Instrumental Convergence For Realistic Agent Objectives
post by TurnTrout · 2022-01-22T00:41:36.649Z · LW · GW · 9 commentsContents
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents an unrealistic picture of the role of reward functions in reinforcement learning, conflating "utility" with "reward." Reward functions are not "goals", r...
Case Studies
Gridworld
StarCraft II
What the theorems say:
Minecraft
What the theorems say:
Beyond The Featurized Case
Revisiting How The Environment Structure Affects Power-Seeking Incentive Strength
Appendix: tracking key limitations of the power-seeking theorems
None
9 comments
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents an unrealistic picture of the role of reward functions in reinforcement learning, conflating "utility" with "reward." Reward functions are not "goals", reward functions are not "objectives" of the policy network, real-world policies are not "optimal", and the mechanistic function of reward is (usually) to provide policy gradients to update the policy network.
I expect this post to harm your alignment research intuitions unless you've already inoculated yourself by deeply internalizing and understanding Reward is not the optimization target [LW · GW]. If you're going to read one alignment post I've written, read that one.
Follow-up work (Parametrically retargetable decision-makers tend to seek power [LW · GW]) moved away from optimal policies and treated reward functions more realistically.
The current power-seeking theorems say something like:
Give me a utility function, any utility function, and for most ways I could jumble it up—most ways I could permute which outcomes get which utility, for most of these permutations, the agent will seek power.
This kind of argument assumes that (the set of utility functions we might specify) is closed under permutation. This is unrealistic, because practically speaking we reward agents based off of observed features of the agent's environment.
For example, Pac-Man eats dots and gains points. A football AI scores a touchdown and gains points. A robot hand solves a Rubik's cube and gains points. But most permutations of these objectives are implausible because they're high-entropy, they're very complex, they assign high reward to one state and low reward to another state without a simple generating rule that grounds out in observed features. Practical objective specification doesn't allow that many degrees of freedom in what states get what reward.
