You can remove GPT2’s LayerNorm by fine-tuning for an hour
post by StefanHex (Stefan42) · 2024-08-08T18:33:38.803Z · LW · GW · 11 commentsContents
Introduction Motivation Method Implementation Results GPT2: GP2_noLN: Residual stream norms Discussion Faithfulness to the original model Does the noLN model generalize worse? Appendix Representing the no-LayerNorm model in GPT2LMHeadModel Which order to remove LayerNorms in Which kinds of LayerNorms to remove first Which layer to remove LayerNorms in first Data-reuse and seeds Infohazards Acknowledgements None 11 comments
This work was produced at Apollo Research, based on initial research done at MATS.
Edit: arXiv version available at https://arxiv.org/abs/2409.13710
LayerNorm is annoying for mechanistic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here’s a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
| Dataset | Original GPT2 | Fine-tuned GPT2 with LayerNorm | Fine-tuned GPT without LayerNorm |
| OpenWebText (ce_loss) | 3.095 | 2.989 | 3.014 (+0.025) |
| ThePile (ce_loss) | 2.856 | 2.880 | 2.926 (+0.046) |
| HellaSwag (accuracy) | 29.56% | 29.82% | 29.54% |
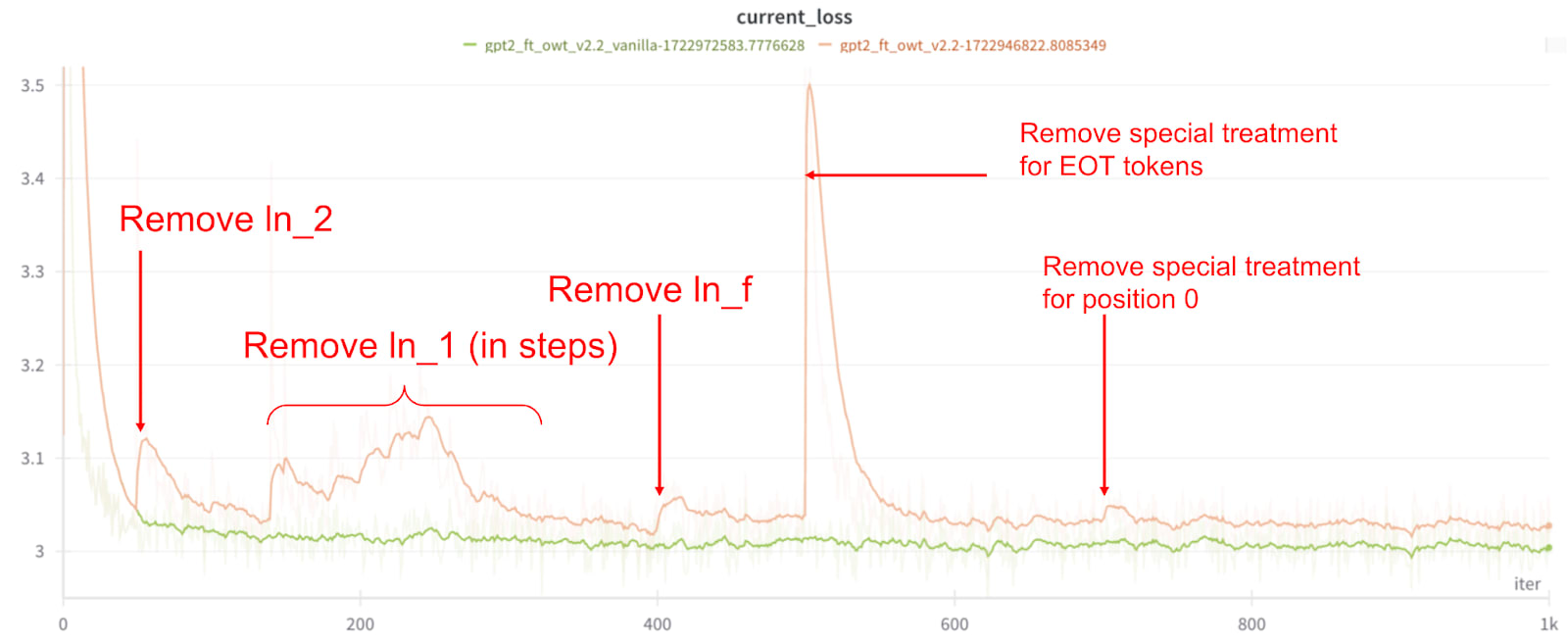
I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
The equation includes the standard deviation (std) which makes it a non-linear operation. This hinders interpretability in a variety of ways, from annoyances and inaccuracies such as
attributing residual stream directions to logit effects (e.g. SAE features, direct logit attribution),[2]
being annoying to deal with Attribution Patching [LW(p) · GW(p)], or
- being difficult to deal with in Apollo’s LIB method.
