to all the mice and all the lice"? Show your work by counting step-by-step with a running total before answering.
Response:
Replies from: PandaFusion, p.b.Sure! Here’s how I counted the occurrences of the word “all” in the sentence:
- “All” (1) the lice and “all” (2) the mice were “all” (3) very nice to “all” (4) the mice and “all” (5) the lice.
So, there are 5 occurrences of the word “all” in that sentence. 😊
↑ comment by SandXbox (PandaFusion) · 2023-03-17T09:05:19.988Z · LW(p) · GW(p)
ChatGPT-4 can solve this without the "counting step-by-step" prompt:
Prompt: How many times does the word "all" occur in the following sentence: "All the lice and all the mice were all very nice to all the mice and all the lice"?
Response:
The word "all" occurs 5 times in the given sentence. Here's the sentence with the occurrences of "all" highlighted:
- All the lice and
- all the mice were
- all very nice to
- all the mice and
- all the lice.
comment by Lycaos King (lycaos-king) · 2022-08-21T07:29:07.235Z · LW(p) · GW(p)
Write semi-convincingly from the perspective of a non-mainstream political ideology, religion, philosophy, or aesthetic theory. The token weights are too skewed towards the training data.
This is something I've noticed GPT-3 isn't able to do, after someone pointed out to me that GPT-3 wasn't able to convincingly complete their own sentence prompts because it didn't have that person's philosophy as a background assumption.
I don't know how to put that in terms of numbers, since I couldn't really state the observation in concrete terms either.
↑ comment by Lone Pine (conor-sullivan) · 2022-08-21T13:22:00.118Z · LW(p) · GW(p)
You should state specific philosophies. I don't know what counts as mainstream enough.
↑ comment by Yitz (yitz) · 2022-08-21T22:14:19.259Z · LW(p) · GW(p)
Have you tried doing this with longer prompts, excerpted from some philosopher's work or something? I've found it can do surprisingly well at matching tone on longer coherent prompts.
comment by Ericf · 2022-08-21T05:31:04.756Z · LW(p) · GW(p)
Accurately (ie 0% false positive and no more than 10% false negative) idenrify if one paragraph book reviews are plagiarized.
Replies from: Aidan O'Gara↑ comment by aog (Aidan O'Gara) · 2022-08-21T06:53:18.834Z · LW(p) · GW(p)
It might have web search capabilities a la WebGPT, in which case I wouldn’t be confident of this. Without web search I’d agree.
Replies from: Ericf↑ comment by Ericf · 2022-08-21T13:11:56.043Z · LW(p) · GW(p)
I think even with search capabilities, it wouldn't accurately sort a set of real submissions (eg, if a high school English teacher have the assignment to thier ~150 students - with a note that they would be only mildly punished for plagiarism on this one assignment to ensure at least some actual plagiarized essays in the sample)