How uniform is the neocortex?
post by zhukeepa · 2020-05-04T02:16:50.650Z · LW · GW · 23 commentsContents
How uniform is the neocortex? Cortical function is largely determined by input data Deep learning and cortical generality Canonical microcircuits for predictive coding My current take None 23 comments
How uniform is the neocortex?
The neocortex is the part of the human brain responsible for higher-order functions like sensory perception, cognition, and language, and has been hypothesized to be uniformly composed of general-purpose data-processing modules. What does the currently available evidence suggest about this hypothesis?
"How uniform is the neocortex?” is one of the background variables in my framework for AGI timelines [AF · GW]. My aim for this post is not to present a complete argument for some view on this variable, so much as it is to:
- present some considerations I’ve encountered that shed light on this variable
- invite a collaborative effort among readers to shed further light on this variable (e.g. by leaving comments about considerations I haven’t included, or pointing out mistakes in my analyses)
There’s a long list of different regions in the neocortex, each of which appears to be responsible for something totally different. One interpretation is that these cortical regions are doing fundamentally different things, and that we acquired the capacities to do all these different things over hundreds of millions of years of evolution.
A radically different perspective, first put forth by Vernon Mountcastle in 1978, hypothesizes that the neocortex is implementing a single general-purpose data processing algorithm all throughout. From the popular neuroscience book On Intelligence, by Jeff Hawkins[1]:
[...] Mountcastle points out that the neocortex is remarkably uniform in appearance and structure. The regions of cortex that handle auditory input look like the regions that handle touch, which look like the regions that control muscles, which look like Broca's language area, which look like practically every other region of the cortex. Mountcastle suggests that since these regions all look the same, perhaps they are actually performing the same basic operation! He proposes that the cortex uses the same computational tool to accomplish everything it does.
[...]
Mountcastle [...] shows that despite the differences, the neocortex is remarkably uniform. The same layers, cell types, and connections exist throughout. [...] The differences are often so subtle that trained anatomists can't agree on them. Therefore, Mountcastle argues, all regions of the cortex are performing the same operation. The thing that makes the vision area visual and the motor area motoric is how the regions of cortex are connected to each other and to other parts of the central nervous system.
In fact, Mountcastle argues that the reason one region of cortex looks slightly different from another is because of what it is connected to, and not because its basic function is different. He concludes that there is a common function, a common algorithm, that is performed by all the cortical regions. Vision is no different from hearing, which is no different from motor output. He allows that our genes specify how the regions of cortex are connected, which is very specific to function and species, but the cortical tissue itself is doing the same thing everywhere.
If Mountcastle is correct, the algorithm of the cortex must be expressed independently of any particular function or sense. The brain uses the same process to see as to hear. The cortex does something universal that can be applied to any type of sensory or motor system.
The rest of this post will review some of the evidence around Mountcastle’s hypothesis.
Cortical function is largely determined by input data
When visual inputs are fed into the auditory cortices of infant ferrets, those auditory cortices develop into functional visual systems. This suggests that different cortical regions are all capable of general-purpose data processing.
Humans can learn how to perform forms of sensory processing we haven’t evolved to perform—blind people can learn to see with their tongues, and can learn to echolocate well enough to discern density and texture. On the flip side, forms of sensory processing that we did evolve to perform depend heavily on the data we’re exposed to—for example, cats exposed only to horizontal edges early in life don’t have the ability to discern vertical edges later in life. This suggests that our capacities for sensory processing stem from some sort of general-purpose data processing, rather than innate machinery handed to us by evolution.
Blind people who learn to echolocate do so with the help of repurposed visual cortices, and they can learn to read Braille using repurposed visual cortices. Our visual cortices did not evolve to be utilized in these ways, suggesting that the visual cortex is doing some form of general-purpose data processing.
There’s a man who had the entire left half of his brain removed when he was 5, who has above-average intelligence, and went on to graduate college and maintain steady employment. This would only be possible if the right half of his brain were capable of taking on the cognitive functions of the left half of the brain.
The patterns identified by the primary sensory cortices (for vision, hearing, and seeing) overlap substantially with the patterns that numerous different unsupervised learning algorithms identified from the same data, suggesting that the different cortical regions (along with the different unsupervised learning algorithms) are all just doing some form of general-purpose pattern recognition on its input data.
Deep learning and cortical generality
The above evidence does not rule out the possibility that the cortex's apparent adaptability stems from developmental triggers, rather than some capability for general-purpose data-processing. By analogy, stem cells all start out very similar, only to differentiate into cells with functions tailored to the contexts in which they find themselves. It’s possible that different cortical regions have hard-coded genomic responses for handling particular data inputs, such that the cortex gives one hard-coded response when it detects that it’s receiving visual data, another hard-coded response when it detects that it’s receives auditory data, etc.
If this were the case, the cortex’s data-processing capabilities can best be understood as specialized responses to distinct evolutionary needs, and our ability to process data that we haven’t evolved to process (e.g. being able to look at a Go board and intuitively discern what a good next move would be) most likely utilizes a complicated mishmash of heterogeneous data-processing abilities acquired over evolutionary timescales.
Before I learned about any of the advancements in deep learning, this was my most likely guess about how the brain worked. It had always seemed to me that the hardest and most mysterious part of intelligence was intuitive pattern-recognition, and that the various forms of intuitive processing that let us recognize images, say sentences, and play Go might be totally different and possibly arbitrarily complex.
