NVIDIA and Microsoft releases 530B parameter transformer model, Megatron-Turing NLG
post by Ozyrus · 2021-10-11T15:28:47.510Z · LW · GW · 36 commentsContents
36 comments
In addition to reporting aggregate metrics on benchmark tasks, we also qualitatively analyzed model outputs and have intriguing findings (Figure 4). We observed that the model can infer basic mathematical operations from context (sample 1), even when the symbols are badly obfuscated (sample 2). While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
We also show samples (the last row in Figure 4) from the HANS task where we posed the task containing simple syntactic structures as a question and prompted the model for an answer. Despite the structures being simple, existing natural language inference (NLI) models often have a hard time with such inputs. Fine-tuned models often pick up spurious associations between certain syntactic structures and entailment relations from systemic biases in NLI datasets. MT-NLG performs competitively in such cases without finetuning.
Seems like next big transformer model is here. No way to test it out yet, but scaling seems to continue, see quote.
It is not mixture of experts, so parameters mean something as compared to WuDao [LW · GW](also it beats GPT-3 on PiQA and LAMBADA).
How big of a deal is that?
36 comments
Comments sorted by top scores.
comment by Jack Stone · 2021-10-12T01:31:29.192Z · LW(p) · GW(p)
I want to briefly preface this post by saying that this is my first on LW and I have no professional background in machine learning—I monitor the AI page as a sort of early-warning radar for AGI—so bear that in mind and feel free to correct any errors here.
With that out of the way, I did a back-of-the-envelope calculation for the amount of compute used to train the model, based on the numbers given in the NVIDIA post:
280 DGX A100 servers x 8 GPUs/server x 126 teraFLOP/GPU/second x 60.1 seconds/batch = 1.70 x 10^7 teraFLOP/batch = 17,000 petaFLOP/batch
271 billion tokens / 2048 tokens/sequence / 1920 sequences/batch = 68,919 batches
17,000 petaFLOP/batch x 68,919 batches = 1.17 x 10^9 petaFLOP
1.17 x 10^9 petaFLOP = 1.17 x 10^9 petaFLOPs seconds = 13,542 petaFLOPs days
That's ~3.72 times the 3640 petaFLOPs days used to train GPT-3, so compute cost seems to be scaling slightly supralinearly with parameter count, although I'm not sure how much I'd read into that given the different architectures, token counts, etc.
Aside from the number of parameters, there doesn't seem to be much novelty here, just a scaled-up version of previous language models. It's not multimodal, either, despite that seeming to be the direction the field is moving in.
My tentative take on this is that it's more of a hardware showcase for NVIDIA than an attempt to make a bold leap forward in deep learning. NVIDIA gets to show off the power of their tech to train huge neural nets, and Microsoft gets a modestly more powerful language model to work with.
As I said before, please let me know if there are any mistakes in my calculation or if you disagree with my assessment—I'd be interested to get feedback.
Replies from: Jsevillamol↑ comment by Jsevillamol · 2021-10-12T08:00:20.016Z · LW(p) · GW(p)
Here is your estimate in the context of other big AI models:
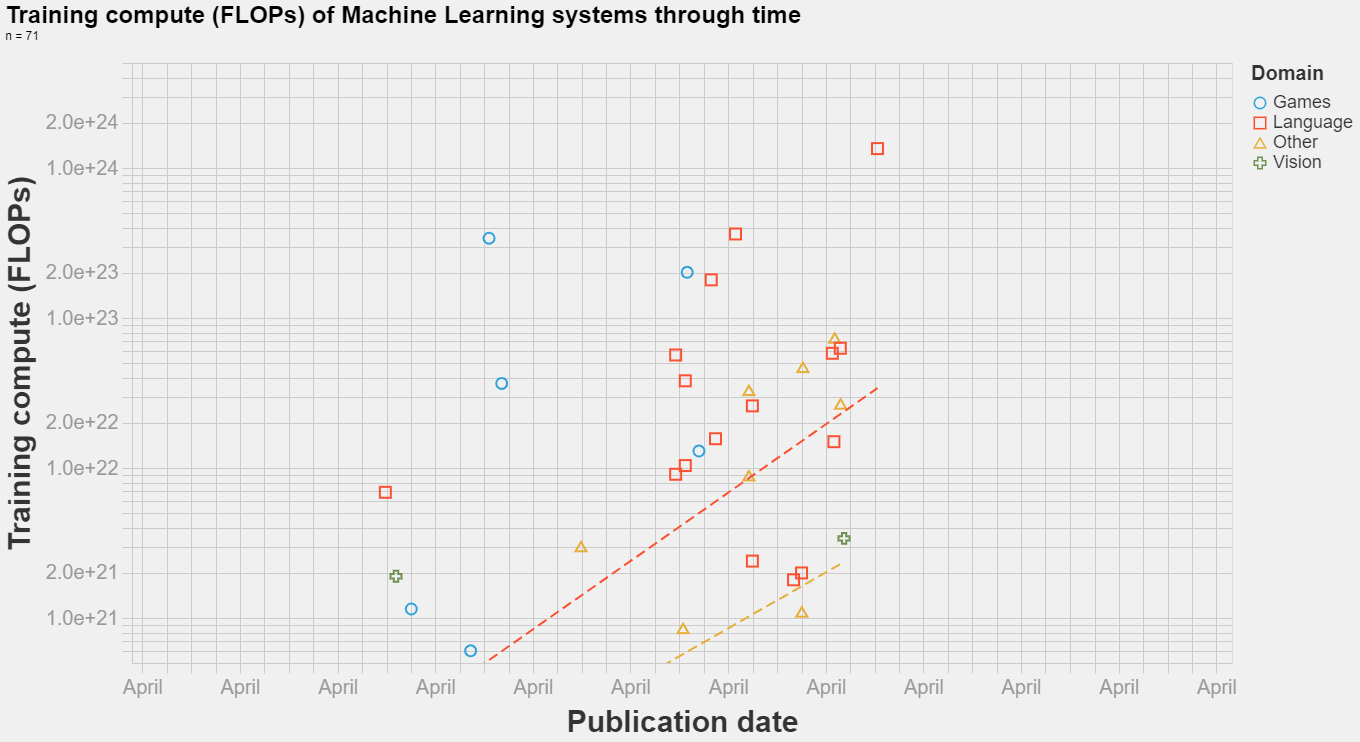
An interactive visualization is available here.
Replies from: Jack Stone↑ comment by Jack Stone · 2021-10-13T01:58:57.040Z · LW(p) · GW(p)
Thanks—this is very interesting
comment by Quintin Pope (quintin-pope) · 2021-10-11T19:17:04.919Z · LW(p) · GW(p)
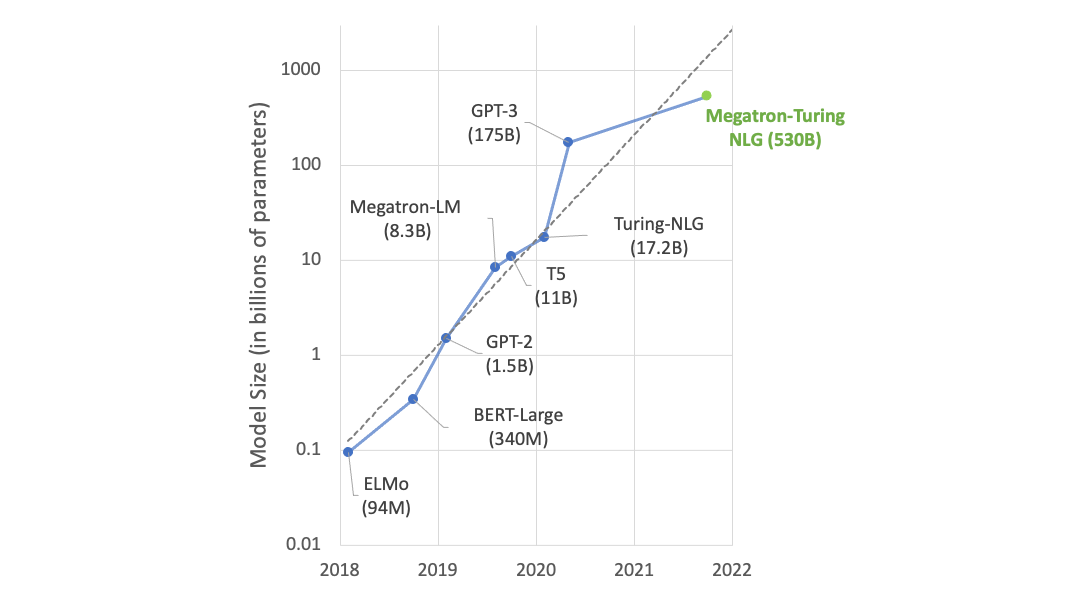
This seems to reflect a noticeable slowdown in the rate at which language model sizes increase. Compare the trend line you'd draw through the prior points to the one on the graph.
