EAI Alignment Speaker Series #1: Challenges for Safe & Beneficial Brain-Like Artificial General Intelligence with Steve Byrnes
post by Curtis Huebner, Steven Byrnes (steve2152) · 2023-03-23T14:32:53.800Z · LW · GW · 0 commentsThis is a link post for https://youtu.be/spCv1RwLwEo
Contents
Getting started The talk General motivation Very big picture of brain algorithms: “Learning Subsystem” & “Steering Subsystem” The second thing that my two-subsystem picture is NOT is “blank slate” or “nurture rather than nature”. “Steering Subsystem” as the ultimate source of motivations, drives, values, etc. Q&A “What kinds of images would cause a human's learned dog detector circuitry to maximally activate?” “What's your model of how empathetic modeling works in humans?” “What kinds of technical work can we do today? What are some proximal or medium term goals?” “How common do you think sociopathy or psychopathy are in nonhumans? And what does that imply?” What infrastructure / engineering would help with this research agenda? Question about schizophrenia How to do this research Examples of how you’ve had to change your model Schizophrenia visual perception quiz answer Eliezer Yudkowsky + Scott Alexander post Alignment agendas that can’t work and your cruxes for why not Wrap-up None No comments
A couple months ago EleutherAI started an alignment speaker series, some of these talks have been recorded. This is the first instalment in the series. The following is a transcript generated with the help of Conjecture's Verbalize and some light editing:
Getting started
1 CURTIS
00:00:22,775 --> 00:00:56,683
Okay, I've started the recording. I think we can give it maybe a minute or two more and then I guess we can get started. I've also got the chat window as part of the recording. So if anyone has something they want to write out, feel free to put that in. Steve, you want to do questions throughout the talk, or should we wait till the end of the talk before we ask questions?
2 STEVE
00:00:59,405 --> 00:01:09,452
Let's do throughout, but I reserve the right to put people off if something seems tangential or something.
3 CURTIS
00:01:10,200 --> 00:01:12,101
Awesome. All right, cool. Let's go with that then.
[…]
10 STEVE
00:02:02,246 --> 00:21:41,951
The talk

All right. Thanks, everybody, for coming. This is going to be based on blog posts called Intro to Brain-Like AGI Safety [? · GW]. If you've read all of them, you'll find this kind of redundant, but you're still welcome to stay. My name is Steve Byrnes and I live in the Boston area. I'm employed remotely by Astera Institute, which is based in Berkeley. I'm going to talk about challenges for safe and beneficial brain-like Artificial General Intelligence for the next 35 minutes. Feel free to jump in with questions.
Don't worry, I'm funded by an entirely different crypto billionaire. …That joke was very fresh when I wrote it three months ago. I need a new one now.

Okay, so I'll start with—well, we don't have to talk about the outline. You'll see as we go.
General motivation

Start with general motivation. Again, I'm assuming that the audience has a range of backgrounds, and some of you will find parts of this talk redundant.
The big question that I'm working on is: What happens when people figure out how to run brain-like algorithms on computer chips? I guess I should say “if and when”, but we can get back to that. And I find that when I bring this up to people, they they tend to have two sorts of reactions:
- One is that we should think of these future algorithms as “like tools for people to use”.
- And the other is that we should think of them as “like a new intelligent species on the planet”.
So let's go through those one by one.

Let’s start with the tool perspective. This is the perspective that would be more familiar to AI people. If we put brain-like algorithms on computer chips, then that would be a form of artificial intelligence. And everybody knows that AI today is a tool for people to use.
So on this perspective, the sub-problem I'm working on is accident prevention. We want to avoid the scenarios where the AI does something that nobody wanted it to do—not the people who programmed it, not anybody. So there is a technical problem to solve there, which is: If people figure out how to run brain-like algorithms on computer chips, and they want those algorithms to be trying to do X—where X is solar cell research or being honest or whatever you can think of—then what source code should they write? What training environment should they use? And so on. This is an unsolved problem. It turns out to be surprisingly tricky, for some pretty deep reasons that mostly are not going to be in the scope of this talk, but you can read the series [? · GW].
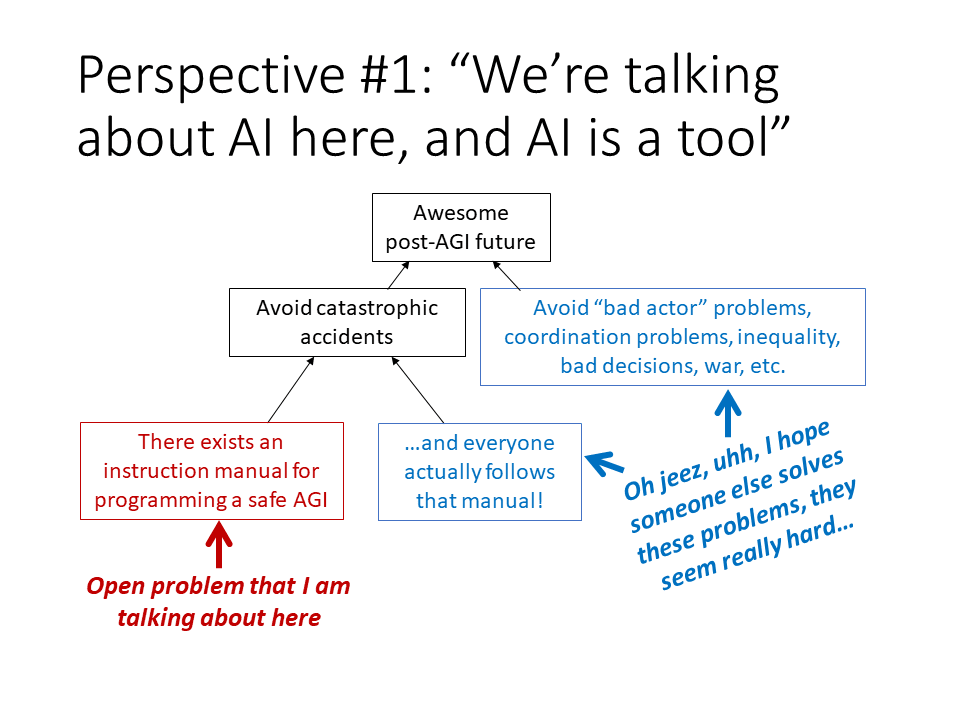
This slide is the bigger picture of that. So if we want our awesome post-AGI future, then we want to avoid, y'know, catastrophic accidents where the AI gets out of control and self-replicates around the Internet and kills everybody. That's one helpful ingredient. The other ingredient is that we want to avoid war and inequality and bad actors and coordination problems and all those other things.
Within the “avoid catastrophic accidents” category, we want there to be some instruction manual or procedure that you can follow, where you get the AGI that doesn't kill everybody. And then you also need everybody to actually follow that manual.
I'm not going to talk about these blue boxes and I don't generally work on them much. I'm going to talk about this red part.
So that was the first perspective, where AI is a tool for people to use.