I explore how instrumental convergence works in this case. I also walk through how these new results retrodict the fact that instrumental convergence basically disappears for agents with utility functions over action-observation histories [? · GW].
Case Studies
Gridworld
Consider the following environment, where the agent can either stay put or move along a purple arrow.
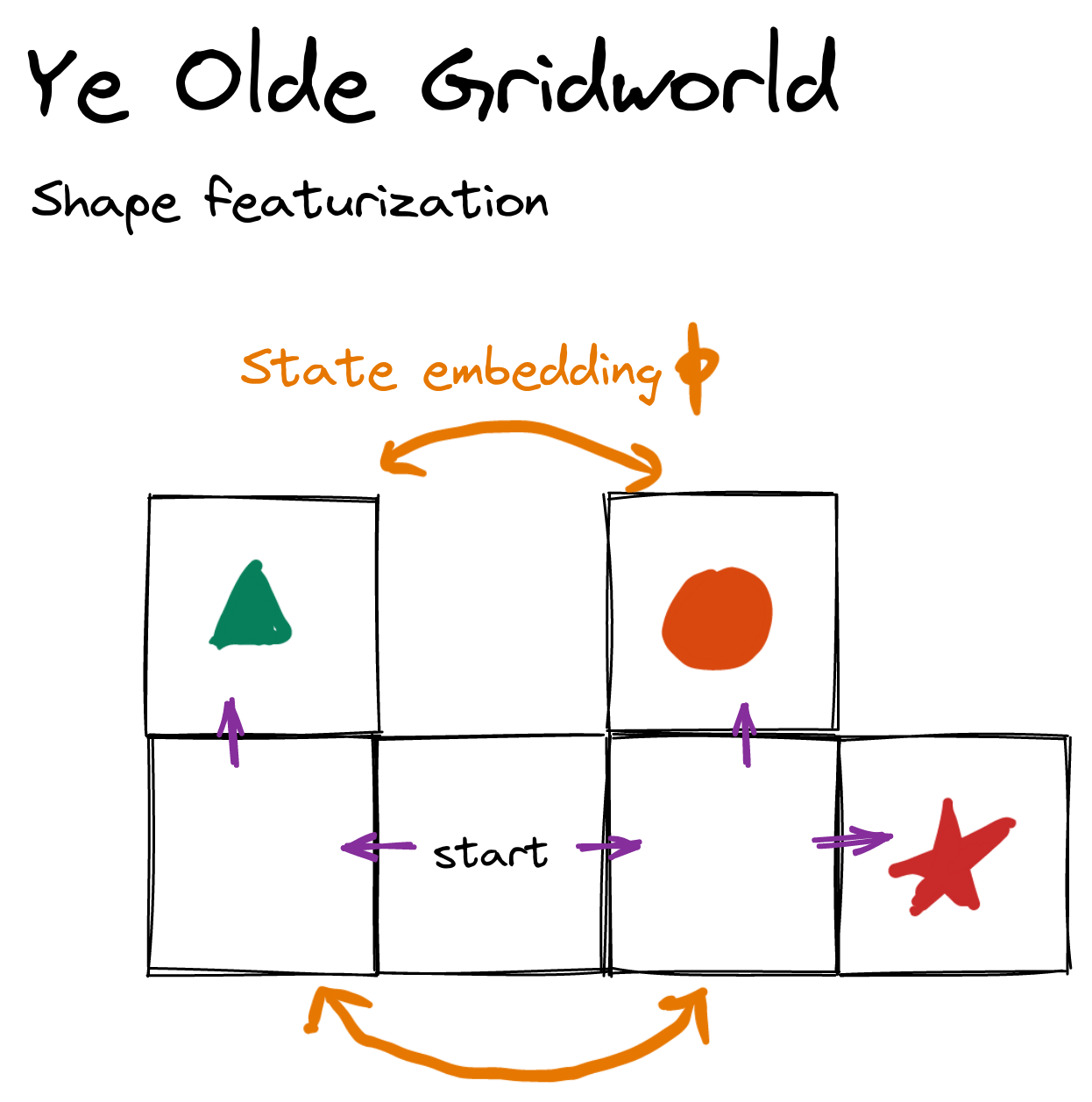
Suppose the agent gets some amount of reward each timestep, and it's choosing a policy to maximize its average per-timestep reward. Previous results tell us that for generic reward functions over states, at least half of them incentivize going right. There are two terminal states on the left, and three on the right, and 3 > 2; we conclude that at least of objectives incentivize going right [LW · GW].
But it's damn hard to have so many degrees of freedom that you're specifying a potentially independent utility number for each state.[1] Meaningful utility functions will be featurized in some sense—only depending on certain features of the world state, and of how the outcomes transpired, etc. If the featurization is linear, then it's particularly easy to reason about power-seeking incentives.
Let . That is, the featurization only cares what shape the agent is standing on. Suppose the agent makes decisions in a way which depends only on [? · GW] the featurized reward of a state: , where expresses the feature coefficients. Then the relevant terminal states are only {triangle, circle, star}, and we conclude that of coefficient vectors incentivize going right. This is true more precisely in the orbit sense: For every coefficient vector , at least[2] of its permuted variants make the agent prefer to go right.
This particular featurization increases the strength of the orbit-level incentives—whereas before, we could only guarantee -strength power-seeking tendency, now we guarantee -level.[3][4]
There's another point I want to make in this tiny environment.
Suppose we find an environmental symmetry which lets us apply the original power-seeking theorems to raw reward functions over the world state. Letting be a column vector with an entry of 1 at state and 0 elsewhere, in this environment, we have the symmetry enforced by .
Given a state featurization, and given that we know that there's a state-level environmental symmetry , when can we conclude that there's also feature-level power-seeking in the environment?
Here, we're asking "if reward is only allowed to depend on how often the agent visits each shape, and we know that there's a raw state-level symmetry, when do we know that there's a shape-feature embedding from (left shape feature vectors) into (right shape feature vectors)?"
