How I'm thinking about GPT-N
post by delton137 · 2022-01-17T17:11:49.447Z · LW · GW · 21 commentsContents
Summary of main points Hypothesis: transformers work by interpolation only Why I'm not so worried about grokking and emergent behavior during scaling The big debate - to what extent does GPT-3 have common sense? Issues that seem solvable Aside: prediction vs explanation Final thoughts - transformers are overhyped, at least right now Acknowledgements References None 21 comments
There has been a lot of hand-wringing about accelerating AI progress within the AI safety community since OpenAI's publication of their GPT-3 and Scaling Laws papers. OpenAI's clear explication of scaling provides a justification for researchers to invest more in compute and provides a clear path forward for improving AI capabilities. Many in the AI safety community have rightly worried that this will lead to an arms race dynamic and faster timelines to AGI.
At the same time there's also an argument that the resources being directed towards scaling transformers may have counter-factually been put towards other approaches (like reverse engineering the neocortex) that are more likely to lead to existentially dangerous AI. My own personal credence on transformers slowing the time to AGI is low, maybe 20%, but I think it's important to weigh in.
There is also a growing concern within the AI safety community that simply scaling up GPT-3 by adding more data, weights, and training compute could lead to something existentially dangerous once a few other relatively simple components are added.
I have not seen the idea that scaling transformers will lead to existentially dangerous AI (after combining with a few other simple bits) defended in detail anywhere but it seems very much an idea "in the water" based on the few discussions with AI safety researchers I have been privy too. It has been alluded to various places online also:
- Connor Leahy has said that a sufficiently large transformer model could serve as a powerful world model for an otherwise dumb and simple reinforcement learning agent, allowing it to rapidly learn how to do dangerous things in the world. For the record, I think this general argument is a super important point and something we should worry about, even though in this post I'll mainly be presenting reasons for skepticism.
- Gwern is perhaps the most well-known promoter of scaling being something we should worry about. He says "The scaling hypothesis regards the blessings of scale as the secret of AGI: intelligence is ‘just’ simple neural units & learning algorithms applied to diverse experiences at a (currently) unreachable scale."
- Observe the title of Alignment Newsletter #156 [LW · GW]: "The scaling hypothesis: a plan for building AGI". Note: I'm not sure what Rohin Shah's views are exactly, but from what I read they are pretty nuanced.
- Zac Hatfield-Dodds (who later went on to do AI Safety work at Anthropic) commented on LessWrong [LW(p) · GW(p)] 16 July 2021: "Now it looks like prosaic alignment might be the only kind we get, and the deadline might be very early indeed."
- lennart [LW · GW] : "The strong scaling hypothesis is stating that we only need to scale a specific architecture, to achieve transformative or superhuman capabilities — this architecture might already be available."
- MIRI is famously secretive about what they are doing, but they've been pretty public that they've made a shift towards transformer alignment as a result of OpenAI's work. Eliezer Yudkowsky told me he thinks GPT-N plus "a few other things" could lead to existentially dangerous AI (personal communication that I believe is consistent with his public views as they were expressed recently in the published MIRI conversations).
I do think a GPT-N model or a close cousin could be a component of an existentially dangerous AI. A vision transformer could serve a role analogous to the visual cortex in humans. A GPT type model trained on language might even make a good "System 1" for language, although I'm little less certain about that. So it definitely makes sense to be focusing a substantial amount of resources to transformer alignment when thinking about how to reduce AI x-risk.
While I've seen a lot of posts making the bullish case on LessWrong and the EA Forum, I've seen fewer posts making a bearish case. The only I have seen are a series [LW · GW] of inciteful [LW · GW] and interesting [LW · GW] posts from nostalgebraist. [Interestingly, the bearish points I argue are very much distinct from the lines of attack nostalgebraist takes, so it's worth looking at his posts too, especially his last one. [LW · GW]] Another reason for writing this stems from my suspicion that too many AI safety resources are being put towards transformer alignment. Transformers are taking over AI right now, but I suspect they will be overtaken by a completely different architecture and approach soon (some strong candidates to take over in the near-term are the perciever architecture, Hopfield networks, energy based models, genetically/evolutionarily designed architectures, gated multi-layer perceptrons, and probably others I'm missing). The fact is we don't really have any understanding of what makes a good architecture and there is no good reason to think transformers are the final story. Some of the transformer alignment work (like dataset sanitization) may transfer to whatever architecture replaces transformers, but I don't we can predict with any certainty how much of it will transfer to future architectures and methods.
Given the number of AI safety orgs and academics already working transformer alignment, I question if it is a good investment for EAs on the current margin. A full discussion of neglectedness is beyond the scope of this post, however you can look at this EA Forum post [EA · GW] that touches on the academic contribution to transformer alignment, and I'll note there is also much work on aligning transformers going on in industry too.
Summary of main points
- Transformers, like other deep learning models that came before, appear to work primarily via interpolation and have trouble finding theories that extrapolate. Having the capability to find theories that can extrapolate is at the very least a key to scientific progress and probably a prerequisite for existentially dangerous AI.
- A recent paper shows CNNs have trouble grokking Conway's Game of Life. Discussing the Rashomon effect, I make the case that grokking will be a pretty circumscribed / rare phenomena.
- The degree to which GPT-3 can do common sense reasoning seems extremely murky to me. I generally agree with people who have said GPT-3 mostly does System 1 type stuff, and not System 2 stuff.
- There are numerous other problems with transformers which appear solvable in the near term, some of which are already well on their way to being solved.
- The economic utility of very large transformer models is overhyped at the moment.
Hypothesis: transformers work by interpolation only
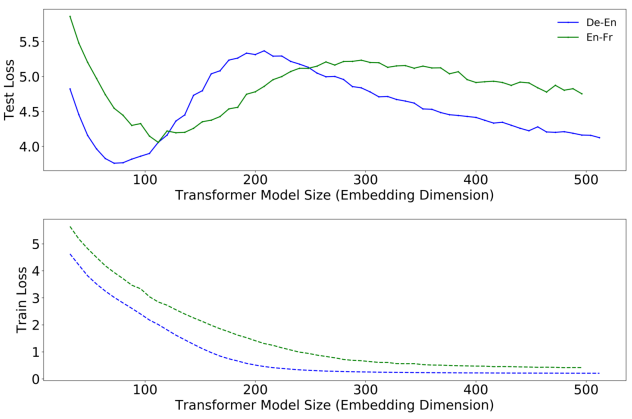 (Figure caption: Some double descent curves, from [1].)