The other perspective is that: if we put brain-like algorithms on computer chips, then we should think of this as a new intelligent species that we're inviting to our planet. Not just that, but a new intelligent species which will, in all likelihood, eventually vastly outnumber humans, and think much faster than humans, and be more insightful and creative and competent, and they'll be building on each other's knowledge, and solving problems by inventing tools, and making plans, and pivoting when the plans fail—all the things that humans, and groups of humans, and societies of humans can do, presumably these algorithms (and/or groups of these algorithms) can do too.

So if we’re inviting this intelligent species onto our planet, then how do we make sure it's a species that we actually want to share the planet with? And how do we make sure that they want to share the planet with us?
And again, there's a technical problem: whatever properties we want the species to have, we need to write the source code, or come up with training environments or whatever it is, to make sure that that actually happens.
And I think that high functioning sociopaths are an illustrative example here. They do exist, and that suggests that it's at least possible to put brain-like algorithms on computer chips that lack any inherent motivation to compassion and friendship. And I would go further and say that not only is it possible, but it’s strictly easier to do that—I think that compassion and friendship have to be added into the source code, and I think that we don't currently know how to do that. So I think we should try to figure it out!

Okay, so what about other paths to AGI? After all, we don't have to make AGI by putting brain-like algorithms on computer chips.
If AGI winds up in the general category of model-based reinforcement learning, then I claim that the stuff that I work on in general, and the stuff in this talk in particular, will probably be at least somewhat useful. I'll get back to model-based RL later in the talk. If it's not in the general category of model-based RL, then maybe what I'm talking about won't be so useful.
So then I have this polite diplomatic cop out claim that says we should be contingency-planning for any plausible path to AGI. Or I guess you could call it a “threat model” instead of “path to AGI” if you're more of a doomer like me.
What I actually believe, but won't argue for in this talk, is that we're very likely to wind up with “brain-like AGI”, for better or worse, which makes this an even better idea to be thinking about.
Very big picture of brain algorithms: “Learning Subsystem” & “Steering Subsystem”

OK, so moving on from general motivation, I next want to talk about a very big picture of brain algorithms in terms of these two things that I made up called “Learning Subsystem” and “Steering Subsystem”, which I’ll define in a moment.

As we start diving into brains, the first thing that I want to say is that we do actually already know enough about brain algorithms to say useful things about a hypothetical brain-like AGI.
I do get some push-back at this point, where people joke about how complicated the brain is. I joke about how complicated the brain is too! The brain is very complicated!

Nevertheless, I claim that “understanding the brain well enough for future researchers to make brain-like AGI” is different from and much simpler than “understanding the brain” full stop. And there are a few reasons for that.

First is that learning algorithms are much simpler than trained models. Probably a bunch of people here at EleutherAI know how to make a convolutional neural net, but basically nobody could look at the hundred million parameters of a trained image classifier and explain in full detail how it can tell apart different breeds of dog. So by the same token, if you look at the neuroscience and cognitive science literature, especially cognitive science, there's a lot of discussion about how an adult human does some intelligent thing. And I claim that that's at least partly a question about trained models, and not purely a question about learning algorithms. So I claim that people will be building brain-like AGI long before they know the answer to lots of questions like that in cognitive science.
The second issue is that algorithms tend to be much simpler than their physical instantiations. So again, here at EleutherAI, everybody would be laughed out of town if they didn't know how to program a convolutional neural net. And yet, almost nobody here probably understands everything that goes into the physical implementation of that convolutional neural net in the physical universe made out of atoms. So that includes everything from Schottky junctions and transistors and quantum tunneling and photolithography, and then up a level there’s GPU instruction sets, and CUDA compilers, and on and on. It’s just incredibly complicated. So by the same token, if you zoom into the brain, you find a fractal-like unfolding of beautifully complex machinery. And I claim that people will be building brain-like AGI long before anyone understands all of the complexity that goes into this physical object, the brain.
And then last but not least, and somewhat relatedly, not everything in the brain is required for brain-like AGI. So for example, you can find generally intelligent people—they can make plans, they can live independently, and so on—but they're lacking maybe an entire cortical hemisphere, or they're missing a cerebellum, or they don't have a sense of smell. As a particular example, somewhere in your medulla, I think, is some brain circuitry that says, okay, this is a good time to vomit. And when you vomit, you contract the following 17 muscles in the following order, blah, blah, blah, release these hormones. And nobody is going to be reverse engineering how that works before we have brain-like AGI.
Okay, so that's sorta my motivational speech that we shouldn't be put off from studying the brain because the brain is so complicated.