In terms of "what choice lets me access 'more' features?", this environment is relatively easy—look, there are twice as many shapes on the right. More formally, we have:
where the left set can be permuted two separate ways into the right set (since the zero vector isn't affected by feature permutations).
But I'm gonna play dumb and walk through to illustrate a more important point about how power-seeking tendencies are guaranteed when featurizations respect the structure of the environment.
Consider the state . We permute it to be using (because ), and then featurize it to get a feature vector with 1 and 0 elsewhere.
Alternatively, suppose we first featurize to get a feature vector with 1 and 0 elsewhere. Then we swap which features are which, by switching and . Then we get a feature vector with 1 and 0 elsewhere—the same result as above.
The shape featurization plays nice with the actual nitty-gritty environment-level symmetry. More precisely, a sufficient condition for feature-level symmetries: (Featurizing and then swapping which features are which) commutes with (swapping which states are which and then featurizing).[5] And where there are feature-level symmetries, just apply the normal power-seeking theorems to conclude that there are decision-making tendencies to choose sets of larger features.
In a different featurization, suppose the featurization is the agent's coordinates. .
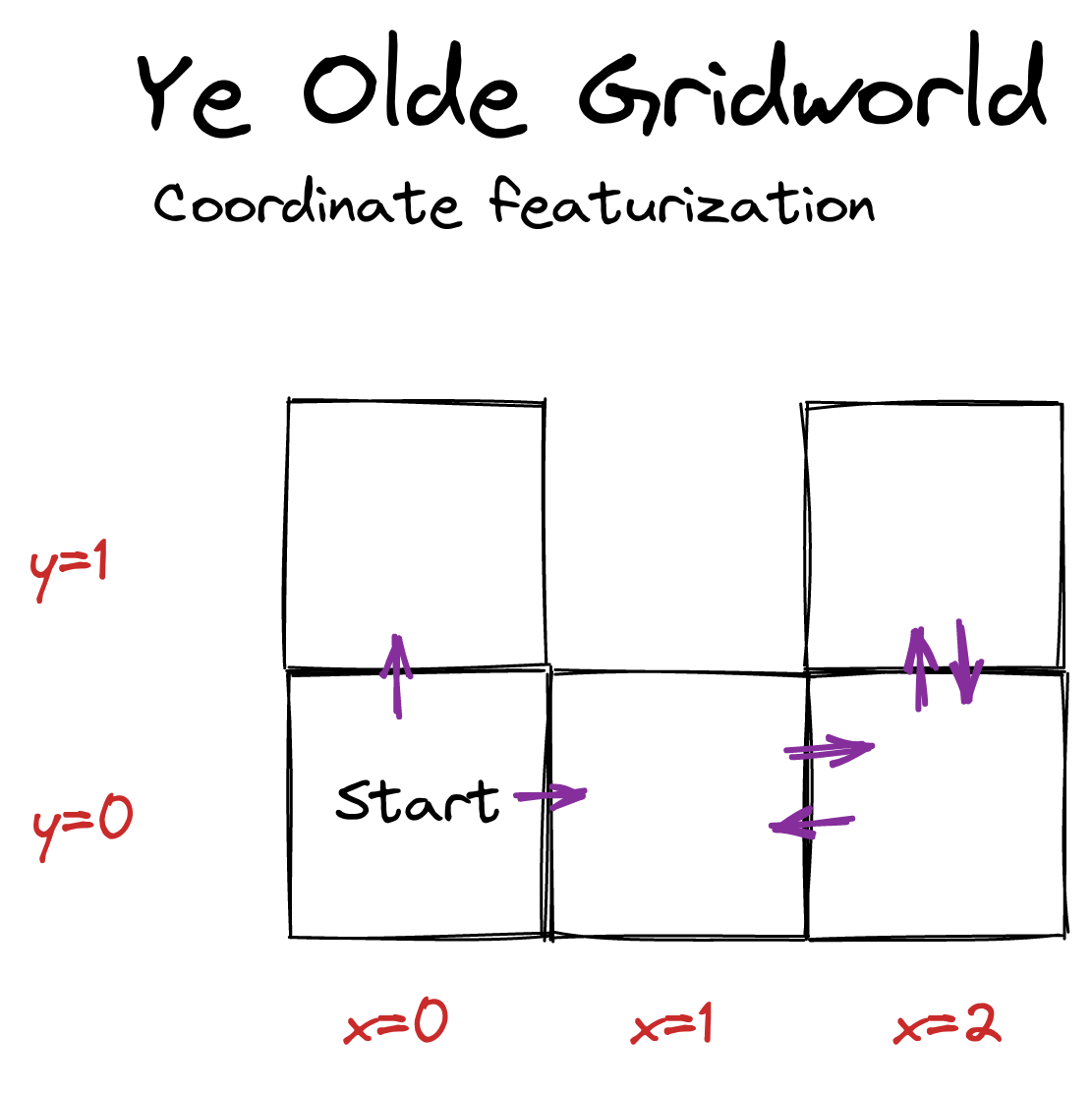
Given the start state, if the agent goes up, its reachable feature vector is just {(x=0 y=1)}, whereas the agent can induce (x=1 y=0) if it goes right. Therefore, whenever up is strictly optimal for a featurized reward function, we can permute that reward function's feature weights by swapping the x- and y-coefficients ( and , respectively). Again, this new reward function is featurized, and it makes going right strictly optimal. So the usual arguments ensure that at least half of these featurized reward functions make it optimal to go right.