I'm still disappointed at the limited context window (2048 tokens). If you're going to spend millions on training a transformer, may as well make it one of the linear time complexity variants.
It looks like Turing NLG models are autoregressive generative, like GPTs. So, not good at things like rephrasing text sections based on bidirectional context, but good at unidirectional language generation. I'm confused as to why everyone is focusing on unidirectional models. It seems like, if you want to provide a distinct service compared to your competition, bidirectionality would be the way to go. Then your model would be much better at things like evaluating text content, rephrasing, or grammar checking. Maybe the researchers want to be able to compare results with prior work?
Replies from: Xylitol↑ comment by Xylitol · 2021-10-12T00:13:47.519Z · LW(p) · GW(p)
I'd hesitate to make predictions based on the slowdown of GPT-3 to Megatron-Turing, for two reasons.
First, GPT-3 represents the fastest, largest increase in model size in this whole chart. If you only look at the models before GPT-3, the drawn trend line tracks well. Note how far off the trend GPT-3 itself is.
Second, GPT-3 was released almost exactly when COVID became a serious concern in the world beyond China. I must imagine that this slowed down model development, but it will be less of a factor going forward.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-10-12T01:18:21.713Z · LW(p) · GW(p)
If you just look at models before GPT-3, the trend line you’d draw is still noticeably steeper than the actual line on the graph. (ELMO and BERT large are below trend while T5 and Megatron 8.3B are above.) The new Megatron would represent the biggest trend line undershoot.
Also, I think any post COVID speedup will be more than drown out by the recent slow down in the rate at which compute prices fall. They were dropping by an OOM every 4 years, but now it’s every 10-16 years.
Replies from: avturchin, Xylitol↑ comment by avturchin · 2021-10-12T11:42:39.777Z · LW(p) · GW(p)
We miss GPT-4 data point for this chart. New Megatron is more like one more replication of GPT-3, and another one is new Chinese 245 Billion parameters model. But Google had trillion parameter model in fall 2020.
Replies from: sanxiyn, sanxiyn↑ comment by sanxiyn · 2021-10-12T12:50:55.384Z · LW(p) · GW(p)
Better citation for Chinese 245B model here: Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning.
↑ comment by sanxiyn · 2021-10-12T12:49:16.325Z · LW(p) · GW(p)
Google had trillion parameter model in fall 2020.
That's new to me. Any citation for this?
Replies from: tonyleary, avturchin↑ comment by avturchin · 2021-10-12T15:25:33.734Z · LW(p) · GW(p)
It was not google, but Microsoft: in September 2020 they wrote: "The trillion-parameter model has 298 layers of Transformers with a hidden dimension of 17,408 and is trained with sequence length 2,048 and batch size 2,048." https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
Replies from: gwern↑ comment by gwern · 2021-10-12T17:06:04.090Z · LW(p) · GW(p)
That was just the tech demo. It obviously wasn't actually trained, just demoed for a few steps to show that the code works. If they had trained it back then, they'd, well, have announced it like OP! OP is what they've trained for-reals after further fiddling with that code.
↑ comment by Xylitol · 2021-10-12T03:08:57.530Z · LW(p) · GW(p)
I'm not sure how relevant the slowdown in compute price decrease is to this chart, since it starts in 2018 and the slowdown started 6-8 years ago; likewise, AlexNet, the breakout moment for deep learning, was 9 years ago. So if compute price is the primary rate-limiter, I'd think it would have a more gradual, consistent effect as models get bigger and bigger. The slowdown may mean that models cost quite a lot to train, but clearly huge companies like Nvidia and Microsoft haven't started shying away yet from spending absurd amounts of money to keep growing their models.
comment by MrThink (ViktorThink) · 2021-10-11T15:52:44.531Z · LW(p) · GW(p)
It's very interesting to see the implications of how well transformers will continue to scale.
Here are some stats:
| Megatron-Turing NLG on Lambada | GPT-3 | |
| Lambada (few shot) | 0.872 | 0.864 |
| PiQA (zero shot) | 0.820 | 80.5 |
| PiQA (one shot) | 0.810 | 80.5 |
| PiQA (few shot) | 0.832 | 82.8 |
Megatron-Truing NLG performs better, and even if the difference is small, I've seen comparisons with smaller models where even small differences of 1% means there is a noticeable difference in intelligence when using the models for text generation.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-10-11T19:43:16.802Z · LW(p) · GW(p)
“…even small differences of 1% means there is a noticeable difference in intelligence when using the models for text generation.”
