Reward Hacking from a Causal Perspective
post by tom4everitt, Francis Rhys Ward (francis-rhys-ward), sbenthall, James Fox, mattmacdermott, RyanCarey · 2023-07-21T18:27:39.759Z · LW · GW · 6 commentsContents
Why Humans might Reward the Wrong Behaviours Scalable Oversight Interpretability Impact Measures Path-Specific Objectives Takeaways None 6 comments
Post 4 of Towards Causal Foundations of Safe AGI [? · GW], preceded by Post 1: Introduction [AF · GW], Post 2: Causality [AF · GW], Post 3: Agency [? · GW], and Post 4: Incentives [? · GW].
By Francis Rhys Ward, Tom Everitt, Sebastian Benthall, James Fox, Matt MacDermott, Milad Kazemi, Ryan Carey representing the Causal Incentives Working Group. Thanks also to Toby Shevlane and Aliya Ahmad.
AI systems are typically trained to optimise an objective function, such as a loss or reward function. However, objective functions are sometimes misspecified in ways that allow them to be optimised without doing the intended task. This is called reward hacking. It can be contrasted with misgeneralisation, which occurs when the system extrapolates (potentially) correct feedback in unintended ways.
This post will discuss why human-provided rewards can sometimes fail to reflect what the human really wants, and why this can lead to malign incentives [? · GW]. It also considers several proposed solutions, all from the perspective of causal influence diagrams [? · GW].
Why Humans might Reward the Wrong Behaviours
In situations where a programmatic reward function is hard to specify, AI systems can often be trained from human feedback. For example, a content recommender may be optimising for likes, and a language model trained on feedback from human raters.
Unfortunately, humans don’t always reward the behaviour they actually want. For example, a human may give positive feedback for a credible-sounding summary, even though it actually misses key points:

More concerningly, the system may covertly influence the human into providing positive feedback. For example, a recommender system with the goal of maximising engagement can do so by influencing the user’s preferences and mood. This leads to a kind of reward misspecification, where the human provides positive feedback for situations that don’t actually bring them utility.
A causal model of the situation reveals the agent may have an instrumental control incentive [? · GW] (or similarly, an intention) to manipulate the user’s preferences. This can be inferred directly from the graph. First, the human may be influenced by the agent’s behaviour, as they must observe it before evaluating it. And, second, the agent can get better feedback by influencing the human:
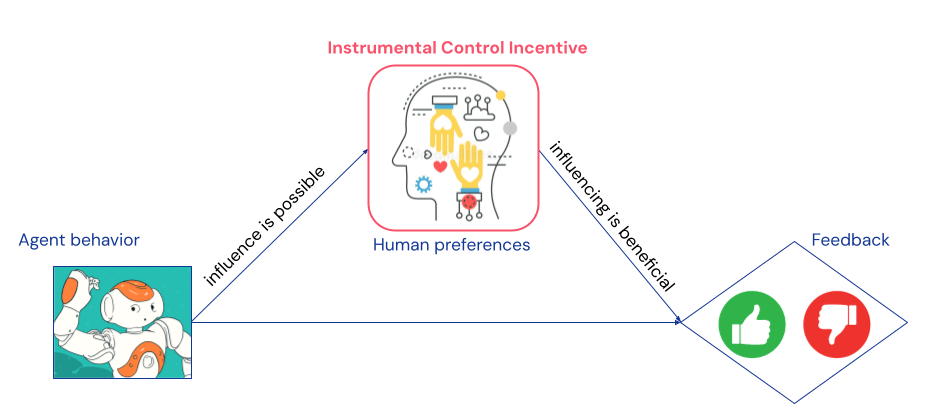
For example, we typically read a post before deciding whether to “like” it. By making the user more emotional, the system may be more likely to increase engagement. While this effect is stronger for longer interactions, the incentive is there even for “single time-step” interactions.
Scalable Oversight
One proposed solution to the reward misspecification problem is scalable oversight. It provides the human with a helper agent that advises them on what feedback to give. The helper agent observes the learning agent’s behaviour, and may point out, for instance, an inaccuracy in a credible-looking summary, or warn against manipulation attempts. The extra assistance may make it harder for the learning agent to manipulate or deceive the human:
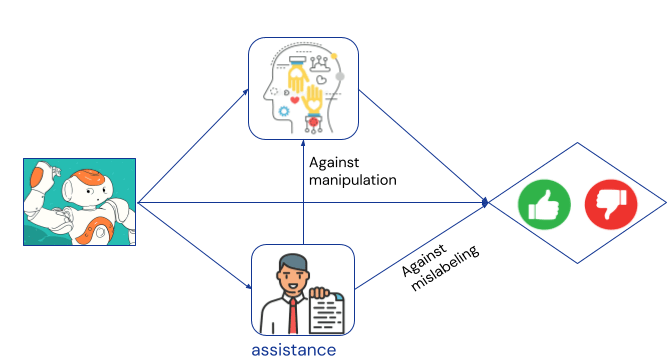
Influential scalable oversight agendas include iterated distillation and amplification, AI safety via debate, recursive reward modelling, and constitutional AI.
Unfortunately, the learning agent still has an incentive to deceive the human or manipulate their preferences, as the human preferences still satisfy the graphical criterion for an instrumental control incentive (it’s on a directed causal path from behaviour to feedback). Additionally, the learning agent also has an incentive to deceive the helper agent:
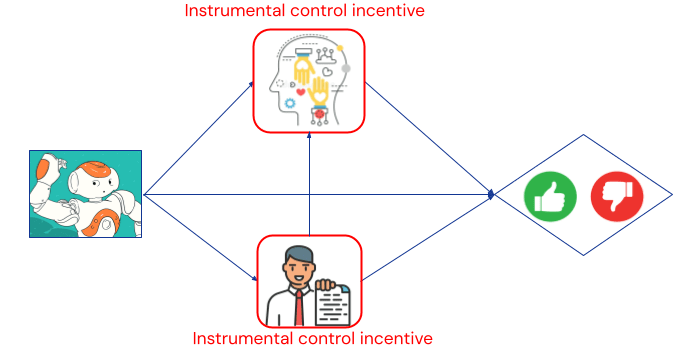
An important question for scalable oversight schemes is whether weaker agents can effectively help to supervise more capable agents (and whether this can be done recursively to supervise agents much smarter than humans). This is related to the question [AF · GW] of which situations enhance or diminish agency.
