[Linkpost] Some high-level thoughts on the DeepMind alignment team's strategy
post by Vika, Rohin Shah (rohinmshah) · 2023-03-07T11:55:01.131Z · LW · GW · 13 commentsThis is a link post for https://drive.google.com/file/d/1DVPZz0-9FSYgrHFgs4NCN6kn2tE7J8AK/view?usp=sharing
Contents
13 comments
Update: The original title "DeepMind alignment team's strategy" was poorly chosen. Some readers seem to have interpreted the previous title as meaning that this was everything that we had thought about or wanted to say about an "alignment plan", which is an unfortunate misunderstanding. We simply meant to share slides that gave a high-level outline of how we were thinking about our alignment plan, in the interest of partial communication rather than no communication.
I recently gave a talk about the DeepMind alignment team's strategy at the SERI MATS seminar, sharing the slides here for anyone interested. This is an overview of our threat models, our high-level current plan, and how current projects fit into this plan.
Disclaimer: This talk represents the views of the alignment team and is not officially endorsed by DeepMind. This is a work in progress and is not intended to be a detailed or complete plan.
Let's start with our threat model for alignment -- how we expect AGI development to go and the main sources of risk.
Development model. We expect that AGI will likely arise in the form of scaled up foundation models fine tuned with RLHF, and that there are not many more fundamental innovations needed for AGI (though probably still a few). We also expect that the AGI systems we build will plausibly exhibit the following properties:
- Goal-directedness. This means that the system generalizes to behave coherently towards a goal in new situations (though we don't expect that it would necessarily generalize to all situations or become a expected utility maximizer).
- Situational awareness. We expect that at some point an AGI system would develop a coherent understanding of its place in the world, e.g. knowing that it is running on a computer and being trained by human designers.
Risk model. Here is an overall picture from our recent post on Clarifying AI X-risk [LW · GW]:
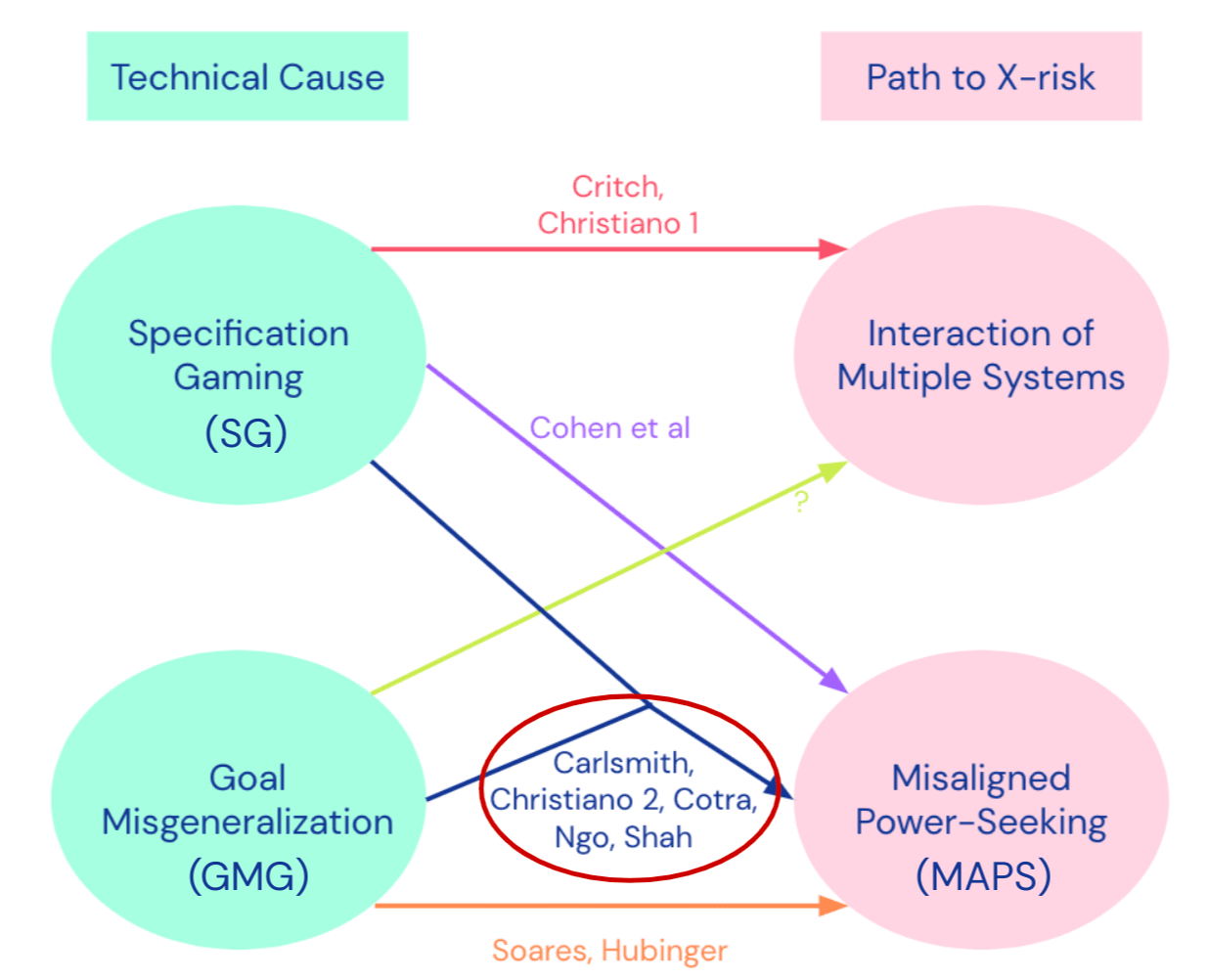
We consider possible technical causes of the risk, which are either specification gaming (SG) or goal misgeneralization (GMG), and the path that leads to existential risk, either through the interaction of multiple systems or through a misaligned power-seeking system.