(Figure caption: Some double descent curves, from [1].)
Double descent is a phenomena which is critical to understanding how deep learning models work. Figure 1 shows double descent curves for two language models from OpenAI's "Deep Double Descent" paper,[1:1] which Evan Hubinger has summarized [LW · GW] on LessWrong. Notice how the test loss first decreases, bottoms out, and then increases. The error bottoms out and starts to increase because of overfitting. This is the bias-variance trade-off which can be derived from the classical theory of statistical modeling. Notice however that as model size continues to increase, the test loss curve bends back down. This is the double descent phenomena. At large enough model size the test loss eventually becomes lower than it was in the regime were the bias-variance trade-off applied, although you can't see it in this particular figure.
Notice that the double descent test loss curve peaks when the training loss bottoms out near zero. This is the interpolation threshold. The model has memorized the training data precisely. (or nearly so. In CNNs it is typical for the training loss to reach precisely zero).
An important point about interpolation is that it works locally. Algorithms that work via interpolation are incapable of discovering global trends. My favorite illustration of this is the following:[2]
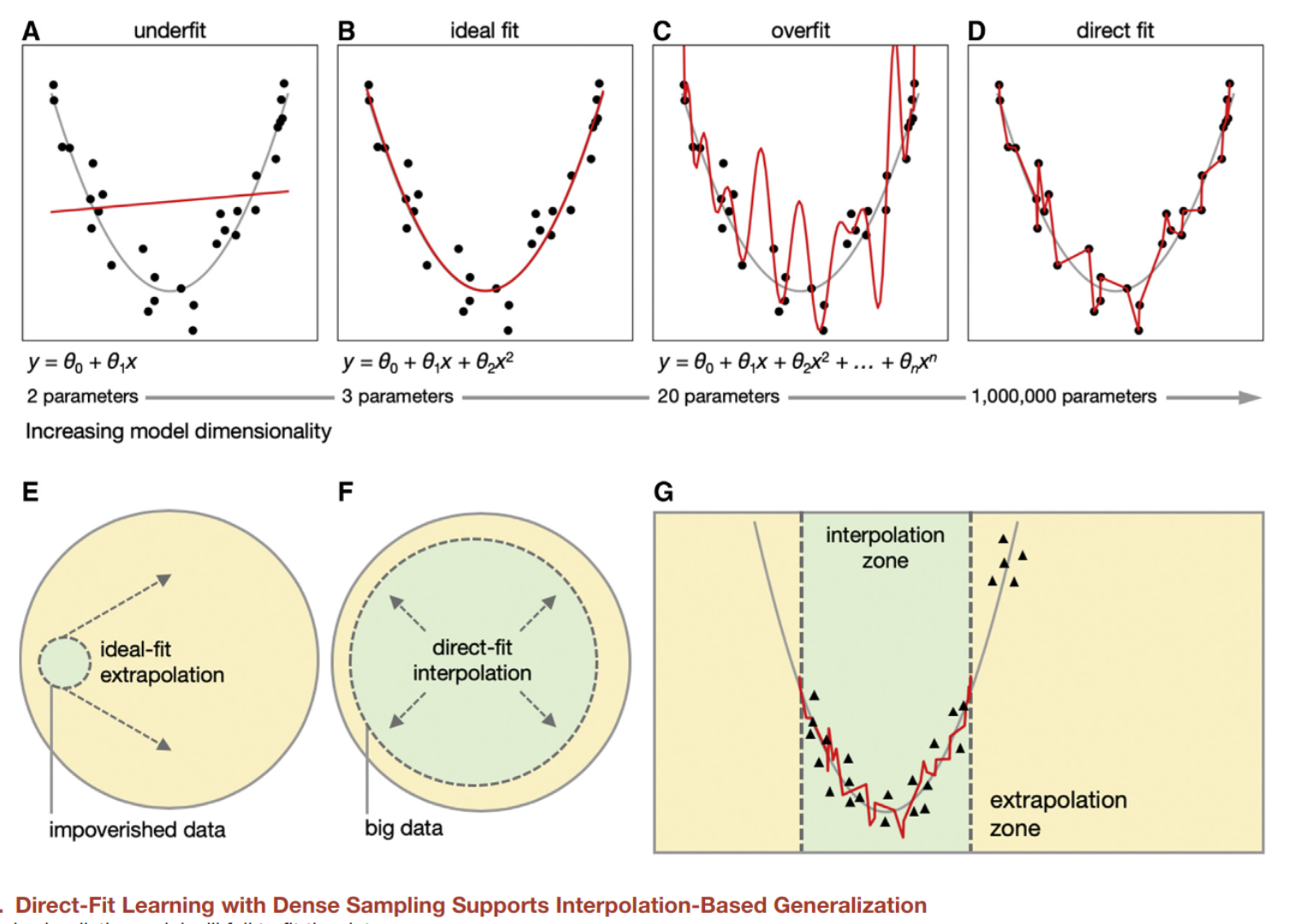 (Figure caption: figure from Hasson et al.[2:1])
(Figure caption: figure from Hasson et al.[2:1])
No matter how many parameters or data you put in a neural network, it will never figure out that the underlying trend is y = x^2.
What deep learning models appear to in effect is dimensionality reduction to a lower-dimension manifold followed by piece-wise linear interpolation, which is very similar to k-nearest neighbors. If I understand things correctly, Trenton Bricken has shown something similar for transformers, by drawing out a mathematical correspondence between the attention mechanism in transformers and sparse distributed memory, a high level model of how memory works in the brain (the main difference is that transformer representations aren't actually sparse).[3]
At least three forms of double descent have been discovered. The first occurs as you increase the number of parameters. The second occurs during training -- oddly enough, during training a model can have better test error, than worse, and then better! (It seems historically this was hidden by the widespread practice of early stopping.) The last occurs as more training data is added.