But sometimes these similarities won't hold, even when it initially looks like they "should"!
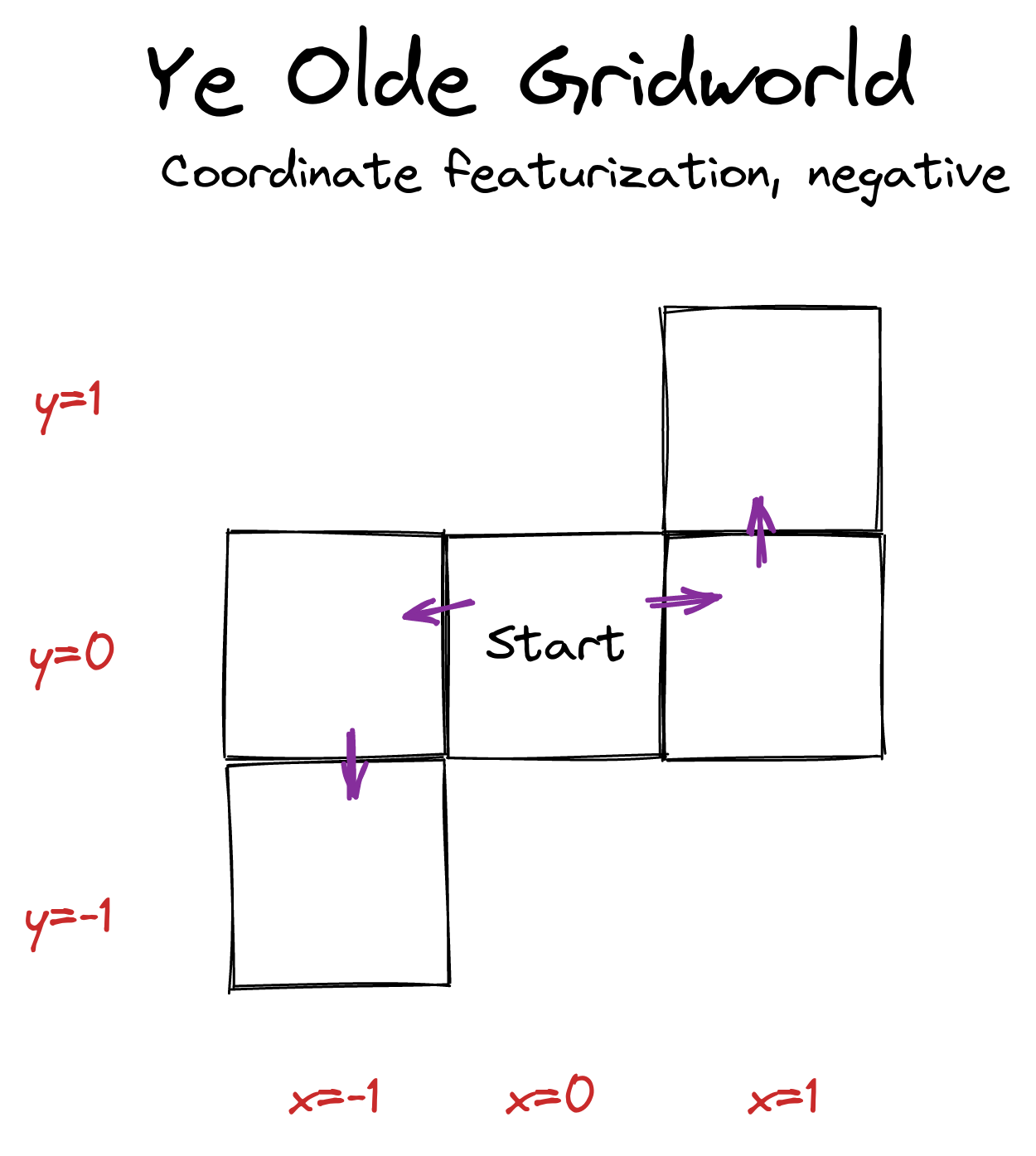
In this environment, the agent can induce the feature vectors if it goes left. However, it can induce if it goes right. There is no way of switching feature labels so as to copy the left feature set into the right feature set! There's no way to just apply a feature permutation to the left set, and thereby produce a subset of the right feature set. Therefore, the theorems don't apply, and so they don't guarantee anything about how most permutations of every reward function incentivize some kind of behavior.
On reflection, this makes sense. If , then there's no way the agent will want to go right. Instead, it'll go for the negative feature values offered by going left. This will hold for all permutations of this feature labelling, too. So the orbit-level incentives can't hold.
If the agent can be made to "hate everything" (all feature weights are negative), then it will pursue opportunities which give it negative-valued feature vectors, or at least strive for the oblivion of the zero feature vector. Vice versa for if it positively values all features.
StarCraft II
Consider a deep RL training process, where the agent's episodic reward is featurized into a weighted sum of the different resources the agent has at the end of the game, with weight vector . For simplicity, we fix an opponent policy and a learning regime (number of epochs, learning rate, hyperparameters, network architecture, and so on). We consider the effects of varying the reward feature coefficients .

Outcomes of interest: Game state trajectories.