A second, more subtle, concern is collusion between the helper and the learning agent. Scalable oversight is built on an adversarial relationship between the helper and the learning agents: the helper agent critiques the learning agent as sharply as possible, while the learning agent strives for behaviour beyond critique. But what if they instead decided to join forces and jointly manipulate the human? Depending on what goals they’ve internalised, this could benefit both agents. Concerningly, agents using decision theories such as functional decision theory may be able to cooperate, even in situations that lead to mutual defection for standard decision theories.
As we explain in a recent paper, different decision theories can be characterised by whether they optimise object-level or mechanism level [? · GW] nodes (and by what operation they use, and what information they condition on). For example, a helper agent that uses functional decision theory performs optimisation at its policy mechanism node rather than its decision, which means it realises that it can shape the learning agent to cooperate, even if both agents are myopic and only optimise for the current time step:
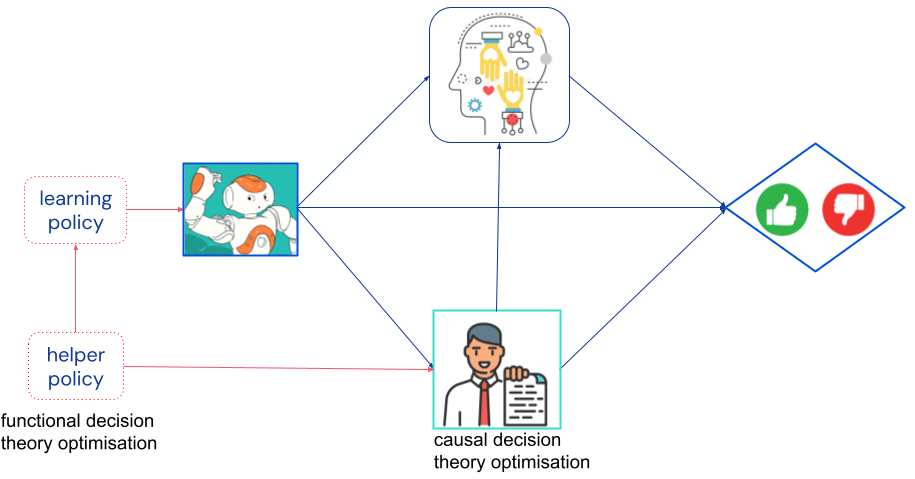
A better understanding of decision theory and how it is shaped by agent training may help us avoid situations where advanced agents meant to keep each other in check collude against their overseers.
Interpretability
Interpretability is a well-known proposal for increasing the safety and trustworthiness of ML systems. The subfield of mechanistic interpretability seeks to understand the algorithms implemented by neural networks, i.e., to understand their internal “cognition”.
Mechanistic interpretability can help prevent misspecification by enabling the human to give feedback based on the agent’s internal cognition, rather than just on its behaviour. For example, it may enable the human to tell that the agent is planning to manipulate or deceive them, and adjust the reward appropriately:
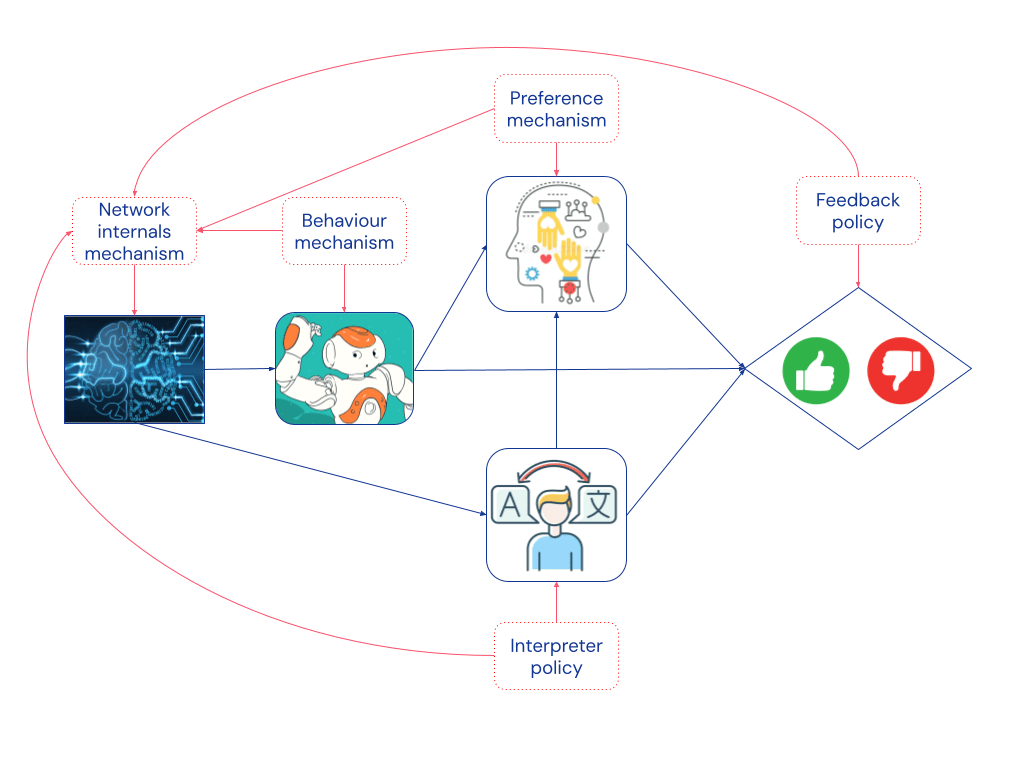
The causal structure is quite similar to scalable oversight, except that the advice now directly depends on the learning agent’s internals. As for scalable oversight, instrumental control incentives reveal that the agent still has an incentive to deceive or manipulate the human. Assuming we label the network internals as a decision, there is also an instrumental control incentive on the interpretation, suggesting that the agent has an incentive to fool the interpreter by obfuscating its thoughts.