So now that we're going to dive into the brain a little bit, a key term or concept that I find very useful—and it's really central to how I think about the brain—is “learning from scratch”. I'll give two examples of “learning from scratch” and then I'll say what they have in common.
The first example is any machine learning algorithm that's initialized from random weights. And the second example is a blank flash drive. You just bought it from the store and the bits are all random, or they're all zeros, or whatever.
What do these have in common? They initially can only emit signals that are random garbage, but over time they can emit more and more useful signals, thanks to some learning algorithm or other algorithm that updates an internal memory store within this module.
So for the blank flash drive: you can't get any information off of a blank flash drive until you've already written information onto it. And in the case of a machine learning algorithm: your randomly-initialized ConvNet is going to output total garbage when you first turn it on. But then gradient descent makes it more and more useful.
By the same token, we can look at the brain and, and we can entertain the hypothesis that some part of the brain is “learning from scratch” in that sense. So it's built by the genome. And when it's built by the genome, it is not able to do anything biologically useful for the organism. It emits random outputs. It’s not helping the organism survive and thrive and reproduce. But this piece of the brain gradually learns and changes over the course of a lifetime. And by the time the animal is an adult, it's very useful.
Memory systems are obvious examples. Having the ability to form new memories does not help you in the moment. It only helps you via the fact that you were previously forming memories earlier in life. Just like that blank flash drive.

So my hypothesis is that a whopping 96% of the human brain by volume “learns from scratch” in this sense. That includes the whole cortical mantle—the neocortex, the hippocampus, the amygdala, … I'm lumping in the thalamus here. It’s fine if you don't know what these terms mean. The whole striatum and the cerebellum, too, plus other bits and pieces.
The major exceptions, I think, are the hypothalamus and brainstem. I think that those absolutely do not learn from scratch. I think that they're doing very useful things for an animal right from birth, just based on the way that they're built.

So, should we believe my hypothesis that all these different parts of the brain are “learning from scratch”? My take is that there's lots of strong evidence. I have a blog post with all the details [LW · GW]. I find that a few neuroscientists agree with me and a few disagree. It seems that a great many have never considered the hypothesis in the first place. For example, there's a semi-famous review article about the role of learning algorithms in the brain. It says, “Some people think that the brain has learning algorithms. But newborns are able to do all these neat things. Therefore, maybe we should think of it as pre-trained learning algorithms or something.” He doesn't even entertain the hypothesis that maybe there are pure learning algorithms in some parts of the brain, and there are things that are not learning algorithms at all in other parts of the brain—which I see as a very viable hypothesis. In particular, there's some evidence that newborn behavior is significantly driven by the brainstem.
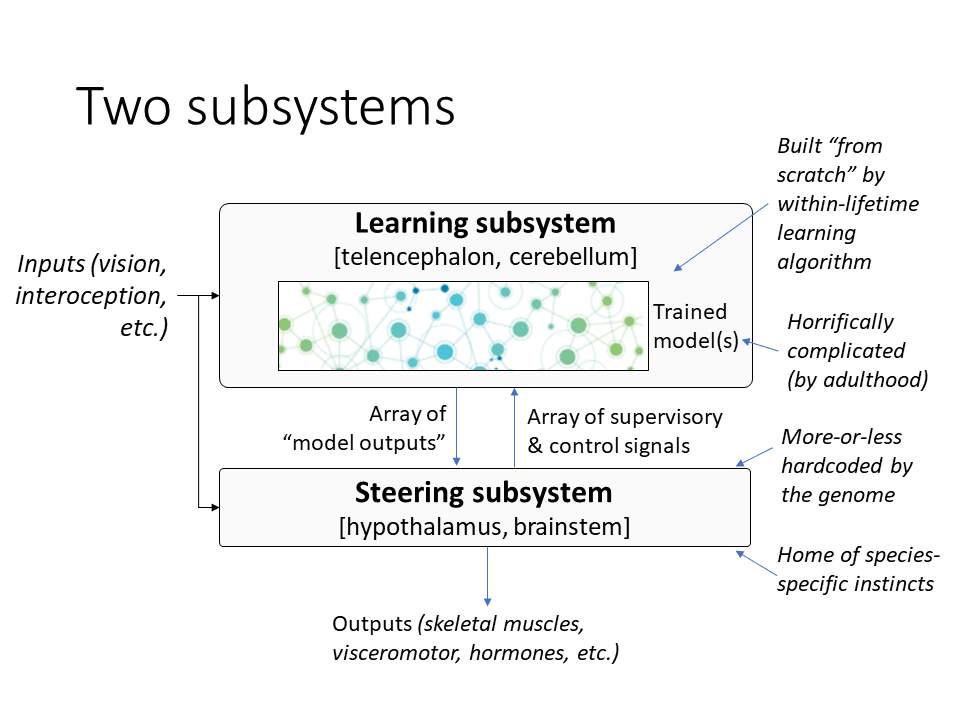
OK, so if you buy this picture—and we can argue about it in the Q&A—if you buy this picture, then you wind up thinking of the brain as two subsystems, a “Learning Subsystem” and a “Steering Subsystem”, defined by whether or not they’re “learning from scratch”. And I'll get back to why I'm calling it “steering” in a little bit. The Learning Subsystem has some trained models in it, which are horrifically complicated by the time you're an adult. And they’re built by learning algorithms.
I should clarify a few things that this picture is not, because I get a lot of misunderstandings.