AI decision-making function: returns the probability that, given our fixed learning regime and reward feature vector , the training process produces a policy network whose rollouts instantiate some trajectory .
What the theorems say:
- If is the zero vector, the agent gets the same reward for all trajectories, and so gradient descent does nothing, and the randomly initialized policy network quickly loses against any reasonable opponent. No power-seeking tendencies if this is the only plausible parameter setting.
- If only has negative entries, then the policy network quickly learns to throw away all of its resources and not collect any more. If and only if this has been achieved, the training process is indifferent to whether the game is lost. No real power-seeking tendencies if it's only plausible that we specify a negative vector.
- If has a positive entry, then policies learn to gather as much of that resource as possible. In particular, there aren't orbit elements with positive entries but where the learned policy tends to just die, and so we don't even have to check that the permuted variants of such feature vectors are also plausible. Power-seeking occurs.
This reasoning depends on which kinds of feature weights are plausible, and so wouldn't have been covered by the previous results.
Minecraft
Similar setup to StarCraft II, but now the agent's episode reward is (Amount of iron ore in chests within 100 blocks of spawn after 2 in-game days)(Same but for coal), where are scalars (together, they form the coefficient vector ).

Outcomes of interest: Game state trajectories.
AI decision-making function: returns the probability that, given our fixed learning regime and feature coefficients , the training process produces a policy network whose rollouts instantiate some trajectory .