So I was very surprised when I learned that a single general method in deep learning (training an artificial neural network on massive amounts of data using gradient descent)[2] led to performance comparable or superior to humans’ in tasks as disparate as image classification, speech synthesis, and playing Go. I found superhuman Go performance particularly surprising—intuitive judgments of Go boards encode distillations of high-level strategic reasoning, and are highly sensitive to small changes in input. Neither of these is true for sensory processing, so my prior guess was that the methods that worked for sensory processing wouldn’t have been sufficient for playing Go as well as humans.[3]
This suggested to me that there’s nothing fundamentally complex or mysterious about intuition, and that seemingly-heterogeneous forms of intuitive processing can result from simple and general learning algorithms. From this perspective, it seems most parsimonious to explain the cortex’s seemingly general-purpose data-processing capabilities as resulting straightforwardly from a general learning algorithm implemented all throughout the cortex. (This is not to say that I think the cortex is doing what artificial neural networks are doing—rather, I think deep learning provides evidence that general learning algorithms exist at all, which increases the prior likelihood on the cortex implementing a general learning algorithm.[4])
The strength of this conclusion hinges on the extent to which the “artificial intuition” that current artificial neural networks (ANNs) are capable of is analogous to the intuitive processing that humans are capable of. It’s possible that the “intuition” utilized by ANNs is deeply analogous to human intuition, in which case the generality of ANNs would be very informative about the generality of cortical data-processing. It's also possible that "artificial intuition" is different in kind from human intuition, or that it only captures a small fraction of what goes into human intuition, in which case the generality of ANNs would not be very informative about the generality of cortical data-processing.
It seems that experts are divided about how analogous these forms of intuition are, and I conjecture that this is a major source of disagreement about overall AI timelines. Shane Legg (a cofounder of DeepMind, a leading AI lab) has been talking about how deep belief networks might be able to replicate the function of the cortex before deep learning took off, and he’s been predicting human-level AGI in the 2020s since 2009. Eliezer Yudkowsky has directly talked about AlphaGo providing evidence of "neural algorithms that generalize well, the way that the human cortical algorithm generalizes well" as an indication that AGI might be near. Rodney Brooks (the former director of MIT’s AI lab) has written about how deep learning is not capable of real perception or manipulation, and thinks AGI is over 100 years away. Gary Marcus has described deep learning as a “wild oversimplification” of the "hundreds of anatomically and likely functionally [distinct] areas" of the cortex, and estimates AGI to be 20-50 years away.
Canonical microcircuits for predictive coding
If the cortex were uniform, what might it actually be doing uniformly?
The cortex has been hypothesized to consist of canonical microcircuits that implement predictive coding. In a nutshell, predictive coding (aka predictive processing) is a theory of brain function which hypothesizes that the cortex learns hierarchical structure of the data it receives, and uses this structure to encode predictions about future sense inputs, resulting in “controlled hallucinations” that we interpret as direct perception of the world.
On Intelligence has an excerpt that cleanly communicates what I mean by “learning hierarchical structure”:
[...] The real world's nested structure is mirrored by the nested structure of your cortex.
What do I mean by a nested or hierarchical structure? Think about music. Notes are combined to form intervals. Intervals are combined to form melodic phrases. Phrases are combined to form melodies or songs. Songs are combined into albums. Think about written language. Letters are combined to form syllables. Syllables are combined to form words. Words are combined to form clauses and sentences. Looking at it the other way around, think about your neighborhood. It probably contains roads, schools, and houses. Houses have rooms. Each room has walls, a ceiling, a floor, a door, and one or more windows. Each of these is composed of smaller objects. Windows are made of glass, frames, latches, and screens. Latches are made from smaller parts like screws.
Take a moment to look up at your surroundings. Patterns from the retina entering your primary visual cortex are being combined to form line segments. Line segments combine to form more complex shapes. These complex shapes are combining to form objects like noses. Noses are combining with eyes and mouths to form faces. And faces are combining with other body parts to form the person who is sitting in the room across from you.
All objects in your world are composed of subobjects that occur consistently together; that is the very definition of an object. When we assign a name to something, we do so because a set of features consistently travels together. A face is a face precisely because two eyes, a nose, and a mouth always appear together. An eye is an eye precisely because a pupil, an iris, an eyelid, and so on, always appear together. The same can be said for chairs, cars, trees, parks, and countries. And, finally, a song is a song because a series of intervals always appear together in sequence.
In this way the world is like a song. Every object in the world is composed of a collection of smaller objects, and most objects are part of larger objects. This is what I mean by nested structure. Once you are aware of it, you can see nested structures everywhere. In an exactly analogous way, your memories of things and the way your brain represents them are stored in the hierarchical structure of the cortex. Your memory of your home does not exist in one region of cortex. It is stored over a hierarchy of cortical regions that reflect the hierarchical structure of the home. Large-scale relationships are stored at the top of the hierarchy and small-scale relationships are stored toward the bottom.
The design of the cortex and the method by which it learns naturally discover the hierarchical relationships in the world. You are not born with knowledge of language, houses, or music. The cortex has a clever learning algorithm that naturally finds whatever hierarchical structure exists and captures it.
The clearest evidence that the brain is learning hierarchical structure comes from the visual system. The visual cortex is known to have edge detectors at the lowest levels of processing, and neurons that fire when shown images of particular people, like Bill Clinton.
What does predictive coding say the cortex does with this learned hierarchical structure? From an introductory blog post about predictive processing:
[...] the brain is a multi-layer prediction machine. All neural processing consists of two streams: a bottom-up stream of sense data, and a top-down stream of predictions. These streams interface at each level of processing, comparing themselves to each other and adjusting themselves as necessary.
The bottom-up stream starts out as all that incomprehensible light and darkness and noise that we need to process. It gradually moves up all the cognitive layers that we already knew existed – the edge-detectors that resolve it into edges, the object-detectors that shape the edges into solid objects, et cetera.
The top-down stream starts with everything you know about the world, all your best heuristics, all your priors, [all the structure you’ve learned,] everything that’s ever happened to you before – everything from “solid objects can’t pass through one another” to “e=mc^2” to “that guy in the blue uniform is probably a policeman”. It uses its knowledge of concepts to make predictions – not in the form of verbal statements, but in the form of expected sense data. It makes some guesses about what you’re going to see, hear, and feel next, and asks “Like this?” These predictions gradually move down all the cognitive layers to generate lower-level predictions. If that uniformed guy was a policeman, how would that affect the various objects in the scene? Given the answer to that question, how would it affect the distribution of edges in the scene? Given the answer to that question, how would it affect the raw-sense data received?
