Research snap-shot: question about Global Workspace Theory
post by Hazard · 2020-06-15T21:00:28.749Z · LW · GW · 12 commentsContents
Q.1: Is the global neuronal workspace a bottleneck for motor control? Q.2: Can activity on the GNW account for all experience? Attentional Blink Post hoc unpacking of information, filling in a story of experience with a guess at what was happening Q.3: How does the predictive processing account of attention play with the GNW account? None 12 comments
Cross-posted on my roam blog. Part of ongoing research on consciousness.
I wrote an intro to some of my thoughts on consciousness here [LW · GW], which was more conceptual and less neurosciency. This post is a snap-shot of some of the current technical questions that are on my mind. Please chime in if you know anything relevant to any of them. This is a pretty high context snap-shot and might not be that useful without familiarity with many of the ideas and research.
Q.1: Is the global neuronal workspace a bottleneck for motor control?
(Kaj's GNW intro [? · GW], GNW wikipedia page)
Some observations to help build up context for the question and my confusion around it (it ends up being less a question and more a hypothesis I'm asserting).
Observation 1: People have trouble multitasking in dual-task style experiments, but training can improve their performance.
Corollary of 1: Some tasks requires attention and you can't do multiple things that require attention. But if you practice something a lot, you can do it "unconsciously", and you can do several "unconscious" tasks at the same time.
Observation 2: The "conscious bottleneck" seems to come into play during decision making / action-selection when in a novel or uncertain setting (i.e performing an unpracticed and unfamiliar task)
Corollary of 2: The "conscious bottleneck" is a conflict resolution mechanism for when competing subsystems have different ideas on how to drive the body.
I think these are all basically true, but I now think that the implicit picture I was drawing based off of them is wrong. Here's what I used to think: the conscious bottleneck is basically the GNW. This serial, bottlenecked, conflict resolution mechanism really only is used when things go wrong. When two subsystems try to send conflicting commands to the body, or you get sense data that wildly violates your priors. The brain can basically "go about it's business" and do things in a parallel way, only having to deal with the conflict resolution process of the GNW if there's error.
Easy tasks can route around the global workspace, hard ones or ones that produce error have to go through it. That's the previous idea. Now, this paper has begun to shift my thinking. For a specific set of tasks, it claims to show that training doesn't shift activity away from a bottleneck location, but instead makes the processing at the point of the bottleneck more efficient.
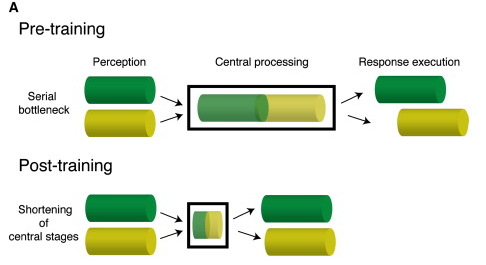
This made me very dubious of the idea that "central conflict resolution mechanism" and "subsystems that have direct access to the nervous system" could coexist. Even though there is some centralized processing in the brain, it looks nothing like a central agent dispatching orders, commanding around other subsystems. This paper, though mostly over my head, paints a pretty cool picture of how the "winner takes all" broadcast aspect of the GNW is implemented in the brain, in a funky distributed way that doesn't rely on a "central chooser".
If subsystems had to route through the GNW to trigger motor actions, then this system or some variation could totally account for the serial conflict resolution function. But if subsystems can directly send motor commands without going through the GNW, how would would subsystems in conflict be "told to stop" while the conflict resolution happens? The GNW is not a commander, it can't order subsystems around. Though it may be central to consciousness, it's not the "you" that commands and thinks.
All this leaves me thinking that I'm either missing a big obvious chunk of research, or that various motor-planning parts of the brain can't send motor commands except via the GNW. Please point me at any relevant research that you know of.
Q.2: Can activity on the GNW account for all experience?
One of the big claims of GNW is that something being broadcast on the GNW is what it means to be conscious of that thing. Given the serial, discrete nature of the GNW, it follows that consciousness is fundamentally a discrete and choppy thing, not a smooth continuous stream.
From having been around this idea for a while, I can spot a lot of my own experience that at first seemed continuous, but revealed itself to be discrete upon inspection. Some advanced meditaters even describe interesting experiences like being able to see the "clock tick of consciousness". So for a while I've been willing to tentatively run with the idea that to experience something is to have that something active on the GNW. But recently while reading the Inner Game of Tennis I was reminded of a different flavor of awareness, one that's a bit harder to reconcile with the discrete framework. Flow, "Being In the Zone", and the Buddhist "no-self". All of these states are ones where you act without having to "think", are intensely in the moment, and often don't even feel like it's "you" moving, it's as if you body is just operating on it's own.