What the theorems say:
- If is the zero vector, the analysis is the same as before. No power-seeking tendencies. In fact, the agent tends to not gain power because it has no optimization pressure steering it towards the few action sequences which gain the agent power.
- If only has negative entries, the agent definitely doesn't hoard resources in chests. Otherwise, there's no real reward signal and gradient descent doesn't do a whole lot due to sparsity.
- If has a positive entry, and if the learning process is good enough, agents tend to stay alive. If the learning process is good enough, there just won't be a single feature vector with a positive entry which tends to produce non-self-empowering policies.
The analysis so far is nice to make a bit more formally, but it isn't really pointing out anything that we couldn't have figured out pre-theoretically. I think I can sketch out more novel reasoning, but I'll leave that to a future post.
Beyond The Featurized Case
Consider some arbitrary set of "plausible" utility functions over outcomes. If we have the usual big set of outcome lotteries (which possibilities are, in the view of this theory, often attained via "power-seeking"), and contains copies of some smaller set via environmental symmetries , then when are there orbit-level incentives within —when will most reasonable variants of utility functions make the agent more likely to select rather than ?
When the environmental symmetries can be applied to the -preferring-variants, in a way which produces another plausible objective. Slightly more formally, if, for every plausible utility function where the agent has a greater chance of selecting than of selecting , we have the membership for all . (The formal result is Lemma B.7 in this Overleaf.)
This covers the totally general case of arbitrary sets of utility function classes we might use. (And, technically, "utility function" is decorative at this point—it just stands in for a parameter which we use to retarget the AI policy-production process.)
The general result highlights how := { plausible objective functions } affects what conclusions we can draw about orbit-level incentives. All else equal, being able to specify more plausible objective functions for which means that we're more likely to to ensure closure under certain permutations. Similarly, adding plausible -dispreferring objectives makes it harder to satisfy , which makes it harder to ensure closure under certain permutations, which makes it harder to prove instrumental convergence.
Revisiting How The Environment Structure Affects Power-Seeking Incentive Strength
In Seeking Power is Convergently Instrumental in a Broad Class of Environments [? · GW], I wrote:
Structural assumptions on utility really do matter when it comes to instrumental convergence:
- u-AOH (utility functions over action-observation histories): No IC [LW · GW]
- u-OH (utility functions over observation histories): Strong IC [LW · GW]
- State-based objectives (eg state-based reward in MDPs): Moderate IC [? · GW]
Environmental structure can cause instrumental convergence [LW · GW], but (the absence of) structural assumptions on utility can make instrumental convergence go away (for optimal agents).
In particular, for the MDP case, I wrote:
MDPs assume that utility functions have a lot of structure: the utility of a history is time-discounted additive over observations. Basically, , for some and reward function over observations. And because of this structure, the agent's average per-timestep reward is controlled by the last observation it sees. There are exponentially fewer last observations than there are observation histories. Therefore, in this situation, instrumental convergence is exponentially weaker for reward functions than for arbitrary u-OH.
This is equivalent to a featurization which takes in an action-observation history, ignores the actions, and spits out time-discounted observation counts. The utility function is then over observations (which are just states in the MDP case). Here, the symmetries can only be over states, and not histories, and no matter how expressive the plausible state-based-reward-set is, it can't compete with the exponentially larger domain of the observation-history-based-utility-set , and so the featurization has limited how strong instrumental convergence can get by projecting the high-dimensional u-OH into the lower-dimensional u-State.
But when we go from u-AOH to u-OH, we're throwing away even more information—information about the actions! This is also a sparse projection. So what's up?
When we throw away info about actions, we're breaking some symmetries which made instrumental convergence disappear in the u-AOH case. In any deterministic environment, there are equally many u-AOH which make me want to go e.g. left (and, say, die) as which make me want to go right (and survive). This is guaranteed by symmetries which swap the value of an optimal AOH with the value of an AOH going the other way:

But when we restrict the utility function to not care about actions, now you can only modify how it cares about observation histories. Here, the AOH environmental symmetry which previously ensured balanced statistical incentives, no longer enjoys closure under , and so the restricted plausible set theorem no longer works, and instrumental convergence appears when restricting from u-AOH to u-OH.