As these two streams move through the brain side-by-side, they continually interface with each other. Each level receives the predictions from the level above it and the sense data from the level below it. Then each level uses Bayes’ Theorem to integrate these two sources of probabilistic evidence as best it can.
[...]
“To deal rapidly and fluently with an uncertain and noisy world, brains like ours have become masters of prediction – surfing the waves and noisy and ambiguous sensory stimulation by, in effect, trying to stay just ahead of them. A skilled surfer stays ‘in the pocket’: close to, yet just ahead of the place where the wave is breaking. This provides power and, when the wave breaks, it does not catch her. The brain’s task is not dissimilar. By constantly attempting to predict the incoming sensory signal we become able [...] to learn about the world around us and to engage that world in thought and action.”
The result is perception, which the PP theory describes as “controlled hallucination”. You’re not seeing the world as it is, exactly. You’re seeing your predictions about the world, cashed out as expected sensations, then shaped/constrained by the actual sense data.
An illustration of predictive processing, from the same source:
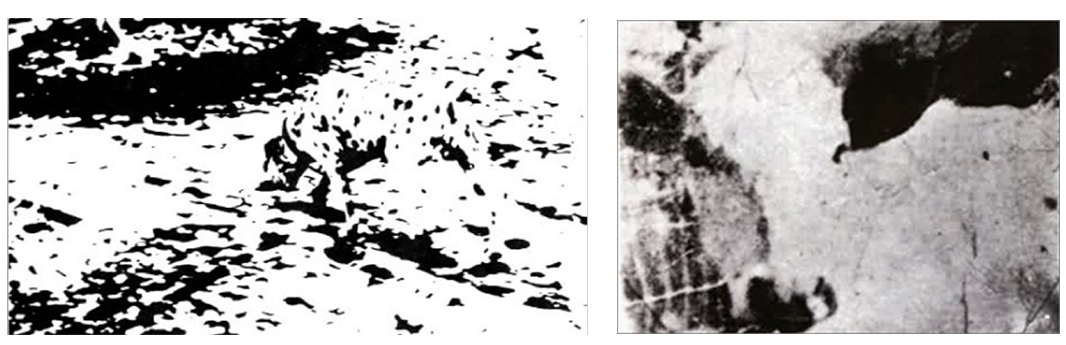
This demonstrates the degree to which the brain depends on top-down hypotheses to make sense of the bottom-up data. To most people, these two pictures start off looking like incoherent blotches of light and darkness. Once they figure out what they are (spoiler) the scene becomes obvious and coherent. According to the predictive processing model, this is how we perceive everything all the time – except usually the concepts necessary to make the scene fit together come from our higher-level predictions instead of from clicking on a spoiler link.
{kind=link}
Predictive coding has been hailed by prominent neuroscientists as a possible unified theory of the brain, but I’m confused about how much physiological evidence there is that the brain is actually implementing predictive coding. It seems like there’s physiological evidence in support of predictive coding being implemented in the visual cortex and in the auditory cortex, and there’s a theoretical account of how the prefrontal cortex (responsible for higher cognitive functions like planning, decision-making, and executive function) might be utilizing similar principles. This paper and this paper review some physiological evidence of predictive coding in the cortex that I don’t really know how to interpret.
My current take
I find the various pieces of evidence that cortical function depends largely on data inputs (e.g. the ferret rewiring experiment) to be pretty compelling evidence of general-purpose data-processing in the cortex. The success of simple and general methods in deep learning across a wide range of tasks suggests that it’s most parsimonious to model the cortex as employing general methods throughout, but only to the extent that the capabilities of artificial neural networks can be taken to be analogous to the capabilities of the cortex. I currently consider the analogy to be deep, and intend to explore my reasons for thinking so in future posts.
I think the fact that predictive coding offers a plausible theoretical account for what the cortex could be doing uniformly, which can account for higher-level cognitive functions in addition to sensory processing, is itself some evidence of cortical uniformity. I’m confused about how much physiological evidence there is that the brain is actually implementing predictive coding, but I’m very bullish on predictive coding as a basis for a unified brain theory based on non-physiological evidence (like our subjective experiences making sense of the images of splotches) that I intend to explore in a future post.
Thanks to Paul Kreiner, David Spivak, and Stag Lynn for helpful suggestions and feedback, and thanks to Jacob Cannell for writing a post [LW · GW] that inspired much of my thinking here.
This blog post comment has some good excerpts from On Intelligence. ↩︎
Deep learning is a general method in the sense that most tasks are solved by utilizing a handful of basic tools from a standard toolkit, adapted for the specific task at hand. Once you’ve selected the basic tools, all that’s left is figuring out how to supply the training data, specifying the objective that lets the AI know how well it’s doing, throwing a lot of computation at the problem, and fiddling with details. My understanding is that there typically isn’t much conceptual ingenuity involved in solving the problems, that most of the work goes into fiddling with details, and that trying to be clever doesn't lead to better results than using standard tricks with more computation and training data. It's also worth noting that most of the tools in this standard toolkit have been around since the 90's (e.g. convolutional neural networks, LSTMs, reinforcement learning, backpropagation), and that the recent boom in AI was driven by using these decades-old tools with unprecedented amounts of computation. ↩︎
AlphaGo did simulate future moves to achieve superhuman performance, so the direct comparison against human intuition isn't completely fair. But AlphaGo Zero's raw neural network, which just looks at the "texture" of the board without simulating any future moves, can still play quite formidably. From the AlphaGo Zero paper: "The raw neural network, without using any lookahead, achieved an Elo rating of 3,055. AlphaGo Zero achieved a rating of 5,185, compared to 4,858 for AlphaGo Master, 3,739 for AlphaGo Lee and 3,144 for AlphaGo Fan." (AlphaGo Fan beat the European Go champion 5-0.) ↩︎
Eliezer Yudkowsky has an insightful exposition of this point in a Facebook post. ↩︎
23 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2020-05-04T18:22:36.454Z · LW(p) · GW(p)
Thanks for writing this up! I love this topic and I think everyone should talk about it more!