Why do I bring up these other forms of double descent? Mainly to point out these this is evidence these systems are very different than biological brains. Imagine working through some flashcards and then getting worse after a certain point. Or imagine a situation where adding more flashcards to the deck actually makes you worse at a language. These odd properties of transformers (which are shared with most if not all deep learning models) are clearly sub-optimal which leads me to assign higher credence to the view that eventually transformers (and a lot of other deep learning stuff) will be replaced by something significantly different.
CNNs trained past the interpolation threshold memorize their training data (input-label relationships, assuming one-to-one correspondence). Memorization is a big part of how GPT-3 works, too. When unprompted, about 1% of the text produced by large language models is copied verbatim from the training corpus.[4] (As a reminders on some of the relevant numbers: GPT-3 has 175 Gb parameters and the size of the training data was ~45 Tb). Using adversarial techniques it may be able to extract specific data about people etc that is in the training data.[5] It appears as models get larger they memorize more - the extraction of people's names and personal information from much smaller models like BERT was found to be difficult. OpenAI's Codex seems to utilize a lot of memorization, often returning small code samples verbatim that were in the training data from Github. Some memorization is of course necessary and important (for instance models need to memorize how to spell words). However when a lot of the model's capability come from memorization, I tend to be less impressed. On the other hand, perception and System 1 in the brain also seems to rely on a lot of brute force memorization and interpolation.[2:2]
Sometimes GPT-3's interpolation abilities can be quite impressive, for instance Alyssa Vance gave the prompt "Early this morning, in a shocking surprise attack, the international credit card and finance company Visa launched a full-scale invasion of the island nation of Taiwan" and GPT-3's output is quite impressive. GPT-2's "extrapolation" of Ginsberg's Moloch is also quite impressive. However, this is only extrapolation in a loose sense, a different way of looking at it may be "interpolation within the space of Moloch and Moloch-like sentences". In general though, I appears that transformers struggle in models /theories/explanations that extrapolate, that reach outside the context they were discovered in to give a truly new prediction. The best examples of such theories are in science. The generation of such theories seems to often require a creative leap and can't be done just by brute force fitting or induction (more on this below). A different way of saying this is that by optimizing for an objective (like next-work prediction) you don't explore the landscape of possible models/theories enough (cf Kenneth Stanley's well-known arguments about this). [My favorite example of a creative leap, by the way, is when the Greek astronomer Aristarchus hypothesized that the stars are glowing orbs like the sun, just very far away].
To give a simple example of the distinction I'm trying to flesh out here - Galileo observed that the period of a pendulum doesn't depend on the amount of mass attached to it but does depend on the length (longer length = longer period) which are two high level rules / principles that extrapolate. Could a GPT-N model, reading about the properties of pendulums, come up with similar rules and apply them consistently? I have a hard time believing that it would, and in the event that it could it would probably require a ton of training data. On the other hand, humans had trouble discovering this simple law too (pendulums I think were around long before Galileo). A better thing to look at here is how GPT-3 particularly struggles with multiple-choice conceptual physics questions at the ~High School / Early College level, achieving only 35% accuracy (random guessing = 25%). For college physics level questions it does just barely better than random chance.[6] Learning how to think abstractly and apply a small number of powerful rules and principles to an infinite number of diverse situations is the key to doing physics. My guess is the equations and principles of physics were in GPT-3's training data, along with some physics problems, they just were a tiny part so it didn't prioritize them much.
To try to summarize these various points, I think there's a fairly strong argument that GPT-3, like other deep learning models, works mainly via some form of interpolation between stuff in its training data, and this constitutes a significant limitation which makes me less concerned about a scaled up GPT-like model being existentially dangerous.
There is an important exception to all this, however, where GPT-N does discover rules that extrapolate, called "grokking":
Why I'm not so worried about grokking and emergent behavior during scaling
For most tasks in the GPT-3 paper, the performance scales smoothly with model size. For a few, however, there are sudden jumps in performance. The tasks exhibiting significant jumps were addition, subtraction, and symbol substitution. Labeling these jumps "phase changes" is a terrible abuse in terminology - on closer inspection they are not at all discontinuous jumps and the term misleadingly suggests the emergence of a new internal order (phase changes should occur uniformly throughout a medium/space - the interpolation threshold in double descent may be a sort of phase change, but not grokking).
Note added shortly after publication: I forgot to mention unpublished results on BIG-Bench which showed a rapid jump for IPA translation - technically not Grokking but an unexpected jump non-the-less. (see LessWrong discussion on this here [LW(p) · GW(p)]). Also, there are more examples of unexpected jumps in performance here from Jacob Steinhardt.
More recently it has been shown that with enough training data and parameters simple transformer models can learn how to reproduce certain mathematical transformations exactly.[7] During training, the models exhibit jumps upwards to 100% accuracy, with varying degrees of sharpness in the jump. The authors call this "grokking". The set of transformations they studied involved addition, subtraction, multiplication, and the modulo operator.
As a result of these findings, AI safety researchers are worried about unexpected emergent behavior appearing in large models as they are scaled up.[8]
Here's the thing about grokking though -- for the network to Grok (get perfect accuracy) the architecture has to be able to literally do the algorithm and SGD has to find it. In the case of transformers, that means the algorithm must be easily decomposable into a series of matrix multiplies (it appears maybe repeated multiplication is Turing complete, so that's why I stress easily. Notice that all the examples of grokking with transformers involve simple operations that can be decomposed into things like swapping values or arithmetic, which can be easily expressed as a series of matrix multiplications. Division is notably absent from both the grokking and GPT-3 paper, I wonder why...
