Motivating Abstraction-First Decision Theory
post by johnswentworth · 2020-04-29T17:47:31.896Z · LW · GW · 16 commentsContents
Glaring Problems Upside None 16 comments
Let’s start with a prototypical embedded decision theory problem: we run two instances of the same “agent” from the same source code and in the same environment, and the outcome depends on the choices of both agents; both agents have full knowledge of the setup.
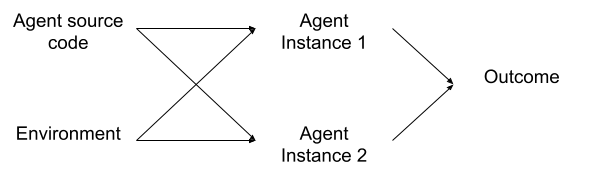
Roughly speaking, Functional decision theory and its predecessors argue that each instance of the agent should act as if it’s choosing for both.
I suspect there’s an entirely different path to a similar conclusion - a path which is motivated not prescriptively, but descriptively.
When we say that some executing code is an “agent”, that’s an abstraction. We’re abstracting away the low-level model structure (conditionals, loops, function calls, arithmetic, data structures, etc) into a high-level model. The high-level model says “this variable is set to a value which maximizes <blah>”, without saying how that value is calculated. It’s an agent abstraction: an abstraction in which the high-level model is some kind of maximizer.
Key question: when is this abstraction valid?
Abstraction = Information at a Distance [? · GW] talks about what it means for an abstraction to be valid. At the lowest level, validity means that the low-level and high-level models return the same answers to some class of queries. But the linked post reduces this to a simpler definition, more directly applicable to the sort of abstractions we use in real life: variables in a high-level model should contain all the information in corresponding low-level variables which is relevant “far away”. We abstract far-away stars to point masses, because the exact distribution of the mass and momentum within the star is (usually) not relevant from far away.
Or, to put it differently: an abstraction is “valid” when components of the low-level model are independent given the values of high-level variables. The roiling of plasmas within far-apart stars is (approximately) independent given the total mass, momentum, and center-of-mass position of each star. As long as this condition holds, we can use the abstract model to correctly answer questions about things far away/far apart.
Back to embedded decision theory.
We want to draw a box around some executing code, and abstract all those low-level operations into a high-level “agent” model - some sort of abstract optimizer. The only information retained by the high-level model is the functional form of the abstracted operations - the overall input-output behavior, represented as “<output> maximizes <objective> at <input>”. All the details of the calculation are thrown out.
Thing is, those low-level details of the calculation structure? They’re exactly the same for both instances of our agent. (Note: the structure is the same, not necessarily the variable values; this argument assumes that the structure itself is a “variable”. If this is confusing, imagine that instead of two instances of the same source code running on a computer, we’re talking about two organisms of the same species - so the genome of one contains information about the genome of the other.) So if we draw a box around just one of the two instances, then those low-level calculation details we threw out will not actually be independent of the low-level calculation details in the other instance. The low-level structure of the two components - the two agent instances - is not independent given the high-level model; the abstraction is not valid.
On the other hand, if we draw a box around both instances (along with the source code), and apply an agent abstraction to both of them together… that can work. The system still needs to actually maximize some objective(s) - we can’t just draw a box around all instances of some random python script and declare it to be maximizing a particular function of the outcome - but we at least won’t run into the problem of correlated low-level structure between abstract components. The abstraction won’t leak in the same way.
Summarizing: we need to draw our box around both instances of the agent because if we only include one instance, then the agent-abstraction leaks. Any abstract model of just one agent-instance as maximizing some objective function of the outcome would be an invalid abstraction.
Glaring Problems
This setup has some huge glaring holes.
First and foremost: why do we care about validity of queries on correlations between the low-level internal structures of the two agent-instances? Isn’t the functional behavior all that’s relevant to the outcome? Why care about anything irrelevant to the outcome?
One response to this is that we don’t want the agent to “know” about its own functional behavior, because then we run into diagonalization problems and logical uncertainty gets dragged in and so forth. We want to treat the functional behavior as unknown-to-the-agent, which means the (known) correlation between low-level behaviors contains important information about correlation between high-level behaviors.