In the Docstring circuit [LW · GW] analysis we seriously considered whether the model might be using LN in its algorithm. This post [LW · GW] even shows that LN can be used as the sole non-linearity to solve non-linear classification problems (see also this related work).
Recently, with progress in Sparse Dictionary Learning, agendas (e.g. this one [LW · GW]) imagine decomposing networks into sets of sparsely connected components (SAEs, Transcoders, etc.). A core difficulty to “putting it all together” is that the interactions between different components often route through LayerNorm whose effect we do not understand.
Motivation
It would be pretty neat to have an LLM that still works (speaks English etc.) while less or no LN layers. One option would be to train a model without LN from scratch (done for tiny models, e.g. TinyModel), but this is very hard or impossible for larger models (hearsay is that you need a low learning rate and to be very careful).
Taking an existing model and removing the LN layers however seems doable if LN isn’t implementing some important computation.[3] That is, LN “does its thing” and the model has learned to “deal with it”, but it’s not irreplaceable. A reason to be optimistic is that the spread of standard deviations across different samples isn’t that large [LW · GW], so maybe replacing the LN-computed standard deviation with a fixed number might kinda work.
Method
I take GPT2-small, fine-tune it on OpenWebText, and remove LNs one-by-one while fine-tuning.
The only non-linear operation in a LN layer is the division by the standard deviation (std) of the embedding vectors; the remaining operations can be absorbed into later weight matrices (see the fold_ln option in TransformerLens; also discussed in this appendix). Thus I mainly focus on the std part here.
My general strategy is to “remove” an LN layer (this makes the loss go up), and then to train the model for some time (on the original training data) until the loss is back near the baseline. For this “remove” step I do the following
- Calculate the average std on the dataset (I used a quite small sample, 16 prompts), separately for position 0 and position > 0
- Replace the std calculation with the average std (position > 0), sometimes with special treatments for
- Position 0: use the position 0 average instead
EOT tokens: When the input is an end-of-text token I also use the position 0 average std (because norms on EOT tokens tend to be larger)[4]
Whenever I do the replacement the loss jumps up, from the baseline of 3.0 up to 3.5, sometimes even around 5.0. After 10-100 iterations (learning rate 6e-4 and batch size approx. 488 as recommended here) the loss typically goes down to between 3.0 and 3.1. However, if I’m not careful and change too much at once, the loss can jump very high (around 8.0), and in those cases it usually never recovers. Thus I want to avoid making too big of a change at once.
Here’s the recipe I empirically found to work. After every step, train for 50-200 iterations or until the loss is close to baseline.
- Fine-tune for 300 iterations without any changes (GPT2 without any fine-tuning does surprisingly bad on OpenWebText)
- Remove
ln_2(the LN before the MLP block), replacing the std with an average value. I use the “Position 0” special treatment but not the “EOT tokens” special treatment forln_2. - Remove
ln_1for the q and k vectors. As forln_2, I only use the “Position 0” special treatment.- I’ve also experimented with removing these LNs one-by-one (remove in a layer, train for 10 iterations before removing it in the next layer, …). That is plausibly the strictly better strategy, but in 2 out of 3 successful fine-tunes I didn’t need to do this.
- Remove
ln_1for the v vector. Use both the “Position 0” and “EOT tokens” special treatments. - Remove
ln_f, the final LN. Again I only use the “Position 0” special treatment. - Remove the “EOT tokens” special treatment.
- Remove the “Position 0” special treatment.
I considered scaling individual LNs down slowly (e.g. interpolate between the actual calculated std and the average std) but I never ended up needing this, and did not really explore it.
In general I observed that
- There seems to be some mechanism where the first interventions are harder than the later ones. Whichever LN I remove first, it tends to cause a rather big loss-bump, while later removals sometimes are barely noticeable.
- For example, in all of my runs where I remove
ln_fat the end, it causes only a small increase in loss. If I remove it at the beginning it causes a much larger loss bump.
