Towards a formalization of the agent structure problem
post by Alex_Altair · 2024-04-29T20:28:15.190Z · LW · GW · 6 commentsContents
What are "agent behavior" and "agent structure"? Motivation A loose formalism The setting The environment class & policy class A measure of performance Filter the policy class Take the limit Alternatives & options for a tighter formalism Setting Performance measure Filtering Other theorem forms None 7 comments
In Clarifying the Agent-Like Structure Problem [LW · GW] (2022), John Wentworth [LW · GW] describes a hypothetical instance of what he calls a selection theorem. In Scott Garrabrant [LW · GW]'s words, the question is, does agent-like behavior imply agent-like architecture [LW · GW]? That is, if we take some class of behaving things and apply a filter for agent-like behavior, do we end up selecting things with agent-like architecture (or structure)? Of course, this question is heavily under-specified. So another way to ask this is, under which conditions does agent-like behavior imply agent-like structure? And, do those conditions feel like they formally encapsulate a naturally occurring condition?
For the Q1 2024 cohort of AI Safety Camp, I was a Research Lead for a team of six people, where we worked a few hours a week to better understand and make progress on this idea. The teammates[1] were Einar Urdshals [LW · GW], Tyler Tracy [LW · GW], Jasmina Nasufi [LW · GW], Mateusz Bagiński [LW · GW], Amaury Lorin [LW · GW], and Alfred Harwood [LW · GW].
The AISC project duration was too short to find and prove a theorem version of the problem. Instead, we investigated questions like:
- What existing literature is related to this question?
- What are the implications of using different types of environment classes?
- What could "structure" mean, mathematically? What could "modular" mean?
- What could it mean, mathematically, for something to be a model of something else?
- What could a "planning module" look like? How does it relate to "search"?
- Can the space of agent-like things be broken up into sub-types? What exactly is a "heuristic"?
Other posts on our progress may come out later. For this post, I'd like to simply help concretize the problem that we wish to make progress on.
What are "agent behavior" and "agent structure"?
When we say that something exhibits agent behavior, we mean that seems to make the trajectory of the system go a certain way. We mean that, instead of the "default" way that a system might evolve over time, the presence of this agent-like thing makes it go some other way. The more specific of a target it seems to hit, the more agentic we say it behaves. On LessWrong, the word "optimization [LW · GW]" is often [LW · GW] used [? · GW] for this type of system behavior. So that's the behavior that we're gesturing toward.
Seeing this behavior, one might say that the thing seems to want something, and tries to get it. It seems to somehow choose actions which steer the future toward the thing that it wants. If it does this across a wide range of environments, then it seems like it must be paying attention to what happens around it, use that information to infer how the world around it works, and use that model of the world to figure out what actions to take that would be more likely to lead to the outcomes it wants. This is a vague description of a type of structure. That is, it's a description of a type of process happening inside the agent-like thing.
So, exactly when does the observation that something robustly optimizes imply that it has this kind of process going on inside it?
Our slightly more specific working hypothesis for what agent-like structure is consists of three parts; a world-model, a planning module, and a representation of the agent's values. The world-model is very roughly like Bayesian inference; it starts out ignorant about what world its in, and updates as observations come in. The planning module somehow identifies candidate actions, and then uses the world model to predict their outcome. And the representation of its values is used to select which outcome is preferred. It then takes the corresponding action.
This may sound to you like an algorithm for utility maximization. But a big part of the idea behind the agent structure problem is that there is a much larger class of structures, which are like utility maximization, but which are not constrained to be the idealized version of it, and which will still display robustly good performance.
So in the context of the agent structure problem, we will use the word "agent" to mean this fairly specific structure (while remaining very open to changing our minds). (If I do use the word agent otherwise, it will be when referring to ideas in other fields.) When we want talk about something which may or may not be an agent, we'll use the word "policy". Be careful not to import any connotations from the field of reinforcement learning, here. We're using "policy" because it has essentially the same type signature. But there's not necessarily any reward structure, time discounting, observability assumptions, et cetera.
