What mistakes has the AI safety movement made?
post by EuanMcLean (euanmclean) · 2024-05-23T11:19:02.717Z · LW · GW · 29 commentsContents
How to read this post Too many galaxy-brained arguments & not enough empiricism Problems with research Too insular Bad messaging AI safety’s relationship with the leading AGI companies The bandwagon Pausing is bad Discounting public outreach & governance as a route to safety Conclusion None 29 comments
This is the third of three posts summarizing what I learned when I interviewed 17 AI safety experts about their "big picture" of the existential AI risk landscape: how AGI will play out, how things might go wrong, and what the AI safety community should be doing. See here [LW · GW] for a list of the participants and the standardized list of questions I asked.
This post summarizes the responses I received from asking “Are there any big mistakes the AI safety community has made in the past or are currently making?”
“Yeah, probably most things people are doing are mistakes. This is just some random group of people. Why would they be making good decisions on priors? When I look at most things people are doing, I think they seem not necessarily massively mistaken, but they seem somewhat confused or seem worse to me by like 3 times than if they understood the situation better.” - Ryan Greenblatt
“If we look at the track record of the AI safety community, it quite possibly has been harmful for the world.” - Adam Gleave
“Longtermism [? · GW] was developed basically so that AI safety could be the most important cause by the utilitarian EA calculus. That's my take.” - Holly Elmore
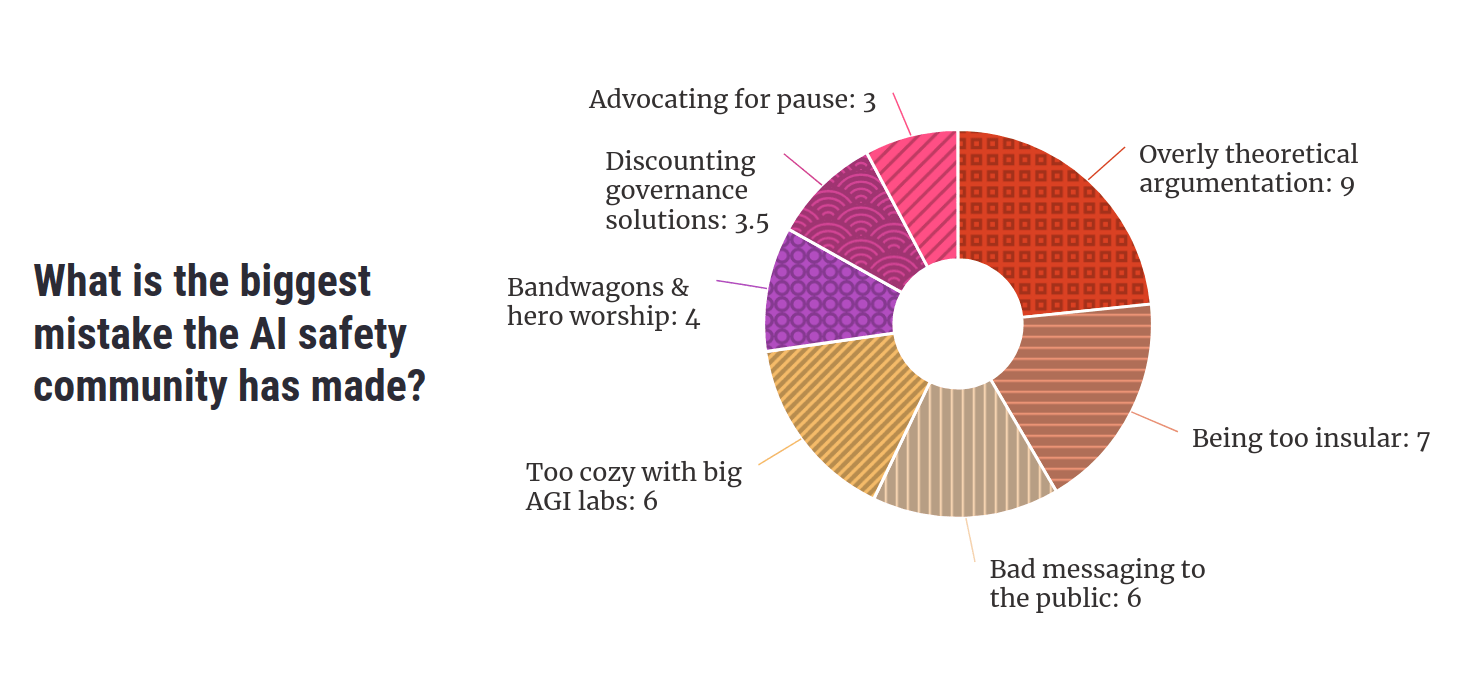
Participants pointed to a range of mistakes they thought the AI safety movement had made. Key themes included an overreliance on theoretical argumentation, being too insular, putting people off by pushing weird or extreme views, supporting the leading AGI companies, insufficient independent thought, advocating for an unhelpful pause to AI development, and ignoring policy as a potential route to safety.
How to read this post
This is not a scientific analysis of a systematic survey of a representative sample of individuals, but my qualitative interpretation of responses from a loose collection of semi-structured interviews. Take everything here with the appropriate seasoning.
Results are often reported in the form “N respondents held view X”. This does not imply that “17-N respondents disagree with view X”, since not all topics, themes and potential views were addressed in every interview. What “N respondents held view X” tells us is that at least N respondents hold X, and consider the theme of X important enough to bring up.
The following is a summary of the main themes that came up in my interviews. Many of the themes overlap with one another, and the way I’ve clustered the criticisms is likely not the only reasonable categorization.
Too many galaxy-brained arguments & not enough empiricism
“I don't find the long, abstract style of investigation particularly compelling.” - Adam Gleave
9 respondents were concerned about an overreliance or overemphasis on certain kinds of theoretical arguments underpinning AI risk: namely Yudkowsky’s arguments in the sequences [? · GW] and Bostrom’s arguments in Superintelligence.
“All these really abstract arguments that are very detailed, very long and not based on any empirical experience. [...]