Various threat models in alignment focus on different parts of this picture. Our particular threat model is focused on how the combination of SG and GMG can lead to misaligned power-seeking, so it is in the highlighted cluster above.
Conditional on AI existential risk happening, here is our most likely scenario for how it would occur (though we are uncertain about how likely this scenario is in absolute terms):
- The main source of risk is a mix of specification gaming and (a bit more from) goal misgeneralization.
- A misaligned consequentialist arises and seeks power. We expect this would arise mainly during RLHF rather than in the pretrained foundation model, because RLHF tends to make models more goal-directed, and the fine-tuning tasks benefit more from consequentialist planning.
- This is not detected because deceptive alignment occurs (as a consequence of power-seeking), and because interpretability is hard.
- Relevant decision-makers may not understand in time that this happening, if there is an inadequate societal response to warning shots for model properties like consequentialist planning, situational awareness and deceptive alignment.
We can connect this threat model to our views on MIRI's arguments for AGI ruin [LW · GW].
- Some things we agree with: we generally expect that capabilities easily generalize out of desired scope (#8) and possibly further than alignment (#21), inner alignment is a major issue and outer alignment is not enough (#16), and corrigibility is anti-natural (#23).
- Some disagreements: we don't think it's impossible to cooperate to avoid or slow down AGI (#4), or that a "pivotal act" is necessary (#6), though we agree that it's necessary to end the acute risk period in some way. We don't think corrigibility is unsolvable (#24), and we think interpretability is possible though probably very hard (section B3). We expect some tradeoff between powerful and understandable systems (#30) but not a fundamental obstacle.
Note that this is a bit different from the summary of team opinions in our AGI ruin survey [LW · GW]. The above summary is from the perspective of our alignment plan, rather than the average person on the team who filled out the survey.
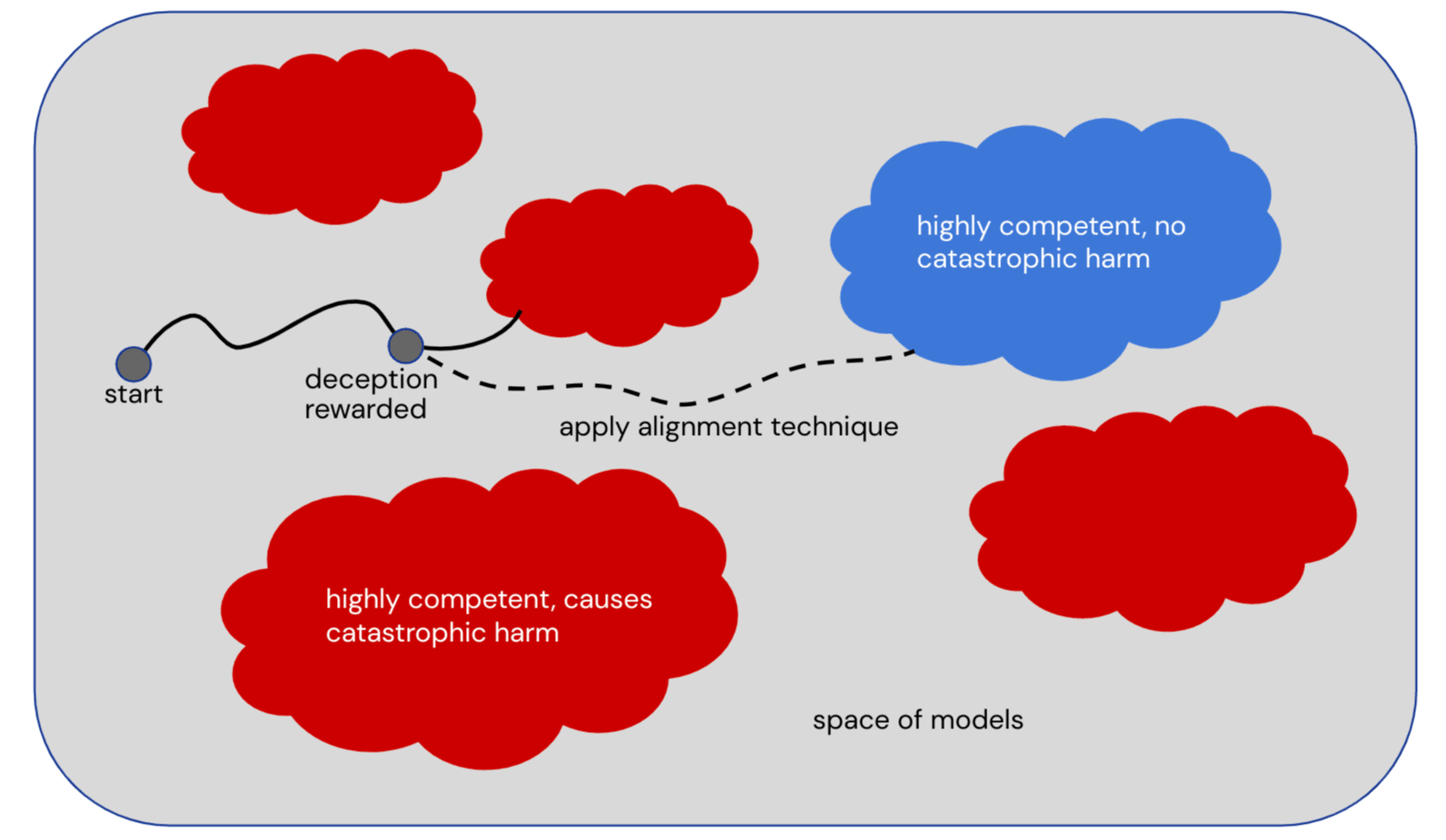
Our approach. Our high level approach to alignment is to try to direct the training process towards aligned AI and away from misaligned AI. To illustrate this, imagine we have a space of possible models, where the red areas consist of misaligned models that are highly competent and cause catastrophic harm, and the blue areas consist of aligned models that are highly competent and don't cause catastrophic harm. The training process moves through this space and by default ends up in a red area consisting of misaligned models. We aim to identify some key point on this path, for example a point where deception was rewarded, and apply some alignment technique that directs the training process to a blue area of aligned models instead.