A disproof of the idea, that is, a proof that you can have a policy that is not-at-all agent-structured, and yet still has robustly high performance, is, I think, equally exciting. I expect that resolving the agent structure problem in either direction would help me get less confused about agents, which would help us mitigate existential risks from AI.
Motivation
Much AI safety work is dedicated to understanding what goes on inside the black box of machine learning models. Some work, like mechanistic interpretability, goes from the bottom-up. The agent structure problem is attempting to go top-down.
Many of the arguments trying to illuminate the dangerousness of ML models will start out with a description of a particular kind of model, for example mesa-optimizers [? · GW], deceptively [LW · GW] aligned [? · GW] models, or scheming AIs [? · GW]. They will then use informal "counting arguments" to argue that these kinds of models are more or less likely, and also try to analyze whether different selection criteria change these probabilities. I think that this type of argument is a good method for trying to get at the core of the problem. But at some point, someone needs to convert them to formal counting arguments. The agent structure problem hopes to do so. If investigation into it yields fruitful results and analytical tools, then perhaps we can start to built a toolkit that can be extended to produce increasingly realistic and useful versions of the results.
On top of that, finding some kind of theorems about agent-like structures will start to show us what is the right paradigm to use for agent foundations. When Shannon derived his definition of information from four intuitive axioms, people found it to be a highly convincing reason to adopt that definition. If a sufficiently intuitive criterion of robust optimization implies a very particular agent structure, then we will likely find that a similarly compelling reason to consider that definition of agent structure going forward.
A loose formalism
I've been using the words "problem" or "idea" because we don't have a theorem, nor do we even a conjecture; that requires a mathematical statement which has a truth-value that we could try to find a proof for. Instead, we're still at the stage of trying to pin down exactly what objects we think the idea is true about. So to start off, I'll describe a loose formalism.
I'll try to use enough mathematical notation to make the statements type-check, but with big holes in the actual definitions. I'll err towards using abbreviated words as names so it's easier to remember what all the parts are. If you're not interested in these parts or get lost in it, don't worry; their purpose is to add conceptual crispness for those who find it useful. After the loose formalism, I'll go through each part again, and discuss some alternative and additional ways to formalize each part.
The setting
The setting is a very common one when modelling an agent/environment interaction.