Lots of trust in loose analogies, thinking that loose analogies let you reason about a topic you don't have any real expertise in. Underestimating the conjunctive burden of how long and abstract these arguments are. Not looking for ways to actually test these theories. [...]You can see Nick Bostrom in Superintelligence stating that we shouldn't use RL to align an AGI because it trains the AI to maximize reward, which will lead to wireheading. The idea that this is an inherent property of RL is entirely mistaken. It may be an empirical fact that certain minds you train with RL tend to make decisions on the basis of some tight correlate of their reinforcement signal, but this is not some fundamental property of RL.”
- Alex Turner
Jamie Bernardi argued that the original view of what AGI will look like, namely an RL agent that will reason its way to general intelligence from first principles, is not the way things seem to be panning out. The cutting-edge of AI today is not VNM-rational agents who are Bayesianly-updating their beliefs and trying to maximize some reward function. The horsepower of AI is instead coming from oodles of training data. If an AI becomes power-seeking, it may be because it learns power-seeking from humans, not because of instrumental convergence!
There was a general sense that the way we make sense of AI should be more empirical. Our stories need more contact with the real world – we need to test and verify the assumptions behind the stories. While Adam Gleave overall agreed with this view, he also warned that it’s possible to go too far in the other direction, and that we must strike a balance between the theoretical and the empirical.
Problems with research
This criticism of “too much theoretical, not enough empirical” also applied to the types of research we are doing. 4 respondents focussed on this. This was more a complaint about past research, folks were typically more positive about the amount of empirical work going on now.
2 people pointed at MIRI’s overreliance on idealized models of agency in their research, like AIXI [? · GW]. Adrià Garriga-Alonso thought that infrabayesianism [? · GW], parts of singular learning theory and John Wentworth’s research programs [AF · GW] are unlikely to end up being helpful for safety:
“I think the theory-only projects of the past did not work that well, and the current ones will go the same way.” - Adrià Garriga-Alonso
Evan Hubinger pushed back against this view by defending MIRI’s research approach. He pointed out that, when a lot of this very theoretical work was being done, there wasn’t much scope to do more empirical work because we had no highly capable general-purpose models to do experiments on – theoretical work was the best we could do!
“Now it's very different. Now, I think the best work to do is all empirical. Empirical research looks really good right now, but it looked way less good three, four years ago. It's just so much easier to do good empirical work now that the models are much smarter.” - Evan Hubinger
Too insular
8 participants thought AI safety was too insular: the community has disvalued forming alliances with other groups and hasn’t integrated other perspectives and disciplines.
2 of the 8 focussed on AI safety’s relationship with AI ethics. Many in AI safety have been too quick to dismiss the concerns of AI ethicists that AI could exacerbate current societal problems like racism, sexism and concentration of power, on the grounds of extinction risk being “infinitely more important”. But AI ethics has many overlaps with AI safety both technically and policy:
“Many of the technical problems that I see are the same. If you're trying to align a language model, preventing it from saying toxic things is a great benchmark for that. In most cases, the thing we want on an object level is the same! We want more testing of AI systems, we want independent audits, we want to make sure that you can't just deploy an AI system unless it meets some safety criteria.” - Adam Gleave
In environmentalism, some care more about the conservation of bird species, while others are more concerned about preventing sea level rise. Even though these two groups may have different priorities, they shouldn’t fight because they have agree on many important subgoals, and have many more priorities in common with each other than with, for example, fossil fuel companies. Building a broader coalition could be similarly important for AI safety.
Another 2 respondents argued that AI safety needs more contact with academia. A big fraction of AI safety research is only shared via LessWrong or the Alignment Forum rather than academic journals or conferences. This can be helpful as it speeds up the process of sharing research by sidestepping “playing the academic game” (e.g. tuning your paper to fit into academic norms), but has the downside that research typically receives less peer review, leading to on average lower quality posts on sites like LessWrong. Much of AI safety research lacks the feedback loops that typical science has. AI safety also misses out on the talent available in the broader AI & ML communities.
Many of the computer science and math kids in AI safety do not value insights from other disciplines enough, 2 respondents asserted. Gillian Hadfield argued that many AI safety researchers are getting norms and values all wrong because we don’t consult the social sciences. For example: STEM people often have an assumption that there are some norms that we can all agree on (that we call “human values”), because it’s just “common sense”. But social scientists would disagree with this. Norms and values are the equilibria of interactions between individuals, produced by their behaviors, not some static list of rules up in the sky somewhere.
Another 2 respondents accused the rationalist sphere of using too much jargony and sci-fi language. Esoteric phrases like “p(doom)”, “x-risk” or “HPMOR” can be off-putting to outsiders and a barrier to newcomers, and give culty vibes. Noah conceded that shorthands can be useful to some degree (for example they can speed up idea exchange by referring to common language rather than having to re-explain the same concept over and over again), but thought that on the whole AI safety has leaned too much in the jargony direction.
Ajeya Cotra thought some AI safety researchers, like those at MIRI, have been too secretive about the results of their research. They do not publish their findings due to worries that a) their insights will help AI developers build more capable AI, and b) they will spread AGI hype and encourage more investment into building AGI (although Adam considered that creating AI hype is one of the big mistakes AI safety has made, on balance he also thought many groups should be less secretive). If a group is keeping their results secret, this is in fact a sign that they aren’t high quality results. This is because a) the research must have received little feedback or insights from other people with different perspectives, and b) if there were impressive results, there would be more temptation to share it.
Holly Elmore suspected that this insular behavior was not by mistake, but on purpose. The rationalists wanted to only work with those who see things the same way as them, and avoid too many “dumb” people getting involved. She recalled conversations with some AI safety people who lamented that there are too many stupid or irrational newbies flooding into AI safety now, and the AI safety sphere isn't as fun as it was in the past.