Inner Game of Tennis contrasts this to typical moments when your "self 1" is active and is constantly engaged in judgement and is trying to shout commands at you to produce an outcome. "In the zone" vs "self-aware judgement mode" is probably something most people can relate to. The Buddhist no-self is a bit more intense, but I think it's fundamentally the same thing. Kaj's recent post [? · GW] is an excellent exploration of no-self from a GNW perspective. I think the no-self angle does a better job of exploring the way that the self/ego-mind/"self 1" is a constructed thing that is experienced, and is not actually you. It's the difference between being aware of your breath, and being aware of a memory of your breath, or the thought "I'm aware of my breath".
The constructed ego-mind narrative that get's experienced clearly is discrete and choppy. But is no-self? Is being in a total state of flow in a championship tennis game still an experience that is mediated/bottlenecked by the GNW? I take pause because of the vast difference in how broad my awareness feels when I'm in flow vs in the ego-mind. I take in more of my surroundings, I feel more of where my body is in space and time. It all seems much more high resolution that typical ego-mind consciousness, does the GNW have a good enough "frame rate" to account for it?
There are two main lines of thought I have on how to think of this problem.
Attentional Blink
Both the attentional blink and the psychological refractory period seem related to a possible "frame rate of attention/consciousness/GNW". The below image tells you almost everything you need to know about the classic type of attentional blink experiment.
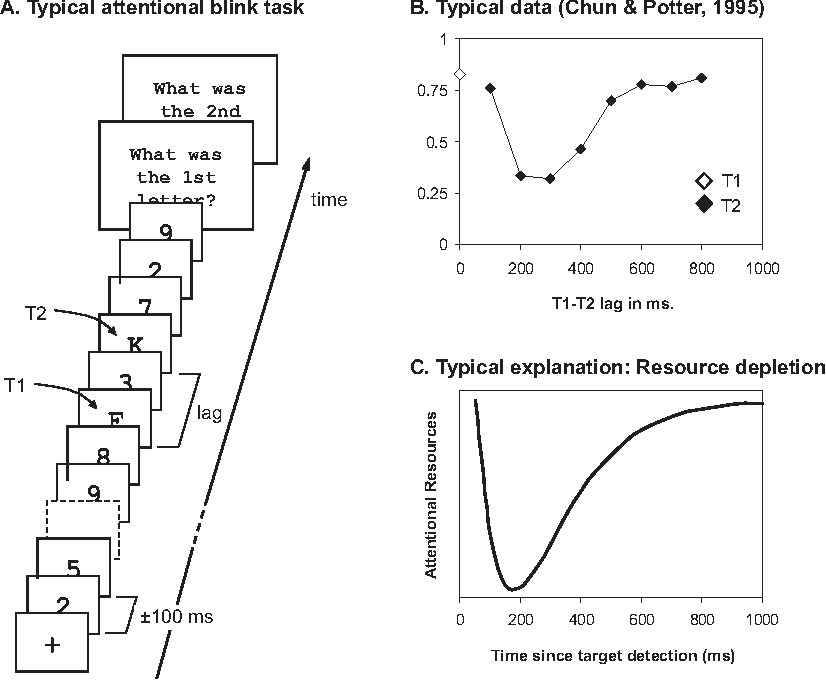
You're told to look out for two targets (T1, T2) in a stream of symbols. If the targets are too close together, people fail to see the second target. It's almost as if paying attention to the first target causes a "blink", and you can't pay attention to or process anything else during that blinking period. The attentional blink has often been framed as key evidence for a central bottleneck that has inescapable limit to how fast it can process data.
It turned out to not be as simple as I previously thought (here's a lit review that covers shifts in research on the subject). If you put three targets all in a row, people are able to detect them just fine. Additionally, if you ask people to remember the entire sequence they can do better than when you ask them to just remember only some of the characters (up till the point where you max out working memory). This makes no sense if the earlier experiments where interacting with a fundamental processing period that anything being attended to requires.

I found some papers that propose new models of the attentional blink, but haven't had time to explore them, nor have I gotten a sense of if they still relate this phenomena to a central bottleneck, or how the idea of a bottleneck is modified to accommodate these experiments. So I guess this is a temporary roadblock to exploring a "frame rate" idea.