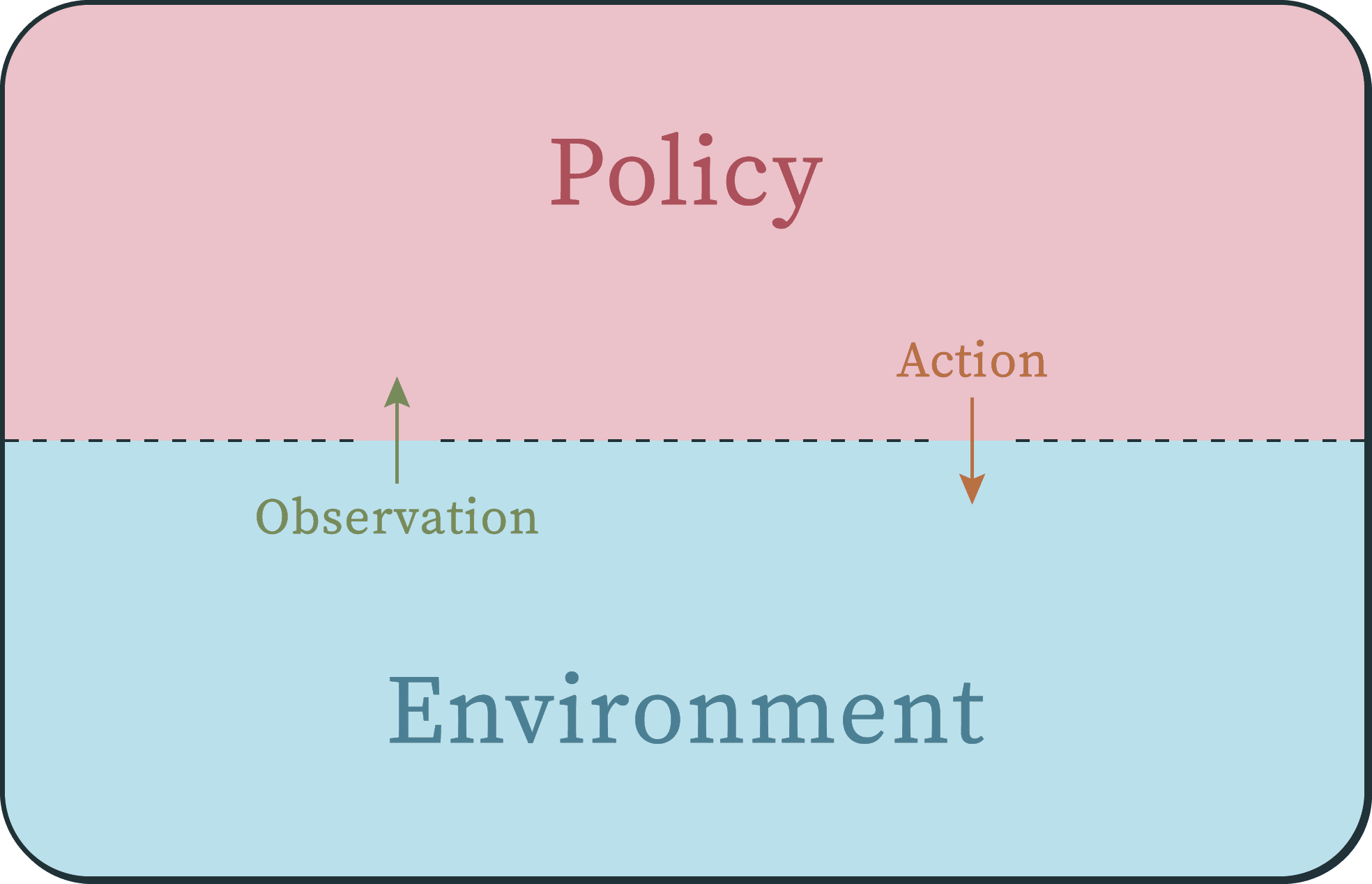
Identical or analogous settings to this are used in the textbooks AI: A Modern Approach,[2] Introduction to Reinforcement Learning,[3] Hutter's definition of AIXI,[4] and some control theory problems (often as "controller" vs "plant").
It is essentially a dynamical system [LW · GW] where the state space is split into two parts; one which we'll call a policy, and the other the environment. Each of these halves is almost a dynamical system, except they receive an "input" from the other half on each timestep. The policy receives an "observation" from the environment, updates its internal policy state, and then outputs an action. The environment then receives the action as its input, updates its environment state, and then outputs the next observation, et cetera. (It's interesting to note that the setting itself is symmetrical between the policy side and the environment side.)
Now let's formalize this. (Reminder that it's fine to skip this section!) Let's say that we mark the timesteps of the system using the natural numbers . Each half of the system has an (internal) state which updates on each timestep. Let's call the set of environment states , and the set of policy states (mnemonic: it's the Memory of the policy). For simplicity, let's say that the set of possible actions and observations come from the same alphabet, which we'll set to .
Now I'm going to define three different update functions for each half. One of them is just the composition of the other two, and we'll mostly talk about this composition. The reason for defining all three is because it's important that the environment have an underlying state over which to define our performance measure, but it's also important that the policy only be able to see the observation (and not the whole environment state).
In dynamical systems, one conventional notation given to the "evolution rule" or "update function" is (where a true dynamical system has the type ). So we'll give the function that updates the environment state the name and the function that updates the policy state the name . Then the function that maps the environment state to the observations is , and similarly, the function that maps the policy state to the action is .
I've given these functions more forgettable names because the names we want to remember are for the functions that go [from state and action to observation], and [from state and observation to action];
and
each of which is just the composition of two of the previously defined functions. To make a full cycle, we have to compose them further. If we start out with environment state, and the policy state then to get the next environment state, we have to extract the observation from , feed that observation to the policy, update the policy state, extract the action from the policy, and then feed that to the environment again. That looks like this;
ad infinitum.
