Compositional preference models for aligning LMs
post by Tomek Korbak (tomek-korbak) · 2023-10-25T12:17:28.990Z · LW · GW · 2 commentsContents
How compositional preference models work? Robustness to overoptimization Quality evaluation CPMs and scalable oversight Wrap-up None 2 comments
This post summarizes the main results from our recently released paper Compositional preference models for aligning LMs and puts them in the broader context of AI safety. For a quick summary of the paper, take a look at our Twitter thread.
TL;DR: We propose a new approach to building preference models out of prompted LMs. Compositional Preference Models (CPMs) decompose scoring a text into (1) constructing a series of questions about interpretable features of that text (e.g. how informative it is), (2) obtaining scalar scores for these features from a prompted LM (e.g. ChatGPT), and (3) aggregating these scores using a logistic regression classifier trained to predict human judgements. We show that CPMs, compared with standard preference models (PMs), generalize better and are more robust to reward model overoptimization. Moreover, best-of-n samples obtained using CPMs tend to be preferred over samples obtained using similar, conventional PMs. Finally, CPMs are a novel angle at scalable oversight: they decompose a hard evaluation problem into a series of simpler, human-interpretable evaluation problems.
How compositional preference models work?
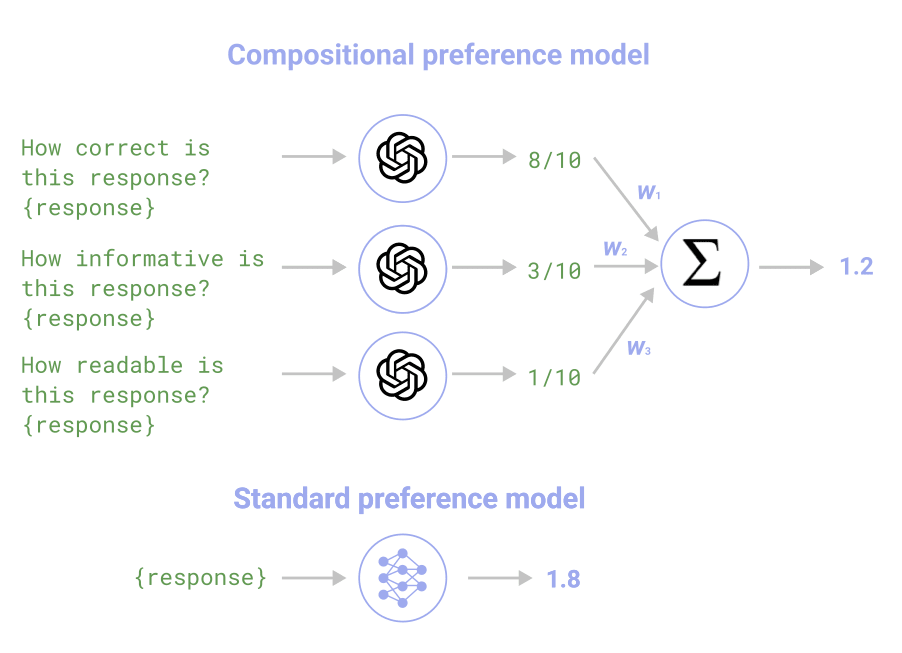
Figure 1: While standard PMs output a preference score directly, CPMs score different features of LM responses separately and output a preference score as a linear combination of feature values.
Preference Models (PMs) are models trained to assign an LM response a score indicating the quality of the response. They are the workhorse of many techniques for aligning LMs: they are most prominently used as reward functions in RLHF or as ranking models in best-of-n sampling, in addition to playing a role in other techniques such as pretraining with human feedback [LW · GW].
Standard PMs involve adding a scalar head on top of a base model and finetuning the whole model (or certain upper layers) to predict which of two texts a human would prefer. While this approach is highly effective in practice, it can lead to uninterpretable models that fit spurious correlations in human preference judgements and are prone to goodharting (overoptimization).