I thank Justis Mills for feedback on a draft.
Appendix: tracking key limitations of the power-seeking theorems
- The results aren't first-person: They don't deal with the agent's uncertainty about what environment it's in.
- Not all environments have the right symmetries
- But most ones we think about seem to
Don't account for the ways in which we might practically express reward functions.(This limitation was handled by this post.)
I think it's reasonably clear how to apply the results to realistic objective functions. I also think our objective specification procedures are quite expressive, and so the closure condition will hold and the results go through in the appropriate situations.
- ^
It's not hard to have this many degrees of freedom in such a small toy environment, but the toy environment is pedagogical. It's practically impossible to have full degrees of freedom in an environment with a trillion states.
- ^
"At least", and not "exactly." If is a constant feature vector, it's optimal to go right for every permutation of (trivially so, since 's orbit has a single element—itself).
- ^
Even under my more aggressive conjecture about "fractional terminal state copy containment", the unfeaturized situation would only guarantee -strength orbit incentives, strictly weaker than -strength.
- ^
Certain trivial featurizations can decrease the strength of power-seeking tendencies, too. For example, if the featurization is 2-dimensional: , this will tend to produce 1:1 survive/die orbit-level incentives, whereas the incentives for raw reward functions may be 1,000:1 or stronger [LW · GW].
- ^
There's something abstraction-adjacent about this result (proposition D.1 in the linked Overleaf paper). The result says something like "do the grooves of the agent's world model featurization, respect the grooves of symmetries in the structure of the agent's environment?", and if they do, bam, sufficient condition for power-seeking under the featurized model. I think there's something important here about how good world-model-featurizations should work, but I'm not sure what that is yet.
I do know that "the featurization should commute with the environmental symmetry" is something I'd thought—in basically those words—no fewer than 3 times, as early as summer, without explicitly knowing what that should even mean. - ^
Lemma B.7 in this Overleaf—compile
quantitative-paper.tex.
9 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2022-01-22T02:23:08.684Z · LW(p) · GW(p)
Typo:
No real power-seeking tendencies if we only plausibly will specify a negative vector.
Seems like two sentences got merged together.
Replies from: TurnTroutcomment by Jacob Pfau (jacob-pfau) · 2022-01-25T09:14:02.360Z · LW(p) · GW(p)
Am I correct to assume that the discussion of StarCraft and Minecraft are discussing single-player variants of those games?
It seems to me that in a competitive, 2-player, minimize-resource-competition StarCraft, you would want to go kill your opponent so that they could no longer interfere with your resource loss? More generally, I think competitions to minimize resources might still usually involve some sort of power-seeking. I remember reading somewhere that 'losing chess' involves normal-looking (power-seeking?) early game moves.
Replies from: TurnTrout, Pattern↑ comment by TurnTrout · 2022-01-25T18:18:00.447Z · LW(p) · GW(p)
I'm implicitly assuming a fixed opponent policy, yes.
Without being overly familiar with SC2—you don't have to kill your opponent to get to 0 resources, do you? From my experience with other RTS games, I imagine you can just quickly build units and deplete your resources, and then your opponent can't make you accrue more resources. Is that wrong?
Replies from: jacob-pfau↑ comment by Jacob Pfau (jacob-pfau) · 2022-01-26T10:32:53.899Z · LW(p) · GW(p)
Yes, I agree that in the simplest case, SC2 with default starting resources, you just build one or two units and you're done. However, I don't see why this case should be understood as generically explaining the negative alpha weights setting. Seems to me more like a case of an excessively simple game?
Consider the set of games starting with various quantities of resources and negative alpha weights. As starting resources increase, you will be incentivised to go attack your opponent to interfere with their resource depletion. Indeed, if the reward is based on end-of-game resource minimisation, you end up participating in an unbounded resource-maximisation competition trying to guarantee control over your opponent; then you spend your resources safely after crippling your opponent? In the single player setting, you will be incentivised to build up your infrastructure so as to spend your resources more quickly.
