[Team Update] Why we spent Q3 optimizing for karma
post by Ruby · 2019-11-07T23:39:55.274Z · LW · GW · 27 commentsContents
Why target a simple, imperfect metric? Choosing a metric Design of the metric What we did to raise the metric How did we do? Summary Detailed Analysis What contributed to our performance? Shortform Petrov Day Author Outreach AI Alignment Writing Day Novum Organum Removing Login Expiry Making Login Easier LessLong (Shortform) Launch Party Subscriptions & LessWrong Docs (our new editor) Overall, how well did we accomplish our goals for this exercise? Finale Take-aways None 27 comments
In Q3 of 2019, the LessWrong team picked the growth of a single metric as our only goal. For the duration of this quarter, the overwhelming consideration in our decision-making what would most increase the target metric.
Why target a simple, imperfect metric?
The LessWrong team pursues a mixture of overlapping long-term goals, e.g. building a place where people train and apply rationality [LW · GW], building a community and culture with good epistemics [LW · GW], and building technologies which drive intellectual progress on important problems [LW · GW].
It’s challenging to track progress on these goals. They’re broad, difficult to measure, we don’t have complete agreement on them, and they change very slowly providing an overall poor feedback loop. If there’s a robust measure of “intellectual progress” or “rationality skills learnt [LW · GW]” which doesn’t break down when being optimized for, we haven’t figure them out yet. We’re generally left pursuing hard to detect things and relying on our models to know that we’re making progress.
Though this will probably continue to be the overall picture for us, we decided that for three months it would be a good exercise for us to attempt maximizing a metric. Given that it’s only three months, it seem relatively safe [1] to maximize a simple metric which doesn’t perfectly capture everything we care about. And doing so might have the following benefits:
- It would test our ability to get concrete, visible results on purpose.
- It would teach us to operate with a stronger empirical feedback loop.
- It would test how easily we can drive raw growth [2], i.e. see what rate of growth we get for our effort.
- The need to hit a clear target would introduce a degree or urgency and pressure we are typically lacking. This pressure might prompt some novel creativity.
- Targeting a metric is what YC advises their startups and it seems worth following that school of thought and philosophy for a time (see excerpts below).
So we decided to pick a metric and optimize for it throughout Q3.
[1] We had approval for this plan from our BDFL/admin, Vaniver. [LW · GW] For extra safety, we shared out plans with trusted-user Zvi [LW · GW] and told him we'd undo anything on the site he thought was problematic. We ran the plan by others too, but stopped short of making a general announcement lest this confound the exercise.
[2] Historically the team has been hesitant to pursue growth strategies out of fear that we could grow the site in ways which make it worse, e.g. eroding the culture while Goodharting on bad metrics. Intentionally pursuing growth for a bit is a way to test the likelihood of accidentally growing the site in undesirable ways.
Choosing a metric
The team brainstormed over fifty metrics with some being more likely candidates than others. Top contenders were number of posts with 50+ karma/week, number of weekly logged-in users, and number of people reading the Sequences.
(We tried to be maximally creative however and the list also included MealSquares sold, impact-adjusted plan changes, and LessWrong t-shirts worn. Maybe we'll do one of those next time)
Ultimately, the team decided to target a metric derived from the amount of karma awarded via votes on posts and comments. Karma is a very broad metric and the amount given out can be increased via multiple methods, all of which we naively approve of increasing, e.g. increasing the number of posts, number of comments, and number of people reading posts and voting. This means that by targeting the amount of karma given out, we’re incentivizing ourselves to increase multiple valuable other “sub-metrics”.
Design of the metric
We did not target the raw amount of karma given out but instead a slightly modified metric:
- Remove all votes made by LessWrong team members
- Multiply the value of all downvotes by 4x
- Aggregate karma to individual posts/comments and raise the magnitude to the power of 1.2
Clause #2 was chosen to disincentivize the creation of demon threads which otherwise might produce a lot of karma in their protracted, heated exchanges.
Clause #3 was chosen to heighten to reward/punishment for especially good or especially bad content. We’re inclined to think that single 100-karma post is worth more than four 25-karma posts and the exponentiation reflects this. (For comparison: 25^1.2 is 47.6, 100^1.2 is 251.2. So in our metric, one 100-karma post was worth about 30% more than four 25-karma posts).
In developing the metric, we experimented with a few different parameters and and checked them against our gut sense of how valuable different posts were.
[There’s some additional complexity in the computation in that the effect of each vote is calculated as the difference in the karma metric of a post/comment before and after the vote. This is necessary to compute changes in the metric nicely over time but makes no difference if you compute the metric for all time all at once.]
Following Paul Graham’s advice, we targeted 7% growth in this metric per week throughout Q3. This is equivalent to increasing the metric by 2.4x. Since PG’s advice was a major influence on us here, I’ll include a few excerpts [emphasis added]:
A good growth rate during YC is 5-7% a week. If you can hit 10% a week you're doing exceptionally well. If you can only manage 1%, it's a sign you haven't yet figured out what you're doing.
...
In theory this sort of hill-climbing could get a startup into trouble. They could end up on a local maximum. But in practice that never happens. Having to hit a growth number every week forces founders to act, and acting versus not acting is the high bit of succeeding. Nine times out of ten, sitting around strategizing is just a form of procrastination. Whereas founders' intuitions about which hill to climb are usually better than they realize. Plus the maxima in the space of startup ideas are not spiky and isolated. Most fairly good ideas are adjacent to even better ones.
...
The fascinating thing about optimizing for growth is that it can actually discover startup ideas. You can use the need for growth as a form of evolutionary pressure. If you start out with some initial plan and modify it as necessary to keep hitting, say, 10% weekly growth, you may end up with a quite different company than you meant to start. But anything that grows consistently at 10% a week is almost certainly a better idea than you started with.