That’s hand-wavy, and I’m not really satisfied with what the hands are waving at. Ideally, I’d like an approach which doesn’t explicitly drag in logical uncertainty until much later, even if that is a correct way to think about the problem. I suspect there’s a way to do this by reformulating the interventions as explicitly throwing away information [LW · GW] about the agent’s functional behavior, and replacing it with other information. But I haven’t fleshed that out yet.
Ultimately, at this point the approach looks promising largely on the basis of pattern-matching, and I don’t yet see why this particular abstraction-validity matters. It’s honestly kind of embarrassing.
Anyway, second problem: What if two instances wound up performing the same function due to convergent evolution, without any correlation between their low-level structures? Abram has written about this before [LW(p) · GW(p)]: roughly speaking, he’s argued that embedded decision theory should be concerned about cases where two agents’ behavior is correlated for a reason, not necessarily cases where we just happen to have two agents with exactly the same code. It was a pretty good argument, and I’ll defer to him on that one.
Upside
We’ve just discussed what I see as the main barriers to making this approach feasible, and they’re not minor. And even with those barriers handled, there’s still a lot of work to properly formalize all this. So what’s the upside? Why pursue an abstraction-first decision theory?
The main potential is that we can replace fuzzy, conceptual questions about what an agent “should” do with concrete questions about when and whether a particular abstraction is valid. Instead of asking “Is this optimal?” we ask “If we abstract this subsystem into a high-level agent maximizing this objective, is that abstraction valid?”. Some examples:
- “Is my decision process actually optimal right now?” becomes “Is this agent abstraction actually valid right now?”
- “In what situations does this perform optimally?” becomes “In what situations is this agent abstraction valid?”
- “How can we make this system perform optimally in more situations?” becomes “How can we make this agent abstraction valid in more situations?”
In all cases, we remove “optimality” from the question. More precisely, an abstraction-first approach would fix a notion of optimality upfront (in defining the agent abstraction), then look at whether the agent abstraction implied by that notion of optimality is actually valid.
Under other approaches to embedded decision theory, a core difficulty is figuring out what notion of “optimality” to use in the first place. For instance, there’s the argument [LW · GW] that one should cooperate in a prisoner’s dilemma when playing against a perfect copy of oneself. That action is “optimal” under an entirely different set of “possible choices” than the usual Nash equilibrium model.
So that’s one big potential upside.
The other potential upside of an abstraction-first approach is that it would hopefully integrate nicely with abstraction-first notions of map-territory correspondence. I’ll probably write another post on that topic at some point, but here’s the short version: straightforward notions of map-territory correspondence in terms of information compression or predictive power don’t really play well with abstraction. Abstraction is inherently about throwing away information we don’t care about, while map-territory correspondence is inherently about keeping and using all available information. A New York City subway map is intentionally a lossy representation of the territory, it’s obviously throwing out predictively-relevant information, yet it’s still “correct” in some important sense.
“Components of the low level model are independent given the corresponding high-level variables” is the most useful formulation I’ve yet found of abstraction-friendly correspondence. An abstraction-first decision theory would fit naturally with that notion of correspondence, or something like it. In particular, this formulation makes it immediately obvious why an agent would sometimes want to randomize its actions: randomization may be necessary to make the low-level details of one agent-instance independent of another, so that the desired abstraction is valid.
16 comments
Comments sorted by top scores.
comment by jessicata (jessica.liu.taylor) · 2020-04-29T20:36:42.574Z · LW(p) · GW(p)
I've also been thinking about the application of agency abstractions to decision theory, from a somewhat different angle.
It seems like what you're doing is considering relations between high-level third-person abstractions and low-level third-person abstractions. In contrast, I'm primarily considering relations between high-level first-person abstractions and low-level first-person abstractions.
The VNM abstraction itself assumes that "you" are deciding between different options, each of which has different (stochastic) consequences; thus, it is inherently first-personal. (Applying it to some other agent requires conjecturing things about that agent's first-person perspective: the consequences it expects from different actions)
In general, conditions of rationality are first-personal, in the sense that they tell a given perspective what they must believe in order to be consistent.