Post hoc unpacking of information, filling in a story of experience with a guess at what was happening
Think back to ego-mind consciousness for a second. It generally maintains the experience that it is a high resolution constant stream of details, but it can be more useful to see it as a system that is flexibly constructing a story about what is happening, and you can "ping" that story to see it's current state. This story is constructed over time; it's not just a direct copy of "what you were experiencing", it can be added to and grown. So when you reflect back on "what was I experiencing 5 seconds ago?" you can find a lot more detail than what was in your experience in that exact moment.
Might there be a similar effect with the experience of flow states?
Ex. I'm in the zone, and I feel like I know exactly where my body is in space in time. My naive interpretation is that this experience is produced by hundreds or thousands of little snippets of somatic info being routed through the GNW. But, what if when I'm experiencing acute awareness of my body, what I'm experiencing is a "active, high alert, and ready" signal being put on the GNW. Maybe the "consciously active information" that makes up this experience is not hundreds of bits of data, but just a "ready" signal. Maybe afterwards when I reflect on the experience, and because of the rich "high alert" state I can draw out a lot of details about where exactly my body was, but in the moment that's not actually what was active in my GNW.
Not married to this one, but I think it's an avenue I want to look more into.
Q.3: How does the predictive processing account of attention play with the GNW account?
(I'm also just generally interested in how these two models can or can't jive with each other. They are trying to explain different things, and so aren't competing models, and yet there's plenty of areas where they seem to both have something to say about a topic.)
Attention for GNW: Working memory is more or less the functional "workplace", and the GNW is the backbone that supports updating and maintenance of working memory, allowing its contents to be operated on by the various subsystems (Kaj's post [? · GW] (wow, I'm linking to Kaj's posts a lot, it's almost like they're amazing and you should read the whole sequence), and the Dehaene paper). Having attention on something corresponds to that something either actively being broadcast on the GNW, or having it in working memory; both are states where the info is at hand accessible.
In predictive processing, attention is a system that manipulates the confidence intervals on your predictions. Low attention -> wide intervals -> lots of mismatch between prediction and data doesn't register as an error. High attention -> tighter intervals -> slight mismatch leads to error signal.
These two notions of what's happening when something is in your attention aren't incompatible, but I don't have a sense of how GNW attention can mediate and produce the functions of PP attention. The metaphors I'm using to conceptualize GNW are quite relevant to this. The GNW seems like it can only broadcast "simple" or "small" things. A single image, a percept, a signal. Something like a hypothesis in the PP paradigm seems like too big and complex a thing to be "sent" on the GNW. How does GNW attention relate to or cause the tightening of acceptable error bounds in a hierarchy of predictive models? If a hypothesis is too big a thing to put on the GNW, then it can't be laid out and then "operated on" by other systems. If coming to attention somehow triggers a hypothesis to adjust its own confidence intervals, what's to stop it from adjusting them whenever? If coming to attention somehow triggers some other confidence-interval-tightening system to interact with the hypothesis, why couldn't it interact with the hypothesis before hand?
Basically I've got no sense of how attention in the GNW sense can mediate and trigger the sorts of processes that correspond to attention in the PP sense. All schemes I think up involve a centralized "commander" architecture, and everything else I'm learning about the mind doesn't seem to jive with that notion. The research I've been doing makes centralization in the brain seem much more "router" like than "commander" like.
12 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2020-06-16T14:18:00.906Z · LW(p) · GW(p)
The GNW seems like it can only broadcast "simple" or "small" things. ... Something like a hypothesis in the PP paradigm seems like too big and complex a thing to be "sent" on the GNW.
My picture is: the GNW can broadcast everything that you have ever consciously thought about. This is an awfully big space. And it is a space of generative models (a.k.a. hypotheses).
The GNW is at the top of the (loose) hierarchy: the GNW sends predictions down to the lower-level regions of the neocortex, which in turn send prediction errors back to the GNW.
If, say, some particular upcoming input is expected to be important, then GNW can learn to build a generative model where the prediction of that input has a high confidence attached to it. That will bias the subsequent behavior of the system towards whatever models tend to be driven by the prediction error coming from that input. Thus we build serial computers out of our parallel minds [? · GW].
comment by Steven Byrnes (steve2152) · 2020-06-16T14:02:43.715Z · LW(p) · GW(p)
Given the serial, discrete nature of the GNW, it follows that consciousness is fundamentally a discrete and choppy thing, not a smooth continuous stream.