What we did to raise the metric
At the highest level, we wanted to increase the number of posts, increase the number of comments, and increase the number of people viewing and voting. Major projects we worked on towards this included:
- The launch of Shortform
- We’d been experiencing demand for Shortform and metric quarter seemed like a good time to introduce a new section of the site with lower cost to entry.
- Subscriptions
- We failed to launch this during metric quarter, but we envisioned that subscriptions would increase the content people read and vote on.
- Reaching out to authors
- We reached out to a number of people who currently or previously have written top content for LessWrong to find out how we could help them write more.
- Setting up automatic cross-posting for top authors
- For authors whose material is a good fit for LessWrong, we reached out to them and asked about having their posts automatically cross-posted to LessWrong.
- Removing login 90-day log-in expiry so that people stay signed in and able to vote/comment/post.
- Making it easier to create an account or sign-in.
- The LessLong Launch party.
- We hosted a large party in Berkeley both to push the launch of Shortform but also generally to signal LessWrong’s activity and happeningness.
Other activities in this period which contributed were:
- Petrov Day
- MIRI Summer Fellows Program
These projects contributed significantly to the metric, but we would have probably done counterfactually even if we weren’t targeting the metric. (in truth the same can be said for everything else we did).
Targeting the metric did cause us to delay some other projects. For instance, we deprioritized reducing technical debt and new analytics infrastructure this quarter.
How did we do?
Summary
While our target was 7%/week growth, we achieved growth equivalent to 2%/week. As far as hitting the stated target went, we unambiguously failed.
In retrospect, 7% was probably a mistaken target. We perhaps should have been comparing ourselves to LessWrong's historical growth rates, which we in fact we did exceed. Our actual growth in this period of 2%/week over 3-4 months is higher than LessWrong's typical rate of growth throughout most of its history which was at best equivalent 0.5%-1%. Compounded over three months, that's the difference between 15% and 29% growth.
(LessWrong grew between 2009 and 2012 at around 0.5-1.0%/week and then began declining until 2017 when the LW2.0 project was started.)
However, the 7% target was probably still a good choice when we began. It was conceivably achievable and worth testing. For one thing, historically LessWrong didn't have a full-time team in the past who were deliberately working full-time to drive growth. Given the resources we were bringing to bear, it was worth testing if we could dramatically outperform the more "natural" historical growth rates. We have learnt that the answer, unfortunately, is "not obviously or easily."
Also, notwithstanding the failure to hit the target, the exercise still helped with our goals of becoming more empirical, using a stronger feedback loop, being more creative, feeling more urgency, testing hypotheses about growth, and generally applying and testing more of our models against reality. I think the experience has nudged our decision-making and processes in a positive direction even as we return to pursuing long-term, slow-feedback, difficult-to-measure objectives.
Detailed Analysis
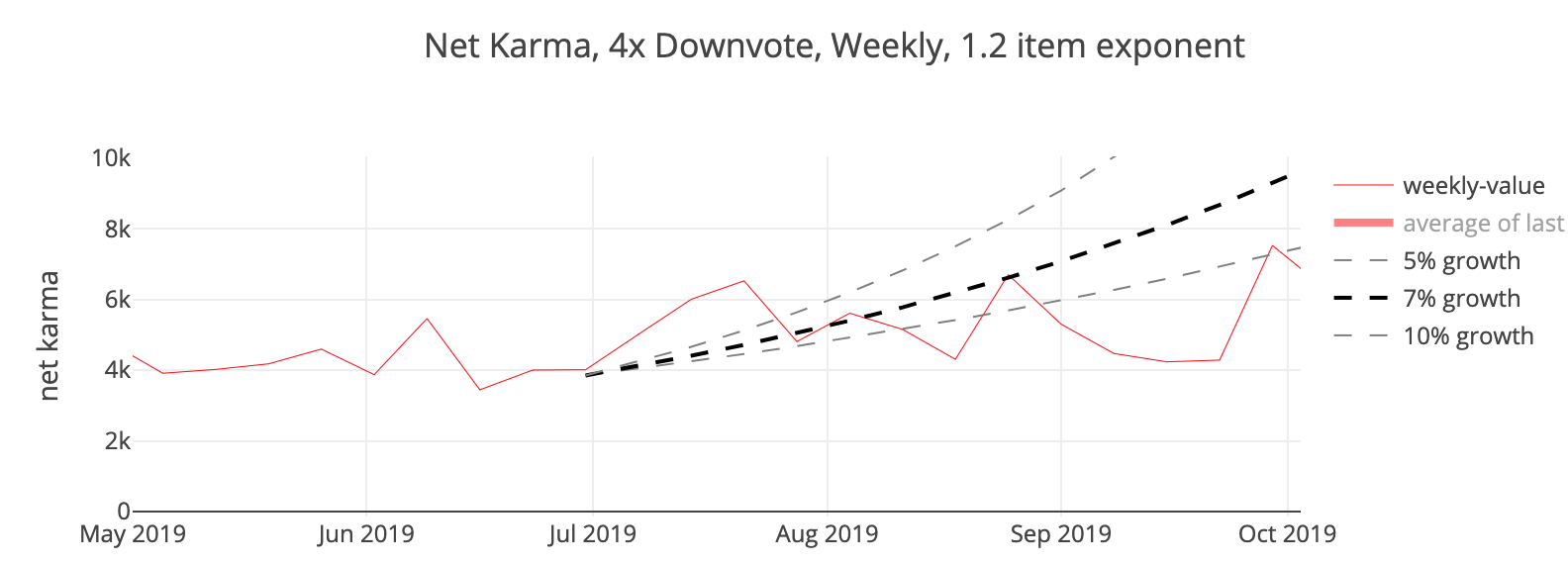
The first graph (above) here shows the karma metric each week and displays clearly that the value does not go up monotonically, but rather fluctuates a fair bit, usually related to the occurrence of events like Petrov Day, Alignment Writing Day, or the publication of controversial posts. This is normal for all the metrics, yet makes it difficult to discern overall trends.