The first thing that my two-subsystem picture is NOT is old brain versus new brain, or triune brain. Jeff Hawkins talks about “old brain and new brain”; Paul MacLean and others have talked about “triune brain”. These are kinda discredited theories for various reasons.
One thing is: I draw the boundaries differently than they do. For example, I think that the amygdala and the hypothalamus are very, very different: the amygdala is a learning algorithm and the hypothalamus is not. But Triune Brain theory lumps them together.
Another thing is: Both subsystems are extremely old—I think they predate vertebrates. Even if you look at the fruit fly nervous system, I believe there's good evidence that you can divide it into a Learning Subsystem and a Steering Subsystem. Of course, our learning subsystems are a whole lot more complicated than they were 650 million years ago; and likewise, our steering subsystems are more complicated too. But they're both “old”.
The second thing that my two-subsystem picture is NOT is “blank slate” or “nurture rather than nature”.
For one thing, I have this whole part of the brain that is just chock full of species-specific instincts.
And another thing is that—obviously for you EleutherAI people—learning algorithms can and do have internal structure: architecture, hyperparameters, and so on. It's not just like I'm going to make a learning algorithm by opening a blank Python interpreter and pressing go! You have to you have to put stuff in there! You need a learning rule, and so on.
And then last but not least, “learning” is not the same as “a human is deliberately teaching me”. For example, if you have a robot in a sealed box, and it is has an RL algorithm to learn how to control its own body based on internal loss functions, that's a perfectly viable learning algorithm, and you can imagine the brain doing something kind of like that. But that's not the kind of “learning” that people think of in behaviorism. It's all internal.
The third thing that my two-subsystem picture is NOT is plasticity versus non-plasticity. So that means like, for example, synaptic plasticity is when a synapse gets stronger or weaker—or is created or destroyed—in the brain. (A synapse is a connection between neurons.) So you definitely need plasticity to form a learning algorithm in the brain. The adjustable parameters need to be adjusted. But you also might need plasticity in things that are not learning algorithms. For example, imagine you have a counter that is sporadically updated, and it’s counting how many times the rat has won a fight in its life. There is something like that, I think, in the brainstem of the rat. The genome would implement that by a plasticity mechanism. But nobody would call that a “learning algorithm”. It's not the thing that you do in a machine learning course. It's the thing that you do in other kinds of algorithms courses. It's just a counter.
And then the last thing that my two-subsystem picture is NOT is some brilliant idea that I made up that's totally different from machine learning. For example, you can go to pretty much any GitHub repository for an arxiv machine learning paper, and divide it into Learning Subsystem and Steering Subsystem, if you really wanted to. For example, in AlphaZero, there's presumably some C code that checks whether it's checkmate or not, and in this kind of breakdown, we would say that this C code is part of the Steering Subsystem.
11 HOST
00:21:42,131 --> 00:22:13,334
Before we keep going, though, it looks like we've got some questions in the chat, or at least Nick has one. He's asking: Give a little bit more detail about specifically what you mean when you say “brain-like”. And I think I think he actually posted this when you were talking about the two subsystems from a couple of slides ago. And he was wondering if that's explicitly making reference to those two subsystems.
12 STEVE
00:22:15,276 --> 00:22:46,882
Yeah, I figured that I was kind of addressing that in this slide I’m on. I don't think that two subsystems is a brilliant new idea. I think it's a useful frame of reference that neuroscientists should use more. I think it's really obvious when you're writing the source code yourself that some things are learning algorithms, and other parts of the code are not. But I don't think that that sort of intuition has trickled into neuroscience much. So that's why I spend a lot of time bringing it to people's attention.
13 EAI MEMBER 1
00:22:46,902 --> 00:23:08,036
I raised that question partially because I didn't think that you were saying that there were two explicit subsystems that could be implicitly combined somewhere. I'm just trying to figure out whether or not, y'know, some implicit existence of those systems implies that it's “brain-like” or not. I'm thinking about the definition of “brain-like” more than more than trying to put you in a box in that respect.
14 STEVE
00:23:09,240 --> 00:23:24,030
Yeah, the let's see. The I think the most important thing is what I mentioned earlier, the question of whether it's model-based reinforcement learning or not. Okay. […] So, yeah, I'll talk a little bit more about that later. When I say “brain-like”, that allows me to make lots of assumptions because then I can say, “that's how the brain works”.
17 EAI MEMBER 1
00:23:54,641 --> 00:23:55,701
Understood. Thanks. […]
19 STEVE
00:24:01,405 --> 00:34:21,323
Okay.
“Steering Subsystem” as the ultimate source of motivations, drives, values, etc.

Ah, here it is:

At least from a safety perspective, I think that what the brain is doing, we should think of it as one version of model-based reinforcement learning. And I don't think this should be controversial. It seems sort of obvious to me:
- There's a model—I can make predictions. If I go to the store, then I can buy a candy bar.
- And the model is updated by self supervised learning. If I didn't expect the ball to bounce, but the ball bounces, then when I see the ball falling towards the floor next time, it won't be unexpected.
- And then there's reinforcement learning. If I touch the hot stove, then I burn my finger and I probably won't do it again.

But model-based reinforcement learning is a very big tent—in the sense that you can probably download any number of arxiv papers that describe themselves as “model-based reinforcement learning”, and they'll all be different from each other, and they'll all be different from the brain, too. The details won't really matter for this talk. You can check out the blog post series for a little bit more discussion [LW · GW].

OK, I didn't say before why I was using the term “Steering Subsystem”. The Steering Subsystem does a lot of things. It helps the regulate heart rate, and makes sure that you keep breathing while you sleep so that you don't die, and hundreds of other things like that. But one particularly important (for our purposes) thing that the Steering Subsystem does is to “steer” the learning subsystem to emit ecologically-useful outputs, by sending it rewards.
So you touch a hot stove, then the steering subsystem sends negative reward and then you're less likely to do it again in the future. Not only that, but if you think about touching the hot stove, then that thought might be a little aversive, if you don't like burning yourself, which most people don't. And this is kind of analogous to how a reinforcement learning reward function steers AlphaZero to do certain things. So if you build AlphaZero with a reward function that rewards winning at chess, then it gets really good at winning at chess, and it tends to make moves that result in winning at chess. And if you send it rewards for losing at chess, then you can guess what happens.