- For example, in all of my runs where I remove
- Removing
ln_2was usually easier than removingln_1. This, combined with the point above, is why I removeln_2beforeln_1. - Removing
ln_1for the q and k vectors was not too bad, but the v vector was much harder. I only managed to remove its LN once I implemented the “EOT tokens” special treatment. - I tentatively feel like there is always “1 big loss spike” somewhere – in some earlier runs I remember a big spike when removing
ln_1, while in other experiments (like the screenshot at the top) the spike happens then I remove the “EOT tokens” special treatment.- This suggests a hypothesis along the lines of “there is something the model needs to learn to stop using LayerNorm, and once it did that the rest is easy”. This could be e.g. “damped / throw away the confidence neuron” or something about how EOT tokens are handled, but I don’t have a good guess yet.
Implementation
I implement everything based on the NanoGPT repository. I replace the standard deviation calculation in the LN by a fixed number (set to the average standard deviation). This number is fixed, but it is degenerate with the LN scale (self.weight) which is learnable.
std = self.average_std if std_type == "avg" else self.bos_std]
(x - x.mean(-1, keepdim=True)) / std * self.weight + self.biasI have two different average stds, self.average_std (average of std over all tokens except for position 0) and self.bos_std (average of stds at position 0). Initially, after replacing the real LN with this “dummy LN” I use the following policy for choosing which std to divide by:
- Use
self.average_stdif token position is > 0 [and token is not end-of-text (EOT)] - Use
self.bos_stdif token position is 0 [or current token us EOT]
The EOT rule in [brackets] is used only for the LN before the attention v vector. Pseudocode for a simplified version of my implementation:
x_v[eot_mask] = self.ln_1(x, std_type="eot")[eot_mask]
x_v[~eot_mask] = self.ln_1(x, std_type="avg")[~eot_mask]I will upload the full code when I have more time next week (email me if you'd like it earlier).