Bad messaging
“As the debate becomes more public and heated, it’s easy to fall into this trap of a race to the bottom in terms of discourse, and I think we can hold better standards. Even as critics of AI safety may get more adversarial or lower quality in their criticism, it’s important that we don’t stoop to the same level. [...] Polarization is not the way to go, it leads to less action.” - Ben Cottier
6 respondents thought AI safety could communicate better with the wider world. The AI safety community do not articulate the arguments for worrying about AI risk well enough, come across as too extreme or too conciliatory, and lean into some memes too much or not enough.
4 thought that some voices push views that are too extreme or weird (but one respondent explicitly pushed against this worry). Yudkowsky is too confident that things will go wrong, and PauseAI is at risk of becoming off-putting if they continue to lean into the protest vibe. Evan thought Conjecture has been doing outreach badly – arguing against sensible policy proposals (like responsible scaling policies) because they don’t go far enough. David Krueger however leaned in the opposite direction: he thought that we are too scared to use sensationalist language like “AI might take over”, while in fact, this language is good for getting attention and communicating concerns clearly.

Ben Cottier lamented the low quality of discourse around AI safety, especially in places like Twitter. We should have a high standard of discourse, show empathy to the other side of the debate, and seek compromises (with e.g. open source advocates). The current bad discourse is contributing to polarization, and nothing gets done when an issue is polarized. Ben also thought that AI safety should have been more prepared for the “reckoning moment” of AI risk becoming mainstream, so we had more coherent articulations of the arguments and reasonable responses to the objections.
Some people say that we shouldn’t anthropomorphize AI, but Nora Belrose reckoned we should do it more! Anthropomorphising makes stories much more attention-grabbing (it is “memetically fit”). One of the most famous examples of AI danger has been Sydney: Microsoft’s chatbot that freaked people out by being unhinged in a very human way.
AI safety’s relationship with the leading AGI companies
“Is it good that the AI safety community has collectively birthed the three main AI orgs, who are to some degree competing, and maybe we're contributing to the race to AGI? I don’t know how true that is, but it feels like it’s a little bit true.
If the three biggest oil companies were all founded by people super concerned about climate change, you might think that something was going wrong."
- Daniel Filan
Concern for AI safety had at least some part to play in the founding of OpenAI, Anthropic and DeepMind. Safety was a stated primary concern that drove the founding of OpenAI. Anthropic was founded by researchers who left OpenAI because it wasn’t sufficiently safety-conscious. Shane Legg, one of DeepMind’s co-founders, is on record for being largely motivated by AI safety. Their existence is arguably making AGI come sooner, and fuelling a race that may lead to more reckless corner-cutting in AI development. 5 respondents thought the existence of these three organizations is probably a bad thing.
Jamie thought the existence of OpenAI may be overall positive though, due to their strategy of widely releasing models (like ChatGPT) to get the world experienced with AI. ChatGPT has thrust AI into the mainstream and precipitated the recent rush of interest in the policy world.
3 respondents also complained that the AI safety community is too cozy with the big AGI companies. A lot of AI safety researchers work at OpenAI, Anthropic and DeepMind. The judgments of these researchers may be biased by a conflict of interest: they may be incentivised for their company to succeed in getting to AGI first. They will also be contractually limited in what they can say about their (former) employer, in some cases even for life.
Adam recommended that AI safety needs more voices who are independent of corporate interests, for example in academia. He also recommended that we shouldn’t be scared to criticize companies who aren’t doing enough for safety.
While Daniel Filan was concerned about AI safety’s close relationship with these companies, he conceded that there must be a balance [EA · GW] between inside game (changing things from the inside) and outside game (putting pressure on the system from the outside). AI safety is mostly playing the inside game – get involved with the companies who are causing the problem, to influence them to be more careful and do the right thing. In contrast, the environmentalism movement largely plays an outside game – not getting involved with oil companies but protesting them from the outside. Which of these is the right way to make change happen? Seems difficult to tell.
The bandwagon
“I think there's probably lots of people deferring when they don't even realize they're deferring.” - Ole Jorgensen
Many in the AI safety movement do not think enough for themselves, 4 respondents thought. Some are too willing to adopt the views of a small group of elites who lead the movement (like Yudkowsy, Christiano and Bostrom). Alex Turner was concerned about the amount of “hero worship” towards these thought leaders. If this small group is wrong, then the entire movement is wrong. As Jamie pointed out, AI safety is now a major voice in the AI policy world – making it even more concerning that AI safety is resting on the judgements of such a small number of people.
“There's maybe some jumping to like: what's the most official way that I can get involved in this? And what's the community-approved way of doing this or that? That's not the kind of question I think we should be asking.” - Daniel Filan
Pausing is bad
3 respondents thought that advocating for a pause to AI development is bad, while 1 respondent was pro-pause[1]. Nora referred me to a post she wrote arguing that pausing is bad. In that post, she argues that pausing will a) reduce the quality of alignment research because researchers will be forced to test their ideas on weak models, b) make a hard takeoff [? · GW] more likely when the pause is lifted, and c) push capabilities research underground, where regulations are looser.
Discounting public outreach & governance as a route to safety
Historically, the AI safety movement has underestimated the potential of getting the public on-side and getting policy passed, 3 people said. There is a lot of work in AI governance these days, but for a long time most in AI safety considered it a dead end. The only hope to reduce existential risk from AI was to solve the technical problems ourselves, and hope that those who develop the first AGI implement them. Jamie put this down to a general mistrust of governments in rationalist circles, not enough faith in our ability to solve coordination problems, and a general dislike of “consensus views”.
Holly thought there was a general unconscious desire for the solution to be technical. AI safety people were guilty of motivated reasoning that “the best way to save the world is to do the work that I also happen to find fun and interesting”. When the Singularity Institute pivoted towards safety and became MIRI, they never gave up on the goal of building AGI – just started prioritizing making it safe.
“Longtermism was developed basically so that AI safety could be the most important cause by the utilitarian EA calculus. That's my take.” - Holly Elmore
She also condemned the way many in AI safety hoped to solve the alignment problem via “elite shady back-room deals”, like influencing the values of the first AGI system by getting into powerful positions in the relevant AI companies.