On cortical uniformity:
My take (largely pro-cortical-uniformity) is in the first part of this post [LW · GW]. I never did find better or more recent sources than those two book chapters, but have gradually grown a bit more confident in what I wrote for various more roundabout reasons. See also my more recent post here [LW · GW].
On the similarity of neocortical algorithms to modern ML:
I am pretty far on the side of "neocortical algorithms are different than today's most popular ANNs", i.e. I think that both are "general" but I reached that conclusion independently for each. If I had to pick one difference, I would say it's that neocortical algorithms use analysis-by-synthesis—i.e., searching through a space of generative models for one that matches the data—and relatedly planning by probabilistic inference. This type of algorithm is closely related to probabilistic programming and PGMs—see, for example, Dileep George's work. In today's popular ANNs, this kind of analysis-by-synthesis and planning is either entirely absent or arguably present as a kind of add-on, but it's not a core principle of the algorithm. This is obviously not the only difference between neocortical algorithms and mainstream ANNs. Some are really obvious: the neocortex doesn't use backprop! More controversially, I don't even think the neocortex even uses real-valued variables in its models, as opposed to booleans—well, I would want to put some caveats on that, but I believe something in that general vicinity.
So basically, I think the algorithms most similar to the neocortex are a bit of a backwater within mainstream ML research, with essentially no SOTA results on popular benchmarks ... which makes it a bit awkward for me to argue that this is the corner from which we will get AGI. Oh well, that's what I believe anyway!
On predictive coding:
Depending on context, I'll say I'm either an enthusiastic proponent or strong critic of predictive coding. Really, I have a particular version of it I like, described here [LW · GW]. I guess I disagree with Friston, Clark, etc. most strongly in that they argue that predictive coding is a helpful way to think about the operation of the whole brain, whereas I only find it helpful when discussing the neocortex in particular. Again see here [LW · GW] for my take on the rest of the brain. My other primary disagreement is that I don't see "minimizing prediction error" as a foundational principle, but rather an incidental consequence of properly-functioning neocortical algorithms under certain conditions. (Specifically, from the fact that the neocortex will discard generative models that get repeatedly falsified.)
I think there is a lot of evidence for the neocortex having a zoo of generative models that can be efficiently searched through and glued together, not only for low-level perception but also for high-level stuff. I guess the evidence I think about is mostly introspective though. For example, this book review about therapy [? · GW] has (in my biased opinion) an obvious and direct correspondence with how I think the neocortex processes generative models [LW · GW].
Replies from: jalex-stark-1↑ comment by Jalex Stark (jalex-stark-1) · 2020-05-06T03:13:56.628Z · LW(p) · GW(p)
Some are really obvious: the neocortex doesn't use backprop!
That doesn't seem obvious to me. Could you point to some evidence, or flesh out your model for how data influences neural connections?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-05-06T13:50:38.463Z · LW(p) · GW(p)
Hmm, well I should say that my impression is that there's frustrating lack of consensus on practically everything in systems neuroscience, but "brain doesn't do backpropagation" seems about as close to consensus as anything. This Yoshua Bengio paper has a quick summary of the reasons:
The following difficulties can be raised regarding the biological plausibility of back-propagation: (1) the back-propagation computation (coming down from the output layer to lower hidden layers) is purely linear, whereas biological neurons interleave linear and non-linear operations, (2) if the feedback paths known to exist in the brain (with their own synapses and maybe their own neurons) were used to propagate credit assignment by backprop, they would need precise knowledge of the derivatives of the non-linearities at the operating point used in the corresponding feedforward computation on the feedforward path, (3) similarly, these feedback paths would have to use exact symmetric weights (with the same connectivity, transposed) of the feedforward connections, (4) real neurons communicate by (possibly stochastic) binary values (spikes), not by clean continuous values, (5) the computation would have to be precisely clocked to alternate between feedforward and back-propagation phases (since the latter needs the former’s results), and (6) it is not clear where the output targets would come from.
(UPDATE 1 YEAR LATER: after reading more Randall O'Reilly, I am now pretty convinced that error-driven learning is one aspect of neocortex learning, and I'm open-minded to the possibility that the errors can propagate up at least one or maybe two layers of hierarchy. Beyond that, I dunno, but brain hierarchies don't go too much deeper than that anyway, I think.)
Then you ask the obvious followup question: "if not backprop, then what?" Well, this is unknown and controversial; the Yoshua Bengio paper above offers its own answer which I am disinclined to believe (but want to think about more). Of course there is more than one right answer; indeed, my general attitude is that if someone tells me a biologically-plausible learning mechanism, it's probably in use somewhere in the brain, even if it's only playing a very minor and obscure role in regulating heart rhythms or whatever, just because that's the way evolution tends to work.
But anyway, I expect that the lion's share of learning in the neocortex comes from just a few mechanisms. My favorite example is probably high-order sequence memory learning. There's a really good story for that:
-
At the lowest level—biochemistry—we have Why Neurons Have Thousands of Synapses, a specific and biologically-plausible mechanism for the creation and deactivation of synapses.
-
At the middle level—algorithms—we have papers like this and this and this where Dileep George takes pretty much that exact algorithm (which he calls "cloned hidden markov model"), abstracted away from the biological implementation details, and shows that it displays all sorts of nice behavior in practice.
-
At the highest level—behavior—we have observable human behaviors, like the fact that we can hear a snippet of a song, and immediately know how that snippet continues, but still have trouble remembering the song title. And no matter how well we know a song, we cannot easily sing the notes in reverse order. Both of these are exactly as expected from the properties of this sequence memory algorithm.