I wish we had better automated metrics for that sort of subjective quality measure. A user study of subjective quality/usefulness would have been good too. That’s not too much to ask of Microsoft, and since they’re presumably aiming to sell access to this and similar models, it would be good for them to provide some indication of how capable the model feels to humans.
comment by StellaAthena · 2021-10-16T22:56:48.007Z · LW(p) · GW(p)
It’s interesting how Microsoft and NVIDIA are plugging EleutherAI and open source work in general. While they don’t reference EleutherAI by name, the Pile dataset used as the basis for their training data and the LM Evaluation Harness mentioned in the post are both open source efforts by EleutherAI. EleutherAI, in return, is using the Megatron-DS codebase as the core of their GPT-NeoX model architecture.
I think that this is notable because it’s the first time we’ve really seen powerful AI research orgs sharing infra like this. Typically everyone wants to do everything bespoke and make their work all on their own. This is good for branding but obviously a lot more work.
I wonder if MSFT and NVIDIA tried to make a better dataset than the Pile on their own and failed.
Replies from: gwern↑ comment by gwern · 2021-10-17T01:13:57.130Z · LW(p) · GW(p)
I think that this is notable because it’s the first time we’ve really seen powerful AI research orgs sharing infra like this. Typically everyone wants to do everything bespoke and make their work all on their own. This is good for branding but obviously a lot more work.
It may just be the incentives. "Commoditize your complement".
Nvidia wants to sell GPUs, and that's pretty much it; any services they sell are tightly coupled to the GPUs, they don't sell smartphones or banner ads. And Microsoft wants to sell MS Azure, and to a lesser extent, business SaaS, and while it has many fingers in many pies, those tails do not wag the dog. NV/MS releasing tooling like DeepSpeed, and being pragmatic about using The Pile since it exists (instead of spending scarce engineer time on making one's own just to have their own), is consistent with that.
In contrast, Facebook, Google, Apple, AliBaba, Baidu - all of these sell different things, typically far more integrated into a service/website/platform, like smartphones vertically integrated from the web advertising down to the NN ASICs on their in-house smartphones. Google may be unusually open in terms of releasing research, but they still won't release the actual models trained on JFT-300M/B or web scrapes like their ALIGN, or models touching on the core business vitals like advertising, or their best models like LaMDA* or MUM or Pathways. Even academics 'sell' very different things than happy endusers on Nvidia GPUs / MS cloud VMs: prestige, citations, novelty, secret sauces, moral high grounds. Not necessarily open data and working code.
* The split incentives lead to some strange behavior, like the current situation where there's already like 6 notable Google-authored papers on LaMDA revealing fascinating capabilities like general text style transfer... all of which won't use its name and only refer to it as "a large language model" or something. (Sometimes they'll generously specify the model in question is O(100b) parameters.)
comment by Matthew Barnett (matthew-barnett) · 2021-10-11T17:34:37.278Z · LW(p) · GW(p)
Does anyone know if there are samples from the model?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-10-11T19:30:52.938Z · LW(p) · GW(p)
I can only find the four examples near the end of the blog post (just above the "Bias in language models" section).
comment by gwern · 2022-01-31T17:44:30.078Z · LW(p) · GW(p)
Paper is out: https://arxiv.org/abs/2201.11990
comment by Kamil Pabis (kamil-pabis) · 2021-10-12T15:06:04.690Z · LW(p) · GW(p)
How limiting are poor corpus quality and limited size for these models? For example, Megatron-Turing NLG was only trained on PubMed extracts but not on PubMed Central, which is part of the Pile dataset. Was this perhaps intentional or an oversight?
Regarding medical texts, I see many shortcomings of the training data. PubMed Central is much smaller at 5 million entries than the whole PubMed corpus at 30 million entries, which seems to be unavailable due to copyright issues. However, perhaps bigger is not better?
Regarding books, how relevant is the limited size and breadth of the corpus? Books3 contains 200k books out of some 10 million that should be available via amazon.
Regarding copyright, could a less ethical actor gain an advantage by incorporating sci-hub and libgen content, for example? These two together claim to include 50 million medical articles and another 2 million books.
Replies from: gwern↑ comment by gwern · 2021-10-12T17:00:31.433Z · LW(p) · GW(p)
Not very, now. Compute & implementation are more limiting.