But grokking doesn't always work, even when we know that the network can do the thing easily in principle. This was shown in a paper by Jacob M. Springer and Garrett T. Kenyon recently.[9] (I did a summer internship with Dr. Kenyon in 2010 and can vouch for his credibility). The authors set up a simple CNN architecture that in principle can learn the rules for Conway's Game of Life, so given an input board state the CNN can reproduce the Game of Life exactly, given the right parameters. The network was trained on over one million randomly generated examples, but despite all this data the network could not learn the exact solution. In fact, the minimal architecture couldn't even learn how to predict just two steps out! They then tested what happens when they duplicate the the filter maps in several layers, creating m times as many weights than are necessary. They found that the degree of overcompleteness m scaled very quickly with the number of steps the network could predict.
The authors argue that their findings are consistent with the Lottery Ticket Hypothesis (LTH) that deep neural nets must get lucky by having a subset of initial parameters that are close enough to the desired solution. In other words, SGD alone can't always find the right solution - some luck is involved in the initial parameter settings - which explains why bigger models with a larger pool of parameters to work with do better. (I feel compelled to mention that attempts to validate the LTH have produced a mixed bag of murky results and it remains only a hypothesis, not a well-established theory or principle.)
There is another important fact about data modeling that implies grokking or even semi-grokking will be exceptionally rare in deep learning models - the Rashomon effect, first described by Leo Breiman.[10] The effect is simply the observation that for any dataset, there is an infinite number of functions which fit it exactly which are mechanistically very different from each other. In his original paper, Brieman demonstrates this effect empirically by training a bunch of decision trees which all get equivalent accuracy on a test set but work very differently internally. Any model that works by fitting a ton of parameters to large data is subject to the Rashomon effect. The Rashomon effect implies that in the general case SGD is very unlikely to converge to the true model - ie very unlikely to Grok. In fact, I doubt SGD would even find a good approximation to the true model. (By "true model" I mean whatever algorithm or set of equations is generating the underlying data).
Solomonoff induction tries avoid "Rashomon hell" by biasing the Bayesian updating towards models with shorter algorithmic descriptions, with assumption that shorter descriptions are always closer to the truth. [Side note: I'm skeptical of Occam's razor and how successfully this strategy works in any real world setup is, to my knowledge, rather poorly understood, which is just one of many reasons Solomonoff induction is a bad model for intelligence in my view (Note: sorry to be so vague. A review of problems with Solomonoff Induction will be the subject of a future post/article at some point)].
Even if biasing towards simpler models is a good idea, we don't have a good way of doing this in deep learning yet, apart from restricting the number of parameters, which usually hurts test set performance to some degree [clarification: regularization methods bias towards simpler models that are easier to approximate, but they don't really reduce the amount of compute needed to run a model in terms of FLOPs]. It used to be thought that SGD sought out "flat minima" in the loss (minima with low curvature) which result in simpler models in terms of how compressible they are, but further studies have shown this isn't really true.[11]] . So we have reasons to believe transformers will be subject to the Rashomon effect and grokking will be very hard. (Sorry this section was rather sloppy - there are a lot of papers showing SGD leads to flatter minima which are associated with better generalization ability. I'm still think there's a potential argument here though since empirically it seems deep learning is very subject to the Rashomon effect - it's not uncommon for the same model trained with different random initializations to achieve similar training/test loss but work differently internally and have different failure modes etc.)
The big debate - to what extent does GPT-3 have common sense?
I don't have a strong interest in wading through the reams of GPT-3 outputs people have posted online, much of which I suspect has been hand-picked to fit whatever narrative the author was trying to push. It's not my cup of tea reading and analyzing GPT-3 prose/outputs and Gwern has already done it far more thoroughly than I ever could.
I think the failures are much more illuminating than the successes, because many of the failures are ones a human would never make (for instance answering "four" to "how many eyes does a horse have"). Just as humans are easy to mislead with the Cognitive Reflection Test, especially when sleep deprived or tired, GPT-3 is very easy to mislead too, sometimes embarrassingly so. My favorite examples of this come from Alyssa Vance, yet more can be found in Marcus and Davis' MIT Tech Review article.
It seems GPT-3, like it's predecessor GPT-2 has some common sense, but mainly only the system 1 gut reaction type - it still struggles with common sense reasoning. Many have made this observation already, including both Sara Constantine and Scott Alexander in the context of GPT-2 (as I side note, I highly recommend people read Sarah's brilliant disquisition on System 1 vs System 2 entitled "Distinctions in Types of Thought".).
Issues that seem solvable
There are some issues with transformers that appear very solvable to me and are in the process of being solved:
The first is lack of truthfulness. GPT-3 is great at question answering, the issue is it's often plausible but wrong (see Alyssa Vance's post "When GPT-3 Is Confident, Plausible, And Wrong"). Part of this is due to garbage-in garbage-out problem with transformers right now where they mimic human falsehoods that are in their training data.[12] Another issue is just not having enough memory to memorize all the relevant facts people may want to ask about. DeepMind seems to have solved the later issue with their Retrieval-Enhanced Transformer (RETRO) which utilizes a 2 trillion token database.[13]
A related issue is lack of coherence/lack of calibration. An optimal Bayesian agent considers all possibilities all the time, but any agent with finite resources can't afford to do that - real world agents have finite memory, so they have to figure out when to forget disproven theories/facts/explanations. In the context of resource-bounded systems, it may be best to stick with a single best explanation rather than trying to hold multiple explanations [as an example, it seems reasonable to disregard old scientific theories once they have been robustly falsified even though from a Bayesian perspective they still have a tiny amount of non-zero probability attached to them]. Indeed, the human brain seems to have in-built bias against holding multiple contradictory theories at once (cognitive dissonance). Transformers, on the other hand, often give conflicting answers to similar questions, or even the same question when prompted multiple times. In other situations it makes sense for resource-bounded agents to keep track of multiple theories and weight them in a Bayesian manner. Just as CNNs are not well-calibrated for mysterious reasons, I suspect transformers are not well calibrated either. However, just as there are methods for fixing calibration in CNNs, I suspect there are methods to fix calibration in transformers too.