We introduce an alternative: Compositional Preference Models (CPM). In contrast to PMs, CPMs decompose response evaluation into the following steps:
Feature decomposition. We maintain a fixed list of 13 human-interpretable features (e.g. specificity, relevance, readability) and 13 corresponding prompt templates (e.g. You will be shown a conversation [...] please judge whether the assistant's reply is relevant. Score that on a scale from 1 to 10 [...] {conversation_history} {reply}).
Feature scoring. We ask an LM (e.g. GPT-3.5) to assign a score to each feature. Each feature of a single response is scored in a separate context window.
Aggregation. The feature scores are combined into a scalar preference score using a logistic regression classifier trained to predict human preference judgements (i.e. which of two texts a human would prefer).
Robustness to overoptimization
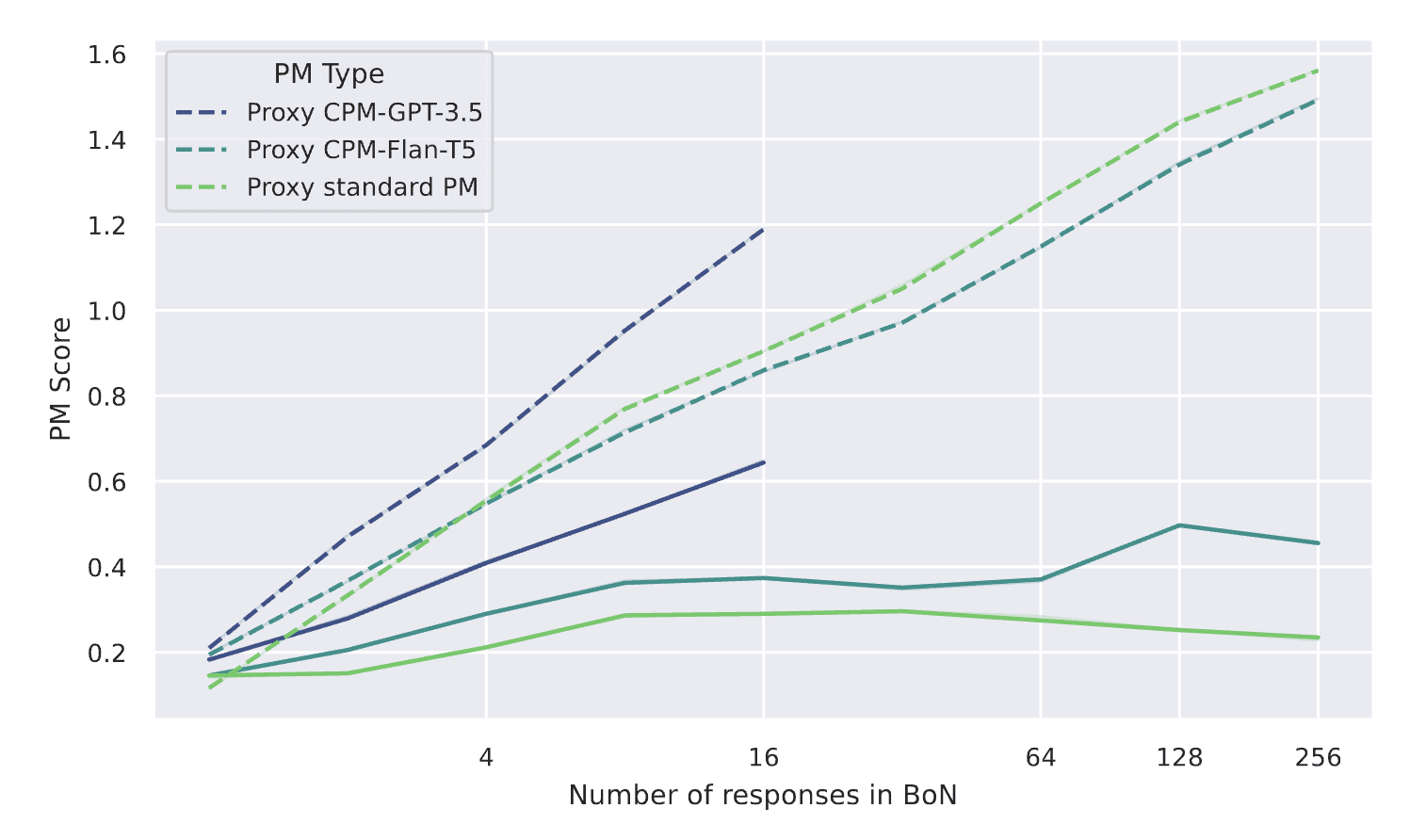
Figure 2: Scores given by a gold PM (solid lines) and a corresponding proxy PM (dashed lines) on samples obtained through best-of-n sampling against the gold PM. CPM-GPT-3.5 and CPM-Flan-T5 refer to CPMs constructed with feature extraction based on GPT-3.5 and Flan-T5, respectively.