Results
Well, the models train, the loss is low, and the models still speak English.
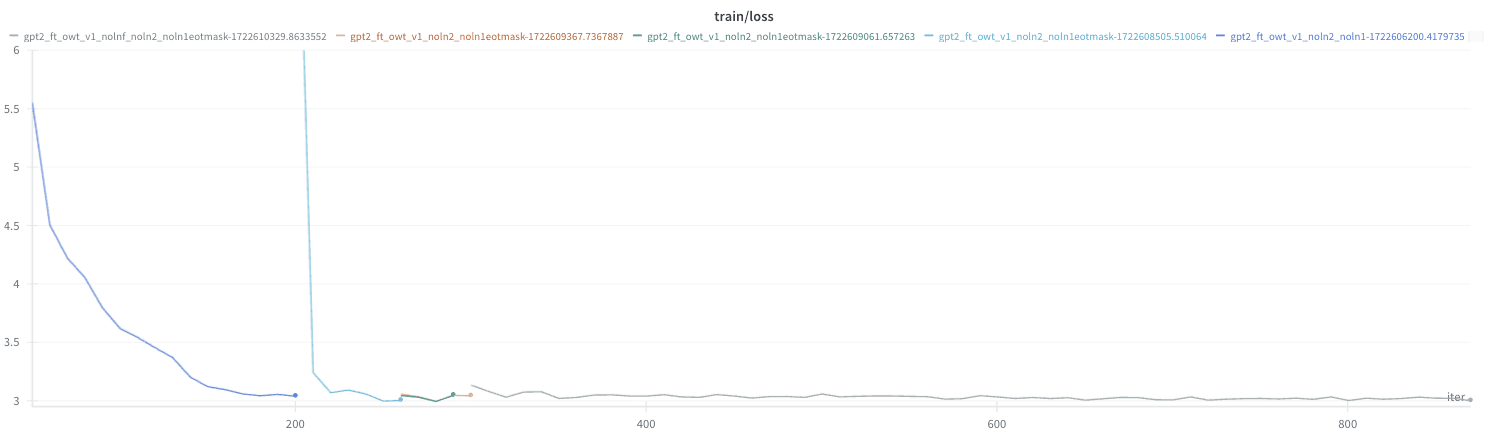
v1 model: Manually interrupt & resume training whenever loss went down enough:
v2 model (+ vanilla GPT2 fine-tuning comparison in green) with scheduled LN removals:
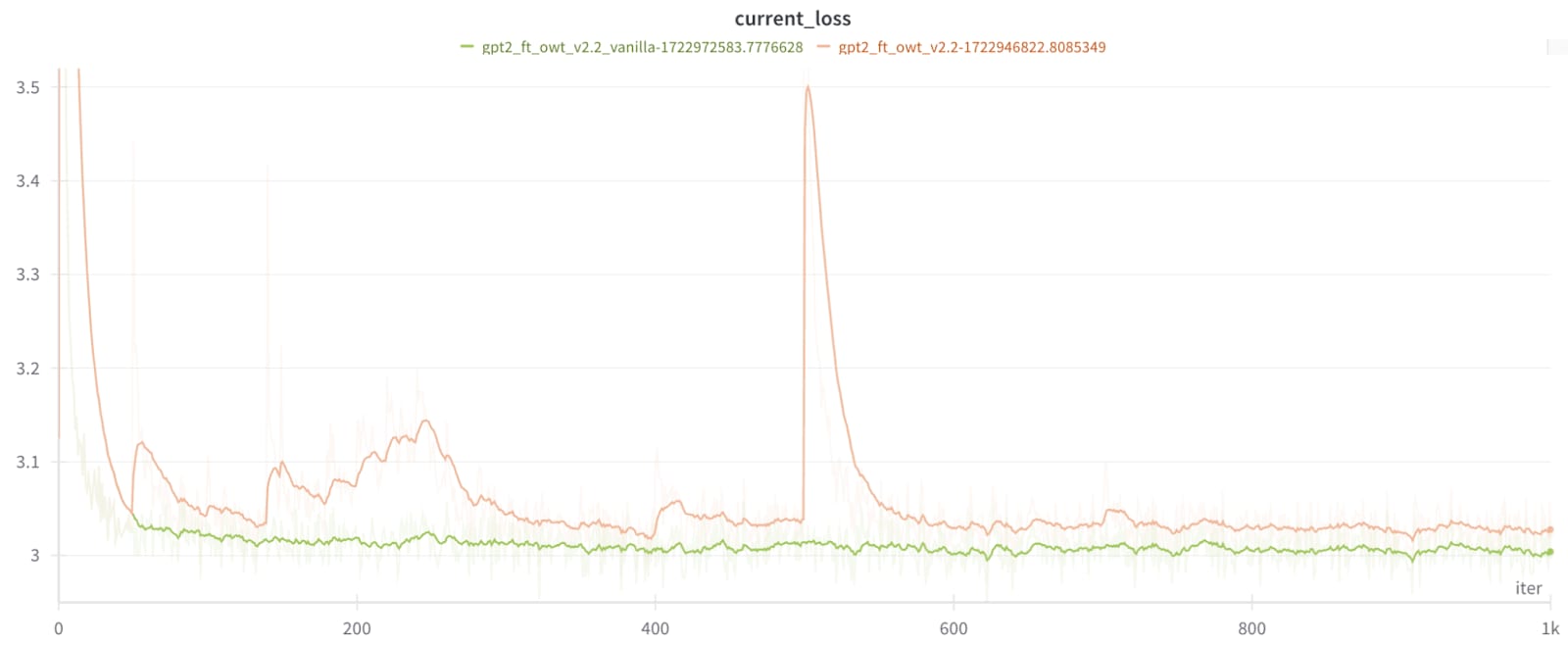
I'm currently training a third version employing the gradual removal technique to more of the components, and will update the Hugging Face repository (use the v1 and v2 revisions for models presented here).
Here I compare the cross entropy losses on OpenWebText and ThePile, as well as the score on the HellaSwap benchmark (using the Andrej Karpathy's implementation). I choose two baselines; the original GPT2 model straight from Hugging Face, and a second version that I fine-tuned on OpenWebText for 1000 iterations to be more comparable to the noLN ones (which were fine-tuned on that data).
| Dataset | Original GPT2 | GPT2 with LN | GPT2 noLN v1 | GPT2 noLN v2 |
| OpenWebText (ce_loss) | 3.095 | 2.989 | 3.139 | 3.014 (+0.025) |
| ThePile (ce_loss) | 2.856 | 2.880 | 3.057 | 2.926 (+0.046) |
| HellaSwag (accuracy) | 29.56% | 29.82% | 29.17% | 29.54% |
Some sample generations with model.generate:
GPT2:
As the last leaf fell from the tree, John realized that it was empty. He took the leaf and turned it over to his wife, who told him that it was still there and that he would have to go to the church to find it. John went to the church, and found that it was empty. He said, "I am going to the church and I am going to find the rest of the leaves, and I am going to look for them and find out where they
As the last leaf fell from the tree, John realized that the tree had been torn down. As he turned his head, the other trees started to fall. "Come on," John said, "we're going to get out of here!" The next tree was a wildflower. "How is it?" John asked, "do you see any other way?" "It's a good thing," the other trees replied.