We can apply a 4-week moving average filter in order to smooth the graph and see the trend a little better.

The latter graph shows the overall increase since July, i.e., the beginning of our "metric quarter." However, smaller differences at the weekly level become larger differences at the monthly and quarterly level.


The value of the karma metric in Q3 was 39% higher than than in Q2, 71k vs 51k. This is the largest growth since when the LW2 project began in late 2017 and when it first launched in 2018.
In the summary, I stated that this growth compares favorable to LessWrong's historical growth rates. Due to changes in how karma is computed introduced with LW2, we can't compare our karma metric backwards in time. Fortunately, the number of votes is a good proxy.
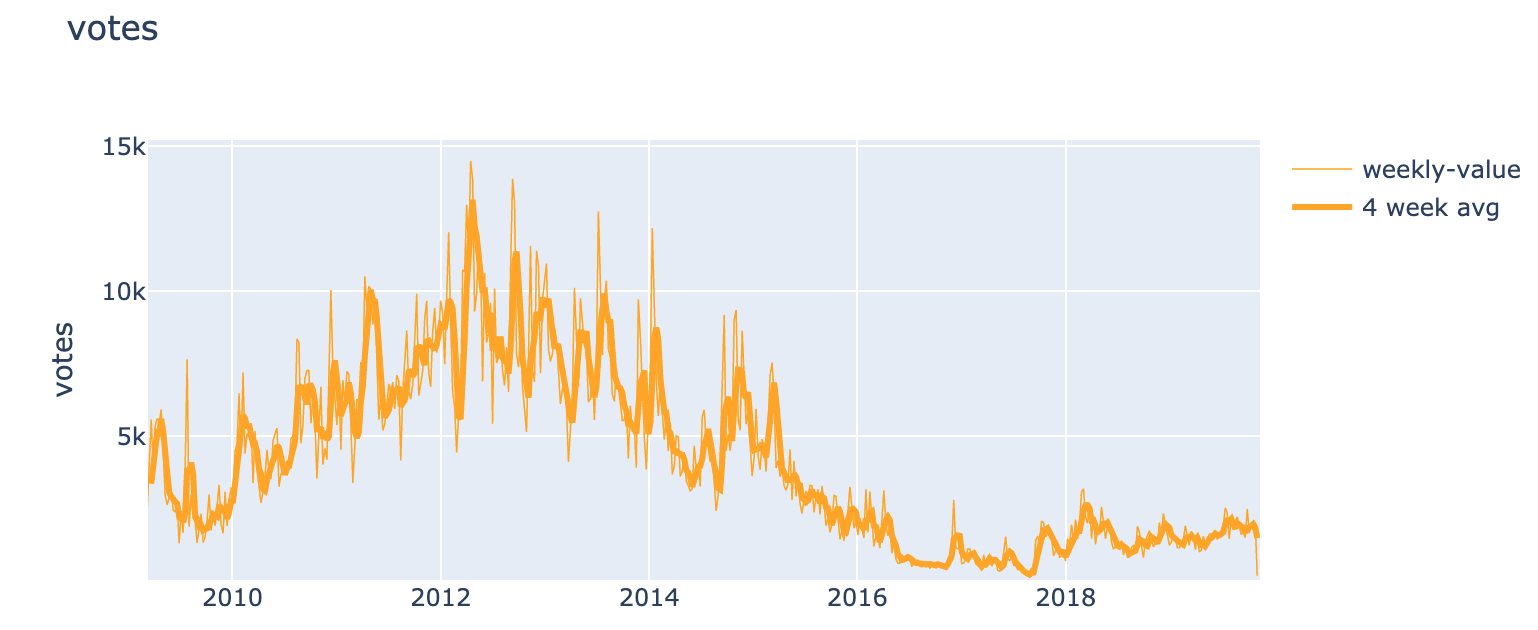
In absolute terms, LW2.0 has some catching up to do; growth-wise we compare nicely. The number of votes on LessWrong grew dramatically between 2009 and 2012 as can be seen in the graph. Growth in votes was 87% in 2009, 41% in 2011, 24% in 2012 and 92% in 2018 [3] . Those are the growth numbers for the entire years and correspond to average weekly growth rates of 1.2%, 0.7%, 0.4%, and 1.3%.
In comparison to that, growing votes by 40% in just one quarter (= 2.5%/week) is pretty good. The real question is whether this growth will be sustained. Yet so far so good. October saw the highest level of the karma metric so far in 2019.
We didn't hit 7%, but it's heartening that seemingly we managed to do something.
[3] Other years saw negative growth ranging between -20% and -65%.
What contributed to our performance?
As above, Q3 was 39% higher on the target metric relative to Q2, going from 51k to 71k. We can examine the contribution of our different activities to this. Where did the extra 20k come from?
Shortform
Karma granted to shortform posts and comments amounted to 5.5k KM or 7.7% of the total score for Q3 and 25% of the difference between Q2 and Q3. This is not fully counterfactual since we can assume Shortform cannibalized some activity from elsewhere on the site, however there has definitely been net growth.