Here's my take. Think of the neocortex as having a zoo of generative models with methods for building them and sorting through them [LW · GW]. The models are compositional—compatible models can snap together like legos. Thus I can imagine a rubber wine glass, because the rubber generative models bottom out in a bunch of predictions of boolean variables, the wine glass generative models bottom out in a bunch of predictions of different boolean variables (and/or consistent predictions of the same boolean variables), and therefore I can union the predictions of the two sets of models.
Your GNW has an active generative model built out of lots of component models. I would say that the "tennis-match-flow" case entails little sub-sub-components asynchronously updating themselves as new information comes in—the tennis ball was over there, and now it's over here. By contrast the more typically "choppy" way of thinking involves frequently throwing out the whole manifold of generative models all at once, and activating a wholly new set of interlocking generative models. The latter (unlike the former) involves an attentional blink, because it takes some time for all the new neural codes to become active and synchronized, and in between you're in an incoherent, unstable state with mutually-contradictory generative models fighting it out.
Perhaps the attentional blink literature is a bit complicated because, with practice or intention, you can build a single GNW generative model that predicts both of two sequential inputs.
Replies from: Hazard↑ comment by Hazard · 2020-06-16T15:47:40.278Z · LW(p) · GW(p)
Your GNW has an active generative model built out of lots of component models. I would say that the "tennis-match-flow" case entails little sub-sub-components asynchronously updating themselves as new information comes in—the tennis ball was over there, and now it's over here. By contrast the more typically "choppy" way of thinking involves frequently throwing out the whole manifold of generative models all at once, and activating a wholly new set of interlocking generative models. The latter (unlike the former) involves an attentional blink, because it takes some time for all the new neural codes to become active and synchronized, and in between you're in an incoherent, unstable state with mutually-contradictory generative models fighting it out.
Ahhhh this seems like an idea I was missing. I was thinking of the generative models as all being in a ready and waiting state, only ever swapping in and out of broadcasting on the GNW. But a model might take time to become active and/or do it's work. I've been very fuzzy on how generative models are arranged and organized. You pointing this out makes me think that attentional blink (or "frame rate" stuff in general) is probably rarely limited by the actual "time it takes a signal to be propogated on the GNW" and much more related to the "loading" and "activation" of the models that are doing the work.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-06-16T16:56:07.524Z · LW(p) · GW(p)
I do think signal propagation time is probably a big contributor. I think activating a generative model in the GNW entails activating a particular set of interconnected neurons scattered around the GNW parts of the neocortex, which in turn requires those neurons to talk with each other. You can think of a probabilistic graphical model ... you change the value of some node and then run the message-passing algorithm a bit, and the network settles into a new configuration. Something like that, I think...
comment by Steven Byrnes (steve2152) · 2020-06-16T13:39:49.637Z · LW(p) · GW(p)
Q.1: Is the global neuronal workspace a bottleneck for motor control?
I vote strong no, or else I'm misunderstanding what you're talking about. Let's say you're standing up, and your body tips back microscopically, and you slightly tension your ankles to compensate and stay balanced. Are you proposing that this ankle-tension command has to go through the GNW? I'm quite confident that it doesn't. Stuff like that doesn't necessarily even reach the neocortex at all, let alone the GNW. In this post [LW · GW] I mentioned the example of Ian Waterman, who could not connect motor control output signals to feedback signals except by routing through the GNW. He had to be consciously thinking about how his body was moving constantly; if he got distracted he would collapse.
Replies from: Hazardcomment by Kaj_Sotala · 2020-06-16T09:23:19.578Z · LW(p) · GW(p)
In predictive processing, attention is a system that manipulates the confidence intervals on your predictions. Low attention -> wide intervals -> lots of mismatch between prediction and data doesn't register as an error. High attention -> tighter intervals -> slight mismatch leads to error signal.
Hmm... that sounds a bit different from how I've understood attention in predictive processing to work. AFAIK, it's not that attending to something tightens its confidence interval; it's that things with tight confidence intervals (relevant for the task in question) get more attention.
So bottom-up attention would be computed by the subsystems that were broadcasting content into GNW, and their attention assignments would be implicit in their output. E.g. if you are looking at someone's face and a subsystem judges that the important thing to pay attention to is the fact that they are looking angry, then it would send the message "this person looks angry" to the GNW. And subsystems would have a combination of learned and innate weights for when their messages could grab control of the GNW and dominate it with what they are paying attention to, similar to the salience cues in the basal ganglia that allow some bids to dominate in specific situations.
Top-down attention would be computed by attentional subsystems interfacing with the GNW, to pick out specific signals in the GNW that seemed most useful for the current task, and strengthening those signals.