So we get in our time machine and we look at these future AGIs that people will have built. And what might we find in the Steering Subsystems of those AGIs? Here are three types of ingredients.
The first category of Steering Subsystem ingredients is: things that the steering subsystem just needs to do in order to get general intelligence. An example, in all probability, is curiosity drive. I think there's a lot of evidence from the machine learning literature that if you don't have curiosity, then, in a sparse reward environment like the real world, the agent might not learn things. Obviously, curiosity drive exists in humans. And I expect curiosity drive to be in future AGIs, because otherwise they wouldn't be AGIs. That's not to say that it's a good thing. In fact, curiosity is sort of generically dangerous, because we don't want the AGI to choose “satisfying its own curiosity” over “doing things that the humans want it to do” (or “increasing human flourishing” or whatever we were hoping for).
The second category of Steering Subsystem ingredients is: Everything else in the human steering subsystem. And the prime example here, that I'll get back to in a little bit, is social instincts, which I claim are also related to moral instincts—the drive to be nice to your friends, and probably also mean to your enemies. Social instincts tend to be present in competent humans, with some exceptions like high-functioning sociopaths. Well, I think high functioning sociopaths do have some social instincts, but I think they have very different social instincts from other people.
We do not expect social instincts by default to show up in future AGIs, unless we, first of all, figure out exactly how they work, and second of all, convince whoever is coding those AGIs to actually put them in.
And then the third category of Steering Subsystem ingredients is every other possibility, most of which are wildly different from biology. So, you know, a drive to have somebody press the reward button, a drive to invent a better solar cell, a drive to have stock prices go up, you name it. Whoever is writing the code can just put literally anything into the reward function that they want to put in, assuming that they have some way to turn that thing into Python code. So things in this category are obviously not present in humans. But by default, I would assume that AI developers are going to mess around with lots of different possibilities like that, because that's what people do in reinforcement learning today.

So how do these things work? And in particular, how does the steering subsystem know when to provide reward? This is the million dollar question that I wish everybody would work on more. And the reason that it's not obvious is that the hypothalamus and the brainstem are basically kind of stupid. They don't understand the world. They don't know what's going on. They don't know about college debt, or human flourishing, or space travel. Arguably, they don't “know” anything at all. The world model—our understanding of the world—is part of the Learning Subsystem, not here in the hypothalamus and brainstem. So how are we going to entrust the hypothalamus and brainstem to provide ground truth about whether the human is thinking good thoughts and doing good things?

So one part of the answer—not the whole answer, but one part of it—is that the Steering Subsystem, as it turns out, has its own often-neglected sensory processing systems. So I actually drew that into this diagram from earlier in the talk, but you might have missed it. I put it with a star here:
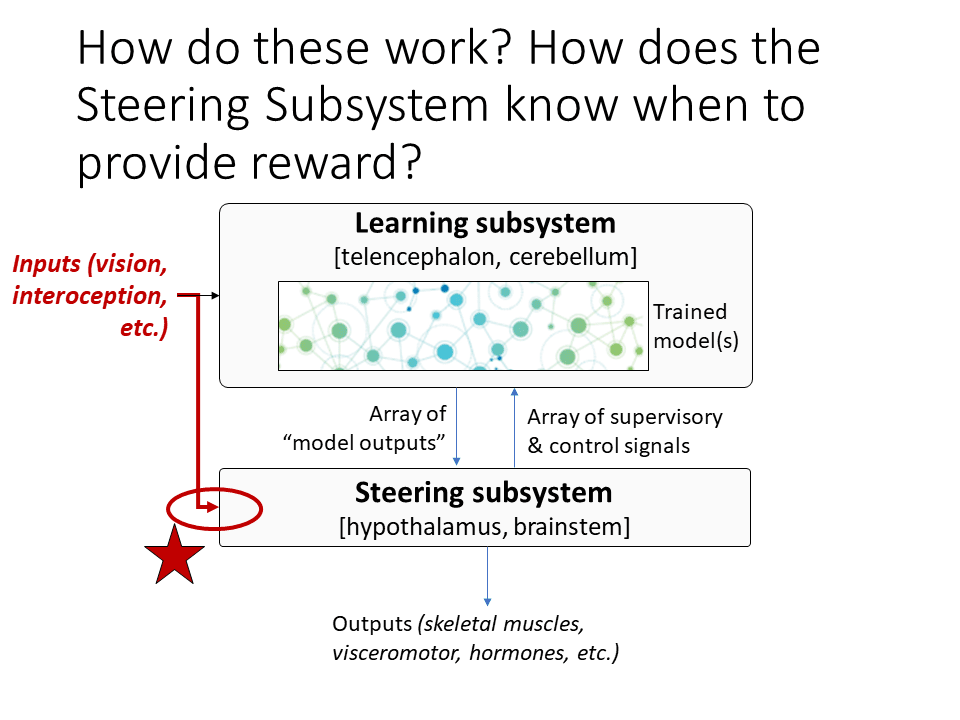
So when you get inputs from the outside world, they tend to go both to the learning subsystem and to the steering subsystem. So visual information goes to the visual cortex, but it also goes to the superior colliculus in the brainstem. Taste goes to the gustatory cortex in the insular cortex, but it also goes to the medulla in the brainstem. I think there’s a direct path for smell information into the hypothalamus, and so on.

So if there are innate rewards, this is one way to implement them. You could have these brainstem or hypothalamus modules that are looking at the sensory inputs and doing some kind of processing on them. And they're not very sophisticated, but they are able to apparently do things like detect whether you're looking at a face or not, at least well enough to make these systems work. I think that the superior colliculus can detect faces, and snakes, and probably it’s related to fear of heights and things like that.