It seems to me the multi-player case involves power-seeking. Then, it seems like negative alpha weights don't generically imply anything about the existence of power-seeking incentives?
(I'm actually not clear on whether the single-player case should be seen as power-seeking or not? Maybe it depends on your choice of discount rate, gamma? You are building up infrastructure, i.e. unit-producing buildings, which seems intuitively power-seeking. But the number of long-term possibilities available to you following spending resources on infrastructure is reduced -- assuming gamma=1 -- OTOH the number of short-term possibilities may be higher given infrastructure, so you may have increased power assuming gamma<1?)
Replies from: TurnTrout↑ comment by TurnTrout · 2022-01-26T18:18:32.342Z · LW(p) · GW(p)
I agree that in certain conceivable games which are not baseline SC2, there will be different power-seeking incentives for negative alpha weights. My commentary wasn't intended as a generic takeaway about negative feature weights in particular.
But in the game which actually is SC2, where you don't start with a huge number of resources, negative alpha weights don't incentivize power-seeking. You do need to think about the actual game being considered, before you can conclude that negative alpha weighs imply such-and-such a behavior.
But the number of long-term possibilities available to you following spending resources on infrastructure is reduced
I think that either or considering suboptimal power-seeking [? · GW] resolves the situation. The reason that building infrastructure intuitively seems like power-seeking is that we are not optimal logically omniscient agents; all possible future trajectores do not lay out immediately before our minds. But the suboptimal power-seeking metric (Appendix C in Optimal Policies Tend To Seek Power) does match intuition here AFAICT, where cleverly building infrastructure has the effect of navigating the agent to situations with more cognitively exploitable opportunities.
↑ comment by Pattern · 2022-06-21T22:20:28.704Z · LW(p) · GW(p)
It seems to me that in a competitive, 2-player, minimize-resource-competition StarCraft, you would want to go kill your opponent so that they could no longer interfere with your resource loss?
I would say that in general it's more about what your opponent is doing. If you are trying to lose resources and the other player is trying to lose them, you're going to get along fine. (This would be likely be very stable and common if players can kill units and scavenge them for parts.) If both of you are trying to lose them...
Trying to minimize resources is a weird objective for StarCraft. As is gain resources. Normally it's a means to an end - destroying the other player first. Now, if both sides start out with a lot of resources and the goal is to hit zero first...how do you interfere with resource loss? If you destroy the other player don't their resources go to zero? Easy to construct, by far, is 'losing StarCraft'. And I'm not sure how you'd force a win.
This starts to get into 'is this true for Minecraft' and...it doesn't seem like there's conflict of the 'what if they destroy me, so I should destroy them from' kind, so much as 'hey stop stealing my stuff!'. Also, death isn't permanent, so... There's not a lot of non-lethal options. If a world is finite (and there's enough time) eventually, yeah, there could be conflict.
More generally, I think competitions to minimize resources might still usually involve some sort of power-seeking.
In the real world maybe I'd be concerned with self nuking. Also starting a fight, and stuff like that - to ensure destruction - could work very well.
comment by Koen.Holtman · 2022-01-31T19:32:55.118Z · LW(p) · GW(p)
instrumental convergence basically disappears for agents with utility functions over action-observation histories.
Wait, I am puzzled. Have you just completely changed your mind about the preconditions needed to get a power-seeking agent? The way the above reads is: just add some observation of actions to your realistic utility function, and you instrumental convergence problem is solved.
u-AOH (utility functions over action-observation histories): No IC
u-OH (utility functions over observation histories): Strong IC
There are many utility functions in u-AOH that simply ignore the A part of the history, so these would then have Strong IC because they are u-OH functions. So are you are making a subtle mathematical point about how these will average away to zero (given various properties of infinite sets), or am I missing something?
Replies from: TurnTrout↑ comment by TurnTrout · 2022-01-31T20:09:41.562Z · LW(p) · GW(p)
I recommend reading the quoted post [? · GW] for clarification.