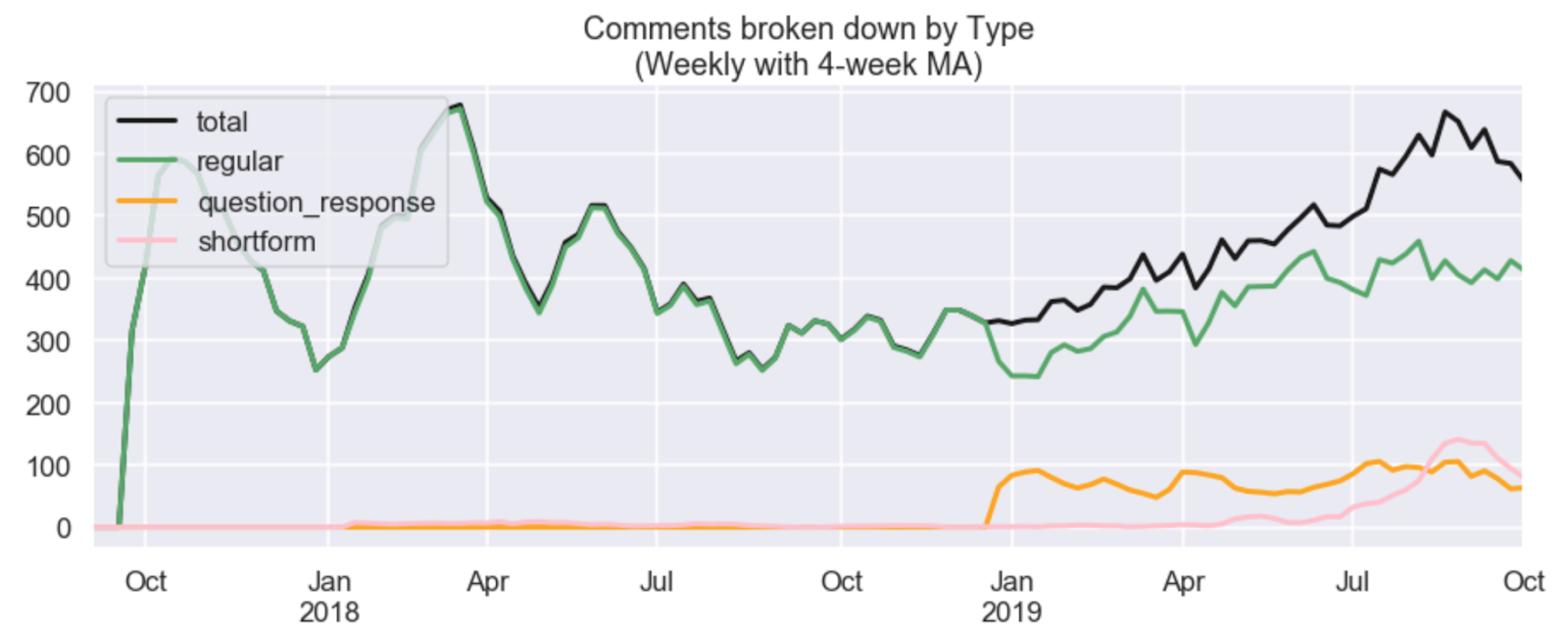
We see that the total number of comments (including all Shortform activity and all responses to questions) grew since July due to the introduction of Shortform while the number of regular comments did not shrink.
Petrov Day
Our Petrov Day commemoration had an outsized impact with the two posts plus their comments (1 [? · GW], 2 [? · GW]) together generating 2.4k KM, or 3.3% of total karma for Q3 and 12% of the difference from Q2 to Q3.
It was a very good return on time spent by the team.
Author Outreach
In the hope of causing there to be more great content, we reached out to a number of authors to see what we could do get them posting. A lower bound on the KM we achieved this way is 2.7k, or 3.5% of total / 13.5% of difference.
AI Alignment Writing Day
The posts from MSFP writing day [? · GW] generated 3.0k KM, or 4.2% of total / 15% of the difference. However this is definitely something we would have done anyway and is not obviously something we should count as a special intentional activity to drive karma.
Novum Organum
The posting of the Novum Organum sequence [? · GW] was motivated by having more content to get more karma. The fives posts posted in Q3 netted 0.3k KM, or 0.4% of total / 1.5% of difference. Not that impactful on the metric.
Removing Login Expiry
Vulcan, the framework upon which LW2.0 was built, automatically signed people out after 90 days. This would require them log-in again before voting, commenting, or posting. We removed this and the number of logged-in users rose for several months going from 600 logged-in users/week to over 800 logged-in users/week. This seems to have flowed onto the number of unique people voting each week.
Making Login Easier
The more people logged-in, the more people who can vote, comment, and post. We improved the login popup and added more prompts for login to the site. There was no large or definite change in the rate of logins after this.
LessLong (Shortform) Launch Party
It’s unclear whether this party drove much immediate activity on LessWrong in Q3. We hosted this primarily off the model that it would be good to do something that made LessWrong seem really alive.
Subscriptions & LessWrong Docs (our new editor)
Though we worked on subscriptions and the new editor throughout Q3, our failure to release these means that they naturally didn’t generate any karma in Q3. Planning fallacy? (Subscriptions overhaul is now out [LW · GW], new editor is nearing beta release.)
Overall, how well did we accomplish our goals for this exercise?
Above I listed multiple reasons it would be a good idea to target a metric for a quarter, and regardless of well we maximized the metric, we can still ask if we achieved the goals one-level up.
It would test our ability to get concrete, visible results on purpose.
It would teach us to operate with a stronger empirical feedback loop.
I think the exercise helped along this dimension.
- The metric target had the team [4] everyday looking at our dashboard and regularly asking questions about the impact of different posts.
- We were forced to make plans based on the short-term predictions of our models. This enabled us to learn where we learnt where we wrong.
- For example, I overestimate the amount of KM generated by Novum Organum and underestimated that from Petrov Day.
- Even after the end of Metric Quarter, team members want to continue to monitor the numbers and include these as an input to our decision-making.
[4] With the exception of Ben Pace who was in the Europe for most of the period.
It would test how easily we can drive raw growth [1], i.e. see what rate of growth we get for our effort.
By putting almost all of our effort into growth for three months, we were definitely able to make the metric jump up some. This was most salient with time-bound events like specific high-engagement posts or events like Petrov Day, yet seems to be true of long-term features like Shortform too (however Shortform is gotten a little bit quiet lately - I'll be looking into that).