This sequence memory thing obviously isn't the whole story of what the neocortex does, but it fits together so well, I feel like it has to be one of the ingredients. :-)
comment by Ruby · 2021-12-12T20:31:02.737Z · LW(p) · GW(p)
This post is what first gave me a major update towards "an AI with a simple single architectural pattern scaled up sufficiently could become AGI", in other words, there doesn't necessarily have to be complicated fine-tuned algorithms for different advanced functions–you can get lots of different things from the same simple structure plus optimization. Since then, as far as I can tell, that's what we've been seeing.
comment by Kaj_Sotala · 2020-05-09T10:22:28.228Z · LW(p) · GW(p)
Curated. This post addresses an important topic with a lot of relevance to AI timelines. I particularly like what feels like a collaborative spirit of the post, where you share your reasons for your current beliefs, without trying to make a strong argument trying to persuade us of any given conclusion. That seems good for encouraging a discussion.
comment by jonathanstray · 2020-05-04T17:07:59.877Z · LW(p) · GW(p)
So I was very surprised when I learned that a single general method in deep learning (training an artificial neural network on massive amounts of data using gradient descent)[2] [LW · GW] led to performance comparable or superior to humans’ in tasks as disparate as image classification, speech synthesis, and playing Go. I found superhuman Go performance particularly surprising—intuitive judgments of Go boards encode distillations of high-level strategic reasoning, and are highly sensitive to small changes in input.
I think it may be important to recognize that AlphaGo (and AlphaZero) use more than deep learning to solve Go. They also use tree search, which is ideally suited to strategic reasoning. Neural networks, on the other hand, are famously bad at symbolic reasoning tasks, which may ultimately have some basis in the fact that probability does not extend logic.
Replies from: gwern, zhukeepa↑ comment by gwern · 2020-05-08T02:43:02.867Z · LW(p) · GW(p)
And MuZero, which beats AlphaZero and which does not use symbolic search over a simulator of board states but internal search over hidden state and value estimates?
Neural networks, on the other hand, are famously bad at symbolic reasoning tasks, which may ultimately have some basis in the fact that probability does not extend logic.
Considering all the progress on graph and relational networks and inference and theorem-proving and whatnot, this statement is giving a lot of hostages to fortune.
↑ comment by zhukeepa · 2020-05-04T17:44:48.834Z · LW(p) · GW(p)
Yep! I addressed this point in footnote [3].
Replies from: ankesh-anand↑ comment by Ankesh Anand (ankesh-anand) · 2020-05-08T00:16:49.713Z · LW(p) · GW(p)
The raw neural network does use search during training though, and does not rely on search only during evaluation.
comment by waveman · 2020-05-04T07:30:52.067Z · LW(p) · GW(p)
Good summary and exposition of the situation.
In "On Intelligence", there is a hand-wavy argument that actions as well as perception can be seen as a sort of prediction. When I read this, it kind of made sense. But afterwards, when I was thinking how I would implement this insight in code, I began to feel a bit unclear about exactly how this would work. I have never seen a clear exposition from Jeff Hawkins or Numenta (his company). This is surprising because I generally find he provides very clear explanations for his ideas.
Does anyone have a clear idea of how actions would work as some kind of prediction? A pointer to something on this would be good also.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-05-04T18:26:47.235Z · LW(p) · GW(p)
I guess the classic reference would be Planning as Probabilistic Inference, but see also my post here more specifically about the brain [LW · GW]. A practical example would be Dileep George's 2017 Schema Networks paper. Does that answer your question?
comment by Slider · 2020-05-11T17:10:59.832Z · LW(p) · GW(p)
Might be relevant I might have experiences which are really rare as I think for some time is (at least) was a seeing human that echolocated. That edgecase might be a problem for some of the options.
If there is a general processing algorith then it poses some challenges that are more naturally solved in a "biology hardwired" view. If sensory processing is responsive to experienced data and different individuals why does a species have a relatively stable brain-region map? Shoudn't individuals have processing units in pretty random places? (stop if you want to think your stance alone mine follows) Sense apparatus (ears, toungue) are biological hardwired and lowest level sensory processing is likely to be directly adjacent to that and higher level processing directly adjacent to that level. Like it is hard to learn advanced mathematical conce3pts before learning the fundamentals, the data dependency of the perceptions projects to a wiring spatial adjacency constraints. The naivest view of this sort would say that the visual processing system should be in the front of the brain rather than the back. One could mix as some wires being more or less hardcoded and different kinds of basic substrates be more easily employable to some kinds of tasks. For example vision probably benefits from massive parallelization but audio doesn't really (but time resolution is important for audio but not that much for vision).
I happen to believe that humans can learn to echolocate (despite knowing there is atleast one philosphy paper arguing that humans can't know what it is like to be a bat) but bats learn it consistently. If humans do have ears and they do have the freqeuncy and time resolutions neccesarily to do the operations why they don't naturally pick up on the skill? Here blind people are in a special place in that they have incentive to echolocate as it is their only access to remote 3d perception. As a seeing echolocator, it was comparatively much more burdensome to hear the environment than to see it. There are some edgecase benefits, sound can bend and reflect around corners which makes for perception for out of line-of-sight objects and different objects are opaque to light vs sound (it was very funny to realise that windows are very light transparent but very "bright" in audio (well hard)). But given an option the vision starves audio the development of audio skills.