So that's one part of the answer, but it's not the whole answer, because, for example, I don't think your brain can calculate whether or not to feel envious from just running simple heuristics on sensory inputs.

So, an open problem that I'm especially interested in is: how does the steering subsystem build social instincts? I think empathetic stimulation is involved. Mostly, I don't have a great answer here. I have some sort of vague speculations in post 13 of the series, Symbol Grounding and Human Social Instincts [LW · GW].

So just a few more words on this project. Why do I think this is so important? And I have two answers. The modest answer is: for better understanding. I would love to get to a place where we have a science that can reach conclusions of the form: “You take an AGI with innate drive X and you give a training environment Y and you wind up with an “adult” AGI that wants Z.” So that's where we want to get. And if we understood human social instincts better, then we would have nice examples that could ground that future science, particularly in the very important domains of how we think of ourselves and others and morality and things like that.

A more bold answer is it would be nice to have specific ideas that we could steal. And there's the sorta unsophisticated version of that where we just slavishly copy human social instincts into an AGI. And I don't endorse that. I think for one thing, AGIs are going to have a different training environment. They're probably not going to grow up with human bodies in a human culture. And also, human social instincts leave a lot to be desired, for various reasons. Like nobody wants to build AGIs that have teenage angst, or at least nobody should want that. A much better approach is to understand how human social instincts work and then maybe adapt some of them to work for AGIs, presumably in conjunction with other non-biological ingredients like interpretability and so on.

So that brings me to my conclusion. I think that this is a very big deal when people put these algorithms on computer chips. I mean, probably most of you are already sold on this, but it's a very big deal, probably the best or worst thing that will ever happen to humanity, certainly the weirdest. And there's technical work that we can do today to help. And thank you for listening! I guess I'll just jump right into questions. I noticed there's a few in the chat.
Q&A
20 HOST
00:34:22,084 --> 00:34:22,544
Looks like it.
21 STEVE
00:34:24,245 --> 00:38:42,470
“What kinds of images would cause a human's learned dog detector circuitry to maximally activate?”
“What should everyone call you” says: what kinds of images would cause a human's learned dog detector circuitry to maximally activate? Yeah, I don't have any opinion on that. I don't think that's particularly very safety relevant. I'd be curious when we figure out everything about the brain, that does sound like a fun question that I'd be interested in the answer to.
“What's your model of how empathetic modeling works in humans?”
“What should everyone call you” asks: What's your model of how empathetic modeling works in humans? I think I'm just going to pass on that one and say you should read post number 13 of my series [LW · GW]. Well, okay, I'll give a very short answer. For example, if you see a chair, then it tends to activate your latent world model neurons involved in the concept of “chair”, sorta unintentionally and without any thought and automatically and extremely quickly. I think by the same token, you have some things in your world model that are related to me getting punched in the stomach, and I think that if I see somebody else getting punched in the stomach, then there's probably going to be some overlap of those learned models in the latent space. And that's going to also activate the sort of same cringe things that the “me getting punched in the stomach” activates. I'm not sure that was a great answer, but that's the best that I want to do without, you know, spending the next 20 minutes on it.
“What kinds of technical work can we do today? What are some proximal or medium term goals?”
Okay, next is Nick. “What kinds of technical work can we do today? What are some proximal or medium term goals?” So, obviously I have the thing that I'm working on, which is to unravel what the heck, if anything, is happening in the hypothalamus and brainstem that leads mechanistically, one step after another, into humans having the full range of social instincts, from sadness to envy, assuming—I mean, there's some controversy over exactly what is innate versus what is learned. And that's part of the question that I'm interested in.
So I'm working on that much of the time.
And if you look at the last post of my series [LW · GW], that's one of seven open problems that I'd be delighted for people to spend time working on. I'm not going to go through the other ones here. You can just read that post.
“How common do you think sociopathy or psychopathy are in nonhumans? And what does that imply?”
Okay, solar fire has a question. “How common do you think sociopathy or psychopathy”—by the way, I don't know how those differ. I'm not sure that they really do. I feel like I've read a lot of different explanations of the difference between sociopaths and psychopaths and they're all inconsistent. So I mostly just sort of round those two terms to the same thing. If somebody is an expert, I'd be interested for you to politely teach me what the actual difference is. But let's just say either of them.—“How common are those in nonhumans? And what does that imply?”
I have no idea. I have never heard of psychopathic rats. For all I know, they exist. And if anybody has seen any papers about them, you should email them to me. My email is steven.byrnes@gmail.com.
What infrastructure / engineering would help with this research agenda?