At the same time, getting growth was not super easy. We're unlikely to 10x the site unless we try quite hard for some time. Which causes me to conclude that it's unlikely that we ought to fear growth: things probably won't happen so quickly that we'll be unable to react. My personal leaning is that should always be trying to grow at least a little bit, if only to keep from shrinking.
The need to hit a clear target would introduce a degree or urgency and pressure we are typically lacking.
This effect was real. We definitely experienced sitting around, looking at the metric, and thinking how are we going to make it up go up this week? Unfortunately, this effect flagged a little after the first month when some of us became pessimistic about maintaining the 7% target. I think if the target was one where it continued to seem like had a shot, we'd have continued to feel more pressure to not fall below it. Overall though, we did keep trying to hit it then there.
I found myself working harder and longer of projects I enjoy less but thought would be more impactful for the metric. This makes me wonder about how much my usual slow-feedback, less-constrained activities is decided by pleasantness of the activities. It feels like a wake-up call to really be asking myself about what actually matters all the time.
Finale Take-aways
We're back to our more usual planning style where we're optimizing for long-term improvement of difficult-to-measure quantities, but I think we're retaining something of the empirical spirit of trying to make predictions about the results of our actions and comparing this to what actually happens.
27 comments
Comments sorted by top scores.
comment by johnswentworth · 2019-11-08T00:58:02.990Z · LW(p) · GW(p)
I'm gonna heckle a bit from the peanut gallery...
First, trying to optimize a metric without an A/B testing framework in place is kinda pointless. Maybe the growth achieved in Q3 was due to the changes made, but looking at the charts, it looks like a pretty typical quarter. It's entirely plausible that growth would have been basically the same even without all this stuff. How much extra karma was actually generated due to removing login expiry? That's exactly the sort of thing an A/B test is great for, and without A/B tests, the best we can do is guess in the dark.
Second (and I apologize if I'm wrong here), that list of projects does not sound like the sort of thing someone would come up with if they sat down for an hour with a blank slate and asked "how can the LW team get more karma generated?" They sound like the sort of projects which were probably on the docket anyway, and then you guys just checked afterward to see if they raised karma (except maybe some of the one-shot projects, but those won't help long-term anyway).
Third, I do not think 7% was a mistaken target. I think Paul Graham was right on this one: only hitting 2% is a sign that you have not yet figured out what you're doing. Trying to optimize a metric without even having a test framework in place adds a lot of evidence to that story - certainly in my own start-up experience, we never had any idea what we were doing until well after the test framework was in place (at any of the companies I've worked at). Analytics more generally were also always crucial for figuring out where the low-hanging fruit was and which projects to prioritize, and it sounds like you guys are currently still flying blind in that department.
So, maybe re-try targeting one metric for a full quarter after the groundwork is in place for it to work?
Replies from: habryka4, habryka4, Ruby↑ comment by habryka (habryka4) · 2019-11-08T01:48:08.017Z · LW(p) · GW(p)
First, trying to optimize a metric without an A/B testing framework in place is kinda pointless. Maybe the growth achieved in Q3 was due to the changes made, but looking at the charts, it looks like a pretty typical quarter. It's entirely plausible that growth would have been basically the same even without all this stuff. How much extra karma was actually generated due to removing login expiry? That's exactly the sort of thing an A/B test is great for, and without A/B tests, the best we can do is guess in the dark.
I don't think A/B testing would have really been useful for almost any of the above. Besides the login stuff all the other things were social features that don't really work when only half of the people have access to them. Like, you can't really A/B test shortform, or subscriptions, or automatic crossposting, or Petrov Day, or MSFP writing day, which is a significant fraction of things we worked on. I think if you want to A/B test social features you need a significantly larger and more fractured audience than we currently have.
I would be excited about A/B tests when they are feasible, but they don't really seem easily applicable to most of the things we build. If you do have ways of making it work for these kinds of social features, I would be curious about your thoughts, since I currently don't really see much use for A/B tests, but do think it would be good if we could get A/B test data.
Replies from: Ruby↑ comment by Ruby · 2019-11-08T02:21:26.451Z · LW(p) · GW(p)
Heckling appreciated. I'll add a bit more to Habryka's response.
Separate from the question of whether A/B would have been applicable to our projects, I'm not sure why think it's pointless to try to make inferences without them. True, A/B tests are cleaner and more definitive, and what we observed is plausibly what would have happened even with different activities, but that isn't to say we don't learn a lot when the outcome is one of a) metric/growth stays flat, b) small decrease, c) small increase, d) large decrease, e) large increase. In particular, the growth we saw (increase in absolute and rate) is suggestive of doing something real and also strong evidence against the hypothesis that it'd be very easy to drive a lot of growth.
Generally, it's at least suggestive that the first quarter where we explicitly we focus on growth is one where we see 40% growth from last quarter (compared to 20% in the previous quarter to the one before). It could be a coincidence, but I feel like there are still likelihood ratios here.
When it comes to attribution too, with some of these projects it's easy to get much more of an idea even without A/B testing. I can look at the posts from authors who we contacted and reasonably believe counterfactually would not have otherwise posted and see how much karma that generated. Same from Petrov Days and MSFP.
Replies from: johnswentworth, habryka4↑ comment by johnswentworth · 2019-11-08T05:35:33.061Z · LW(p) · GW(p)
Responding to both of you here: A/B tests are a mental habit which takes time to acquire. Right now, you guys are thinking in terms of big meaty projects, which aren't the sort of thing A/B tests are for. I wouldn't typically make a single A/B test for a big, complicated feature like shortform - I'd run lots of little A/B tests for different parts of it, like details of how it's accessed and how it's visible. It's the little things: size/location/wording of buttons, sorting on the homepage, tweaking affordances, that sort of thing. Think nudges, not huge features. Those are the kinds of things which let you really drive up the metrics with relatively little effort, once you have the tests in place. Usually, it turns out that one or two seemingly-innocuous details are actually surprisingly important.