Richard Ngo gave me similar vibes, arguing that AI safety is too structurally power-seeking: trying to raise lots of money, trying to gain influence in corporations and governments, trying to control the way AI values are shaped, favoring people who are concerned about AI risk for jobs and grants, maintaining the secrecy of information, and recruiting high school students to the cause. We can justify activities like these to some degree, but Richard worried that AI safety was leaning too much in this direction. This has led many outside of the movement to deeply mistrust AI safety (for example).
“From the perspective of an external observer, it’s difficult to know how much to trust stated motivations, especially when they tend to lead to the same outcomes as deliberate power-seeking.” - Richard Ngo
Richard thinks that a better way for AI safety to achieve its goals is to instead gain more legitimacy by being open, informing the public of the risks in a legible way, and prioritizing competence.
More abstractly, both Holly and Richard reckoned that there is too much focus on individual impact in AI safety and not enough focus on helping the world solve the problem collectively. More power to do good lies in the hands of the public and governments than many AI safety folk and effective altruists think. Individuals can make a big difference by playing 4D chess, but it’s harder to get right and often backfires.
“The agent that is actually having the impact is much larger than any of us, and in some sense, the role of each person is to facilitate the largest scale agent, whether that be the AI safety community or civilization or whatever. Impact is a little meaningless to talk about, if you’re talking about the impact of individuals in isolation.” - Richard Ngo
Conclusion
Participants pointed to a range of mistakes they thought the AI safety movement had made. An overreliance on overly theoretical argumentation, being too insular, putting the public off by pushing weird or extreme views, supporting the leading AGI companies, not enough independent thought, advocating for an unhelpful pause to AI development, and ignoring policy as potential a route to safety.
Personally, I hope this can help the AI safety movement avoid making similar mistakes in the future! Despite the negative skew of my questioning, I walked away from these conversations feeling pretty optimistic about the direction the movement is heading. I believe that as long as we continue to be honest, curious and open-minded about what we’re doing right and wrong, AI safety as a concept will overall have a positive effect on humanity’s future.
- ^
Other respondents may also have been pro or anti-pause, but since the pause debate did not come up in their interviews I didn’t learn what their positions on this issue were.
29 comments
Comments sorted by top scores.
comment by PhilosophicalSoul (LiamLaw) · 2024-05-24T22:13:48.905Z · LW(p) · GW(p)
I think these points are common sense to an outsider. I don't mean to be condescending, I consider myself an outsider.
I've been told that ideas on this website are sometimes footnoted by people like Sam Altman in the real world, but they don't seem to ever be applied correctly.
- It's been obvious from the start that not enough effort was put into getting buy-in from the government. Now, their strides have become oppressive and naive (the AI Act is terribly written and unbelievably complicated, it'll be three-five years before it's ever implemented).
- Many of my peers who I've introduced to some arguments on this website who do not know what alignment research is identified many of these 'mistakes' at face value. LessWrong got into a terrible habit of fortifying an echo chamber of ideas that only worked on LessWrong. No matter how good an idea, if it cannot be simply explained to the average layperson, it will be discarded as obfuscatory.
- Hero worship & bandwagons seems to be a problem with the LessWrong community inherently, rather than something unique to the Alignment movement (again, I haven't been here long, I'm simply referring to posts by long-time members critiquing the cult-like mentalities that tend to appear).
- Advocating for pause - well duh. The genie is out of the bottle, there's no putting it back. We literally cannot go back because the gravy train of money in the throats of those with the power to change things aren't going to give that up.
I don't see these things as mistakes but rather common-sense byproducts of the whole: "We were so concerned with whether we could, we didn't ask whether we should," idea. The LessWrong community literally couldn't help itself, it just had to talk about these things as rationalists of the 21st century.
I think... well, I think there may be a 10-15% chance these mistakes are rectified in time. But the public already has a warped perception of AI, divided on political lines. LessWrong could change if there was a concerted effort - would the counterparts who read LessWrong also follow? I don't know.
I want to emphasise here, since I've just noticed how many times I mentioned LW, I'm not demonising the community. I'm simply saying that, from an outsider's perspective, this community held promise as the vanguards of a better future. Whatever ideas it planted in the heads of those at the top a few years ago, in the beginning stages of alignment, could've been seeded better. LW is only a small cog of blame in the massive machine that is currently outputting a thousand mistakes a day.
comment by Thomas Kwa (thomas-kwa) · 2024-05-24T21:55:13.402Z · LW(p) · GW(p)
My opinions:
Too many galaxy-brained arguments & not enough empiricism
Our stories need more contact with the real world
Agree. Although there is sometimes a tradeoff between direct empirical testability and relevance to long-term alignment.
Adrià Garriga-Alonso thought that infrabayesianism [? · GW], parts of singular learning theory and John Wentworth’s research programs [AF · GW] are unlikely to end up being helpful for safety:
Agree. Thinking about mathematical models for agency seems fine because it is fundamental and theorems can get you real understanding, but the more complicated and less elegant your models get and the more tangential they are to the core question of how AI and instrumental convergence work, the less likely they are to be useful.
Evan Hubinger pushed back against this view by defending MIRI’s research approach. [...] we had no highly capable general-purpose models to do experiments on
Some empirical work could have happened well before the shift to empiricism around 2021. FAR AI's Go attack work could have happened in shortly after LeelaZero was released in 2017, as could interpretability on non-general-purpose models.
Too insular
Many in AI safety have been too quick to dismiss the concerns of AI ethicists [... b]ut AI ethics has many overlaps with AI safety both technically and policy:
Undecided; I used to believe this but then heard that AI ethicists have been uncooperative when alignment people try to reach out. But maybe we are just bad at politics and coalition-building.
AI safety needs more contact with academia. [...] research typically receives less peer review, leading to on average lower quality posts on sites like LessWrong. Much of AI safety research lacks the feedback loops that typical science has.
Agree; I also think that the research methodology and aesthetic of academic machine learning has been underappreciated (although it is clearly not perfect). Historically some good ideas like the LDT paper were rejected in journals, but it is definitely true that many things you do for the sake of publishing actually make your science better, e.g. having both theory and empirical results, or putting your contributions in an ontology people understand. I did not really understand how research worked until attending ICML last year.