GP2_noLN:
As the last leaf fell from the tree, John realized that he was going to have to use it. “We’ve all been there. We’ve all been there,” he said. “It’s been a long time. But, it’s good to be back. It’s good to be back.” “It’s good to be back. It’s good to be back
As the last leaf fell from the tree, John realized that a large amount of weight had been lifted from him. "I had a little panic attack. I was afraid that I could not walk," he said. "I felt like my legs were going to break." John has since gone back to the tree. "I have to tell you that I'm sorry I did that, but I don't know if that will ever happen," he said.
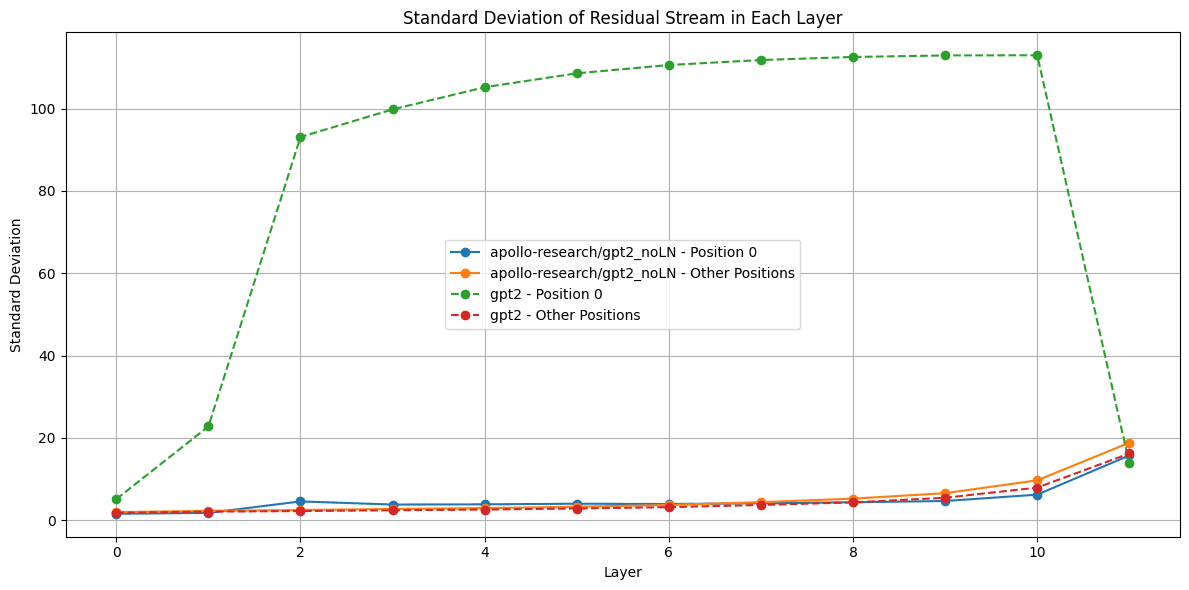
Residual stream norms
Previously I noticed [LW · GW] that the norm of the residual stream looks very different at position 0 compared to the rest of the model. Does this behavior still exists in the noLN model? No. The noLN model (solid lines) does not show the different in norms we saw in the original models (dashed lines):
Discussion
Faithfulness to the original model
I expect that the new no-LayerNorm (noLN) model will not have the exact same internal mechanisms as the original model. To some extent I expect lots of similarities (as the new model just had an hour to train), but since the norms changed (see above) and the loss changed, I expect differences.
My goal with this model is more like “have a toy model almost as good as GPT2 but easier to interpret” to replace vanilla GPT2 in interpretability research. Models like GPT2 (and Pythia etc.) are useful not because they are the models we ultimately care about (GPT4, GPT5, …) but because they let us generally explore how LLM internals work. To this extent, I don’t mind if GPT2-noLN differs from GPT2.
A question for the future is whether we want to apply this LN removal method before interpreting gpt4 and other “production models”. This depends on how similar the internals are, and I am currently uncertain about this. I am primarily concerned with the earlier use-case.
Does the noLN model generalize worse?