It's true that you don't necessarily need A/B tests to attribute growth to particular changes, especially if the changes are big things or one-off events, but that has some serious drawbacks even aside from the statistical uncertainty. Without A/B tests, we can't distinguish between the effects of multiple changes made in the same time window, especially small changes, which means we can't run lots of small tests. More fundamentally, an A/B test isn't just about attribution, it's about having a control group - with all the benefits that a control group brings, like fine-grained analysis of changes in behavior between test buckets.
Replies from: cousin_it, Vaniver↑ comment by cousin_it · 2019-11-08T10:57:25.828Z · LW(p) · GW(p)
I think incremental change is a bit overrated. Sure, if you have something that performs so well that chasing 1% improvements is worth it, then go for it. But don't keep tweaking forever: you'll get most of the gains in the first few months, and they will total about +20%, or maybe +50% if you're a hero.
If your current thing doesn't perform so well, it's more cost-effective to look for big things that could bring +100% or +1000%. A/B tests are useful for that too, but need to be done differently:
-
Come up with a big thing that could have big impact. For example, shortform.
-
Identify the assumptions behind that thing. For example, "users will write shortform" or "users will engage with others' shortform".
-
Come up with cheap ways to test these assumptions. For example, "check the engagement on existing posts that are similar to shortform" or "suggest to some power users that they should make shortform posts and see how much engagement they get". At this step you may end up looking at metrics, looking at competitors, or running cheap A/B tests.
-
Based on the previous steps, change your mind about which thing you want to build, and repeat these steps until you're pretty sure it will succeed.
-
Build the thing.
↑ comment by johnswentworth · 2019-11-11T17:54:40.458Z · LW(p) · GW(p)
This line of thinking makes a major assumption which has, in my experience, been completely wrong: the assumption that a "big thing" in terms of impact is also a "big thing" in terms of engineering effort. I have seen many changes which are only small tweaks from an engineering standpoint, but produce 25% or 50% increase in a metric all on their own - things like making a button bigger, clarifying/shortening some text, changing something from red to green, etc. Design matters, it's relatively easy to change, but we don't know how to change it usefully without tests.
Replies from: cousin_it↑ comment by cousin_it · 2019-11-11T18:14:18.488Z · LW(p) · GW(p)
Agreed - I've seen, and made, quite a few such changes as well. After each big upheaval it's worth spending some time grabbing the low hanging fruit. My only gripe is that I don't think this type of change is sufficient over a project's lifetime. Deeper product change has a way of becoming necessary.
↑ comment by Vaniver · 2019-11-08T17:39:12.697Z · LW(p) · GW(p)
I think the other thing A/B tests are good for is giving you a feedback source that isn't your design sense. Instead of "do I think this looks prettier?" you ask questions like "which do users click on more?". (And this eventually feeds back into your design sense, making it stronger.)
Replies from: Ruby↑ comment by habryka (habryka4) · 2019-11-08T02:24:16.314Z · LW(p) · GW(p)
Yes, heckling is definitely appreciated!
↑ comment by habryka (habryka4) · 2019-11-08T01:43:09.113Z · LW(p) · GW(p)
Second (and I apologize if I'm wrong here), that list of projects does not sound like the sort of thing someone would come up with if they sat down for an hour with a blank slate and asked "how can the LW team get more karma generated?"
It is a list of projects we prioritized based on how much karma we expect they would generate over the long run, filtered by things that didn't seem like obviously goodharty ideas.
If these don't seem like the things you would have put on the list, what other things would you have put on the list? I am genuinely curious, since I don't have any obvious ideas for what I would have done instead.
Replies from: Ruby↑ comment by Ruby · 2019-11-08T02:28:05.611Z · LW(p) · GW(p)
A number of these projects were already on our docket, but less visible is the projects which were delayed and the fact that those selected might not have been done now otherwise. For example, if we hadn't been doing metric quarter, I'd like have spent more of my time continuing work on the Open Questions platform and much less of my time doing interviews and talking to authors. Admittedly, subscriptions and the new editor are projects we were already committed to and had been working on, but if we hadn't thought they'd help with the metric, we'd have delayed it to the next quarter the way we did with many of other project ideas.
We did brainstorm however, but as Oli said, it wasn't easy to come with any ideas which were obviously much better.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-08T05:50:52.504Z · LW(p) · GW(p)
Responding to both of you with one comment again: I sort of alluded to it in the A/B testing comment, but it's less about any particular feature that's missing and more about the general mindset. If you want to drive up metrics fast, then the magic formula is a tight iteration loop: testing large numbers of small changes to figure out which little things have disproportionate impact. Any not-yet-optimized UI is going to have lots of little trivial inconveniences and micro-confusions; identifying and fixing those can move the needle a lot with relatively little effort. Think about how facebook or amazon A/B tests every single button, every item in every sidebar, on their main pages. That sort of thing is very easy, once a testing framework is in place, and it has high yields.
As far as bigger projects go... until we know what the key factors are which drive engagement on LW, we really don't have the tools to prioritize big projects. For purposes of driving up metrics, the biggest project right now is "figure out which things matter that we didn't realize matter". A/B tests are one of the main tools for that - looking at which little tweaks have big impact will give hints toward the bigger issues. Recorded user sessions (a la FullStory) are another really helpful tool. Interviews and talking to authors can be a substitute for that, although users usually don't understand their own wants/needs very well. Analytics in general is obviously useful, although it's tough to know which questions to ask without watching user sessions directly.
Replies from: Ruby↑ comment by Ruby · 2019-11-09T02:04:04.996Z · LW(p) · GW(p)
I see the spirit of what you're saying and think there's something to it though it doesn't feel completely correct. That said, I don't think anyone on the team has experience with that kind of A/B testing loop and given that lack of experience, we should try it out for at least a while on some projects.