Notice that this type of setting is not an embedded agency [? · GW] setting. Partly that is a simplification so that we have any chance of making progress; using frameworks of embedded agency seem substantially harder. But also, we're not trying to formulate a theory of ideal agency; we're not trying to understand how to build the perfect agent. We're just trying to get a better grasp on what this "agent" thing is at all. Perhaps further work can extend to embedded agency.
The environment class & policy class
The class of environments represents the "possible worlds" that the policy could be interacting with. This could be all the different types of training data for an ML model, or it could be different laws of physics. We want the environment class to be diverse, because if it was very simple, then there could likely be a clearly non-agentic policy that does well. For example, if the environment class was mazes (without loops), and the performance measure was whether the policy ever got to the end of the maze, then the algorithm "stay against the left wall" would always solve the maze, while clearly not having any particularly interesting properties around agency.
We'll denote this class by , whose elements are functions of the type defined above, indexed by . Note that the mechanism of emitting an observation from an environment state is part of the environment, and thus also part of the definition of the environment class; essentially we have .
So that performance in different environments can be comparable with each other, the environments should have the same set of possible states. So there's only one , which all environments are defined over.
Symmetrically, we need to define a class of policies. The important thing here is to define them in such a way that we have a concept of "structure" and not just behavior, because we'll need to be able to say whether a given policy has an agent-like structure. That said, we'll save discussion for what that could mean for later.