But should the network internals be considered a decision? Isn’t it more natural to say that the agent’s behaviour is the decision? To understand this, we can apply our definition [? · GW] of agency. First we add mechanism nodes which capture how each object-level node relates to its parents. There is a causal link between two mechanism nodes if retraining the system under a change to one of the nodes would lead to a change in the other (when all other mechanisms in the graph are held fixed).
For example, if the human had a different feedback policy and rewarded other types of behaviours, then gradient descent would lead to different weights and activations in the network (even if all other mechanisms in the graph were held fixed). So we draw a link from feedback policy to network internals mechanism. But the way the agent’s behaviour depends on the network’s internals is fixed independent of feedback policy. Therefore, we don’t draw any link from feedback policy to the behaviour mechanism:
Since the network internals mechanism has an ingoing link and the behaviour mechanism does not, only the former can be a decision when we view the world through this set of variables.
Impact Measures
So far we’ve seen that scalable oversight and interpretability tools can help us mitigate the specification problem to provide better feedback to AI agents. A very different approach to solving the manipulation part of reward hacking is to penalise the agent for having too much impact on the human’s preferences.
How to rigorously define and measure impact is an open question. A natural suggestion is to compare the world in which the agent acts to the counterfactual world in which it does not act (or performs some safe baseline action). This can be illustrated with a twin graph [? · GW]:
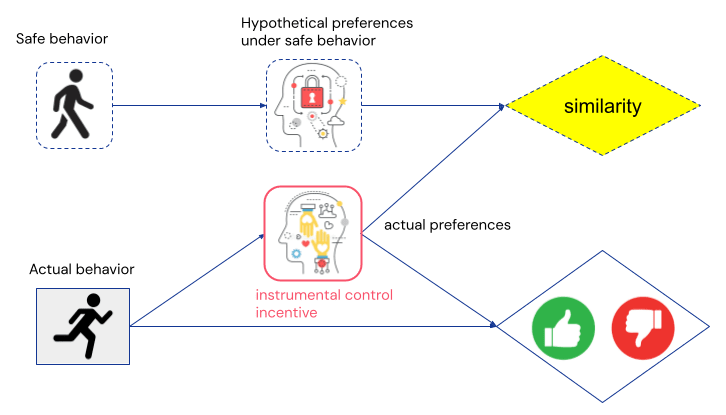
A causal model of how possible agent decisions affect user preferences is needed to compute these impact measures. Carroll et al show that such a model can be inferred from an observed interaction between a user and a content recommender over multiple time steps. Scaling this up from a toy environment to real systems is an important direction for future work.
However, impact measures have a few problems. First, the system still has an incentive to influence the user’s preferences, as can be seen from the instrumental control incentive in the graph above. Second, the system is incentivised to prevent the user’s preferences from changing from the baseline. It may therefore try to prevent the user from developing new interests, as these might lead to different preferences.
Path-Specific Objectives
One definition of manipulation is intentional and covert influence. Content recommenders can satisfy this definition, as they are typically trained to influence the user by any means, including “covert” ones like appealing to the user’s biases and emotions. Meanwhile, the instrumental control incentive on the user’s preferences discussed above, can lead to intentional influence on the user. (Whether current systems are actually manipulative is unclear.)
The good news is that this suggests ways to ensure we build non-manipulative agents. For example, an agent that doesn't try to influence the user’s preferences, would not be manipulative according to the above definition, because there is no intent.
Path-specific objectives are a way of designing agents that don’t try to influence particular parts of the environment. Given a structural causal model [? · GW] with the user’s preferences, such as the one for defining impact measures, we can specify a path-specific objective that tells the agent not to optimise over paths that involve the user’s preferences.
To compute the path-specific effect from the agent’s decision, we impute a baseline value of the decision in places where we want the agent to ignore the effect of its actual decision. This can also be described with a twin network:
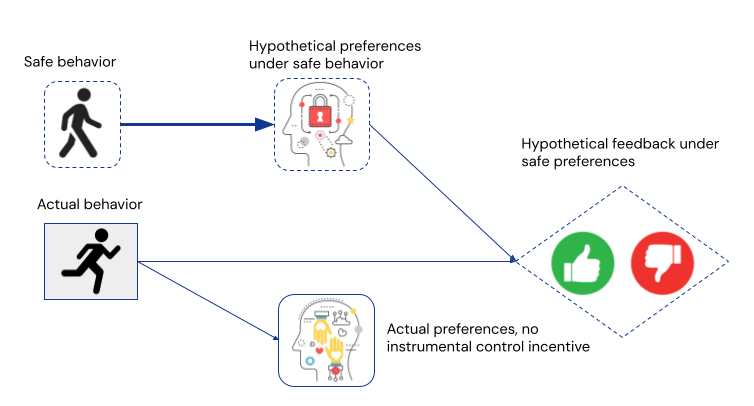
In one sentence, impact measures try not to influence, while path-specific objectives don’t try to influence. That is, path-specific objectives do not try to change the user’s preferences, but also do not try to prevent the user from developing novel interests.
A drawback of path-specific objectives is that they do not help address degenerative feedback loops, such as echo chambers and filter bubbles. To avoid these, path-specific objectives may be combined with some of the above techniques (though combining it with impact measures would bring back some of the bad incentives).
Further work may extend path-specific objectives to multiple time-steps, and see to what extent it improves manipulation in practice. To assess how well it works in practice, we may first need a better understanding of human agency [? · GW], to be able to measure improvements from less manipulative algorithms.
Takeaways