To date, I've been working just to get us to have more of an analytics-mindset plus basic thorough analytics throughout the app, e.g. tracking on each of the features/buttons we build, etc. (This wasn't trivial to do with e.g. Google Tag Manager so we've ended up building stuff in-house.) I think trying out A/B testing would likely make sense soon, but as above, I think there's a lot of value even before it with more dumb/naive analytics.
We trialled FullStory for a few weeks and I agree it's good, but also we just weren't using it enough to justify it. LogRocket offers monthly subscription though and likely we'll sign up for that soon. (Once we're actually using it fully, not just trialling, we'll need to post about it properly, build opt-out, etc. and be good around privacy - already in trial we hid e.g. voting, usernames.)
To come back to the opening points in the OP, we probably shouldn't get too bogged down trying to optimize specific simple metrics by getting all the buttons perfect, etc., given the uncertainty over which metrics are even correct to focus on. For example, there isn't any clear metric (that I can think of) that definitely answers how much to focus on bringing in new users and getting them up to speed vs building tools for existing users already producing good intellectual progress. I think it's correct that have to use high-level models and fuzzier techniques to think about big project prioritization. A/B tests won't resolve the most crucial uncertainties we have though I do think they're likely to hugely helpful in refining our design sense.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-09T03:16:13.467Z · LW(p) · GW(p)
I actually agree with the overall judgement there - optimizing simple metrics really hard is mainly useful for things like e.g. landing pages, where the goals really are pretty simple and there's not too much danger of Goodharting. Lesswrong mostly isn't like that, and most of the value in micro-optimizing would be in the knowledge gained, rather than the concrete result of increasing a metric. I do think there's a lot of knowledge there to gain, and I think our design-level decisions are currently far away from the pareto frontier in ways that won't be obvious until the micro-optimization loop starts up.
I will also say that the majority of people I've worked with have dramatically underestimated the magnitude of impact this sort of thing has until they saw it happen first-hand, for whatever that's worth. (I first saw it in action at a company which achieved supercritical virality for a short time, and A/B-test-driven micro-optimization was the main tool responsible for that.) If this were a start-up, and we needed strong new user and engagement metrics to get our next round of funding, then I'd say it should be the highest priority. But this isn't a startup, and I totally agree that A/B tests won't solve the most crucial uncertainties.
↑ comment by Ruby · 2019-11-08T02:33:31.878Z · LW(p) · GW(p)
Trying to optimize a metric without even having a test framework in place adds a lot of evidence to that story - certainly in my own start-up experience, we never had any idea what we were doing until well after the test framework was in place (at any of the companies I've worked at). Analytics more generally were also always crucial for figuring out where the low-hanging fruit was and which projects to prioritize, and it sounds like you guys are currently still flying blind in that department.
I think I agree with the general spirit here. Throughout my year with the LessWrong team, I've been progressively building out analytics infrastructure to reduce my sense of the "flying blind" you speak of. We're not done yet, but I've now got a lot of data at my fingertips. I think the disagreement here would be over whether anything short of A/B testing is valuable. I'm pretty sure that it is.
comment by Wei Dai (Wei_Dai) · 2019-11-08T06:39:45.879Z · LW(p) · GW(p)
Due to changes in how karma is computed introduced with LW2, we can’t compare our karma metric backwards in time. Fortunately, the number of votes is a good proxy.
I'm not sure about this. At least for me personally, I feel like voting is more costly on LW2 than on LW1, and I probably vote substantially less as a result. (Not totally sure because I haven't kept statistics on my own voting behavior.) The reasons are:
- Having to decide between strong vs weak vote.
- Having a high enough karma that my vote strengths (3 for weak and 10 for strong) are pretty identifiable, so I have to think more about social implications. (Maybe I shouldn't, but I do.)
- Sometimes I'm uncomfortable voting something up or down by at least 3 points because I'm not sure of my judgement of its quality.
Hmm, on second thought the number of people in my position is probably small enough that this isn't likely to significantly affect your "number of votes" comparison. I'll leave this here anyway as general feedback on the voting system. (To be clear I'm not advocating to change the current system, just offering a data point.)
Another thing I've been wondering about is, there's generally less voting per post/comment on LW2 than on LW1, but the karma on comparable posts seems more similar. Could it be that people have inherited their sense of how much karma different kinds of posts/comments "deserve" from LW1 and tend to stop voting up a post once it reaches that amount, which would result in similar karma but fewer votes?
Replies from: Viliam, Kaj_Sotala, Benito↑ comment by Viliam · 2019-11-08T21:50:48.613Z · LW(p) · GW(p)
Having a high enough karma that my vote strengths (3 for weak and 10 for strong) are pretty identifiable, so I have to think more about social implications.
I think the other comments show that you are not that identifiable.
Having to decide between strong vs weak vote.
Just always do the weak vote and don't think about it.
↑ comment by Kaj_Sotala · 2019-11-08T09:41:27.973Z · LW(p) · GW(p)
To offer another data point, my vote weights are also 3 / 10, and it hasn't occurred to me to think about these things. I just treat my "3" as a "1", and usually only strong-upvote if I get a clear feeling of "oh wow, I want to reward this extra hard" (i.e. my rule is something like "if I feel any uncertainty about whether this would deserve a strong upvote, then it doesn't").
↑ comment by Ben Pace (Benito) · 2019-11-08T07:15:27.624Z · LW(p) · GW(p)
Having a high enough karma that my vote strengths (3 for weak and 10 for strong) are pretty identifiable, so I have to think more about social implications. (Maybe I shouldn't, but I do.)
Hmm, I was starting to notice that a bit myself, and I think this is especially strong the more vote weight you have, which is an incentive counter to the very point of weighted voting. One option is to obscure some karma things a little to avoid this.