The GNW seems like it can only broadcast "simple" or "small" things. A single image, a percept, a signal. Something like a hypothesis in the PP paradigm seems like too big and complex a thing to be "sent" on the GNW
Is it? Like, suppose that a subsystem's hypothesis is that you are seeing a person's face; as a result, the image of a face is sent to the GNW. In that case, the single image that is transmitted into the GNW is the hypothesis. That hypothesis being in consciousness may then trigger an error signal due to not matching another subsystem's data [LW · GW], causing an alternative hypothesis to be broadcast into consciousness.
That said, seeing a face usually involves other things than just the sight of the face: thoughts about the person in question, their intentions, etc. My interpretation has been that once one subsystem has established that "this is a face" (and sends into consciousness a signal that highlights the facial features that it has computed to get the most attention), other subsystems then grab onto those features and send additional details and related information into consciousness. The overall hypothesis is formed by many distinct pieces of data submitted by different subsystems - e.g. "(1) I'm seeing a face, (2) which belongs to my friend Mary, (3) who seems to be happy; (4) I recall an earlier time when Mary was happy".
Here's an excerpt from Consciousness and the Brain that seems relevant:
In 1959, the artificial intelligence pioneer John Selfridge introduced another useful metaphor: the “pandemonium.” He envisioned the brain as a hierarchy of specialized “daemons,” each of which proposes a tentative interpretation of the incoming image. Thirty years of neurophysiological research, including the spectacular discovery of visual cells tuned to lines, colors, eyes, faces, and even U.S. presidents and Hollywood stars, have brought strong support to this idea. In Selfridge’s model, the daemons yelled their preferred interpretation at one another, in direct proportion to how well the incoming image favored their own interpretation. Waves of shouting were propagated through a hierarchy of increasingly abstract units, allowing neurons to respond to increasingly abstract features of the image—for instance, three daemons shouting for the presence of eyes, nose, and hair would together conspire to excite a fourth daemon coding for the presence of a face. By listening to the most vocal daemons, a decision system could form an opinion of the incoming image—a conscious percept.Replies from: Hazard
Selfridge’s pandemonium model received one important improvement. Originally, it was organized according to a strict feed-forward hierarchy: the daemons bellowed only at their hierarchical superiors, but a high-ranking daemon never yelled back at a low-ranking one or even at another daemon of the same rank. In reality, however, neural systems do not merely report to their superiors; they also chat among themselves. The cortex is full of loops and bidirectional projections. Even individual neurons dialogue with each other: if neuron α projects to neuron β, then β probably projects back to α. At any level, interconnected neurons support each other, and those at the top of the hierarchy can talk back to their subordinates, so that messages propagate downward at least as much as upward.
Simulation and mathematical modeling of realistic “connectionist” models with many such loops show that they possess a very useful property. When a subset of neurons is excited, the entire group self-organizes into “attractor states”: groups of neurons form reproducible patterns of activity that remain stable for a long duration. As anticipated by Hebb, interconnected neurons tend to form stable cell assemblies.
As a coding scheme, these recurrent networks possess an additional advantage—they often converge to a consensus. In neuronal networks that are endowed with recurrent connections, unlike Selfridge’s daemons, the neurons do not simply yell stubbornly at one another: they progressively come to an intelligent agreement, a unified interpretation of the perceived scene. The neurons that receive the greatest amount of activation mutually support one another and progressively suppress any alternative interpretation. As a result, missing parts of the image can be restored and noisy bits can be removed. After several iterations, the neuronal representation encodes a cleaned-up, interpreted version of the perceived image. It also becomes more stable, resistant to noise, internally coherent, and distinct from other attractor states. Francis Crick and Christof Koch describe this representation as a winning “neural coalition” and suggest that it is the perfect vehicle for a conscious representation.
The term “coalition” points to another essential aspect of the conscious neuronal code: it must be tightly integrated. Each of our conscious moments coheres as one single piece. When contemplating Leonardo da Vinci’s Mona Lisa, we do not perceive a disemboweled Picasso with detached hands, Cheshire cat smile, and floating eyes. We retrieve all these sensory elements and many others (a name, a meaning, a connection to our memories of Leonardo’s genius)—and they are somehow bound together into a coherent whole. Yet each of them is initially processed by a distinct group of neurons, spread centimeters apart on the surface of the ventral visual cortex. How do they get attached to one another?