In general there migth be attention and software limitations too, not just data. Part of why picked up the skill was that I watched a tv program featuring a blind echolocator and was super interested whether that could be learned. Learning took time that was sustained by my interest and possibly knowledge that it might be possible. And to be interested in random obscure things might be part of my neurotype. But as the skill progressed there was a shift and I fel tthat the new kind of processing shared similarities with vision. I have encountered a joke about drugs that "smell blue" is an impossible experience but part of getting echolocation to work was to "see audio" rather than "hear". It felt like a subskill that when I realised I could apply to hearing made me suddenly much more capable of constructing richer experiences. I could locate in a 3d field where the echo bounces were happening. And it had sufficient automaticity that when I was not actively trying to make anything sensory happen but was just walking down the street I was suddenly surprised/fearful of something to the left of me. It turned out to be car ramp suddenly opening up into the building where previuosly the street was straigth close wall. Reflecting upon the experience I figured that the sound source was my footsteps and that I noticed a perception change and placed it in 3d before being aware via which channels I had percieved it. But someone who doesn't have the lower level sensory experiences can't use them to learn about their environments audio structure. It was a typical public street but other walking on it probably don't have experiences that help develop their ears. Deeper rumination on the issue lead me also to believe that there are earlier "ear-skill levels". While humans are typically thought as stereo-hearers ie that they can sense from which directions sounds are coming from it is not uncommon for people to fail to be stereohearer and only hear what sound is happening and not from where ie "monohearer" (there is a mouse here, is in the floor, roof or ceiling?). Yet common lanaguge often refers to a single binary "can hear? yes/no".
comment by Charlie Steiner · 2020-05-04T10:12:24.611Z · LW(p) · GW(p)
Hierarchical predictive coding is interesting, but I have some misgivings that it does a good job explaining what we see of brain function, because brains seem to have really dramatic attention mechanisms.
By "attention" I don't mean to imply much similarity to attention mechanisms in current machine learning. I partly mean that not all our cortex is going at full blast all the time - instead, activity is modulated dynamically, and this interacts in a very finely tuned way with the short-term stored state of high-level representations. It seems like there are adaptations in the real-time dynamics of the brain that are finely selected to do interesting and complicated things that I don't understand well, rather than them trying to faithfully implement an algorithm that we think of as happening in one step.
Not super sure about all this, though.
Replies from: Kaj_Sotala, steve2152, steve2152↑ comment by Kaj_Sotala · 2020-05-05T14:40:11.327Z · LW(p) · GW(p)
Hierarchical predictive coding is interesting, but I have some misgivings that it does a good job explaining what we see of brain function, because brains seem to have really dramatic attention mechanisms.
By "attention" I don't mean to imply much similarity to attention mechanisms in current machine learning. I partly mean that not all our cortex is going at full blast all the time - instead, activity is modulated dynamically, and this interacts in a very finely tuned way with the short-term stored state of high-level representations.
I'm not sure that this is an argument against predictive coding, because e.g. Surfing Uncertainty talks a lot about how attention fits together with predictive coding and how it involves dynamic modulation of activity.
In the book's model, attention corresponds to "precision-weighting of prediction error". An example might be navigating a cluttered room in dim versus bright lightning. If a room is dark and you don't see much, you may be sensing your way around with your hands or trying to remember where everything is so you don't run into things. Your attention is on your sense of touch, or your memory of the room. On the other hand, if you can see clearly, then you are probably mainly paying attention to your sense of sight, since that just lets you see where everything is.
Another way of putting this is that if the room is very dark, the sensory data generated by your vision has low precision (low confidence): it is not very useful for generating predictions of where everything is. Your sense of touch, as well as your previous memories, have higher precision than your sense of vision does. As a result, signals coming from the more useful sources are weighted more highly when attempting to model your environment; this is subjectively experienced as your attention being on your hands and previous recollections of the room. Conversely, when it gets brighter, information from your eyes now has higher precision, so will be weighted more strongly.
Some relevant excerpts from the book:
If we look for them, most of us can find shifting face-forms hidden among the clouds. We can see the forms of insects hidden in the patterned wallpaper or of snakes nestling among the colourful swirls of a carpet. Such effects need not imply the ingestion of mind-altering substances. Minds like ours are already experts at self-alteration. When we look for our car keys on the cluttered desk, we somehow alter our perceptual processing to help isolate the target item from the rest. Indeed, spotting the (actual) car keys and ‘spotting’ the (non-existent) faces, snakes, and insects are probably not all that different, at least as far as the form of the underlying processing is concerned. Such spottings reflect our abilities not just to alter our action routines (e.g., our visual scan paths) but also to modify the details of our own perceptual processing so as better to extract signal from noise. Such modifications look to play a truly major role in the tuning (both long- and short-term) of the on-board probabilistic prediction machine that underpins our contact with the world. The present chapter explores the space and nature of such online modifications, discusses their relations with familiar notions such as attention and expectation, and displays a possible mechanism (the ‘precision-weighting’ of prediction error) that may be implicated in a wide range of signal-enhancement effects. [...]Replies from: steve2152
The perceptual problems that confront us in daily life vary greatly in the demands they make upon us. For many tasks, it is best to deploy large amounts of prior knowledge, using that knowledge to drive complex proactive patterns of gaze fixation, while for others it may be better to sit back and let the world do as much of the driving as possible. Which strategy (more heavily input-driven or more heavily expectation-driven) is best is also hostage to a multitude of contextual effects. Driving along a very familiar road in heavy fog, it can sometimes be wise to let detailed top-down knowledge play a substantial role. Driving fast along an unfamiliar winding mountain road, we need to let sensory input take the lead. How is a probabilistic prediction machine to cope?
It copes, PP suggests, by continuously estimating and re-estimating its own sensory uncertainty. Within the PP framework, these estimations of sensory uncertainty modify the impact of sensory prediction error. This, in essence, is the predictive processing model of attention. Attention, thus construed, is a means of variably balancing the potent interactions between top-down and bottom-up influences by factoring in their so-called ‘precision’, where this is a measure of their estimated certainty or reliability (inverse variance, for the statistically savvy). This is achieved by altering the weighting (the gain or ‘volume’, to use a common analogy) on the error units accordingly. The upshot of this is to ‘control the relative influence of prior expectations at different levels’ (Friston, 2009, p. 299). Greater precision means less uncertainty and is reflected in a higher gain on the relevant error units (see Friston, 2005, 2010; Friston et al., 2009). Attention, if this is correct, is simply a means by which certain error unit responses are given increased weight, hence becoming more apt to drive response, learning, and (as we shall later see) action. More generally, this means the precise mix of top-down and bottom-up influence is not static or fixed. Instead, the weight given to sensory prediction error is varied according to how reliable (how noisy, certain, or uncertain) the signal is taken to be.