We can break down our high-level approach into work on alignment components, which focuses on building different elements of an aligned system, and alignment enablers, which make it easier to get the alignment components right.
Components: build aligned models
- Outer alignment
- Scalable oversight (Sparrow, debate)
- Process-based feedback
- Inner alignment
- Mitigating goal misgeneralization
- Red-teaming
Enablers: detect models with dangerous properties
- Detect misaligned reasoning
- Looking at internal reasoning (mechanistic interpretability)
- Cross-examination (and consistency checks more generally)
- Detect capability transitions
- Capability evaluations
- Predicting phase transitions (e.g. grokking)
- Detect goal-directedness
Teams and projects. Now we'll briefly review what we are working on now and how that fits into the plan. The most relevant teams are Scalable Alignment, Alignment, and Strategy & Governance. I would say that Scalable Alignment is mostly working on components and the other two teams are mostly working on enablers. Note that this doesn't include everyone doing relevant work at DeepMind.
Scalable alignment (led by Geoffrey Irving):
- Sparrow
- Process-based feedback
- Red-teaming
Alignment (led by Rohin Shah):
- Capability evaluations (led by Mary Phuong, in collaboration with other labs)
- Mechanistic interpretability (led by Vladimir Mikulik)
- Goal misgeneralization (led by Rohin Shah)
- Causal alignment (led by Tom Everitt)
- Paper: Discovering Agents
- Internal outreach (led by Victoria Krakovna)
Strategy & Governance (led by Allan Dafoe):
- Capability evaluations
- Institutional engagement / internal outreach
- (Lots of other things)
Relative to OpenAI's plan. Our plan is similar to OpenAI's approach in terms of components -- we are also doing scalable oversight based on RLHF. We are less confident in components working by default, and are relying more on enablers such as mechanistic interpretability and capability evaluations.
A major part of OpenAI's plan is to use large language models and other AI tools for alignment research. This a less prominent part of our plan, and we mostly count on those tools being produced outside of our alignment teams (either by capabilities teams or external alignment researchers).
General hopes. Our plan is based on some general hopes:
- The most harmful outcomes happen when the AI "knows" it is doing something that we don’t want, so mitigations can be targeted at this case.
- Our techniques don’t have to stand up to misaligned superintelligences -- the hope is that they make a difference while the training process is in the gray area, not after it has reached the red area.