Many of the computer science and math kids in AI safety do not value insights from other disciplines enough [....] Norms and values are the equilibria of interactions between individuals, produced by their behaviors, not some static list of rules up in the sky somewhere.
Plausible but with reservations:
- I think "interdisciplinary" can be a buzzword that invites a lot of bad research
- Thinking of human values as a utility function can be a useful simplifying assumption in developing basic theory
[...] too much jargony and sci-fi language. Esoteric phrases like “p(doom)”, “x-risk” or “HPMOR” can be off-putting to outsiders and a barrier to newcomers, and give culty vibes.
Disagree. This is the useful kind of jargon; "x-risk" is a concept we really want in our vocabulary and it is not clear how to make it sound less weird; if AI safety people are offputting to outsiders it is because we need to be more charismatic and better at communication.
Ajeya Cotra thought some AI safety researchers, like those at MIRI, have been too secretive about the results of their research.
Agree; I think there had been a mindset where since MIRI's plan for saving the world needed them to reach the frontier of AI research with far safer (e.g. non-ML) designs, they think their AI capabilities ideas are better than they are.
Holly Elmore suspected that this insular behavior was not by mistake, but on purpose. The rationalists wanted to only work with those who see things the same way as them, and avoid too many “dumb” people getting involved.
Undecided; this has not been my experience. I do think people should recognize that AI safety has been heavily influenced by what is essentially a trauma response from being ignored by the scientific establishment from 2003-2023,
Bad messaging
6 respondents thought AI safety could communicate better with the wider world.
Agree. It's wild to me that e/acc and AI safety seem memetically evenly matched on Twitter (could be wrong about this, if so someone please correct me) while e/acc has a worse favorability rating than Scientology in surveys.
4 thought that some voices push views that are too extreme or weird
I think Eliezer's confidence is not the worst thing because in most fields there are scientists who are super overconfident. But probably he should be better at communication e.g. realizing that people will react negatively to raising the possibility of nuking bombing datacenters without lots of contextualizing. Undecided on Pause AI and Conjecture.
Ben Cottier lamented the low quality of discourse around AI safety, especially in places like Twitter.
I'm pretty sure a large part of this is some self-perpetuating thing where participating in higher-quality discourse on LW or better, your workplace Slack is more fun than Twitter. Not sure what to do here. Agree about polarization but it's not clear what to do there either.
AI safety’s relationship with the leading AGI companies
3 respondents also complained that the AI safety community is too cozy with the big AGI companies. A lot of AI safety researchers work at OpenAI, Anthropic and DeepMind. The judgments of these researchers may be biased by a conflict of interest: they may be incentivised for their company to succeed in getting to AGI first. They will also be contractually limited in what they can say about their (former) employer, in some cases even for life.
Agree about conflicts of interest. I remember hearing at one of the AI safety international dialogues, every academic signed but no one with a purely corporate affiliation. There should be some way for safety researchers to divest their equity rather than give it up / donate it and lose 85% of their net worth, but conflicts of interest will remain.
The bandwagon
Many in the AI safety movement do not think enough for themselves, 4 respondents thought.
Slightly agree I guess? I don't really have thoughts. It makes sense that Alex thinks this because he often disagrees with other safety researchers-- not to discredit his position.
Discounting public outreach & governance as a route to safety
Historically, the AI safety movement has underestimated the potential of getting the public on-side and getting policy passed, 3 people said. There is a lot of work in AI governance these days, but for a long time most in AI safety considered it a dead end. The only hope to reduce existential risk from AI was to solve the technical problems ourselves, and hope that those who develop the first AGI implement them. Jamie put this down to a general mistrust of governments in rationalist circles, not enough faith in our ability to solve coordination problems, and a general dislike of “consensus views”.
I think this is largely due to a mistake by Yudkowsky [LW(p) · GW(p)], which is maybe compatible with Jamie's opinions.
I also want to raise the possibility that the technical focus was rational and correct at the time. Early MIRI/CFAR rationalists were nerds with maybe -1.5 standard deviations of political aptitude on average. So I think it is likely that they would have failed at their policy goals, and maybe even had three more counterproductive events like the Puerto Rico conference where OpenAI was founded. Later, AI safety started attracting political types, and maybe this was the right time to start doing policy.
[Holly] also condemned the way many in AI safety hoped to solve the alignment problem via “elite shady back-room deals”, like influencing the values of the first AGI system by getting into powerful positions in the relevant AI companies.
It doesn't sound anywhere near as shady if you phrase it as "build a safety focused culture or influence decisions at companies that will build the first AGI", which seems more accurate.
Replies from: kabir-kumar-1, ryan_greenblatt, gilch↑ comment by Kabir Kumar (kabir-kumar-1) · 2024-05-26T19:08:05.225Z · LW(p) · GW(p)
But maybe we are just bad at politics and coalition-building.
Mostly due to a feeling of looking down on people imo
Replies from: gilch↑ comment by ryan_greenblatt · 2024-05-29T00:38:02.658Z · LW(p) · GW(p)
But probably he should be better at communication e.g. realizing that people will react negatively to raising the possibility of bombing datacenters without lots of contextualizing.
I'm confident he knew people would react negatively but decided to keep the line because he thought it was worth the cost.
Seems like a mistake by his own lights IMO.
↑ comment by gilch · 2024-05-27T23:51:10.281Z · LW(p) · GW(p)
But probably he should be better at communication e.g. realizing that people will react negatively to raising the possibility of nuking datacenters without lots of contextualizing.
Yeah, pretty sure Eliezer never recommended nuking datacenters. I don't know who you heard it from, but this distortion is slanderous and needs to stop. I can't control what everybody says elsewhere, but it shouldn't be acceptable on LessWrong, of all places.
He did talk about enforcing a global treaty backed by the threat of force (because all law is ultimately backed by violence, don't pretend otherwise). He did mention that destroying "rogue" datacenters (conventionally, by "airstrike") to enforce said treaty had to be on the table, even if the target datacenter is located in a nuclear power who might retaliate (possibly risking a nuclear exchange), because risking unfriendly AI is worse.