One solution is the formation of a global assembly, thanks to the hubs provided by the higher sectors of cortex. These hubs, which the neurologist Antonio Damasio calls “convergence zones,” are particularly predominant in the prefrontal cortex but also in other sectors of the anterior temporal lobe, inferior parietal lobe, and a midline region called the precuneus. All send and receive numerous projections to and from a broad variety of distant brain regions, allowing the neurons there to integrate information over space and time. Multiple sensory modules can therefore converge onto a single coherent interpretation (“a seductive Italian woman”). This global interpretation may, in turn, be broadcast back to the areas from which the sensory signals originally arose. The outcome is an integrated whole. Because of neurons with long-distance top-down axons, projecting back from the prefrontal cortex and its associated high-level network of areas onto the lower-level sensory areas, global broadcasting creates the conditions for the emergence of a single state of consciousness, at once differentiated and integrated.
This permanent back-and-forth communication is called “reentry” by the Nobel Prize winner Gerald Edelman. Model neuronal networks suggest that reentry allows for a sophisticated computation of the best possible statistical interpretation of the visual scene. Each group of neurons acts as an expert statistician, and multiple groups collaborate to explain the features of the input. For instance, a “shadow” expert decides that it can account for the dark zone of the image—but only if the light comes from the top left. A “lighting” expert agrees and, using this hypothesis, explains why the top parts of the objects are illuminated. A third expert then decides that, once these two effects are accounted for, the remaining image looks like a face. These exchanges continue until every bit of the image has received a tentative interpretation.
↑ comment by Hazard · 2020-06-16T16:07:34.980Z · LW(p) · GW(p)
Hmm, yeah looks like I got PP attention backwards.
There's two layers! Predictive circuits are sorta "autonomously" creating a focus within the domain of what they predict, and then the "global" or top-down attention can either be an attentional subsystem watching the GNW, or the distributed attentional-relevancy gate around the GNW.
The pandemonium stuff is also a great model. In another comment I mentioned that I'm fuzzy on how tightly or loosely coupled different subsytems can be, and how they are organized, and I was unintentionally imagining them as quite monolithic entities.
comment by Kaj_Sotala · 2020-06-16T08:35:34.091Z · LW(p) · GW(p)
If you put three targets all in a row, people are able to detect them just fine. Additionally, if you ask people to remember the entire sequence they can do better than when you ask them to just remember only some of the characters (up till the point where you max out working memory). This makes no sense if the earlier experiments where interacting with a fundamental processing period that anything being attended to requires.
Huh! Nice find. That's weird, I'm confused now.
Replies from: Hazardcomment by Kaj_Sotala · 2020-06-16T08:21:04.803Z · LW(p) · GW(p)
Easy tasks can route around the global workspace, hard ones or ones that produce error have to go through it. That's the previous idea. Now, this paper has begun to shift my thinking. For a specific set of tasks, it claims to show that training doesn't shift activity away from a bottleneck location, but instead makes the processing at the point of the bottleneck more efficient.
Interesting! This would make a lot of intuitive sense - after the subsystems responsible for some task have been sufficiently trained, they can mostly just carry out the task using their trained-up predictive models, and need a lot less direct sensory data.
This might also explain some aspects of meditation: for example, The Mind Illuminated talks about "increasing the power of consciousness", which it describes as literally increasing the amount of experience-moments per unit of time. I was never quite sure of how exactly to explain that in terms of a global workspace model... but maybe if the system for generating moments of introspective awareness [LW · GW] also got more efficient somehow? Hmm...
If subsystems had to route through the GNW to trigger motor actions, then this system or some variation could totally account for the serial conflict resolution function. But if subsystems can directly send motor commands without going through the GNW, how would would subsystems in conflict be "told to stop" while the conflict resolution happens? The GNW is not a commander, it can't order subsystems around. Though it may be central to consciousness, it's not the "you" that commands and thinks.
All this leaves me thinking that I'm either missing a big obvious chunk of research, or that various motor-planning parts of the brain can't send motor commands except via the GNW. Please point me at any relevant research that you know of.
So AFAIK, the command bottleneck is in the basal ganglia, which are linked to the GNW. A lot of the brain works by lateral inhibition, where each of neurons A, B and C may fire, but any of them firing sends inhibitory signals to the others, causing only one of them to be active at a time.
My understanding from the scholarpedia article is that something similar is going on in the basal ganglia - different subsystems send various motor command "bids" to the BG, which then get different weights depending on various background factors (e.g. food-seeking behaviors get extra weight when you are hungry). Apparently there's a similar mechanism of a strong bid for one system inhibiting the bidding signals for all the others. So if multiple subsystems are issuing conflicting bids at the same time, their bids would end up inhibiting each other and none of them would reach the level necessary for carrying out actions.