22 HOST
00:38:45,380 --> 00:39:08,555
So I've got a question. If you had the opportunity to, I guess, have some engineers develop some infrastructure of some kind, maybe some tools or something like that to help with this research agenda, do you have any idea what that would look like? Is that something you've put some thought into?
23 STEVE
00:39:10,820 --> 00:40:41,527
I can't think of anything, but I also haven't put much thought into it. There's a group called Project Aintelope [LW · GW] led by Gunnar Zarncke, that is doing some sort of—I don't know the details and I'm probably going to describe this poorly, but I understand that they're doing some kind of grid world that's supposedly related to social instincts. I don't understand exactly what they're trying to do, or what's going to come out of it. But they've thought about it a lot and maybe they have some great idea. I don't have much opinion either way.
I am mostly reading neuroscience papers and coming up with extremely simple toy models, that are so simple that I don't really need to do anything other than like write down the pseudocode and say, “obviously this is wrong because it predicts the wrong things, I guess I need different pseudocode”. Once I have something that's even remotely plausible, then I would be presumably spend more time thinking about how to test it more carefully.
24 HOST
00:40:41,547 --> 00:40:45,069
I see. Thank you.
Question about schizophrenia
25 CONNOR
00:40:54,320 --> 00:42:22,100
I don't mind me asking a question, which is a bit unrelated, but Steve, I had to ask you about your recent post on schizophrenia [LW · GW], if you don't mind. So it pretty strongly contradicts my pet theory. And I was just wondering your thoughts on that. So it seems that one of the things, so for people who don't know, Steve recently wrote a great post about his, you know, he says low-confidence theory about what schizophrenia might be. He thinks it might be related to a lessening of long range connections in the brain. And I think there's a lot of cool evidence he puts in his post for that. But I can't help but notice it seems to contradict the most common theory of schizophrenia, which is that it's a saliency disorder. So what you see sometimes in schizophrenic people is that they spontaneously hyper-focus on specific things and become unable to shift attention away from them. And they like, they'll like hyper-focus on like sounds or voices or concepts or so on. And it seems to me that that is kind of like more of a striatal kind of thing or it's, like, my pet theory is that schizophrenia is higher noise levels on the single neuron level, which leads to micro seizures. And I would be interesting if you think that your theory just explains like these like saliency problems as well because it feels like it's supposed to address that.
26 STEVE
00:42:22,320 --> 00:43:36,100
Yeah, just to be crystal clear. I think I've spent four work days of my life trying to understand schizophrenia. One of them was writing that post. One of them was last summer when I came up with the theory. One of them was writing a different post on whether schizophrenia is related to blindness or not [LW · GW], and I decided that it wasn't. And then I think a few years earlier, I had spent a day and not gotten anywhere. So I am like extremely, extremely not even close to knowing the symptoms of schizophrenia, let alone the body of theory. But I have a rule-of-thumb that if I can write a decent blog post in four hours, I should just do it. So that was one of those.
If you email me resources on that saliency thing…I don't have anything that pops into my head that is intelligent on that topic. You should email me, or else I'll try to remember to think about it at some point. I got good feedback in the comments section of my post, and that was really all I was hoping for.
27 CONNOR
00:43:36,120 --> 00:43:36,920
All right.
How to do this research
28 CONNOR
00:43:37,260 --> 00:43:47,042
Thanks. If I can ask a second question, which is more on topic, assuming I wanted to do this research myself, like I want to be the next Steve Byrnes, how would you recommend I get started?
28 STEVE
00:43:48,260 --> 00:44:48,042
Yeah, so my research method is that I try to understand how the brain works, and then read neuroscience papers, and then I'm surprised by some fact about the brain that goes against my prior expectations, and then I make my model better. And iterate, iterate, iterate, for the last couple of years. And hopefully my model has been getting progressively less incorrect over time. I am happy to talk to people about like very specific things that I'm currently confused about in terms of what's going on in the brain. I guess I don't have any great answer to that question. Yeah, reach out, I'm happy to chit-chat with people.
Examples of how you’ve had to change your model
29 EAI MEMBER 1
00:44:50,323 --> 00:45:01,931
Could you give us any examples of like how you've had to change a model or anything like that? Or, you know, just even some iterations would be kind of cool to get some concrete grasp on like what kind of thoughts you're having?
30 STEVE
00:45:03,160 --> 00:45:38,325
Yeah, so I think it was like two weeks ago, maybe a month ago, I went back through the Intro to Brain-Like AGI Safety blog posts and made some changes. I deleted one whole section that seemed importantly wrong. Let's see. They're all on—I have a changelog written down somewhere. You can message me and I can walk you through it if you're interested.
31 EAI MEMBER 1
00:45:38,785 --> 00:45:39,286
That sounds great.
Schizophrenia visual perception quiz answer
32 EAI MEMBER 2
00:45:41,907 --> 00:45:43,008
Here's a silly question.
33 EAI MEMBER 2
00:45:44,169 --> 00:45:51,514
On the schizophrenia one, which of the percentages is the actual correct one for the circle thing?