Also symmetrically, we'll denote this class by , whose elements are functions of the type defined above, indexed by .
Now that we have both halves of our setup defined and coupled, we wish to take each policy and run it in each environment. This will produce a collection of "trajectories" (much like in dynamical systems) for each policy, each of which is a sequence of environment states.
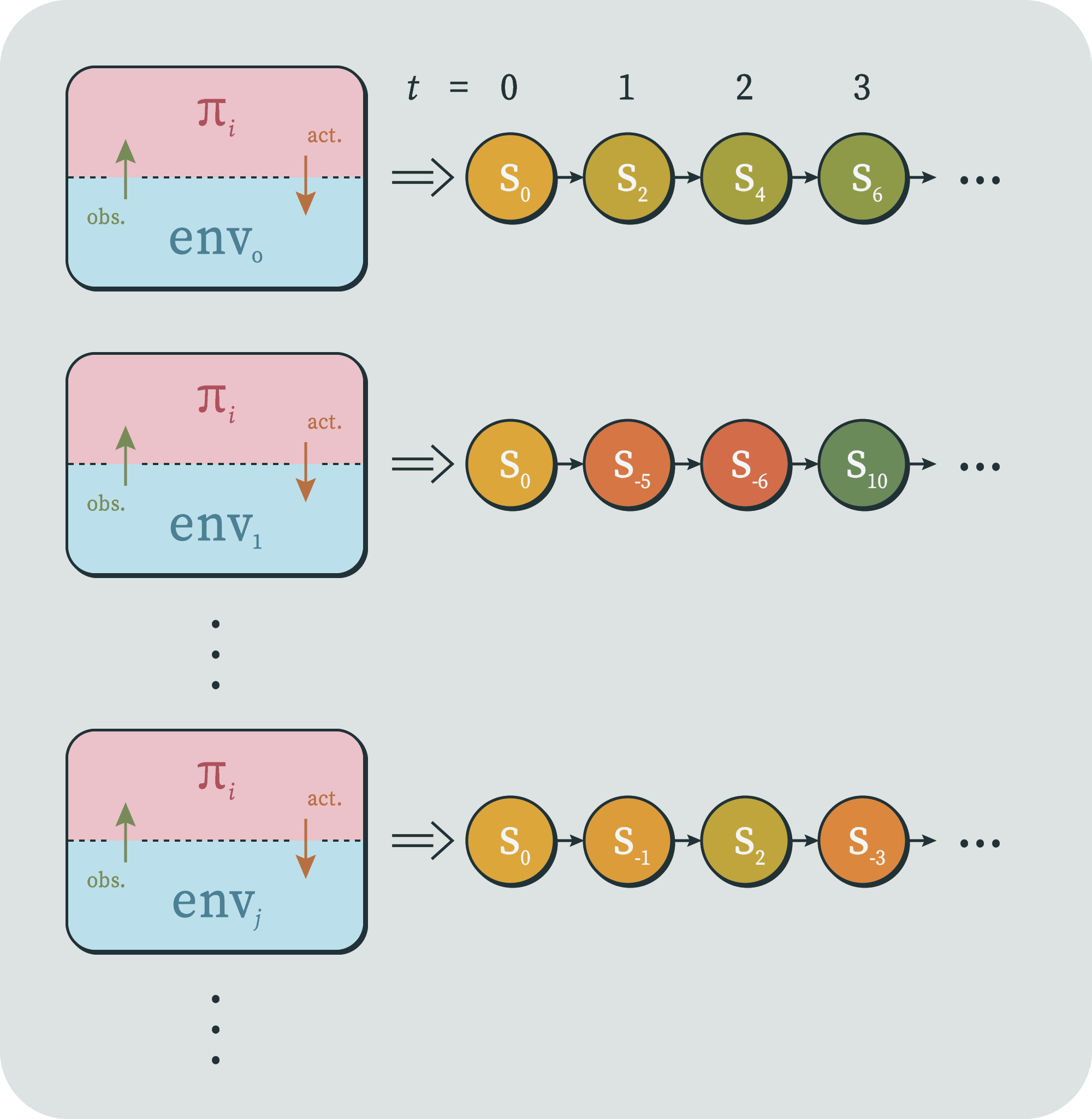
If we wished, we could also name and talk about the sequence of policy states, the interleaved sequence of both, the sequence of observations, of actions, or both. But for now, we'll only talk about the sequence of environment states, because we've decided that that's where one can detect agent behavior.
And if we wished, we could also set up notation to talk about the environment state at time produced by the coupling of policy and environment , et cetera. But for now, what we care about is this entire collection of trajectories up to time , produced by pairing a given with all environments.
A measure of performance
In fact, we don't even necessarily care to name that object itself. Instead, we just want to have a way to talk about the overall performance of policy by time deployed across all environments in . Let's call that object . For simplicity, let's say it returns a real number
Presumably, we want to obey some axioms, like that if every state in is worse than every state in , then . But for now we'll leave it totally unspecified.
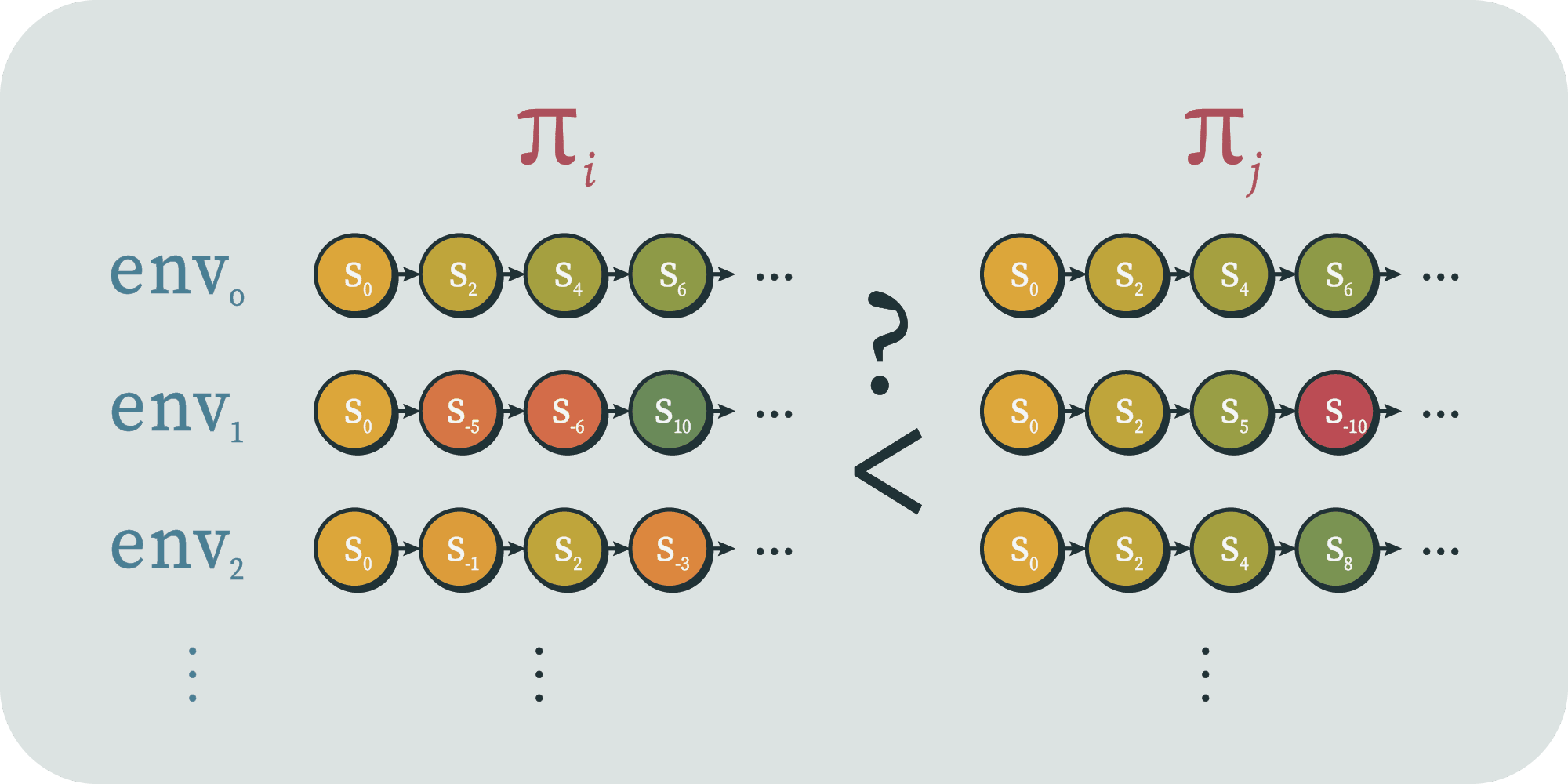
Filter the policy class
After we run every policy in every environment, they each get an associated performance value , and we can "filter out" the policies with insufficient performance. That is, we can form a set like the following;
What can we say about what policies are left? Do they have any agent structure yet?