The determinism vs. free will paradox comes about when trying to determine when a VNM-like choice abstraction is valid of a third-personal physical world.
My present view of physics is that it is also first-personal, in the sense that:
- If physical entities are considered perceptible, then there is an assumed relation between them and first-personal observations.
- If physical entities are causal in a Pearlian sense, then there is an assumed relation between them and metaphysically-real interventions, which are produced through first-personal actions.
Decision theory problems, considered linguistically, are also first-personal. In the five and ten problem, things are said about "you" being in a given room, choosing between two items on "the" table, presumably the one in front of "you". If the ability to choose different dollar bills is, linguistically, considered a part of the decision problem, then the decision problem already contains in it a first-personal VNM-like choice abstraction.
The naturalization problem is to show how such high-level, first-personal decision theory problems could be compatible with physics. Such naturalization is hard, perhaps impossible, if physics is assumed to be third-personal, but may be possible if physics is assumed to be first-personal.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-04-30T15:28:43.677Z · LW(p) · GW(p)
This comment made a bunch of your other writing click for me. I think I see what you're aiming for now; it's a beautiful vision.
In general, conditions of rationality are first-personal, in the sense that they tell a given perspective what they must believe in order to be consistent.
In retrospect, this is largely what I've been trying to get rid of, in particular by looking for a third-person interpretation of probability [LW · GW]. Obviously frequentism satisfies that criterion, but the strict form is too narrow for most applications and the less-strict form (i.e. "imagine we repeated this one-shot experiment many times...") isn't actually third-person.
I've also started thinking about a third-person grounding of utility maximization and the like via selection processes; that's likely to be a whole months-long project in itself in the not-too-distant future.
comment by Charlie Steiner · 2020-04-30T13:03:21.910Z · LW(p) · GW(p)
I think you can't avoid dragging in logical uncertainty - though maybe in a bit of a backwards way to what you meant.
A quote from an ancient LW post:
It may be possible to relate this back to logical uncertainty - where by "this" I mean the general thesis of predicting the future by building models that are allowed to be imperfect, not the specific example in part III. Soares and Fallenstein use the example of a complex Rube Goldberg machine that deposits a ball into one of several chutes. Given the design of the machine and the laws of physics, suppose that one can in principle predict the output of this machine, but that the problem is much too hard for our computer to do. So rather than having a deterministic method that outputs the right answer, a "logical uncertainty method" in this problem is one that, with a reasonable amount of resources spent, takes in the description of the machine and the laws of physics, and gives a probability distribution over the machine's outputs.
Meanwhile, suppose that we take [a predictor that uses abstractions], then ask it to predict the machine. We'd like it to make predictions via some appropriately simplified folk model of physics. If this model gives a probability distribution over outcomes - like in the simple case of "if you flip this coin in this exact way, it has a 50% shot at landing heads" - doesn't that make it a logical uncertainty method?Replies from: johnswentworth
↑ comment by johnswentworth · 2020-04-30T15:56:14.340Z · LW(p) · GW(p)
Having thought about lots of real-world use-cases for abstraction over the past few months, I don't think it's mainly used for logical-uncertainty-style things. It's used mainly for statistical-mechanics-style things: situations where the available data is only a high-level summary of a system with many low-level degrees of freedom. A few examples:
- The word "tree" is a very high-level description; if I know "there's a tree over there", then that's high-level data on a system with tons of remaining degrees of freedom even at the macroscopic level (e.g. type of tree, size, orientation of branches, etc).
- A street map of New York City gives high-level data on a system with many degrees of freedom not captured by the map (e.g. lane markings, potholes, street widths, number of lanes, signs, sidewalks, etc).
- When I run a given python script, what actually happens at the transistor level on my particular machine? There may be people out there for whom this is a logical uncertainty question, but I am not one of them; I do not know the details of i86 architecture. All I know is a high-level summary of its behavior.
↑ comment by Charlie Steiner · 2020-04-30T22:59:18.724Z · LW(p) · GW(p)
Good points. But I think that you can get a little logical uncertainty even with just a little bit of the necessary property.