Corpus quality definitely affects how much bang per FLOP you get, at a moderate (neither extreme nor negligible) sort of constant factor. The Pile is better than what OA used, so an otherwise-identical GPT-3 trained on it would be noticeably better. (But this only goes so far and you will have a hard time doing much better than The Pile in terms of cleaner higher-quality text.)
Corpus size is unimportant because existing corpuses are enough: the optimal training method is to do 1 epoch, never reusing any data. But you are usually limited by compute, and the compute you have uniquely specifies the model size and n. Even for Nvidia/MS using their supercomputer with 5k+ A100s, that n is a lot smaller than what The Pile etc already contains. (See the part about over/undersampling and how few tokens they trained on compared to the full dataset. GPT-3 did the same thing: oversampled WP and books, but then didn't use more than a fraction of their CC subset etc.) So in other words, PMC vs PM is irrelevant because even if you bothered to get the full PM corpus, they already had more text than they could afford to train on. They don't want to throw out the other data in order to train on mostly PM, so just PMC is fine.
(When you have too much data, what you can do to get some value out of it is you can filter it more aggressively to cut it down to just that amount you can afford - but filtering itself is an open research challenge: lots of nasty software engineering, and you may wind up sabotaging your model if you eliminate too much data diversity by mistaking diverse difficult data for bad data & filtering it out. And if you do it right, you're still limited by the first point that data cleaning only buys you so much in constant factors.)
Replies from: gwern↑ comment by gwern · 2022-01-25T18:18:45.919Z · LW(p) · GW(p)
I should clarify that we aren't data-limited in the sense of large natural data dumps, but we are data-limited in other kinds of data in terms of triggering interesting latent capabilities.
In terms of raw data, The Pile and CC have more data than you need for the foreseeable future. This does not apply to other kinds of data, like curated sets of prompts. If you think of the pretraining paradigm, the point of large natural real world datadumps is not to be large or because we care about them or because the updates on 99% of the data will be useful, but that by virtue of their sheer size and indiscriminateness, they happen to contain, hidden throughout like flecks of gold in a giant river of sand, implicit unlabeled 'hard tasks' which foster generalization and capabilities through the blessing of scale. One might go through a gigabyte of text before finding an example which truly stresses a model's understanding of "whether a kilogram of feathers weighs more than a kilogram of toasters" - these are simply weird things to write, and are mostly just implicit, and most examples are easily solved by shortcuts. The more easy examples you solve, the more gigabytes or terabytes you have to process in order to find a bunch of examples you haven't already solved, and the bigger your model has to be to potentially absorb the remainder. So there are diminishing returns and you rapidly run out of compute before you run out of raw data.
However, if you can write down a few examples of each of those tasks and produce a highly concentrated dose of those tasks (by distilling the dumps, collating existing challenging benchmarks' corpuses, recruiting humans to write targeted tasks, using adversarial methods to focus on weak points etc.), you can potentially bring to the surface a lot of learning and meta-learning. This is hard to do because we don't know what most of those hard tasks are: they are the water in which we swim, and we don't know what we know or how we know it (which is much of why AI is hard). But you can still try. This has been a very effective approach over the past year or so, and we have yet to see the limits of this approach: the more varied your prompts and tasks, the better models work.
comment by TheSupremeAI · 2021-10-11T17:14:51.096Z · LW(p) · GW(p)
While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
Pretty optimistic that AGI is going to be achieved by the end of the decade
Replies from: Capybasilisk, quintin-pope, JohnSteidley↑ comment by Capybasilisk · 2021-10-12T08:50:06.502Z · LW(p) · GW(p)
Leo Gao thinks it might be possible to ride language models all the way to AGI (or something reasonably close):
https://bmk.sh/2021/06/02/Thoughts-on-the-Alignment-Implications-of-Scaling-Language-Models/
↑ comment by Quintin Pope (quintin-pope) · 2021-10-11T19:21:48.915Z · LW(p) · GW(p)
I don't think that's likely. Rates of increase for model size are slowing. Also, the scaling power-laws for performance and parameter count we've seen so far suggest future progress is likely ~linear and fairly slow.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2021-10-12T00:36:33.460Z · LW(p) · GW(p)
That only covers the possibilities where even more compute than currently available is crucial. In the context of ridiculing GPT-n, that can't even matter, as with the same dataset and algorithm more compute won't make it an AGI. And whatever missing algorithms are necessary to do so might turn out to not make the process infeasibly more expensive.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-10-12T01:08:23.408Z · LW(p) · GW(p)
“…whatever missing algorithms are necessary to do so might turn out to not make the process infeasibly more expensive.”