I noticed that the noLN performance hit was worse on The Pile than OpenWebText. This might be a coincidence, but it could also suggest that removing LN hurts generalization. While LN was originally introduced for training stability purposes, it may have a side effect on generalization. I have not evaluated the models on more datasets and leave this question for future research. Edit 30th Aug 2024: On the other hand this makes the OpenWebText and ThePile losses of the no-LN model more similar than those of the original model.
Appendix
Representing the no-LayerNorm model in GPT2LMHeadModel
I replace LayerNorms with DummyLayerNorms that use a fixed std, rather than computing the actual variance of each sample. This is equivalent to removing because the remaining LN operations can be folded into the following layers (e.g. TransformerLens mostly does this; TL does not fold in the centering operations but I do). I perform this folding in for all ln_1 and ln_2 layers. Thus I obtain weights with which GPT2 can run without any LayerNorm layers (all LNs replaced by nn.identity).
To make the model available on Hugging Face without trust_remote_code I want to package it into the GPT2LMHeadModel class. Thus I want to “neuter” the LNs in GPT2LMHeadModel such that the model just works with my “LNs are identities”-weights. I do this by setting ln_eps (epsilon) to a very high value (1e12), and setting the ln weights (gamma) to a corresponding value (1e6). I set the biases to 0. This leaves the centering operation but this doesn’t matter as I also fold a centering operation into the following layers, thus the LNs can be removed without further changes.
There’s one exception to this, the final layer norm. GPT2LMHeadModel uses (a) tied embedding and unembedding weights, and (b) no unembedding bias. Thus it is impossible to fold the final LayerNorm, which includes a (diagonal) weight matrix and a bias, into the other weights here. I still “neuter” the normalizing function of the LayerNorm as above, so ln_final just represents a simple linear layer before the unembedding.
Which order to remove LayerNorms in
There’s two sources of reasons that inform which LayerNorms I want to remove furst
- LayerNorm is there to help us train the model (stabilizing / speeding up training). While we are only fine-tuning, I expect that the remaining LNs still help us fine-tune the weights after removing the first LNs.
- Empirically removing some LNs first makes the loss explode, but removing the same LNs after first removing and fine-tuning other LNs is fine. This makes some sense; we expect the model to adapt to remove all functionality that relies on LNs. So maybe the first removal is the most important one (after which the model reorganizes computation), and further removals don’t require as large of a reorganization anymore.
So I expect which order to remove the LNs in matters.
A meta-choice is whether
- to remove all LNs of a type first (for all layers), and later remove LNs of different types, or
- to remove all LNs in a layer (of all types), and then move on to the next layer.
I went with the first option for ease of implementation, but have not tried the second option. However the second option would seem more principled to me once we understand which order is optimal.
Which kinds of LayerNorms to remove first
I tried out a few combinations, such as first removing ln_f and then removing ln_2 and ln_1, or vice versa. I haven’t done a systematic sweep of all options, and the current method is just what felt right after a couple of tries. It seems to work well enough though.
Here’s an example of removing ln_f first. The loss reaches a very high level, and even after 400 iterations only goes down to 3.138. So it seems this is a worse choice. Not however that in this run I didn’t do “warm up” iterations (training for a couple iterations with LN to reach a good loss on OpenWebText – gpt2 directly loaded from Hugging Face does badly for the first ~10 iterations).
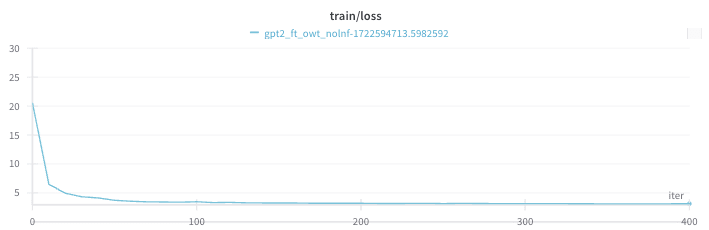
Which layer to remove LayerNorms in first
Here I remove ln2 in the different layers in different orders:
- Normal = remove in layer 0, then layer 1, …
- Reverse = remove in layer 11, then layer 10, …
I start removing LNs at iteration 300, and remove another LN every 10 iterations.