34 STEVE
00:45:53,080 --> 00:46:00,885
Um, I tried screenshotting it and clipping it in PowerPoint and I think it's 40%.
35 EAI MEMBER 2
00:46:00,905 --> 00:46:01,325
I was right.
36 STEVE
00:46:04,347 --> 00:46:04,687
Whoo!
37 EAI MEMBER 1
00:46:05,708 --> 00:46:06,148
Yeah, nice.
38 STEVE
00:46:07,869 --> 00:46:14,501
Maybe you have schizophrenia. I guess I shouldn't cheer about that.
Eliezer Yudkowsky + Scott Alexander post
39 CURTIS
00:46:23,927 --> 00:46:57,493
I guess there's another a little bit of a tangent question. There was recently a post on lesswrong where Eliezer was talking with Scott. [LW · GW] And I believe you had some disagreements with him about, I guess the model that he had in terms of like hardcoded…—I can't actually remember the exact details. Do you want to give us some comments on that?
40 STEVE
00:46:59,760 --> 00:51:29,151
Yeah, I put several comments on the post and then elaborated on one aspect of that with a post called Heritability, Behaviorism, and Within-Lifetime Reinforcement Learning [LW · GW] a few days ago.
Let's see. So, there’s sorta a school of thought associated with—Steven Pinker advocates for it a lot, and it dates back to Cosmides and Tooby—it’s called evolved modularity. It's popular in evolutionary psychology and cognitive science to say that there are a lot of things that…
Okay, um, I'm not going to describe this well because I don't really understand the perspective. But let's see. So, we humans have a intuitive sense of physics, for example, and people's intuitions tend to point the same direction, even when that direction is not like veridically describing reality. For example, most people will make the same mistakes in intro physics courses, because the same things are unintuitive to everybody. So when I look at data like that, I would say: well, everybody has similar learning algorithms, and everybody has similar training data, namely, you know, picking up objects as kids and so on. And therefore everybody winds up with similar learned models at the end. And that's my explanation for intuitive physics being similar across cultures and so on.
The Pinker / Cosmides / Tooby type explanation for the same thing would be to say that “intuitive physics” is somehow in the genome. The genome builds this module into the brain that does intuitive physics.
And that's especially relevant when we get to things like human social instincts—things like envy and status drive and so on. I think that it's possible to explain those things in model-based reinforcement learning terms. That's this whole research project about social instincts that I was talking about. But I don't actually know the explanation right now, to my own satisfaction. I have enough vague ideas that I feel like an explanation probably exists. But there's a really big “symbol grounding problem” that I talk about in post 13 [LW · GW]. And, um, I could imagine a world where the correct answer is just: “It doesn't work. There is no way to solve this symbol grounding problem. You just started out going the wrong direction. Instead, in reality, it’s more like the Pinker / Cosmides / Tooby type explanation. There's a thing in the brain that's like ‘this is a person who I like who has high status’. And it's not just a generic kind of learning algorithm. There's some genetically-hardcoded algorithm that is very specific to the human social world, and there are blank slots in the algorithm, and the different people you know slot into that algorithm, and then the algorithm does some analysis and figures out who has high status or not. And then this can all be hardcoded in a very specific and straightforward way.”
And I think my impression is that Eliezer Yudkowsky and Nate Soares subscribe to something like that. They think that the brain has, you know, “people analysis code” that's a lot more specific than I think it is. And yeah, until I have a complete explanation of human social instincts in the framework that I think is right, then I can hardly blame people for thinking that the right explanation is something different.
I don't know if that helps. You can ask follow up questions.
41 CURTIS
00:51:36,865 --> 00:51:48,813
I see, I don't have to, I don't have a super clear, you know, super, super detailed model, but I think that more or less kind of answers. At least it gives me a clearer picture of what's going on.
42 STEVE
00:51:50,634 --> 00:51:53,076
Okay, maybe I'll do the one in the chat next.
43 CURTIS
00:51:53,396 --> 00:51:53,556
Sure.
Alignment agendas that can’t work and your cruxes for why not
44 STEVE
00:51:55,001 --> 00:54:08,823
“What should everyone call you” asks: “Can you give one example of an alignment agenda you think can't work, and your cruxes for why not?”
I think most of my disagreements with people pursuing different agendas arise at the “threat model” step and not at the “solution” step. I think that we should be worried about and thinking about an AGI that is some kind of model-based reinforcement learning, and that is quote unquote “trying” to do things in a relatively straightforward and human-like sense. And that sorta “trains” in a way that's somewhat analogous to how a human learns during their lifetime. So there are a lot of research agendas that don't address that. Like Risks From Learned Optimization [? · GW], and Vanessa Kosoy's research agenda [LW · GW], and debate [? · GW], and Eliciting Latent Knowledge [? · GW], and all these things about conditioning language models. All of those are not really addressing that threat model.
Again, my polite diplomatic thing to say is that we should be addressing lots of different threat models, and kumbaya, live and let live. That's probably the short version of my answer.
[Note: Shortly after this talk, Steve also wrote a post “Why I’m not working on {debate, RRM, ELK, natural abstractions}” [LW · GW]]
Wrap-up
45 CURTIS
00:54:16,749 --> 00:55:07,145
All right. Does anyone else have any other questions? All right. Otherwise, thank you very much for your time and for putting this together. Um, yeah. I should probably work on my host speech leading in.
46 STEVE
00:55:08,346 --> 00:55:19,276
I also want to reiterate that I'm happy to talk more to anybody. You can DM me here. You can also email me at steven.byrnes@gmail.com.
47 CONNOR
00:55:20,346 --> 00:55:43,276
Thanks so much, Steve. As someone who has emailed and DM'd Steve before I can recommend it. Steve is doing really really great work. If you read any of his stuff, if you have a bunch of time, his Intro to Brain-Like AGI Safety [? · GW] is like one of my favorite thing written on lesswrong this year, so highly recommend that it's really interesting work and I think under-appreciated, so thanks so much Steve.
47 STEVE
00:55:44,020 --> 00:55:44,600
Thank you!
48 EAI MEMBER 1
00:55:45,280 --> 00:55:46,321
Thanks to you, really appreciate it.
49 CURTIS
00:55:48,422 --> 00:56:09,396
All right. Thanks, Steve. Cool. All right. I think we can I think we can call it here then. Thanks for coming, everybody. And, we'll try we'll see if the recording actually worked. But we'll see what we can do to make this this talk available. Afterwards.
50 EAI MEMBER 1
00:56:12,080 --> 00:56:22,206
I have a quick meta question about the series. How did this come about, and do you have any expectation for what a schedule is like or anything like that? If not, that's fine, I just figured this is a good chance to ask.
51 CURTIS
00:56:22,527 --> 00:56:26,549
Yeah, sure. So, “I decided to do it” is how it came about.
52 EAI MEMBER 1
00:56:27,830 --> 00:56:28,050
Nice.
53 CURTIS
00:56:28,270 --> 00:57:26,945
It was just like, oh, we should do this. And in terms of like scheduling, I, I'm thinking, either like once every two or once every three weeks, depending on kind of how much material I can, and how many speakers I can actually line up. But yeah, that's sort of like the regularity, and I think another thing is that I want it to stay pretty technical. I've done a lot of like, sort of like introductory talks, but I think I think maybe, you know, well you know we can we can have a mix of those and then also like really, you know, kind of get into the weeds, kind of stuff. And that's that's that's why I'm looking to get in the long run, out of out of thesetalks really getting into more technical alignment research.
54 EAI MEMBER 1
00:57:30,047 --> 00:57:30,847
Alright, cool. Thanks.
55 CURTIS
00:57:35,000 --> 00:57:36,765
Alright, I will kill the recording now.
0 comments
Comments sorted by top scores.