I think this is very unlikely because the human brain uses WAY more compute than GPT-3 (something like at least 1000x more on low end estimates). If the brain, optimized for efficiency by millions of years of evolution, is using that much compute, then lots of compute is probably required.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2021-10-12T10:32:06.589Z · LW(p) · GW(p)
Backpropagation is nonlocal and might be a couple of orders of magnitude more efficient [LW(p) · GW(p)] at learning than whatever it is that brain does. Evolution wouldn't have been able to take advantage of that, because brains are local. If that holds, it eats up most of the difference.
But also the output of GPT-3 is pretty impressive, I think it's on its own a strong argument that if it got the right datasets (the kind that are only feasible to generate automatically with a similar system) and slightly richer modalities (like multiple snippets of text and not one), it would be able to learn to maintain coherent thought. That's the kind of missing algorithms I'm thinking about, generation of datasets and retraining on them, which might require as little as hundreds of cycles of training needed for vanilla GPT-3 to make it stop wandering wildly off-topic, get the point more robustly, and distinguish fiction from reality. Or whatever other crucial faculties that are currently in disarray but could be trained with an appropriate dataset that can be generated with what it already got.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-10-12T21:25:19.522Z · LW(p) · GW(p)
- Deep learning/backprop has way more people devoted to improving its efficiency than Hebbian learning.
- Those 100x slowdown results were for a Hebbian learner trying to imitate backprop, not learn as efficiently as possible.
- Why would training GPT-3 on its own output improve it at all? Scaling laws indicate there’s only so much that more training data can do for you, and artificial data generated by GPT-3 would have worse long term coherence than real data.
↑ comment by gwern · 2021-10-12T22:20:24.206Z · LW(p) · GW(p)
Why would training GPT-3 on its own output improve it at all?
Self-distillation is a thing, even outside a DRL setting. ("Best-of" sampling is similar to self-distillation in being a way to get better output out of GPT-3 using just GPT-3.) There's also an issue of "sampling can prove the presence of knowledge but not the absence" in terms of unlocking abilities that you haven't prompted - in a very timely paper yesterday, OA demonstrates that GPT-3 models have much better translation abilities than anyone realized, and you can train on its own output to improve its zero-shot translation to English & make that power accessible: "Unsupervised Neural Machine Translation with Generative Language Models Only", Han et al 2021.
↑ comment by Vladimir_Nesov · 2021-10-12T22:56:22.410Z · LW(p) · GW(p)
You generate better datasets for playing chess by making a promising move (which is hard to get right without already having trained on a good dataset) and then seeing whether the outcome looks more like winning than for other promising moves (which is easier to check, with blitz games by the same model). The blitz games start out chaotic as well, not predicting actual worth of a move very well, but with each pass of this process the dataset improves, as does the model's ability to generate even better datasets by playing better blitz.
For language, this could be something like using prompts to set up additional context, generating perhaps a single token continuing some sequence, and evaluating it by continuing it to a full sentence/paragraph and then asking the system what it thinks about the result in some respect. Nobody knows how to do this well for language, to actually get better and not just finetune for some aspect of what's already there, hence the missing algorithms. (This is implicit in a lot of alignment talk, see for example amplification and debate [LW · GW].) The point for timelines is that this doesn't incur enormous overhead.
↑ comment by Vladimir_Nesov · 2021-10-12T22:16:48.041Z · LW(p) · GW(p)
These are all terrible arguments: the 100x slowdown for a vaguely relevant algorithm, the power of evolution, the power of more people working on backprop, the esimates of brain compute themselves. The point is, nonlocality of backprop makes relevance of its compute parity with evolved learning another terrible argument, and the 100x figure is an anchor for this aspect usually not taken into account when applying estimates of brain compute to machine learning.
↑ comment by John Steidley (JohnSteidley) · 2021-10-11T18:36:13.691Z · LW(p) · GW(p)
I can't tell what you mean. Can you elaborate?
Replies from: BossSleepy↑ comment by Randomized, Controlled (BossSleepy) · 2021-10-11T20:30:04.826Z · LW(p) · GW(p)
Quintin is arguing that AGI is unlikely by end of decade
Replies from: JohnSteidley↑ comment by John Steidley (JohnSteidley) · 2021-10-11T20:45:03.611Z · LW(p) · GW(p)
I wasn't replying to Quintin