Agency from a causal perspective
post by tom4everitt, mattmacdermott, James Fox, Francis Rhys Ward (francis-rhys-ward), Jonathan Richens (jonrichens) · 2023-06-30T17:37:58.376Z · LW · GW · 5 commentsContents
The Importance of Understanding Agency Degrees of freedom Influence Adaptation Coherence and Self-preservation Putting it all together Future work None 5 comments
Post 3 of Towards Causal Foundations of Safe AGI [? · GW], preceded by Post 1: Introduction [AF · GW] and Post 2: Causality [AF · GW].
By Matt MacDermott, James Fox, Rhys Ward, Jonathan Richens, and Tom Everitt representing the Causal Incentives Working Group. Thanks also to Ryan Carey, Toby Shevlane, and Aliya Ahmad.
The purpose of this post is twofold: to lay the foundation for subsequent posts by exploring what agency means from a causal perspective, and to sketch a research program for a deeper understanding of agency.
The Importance of Understanding Agency
Agency is a complex concept that has been studied from multiple perspectives, including social science, philosophy, and AI research. Broadly it refers to a system able to act autonomously. For the purposes of this blog post, we interpret agency as goal-directedness, i.e. acting as if trying to direct the world in some particular direction.
There are strong incentives to create more agentic AI systems. Such systems could potentially do many tasks humans are currently needed for, such as independently researching topics, or even run their own companies. However, making systems more agentic comes with an additional set of potential dangers [AF · GW] and harms, as goal-directed AI systems could become capable adversaries if their goals are misaligned with human interest.
A better understanding of agency may let us:
- Understand dangers and harms from powerful machine learning systems.
- Evaluate whether a particular ML model is dangerously agentic.
- Design systems that are not agentic, such as AGI scientists or oracles, or which are agentic in a safe way.
- Lay a foundation for progress on other AGI safety topics, such as interpretability, incentives, and generalisation.
- Preserve human agency, e.g. through a better understanding of the conditions under which agency is enhanced or diminished.
Degrees of freedom
(Goal-directed) agents come in all shapes and sizes – from bacteria to humans, from football teams to governments, and from RL policies to LLM simulacra [AF · GW] – but they share some fundamental features.
First, an agent needs the freedom to choose between a set of options.[1] We don’t need to assume that this decision is free from causal influence, or that we can’t make any prediction about it in advance – but there does need to be a sense in which it could either go one way or another. Dennett calls this degrees of freedom.
For example, Mr Jones can choose to turn his sprinkler on or not. We can model his decision as a random variable with “watering” and “not watering” as possible outcomes:
Freedom comes in degrees. A thermostat can only choose heater output, while most humans have access to a range of physical and verbal actions.
Influence
Second, in order to be relevant, an agent’s behaviour must have consequences. Mr Jones decision to turn on the sprinkler affects how green his grass becomes:

The amount of influence varies between different agents. For example, a language model’s influence will heavily depend on whether it only interacts with its own developers, or with millions of users through a public API, and causal influence of our actions seems to determine sense of agency in humans. Suggested measures of influence include (causal) channel capacity, performative power, and power in Markov decision processes.
Adaptation
Third, and most importantly, goal-directed agents do things for reasons. That is, (they act as if) they have preferences about the world, and these preferences drive their behaviour: Mr Jones turns on the sprinkler because it makes the grass green. If the grass didn’t need water, then Mr Jones likely wouldn’t water it. The consequences drive the behaviour.
This feedback loop, or backwards causality [AF · GW], can be represented by adding a so-called mechanism node to each object-level node in the original graph. The mechanism node specifies the causal mechanism [AF · GW] of its associated object-level node, i.e. how the outcome of the object-level node is determined by its object-level parents. For example, a mechanism node for the sprinkler specifies Mr Jones’ watering policy, and a mechanism node for the grass specifies how the grass responds to different amounts of water:[2]
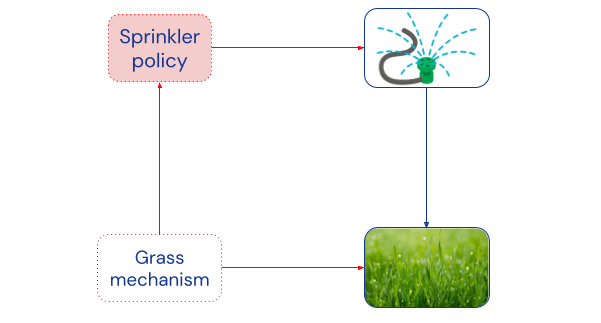
By explicitly representing causal mechanisms with nodes, we can consider interventions on them. For example, an intervention on grass mechanism might change the type of grass to one that requires less water. The link from grass mechanism to sprinkler policy says that such an intervention could influence Mr Jones’ watering habits.[3] That is, he would adapt his behaviour to still achieve his goal.