One obvious problem is that there could be a policy which is the equivalent of a giant look-up table; it's just a list of key-value pairs where the previous observation sequence is the look-up key, and it returns a next action. For any well-performing policy, there could exist a table version of it. These are clearly not of interest, and in some sense they have no "structure" at all, let alone agent structure.
A way to filter out the look-up tables is to put an upper bound on the description length of the policies. (Presumably, the way we defined policies in to have structure also endowed them with a meaningful description length.) A table is in some sense the longest description of a given behavior. You need a row for every observation sequence, which grows exponentially in time. So we can restrict our policy class to policies less than a certain description length . If the well-performing table has a compressed version of its behavior, then there might exist another policy in the class that is that compressed version; the structure of the compression becomes the structure of the shorter policy.
Now we have this filtered policy set;
Take the limit
Of course, for an arbitrary , , and we don't expect the remaining policies to be particularly agent structured. Instead, we expect agent structure to go up as they go up, up, and down respectively. That is, as we run the policies for longer, we expect the agents to pull ahead of heuristics. And as we increase the required performance, we also less agent-structured things to drop out. And as we decrease , we expect to filter out more policies with flat table-like structure or lucky definitions. But what exactly do we mean by all that?
Here's one snag. If we restrict the description length to be too small, then none of the policies will have high performance. There's only so much you can do in a ten-line python program. So to make sure that doesn't happen, let's say that we keep , where is a policy that is an agent, whatever we mean by that. Presumably, we're defining agent structure such that the policy with maximum agent structure has ideal performance, at least in the long run.