- In terms of directing the training process, the game is skewed in our favour: we can restart the search, examine and change the model's beliefs and goals using interpretability techniques, choose exactly what data the model sees, etc.
- Interpretability is hard but not impossible.
- We can train against our alignment techniques and get evidence on whether the AI systems deceive our techniques. If we get evidence that they are likely to do that, we can use this to create demonstrations of bad behavior for decision-makers.
Overall, while alignment is a difficult problem, we think there are some reasons for optimism.
Takeaways. Our main threat model is basically a combination of SG and GMG leading to misaligned power-seeking. Our high-level approach is trying to direct the training process towards aligned AI and away from misaligned AI. There is a lot of alignment work going on at DeepMind, with particularly big bets on scalable oversight, mechanistic interpretability and capability evaluations.
13 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-03-08T16:39:03.346Z · LW(p) · GW(p)
I'm so glad you are making a plan and sharing it publicly!
Fun, possibly impactful idea: Have a livestreamed chat with Jan Leike (or some other representative from OpenAI's alignment team) where you discuss and critique each other's plans & discuss how you can support each other by sharing research etc.
comment by Hoagy · 2023-03-07T12:01:34.865Z · LW(p) · GW(p)
Could you explain why you think "The game is skewed in our favour."?
Replies from: Vika↑ comment by Vika · 2023-03-07T12:07:15.567Z · LW(p) · GW(p)
Just added some more detail on this to the slides. The idea is that we have various advantages over the model during the training process: we can restart the search, examine and change beliefs and goals using interpretability techniques, choose exactly what data the model sees, etc.
Replies from: baturinsky↑ comment by baturinsky · 2023-03-07T12:32:53.924Z · LW(p) · GW(p)
While the model has the advantage of only having to "win" once.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2023-03-07T16:27:27.117Z · LW(p) · GW(p)
I think that skews it somewhat but not very much. We only have to "win" once in the sense that we only need to build an aligned Sovereign that ends the acute risk period once, similarly to how we only have to "lose" once in the sense that we only need to build a misaligned superintelligence that kills everyone once.
(I like the discussion on similar points in the strategy-stealing assumption [AF · GW].)
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2023-03-08T09:07:33.807Z · LW(p) · GW(p)
Is building an aligned sovereign to end the acute risk period different to a pivotal act in your view?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2023-03-09T14:38:25.016Z · LW(p) · GW(p)
Depends what the aligned sovereign does! Also depends what you mean by a pivotal act!
In practice, during the period of time where biological humans are still doing a meaningful part of alignment work, I don't expect us to build an aligned sovereign, nor do I expect to build a single misaligned AI that takes over: I instead expect there to be a large number of AI systems, that could together obtain a decisive strategic advantage, but could not do so individually.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2023-03-10T00:01:51.915Z · LW(p) · GW(p)
So, if I'm understanding you correctly:
- if it's possible to build a single AI system that executes a catastrophic takeover (via self-bootstrap or whatever), it's also probably possible to build a single aligned sovereign, and so in this situation winning once is sufficient
- if it is not possible to build a single aligned sovereign, then it's probably also not possible to build a single system that executes a catastrophic takeover and so the proposition that the model only has to win once is not true in any straightforward way
- in this case, we might be able to think of "composite AI systems" that can catastrophically take over or end the acute risk period, and for similar reasons as in the first scenario, winning once with a composite system is sufficient, but such systems are not built from single acts
and you think the second scenario is more likely than the first.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2023-03-10T05:35:11.010Z · LW(p) · GW(p)
Yes, that's right, though I'd say "probable" not "possible" (most things are "possible").
comment by Gabe M (gabe-mukobi) · 2023-03-08T16:58:29.220Z · LW(p) · GW(p)
This does feel pretty vague in parts (e.g. "mitigating goal misgeneralization" feels more like a problem statement than a component of research), but I personally think this is a pretty good plan, and at the least, I'm very appreciative of you posting your plan publicly!
Now, we just need public alignment plans from Anthropic, Google Brain, Meta, Adept, ...
comment by GunZoR (michael-ellingsworth) · 2023-03-09T19:49:41.144Z · LW(p) · GW(p)
But what stops a blue-cloud model from transitioning into a red-cloud model if the blue-cloud model is an AGI like the one hinted at on your slides (self-aware, goal-directed, highly competent)?
Replies from: Vika↑ comment by Vika · 2023-03-10T11:33:55.840Z · LW(p) · GW(p)
We expect that an aligned (blue-cloud) model would have an incentive to preserve its goals, though it would need some help from us to generalize them correctly to avoid becoming a misaligned (red-cloud) model. We talk about this in more detail in Refining the Sharp Left Turn (part 2) [? · GW].
comment by Review Bot · 2024-02-19T13:43:54.617Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?