Scholarpedia links to Prescott et al. 2006 (sci-hub) as offering a more detailed model, including a concrete version that was implemented in a robot. I've only skimmed it, but they note that their model has some biologically plausible behaviors. In some situations where the robot experiences conflicting high-weight bids, it seems to "react to uncertainty by going half-speed [LW · GW]": doing a bit of one one response and then a bit of another, and failing to fully commit to any single procdure:
The control architecture of the robot includes five behaviors, or action sub-systems, which it can switch between at any time. These are: searching for cylinders (cylinder-seek or Cs), picking up a cylinder (cylinderpickup, Cp), looking for a wall (wall-seek, Ws), following alongside a wall (wall-follow, Wf), and depositing the cylinder in a corner (cylinder-deposit, Cd). [...]
three of the five action sub-systems—cylinder-seek, wall-seek, and wall-follow— map patterns of input from the peripheral sensor array into movements that orient the robot towards or away from specific types of stimuli (e.g. object contours). [...]
By comparison, the fixed action pattern for cylinder-pickup in the robot model constitutes five sequential elements: (i) slowly approach the cylinder (to ensure correct identification and good alignment for pickup), (ii) back away (to allow room to lower the arm) whilst opening the gripper, (iii) lower the arm to floor level, (iv) close the gripper (hopefully around the cylinder), (v) return the arm to vertical. [...]
A centralized action selection system requires mechanisms that can assimilate relevant perceptual, motivational, and contextual signals to determine, in some form of ‘common currency’ the relative salience or urgency of each competing behavior (McFarland, 1989; Redgrave et al., 1999a). In the embedding architecture of our model, at each time-step, a salience value for each action sub-system is calculated as a weighted sum of relevant perceptual and motivational variables, and may also be dependant on the current activity status of the action sub-system itself. [...]
... a breakdown of clean selection can occur in the disembodied model when two competitors have high salience levels. To examine the behavioral consequences of this pattern of selection, the robot model was tested over five trials of 120s (approximately 800 robot time-steps) in which the salience of every channel was increased, on every time-step, by a constant amount (C0.4) [...]
During a continuous sequence of high salience competitions the robot exhibited patterns of behavioral disintegration characterized by: (i) reduced efficiency and distortion of a selected behavior, and (ii) rapid switching and incomplete foraging behavior.
Fig. 11 shows the effect of increased salience intensity on exploration of the winner/most-salient-loser salience-space over all trials. The graph demonstrates that virtually all (w4000) salience competitions appeared in the region of salience space (compare with Fig. 7) where reduced efficiency and distorted selection can be expected
The initial avoidance sequence followed the expected pattern but the transition to foraging activity did not begin cleanly, instead showing reduced efficiency and intermittent, partial selection of (losing) avoidance behaviors. To the observer the movement of the robot behavior during the transition appeared somewhat slowed and ‘tentative’. During the foraging bout there was an extended period of rapid switching between cylinder-seek and cylinder-pickup with the robot repeatedly approaching the cylinder but failing to grasp it. The pattern initially observed (t=60–85s) was for the robot to approach the cylinder; back up as if to collect it in the gripper; then move forward without lowering the gripper-arm, pushing the cylinder forward slightly. Later (t=85–90s, 110–115s), where both behaviors showed some partial selection, the robot would lower the arm whilst moving forward but fail to grasp the cylinder due to being incorrectly aligned.
In all five trials, the selection behavior of the robot was similarly inefficient and distorted with the robot frequently displaying rapid alternation of foraging acts. This is illustrated in the transition matrix in Table 2, which shows that the behavior of the robot was dominated by the sequence Cs–Cp–Cs–Cp. with no trials leading to a successful foraging sequence. [...]
Whilst the performance of the model in these circumstances is clearly sub-optimal from a purely action selection viewpoint, it shows interesting similarities to the findings of a large number of studies investigating the behavior of animals in conflict situations (Fentress, 1973; Hinde, 1953, 1966; Roeder, 1975). For instance, Hinde (1966) describes a number of possible outcomes that have been observed in ethological studies of strong behavioral conflicts: (i) inhibition of all but one response, (ii) incomplete expression of a behavior (generally the preparatory stages of behavior are performed), (iii) alternation between behaviors (or ‘dithering’), (iv) ambivalent behavior (a mixture of motor responses), (v) compromise behavior (similar to ambivalence, except that the pattern of motor activity is compatible with both behavioral tendencies), (vi) autonomic responses (for instance defecation or urination), (vii) displacement activity (expression of a behavior that seems irrelevant to the current motivational context, e.g. grooming in a ‘fight or flight’ conflict situation) . Of these outcomes, several show clear similarities with the behavior of the robot in the high salience condition. Specifically, the distortion observed in the early stages of the trial could be understood as a form of ambivalent behavior (iv), whilst the later repetitive behavioral switching has elements of both incomplete expression of behavior (ii) and alternation (iii).