There's a similar snag around the performance . At a given timestep , regardless of the policy class, there are only a finite number of action sequences that could have occurred (namely ). Therefore there are a finite number of possible performances that could have been achieved. So if we fix and take the limit as , we will eventually eliminate every policy, leaving our filtered set empty. This is obviously not what we want. So let's adjust our performance measure, and instead talk about , which is the difference from the "ideal" performance.
Let's name one more object: the degree of agent structure.
For simplicity, let's just say that ideal agents have . Perhaps we have that a look-up table has . Presumably, most policies also have approximately zero agent structure, like how most weights in an ML model will have no ability to attain low loss.
Now we're ready to state the relevant limit. One result we might wish to have is that if you tell me how many parameters are in your ML model, how long you ran it for, and what its performance was, then I could tell you the minimum amount of agent structure it must have. That is, we wish to know a function such that for all , we have that .
Of course, this would be true if were merely the constant function . But ideally, it has some property like
But maybe we don't! Maybe there's a whole subset of policies out there that attain perfect performance in the limit while having zero agent structure. And multivariable limits can fail to exist depending on the path. So perhaps we only have
or
Of course, this is still not a conjecture, because I haven't defined most of the relevant objects; I've only given them type signatures.
Alternatives & options for a tighter formalism
While we think that there is likely some version of this idea that is true, it very well might depend on any of the specifics described above. And even if it's true in a very general sense, it seems useful to try to make progress toward that version by defining and proving or disproving much simpler versions. Here are some other options and considerations.
Setting
The state space could be finite, countably infinite, uncountably infinite, or higher. Or, you could try to prove it for a set of arbitrary cardinality.
The time steps could be discrete or continuous. You could choose to run the policies over the intervals or .
The dynamics of the policies and environment could each be deterministic, probabilistic, or they could be one of each.
The functions mapping states to observations/actions could also deterministic or probabilistic. Their range could be binary, a finite set, a countably infinite set, et cetera.
The dynamics of the environment class could be Markov processes. They could be stationary or not. They could be ordinary homogeneous partial linear differential equations, or they could be extraordinary heterogeneous impartial nonlinear indifferential inequalities (just kidding). They could be computable functions. Or they could be all mathematically valid functions between the given sets. We probably want the environment class to be infinite, but it would be interesting to see what results we could get out of finite classes.
The policy dynamics could be similar. Although here we also need a notion of structure; we wish for the class to contain look-up tables, utility maximizers, approximate utility-maximizers, and also allow for other algorithms that represent real ML models, but which we may not yet understand or have realized the existence of.
Performance measure
The most natural performance measure would be expected utility. This means we would fix a utility function over the set of environment states. To take the expectation, we need a probability measure over the environment class. If the class is finite, this could be uniform, but if it is not then it cannot be uniform. I suspect that a reasonable environment class specification will have a natural associated sense of some of the environments being more or less likely; I would try to use something like a descriptions length to weight the environments. This probability measure should be something that an agent could reasonably anticipate, e.g. incomputable probability distributions seems somewhat unfair.
(Note that measuring performance via expected utility does not imply that we will end up with only utility maximizers! There could be plenty of policies that pursue strategies nowhere near the VNM axioms, which nonetheless tend to move up the environment states as ranked by the utility function. Note also that policies performing well as measured by one utility function may be trying to increase utility as measured by a different but sufficiently similar utility function.)
All that said, I suspect that one could get away with less than fully committing to a utility function and probability measure over environments. Ideally, we would be able to say when the policies tended to merely "optimize" in the environments. By my definition, that means the environment states would have only an order relation over them. It is not clear to me exactly when an ordering over states can induce a sufficiently expressive order relation over collections of trajectories through those states.
Filtering
Another way to filter out look-up table policies is to require that the policies be "robust". For any given (finite) look-up table, perhaps there exists a bigger environment class such that it no longer has good performance (because it doesn't have rows for those key-value pairs). This wouldn't necessarily be true for things with agent structure, since they may be able to generalize to more environments than we have subjected them to.
Other theorem forms
One can imagine proving stronger or weaker versions of a theorem than the limit statement above. Here are natural-language descriptions of some possibilities;
- Policies that do better than average have a positive quantity of agent-like structure
- The only optimally-performing policy is exactly the one with an agent structure.