Replies from: matthew-barnett, thomas-kwa↑ comment by Matthew Barnett (matthew-barnett) · 2024-05-29T00:03:53.527Z · LW(p) · GW(p)
He did talk about enforcing a global treaty backed by the threat of force (because all law is ultimately backed by violence, don't pretend otherwise)
Most international treaties are not backed by military force, such as the threat of airstrikes. They're typically backed by more informal pressures, such as diplomatic isolation, conditional aid, sanctions, asset freezing, damage to credibility and reputation, and threats of mutual defection (i.e., "if you don't follow the treaty, then I won't either"). It seems bad to me that Eliezer's article incidentally amplified the idea that most international treaties are backed by straightforward threats of war, because that idea is not true.
↑ comment by Thomas Kwa (thomas-kwa) · 2024-05-27T23:57:04.156Z · LW(p) · GW(p)
Thanks, fixed.
comment by keltan · 2024-05-24T05:18:05.891Z · LW(p) · GW(p)
I see the Pause AI protests and I cringe. They give me the same feeling I get when I see vegans walk into McDonald’s covered in blood. It feels like: “oh, look. A group that I am a part of is now going to be tied to this small groups actions. That kinda sucks because I wouldn’t do that myself. Totally get their feeling though. Good for them sorta maybe, but also please stop.”
I understand that Scott Alexander talked about PETA and animal ethics a while ago. But I think AI safety has an opportunity right now to take a different approach than PETA had to.
People are already scared. This doesn’t impact “the other” this impacts them. Make that clear. But make it clear is a way that your uncle won’t laugh at over Christmas dinner.
Edit: I just reread this and feel it was a bit harsh on the PAI people. I’m sorry about that. I’d like to point to Chris_Leong’s comment below. It offers something that feels like a better critique than the one I made originally.
Replies from: Odd anon, tomdlal, metachirality, Chris_Leong↑ comment by Odd anon · 2024-05-24T08:27:37.558Z · LW(p) · GW(p)
Make that clear. But make it clear is a way that your uncle won’t laugh at over Christmas dinner.
Most people agree with Pause AI. Most people agree that AI might be a threat to humanity. The protests may or may not be effective, but I don't really think they could be counterproductive. It's not a "weird" thing to protest.
Replies from: keltan↑ comment by keltan · 2024-05-24T10:36:05.657Z · LW(p) · GW(p)
That’s interesting that you don’t consider it a “”weird” thing to protest”.
I guess I want to explicitly point that part out and ask if you stand by the statement? Or maybe I define weird differently? To me weird inside this context means:
“A thing or action that is out of the ordinary in a way that someone encountering it for the first, second, or third time, wouldn’t see as quirky. But as a red flag. If not pre-attached to that thing or person performing the action, a the person seeing it for the first time might form a negative opinion based on the feeling they get seeing it”
↑ comment by tomdlal · 2024-05-24T23:35:44.439Z · LW(p) · GW(p)
(PAI person here)
What is it about the PauseAI protests that gives you the same feeling that the animal rights protesters covered in blood give you?
I agree that we should avoid covering ourselves in blood (or similar).
But so far, all we've done is wear shirts, talk to the public, hand out leaflets, hold signs, give speeches, and chant.
Personally, I don't find any of those activities cringy, with the exception of a few chants that didn't catch on and awkwardly petered out. But perhaps you've seen something in person or on video that I haven't?
Replies from: keltan↑ comment by keltan · 2024-05-26T04:40:10.264Z · LW(p) · GW(p)
Hi! Thank you very much for taking the time to write such a considered response to my ramble of a comment.
Your first question is a hard one to express in text. Instead, I’ll try hard to write a list of requirements for a situation to generate that feeling for me. Then you might be able to image a scenario that meets the requirements and get a similar feeling?
Requirements:
- I must deeply care about the core idea of the subject. For example, I deeply care about animals not coming to harm, or about the world being destroyed by ASI.
- I must disagree with the way it is being protested. For example, the use of loudspeakers, or shouting. Seeming angry gives a sense of irrationality, even if the idea itself is rational.
- I have only seen this in twitter feed context
- I am already scared of the reaction my employer, family, or friends would have if I expressed the idea. For example, I’m afraid when I have to tell a waiter at a restaurant that I’m vegan, because it is a “weird” idea. “Weird” defined above.
What I’ve seen:
- Again, just on twitter
- Extremely small protest groups reminds me of all the antivax or 5G protests I’ve seen irl
- Loudspeakers and yelling
- Leaders on loudspeakers addressing individual open AI employees from outside of gates. In what seems to be a threatening tone. While not necessarily being threatening in context.
- Protestors not taking the inferential distance into account. Which I assume would lead to a confused public. Or individuals presuming the protestors are Luddites.
Thank you again for your reply. I enjoyed having to make this as explicit as possible. Hopefully it helps make the feeling I have clearer.
And thanks you for doing something. I’m not doing anything. I think something is better than nothing.
Replies from: tomdlal↑ comment by tomdlal · 2024-05-26T14:31:36.762Z · LW(p) · GW(p)
Thanks for explaining more.
I sympathise with your feelings around veganism - I too feel a bit awkward saying the V word in some contexts. Some of those feelings are probably down to an internalised veganphobia that I can't shake off despite having been vegan for 4 years. I'm not sure how relevant the vegan/animal rights analogy is to AI safety. As mentioned elsewhere in this thread, Pause is already a popular idea, veganism is not. That probably gives pause advocates some leeway to be bit more annoying.
When trying to change the world, you need to make a trade-off between annoyingness/publicity and obscurity/respectability.
On one extreme, you never mention your issue unless asked. No one listens to you.
On the other extreme, you scream your issue into people's faces in Times Square whilst covered in your own faeces and stream everything on YouTube. No one takes you seriously.
There's a sweet spot somewhere in the middle of the two.