Given the right variables and experiments, adaptation can be detected with causal discovery algorithms, and can thereby potentially be used to discover agents [AF · GW]. In particular, when one mechanism variable adapts to changes in another, the first may belong to a decision node and the second to a utility node that the decision is optimising. If the agents are ideal game-theoretic players, refinements [AF · GW] of these conditions yield necessary and sufficient criteria for detecting decision and utility nodes.
Adaptation comes in degrees. Dennett makes a distinction between Darwinian, Skinnerian, Popperian, and Gregorian agents, depending on whether they adapt by evolution, experience, planning, or by learning from others. For example, a human who notices the cold puts on a coat, while a species may grow warmer fur over evolutionary timescales. Language models likely fall on the highest, Gregorian, level, as they can be taught some things in the prompt, and learn many things from humans during pre-training.
Quantitative measures of adaptation can be obtained by considering how quickly and effectively an agent adapts to different interventions. The speed of adaptation can be measured if we extend our framework with mechanism interventions at different timescales (e.g. at evolutionary or human timescales). The effectiveness of a particular adaptation can be quantified by comparing the agent's performance in the presence and the absence of an intervention. One common performance measure using reward functions is (worst-case) regret. Finally, which environment interventions the agent appropriately adapts to measures how robust it is, and which utility interventions measures its retargetability [AF · GW] or task generality.
In a subsequent post, we will present a result showing that adaptation requires the agent to have a causal model. This result will connect the behavioural perspective taken in this post with the agent’s internal representation.
Coherence and Self-preservation
Related to adaptation is how coherently an agent pursues a long-term goal? For example, why is it that governments can pursue large infrastructure projects over decades, while (current) language agents (such as autoGPT) veer off course quickly? First, building on the above discussion, we can operationalise a goal in terms of what mechanism interventions the agent adapts to. For example, a sycophantic [LW · GW] language model that adapts its answers to the user’s political leanings, might have the goal of pleasing the user or get more reward. Extending this, coherence can be operationalised by how similar the goal is for different decision nodes. Curiously, more intelligence doesn’t necessarily bring more coherence.
An agent that does not persist cannot coherently pursue a goal. This is likely the reason that we (humans) want to preserve our own agency,[4] as alluded to in the intro post [AF · GW]. Current language models express a desire for self-preservation. In contrast, more limited systems like content recommenders and GPS navigation systems exhibit no self-preservation drive at all, in spite of being somewhat goal-directed.
Putting it all together
So far, we have discussed eight dimensions of agency: degrees of freedom, influence, adaptation (speed, effectiveness, robustness, retargetability), coherence, and self-preservation. To the list can also be added (Markov) separation [? · GW] from [LW · GW] the environment (e.g. a cell wall, skin, or encryption of internal emails, captured by d-separation in causal graphs), and the amount of information or perception the agent has of its environment.
The dimensions are all about the strength or quality of different causal relationships, and can be conceptually associated with different parts of our diagram from above:
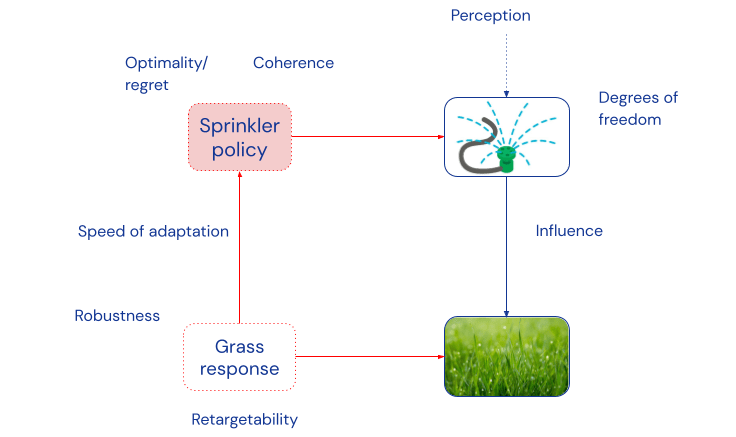
These dimensions also emphasise the point that agency comes in degrees, and there are several different dimensions along which a system can be more or less agentic. For example, a human is more agentic than a fish, which is more agentic than a thermostat, while AlphaGo exceeds humans in coherence but has much fewer degrees of freedom.