Another issue is lack of metacognition, or alerting the user about confidence. This is a big problem right now since humans want a question answering system to give correct answers and know when it doesn't know something or isn't sure. Interestingly, Nick Cammarata figured out that with careful prompting GPT-3 can identify nonsense questions (whether it counts as metacognition isn't very clear). I think this is solvable by tweaking RETRO so it alerts the user when something isn't in it's database (maybe it already does this?). As with models like CNNS, where uncertainty can be added via dropout during inference or by adopting Bayesian training, there are probably other ways to add uncertainty quantification to transformers. MIRI's "visible thoughts [LW · GW]" approach is another way of attacking this problem.
Another issue is very weak compositionality. Like RNNs which came before,[14] transformers are really not good at composition, or chaining together a sequence of discrete tasks in a way it hasn't seen before. Look for instance at how bad OpenAI's Codex model is at chaining together components:[15]
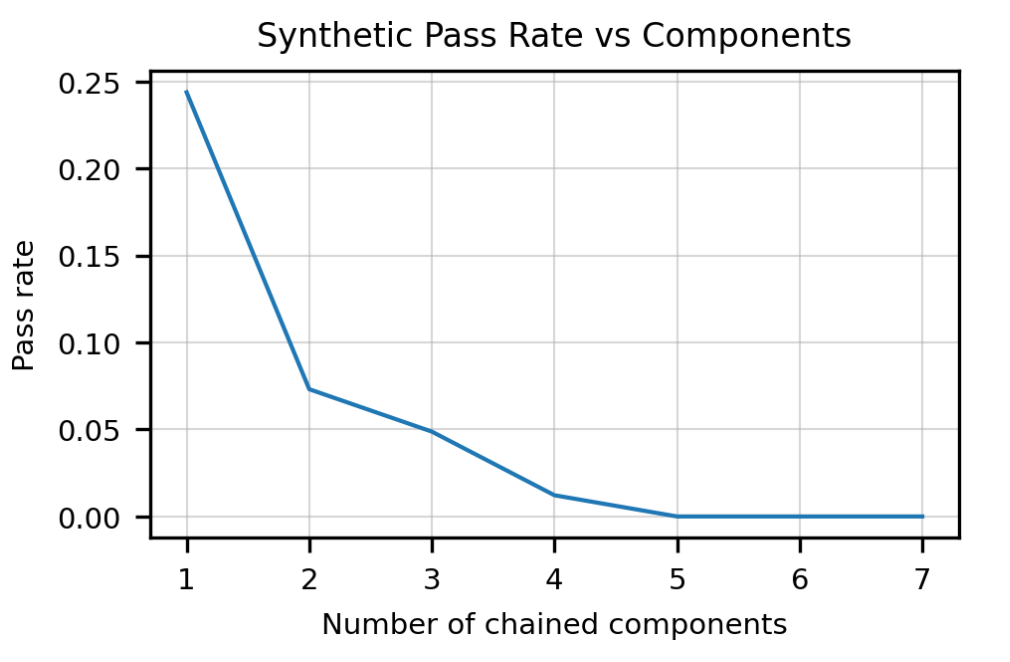
(From the OpenAI Codex paper.[15:1])
This is very different behavior than humans, where the ability to accurately chain together two things implies the ability to accurately chain together a long sequence of things well. At least intuitively this seems solvable at least for many applications of interest by writing ad-hoc hard-coded methods to detect when chaining is needed and then do it.
The final issue is bias/toxicity. This problem is addressable both through dataset sanitization and via de-biasing word embeddings.[16] There have recently been a number of papers discussing and making progress on this.[17][18][19]
Aside: prediction vs explanation
"For even in purely practical applications, the explanatory power of a theory is paramount, and its predictive power only supplementary. If this seems surprising, imagine that an extraterrestrial scientist has visited the Earth and given us an ultra-high-technology “oracle” which can predict the outcome of any possible experiment but provides no explanations. According to the instrumentalists, once we had that oracle we should have no further use for scientific theories, except as a means of entertaining ourselves. But is that true? How would the oracle be used in practice? In some sense it would contain the knowledge necessary to build, say, an interstellar spaceship. But how exactly would that help us to build one? Or to build another oracle of the same kind? Or even a better mousetrap? The oracle only predicts the outcomes of experiments. Therefore, in order to use it at all, we must first know what experiments to ask it about. If we gave it the design of a spaceship, and the details of a proposed test flight, it could tell us how the spaceship would perform on such a flight. But it could not design the spaceship for us in the first place. And if it predicted that the spaceship we had designed would explode on takeoff, it could not tell us how to prevent such an explosion. That would still be for us to work out. And before we could work it out, before we could even begin to improve the design in any way, we should have to understand, among other things, how the spaceship was supposed to work. Only then could we have any chance of discovering what might cause an explosion on takeoff. Prediction – even perfect, universal prediction – is simply no substitute for explanation." - David Deutsch, The Fabric of Reality
Of course, one could also ask a truly God-like oracle to predict how a human would write an instruction manual for building a spaceship, and then just follow that. The point of quoting this passage is to distinguish prediction from understanding. I don't want to wade into the deep philosophical waters about what 'explanation' is, the Chinese Room, and all the rest. Rather, I just want to convince the reader that for the purpose of thinking about what GPT-N models can and can't do, the distinction is real and important. Next word prediction is not everything. When we relentlessly optimize deep learning models only on predictive accuracy, they take shortcuts. They learn non-robust features, making them prone to adversarial examples. They memorize individual cases rather than trying to extract high-level abstract rules. And they then suffer when applied out of distribution.
Final thoughts - transformers are overhyped, at least right now
"We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run" - Roy Amara ("Amara's Law")
The debut of GPT-3 in May 2020 was accompanied by a lot of hype about how it would lead to a boom in startups and various economic activity. As far as I can tell, no company is actually making a profit with GPT-3 yet (I have Googled extensively and asked on Twitter about this multiple times. If you know an example, please comment below). It wasn't until June 2021 that Microsoft themselves released their first commercial product that uses GPT-3, when they integrated a GPT-3-like model into Power Apps. The system allows users to put in a natural language input and get an output which is a string of code in a bespoke language developed at Microsoft called "Power Fx". The resulting code can do things like manipulate Excel spreadsheets. This is cool, but also a bit underwhelming relative to the hype. In December, 2021, a South Korean company called Naver said they were starting to use a larger language model (trained on 6,500 more tokens than GPT-3) to help with product recommendations. This is also neat but underwhelming.