All of the activities that PauseAI engages in are seen by the public as acceptable forms of protest.
Although, of course, the details can always be improved, so I appreciate your thoughts. My hunch is that we're probably at around about the right level of annoyingness. (although my personal preference to avoid being seen as weird may bias me against adopting more annoying tactics - even if they have higher expected value).
↑ comment by metachirality · 2024-05-24T05:52:42.637Z · LW(p) · GW(p)
The thing that got me was Pause AI trying to coalition with people against AI art. I don't really have anything against the idea of a pause but Pause AI seems a bit simulacrum level 2 for me.
↑ comment by Chris_Leong · 2024-05-24T05:35:27.858Z · LW(p) · GW(p)
I think it comes down to exactly how the protests run.
I'm not a fan of chants like "Pause AI, we don't want to die" as that won't make sense to people with low context, but there's a way of doing protesting that actually builds credibility. For example, I'd recommend avoiding loudspeakers and seeming angry vs. just trying to come across as reasonable.
↑ comment by keltan · 2024-05-24T10:39:20.205Z · LW(p) · GW(p)
IMO I’d feel a lot better if it was less angryish. I think there probably is something like a protest that I can imagine working. I’m not sure if I’d call it a protest? Unless, have you got example protests?
I can image a “change my mind” type of stall/stalls. Where people have calm conversations to explain the situation to the public.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2024-05-24T11:45:42.865Z · LW(p) · GW(p)
I think it's fine to call it a protest, but it works better if the people are smiling and if message discipline is maintained. We need people to see a picture in the newspaper and think "those people look reasonable". There might be a point where the strategy changes, but for now it's about establishing credibility.
comment by Chris_Leong · 2024-05-24T05:05:24.476Z · LW(p) · GW(p)
I prob. would have been slightly clearer in the conclusion that this is really only a starting point as it identifies issues where at least N people thought it was an issue, but it doesn't (by design) tell us what the rest thought, so we don't really know if these are majority or minority views.
Just to add my personal opinion: I agree with some of the criticisms (including empirical work being underrated for a long time although maybe not now and excessive pessimism on policy). However, for many of the other, I they might seem like obvious mistakes at first, but once you dig into the details it becomes a bit more complicated.
comment by DPiepgrass · 2024-05-23T18:11:57.067Z · LW(p) · GW(p)
9 respondents were concerned about an overreliance or overemphasis on certain kinds of theoretical arguments underpinning AI risk
I agree with this, but that "the horsepower of AI is instead coming from oodles of training data" is not a fact that seems relevant to me, except in the sense that this is driving up AI-related chip manufacturing (which, however, wasn't mentioned). The reason I argue it's not otherwise relevant is that the horsepower of ASI will not, primarily, come from oodles of training data. To the contrary, it will come from being able to reason, learn and remember better than humans do, and since (IIUC) LLMs function poorly if they are trained only on a dataset sized for human digestion, this implies AGI and ASI need less training data than LLMs, probably much less, for a given performance level (which is not to say more data isn't useful to them, it's just not what makes them AGI). So in my view, making AGI (and by extension AGI alignment) is mainly a matter of algorithms that have not yet been invented and therefore cannot be empirically tested, and less a matter of training data. Making ASI, in turn, is mainly a matter of compute (which already seems too abundant).
(disclaimer: I'm not an AI expert. Also it's an interesting question whether OpenAI will find a trick that somehow turns LLMs into AGI with little additional innovation, but supposing that's true, does the AGI alignment community have enough money and compute to do empirical research in the same direction, given the disintegration of OpenAI's Superalignment Team?)
I agree the first AGIs probably won't be epistemically sound agents maximizing an objective function: even rationalists have shown little interest in computational epistemology, and the dangers of maximizers seem well-known so I vaguely doubt leading AGI companies are pursuing that approach. Epistemically-poor agents without an objective function are often quite dangerous even with modest intelligence, though (e.g. many coup attempts have succeeded on the first try). Capabilities people seem likely to try human-inspired algorithms, which argues for alignment research along the same lines, but I'm not sure if this will work:
- A random alignment researcher would likely invent something different than a random (better-funded) capabilities researcher, so they'd end up aligning the "wrong" architecture (edit: though I expect some transferability of whatever was learned about alignment to comparable architectures)
- Like GoF research, developing any AGI has a risk that the key insight behind it, or even the source code, escapes into the wild before alignment is solved
- Solving alignment doesn't force others to use the solution.
So while the criticism seems sound, what should alignment researchers do instead?
Other brief comments:
- Too insular: yes, ticking off "AI safety" and e/acc researchers does us no favors ― but to what extent can it be avoided?
- Bad messaging―sure, can we call it AGI alignment please? And I think a thing we should do even for our own benefit is to promote detailed and realistic stories (ideally after review by superforecasters and alignment researchers) of how an AGI world could play out. Well-written stories are good messaging, and Moloch knows human fiction needs more realism. (I tried to write such a story, had no time to finish it, so published a draft [LW · GW] before noticing the forum's special rules, and it was not approved for publication) P.S. It doesn't sound like Evan and Krueger contradict each other. P.P.S. a quip for consideration: psychopathy is not the presence of evil, but the absence of empathy. Do you trust AI corporations to build empathy? P.P.P.S. what about mimetic countermessaging? I don't know where the "AI safety is a immense juggernaut turning everyone into crazy doomers" meme comes from (Marc Andreesson?) but it seems very popular.
- "Their existence is arguably making AGI come sooner, and fueling a race that may lead to more reckless corner-cutting": yes, but (1) was it our fault specifically and (2) do we have a time machine?
- "general mistrust of governments in rationalist circles, not enough faith in our ability to solve coordination problems, and a general dislike of “consensus views”" Oh hell yes. EAs have a bit different disposition, though?
comment by Orpheus16 (akash-wasil) · 2024-05-29T03:32:49.151Z · LW(p) · GW(p)
6 respondents thought AI safety could communicate better with the wider world. The AI safety community do not articulate the arguments for worrying about AI risk well enough, come across as too extreme or too conciliatory, and lean into some memes too much or not enough.