We can illustrate this using our earlier example. Visual input, in the fog, will be estimated to offer a noisy and unreliable guide to the state of the distal realm. Other things being equal visual input should, on a bright day, offer a much better signal, such that any residual error should be taken very seriously indeed. But the strategy clearly needs to be much more finely tuned than that suggests. Thus suppose the fog (as so often happens) briefly clears from one small patch of the visual scene. Then we should be driven to sample preferentially from that smaller zone, as that is now a source of high-precision prediction errors. This is a complex business, since the evidence for the presence of that small zone (right there!) comes only from the (initially low-weighted) sensory input itself. There is no fatal problem here, but the case is worth describing carefully. First, there is now some low-weighted surprise emerging relative to my best current take on the the visual situation (which was something like ‘in uniformly heavy fog’). Aspects of the input (in the clear zone) are not unfolding as that take (that model) predicted. However, my fog-model includes general expectations concerning occasional clear patches. Under such conditions, I can further reduce overall prediction error by swopping to the ‘fog plus clear patch’ model. This model incorporates a new set of precision predictions, allowing me to trust the fine-grained prediction errors computed for the clear zone (only). That small zone is now the estimated source of high-precision prediction errors of the kind the visual system can trust to recruit clear reliable percepts. High-precision prediction errors from the clear zone may then rapidly warrant the recruitment of a new model capable of describing some salient aspects of the local environment environment (watch out for that tractor!).
Such, in microcosm, is the role PP assigns to sensory attention: ‘Attention can be viewed as a selective sampling of sensory data that have high-precision (signal to noise) in relation to the model’s predictions’ (Feldman & Friston, 2010, p. 17). This means that we are constantly engaged in attempts to predict precision, that is, to predict the context-varying reliability of our own sensory prediction error, and that we probe the world accordingly. This kind of ‘predicted-precision based’ probing and sampling also underlies (as we will see in Part II) the PP account of gross motor activity. For the present, the point to notice is that in this noisy and ambiguous world, we need to know when and where to take sensory prediction error seriously, and (more generally) how best to balance top-down expectation and bottom-up sensory input. That means knowing when, where, and how far, to trust specific prediction error signals to select and nuance the model that is guiding our behaviour.
An important upshot is that the knowledge that makes human perception possible concerns not only the layered causal structure of the (action-salient—more on that later) distal world but the nature and context-varying reliability of our own sensory contact with that world. Such knowledge must form part and parcel of the overall generative model. For that model must come to predict both the shape and multiscale dynamics of the impinging sensory signal and the context-variable reliability of the signal itself (see Figure 2.2). The familiar idea of ‘attention’ now falls into place as naming the various ways in which predictions of precision tune and impact sensory sampling, allowing us (when things are working as they should) to be driven by the signal while ignoring the noise. By actively sampling where we expect (relative to some task) the best signal to noise ratio, we ensure that the information upon which we perceive and act is fit for purpose.
↑ comment by Steven Byrnes (steve2152) · 2020-05-05T15:30:53.661Z · LW(p) · GW(p)
Yeah I generally liked that discussion, with a few nitpicks, like I dislike the word "precision", because I think it's confidence levels attached to predictions of boolean variables (presence or absence of a feature), rather than a variances attached to predictions of real numbers. (I think this for various reasons including trying to think through particular examples, and my vague understanding of the associated neural mechanisms.)
I would state the fog example kinda differently: There are lots of generative models trying to fit the incoming data [LW · GW], and the "I only see fog" model is currently active, but the "I see fog plus a patch of clear road" model is floating in the background ready to jump in and match to data as soon as there's data that it's good at explaining.
I mean, "I am looking at fog" is actually a very specific prediction about visual input—fog has a specific appearance—so the "I am looking at fog" model is falsified (prediction error) by a clear patch. A better example of "low confidence about visual inputs" would be whatever generative models are active when you're very deep in thought or otherwise totally spaced out, ignoring your surroundings.
↑ comment by Steven Byrnes (steve2152) · 2020-05-05T15:31:57.500Z · LW(p) · GW(p)
The way I think of "activity is modulated dynamically" is:
We're searching through a space of generative models for the model that best fits the data and lead to the highest reward [LW · GW]. The naive strategy would be to execute all the models, and see which one wins the competition. Unfortunately, the space of all possible models is too vast for that strategy to work. At any given time, only a subset of the vast space of all possible generative models is accessible, and only the models in that subset are able to enter the competition. What subset it is can be modulated by context, prior expectations ("you said this cloud is supposed to look like a dog, right?"), etc. I think (vaguely) that there are region-to-region connections within the brain that can be turned on and off, and different models require different configurations of that plumbing in order to fully express themselves. If there's a strong enough hint that some generative model is promising, that model will flex its muscles and fully actualize itself by creating the appropriate plumbing (region-to-region communication channels) to be properly active and able to flow down predictions.
Or something like that... :-)
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2020-05-05T19:22:35.387Z · LW(p) · GW(p)
It's connecting this sort of "good models get themselves expressed" layer of abstraction to neurons that's the hard part :) I think future breakthroughs in training RNNs will be a big aid to imagination.
Right now when I pattern-match what tou say onto ANN architectures, I can imagine something like making an RNN from a scale-free network and trying to tune less-connected nodes around different weightings of more-connected nodes. But I expect that in the future, I'll have much better building blocks for imagining.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-05-06T13:58:37.173Z · LW(p) · GW(p)
In case it helps, my main aids-to-imagination right now are the sequence memory / CHMM story (see my comment here [LW(p) · GW(p)]) and Dileep George's PGM-based vision model and his related follow-up papers like this, plus miscellaneous random other stuff.
↑ comment by Steven Byrnes (steve2152) · 2020-05-04T18:32:39.468Z · LW(p) · GW(p)
What do you mean by "an algorithm that we think of as happening in one step"?