Future work
The high-level discussion in this post has aimed to explain the conceptual connections between agency and causality: adaptation in particular is a causal notion, capturing how behaviour is causally influenced by interventions on the environment and the agent’s goals. Subsequent posts will build on this idea.
We would also like to highlight some lines of future work suggested by this perspective:
- What are the key dimensions of agency? Can we come up with a unified formalisation of the above concepts? How do they relate to optimisation power [LW · GW] and the ground of optimisation [LW · GW]? Is there a basis set of mutually independent agency dimensions of which all other concepts are a function?
- Can we measure goal-directedness in language models and in humans? Perhaps overall goal-directedness or optimisation power [LW · GW] can be (upper) bounded by an agent’s influence, adaptation, coherence, and so on. This could feed into an evaluation of a system's dangerous capabilities.
- Can we design agents that are only partially goal-directed? Systems like content recommenders and GPS navigation systems exhibit no self-preservation at all, in spite of being somewhat goal-directed. Current language models exhibit some self-preservation, but perhaps this can be avoided? Evolution has likely simultaneously been selecting for all of the above concepts when developing biological agents, but artificial systems need not face much evolutionary pressure. If inadvertent [AF · GW] and deliberate creation of coherently self-preserving agents can be avoided, this could [? · GW] potentially offer a path to reap most of the benefits of AI, with only a fraction of the danger.
- Can we better understand the conditions under which agency emerges from less agentic components? When is agency enhanced and when is it diminished? When does a digital assistant or content recommender boost vs undermine my agency? What if I play chess with the help of AlphaZero?
The next post will focus on incentives. Understanding incentives is important for promoting the right kind of behaviour in the AI systems we design. As we shall see, the incentives analysis builds naturally on the notion of agency discussed in this post.
- ^
Some uses of the term agent might allow for a system to be an agent even if it has no way to choose an action, such as a completely paralysed person. We don’t use the term in this sense, focusing instead on goal-directed systems that act. It is also worth noting that for us, agency is relative to the “frame” defined by the variables in the model. If Mr Jones’s sprinkler broke, he’d have no agency relative to the frame in this post, but he may still have agency according to other frames (he might still be able to freely walk around his garden, for example).
- ^
Mechanism nodes enable a formalisation of pre-policy and post-policy interventions, discussed [AF · GW] in the previous post. Pre-policy interventions are interventions that agents can adapt their policy to. They correspond to interventions on mechanism nodes. Post-policy interventions are interventions that agents cannot adapt their policy to. They correspond to interventions on object-level nodes. For example, the mechanism edge from grass mechanism to sprinkler policy says that Mr Jones can adapt to pre-policy interventions. But there is no edge from object-level grass to sprinkler policy, so he cannot adapt his policy to (post-policy) interventions on grass.
- ^
An alternative interpretation, natural from a finite-factored sets [AF · GW] perspective, is to interpret the agent’s behaviour as answering a more fine-grained question than its goal, and the object-level nodes as answering more fine-grained questions than their mechanisms. Relatedly, causal relationships can be inferred from algorithmic information theory, which is convenient when discussing independence between non-intervervenable nodes.
- ^
Such meta-preferences are sometimes seen as a hallmark of agency. They can likely be modelled analogously to normal preferences by adding another layer of mechanism nodes (i.e. mechanism nodes for mechanism nodes)
5 comments
Comments sorted by top scores.
comment by Chipmonk · 2023-08-12T19:53:20.558Z · LW(p) · GW(p)
goal-directed agents do things for reasons
(this is so good!)
comment by Chipmonk · 2023-07-04T23:55:04.133Z · LW(p) · GW(p)
The link on "d-separation" is broken. I think it should be http:// not https://
↑ comment by tom4everitt · 2023-07-07T17:24:15.892Z · LW(p) · GW(p)
fixed now, thanks! (somehow it added https:// automatically)
comment by Chipmonk · 2023-07-04T23:51:40.267Z · LW(p) · GW(p)
I have a lot of thoughts on separation/Markov blankets/boundaries/membranes. — «Boundaries/Membranes» and AI safety compilation [LW · GW] — I'm writing a draft currently and this seems extremely related. Would one of you guys like to chat? DM me
Replies from: tom4everitt↑ comment by tom4everitt · 2023-07-07T17:28:46.623Z · LW(p) · GW(p)
Thanks, that's a nice compilation, I added the link to the post. Let me check with some of the others in the group, who might be interested in chatting further about this