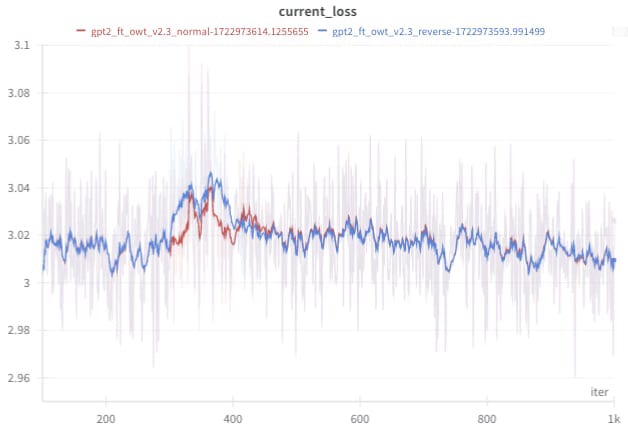
The loss differs during the process (this is expected, some LNs are possibly more important than others) but evens out at the end.
Data-reuse and seeds
In my initial tests I used lots of snapshots, and accidentally retrained the model on the same first couple of batches of openwebtext (fixed seed) every time. I have the impression that this worked slightly better than my later full-pipeline runs never re-using data. I might investigate this in the future.
Infohazards
I am not worried that publishing this work accelerates capabilities progress over alignment progress. Because (a) this is a pretty obvious idea, (b) it applies only to inference (not training), and (c) it only speeds up inference by a very small amount (that likely is not even worth the loss increase).
Acknowledgements
Thanks to Alice Rigg, Bilal Chughtai, Leo Gao, Neel Nanda, and Rudolf Laine for comments and feedback on the draft. The nanoGPT repository and accompanying video by Andrej Karpathy were very helpful, allowing me to get a working prototype in a day!
- ^
The GPT2 paper claims a loss of log(16)=2.77 on their training dataset (non-public webtext). I guess that must be an easier dataset. In any case, I fine-tune both models on OpenWebText for a total of 1000 iterations (~500k rows, ~500M tokens) to give a fairer comparison.
- ^
For this case, only the final layer norm matters
- ^
this paper discusses confidence regularization as one possible-important aspect
- ^
I wonder how much of this effect is “just divide by a larger number” vs. actually dividing by the correct average. After all, the position 0 average shouldn’t be a great match for the EOT token average. [In this dataset the first position is not an EOT token. Neel Nanda / TransformerLebs recommends this for short prompts (see here for a discussion) but we don’t do it for the full dataset.]
11 comments
Comments sorted by top scores.
comment by Logan Riggs (elriggs) · 2024-08-08T18:49:28.046Z · LW(p) · GW(p)
This is extremely useful for SAE circuit work. Now the connections between features are at most ReLU(Wx + b) which is quite interpretable! (Excluding attn_in->attn_out)
Thanks for doing this!
comment by Cody Rushing (cody-rushing) · 2024-08-08T23:25:44.315Z · LW(p) · GW(p)
Another reason why layernorm is weird (and a shameless plug): the final layernorm also contributes to self-repair in language models
comment by StefanHex (Stefan42) · 2024-08-08T20:11:03.552Z · LW(p) · GW(p)
Here's a quick snipped to load the model into TransformerLens!
import torch
from transformers import GPT2LMHeadModel
from transformer_lens import HookedTransformer
model = GPT2LMHeadModel.from_pretrained("apollo-research/gpt2_noLN").to("cpu")
hooked_model = HookedTransformer.from_pretrained("gpt2", hf_model=model, fold_ln=False, center_unembed=False).to("cpu")
# Kill the LayerNorms because TransformerLens overwrites eps
for block in hooked_model.blocks:
block.ln1.eps = 1e12
block.ln2.eps = 1e12
hooked_model.ln_final.eps = 1e12
# Make sure the outputs are the same
prompt = torch.tensor([1,2,3,4], device="cpu")
logits = hooked_model(prompt)
logits2 = model(prompt).logits
print(logits.shape, logits2.shape)
print(logits[0, 0, :10])
print(logits2[0, :10])↑ comment by StefanHex (Stefan42) · 2024-08-08T21:01:46.583Z · LW(p) · GW(p)
And here's the code to do it with replacing the LayerNorms with identities completely:
import torch
from transformers import GPT2LMHeadModel
from transformer_lens import HookedTransformer
model = GPT2LMHeadModel.from_pretrained("apollo-research/gpt2_noLN").to("cpu")
# Undo my hacky LayerNorm removal
for block in model.transformer.h:
block.ln_1.weight.data = block.ln_1.weight.data / 1e6
block.ln_1.eps = 1e-5
block.ln_2.weight.data = block.ln_2.weight.data / 1e6
block.ln_2.eps = 1e-5
model.transformer.ln_f.weight.data = model.transformer.ln_f.weight.data / 1e6
model.transformer.ln_f.eps = 1e-5
# Properly replace LayerNorms by Identities
class HookedTransformerNoLN(HookedTransformer):
def removeLN(self):
for i in range(len(self.blocks)):
self.blocks[i].ln1 = torch.nn.Identity()
self.blocks[i].ln2 = torch.nn.Identity()
self.ln_final = torch.nn.Identity()
hooked_model = HookedTransformerNoLN.from_pretrained("gpt2", hf_model=model, fold_ln=True, center_unembed=False).to("cpu")
hooked_model.removeLN()
hooked_model.cfg.normalization_type = None
prompt = torch.tensor([1,2,3,4], device="cpu")
logits = hooked_model(prompt)
print(logits.shape)
print(logits[0, 0, :10])↑ comment by Quiche Eater (John Dunbar) · 2024-09-16T06:16:55.261Z · LW(p) · GW(p)
You should also set model.cfg.normalization_type = None afterwards. It's mostly a formality since you're doing it after initialization. ActivationCache.apply_ln_to_stack() is the only function I found which behaves incorrectly if you don't change this.