I think of it as analysis-by-synthesis, a.k.a. "search through a space of generative models for one that matches the data". The search process doesn't have to be fast, let alone one step—the splotchy pictures in this post are a good example, you stare at them for a while until they snap into place. Right? Or sorry if I'm misunderstanding your point.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2020-05-04T19:57:35.912Z · LW(p) · GW(p)
I'm saying the abstraction of (e.g.) CNNs as doing their forward pass all in one timestep does not apply to the brain. So I think we agree and I just wasn't too clear.
For CNNs we don't worry about top-down control intervening in the middle of a forward pass, and to the extent that engineers might increase chip efficiency by having different operations be done simultaneously, we usually want to ensure that they can't interfere with each other, maintaining the layer of abstraction. But the human visual cortex probably violates these assumptions not just out of necessity, but gains advantages.
comment by streawkceur · 2020-05-09T14:19:44.105Z · LW(p) · GW(p)
Deep learning is a general method in the sense that most tasks are solved by utilizing a handful of basic tools from a standard toolkit, adapted for the specific task at hand. Once you’ve selected the basic tools, all that’s left is figuring out how to supply the training data, specifying the objective that lets the AI know how well it’s doing, throwing a lot of computation at the problem, and fiddling with details. My understanding is that there typically isn’t much conceptual ingenuity involved in solving the problems, that most of the work goes into fiddling with details, and that trying to be clever doesn't lead to better results than using standard tricks with more computation and training data. It's also worth noting that most of the tools in this standard toolkit have been around since the 90's (e.g. convolutional neural networks, LSTMs, reinforcement learning, backpropagation), and that the recent boom in AI was driven by using these decades-old tools with unprecedented amounts of computation.
Well, the "details" are in fact hard to come up with, can be reused across problems, and do make the difference between working well and not working well! It's a bit like saying that general relativity fills in some details in the claim that nature is described by differential equations, which was made much earlier.
In the AlexNet paper [1], ReLU units were referred to as nonstandard and referenced from a 2010 paper, and Dropout regularization was introduced as a recent invention from 2012. In fact, the efficiency of computer vision DL architectures has increased faster than that of the silicon since then (https://openai.com/blog/ai-and-efficiency/).
My understanding of the claim made by the "bitter lesson" article you link to is not that intellectual effort is worthless when it comes to AI, but that the effort should be directed at improving the efficiency with which the computer learns from training data, not implementing human understanding of the problem in the computer directly.
In a very general sense, e.g. attention mechanisms can be understood to be inspired by subjective experience though (even though here, as well, the effort was in developing things that work for computers, not in thinking really hard about how a human pays attention and formalizing that).
comment by manuherran · 2020-05-08T12:56:02.557Z · LW(p) · GW(p)
Its interesting to note that only mammals have neocortex [1] and birds for instance don't even have cortex [2]. But since birds have sensory perception, cognition and language, and some of them are also very smart [3] [4] [5], it seems that, either sensory perception, cognition, and language are processed also (even mainly) in other parts of the brain, either birds and other animal species have structures equivalent to the cortex and neocortex and we should stop saying that "only mammals have neocortex" [6].
In the meantime, it sounds less wrong, instead of saying "The neocortex is *the* part of the human brain *responsible* for higher-order functions like sensory perception, cognition, and language...", to say "The neocortex is *a* part of the human brain that *plays a relevant role* in higher-order functions like sensory perception, cognition, and language...". This is because, if we combine the widely accepted idea that "only mammals have neocortex" with the expression "neocortex is the part of the brain responsible for higher-order functions", it seems to indicate that individuals without neocortex do not have higher-order functions, which is false, and we would be, perhaps inadvertently, promoting discrimination of non-human animals without neocortex, such as birds or fish.
[1] https://en.wikipedia.org/wiki/Neocortex
[2] https://www.theguardian.com/science/neurophilosophy/2016/jun/15/birds-pack-more-cells-into-their-brains-than-mammals
[3] https://www.gizhub.com/crows-smarter-apes-language
[4] https://www.bbc.com/future/article/20191211-crows-could-be-the-smartest-animal-other-than-primates
[5] http://m.nautil.us/blog/why-neuroscientists-need-to-study-the-crow
[6] https://www.sciencedaily.com/releases/2012/10/121001151953.htm
↑ comment by Steven Byrnes (steve2152) · 2020-05-08T17:03:27.724Z · LW(p) · GW(p)
It's certainly true that you can't slice off a neocortex from the rest of the brain and expect it to work properly by itself. The neocortex is especially intimately connected to the thalamus and hippocampus, and so on.
But I don't think bringing up birds is relevant. Birds don't have a neocortex, but I think they have other structures that have a similar microcircuitry and are doing similar calculations—see this paper.
You can arrange neurons in different ways without dramatically altering the connectivity diagram (which determines the algorithm). The large-scale arrangement in the mammalian neocortex (six-layered structure) is different than the large-scale arrangement in the bird pallium, even if the two are evolved from the same origin and run essentially the same algorithm using the same types of neurons connected in the same way. (...as far as I know, but I haven't studied this topic beyond skimming that paper I linked above.)
So why isn't it called "neocortex" in birds? I assume it's just because it looks different than the mammalian neocortex. I mean, the people who come up with terminology for naming brain regions, they're dissecting bird brains and describing how they look to the naked eye and under a microscope. They're not experts on neuron micro-circuitry. I wouldn't read too much into it.
I don't know much about fish brains, but certainly different animals have different brains that do different things. Some absolutely lack "higher-order functions"—e.g. nemotodes. I am comfortable saying that the moral importance of animals is a function F(brain) ... but what is that function F? I don't know. I do agree that F is not going to be a checklist of gross anatomical features ("three points for a neocortex, one point for a basal ganglia..."), but rather it should refer to the information-processing that this brain is engaged in.
I haven't personally heard anyone suggest that all mammals are all more morally important than all birds because mammals have a neocortex and birds don't. But if that is a thing people believe, I agree that it's wrong and we should oppose it.