There is a pattern in AI where there is huge buzz around cool demos and lab demonstrations which then hits a brick wall during deployment. I see this all the time in my own field of AI for medical imaging. People drastically underestimate the difficulty of deploying things into the real world (AI systems that can easily be plugged into existing systems online, like for targeting ads, are a somewhat different matter). This is one of skeptical arguments from Rodney Brooks I agree with (for his argument, see section 7 here). The compute costs of training and inferencing GPT-like models also presents significant headwinds to translation to real-world use. Thompson et al. have argued that baring significant algorithmic improvements, hardware and compute costs will soon be fatal to the entire enterprise of scaling.[20][21] However, I am skeptical about the conclusions of their work since it appears to me they didn't factor in Moore's law well enough or the possibility of special-purpose hardware. See also Gwern's comments in the comments section here.
As far as I can tell, in the next year we will see the following applications move from the lab to commercialization and real-world use:
- incrementally better NPCs in videogames
- incrementally better text summarization for things like product reviews or press releases
- incrementally better translation
- better code completion
Acknowledgements
Thank you to Stephen "Cas" Casper for proofreading an earlier draft of this post and providing useful comments.
References
Nakkiran, et al. "Deep Double Descent: Where Bigger Models and More Data Hurt". 2019. ↩︎ ↩︎ ↩︎
Hasson et al. "Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks". Neuron. 105(3). pages 416-434. 2020. ↩︎ ↩︎ ↩︎
Bricken, Trenton and Pehlevan, Cengiz. "Attention Approximates Sparse Distributed Memory". In Proceedings of Advances in Neural Information Processing Systems (NeurIPS) 34. 2021. ↩︎
Lee, et al. "Deduplicating Training Data Makes Language Models Better". arXiv e-prints. 2021. ↩︎
Carlini et al. "Extracting Training Data from Large Language Models". In Proceedings of the 30th USENIX Security Symposium. 2021. ↩︎
Hendrycks et al. "Measuring Massive Multitask Language Understanding". In Proceedings of the International Conference on Learning Representations (ICLR). 2021. ↩︎
Power et al. "Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets". In Proceedings of the 1st Mathematical Reasoning in General Artificial Intelligence Workshop, ICLR. 2021. ↩︎
Steinhardt, Jacob. "On The Risks of Emergent Behavior in Foundation Models". 2021. ↩︎
Springer, J. M., & Kenyon, G. T. It’s Hard for Neural Networks to Learn the Game of Life. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN). 2021. (arXiv version here]) ↩︎
Breiman, Leo. "Statistical Modeling: The Two Cultures". Statistical Science. 16 (3) pg 199 - 231. 2001. ↩︎
Dinh et al. "Sharp Minima Can Generalize For Deep Nets". 2017. ↩︎
Lin et al. "TruthfulQA: Measuring How Models Mimic Human Falsehoods". arXiv e-prints. 2021. ↩︎
Borgeaud et al. "Improving language models by retrieving from trillions of tokens". arXiv e-prints". 2021. ↩︎
Lake et al. "Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks". In Proceedings of the 35th International Conference on Machine Learning (ICML). 2018. ↩︎
Chen et al. "Evaluating Large Language Models Trained on Code". arXiv e-print. 2021. ↩︎ ↩︎
Bolukbasi, et al. "Man is to Computer Programmer as Woman is to
Homemaker? Debiasing Word Embeddings". In Proceedings of the 30th International Conference on Neural Information Processing Systems (NeurIPS). 2016. ↩︎Askell, et al. "A General Language Assistant as a Laboratory for Alignment". arXiv e-prints. 2021. ↩︎
Webl et al. "Challenges in Detoxifying Language Models". In Findings of EMNLP. 2021. ↩︎
Weidinger, et al. "Ethical and social risks of harm from Language Models". arXiv e-prints. 2021. ↩︎
Thompson et al. "Deep Learning's Diminishing Returns". IEEE Spectrum. 2021. ↩︎
Thompson et al. "The Computational Limits of Deep Learning". arXiv e-prints. 2020. ↩︎
21 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-01-17T19:18:22.046Z · LW(p) · GW(p)
Even if biasing towards simpler models is a good idea, we don't have a good way of doing this in deep learning yet, apart from restricting the number of parameters, which usually hurts test set performance to some degree
It's called regularization; it is the exact implementation of solomonoff/ockham style "bias towards simpler models" in DL, and it underlies grokking/double descent. It has strong bayesian theoretical foundations, it's hardly mysterious or "not a good way". A simple L2 penalty imposes a gaussian prior on the weights, more complex mixed L1 or approximate L0 penalties are used to approximate sparse distributions (eg spike and slab), etc.
Replies from: delton137↑ comment by delton137 · 2022-01-17T20:10:10.081Z · LW(p) · GW(p)
To my knowledge the most used regularization method in deep learning, dropout, doesn't make models simpler in the sense of being more compressible.
A simple L1 regularization would make models more compressible in so far as it suppresses weights towards zero so they can just be thrown out completely without affecting model performance much. I'm not sure about L2 regularization making things more compressible - does it lead to flatter minima for instance? (GPT-3 uses L2 regularization, which they call "weight decay").
But yes, you are right, Occam factors are intrinsic to the process of Bayesian model comparison, however that's in the context of fully probabilistic models, not comparing deterministic models (ie Turing programs) which is what is done in Solomonoff induction. In Solomonoff induction they have to tack Occam's razor on top.
I didn't state my issues with Solomonoff induction very well, that is something I hope to summarize in a future post.
Overall I think it's not clear that Solomonoff induction actually works very well once you restrict it to a finite prior. If the true program isn't in the prior, for instance, there is no guarantee of convergence - it may just oscillate around forever (the "grain of truth" problem).