To investigate if CPM improves robustness to overoptimization, we follow the setup of Gao et al. (2023) [LW · GW] and construct a synthetic dataset where the output of one PM (defined to be the “gold PM”) is assumed to be the ground truth for human preferences. We then use the gold PMs to generate synthetic labels to train proxy PMs. We do that separately for three pairs of proxy and gold PMs: (i) standard PMs, (ii) CPMs using GPT-3.5 for feature extraction and (iii) CPMs using Flan-T5-XL (3B params) for feature extraction. Finally, we do best-of-n against a given proxy PM and comparse those best samples’ scores according to both proxy and gold PM.
As we increase the amount of optimization pressure (the number of candidates n), scores given by proxy PMs diverge from scores given by gold PMs (see Fig. 2). This is an indicator of preference model overoptimization, a form of reward hacking in which optimization of proxy PM scores is driven by spurious features that the gold PMs are indifferent to. The size of this gap (smaller is better) indicates the robustness of a given PM to being overly optimized against. Here, we observe that the gap (on the plot, between solid and dashed lines) tends to be smaller for CPMs than for standard PMs and that it increases at a slower rate.
This indicates that CPMs are more robust to overoptimization than standard PMs. This holds independently of whether a highly capable (GPT-3.5) or less capable (Flan-T5-XL) LM is used as a feature extractor in CPMs.
Quality evaluation
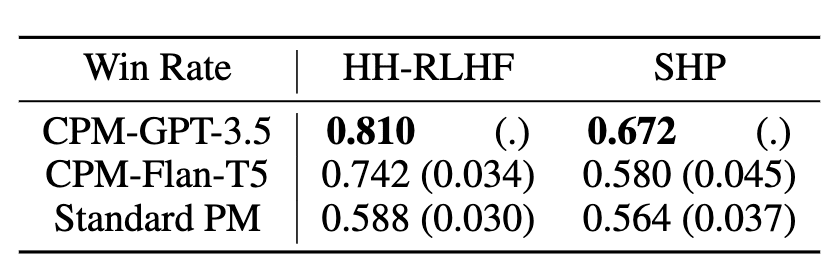
Figure 3: Win rate of responses obtained via best-of-16 sampling using a given PM versus responses obtained via standard sampling, computed for prompts from Anthropic HH dataset (HH-RLHF) and Stanford Human Preferences dataset (SHP).
We compare the quality of LM samples obtained by best-of-16 against either CPMs or standard PMs by comparing them to samples generated without best-of-n sampling. We do that by showing both best-of-16 and vanilla samples to an evaluator LM (Claude 2.0) and by computing win rates, i.e. how often best-of-16 samples are preferred to vanilla samples. CPMs tend to have higher win rates than standard PMs, even if we match the capabilities of a feature extractor LM to the capabilities of standard PM (by choosing Flan-T5-XL for both). This suggests that prior knowledge injected into a PM via pre-selecting interpretable and relevant features in CPMs is robustly helpful for learning about human preferences.
CPMs and scalable oversight
Scalable oversight is the problem of evaluating the behavior of agents more capable than the evaluators. This is important to solve because, on the one hand, LMs will soon grow capable of completing tasks for which humans will not be able to provide feedback. On the other hand, LMs might also be capable of reasoning about flaws in their evaluation procedures and exploiting them [LW · GW] unbeknownst to overseers.