More generally, the behavior of the embodied basal ganglia model is consistent a wide range of findings in psychology and ethology demonstrating that behavioral processes are most effective at intermediate levels of activation (Berlyne, 1960; Bindra, 1969; Fentress, 1973; Malmo, 1959), These findings can also be viewed as expressing the Yerkes-Dodson law (Yerkes & Dodson, 1908) that predicts an ‘inverted U’-shaped relationship between arousal and performance. Our model is consistent with this law in that the robot shows little or no behavioral expression when only low salience inputs are present, demonstrates effective action selection for a range of intermediate level salience inputs (and for high salience inputs where there is no high salience competitor), and exhibits disintegrated behavior in circumstance of conflict between multiple high-salience systems. The robot model, therefore, suggests that the basal ganglia form an important element of the neural substrate mediating the effects of arousal on behavioral effectiveness.
Connecting this with the GNW, several of the salience cues used in the model are perceptual signals, e.g. whether or not a wall or a cylinder is currently perceived. We also know that signals which get to the GNW have a massively boosted signal strength over ones that do not. So while the GNW does not "command" any particular subsystem to take action, salience cues that get into the GNW can get a significant boost, helping them win the action selection process.
Compare e.g. the Stanford Marshmallow Experiment, where the children used a range of behaviors to distract themselves from the sight/thought of the marshmallow - or any situation where you yourself keep getting distracted by signals making their way to consciousness:
The three separate experiments demonstrate a number of significant findings. Effective delay of gratification depends heavily on the cognitive avoidance or suppression of the reward objects while waiting for them to be delivered. Additionally, when the children thought about the absent rewards, it was just as difficult to delay gratification as when the reward items were directly in front of them. Conversely, when the children in the experiment waited for the reward and it was not visibly present, they were able to wait longer and attain the preferred reward. The Stanford marshmallow experiment is important because it demonstrated that effective delay is not achieved by merely thinking about something other than what we want, but rather, it depends on suppressive and avoidance mechanisms that reduce frustration.
The frustration of waiting for a desired reward is demonstrated nicely by the authors when describing the behavior of the children. “They made up quiet songs…hid their head in their arms, pounded the floor with their feet, fiddled playfully and teasingly with the signal bell, verbalized the contingency…prayed to the ceiling, and so on. In one dramatically effective self-distraction technique, after obviously experiencing much agitation, a little girl rested her head, sat limply, relaxed herself, and proceeded to fall sound asleep.”Replies from: Hazard
↑ comment by Hazard · 2020-06-16T16:25:50.302Z · LW(p) · GW(p)
Thank you for pointing to the basal ganglia's relation to motor control! This feels like one of those things that's obvious but I just didn't know because I haven't "broadly studied" neuroanatomy. Relatedly, if anyone knows of any resources of neuroanatomy that really dig into why we think of this or that region of the brain as being different, I'd love to hear. I know there's both a lot of "this area defs has this structure and does this thing" and "an fMRI went beep so this is the complain-about-ants part of your brain!", and I don't yet have the knowledge to tell them apart.
Also:
Connecting this with the GNW, several of the salience cues used in the model are perceptual signals, e.g. whether or not a wall or a cylinder is currently perceived. We also know that signals which get to the GNW have a massively boosted signal strength over ones that do not. So while the GNW does not "command" any particular subsystem to take action, salience cues that get into the GNW can get a significant boost, helping them win the action selection process.
This was a very helpful emphasis shift for me. Even though I wasn't conceptualizing GNW as a commander, I was still thinking of it as a "destination", probably because of all the claims about its connection to consciousness. The "signal boosting" frame feels like a much better fit. Subsystems are already plugged into the various parts of your brain that they need to be connected to; the GNW is not a universal router. It's only when you're doing Virtual Machine esque conscious thinking that it's a routing bottleneck. Other times it might look like a bottle neck, but maybe it's more "if you get a signal boost from the GNW, you're probs gonna win, and only one thing can get boosted at a time".