Replies from: Vaniver↑ comment by Vaniver · 2019-11-08T17:37:23.796Z · LW(p) · GW(p)
FWIW I don't have this effect (and am also at 3/10). But I think I was also always in the "if I like something at 50, I will upvote it anyway" camp instead of in the "I think this should have a karma of 40, and since it's at 50, I don't need to upvote it" camp.
comment by John_Maxwell (John_Maxwell_IV) · 2019-11-09T06:11:41.003Z · LW(p) · GW(p)
Cool project!
I suggest you make Q3 "growth quarter" every year, and always aim to achieve 1.5x the amount of growth you were able to achieve during last year's "growth quarter".
You could have an open thread soliciting growth ideas from the community right before each "growth quarter".
comment by Thomas Kwa (thomas-kwa) · 2020-03-23T00:00:49.325Z · LW(p) · GW(p)
Clause #3 was chosen to heighten to reward/punishment for especially good or especially bad content. We’re inclined to think that single 100-karma post is worth more than four 25-karma posts and the exponentiation reflects this. (For comparison: 25^1.2 is 47.6, 100^1.2 is 251.2. So in our metric, one 100-karma post was worth about 30% more than four 25-karma posts).
Is the idea behind this that a high-quality post can provide more than a single strong-upvote of value per person, and that total karma is a proxy for this excess value?
comment by shanen · 2021-01-30T22:57:43.831Z · LW(p) · GW(p)
Pretty sure this comment is going to go badly. Please excuse me for my incoherence, amplified by my limited time. But I have a number of strong reactions. The three strongest are:
(1) I do not want to reduce humans to or be reduced to a single metric. Symmetry violation (of the Golden Rule).
(2) Arbitrary scaling should be avoided by normalization. Most obvious example is weighting down votes by 4. From a symmetry perspective, the weighting should reflect which way the votes are cast and who is casting the votes. (I also think negative votes should be justified, but that's a new aspect.)
(3) Insufficiently detailed accounting for the costs of the project. However I am quite favorably impressed that success criteria were at least considered. (Is cost recovery a symmetry? (But in actionable terms, I don't know if I would have pledged money to implement this project. I'm having trouble seeing it as a step in any positive direction.))
Now for the worst part. I have a delusion of a better solution approach. As a joke, "I know it when I see it" and this isn't it and doesn't even seem to be a step in a "right and proper" direction. I think a simple up-down vote is okay, but should mostly be limited to defining a weight that is applied to a multidimensional vector. I've described it as MEPR elsewhere, but here I'm going to retag it as DK for Deeper Karma.
Defining the direction of that DK vector should involve an optional deeper reaction. Rather than +/- it would involve looking at some dimensions and voting them up or down. As much as possible, the dimensions should be orthogonal and symmetric. (In the OP, this use of "dimension" is close to "metric" selection.)
A few examples of dimensions: Simple dimension of humor, with + for funny and - for unfunny. The age of the identity is a one-way metric, but it can be normalized on a scale from youngest to oldest. Really messy dimension but a dimension for fox versus hedgehog would be interesting. (Considering how IBM and the google analyze identities, there are hundreds of such dimensions, but we human beings have limited attention spans and at any one time the number of dimensions should be limited, perhaps to 5 or 7.)
Now for an elevator ride past the trickiest symmetry. It is necessary to begin by dividing DK in twain. Let's call them DK-A for Artifact and DK-I for Identity (that created the artifact). Now "You will know them by their fruits." Reacting to an artifact will change it's DK-A, and the identity whose comments earned those reactions will have those reactions reflected in the DK-I.
In addition, in the process of giving reactions, the identity's DK-I should be considered. The humor dimension is a simple example. If someone has earned many positive humor reactions, then it should count more when that identity reacts to another artifact by assessing it as +/- humor. In contrast, an identity with negative humor should not be able to affect humor scores much.
Now for the messy bit that seems to confuse people. How can the DK be displayed? I imagine the DK-I should be paired with its identity. I would actually favor a little radar diagram with selected dimensions. Clicking on the identity's own link would take you to whatever the identity wants to say about itself, but clicking on the DK-I icon will take you to the details about all of the data that contributes to the DK-I. (Symmetry time again. The comment (as a public artifact) would have a DK-A link for its data and history.)
Why do this? Now we're getting into the cans of worms by the six-packs of cans. But I can reduce it to two major cans:
(1) My time is limited and there is always much more content than I could read. (Ditto videos or podcasts or pictures or whatever.) DK could help me filter.
(2) I want to become a better person and looking at my own DK-I would be useful feedback in improving. Am I being too much of a prick? For example, I don't want to be rude, but I think too many of my reactions are negative in ways that seem negative on the polite dimension, and my own DK-I would let me get an honest assessment of how rude (or polite) other people think I am.
Already spent much more time than I had intended, but mostly I have to apologize for having taken up so much of your time. I think this description is quite shallow and confusing. If you have been able to follow it then you deserve some kudos and DK-I positive for reading skills' dimensions. Also you are being quite polite to a stranger, and your DK-I should go up for that reason. (Not only are I one, but I'm currently reading L'Étranger with Japanese annotations.)
Oh yeah. One more thing. It would be interesting if the the website itself could pick out DK-A dimensions of interest and relevance. That would simply the rating process if you opted to look at the deeper karma instead of the simple +/- reaction.
Replies from: Ruby↑ comment by Ruby · 2021-01-31T21:32:58.512Z · LW(p) · GW(p)
Thanks for this detailed feedback! I can't delve into properly today, but I hope to look at it soon.
Replies from: shanen↑ comment by shanen · 2021-02-02T19:43:44.738Z · LW(p) · GW(p)
Is an ACK called for?
I would add one more aspect if I didn't suspect it's a moot topic. The financial side. Someone has to cover the costs of things... I personally favor cost-recovery from wannabe donors and actual beneficiaries. However I think LessWrong may use the big donor model, which only works as long as the donor's pockets stay full and the donor doesn't make too many bad calls.