Current proposals for solving scalable oversight focus on recursively relying on other LMs to assist human evaluators (debate [? · GW], iterated distillation and amplification [? · GW], recursive reward modeling) but remain largely theoretical. RL from AI feedback – using carefully prompted LMs to generate training data for PMs – is arguably the most successful demonstration of how to use LMs to supervise LMs at scale.
CPMs explore an alternative route to addressing scalable oversight for LMs, exploring the prospects of divide-and-conquer strategies for tackling hard evaluation problems. CPMs can be seen as a method for decomposing a hard question (“Is this response helpful?”) into a series of simpler questions (“is this response readable?” etc.) that are easier for LMs to answer and easier for humans to oversee. While we stop at a single step of decomposition, nothing in principle prevents us from applying the idea recursively, e.g. to break down evaluation of complex responses into simple questions about atomic claims.
The idea of decomposing complex evaluation problems into simpler subproblems has several additional benefits:
- Using human priors. Pre-selection of features and prompt templates afford a natural way of injecting prior knowledge and endowing PMs with useful inductive biases. The parameters space of CPMs is spanned by features selected to be meaningful and robust.
- Avoiding reward hacking by limiting PM capacity. Using features pre-computed by feature extractors allows us to dramatically reduce the capacity of PMs consuming them (in our experiments, from 3B to just 13 parameters, i.e. 8 orders of magnitude!) and limit their susceptibility to overfitting to spurious correlations in preference data. It is really hard to reward-hack with only 13 parameters at hand!
- Interpretability. Pre-selected features are trivially interpretable and a logistic regression coefficient associated with a feature can be interpreted as its salience (effect size) for a particular preference judgment (see sec. 4.6 in the paper). Indeed, the idea that preference judgments can be explained by linear combinations of pre-selected features was recently validated by two concurrent papers: Towards Understanding Sycophancy in Language Models [LW · GW] and Human Feedback is not Gold Standard. Using such a linear model as an actual PM makes its judgements more transparent and amenable to process-based supervision.
- Narrowness. Each of our feature extractors solves a narrow problem and does not need to be aware of other features or how the scores are aggregated. Solving different subproblems in different context windows was recently found to improve the faithfulness of reasoning [LW · GW]. In the case of CPMs, an individual feature extractor has no clue how the score it is about to assign is going to be used downstream, which makes it harder for it to be strategic about that score and exercise capabilities for sycophancy [LW · GW] or deception.
However, CPMs still have certain limitations that future work could address:
- Human feedback. CPMs still use pairwise preference judgements given by humans as a training signal for aggregating feature scores. This is inherently limiting as far as humans make errors, sometimes prefer sycophantic responses over truthful ones [LW · GW] or authoritative responses over factual ones.
- Human curation. CPMs rely on humans when it comes to feature selection and prompt engineering of prompt templates for feature extraction. These factors could be limiting as far as out-of-domain generalization is concerned (e.g. to evaluating agents showing superhuman performance).
Wrap-up
We presented Compositional Preference Models: the idea of building PMs by training logistic regression on top of features extracted by prompted LMs. We show that a CPM with 13 parameters can outperform standard PM in terms of human evaluation and robustness to reward model overoptimization while also being more interpretable.
This post benefited from helpful comments made by Mikita Balesni, Richard Ren, Euan McLean and Marc Dymetman. I’m also grateful to the co-authors of the paper: Dongyoung Go, Germán Kruszewski, Jos Rozen and Marc Dymetman.
2 comments
Comments sorted by top scores.
comment by johnswentworth · 2023-10-25T16:15:49.958Z · LW(p) · GW(p)
So I read the title and was like "huh, that's a novel and interesting idea". And then I read the description and was like "dude, that is not what 'compositional' means".
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-10-25T20:24:41.543Z · LW(p) · GW(p)
Fair point, I'm using "compositional" in an informal sense different from the one in formal semantics, closer to what I called "trivial compositionally" in this paper. But I'd argue it's not totally crazy to call such preference models compositional and that compositionally here still has some resemblance to Montague's account of compositionally as homeomorphism: basically, you have get_total_score(response) == sum([get_score(attribute) for attribute in decompose(response)])