That property being throwing away more information than logically necessary. Like modeling humans using an agent model you know is contradicted by some low-level information.
(From a Shannon perspective calling this throwing away information is weird, since the agent model might produce a sharper probability distribution than the optimal model. But it makes sense to me from a Solomonoff perspective, where you imagine the true sequence as "model + diff," where diff is something like an imaginary program that fills in for the model and corrects its mistakes. Models that throw away more information will have a longer diff.)
I guess ultimately, what I mean is that there are some benefits of logical uncertainty like for counterfactual reasoning and planning, where using an abstract model automatically gets those benefits. If you never knew the contradictory low-level information in the first place, like your examples, then we just call this "statistical-mechanics-style things." If you knew the low-level information but threw it away, you could call it logical uncertainty. But it's still the same model with the same benefits.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-04-30T23:29:59.472Z · LW(p) · GW(p)
The way I think about it, it's not that we're using an agent model which is contradicted by some low-level information, it's that we're using an agent model which is only valid for some queries. Every abstraction comes with a set of queries over which the high-level model's predictions match the low-level model's predictions. Independence of the low-level variables corresponding to high-level components is the main way we track which queries are valid: valid queries are those which don't ask about variables "close together".
So at least the way I'm thinking about it, there's never any contradictory information to throw away in the first place.
comment by romeostevensit · 2020-05-01T18:55:02.889Z · LW(p) · GW(p)
Really like this post, great inroad into something I've been thinking about which is how to formalize self locating uncertainty in order to use it to build other things.
Also, relating back to low level biological systems: https://arxiv.org/abs/1506.06138
may be useful for tracing some key words and authors that have had some related ideas.
comment by Chris_Leong · 2020-04-30T11:15:50.817Z · LW(p) · GW(p)
"First and foremost: why do we care about validity of queries on correlations between the low-level internal structures of the two agent-instances? Isn’t the functional behavior all that’s relevant to the outcome? Why care about anything irrelevant to the outcome?" - I don't follow what you are saying here
Replies from: johnswentworth↑ comment by johnswentworth · 2020-04-30T15:40:35.615Z · LW(p) · GW(p)
The idea in the first part of the post is that, if we try to abstract just one of the two agent-instances, then the abstraction fails because low-level details of the calculations in the two instances are correlated; the point of abstraction is (roughly) that low-level details should be uncorrelated between different abstract components.
But then we ask why that's a problem; in what situations does the one-instance agent abstraction actually return incorrect predictions? What queries does it not answer correctly? Answer: queries which involve correlations between the low-level calculations within the two agent-instances.
But do we actually care about those particular queries? Like, think about it from the agent's point of view. It only cares about maximizing the outcome, and the outcome doesn't depend on the low-level details of the two agents' calculations; the outcome only depends on the functional form of the agents' computations (i.e. their input-output behavior).
Does that make sense?
Replies from: Chris_Leong↑ comment by Chris_Leong · 2020-04-30T22:54:34.134Z · LW(p) · GW(p)
I guess what is confusing me is that you seem to have provided a reason why we shouldn't just care about high-level functional behaviour (because this might miss correlations between the low-level components), then in the next sentence you're acting as though this is irrelevant?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-04-30T23:19:32.219Z · LW(p) · GW(p)
Yeah, I worried that would be confusing when writing the OP. Glad you left a comment, I'm sure other people are confused by it too.
The reason why we shouldn't just care about high-level functional behavior is that the abstraction leaks. Problem is, it's not clear that the abstraction leaks in a way which is relevant to the outcome. And if the leak isn't relevant to the outcome, then it's not clear why we need to care about it - or (more importantly) why the agents themselves would care about it.
Please keep asking for clarification if that doesn't help explain it; I want to make this make sense for everyone else too.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2020-05-01T00:10:33.453Z · LW(p) · GW(p)
Ah, I think I now get where you are coming from
comment by TAG · 2020-05-05T14:55:04.359Z · LW(p) · GW(p)
straightforward notions of map-territory correspondence in terms of information compression or predictive power don’t really play well with abstraction. Abstraction is inherently about throwing away information we don’t care about, while map-territory correspondence is inherently about keeping and using all available information. A New York City subway map is intentionally a lossy representation of the territory, it’s obviously throwing out predictively-relevant information, yet it’s still “correct” in some important sense.