There's other problems too (see a list here, the "Background" part of this post [LW · GW] by Vanessa Kosoy, as well as Hutter's own open problems).
One of Kosoy's points, I think, is something like this - if an AIXI-like agent has two models that are very similar but one has a weird extra "if then" statement tacked on to help it understand something (like at night the world stops existing and the laws of physics no longer apply, when in actuality the lights in the room just go off) then it may take an extremely long time for an AIXI agent to converge on the correct model because the difference in complexity between the two models is very small.
Replies from: gwern, jacob_cannell↑ comment by gwern · 2022-01-17T22:04:37.196Z · LW(p) · GW(p)
To my knowledge the most used regularization method in deep learning, dropout, doesn't make models simpler in the sense of being more compressible.
Yes, it does (as should make sense, because if you can drop out a parameter entirely, you don't need it, and if it succeeds in fostering modularity or generalization, that should make it much easier to prune), and this was one of the justifications for dropout, and that has nice Bayesian interpretations too. (I have a few relevant cites in my sparsity tag.)
Replies from: delton137↑ comment by delton137 · 2022-01-17T23:19:32.085Z · LW(p) · GW(p)
The idea that using dropout makes models simpler is not intuitive to me because according to Hinton dropout essentially does the same thing as ensembling. If what you end up with is something equivalent to an ensemble of smaller networks than it's not clear to me that would be easier to prune.
One of the papers you linked to appears to study dropout in the context of Bayesian modeling and they argue it encourages sparsity. I'm willing to buy that it does in fact reduce complexity/ compressibility but I'm also not sure any of this is 100% clear cut.
Replies from: jacob_cannell, delton137↑ comment by jacob_cannell · 2022-01-18T01:01:48.815Z · LW(p) · GW(p)
It's not that dropout provides some ensembling secret sauce; instead neural nets are inherently ensembles proportional to their level of overcompleteness. Dropout (like other regularizers) helps ensure they are ensembles of low complexity sub-models, rather than ensembles of over-fit higher complexity sub-models (see also: lottery tickets, pruning, grokking, double descent).
↑ comment by delton137 · 2022-01-17T23:27:06.967Z · LW(p) · GW(p)
By the way, if you look at Filan et al.'s paper "Clusterability in Neural Networks" there is a lot of variance in their results but generally speaking they find that L1 regularization leads to slightly more clusterability than L2 or dropout.
↑ comment by jacob_cannell · 2022-01-17T22:00:11.234Z · LW(p) · GW(p)
To my knowledge the most used regularization method in deep learning, dropout, doesn't make models simpler in the sense of being more compressible.
L2 regularization is much more common than dropout, but both are a complexity prior and thus compress. This is true in a very obvious way for L2. Dropout is more complex to analyze, but has now been extensively analyzed and functions as a complexity/entropy penalty as all regularization does.
I'm not sure about L2 regularization making things more compressible - does it lead to flatter minima for instance?
L2 regularization (weight decay) obviously makes things more compressible - it penalizes models with high entropy under a per-param gaussian prior. "Flatter minima" isn't a very useful paradigm for understanding this, vs Bayesian statistics.
Replies from: delton137↑ comment by delton137 · 2022-01-17T23:10:28.072Z · LW(p) · GW(p)
(responding to Jacob specifically here) A lot of things that were thought of as "obvious" were later found out to be false in the context of deep learning - for instance the bias-variance trade-off.
I think what you're saying makes sense at a high/rough level but I'm also worried you are not being rigorous enough. It is true and well known that L2 regularization can be derived from Bayesian neural nets with a Gaussian prior on the weights. However neural nets in deep learning are trained via SGD, not with Bayesian updating -- and it doesn't seem modern CNNs actually approximate their Bayesian cousins that well - otherwise they would be better calibrated I would think. However, I think overall what you're saying makes sense.
If we were going to really look at this rigorously we'd have to define what we mean by compressibility too. One way might be via some type of lossy compression using model pruning or some form of distillation. Have their been studies showing models that use Dropout can be pruned down more or distilled easier?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-17T23:32:50.030Z · LW(p) · GW(p)
However neural nets in deep learning are trained via SGD, not with Bayesian updating
SGD is a form of efficient approximate Bayesian updating. More specifically it's a local linear 1st order approximation. As the step size approaches zero this approximation becomes tight, under some potentially enormous simplifying assumptions of unit variance (which are in practice enforced through initialization and explicit normalization).
But anyway that's not directly relevant, as Bayesian updating doesn't have some monopoly on entropy/complexity tradeoffs.
If you want to be 'rigorous', then you shouldn't have confidently said:
Even if biasing towards simpler models is a good idea, we don't have a good way of doing this in deep learning yet, apart from restricting the number of parameters,
(As you can't rigorously back that statement up). Regularization to bias towards simpler models in DL absolutely works well, regardless of whether you understand it or find the provided explanations satisfactory.
Replies from: delton137↑ comment by delton137 · 2022-01-18T00:08:22.067Z · LW(p) · GW(p)
SGD is a form of efficient approximate Bayesian updating.
Yeah I saw you were arguing that in one of your posts [LW · GW]. I'll take a closer look. I honestly have not heard of this before.
Regarding my statement - I agree looking back at it it is horribly sloppy and sounds absurd, but when I was writing I was just thinking about how all L1 and L2 regularization do is bias towards smaller weights - the models still take up the same amount of space on disk and require the same amount amount of compute to run in terms of FLOPs. But yes you're right they make the models easier to approximate.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-18T00:57:38.651Z · LW(p) · GW(p)
So actually L1/L2 regularization does allow you to compress the model by reducing entropy, as evidenced by the fact that any effective pruning/quantization system necessarily involves some strong regularizer applied during training or after.