I think this accurately captures a core debate in AI comms/AI policy at the moment. Some groups are worried about folks coming off as too extreme (e.g., by emphasizing AI takeover and loss-of-control risks) and some groups are worried about folks worrying so much about sounding "normal" that they give an inaccurate or incomplete picture of the risks (e.g., by getting everyone worried about AI-generated bioweapons, even if the speaker does not believe that "malicious use from bioweapons" is the most plausible or concerning threat model.)
My own opinion is that I'm quite worried that some of the "attempts to look normal" have led to misleading/incorrect models of risk. These models of risk (which tend to focus more on malicious use than risks from autonomous systems) do not end up producing reasonable policy efforts.
The tides seem to be changing, though—there have been more efforts to raise awareness about AGI, AGI takeover, risks from autonomous systems, and risks from systems that can produce a decisive strategic advantage. I think these risks are quite important for policymakers to understand, and clear/straightforward explanations of them are rare.
I also think status incentives are discouraging (some) people from raising awareness about these threat models– people don't want to look silly, dumb, sci-fi, etc. But IMO one of the most important comms/policy challenges will be getting people to take such threat models seriously, and I think there are ways to explain such threat models legitimately.
comment by Meme Marine (meme-marine) · 2024-05-30T00:03:34.711Z · LW(p) · GW(p)
I think one big mistake the AI safety movement is currently making is not paying attention to the concerns of the wider population about AI right now. People do not believe that a misaligned AGI will kill them, but are worried about job displacement or the possibility of tyrannical actors using AGI to consolidate power. They're worried about AI impersonation and the proliferation of misinformation or just plain shoddy computer generated content.
Much like the difference between more local environmental movements and the movement to stop climate change, focusing on far-off, global-scale issues causes people to care less. It's easy to deny climate change when it's something that's going to happen in decades. People want answers to problems they face now. I also think there's an element of people's innate anti-scam defenses going off; the more serious, catastrophic, and consequential a prediction is, the more evidence they will want to prove that it is real. The priors one should have of apocalyptic events are quite low; it doesn't actually make sense that "They said coffee would end the world, so AGI isn't a threat" but it does in a way contribute Bayesian evidence towards the inefficacy of apocalypse predictions.
On the topic of evidence, I think it is also problematic that the AI safety community has been extremely short on messaging for the past 3 or so years. People are simply not convinced that an AGI would spell doom for them. The consensus appears to be that LLMs do not represent a significant threat no matter how advanced they become. It is "not real AI", it's "just a glorified autocomplete". Traditional AI safety arguments hold little water because they describe a type of AI that does not actually exist. LLMs and AI systems derived from them do not possess utility functions, do understand human commands and obey them, and exhibit a comprehensive understanding of social norms, which they follow. LLMs are trained on human data, so they behave like humans. I have yet to see any convincing argument other than a simple rejection that explains why RLHF or related practices like constitutional AI do not actually constitute a successful form of AI alignment. All of the "evidence" for misalignment is shaky at best or an outright fabrication at worst. This lack of an argument is really the key problem behind AI safety. It strikes outsiders as delusional.
comment by lemonhope (lcmgcd) · 2024-05-24T07:30:50.102Z · LW(p) · GW(p)
I would add one. I haven't found a compelling thing to aim for long term. I have asked many people to describe a coherent positive future involving AI. I have heard no good answers. I have been unable to produce one myself.
Are we playing a game that has no happy endings? I hope we are not.
comment by Ebenezer Dukakis (valley9) · 2024-05-24T03:55:05.822Z · LW(p) · GW(p)
IMO it's important to keep in mind that the sample size driving these conclusions is generally pretty small. Every statistician and machine learning engineer knows that a dataset with 2 data points is essentially worthless, yet people are surprisingly willing to draw a trend line through 2 data points.
When you're dealing with small sample sizes, in my view it is better to take more of a "case study" approach than an "outside view" approach. 2 data points isn't really enough for statistical inference. However, if the 2 data points all illuminate some underlying dynamic which isn't likely to change, then the argument becomes more compelling. Basically when sample sizes are small, you need to do more inside-view theorizing to make up for it. And then you need to be careful about extrapolating to new situations, to ensure that the inside-view properties you identified actually hold in those new situations.
comment by Seth Herd · 2024-05-27T04:45:26.101Z · LW(p) · GW(p)
At Festivus, we have the ritual of the Airing of Grievances.
This is a joke, which is funny because airing grievances is usually a terrible idea. It should be done carefully and gently, to avoid making enemies. In this case, we really need to not start infighting within the AI safety movement. Infighting appears to be a major cause of movements failing. Polarization seems much easier to create than to undo.
There are plenty of different opinions on what the best strategy is, and a lot of them are more reasonable than they look at a one-paragraph critique. Each of these is worth a post and discussion. It's a very complex issue
This manner of Airing of Grievances feels sort of like going to Alice and saying "what do you think Bob does that's stupid?". then going to Bob with the same question about critiques of Alice, then telling both of them what the other said. Maybe you should do that in some situations, but you'd usually encourage them to talk to each other, and to be careful and nice about it.
comment by Shankar Sivarajan (shankar-sivarajan) · 2024-05-25T01:58:52.632Z · LW(p) · GW(p)
Alternatively, the "AI safety" movement has made no mistakes of consequence, and has already won decisively.
(Yes, this might basically be the old joke about the Jew reading Der Stürmer, coming from me, who hates the movement and all its works, but I think its success, and the overwhelming power and influence it now wields, is severely underestimated by its allies.)
Replies from: Mitchell_Porter, nikolas-kuhn↑ comment by Mitchell_Porter · 2024-05-26T15:00:15.420Z · LW(p) · GW(p)
Please explain. Do you think we're on a path towards a woke AI dictatorship, or what?
↑ comment by Amalthea (nikolas-kuhn) · 2024-05-25T12:30:54.038Z · LW(p) · GW(p)
Have you ever written anything about why you hate the AI safety movement? I'd be quite curious to hear your perspective.