- Agent structure is formally undecidable.
- Well-performing policies end up containing a model of the particular environment they're in.
There are also other variables I could have put in the limit statement. For example, I'm assuming a fixed environment class, but we could have something like "environment class size" in the limit. This might let us rule out the non-robust look-up table policies without resorting to description length.
I also didn't say anything about how hard the performance measure was to achieve. Maybe we picked a really hard one, so that only the most agentic policies would have a chance. Or maybe we picked a really easy one, where a policy could achieve maximum performance but choosing the first few actions correctly. Wentworth's qualification of "a system steers far-away parts of the world" could go in here; the limit could include the performance measure changing to measure increasingly "far-away" parts of the environment state (which would require that the environments be defined with a concept of distance).
I didn't put these in the limit because I suspect that there are single choices for those parameters that will still display the essential behavior of our idea. But the best possible results would let us plug anything in and still get a measure over agent structure.
- ^
In a randomized order.
- ^
https://aima.cs.berkeley.edu/ 4th edition, section I. 2., page 37
- ^
http://incompleteideas.net/book/the-book-2nd.html 2nd edition, section 3.1, page 48
- ^
http://www.hutter1.net/ai/uaibook.htm 1st edition, section 4.1.1, page 128
6 comments
Comments sorted by top scores.
comment by Garrett Baker (D0TheMath) · 2024-05-16T06:58:38.434Z · LW(p) · GW(p)
You may be interested in this if you haven’t seen it already: Robust Agents Learn Causal World Models (DM):
It has long been hypothesised that causal reasoning plays a fundamental role in robust and general intelligence. However, it is not known if agents must learn causal models in order to generalise to new domains, or if other inductive biases are sufficient. We answer this question, showing that any agent capable of satisfying a regret bound under a large set of distributional shifts must have learned an approximate causal model of the data generating process, which converges to the true causal model for optimal agents. We discuss the implications of this result for several research areas including transfer learning and causal inference.
h/t Gwern
Replies from: Alex_Altair↑ comment by Alex_Altair · 2024-05-19T20:21:56.518Z · LW(p) · GW(p)
Yep, that paper has been on my list for a while, but I have thus far been unable to penetrate the formalisms that the Causal Incentive Group uses. This paper in particular also seems have some fairly limiting assumptions in the theorem.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2025-02-18T01:50:31.405Z · LW(p) · GW(p)
For anyone reading this comment thread in the future, Dalcy wrote an amazing explainer for this paper here [LW · GW].
comment by Jonas Hallgren · 2024-04-30T13:18:43.985Z · LW(p) · GW(p)
There is a specific part of this problem that I'm very interested in and that is about looking at the boundaries of potential sub-agents. It feels like part of the goal here is to filter away potential "daemons" or inner optimisers so it feels kind of important to think of ways one can do this?
I can see how this project would be valuable even without it but do you have any thoughts about how you can differentiate between different parts of a system that's acting like an agent to isolate the agentic part?
I otherwise find it a very interesting research direction.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2024-04-30T17:16:21.865Z · LW(p) · GW(p)
Hm... so anything that measures degree of agent structure should register a policy with a sub-agent as having some agent structure. But yeah, I haven't thought much about the scenarios where there are multiple agents inside the policy. The agent structure problem is trying to use performance to find a minimum measure of agent structure. So if there was an agent hiding in there that didn't impact the performance during the measured time interval, then it wouldn't be detected (although it would detect it "in the limit").
That said, we're not actually talking about how to measure degree of agent structure yet. It seems plausible to me that whatever method one uses to do that could be adapted to find multiple agents.
comment by Tyler Tracy (tyler-tracy) · 2024-05-15T00:24:26.137Z · LW(p) · GW(p)
I'm intrigued by the distinction between the policy function and the program implementing it, as their structures seem different.
For example, a policy function might be said to have the structure of mapping all inputs to a single output, and the program that implements it is a Python program that uses a dictionary. Does this distinction matter?
When we talk about agent structure, I'd imagine that we care both about the structure of the actions that the agent takes and the structure of the computation the agent does to decide on the actions.