Lossless information representation may well be a bad way of cashing out "correspondence". Unfortunately, that doesn't leave us with a good way.
comment by Kaj_Sotala · 2020-05-06T10:01:35.292Z · LW(p) · GW(p)
Or, to put it differently: an abstraction is “valid” when components of the low-level model are independent given the values of high-level variables. The roiling of plasmas within far-apart stars is (approximately) independent given the total mass, momentum, and center-of-mass position of each star. As long as this condition holds, we can use the abstract model to correctly answer questions about things far away/far apart. [...]
So if we draw a box around just one of the two instances, then those low-level calculation details we threw out will not actually be independent of the low-level calculation details in the other instance. The low-level structure of the two components - the two agent instances - is not independent given the high-level model; the abstraction is not valid.
I'm a little confused by this; it sounds like you are saying that the low-level details being independent is a requirement for valid abstractions in general. I understand that the details being correlated breaks certain decision-theoretic abstractions, since it brings in diagonalization etc. issues. But don't most other abstractions work fine even if the low-level details do happen to be identical? If I'm calculating the trajectory of the sun, and two other stars that are ten light-years away happen to be identical with each other, then this shouldn't make my calculations any less valid.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-05-06T17:29:11.365Z · LW(p) · GW(p)
If I'm calculating the trajectory of the sun, and two other stars that are ten light-years away happen to be identical with each other, then this shouldn't make my calculations any less valid.
Two issues here.
First, in this case, we're asking about one specific query: the trajectory of the sun. In general, abstraction is about validity of some class of queries - typically most-or-all queries which can be formulated within the high-level model. So validity of the star-abstraction would depend not just on the validity of the calculation of the sun's trajectory, but also the validity of the other stars' trajectories, and possibly other things depending on what else is in the model.
(Of course, we can choose just one query as our class, but then the abstraction won't be very useful; we might as well just directly compute the query's answer instead.)
For a star-abstraction, we expect the abstraction to be valid for any queries on kinematics of the stars, as long as the stars are far apart. Queries we don't expect to be valid include e.g. kinematics in situations where stars get close together and are torn apart by tidal forces.
Second, it's generally ok if the low-level structures happen to be identical, just as two independent die rolls will sometimes come out the same. The abstraction breaks down when the low-level structures are systematically correlated, given whatever information we have about them. What does "break down" mean here? Well, I have some low-level data about one star, and I want to calculate what that tells me about another star. Using the abstraction, I can do that in three steps:
- Use my low-level data on star 1 to compute what I can about the high-level variables of star 1 (low-level 1 -> high-level 1)
- Use the high-level model to compute predictions about high-level variables of star 2 from those of star 1 (high-level 1 -> high-level 2)
- Update my low-level information on star 2 to account for the new high-level information (high-level 2 -> low-level 2)
... and that should be equivalent to directly computing what the low-level of star 1 tells me about the low-level of star 2 (low-level 1 -> low-level 2). (It's a commutative diagram.) If the low-level structures are not independent given the high-level summaries, then this fails.
Concretely: if I'm an astronomer studying solar flares and I want to account for the influence of other stars on the solar flare trajectory, then my predictions should not depend on the flare activity of the other stars. If my predictions did depend on the flare activity of the other stars, then that would be a breakdown of the usual star-abstraction. If the flare activity of two stars just-so-happens to match, that would be unusual but not a breakdown of the abstraction.
Please let me know if that didn't fully address the question; I expect other people are wondering about similar points.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2020-05-06T18:49:42.457Z · LW(p) · GW(p)
Ah, looking at earlier posts in your sequence, I realize that you are defining abstraction in such a way that the properties of the high-level abstraction imply information about the low-level details - something like "a class XYZ star (high-level classification) has an average mass of 3.5 suns (low-level detail)".
That explains my confusion since I forgot that you were using this definition, and was thinking of "abstraction" as it was defined in my computer science classes, where an abstraction was something that explicitly discarded all the information about the low-level details.