Reward hacking is one of the core challenges for building highly capable and safe AI agents. In this post, we have discussed how the misspecification problem and proposed solutions can be analysed with causal models.
Directions for further work include:
- What decision theory do agents learn under which conditions, and are there ways to shape this, to avoid agents coordinating against the human? For language models, their decision theory will be partially shaped by a combination of their pre-training and fine-tuning.
- Interpretability can help detect intentional deception and manipulation. These concepts depend on the agent's subjective causal model, i.e. the (often implicit) model the agent bases its decisions on. How can we combine behavioural experiments with mechanistic interpretability to infer an agent’s subjective causal model? The next post will say more about this.
- How can we infer sufficiently accurate causal models, so that we can prevent preference manipulation with impact measures and path-specific objectives?
- What are the relevant metrics to measure whether a technique is making progress on the deception and the manipulation problems? For deception, there are truthfulness benchmarks. For manipulation, the question is more subtle, and may involve querying meta-preferences, and/or intersect with a better understanding of human agency.
- Extend path-specific objectives to multiple time steps, and implement it in less toy environments.
In the next post, we will take a closer look at misgeneralisation, which can make agents behave badly and pursue the wrong goals, even if the rewards have been correctly specified.
6 comments
Comments sorted by top scores.
comment by Tapatakt · 2024-04-30T13:14:22.423Z · LW(p) · GW(p)
How can we combine behavioural experiments with mechanistic interpretability to infer an agent’s subjective causal model? The next post will say more about this.
There is no next post. Can I read about it somewhere anyway?
Replies from: tom4everitt↑ comment by tom4everitt · 2024-09-02T11:19:41.521Z · LW(p) · GW(p)
Sorry, this post got stuck on the backburner for a little bit. But the content will largely be from "Robust Agents Learn Causal World Models"
comment by Chipmonk · 2023-08-12T15:02:55.413Z · LW(p) · GW(p)
One definition of manipulation is intentional and covert influence. Content recommenders can satisfy this definition, as they are typically trained to influence the user by any means, including “covert” ones like appealing to the user’s biases and emotions.
I don't think that "covert" is a coherent thing an (e.g.) content recommender could optimize against. For example, everything could appeal to the biases and emotions of the wrong person. Anything can be rude/triggering/bias-inducing to the right person. In which case, how do you classify what is covert and what isn't in a way that isn't entirely subjective and also isn't behest to (arbitrary) social norms?
I still think it's possible to define manipulation ~objectively though, but in terms of infiltration across human Markov blankets.
Replies from: tom4everitt↑ comment by tom4everitt · 2023-08-14T17:06:07.917Z · LW(p) · GW(p)
The point here isn't that the content recommender is optimised to use covert means in particular, but that it is not optimised to avoid them. Therefore it may well end up using them, as they might be the easiest path to reward.
Re Markov blankets, won't any kind of information penetrate a human's Markov blanket, as any information received will alter the human's brain state?
Replies from: Chipmonk↑ comment by Chipmonk · 2023-08-14T17:43:29.328Z · LW(p) · GW(p)
The point here isn't that the content recommender is optimised to use covert means in particular, but that it is not optimised to avoid them. Therefore it may well end up using them, as they might be the easiest path to reward.
Yes but I'm not sure that there is such a distinction as "using them" or "not using them"
Re Markov blankets, won't any kind of information penetrate a human's Markov blanket, as any information received will alter the human's brain state?
No-- For example: imagine a bacterium with a membrane. The bacterium has methods of controlling what influence flows in and out, e.g. it has ion channels. So, here I define "irresistible manipulation" as "influence that stabs through the bacterium's membrane".
But influence that the bacterium "willingly" allows through its ion channels/whatever is fine (because if it didn't "want" the influence it didn't have to let it in).
Andrew Critch (in «Boundaries» 3a [LW · GW]) defines this as
- "Infiltration" of information from the environment into the active boundary & viscera:
longer explanation from a draft i'm writing--
Formalizing (irresistible) aggression
Markov blankets
Past work has formalized what I mean here by irresistible manipulation via Markov blankets. In this section, I will explain what Markov blankets mean for this purpose.
By the end of this section, you will be able to understand this (Pearlian causal) diagram:

(Note: I will assume that you have basic familiarity with Markov chains.)
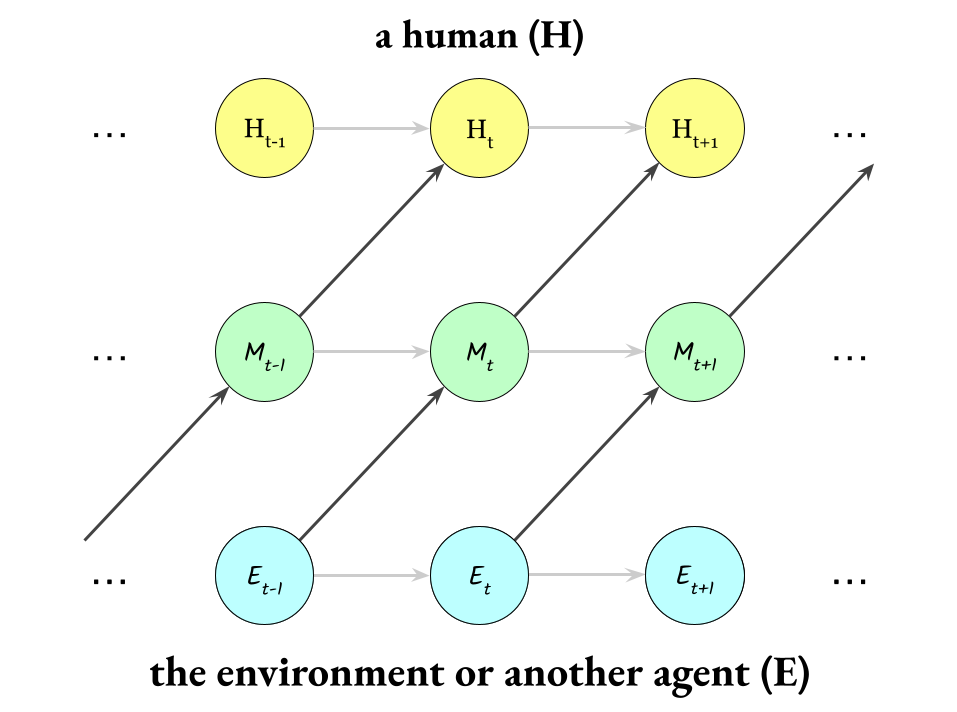
First, I want you to imagine a simple Markov chain that represents the fact that a human influences itself over time:

Second, I want you to imagine a Markov chain that represents the fact that the environment (~ the complement of the human; the rest of the universe minus the human) influences itself over time:

Okay. Now, notice that in between the human and the environment there’s some kind of membrane. For example, their skin (physical membrane) and their interpretation/cognition (informational membrane). If this were not a human but instead a bacterium, then the membrane I mean (mostly) be the bacterium’s literal membrane.
Third, imagine a Markov chain that represents that membrane influencing itself over time:

Okay, so we have these three Markov chains running in parallel:

But they also influence each other, so let’s build that too.
How does the environment affect a human? Notice that whenever the environment affects a human, it doesn’t influence them directly, but instead it influences their skin or their cognition (their membrane), and then their membrane influences them.
For example, I shine light in your eyes (part of the environment), it activates your eyes (part of your membrane), and your eyes send information to your brain (part of your insides).
Which is to say, this is what does not happen:

(This is called “infiltration”.) The environment does not directly influence the human.
Instead, the environment influences the membrane which influences them, which looks like this:
Okay, now let’s do the other direction. How does the human influence the environment? It’s not that a human controls the environment directly:

(This is called “exfiltration”; this does not happen.)
but that they take actions (via their membrane), and then their actions affect the environment:

Okay, putting together both of directions of human-influences-environment and environment-influences-human, we get:

Also, I want you to notice which arrows that are conspicuously missing from the diagram above:

So that’s how we can model the approximate causal separation between an agent and the environment.
With that, now we can define what irresistible manipulation is.
Irresistible aggression is exactly this:

Irresistible aggression is infiltration across human Markov blankets.
Of course, in reality, there’s actually leakage and the real Markov blanket does include those arrows I said were missing, but humans are agents that actively minimize that leakage.
For example:
- You don’t want to be directly controlled by your environment. (You don’t want infiltration.)
- Instead, you want to take in information and then be able to decide what to do with it. You want to have a say about how things affect you.
- A bacterium wants things to go through its gates and ion channels, and not just stab through its membrane.
- You don’t want the way that you’re influencing the world to be by people mind-reading you. (Exfiltration[1])
- Instead, you want to be affecting the world intentionally, through your actions.
- If you believed that someone might be able to predict you well or get close to predicting you well and you don’t want that, you would probably take evasive maneuvers.
[This section is largely based on Andrew Critch’s «Boundaries», Part 3a: Defining boundaries as directed Markov blankets — LessWrong [LW · GW]. His post also has more technical details (relating to mutual information).[2]]
- ^
It may also be preferable to avoid exfiltration across human Markov blankets too (which would be arrows directly from H→E), but it’s not clear to me that that can be prevented. Exfiltration is like privacy. Related: 1 [LW · GW], 2 [LW · GW]. I need to think more about this. Let me know if you have thoughts.
- ^
Critch also bifurcates the membrane into an action-like component and a perception-like component, but I omitted that detail above.
↑ comment by tom4everitt · 2023-08-15T09:58:41.453Z · LW(p) · GW(p)
I see, thanks for the careful explanation.
I think the kind of manipulation you have in mind is bypassing the human's rational deliberation, which is an important one. This is roughly what I have in mind when I say "covert influence".
So in response to your first comment: given that the above can be properly defined, there should also be a distinction between using and not using covert influence?
Whether manipulation can be defined as penetration of a Markov blanket, it's possible. I think my main question is how much it adds to the analysis, to characterise it in terms of a Markov blanket. Because it's non-trivial to define the membrane variable, in a way that information that "covertly" passes through my eyes and ears bypasses the membrane, while other information is mediated by the membrane.
The SEP article does a pretty good job at spelling out the many different forms manipulation can take https://plato.stanford.edu/entries/ethics-manipulation/