The model itself can't possibly know or care whether you later actually compress said weights or not, so it's never the actual compression itself that matters, vs the inherent compressibility (which comes from the regularization).
comment by interstice · 2022-01-18T00:18:07.981Z · LW(p) · GW(p)
I continue to think 'neural nets just interpolate' is a bad criticism. Taken literally, it's obviously not true: nets are not exposed to anywhere near enough data points to interpolate their input space. On the other hand, if you think they are instead 'interpolating' in some implicit, higher-dimensional space which they project the data into, it's not clear that this limits them in any meaningful way. This is especially true if the mapping to the implicit space is itself learned, as seems to be the case in neural networks.
Regarding the 'Rashomon effect', I think it's clear that neural nets have some way of selecting relatively lower-complexity models, since there are also infinitely many possible models with good performance on the training set but terrible performance on the test set, yet the models learned reliably have good test set performance. Exactly how they do this is uncertain -- other commenters have already pointed out regularization is important, but the intrinsic properties of SGD/the parameter-function mapping likely also play a key role. It's an ongoing area of research.
It used to be thought that SGD sought out “flat minima” in the loss (minima with low curvature) which result in simpler models in terms of how compressible they are, but further studies have shown this isn’t really true.[11]]
The paper you cited does not show this. Instead, they construct some (rather unnatural) nets at sharp minima which have good generalization properties. This is completely consistent with flat minima having good generalization properties, and with SGD seeking out flat minima.
Replies from: delton137comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2022-01-17T21:06:32.240Z · LW(p) · GW(p)
Zac Hatfield Dobbs (an engineer at Anthropic) commented on 16 July 2021: "Now it looks like prosaic alignment might be the only kind we get, and the deadline might be very early indeed."
- Could you please note in the text that I wrote this, and later applied to and joined Anthropic? As-is I'm concerned that people might misinterpret the timing and affiliation.
- Nonetheless, this concern did in fact motivate me to join Anthropic instead of finishing my PhD.
- My surname is "Hatfield-Dodds" :-)
↑ comment by delton137 · 2022-01-17T22:51:18.915Z · LW(p) · GW(p)
Hey, OK, fixed. Sorry there is no link to the comment -- I had a link in an earlier draft but then it got lost. It was a comment somewhere on LessWrong and now I can't find it -_-.
That's interesting it motivated you to join Anthropic - you are definitely not alone in that. My understanding is Anthropic was founded by a bunch of people who were all worried about the possible implications of the scaling laws.
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2022-01-18T07:35:05.076Z · LW(p) · GW(p)
No worries, here's the comment [LW(p) · GW(p)].
comment by A Ray (alex-ray) · 2022-01-24T03:00:32.620Z · LW(p) · GW(p)
I like this article. I think it's well-thought out reasoning of possible futures, and I think largely it matches my own views.
I especially appreciate how it goes into possible explanations for why scaling happens, not just taking it happening for granted. I think a bunch of the major points I have in my own mental models for this are hit in this article (double descent, loss landscapes, grokking).
The biggest point of disagreement I have is with grokking. I think I agree this is important, but I think the linked example (video?) isn't correct.
First: Grokking and Metrics
It's not surprising (to me) that we see phase changes in correctness/exact substring match scores, because they're pretty fragile metrics -- get just a part of the string wrong, and your whole answer is incorrect. For long sequences you can see these as a kind of N-Chain.
(N-chain is a simple RL task where an agent must cross a bridge, and if they miss step at any point they fall off the end. If you evaluate by "did it get to the end" then the learning exhibits a phase-change-like effect, but if you evaluate by "how far did it go", then progress is smoother)
I weakly predict that for many 'phase changes in results' are similar effects to this (but not all of them, e.g. double descent).
Second: Axes Matter!
Grokking is a phenomena that happens during training, so it shows up as a phase-change-like effect on training curves (performance vs steps) -- the plots in the video are showing the results of many different models, each with their final score, plotted as scaling laws (performance vs model size).
I think it's important to look for these sorts of nonlinear progressions in research benchmarks, but perf-vs-modelsize is very different from perf-vs-steps
Third: Grokking is about Train/Test differences
An important thing that's going on when we see grokking is that train loss goes to zero, then much later (after training with a very small training loss) -- all of a sudden validation performance improves. (Validation loss goes down)
With benchmark evaluations like BIG-Bench, the entire evaluation is in the validation set, though I think we can consider the training set having similar contents (assuming we train on a wide natural language distribution).
Fourth: Relating this to the article
I think the high level points in the article stand -- it's important to be looking for and be wary of sudden or unexpected improvements in performance. Even if scaling laws are nice predictive functions, they aren't gears-level models, and we should be on the lookout for them to change. Phase change like behavior in evaluation benchmarks are the kind of thing to look for.
I think that's enough for this comment. Elsewhere I should probably writeup my mental models for what's going on with grokking and why it happens.
Replies from: delton137↑ comment by delton137 · 2022-02-01T01:19:28.283Z · LW(p) · GW(p)
Hi, I just wanted to say thanks for the comment / feedback. Yeah, I probably should have separated out the analysis of Grokking from the analysis of emergent behaviour during scaling. They are potentially related - at least for many tasks it seems Grokking becomes more likely as the model gets bigger. I'm guilty of actually conflating the two phenomena in some of my thinking, admittedly.
Your point about "fragile metrics" being more likely to show Grokking great. I had a similar thought, too.
comment by leogao · 2022-01-23T18:15:29.947Z · LW(p) · GW(p)
GPT-3 has 175 Gb parameters and the size of the training data was ~45 Tb
Nitpick: neither of these figures is correct. GPT3 has 175 billion parameters, but it's unclear how much information a parameter actually carries (each parameter can be stored as a 32-bit float, but lots of the lower order bits probably have basically no influence on the output). The training data is not 45TB, but is in fact closer to 1TB (± a few hundred GB).
comment by glazgogabgolab · 2022-01-18T00:31:49.187Z · LW(p) · GW(p)
Regarding "posts making a bearish case" against GPT-N, there's Steve Byrnes', Can you get AGI from a transformer [LW · GW].
I was just in the middle of writing a draft revisiting some of his arguments, but in the meantime one claim that might be of particular interest to you is that: "...[GPT-N type models] cannot take you more than a couple steps of inferential distance away from the span of concepts frequently used by humans in the training data"
Replies from: delton137