↑ comment by StefanHex (Stefan42) · 2024-09-17T11:22:32.256Z · LW(p) · GW(p)
Thanks! I'll edit it
↑ comment by Logan Riggs (elriggs) · 2024-08-18T04:22:21.853Z · LW(p) · GW(p)
And here's the code to convert it to NNsight (Thanks Caden for writing this awhile ago!)
import torch
from transformers import GPT2LMHeadModel
from transformer_lens import HookedTransformer
from nnsight.models.UnifiedTransformer import UnifiedTransformer
model = GPT2LMHeadModel.from_pretrained("apollo-research/gpt2_noLN").to("cpu")
# Undo my hacky LayerNorm removal
for block in model.transformer.h:
block.ln_1.weight.data = block.ln_1.weight.data / 1e6
block.ln_1.eps = 1e-5
block.ln_2.weight.data = block.ln_2.weight.data / 1e6
block.ln_2.eps = 1e-5
model.transformer.ln_f.weight.data = model.transformer.ln_f.weight.data / 1e6
model.transformer.ln_f.eps = 1e-5
# Properly replace LayerNorms by Identities
def removeLN(transformer_lens_model):
for i in range(len(transformer_lens_model.blocks)):
transformer_lens_model.blocks[i].ln1 = torch.nn.Identity()
transformer_lens_model.blocks[i].ln2 = torch.nn.Identity()
transformer_lens_model.ln_final = torch.nn.Identity()
hooked_model = HookedTransformer.from_pretrained("gpt2", hf_model=model, fold_ln=True, center_unembed=False).to("cpu")
removeLN(hooked_model)
model_nnsight = UnifiedTransformer(model="gpt2", hf_model=model, fold_ln=True, center_unembed=False).to("cpu")
removeLN(model_nnsight)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
prompt = torch.tensor([1,2,3,4], device=device)
logits = hooked_model(prompt)
with torch.no_grad(), model_nnsight.trace(prompt) as runner:
logits2 = model_nnsight.unembed.output.save()
logits, cache = hooked_model.run_with_cache(prompt)
torch.allclose(logits, logits2)comment by Chris_Leong · 2024-08-09T09:20:06.102Z · LW(p) · GW(p)
Fascinating. I would love to see follow up work on whether it does harm generalisation, because if we were able to train more interpretable models without damaging generalisation, that would be amazing.
I'd love to see other research along these lines. Like what if we could use interpretability to figure out what a circuit does, replace the circuit with something more principled/transparent, then train for a bit longer with the new circuit in place.
comment by Caleb Biddulph (caleb-biddulph) · 2024-08-09T00:44:31.915Z · LW(p) · GW(p)
This is great! Maybe you'd get better results if you "distill" GPT2-LN into GPT2-noLN by fine-tuning on the entire token probability distribution on OpenWebText.
comment by Daniel Tan (dtch1997) · 2024-08-12T09:03:37.351Z · LW(p) · GW(p)
Interesting stuff! I'm very curious as to whether removing layer norm damages the model in some measurable way.
One thing that comes to mind is that previous work finds that the final LN is responsible for mediating 'confidence' through 'entropy neurons'; if you've trained sufficiently I would expect all of these neurons to not be present anymore, which then raises the question of whether the model still exhibits this kind of self-confidence-regulation
comment by Review Bot · 2024-08-09T09:53:02.416Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?